modis数据预处理有哪些步骤

粉丝24获赞285
相关视频
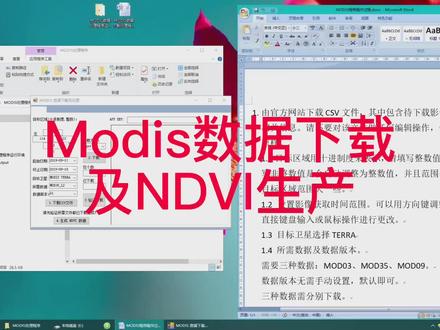 02:59查看AI文稿AI文稿
02:59查看AI文稿AI文稿modis 数据下载,即 end v 生产。第一步, c s v 文件下载 第二步, modis 数据下载 第三步,数据下载验证 第四步,生成 envelope 数据。
28粮安天下 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿数据预处理主要包括什么啊?一数据过滤,去掉不需要的,保留需要的。第二呢就是缺失值处理,那对缺失值进行补全 的那种插纸方法,默认纸啊、平均纸啊、线性插纸啊这种。第三呢就是消除异常或者错误数据。第四就是合并多个数据圆的数据,第五就是数据汇总, ok, 你就是这样子的分享。
96IT小白进阶记 14:18查看AI文稿AI文稿
14:18查看AI文稿AI文稿大家好,我是北海上期课程呢,我们讲解了如何去查找数据,而在比赛当中有可能官方已经给你了数据,但是这些数据我们不能直接拿过来用,因为他可能会是存在问题的,我们需要进行一个预处理。 首先就是比赛提供的数据有可能会出现缺失值,也就是给你一个一个赛表格当中,我们可能会发现有些表格是 nice 或者是空的, 那么这时候我们就要进行缺失值的一个处理。首先第一种情况就是缺失的太多了,假如说我们调查人口信息给你,给了你年龄、性别、地区分布等等这些数据,结果我们发现其中有一列年龄的这个缺失了百分之四十,那么怎么办呢?我们直接把他删掉, 因为百分之四十已经缺的是相当的大了,这时候你如果说在想办法去补的话,那么和实际的情况可能 相差非常大,所以说当这个数据缺失的太多的时候,我们就直接把这项指标删掉,后面在做题的时候压根不考虑它就完事了。当然了,这个缺失多少算是太多,并没有一个硬性的标准,我们只是说你看到缺了百分之四十了,这已经相当大了,所以说我们就把它删除就可以了。 那假如说我们十四亿人,你缺了几百个数据,那就不算太多,那你不可能说直接把某个数据直接删掉,那肯定不行, 所以说我们要根据实际情况来。然后就是另一种情况,假如说我们十四亿个人啊,缺失了几百几千个数据,这没问题,比较常见呢,就是遇到人口的数量、年龄,一些基数比较大的同居数据, 他的一个最大的特点就是对个体的精度要求不大,大家要注意这一点。对个体精度,比如说我们调查了十四亿人的一个年龄, 那么我们假如说把一个人的年龄写错了,对于我们整体国家的一个年龄分布并没有太大的影响。 所以说这时候我们可以用最简单的处理,也就是用均值和重数查补。这时候要分成两种情况,一个是定量, 什么叫定量的数据呢?比如关于身高、年龄,他是用一个数字来表示的,这时候我们就可以取全体的均值来补。这个确实, 比如说一个人的身高没有,我不知道他身高多少,那怎么办呢?我们选取全国的人的一个平均身高来作为他的身高补上去,这样一来补起来并没有太大的问题,因为缺失几十个人、几百个人的数据,我们用均值来补,对于整体的十四亿人的数据影响并不大, 这是定量的数据。还有一个是定信的数据,比如说我们关于一群人的性别、文化程度,这些呢,并不是一个准确的数字, 那么这时候我们就可以用次数最多的值来补缺失。假如说我们统计全国百分之五十一是男性,百分之四十九是女性,然后有一两个人的数据缺失了,不知道他性别,那么就可以把他设为男性,这就是一个定性的数据,用次数最多的值来补缺 好,这是我们一个最简单的处理方法。但是大家看到啊,他的使用条件就是对个体精度不高, 基数非常大的情况下才能用,那么假如说我对个体精度要求很高的话,我不允许你这样用均值或者是用重数来补,那么怎么办呢?就用到了我们常用的一个办法,叫做牛顿差之法。 差之法最直观的原理就是用一个固定的公式,我们来构造一个禁色的函数,再补上这个确实值就可以了,特点呢就是普遍适用性比较强。这就相当于我们根据已有的数 数据啊,去画出一个近似的函数,在这个函数上找到空缺的位置,然后以这个近似函数的值来作为我们缺失的这个值。 但是呢,牛的差之法也有一个非常显著的缺点,就在边缘区域呢,他会出现不明显的震荡,比如说,哎,我们根据已有的数据画出来一个简单的函数图像,假如说这样的,那么在边缘区域靠近边缘的地方,左右两端,我会发现他非常剧烈的震荡了, 哎,可能和我们区间中间的一些情况不太符合,他不该出现这种非常强烈的震荡, 那么这时候牛顿插织法就不再适用了。更多情况下呢,我们是在比如说热血、温度,地形测量等等,这些,只追求函数值的精确。我们不关心你温度变化怎么样,也不关心你这个地形 不是突然间变高,突然间变低,不关心你这个变化的。对于这种数据,我们可以使用牛顿差之法,只关心函数值的精确就可以了。 好,这是牛顿插织法的一个特点。那么假如我们对这个导数有要求,那该怎么办呢?就要用到第三种方法,也就是样调插织法, 他的特点就是用分段光滑的曲线去插直,光滑意味着这个曲线不仅连续,而且还有连续的区域,什么意思呢?我们刚才牛顿插织法求出来的可能是这个数据的中间,我们不考虑边缘的话,中间拟合的非常好,但是在边缘出现了龙格现象,也就是 非常剧烈的变化,那么我们不想出现这种现象,就要用到样调插织法。比较常见的问题就是一些零部件加工,最典型的例子就是飞机的机翼,我们不能有任何的棱角,还 就是像一些机床的零件,必须得是非常光滑的,否则会造成非常大的磨损。还有就是类似于水库的一些水流量的问题,我们不可能说突然一下把所有的闸门全打开,或者突然一下把所有的闸门全关上,这种造成水的突然断流,或者突然间大范围放水,这是不可以的。 对于这种情况也是要求一个光滑的曲线去插直,同时呢还有一个医学图像上的问题,叫做机械漂移,我们在这不多说,因为这个问题出现的概率不大,有兴趣的同学可以去查一下关于样调插织法在这个机械漂移上的应用。 还有现在就是机器人的技术已经非常先进了,那么机器人的轨迹也是一个非常光滑的曲线,我们不可能让机器人突然一下加速或者突然一下停下来,这都是不现实的。那么对于这种精度要求高,而且没有突变的数据,我们就要使用样调差值法, 最大的特点就是这两个字光滑,大家要注意啊,我们这三种方法他是各有各自的特点的, 没有说哪种方法更好,只有说哪种方法更合适。我们在这列出了试用赛题 以后,大家在遇到相应的问题的时候,要想到用哪种处理缺失值的方法,至于哪种方法的具体原理该怎么计算,我在这不多讲,大家在一些书籍或者网上的一些博客都可以找到非常详细的讲解,我们在这重点是告诉大家他适用于哪些赛题。 其次呢,这三种方法已经足够用了,还有其他的比如分段、差值等等方法,我们在这不再一一介绍了,大家只要掌握这三种就完全足够了。处理缺失值 好,除了缺纸之外呢,还有种情况叫做异常值好,最简单的例子,假如给你一群人的身高数据,你发现当中有个三米二的, 或者说有一个零点一米的,那么显然这个值不正常啊,不应该有人有三米二这个高度,所以说这就是一个异常值,我们怎么办呢?得把它去掉,然后用上一页我们所讲的处理缺失值的办法去把它补上。那么我们首先得找到这个异常值该怎么找? 最常用的一个办法就是正态分布三 c 个码原则。什么意思呢?学过概论同学都知道,正态分布他的图像啊,就是一个典型的中间多两头少的一个情况。三 c 个码 我们画一个区间,哎,这个区间就是我们所写的这个平均值减去三倍的标准差, 以及平均值加上三倍的标准差作为区间的两边,那么样本在这个区间之内出现的概率就是百分之九九点七三,大家可以看到只有不到百分之零点三的概率才会出 现在这个区间范围之外,那么对于这个区间范围之外,我们就可以把它定为异常值了。就好比我们大多数人都是一米五到一米八之间的,然后会发现蹦出个三米二的,他就一定是在这个区间范围之外,那么就把它定为异常值,当成异常值处理就可以了。 计算的方法啊也很简单,他两步我们先求出这个军值和标准差,这些数据我们都会直接求,没什么问题,然后每个数据值是否在这个区间范围内不在的,就定为异常值就可以了。 试用的题目也非常广泛,比如人口数据测量的误差,还有生产加工质量,比如我们对一些产品进行抽查,测他的质量,还有就是学生考试成绩等等。在日常生活当中,凡是符合正态分布的,都可以使用三 c 个码原则来判断是否存在异常值。但是 大家也注意啊,如果说某一种数据,比如说公交车站人数,这是属于一个排队论的问题,排队论是运输学当中一个典型的问题,他自身是符合薄松分布的,那么对于这种问题,我们就不适合用正态分布的思路去解决他了, 这时候该怎么办呢?我们还有一种更好的办法叫做画香型图,怎么画呢?大家看到啊,这东西画出来就像一个箱子一样,中间的,那么该那么看一下这个香型图到底是怎么做的。 首先呢,我们就是把数据从小到大的排序,哎,下边的数据是小的,上面的数据数值大的,比如我们身高我在这排了一个,第一个数是零点一, 哎,然后后面我们排到了一点三,排到了一点五,排到了一点六,然后我们排到了二,排到了三点二, 排到了五,大家看到啊,我们一眼就能看出来这个五,还有这个零点一,显然应该是异常值,人的身高不应该是这个数,所以说,哎,我们先把他从小到大排序先看一下, 然后我们定义一个变量,叫做下四分位数 q 一,这什么意思呢?下四分位数,我们定他的变量是叫做 q 一,他就是排名第百分之二十五的数值。 假如我们总共一百个人,我们从小到大排序,按他的身高从低到高排序,排在第二十五的人,他假如他身高是一米五,那么我们这个下四分位数就是一点五了,谁排第百分之二十五,谁谁对应的数值就是下四分位数。 同样道理,相应的有一个上司分位数,那么就是排在第七十五位的啊,在百分比当中就是排百分之七十五的,他的数值就定为上 四分位数,我们设为 q 三,相应的呢,还有一个中位数,这个就知道大家,这个大家都知道,就是一个排在中间的那个人的数值,也就是第百分之五十的,我们可以把它设为 q 二。好,我们继续来看,设了下四分为数,上四分为数之后有什么用呢? 我们再来一个概念,叫做四分畏惧啊,我们写作是 i k 二,也就是用 q 三减去 q 一,那么我们得到的就是这个区间范围内的,大家可以看到 就是我们话说这个箱子啊,箱子中间这一个范围最高和最低,最高就是上次分数,我说的是在箱子里面最高啊,不是说我们整体数据的最高,在这个箱子里面最大的就是 q 三,最小的就是 q 一, 得到的中间的差值,也就是我们所说的四分畏惧,排名第百分之七十五的,减去第百分之二十五的数值,得 得到的这个区间范围,那么我们怎么用它来找细长直?就和正态分布类似的正态分布,我们是用这个 u 减去三 c 个码, u 加二三 c 个码,那么在这呢,我们设一个合理区间,一般是设置 q 一,减去一点五乘以 i q 二。 在这之前我们先说一个概念啊,这个 iq 二是什么意思?他代表着什么意义呢? iq 二越大, 那么我们这个箱子是不是就越长啊?大家看到他是这个上四分位数和下四分位数差的比较大,他是画出来就越长,那假如说这个 iq 二越小,那画出箱子是不是就越扁啊? 他的上面这个 q 三和 q 一和下面的 q 一相差比较小,那么他画出来就是比较扁的,这是最直观的一个感觉,哎,一个长一个扁,这就是正四,这就是四分畏惧。 箱子扁就意味着数据集中,大家明白这一点,数据全都集中在一个范一个小范围内了,那大就意味着数据是分散的。那么我们设计一个合理区间, 这个箱子里面已经包括了大部分的数据,那这是个我们再给他多加一个允许的范围, 也就是我们设置的这个 q 一,减去一点五乘以二, q 二, q 三加上一点五乘以二。 q 二本身二 q 二代表着集中的程度,你再给他加一个长数乘以他这个一点五呢,是我们数学统计上常用的一个数值,他并没有非常严格的科学推理,我们习惯用一点五,就用了一点五, 我们再给他加上这么一个范围,让这个区间更大一点 q 一减去这个数, q 三加上这个数。哎,这就是我们所设的上级线和下级线,这样 以来我们上级线和下级线之间包括了我们中间的这个箱子,在箱子之外又多了两段距离,这整个区间范围呢,我们就设它为正常纸。 假如说你比如说我们这个图当中看到有个异常值,他这个点他在下极限之外了,那同样的,假如说我们在上极限之外也有一个点,那这两个点,比如说这个人是五米的,三米二的,他在上极限之外了,那么我们就可以判断他为异常值。同样的太低的,比如零点一在下极限之外了,我们就可以判他也为异常值。 这就是我们香型图的一个原理,它的适用呢是非常广泛的,我们上面所说的 三 c 个满原则,更多的适用于正态分布,那你破洞分布相对来说不太适合用正态分布,那么这时候可以画一个香型图来解决这个问题。整体呢,我们还是找 到这个上司分位数和下司分位数来确定他一个集中的区间,再把这个区间稍微的扩大一下,怎么扩大就用这个 iq 二 四分为距来给他多加一点,然后在这个区间范围内就是正常值,这就是我们香型图的一个概念,具体该怎么画出来,怎么样求值,大家在网上或者书籍上都能够找到资料,我们在这不多说。好,这就是我们处理异常值的方法, 那么我们找到了异常值之后,把它删掉,然后当做缺失值处理就可以了。我们上一页所讲的缺失值处理方法都可以拿来用。好,这就是我们整个数据预处理的过程,比赛给了你数据,你不能直接拿过来用, 一定要进行数据处理,最基本的处理就是缺失值和异常值的处理,其他的呢?还有更多的一些预处理的方法,我们在这不多讲,没有必要,大家只要处理了缺失值和异常值就足够了。好,这就是我们本节课的内容。
466数学建模BOOM 03:46查看AI文稿AI文稿
03:46查看AI文稿AI文稿我们在数学建模参赛过程中啊,其实经常会遇到一个问题,就是组委会给我们的信息有可能是有有问题的, 那么这个有问题呢?那么不一定是组委会啊,他故意的啊,有的时候他也是故意的,要考验一下学生到底有没有这种敏感性,到底对数据有没有一个处理。 也有的时候呢,是组委会获取这个数据的时候,那么因为因为一些误差啊,比如说观测误差,仪器误差,人为误差等等影响的,那么导致这个数据数据在获取、存储或者是哎,那么等等过程中,那么出现了一定的问题, 那么如果你对这些数据不进行处理的话,而盲目的将带有问题的数据进行建模的, 那么你的结果最终有可能出现一个很大的偏差,所以说哈,那么建模结果的好坏的基础就是你要一定要把数据一处理给做好。那么数据一一处理呢?一般包括哪些方面呢?包括数据清洗、数据集成、数据变换和数据规约 啊,我们讲一讲这四大部分。那么首先什么叫数据清洗啊?一会我们会都讲到哈,我们现在这里大概的来讲一讲,数据清洗是什么 啊?清洗呢,就是给数据洗个澡啊,说白了数据中存在一些错误数据或者异常数据,我们将这些错误数据,异常数据给他找出来以后,然后进行相关的一些处理啊,给让他变成一个符合常规的啊,正确的或者是近似于正确的那么一 数据,我们把它叫做数据清洗。那么数据基层是什么意思啊?指的是将不同格式不同获取规范啊,那么不同获取逻辑的数据把它集合在一块,然后呢进行集中化的一个处理, 我们把这种叫做数据去数据继承,因为你在获取数据的时候,有可能格式是不一样的,是吧?有可能数据员等等各种渠道信息是不一样的,所以你获取的数据要把它组合起来啊。你比如说你有可能获取的是文本型数据啊,比如好坏优秀不优秀,那么这种文本型的数据, 那么同样呢,你也有可能获取的是数值型数据,比如说测量结果,测量值,那么如何将文本型数据和数值型数据把它结合在一块来进行统一的建模呢?那么这就叫数据集成啊,主要涉及到格式方面 转换问题。那么数据变换什么意思啊?指的是我将数据啊,按照一定的规范使它变成一个统一的数据结啊,比如说有些数据呢,越大越好,而有些数据呢,越小越好,有的数据呢,反而在中间越好, 对不对?所以你就需要用到合适的方法,让这些数据都变成越大越好的,或者都变成越小越好的。 那那有些数据量级还不一样别有些数据吧,动辄几千上万,而有些数据呢,不会超过一,那么你如果盲目的把他们甲醛叠在一块的话,那么很有可能出现大鱼吃小鱼。就是就是,说白了量级大的数据很有可能对结果有至关重要的一个影响, 所以这个时候呢,你就需要用到数据规划啊,这这些方法数,什么叫数据规约呢? 规约我们所说的就是数据降为哈,指的是数据啊,那么存在很多荣誉,或者是说数据的维度太高了,计算起来非常的复杂,非常的繁琐。 那么我们能否用几个关键的指标代替掉原先高维的维度比较高的数据呢?那么这个呢?叫做数据规约啊,我们数据处理一般是包括这样四大模块。
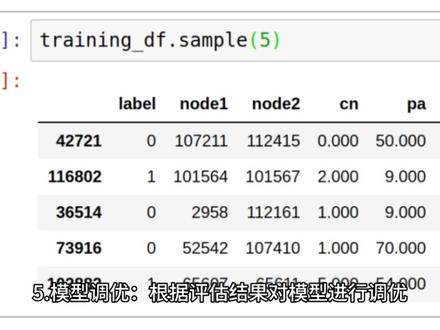 01:25
01:25 13:14查看AI文稿AI文稿
13:14查看AI文稿AI文稿下面我们来学习一下数据的预处理,这张 ppt 给我们一个很清晰的定义,数据预处理是数据挖掘的重要步骤, 是为应对分析中出现的无效数据、超限数据、缺失数据以及矛盾数据而对原始数据进行的一些前处理工作。 它主要包括数据清洗、不一致数据处理、数据集成、数据转换和数据规约。数据清洗的主要目标就是去除原数据之中的脏数据啊,主要是包括一些错误 或者是说有冲突的数据。此外呢,还包括清理噪声数据、无关数据、处理遗漏的数据。 那么数据清洗的主要要求有这么几点啊?第一个就是数据清洗之后的可信性啊,它包括清精确性、完整性、一致性、有效性、唯一性等等指标。 第二个呢就是数据的可用性,他主要的考察指标包括时间性和稳定性,时间性主要是描述数据是当前数据还是历史数据 稳定性,描述数据是否稳定,是否是在有效期之内。另外呢,数据清洗它是一项十分繁重的工作啊,需要投入大量的时间、人力 和物力。在进行数据清洗之前,我们要考虑其物质和时间开设的大小是否会超过我们所能够承受的能力。那么我们先来看一看数据清洗的一些方法。第一个呢,就是缺失数据的处理, 它主要包括这么几个方法,第一个呢就是忽略数据,第二个是推测缺值,第三个填充遗漏项,第四个替代缺失值,第五个建立预测模型等等。 如果只有极少数的缺值或者说缺失的部分数据对后续的处理影响不大,则可以将相关的记录直接忽略不计或者是删除。对于推测缺值而说它的主要意思,我可以举个例子, 比如说我们班同学的学号啊,可以推断出学生所在的年级院系等信息啊。如果说我们的数据中缺少了一些年级院系信息,那么我们也可以通过学号推断得到。 第三个填充遗漏项,就是说将遗漏的属性值用同一个长数来替换。 比如在我们的结构疲劳实验中,对于那些已经到达预期疲劳实验次数,但仍然没有损坏的构件,我们常会用一些简单的标记来标识它的疲劳寿命。 第四个替代缺失值,这个里面我们经常会用一些默认值、中间值、平均值、数据的分布特征等等来进行替代。最后一个呢,就是建立缺失模型,既为有 缺失的属性数据啊,建立一个预测模型,通过回归分析或者是说自主学习等等技术来预测结果股权缺失的属性。 这一页呢,就是给大家提供了一个缺失数据的处理的视力,大家可以看到啊,在这张图表上有一些啊缺失值,那么我们尝试 运用一些啊预测模型来对这个缺失的数据进行一些填补啊,这就是一个数据缺失值的一个处理的基本方法, 下面我们来看一看啊。另外一个概念就是异常值的处理啊,异常值通常又被称为离群点,对异常值的处理通常有以下几种方法啊,第一个呢, 就是简单的统计分析,拿到数据之后,我们可以对数据进行一个简单的描述性的统计性分析,比如说最大值和最小值,可以用来判断这个变量的取值是否超过了合理的范围, 比如说结构的使用寿命啊,不可能是一个负数,但是如果我们得到的数据是一个负数,这显然就是不合常理的,是一个异常值。 第二个呢,就是三 c 个码原则,异常值为一组测定值中与平均值的偏差超过三倍标准差的一个值啊,这就是他的三 c 个码的一个原则。再有就是相形图啊,也是一种啊, 可以识别异常值的一个方法,他也是基于统计分析得到的。再有一个呢,就是建立一个数据模型啊,异常值是与 那些模型不能够完全拟合的对象,格鲁布斯也是一种统计的分析方法。最后一个基于句类,也就是说将彼此相似的对象组合成一个出类。如果说一个数据不属于任何的主类,那么就可以认为这个数据它是一个异常数据。 下面我们来看一看噪声的处理啊。首先我们看一看噪声是什么啊?噪声是指被测量的变量的一个随机错误或边差,他包括错误的值或者是偏离期望的孤立点 啊,他的来源呢,有可能是过早的计算,不准确的测量,传递的误差,算术法的局限,环境的干扰,甚至是敌对欺骗等等。那么处理噪声的方法主要是有分箱、 剧类和回归等等啊。下面我们来看看分箱操作。所谓的分箱操作就是把待处理的数据按照一定的规则放进一些箱子中啊,考察每一个箱子中的数据, 通过考察邻居,也就是说我们说的周围的值,对各个箱子中的数据进行一些平滑处理啊。那么分箱技术需要解决的主要问题有啊,分箱方法,还有数据平滑的方法。 分箱方法中呢,有等宽分箱,就是说每一个桶的区间范围是相同的,另外一个呢是等身分箱,也就是说每个桶它的样本数量是相同的。 另外一方面呢就是数据的平滑方法,我们可以按照平均值或者中值来进行平滑处理,我们也可以按照这个箱中 的边界值来进行平滑处理。那么我们现在来看一看分箱啊,这个是一个等身分箱的视力,我们先把这个箱子的样本进行一个等身分箱,那么分箱之后,我们可以进行一些 相中的操作,比如说均值平滑,又比如说边界平滑,又比如说中位数的平滑啊。每一种方法,最后我们可以把相中的值可以换成统一的一个值啊,实现噪音的排除。 下面我们来看一看剧内啊,剧内呢就是将类似的值组织成群或者积累直观的落在剧内集合之外的值被视为局外者或者说是噪音。下面我们看一看不一 数据的处理,那么对于有一些事物呢,所记录的数据可能存在一些不一致啊,处理这些不一致数据,我们有的时候可以用人工的方式来加以更正,有的时候呢又可以运用我们的知识啊,来对违反一些常规的数据进行排除。 下面呢是数据集成的概念,所谓数据集成呢,就是将多个文件或者是说多数据库运行环境中的易购数据进行合并、处理、解决与易的统一性。 数据的来源呢,它是多样化的,不同的数据库之间通常都存在着巨大的差异,把来自不同数据员的数据合并到一起,以适应挖掘的需要,是数据集成的主要目的。数据集成需要解决的 问题有模式集成,模式集成他主要是实实体。模式集成,他主要是指实体识别,也就是说找出不同原数据的属性之间的关系,判定他是否属于相同的实体,还是说是不同的实体。 你比如说我们在对一个桥梁他的健康状况进行评分的时候,有的时候我们会用 a、 b、 c、 d、 e 五等五个级别, 但有一些评价体系又会把它评价成为一二三、四、五五个级别,怎么能够确定这些来自于不同原数据互动的属性是否属于同一实体呢?这个就是我们实体识别需要做的工作。 另一方面,数据的集成过程中往往会有数据的龙鱼,因此呢,需要进行数据之间的相关性分析啊,决定这个数据是否是重复的,然后再根据这个来决定是否需要删除龙鱼数据。再有, 数据羽翼上的奇异性是数据集成的最大难点,在目前呢,也没有很好的解决办法。你比如说大多数的国家,他在采用应力单位的时候使用的是照帕,但是在部分音质国家,应力单位却用 ksi。 下面我们来看一看数据转换。数据转换的目的呢,就是将原始的数据转换或统一成适合于数据挖掘的形式。那么数据转换主要涉及如下一些内容,第一个呢就是光滑, 也就是去掉数据中的噪声,这种技术呢包括分箱回归和剧类等等。分箱剧类我们前面已经提到了啊,回归顾名思义就是对数据进行一个回归。第二个呢就是聚集,对数据进行汇总或者是聚集。 你比如说材料的强度设计值,可以统一使用百分之九十五保证率对应的去浮强度啊,偏保守地进行表示。还有一些其他的土木工程实验数据,可以用平均值来表示。 第三个是数据放话,使用概念分层啊,用高层次的概念来替换低层次的原始数据。你比如说年龄 age 啊,我们可以把它意识到较高层次的概念,比如说我们有 有一个 a 举的数值,那么我们可以把它定义成是年轻的,还是说是中年,还是说是新娘年龄比较大的。 再来就是数据的规范化,规范化呢是指数据集成按照规范的条件进行合并, 也就是属性值晾缸的归一化处理,目的是消除数值属性因大小不一而造成的挖掘结果的偏差。这里可以看到常见的规范化,有最小最大规范化, 有零君子规范化,也有零一规范化啊,比如说零一规范化里面,我们经常对结构进行一个阵型分析,经常会用到零一规范化。第五个有给定的属性构造和添加新的属性啊,以帮助提高 精度和对高维数的数据进行理解。你比如说我们可以根据属性高宽来添加一个属性面积。再来就是数据归约,当数据库中的数据级非常大的时候呢,那么进行数据分析和挖掘就需要很长的时间。 数据归约技术可以用来得到数据级的归约表示啊,他的量很小,但是呢,仍然可以接近保持原始数据的完整性,使得挖掘更有效,并且能够产生几乎相同的分析结果。 数据规约的方法有这么几种,第一个就是数据立方体,是数据的多维建模语,表示,由维和事实组成。第二个是违规约, 通过删除不相关的属性或者维度啊,减少数据量。第三个是数据压缩,运用数据编码或者变换得到原始数据的规约或者压缩,表示 数据压缩可以分为无损压缩和有损压缩,再有就是数值压缩,他是选择替代的较少的一个数据表示形式来减小数据量。数值压缩呢,可以选择有参,也可以选择无参压缩。 以上呢,就是我们这一章的内容。
 28:56
28:56 02:30查看AI文稿AI文稿
02:30查看AI文稿AI文稿ai 大模型三大要素之一,大数据第四节数据预处理之数据清洗数据清洗是数据分析和数据科学工作中至关重要的一步,直接影响到数据分析的质量和结果的准确性。 以下是数据清洗过程中的几个关键步骤及实施方法。一、去除重复值 removing duplicates 目的,确保数据集中的每个记录都是唯一的, 避免重复数据对分析结果造成偏差。方法,使用数据处理工具或编程语言,如拍散的 pandas 库来识别和删除重复的记录。在数据导入时设置去重规则,防止重复数据的输入。 根据业务逻辑,有时可能需要保留重复记录,可以根据具体情况决定是否去除。二、填补缺失值 飞灵 missing values 目的,处理数据中的空缺或缺失值,以便进行完整的分析。方法,删除,如果缺失值的数量较少,可以直接删除含有缺失值的记录。填充,使用统计方法,如平均值、 中位数、重数或基于模型的预测来填补缺失值差值,对于时间序列数据,可以使用差值方法,如现行差值来估算缺失值。 高级方法,使用机器学习算法,如 knn 差值,基于模型的差值来填补缺失值。 这些方法能够考虑数据的其他特征。三、纠正错误 correction errors 目的,修正数据中的错误,确保数据的准确性和一致性。方法,数据较验定义数据较 调研规则,如数据类型、数据格式、取值范围等。检查并修正不合规的数据。文本清洗,对于文本数据进行拼写检查,去除噪声,如特殊字符、停用词等操作。异常值检测,通过统计分析方法,如镶嵌图、 c 分数来识别和处理异常值。数据转换,将非标准或不一致的数据转换为统一的格式,如日期、时间格式的统一、文本大小写的统一等。 数据清洗是一个迭代和细致的过程,需要根据数据的特点和分析目标进行多次迭代和调整。清洗后的数据及将为后续的数据分析、建模和可视化提供坚实的基础,从而得到更加可靠和有价值的动建。
13航淳技术 20:14
20:14 03:39查看AI文稿AI文稿
03:39查看AI文稿AI文稿欢迎大家收看今天的课程,今天我们主要讲的是第一张发的入文基础啊,在讲发是一个软件之前,我们来先来讲一下关于数据预处理, 因为我们这门课程的话,主要是基于通过 spass 这个软件来处理数据,对数据进行率处理。 好,那我们先来看一下什么是数据处理。数据处理呃的话,它指的是 对所收集的这些数据进行分类或分组之前所做的审核、筛选、排序等必要的处理。大家知大家知道啊,我们一般拿到手的数据不可能是 给你一个很完整的,就是嗯,你心目中想要的这个数据,那这个时候的话,你想对数据进行一些呃深层次的挖掘的话,那可可能是没有那么容易的,那这个时候的话就需要用到我们这个数据预处里了, 所以说这就是呃这个玉柱里的一个来源,当然他也是我们数据挖掘中不可或缺的一部分。 好,那我们来看一下为什么说呃我们要对数据进行预处理的。首先我们拿到的数据 一般哦不能说全部哈,因为呃还是有很多数据是比较完整的,但是一般的数据他都会有一个数据缺失或者是数据异常,这个时候我们就要对 数据进行处理,可能是有些缺失值或者是异常值啊,那还有一个就是我们可能对数据进行抽取部分和抽样部分,因为嗯,在那么庞大的数据中,我们可能只需要部分 呃的数据来进行处理,那么这个时候呃在数据与处理中的这个数据抽样就是形容非常重要的一部分, 还有就是呃数据有可能会有重复性啊,那这个时候我们就可能要去从,还有有些噪声啊,我们要去造啊。还有如果是维度高的话,比如他有非常非常多的变量, 但这些电量的话,我们可能很多的可能都是没有用到的,那这个时候我们需要对数据进行降为,所以说呃,这就是为我们为什么要 进行数据预处理的一个原因。好,那我们数据预处理的主要一些内容是什么?有可能是对数据进行排序啊, 或者是对数据进行一些筛选选举啊,或者是对数据分类汇总啊,这些都是我们后面会在讲大师的这个操作的时候都会讲到。那当然还有数据分组跟呃确认值一强制的一些处理。 那这就是我,我们对数据预处理这个有一个呃,比较笼统的一个概念, 嗯,大概就是呃数据预处理,我们今天就讲到这里啊,我们今天讲的是主要是一个数据预处理的一个概念。然后还有一个就是为什么要进行预处理?呃是可能是因 因为我们的这个数据的一些不完整性,或者是想要达到我们需要的一个目的来进行一个数据的预处理。还有就是说,呃,我们数据预处理搬掉处理的一个内容。好,那我们今天的课程就到这边。
128追梦吧,少年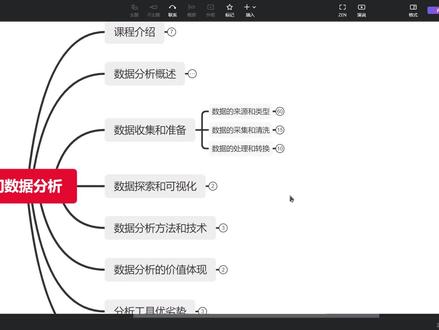 20:10查看AI文稿AI文稿
20:10查看AI文稿AI文稿在上一节课呢,我们讲了那个数据分析的这么一个概述,那么讲的这个数据分析概述呢,就了解了我们去做数据分析会涉及到的一些点, 然后在涉及到的这些点当中呢,我们就会去了解到我们这数据分析他其实是离不开数据的收集跟准备,那么在这个数据收集跟准备当中,我们又会涉及到哪些东西呢?我们来一起来看一下啊。 呃,首先第一个是数据的来源跟类型啊,其次呢就是数据的采集跟清洗这一块呢,主要就是去讲解我们的一个数据他是怎么去采集过来, 采集过来之后哪些数据我们去需要去做一个清洗。那么第三个呢就是一个数据的处理和转换,那么这一块呢,主要就是对数据去做一些预促 处理和他的一些呃初级的一些加工。那么我们这一块这一节课呢,主要是分这三个内容来讲,那么我们先来看这个数据的来源跟类型, 那么像数据来源这一块呢,其实我们就是包含呢有几个方面啊?第一个呢是按照他的这个呃存储的这个方式来分, 那么他会区分为内部数据跟外部数据,那么像这两个板块的一个内部数据呢,很好理解,就是存储在我们内部的一些数据库里面的一些数据, 那么像外部数据呢,他就是面对一些市场的一些数据,那么像这两个数据的一个区分呢,就是内部数据他会比较好获取一些,那么像外部数据呢,他可能就收集起来就比较复杂一些。那么还有呢,按他的一个结构 去进行一个划分,那么他会区分为这个结构化数据,那还有一个非结构化数据,那还有一个时间序列的这么一个数据,还有一个是多维的数据,那么按照结构呢,把它分为这四种, 那么这四种呢?具体可能有些小伙伴就不太理解了,那么我们接下来会去给他做一一的去做一个解释。那最后呢是一个实时数据,那么这个数据其实很好理解,就是我们获取到的数据就是他一旦产生数据,我们就能把他获取到,那么像这部分数据呢,他就主要是一个实时数据。 那么首先我们先从内部数据开始讲起,那其实从内部数据呢,我们是可以给他去区分为呃这么几个数据主题的,第一个呢是销售数据,第二个呢是客户数据,第三个呢是员工数据,第四个是财务数据,第五个是 库存数据,然后第六个呢是供应链的数据,那么像这些数据呢,它都是分不同主题去进行一个存储,那么我们在调用的时候呢,就去呃单独的去调用我们对应的一些呃主题的一些数据也就可以了。 那么在我们数据分析的过程当中,肯定就会涉及到像可能不同的一些数据主题的这么一些数据,他需要去进行一个组合调用。那么像 呃我们的一个销售数据跟客户数据这一块,那么像这这两个板块呢,就是我们经常去算一些用户的复购率啊,或者说像用户价值分成的那个 rfm 的那个模型,他也都会用到 这两个数据的一个组合,那么在这里呢,我们就会去用一些数据库工具的,像一些呃 left join 这种工具呢,去这种方法呢去进行一个调用,那么这个呢是关于数据主题,那么像数据存储呢,其实很显然是存在我们的一个数据库的,那么像这种数据库里面呢,他是比较好调用的,那么他所有的数据都会集成在我们的这个数据库里面, 那么包括我们的一个数据库之外呢,其实我们还会存在一些像 erp 系统这个呢,主要存储的是一些像我们的一些 呃业务的操作的数据。那么还有一个,那就是我们的 crm 的这么一个系统,那么这个系统呢,它主要就是去存储我们一些用户的一些数据,像很多销售型的公司,他都会用到这个 crm 系统去存储他的一个呃 客户的一个数据。那么再往下呢,就是我们的一个外部数据,外部数据这一块呢,其实我们的一个整个数据来源 他是比较宽泛的,那么在这个数据来源当中呢,他首先是会有三个来源,第一个呢是第三方数据的一个提供商,然后第二个呢是我们的一些公共数据,第三个呢是我们的一些社交媒体数据。 呃,很好理解啊,像我们会用到一些第三方的一些数据提供商呢,像我们在做电商的时候可能会用到的一些 ga 的这么一个工具,还有那个呃国内比较流行的那个 gio 的这么一个 呃流量的这么一个工具,他们都属于是那个第三方的一些数据提供商。那么还有呢就是像包括 呃我们去走一些海关,然后他们会给我们提供一些像那种海关的一些数据查询的一些接口,那么这种呢,他也是海关数据的一些提供商,那么像公共数据呢就很好理解。公共数据呢就 是我们去获取的一些像国家的一些进出口贸易的这么一些数据,他那种数据他就属于那种公共数据。那么还有像社交媒体这一块的数据呢,也很好理解,就是我们在呃使用到的一些像微博,呃微信公众号, 还有就是我们的一些呃其他的一些网站,他会有一些像那种社交媒体的这么一些评论或者说是文章,那么像那些他就是属于我们那些社交媒体的数据,那么像这些数据他其实都可以用来去监控我们的一个整个市场趋势,还有就是我们的一个舆论导向。 那么在这些外部数据的获取当中呢,我们会用到一些像 a p i、 接口爬虫或者是手动下载的这么一些形式,去把这些外部数据呢去留存到我们的这个数据里系统里面来。那么 这个外部数据我们的一个主要用途呢?其实它就是用于一个市场研究,然后竞争情报以及一些消费者行为的一个分析。那么这个呢就是我们所指的一些外部数据,它是怎么样子的一个数据? 那么我们再往下去细分,他在结构化数据这个板块呢?他像这个结构化,什么叫结构化数据呢?其实像结构化数据就是具有明确定义的一些数据结构和格式的一些数据,他叫结构化的数据, 像这种数据呢,他通常都是以那种表格数据库,电子表格的这种形式呢,存在的一些数字日期跟文本, 那么像这种的就很好理解,他是有一个比较呃结构的这么一个数据,他可能就是一个表单,或者说是一些呃特定的一些表格的一些形式。那么我们像 这种数据的一些处理方式呢,我们就是用一些关系型的数据库去直接去写查询的语句,就可以直接调用。那么还有呢,就是用 excel 这种形式去处理一些像 excel 的一些文档或者 csv 的一些文档,通过这些形式呢去进行一个存储跟处理。 那么这个呢是结构化数据这一块呢,也是我们在做数据分析的时候,我们会接触到的相对比较多的一些数据,那么像这种数据呢,我们就是结构化的数据, 那么再往下呢,就是一个非结构化的数据,那么像这种非结构化的数据呢,其实它就是没有一个特定的一个结构或者格式来存储,那么像这种 数据呢,它通常是以一些文本,像我们去查询的一些文章,其实它就是属于那种非结构化的一些数据,还有呢就是我们所说的一些图, 图片、图像,还有就是我们发的一些语音还有视频这些数据呢,他就是一个非结构化的数据。那么我们对于这种非结构化的一些数据呢,我们那些处理方式就要呃稍微复杂一点,我们就会用到一些啊自然 语言处理、图像处理这些技术呢,去进行一些处理和分析,那么像这里面呢,他就会涉及到这种就是 nlp 的一些算法, nlp 呢他就是一个自然语言处理的这么一个算法, 那么在这里呢,就是这个非结构化数据呢,其实我们在数据分析的这个领域,其实是遇到的比较少的,那么还有再往下呢,就是我们的一个时间序列的一个数据, 那么时间序列的这个数据呢,我们就是按照时间顺序排列的一些数据,像我们的一些每天的一个股票的价格气象的数据啊,还有网 在访问量这种数据呢,他就是以这种就是时间序列的一种形式去存储的。那么当然其实像这种时间序列的一个数据呢,他也是属于结构化数据的范畴,那么在这里我们把它单独拎出来呢,是因为像这种 时间序列的这么一个数据呢,他是相较于会更加的有结构一些,因为他都是以每天的这种形式去存储,他是呃存在一定的这种,就是 像我们的一些重复,或者会产生一些勇于的一些数据,那么像时间序列的数据,他的处理起来跟那种常规性的结构化数据有点不太一样。 那么像这种呢,我们也是通过一些关系新数据库,还有 excel 这种形式去进行一些存储跟处理。那么像我们这种时间序列数据呢,我们的一个用途就是时间序列的一些分 分析,像趋势分析、季节性分析这些,我们都会用到一些时间序列的数据,那么在这里可能小伙伴就会有疑问,那么像这种我们每天的一个销量,其实这种算不算我们的时间序列,其实他也是算的,那么像我们去呃 电商里面的一些订单数据,它其实也算是我们的一个时间训练的数据, 那么像这个呢,时间序列的数据其实就是呃也相对比较好处理一点,我们再去做数据分析的时候也会遇到的比较多。 还有呢就是我们的一个多维数据,多维数据这一块呢,其实他就是包含多个纬度或者属性的这么一些数据,他的一些形形态呢,主要是就是像那种数据立方体或者多维的数组,那么像这种形式他去生成的一些数据, 那么像这种处理方式呢,他就要用特定的 o、 l、 a、 p 的这种在线分析处理的这么一个方式,还有数据挖掘的这些算法去进行一个我们多维数据的一个处理。其实 在我们的一些就是常用的一些方法当中,我们的一个 rfm 模型呢,它就是一个比较典型的一个三维数据的一个数组。 那么像这种呢,我们去生成的他就是一个有三个维度的一个结构,那么他有就是购买金额的维度,购买数量的维度以及呃距今购买日期的这么一个维度。那么像这种呢,他是以三个维度来去评判这个数据他的好与不好。 那么像实时数据这一块呢,其实他就很简单了,就是我们实时生成的或者是收集的一些数据。那么在这里面我们会涉及到什么数据方式呢?像我们 们在呃电商领域的这种仓库,他去发货,那么我们在发货的时候呢,我们肯定就要去扫那些 sq 的一些条码,那么通过那个扫码枪去扫那个条码呢?他生成的数据呢?其实就是一个实时数据。那么像这种他既然实时产生了,我们就要去实时对他去进行一些分析, 那么像这种实时数据,他的一些分析工具呢?他的一些数据传输工具呢?这个还是比较多的。那么像他的一些处理工具,跟我们的一些关系型数据库的一些处理方式是一样的,他也都可以用我们的关系型数据库去进行一个处理, 或者说用 excel 去进行处理,那么他其实就只是在数据传输的时候,对这个时效性的要求会比较高。他可能就像我们去聊微信一样,就是他产生一条数据,对面就要收到一条数据,那么在中间的过程当中,他就会 涉及到一个网络,网络传输的这么一个动作。那么像市面上比较多的一些像这种传输工具叫菲令克卡夫卡这些他都是可以去实现这个实时数据的这么一个传输,他也是用的 相对比较多一些。但是我们在做数据分析的时候,因为计算量比较大,我们比较少会用这种实时数据去进行计算,那么主要的还是像那种离线数据,像 t 加一的这么一个数据去进行一个分析, 那么有了数据了之后,我们就要去对他去进行一个采集,那么了解了我们的数据来源和类型,我们就要去对对这个数据去进行一个采集。 那么在这个采集的过程当中呢,我们会设置一些什么点呢?首先我们就要去去了解我们的一个数据采集的一个计划,那么在这里呢,我们就是 主要去制定详细的数据采集的计划,包括我们确定采集的数据类型、来源,采集方法跟采集频率。那么在还有呢就是我们要去进行一个数据员的识别,那么我们要去了解我们采集的这些数据呢, 他是一个什么样子的一个数据,那么他可能存在内部的数据员或者是外部的数据员,那么像这些数据员他具体的一个结构以及我们采集的方式他不太一样。 那么还有呢就是我们的一些数据采集的方法,那么像网页抓取呢这种它主要就是用于那种外部数据的一个连接,还有 api 调用,他也是在一些数据提供商上面,他会用一些 api 进行调用的这种形式去采集我们的数据。 那么还有呢就是像内部数据呢,我们就会用一些数据库连接的这么一些形式,还有像文件下载这种,我们可以 从一加 p 或者是 crm 里面去下载他的一些表达数据,那么这种呢主要是针对我们那些内部的一些数据,当然外部呢他也会存在这种就是文件下载的这种形式。像我用的比较多的就是呃国家提供的那个 就是汇率的中间价的这么一个数据,我基本上都会呃一周去下载一次,因为像这种的他是一个实时的一个汇率波动,那么在这里呢就是我去采集的一个次数越多,那么我能够拿到的一个波动数据,他就会越灵敏, 那么在数据采集工具当中呢,我们也会向 vivo 抓取工具,那么像这种工具呢,像 python 这些工具,它就是有这种爬虫的能力,那么像这种呢,它也是一个 vivo 的一个抓取工具,那么 除了拍摄这种需要编程的,那么我们其实还可以用像一些加瓦这些编程工具去获取。那么除了这些,我们还有一些像市面上用的比较多的,像火车头、八爪鱼这种 抓取工具,我们也是 ok 的,也是可以去爬取我们的一些网络数据。除了这些工具,我们还可以用这些 etl 的工具去做一个采集,那么在这个 etl 的工具当中呢, 我们肯定就会用到一些像什么呃, ketler、 deter 叉这种就是离线的 etl 工具。那么还有像我们刚刚提到的像什么飞宁可卡福卡这种,它的一个实时数据 etl 的工具,它也是 ok 的。 那么像这种数据采集的工具呢,他可能还会涉及到像 excel 的这么一个表单的数据,那么像这种 excel 表单的数据呢,就是我给你个 excel 表,然后你帮我填回来给 就可以了。那么在这里呢,我们要去注意的一个点就是数据的一个质量控制,那么在采集的过程当中,我们是要去确保我们采集的一个数据的准确、完整、一致和可靠的,因为如果说我们采集下来的数据就是他不准确或者不完整, 他不是一致的话,这种的话我们可能去后后续去做的一些工作,像我们分析出来的一个准确性可能会受到偏差。那么还有就是我们去做数据清洗的这么一个呃时间就会比较长, 那么这个呢就是我们的一些数据采集和清洗的这么一个内容。那么再往后我们采集回来之后,我们做了清洗之后,其实我们就要开始对数据去进行一个呃处理和转换,那么在处理和转换这里呢,我们会设计到几个方 方法,第一个呢就是缺失值的处理,第二个呢是异常值的处理,那么像这种缺失值跟异常值的处理呢,我们主要就是去识别和处理数据中的缺失值或者是异常值,那么 在这里面呢,他就会包括像删除啊或者插补替代的一些方法去处理这个异常值或者是缺失值。那么在这里呢,我们去 做这么一些方法,主要是为了保证我们后面分析的一些准确性,因为这些缺失值或者异常值他可能会影响到我们的一个分析结论, 那么像他的一个准确性的话,可能就会受到一些影响。那么在这里呢,我们会尽量的把我们的缺失值和异常值去做一个呃删除、插补或者是替代的一个工作。那么除了这些异常值的处理,我们还会涉及到一些数据的一个 格式化,那么也就是将我们的数据转换成统一的格式,包括日期格式、数字格式跟文本格式等等。那么像这些格式呢,就是我们根据我们的一个分析需求,去具体的把我们的数据去做一个格式化的处理。 还有呢就是去做一个数据驱虫,因为我们在取出来的数据当中,他有可能就是同一笔数据,他可能取的会有两条数据这种情况,那么这种情况因为可能是软件的重复 呃使用导致的,所以在这里面呢,我们也要去把这些数据去做一个驱虫的处理去就是保证我们在整个数据当中他是一个唯一的。 那么在数据标准化当中呢?我们为什么要去做一些数据标准化呢?也就是我们要把我们的数据呃转换成相同的单位比例或者是 维度的这么一个范围,比较他的大小,或者说是去进行一个加减计算他的一些评分什么的。那么在评分体系里面,这个数据标准化是用的相对比较多,因为你的销量跟你的销售额肯定他不是同一个维度的, 那么在这里呢,我们就要想办法去给他转换成同一个维度,因为你销量一件,可能你的销售额就是一百件,那么在这里你的一跟一百肯定是一百比较大, 那么同样的有另外一个产品他销售了两件,但是他销售额呢是有五百的,那么其实你这样去盘算下来的话呢, 二跟五百这样比较下来,他肯定是五百会更大一些。所以在这里呢我们要先做一个数据标准化的这么一个动作,然后呢去进行一个比较,他会比较好一些,去做一些评分,这样子的话会用的比较多。那么我 我们常用的一些数据标准化的一些算法呢,就是呃 minimax 的标准化,还有呢就是 z corey 的一个标准化,还有呢就是一个 log 函数的一个标准化,这些呢是我们比较常用的一些标准化的一些方式。 呃,最后呢就是我们在数据处理当中呢,其实我们就会涉及到一个数数据合并,那也就是像刚刚我们在最开始的时候提到的,我们在 销售数据跟用户数据的时候,因为我们算什么复购率,或者是 r f f 模型的时候,我们要去把这个用户数据跟我们的销售数据去进行一个合并,那么也就是他不同的一些数据员获取到的数据,我们要把它去合并到一个数据级里面, 那么这样子呢,去进行一个综合分析,然后分析我们的复购率,分析我们的一个用户分成这样子的一些数据,那么像这种呢,它就是一个数据合并,那么 那么在我们的一个数据库语言当中呢,我们可以用那个 left join 这么一个方法去进行一个合并,或者是 in the join, 或者是那个一个外连接。那么这个 left join 这个可以怎么去理解呢?就是我们在数学上面所学到的那种交集,或者说是并集的这么一个形式,他叫数据的一个连接,那么在数据库的代码里面他叫数据连接,那么在我们的一些数据处理上面呢,我们叫做数据合并, 那么这个呢,其实他只是说叫法不同,他的并不会特别影响啊。然后呢我们在 excel 当中呢,也会有这种数据合并的一个情况,那么其实我们在 用那个 excel 的时候,会有一个东西叫合并计算,那么像这种合并计算呢,他也就是把两个不同数据员的数据呢去合并成同一个数据级,然后呢在这里去做一个综合分析,那么在 excel 里面也是可以实现的,这样子可能会大家比较好理解一点。
16Adrian. 05:19查看AI文稿AI文稿
05:19查看AI文稿AI文稿同学们大家好,我们目前已经学过了关于句类算法的基本知识,下面我们将进行一个完整的时间案例,从数据的摘取,数据的预处理,可实化到最终应用算法来进行分析和建模的过程。然后呢,通过这个案例,同学们会学到什么?首先第一步加载数据集,并且观察 我的数据结到底是什么样的,识别其中的出错的点和缺失的值,对它进行处理。与此同时呢,我们还会学会重新对数据进行编码, 以达到的什么目的呢?就是说可以让拍摄来识别一些之前被替换掉的那些不能识别的字符,我们可以用可以识别的字符让他进行识别。 然后下一步就是对缺失值的处理,首先第一个就是找到缺失值,缺失值呢一般会以像副版九百九十九, 然后呢还有就是 no, 还有 no 这些值来进行标注,然后呢,下一步就是删除缺失值,删除呢,总共大概有四种常见的方法,然后在下一节课的具体的项目中我们会介绍, 然后接下来的下一步,通过删除清除,还有一些去除这些对数据的一些基本操作,还有转换数据的类型。之后呢,我们会进入到特征工程,特征工程主要包含的几个方向,一个是对于剧类的一个类别的识别和组合, 很可能就是有些特征呢,他单独并不是非常有用,但是呢,当两个特征组合在一起的时候,其实对于剧类来说是非常有用的,所以说我们要对特征进行组合和摘取,去除对我们未来预测没有用的特征, 保留有用的特征,这个就是一个特征工程的聚合,也就是特征的识别。 接下来我们会对特征进行一个可视化,我们可以用这种香型图来识别到底每一个特征,他具体对于价格呀,对于其他的一些我们所希望预测的这些变量有什么影响, 这是一个可视化的功能,然后呢,我们会通过生成这种的图表来对他进行分析。当然了这个香型图上面的这些黑色的点其实就是异常点啊,这个在下一课中我们也会统一的进行讲述。 然后接着的下一步,也就是数字变量的转换。为了更便于识别,我们把前面的这些很多零的或不容易识别的这些数进行一个转换。我们常用的有什么密转换,还有 log 的对数转换。转换完之后呢, 整个图的图表的形态其实是不会发生太多的变化的,但是我们看这边的这个竖轴上的这些点,由原来的零点零零零零几啊变成了一,然后呢零点八这些可识别的数,所以说他同比例的缩放之后呢,会更加便于我们的分析。 当然了整个数据的倾斜程度这些是不发生改变的,所以说对数转换以及等等的这些密转换,这些数据转换只会有助于我们的分析,并不会改变我们数据及原有的形貌。 然后最后我们会生成一些可视化的散点图,然后来观测到底每一个变量的影响是多少,我们甚至可以通过他这个颜色的深浅,发现他的一个在某一个区间内的一个聚合的程度,当然了原颜 颜色越深,他的聚合其实就是越明显的。同样这个例子讲述完成之后,可以给大家留一个下一个作业,同样我们也可以进行数据的预处理、编码等等的操作。但是最后呢,我们会发现我们可以引入一种 这种钢琴图,钢琴图是用来干什么的呢?它其实就是两副密度图的一个背对背的叠加,对吧?我们可以看出每一个值的区间内部到底这个值的分布有多少, 我们可以看出它的频率对吗?所以说箱型图跟这个小提琴图都是我们需要掌握的一个分析工具。比如说这个图,我们对于贷款的数额来看,其实有两种,一个是违约的,一个是不违约的,他们之间呢,你看啊,有一个这个上面的这个越来 来越细的这块说明再往上走的时候,其实他的这个 value 是越来越高的,但是呢,这个区间的人却越来越少,相比之下 value 在大概三千左右的,对于蓝色来说是最多的,对于这个橘红色来说也是最多的。 这个是其实 y 六出于相等的情况下的,就是等频率的情况,当然也有不等的。我们看上面的这张图,橘红色的 y 六的最大值很可能是在三点二五,但是呢,这个蓝色的最大值其实是在三点五零。所以说我们通过背靠背的这种 密度图,我们可以观测到它具体的每一个数值的分布的人员到底有多少,或者说对应的变量有多少,这个也是我们数据分析中一个比较常用的工具。所以说通过这个实践 之后,下一步我们把数据的预处理的工作做完之后,就进入了我们最熟悉的,也就是数据的一个聚合和聚累的过程。我们会用 kmins 算法对这些数据,像汽车工业的这些数据,还有这些客户贷款量的数据来进行聚累。
3故里街





