Llms大模型新手教程

粉丝5.9万获赞28.3万
相关视频
 25:11查看AI文稿AI文稿
25:11查看AI文稿AI文稿okay, so let's begin first of all what is a large language model really well, a large language model is just two files right, there will be two files in this hypothetical directory so for example we're going with the specific example of the lama 270b model this is a large language model released by meta ai and this is basically the llama series of language models the second iteration of it and this is the 70 billion parameter model of a of the series so there's multiple models belonging to the llamato series, 7 billion, 13 billion, 34 billion and 70 billion is the biggest one now many people like this model specifically because it is probably today the most powerful open weights model so basically the weights and the architecture and a paper was all released by metas, so anyone went can work with this model very easily by themselves this is unlike many other language models that you might be familiar with for example if you're using chatupt or something like that the model architecture was never released it is owned by open ai and you're allowed to use the language model through a web interface, but you don't have actually access to that model so in this case the llama270b model is really just two files on your file system, the parameters file and the run some kind of a code that runs those parameters so the parameters are basically the weights or the parameters of this neural network that is the language model we'll go into that in a bit because this is a seventy billion parameter model uh, every one of those parameters is stored as two bites and so therefore the parameters file here is hundred and forty gigabytes and it's two bites because this is a float 16 number as the data type now in addition to these parameters that's just like a large list of parameters for that neural network you also need something that runs that neural network and this piece of code is implemented in our run file now this could be a c file or a python file or any other programming language really it can be written any arbitrary language but c is sort of like a very simple language just to give you a sense and it would only require about 500 lines of c with no other dependencies to implement the neural network architecture and that uses basically the parameters to run the model so it's only these two files you can take these two files and you can take your macbook and this is a fully self contained package this is everything that's necessary you don't need any connectivity to the internet or anything else you can take these two files you can pile your c code you get a binary that you can point at the parameters and you can talk to this language model so for example you can send it text like for example write a poem about the company scale ai and this language model will start generating text and in this case it will follow the directions and give you a point about scale ai now the reason that i'm picking on scale ai here and you're going to see that throughout the talk is because the event that i originally presented this talk with was run by scale ai and so i'm picking on them throughout throughout the slides a little bit just in an effort to make it concrete so this is how we can run the model just requires two files just requires a macbook i'm slightly cheating here because this was not actually in terms of the speed of this video here this was not running a seventy billion primary model it was only running a seven billion primary model a seventy b would be running about ten times slower but i wanted to give you an idea of sort of just a text generation and what that looks like so not a lot is necessary to run the model this is a very small package but the computational complexity really comes in when we'd like to get those parameters so how do we get the parameters and where are they from because whatever is in the run that sea file, the neural network architecture and serve the forward pass of that network everything is algorithmically understood and open and so on, but the magic really is in the parameters and how do we obtain them so to obtain the parameters basically the model training as we call it is a lot more involved than model inference which is the part that i showed you earlier so model inference is just running it on your macbook model training is a competitionally very involved process so basically what we're doing doing can best be served understood as kind of a compression of a good chunk of internet so because llama27b is an open source model we know quite a bit about how it was trained because meta released that information in paper so these are some of the numbers of what's involved you basically take a chunk of the internet that is roughly you should be thinking ten terabytes of text this typically comes from like a crawl of the internet so just imagine uh just collecting a tons of text from all kinds of different websites and collecting it together so you take a large aquam internet then you procure a gpu cluster and these are very specialized computers intended for very heavy competitional workloads like training of neural artworks you need about six thousand gpus and you would run this for about twelve days to get a llama two seventy b and this would costs you about two million dollars and what this is doing is basically it is compressing this large chunk of text into what you can think of as a kind of a zip file so these parameters that i showed you in an earlier slide are best kind of thought of as like a zip file of the internet and in this case what would come out are these parameters hundred and forty gigabytes so you can see that the compression ratio here is roughly like a hundred x roughly speaking but this is not exactly a zip file because a zip file is lossless compression what's happening here is a lossy compression we're just kind of like getting a kind of a gestalt of the text that we trained on we don't have an identical copy of it in these parameters and so it's kind of like a lossy compression you can think about it that way the one more thing to point out here is these numbers here are actually by today's standards in terms of state of the art rookie numbers so if you want to think about state of the art neural networks like say what you might use in chat apt or clod or bard or something like that these numbers are off by factor of 10 or more so you would just go in and you would just like start multiplying by quite a bit more and that's why these training runs today are many tens or even potentially hundreds of millions of dollars at very large clusters, very large data sets and this process here is very involved to get those parameters once you have those parameters running the neural network is fairly competitionally cheap okay so what is this neural network really doing right i mentioned that there are these parameters this neural network basically is just trying to predict the next word in a sequence you can think about it that way so you can feed in a sequence of words for example catsat on a this feeds in into a neural net and these parameters are dispersed throughout this neural network and there's neurons and they're connected to each other and they all fire in a certain way you can think about it that way and outcomes a prediction for what word comes next so for example in this case this neural network might predict that in this context of four words the next word will probably be a mat with say ninety seven percent probability so this is fundamentally the problem that the neural network is performing and this you can show mathematically that there's a very close relationship between prediction and compression which is why i serve allude to this neural network as a kind of training it is kind of like a compression of the internet because if you can predict sort of the next word very accurately you can use that to compress the data set so it's just the next word prediction your network you give it some words it gives you the next word now the reason that what you get out of the training is actually quite a magical artifact is that basically the next word perdition task you might think is very simple objective but it's actually a pretty powerful objective because it forces you to learn a lot about the world inside the parameters of the neural network so here i took a random web page at the time when i was making this talk i just grabbed it from the main page of wikipedia and it was about ruth handler and so think about being the neural network and you're given some amount of words and trying to predict the next word in a sequence well in this case, i'm highlighting here in red some of the words that would contain a lot of information and so for example in if your objective is to predict the next word presumably your parameters have to learn a lot of this knowledge you have to know about ruth and handler and when she was born and when she died who she was what she's done and so on and so in the task of next war production you're learning a ton about the world and all this knowledge is being compressed into the weights the parameters now how do we actually use these neural networks well once, we've trained them i showed you that the model inference is a very simple process we basically generate what comes next we sample from the model so we pick a word and then we continue feeding it back in and get the next word and continue feeding that back in so we can iterate this process and this network then dreams internet documents so for example if we just run the neural network or as we say perform inference we would get sort of like web page dreams you can almost think about that way right because this network was trained on web pages and then you can sort of like let it loose so on the left we have some kind of a java code dream it looks like in the middle, we have some kind of a what looks like almost like an amazon product dream and on the right we have something that almost looks like wikipedia article focusing for a bit on the metal one as an example the title, the author, the isb and number everything else this is all just totally made up by the network, the network is dreaming text from the distribution that it was trained on it's just mimicking these documents, but this is all kind of like hallucinated so for example the eyes be in number this number probably, i would guess almost certainly does not exist uh the model network just knows that what comes after eyes be in column is some kind of a number of roughly this length and it's got all these digits and it just like puts it in it just kind of like puts in whatever looks reasonable so it's parating the train dataset distribution on the right the black nose dace, i looked it up and it is actually a kind of fish and what's happening here is this text for betham is not found in a training set documents, but this information if you actually look it up is actually roughly correct with respect to this fish and so the network has knowledge about this fish it knows a lot about this fish it's not going to exactly parrot documents that it saw in the training set, but again in some kind of a lot some kind of a lossy compression of the internet it kind of remembers to get styled it kind of knows the knowledge and it just kind of like goes and it creates the form it creates kind of like the correct form and fills it with some of that's knowledge and you're never hundred percent sure if what it comes up with is as we call hallucination or like an incorrect answer or like a correct answer necessarily, so some of the stuff could be memorized and some of it is not memorized and you don't exactly know, which is which but for the most part this is just kind of like hallucinating or like dreaming internet text from its data distribution okay let's now switch gears to how does this network work? how does it actually perform this next word prediction task what goes on inside it? well, this is where things complicated a little bit this is kind of like the schematic diagram of the neural network if we kind of like zoom in into the toy diagram of this neural net this is what we call the transformer neural network architecture and this is kind of like a diagram of it now what's remarkable about this neural net is we actually understand in full detail the architecture we know exactly what mathematical operations happen at all the different stages of it the problem is that these one hundred billion parameters are dispersed throughout the entire neural network and so basically these billing parameters of billions of parameters are throughout the neural lot and all we know is how to adjust these parameters alternatively to make the network as a whole better at the next word prediction task, so we know how to optimize these parameters we know how to adjust them over time to get a better next word prediction, but we don't actually really know what these hundred billion parameters are doing we can measure that it's getting better at the next work prediction, but we don't know how these parameters collaborate to actually perform that we have some kind of models that you can try to think through on a high level for what the network might be doing so we kind of understand that they build and maintain some kind of a knowledge database but even this knowledge database is very strange and imperfect and weird so a recent viral example is what we call the reversal course so as an example if you go to chat gpt and you talk to gpt for best language model currently available you say who is tom cruise mother it will tell you it's merely fifer which is correct but if you say who is merely fifer son it will tell you it doesn't know so this knowledge is weird and it's kind of one dimensional and you have to sort of like this knowledge isn't just like stored and can be accessed in all the different ways if sort of like ask it from a certain direction almost and so that's really weird and strange and fundamentally we don't really know because all you can kind of measure is whether it works or not and with what probability so long story short think of llms as kind of like mostly mostly inscrutable artifacts they're not similar to anything else we might built in an engineering discipline like they're not like a car where we serve understand all the parts there are these neuralness that come from a long process of optimization and so we don't currently understand exactly how they work although there's a field called interpretability or mechanistic interpretability trying to kind of go in and try to figure out like what all the parts of this neural net are doing and you can do that to some extent, but not fully right now, but right now we kind of treat them mostly as empirical artifacts we can give them in some inputs and we can measure the outputs we can basically measure their behavior we can look at the text that they generate in many different situations and so i think this requires basically correspondingly sophisticated evaluations to work with these models because they're mostly empirical, so now let's go to how we actually obtain an assistant so far we've only talked about these internet document generators right and so that's the first stage of training we call that stage pre training we're now moving to the second stage of training which we call fine tuning and this is where we obtain what we call an assistant model because we don't actually really just want document generators that's not very helpful for many tasks we want to give questions to something and we wanted to generate answers based on those questions so we really want an assistant model instead and the way you obtain these assistant models is fundamentally through the following process we basically keep the optimization identical, so the training will be the same as just the next work prediction task, but we're going to swap out the data set on which we are training so it used to be that we are trying to train on internet documents we're going to now swap it out for datasets that we collect manually and the way we collect them is by using lots of people so typically a company will hire people and they will give them labeling instructions and they will ask people to come up with questions and then write answers for them so here's an example of a single example that might basically make it into your training set so there's a user and it says something like can you write a short introduction about the relevance of the term on up sunny and economics and so on and then there's assistant and again the person fills in what the ideal response should be and the ideal response and how that is specified and what it should look like all just comes from labeling documentations that that we provide these people and the engineers at a company alike open ai or anthropic or whatever else will come up with these lead labeling documentations now the pretreating stage is about a large quantity of text, but potentially low quality because it just comes from the internet and there's tens of hundreds of terabyte tech offict and it's not all very high quant quality but in this second stage we prefer quality over quantity so we may have many fewer documents for example hundred thousand, but all of these documents now are conversations and there should be very high quality conversations and fundamentally people create them based only a bling instructions so we swap out the data set now and we train on these q amp。 a documents we and this process is called fine tuning once you do this you obtain what we call an assistant model so this assists the model now subscribes to the form of its new training documents so for example if you give it a question like can you help me with this code it seems like there's a bug print hello world even though this question specifically was not proud of the training set the model after its fine tuning understands that it should answer in the style of a helpful assistant to these kinds of questions and it will do that so it will sample word by word again from left to right from top to bottom all these words that are the response to this query and so it's kind of remarkable and also kind of empirical and not fully understood that these models are able to sort of like change their formatting into now being helpful assistance because they've seen so many documents of it in the fine training stage, but they're still able to access and somehow utilize all of the knowledge that was built up during the first stage the pre training stage so roughly speaking pre training stage is um training on trains on a ton of internet and is about knowledge and the fine training stage is about what we call alignment it's about sort of giving um it's about changing the formatting from internet documents to question and answer documents in kind of like a helpful system manner so roughly speaking here are the two major parts of obtaining something like chat gpt there's the stage one pre training the end stage 2 fine training in the pre training stage you get a ton of text from the internet you need a cluster of gpus so these are special purpose sort of computers for these kinds of peril processing workloads this is not just things that you can buy and best buy these are very expensive computers and then you compress the text into this neural network into the parameters off it typically this could be a few sort of millions of dollars and then this gives you the base model because this is a very competitionally expensive part this only happens inside companies maybe once a year or once after multiple months because this is kind of like very expensive, very expensive to actually perform once you have the base model you enter definering stage which is computationally a lot cheaper in the stage you write out some legal instructions that basically specify how your assistant should behave then you hire people so for example scalei is a company that actually would would work with you to actually basically create documents according to your labeling instructions you collect 100 thousand as an example high quality ideal q amp。 a responses and then you would fine tune the base model on this data this is a lot cheaper this would only potentially take like one day or something like that instead of a few months or something like that and you obtain what we call an assistant model then you run a lot of evaluations you deploy this and you monitor collect misbehaviors and for every misbehavior you want to fix it and you go to step on and repeat and the way you fix the misbehaviors roughly speaking is you have some kind of a conversation where the assistant gave an incorrect response so you take that and you ask a person to fill in the correct response and so the person overwrites the response with the correct one and this is then inserted as an example into your training data and the next time you do the fine tuning stage the model will improve in that situation so that's the iterative process by which you improve this because fine tuning is a lot cheaper you can do this every week every day or so on and companies often will iterate a lot faster on the fine tuning stage instead of the pre training stage one other thing to point out is for example, i mentioned the llama two series the llama two series actually when it was released by meta contains both the base models and the assistant models so they release both of those types the base model is not directly usable because it doesn't answer questions with answers it will if you give it questions, it will just give you more questions or it will do something like that because it's just an internet document sampler, so these are not super helpful or they are helpful is that meta has done the very expensive part of these two stages they've done the stage one and they've given you the result and so you can go off and you can do your own fine tuning and that gives you a ton of freedom but meta and addition has also released assistant models so if you just like to have a question answer you can use that assistant model and you can talk to it okay so those are the two major stages now see how in stage two i'm saying end or comparisons i would like to briefly double click on that because there's also a stage three of fine tuning that you can optionally go to or continue to in stage three of fine tuning you would use comparison labels so let me show you what this looks like the reason that we do this is that in many cases it is much easier to compare candidate answers than to write an answer yourself if you're a human labler so consider the following concrete example suppose that the question is to write a haiku about paperclips or something like that from the perspective of a labeler, if i'm asked to write a haiku that might be a very difficult task right like i might not be able to write a haiku, but suppose you're given a few candidate hikus that have been generated by the assistant model from stage 2 well, then as a labeler you could look at these hikus and actually pick the one that is much better and so in many cases it is easier to do the comparison instead of the generation and there's a stage three of fine tuning that can use these comparisons to further fine tune the model and i'm not gonna go into the full mathematical detail of this at open ai, this process is called a reinforcement learning from human feedback or rlhf, and this is kind of this optional stage three that can gain you additional performance in these language models and it utilizes these comparison labels, i also wanted to show you very briefly one slide showing some of the labeling instructions that we give to humans so this is an excerpt from the paper instruct gpd by opening eye and it just kind of shows you that we're asking people to be helpful, truthful and harmless these labeling documentations though can grow to you know tens or hundreds of pages and can be pretty complicated, but this is roughly speaking what they look like one more thing that i wanted to mention is that i've described the process and evenly as humans doing all of this manual work, but that's not exactly right and it's increasingly less correct, and and that's because these language models are simultaneously getting a lot better and you can basically use human machine sort of collaboration to create these labels with increasing efficiency and correctness and so for example you can get these language models to sample answers and then people sort of like cherry pick parts of answers to create one sort of single best answer or you can ask these models to try to check your work or you can try to ask them to create the comparisons and then you're just kind of like in an oversight roll over it so this is kind of a slider that you can determine and increasingly at these models are getting better words moving the slider sort of to the right okay finally i wanted to show you a leaderboard of the current leading larger lockage models out there so this for example is a chatbot arena it is managed by team at berkeley and what they do here is they rank the different language models by their elo rating and the way you calculate elo is very similar to how you would calculate in chess so different chess players play each other and uh you depending on the wind rates against each other you can calculate the eat their elos course you can do the exact same thing with language models so you can go to this website you enter some question you get responses from two models and you don't know what models they were generated from and you pick the winner and then depending on who wins and who loses you can calculate the elo scores so the higher the better so what you see here is that crowding up on the top you have the proprietary models these are closed models you don't have access to the weights they are usually behind a web interface and this is gpt series from open ai and a clod series from anthropic and there's a few other series from other companies as well, so these are currently the best performing models and then right below that you are going to start to see some models that are open weights so these weights are available a lot more is known about them there are typically papers available with them and so this is for example the case paulama two series from meta or in the bottom you'll see zefri 7b beta that is based on the mystrial series from another startup in france, but roughly speaking what you're seeing today in the ecosystem is that the closed models work a lot better, but you can't really work with them fine tune them download them etc you can use them through a web interface and then behind that are all the open source models and the entire open source ecosystem and all the stuff works worse, but depending on your application that might be good enough and so importantly i would say the open source ecosystem is trying to boost performance and sort of chase the proprietary ecosystems and that's roughly the dynamic that you see today in the industry。
91萧珩 AIGC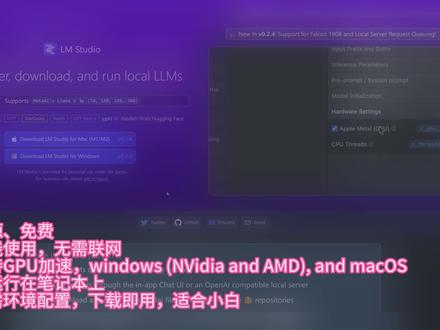 03:12查看AI文稿AI文稿
03:12查看AI文稿AI文稿全网最简单的免费使用各种 l l m 模型教程,如果你想使用人工智能产品帮助提升工作效率,但是又没有米,不会魔法,不会拍摄,也不懂如何配置环境,那么这个视频教程绝对适合你。 今天这个视频主要给大家分享一款免费开源的 l m 软件, l m to deal。 l m to deal 是一个易于使用且功能强大的本地机,可在 windows 和 macos 上使用,并具有 gpu 加速功能,支持很多主流 l l m 模型, 比如辣妈 m p t replate 等。下面给大家讲一下如何使用以及使用过程中的注意细节。首先要在官网下载 l m studio 软件, 我们先测试一下 windows 系统下的使用体验,下载后直接装机就可以打开软件, 这就是软件的主页面,在主页中会有一些推荐的模型,可以在推荐项中选中直接下载,也可以点击详情更加精细的筛选,选择适合自己机器配置的模型。 页面最右侧会有每个模型所需的内存要求,找到合适的模型后点击下载。 下载完成后切换到聊天页面,就可以在模型选择这里看到刚才下载好的模型,点击想要使用的模型,等待加载完成就可以对话了。 在对话栏下方可以看到推理的一些性能参数,每秒十个 token, 速度还是可以 在页面右侧是一些推理设置参数,自定义 proper 及硬件配置等。注意要关闭 tp entire modeling rem 选项,不然推理速度会很慢。如果电脑有 gpu, 可以在这里开启 epu 加速,可以提高推理速度。该软件也支持本地 server 模式启动,并支持 opiapi, 方便开发下游应用调试。 最后一个 type 式模型文件管理可以在这里配置模型的默认下载路径,以及查找删除模型、配置模型预设等。以上就是在 windows 加使用 l f to deal 的主要流程下, 下面讲一下在 macos 下使用 lfgodo 的注意点。我这台电脑是 mr pro, 十六 g 内存可以运行十六 g 以下的模型。因为苹果 m 系列处理器是共享内存,所以十六 g 内存就相当于十六 g 现存,也支持 gpu 加速, 前提是要在这里打开 gpu 加速选项,可以在参数栏看到推理性能,每秒生成十三点七三个 token, 真是不得了。 其他配置都是和 windows 保持一致,这里就不再赘述了。如果这个视频对你有帮助,就点赞关注吧,谢谢观看!
291pickkkiy 02:31查看AI文稿AI文稿
02:31查看AI文稿AI文稿欢迎来到未来练习社,今天的主题是叉 g p t prompt 提示词的课程,那今天的参考资料其实是吴恩达博士和 openni 官方出的一期提示词工程教学视频,我会将视频的内容拆除几期,和大家用我自己的理解来分享这个课程。那么首先想要了解提示词,我们就要了解现在最火爆的 l l m 是什么。 l l m 等于 large language model 大型语言模型,像大家熟知的大大型语言模型有 g p t 三, g p t 四 lamda, 也就是谷歌的 bard, 然后 blue 就 howling face 还有 lama 等等这些模型。其实大型语言模型可以分成两部分,一个是基础大模型 base l l m s, 还有指令调试大模型, 呃, instruction tuned l m m 这两个区别是什么呢?那其实基础大模型他的能力是通过文本训练数据预测下一句话是什么,也就是他其实有很多很多的数据样本,他通过学习之后,他可以知道你的下一句话想说什么。呃,举个例子,比如说如果我们给他一个提示词,说很久以前有一只独角兽,那基础大模型他就会回答说无忧无虑的和他的伙伴住在森林里。 但是当我们问的一个问题的时候,比如说我们问到法国的首都在哪里,那技术大模型,根据他被训练的一些数据,网上的一些内容,他其实可能会问一些相关的其他问题,比如说法国的人口有多少,法国的流通货币是什么?法国最大的城市是哪里?而他不会直接去回答这个问题, 那么指令调试大模型就可以做类似的事情,也就是他可以尝试执行指令。那同样是这个例子,如果我们问他法国的首都在哪里,他就会回答,法国的首都在巴黎。那其实指令调试大模型,也就是咱们所谓的微调模型。指令调试的步骤 大概分为这几类,首先通过基础大模型,因为他已经经过了大量的文字训练数据去训练,所以把它作为一个基础进行微调调的方式,也就是通过指令教育这个大模型,更好地去遵循和执行他即将获得的 的直流。那最后呢,我们也会用一种方法叫 r l h f, 也就是人类反馈,强化学习,不断地通过人工干预纠正大模型的错误,告诉大模型哪个是对的呢? 是错的,让他更好的去帮助人类去做一些指定的工作。那么其实如何理解微调模型的意义呢?就是假设你有一个很聪明的助手,那么但他不知道他需要完成什么样的任务,或者他不知道你想给他的任务是什么,那你就需要通过描述告诉他任务内容。 举个例子,比如说你如果告诉大模型,请给我写一篇关于马斯克的文章,那这个指令其实是并不具体的,他可能写出任何形式的文章出来。那如果你在指令当中加入一些 细节的描述,比如说他的商业成就是什么?他的自然生活是什么样的?他的人类共性有哪些呢?那其实这个大模型就会写出更好的文章,或者你可以指定一个口吻,你是想让 ai 以专业记者的口吻描述这个事情,还是以幽默风趣的把它方式来描述, 或者写这张这篇文章之前,你可以告诉大模型你需要去阅读哪些内容以来帮助他更好的去完成一个任务,这都是你在微调当中可以做的一件事情。那么下一个课题我们将讲到提示四工程的两大原则。关注我,了解更多 ai 信息。
237未来研习社 00:46查看AI文稿AI文稿
00:46查看AI文稿AI文稿一口气吹爆吴恩达 a m 入门新手发课程吴恩达老师推出的大模型系列教程针对初学者提供了宝贵的机会, 帮助他们快速掌握基于大型语言模型 yam 开发技能。这些教程从大模型时代的开发者基础技能入手,一一理解的方式,介绍了如何使用大模型的 第二格兰,趁架构来快速构建具备强大能力的应用。这些教程专注于面向初学者的开发者, 详细解释了如何创建 promp, 并利用 opennal 提供的 p i 实现各种常见功能,包括总结、推断、转换等。他们为入门要开发提供了经典的教程材料,帮助开发者迅速掌握这一领域的关键技能。
95Moni学长 03:57查看AI文稿AI文稿
03:57查看AI文稿AI文稿大元模型的六种底层能力,你会用哪个?在中国人民大学高龄人工智能学院的一篇论文中,把大元模型的能力分为了两个级别。其中初级能力分别是语言深沉、知识利用和复杂推理 高级能力分别是人类对齐、外界环境交互和工具操作。这些名字对咱们普通人来说听不太懂,今天我们用通俗的语言来解读一下,揭开他们的神秘面纱。 首先,语言生成能力。他呢,就像一位经验丰富的作家,可以进行基础的写作,也可以创作诗歌、故事和剧本等, 还可以用来做翻译、编辑和校对。对于企业,可以用它来做内容营销,撰写博客、文章、新闻稿和社交媒体内容,也可以编写产品书、 说明、用户手册和帮助文档等等。只要是与文字有关的任务,都可以用这种能力来实现。哎呦,我的太好了。第二种能力,知识利用。他的就像一个百科全书,可以回答各种问题, 回答我三个很简单的问题,好问吧。提供各个领域的信息,也可以对长篇文章进行摘要,提供关键信息。对于企业呢,可以用它来做市场调查,收集和分析行业趋势以及竞争对手的信息等等。 另外呢,可以用来做教育培训,提供业务支持,为员工剪辑打火。还可以用它来做决策支持,提供关键信息,帮助公司制定战略和计划。第三种能力逻辑推理。 谈的就像一位经验丰富的侦探,能够根据现有的信息和证据进行逻辑推理,找出 隐藏在背后的规律和关系。可以用来对复杂问题进行推理和解释,生成世界上没有的答案。对于企业呢,可以用来做风险评估,分析潜在风险,为公司提供预警。 也可以用来做项目管理,评估项目进度,提出优化切记。还可以用来做商业顾问,分析商业模式和市场机会等等。 第四种能力使用工具。他呢,就像真人一样,可以利用工具来帮助自己完成任务。在初中的课本当中就有讲到人和动物的区别是会不会使用工具,那现在哎呀也会使用工具,这个就有点意思了。 他可以使用工具来扩展自己的能力边界,做更多的事情。比如可以用来做数据决策,利用数据分析工具来为公司提供数据支持。也可以用来做软件开, 协助开发团队进行代码审查和调试。也可以用来做设计油画,为设计团队提供建议,提高产品的用户体验。关于工具的使用,还有很多场景,后面的视频呢,会专门来介绍这个内容。 第五种能力人类对齐。他呢,就像一位善解人意的朋友,他能够理解人类的情感价值观和需求。可以用来做情感分析,理解并分析文本中的情感,比如快乐、悲伤还是愤怒。 开发者呢,可以用来做价值观引导,在回答问题或提供建议时,遵循人类的价值观和道德观。对于企业呢,可以用来维护品牌形象,确保公司输出的内容符合品牌价值观和调性。第六种能力呢,是外界交互能力。他呢,就是一位活在现实 世界中的智能机器人,他能够与外部环境互动,帮助我们更好的适应和掌控外部环境。人们可以通过语言指令来控制机器人执行任务。未来的门店或家庭里面的机器人呢?会变得越来越灵活。 智能家居、智能办公和智能工厂会有很大的想象空间。其实大圆模型的能力和用法远远不止这些。 ai 的能力边界需要人的创造力和想象力来突破。我们应该利用 ai 的顶层能力来探索更多的功能和使用场景,而不是停留在现在的思想和方法上面。
 02:55查看AI文稿AI文稿
02:55查看AI文稿AI文稿大家好,欢迎来到深度学习词典第六课本系列视频是一个通俗易懂的速成课程, 运用简洁明了的方式介绍人工智能和深度学习的各种相关概念,非常适合零基础的新手小白入门, 坚持学完,相信你一定会有所收获。人类需要通过语言进行沟通,其实 ai 也一样,如今 ai 非常擅长与人对话,这都归功于一类强大的神经网络。 l l m, 英文全称 large language model。 l l m 是一种基于深度学习和大量数据学习的人工智能算法, 可以理解、生成和预测新内容。语言模型并不新鲜的事物。第一个人工智能语言模型的出现可以追溯到一九九六年,但是大型语言模型使用的训练数据及要大的多, 这意味着人工智能模型的能力会显著提升。目前大预言模型最常见的应用之一是使用人工智能聊天机器人生成内容。由于各大竞争对手都希望脱颖而出,越来越多的公司出现在这个市场上,其中如 check、 gpt 和 but 作为行业内的领先者, 一直处于相互竞争状态。那么大型语言模型到底有多大呢? l l m 训练数据级的大小应该为多大呢?这没有一个普遍公认的数值,但他通常在拍字节的范畴内。具体来说,一拍字节等于一千零二十四 tb, 通常我们人类大脑被认为可以存储二点五拍字节的记忆数据。 l l m 训练由多个步骤组成,通常从无监督学习开始,模型开始推导,建立词汇和含义之间的联系,然后通过监督 学习进行微调训练。数据传输给一个 transform 模型,他运用自注意力机制,使得 l l m 能够识别出词汇之间的关系和连接。 l l m 一旦经过训练,他就可以作为任何人工智能应用的基础。 l l m 可以生成文本,翻译语言、总结或重写内容,组织内容,分析语言的情感,如幽默或语气,并与用户进行自然交谈。与老一代的人工智能聊天机器人技术不同, l l m 还可以作为企业和个人定制化使用的基础。这特别有用,他们快速、准确、灵活,易于训练。 然而,用户也应该注意到, l l m 面临许多挑战,比如部署和运营成本的巨大开销。由于训练数据而产生的偏见、人工智能幻觉及响应。不基于训练数据故障,排出 复杂性故障。 tok 恶意设计的词汇输入导致 lolm 发生异常。好了,恭喜小伙伴们一直坚持观看,学习完这一节,你已经使用过 llm 了吗?你体验到了哪些好处和挑战?欢迎留言你的想法。使用深度学习词典, 将开始熟悉深度学习领域所需的所有基本概念,并开启属于你自己的 ai 之路。
 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿首发即封神,吴元达老师带你通关 lm! 这份教程专为入门 lm 开发的开发者设计,通俗易懂的讲解了如何构建提示词,并利用 opennail 提供的 ipi 实现诸如总结、推断、转换等多种常用功能, 成为入门 yam 开发的必备教程。此外,教程还结合了知名的大模型开源框架 lanchen, 教导开发者如何基于该框架打造功能使用能力全面的应用程序。数据准备予以处理。 学员将学习如何处理大规模数据及涵盖数据加载、清洗、特征工程以及数据增强等方面。训练大模型课程将讲解如何高效的训练大规模深度学习模型,包括参数初始化、油画算法批量规矩化、 正则化等。模型评估与调优,学生将了解如何评估大模型性能,选择合适指标并进行模型调优。大规模部署课程或许会涉及将大模型部署到生产环境中的方法,以便在实际应用中发挥作用。 多元应用领域大模型可应用于诸多领域,如自然语言处理、计算机视觉、强化学习、音频处理等。课程或许会涵盖不同领域中大模型的应用案例。这份教程适合拍发初学者,从基础入手,逐步深入, 让开发者能够熟练掌握构建提示词和利用 openn a p i 实现多种功能的技巧。同时结合烂秤框架教程还将教导开发者如何开发具有实用功能和全面的 能力的应用程序。通过学习,学员将能够掌握数据处理、模型训练、评估、调优和大模型部署等关键技术,并在多个应用领域中运用大模型。
91论文搬砖学长








