emeditor怎么统计词频
今天和大家分享一个非常强大的磁频统计工具, 瓷瓶统计呢,是我们在做亚马逊运营过程中经常会使用到的一种关键词寻找的方法,那我们在写历史的过程当中,可能会将竞争对手的标题以及对应的 revol 进行瓷瓶层面的加和重组, 以求寻找到核心的产品关键词,然后属性词或者修饰词,或者是我们在分析自己的广告报告的过程当中,也可能会对于关键词报告当中的词组,以及对应的,比如订单量或者是展示量点击量啊,拆解到词的层面来进行二次的加合, 帮我们寻找到更优质的属性词。但是市面上常见的工具啊,都只能对于关键词本身进行词频的统计,无法将关键词对应 定的数据也同步进行加缠。那今天和大家分享的工具就是解决这个问题的,我们一起来看一下他是如何使用,以及和市面上常见的磁屏统计工具有什么样的区别, 那我们一起来看一下,这个是我们比如说寻找到的呃一些产品的关键词,那后面呢?对应是他的呃,比如说蕊蕊的数量,或者是我们如果在做关键词报告统计的时候,这里可以放我们认一下啊,放个数据,比如说点击量或者是展示量, 那我们只需要点击开始统计系统就自动会对相应的关键词,相应的关键词进行拆解,将每一个词对应的 revo 的数量是拆解到每一个词对应的 revel 数量进行加合, 那这就是一个非常强大的工具,那他和市面上常见的,比如说我们会看到一些磁性统计的工具, 我们粘在这里的时候,这些工具只能对于关键词本身在所有的关键词当中重复的数量进行统计,而无法将这些关键词对应的数据的数值进行二次的求和加成。这就是这个工具区别于市面上常见工具的一个呃,非常强大的地方。 那这个工具呢?本人是通过一个腮红工具来写的,如果需要的小伙伴们可以私信给我,我将这个工具免费的分享给大家啊。好了,今天的分享就到这里了,点赞加关注,谢谢大家!

粉丝1.4万获赞6.9万
相关视频
 00:54
00:54 01:36查看AI文稿AI文稿
01:36查看AI文稿AI文稿两分钟制作超火的磁云图!磁云图目前被广泛应用于关键词分析、数据汇报等场景, 通过词频统计,从视觉角度过滤大量低频信息,使观众一眼就能看到关键突出信息。今天我们使用免费的数据分析工具 bdp 个人版来制作。在电脑网页登录后,在工作表界面右上角点击上传数据,选择本地需要分析的数据表。 这里我们使用数据分析相关岗位需求的数据作为视力数据分析岗位职责关键词自断, 点击右上角新建图表, 将岗位关键 磁自断脱至维度栏。在右侧图表列表中选择磁云图,系统将自动分析磁频形成磁云图。在 bbb 中还可以选择三 d 磁云形式展现动态的磁云 词语,图中每个关键词和词频数据均可显示, 还可以将统计好的关键词和词频数据导出。 炫酷又简单的磁云图,你也来试试吧!更多关于图表制作、数据分析的分享,下期见!
2125海致驭数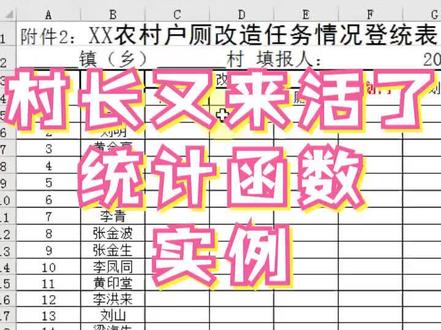 05:48查看AI文稿AI文稿
05:48查看AI文稿AI文稿我们来学一个,办公室里有个小伙伴呢,通过微信发来一个这样的表格,我们一看就是个大项目,对吧?这个村要改造厕所了, ok, 那么他的问题是什么?就是说啊,因为全村有一部分人家需要改造啊,不是所有人家,那么上面领导呢,给了一个计划名单,就是说这些人家都要去改造啊,大概有一两百个, 然后呢,在这个总表里面呢,大概有七八百户啊,那么就是说啊,要找出谁家要改造啊,是在计划内的,然后再到后面这个格打个勾, 比如说他家要改造,后面对,那打勾,那这个活呢,其实很简单,就是找呗,一个茶然后打勾,一个茶打勾,但这个活啊,干起来确实很累啊,啊,好多家呢,然后呢,一个茶很费劲啊,隔壁村也在茶啊,他想要更快啊,想第一个交给领导啊,所以说问有没有办法快速搞定,其实 肯定有了,我们的解题思路是什么呢?就是说用康的一法术统计对应的人名字有没有出现在计划名单里面,如果有的话,他就会返回一个统计结果一或者二啊,重复的话会二,如果不重复的话就一啊,如果没有的话就返回零, ok, 那么我们这是说统计他有没有出现, 这是思路一啊,啊,思路二是什么?要打勾啊,打勾的话,用用法术来判断一下,符合条件,打勾,不符合条件不打勾, ok, 来看怎么弄,说等于号,就看哈易符,先写易符括弧,然后呢,注意看易符的第一个条件呢,就直接写康的易符啊, clunt f。 然后呢,看这幅的参数呢,非常简单,第一个是条件范围,第二个是条件,那条件范围什么?就是说我们的计划名单,直接点这个计划名单,然后呢把这个对应的列给框上啊,就是这么多名字给他框上就好了。 好,挂好以后呢,我们再输一个逗号,然后呢注意看,逗号要用文书的发出啊,然后你再返回钟表,钟表里面注意看,我们要根据什么查, 根据这个户主就总表里面每一户都要去查一下,看看他在他家在不在里面啊,是不是在计划里面啊,点一下这个名字啊, ok, 那这样呢,就是说可以查出来他家在不在里面,如果在他就会返回一啊,如果重复的话返二, 如果不在就返回零,那么我们给个条件,大于零,大于零的话他就是肯定在里面了,对吧?然后逗号,那么如果他家在这个改造计划表里面,那么我们给他返回一个双引号,然后呢中间打个勾, 对呀,这是用反数的应用哈,要举反三哈,现在知道怎么用了吧?然后打勾,然后 号如果不在里边,注,注意啊,如果不在里面,直接给个双引号,直接给双引号,双引号中间不写东西去代表留空,单元格里面啥也没有,是这个意思啊,那这样写完以后,我们就可以统计出谁家在计划表里面,然后按确定。哎呦吼, 低户没有,为啥没有呢?低户不在里边,然后呢我们再选择这个单元格,右下角双击填充,那在里面呢,全部打上钩了, ok, 那么为了我们做的活严谨性,要去核对一下数据,这是非常重要的啊,我们核对这里面到底有多少户,看跟领导给的数据是否一样, 还是用康的一幅,然后呢统计一下这个数据哈,这是在 f 里哇,我们这里面快一点, f 冒号, f 逗号,最后的条件呢?是什么呢?条件呢?就是说是选择的是 这个啊,勾,就是我这里到底有多少勾,可以统计一下,然后确定啊,一百六十六胡就出来了。 ok, 那么在计划名单里面我们要去核对啊,对吧?还得核对,这里面核对就简单了吧,用 ctrl a clunt a 啊,就是统计飞空单元格个数啊,直接选中比例,然后确定一百六十一,这两个数据是不一样的, 不一样,那这时候我们就要琢磨了,为什么不一样?一个是一百六十六,一个六一百六十一,这里面可能会出现重复啊,也可能是一家报了几个,比如说儿子在父母名下 登记的这个信息,那这个时候呢,就要去验证数据啊,验证数据谁家是重复的?去核对啊,是不是等于康的一幅啊?真正干活其实挺累啊, 不是那么轻松呢,就是这个是验证,看那个验证的时候呢,是反过来验证了啊,这个时候不是对他进行验证,而是看一下这个里面的数据哈,选择 这个车头,改造这个钟表,然后呢选择的是对应的是 b 列啊, b 列,那么我们就直接写啊, b 冒号, b 逗号,逗号,条件就是说是呃,计划内名单 点这个啊,然后确定,然后呢他出现一次,然后往下填充,他出现两次,证明他家。有可能是重复,也可能是说 啊,他在自己啊,父亲名下啊,就是说户主名下啊,两套房嘛,一个登记在自己老头子名下哈,那这 这样的统计出来一个结果,就是说啊,他是俩,然后往下看有没有俩,就是说这位也是俩。那么这个时候呢,就是对这一列数据啊,最上面数据进行筛选啊,筛选,然后呢注意看啊,筛选,筛选完以后呢, 在这里面把二单勾确定,也就是说出现重复的这些信息,我们要去核对, 看看他到底是登记错了还是说这个。呃,他是挂在自己啊,父母名下就是两套房吗?一套房在这,另外一套房在那,登记的时候呢,全是登记在老头子名下,这种情况在农村里面也是经常会出现的, 那么你去核对数据有没有错,没有错的话就证明大功告成。 ok, 学会的同学点个赞哦。
2020山竹Excel表格教学 03:35查看AI文稿AI文稿
03:35查看AI文稿AI文稿使用拍摄处理一下,今天给大家分享一个复杂的功能,使用拍摄,咱们读取一个 word 文件,将里面的文本听分词了以后,统计词评, 然后把这个结果输入到 a 三文件中。咱们先来看我的演示,我有一个物理文档,打开,打开了以后是一篇中文的文章,里面有很多汉字,也有数字,对这个文本我进行分词,然后词片统计,会得到一个结果的文件, 这文件是 x 文件,我们打开,打开了以后,我们看到有两列,分别是词语以及对应的词频,这个词频是从高到低进行排序的, 我们看到刚才的文章中使用最多的词语是拍散,然后使用语言程序等等一些词语,这样的一个同 结果很方便的能够实现更多的数据的分析。我们来看一下用拍摄怎么完成呢?本次代码我使用胶布坦用的不合金演示,要完成这个目标,我们需要用到三个库, 潘森、道克斯,可以读取 word 文件,然后接吧,可以进行中文的分词。第三个就是潘纳斯,可以进行数据的统计,如果想在吉普特中安装库,可以在前面加个叹号,然后使用配备仪器到进行安装, 比如说我运行这个,他提示两个包已经安装好了。第二大步,咱们怎么读取 word 文档到一个大的自助串呢?比如倒侧这个包, 然后使用道克斯丁刀口门头传入文件名,就可以读取一个对象。然后呢咱们使用刀口 说明他点派二寡妇,就是每个段落得到段落的文本,把他们使用空格联合在一起。 我们看一下这个康单特有两万四个字符,我们看一下前十个,大家看到这就是一个正常读取的 word 文档的内容,得到了这样的一个大的组串,咱们使用中文分词,这里使用结巴引入,然后咱们直接使用结巴点 cat, 可以进行中文的分词 运行,对他分字的结果,咱们获取他的长度大于一的那些字符,也就是说单个字符咱们就不需要分析了。运行,然后呢看一下前三个分字好的字符, 就这样的一个拍摄,计算机程序设计等等一些词语。那么分词好了以后,咱们怎么统计词频呢? 在这里我使用拍摄呢 xs 点 ctrl, 他可以很方便的进行视频的统计。把三个类似就是分词列表传入这个 ctrl 运行,统计完了以后打印了结果,我们看一下前十行,就是拍摄计算机程序设计, 最后的话想输入的比赛文件可以使用潘纳斯来搞定,潘纳斯引入数据是 ctrl, 点艾特姆斯就是他的数据,那他列名是 word, ctrl 运行, 看一下,我们看到都取到了一个表格中,对这个数据咱们使用哨特歪这个词可以进行排序,就是看到这一列,而森林里 boss 是降血的意思。运行,再看一下前几行,这就是排序后的结果, 最后的话想出的一下文件就是颠覆点图个线来完成。执行完这一步,我们就在当前目录下 看到了最终的一赛文件,这就是本届我想分享的内容,使用拍森,到此咱们可以读取 word 文件,使用结巴这个扣可以进行中文分词使用,拍打词可以输入到给赛文件,希望对你有所帮助。
333Python导师-蚂蚁 07:04查看AI文稿AI文稿
07:04查看AI文稿AI文稿嗨,大家好,今天给大家带来一个分享,拍摄读取 word 文件,将里面的文本进行持平的统计,然后将统计的结果输出给 axcel 文件。大家看到我这个目录呢,有三个文件,其中有个大口文件,我打开, 打开了以后是一个 word 文档,里面有一些内容,这个内容呢,我是从百度百科复制的拍摄次条的内容复制过来的。第二个文件就是我们分析的结果,它是一个 b c r 给我打开, 打开了以后会看到有两列,第一列是词语,第二列是这个道口文件中这个词语对应的词品,它是一个降序的排列, 只有耐中出现最多的是拍死两百二十次,然后有个使用语言,后面有程序模块函数等等。这个幕下还有第三个文件,就是这个 ip y n b, 这是拍摄的一个程序文件,使用键盘功课进行打开和使用。 打开这个拍摄代码,我们进入了,我们进入了交朋友的 oppo 他的界面,咱们来看一下怎么实现这个需求,就是拍摄读取 word 文件,统计测评输出给 acl 文件。首先第一步安装死一代的包,这里我需要安装三个包,分别是派森 读取我的文件,第二个七八与周英文的分词,第三个叫潘纳斯,用于很方便的把数据呢输出来给塞尔文件。这里介绍个知识就 不可,可以在前面加个叹号,运行社员命令。比如在这里我使用拍拍频道可以安装这三个包,为了安装的快一点,这里我使用了清华他的配备员运行这一步, 咱们看到它就有安装,下载速度的话也非常的快。 ok, 等了一会,三个包安装完成,我们来用。第二步读取倒数文件到一个大的轴串,咱们引入这个倒刺 这个模块,然后呢请到 x 点 wc, 传入刚才的这个 word 文件名,把它读取给 docome 的一个对象运行。 然后呢怎么读取里面的数据?是这样的,放循环拍 rap, 因 w 带了对象来说去他的泰克斯特去除你们的文本,这个时候所有的段落变成了一个列表,我是用一个空格进分格变成一个最终的大族串运行。 然后呢看一下这个大字母串它的长度,它长度是两万四千。我们可以看一下前几个内容是什么样子的,比如说 使用拍摄的切片,看前十个,咱们看到这就是咱们读取号的位置的内容。 ok, 第一步就完成了,咱们读取了倒钩文件。第三步咱们进行中文的分册,因为要统计四平, 你当然得把每个词给拆出来,这里建的是接巴这个词库引弱。然后呢怎么分词?很简单,接把点咔嚓,插入 卡萨瓦迪 foss, 意思是说,意思是说精确拆分,一般用这个就可以,它的结果是一个三观差的类似的,我们看它的态度是什么?我们看到它是个简单 v 叉,你要选它的话呢,需要进行放循环,或者是用类似的进行改变。 在这里我加一个操作,就是说过滤店里面的标点符号,或者说无意义的单字,一般来说这一步需要用正的表达式来进行清理。 在这里呢我来简单起见,我过滤掉单词的长度,等于一通车的方式来过滤掉标点符号以及单个字,用单个字一般来说是没有意义的,我是这样进行的,分握的音 三个门槛类似就这个分子类表,如果这个位的长度大一的时候呢才放到结果里面里面运行。然后呢咱们可以看一下前三 三十个册,大家看到这个分子后的结果就是拍摄计算机程序设计语言等等,并且他是从前往后有一个顺序的关系。 这个第三步,咱们把一个大的怎么算呢?拆成一个一个的词,方便进行第四步的持平的统计,它的统一词平有一个叫康特的类比较好用,给大家介绍一下。首先 fmc x 引爆的 ctrl 运行, 然后呢把刚才这个类似的直接传给看到这个类的这个对象,这个时候他已经完成了统计,我怎么看等待结果呢?可以看看点艾特马斯 类似一个字典的使用方式,然后呢使用类似的变成个类似的,取前十个得到他的 word 以及 ctrl 打印运行。咱们看到这一统一 来拍摄计算机程序设计等等每个词他的实验的次数就是后面这个数字,当然这个时候呢是没有顺序的是第五步,咱们可以构造潘纳斯,选潘达斯功能进行排序。 首先引爆的 plus, 然后呢咱们使用 p 点 dwfame 创建领域的 cm, 第一个参数就是咱们的 把它变成个类似的,大家注意这个时候这个类似的里面是两下,第一个列呢是 word, 第二列呢是 cat, 所以说咱们给这个 fm 第二个参数就列明分别是 word 以及 ctrl 运行。咱们看一下这个颠覆的前几行,大家看到变成一个表格的形式,然后是每个词和注意的次数,这三句排序很简单, df 点色的 w 数 来抵抗,他意思说看了这一列进行排序,而是定义 boss, 就是说降血排列 逆行。再看一下前几行,打开了这个,看到呢就是一个降序排列了,然后第一列是对应的 word 单词, 最后一步咱们把结果输入给赛文件,对于判断来说非常简单。第二个点拖一下传入结果的一个下载名称,因大可能意思,意思是说不用管前面这个数字,缩影列 运行, ok, 运行完毕,咱们回到目录,你会看到这个赛文件呢,时间进行的更新是刚才最新的,然后打开就是咱们所看到的 word 看的这两列, ok, 简单回顾一下本次分享的知识点,首先咱们可以 拍三倒库式这个模块呢,读取我的文档,将它内容读去了以后呢可以使用接八进行分词,分词了以后咱们可以使用拍摄的开声词,点 ctrl 这个类进行词典的统计, 统计的结果可以选判断资金排序,然后输入这个赛文件,欢迎大家关注我来观看更多的拍摄,更多的视频,我们下次见,拜拜!
278Python导师-蚂蚁 24:29查看AI文稿AI文稿
24:29查看AI文稿AI文稿下面我们讲解实力十、文本词品统计。首先对文本词品统计的问题做一个基本分析, 我们有这样一个需求,首先有一篇文章,我们想了解这篇文章出现了哪些单词,而且哪些单词出现的最多,我们该怎么做呢? 其实这个需求呢,忽略了一个基本问题,我们的这篇文章或者这个文本是英文的还是中文的?既然我们有这样的需求,我们就既把英文的,又把中文的都解决出来。 那么在本问题中,我们将给出英文文本和中文文本分别 进行的文本词频统计的实力。其中英文文本中,我们以哈姆雷特、莎士比亚的小说作为蓝本,分析其中出现单词的词频。 对于中文文本,我们使用三国演义来分析其中近百位人物的出场次数,其中的 hamlet 和三国演义的文本,同学们可以在网上的链接中进行下载。 下面我们对 hamlet 英文词品统计实力进行讲解。首先我们想一下,我们需要做的是获得一个 hamlet 的英文文章,并且将其中出现最多 多的单词输出。但是对于英文呢,我们会有一些单词表达方面的不同,比如有些单词会有大小写, 虽然单词之间会用空格来区分,但是他还会有逗号、冒号、叹号等多种标点符号的使用。所以我们要能够将文本进行噪音处理,规划, 提取其中的每一个单词作为第一步骤,在这个基础上才有可能进一步统计每一个单词出现的词拼数量, 这是一个基本的思路。下面我们给出代码,同学们来一起看一下。我们定义这个小函数叫 get text, 顾名思义,它能够获得一个文本的具体信息。首先我们打开 hamlet 这个文件,我们使用 open hamlet 点 test 点啊,并且最后用点锐的方法。 同学们可能会说,这里边老师还没有讲如何用 python 打开一个文件,那么这一行代码同学们先记住 照抄写下来就可以了。我们将在下周中重点讲解文件打开,读取,写入等基本方法。 这里边呢,同学们记住这是一行打开文件的代码即可。为了避免大小写对词品统计的干扰,我们使用 text 点 lower 来将所有的英文字符变成小写, 变成小写之后仍然保存在太子变量中。再进一步,我们要去掉所有文本中出现的各种特殊符号。由于特殊符号都是在单词与单词之间进行分隔,所以我们使用空格来替换这些特殊符号。 那如何去掉其中的特殊符号呢?哎,我们可以使用 for in 的方式逐一的获得特殊符号,并且用文本操作将特殊符号替换为空格。请同学们仔细观察 for in 的这两个代码,它能够将 每一个特殊的符号拿来在文本中。使用 replace 方法将这个特殊符号替换为空格,替换之后仍然保存在 text 文本中。最后这个 text 文本经过这样的一段函数处理,就形成了规划结果。这个结果呢是其中的文本的所有单词都是小写的,单词与单词之间使用空格来分隔,而且没有任何的特殊符号或者标点符号 好。经过函数这样的处理,我们就获得了一个非常干净的皈依化的一段文本。好,再往下看,我们的主函数的第一行代码 harmlet test 等于 get test, 我们对文件进行读取,并且对文本进行规划。由于所有单词之间都是空格分格,我们就可以使用点 sbe 的方法,用空格分隔他们变成一个列表,请同学们再回顾。在字幕串 中,我们讲解了点 speed 的方法,他默认呢采用空格将字幕串中的信息进行分隔,并且以列表形式返回给变量。所以 words 是一个列表类型,里边每一个元素就是一个空格分开的单词。 为了对每一个单词进行出现次数的标记,我们想想该用什么样的数据结构呢? 一个单词和他出现的次数构成了一种映射,所以我们需要定一种字典类型来表达单词跟出现频率之间的对应关系。 好,这个字典类型叫 cons。 首先是一个空字典,然后呢,我们逐一的去从 words 这个列表 中取出每一个元素。取出之后,我们尝试一下这个元素是否在 conts 中。这里边用到了一个 conse 中的方法,我们说过它很重要,叫 counts their get 字典的点盖的方法,用来从字典中获得某一个键对应的值,如果这个键不存在在字典中,也就是尚未在字典中,我们给周末任职, 在这里边给出一个函数叫 conts 点 get word 零,它指的是用当前的某一个英文单词作为见,所以字典如果它在里边,那就返回它的次数, 后面再加一,那么说明这个单词又出现了一次。如果这个单词不在这个字典中,那我们就把它加到字典中,并且复 给当前的值为零。那么零加一呢?是一,因为这个单词出现过一次,那么 cons 前面的 word 等于 cons, 点 get 加一就是等于零。加一相当于在字典中新增了一个元素,通过这样两行的代码, 我们就能够逐一的便利列表中的每一个元素,并且用字典类型去记录每一个元素出现的次数。 仅仅只有两行代码。将字典类型便利完或统计完所有出现的次数之后,我们需要对词频出现次数进行排序。首先呢,我们将字典类型转换成列表类型,便于操作。 我们通过 list 将 consider items 变成一个列表类型,然后对于列 表类型使用它的 saw 的方法。那么这行代码中呢?我们用到了一个参数, key 等于 lambda x 冒号 x 方块一 rewards 等于处。如果有经历的同学 可以去查阅一下列表类型的一个 saw 的方法,它其中的一个参数蓝不等,用来指定在列表中使用哪一个 多元选项的列作为排序列,而默认的排序方法是从小到大 rewards 设为处,那么返回的排序就是从大到小。当然这个方法的理解还有一点点复杂,请同学们在现阶段把这行代码记住, 他能完成的工作就是对一个列表按照建职队的两个元素的第二个元素进行排序, 排序的方式是由大到小的倒排好,进一步排序完之后,那么他的信息保存在 items 中,那么 item 中的第一个元素就是出现单词次数最多的元素, 我们可以使用 four i 音润指时的方式,将其中的前十个出现最多的单词以及他对应的次数打印出来,这就是整段代码。 这段代码我们再回顾一下。我们首先定义了一个函数大夫 get test, 它能够对读日文本进行规划处理,将所有的英文字符变为统 统一的小写,将其中的所有的特殊字符去掉,替换为空格。紧接着,我们用一个字典类型对每一个单词以及出现的次数进行了映射对应。 再进一步呢,我们将字典类型转换为列表类型,通过排序获得当前最高的单词出现次数。再之后,我们用一个复印对前十位单词出现次数的元素以及他的次数进行打印输出。 其中唯一呢, items, their, salt 以及 lamt 函数的使用,同学们可能会有一些障碍,请同学们先记住它。后边有时间同学们可以去仔细查阅一下列表的点 salt 方法,而这种搭配也是非常常用的一种方式。 好,这段代码运行之后,输出结果如下。从结果我们看到,在拉哈姆雷特的经典的文献中,出现最多的单词是 the, 出现了一千一百三十八次,而像名字 hamlet 才出现了四百多次。 那通过这样的单词统计,你可以了解莎士比亚写作的特点和风格。好,准备好电脑,跟老师一起把这段代码写一遍。 下面我们对三国演义人物出场统计实力做个简要讲解。三国演义与 homelet 不同,它是一段中文文本,既然我们要对它里边的词频做相关的分析,首先要对中文进行分词, 之前我们讲解过中文的分词库结巴,我们就可以使用结巴来完成它。除了使用结巴进行分词,中文不存在大小写问题,所以大小写可以很好的处理。 中文的标点符号在分词的过程中都将会被处处理掉,所以我们也不需要处理特殊符号,因此这段代码相比哈姆雷特的代码其实变得更加简单。好,我们一起来看 一下。首先 input 结巴来调用结巴,故 进一步呢,我们用 open 函数打开 three kingdoms 点 tst, 这是一个有三国演义全文的一个电子版文件, 对于文件的打开,我们暂时先记住它。进一步,我们使用结巴 lcat 对它进行分词处理,形成了一个列表类型的 带有所有单词的列表,叫 words。 到这里大家会说哦, words 好像跟哈姆雷特的 words 是一样的。是的,那么接下来我们要做的事情就是 构造一个字典 cons, 足以便利 words 中的每一个中文单词,并且将 中文单词进行处理。通过字典来进行技术,需要使用 cons 点 get 方法。技术完之后呢,我们将带有技术的字典 cons 转换为列表类型列表的 items 变量的 salt 方法进一步对这个列表进行排序,然后用 fouri intrend 方式将其中的前十五位单词打印输出。 后边的东西呢,与哈姆雷特是完全一样的,前边部分仅仅对中文单词进行了分词,并且构造了一个中文单词的列表类型。 经过这样的一段代码,我们就能够将三国演义的词频进行一个基本的统计和分析。 好,我们运行一下。在输出的结果中,好像曹操的排名很高,第二名是孔明,但是往下看呢,我们发现好多地方比较奇怪,比如孔明和孔明曰 实际上是一个人,只是由于分词的原因,将孔明曰和孔明做成了两个不同的单词,像其中呢二人以及却说他并不是中文的人名,而是单词的组合。 所以到这里我们看到这段代码,尽管可以将中文进行分词,并且听词名统计,但是离我们要求的三国演义人物出场次数的统计还有一定距离,所以 我们期待改造这段代码,让他能够真正的完成人物出场统计。 下面我们对三国演义人物出场统计实力做个深入讲解。在之前的讲解中,我们已经能够将一个中文文本进行词频统计,但是词频和人物出场之间的关联还需要进一步的处理。 词品统计是程序完成的基本功能,但是如果到人物出场统计,他就是一个面向问题的需求,面向问题就需要我们增加更多的代码, 使他运行的结果符合问题的结果。简单说,为什么之前中文分 词的词编统计不能作为人物出场呢?因为其中出现了大量跟人名无关的,像将军却说荆州二人等等这样的词,他并不是三国演义里出现的人名。 同时像诸葛亮、孔明曰和孔明其实是一个人,那关公、云长跟关羽也是一个人,但是是不同的称谓,而这种称谓之间应该关联起来。 所以我们需要进一步完成的是,在词品统计的基础上,怎么去面向问题改造我们的程序? 这里边我们给出三国演义人物数量统计代码的升级版,在这个升级版中,我们要给出一些排除词库, 也就是说对于某些确定不是人名的词,即使我们做了词名统计,我们也要把它删除掉。 我们构造一个集合叫 excluse, 在 excluse 中我们将一些确定不是人名,但是又排序比较靠前的单词列进去,比如将军却说荆州二人不可不能如此等等, 这样的单词怎么获得呢?啊?就是我们不断的运行程序,根据结果发现其中前多少位有多少的单词确定不是人名,我们就把它加到 excluse 这个集合中。 那么进一步在进行词宾统计的时候,我们首先需要对一些 词语进行整合,我们可以判断其中像诸葛亮、孔明曰孔明他们这样的,很明显确定是同一个人的词语,进行人民的关联。 在这两个处理过程之后,我们就可以沿用此宾统计的方式对人物出场进行统计。 改造后的代码呢,相对比较简单,请同学们阅读这段代码,去理解其中对排除词库以及对名称关联的处理方法。好,接下来我们运行这段程序, 我们看到曹操、孔明、刘备等的人物出场次数已经发生了变化,那么之后呢,还会有像商议, 像如何像主攻军事这样的非人名词汇,所以我们也要进一步的将这样的词汇加到我们的排读词库中,进一步优化输出结果。 经过不断优化修改我们的程序,这里边老师隆重发布三国演义人物出场顺序的前二十名,第一名是曹操,第二名是孔明,第三名刘备,第四关羽张飞。 尽管我们说三国演义对汉室,对刘备有很明显的倾向性,但是人物出场最多的还是曹操,这个结果会不会让你惊讶呢? 准备好电脑,跟老师一起编写代码,并且去优化这段程序。 下面我们对文本词品统计实力来个举一反三。 在这个实例中,我们讲解了英文的 hamlet 和中文的三国演义的词品统计以及人物出场统计, 尤其三国演义人物出场统计的实力非常有代表性。 作为举一反三,我们最主要的是考虑这段代码还可以用在哪些应用问题上。既然我们能对三国演义的人物出场经统计,那么红楼梦呢, 西游记呢,水浒传呢,这一系列的名著我都可以统计他的人物出场次数。除了名著之外,我们可以对政府工作报告、科研论文、新闻报道中出现的大量的词频进行分析, 进而找到每篇文章的重点内容。除了做基本的词频分析,人物统计分析,进一步我们还可以对文本的 词语或词汇绘制词语,让它具有更直观的展示效果。当然,这一部分我们将在后续的课程中来介绍。 文本词名统计实力是充分利用组合数据类型中的集合序列以及字典完成 工程的非常好的实力。请同学们一定要去找一个扩展的文本来去实践一下这段代码。你掌握了这段代码,那么对于 python 语言来处理很多问题你都会变得得心应手。
255JohnChen 04:01查看AI文稿AI文稿
04:01查看AI文稿AI文稿收到很多朋友留言,在数据统计中会有很多同产品名称下有多个产品型号的现象, 这种如何自动统计他的出路库情况呢?我们来看一下表格完成后的效果。这组数据中产品名称为华为手机的名下分别有 a 七、 a 八、 a 九等型号, 我们的实时库存总账中会根据不同的名称及型号来自动显示实时的库存量。我们来演示一下,我们再输了一个型号为 a 九的华为手机, 这样后面的公式会根据前面的两个条件参数来自动计算出入库记录中的库存情况。我们来看现在 a 九的总入库量为三十,出库没有显示, 我们在出入库记录中加一条 a 九的出库记录来看一下。我们切回实时库存总账看一下, 现在出库也自动计算过来了,这个自动统计是如何实现的呢?我们先删除原有的公式,重新一步步操作一下。 例如我们来统计华为手机 a 七的出入库情况,先来看总入库量,他就是统计满足条件一,产品名称为华为手机, 条件二,产品型号为 a 七,条件三,产品出入库状态为入库。对满足这三个条件的数量进行求和。这我们用到三部 ex 多条件求和函数, 它也是咱们这个表格的主函数。三木一副死的函数语法,参数为求和区域,区域一、条件一、区域二、条件二、区域三、条件三等等,最多可设置一百二十七组条件。我们在第三单元格内输入公式 等于三 m e x 求和区域,我们选择出入库记录表的 f 列,也就是数量列。区域一,我们选择出入库记入表中的 c 列,也就是产品名称列。 条件一,我们选择 b 三产品名称单元格。区域二,我们选择出入库记录中的地列,也就是产品型号列。条件二,我们选择 c 三 产品型号单元格。区域三,我们选择出路库记录表的异列,也就是出路库列。条件三,我们在英文状态下的双引号内输入路库, 这样我们的总路库公式就设置 ok 了,回车完成,我们再来看总出库量,总出库量的统计公式同总路库量基本相同,只有条件三的参数不同,其他的均相同。 所以我们可以复制第三单元格的公式,把公式内的条件三参数入库改为出库即可。 库存比较简单,我们可以直接用减法输入,等于第三减一三回车完成,在备注的位置, 我们可以加一个库存提醒,输入以下公式。这个公式分两段来理解,第一段的意思是, 当 c 三单元格为空的话,我就为空,这个只是为了使表格更美观一些,如果不为空的话,我们计算 f 三的库存是否大于或等于十, 如果是的话,显示库存充足,如果不是的话就显示。注意补货这个库存时可以根据自己的需求来做变更。公式设置,完成下拉填充, 我们输入几个数值测试一下,你学会了吗?持续更新,点关注,不迷路!
4371Excel教学--过客吉祥 04:00查看AI文稿AI文稿
04:00查看AI文稿AI文稿当我一个人准备发医学 sci 时,刘梅纯纯演,我就不信我就写不出论文。有什么了不起的,我告诉你们啊,从明天开始我就开始写,下礼拜我就发屌, 而我的室友没去过实验室,却又发了一篇 sei, 这次影响因子四点九八一,快来看看他是怎么做到的。解锁式的设计的话,我们是采取一个叫 picos 原则,我简单和你说两个方法哈, 找同意词。第一个就是在泡面里面的见识里面,比如说我输入一个,这个是他的一个主题词,嗯,然后我们点击进去,然后在这个地方基本上就可以看到他有四个表达方式,这四个表达方式呢,都得要现在几个一起用。二连接就是他的一个同义词。嗯,这是第一种寻找的方法。第二种呢,就是直接在泡面里面查找,然后你限定麦塔分析,然后找一些,因为每一天的麦塔他如果按照流程 来写的话,他都会给出他的一个解锁式,所以你就可以进行一个参考。这四个值应该就是这样,对于这组数据而言,这个能懂吗?这个大概能懂。第一次做整装型的这个值还是不是理解很深刻的?对,就是每一个值他有一个对应的公式,灵敏度、特异度,只能准确性,其实公式都来自于那四个值,进行拆解,然后计算就行了。这个的话那就提供了一个计算器的功能, 算的话还还没算过,到时候我根据你这个视频大家再算一下,可以的,把所有的数据都提取完了。这四个值啊,下一步呢,你就把他们列入到一下表里面,然后打开一些塔,然后录入一个大概类似这样的一个数据,然后录入成这种格式的。我现在教你怎么做图啊,那些卖塔里面就是在他做图。第一个我们先做一个灵敏度和特异度的一个分别图,这个的话呢,这个文件质量要要 评估的,我们做完图之后再做评估也可以的。然后我们把数据输入带入之后输入这一串代码,这一串代码代表的是灵敏度特异度的一个森林图的一个代码,回车之后他会自动的出一个图,就灵敏度特异度森林图,大概是这样一个图,然后这个图怎么看呢?首先先看这个灵敏度,左下角灵敏度零点八三,这个位置后面是他的一个直径区间。今晚就和你说那么多,第一个灵敏度特异度森林图,第二个漏斗图,第三个 sr 曲线,然后第四个麦塔回归,第五个是那个 facen 图去想寻找那个临床适用性的。第六个呢,是一个玉质效应的探讨,整个的麦塔基本上就是这六大手段就可以。行,那你先回去把数据整理,谣要讨一遍数据看一下。好的好的,然后呢和你说一下每一项评分具体要怎么做。 首先呢我们用到的工具呢,叫做 quad dns。 二、这个叫评分量表,是用来评价每一篇文章它的质量到底如何,每一篇文章分别对应七个项目,然后最后呢再去用 remain 把那个图做出来,嗯,然后你参考这个 pdf 里面这个表示这里的第一个偏引风险,它里面有一个病例选择,哈,这叫偏引风险,这个叫病例选择对应这一列,这一列呢,我们只设定一个问题就可以了。 这个问题就是这个问题一,是否纳入了连续性的病例?那怎么看一篇文章有没有纳入连续性病例呢?他一般都会在方法和材料部分说明啊, 说有那个单词叫 consecutive, 这个叫连续的,那个英文如果他是连续性的话,那他就是低风险,如果没有这个 consecutive 或者 sequence, sequence 也是连续性的意思,没有这些词也没有这个表达啊,这种的话就叫不清楚 unclear, 然后你就在这篇读出这篇文章,这是 unclear 之前 u, 然后呢是 low, 就是低风险的意思, h 就是 high 的意思,高风险。这是第一个问题。第二个项目是再评价整顿试验,对应的是这个 indest test。 这次课的主要目的呢是,第一,看一下你的那些图表,你不是已经做好了吗?嗯,看看他的规范程度怎么样。然后看完图表之后呢,我会和你说一下大概呢,需要怎么写作,因为因为你现在呢,其实数据啥的都已经整理好了,现在下一步呢,就是写作了。然后这是你的一些图表,我大概都看了一下, 你的这个麦卡回归呢,是找不到一直性来源的,只有那个敏感性分析可以找到。然后我具体的看了一下你的表格,这里存在一些问题,我和你说一下哈。 首先第一个啊,这个勾时间的后面有一个 number 配裙子,但他下面是你没写的,所以我建议把你删掉。这个符号呢,一般在英文当中不太容易出现,我建议改为逗号。然后呢?你看这里解释的话,你像一些 surgery, 你得写他全称在这个地方 是最后一行吗?就是那个 ag 啊,就是先辅助化疗,这个算是化疗里面吗?这算化疗吗?还是化疗的一种?还是另外把它列出来?可以单独把它列出来吗?按 ag 你写它全称就可以了,在下面解释一下。我的意思就是说如果能合并了,最好把它统一一下,不能合并了就把它全称都写出来。 那就说所有的问题的回答思路啊。第一点,那肯定是要非常感谢这个省稿人提出这个建议。这第一句话,那第二句话呢?是说对于他这个问题的一个解答。你说我们已经根据您的要求在文中进行了修改,并且使他啊高亮化或者雕红了。然后这个解锁式的话, 我建议你就是最好能够把它放在一个附加材料里。你目前有附加材料吗?附加材料没有,那就是各个数据库的检索室,你还保留吗?嗯,那我是已有的,就是你看看能不能放在一个附加材料里,然后做成大概这样子的一个模板,就具体罗列出每一个库,他的那个检索室的那种,然后把它放在附加材料,这样的话就相当于基本上就能够回答他这个问题了。让你提供一个完整的检索室吗?对吧?嗯。
 06:58查看AI文稿AI文稿
06:58查看AI文稿AI文稿我们一起来看一下这道题,这是一位粉丝的投稿题目呢,是这样的,他说给另一段文章,让我们输出每个字母出现的次数, 然后文章已井号结束,那它呢要求我们输入多组数据,长度呢要小于二百,输出形式,形式就是 a 有多少个,多少个, e 有多少个多少个,以此 往后输出一直到 z。 那我们这道题的解决办法我们首先想到说是要统计字母出现的次数,首先肯定要有 一个统计,那我们该如何去统计?复合统计是不是还是要用循环来一个一个的取循环,那循环的条件,我们这要用 这个井号,如果等于井号的时候,我们就结束循环。其实我们仅要便利这个文章,我们还需要知道这个 位置在哪,是不是因为它的输出形式是这个样子了?那我们是不是要定义数组、应数组来存储我们的这些位置一次就是我们需要用到的一些标准的函数, 用这个来获取获取输入,就是这样我们基本上所有的解决办法都已经实现了,那我 我们就将这个解决办法来执行马化。那首先我们用这个功能函数来实现,首先我们定义了一个函数,这里呢我们要传入一个 等型的人进来,主函数里面我们需要另一个 不足,用数组最大的是二百个,用上我们的 as 函数来输入,最后我们直接要用它就可以了,把这个值盘进来,这样我们的输入我已经完成了。 接下来就是我们在这里的功能函数来实现统计输出的功能,那我们统计的时候 就首先要定一个数组,这数组我们一般定义二十七个,因为我们要知道数组是从零开始的,我们的字母一般都是由 这六个,所以我们直接定义二十七,第一个就是空的,我们不管他,让他占位,也就是零号,元零号定义数组的时候定义二十七个,亿, 零号所引用来占位,我们可以不管它,那我们第二个三个,所以就可以直接写了,在这里 来定义一下,就是 a, b, c, d, e, f, c, h 是我们的字符,字符定义好了过后呢,我们就要定义我们的 存储的数据位置,我们也同样的听要二十七个,接下来就是我们对含入的数据进行循环,我们这里选择的是循环,这样的话我们从零开始就可以直接 得到,用 s, s 来判断它不是等于它就可以了,我们的 i 直接加, 那如果,如果什么我们的这个爱的范围是在 a 到 z, 这就说明这是我们的小姐制服,那注意既然是我们的小姐制服,它的存储位置是不是应该在相应的位置上面,那在这里我们就要知道 我们要用这个,我们知道我们的 a 是放在一个位置的,那么它 a 的二十一个码是不是九十七, b 的阿斯格马是九十八,所以我们的 a 存在第一个,他们之间的差是不是九十六,我们这里其实会使用到他的阿斯格马,也就是 ss 的值点去 九十六,那这样的话我们如果是 a 的话就会存到一号位, b 的话就会存到二号位,是不是直接把他的二十个码减九十六就可以了, 这样我们就结束了所有的胸环,接下来我们来分别打印一下,从一开始进行打印,第一步我们打印的其实是字符,把字符都打印出来,那 啊,我们这里就是 s, s, i, 从一开始打印,最后我们在相应的位置上把它的值 打印出来就可以了,以是字符表,符表应该是是 s, t, r, 这样的话我们这个函数就应该可以实现全部功能了。好在这里呢,我们来变异运行一下,然后我们来输入一个,好, are you? 滚号结束,看一下我们的统计情况,我们的 a 出现了两次, 我们的 e 出现了一次, h 出现了一次, o 出现两次啊,出现一次, u 出现一次, y 出现一次,那这样我们这个功能就已经实现了。其实在这个地方我们也不用这样写,不用这样去定义数组,直接用他的阿斯格马来进行减就可以了, 也就是这一步我们可以不用这样写,在打印的时候我们直接打印什么?哎,这里直接打印九十 七,因为 a 的 r, s 格码是九十七,它是第一个位置,是不是只用打印上五十六啊? i, 那我们来运行一下,看可不可以哦,这个地方我没有给他注视掉,摁一下,再输入一个,好, are you? 你看一直按 的话结果是一样的,我们不需要使用副组,直接来进行打印也是可以的。一道题我们就讲解完毕,如果大家有更好的方法可以写在评论区,我们一起交流一下。
15程序设计攻城狮 04:31查看AI文稿AI文稿
04:31查看AI文稿AI文稿今天我们来学习制作一个简单的实时库存统计表,这个知识点我们也经常以各种类型的案例来提到,他对公司统计和做生意的朋友来说是一个非常重要的知识点。如 如果库存货物积压过多,会造成成本浪费或产品出现过期现象,如果库存过少,会影响正常的运营和使用。所以我们要对库存做一个这样的统计表,并设置库存预警。例如此表,我们根据不同的产品设置了不同数量的最大和最小库存, 每天的进货出货做了一个这样的记录表,例如我们的电视机最大库存是五十台,最小库存量是十台,当我们的库存大于五十台时,他会用黄色填充显示提醒我们库存过大。当库存 小于十台时,他会用红色填充显示提醒我们库存过低要尽快进货。这样我们通过颜色可以直观的看出哪些产品需要进货,哪些产品不需要进货。这个库存会根据每天的进货出货量自动变颜色来给我们做提醒。 我们一步步来操作,看如何实现。首先我们要实现库存的自动计算,实施库存就是入库数量减去出库数量,我们会用到萨木易夫函数,这个函数共有三个参数,条件、区域、 条件、求和区域。我们先来求所有的路库数量,我们输入等于三木易条件区域,也就是我们的 e 四到 t 四的出路库,我们选中公式按 f 四决定 条件,我们选择 e 四的路,也就是路库,选中公式按 f 四绝对引用求和条件,我们选择 e 五到 t 五的数据区域 回车完成,这样我们的入库数量就求出来了。我们知道入库减出库等于实时库存,我们再来求一下出库数量,我们在公式后面输入一个减号萨姆逸夫 条件区域同样为 e 四到 t 四的出路库,并按 f 四绝对引用 条件,我们选择 f 四的出,也就是出库,并按 f 四绝对引用。求和区域,我们同样选择 e 五到 t 五的数据区域 回车完成下拉填充,这样我们的实时库存就求出来了。接下来我们再来设置库存的提醒,选中数据, 开始菜单下条件格式新建规则,使用公式确定要设置格式的单元格,在公式内 输入等于选择 b 五的实时库存。删除绝对引用符号,输入小于等于选择 d 四的最小库存, 删除绝对引用符号,意思是当实时库存小于等于设置的最小库存时,点击格式选择填充。例如,我们选择一个红色 确定完成,这样低于最小库存提醒我们就设置好了,我们再来选中数据,开始菜单下条件格式新建规则,使用公式确定要设置格式的单元格,在公式内输入等于选择 b 五的实时库存, 删除决定。引用符号输入大于等于选择 c 四的最大库存,删除决定。引用符号,意思是当实时库存大于等于设置的最大库存时, 点击格式选择填充。例如,我们选择黄色确定完成,这样高于最大库存提醒我们也设置好了。例如,我们九月三号电视没有入库,但出库出了十五 舞台,这时库存显示为正常状态,笔记本入库了五十台,出库了十台,库存状态也实时做了更新。 新日期添加,我们可以选择最后这一个空日期的列,右键插入拖拽日期填充,这样公式也会自动引用,你学会了吗?持续更新,点关注不迷路!
5300Excel教学--过客吉祥 01:02查看AI文稿AI文稿
01:02查看AI文稿AI文稿好,大家继续来看哈,上次我们编函数已经编到了,我已经找到了某个学校啊,在这三张表中把 a 二这个运,这个学校已经找到了,那么我还要找班级, 找班级跟找学校是一样,那么我直接把这段参数 ctrl 加 c 直接,那么班级是 b, 冒号 b, 对吧?在 b 冒号 b 这里的,因为前面都一样的,我改成 b 就行,所以大小写是无所谓的。那在这里面呢?我们找到 零七幺零这个班级对不对?好,找到这个班级以后加括号,那么现在他得到的是两个数数,得到的是两个数数啊, 那么我们需要把这个数组进行相加,那这个时候我们在前面需要用大加括号跳回车,那么参考人数 十二个人就出来,你学会了吗?后面的人数我们直接拖动鼠标就可以全部,这次整个的就学习完毕了,关键你要了解这些函数里面的千套关。
265明宇电脑培训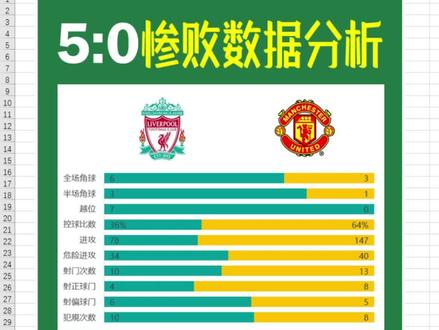 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿大家好,我是乐可,最近一轮英超比赛中,利物浦零比五狂胜满脸,我想找出失利的原因,我们需要对比赛数据进行分析,下面有一张我通过相关网站得到比赛数据,并通过百分比堆积条形图对比赛数据进行了一个直观的数据对比分析。 那么今天呢,我们不去复盘比赛,我们一起来学习一下如何使用百分比堆积条形图来对比赛数据进行分析。点击插入选项卡选择,选择百分比堆积条形图,调整图表大小相关位置。 做到商城后,我们的全场角球是在最后一行,而在数据中,我们的全场角球是在第一行。我们需要对最高轴的顺序进行修改,点击最高轴, 勾选逆序类别,点击图标元素勾选去掉网格线,点击图标中 勾选去掉主要,横向组装中勾选去掉头角标题, 鼠标右键设置图表区域格式,点选无填充,点选无线条。点击任意调音图,选择系列选项,前期宽度调整为百分之五十。 再次点击图表元素,勾选数据标签,点击橙色调整图,选择图标标签为图表标签内侧,点击蓝色调整图,选择数据标签为轴内侧。 修改图表的字体为微软雅黑 手动键,点击 蓝色调音图,设置数据系列格式修改填充色为深青色,同样点击橙色调用图修改填充色为橙色。 这样我们的比赛数据分析对比图就已经做好了。球队的 logo 可以直接从网上进行下载,直接插入图片即可,有不明白的小伙伴可以在评论区下方留言我。
50乐客e办公 08:34查看AI文稿AI文稿
08:34查看AI文稿AI文稿这节课呢,我们来学习销售统计表的制作,销售统计表的他的种类繁多,常用的呢是用来统计一些几种商品啊,一年或者个月的一些销售数量啊,以及销售的金额。 下面呢我们就来制作它,我们这节课主要要讲的重点呢就是格式栏里面的边框与底纹,我们现在呢来建一个文档, 我们仍然打开表格里面的插入,插入表格,我们插入一个 插入,插入一个酒链 十行的一个表格,我们单击确定,然后我们可以把整体调小一点,调成四号字, 然后以后呢我们现在开始输入,我们从下面输入起, 这两格呢是需要合并的,因为它是某一个商品,我们单击合并,我们可以把表格与边框的栏调出来,这样的话就方便于我们来拆分和合并,我们把它调在下面,因为所有的呢都是一样的,所以 我们可以把它全部都选中,按住键盘上的 ctrl 键来复制, 然后我们再一个一个的合并。前面我们讲到合并,除了这种方法以外还有什么?对,还有把它给拆分,对吧?拆分栏里面我们仍然的要求是一列, 是一列吗?我们要求十三列对吧?行,虽然是一行确定,然后同样可以变成一个,这样子就不用我们一个一个的去合并了,选择好以后呢,我们把这里也要合并掉, 下面呢我们在这里呢再输入一个斜线头,我们前面讲呢,输入斜线头的时候呢, 我们可以选择表格里面的斜线头的一些绘制斜线头的表头,对吧?这个呢但是他有个弊端,就是说书的文字会很小, 像我们这里的话,如果只有一杠,我们可以采取什么样的办法呢?我们首先选中这一个单元格,然后单击表格里面的表格与边框, 我们找到边框这里,然后呢我们看到这边有一个预设预览的一个区域,对吧?旁边呢有一些一杠啊,我们点击一下上面一杠就没有了,再点击一下就回来了,对吧?旁边呢还有一些斜杠, 我们同样也可以用这种方法,我们插入一个斜杠,确定同样这里呢也会插入一个斜杠,也不用我们去做斜线头, 这样子错了。文字的话,我们同样可以自己来输入一些文字,比如我们输入商品和月费, 对吧?把它移过来就可以了,这样子做法呢是比较快捷的方法, 做好以后呢我们下面来做,下面的 我们就做到 月份为止吧,下面打一个,总计 我们就输一些商品 abcd 这样的输入好以后呢,我们现在要把这个表格呢稍微美化一点。 怎么美化呢?我们首先呢可以可不可以把这个标题栏和内容以下的一些内容呢?这一杠我们可不可以把它加粗一点呢?这样的话就会有明显的区别,对吧?我们怎么加粗呢?同样我们选中这一,我们选 这一行,这时候我们会发现呢,我们所要加黑的内衣栏,加黑的内一根线是不是在这一这一行的上面呀?是的。然后我们继续选择表格与边框, 因为我们刚刚已经选择了单元格,我们所要选择的是什么?在上面那一栏,对吧?我们把这里去掉,然后在这里呢选择一个黑一点的,我们可以在这里呢选择半数,选择一个两磅的, 因为我们前面选中的那一栏是要在上面那一横加粗,所以呢我们在上面单击这样确定,这样我们来看一下是不是我们选中的这一行上面的那根线已经被加粗了,对吧?这个呢就是运用表格与边框, 我们可以自由的来做一些比较漂亮的一些形状,比如说我们在那个数量金额啊,这每个商品栏里面,我们都需要把这中间这根线变成一些 双杠线,这样的话就有区别一点,我们同样呢可以选择好这一栏,对吧?选择好商品整个一个过程, 我们除了这样选择以外,还可以怎么样选择?我们可以自由的选择,我们还可以这样选择,对吧?这样选择的话就是说中间的一根线,我们这样选择的话,是不是最右边的一根线,对吧?我们选择好以后选择表格与边框, 然后我们现在呢需要去掉的是这一根线,我们先把它去掉,记住已经是去掉了,然后我们单击这一根线,我们是要把这里加上,对吧?确定 这样的话这边就去多了一根双杠线,然后我们同样的方法,我们在这里呢这根线去掉, 我们可以首先取消,我们可以采取什么样的办法?我们可以选中这一栏,对吧?我们可以把左右两边的线都变成双杠线,这样是不是快一点啊?然后把左右两根线都去掉,选择双杠线 选择好以后加在两边,确定这样两边都已经加好了,对吧?然后我们可以把总计呢 这一栏上头也可以加一根比较粗一点的线,我们选择表格与边框,然后把下面上面的一根线去掉,对吧?去掉以后呢,我们选择一个半数, 选择一个仍然是两棒的,单击一下就可以了,确定这样的话也做好了,我们现在发现呢,这些文字都没有剧中,对吧?我们要选中他们剧中怎么选择?让我们全部选中,出现一个上下左右的标键的时候,我们单击一下, 然后在表格与边框栏里面选择全体剧中,对吧?就全部的剧中了,但是我唯一的我们这一栏呢不需要剧中,我们要可以把它调动一下, 如果觉得字有点大的话,我们可以把它的字体缩小一半, 这样就可以, 对吧?这个呢就是一张日上那个销售统计表,我们就做好了,大家可以运用边框与底纹来对整个的表格进行一些修饰。
30张昆微课







猜你喜欢
- 1.0万铁院红叶