如何用 solo 像康爷一样踩样? 康爷很喜欢将一首老歌里的人生部分做变速变调,切片处理,最终变成他新歌伴奏的一部分。 为了避免踩洋版权的问题,我们先来自己用 solo 生成一首这样的老歌。我这边整理了一百套常用曲风的提示词,包括完整的提示词,排除词,还有歌词栏里面的编曲原标签,感兴趣的朋友可以私信我了解。像这种老歌属于 moontonso, 那 么拉一个这样的提示词进来,然后歌词就选择自动生成。点 击歌词栏右上角的魔法棒,然后选择 rifle song, 两个版本随便选择一篇,然后高级选项,我们把 star influence 往右拉一点,点击 create, 一 键生成。 ok, 就是 它。生成出来之后,我感觉这段人生还蛮有特点的, 那我们就踩秧这一句。但首先我们要把人声分离出来,分离完成之后,点击右侧 remix edit, 选择 just speed, 调整歌曲的速度和音调,拉到一点三三倍左右,点击 create, 重新生成之后,我们就得到了一个变速变调之后的人声。 现在我们就是要采样这段人生。然后继续点击 remix edit, 选择 sample this song, 拖动这个粉色的框框,选中我们要采样的区域。然后还是从我们的提示词库里面,这次我们复制一段说唱的提示词进来,歌词继续让 solo 自动生成高级选项,这边风格影响和音频影响都往右拉,然后 create, 一 键生成。 ok, 来听一下最终采样之后的成品吧。 black coat drag through the highway eyes close close still see the smoke grass co grey hangs like a dope my reflection walks the wrong way 关注我,解锁更多 ai 音乐爆款技巧!

粉丝1.8万获赞9.7万
相关视频
 02:44查看AI文稿AI文稿
02:44查看AI文稿AI文稿ok, 现在速度终于支持用自己音色去生成歌曲了。在今天更新的这个 v 五点五版本里面,我们看多了一个这个 new feature, 原本二六旁边的 persona 没有了,现在变成了 voice。 如果我们点开这个橘黄色框框,我们看到它这边有一个支持用你之前做过的歌的音色, 还有你可以上传一段音频,然后还有就是你可以录制自己的声音了,那我们来录一个周杰伦。爱琴海最近很火,这个 hook 哎,正好,然后选择这个 don, 好 让我们选择这个 use voice, 它要验证我们的声音。 ok, 声音如同清晨鸟鸣一般美妙自然。 你认为你唱歌水平怎么样?那我猜初级的话,他可能会去给你美化。如果是 professional 的 话,大概就是说他会保留你最原本的声音。虽然我不是 professional, 但我想看一下他最大限度能保留我声音到什么程度。好吧,那我们就选 professional, 我 们来一句句对比一下啊, 我觉得他可能是就是因为我翻唱周杰伦,然后呢,他取了原本周杰伦的声音和我的声音做了一个融合,就出现了现在这个声音。那这样吧,我们不翻唱了。好吧,我们现在这一次是用 my voice 原创, 哎,这有点像了, 这个有点像了,这个我觉得有点像了,虽然他肯定还是唱的比我好听。对,他甚至还能美化声音了现在。 ok, 所以 我们刚刚试完了以后,发现用这个 my voice 做原创,它真的是可以把声音还原到百分之八十到九十这样。但是呢,如果我们做翻唱的话,它可能会被我们原曲里面的音色影响到,然后这次的更新还带来一个非常重要的东西,就是未来的 su 五点五模型里面,它允许你根据自己的品味 去搭建自己的模型,点开以后他说你可以上传二十四首歌,然后这样的话就可以去训练一个你自己的 solo 模型,所以这个东西我会在后面的视频里面跟大家详细探索一下。 ok, 这期关于 voice 视频就到这边,然后大家可以自己去尝试一下,看看效果如何。也欢迎大家在评论区留言,我们下期见!关注我,解锁更多 ai 音乐爆款技巧!
694白帽子(AI音乐研究中) 01:40查看AI文稿AI文稿
01:40查看AI文稿AI文稿你是不是用苏诺局部修改歌词的时候,明明只想改几个字,结果旋律全变了,气想砸电脑。其实这个情况我非常懂,你因为我们抽卡抽到一个心仪的旋律确实不容易,然后就因为改了一两个词,整个风格全跑偏了,前面努力全白费,非常有挫败感。这个问题的根本是苏诺的算法逻辑的高贵, 把歌词和旋律深度绑定了,所以局部修改就像牵一发动全身。当我们在编辑器里面选中这句歌词的时候,系统以为的是我们要重构这整句的音乐,所以他把旋律和歌词一起全改了。那对策也很简单,我们只需要懂得一个概率原理。 比如原本我们一次性替换掉一整句,这句歌词里面有十一个字,那每个字都有可能是德尔密发搜那些七个音符其中之一,那么送到重新生成的时候,就至少有七乘十一,总共七十七种可能性。这个时候我们想要保证原本旋律的概率就是七十七分之一,但如果我们只改一个字,概率瞬间变成了七分之一, 结合上下文的旋律,能适配在这里的音符大概就只有两三个,那这样的话,我们就有很大概率可以保证旋律不变了。接下来我们分别实验一下,首先我们听下原本的旋律,他这个停不下的下字没发音出来,然后我们进到编辑器里面,先只修改一个词, ok, 很 完美,词改过来了,旋律一致,音色也不变,但如果我们改一整句呢? 面目全非, ok, 以上就是局部修改的正确用法。然后最近我准备做一系列视频,解决大家用苏诺时遇到的困难,所以大家有什么问题都可以在评论区留言,我不会在里面一条条回复,但我会跳出点赞最多,最多人关心,还有最有代表性的问题,做成视频回答你关注我,解锁更多 ai 音乐爆款技巧!
936白帽子(AI音乐研究中) 04:22查看AI文稿AI文稿
04:22查看AI文稿AI文稿其实苏诺之前有过一次不小心的官方泄露,当时在高级选项这里曾短暂的出现过一个 max mode 的 按钮,花费更多的积分,消耗更大的算力,就可以得到最高品质的音质。虽然这个功能很快就下架了,但在国外的论坛里面,这个 max mode 的 程序语言脚本还是被扒了出来,并且实际上它还是可以工作的。 也就是这样一串代码,只要我们放进提示词里面,就可以解锁最高版本的音质。所以今天我们就来做一个测试,看看是否真的有效。我首先正常在 solo 里面生成一首歌,之后用这个 maxmore 翻唱,里边我们把它们直接下载下来,放进复制软件对比一下。 ok, 那 么现在这边有两条音轨,第一条这个红色音轨呢,是我用正常方式生成的,这边没有 maxmore, 底下这个蓝色的是用 maxmore 生成版本。我们先来听一下这个红色的, 这人声也还可以, 钢琴就能听出来不是那么的清楚了。 嗯,吉他也非常赞。 我来听一下后面那个鼓怎么样? 呃,对,鼓也是软啪啪的。 好,那我们现在来听一下下面这鬼,这个蓝色,这鬼用 maxm 声唱的版本 哦,这个前奏上来就已经感觉很浑厚了,那可能是因为他这个编曲不太一样。 对,但这钢琴听上去就很厚实,然后人声也更立体一些, 这段就明显更饱满了。这弦乐 啊,准备听他的鼓 哦,这个就真的就是感觉敲到心脏上了,这股很有力量。 呃,整体的低音的部分都会更好一些。 ok, 那 基本就是这样,我觉得是挺大区别的, 大家可能从手机上听的话区别不会很大,但我这个音响放出来真的非常不一样,我们可以看一下他这个波形,就是明显感觉到红色的这一轨的波形被砍的很齐, sony 一 贯的作风就是它的高频会被削掉,而这边蓝色的我们可以看到明显这个高低落差会更多一些,相当于就是保留了更多的高频,所以这就是为什么他可能听上去动态更强一些。 ok, 那 基本就是这样,反正这首歌测试下来,我感觉确实是这个 maxmore 要强不少,大家可以在自己做歌的时候去尝试一下。输入这两串代码,那这一小行字是放在歌词栏最上面的,那底下这几行是放在提示词栏里面的,那大家听下来觉得这个区别大吗?我们可以在评论区讨论一下,关注我,解锁更多 ai 音乐爆款技巧!
3608白帽子(AI音乐研究中) 02:34查看AI文稿AI文稿
02:34查看AI文稿AI文稿想要苏诺里某首好听的歌曲的人声部分固定下来,以前啊一直是个难题,换首歌曲人声就变了。今天苏诺更新了 persona 这个功能,新的版本就很好的解决了上面的问题,一起来看看吧。 ai music 介绍之前,我们先来听听效果。 很多人是你连他表面的光 怎么样?这是我们小旭四零四 ai 歌手计划的彝族歌姬吟的原创歌曲,这两首听上去是不是同一个歌手演唱 的效果还是非常不错的。现在保存 persona sumo 会自动帮你剥离人生,你可以截取最满意的三十秒片段保存。 注意看,生成新歌时多了一个 new 模式,比起旧版 legacy, 新模式对音色的还原度简直是降维打击。但问题来了,如何让 persona 发挥出最好的效果呢?关键就在这个 audio influence 参数 划重点了。根据我们实测,这个参数直接决定了你的 ai 歌手还原度有多高。零到二十,只有原歌手的一点影子,相似度并不高,二十到四十 这是黄金区间,相似度能达到百分之八十多,既保住了音色,又留有创作空间。四十以上,相似度飙升到百分之九十多,但别高兴太早,参数越高, solo 就 会越死板。他会强行复刻原曲的旋律动机,让你很明显的听到原本曲子的影子。 就像是一个很有个人风格的制作人,在创作新的曲子的时候,总会用到自己熟悉的或者有标志的那么一段动机,这会让之后生成的每一首曲子都 会多多少少有彼此的影响。还有一个扎心的实测结论, audio influence 的 数值越高,音质越差,调到最高时你会发现乐器频段打架混音糊成一片,甚至有种梦回 solo v 三版本的颗粒感。 所以 ai 音乐目前还是没法做到完全的,既要又要,想要固定音色,就得在音质和旋律自由度上做点小牺牲。有了这个 persona 功能的新版本,我们就能很好地固定 solo 中歌曲的人声演唱部分了, 这对要制作数字人歌手来说确实非常方便。好了, sono 的 这个 persona 小 技巧你学会了吗?咱们下次见。
937小旭 AI Studio 02:05查看AI文稿AI文稿
02:05查看AI文稿AI文稿你玩 solo 用 cover 功能是不是还在盲目的抽卡赌运气?像这样浪费再多积分也很难做出好歌,因为你对 cover 功能的开发利用率可能连百分之一都不到。今天教你三个隐藏玩法,瞬间提升歌曲质量,效率翻倍!尤其是最后一个,是很多大神压箱底的秘法。第一,用 cover 功能无损修复音质。针对 solo 伴奏全是毛刺的歌曲, 我们只需要把人声和伴奏分离,点击 audio upload, 然后只上传伴奏轨道,在歌词栏填入 instrumento, 然后直接选 cover, 保持提示词一致,这样 cover 出来的伴奏和我们的人声再拼接到一起,音质好了不是一点半点。 第二,用 cover 把你的灵感具象化。如果你脑子里有一个旋律,却不会编曲,选择 audio, 让 record 对 着 suno 吹段口哨,录进去以后点 cover 风格填你想要的, suno 会把你的口哨精准扩写成完整的伴奏。 第三,跨词源融合曲风。假如你想做一首中文 rmb 流行歌,但以前直接生成的 rmb 旋律没有记忆点,那么 可以先做一首朗朗上口的纯流行歌,把人声拆出来上传 cover, 然后再输入 rnb 的 提示词,这样就得到了一个流行洗脑的旋律,搭配上 rnb 的 氛围编曲,甚至你还可以用一个更适配这段旋律的性别,这样的歌曲既容易传播,同时也具备高级的听感。 ok, 学会了以上这三招,你才算真正入门的 solo! 还没看懂的赶紧点赞收藏,多看几遍!关注我,解锁更多 ai 音乐爆款技巧!
1604白帽子(AI音乐研究中) 01:43查看AI文稿AI文稿
01:43查看AI文稿AI文稿sono 上传自己的音色制作 persona 方法我找到了,这一段是我自己录制的唱歌声音,我们来听一下。 ok, 但是在右边的三个点,如果我们直接点它,然后选择 create 里面这个 make persona, 我 们会发现它是灰色的,用不了,就是因为它之前把这个功能禁掉了。但是我现在发现了一个新的方法,就是我们点击这首歌右边的 remix and edit, 然后拉到最下面,选择这个 at instrumental, 到这边以后,歌词栏正常填提示词,不填,让 vocal gender 性别不选,让 awareness 向左拉到百分之十左右, audio influence 向右拉满中间 style influence 也没有提示词,所以百分之五十不动。接下来我们听一下这个 好,它这个 instrumental 就是 说给我的人声添加伴奏,但是它这个伴奏听得非常的拉,所以我们不用管它,我们只要取人声就好。这边我已经弄好了方法,到这里就跟之前一样了,点击三个点,然后 create, 它这边应该会有一个 make persona, 那 我们重新来一遍啊,点击 create 生成, 然后我们等他这边全都转完。 ok, 下面这个已经有了,点击右边的三个点, create, make persona yeah, 这样就对了,到这里之后你就正常操作就好了,当然至少你要唱歌比我好听,再上传自己的音色,反正我是不会用的,因为他并不会把我的声音变得更好听。关注我,解锁更多 ai 音乐爆款技巧!
1416白帽子(AI音乐研究中) 01:23查看AI文稿AI文稿
01:23查看AI文稿AI文稿我今天才发现苏诺的人声音色竟然是可以通过年龄来控制的,最近这个发如雪史诗版非常的火,很多朋友问我这个人声音色是怎么做的,然后我今天尝试复刻了一下,我们来听听像不像。首先是原博主改编的版本, ok, 接下来是我改编的版本,我觉得提示词里面说我要一个五十岁的中年男生,我们来听下效果。 然后为了看这个年龄到底有没有影响,我保持其他东西都不变,就把这个五十岁改成了一个二十岁。我们再听一下, 哎,可以听到,虽然我要求都是一个撕裂感的男生,但是这个五十岁听起来就是比二十岁多了一些沧桑。 ok, 这就是今天刚刚探索出来一个小捷径,大家可以在自己的歌曲里面试一下。关注我,解锁更多 ai 音乐爆款技巧!
655白帽子(AI音乐研究中) 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿苏诺今天凌晨更新了他的 v 五点五版本,终于可以用自己的人生来创建歌曲了,这也是我们期待已久的新功能。 你进来以后会先看到这个新的五点五的标记,这次的新功能可以是录制的,也可以是上传的,用到我们自己的声音,根据我们上传的内容进行风格型的创作,可以创造出符合我们的个人风格的音乐。 好,进来的时候我们就可以看到曾经的 sony 改成了 voice, 这时候我们就可以在这里面创建传,有一个是录音的按键,然后有一个上传的,上传我们已有的 alter 的 界面,也可以在我们的 library 里选择, 然后这里要打上勾,这里是一个关于法律的条款,也就是,呃,我们允许它使用我们的声音, 然后这下面有一个简单的介绍啊,可以用各种不同的风格和语言去演唱一个好的麦克风,至少要唱十秒和找一个安静的地方, 所以我直接可以上传一个,这里要把这个我们说话的声音录进去,以确保刚才的演唱和这文字和我们说话是本人。我现在在想如果这个人的说话声和唱歌声音不一样怎么办呢?这次升级的一个第二个功能是在这里 你可以有一个创建自己的模型,它需要花费一百个快的,就是至少有六首歌,然后当然你可以创建二十四首歌,然后各种风格你可以一直上传,但是还蛮费时间的在这里去创建 好,那么现在还有一个功能是属于我自己的一个风格,这个功能是在我们个人的这个简介里面, 呃,也就是说当我们开启了这个功能以后,我们在这里面输入文字,他就会很智能的去知道我们自己要树立自己怎么样的一个账户的风格,还有我们听到的歌曲和创作出来的歌曲, 但是什么样的风格都可以在这里面有一个呃,个性化的一个标注,那么这就是我们这次升级的三个主要功能,因为他这个版本刚刚上线,有很多的使用具体说明和评测体验,我后续的视频会陆续上线,也欢迎大家留言探讨。
175苏楚力AI音乐社 01:25查看AI文稿AI文稿
01:25查看AI文稿AI文稿真心希望各位观众老爷们不要白嫖,你的三连是我更新的动力,用 solo 做了一首粤语歌,大家听听看他的发音标准吗? 那这个是怎么做的?那第一步呢?其实我们先打开一个 ai, 跟 ai 直接说给我用粤语白话写一篇歌词, 那第二步的关键点就是让它用繁体中文来进行书写。那第三步呢?其实就是让它来按照格式来修改一下 原标签。那第四步我们直接把这个歌词给复制下来,进入到 solo 当中,我们点击 create 创作直接给贴上来。那底下这里呢,我们设置好对应的风格, 以及我们去调节一下高级选项。最后呢再直接点击 create 一 键生成就可以了。为了让大家轻松掌握 ai 音乐制作,你们的流派风格关键词库我也已经全部准备好了。
 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿这条视频告诉你新手怎么用自己的声音来生成 solo 歌曲,操作方法非常简单,赶紧点赞收藏,下次用的时候咱们直接拿出来看。那这是 solo 最近更新的 v 五点五的新功能,我们进入 solo 后呢,点击嗓音创建声音,勾选一下这个 点记录就能录我们的人生了。最好呢是唱一首我们比较擅长的歌曲,然后呢,时间不少于十秒钟,不明不白。 歌曲录完后呢,我们再按照提示验证人生。声音如音乐般悠扬动听自然。验证完呢,会出现这个界面,如果你对自己的唱功很自信的话呢,就选专业,他会最大程度的保留你原始的音色。如果说一般,那我们就选中间这一个, 反正越往上的选项的声音的美化程度就会越高。点击保存,我们就可以直接用了。来浅听一下用我的声音深情的歌曲吧, 整体还是挺像的,如果说好好录的话呢,效果应该会更好,那你们赶紧也去试试吧!
30蓝BLUEKS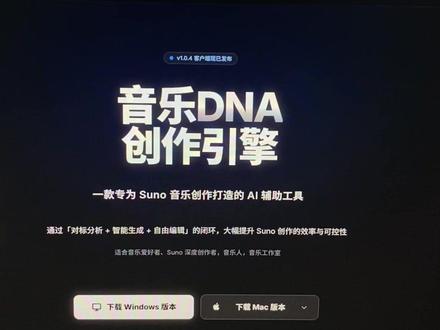 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿不会写速度提示词,不会写歌词的朋友们看过来,这是一款我个人开发的 ai 音乐创作辅助工具,目前呢也是更新到了为一点零点四的版本,那比方说我们想要做一首周杰伦风格的歌曲怎么办?我们直接把这首歌曲呢导到这个软件里面,那他呢就会分析出这首歌的所有标签,风格,情绪, 然后配器人声,还有什么混音啊,旋律和声,编曲,还有曲式的结构。下一步我们直接在这边输入我们的歌曲主题,还有呢我们想要的歌词风格,语言和排版要求,或者我们在这边直接导一个我们自己的歌词,然后右下角呢还可以对歌词进行优化。那么现在在主题创作里面随便输入一个主题, 输入完以后呢,直接点启动 ai 创作引擎,那他呢就会把配套的 solo 提示词跟歌词一并的生成出来。 来,我们看啊,这个是 sumo 的 提示词,那这个提示词呢就是根据我们左边的这些标签,它给你总结归纳出来的,然后右边呢就是我们的歌词了,它这个歌词呢也是带原标签的,就是每一个段落前呢,它都会有这一个具体的注视,那如果这个歌词我们要改怎么办呢?当然我们可以自己 自己去手动的去编辑,或者呢我们直接可以让 ai 去进行重写, 也可以增加段落,对吧?增加歌词,增加标签,段落都可以,如果整体都不满意呢,我们点一个重新生成就可以了。最后呢我们在右上角这边点一个中心切换,然后复制一键跳转到速度里面 粘贴点击创造,是不是特别傻瓜啊?如果说你自己要去写这一套提示词跟歌词的话,你肯定要花很长时间,那这工具的下载地址呢?在这边有需要的朋友们赶紧去试试看。
29蓝BLUEKS 01:13查看AI文稿AI文稿
01:13查看AI文稿AI文稿二零二六最新 solo 中文版,直接打开就能生成歌曲,无需点数,我用它生成的歌曲已经成功签约上个月战绩。话不多说,直接演示生成过程。首先打开 ai 作曲,支持两种生成模式,这个灵感模式就是用一句话生成歌曲,点击这里就能看见提示词示意,点击这里还能进行提示词优化。如果想要生成纯音乐, 打开这里关闭,就是默认生成带歌词的歌曲模型,选择最新 b 五即可。点击生成就能收获两首歌曲。但如果想改成有人生的演奏,该怎么操作?我们点击这里歌曲,然后点击这里进入编辑器,点击智能演唱,选择刚刚那首歌的音轨,选择男生,点击其中一个,点击生成就能收获一首不改变旋律, 带有了人生的歌曲,听听效果 是不是还不错啊?接下来看看高级模式,在这输入自己写的歌词, 会写的话就选这个自动生成,然后在这填入或选择歌曲风格,你也可以在这上传喜欢的歌曲或旋律,供他参考。生成设置完毕就点击生成歌曲就生成出来了。最后我把 ai 音乐变现步骤和 ai 音乐进阶版的教程都打包好了,三连均可安排哦!
7太空舱 08:03查看AI文稿AI文稿
08:03查看AI文稿AI文稿兄弟们, ai 音乐圈真正的终极王炸来了!就在昨天, solo v 五点五迎来了史诗级的震撼发布,之前的版本是降维打击,这次 v 五点五版本简直就是宇宙大爆炸,直接把几万块的录音棚压缩到了网页里,送了你一家专属的私人唱片公司。为了让大家光速上手, 关于怎么高质量录制干音,怎么选歌训练大模型以及 v 五点五最新的高阶提示词公式,我都整理成了一份终极懒人保姆包了,直接上干货!揭秘三大逆天功能!第一个核弹级大招,全网呼声最高的专属人声克隆!它基本原理就是录制你的声音样本 或上传录音。这样你就相当于在苏 no 中创建了一个语音模型。一旦创建了语音模型,就可以在生成的任何歌曲中使用它。 因此不是一些随机的苏牛声音唱你的曲目,而是你可以唱任何歌曲。让我们去苏诺网站,点击左侧边栏的 create, 并切换到高级模式,查看名为 lucas 的 新选项 persona 已改为 voice, 不 过别担心,什么都没变。实际上你仍然可以像以前一样使用它们,它们在力五点五版中听起来更好。可以创建自己的声音。 点击 create voice, 然后打开 record, 可以 在其中录制自己的声音。上传样本或从你的 solo 库中选择音频。 用你想要的风格和语言唱歌。如果你有一个好的麦克风,最好尝试在安静的空间录制没有背景噪音,说话的时间越长,录音越能准确你的声音。这里建议至少三十秒或更长时间。我这边选择上传选项, 因为我已经有自己唱歌的录音了。我会选择它并将其上传到这里。如果你的音频有背景音乐,苏诺会自动为你分离人声。一旦语音上传, 你可以听他并修剪任何不需要的部分。只保留干净的声音样本。接下来选中复选框,以确认这是您自己的声音。确定没有用别人或任何歌手的声音,然后点击使用语音。 素牛现在会确认这是你的声音。让你读一个短语,显示在屏幕上。该短语可以用多种语言显示。从这个下拉列表中,我会用英语阅读并单机复选标记。 素牛会将您的声音与上传的样本进行比较,然后就来到这个页面。你可以给你的声音起个名字。为了容易辨认,您还可以删除默认图像并生成 ai 头像或上传您自己的照片,并将其设置为头像。请注意, 语音是通过录音或上传创建的,不能公开。他们在你的速牛个人资料中保持私密。单机保存您的声音已准备好。在模型选择中。在模型中选择最新版本力五点五, 然后选择语音。让我们写一些歌词,并在风格描述中创建一首歌曲。输入你想要的流派或氛围。然后点击个性化魔术魔杖,根据您的喜好增强提示 单机更多选项已调整其他设置。您可以指定语音性别,并增加音频影响滑块。如果你想让声音更像你的默认值调为百分之二十五,可以先保存,然后给你的歌起个标题。点击创作,看看生成效果怎么样。这是语音样本。 there's nothing in the world like the way that it hits so when you're laying back laying back on the drift。 这是苏 no 创造的。 如果您想从现有歌曲中创建新的声音,选择曲目,点击三点菜单,然后去创建语音。 搜 new 将开始处理人声。一旦准备好了,你可以点击并拖动波形。选择最喜欢的人声部分,然后给它起个名字,方便以后容易认出来。你也可以选择公开。 如果你希望其他速牛用户使用你的声音,然后点击保存。生成后就是这样。如果您打开语音部分,您的新语音就可以使用了。 你会看到目前创建的所有声音。如果你有任何遗漏的声音,您可以将它们升级到力舞版本,以获得更好的声音一致性。例如,这是我最喜欢的声音之一, 那我们选择这个声音。保持当前风格,添加一些歌词,选择一种 style, 给它起一个歌曲标题,然后点击创建,这就是我们得到的。 就这样,您可以使用相同的声音创作任何流派的歌曲, 任何风格,即使是不同的语言。如果你觉得克隆声音还不够炸,那第二个大招,自定义专属大模型绝对让你原地起飞。您可以在自己的曲库上训练肃纽,并创建您自己的自定义版本的肃纽。接下来展示它是怎么操作的。 在模型菜单栏中有一个名为创建自定义模型的新选项,点击它就会打开一个窗口,这是上传音乐的地方。为了达到最佳效果,您可以上传超过二十四首歌曲,但需要至少六个人来训练模型。我们点击批量上传。 我的电脑上有九首歌,我想让素妞学习。歌曲上传后,可以给这个模型起个名字,就叫沙漠女武神吧。然后点击创建自定义模型,素妞将开始在后台训练。他如果想检查情况,可点击模型,他目前正在训练。与此同时,我 来解释一下这些数据。我用了的歌曲上传了四首女生演唱,带有中东节奏的重金属音乐,复杂的拍子和现场表演氛围。我们可以听一下训练的歌曲。 现在看起来模型已经生成好了,那我们选择它并测试它。先添加一些歌词,将样式部分留空,看看它会出现什么。 one, two, three hit, it let's go。 这是有趣的部分。即使我切换流派或声音,它仍然倾向于相同风格的音乐。那是因为这个自定义模型只在这个数据上训练,所以无论你为它什么,它都会学。 第三个,即刻即降为打击 ai 音乐品味记忆系统,它就像音乐版的叉 g p t。 自定义指令, 酥妞会捕捉您的创意偏好和风格,你一贯做出的声音选择,还有你喜欢的歌曲种类,不喜欢或点击返回。如果你点击你的头像并进入 my taste, 你 会看到酥妞已经开始建立个人档案了。根据您的使用情况, 例如,他发现我喜欢戏剧性的流行民谣和现场表演强劲的流行摇滚。他也理解我的歌曲创作主题,爱失去任性以及我的制作风格以及首选语言和语音。当然,你可以编辑或随时改进来,更好匹配你的喜好。 把它想象成叉 gpt 中的自定义说明。针对你的音乐口味档案,让酥妞推荐更好的风格建议,并创作更好的歌曲。到目前为止,您最想尝试哪些功能呢?那今天的内容就先到这里了,我们下期再见。
 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿就很多人说苏诺威五新出的人声克隆功能出来不像自己的声音,其实这个根本问题在于克隆的时间太少了,平台现在要求是十秒钟以上就可以,但你要知道这个是唱歌,不是说话,唱歌的方法和位置要比说话复杂很多,所以你哪怕上传是三四分钟的一首完整的歌, 那它的出来的效果也不会特别好,因为我们唱歌的都知道,不同的歌可能用不同的方式,不同的咬字。如果说你只是想要克隆这个功能的话呢,我建议可以使用一下 ace studio, 它的人声克隆功能的采集时间最低是半个小时,最高可以到两个小时,这样的一个时长也是能够非常精确的保证你的人生更像你自己。不过呢,这个后期可能稍微有点复杂,需要 呃我们借助于宿主还有人声调教的一些手法,它的使用难度也是相对比较高的,所以大家可以根据自己的呃基础去判断一下自己更适合于什么。 因为 solo 它主打的还是音乐生成和音乐制作,它目前的克隆功能作为一首歌的导唱是没有问题的,但是你是想要这首歌出来就是成品,非常的像你,我觉得它还有很大的差距。
26苏楚力AI音乐社 04:21查看AI文稿AI文稿
04:21查看AI文稿AI文稿solo 五点五昨天凌晨炸裂登场,三大重磅更新全面剖析,点赞收藏,一起来看看吧! ai music 先说最基本的模型能力,在音乐性和音质上进步并不显著,特有的高频噪音 solo 位还是没有得到很好的改善,以及 ai 位的人声唱腔也并没有显著的提升, 依旧是苏诺一贯祖传的听感。不过先别着急,这次的三大中榜更新,我甚至觉得比模型的更新本身更值得关注。他们分别是 voice 自定义人声音色、自定义模型、个性化、品味。简单说就一句话,极度个性化。我们一个一个来看看。第一, voice 自定义人声音色这个功能 替代了之前的 persona, 它们的区别是,之前的 persona 你 只能使用 solo 深沉的音乐来固定人声音色,但现在的 voice 你 可以自己上传录音,或者直接对着麦克风录音来保存人声音色自由度直接拉满制作 voice 的 入口就在原来 persona 的 地方。录制或上传一段唱歌音频之后, solo 还需要你对着麦克风念一句话,来证明你有权拥有这段录音的音色, 通过二次确认后就可以固定下来你的音色了。这个二次确认也可以理解成 solo 为了避免侵权而加的一道门槛,避免你随便抓取一段知名歌手的人生来克隆。那么来听听我用这个 voice 来演唱我们 ecoline 的 父子乐队歌曲的效果吧。 可以听到,音色的相似度大概是有七成,但一些个人的咬字习惯和一些发音习惯经过 solo 的 处理后 会变淡,所以目前的效果只能说能用,但离百分百复刻真人歌手还是有一些差距。第二,也是我觉得最有趣的功能,就是现在你可以自己定义自己的音乐模型了,入口就在选择模型的选项这里。现在我们不仅可以使用 solo 的 v 五 v 五点五模型,还可以 create custom model, 创建自定义模型。 在这里只需要上传最少六首你自己的音乐,那么苏诺就会学习这些音乐的风格特征和你的个人特征,然后创建一个属于你自己的新模型。例如我将我们 ecolin 已发行的几首歌上传给他,经过几分钟的等待,这个名为 ecolin 的 v 一 的模型就训练完成了。来听听效果 可以听到苏诺确实抓住了我们以往歌曲的一些细节,例如诗征、吉他的 riff 同声、与男生的交织演唱等等。他就像一个乐队专属制作人,了解我们乐队的调性和特征,并且有针对性的为我们创作新歌。之前有人吐槽说 ai 创作的歌曲是公式化的口水歌,但 现在定制模型一出,它可以学习到你独特的风格,千人千面的产出,歌曲个性化和自由度直接拉伸一大截。第三个功能叫做 my taste, 我 的品味在我们的头像旁边,在这里我们可以用一段英文提示词来描述我们对音乐的偏好。例如我这里就写着核心曲风以普通话为主, 融合多种风格的流行乐根基包含嘻哈、电子与民谣、流行歌词与情绪,主题围绕家庭、童年、身份认同等等。 你可以对音乐的曲风、配器、歌词、情绪等等方面做出描述。那么写完这个有什么用呢?当我们在写作提示词的时候,原本润色提示词的按钮变成了蓝色,并且写着 personalized magic wand 个性化魔杖。也 就是说,当我们写了一段音乐提示词之后,可以让 solo 根据 my taste 里面的偏好来为我们个性化的润色提示词,从而让润色后的提示词更贴近我们的偏好。好了,我们总结一下,这次五点五的更新带来了三大核心功能,这些功能都大幅度的提高了我们创作的自由度和个性化, 想做的不仅仅是爆款歌曲的制造机,他更想跟每个音乐人绑定,成为音乐人形影不离,相互融合的 ai 音乐助手。好了, v 五点五你用上了吗?这些功能你觉得怎么样?欢迎在评论区告诉我你的答案。 这里是小旭音乐 ai 时代音乐人的领航员,咱们下次见!
366小旭 AI Studio 01:28查看AI文稿AI文稿
01:28查看AI文稿AI文稿你的 solo 和我的 solo 可能已经不是同一个工具了,而且差距会越来越大。今天我们来讲 solo v 五点五更新里面最被严重低估的一个功能, my taste。 我 的品味很多人不知道,其实 solo 一 直在偷偷的学习你,你给那首歌点了赞,那首歌刚生成出来就被你扔进垃圾桶,他都记得清清楚楚。并且通过你的行为数据,他可以精准的判断你喜欢的曲风,你的歌曲情绪,你的编曲习惯,甚至你的人生语言和音色选择。 重点来了,从今往后,你的提示词写再好,可能也不如你的 my taste 一 样对一秒。因为以后提示词哪怕你只写一个词,比如说 pop 流行乐,然后点一下提示词栏右上角这个蓝色魔法杖, my taste 就 会介入,它会自动帮你补齐一整段专业描述。它不是瞎猜,而是把你长期的审美习惯翻译成 ai 能听懂的提 示语言。而如果你的音乐审美跟别人的歌就是会比你的更有质感。所以,如果你认为你的 solo 现在已经学歪了,那怎么办呢?也别着急, 点开你的头像,然后进入这个 my taste 页面,你看到在这里就是苏诺给你贴的神秘标签,如果你不认可其中某一个部分的话,可以去把它删掉,或者你想重新定位风格的话,你可以整篇删掉重写。 这要记住一个关键的区别,虽然写这个 my taste 和写提示词差不多,但写提示词是要去具体的写细节,比如说歌曲速度和乐器使用。但写这个 my taste 时候,更重要是写整体的风格,情绪还有氛围,通过这个方式让苏诺记住你的风格, 从此之后每生成出来一首歌都带有你的味道。所以大家抓紧去看一看你的 my taste 现在长什么样子,你可以在评论区告诉我,在 solno 眼里,他认为你是一个什么样的音乐人呢?关注我,解锁更多 ai 音乐爆款技巧!
389白帽子(AI音乐研究中)



