apache shenyu使用教程
零基础学 it, 月薪过万就来黑马程序员,黑马程序员成就 it 黑马。亲爱的小伙伴们,大家好, 那接下来呢,咱们一起来学习一门新的大数据的一个框架,叫呼地,他是当下比较流行的一个牛市的数据户平台。 好,首先我们看一下我们本次这个框架的学习分为几块内容,主要呢分为三个部分,第一部分我们讲解一下忽地的一些基础的入门的东西,那主要讲解整个忽地框架的一个概数。 然后呢,我们快速的去通过案例来演示,让大家感受一下蝴蝶能够做什么。最后我们讲一下蝴蝶的一些基本的核心的概念。好, 在这里我们首先给大家抛个问题,护理是什么呢?我们为什么要用它呢?哎,这都是我们要去讲解的。首先我们去理解一下护理,它就是帮助我们干嘛管理数据。哎,我们知道我们在学大数据框架当中, 其中有一个汉武框架叫竖仓工具,他也是帮我们管理数据的,那我们护理呢,跟汉武差不多,他也是来管理数据的,护理他 不存储数据,也不分析数据,他只是管理数据,比如使用互利帮助我们管理存储在 hdf4 分布式文件系统上的数据。哎,我们都知道 hdf 的文件系统可以自己去管理数据吗?把一个大的数据, 我日直数据文件存到 hds, 他会划分成很多 block 进行存储,那我们互利怎么还要去做呢?哎,互利帮助我们更好的管理,比如我们知道 数据存在 iqtf 统计系统是小文件,是影响我们读写数据的性能的,那我们互利呢,他就可以把小文件呢,自动的合并成大文件。再比如我们知道 ig df 总经系统,他的设计目标就是一次写入,多次读取,当我们数据写入以后,我们是不好进行更新删除的, 但是当我们使用护理来管理存在 htm 数据的时候呢,我们是可以对数据进行更新删除的。此外我们护理还有一个功能,就是我们可以实时的把数据给 写到我们文艺系统工具,我们叫实时的牛市入胡。好,这就是我们要给大家去讲的忽例。好,那忽例呢,是诞生于 国外的优步公司的,因为优步啊,他们有很多很多的乘客的这些业务数据,业务数据呢,往往是变化的,他们需要对这些数据进行分析,哎,他们就想到了数据我们要进行更新删除 啊,我们也需要有很多小文件进行合并,包括牛市的把数据给他入户等等等等,这就是忽地的诞生背景。好,第二块呢,我们给大家讲解什么呢?整个忽地的一个使用 呼地,他是管理数据的,并不存储和分析,那户地就要与我们讲的这个存储引擎和分析引擎进行集成,才能更好的发挥他的作用。 那在这里面,我们实际的项目是开发当中呢,往往我们呢忽略管理的数据都是存在 hdf 总经系统上的, 就相当于我们讲的害物框架一样,害物表中的数据都在 gdf 等系统。护理也是护理,一开始呢,诞生的时候就是与 spa 进行整合的,通过 spa 把数据写到护理当中,也从护理当中怎么样读数据? 好,那后来呢?由于护理的发展哎,比较好,大家都在用它,弗林克框架呢也成熟了,后来新的版本护理与弗林克呢,也可以进行整合 进行,通过弗林克实时的把数据写到护理当中,实时的从护理中进行批量加载和流失的读取分析,这是我们第二块的重点内容,与 spark 以及弗林克的整合使用 好,第三块呢,我们来讲一下护理在实际的工业生产环境中如何去使用,在这里我们通过护理在我们船制教育博学股和船制数据中心中的一个使用,带大家去体会一下。 我们分别通过两个案例来使用,一个是与 spa 的整合,一个是与弗宁克的整合。好,那这三个内容呢?大家可以看到, 在我们讲互利课程的时候呢,我们用的是比较新的版本,零点九版本,那互利呢,就在前两天发布了零点一零版本, ok, 好,那在这里可以看到我们互利于 spa 的整合,我们用的是 spa 和是三点零版本,与弗林的整合用的是一点一二版本, ok, 好,那在这十个案例当中呢,这两个案例呢,我们都是通过牛 试的方式把数据呢给他入壶,最终我们通过 spa 和烧烤,通过 have, 通过 fling 的烧烤,通过普利索道来进行我们的数据的一个查询读取, 查询当中分为批量查询和有时查询, ok, 这是咱们本次互利课程的一个利用提高。

粉丝7.8万获赞28.5万
相关视频
 03:45
03:45 20:59
20:59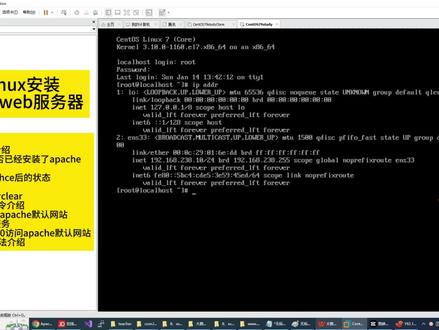 14:40查看AI文稿AI文稿
14:40查看AI文稿AI文稿上一节课我们安装好了这一台圣特 os 服务器,安装好服务器的目的是什么?百分之九十以上的服务器应该都是在提供服务, 百分之九十以上的服务呢?可能都是 web 服务,像这一种网站类型的服务。 所以今天我们就要把安装好的这一台 ip 为幺九二点幺六八点二三八点幺零,这一台,把它做成提供网站服务, 我们可以通过在地址栏当中输入 ip 地址就可以访问到这一个网站,这一个网站是 apart 提供的网站, 我们今天的目的就是安装一个 aparts web 服务器,让他提供网站服务。 leaders 安装 apart 目的是使用 center os 服务器架设网站。 现在的互联网世界网站基本上由这三种 web 武器构成, 一种是 enginx web 服务器,一种是 aparty web 服务器,一种是 i i s web 服务器。 我们今天讲用 apart 起来架设一个网站,架设网站必须用到 web 服务器。首先我们使用上一节课我们介绍的 scale 这一个网络工具去连接我们的虚拟机,大家单击文件新建在主机名里面输入幺九二点幺六八点二三八点幺零, 这个地址一定是和你的虚拟机的地址是一一对应的, 名称可以自定义,张三李四王五均可。我这里就给他取一个 apart 起的名字,后面带上这个 ip。 这样呢,我就知道这台机提供 apart 服务,它的 ip 是这个地址。接下来单机确定,再双击 这一个图标,请输入用户名,填入 root, 勾选记住用户名,单击确定, 在这个位置输入密码,勾选记住密码,单击确定现在已经登录到了这一台 center os 的服务器。 接下来我们检查一下 center os 服务器是否安装了 apart 器, 检查是否安装了 apart 的命令是 h t t p d 复位, 我在这个地方输入 h t t p d 复位,会发现未找到命令, 说明我们没有安装 apart。 起伏。既然没有安装,我们第三步就来开始安装。 在 center os 里面安装软件,卸载软件,查看软件的命令是 yum, 安装后面跟 install, 卸载后面跟 remove, 查看后面跟 list。 现在我们是安装,所以我们就 y u m install 阿帕奇。这一个软件是要用 h t t p d 这几个关键字,所以合起来的命令就是 y u m install h t t p d 就表示 安装 apart。 下面我在这里输入 yum 已经 store httpd 按回车, 现在他就去下载相应的数据, 下载完后问你是否开始安装,这个时候输 yes, 回车他就开始安装 apart, 在这种状态表示安装完毕。 在刚才有一个询问状态,询问你是否开始安装。在安装软件的时候,有些软件会多次询, 如果你不想回答问题,直接在后面输一个横杠 y 就可以了,他会自己帮你把所有的问题都回答为 yes。 所以如果你们以后安装软件想要偷懒,直接后面跟一个杠号 y 就可以了。 这是安装阿帕奇。接下来我们又来查看阿帕奇安装后的状态, 我们还是使用刚才一样的指令 h t t p d 杠微回车,你会发现现在有了阿帕奇这一个软件的信息。这是第四步。接下来我们要启动阿帕 part, 启动 apart, 我们要学一个命令叫 system control, 这个是启动服务的一个指令, 这个管理服务的指令后面可以跟 start 表示启动服务。现在我们就是要启动 httpd 服务,也就是启动 apart 起服务,所以一会儿我们会输入这一条命令, 除了启动以外,还有停止某一个服务,还有重新启动某一个服务,还有查看服务的状态。这一些指令 还有两个,开机自启动,取消开机自启动的指令,所以接下来 我们就去启动 h t t p d 这一个 apart 企的服务。 这里顺带介绍一个指令叫 clear, clear 是清除整个屏幕的意思,这样可以让屏幕区域显得更干净,老师上课更方便。 清理完屏幕后,我们执行刚才的管理服务的命令, system c t l start h t t p d 回车它就启动了 apart 这一个 web 服务, 我们如何知道它启动了呢?刚才我们讲到我们可以用 status 去查看它的状态,所以 接下来我执行这一个服务管理的命令,去查看阿帕奇的服务状态。这里标了一个 running, 就表示阿帕奇服务已经正在运行当中。 apart 起服务既然已经运行,那我们就测试从 win 十去访问这一个 apart 起的网站。 接下来我就在浏览器里面输入幺九二点幺六八点二三八点幺零去访问 uphat 这一个站点, 但是你会发现访问不了这一个网站。这边的 apart 起是七 启动了的,也就是啊,这一台机器已经能够提供网站服务,那为何在这里却不能访问这一台安装好的网站呢? 接下来我们再来介绍一个知识点,防火墙。每一台服务器在启动的时候,一般防火墙是开启的, 这是为了计算机的安全。防火墙跟阿帕奇一样,他也是一个服务, 也是用 system c t l 这一条指令来管理。刚才讲到网站是叫 web 服务, part 起也是一种 web 服务,现在我们接触到的是防火墙服务,所以我们还是用 system ctrl 去管理这一个防火墙的服务。 我们首先使用状态命令去查看防火墙的服务是否开启。 下面我在这里输入 system ctl status fire wall d 这是防火墙服务的标识。回车你会发现防火墙服务正在运行当中, 所以我们刚才在这个地方输入这一个 ip, 却访问不了 apart 起伏原因是防火墙正在运行, 所以接下来我们要去关闭防火墙,禁止防火墙开机至启动。 我打开命令窗口清一下屏幕,然后使用服务管理指令停掉防火墙 回车。接下来我去查看一下防火墙服务的状态, 你会发现它 in active 表示防火墙已经被关闭了。为了以后每一次开机防火 墙不自动启动,我们还需要使用这一条指令 disable 掉防火墙服务,这样下一次我们开计算机的时候就不会开启防火墙服务。下面我去执行这一条指令。 防火墙服务既然关闭了,我们接下来就可以从 win 十访问 apart 这一个网站了嘞,下面我来测试一下, 在未关闭防火墙时是无法访问此网站。现在我单机回车,你会发现我们已经可以进入阿帕奇这一个网站。 赞的界面,这就是啊,这一节课讲的主题, lytics 安装 aparts web 服务器。 在今天这一讲,有两个命令需要大家掌握,一个是软件管理的命令,管理里安装一个软件,卸载一个软件,查看已经安装的软件。 第二个是服务的管理,开启一个服务,停止一个服务,查看服务的状态。 所以今天这节课对于你理解 lilyx 操作系统比较重要。我们拿 windows 来对比,这个 y u m 就相当于你的控制 面板,这一个控制面板里面的程序和功能, 里面所有的你的本机安装的软件,你在这一个界面可以卸载你已经安装的软件,可以管理你已经安装的软件,这应该就相当于 y u m 这一条指令的作用。 system ctrl 又相当于什么呢?它相当于你在电脑右键单机管理 里面的服务和应用程序里面的服务这一些。是 啊, windows 的服务,这些服务如何去管理,就是我们学习的这一条指令。 所以今天学习的内容,我们和 windows 做一个对比,大家会发现用这种对比的方式来理解 center os 操作系统应该更加简单。 关于在 center o s 七点九当中安装 apart 起我们就讲完了, 下一节课我们就讲自己做一个网页,把这一个网页的效果呈现在这里,而不是使用阿帕奇的默认网页。我们自己做一个 最简单的网页,在网页当中画一个矩形,给他填上颜色,然后让他呈现在浏览器当中,以锻炼我们使用阿帕奇部署网站的能力,锻炼我们编写 htm 代码的能力。 这节课我们就上到这里,大家下课休息。
128有思俱乐部抖音号 03:55查看AI文稿AI文稿
03:55查看AI文稿AI文稿哈喽,大家好,那这个视频呢,我们来介绍一下大数据处理框架 spar, 相比于好多款 max 六死,他不仅带来了编程上的便利,带来近百倍的系统提升,那我们一起来看一下。好,那这种我们来先来介绍一下几个 spa 和任务创业过程中的几个核心概念。那我们来看这张图,它包括了抓尾, class manager, 或者我们称之为 master walker 以及 ize cuter 这么四个核心的概念。那当你提交一个 spa 和应用的时候,他就会对应生成一个抓尾的进程, 那他呢,会注册当前十八个任务到 class manager, 并且申请需要的资源,那 class manager 就会协调多个 worker 去申请到你所需要的一个资源。比如说你需要申请三个实力,每个事业包括一个 cpu 和五百种类型,那这边就会申请到这么三个 来满足你的计算需求,那申请到的 s q t 又会反向注册到这里的 driver, 从而使得 driver 和 s q t。 那我们一起来开始运行的 spoke 程序,比如说从 s s 来读取你的原数据,创建 r d d。 那什么是 r d d 呢? r d d 呢?是 spot 中非常核心的概念,它全称是 resident distributed dead set 弹性分布式数据几, 那简单来说就是你代码中的一份数据几,实际上是划分为多个分区,存在多个节点上的,那这样的特性呢,保证你代码逻辑中对象是一致的,但是呢也符合了大数据天然分布式的特点,方便进行分布式的计算。那二弟弟呢,还有个特点,就说他只能从数据园中,比如说 hdfs 来读取生成获得依据宜幼的 ledd, 通过 transformation 这样的算子来计算生成得到那一个 ldd, 通过算子生成另外一个 ldd, 再生成下一个 ldd, 就形成了一系的 ldd 这样的血缘关系。我们 成这位 lineage, 那 rdd 的第二个特点就是延时计算,那比如说一个 rdd, 经过多次的传说, mace 算子生成了一系列的点点,但是它实际并不执行计算,直到碰到一个 action 的算子,比如说这里的 connect 或者 counter 的时候,才真正开始计算。 那最后呢,我们来介绍一下 spa 和运行式的几个关键概念,那比如说这里的 spa 照吧,我们称之为 ipad case 以及 job stage 和 task 他们是一个依次包含这样的关系,那我们来详细来解读一下。比如说你有一个阶段任务,通过 r d 一,通过 map filter 升成二 d 第三, 然后通过 goof by 生成二弟第四,然后 collect 一下,那然后又通过 map 生成二弟第六,然后最终从事到文件。那当我们提到这个计算任务的时候,那整个计算任务我们称之为一个 application, 那一个 application 又划分为多个兆本,那划分的依据呢,就是一些类似于 collect 或者说 save 这样的 action 算子,比如说这里的 collect 和 save, 就把整个 i p k 省划分为这么两个罩吧,那每个罩之内的话又划分为多个 stage, 那划分 stage 的依据我们称之为 shuffle 算子,比如说这里的 go back key 就是一个典型的杀否算子,那这样的杀号算子呢,就把一个罩部划分为两个 stage, s 零和 stay 之一,那每个 stay 之内部呢,又划分为塔斯克,那塔斯克呢,也是斯巴克运行的最小调度单元,那比如说这里的 mapfut, 那当然斯巴内部可能会做些优化,将多个算子合并在一起,那这属于优化这一盆内容。 那刚刚呢,我们也提到一个非常关键的概念,就是沙否,那沙否也是非常多 spa 程序做优化重要的优化的点。那什么是沙否呢?那沙否呢?也是 spa 中非常核心的概念,非常多关于 spa 和优化的主题就是围绕沙发来展开的,当一个阿迪迪有多个分区,在经过些算子的时候,他不得不经过重新分区才能得到结果,那我们称这样的算子来 沙否算子,那有点类似于斗地主中的洗牌一样,说这里有 idd, 他有这么三个分区,那沙发的过程呢,就是让每个分区中 k 相同的部分,比如说这里蓝色的部分 汇总在同一个节点上的过程,我们称之为沙发。那沙发的过程呢,会牵着大量的磁盘读写以及往外,哦,是一个非常 cos 的过程。那常见的沙发算子呢?比如说赵颖,或者各种 good by 结尾的算子,那我也罗列在了屏幕上。 好,那我们今天也介绍了 spa 可的基本概念架构,还有基本原理。那如果说你有什么感兴趣的话题的话,也可以留言讨论,然后呢,我也会推出系列的 spa 的视频,那如果你喜欢的视频的话,也欢迎关注三零。
749猩球科技 00:59查看AI文稿AI文稿
00:59查看AI文稿AI文稿我是散打狼,今天给客户在 windowsscow 两千零八六十四 v 的系统上将那个 php 的环境,就是用那个 php 撒底,哎这个软件部署环境,然后阿发奇无法启动, 然后解决办法呢?就是首先,呃,首先那个用命令提示服定位到那个阿帕奇的并目录,然后执行一下 hgtpd 顶 ex e, 然后就可以看到错误,错误日字,然后根据错误日字去 去查那个 windows 的错误日字,然后呃查到的那个就看到的那个错误信息, 就说其实我那个呃没有装那个三十二位的 vc 酒,然后我装好以后,我安装了这个以后就可以了。
 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿apache 是世界上使用最广泛的 vip 服务器之一。它是一个开源的软件,可以运行在各种操作系统上, 如 windows、 linux、 micros 等。 a patch 的主要作用是提供 web 服务,它可以解析 http 请求,并将请求转发给相应的程序,如 php、 python 等进行处理, 然后将处理结果返回给客户端。 aparty 还支持多种功能,如虚拟主机、负载均衡、安全控制等,可以满足各种不同的 vip 应用需求。 aparty 的优点包括开源、免费。 apache 是一个开源软件,可以免费使用。高性能, apache 具有高效的处理能力,可以处理大量的并发请求。可靠性, patch 具有良好的稳定性和可靠性,可以长时间稳定运行。可扩展性, a patch 具有良好的可扩展性,可以通过模块化的方式添加各种功能。安全性, a patch 具有多种安全机制, 可以保护 vip 服务器的安全。总之, apache 是一个非常优秀的 web 服务器,广泛应用于各种 vip 应用场景。如果您需要搭建 web 服务器, apache 是一个非常不错的选择。
 07:00查看AI文稿AI文稿
07:00查看AI文稿AI文稿好的,接下来我们来学第一个内容,为什么要学习阿巴提,阿巴提的互利?首先我们看一下第一个概念,什么是数据虎,在讲数据虎之前,首先我们去看一个概念, 我们在大数据当中啊,我们做数据分析,我们往往使用的一种方式就是数仓数据仓库这种方式来管理我们的数据。那我们知道数据仓库,英文叫 data where house, 它是一个数据的一个系统,专门来管理数据的, 他是把数据放在这一放在这个当中,把数据放在这个仓库中,哎,按照分层的方式来进行管理,我们用户呢可以直接从我们的数仓当中呢来读取数据进行分析。那数据仓库的目的是面向我们数据分析啊,构建的一个 集成化的数据环境,我们对数据的分析结果为企业呢提供这种决策的支持。我们可以看到下面这张图,在最右边就是我们的数据,不管是服务器产生的日制数据,还是我们存储的业务数据,我们把它放到数据仓库中, 被我们的仓库进行管理。最后呢我们需要分析的时候呢,从仓库中获取数据。在这里我们都知道, 数据仓库本身它是并不产生数据的,也不消费数据,仅仅就是存储数据, 以一种特定的方式来管理数据。那我们在企业中使用数据仓库管理数据的时候,往往是按照分层的方式来管理,至少分为呢三个层次。我们可以看到啊,那最左边是我们的数据员, 我们的原来的数据存在文件中啊,存在系统中啊,等等等等,那我们需要把数据呢给它抽取到我们数据仓库的第一层叫 ods 层,数据占存区,临时存储。哎,在 ods 层的数据跟我们原来的数据源的数据呢,几乎是一样的, 当紧接着当我们数据存储到 ods 层以后,我们需要对这些数据呢进行一些 转换呀,过滤啊,处理,我们把它放到数据的仓库层。那数据仓库层的数据呢?往往我们可以进行什么呢?直接读取进行分析。那按照我们的应用, 哎不同的主题划分,对仓库层的数据进行分析,分析以后,我们将数据呢放在数据应用层来,应用层的数据可能是我们分析的结果,也可能是我们产生的爆表,也可能是 我们继续挖,继续学习挖掘得到的数据,最终呢对外提供服务。那在这里我们可以看到数据仓库是通过分层至少三层的方式来管理数据的。 好,那在这里面我们看那数据壶呢?数据壶与我们前面讲的数据仓库类似,也是来管理数据的,它是数据存储的一种设计模式 啊,设计模式,数据仓库是通分层来关于数据的。哎,数据壶呢,它不一样,它是一种集中式的数据存储库,就像我们下面这张图一样,我们直接把所有的这种数据呢存储到这个数据壶当中, 就相当于我们江河湖海一样的湖一样,你任意地方的水,你直接进入湖泊就可以了,我们任意的数据直接进入到我们这个湖中,那湖中存储的都 是我们大量的原始数据,类似于我们前面讲的数据仓库中的 ods 层的数据,当数据放在数据壶当中以后,我们要分析数据的话呢,直接到壶中获取就可以分析了。 好,那我们看一下官方是怎么定义数据壶的概念,他说数据壶是一个以原始格式存储系统的一个系统, 纯数据系统,也就是说数据壶中的数据都是最原始的。那最原始数据包括什么呢?比如说数据库中的这种结构化数据,比如说我们这种文本半结构化数据,比如我们讲的配置文件, 以及我们讲的音频、视频图片,都可以放在数据壶当中,他专门存储这些数据的。哎,而且管理这个数据企业中呢,往往我们使用数据壶的话呢,就是把所有数据都放到这里面。 ok, 这就是我们讲的数据后的一个定义,存储的是原始数据。好,那在这里我们可以看到下面有一个概念,同学们 来我们可以类似于呢数据仓库,他就相当于一瓶矿泉水,从湖中舀的一瓶矿泉水, 我把这个数数数据呢放在一个屏当中进行划分的。那我们数据壶呢,它其实就像一个湖泊,湖泊里面可以存储不同地方的来源水来的水,比如说小河流下了水,天上的降雨等等等等,它都都是可以的。 好,那现在呢数据壶呢,更多的在企业中呢,被把它当做是一大型的数据池啊,存储的呢都是我们原始的数据,我们要用的时候呢,直接从壶中获取数据就可以了。那我们看一下下面有这么一张图, 展示出来数据壶中的数据主要可以做于我们讲的这种分析呀,这些报告啊,哎,也可以作为一些高级的分析和积极学习等等。那在这里面我们看到了我们数据仓库中的数据,是不是主要也是最用于报告做分析啊? ok, 那数据壶呢?也是可以的。那这时候同学们就有一点疑问了,都有了数据壶,有了数据仓库,为什么还需要数据壶呢?那我觉得其实主要有两点。第一点在我们现在的数据时态下面, 我们处理的数据不仅仅,也不再是我们以前讲的这种结构半结构化数据了。比如我们所说的这种日制数据,我们讲的这种业务数据,这些都是结构化半结构化数据,我们用竖仓的分层 来管理来做分析是非常好的。那但是我们现在有很多很多的,比如说图片,有很多音频,有很多视频,这种非结构化数据,我们也要进行分析进行处理。你比如说同学们,我们讲一下人脸识别,是不是指纹识别 啊?头像识别,比如我们开车的人都知道,我们通过这种收费站, 通过这个十字路口,是不是都高清探头啊?这种拍照片这些数据我们都要进处理进行识别的。 哎,那这些数据如果放在我们数据仓库中呢,就不是很好的管理了。而且我们对这些非结构化数据,我们在进行处理的时候,其实我们是不需要按照分层一步步做的,我们是直接读取原始数据的,然后做这种高级分析,做这种模型训练。 哎,这个呢是属于仓库中呢所不能解决的问题的。我觉得两点,第一个就是我们的数据类型比较多了 啊,非结构化数据比较多了。第二个我们对这些数据做高级分析的时候呢?我们是不不需要按照分层那种方式一步步来的,很麻烦,所以数据我就诞生了, ok。
23黑马程序员视频库 01:59查看AI文稿AI文稿
01:59查看AI文稿AI文稿高度计功能讲解,首先在正常时间界面按 c 键进入高度计界面,目前显示的是当前高度和温度,按 d 键可以切换到高度趋势界面, 在高度趋势界面,按 c 键可以查询之前的高度曲线,按 d 键返回高度 g 界面,长按 d 键两秒,可以切换温度及高度单位。 长按 b 键两秒,可以进入相对高度设置, 选择 yes 代表相对高度为零。确认选择后长按 b 键两秒确认此次校准。也可以自主输入所在高度。 长按 b 键两秒,先进入相对高度设置界面,再短按 b 键切换到自由高度设置界面,按 b 键进行数字递增, 按 c 键进行数值递减。 长按 b 键两秒确认此次校准还可以设置海平面气压值。长按 b 键两秒,先进入相对高度设置界面,再短按 b 键两次切换到海平面气压值设置界面, 长按 b 键两秒确认此次教程最后就是 恢复默认值设置,长按 b 键两秒,先进入相对高度值设置界面,再短按 b 键三次进入默认值恢复界面,选择 yes, 长按 b 键两秒确认此次校准就可以了,记得关注再走哦!
 13:08
13:08 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿国产开源领域,阿帕奇顶级项目,前有上古神兽应龙,后有治水专家。神语开源江湖,不只聊开源。大家好,我是阿蒙。七月二十六日,阿帕奇软件基金会宣布神语正式毕业,成为阿帕奇顶级项目。阿帕奇神语是一款使用佳宝瑞艾克特开发的响应式 api 开关,具有高性能、动态灵活的流量掌控、热插拔、易部署等特性。 开箱机用可以为用户提供整套生命周期的 api 网关,包括 api 注册服务、代理、协议转换与 api 治理等功能。审语提供了复杂、多样性、任意的匹配策略,这些匹配策略可以进行任意组合,这样能够确保对任意流量的完全掌控,满足任何业务系统的需求。 同时,沈宇基于自身热插拔的系统架构,提供了十分丰富的插件生态组建,涵盖主流的 rpc 代理、限流、熔断、签名教验、 api 治理、可观测性等。至于为什么叫沈宇,官方的解释说灵感来自大禹治水的故事, 网关最重要的作用是如何针对流量进行治理,这与大禹治水有异曲同工之妙。其次是开源社区以公平、公正、公开、认人为贤的方式运营,致敬审语的同时也符合而爬尺位。最后呢,就是审语的名字相对简单,读起来朗朗上口,在国际舞台上 除了能够介绍项目之外,还可以让更多人了解到中华民族的传统美德。从网络资料来看,神语与京东之间似乎有一定的联系,了解的朋友可以评论区留言,我们下期见,拜拜!
1587开源江湖 02:24查看AI文稿AI文稿
02:24查看AI文稿AI文稿今天给大家分享一个开源的现代数据探索和可视化平台,阿帕奇 supersit, 同时也是企业机应用,用于数据分析和数据可视化。阿帕奇 supersit 支持丰富的数据库,作为数据员,比如这里的害物引怕了, 还有咱们常用的 es, 还有买色口,奥瑞口等,基本上平时使用的数据库他都支持。接下来看一下 supersit 的部署和基于买色口实现订单销售的省市可视化图表,看一下通过刀壳部署 supersit 的过程。 首先是拉取镜像,运行镜像,他这里的端口是八零八零,可以根据实际情况调整,我本地映射的端口是八零八八,创建一个人民账号。最后就是配置,配置完成之后通过 ip 和端口就可以访问了。关于刀口和买色扣的安装, 有兴趣的小伙伴可以看一下我之前的视频集合,通过账号和密码就可以登录了。我这里准备了一个订单表,是按照日期统计,列出了每个省的订单金额,说明一下 iso 扣的存储的是国际地区编码,后面生成图表时候会用到。首先是创建买色扣链接,选择 database, 选择创建一个数据库,选择 mastercle, 填写 host, pond, 还有用户名和密码就可以了。接下来添加一个 data 赛的数据集,也就是数据库中的表, 选择添加数据集,然后咱们选择买色口,选择咱们的呆萌,选择咱们的订单表,点击添加就可以了。接下来呢咱们就看一下怎么添加图表。添加图表,选择一个数据集,这是刚才咱们的订单数据集,这里呢有他的所有的图表,他的种 还是比较多的,基本上满足了咱们平时的使用,这里呢咱们选择这个城市的图表,点击创建图表,这里选择国家,选择咱们中国,这个里就是咱们刚才说的那个城市编码,然后咱们选择这个 iso 扣的,这里创建一个统计维度, 这里呢咱们就简单的统计一下金额,选择一个类型是撒 c, 然后这边有一个执行,咱们可以执行一下,看一眼,这里可以看到已经列出了一个城市的可视化图表, 还是非常简单的,并且还可以把图表添加到仪表盘,这里选择仪表盘,选择添加就可以看到咱们创建的图表,咱们直接拖拽就可以了。最后小伙伴们还有什么好用的工具吗?评论区分享一下。
1385程序员老魏








