filter函数占用CPU过大

粉丝153.5万获赞712.1万
相关视频
 08:03查看AI文稿AI文稿
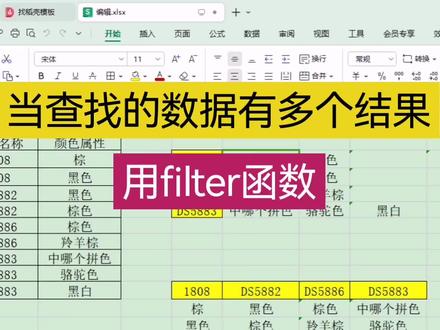
08:03查看AI文稿AI文稿今天分享一下,像这种我想通过商品名称去查找它的颜色属性, 那正常的话我们直接就会想到用到 v look up 函数,但是呢他商品名称他有相同的名称,但是颜色属性 他有多个那个结果,那这时候我们用 we look 函数,他只能查找到第一个结果,那像我这右边右边这种表格,想要查找这种他总共 幺八零八这个名称,这里总共对应的那个属性全部都显示出来,那这个我们就要用到 few 的函数了。我们首先清空一下,我们输入等号,输入 f i f i, 双击输入函数这个参数数组,也就是我们最后要返回的数字,要也就是你要找的那列数据,那么也就是 b 列, 我们选中要按一下 f 四绝对,用一下逗号。第二个参数包括也就是条件的意思,那么条件的话 也就是我们这个商品名称这一列一样要按 x 四绝对引用一下,让他,让他等于就是你刚才第二这个单元格,也就是你要找到的商品名称,这有输入第 第二,然后这个 few 的函数我们就已经输入完了,那么我们如果直接回车的话,因为 wps 不能一键入出那个数组的,如果你是以上的话是可以的,但是这个 wps 是不行的,我们可以选中这个 feel 的函数, 按一下 f 九,我们可以看到他就查找到这个幺八零零,全部的属性全部都查找出来了,只有两个,对吧? 你要直接按回车,他只会显示第一个,那么我们就可以用 index 函数来或把这个两个都提取出来, 那我们输入 i n, 把这个数组那个结果提取出来,双击这个音代的函数数组, 也就是我们刚才用 fit 函数提取的这个数组,然后逗号行序数,也就是你要提取这个数组的 第几个数据,那我们肯定第一个要提取第一个数据,然后往右拉的时候提取第二个数据,所以我们这个第二个参数就用到了 colon 函数 c o l, 双击第一个 colin 函数, 然后这里面输入 a 一,然后右括弧扩上,这时候我们回车,然后向右拉,就是, 哎,我们看一下这个没有提取出来,这是什么原因呢?我们点击一下这里看一下啊,是这样,我们刚才这里面 一那个条件第二单元格忘记锁定了,他一到右边就变成一二单元格,就是条件变成在一二这里来了,所以就 不对了,那么我们选中这个,我们把这个第二单元格要按 f 四绝对引用一下,这时候回车,然后再向右拉,这样才能把这个两个结果都算出来了。 那么我们刚才用 call name 函数,我们可以看到 call name 函数,这里面选中一下,按一下 fg, 我们可以看到这里面就变成二了,向右拉时候,这里数值变成二了, 你就提取出了 few 函数里面的第二个数组里面的第二个数据,也就是那个这 黑色,对吧?那么这里面往右拉,因为我们总共他的属性有多少个我们不知道的,往右拉的话,这边就出现了,没有出现了错误值,那么我们在前面套一个 屏蔽错误值的函数就可以了,那么也就是 if ever 函数,我们输入 if, 双击第二个 if ever 函数,这个第一个参数值就是我们刚才这些数据,然后逗号, 然后两个英文状态双引号,意思就是出现错误值的时候,让它显示空值,然后一颗弧扩上回车,这时候再向右拉就没有了,哎,但是向下拉的时候又错了, 因为我刚才这里面条件第二单元格这里的条件向右拉是不能移动的,向下拉的时候要跟着这个数据去移动的,我刚才直接按 f 四绝对是锁定了他向下拉也不能跟着 相对去移动,这是不行的。那么您如果是想跟着向下移动,向右又不能移动的话,就要在字母的前面加个名人符号,而数字的前面要把这个名人符号给他去掉, 那这时候我们再回车,然后向右拉,向下拉,这时候数据就对了,那么像这种是横着的,对吧?那么我们想向右下面这种条件是竖着的, 但是结果你要是横着显示的,那这个时候跟这一样的也是用 few 的函数,只不过他这个参数,这里面的 index 函数,行序数,这里面 他就不用,不能用 column 函数,而是用肉函数,因为我们这里面要向下拉自动填充,肉函数才会跟着 变成一二,而向右拉只能用 column 函数,才能变成跟着单元格变成一二。如果刚才你 这种上面这种表格,如果你用的是肉函数,他只会都是一,不会跟着变成一二,那这个肉函数和 column 函数是什么意思呢? 其实我们输入一下你就知道了,我们输入等于号,输入 iow 函数,然后这里面输入 ae 回车,然后你向下拉, 他就获取了一二三,就获取了,就从这里前面这个序号一二三。如果你输入的是 b 一的话, 这里面肉函数里面输入 b, e 的话也是一样的,也会显示 一二三,他就会,他就是显示这个这一每个列的对应的这个前面的序号。但是这个肉还是我要向右拉,他全部都是一的,因为你向右拉,这里面变成 a、 c 二了,如果你是这里是 a, 我向右拉就变成 b, e, c, e, d, e, 他全部都会显示一,而向下拉才会变成一二三这样。而 column 函数就跟他正好相反了,你向右拉的时候, 他会跟着这个单元格,就这一列的单元格都是一,这一列单元格都是二,而这一列单元格都是三,所以我们就向右拉的时候,他就会显示一二三,就要用到 call 了么?函数,如果用若函数他只会全部显示一。
252嫦听WPS办公技巧 00:25查看AI文稿AI文稿
00:25查看AI文稿AI文稿你遇到过这样的问题吗?在 office 中, filter 可以直接得出所有的数值,但是在 w、 p、 f 中只能得到一个数值。拖拽公式也会出现一些错误,我们应该先选中一个区域,在第一个单元格输入公式, 同时按下 control, 加 shift 加 enter 键。缺点是多余的部分会显示按 a 错误,你知道怎么解决吗?
141萍水相逢 08:51查看AI文稿AI文稿
08:51查看AI文稿AI文稿今天我们要来介绍一个非常强大而且十分实用的函数,叫做 filter s m l。 这个函数呢原本是用来提取网页数据的,它有两个参数,第一个参数呢,是指有效的 sm l 格式的字物串,第二个参数呢,是指标准的 spass 格式字物串。需要注意的是,这个函数只适用于 excel 二零一三级以上的版本, 如果光是这么介绍的话,你可能会觉得很懵,所以呢,接下来我们要进行更详细的介绍。那什么叫做有效的 s m l 格式的这串呢啊?我们先把隐藏的内容给显示出来, 这个呢就叫做有效的 s m l 格式的这串。关于他的相关知识我们并不需要 进行深入的了解,我在这里呢也只是介绍几个跟菲欧特 s m l 第二个参数书写相关的几个特点。就比如说这个尖括号包裹的一个字母 moxed dot, 就是所谓的根源数的标签, 一般来说,标签都是成对出现的,开始的时候呢,就是这样直接包裹起来,结束的时候呢,就是在字母前面加一个斜杠,那根源数里面包裹的内容就是他的指元数了,他们也是以标签的形式一对一对的出现呢,就比如说这个 price, 然后后面的斜杠 prise, 这样呢就是一对标签,不知道你发现没有,根元素里面可能包含多个紫元素,而紫元素里面也可能包含自己的紫元素,这样呢就形成 多层级的一个结构。而 filter s m l 函数的作用呢,实际上呢,就是把某一个层级中结构的数据啊,也就是某一个标签中包裹的数据给提取出来。 在这么多的标签中,如何精确的定位到我们所需要的标签呢?就比如说,我想把 yet 这个标签里面的数据给提取出来,我们用 filter s m l 函数,我们可以这么写, 第一个参数,我们选择所谓的标准的 sm 格式的周串,然后呢,它的一个路径啊,就是从根目录开始写起 bus stock, 然后呢,接下来这个 book, 他把这个 yet 都包在里面嘛,所以接下来的字母是 book, 接下来呢 才是 yet, 然后我们按回车,你看他就以宿主的形式把我们所需要的年份呐都提取出来,就二零零五,二零零三。 这种写法呢,看起来是很直观,但是呢,他要求我们对成绩结构非常清晰,先后顺序不能搞错,否则函数一定不能错。所以呢,接下来我们要介绍另外一种写法,这种写法呢,他就是不管你在哪一个层级, 哪一个标签,就比如说,我们要提起 yet 标签里面包裹的内容,我们不管他哪一个成绩,我们只需要在标签的名称前面加上两道斜杠, 然后回车也是同样的一个效果哦。又比如说哦,我想把 prize 里面的内容给提取出来,我们把 prize 复制一下, 然后呢,把这个 yet 改成 price, 然后按哦回车,他就把价格都给提取出来了。这个呢,就是 filter s m l 的最基础的用法了。 正是因为函数有这样的一个特点,所以呢,我们在实际的使用过程中,要想方设法的构造出所谓有效的 sm l 格式的自由串。 所以呢,就由我们下面这个最常见的套路了,一般情况下呢,我们是用 smteachu 这个函数把单元格中的自如串中的分隔符进行替换, 然后呢构造成标准的 sm l 格式的字物串,嗯,就是这样的,可以看得出来啊,我们构造出一个简单的两层结构,由 a 标签和咪标 签组成,其中 some titty 的作用呢,就是为了生成多对的 b 标签。然后呢再用 fielter s m l 这个函数把 b 标签中包裹的内容给提取出来,也就是分格服之间的数据给提取出来。 我们先把里面的内容给复制出来, ctrl c, 然后赶紧来看一个例子吧, 就比如说我们有这样的一串文本,其中的姓名啊,科目的名称啊,成绩啊,都写在一起啦,那如何把这些数据单独给分离出来呢啊,最常见的一个做法是,我们选中这些数据,然后切换到数据选项卡, 点击这边的一个分裂,按分格符,然后填入分格符的名称。如果我们不想要覆盖元素 数据的话,我们可以选择目标区域,我们选择的是这里,然后点击完成啊,他就分离出来了。这种分组的方法呢,看似简单,但是呢,跟公式比起来,他还是有许多缺点的。就比如说后续如果我们有新增数据的话,你 必须把原来分离出来的这个数据啊清空,然后呢再重复进行一遍,那如果新增多次的话,那你这个操作就要进行很多次。 同时呢啊,这个深层的结果啊,不能直接被函数所引用。就比如说啊,我想直接通过这个文本计算出一个总成绩,那 你只能分组后,然后呢再选中这两个单元格,然后再进行一个求和。那如果用公式就不一样了,我们直接可以用一个公式把它计算出来, 我们先把这个数据清空一下,然后呢来看一下函数究竟是怎么写的。用的组函数就是今天介绍的 filter s m l。 我们先把刚才复制的文本给粘贴进来,我们先来看一下我们构造的第一个参数究竟是长得啥样。 可以看得出来,我们通过 sometitu 这个函数呢,构造出一个标准的 sml 格式,所以呢,就可以用这个函数来进行提取啦, 这样呢,就提取出来,可能你会说这不是竖向的竖组吗?那如何把它变成横向呢?方法也很简单,那就在前面套一个 transport 啊,这样呢就调转方向了,然后我们选中他往下拉啊,搞定。至于刚才说到的这个直接求和呀,我们可以直接这样子写,我们先把下面的数据给清空掉,我们先把这个全是 pold 给删除掉, 然后点击一下回车,确定这个数字啊,是处于第三行和第五行的这个位置嘛,我们可以用 index, 呃,把这个第三行和第五行的数据啊给取出来,然后呢它产生一个新的数组,然后再用 sum 进行求和就 ok 啦,所以呢,我们是这样子写的, 对吧?把这个第三和第五行取出来,然后用 some, 然后点击一下确定,然后再往下拉, 嗯,这样呢,就求和完毕了。接下来呢,我们来讲一道更难的,就是没有这个明显的分隔符,但是 那我们可以用 test join 来构造出一个分隔符,然后呢再用 future s m l 函数进行提取啊,也就是这一道题了。这道题呢是看见星光训练营里面的一道题, 它的含义就是这里面呢有这么多个图形,然后呢要算出在这一片区域中每个图形的数量。这道题呢有很多种解决方法,这里呢我要介绍的是如何用 filter s m l 这个函数来解决。 首先呢,我们通过 ts join, 用一个分隔符,把这些所有的图形都给连接起来,分隔符就是这个了, 然后一呢就代表忽略空格,这个呢就是这一片区域了,我们点击一下回车啊,这样就连接起来了, 然后呢用刚才的套路啊,把分隔服中的数据给提取出来,用菲尔特 s m l 点击一下回车,这样呢实际上就是把多列啊转化成一列,然后再把唯一值给提取出来,我们只需要用 unique。 最后呢要算出数量的话,就非常简单的,我们只需要用 call if 就可以啦, 然后往下拉。
162阿武教程

















猜你喜欢
- 1432玩法测试师