机器人学习中主成分是原始变量的什么
如何使用啊进行主成分分析并可实化主成分分析的结果?在上一期的视频中,我们介绍了剧烈分析,它可以将观测纸分为若干个组,本质上是对观测纸进行降为。 在这期视频中,我们所要介绍的主成分分析实际上是对变量进行降位,其主要目的是创造少数几个相互镇交的主成分来表示原始数据中的数值变量所蕴含的大部分信息。 首先我们加载 tediverse 和 factor extra 这两个包,然后加载自带的数据及 mt cars。 这是一份关于多款汽车的设计与性能的数据。 接下来我们需要对数据进行预数。里使用 mutant 函数将属于分类变量的 vs 和 am 转换为自负串变量。使用 selective 函数和 is numeric 函数从数据集中挑选出所有数字变量。 下面使用 pr com 函数执行主成分分析。在这里我们将 santa 和点 scale 参数设置为处,其目的是中心化和规划所有数值变量,从而平等地考虑各个数值变量的影响。 接下来我们逐一介绍主成分分析的结果。首先,直接运行批压抗盘数创建的对象可以得到各个主成分在所有变量上的载合值。载合值可以理解为创建 组成分时的各个变量的系数。以第一组成分为例,使用中心化和规划的变量构建的第一组成分与各个变量之间的关系如下面的公式所示,其他组成分与变量之间的关系与之类似。 然后使用萨姆瑞函数获取各个主成分的重要性及主成分的方差占比与累计占比。可以看到第一主成分的方差占比为零点六二八四。第二主成分的方差占比为零点二三一三。 第三组成分的方差占比为零点零五六零,这意味着第一组成分表达了原数据中的百分之六十二点八四的信息,第二组成分表达了原数据中的百分之二十三点一三的信息。第三组成分表达了原数据 中的百分之五点六零的信息。另外,我们还可以看到组成分的方差累计占比及前两个组成分的方差累计占比为零点八五九八。前三个组成分的方差累计占比为零点九一五八, 这意味着前两个主成分或者前三个主成分解释了原数据的百分之八十以上的信息,这是选择主成分个数的一种标准。接下来使用 squee plot 函数绘制碎石图,可视化各个主成分的重要性。 可以看到图中的曲线在 pc 等于三之后基本不再下降,即 pc 等于三是一个拐点。一般来说,主成分分析降为确定的为数就是拐点对应的主成分个数。 最后使用 fact to extra 包中的多个函数可视化组成分分析的结果,使用 fvspcaind 函数可视化所有个体在第一组成分和第二组成分下的分布。 使用 fviz pca vr 函数可是画所有变量在第一组成分和第二组成分下的载合。使用 fviz pc byplot 函数可视画所有个体和变量的双标图。 以上就是对主成分分析在啊语言中的使用介绍,下期想学习什么在评论区中告诉我,期待您的点赞和收藏,祝您早安、午安、晚安。

粉丝937获赞2833
相关视频
 07:58查看AI文稿AI文稿
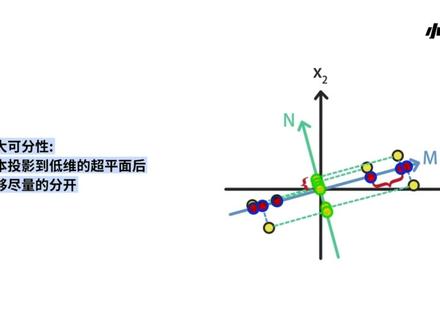
07:58查看AI文稿AI文稿大家好,今天要讲的内容是降维算法 pca 主成分分析。 pca 主成分分析全称 principle component analysis, 是最常用的降维算法。 pca 通过投影的方式将高维的数据映射到低维的空间中。 pca 算法可以保证在所投影的维度上原数据的信息量最大。因此通过 pca 降维可以使用较少的数据维度,保留住较多的原始数据特征。 为了达到降维的目的, pc 可以基于两种思路进行优化,分别是最大可分性和最近重构性。 最大可分性是指样本投影到 dv 的超平面后能够尽量的分开。例如,将平面上的数据投影到直线 m 明显比投影到直线 n 会使样本数据更加分散。 最近重构性是指样本到所投影的 d v。 超平面的距离要尽可能的小,例如平面上的样本到 m 的距离是蓝色线段,到 n 的距离是绿色线段,所有蓝色线段的距离和 小于绿色线段,因此认为 m 比 n 好。 实际上,基于上述两种思路,最终都可以推导出相同的目标函数,也就是无论使用哪一种思路都可以实现 pca 降为算法。 接下来我们会使用一个具体的例子来说明 pca 算法是如何找出样本的主成分实现特征降维的。 已知平面上有六个样本,每个样本包括 x 一和 x 二两个特征。计算这两个特征的平均值要 标记为红色叉子,然后根据红色叉子画出。蓝色叉子代表六个样本的中心位置。 我们将六个样本和中心红色叉子一起向坐标轴的圆点移动,在移动时,各个样本的相对位置保持不变,最终使得蓝色叉子与坐标轴圆点、红色圆圈重合。 这种使样本中心与坐标轴原点重合的过程被称为去中心化。去中心化不会影响样本的分布性质,但会简化后续 pc 降为算法的推导过程。 思考下面这个问题,如果只使用一个维度,如何才能最合理的描述出样本的分布状况呢? 一个维度就是一条直线画出任意一条过圆点的直线, 我们要通过该直线提取样本的成分,而提取样本的成分就是将样本投影到这条直线上。通过投影点来描述样本中的成分。 在投影的过程中将直线旋转,这时会发现样本到直线的距离与投影点到原点的距离会随旋转而变化很明显, 如果样本到直线的距离小或者投影点到原点的距离大,那么直线上的投影点就能更好的描述样本的分布情况,而样本到直线的距离小就对应最近。重构性投影点到原点的距离大对应最大。可分性。 单独来看某一个样本,设它到原点的距离是 a, 到直线的距离是 b, 横点到原点的距离是 c。 根据勾股定理, a 平方等于 b 平方加 c 平方。 由于样本到原点的距离不随直线变化,因此 b 平方加 c 平方的和是固定的。 这里可以发现, b 的增大会使 c 减小, b 的减小会使 c 增大。 因此,优化样本到直线的距离最小和优化投影点到原点的距离最大,这两种方式是等价的,而后者更容易进行数学推导。 投影点到原点的距离最大,代表了在新的维度下样本的方差最大。设第一到第六为投影点到原点的距离。 我们要求出第一平方加第二平方,一直加到第六平方,这个距离取最大值时 红色直线的参数。当求出这条直线后,就称这条直线为主成分一,也就是 pc 一。 观察 p c 一,设 p c 一的斜率是四分之一,它代表样本随着特征 x 一向外移动四个单位就会随着特征 x r 向外移动一个单位, 这也说明了 x 一比 x 二更影响特征的分布。 当完成 pc 一的提取后,可以继续提取 pc 二,它是描述样本分布的另一个维度。为了使 pc 二表示出最多的信息,它需要和 pc 一完全独立, 因此需要再找一条垂直于 pc 一的直线来描述样本。因为样本只有两维特征,所以在平面上只有一条垂直于 pc 一的直线,这样就将 pc 二直接求出来了。 我们将样本在 pc 一和 pc 二上的投影都标记出来,旋转 pc 一到水平的位置,就完成了 pc 主成分分析。 我们可以将主成分 p c 一与 p c r 看作是一个新的坐标系,通过新的坐标系重新表示样本。 总结来说, n v 空间中的样本可以分 解出 n 个主成分,我们通过优先选择方差最大的主成分,从而实现降为这一目标。 那么到这里降为算法 p c a。 主成分分析就讲完了,感谢大家的观看,我们下节课再会。
784小黑黑讲AI 01:00
01:00 01:45查看AI文稿AI文稿
01:45查看AI文稿AI文稿现在的人性机器人最大的问题,所有的数据都是一种复制式的数据,不管用。为什么不管用呢?因为复制的过程中他中间一定会原始的数据是断裂的、割裂的, 这是现在目前所有的人性机器人最大的问题。所有这些东西看起来是善利的问题,哎,我这个善利越提高,芯片水平越提高,我甚至比现在这个四十倍、八十倍、一百倍、一千倍,我马上就能够善存,最需要的、最优解, 但是你解决不了这个问题,你解决不了数据的一个原始的问题。那我们出生的时候,我们去感受到阳光啊、空气啊、水啊,这是原始的数据,而机器人怎么是感受这个东西,我们去描述啊,水啊是液体的呀, hro 啊,清扬解剖的呀,哎,这个谁他 可以流动啊,但是机器人他怎么去感受这个水滴?原始的水滴,这才是最重要的,所以机器人没有这个原始数据这种感受,真正知道这个水是个什么东西。哎呀,谁到手上就这样的东西,你感到是就这样湿湿的这个东西。 你告诉机器人谁是师的?从机器人师那个里面到谁是师的,什么是师的, 他感受不了他原始的这种感受,他是目前来说他没法解决,那对他是不是可以解决呢?可以解决啊,通过一定的一个神经网络。哎,比如说把机器人的大脑里面接一个什么,什么接一个芯片,这个芯片呢?就可以这个感触芯片, 这个感受芯片都可以感感受这个谁啊?这个谁,原来真的是这样的,他将这个自己感受这个数据续到机身里面啊,机器人未来对谁就有一个正确的认识。
44九一董哥 07:22查看AI文稿AI文稿
07:22查看AI文稿AI文稿梅河石油是人类生产中两种最重要的能源和重要的化工原料,前者与工业粮食相比,后者与工业血液相比。 梅核石油是化石燃料,其主要成分是有机物,这意味着他们应该是从地球上的原始生命进化而来的。那么,梅核石油是如何形成的呢?知识探索就在汉渺懂科普, 今天的视频非常非常硬核,请耐心观看完。另外,求你们的一波点赞、关注与评论,感谢感谢!我们开始正题!科学界普遍认为,煤实际上是由古代地球上的植物形成的,其形成过程总体上可分为两个阶段。 在这一阶段,微生物不断分解植物残体并继续合成,如腐殖化作用,最终形成富含碳、氢、氧、氨和其他原 元素或腐泥。低等植物的形成成为泥炭化阶段。第二个阶段称为煤化阶段,需要地壳补贴进行配合。当发现泥炭或腐泥的地壳时,周围的温度和压力将逐渐升高,心、 氧、蛋等元素的含量将继续降低,蛋碳元素将保持不变,单位体积的碳含量将逐渐增加。当达到一定程度时, 就会形成褐酶,褐酶是碳化程度最低的酶。在此基础上,如果地壳继续减少,褐酶的温度和压力将继续升高,导致清 蛋等元素不断减少。由于压力的增加,褐酶的密度和硬度将继续增加,颜色将逐渐变深,从而形成烟酶和无烟酶,但后者的碳含量最高。人们经常在煤矿的横断面上发现一些树木的一致性, 在一些煤矿中发现了烧焦的植物化石,可以认为是上述理论的有力证据。因此,煤是由植物组成的观点早已成为共识。 课后,每层的形成有赖于有力的构造沉积条件,其中,丰富的水资源,水的流动性至关重要。茂盛植物和稳定作物,由于水的流动性不强,他带来的沉积物很少,因此,该环境中的沉积物主要来自植物。植物一代一代的生长并以稳定的速度沉积。 第一代植物的残余物将被第二代植物的残余物掩埋,第二代植物的残余物将被第三代植物的残余物掩埋。在经过泥炭化阶段和煤化阶段后,这些沉积物将形成煤。随着时间的推移,煤层不断堆积,随着时间的推移,形成了超过一百米厚的煤层。古地球上 真的有这么多植物吗?答案是肯定的。在整个地质时代,地球上的煤主要形成于三个时期,王,古生代石炭剂和二叠剂、 中生代侏罗纪和新生代古竞技。地球气候温暖湿润,地表生长着大量的植物,为形成特厚酶层提供了充足的物质条件。正如我们前面所说, 只要有适当的沉积构造条件,煤总是会形成的。一个简单的计算表明,即使煤层的厚度每年仅增加零点零一毫米,一千万年后,其厚度可以达到一百米。我们所说的三个城煤漆都经历了数千万年, 可以看出,厚度超过一百米的眉层似乎厚的离谱,但考虑到如此长的时间跨度,这是合理的。有趣的是,根据研究人员的初步调查,南极洲 有大量的煤炭,南极东部冰盖下的煤炭储量高达五千亿吨。那么煤是如何形成的?实际上,这可以用地球板块的运动来解释。 由于地球板块的运动,地球表面的地球实际上以非常慢的速度移动。三亿多年前,几乎所有人都聚集在一起。 南极洲所处的陆地处于温暖的气候区,其地理结构可以将海洋深处的湿热空气排入地球。南极洲的植物生长的非常繁茂,直到大约一点六五亿年前, 南极洲才开始缓慢的向地球最南端移动。可以看出,这一时期是地球上第一个重要的成酶时期,因此南极洲有大量的酶也就不足为奇了。至于石油的形成,很多书都说它是由古生物形成的,这就是 所谓的石油生物形成理论,这也是一个国际公认的说法,因为有大量证据支持这一理论。在古代动物、植物、微生物和其他生物中,死亡后的有机物会在累积降水后形成沉积物,这些富含有机质的沉积盐在高温高压下逐渐转化为油液盐。 经过一系列的变化,石油被塑造成。由于石油的密度与岩石的密度不同,会出现分层,这就是石油矿床的诞生。事实上,煤和天然气也是由有机制形成的,他们在地球上的储量也很有限。煤炭主要由古代地球植物组成, 而天然气通常伴随着石油。石油形成的温度范围被称为油窗,当温度过高时,石油可以转化为天然气。石油不是由生物组成的,但地球上有大量 碳氢化合物,地下石油是由这些物质经过一系列变化而形成的。根据这项声明,石油在地球上的任何地层和地区都可以找到。 然而,发现的百分之九十九的油田是在沉积岩中发现的。根据放射性同位数的测定,人类发现的最古老的油田形成于大约五亿年前,当时是中生代时期,中生代是在寒五季生命爆发之后。 从那时起,地球上的生物数量变得非常繁盛。通过分析不同层产生的石油,科学家发现他们与生物同时负极的百分比基本一致。当然,非生物石油形成的理论是不可持续的,因此 只有少数科学家支持这一观点。许多人对有机油形成理论是怀疑态度的,原因主要是因为他们相信地球上 不可能有这么多古生物的遗迹。几亿年的生物积累,其残留的有机物非常巨大。研究表明,形成石油需要很多时间,大约二百万年。然而,消耗大量石油只需要一百多年。 人类对能源的需求每年都在增加。按照这个速度,不管地球上有多少石油储备,无法长期承受人类的消耗,因此有了石油枯竭的理论。尽管石油不是由古生物形成的,而是由碳氢化合物不断涌入深层形成的,但它是一种可再生资源。然而, 当人类的消费率高于其再生率时,石油是不够的。一旦煤炭和地球上可开采的石油开采完毕,据估计,世界石油可以使用大约一百年,煤可以使用二百年。未来,人类必须寻找可持续能源, 如何能,太阳能、潮汐能等。无论是无机还是有机,我们都同意一点,即过度燃烧石油会造成空气污染,不受控制的排放会造成全球温室效应。未来地球极端气候的发展可能即将到来,甚至正在发生。因此, 从这个角度来看,即使人类在无限期内仍有有限的用途,核聚变电站仍需开发,否则总有一天地球将不适合人类生存。如果喜欢本期视频,记得点赞、关注、 评论,你们的每一个三连就是对我最大的鼓励与支持。这里是汉秒懂科普,我们下期见!
546Hi秒懂科普 00:19查看AI文稿AI文稿
00:19查看AI文稿AI文稿here we go。












猜你喜欢
- 2157运营罗筐