yolo怎么加负样本

粉丝3.6万获赞7.8万
相关视频
 27:17查看AI文稿AI文稿
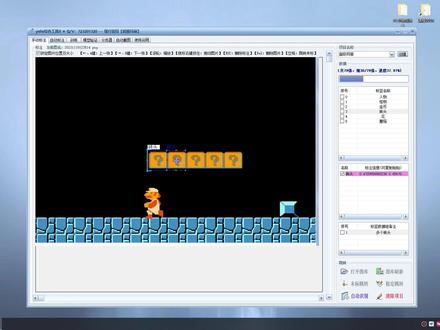
27:17查看AI文稿AI文稿今天我们来全面了解和学习一下肉肉工具训练 ai 模型的步骤和方法。本工具只能训练力三和 b 四模型,力四与力八相比,优点是使用方便快捷,不需要安装任何环境和软件。 潜力四模块可以任何电脑直接调用,对机器设备没有要求。力八相对于力四在性能上有所提升,但也需要更高的硬件要求。目前力三力四识别速度最快都在几毫秒以内,识别精度高,并且我们可以通过增加样本、 增加训练数量和制作副样本等方式提高识别精度。下面我们开始训练模型。首先点击自动截图截取图片样本。工具总共提供了五种截图方式,不同的窗口对截图的方式反馈不同,我们可以自行测试 使用哪种方式截图。点击按钮选择我们需要截图的窗口, 接下来点击开始截图即可,工具自动最小化,开始自动截图, 接着正常玩游戏即可。工具自动后台截图,按二加二可以结束截图并查看。刚刚按了快捷键,但是并没有结束截图,而是弹出了文件夹,原因是热键被游戏窗口占用了。我们直接打开软件,点击按钮查看截图即可。 这个就是方式一截取的图片,后面还有几种方式截图可以自行测试, 可以看到这种方式截图下面会有一圈黑边。 第三种可以自行选择区域截图, 下面我们正式开始提取样本,使用第一种方式截图, 接着正常玩游戏即可。 打开软件查看截图 图片,样本获取完成,准备开始标注样本, 点击手动标注创建项目名称, 打开图库,将样本图片 剪切进图库文件夹, 刷新图库,开始标记图片。 滚轮缩放图片,鼠标右键按住拖放图片 a 键切换上一张, d 键切换下一张。 鼠标右键添加分类, 输入我们要识别的目标分类 画板上侧有快捷键提示, 选中分类,然后框出图片内的目标,按 ask 默认删除最近化的一个标注框, 如果标注框被选中则是删除选中的标注框, 按空格键则会自动跳转到下一个未标注的图片。每个标注框可以自由变换形状或者位置。 按住 c、 t、 r、 l, 可以批量选中标注框进行批量操作。 按 ask 也可以 批量删除 此功能。可以自由跳转到某个图片位置, 或者搜索带某个字符名字的图片位置, 此功能可以删除整个项目。 下面选择分类,开始标注, 点击此处可以锁定图片的位置和大小, 不需要的图片直接按得利删除样本。 我们可以右键复制标注框,快速标注。 我们还可以把任意的标注框组成数据组, 修改数据组的备注, 在其他图片也可以直接粘贴某个数据组。 继续把我们要标注的目标全部框出来, 我们可以通过复制、移动拉伸、变换、创建数据组粘贴等方式来提升标注的效率。 标注了将近一半,不想标注了,我们用个洁净的方法,我们来演示一下如何用自动标注进行标记。 先创建一个文件夹,把我们的样本数据集先保存下来, 接着把我们这个数据集中没有标记的图片全部删除掉。我们进行训练的数据集图片必须是全部标注完的。好了,现在我们这四十一张图片是全部标注完成了的。 点 机上面的训练页面 我们可以看到训练分了快速识别和精确识别,以及使用 cpu 还是 gpu。 训练 同时支持 b 四模型的训练, 可以查看每个参数的含义。 如果你想更改更多参数,可以生成 c f g 网络文件,直接在文件中 更改, 此按钮可以加载任何 c f g 文件进行训练。 b 三和 b 四模型是通用的,建议使用 b 三训练。如果你是新手,可以直接点开始训练即可。初始参数已经全部设置好了, 如果出现这个页面不动,请耐心等待几分钟。这是因为电脑首次训练工具正在自动后台配置环境 开始训练了。 曲线图上面有两个值,一个是 los 值, los 值越低识别越准确。另一个值是训练的次数, 训练是以百次为单位的,至少训练一百次才会生成模型文件。 los 值是浮动变化逐渐下降,最后趋于平缓, 我们也可以随时中断训练。测试模型,如果模型识别不到,可以回来点击继续训练。 提取我们训练好的模型进行备用。 点击模型测试来测试我们的模型识别效果, 可以看到能准确的识别到 我们来直接识别游戏画面, 点击按钮将画面载入,工具 提示我们未加载模型,我们把模型拖动载入 画面与游戏同步,且可以准确识别到。 我们也可以直接在游戏画面上识别。 游戏画面上出现了绘制图形, 我们可以看到绘制的图形和实际进行了偏移,这是因为截图识别尺寸和绘制透明画板的尺寸不一致,我们实际运用中可以更改截图函数,或者对识别结果进行偏移等多种方法处理。 下面我们来演示一下 gpu 识别的方法。点击此处进行模型转换。 gpu 识别的模型格式为 power 格变格式, 转换生成的模型中有带 app 的,这是优化后的模型。 将模型拖动载入, 选择游戏画面,开始识别。 可以看到识别耗时大概是十二毫秒左右,此电脑的显卡为 g t x 幺六六零,如果是 r t x 三零六零的话,识别时间大概为五毫秒。 四十张图片训练的模型识别基本没有问题。 到此我们的模型训练已经完成, 下面演示一下自动标注功能。 新创建一个项目, 重新导入图片, 添加我们要识别的分类, 提示我们未加载模型,将我们已有的模型加载进来, 点击自动识别,自动识别出来的就是已经标记完成, 这样可以极大地提高标注效率。 如果有不合理的,手动调整一下即可。 我们也可以直接点击全部标注, 自动将我们的数据集全部标注完毕。 已经全部自动标注完毕了,接下来自己审核一遍自动标注的样本,对不合理的进行调整即可。 比如这张自动标注漏了,我们自己补上这张也有一点问题, 自动标注还可以只识别我们指定的种类。假如我新建一个种类, 我想让自动标注 只识别其中的蘑菇,这里可以勾选你要识别的种类, 比如自动识别只勾选人物和怪物, 自动识别的时候也只会给你标记人物和怪物, 我们还可以修改分类的名字来进行其他种类的标记。 通过这个方法我们可以随心所欲的进行标记, 比如我们的样本有一千张图片,我们可以先用五十张图片训练一个模型,再用这个模型去自动标记这一千张图片,能极大的提高标注效率。工具的其他功能就不再做讲解,有兴趣的可以看往期视频进行学习。
337搬砖王_教学指导 18:27查看AI文稿AI文稿
18:27查看AI文稿AI文稿作者自己都说了,这玩意儿没啥惊天动地的,就是些小修小补,让它变得更好一点。 摘药里,作者开门见山,目标就是让 yolo 更好用,还得快。怎么做的?搞了一堆小设计改动,还训练了一个新的据说相当不错的分类网络。结果呢, 体积稍微大了点,但精度上去了。关键是速度快。在三百二十乘三百二十分辨率下,二十二毫秒就能跑出二十八点二的 m a p。 跟 s s d 比,精度差不多,但快了三倍。 如果看老一点的 a p 五十指标,也就是 i o u 等于零点五十的平均精度,那更是厉害了。 titan x 上跑五十一毫秒就能达到五十七点九的 a p 五十,比 retina net 那 种慢吞吞的模型快了将近四倍,代码也开源了,地址在这儿。 总之一句话,更快更准。虽然可能没那么经验,但很实用。引言部分作者的风格就很接地气了,他说自己去年其实没怎么搞研究,大部分时间在刷 twitter, 玩了点 games。 这篇论文主要是利用之前 yolo 项目剩下的那点势能做的些改进。为啥要发?因为赶着交稿子,得引用点东西,正好这些改进可以凑数。 他还预告了文章结构,先介绍 love 三是啥,然后展示效果,再聊聊失败的尝试。最后总结一下这一切意味着什么。这种坦诚的态度还挺有意思的。 好,进入正题, love 三的核心思想作者很直白,我们主要透视了不少别人的好点子,同时自己训练了一个新的分类器,这个新分类器比之前的那些更好, 最终效果就是在速度和精度这个老大难问题上找到了一个不错的平衡点。 大家可以看这张图,这是从 folklore 论文里借来的,横轴是推理时间,纵轴是 cocoap。 看到那个紫色的星星没?那就是 you love sun。 它明显地落在了左上方,意味着在差不多的速度下,它的精度比其他很多方法都要高, 尤其是在速度比较快的时候,比如五十毫秒左右, a p 能达到三十二左右。 这说明 yellow 三确实在追求速度和精度的平衡上做得很出色。我们来看看边界框预测这块,这部分基本沿用了 yellow 九零零零的设计,核心就是用维度距类得到的鲜艳毛框 网络,预测的是相对于这些毛矿的偏移量 t x t y t w th。 具体怎么算实际框 b x b y b w b h 呢? 公式在这儿,中心坐标 b x b y 是 通过 sigma 函数处理后的 t x t y 加上单元格的偏移 cx cy。 而宽度和高度 b w b h 则是通过指数函数 e 的 t w 次方和 e 的 th 次方放大或缩小鲜艳框的宽高。 p w p h。 训练的时候用的是简单的军方误差损失。这个机制的好处是它能学习到物体大小分布的鲜艳知识,提高预测效率。 接着是对象性得分,这个得分用来判断一个边界框里有没有东西,或者说这个框是不是真的包含了一个物体。 uof 三用的是逻辑回归来预测这个得分。怎么判断呢? 很简单,如果某个鲜艳框和真实物体的重叠度最高,那它的对象性得分就是一, 如果重叠度不高,低于一个域值,比如零点五,那这个预测就忽略掉,不参与损失计算。注意,这里跟一些其他方法,比如 faster、 r、 c、 n、 n 有 点不同。 u love 三对每个真实物体只分配一个最好的鲜艳框负责。如果一个鲜艳框没有被分配到任何真实物体,那它就只承担对象性预测的损失坐标和类别,预测的损失就不用算了。这样做的好处是简化了训练过程,减少了计算量。 类别预测方面, love 三用了个多标签分类的方法,啥意思呢?就是说一个框可以同时预测多个类别,比如它可以同时预测一个人和一个女人,因为女人也是人嘛。 这里没有用 softmax, 而是用了独立的逻辑分类器,每个类别都有自己的概率输出,训练时用的是二元交叉商损失。作者特别强调,这种方法在处理像 openimage 这种标签重叠很复杂的场景时特别有用。 你想想,如果强制一个框只能选一个类别,那很多情况就描述不出来了。所以,多标签分类让模型更灵活,更能反映真实世界的数据特性。 现在来到 uof 三的一个核心创新点,跨尺度预测。简单说就是不再只在一个尺度上预测边界框,而是同时在三个不同的尺度上进行预测。 这就像给模型装上了不同焦距的镜头,能更好地捕捉不同尺寸的物体。具体怎么做呢?借鉴了 f p n 的 思想,从主干网络提取特征后,先用几个卷积层处理,得到第一层的预测结果, 然后把倒数第二层的特征图进行二倍上裁样,再把它和网络早期层的特征图拼接起来。为什么要拼接? 因为上彩样后的特征图保留了高层的羽翼信息,而早期的特征图包含了更精细的空间细节,两者结合就能产生更丰富的特征。经过进一步处理,得到第二层的预测结果。 再重复一遍类似的操作,就能得到第三层的预测结果。这样一来,第三层的预测就能同时利用到所有之前的计算和最开始的细节信息,这对于检测小物体尤其重要。 既然是跨尺度预测,那每个尺度应该预测什么样的物体呢?作者还是用了 k 均值巨类来找鲜艳筐,只不过这次找到了九个巨类中心,他们把这九个巨类中心平均分配给了三个预测尺度。 具体到 qq 数据集上,这九个具类得到的鲜艳框尺寸分别是,十乘十三、十、六乘三十三、十三乘二十三、三十乘六十一、六十二乘四十五、五十九乘一百一十九、 一百一十六乘九十一百五、十六乘一百九十八、三百七、十三乘三百二十六。 大家可以看看这些尺寸覆盖了从小到大的各种物体,而且在不同尺度上分布的比较均匀。比如第一层可能主要负责预测小物体,用到十乘十、三十、六乘三十这样的小框,第二层用中等大小的框, 第三层用大框来捕捉大物体。这种设计使得模型能够更有效的处理不同尺寸的目标。 有了强大的预测能力,还需要一个给力的大脑来提取特征。有了 v 三,引入了全新的骨干网络,叫做 darknet 五三,这个名字一听就知道是 darknet 系列的升级版, 它是怎么来的呢?作者说这是 u love 二的 darknet e 九和当时流行的 resident 思想的一个混合体。它的特点是交替使用三 x 三和 e x 一 的卷基层,并且借鉴了 resident 的 快捷连接,让信息可以跳过一些层传递。 最关键的是,它比 darknet 一 九大得多,足足有五十三个卷级层,所以就叫它 darknet 五三吧。大家可以看看这个表格,这就是 darknet 五三的结构细节一层层堆叠起来,越来越深,特征也越来越抽象。 这个新来的 darknet 五三到底行不行?作者把它跟当时的几个主流骨干网络做了对比,包括自己的老前辈 darknet 一 九,还有 restnet 一 零一和 restnet 一 五二。评价标准包括 imagenet 上的 top 准确率、计算量、 flops 计算速度、 flops 每秒能算多少亿次浮点运算,以及最终的检测速度、 fps 结果怎么样呢?看表二, darknet 五三在 imagenet 上的精度跟当时的 sota 水平相当,但计算量却更少,速度更快,比 resident 一 零一快了一点五倍,比 resident 一 五二快了二倍。 而且它还实现了最高的 flops, 这意味着它的网络结构更能榨干 gpu 的 性能,效率更高。 resident 虽然层数多,但效率并不高, 所以结论很明确, darknet 五三是一个又强又快的特征提取器,为 yolo 三提供了坚实的基础。 训练方面, yolo 三延续了 yolo 系列一贯的风格,简单粗暴,不需要搞什么复杂的应付样本挖掘,直接在完整图像上训练就行。 当然,为了提高泛化能力和鲁棒性,还是用了很多常规操作。多尺度训练,让模型适应不同尺寸的输入, 大量的数据增强,比如随机裁剪、颜色变换等等,让模型见过更多变化,还有批归一化加速训练并稳定结果。整个训练和测试过程都是用他们自己开发的 darknet 框架完成的, 可以说训练策略相对保守,但效果不错。现在来看看实验结果。 首先看整体表现,特别是 coc 官方那个有点奇怪的平均 mark 指标,就是从 i o u 等于零点五到零点九五积分得到的。 在这个指标上, yellow 三的表现跟 s s d 那 些变种差不多,但速度快了三倍,不过跟 retina net 这些当时最先进的模型比还是有差距。 但是如果我们换个角度看 a p 五十这个老指标,也就是只在 i o u 等于零点五十计算的平均精度,那 loof 三就非常强了,它几乎追平了 retina net 远远超过了 ssd。 这说明什么? 说明 loof 三特别擅长生成位置还不错的边界框,虽然框可能不是完美贴合物体,但大致位置是对的。 但是当 i o u 要求更高时,比如 a p 七十五性能就掉下来了,说明它在精确,对其物体边缘方面还有提升空间。总的来说,尤洛三在速度和实用性上是个很好的选择。 这张图 figure 三更直观地展示了 hueof 三在 a p 五十指标下的速度精度全横横轴是推理时间,纵轴是 m a p 五十。大家可以看到,代表 hueof 三的紫色星星点明显地落在了左上方,而且非常高。这意味着什么? 意味着在同样的速度下, hueof 三的精度比其他模型比如蓝色的 retina 要高, 或者在达到相同精度时, love 三的速度更快。这再次印证了 love 三在速度和精度之间取得了非常好的平衡。作者还幽默地提到,他们修复了一个 love 二的数据加载 bug, 结果 mvp 提升了大约二个百分点,也算是个小彩蛋吧。 再来看看 yellow 三在不同尺寸物体上的表现。过去 yellow 的 一个痛点是小物体检测效果不好,但在 yellow 三这里,情况似乎反转了。得益于跨尺度预测, yl 三在小物体上的 a p s 指标表现相当不错。 然而,凡是有利有弊,它在中等大小 a p m 和大物体 a p l 上的表现反而相对弱一些。 这就有意思了,为什么会出现这种反常现象?作者也坦诚的说,还需要进一步研究才能搞清楚原因。这提醒我们,模型优化往往不是一蹴而就的,有时候改进一个方面可能会带来另一个方面的问题,需要持续探索和调整。 搞科研嘛,不可能一帆风顺,总得尝试一些后来证明行不通的方法。作者在这里也坦白交代了几种失败的尝试。第一种是改用限性激活函数来预测边界框的 x 和 y 偏移量,而不是原来的 sigmoid, 结果发现模型变得不稳定,效果也不好。第二种是直接用限性激活预测 x 和 y 的 绝对偏移,而不是相对偏移,这导致 m v p 下降了大约二个百分点。第三种也是当时很火的 folkloss, 作者也试了,结果 m a p 同样下降了约二个百分点。他们推测,可能是因为 loof 三本身已经通过分离的对象性预测和条件类别预测,对 folkloss 试图解决的类别不平衡问题具有一定的鲁棒性,所以再用 folkloss 反而没帮助 甚至有害。这说明不是所有流行的技术都适用于所有场景,得具体问题具体分析。 还有一种尝试是借鉴 faster rcnn 的 做法,设置双重 i o u 域值来分配正负样本, 比如重叠度大于零点七的算正样本,零点三到零点七之间的忽略,小于零点三的算负样本。 作者也试了类似的策略,但效果并不理想。他们对目前的方案还是挺满意的,觉得已经达到了一个局部最优解。当然,他们也承认,也许这些没成功的方法,只要稍微调整一下,还是有可能起作用的, 只是当时没能稳定的训练出来。这体现了科研中的一种常见情况,有时候不是时限,或者调餐上出了问题。 作者开始反思了,我们费这么大劲搞这些检测器,到底是为了啥?然后他就盯上了评估指标本身,特别是 coc 那 个平均 map 是 从 i o u 等于零点五到零点九五积分得到的,为啥要搞这么复杂? c o c 原文的解释非常模糊,就一句,等评估服务器建好了再说。作者对此颇有微词,他引用了 roscovski 等人的研究,指出人类自己都很难区分 i o u 是 零点三和零点五的框, 那我们用这么精细的指标来评判模型到底有多大意义?这就像用显微镜去看大象, 细节是多了,但整体印象呢?所以作者质疑新的指标是不是真的解决了旧指标的问题,或者说,它至少应该证明自己比旧指标更好,而不是仅仅换了个计算方式。 作者认为, m a p 这个指标本身就有问题,它过度强调了边界框的精度,可能会导致模型为了追求更高的 i o u 而牺牲了分类的准确性。 你想啊,一个框歪了一点点,但类别是对的,和一个框位置很准,但类别搞错了,哪个更让人接受? 肯定是前者吧,但 m a p 可能更看重后者。更严重的是, m a p 只关心每个类别内部的排名。这可能导致一些非常不合理的结果,比如这张图 figure 五, 假设有两张图片,两个检测器, detector 一 和 detector 二给出的结果看起来差别很大,一个框框歪七扭八,另一个框框完美贴合。 但根据 m a p 的 计算规则,在这两张图片上,它们的性能却被认为是完全一样的,甚至都是完美的。这显然是不符合直觉的。这说明 m a p 可能并不能很好地反映检测器在真实世界中的实际表现。 基于对 m a p 的 反思,作者提出了自己的看法,未来的评估指标应该更贴近实际应用的需求。 他认为,与其纠结于每个类别的 a p 排名,不如考虑大局平均精度,或者计算每张图片的 a p 再取平均。他甚至开玩笑说,边界框本身就有点蠢,他其实更相信野马的力量,可惜优喽学不会。 最后,作者还聊了聊计算机视觉技术的应用前景。一方面,他可以做一些好事,比如统计国家公园里的斑马数量,或者帮你追踪家里的猫。 另一方面,他也直言不讳地提到了监控等潜在的负面应用。作为研究者,我们有责任思考我们的工作可能带来的影响,并想办法去缓解潜在的危害。这话说的挺实在的。最后,他还幽默地表示,别啊,我因为我终于退出 twitter 了。 也算是给这篇充满个性的论文画上了一个句号。总结一下, uof 三虽然自称只是渐进式改进,但确实是一个非常实用且高效的检测器。它在保持极快的速度的同时显著提升了检测精度, 尤其是在 a p 五十这个常用指标上表现突出。它的跨尺度预测和改进的骨干网络是关键。 当然,它也不是完美的,比如在高 i o u 要求下的精度和对中大型物体的处理上还有提升空间。 更重要的是,它引发了我们对当前评估指标有效性的思考。尤乐算的成功为我们提供了一个在速度和精度之间取得良好平衡的范例。
2yee 04:44
04:44 10:39查看AI文稿AI文稿
10:39查看AI文稿AI文稿手把手教你运行优楼 v 八区域检测代码。哈喽,各位小伙伴,新店文手把手教你运行优楼 v 八区域技术检测。 首先这个功能是官网上一个月更新的,首先我们进入官网来看一下这个远吗?我们打开浏览器,在搜索栏这里输入 tw, 点 c o 回车,然后在这里搜索 u 一八, 右手一把回正,然后看到第一个就是右手一把了,圆满了。 点击进去,用他的区域代码,在这个 example 文件夹这里,我们点击进去,然后看到这个 ulov 八一整 canter, 这里就是区域检测 这里有,点击进去以后这个就是官网的预测效果了,然后对视频进行区域检测,我们来翻译这个文档, 然后他这里也有安装教程的,然后他说下载原码 pro, 我没有来,我们进行原码下载, 找到这个扣的,然后到这个牙刷包就行了, 到时候我把整个源码分享到我的博客里面,你们从我这里下载就行了。好的,这里已经下载完成了,我们打开它要解压到其他目录, 把它放到其他的工作目录, 我这里新建一个文件夹, 英明叫 又容易罢了。然后选中这个文件夹,确定解压,这个就可以擦掉了。 我们进入刚解压的右楼预报文件夹这里。 然后首先我们准备好 ulo 一八的模型 们看着他的文档来操作 example, 这里区域检测, 他要下载一个 ulov 八的模型,之前我已经下载过了,要把它, 但是模型在这里我已经下载过了,就不会下载,到时候我把全部原码分享出去,然后我们用皮外全部打开 uri 八的原码, 右击打开,然后我们准备一个视频, 把这个视频复制一下,到时候我把这个视频也分享出去, 粘贴到这里,谢谢。 因为环境的话,之前的视频有讲解过了,你们按照之前的视频安装环境就行了,我这里已经安装好了,就不用重新再安装,我们直接选用之前安装的环境, 我这里选这个, 选中完等他更新。然后我们进入先跑文件夹这里找到这个区域检测,这里他这里有个文档, 这个就是区域检测的代码了,我们翻译成中文, 他这里是用命令行来运行的,待会我们不用他的方式来运行, 他这里也有参数的解释。这个 sos 就是放视频路径,这这指定你 cpu 还是 gpu 的,我电脑是 cpu 的,就指定为 cpu, 要这里就是指定模型了,你们可以来看一下这个参数, 然后这个就是跨那个区域的坐标了,你们也 也可以更换其他坐标。 我们直接找到一百九十六行这里,然后把这个权重的路径更改一下, 就把这个路径复制就行,这里把它替换掉, ctrl v, 然后再加一个斜杠,英文状态下的斜杠,因为前面加一个二,用来转移斜杠的, 加这个二就是把这个斜杠转换成这个斜杠,因为 windows 它 啊支持的斜杠是用反斜杠,然后这里用 cpu, 也可以不写这个检测的视频路径,我们加一个参数,在这里复制就行,选择 c, 然后 ctrl b, 后面这个就不用了,后面这个参数一定要删掉,不删掉他会报错的。以后把这个视频录进复制过来。 嗯,复制到这里容易,因为前面加一个二,然后这里二加一个加速, 这里就是检测时候那个视频是否显示,我这里是显示,没错,然后这里是保存,我这里就不保存了, 以后我们直接运行, 你看他的效果就是这样, 这个就是他的跟踪线,然后当我们人进入这个区域时候,他会进行技术,你有病,你有病,这个 这个三就是代表在这个区域的目标数量, 然后我们按住 q 键退出。好的,这期视频讲解到这里。 对了,还有一个问题,如果他提示没有这个这个包的话,你就安装这个包,在终端这里安装 pap, 如果环境没有这个包,你就要安装这个包,因为这个包我已经安装了,所以就不用安装。 好的,这里再补充一点,当我们用了一把 环境配置好了之后,我们直接运行的话,他会爆没有这个模块,那这模块就是我们需要下载, 要这里,这里已经选中你那个环境的话,要在这里点终端,要发现前面是 ps 的, 然后就是不行了,这时候我们需要设置一下,在文件这里点击设置, 然后在这个工具这里,然后点击他,然后找到终端,然后下了路径,选择与终端的环境一样,然后确定,然后我们在新的 一个,然后前面就是变成你虚拟环境的名字,变成你虚拟环境的名字,就代表成功进入你这个虚拟环境了,然后他安装了包,就会安装在你的虚拟环境这里了,有很直接 pip 要安装这个包就行了,这里作为一个补充,安装完之后就可以运行了。好的,这里补充完成这期视频讲解到这里,如果有问题的话评论区留言,喜欢的帮我一键三连,谢谢。
707落花不写码(水代码版) 02:58
02:58













![Yolo小课堂之中控窗口架点篇 [举手] #天霸yolo #三角洲行动 #yolo武将杯aw秀翻全场](https://p3-pc-sign.douyinpic.com/image-cut-tos-priv/b8943bef9db0ebb8c168fcba7ca15b72~tplv-dy-resize-origshort-autoq-75:330.jpeg?lk3s=138a59ce&x-expires=2081422800&x-signature=6tAO7%2Boheh9tweUZtaSLvIXNg%2BM%3D&from=327834062&s=PackSourceEnum_AWEME_DETAIL&se=false&sc=cover&biz_tag=pcweb_cover&l=20251218211859EAFA4E049CE4A21D016B)
