2026美赛f题数据在哪找
好的,接下来呢,我们看一下 f 题哈, f 题的话呢,叫生成是人工智能啊,这个说白了会影响各行各业的工作吗?对不对? 尤其是会影响哪些工作呢?官方呢?给了三种工作类型是吧? stm 和就说白了就是科学工程,比如说工程师啊,是吧?那个那个软件工程师啊之类的啊,数学领域的大神之类的啊,这些专业 对不对?就是我们所说的工科专业,还有叫技工贸易类,比如说厨师啊,水电工啊这种工种啊,工程类的工种,还有就是一些艺术家啊,这三种职业,那么未来生成是人工智能对这三种职业会是一个什么样的影响 对不对啊?怎么人工智能对这专者专者的职业会有一个什么影响啊?这个很关键啊,然后呢?分析,然后呢?这第一问啊,第二问就是分析啊,每个职业确定的特定的高校机构学项目,然后呢提出建议来,就是就是你觉得这三种职业啊,或者这每种职业, 那么如何来安排啊?这个这个针对这个职业项目如何来安排相关的课程来应对未来人工智能的一个发展哈, 还有就是这个,呃啊,以下就是些思考了哈,就是你,你可以作为你的补充啊,本质上来说啊,其实那个没有什么,这个这个这个主要就是两两问比较多一点哈,两问比较多一点哈,然后我们看一下具体的一些细节哈,可以把它生成这么几个小问哈。几个小问? 第一个就是这个,这是一个首先是个综合类题目哈,包括这个优化加决策啊,加评价优化都都在里面哈啊,我们可以分为这么几个小问,第一个就是这个预测啊,每种职业的发展趋势。第二个就是决策啊,教育方案怎么做优化。第三个就是评价啊,多因素影响的一个分析啊, 有多个因素对对于就业什么的影响。然后第五个就泛化推广建议相关的 每个小问,哎,第一个就是选择 stm, 技工、贸易、艺术各一个职业啊,预测啊,伪人工智能对他未来的一个发展的影响。这第一个小问问题为一,这是我们的第一个小问。 第二个就是为了应对职业教育机构设计 ar 项目课程怎么来设置相关的课程对不对?第三个就是分析就业需求外的其他影响因素啊,调整模型与建议。第四个小问就是论正建议的推广性啊,说明适用的范围, 来,我们看一看,可以看一下,可以选择哪些模型来做啊,哪些模型来做。第一个就比如说这个啊,我们说这个啊,记住哈,你们记住, 预测一个政策或者发布一个政策对未来的影响,大部分的概率都会选择用什么系统动力学模型啊,这个是百分之百的啊,大部分 f t f f t 啊,都是用系统动力学模型是最常见的,所以呢,这个题目我估计大部分的同学都会选择系统动力学模型来做的啊 啊,比如说用系统的力学来模拟,那么 ai 到底对于这些啊,学科这些职业,他的一个影响的内容是怎么样的啊?影响内容怎么样?比如 ai 先影响了,哎,怎么怎么,然后又影这个正反馈机制是怎么来构建的?这就叫系统的力学模型 啊,这个很关键啊,来用贝叶斯网络。为什么要融合贝叶斯网络呢?就是来有些不确定性,比如说技术迭代,这 ai 突然间发展的特别快了啊,突然间质的迭代, 那么不, ai 不是 说长期就按照这样的稳不变的或者稳固的发展,他会技术迭代非常的快的,所以我可以融合贝叶斯网络,再加系统里学模拟,我整个的来模拟未来的一个演化程度,工作的一个演化程度,这个很好,这个思路哈。 然后第二位决策,决策的话呢?我可以说,哎,要构建哪些啊?比如说 先确定用 h p 来啊,决策就是端标优化加一层的问题法,先用 h p 算法来优先确定权重标,比如说就业还是最高,还是说论语素养最高,是吧?就业能力肯定是最强的,对不对?每一个目标每一个是吧?这个这个指标他的那个权重先确定一下, 然后构建多标优化模型来优化我的课程,对吧?我设计哪些课程,哪些课程可以入选?哎,我的月儿条件可以是哪些?比如课时,学生的课时是固定的对不对?比如不能说太多对不对,是不是? 还有就是我有一些最基本的一些选优要求,课程要求啊,我都可以作为我的约束条件,这样我构建一个多目标优化模型啊,这叫目标优化模型啊,优化目标就是我的选择的那个,是吧?我我,我的优化目标是什么? 我的就业最好对不对?我就业最好,或者说,哎,因为你学生本身来还是就业吗?就业率最高 可以是我的优化目标,还可以是什么?我学生的能力更强,这叫多目标,目标不唯一啊,目标有很多, 你也可以有别的目标,但是我觉得这两个目标就可以了。就是第一就是就业,就学生的就业比较好,他不会失业。第二个就是这个学生,那么他的这个工作能力啊,整个的学业的能力是比较强的啊,你也可以有其他的,这个没毛病。 来第三个分析就业需求外的其他因素的,就哪些因素还会影响到我的,我的这个课程的设计,或者我的相关的一个建模, 那我们可以评价一下,就评价类某个东西,评价一下相关性分析,确定哪些变量啊?非优化变的,别论理风险创新能力。来来,然后呢,找到这些哪些变量是比较关键的?然后再相关性分析算法,然后呢,识别哪些变量,是吧?之间是高度相关的。然后呢,找到哪些变量啊?影响因素是比较大的。 然后第四个就是建议推广嘛,可以,你可以啊,构建一些其他的来, 比如说可以构建这个案例推案例推理模型, c r c c r c c b p c b 二,加上地理甲醛回归啊,来来,这个是 c c b p 的 c b 二,这个模型没见过哈,基于啊,机构相似案例进行推广,然后 j w r 的 量化啊,地区差异对推广影响的效果的一个影响 啊。其实这个题目吧,本质上来说就第一个问题最关键的啊,第一小问最关键了,就是说啊,和 ai 对 各个因素啊,各个这个 ai 对 那个各个的这个 ai 对 各个行业他未来会什么样的影响?其这个就是性动力学模型,这个很关键啊,这个很也很麻烦,对不对?这个的话,你要把这个模型构建出来以后,你整个的建模是比较流畅和比较顺利的哈 啊?第二小问,其实也还好哈啊?策略就是选课吗?其实就是一个选课模型,明白吧?就是一个选课模型, 我们都知道你可以,你可以那个构建啊?你在数学建模领域,其实这样是一个比较典型的一个优化类算法,就是选课算法,选课模型,选课模型一般你们你们也知道,就是如何,呃?给你们安排选课 对不对?怎么选课?让你的学分达到最高,让你的学习时间达到最短,就是这样的话学分最高,你的占有率的时间最短,这就是一个选课模型,你可以移植到这个地方来,明白吧?移植到这个地方来 啊,这就是一个移植的一个过程哈。这两个搞定了,其实其他的都不难哈。什么评第三位,评价第四位,什么回归啊?其实都还好,第一位和第二位主要就是建模的核心,好吧,这这个的话你要搞定了,很关键。 系统动力学也好,是吧?这个,呃,多多元回归也好,都还好,没有什么难点哈。没有什么太难点,就系统动力学建模会比较复杂一点哈。 来,我们呢也会把相关的源代码然后放到这个位置哈,放到把 f t 的 相关的源代码放在这个位置,以及我的系统文心文档以及我的想用 ai, 一 会呢?我会用 ai 完整的解决这个 这个题目完整的来解决这个题目哈完整啊,非常完整的解决这个题目用我们的 ar 提示词来完整的解决这个。呃 f 题。好吧,到时候呢看看这个相关的模型检验代码呀,调试啊之类都会都会放在这个放在这个文档里面去哈 啊相关有有有取相关的思路源代码啊,大家可以可以那个领取一下。好吧,我把相关的源代码都放在这个地方啊。思路解析相关的好吧来 难度系数不大。三点五分啊,不大啊,难。整个的模型复杂度呢?中等啊,只需要两个模型一个系统立体,一个多,一个多描优化模型啊,还有就是这个呃 难点呢,就是首先呢不同职业类型亮化建模很麻烦,尤其是艺术积木这些呢 内容吧比较复杂一点哈,尤其厨师什么的对吧。这些艺术啊这都比较抽象对不对。难以量化建模啊这个呢算是一个难点哈,非就业因素啊,像创新社会责任论语啊也不好量化,这都属于模糊,模糊因素对不对 啊。核心要点呢就是啊模型需要覆盖三类且具有代表性,数据来源权威可追溯啊,模型需要明确这个 ai 影响职业的核心内容驱动比较自动化替代效率提升啊,就 ai 是 怎么来影响这个工作 的?是是他是吧,他能够提高效率啊,原来两个人的原来一个人三个人一个人的三个人的工作一个人就能干了,他可以提高效率吗?对不对。 还有就是教育建议需具体可行啊,包括课程设置中这里啊学生你不要说这个同学选这个课程吧, 是吧?选了很多课程,内容太多太杂了也不行,对不对?就是需要满足这要求条件,要同一个学生同一时间不能上两门课,对不对?不同的选修课之间不能冲突。是哎,等等之类的 啊,需要这些约束条件需要考虑到位哈。解析思路,按照这样流程来,第一步啊,职业与机构选择,选择代表性职业,然后匹配对应教育机构啊, 然后呢?影响预测模型,构建 sd 模型,然后呢?来哎, sd 模型来整合 ai 技术成熟度,职业自动化率,市场效率来构建这样的一个模拟关系,就是 ai 它是怎么影响的?来构建 sd 模型系统理学模型来演化,来把整个的演化过程给它建立出来, 然后教育方案优化,用 h b 确定目标教育权重啊,哪些权,哪种是哪是比较重要的指标,我们放在优先级第一位上,比如说学生就业放在优先级第一位上是吧?然后多目标规划,多目标规划里面的目标权重也是不一样的哈, 然后呢,构建课程体系,然后第四个要多目标多因素评价,评价非就业因素评价指标体系。然后第五步推广啊,这样的一个思路来哈,互相要点创新点是吧?量化结果给出量化指标体系,然后第五步推广啊,这样的一个思维点也必须要做一点哈, 然后这个题目的话就车长亮化建模的啊,比较好一点。亮化建模的是吧,像一些经管类的啊,文科的也可以做功课类的,慎重啊,因为他不是,他没有什么功课的专业,反而是跟很多教育职业相关的,所以说需要你最好有一定的背景专业来做哈。 啊,这有整个的这个 f 题啊,大家可以看一下哈,然后六个题目来看的话呢,最简单的就这个 a 题,我觉得 a 题真的很简单哈,然后 f 题呢,也还好啊, c 题呢比较麻烦啊, c 题很很麻烦是吧?数据比较难,然后呢,建模也比较复杂哈, e 题的话呢,更麻烦哈。 d 题的话呢,呃,体育赛事的管理就是比较比较杂乱而已哈,然后呢, b 题的话呢?这个这个 b 题呢?这个四分啊,这个这个他就是 也不要,其实难度系数没那么大。就是就是,相对来说吧,月球基地可能很多人就害怕了,就害怕了哈,那整个的难度系数上来说哈,我觉得 a 题 f 题啊,都还是比较不是很难的,尤其是我推荐你做 a 题比较多一点哈, ok, 这就整个的一个选择题,建议难度分析啊,我觉得选 a 题的同学应该是比较多一点的,和 c、 c 题的话呢,因为给了数据,所以选的人应该也比较多一点哈 啊, a 题呢,是我最推荐你选的,也是大家希望大家啊去认真去做一做的哈。 a 题的话呢,难难获奖难度并不大,按照我说的逐层优化,逐层递进的话,拿到一个大奖应该是不成什么问题的哈。 ok, 这就整个 a、 b、 c、 d、 f 题的思路解析啊,小题建议难度难度分析之类的一个文档哈,给大家 准备好了,然后相关的原代码呢?给大家准备好了 a, b, c, d, e, f、 t 的 原代码是吧?啊,都放到相关的资料里面了,休息一下午就开始更新了哈,数据的话呢,老哥会大家继续从全网来寻找来购买哈,购买完之后免费分享给我们所有小伙伴哈,大家注意大家,大家不用担心哈, ok。

粉丝9907获赞5.4万
相关视频
 04:22查看AI文稿AI文稿
04:22查看AI文稿AI文稿f t 的 一个初步的思路已经完成了,后续的话将会给大家带来完整的代码,就是如何发展全人类人工智能吧。 我们这里的话没有全部写完,只是一个大概的一个框架,基于系统动力学多目标优化的深层式 ai 时代职业适配与高等教育课程改革研究。 这个还没写完,后面还要继续完善。需要上述参考资料的话,大家可以看一下视频下方的百度网盘啊,可以获取。 然后是问题重述,这里 体验了三个子问题吗?第一个是量化预测,三类典型职业在二零二五到二零三五就业规模变化, ai 替代辅助比例以及核心技能迭代周期吗?第二类是针对三类夜校学习项目, 在资源约束时设计差异化的 ai 课程体系。三个问题是构建多维度的评价体系,然后这个题目的初步的一个代码,还有这个结果都给大家更新了, 然后这里是问题分析, 问题一,分析框架,然后是核心部署的这样一个拆解流程框架图。 问题二,然后问题三就是多因素评价与方案推广, 这里的话是一个符号的说明,然后这里这一部分是建模求解部分。问题一,这是职业未来预测 结果分析, 直接回忆问题,这是结业的结果吗? 模型检验嘛,然后结果的话是职业类型数据科学家残差值一级,然后是高级烹饪师心没视觉所有的职业,那个 c 小 于零点五且 p 大 于零点九五嘛?模型精度是一级,这个结果的话是满足预测要求的。 后续的话这个是没有,不是最终版的一个初步版的一个思路,后面下午的话我将会给大家收集 进行一个完整的解答,这个检验的一个结果,这个内容的话资料我们是持续更新的,这是三个问题,这里的话只是给大家提供一个大概的框架和思路 啊,是不是东西的话就写到这里,下午的话还要继续写成一份更详细的一份成品论文。
 03:47查看AI文稿AI文稿
03:47查看AI文稿AI文稿好的,小伙伴们大家好哈,还有很多同学说想坐地铁啊,地铁的话找不着数据啊,今天老哥也给大家找到地铁的数据集了啊,地铁数据集还是非常非常全面的哈。啊,你看一下这个数据,光说明就写说有十页的说明啊,十页的说明啊,完整的一个数据集,在这个地方哈,二零二六美赛地铁的数据集啊,在这里哈, 什么?包括二零二五赛季球员薪资数据啊,美国女子篮球运动赛的这个完整的数据集啊,以及这个球队扩张的球队的数据,是吧?以及这个版权啊,媒体版权合同数据 啊,模型参数数据,然后呢?球队估值运营数据啊,球队上座率的数据,高薪资历史啊,高薪资帽的历史数据啊,都有哈,每一个数据呢,我们都在这里都有一个说明哈,就这个数据代表什么意思?在这里有哈, 比如第一个上座率书记啊,这些字段分别代表喊什么意思?比如字段球队的名称,比如说伊里安娜狂热队, lv, 什么拉拉斯拉斯,王牌队,是吧?赛季的年份,二零二二四幺三,二零二四年 平均上座率是吧?上座总人数,然后呢?主场管人数啊,该赛季收清次数啊,包括啊,然后关键随着相关的价值的解析啊,就这个数据集,就这个 啊,上座率数据啊,在这里啊,上座率数据找一下啊,上座率数在这里啊,就这个数据怎么解读啊,里面的含义啊,都在这个表里面写着了哈。 然后第二个数据,比如说扩张球队的数据哈,六只扩张的球队,他们的数据的一个整体情况也是有自断的情况,所在的城市加入联盟的年份,加盟费啊,主场使用啊之类的,然后都有哈,就是扩张嘛,对不对?球队扩张, 然后还有就是媒体版权合同数据,每点点这个这个数据啊,是吧?版权相关的合同期限啊,合同金额和媒体方转播内容啊,分成比例啊,都有哈啊。对,在这个地方每点这个这个位置, 媒体版权合同数据里面也都有哈啊,这就是我们整个的一个完整的数据集哈,你可以比着这个数据说明,然后呢对应的去找相关的数据集即可哈。 啊,同样道理呢,我们还有这个一个一个其他的数据来源,一个一个完整的一个一个表格哈,大家可以看一下哈啊,包括各种各样的数据集,怎么去找啊?包括怎么去找哈 啊?包括比如说这个球队基础的球,球队球员数据,得分数据,然后呢这个得分数据的话可以统计出来这个球队的整体的实力吗?球星的相关实力,赛程比分数据,勇士队啊,历史赛季阵容统计口径, 球员薪资合同口径啊,各种各样的数据集都可以在这个里面去下载哈。啊,如果你不想下载的话,我们有一些基础的数据集就给咱弄好了,大家可以拿去用一下哈,这个数据集的话整理的还是比较完善的哈,大部分数据都是免费的,可以直接下载,包括伤病数据啊,每个球员的一个相关的一些伤病数据合集啊 啊,都在这个地方了啊,可以拿去是吧看一看啊,相关的数据,那个那个有没有自己需要的哈?有没有自己需要的 啊?这就是整个的这个立体的一些数据集啊,包括数据说明、下载方式,然后呢?相关的已经数据下载好的一些数据合集啊,都在这里了啊。 好的,同样的呢,我们还有美赛 f 体的数据哈。美赛 f 体的数据啊?包括什么?呃,这个这个里面是关于艺术家什么的,他们的一些就业数据啊,搞艺术的、音乐家他们的一些数据, 这个里面的数据非常庞大哈。这整个的这个美国的啊,相当于整个的各种工种的一个数据表哈。啊,非常非常的全面哈,里面内容特别特别的多哈,这个 ar 都不一定能处理的了,内容非常大。就整个的这个,呃,工种啊,他这个工作时间、 工作安排啊、加班效应,各种各样的数据集啊,每种工作每种工种的啊,长这个数据啊,都在这里面了哈。
 04:56查看AI文稿AI文稿
04:56查看AI文稿AI文稿然后现在的话,美赛的 a 题到 f 题的所有的题目的中文翻译版已经出来了,先大致看一下,然后等下我给大家更新每一题的一个选题思路分析, 以及怎么解配套的代码使用情况啊。现在先看到美赛的一个 a t, 它是一个智能手机电池的放电建模,和以往的 a t 一 样,还是偏数学肌底类的。 这类题目的话一般难度的话是比较大的,大家选择 a t 的 时候要注意 连续时间模型,然后自己要去收集数据集 这个 pdf 要注意啊,这个总数的话是不超过二十五页的,这个都是翻译后的,大家可以看原来的那个英文版, 然后看一下这个 b t, 今年的 b t 是 一个利用太空电梯系统建立月球执迷的。这题目的话都还是比较新啊,和今年的那个股票里面那个不是很火的吗?那个商业航天啊,都紧密挂钩啊。 嗯, mcm 机构, 你的任务是利用数学模型来确定是从二零五零年开始建造,容纳十万人的需要的材料运输成本和相关的时间表。 然后将现在在那个太空电力系统的三个年港口,然后从选定火箭基地发射的传统火箭进行比较。这是对你建立模型的一个要求 啊,仅使用太空电力系统的三个港口啊,这些,这些是运输系统没有完美的运行状态时考虑的一些情况啊,系绳摇晃,火箭故障对你损坏, 然后再写一封营业 执照,你里面有 ai 的 话,也最后要附上一份使用报告。 而今天的 ct 也是一样的,紧扣商业航天里面的这些内容与核心相关的数据。 嗯,这这类题的话在常规的话以往来看就是数据量比较大,它这个 ct 单独是给了你一个数据表格的。 啊,这个它翻译有点问题,这个其实是明星,明星的这些题目 看这是统计,这个题的话是对你那个处理数据的能力要求较高,你看它 ct 的 这些数据都是公开在这里的,自己要去整理一下 与星共舞是英国的那个节目舞动奇迹里面吧。 啊,第一题是如何管理体育运动,体育商业里面的内容, 一题是被动式太阳能遮阴。 啊,这题目介绍的话就介绍这里,这中文翻译版的话我也全部都给大家整理好了,后续思路一并发给大家。大家直接在视频下方那个企鹅群里进去领取就行,包括我前面发的赛提助攻资料。那这个 fg 是 否要发展全人类人工智能 这一个收集讨论? 嗯,好,等会再给大家更新思路。大家题目的话先看着这里。
14牛顿迭代法 17:51查看AI文稿AI文稿
17:51查看AI文稿AI文稿好,大家好,那这里是本次美赛 c 题目啊,第一问完整代码以及结果的讲解视频, 那本次这个代码呢,量是非常大的啊,因为这个 c 题目呢,数据库处理啊,包括后面这个实际求解啊,这个步骤是非常繁琐的啊,我收获都跟大家去讲清楚啊,包括这个数据处理之后什么样的样子啊,后面就求其结果,因为我们要得出那个投票数嘛,啊,就这个观众的投票数 啊,我都会一一的去给大家展示啊,请大家务必有耐心的把这个视频呢仔细的去看完啊,那目前第二问代码也是已经完毕了啊,等我后面把三四问全部解决完毕之后,我再给大家录一个完整代码的讲解视频吧。好吧,那么这个视频呢,就先给大家讲一下这个第一问吧。呃, 还有就是这个 a 题目啊, a 题目呢,第一问的代码呢 啊, a t m 这个完整代码我也是已经完成了。呃,一会我会再录一个视频给大家讲一下这个 a t m 的 代码,好吧,好,那么这个 a t m 和 c t m 完整原创论文以及相应代码和结果的说明呢, 大家可以看这个视频的评论区啊,我们预计会在明天,也就是一月三十一号的中午左右就会更新完毕这两道题目的完整论文啊,即刻的代码。好,那么废话不多说,我们来看一下这个梅赛 c t m 的 第一问。呃,题目背景 好,包括这个思路呢,我就不用再给大家去多说了吧,因为我前面这两个视频呢,都跟大家讲过了啊,大家可以继续看前面讲个视频,我就直接从代码开始入手了,好吧,呃,首先我们带人第一步首先要去处理这个数据,我们可以看到呢题目给出我们这个原始的数据呢, 他这个非常非常长的这样一个宽表啊,什么叫宽表?就是他很宽,就是他这个宽度呢?大概是有 这个五十三列吧,应该五十三列,然后呢他这个行数一共是这个四百二十二行,然后包括呢这个题目后面有很多的关于这个数据的一些描述啊,包括呢这个数据的一些注示啊,比如说 n a 指是什么意思,那么进零分的是什么意思啊? 啊?再比如说一共矮有四位评委啊,然后各种周次啊,反正各种中东西啊,那么这些呢,都是我们在数据处理过程中需要考虑到的东西, 能理解吧?啊?当然我们这个数据处理呢,在第一步的时候,我们最重要的是要把这个数据呢这个官表呢处理为一个适合我们建模的这样一个长表的格式啊。然后在这个处理为长表的这个格式的过程中呢,我们再去把每一个变量 啊,每一个数值啊,包括什么空值啊,零啊, n a 啊这些呢,都做统一的处理,能理解吧?好,我们来看一下这个具体的数据与处理的过程。 呃,还那句话啊,这道题目呢,还是比较复杂的。呃,目前呢,也可以看到网上各种满天飞的什么完整的每一问的代码呀,思路什么的都出来了,我只能说大家 见仁见智吧。啊,就是你这么快的速度,要是把每一问的代码和结果全部都得出的话,那这个质量你可想而知吧啊,总之呢,呃,我只做好我自己的这个代码和结果啊,呃, 好,大家自己去看一下我这个代码就知道了。好,我们来看一下第一步,呃,我们把这个数据呢先上传到这里啊,这是题目原始的这个数据 啊,这原始的数据,我们首先呢第一步先去读取数据,那么这对于原始数据数据中呢?啊,还有这个 n a 的 这个字符串的我们进行处理,然后呢清理列名,去除掉可能会有的空格,然后呢统一进行小写啊,这是为了方便我们后去读取列名, 接下来我们要去解析他们的淘汰周数,那么关于这个思路的方面呢,我们前面就免费思路的原因给大家讲过了,就是我第一问都用的这个模型呢,是这个 mcmc 啊,这个模型这个方案。那么在后面我不是给大家讲了一个这个 每一问的这个关键信息和一些雷区和注意点吗?啊,包括这个阶段一怎么处理百分比置,然后阶段三这个混合之家评为拯救, 然后在数据惊喜中的一些雷区我也给他讲过了。呃,这个呢,大家自己去看我之前的那个数字讲解视频就可以了,我在这里就不多做赘述了。好吧,就顺着代码去跟大家讲吧。总之第一问我们的目标不就是通过题目之后给我们的啊,这个他是否淘汰以及评委的 啊,这个评分啊,包括一些其他的各种数据来去推断出来,他最初时的就是反建构出他最初时的这个粉丝投票数嘛,对不对啊?这是题目要求我们的第一问要去做的这个事情,看一下题目第一问估算的粉丝投票数,好吧, 好,来看一下数据处理。呃,然后呢,接下来下一步呢,我们是要去解析他们的淘汰周数了,我们需要去知道每一个选手到底是在第几周被淘汰的,或者说他是进入了决赛,那么假如说他是没有结果的话呢,那么他就是说啊,坚持到了最后 啊,这是第一个处理,那我们把决赛的处理呢啊,决赛的这个选手呢?进行一个处理啊,就是说假如说 是这样的,那么他们说明他们参加了所有周四啊,我们可以给他们很大的一个数字,一直去表示他们直到这一季的最后一周他都在,那么这个最大数字呢?我就设置为九十九了啊,大家也可以设置为其他数字都行了的啊,都行的, 这个呢,我,我无所谓的,就是你随便设置一个比较大的数字啊,一一百多也行,总之代表就是说他们一直是重活到了决赛,能理解吧? 好,然后接下来是应用这几级函数,然后我们构建这个长格式数据,去构建这个长格式数据表,我们获取一下它的最大周数,然后提取它所有可能出现的周数, 提取完之后我们去构建这一周这个评委翻数的列名和列表。那么我们这里是假设最多有四个评委,为什么要这样假设呢?因为题目呢,原初始的这个 数据说明里面我们跟我们说过了啊,就是这个 n a 值,通常用于一个,就是说第四位评委的分数啊,假如说这周没有第四位评委,就是一般有三位啊,就是意思就是说最大就是四位嘛,这么个意思。好, 显然在这里我们假设是最多有四个评委,然后提取这一周的分数,然后把这个 n a 值啊和控值呢全部处理 过滤完了之后呢,我们只在这一周有有效分数时候才记录该条数据啊,这周呢,我们就把那些被淘汰之后的周次,我们就自动过滤掉了,因为这个被淘汰之后的周次呢,他的得分都是零嘛,对不对?好,那么接下来就是个长表,他都包含一些什么样的这个 变量啊?一个是他的赛季,一个是他的这个周数啊,然后包括有这个原始列吧,他可以查啊,评委的总分,评委的数量,他是三个还是四个,有的时候可能是三个,有的时候可能是四个,然后呢?这个是本周 啊,由于结果被淘汰的,然后这个全居记录何人该时淘汰,然后呢?这是一个最终名次,这是一个预处理之后的数据啊,这是最终整理出来这个场表 啊,一共就这么几个变量,对,淘秒呢,一共就是两千七百多。行了。好,然后我们去提取它的技术信息表啊,用于这个我们的第三问,这个建模啊,我们一行这个处理就可以了, 处理完了之后呢,我们做一个比较简单的一个结果检查,然后保存这个结果就可以了,我这个结果呢,是保存为了一个域处理后数据啊,那么大家大家可以继续改这个表名啊,这我就不用读,跟大家读说了吧。啊,好, 呃,我们检测的最大周数呢,是一到十一周这个范围,假如呢,我们数据处理之后呢,一共是两千七百七十七行,然后一共是九列包含的总赛季数量呢,一共三十四个赛季嘛,根据这个题目来说, 然后我们检查两个具体的例子吧。啊,好吧,我们来看一下题目给我们的这几个例子, 这个结婚呢,是给我们了一个第一季第四周啊,这几个参赛者,他们最终的这个排名情况啊,排名情况和他们预估的这个粉丝投票数啊,我们就根据这个例子来做一下,来看下代码, 我们可以先看一下这个 s 一 啊,被淘汰的这个人啊,那么他呢是在第四周就被淘汰了,对不对?好,我们来看下代码, 所以呢,他就应该就是说运行完之后呢,他应该被标记为在第四周是淘汰的。其实大家可以看到呢,这个 week 四啊,就是第一赛季的第四周,那么这个人呢,就被标记为淘汰了,后面是个处,对吧?那么另外一个例子就是 s 一 的这个冠军 啊,就是这个评委评判排名的啊,这个第一哦。啊,他就是呢,一直没有被标记过淘汰啊,一直没有被标记过淘汰。好, 那么整个这个数据处理步骤就完成了,然后呢我们检测了一下这两个视力啊,也是正常的合理的啊,但是你们大家也可以去踩,就是说啊,使用一些其他的例子去验证也可以啊,也可以。 ok, 那 么在数据处理全部完成之后呢,我们就要去做这个 啊,实际的我们估算他每一个周四中产生的这个粉丝图飙数 啊,那么这部分的思路呢,我前面也给大家讲过了啊,就是我这题采用的这个模型呢啊,我最终采用的这个方案的是这个避风啊,也是个 mcmc 啊,就是求粉丝投票的这个概率分布情况。 好,我们做一下模拟,那么这部分的核心代码呢?我就不给他展示了,这个核心代码呢,也比较长,呃,也很难,那么这个呢?呃,大家都能拿到我这个论文和代码的人,自己去看就可以了。好吧,呃,我这我就不多赘述了,因为我要保证这个限量,我就给大家展示一下最终这个结果啊,那么最终这个结果呢,我们模拟完之后 也可以得到这样的一个结果,那么这个结果呢啊,我们可以做一些结果分析啊,这个非常非常合理的。然后这里呢,我们求出来其实就是他这个占比,就是投票的占比,大家能理解吗?啊,这是一个投票的占比, 因为我们这个种票数呢,他是不定的啊。这个是还那句话,这个题目在求解决过程中有许多我们需要去注意的点,大家千万不要去忽略啊,去瞎写,哎,记住, 可以看到就像网上各种满天飞的各种思路啊,什么代码视频啊啥的,可能有的很多人都没有讲到这个问题,这是个总票数呢,他是不定的,这是未知的,所以呢,他只是选择一个假设值去产生最终的正确排名,而且呢,这个总票数呢,是我们永远无法得知的,大家能理解吗? 因为我们这个总收视率的是不定的啊,你,你这个总票数可能是,呃,一百万,有可能是一千万,这个没有人能知道,没有人能知道,我们在书学方面成层面的 最多最多就只能纠解出来他们的投票占比,能理解吗?啊?所以在纠解完这个之后呢,我们得到了他最终的这个结果啊,保存为这个,我们打开给大家看一下这个结果这个结果表格,那这就是他们最终得到这个结果表格啊。我们反推出来这个粉丝投票数, 那么当然了,这也就是我们得出来的这个反推出来的是粉丝投票的占比。投票的占比,那有人要问了, 可是人家题目要求的是让我们给出他们的粉丝投票数呀,对不对啊?人家第一位让让我们给出他具体的粉丝投票数呀,我们估算粉丝投票数呀,包括我们第二问,第三问也都是要用这个粉丝投票估算值和其余数据来计算呀。那,那那以现值投票占比怎么办呢?啊?没关系的,没关系的,这这个呢很好处理, 首先代码里面呢,我们再加入这么一段,把这个估算的份额呢去转换为具体的票数就可以了。那么怎么转换啊?其实就是根据它们的舒适率假设一下,假设一下能理解吧, 那它这个,呃,一般来说啊,这个电视节目呢,都是早期赛季是比较火爆的,那么后期是略有下降的,是我们可以设定为啊,早期的这个 s 一 到 s 十是一千五百万票,那么 s 十一到 s 二十是一千万票,那么后面的这些数是六百万票,那么当然在这个数值大家可以自己去先假设, 而且呢这个数值怎么假设呢?跟我们后面两三位的二三位的求解呢?是没有关系的,能理解吧?就后面二三位呢?有人可能要问了,那这个你假设为这么个票数,那么前面赛季是一千五百万票,后面是六百万票,会不会导致我们第二三问求解的时候,出现这个求解不一致的这个情况呀? 对不对?这个是完全不会的,因为我们求解一个人淘汰呀,什么排名啊?这情况呢,都是在单个赛季内去完成的, 不存在说是你这一个第一个赛季跟第三十四个赛季进行对比,这个我情况的是不存在的,那样理解吧。啊,所以我们都是在这个单个这个赛季里面循行求进, 所以呢,当然你们也可以设置为 s, 一 到 s 三四都是稳定的,都是一千万票也行,都行,这个呢,我们只是想把这个投票占比呢去转化为他们的 绝对票数而已,这个呢,其实意义也没有多大,包括这个 a 多少万票,你们给黑市进行修改啊,拿到代码的到时候也可以自己去进行修改啊,我这里设置一千五百万票,你刚刚可以把它设置为你一百五十万票啊,这个这个你多减个零也行嘛。啊,这个这个影响都不大的, 因为我们题目上面给出这个意思呢,哎,他也这个票数呢,也是一个估算的,这个估算的好,我们转化完之后我们就可以得到这样一个结果,我们把这个结果打开给大家看一下啊,那这里就是转化之后的啊,这个总的票数我们拖到最后,我们也给大家看一下 啊,那这里就是最后的这个这一点啊,就是他们的这个投票总数了啊,啊,投票数,这这一点就是他们的投票数。好, 那接下来啊火美这个代码呢,就是做这个一致性的检验和确定性的检验了吗?对不对?这也是题目明确要求我们的,其实我们要去看一下啊,他这个一致性的度量啊,是否是一致性的,然后呢再一个就是呢,这个投票总数呢,是有多大的确定性? 这个一致性度量呢?其实就是说我们这个求解第一问这个模型呢,是精准还是不精准啊?你要就一致性的很低的话,那证明你完全是错的嘛,你投票总数就关键是求解错了的, 就你根据这个投票总数我现在去计算啊,他还跟咱们的淘汰这个结果是完全一致的,比如说我们第一问的这个模型呢,是完全正确且合理的啊,这就是一致性度量的意思。另外一个就是说这个投票的总数呢,有多大的确定性 啊?就这个训练型呢,对于每一个参赛者,每一周或者是总是相同的,是否是总是相同的啊?提供我们一个训练型的度量,这个呢就是我们这个思路得兼独厚的一种优势,因为我们采用这个 mcsm 模型呢, 我们的确定性读量呢,就直接通过我们后延风格的这个标准差和执行区间呢,就会完全能够就直接回答其波中说提出的这个确定性的问题了。哎,所以这也是我为什么最终舍弃掉了其他两个方案。其实我们这个呢,在回答确定性上面呢,是一个非常非常好的一个顶级方案。好,我们来看一下代码, 那么这部不带马的实际确定性度量和一致性检验的这个核心结构,我就给大家展示了,我来开案就用这个结果吧。好吧,那么我在这里呢,我是哎 啊,就是查看了两个人啊,一个是第一个赛季的这个和第一个赛季这个做了一个一次性检验和确定性的毒粮,然后做了一个二十七第二十七个赛季的这个一次性检验和毒粮,那么我为什么会采用二十七赛季呢?啊?这也是根据提议 啊去确定的,就在这个提议里面呢,他是从二十八赛季不是开始变这个规则了吗?啊?二十八赛季开始变规则了,这是因为呢,我们前面中期的这个到二十七赛季发现这个可能啊,这个规则可能不太好或者怎么样的翻开,二十八开赛季不是变了吗?而而且这个二十七赛季呢,不是冲见出现了一个争议吗?就这个人 啊,可能就是因为它出现争议啊,所以最终导致二十八赛季这个规则改变了,所以我们呢最好呢是把二十七赛季呢啊去做一个展示啊,当然你们采用其他赛季也行啊,也行,那我这里给大家展示一下这个第一个赛季的吧。啊,二十七赛季我就给大家展示了,那我这里就会生成一个第一赛季的这样一个趋势图 啊,这就是一个不确定性范围的这样的一个呃呃,图啊,然后这里是他们的不确定性的热力图啊,这是他们的不确定性的热力图, 颜色越红,那就是表示他越不确定啊,那么颜色越淡呢,就是表示他越确定啊。大家这就是完美回答了这个节目中所提出的这个问题啊,一方面我们的一致性呢,全部检验完毕了,再一个呢,我们也就确定性 啊,我们给出了注量啊,也计算出来了啊,然后呢,对于每一个参赛者或者每一周出是否总是相同的,那当然不相同了吗?对不对?那代码这里面热力图都已经给出了吗?每一个这个人啊,每一周他的这个确定性的注量都不一样,我们热力图也获取出来了, 那就完事了啊,二十七赛季的我就不给他多展示了。好,那么第一问完整的这个代码和节目呢,大致就是这个样子啊,我们把第一问的所有决定目标全部都学完毕了,对不对?再来回顾一下啊,这个我们也纠结完毕了,这个也纠结完毕了,这个也纠结完毕了,全部完成了。好吧,呃, 那再给大家说一下,到时候大家拿到我的这个代码和论文的人呢,这个所有代码图片的颜色也都可以进行修改啊,那么关于这个代颜色怎么修改,我到时候在代码里面也都会有注置, 大家到时候拿到我代码和这个代码操作视频的人呢,自己去看就可以了。好吧,那关于问这个完整成品论文和代码的书们,大家可以看这个视频的评论区。 呃,我预计会在明天中午,也是一月三十一号中午左右就更新完毕。呃,美赛 c 题目啊,完整的原创论文签代码和结果,那么到时候呢,也会有一个完整代码和论文的详细视频,那么这个视频呢,只是给大家讲一下第一问, 希望能够帮助到大家,特别是关于这个数据处理部分。呃,希望能够帮助到大家吧,好吧,那么就说到这里吧,呃,谢谢大家。
164数模陪跑保证原创 12:05查看AI文稿AI文稿
12:05查看AI文稿AI文稿好的,接下来呢,我们看一下 f 题哈, f 题的话呢,叫生成是人工智能啊,这个说白了会影响各行各业的工作吗?对不对? 尤其是会影响哪些工作呢?官方呢?给了三种工作类型是吧? s、 t、 e、 m 和就说白了就是科学工程,比如说工程师啊,是吧?那个那个软件工程师啊之类的啊,数学领域的大神之类的啊,这些专业 对不对?就是我们所说的工科专业,还有叫技工贸易类,比如说厨师啊,水电工啊这种工种啊,工程类的工种,还有就是一些艺术家啊,这三种职业,那么未来生成是人工智能对这三种职业会是一个什么样的影响 对不对啊?怎么人工智能对这专者专者的职业会有一个什么影响啊?这个很关键啊,然后呢?分析,然后呢?这第一问啊,第二问就是分析啊,每个职业确定的特定的高校机构学项目,然后呢提出建议来,就是就是你觉得这三种职业啊,或者这每种职业, 那么如何来安排啊?这个这个针对这个职业项目如何来安排相关的课程来应对未来人工智能的一个发展哈, 还有就是这个,呃啊,以下就是些思考了哈,就是你,你可以作为你的补充啊,本质上来说啊,其实那个没有什么,这个这个这个主要就是两两位比较多一点哈,两位比较多一点哈,然后我们看一下具体的一些细节哈,可以把它生成这么几个小问哈。几个小问? 第一个就是这个,这是一个首先是个综合类题目哈,包括这个优化加决策啊,加评价优化都都在里面哈啊,我们可以分为这么几个小问,第一个就是这个预测啊,每种职业的发展趋势。第二个就是决策啊,教育方案怎么做优化。第三个就是评价啊,多因素影响的一个分析啊, 有多个因素对对于就业什么的影响。然后第五个就泛化推广建议相关的 每个小问,哎,第一个就是选择 stm, 技工、贸易、艺术各一个职业啊,预测啊,美人工智能对他未来的一个发展的影响。这第一个小问问题为一,这是我们的第一个小问。第二个就是为了应对职业教育机构设计 ar 项目课程怎么来设置相关的课程 对不对?第三个就是分析就业需求外的其他影响因素啊,调整模型与建议。第四个角度就是论正建议的推广性啊,说明适用的范围,来,我们看一看,可以看一下,可以选择哪些模型来做啊,哪些模型来做。 第一个就比如说这个啊,我们说这个啊,记住哈,你们记住,预测一个政策或者发布一个政策对未来的影响, 大部分的概率都会选择用什么系统动力学模型啊,这个是百分之百的啊,大部分 f t f f t 啊,都是用系统动力学模型是最常见的,所以呢,这个题目我估计大部分的同学都会选择系统动力学模型来做的啊啊,比如说用系统动力学 来模拟,那么 ai 到底对于这些啊,学科这些职业,他的一个影响的内容是怎么样的啊?影响内容怎么样?比如 ai 先影响了,哎,怎么怎么,然后又影这个正反馈机制是怎么来构建的?这就叫兴同力学模型 啊,这个很关键啊,来用贝叶斯网络。为什么要融合贝叶斯网络呢?就是来有些不确定性,比如说技术迭代,这 ai 突然间发展的特别快了啊,突然间质的迭代, 那么不, vr 不是 说长期就按照这样的稳不变的或者稳固的版,它会技术迭代非常的快的,所以我可以融合 b s 网络,再加系统里学模拟,我整个的来模拟未来的一个演化程度,工作的一个演化程度,这个很好,这个思路哈。 然后第二位决策。决策的话呢?我可以说,哎,要构建哪些啊?比如说 先确定用 h p 来啊,决策就是端标优化,加一层的面积把,先用 h p 算法来优先确定权重标。比如说就业还是最高,还是说论语素养最高,是吧?就业能力肯定是最强的,对不对?哪一?每一个目标每一个是吧?这个这个指标他的那个权重先确定一下, 然后构建多标优化模型来优化我的课程,对吧?我设计哪些课程,哪些课程可以入选,哎,我的月儿条件可以是哪些?比较课时,学生的课时是固定的对不对?别不能说太多对不对?是不是? 还有就是我有一些最基本的一些选优要求,课程要求啊,我都可以作为我的约束条件,这样我构建一个多目标优化模型啊,这叫目标优化模型啊,优化目标就是我的选择的那个,是吧?我我,我的优化目标是什么? 我的就业最好对不对?我就业最好,或者说,哎,因为你学生本身来还是就业吗?就业率最高 可以是我的优化目标,还可以是什么?我学生的能力更强,这叫多目标,目标不唯一啊,目标有很多, 你也可以有别的目标,但是我觉得这两个目标就可以了。就是第一就是就业,就学生的就业比较好,他不会失业。第二个就是这个学生,那么他的这个工作能力啊,整个的学业的能力是比较强的啊,你也可以有其他的,这没毛病。 来第三个分析就业需求外的其他因素的,就哪些因素还会影响到我的,我的这个课程的设计,或者我的相关的一个建模。 那我们可以评价一下,就评价类某个同学,评价一下相关性分析,确定哪些变量啊?非优化变量,别论理风险创新能力啊。来来,然后呢,找到这些哪些变量是比较关键的?然后再相关性分析算法,然后呢,识别哪些变量是不之间是高度相关的,然后呢,找到哪些变量啊,影响因素是比较大的。 然后第四个就是建议推广嘛,可以,你可以啊,构建一些其他的来, 比如说可以构建这个案例推案例推理模型, c r c c r c c b p c b, 加上地理甲醛回归啊,来来,这个是 c c b p 的 c b。 二、这个模型没见过哈,基于啊,机构相似案例进行推广,然后 j w r 的 量化啊,地区差异对推广影响的效果的一个影响 啊。其实这个题目吧,本质上来说就第一个问题最关键的啊。第一小问最关键了,就是说啊,和 ai 对 各个因素啊,各个这个 ai 对 那个各个的这个 ai 对 各个行业他未来会什么样的影响?其这个就是性动力学模型,这个很关键啊,这个很也很麻烦,对不对?这个的话你要把这个模型构建出来以后,你整个的建模是比较流畅和比较顺利的哈 啊?第二小问,其实也还好哈啊?策略就是选课吗?其实就是一个选课模型,明白吧?就是一个选课模型, 我们都知道你可以,你可以那个构建啊?你在数学建模领域,其实这样是一个比较典型的一个优化类算法,就是选课算法,选课模型,选课模型一般你们你们也知道,就是如何,呃?给你们安排选课, 对不对?怎么选课?让你的学分达到最高,让你的学习时间达到最短,就是这样的话学分最高,你的占有率的时间最短,这就是一个选课模型,你可以移植到这个地方来,明白吧?移植到这个地方来 啊,这就是一个移植的一个过程哈。这两个搞定了,其实其他的都不难哈。什么评第三位,评价第四位,什么回归啊?其实都还好,第一位和第二位主要就是建模的核心,好吧,这这个的话你要搞定了,很关键。 系统动力学也好,是吧?这个呃,多多元回归也好,都还好,没有什么难点哈。没有什么太难点,就系统动力学建模会比较复杂一点哈。 来,我们呢也会把相关的原代码然后放到这个位置哈。放到把 f t 的 相关的原代码放在这个位置,以及我的系统文心文档以及我的想用 ai, 一 会呢?我会用 ai 完整的解决这个 这个题目完整的来解决这个题目哈完整啊,非常完整的解决这个题目用我们的 ar 提示词来完整的解决这个。呃 f 题。好吧,到时候呢看看这个相关的模型检验代码呀调试啊之类都会都会放在这个放到这个文档里面去哈。 啊想有有取相关的思路源代码啊,大家可以可以那个领取一下。好吧,我把相关的源代码都放在这个地方啊。思路解析相关的好吧来 难度系数不大。三点五分啊不大啊,难整个的模型复杂度呢?中等啊,只需要两个模型一个系统立体,一个多,一个多描优化模型啊,还有就是这个呃 难点呢就是首先呢不同职业类型亮化建模很麻烦,尤其是艺术技木这些呢 内容吧比较复杂一点哈,尤其厨师什么的对吧。这些艺术啊这都比较抽象对不对。难以量化建模啊。这个呢算是一个难点哈,非就业因素啊,像创新社会责任论语啊也不好量化,这都属于模糊,模糊因素对不对 啊。核心要点呢就是啊模型需要覆盖三类且具有代表性,数据来源权威可追溯啊,模型需要明确这个 ai 影响职业的核心内容驱动,别自动化替代效率提升啊。就 ai 是 怎么来影响这个工作 的,是是他是吧,他能够提高效率啊,原来两个人原来一个人三个人一个人的三个人的工作一个人就能干了,他可以提高效率吗对不对。 还有就是教育建议需具体可行啊,包括课程设置中这里啊学生你不要说这个同学选这个课程吧 是吧,选了很多课程,内容太多太杂了也不行,对不对?就是需要满足这要求条件,要同一个学生同一时间不能上两门课,对不对?不同的选修课之间不能冲突。是哎,等等之类的 啊,需要这些约束条件需要考虑到位啊。解析思路,按照这样流程来,第一步啊,职业与机构选择,选择代表性职业,然后匹配对应教育机构啊, 然后呢?影响预测模型,构建 sd 模型,然后呢?来哎, sd 模型来整合 ai 技术成熟度,职业自动化率,市场需求来构建这样的一个模拟关系,就是 ai 它是怎么影响的?来构建 sd 模型系统理学模型来演化,来把整个的演化过程给它建立出来, 然后教育方案优化,用 h b 确定目标教育权重啊,哪些权,哪种是哪些是比较重要的指标,我们放在优先级第一位上,比如说学生就业放在优先级第一位上是吧?然后多目标规划,多目标规划里面的目标权重也是不一样的哈, 然后呢,构建课程体系,然后第四要多目标多因素评价,评价非就业因素评价指标体系。然后第五步推广啊,这样的一个思路来哈,互相要点创新点是吧?量化结果,给出量化指标体系,然后第五步推广啊,这样的一个思路,要给模拟检验也必须要做一点哈, 然后这个题目的话就车长亮化建模的啊,比较好一点。亮化建模的是吧,像一些经管类的啊,文科的也可以做功课类的,慎重啊,因为他不是,他没有什么功课的专业,反而是跟很多教育职业相关的,所以说需要你最好有一定的背景专业来做哈。 啊,这有整个的这个 f 题啊,大家可以看一下哈。然后六个题目来看的话呢,最简单的就这个 a 题,我觉得 a 题真的很简单哈,然后 f 题呢,也还好啊, c 题呢,比较麻烦啊, c 题很很麻烦是吧?数据比较难,然后呢,建模也比较复杂哈, e 题的话呢,更麻烦哈。 d 题的话呢,呃,体育赛事的管理就是比较比较杂乱而已哈。然后呢, b 题的话呢?这个这个 b 题呢?这个四分啊,这个这个他就是 也不要,其实难度系数没那么大。就是就是,相对来说吧,月球基地可能很多人就害怕了,就害怕了哈,那整个的难度系数上来说哈,我觉得 a 题 f 题啊,都还是比较不是很难的,尤其是我推荐你做 a 题比较多一点哈, ok, 这就整个的一个选择题,建议难度分析啊,我觉得选 a 题的同学应该是比较多一点的,和 c、 c 题的话呢,因为给了数据,所以选的人应该也比较多一点哈 啊, a 题呢,是我最推荐你选的,也是大家希望大家啊去认真去做一做的哈。 a 题的话呢,难难获奖难度并不大,按照我说的逐层优化,逐层递进的话,拿到一个大奖应该是不成什么问题的哈。 ok, 这就整个 a、 b, c、 d、 f 题的思路解析啊,小题建议难度难度分析之类的一个文档哈。给大家 准备好了,然后相关的原代码呢?给大家准备好了 a, b, c, d, e, f、 t 的 原代码是吧,都放到相关的资料里面了,休息一下午就开始更新了哈,数据的话呢,老哥会大家继续从全网来寻找来购买哈,购买完之后免费分享给我们所有小伙伴哈,大家注意大家,大家不用担心哈, ok。
4七七学姐 10:10查看AI文稿AI文稿
10:10查看AI文稿AI文稿好的,接下来呢,我们看一下 f 题哈, f 题的话呢叫生成是人工智能啊,这个说白了会影响各行各业的工作吗?对不对? 尤其是会影响哪些工作呢?官方呢?给了三种工作类型是吧? s、 d、 e、 m 和就说白了就是科学工程,比如说工程师啊,是吧?那个那个软件工程师啊之类的啊,数学领域的大神之类的啊,这些专业 对不对?就是我们所说的工科专业,还有叫技工贸易类,比如说厨师啊,水电工啊这种工种啊,工程类的工种,还有就是一些艺术家啊,这三种职业,那么未来生成是人工智能对这三种职业会是一个什么样的影响 对不对啊?怎么人工智能对这专者专者的职业会有一个什么影响啊?这个很关键啊,然后呢?分析,然后呢?这第一问啊,第二问就是分析啊,每个职业确定的特定的高校机构学项目,然后呢提出建议来,就是就是你觉得这三种职业啊,或者这每种职业, 那么如何来安排啊?这个这个针对这个职业项目如何来安排相关的课程来应对未来人工智能的一个发展哈, 还有就是这个,呃啊,以下就是些思考了啊,就是你,你可以作为你的补充啊,本质上来说啊,其实那个没有什么,这个这个这个主要就是两两位比较多一点哈,两位比较多一点哈,然后我们看一下具体的一些细节哈,可以把它生成这么几个小问哈。几个小问? 第一个就是这个,这是一个首先是个综合类题目哈,包括这个优化加决策啊,加评价优化都都在里面哈啊,我们可以分为这么几个小问,第一个就是这个预测啊,每种职业的发展趋势。第二个就是决策啊,教育方案怎么做优化。第三个就是评价啊,多因素影响的一个分析啊, 有多个因素对对于就业什么的影响。然后第五个就泛化推广建议相关的 每个小问,哎,第一个就是选择 stm, 技工、贸易、艺术各一个职业啊,预测啊,美人工智能对他未来的一个发展的影响。这第一个小问问题为一,这是我们的第一个小问。第二个就是为了应对职业教育机构设计 ar 项目课程怎么来设置相关的课程 对不对?第三个就是分析就业需求外的其他影响因素啊,调整模型与建议。第四个角度就是论正建议的推广性啊,说明适用的范围,来,我们看一看,可以看一下,可以选择哪些模型来做啊,哪些模型来做。 第一个就比如说这个啊,我们说这个啊,记住哈,你们记住,预测一个政策或者发布一个政策对未来的影响, 大部分的概率都会选择用什么系统动力学模型啊,这个是百分之百的啊,大部分 f t f f t 啊,都是用系统动力学模型是最常见的,所以呢,这个题目我估计大部分的同学都会选择系统动力学模型来做的啊啊,比如说用系统动力学 来模拟,那么 ai 到底对于这些啊,学科这些职业,他的一个影响的内容是怎么样的啊?影响内容怎么样?比如 ai 先影响了,哎,怎么怎么,然后又影这个正反馈机制是怎么来构建的?这就叫兴同力学模型 啊,这个很关键啊,来用贝叶斯网络。为什么要融合贝叶斯网络呢?就是来有些不确定性,比如说技术迭代,这 ai 突然间发展的特别快了啊,突然间质的迭代, 那么不, vr 不是 说长期就按照这样的稳不变的或者稳固的版,它会技术迭代非常的快的,所以我可以融合 b s 网络,再加系统里学模拟,我整个的来模拟未来的一个演化程度,工作的一个演化程度,这个很好,这个思路哈。 然后第二位决策。决策的话呢,我可以说,哎,要构建哪些啊?比如说 先确定用 h p 来啊,决策就是端标优化,加一层的面积把,先用 h p 算法来优先确定权重标。比如说就业还是最高,还是说论语素养最高,是吧?就业能力肯定是最强的,对不对?哪一?每一个目标每一个是吧?这个这个指标他的那个权重先确定一下, 然后构建多标优化模型来优化我的课程,对吧?我设计哪些课程,哪些课程可以入选,哎,我的月儿条件可以是哪些?比较课时,学生的课时是固定的对不对?别不能说太多对不对,是不是? 还有就是我有一些最基本的一些选优要求,课程要求,哎,我都可以作为我的约束条件,这样我构建一个多目标优化模型啊,这叫目标优化模型啊,优化目标就是我的选择的那个,是吧?我我,我的优化目标是什么? 我的就业最好对不对?我就业最好,或者说,哎,因为你学生本身来还是就业吗?就业率最高 可以是我的优化目标,还可以是什么?我学生的能力更强,这叫多目标,目标不唯一啊,目标有很多, 你也可以有别的目标,但是我觉得这两个目标就可以了。就是第一就是就业,就学生的就业比较好,他不会失业。第二个就是这个学生,那么他的这个工作能力啊,整个的学业的能力是比较强的啊,你也可以有其他的,这没毛病, 来第三个分析就业需求外的其他因素的,就哪些因素还会影响到我的,我的这个课程的设计或者我的相关的一个建模。 那我们可以评价一下,就评价类某个同学,评价一下相关性分析,确定哪些变量啊?非优化变量,别论理风险创新能力啊。来来,然后呢,找到这些哪些变量是比较关键的?然后再相关性分析算法,然后呢,识别哪些变量是不之间是高度相关的,然后呢,找到哪些变量啊,影响因素是比较大的。 然后第四个就是建议推广嘛,可以,你可以啊,构建一些其他的来, 比如说可以构建这个案例推案例推理模型, c r c c r c c b p c b 二,加上地理甲醛回归啊,来来,这个是 c c b p 的 c b 二,这个模型没见过哈,基于啊,机构相似案例进行推广,然后 j w r 的 量化啊,地区差异对推广影响的效果的一个影响。 其实这个题目吧,本质上来说就第一个问题最关键的啊。第一小问最关键了,就是说啊,和 ai 对 各个因素啊,各个这个 ai 对 那个各个的这个 ai 对 各个行业他未来会什么样的影响?其这个就是性动力学模型,这个很关键啊,这个很也很麻烦,对不对?这个的话你要把这个模型构建出来以后,你整个的建模是比较流畅和比较顺利的哈 啊?第二小问,其实也还好哈啊?策略就是选课吗?其实就是一个选课模型,明白吧?就是一个选课模型, 我们都知道你可以,你可以那个构建啊?你在数学建模领域,其实这样是一个比较典型的一个优化类算法,就是选课算法,选课模型,选课模型一般你们你们也知道,就是如何,呃?给你们安排选课 对不对?怎么选课?让你的学分达到最高,让你的学习时间达到最短,就是这样的话学分最高,你的占有率的时间最短,这就是一个选课模型,你可以移植到这个地方来,明白吧?移植到这个地方来 啊,这就是一个移植的一个过程哈。这两个搞定了,其实其他的都不难哈。什么评第三位,评价第四位,什么回归啊?其实都还好,第一位和第二位主要就是建模的核心,好吧,这这个的话你要搞定了,很关键。 系统动力学也好,是吧?这个呃,多多元回归也好,都还好,没有什么难点哈。没有什么太大难点,就系统动力学建模会比较复杂一点哈。 来,我们呢也会把相关的原代码然后放到这个位置哈,放到把 f t 的 相关的原代码放在这个位置,以及我的系统文心文档以及我的想用 ai, 一 会呢?我会用 ai 完整的解决这个 这个题目完整的来解决这个题目哈完整啊,非常完整的解决这个题目用我们的 ar 提示词来完整的解决这个。呃 f t。 好 吧,到时候呢看看这个相关的模型检验代码呀调试啊之类都会都会放在这个放到这个文档里面去哈。 啊想有有取相关的思路源代码啊,大家可以可以那个领取一下。好吧我把相关的源代码都放在这个地方啊。思路解析相关的好吧来 难度系数不大三点五分啊不大啊难整个的模型复杂度呢中等啊,只需要两个模型一个系统立体,一个多,一个多描优化模型啊还有就是这个呃 难点呢就是首先呢不同职业类型亮化建模很麻烦,尤其是艺术技木这些呢 内容吧比较复杂一点哈,尤其厨师什么的对吧。这些艺术啊这都比较抽象对不对。难以量化建模啊这个呢算是一个难点哈非就业因素啊,像创新社会责任论语啊也不好量化,这都属于模糊模糊因素对不对 啊。核心要点呢就是啊模型需要覆盖三类且具有代表性数据来源权威可追溯啊,模型需要明确这个 ai 影响职业的核心内容驱动,别自动化替代效率提升啊。就 ai 是 怎么来影响这个工作 的是是他是吧他能够提高效率啊,原来两个人原来一个人三个人一个人的三个人的工作一个人就能干了他可以提高效率吗对不对。 还有就是教育建议需具体可行啊,包括课程设置中的啊学生你不要说这个同学选这个课程吧 是吧?选了很多课程,内容太多太杂了也不行,对不对?就是需要满足一个要求条件,要同一个学生同一时间不能上两门课,对不对?不同的选修课之间不能冲突。是哎,等等之类的 啊,需要这些约束条件需要考虑到位啊。解析思路,按照这样流程来,第一步啊,职业与机构选择,选择代表性职业,然后匹配对应教育机构啊, 然后呢?影响预测模型,构建 sd 模型,然后呢?来哎, sd 模型,来整合 ai 技术成熟度、职业自动化率、市场需求,来构建这样的一个模拟关系,就是 ai 它是怎么影响的?来构建 sd 模型系统理学模型来演化,来把整个的演化过程给它建立出来, 然后教育方案优化,用 h b 确定目标教育权重啊,哪些权,哪种是哪些是比较重要的指标,我们放在优先级第一位上,比如说学生就业放在优先级第一位上,是吧?然后多目标规划,多目标规划里面的目标权重也是不一样的哈, 然后呢,构建课程体系,然后第四个多目标多因素评价,评价非就业因素评价指标体系,然后第五步推广啊,这样的一个思路。
 14:26查看AI文稿AI文稿
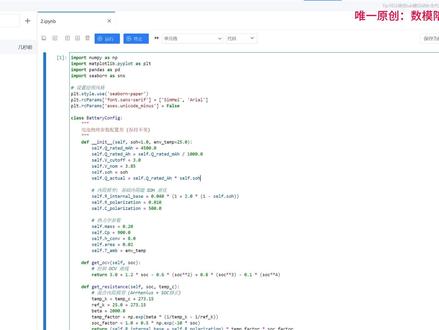
14:26查看AI文稿AI文稿大家好,我是数学建模老哥团队的王老师,那么今天由我给大家带来二六年美赛 a 题的答案解析。答案解析好,我们来看看问题需求 好,问题一需要我们建立一个连续时间方程,来表征一个和电状态模型,然后需要考虑很多 额外影响因素,那么我们的需求就是建立起一个模型,能够体现出这个电量从百分之一百 到这个电量耗尽的整个过程,然后看看需要花多少时间把电量耗尽,就是模拟出整个耗电放电的过程,模拟出耗电放电的过程。好,那么这里呢是我们问题一的代码,之前给大家已经提供过了,我们再来详细的看看 我们的问题一的输出结果。好,那么这一个 sim output 点 csv 里就是我们整个问题一的答案的整个模拟过程。我们可以看到第一列 t s 就是 每一个时刻系统的各个状态,我们以每一秒 为不长完成了整个放电过程的模拟, 一直到一万六千三百零八秒,我们的电池耗尽了。好,那么第二列是 soc, 就是 整个的电池的状况,就是 state of charge, 那 么我们用一来表示满电,然后用零来表示耗尽,然后可以看到这里是在慢慢地减的,而且从图像来看,它们的速率也会有所变化,速率也会有所变化。 好,那么再后面的一些参数也给大家介绍一下,这个 t 杠 c 呢,是一个 电池和设备的等效温度,是通过我们代码里面的热模型积分得到的,考虑了各种温度因素,系统本身带来的以及环境带来的温度,所以可以看到它这里有温度的变化,有温度的变化好,那么这个 t m b c 是 一个环境温度,是一个环境温度 好,然后后面的 o c v v 是 开路电压,开路电压以及 t term v 是 端电压,然后 i a 是 电流电池放电电流,电池放电电流,然后这个 p s y s 是 系统总功耗,系统总功耗包含有各个的系统部件,包含各个系统部件它们的协调作用下 所计算得到的功耗,然后后面依次是屏幕功耗,还有计算子系统功耗,包括 cpu, gpu 等等部件, 然后 radio 就是 无线版块功耗,以此类推。 b 局是一个后台的保持的维持的一个功耗,还有 gps 功耗, 还有这个蓝牙扫描功耗,蓝牙扫描功耗,这是我们的每一个部件都介绍的很详细,都给了非常详细的参数。 然后呢这个是一个屏幕渲染的一个额外功耗,屏幕渲染累合上 cpu, gpu 的 一个额外的功耗,这是考虑他们之间的协调作用,那么这个就是信号和后台的一个协调作用, 还有这个信号弱的一个额外的作用。然后后面是一些其他的参数啊,其他的参数包括有这个信号质量,然后还有这个详细的一些因子参数, 包括 cpu 功耗, gpu 功耗, i s p npu 功耗等等,还有内存的 好不好,好,然后下面这个 u 的是使用率,像这个就是 cpu 的 有效利用率, gpu 的 有效利用率 等等等等。然后这个 p scale soc 是 指这个我们的 soc 制成和能效带来的这个功耗的缩放系数啊,就是越小就是表示这个芯片越优秀,它们在同样的状况下会越省电 啊,他,然后他会动态的把它呈到这个 cpu、 gpu 啊, i s、 p、 npu 这些动态的功号上啊,动态的功号上。那么这是我们第一问的结果,那么同样的 我们也会输出一个 j s o n 表示出再次总结出这一次输出的整个功耗配置。整个参数配置啊,具体是由这些参数推导出来的啊?由这些参数推导出来的,我们也配备了可算的图像,那这一整个曲线 就是我们的电压、电流以及整个放电过程的曲线,整个放电过程的曲线,那么这个还是比较贴合现实的,比较贴合现实的。我们在这个问题一的情景当中,呃为用户配置了一些,呃使用情景,配置了一些使用情景, 呃,用户在这个零到二十分钟是刷短视频和 wifi 的, 所以可以看到在前期的,呃短视频和社交流览阶段,它相对来说啊没那么耗能,和我们的直观感受也是一样的啊,所以看这个曲线比较平缓。然后我们开始打三 d 游戏了,开始打三 d 游戏了, 所以说这个时候涉及到特别大量的计算,就 gpu 和 cpu 在 高效运转以及温度容易升高,那么散热的功耗也要也会升高,所以我们可以看到这些曲线在慢慢的变陡,慢慢的变陡, 你看这里初步的变走了一些,然后后面系统已经适应了整个过程,开始稍微放缓一点点,但是整体的趋势还是很下降的,也符,很符合我们的直觉,很符合直觉。然后到后面就做一些,呃,录像了,这个录像这一段 是吧?就更平缓一些,然后后面导航是更弱的啊,导是更弱的,所以说最后这些是更加平缓一些,然后最后一直到电电池耗尽,电池耗尽, 所以说我们这这一个整个的图像是比较符合我们的感觉的,比较符合感受的。然后这个是整个系统整个手机在本次使用中 的一个温度情况,温度变化看,它就是从二十二度,这是我们设定的环境时温开始变化, 你看就是随着它的不断使用,特别到打三 d 游戏时候,温度达到顶峰,而且这个温度呢,也是比较符合我们日常自己打打游戏时候的感受啊,符合打游戏的感受的。 然后后面随着这个任务的难度,任务的这个对于系统的调用的复杂度慢慢的降低,然后它的温度也会慢慢的回归平稳,回归平稳,慢慢的降低,但是因为手机在运行,运行呢,它还是会发热,对不对?所以说也不至于回到室温啊,不至于回到室温,所以说还是比较贴合现实 好。那么这个图呢,展示了各个阶段的各个部件的工号有多大,然后它大概发挥了怎样的占比啊?发挥了怎样的占比,对吧?这也比较贴现实,你看现在刷短视频的时候, 确实就没有社交流浏览那么高,然后上最高的还是我们的这个三 d 游戏,三 d 游戏,然后在三 d 游戏里可以很明显的看到我们的这个 compute 这个部分就是计算的部分, cpu、 gpu 的 部分占的非常高,也贴合我们对于游戏的理解啊,游戏就是这种计算耗能非常高的这这一个类型的任务, 然后面依次是相机呀,导航呀,然后到待机状态,待机状态对吧?是符合现实过程的,符合现实过程的,那么这个是我们第一问的解析。 好,当然我们还有第二问的答案呢,看第二问需要我们做什么呢?需要我们在不同的情景下去预测呃,去计算出这个耗尽电池耗尽的时间。然后呢还要呃和一些现实现象去做一些对比,看看能不能量化不确定性。 然后呢还要展示模型在不同场景下的差异,然后找出这个快速耗电的具体因素啊,这是我们的需求,我们可以看看我们的答案,可以看看我们的答案。 那对于调用来说,我们就分情景去做一些测试,只需要在代码里面设置具体的情景,那么这里同样的给出具体的情景设置,然后呢会有具体的参数啊,这个参数可以在我们的问题二代码里面去设置啊,可以在问题二代码里面去设置这些场景参数, 这里有耗电的时间以及各种具体的参数啊,你看像这个就是最高的温度啦,然后平均的系统功耗啦,然后这里就是对各个因素去做一些识别, top 一 的这个因素是什么? top 一 的功耗是什么?以此类推啊,以此类推。那么这个就是我们呃 在不同场景下,这个手机的好点表现啊,好点表现。所以这里我们也做了格式化图像,给给了一个大概的排序,我看什么能够呃 续航最久呢?我看这个任务是后台下载,但是是锁屏的,对不对?所以说这个也符合我们的直观感受啊,对吧?我就下载一些东西,下载一些东西屏幕也没亮什么,其他的也没涉及到。计算,主要是一个网络的任务,网络任务,所以说你看相对来说,它的这个情景下 预计耗尽时间是最长的,那什么最短呢?哎,可以看到这些联机游戏,对,联机游戏,他既既打游戏又有联机的需求啊,他又涉及到翻高的计算,要调动调用网络部件,那比这个重度游戏要更短一些,更短一些,也是符合我们的这个 现实中的感受的,对吧?符合现实中的感受的,而他室内室内浏览就比这个 待机推送又要差不多第一半,对吧?那也是符合我们的感受,有时候手机放一天和刷一天,手机大概就是一半,这样的对照大概就是一半这样的对照啊,符合直觉,符合直觉。 好,那么这里有在不同场景下,它各个的工号占比,对吧?工号占比这个也是很贴合着实际的,你看像这个待机推送的,基本上就是等待推送,是吧?对不对?接受推送,它就只有些网络活动,所以你看它的无线的部分占的很大头啊,占大头,同样的像游戏就是计算部分占大头。 好,你看像浏览,那基本上就是浏览一个就是屏幕嘛,然后一个就是我们的网络部分,所以说你看它的屏幕部分和它的无线部分占比会比较高啊,占比会比较比较高,是贴合实际感受的,贴合实际感受的 好。那么第二个任务呢?就是去做这个灵敏度分析啊,我们代码里面同样也有,那么就给了不同的因素做,给他们做的不同程度的一些改变,然后呢把它分为了内部因素、外部因素,然后同样的得到一些灵敏度分析的结果 啊,你看像这些就说明了,稍微增加一些电池容量就能够比较好的增加续航,然后稍微调大一点点,这个支撑节点就会比较大的去影响我们的续航,影响我们的续航, 而且外部因素也是比较符合直觉的,你看像这个屏幕亮度稍微调重一点点对不对?也符合我们的这个直观感受,亮度更亮了一些,那整个续航就会大打折扣,大打折扣,这个耗电就会快很多啊,耗电就会快很多啊,这是我们的第二个 好。第三问呢,其实也是在不同情景下去做一个灵敏度分析啊,灵敏度分析,但是呢,这个灵敏度分析的关键点在于这个建模假设参数取值以及使用模式发生变动的时候,呃,因此, 呃,我们可以去先选中一个呃 baseline, 选中一个基础场景,去算出它的这个基础的部分,然后再去做一些假设啊,什么假设呢 啊?做这些假设,第一个是正常的我们一个模型,然后这里有个 no interaction, 其实 no interaction 呢,就是不考虑任何的交互变化,就像题目说的,把这个 题目说不我们不能做的,把他们的各个部件当做一个啊,心心相加,或者是用一个黑箱算出来,就是他不考虑他们相互作用的这样一个呃模型,把它叫做 intaction, 然后你看还有一些更激进的热策略,还有一些更长的无限,这个 无线电的这个待机状态,待机状态你看你看像后面这两个的话只有一些细微的差异,那么这个都体现在于不同手机品牌厂家对于手机性能的调教上。但是你看像这个影响最大的这个 no interaction 很 明显没有考虑到很多的啊,相互效应,他们相互效应会对这个耗电有叠加作用,所以说 这个结果也是符合我们的预期的,对吧?因为他没考虑到会上映,所以说他比考虑了的的这个续航更长一些啊,续航更长一些啊,也是符合我们的感受的啊。那么对于其他灵敏度分析,那也是同样的, 有这些内部和外部的分为局部的 e j 灵敏度分析啊, once at a time, 对 吧?局部的灵敏度分析得到的结果也是符合观感啊,符合性生活感受, 对吧?你看像这个全局敏感敏感性分析,都说结论也是这样,然后刷新率,对吧?我们稍微提升一点点刷新率,我们我们从六十赫兹提升到九十赫兹,提升到一百二十赫兹,然后这个耗能就是巨大的,这是巨大的, 也是符合这个感感觉的感受的。同样的提升信号质量,那这个整个的这个信号的板块就会节约电量很多,同样的你这个电池的健康度也是会增加续航的,增加续航,对吧?电池越老化,这个电越不耐用,电不耐用,符合感受。 然后下面这是一些具体的参数啊,然后这些参数的格式化图像都都有给画出来,都有给画出来。 好,这是第三问,那么第四问其实就是对之前的我们前三问的分析结果做一些总结,做一些总结,那么我们就可以呃,总结出,呃,给出一些用户,给出这些。
 13:45查看AI文稿AI文稿
13:45查看AI文稿AI文稿好,大家好,那这个视频跟大家讲一下本次美赛 a 提木,呃,第二问完整的代码以及相应的结果。好,那前面这几个视频呢?呃,我在这个里面呢,是已经跟大家讲过了 a 提木,呃,相应的思路啊,以及这个模型的建立。那我这个视频给大家讲一下 c 提木第一问的代码。好,那么 关于这里这个思路啊,我就不给大家多赘述了。好吧,我们来直接看一下这个啊代码我们应该如何去进行编辑,那这次这个代码量呢,也比较大一些啊,但这道题目呢,本身并不算太复杂,主要是在这个代码的, 呃,这个编辑过程中呢,我们要设置很多参数啊,包括这个主要就是第一问的这个公式的推导和方程的建立,这个是非常重要的,因为他直接涉及到我们第二问的这个代码里面,这个模型应该怎么样去设置啊?比如这内种模型是怎么样的啊?然后这里去参数应该怎么去设置,包括这个 这个混合内种模型啊等等这些东西啊,包括我们朋友加入一个热偶盒嘛,对不对?好,呃,那希望大家呢有无备有耐心的把这个视频呢仔细的去看完。 然后这个视频呢只给大家讲一下啊,这个 a 节目第二问的啊这个代码,然后我们预计我在明天就是一月三十一号的中午,九月就更新完毕这道题目完整的论文啊,以现在的结果和代码,那么关于这个完整成品的说明呢,大家可以看这个视频的评论区。好,呃,等到时候更新完毕之后呢,会再发一个这个完整论文和代码的讲解视频啊。好, 这个视频呢,先给大家看一下这个第二问吧。啊,呃,那我前面思路呢,给大家讲过了啊,就是关于这个题目,我在这再给大家强调一点啊,就是我现在也看到网上有各种满天飞的各种思路视频啊啊,包括各种单数找的数据啊等等,这些东西咱务必要注意一点啊。这道题目 的原题目里面已经明确告诉我们了,这是我们必须得用这个,这个数据呢,它只是作为一个知识,而不是替代品。我们的这个数据呢,只能够用于参数的估计和验证,能理解吗? 绝对不能用任何的这个数据去做离散曲线拟合啊,或者说回归啊,或者说没有这种连续实践模型的这样的一个机制 的这样的一些。呃,这个代码啊和模型去做这道题目,这样的话呢,对这道题目呢,不仅没有任何加分作用,只有扣分作用。所以大家如果说收集到就是类似于像这种 啊,我觉得大家随便举个例子啊,比如像这种非常大的这种,呃,这个 excel 表格这种数据呢,这是用不到的,用不到的最多最多你可以用这个去拟合一些相应的参数,但是其实也没有必要,因为我们 这个参数的大部分参数,我们可以在一些常用的参考文献啊,或者是一些包括一些手机啊,上面是会有标定的,大家能理解吗?啊,这个数据是完全可以查出来的,所以我们呢找数据就是外部的数据支持呢啊,其实只需要这样的一些参数表就可以了,以我们在这个模型的, 就是我们在第一问建立的这个模型里面啊,比如我们用这个等效电路模型加热和模型,那么在这个过程里里面呢啊,我们在实际跑代码的时候,就在第二问用这个代码的时候,我们是需要这些方程里面具体的参数的,那么这个时候我们就可以用到这个数据表格了,能理解吗? 啊?那么举个例子,比如说我们用到这个电池物理和这些参数啊,我们可以用到这个浓度量,是这样的啊,标充电压、截止电压啊,充电压等等东西那组 啊,那包括一些其他的硬件主建的啊,功耗参数,比如他的啊,待机的功耗呀,啊,什么什么不是摄像头的功耗呀等等,这些东西能理解吗?好,那这是首先我第一点啊,需要向大家澄清的啊,那么第一问 啊,他是呢只让我们去建立一个连续时间模型,去开发模型,用连续时间方程或方程组来表示和田状态啊,我再给大家说一遍,第一问是纯物理建模,纯公式推导, 然后呢,我们在这个界面的模型和方程组里面呢,必须得包括这些因素,比如说屏幕使用 啊,处理器附载、网络连接、 gps 使用和其他后台任务啊,包括我前面这个数里面跟大家讲过的,我们必须要去包括的这个参数有哪个呢?哎,有温度这个参数,有温度这个参数,因为这个是题目的啊,这个背景里面明确告诉我们的这个温度参数。再一个还有一个就是说 啊,这个题目后面有答有一个,呃,提示,就是关于这个电池老化问题啊,现在电池的这个健康度啊,你的这个前面也提到就是在其生命充周期内充电方式的影响啊,这个答案用手机或者苹果手机啊什么的都知道啊,您这个 不规范的充电行为往往会导致电池健康度的下降,所以呢,最好在我们这个模型里面呢,还能把电池健康度这个参数呢也考虑进去。 好,那么这个具体的模型建立过程我在这里就给大家多注述了,那么后续我在那个完整论文和代码的视频里面呢,会给大家去讲的,然后呢,包括到时候拿了我这个代码和论文的人呢,大家自己去看就可以了啊,我里面会有一个完整的建模,这是第一位建模, 然后我第一问采用的这个模型呢,其实就是这个方案 b 啊,等效电路模型加这个热核模型,那么这个获选前提还是比较高的啊,基本上就是 f 奖或者 o 奖的这个水平了啊,因为我们呢,呃,这个物理意义是非常强的啊。再一个呢,这个模型呢也是比较创新呃,比较 高级的好吧,呃,整个这个模型呢,我就给大家多处说了,看一下第二问的在吗?第二问呢,他是问这个排空时间的预测对不对啊?我们要去预测各种初矢电量水平和使用场景下的排空时间,那么我一共设计了哪几个变量呢啊?我是包括了初矢电量水平,然后还有温度, 哎,然后呢,还有就是这个使用场景呢,就是赋值嘛,就是你你你你一会可能是打游戏啊你,你可能一会实际电量模式啊,这个赋值我也考虑进去了,再一个我还考虑的是这个这个电池健康度的问题啊,你这个电池健康度什么样的?好,我们来看一下代码, 那在代码里面呢,我们的第一个,这个整个的大光格大概有上千行代码,我们只做一个任务,那就是我们把我们第一问建立的这个模型 啊,因为我们这样要用于仿真吗?对不对啊?把它导入进来,然后确定好所有的参数,然后设定好所有的方程,然后把这个仿真模型的搭建好啊,那么我们可以这样看到了,前面就是设定参数啊,的一些代码啊,电池的物理类的参数, 然后呢这些热力系数参数,包括内阻模型,当然了啊,大家都能拿到我的代码,之后呢,这个电池的物理参数这方面呢,大家可以进行修改, 因为呢这个并不是固定的啊,我后面我简数的这个,比如说我这个四千五百毫安时,这个是呢, iphone 十三 pro 还十四 pro 的 一个电池的标称值吧。啊,那你你也可能用其他手机啊,对不对?你比如说你用的是呃 plus 呀啥的,那可能是八千毫安时,这个呢也很正常,对不对啊?你 如果说你用其他毫安时的话,那么你在南马里面把这个四千五你们改成其他数字就可以了啊,四千二什么的都行都行。 好,来举个例子,包括一些其他的参数呢,大家也可以去进行修改,但你不能改的太这个离谱。那么把这些参数全部设定完之后呢,我们来把这个内阻模型啊,混合内阻模型啊,各种曲线啊,各种模型啊,全部导入进来啊,把我们的这个仿真模型呢彻底给它搭建好。好, 那么这部分的核心代码呢?我就不给他多展示了啊,因为我要保证这个限量。呃,大家多少拿到我这个成品论文和代码的人自己去看就可以了。好,我们来看一下啊,我一戳到这里大家看一下,呃,我们把这个仿真模型搭建好。哎, 把这模型已加载啊,那我们就可以准备接下来的多维度的对比实验了。当我前面给大家讲过了,我们多维度是离关里面一共包括哪几个维度呢啊?根据其意而言,我们一共可以包括的维度都有哪些 啊?有这个初时的电量水平,也就是 soc, 然后呢有一个电池电光度,也就是 s o h 啊,有温度啊 t, 还有一个就是我刚刚跟他说的这个覆盖情况啊,你可以随便取一个字母去代替,擦,那么这四种场景下, 哎,我们都可以去看一下。呃,就是哪一种情况下他这个电池快速消耗啊,这个消耗的这个速度是怎么样的啊?包括每种情况下啊,他这个具体的驱动因素,那么这个具体驱动因素呢?这个是跟我们的理论建模有关的啊。 然后呢,他就是问我们还有什么哪些活动或条件会导致他电池寿命的最大程度缩减?那么在第二个里面,这个电池寿命写指的就是他这个使用时间啊,就是你从满电跑到零的这个时间 啊,然后哪些活动对条件对它的改变的初学的小,那么我们来看一下这个代码,其实就是第二,我们这个多维度的对比实验了。好,那这部分核心代码呢?我给大家大概看一下吧, 我们在这里运行仿真啊,运行仿真,然后把这个数据导入进来啊,我们绘图一是这个分布脂肪图,然后这是镶线图啊,我在这里做对比实验呢,我们第一个,我是设置这个不同的 soc, 也就是它的不同的初值电量啊,对不对? soc 好,呃,数字电量我设置为了一啊,然后零点八和零点五,但这个答案可以自己进行设置啊,我设置的是百分之百,百分之八十,百分之五十,你也可以设定,比如说你想跑一个百分之七十的啊,百分之三十的也行嘛,对不对? 好,那么我们把这个数值电量跑一下,然后呢,这个 s o h 就是 我刚跟大家说过的这个电池见光度啊,电池见光度啊,包括其他结果就不给大家多展示了,好吧,嗯,因为我要保存这个限量。好,我直接给大家看下这个结果吧,我给大家举个例子,比如这就是这个 不同的初矢电量下,哎,它的这个曲线,那么这个曲线怎么去理解,怎么去看呢?我来看一下这个题目要求呢,是有很多个具体的求其目标的啊,比如说,呃,这个, 首先是我们要确定它的排空时间嘛,那么在我们代码里面求其出来的这个结果里面的这个排空时间是什么样的呢?啊?其实就是 这个 tte 啊, tte 就是 它的这个实际的使用时间啊,实际的使用时间就是排空那里时间嘛,等排空时间,你看这百分之百的数值电量的话呢,它是十四啊,十四 h, 然后呢这个百分之五十的情况下是五 h 啊,百分之八十的情况下是十一 h。 那 么人家题目还有去我们要去研究什么东西呢?比如说 啊,需要量化它的不确定性,对不对?不确定性,那么在这个不确定性方面呢啊,这也是我们前面的这个输入里面的一个得天独厚的优势啊,就得天独厚优势就是 我们在目的二里面的是运行的是模特卡洛模拟啊,因为我们第一个里面就有这个模特卡洛的这个方程,所以在第二个里面呢,我们就是做这个模特卡洛模拟 来,就是说不仅能够给出一个时间,还能够生成它这个时间的概率分布,能理解吗?比如说啊,有百分之九十五的概率续航在几小时到几小时之间啊,就是我们问题二里面用的不是这个基础版的思路,也是第二个这个思路啊,就是有加入一个随机过程和截止电压的判定, 那么这两个呢,我都加入进去了,选了这这里得出的结果就是蒙特卡罗模拟得出之后的这个结果啊,怎么去看?给大家讲一下,比如说啊,这个百分之百的这个不确定性有多大呢啊?直接看这个方差就可以了,就这个 什么叫不确定性?就是你,你现在有这么的比如说百分之百电量吧啊,那么你能用多长时间呢?有可能能用八个小时,有可能能用二十一个小时,这个是不确定的,这就叫做不确定性,那么你这个不确定到底有多大呢?其实就看就是看他俩之间的差距有多大,也就是这个上界哎,和这个下界之间的这个宽度有多宽, 这个它能理解吗?哎,所以我们可以很明显的看到呢,是在这个百分之百的电压箱,它这个宽度啊,其实这个 se 就是 它的这个标准差啊,那么这个它是最大的啊,所以它的不确定性是最高的。那么百分之五十的电压箱呢啊,它这个标准差是比较小的啊,比较小的 啊,这个也很合理,对不对?因为你你住的店本来就那么就那么多点啊,那你你的使用时间,你大也大不到哪去,小也小不到哪去啊,就就真那么宽的一个幅度,可以任由你去施展啊,大概就这么个意思,大家能理解我在说什么,对吧? 包括这个哪些活动或条件会导致电视证明最大程度缩减,以及哪些活动对于条件呢?对于模型的改变的出奇的小。 那么这个呢,我们就是去重横向的对比一下。哎,这个个因素,我们我们前面刚刚提到那四个因素啊,看这四个因素呢啊,哪些因素对于这个电池寿命影响是最大的?就是也就是排空时间影响是最大的啊,那么哪一些因素呢?他可能影响没那么大,就问我们去做一个横向对比就可以了,横一些吧。 好,那么其他几种呢?我就不给大家去多展示了,好吧,这个呢,大家普通说一点啊,就是 这个问题二里面我们采用的不是这个随机过程吗?对不对啊?因为你这个用户使用习惯他不是恒定的,你不是说你一直亮屏,一直空闲,一直高负荷,他是不断切换的,所以呢,我刚跟他讲过,就在第二问的这个模拟过程中呢 啊,他是存在一个随机的这个输入端的,所以在代码里面呢,我给大家讲一下啊,就在这里我有一个每分钟切换一次状态,那么这里呢,我就是说六十秒啊,六十秒就说每分钟切换一次啊,比如你如果觉得认为是十分钟切换时候呢,那么你可以把它设定为六百啊,也行,这个呢设定的比较自由一点啊。好,那大家继续讲这么多吧 啊,这个 a 题目的第二个我们就全部处理完毕了啊,一些相应的结果分析,这个就在我的论文里面了,大家到时候答案啊,继续看我论文就可以了。然后第三个就是做联名读假设啊,包括第四文啊这些啊,大家到时候等我的那个完整论文和代码的讲解视频吧。啊,这个视频呢,我只讲一下这个第二文。 好,那就说到这里吧,希望能够帮助大家,那么这个视频呢,你们也可以转发到你们的队友群里面,和你的队友呢一起去商讨着来看啊,如果有什么地方没有听懂的话呢,也可以退回去再看。 呃,希望能够帮助大家啊,呃,预祝大家都能够获得满意的奖项,然后我这里面提到的一些可能大家会踩的坑呢,大家也无必要去注意啊,就是说我们的第一问 和第二问,千万千万不要用数据啊去做这个预测啊,或者你和啊这个没有任何意义,你的浮表护照再好看也没有任何意义啊,最多最多你能够用一些数据去你和 啊我这里后面剪就是剪这个表格啊,你的那些参数啊,最多就在你就能做在这个份上了,其他的千万不要再去多做了。好吧,那就这样吧。好,谢谢大家。
66数模陪跑保证原创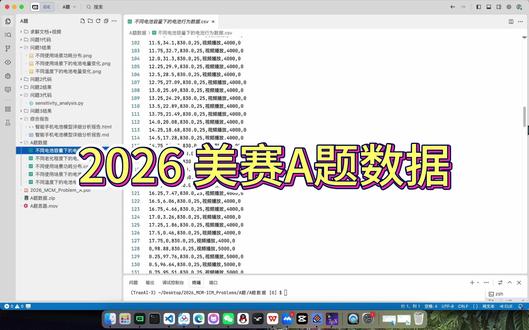 08:03查看AI文稿AI文稿
08:03查看AI文稿AI文稿这里是数学建模老哥,我是你们的阮老师。那么啊,我们是已经获取到了跟 a 题题目直接相关的大部分数据,那么是可以直接用于 a 题的直接模型验证的 啊,那么很多同学应该是比较苦恼这个数据该怎么去收集,感觉这个数据很好收集,但是,呃,想真正整理起来还是挺麻烦的,对吧?好,那么,呃,我这边是 啊,编写了一个脚本,然后把这些数据都整理了一下。好,但这个脚本大家都知道,所以这个也不能发给大家了。 呃,你们如果说有这个技术能力的话,可以自己去写一个脚本,然后去获取一下对应的数据啊,基本上就是相当于把网上的数据给它爬到一块,然后给整理起来了。好,我,所以我们这个数据量非常的大啊,大家可以看到我们比如说这个不同场景下的这个电池电量变化,我们的数据量 啊,都是万级别以上的,那这个的话,你基本上你在同类级别,应该在全网应该是找不到第二家的,对吧?好,那么其他的对应的数据,我们最少都是有几千组数据的,所以这个啊,大家去做对应的一个第一问这个模型验证,对吧?那么第一问你看啊,第一问的要求不是这样的吗? 他要求我们去呃数据作为支持,而非替代,您可以收集或使用数据进行参数估计和验证,如果开放数据有限,您可以使用已经发布的测量或规格啊,前提是参数得到明确验证。好,那实际上就是 你第一问做的这个模型,然后你用真实的实验数据去测测得你这个是相当于,就是 啊验证一个模型是对的吗?好,那么大家来看一下,所以我们这个数据就非常之多了,对吧?比如说我随便,呃,我随便列,列一组,我就列这个不同场景下的一个,呃,电量使用。好, 那么大家来看一下。好,首先第一个是时间啊,对吧?好,然后对应的 soc 啊,然后我们的一个电池总容量,然后我们的温度,然后我们的状态啊,然后我们的状态,然后我们的电池容量,好,然后那么 这边可以看到吧?是不是啊?这个是我们的系数,好,全部都在,是不是?那么以及你到底是什么样的状态 啊?我们这个待机,然后不同的时间,所以不同的组合,各种各样的一个参数组合,我们这边全部都是有的,就是所有的组合我们全部都是给你爬到了, 你想怎么分析就怎么分析,没有任何的问题。明白了,你说我想分析一个特殊的路,加一个特殊的状态,再加一个特殊的电池容量,再加一个特殊的系数,再加一个特殊的,呃,什么?什么?呃, 这个初次容量,等等,你看初次容量,我们这个参数组有多丰富呀?这个相当之丰富,好吧,所以这个我大家完全不用缺数据了,那么 a 题,嗯,基本上这套数据就够够你们做的了,明白了吧?完全足够你们做。好,你看,那么我们浏览了一千多组, 那现在到网页,网页浏览场景了,是吧?好,那网页浏览场景那也是各种各样的参数,来回组合一遍。 好,然后我们再往下,那就视频播放场景,那么视频播放场景再往下,那么对应的其他的场景,好,完全一样的道理,是不是?好,那现在来我们来看一下啊, 从第一个开始,我带大家仔细去看,那么第一个是不同电池容量下的一个电池行为数据, 不同电池容量这地方有,以及对应的各种各样的一个行为,他们的容量到底有多少,是吧?好,第二个不同老化程度下的一个电池的行为数据啊,不同老化程度啊,大家可以看一下, 好啊, u usage 啊, scenery 啊,对吧?不同程度的老化好,然后不同使用场景。好,那这一块,其实这个相当于也是在网上呃,获取到的,然后整理在一块的,那这个是什么意思呢?大家来看一下,这个就是 题目中啊,这样一问,那如果说你找不到对应的一些数据吗?对吧?啊,那么可以用什么呢?可以用已发布的测量规格啊,或者一些参数。好,那么这边啊,我就是根据啊,网上绝大部分啊,那些所谓的科技博主测的一些参数。好,好, 这些工具单位都是好安啊,好安,这个确定一下,我这个我没在单位了。 好,最适合列宽,然后这样子,你看你不同不同的使用场景下啊,他们对应的 啊,不同的功号,比如说你是待机的时候,待机的时候你总功耗,你就一个基础功耗,对吧?你屏幕是黑的,你又不使用 app, 然后网络的话,网络话虽然用,但是你基本是处于待机状态,所以功耗几乎可以设计为零,对吧?好,你网页浏览 啊,网页浏览我们不考虑带定位带等等其他的静态网页了,那么视频播放,那么声音是不是有,对吧?那摄像头不需要,对吧?好,拍照啊,摄像头要,对吧?那 gps 不 需要, 音乐播放等等。好,这个是绝大部分场景,当然我不可能说把有些用户那种特殊的使用场景,就是他可能浏览个网页,然后又听歌,然后又拍照的,那这种网页一般也比较少,是不是?好? 然后再回过头来,我们再来看一下不同场景下的一个电池容量,在这个地方啊,可以得到,是不是完全一模一样的啊?完全一模一样的, 而且为什么我要整理成这样呢?我是特地结合了我们这个题目的实际需求,然后呢?这些字段都是我单独去设置的,都是我单独去设置的,明白了吧? 好,然后将他们整理起来,那么大家做题的时候也方便一点,那要不然的话,你像有些人,他整理数据整理的一堆乱七八糟的,然后你根本不知道哪些有用,哪些没用,对吧?我找的这个数据所有的都是有用的,明白了吧?就 多就是那些没用的数据,我就直接剔除掉了,我找的全部都是能够用于我们直接做题目验证的,比如说你,你画图,你很简单,你直接把这个题目一画,嗯,来,比如说这个啊,视频播放,嗯, 怎么看呢?这个参数量啊,这个你到时候可能要拎一下了,对吧?要,要塞一下啊,不同不同参数情况下,它的一个,它的一个情况是不是好把它整理出来?好,那这个主要就是我们现在的一个大致方案,好,没问题吧? 啊?然后最后啊,不同温度下的一个电子用量变化啊,不同温度下好,大家可以看到 时间, soc 啊, power, 然后 temperature 使用场景,然后我们的电池容量啊,对吧?啊,以及我们最后我们的系数,好,所以这地方都是有的, 是不是啊?都是有的,好,所以这就是我们啊给大家准备的数据啊,所以大家也不用担心说啊,这个数据找不到了,不会做了,是吧, 所以 a 题啊,可以完全做了,放放心大胆的去做啊,没有任何问题的,明白了吧?啊,如果后面数据使用觉得,哎,什么地方出问题了啊,可以在互动区或者说直接在我们的这个群里啊跟我说 啊,然后我会及时的给大家去修正啊,因为啊,爬取的时候可能会出现一点点啊,脏数据进去都有可能啊,但是注意我这个数据是, 嗯,绝对没有缺失值,我检查过了,明白了,所以你们没有必要在上面去做太多的数据处理啊,所以这一点大家注意啊,行吧,好,那这个就是我们目前 a 题的所有的数据, 好,希望大家能够用这套数据啊,取得比较好的奖项,好,谢谢大家啊。
5七七学姐 15:50查看AI文稿AI文稿
15:50查看AI文稿AI文稿好,大家好,那我明天早上六点钟呢,二零二六年的美赛就要开赛了,那本期的美赛呢,我也会跟以往的啊,所有比赛一样,会在啊开赛之后就会给大家发发布一个选集建议以及个体思路的这样的一个视频,那么之后呢,就会选择其中两道题目去完成他的完整原装论文以及相应的代码和结果。 那么比如说你看这个二零二五年,我做的是这个 c 题目和 b 题目等开赛后呢,会发布这样的一个视频,哎,之后你就会有一个每一部分代码结果以及格式化,包括完整原装论文的这样的讲解视频。 那么啊,这个二零二五年是 b c 题目,二零二四年那么做的是这个 c 题目和 f 题目,然后呢,二零二三年啊,我做的是这个 c 题目和 e 题目。好, 那本次比赛啊,二零二六年的美赛呢,我也是一样,我们团队一共是九个人呃,均是获得过国二或者美赛 m g 以上的双月硕士。那么开赛中呢,会嗲嗲之之内就会发布的选题一件以及初步的思路视频,之后呢,就会去完成其中两道题目的完整成品,那么我们大概就是 x m 和 s m 各做一道 关于届时这个完整成品的说明,大家可以看这个视频评论区啊,之后呢,就会到这样的一个文档链接里面去啊,大家也看到左边导航栏里面,我已经把大家可能会关心到的一些问题啊,全部都有跟大家去解释清楚 啊,包括这个选题型的哪样浓轮的时间啊,包括啊查出问题啊等等这些东西,那么这个视频呢,我就去跟大家详细的讲一下啊,届时我们提供的完整成品的说明啊,以及呢去给大家详细的看一下往年我们啊的这个美赛提供的完整成品的说明啊,比如这就是去年的 b 题目, 那么这里是前年的 ct 木打,包括所有的这个代码啊,我也会给大家去展示,就是往年我提供这个代码什么样的形式,大家到时候怎么样去运行,我都会在这个视频里面去给大家讲清楚。好吧,那么请大家务必耐心的把这个视频仔细的去看完,那么相信呢,呃,这个完整成品呢,可以大大的去提高大家的获奖概率。 好吧,那我在我的空间里面呢,是已经有累积长达四年上百场比赛,上千个学员,全部啊,所有学员的这个完整的获奖记录呢,我全都是有总结的啊,这也是全网唯一一家敢让任何人公开访问的。 那比如说我们来看一下二零二五年的美赛,最终一共是两个 f 奖啊,就是在我的学员里面啊,就是拿了我这个完整成品的人里面是两个 f 奖,然后六个 m 奖以及若干的 h 奖。呃,大家可以看一下,这是二零二五年比赛我当时发的这个总结记录啊,大家可以看一下二零二五年的五月二十号发的,那么这个呢?学员的, 呃,四和五呢是 m 奖啊,三是 h 奖,那么这个学员十呢,他是一个 f 奖啊,他们学校的这个 f 和 o 的 学分数是一样的加分,然后这个学员十次呢,也是一个,大家看一下也是一个 f 奖,好, 那么这个呢,就是当时在组做比赛期间啊,我发给他这个,包括这个梅赛 c e 的 打包文件啊,就是我这个完整成品的参考文件啊,那包括呢?相同说明视频代码出错、附件视频等等这些东西,那么稍后这些东西呢?具体这都是些指什么东西啊?我也会,也会在这个视频里面就给大家讲清楚啊,在这个成品包括什么这个栏目里面我会给大家讲清楚。好吧, 那再比如说一些其他比赛的,这是二零二四年研赛,这是学员是一个国一啊,这学员是个国一啊,这,这是二零二四年的美赛啊,是一个学员十七是 h 奖,那么学员十八呢?是一个 f 奖,葡萄奖提名 这个学员是一个 f 奖。呃,他们的助攻模式主要有个论,就是说必须在每一个每次都有一个人开头啊,他就是说呢,感觉我每次的速度都能带得动他们啊。 那么二零二二年国赛啊,这是二零二年国赛的总结,二零二三年联赛的总结啊,那么具体呢,就不给大家多展示了。好吧,这样大家有兴趣的去访问我的空间就可以了啊,那么在我的空间里面呢, 这四年来所有的比赛啊,上千场比赛,我全部都有总结啊,这可能是显示的 bug 啊。没事,我一会给大家拖动看一下,比如这是二零二二年啊,十月十号我发布的这个,我这个置顶说说啊,这是二零二二年的,给大家展开看一下吧。 呃,这个一到七呢,是一个第一次参加拿了一个省一的一个学员啊,他是拿了一个省一,然后呢八到九呢?是一个推入到国家答辩的,来问一下这个答辩的问题, 那么十到十二十一呢?是一个省二啊,那我就给大家看下其他的吧,比如我昨天发布的这个啊。 呃,那么还是那句话,就是我的空间里面呢,有所有的,我往期接四五年来所有学员上百场比赛啊,那么上千个学员所有的获奖记录呢?我全部都是我总结的啊,那么比如这是我昨天发布的,一月二十八号发布的吗?这是二零二四年美赛,学员是拿了一个 m 奖,那么这个学员在我这里也是做了 很多个比赛了啊,这个呢,我当时他做了一个小比赛,是拿了一个国一,我们后来呢,主儿美赛是在我这拿了一个 m 奖啊,这是当时二零二四年的美赛,二月三号我发给他的这个打包文件,含计相应的一些其他的视频。呃,那这个, 这个二零二五年国赛的学员二十八啊,这是我二五年八月二十九号发给他的这打包文件,他是拿了一个什么,然后他来预定这次的美赛 啊,这个就有很多了,我就不能一一个一个给大家展示吧,总之呢,我自己滑动一下,大家也能看到啊,是一月二十三号发的,给大家往后面拖拖拖一点。好吧,来看一下我们去年美赛成绩刚出来的时候,我是怎么发的。 呃,去年美赛成绩应该是四月多,还是说应该是四月多发布的?五月发布的,五月发布。好,那么当时发布之后呢?我五月八号就发布了这个总结的啊,这个说说,当时呢,五月八号的时候报喜的一共是有一个 f 奖和若干个 h 奖, 那么这个学员一和二呢,是一个 h 奖啊,这是当时去年因为我做的是 b 题目和 c 题目嘛,那么就给他发的是 c 题目啊,他是拿了一个 h 奖,然后呢这个学员啊,看一下啊, 看一下,给他发他也是一个 h 奖。好,那在网上看一下啊,比如说这个啊,爵士学院五是一个 m 奖,大家看一下。好,这个学员呢是拿了一个 m 奖 啊,这是当时美赛也是一月多的时候啊,发给他的这个梅赛 c 的 打包文件。这个去年是一个奖牌得分点的变化嘛,他要后面是有些答疑,就是说这个变化点的得分是怎么算的啊? 那么学员五呢,也是一个 m 奖啊,这是当时我来看一下他是他选择是 b 题目啊,因为去年做的是 b c 题目,我 b 题目呢,当时他是有问这个,比如说这个座驾坐标指示是啥啊,包括这些东西也是当时的 n 记录。那么他当时每赛呢是一个 m 奖啊,包括一些其他的,比如说这个,这个学员应该是个 f 奖啊, 这两个是 m 奖,然后这个是有一个 f 奖,然后包括其他我就不给他多展示了。好吧,我们大家在我的 qq 空间呢,都能完整看到。好,那么接下来给大家说一下,这个完整成品都包括一些什么东西啊?啊?在之前我再给大家讲一下啊,呃,一些其他的东西, 这个呢,我们现在每次比赛呢,其实老学员的复购比例基本上是在百分之七十以上的,包括本次美赛呢,大部分的人呢,大部分都是在我这已经学习过其他比赛的人啊,其实呢,新来的这个学员呢,是非常非常少的啊, 真的基本上已经都是在我这做了好几个比赛了啊,包括有学员在我这做了十几个比赛的,也有一次性就做预定四五个比赛。 那么接下来我还是要感谢一下啊,用这个视频感谢一下大家这些老学员的信任啊,认可。好吧,那么这也是对我们助攻指标的一个最好的证明啊,感谢大家的认可。好,那么接下来给大家讲一下这个成语包括什么东西。那首先是呢,是有一篇完整的原创论文,这个格式呢,是大学的 pdf, 那 么在这个 啊,我这个视频展示就给大家展示这个 p f 啊,就以这个 word 形式来去给大家看了,比如二零二五年美赛的 b 题目呢啊,呃,这就是我当时美赛 b 题目啊,一共是五十页的一个完整成品,那么当时呢,就包括这个摘药问题,如入问题分析,我先假设符号说明节目每一问的模型建立于求解。 那么去年的这个 b 题目啊,是这样一个诸诺市旅游的问题啊,大家可以看到呢,这里面我有发表论文,包括每位的目前建议群里面,大家可以看到的,里面包含很多个二级标题和三级标题啊,那么呃,这是因为呢,我要有非常有条理的把整个这个论文呢 啊,全部给它清晰的写出来,包括呢,每个问题里面当然会有将来如果很多个小的问题,我每个小问题都是需要去具体的解决的 啊,比如说,但是问题一呢,怎么?当然首先要去构建这个优化问题了,我后面呢,是这个实际的囚禁。呃,在优化问题里面呢,包括模型啊,目标函数构建,约束条件以及反馈机制的建模。那么包括第二问, 用模型适配和黑广的差异化因素的识别,按照编量以及参数的调整及模型适配的演示,包括影响重要性的分析啊,动态平衡策略啊及问题三,我去年的问题三呢,是要求有一个备忘录吗?对,好,包括整个论文里面,我也会有非常多的黄字提醒大家如何去进行修改,像虫,包括一些论文篇幅呢,也是显得比较长一些 啊。呃,好,那么放大给大家看一下这个论文的剧情是吧?好吧,以去年 b 题目为例, b 题目为例, 那么这里呢,是去年 b 题目的这个摘要部分啊,这是 b 题目的目录部分啊,这是问题重述及问题分析。好,那么这里是模型假设啊,然后呢,这是模型建立于求解部分。好,大家可以看到。好,那么这里呢,就是代码运行的错误的一些图片。 好,那么我来看一下啊,这五点一点三的一个模型灵敏度分析,大家也知道呢,美赛呢,对于这个模型灵敏度分析要求是比较严格的,那么基本上,呃,大部分需要去做这个, 就是能做这种灵敏度分析的啊,这个题目呢,基本上都要去做,所以呢,这个,这个不啊,栏目呢,我当然也是必不可少的啊,我基本上都会去做这个灵敏度分析啊,这里有灵敏度分析。 好,然后呢,这里是问题二,问题二里面的模型建立,然后这里是结果啊,好, 再来给大家看一下去年的 c 题目吧,那么 c 题目呢?去年比今年呢啊,去年这个 c 题目呢,比 b 题目是要稍微难一些的啊,所以整个这个篇幅呢,要比较长一些,因为它里面呢处理的东西太多了啊,就是大家可以看到呢,我这二级标题和三级标题分的非常多, 那么去年呢 b 题目呢,我也给大家奉它看一下吧啊,它 b 题呢,去年是一个这样的一个奥林匹克奖牌的模型啊,奥运会奖牌的模型, 这里是摘药部分,那么这里是目录部分,目录分大家可以看到呢,呃,问题一里面包括数据处理,然后去做格式化,然后构建一下这个预测的模型, 然后呢去进行一个具体的实现啊,去提取他的特征啊,然后去训练他的分类和回归的模型,然后后面是预测他首次获奖,然后呢再做赛事分析,模题二里面呢是做这个引入了一个贝耶斯变化点的检测啊,然后后面还要分析这个教练的贡献度,重述分析和假设,就给大家多说了啊,这是符号说明部分 好,包括呢里面会有很多拱王集体去告辞一些会员的说明,这个答案呢也都务必要去落实。就这个视频呢,也是给呃目前已经在我的预定过这个完整成名的人呢,给出一个指南啊,就是到时候你们拿到这个成品应该怎么去用啊?这个视频呢,也不必自己去看完哦。 我在这里建议大家画一个流程图,好吧啊,这里是做一个模拟器去处理,那么第一位呢,我们首先去做成数据处理啊,做一个数据清洗啊,这个就不用给他给大家多说了吧,这后面包括呢,这就是获取的这些图片。好, 那么除了这个论文之外呢,第二个就在我用借账过程中用到的所有的数据处理的表格和结果表格,包括代码,那么在代码部分呢,我们百分之九十五以上的概率,那本身每站呢,也会依然去采用 python 去进行纠解啊,那么这个呢,我们是采用 notebook 去进行编辑的, 这个呢,当然如果说不会 python 代码的话,也没关系啊,也没关系,我会给你代码的一个完整的运行操作视频,那么大家继续去看就可以了,那么零基础也可以完全的去跟着我的这个操作视频去运行,是很简单的,在运行工具方面呢,只要是支持运行 notebook 的 啊,呃,就可以了啊,比如 sps pro 啊, java 啊, py 叉门啊等等,这东西都行,但你即使门打开或者知道你的 python 不好也行啊,但是不太建议,因为这个呃知识弄得不可学的工具呢,看起来比较直观一些,也简单嘛,对不对啊?那有人说我没,我一接触过这个 python 代码怎么办呢?我完全不会啊, 无所谓的啊,无所谓的到上头你根据我这个代码速度视频来啊,你就直接打开代码就能看到这样的一个东西了啊,比如这是我去年每站 ct 的 代码, 那么这就是我,大家可以看到正好是一年前,对不对?一年前创建时间二零二五年一月二十六号,这是去年我美团的这个 ct 的 代码和结果表,包括中间预处理的所有表格,那么这就是代码部分,这是 q 一 啊,这是 q 一 的格式化部分,那么这里是 q 二。呃,打开 k 局给大家看一下,这里呢,前面是安装库, 呃,包括这个,怎么安装库?这个呢?我的代码速度视频呢,也有给大家去讲啊,其实呢,你无论是零基础,哪怕是高中生拿的代码速度视频也能给大家去讲啊,其实呢,你无论是零基础就可以操作这样的一个版本, 但如果你要是会拍成会弄图的话呢,那当然更好,对不对啊?我支付呢,你不贵,零基础呢,也无所谓啊,运行就完事了嘛,只导入一些数据啊。哎,这就是先去做这个数据处理清洗,这是去年的这个代码, 然后呢,我做了一个音设表,然后提取数据,然后进行计算特征的提取,然后呢啊,这只是做预测,这只是一些混合矩阵,这是分类预测嘛,这是混合矩阵图。哎,这里是这个 数值的预测部分啊,回归预测,哎,回归预测啊,特征重要性的排行。好,那么这里后面是啊,得到一些其他的结构表壳啊,这里是获奖概率的分布,大家都是题目要求的啊, 然后包括说后面有计算得出的这个奖牌的相关性和项目变化的相关性,哎,也得出了,那么后面呢,包括各项目和奖牌数的相关性也得出了, 然后呢,绘制他们的奖牌分布情况全部恢复至了啊,那么整个呢,这个绘制的图片呢?呃,形式呢,基本上是以尼手入门的这样的一个科研任务要求的啊,所以呢,来个看到这个图标呢,也是比较精致的,这是 q 一 的格式化部分哎, q 一 的格式化部分,然后这是 q 二的一些代码, q 二的一些代码, 这应该是去研究那个教练效用的啊, q 三是写一个备忘录就被他展示了,对吧?那再比如说啊,啊,这里是二零二三年 c 写的论文啊,他是当时一个打网球试图得分的一样的一个模型啊,这会我就不用给大家多展示了吧,比如这里是这应该是当时二零二三年 c 题目的一个代码啊, 大家看正好两年前吧,两年前啊,两年前的这样一个东西,好就给大家多展示了,好吧,总之呢,本次美赛我们提供的形式呢,依然是这样的啊,或者给大家给大家一这样一个拍摄的代码啊,那么当然呢,直接根据我这个 啊操作一些视频去操作就可以了,然后呢就会有一个讲解视频,那么这里呢,首先是有一个公开的版本的讲解视频,就是在我的 b 站上面会发布的 啊,这样的一个公开的视频里面会给大家讲一下整体我这个论文是怎么去完成的这样的一个思路啊,包括疑问的代码和结果的一个展示,当然这个展示部分呢,我是会进行打码处理的啊,包括一些重要的代码结构,重要的结果图片啊,包括论文中的这个展示呢,我都不会去完整的去给大家展示啊,这个公开版的视频呢,只是,呃,给大家讲一下这个思路具体是什么样的, 呃,因为我要保持这个限量嘛规避查虫问题好啊,所以呢大家也不用担心这个查虫问题啊,因为我 啊陪我四五年这以来啊只要是按照我论文中黄黄字提醒以及我的啊副这个降重出名视频啊去操作你的人呢啊是没有一个人出问题的,包括去年每三年没有任何一个出问题啊,前沿大前也是。好吧好那这是一个公开讲解的视频啊,最后呢就是一个降重教学视频以及操作的副线视频, 那么这个呢主要是让拿到论文的更好去理解论文中的结果如何去进行复现以及这个论文呢如何去进行修改成虫。因为我这个出的成品呢也是一个限量的成品啊,所以我会特别录制一个降重教学视频以及一个复现论文中所有结果的代码错漏付错漏视频 零基础也能看懂。然后接着呢我会和这个整体论文呢一块发放给你,请务必对照这个论文呢仔细巡查啊,那我这个参考成品呢是一个限量版本啊。呃还有一句话我前头不是给大家讲过了我是一对一的帮大家去做啊 呃 k i 型的务必注意好吧啊那么关于这个文档链接里面的一些其他部分包括说这个信用问题啊,查重问题啊啊是否报答奖啊这些大家自己去看我这文档链接就可以了啊。呃这个呢便捷的还可以玩啊,可以占这个 y g 完整成立的数呢大家可以看这十人的评论区好吧 ok 那 就说到这里吧。呃本次美赛啊我会跟去年的比赛刘冲呢是一模一样,会给大家带来这样的一个助攻。呃呃,大家等明天早上开赛吧啊,六点钟开赛之后,我就会第一时间发布全天 e 及作题速度视频,之后呢也会去实践的去完成其中的两道题目 啊,中兴兴盛呢,我这个视频呢也应该给大家讲的很清楚了。呃,希望到时候能够帮助大家获奖吧。啊呃,再创去年前年大前年美赛的这个辉煌啊,去年呢是两个 f 六个 m, 乐观的意识讲啊,希望今年呢,呃,大家的获奖情况比去年更好更上一层楼啊,希望大家呢都能够 拿到满意的奖项吧。好吧,呃,就说到这里吧,希望能够帮助到大家。那么关于这个美赛技术,我会出到这个完整层面的书门呢,大家可以看这个视频的评论区。好呃,就说到这里啊,谢谢大家。
278数模陪跑保证原创 26:30查看AI文稿AI文稿
26:30查看AI文稿AI文稿好的,小伙伴们,大家好,接下来我们讲 c 题哈,大部分同学呢,我看了一下后台的选择题数据哈,大部分同学都会选择这个 c 题哈, c 题的话呢,怎么说呢,你选这个没问题啊,同学们,我告诉大家哈,你选 c 题没问题,但是你必须要有创新啊,因为大部分的同学都在选这个 c 题,目前 c 题比例已经达到了恐怖的百分之四十哈, a 题百分之三十, c 题百分之四十,两个题目加起来接近百分之七十了,老铁们哈,百分之七十的人都会选这个 c 题啊,都会选这个 c 题 啊,所以说呢,我建议同学们哈,要慎重啊,其实我是非常不建议选这个 c 题的,我觉得吧,你就是大家大部分同学选这个 c 题都是为了图简单啊,但是呢,我告诉你们啊,图简单,不要去图简单哈啊,不要去图简单, 为什么呢?因为 c 题你看着哈,但其实它很麻烦啊,很麻烦 啊, c 题很麻烦,所以说,我建议你们不要去盲目的去做这个 c 题啊,不要盲目做 c 题,好吧,老铁们,我建议你们避开它,因为因为这样的话,获奖是比较难的,你不要图简单,大家说实话都知道,数据都知道,怎么建, 那你说对不对?你,你说你怎么获奖呢?你的创业点怎么来搞呢?对不对?所以说,我不建议大家选 ct 啊,真的,我,我是真心的劝大家啊,要慎重哈,要慎重好吧 啊,老哥,选哪个题?我建议我建议选 a 题或者选 b 题啊,你最好就是选,要么选冷一点,冷门一点的,这样选的人少,竞争压力会小一点,对吧?你选这个 c, 那 么大家都选这个 c 了,所以当然了,我,我不说,不给你分析哈,我给你分析,但你要慎重,你想拿奖,你必须要有创新点, 你必须要有创新点,如果你做这个 c 题没有创新点,那就白搭了,而这个 c 题的创新点 百分之大部分的都是两种创新方案,第一种改进的模型就是你用改进算法去做,第二种融合模型啊,就你选择不同的模型一块来做, 你说交叉你行不行?交叉创新的话,在这个地方的话啊,也可以试一下。好吧,只能也可以试一下,因为我们创新模型的话一般就有这么几种方案吗?所以说这几种方案的话没法说,但是改进算法的话,我觉得在这个地方是最常见比较常见一点的,所以大家呢,如果想做 c 的 同学呢,你要慎重, 你要能够有创新。好吧,你要有创新啊,真的哈,啥也不会,只能选 c 你, 那你,你不至于啥也不会,老铁们,真的不至于,你有 ai 了,理论,你没有不会的题目了,好吧,你没有不会了,而且 c 题呢,也没有那么简单,还是比较复杂的,大家都做, 所以说呢,就看谁做的好了,你想做的好的话,我觉得你和高手竞争是有很大的压力的哈,要有压力的,所以建议同学们呢,要慎重一点哈,要慎重一点 哎, ok 啊,这个这个大家呢要慎重哈啊,与这个题目的话呢,我们简单阅读一段的话,就是与星共舞啊,美国为美国,美国节目舞动奇迹啊, 然后呢,这个这个我们前面呢就是专家投票吗?专家通过什么在线投票?这是他们最喜欢的情侣啊,观众的话每周可以投票一次或多次,上下为当中公布的次数,然后呢,还有就是评委也可以投票之类的,然后选出第前几名来,对不对 啊?评委投票和得分和观众投票的组合方有多种,在美国版节日前两季采用基于排名的组合方式。第二季因什么什么啊啊, 然后,然后呢,就修改了这个争议哈,第二十四季又出现争议了对不对啊?评,尽管评委得分低,仍赢得冠军,作为回应,二十八级就说白了他的他的评分吧,是由评委和 评和这个观众投票来综合决定的。有的时候呢,评委觉得不好,但是观众觉得好,那观众投票多了,那么就有可能得得得这个最终的这个成绩了。但是,但是呢,又因为不专业,比如说一二流子一些选手,那么特别会讨观众喜欢,那也有可能对不对? 还有有有,如果,如果评委特别的占比权重比较大,观众占比比较少的话,那有可能这很多啊,迎合评委的啊,评委的角度不能代表大众的,所以有可能引发歧义啊,就来构建一个比较合理的评价的这么一个啊,评分的这么一个模型啊,这就是整个题目的核心哈, 来开发数学模型啊,估算每个选手在其参赛的每周获得观众投票数啊,就估算这个呢,就是一个基础的预测模型了啊,每个每个这个来,同学们,来,大家告诉我哈, 开发数学模型一个和多个来,你告诉我到底开发几个?首先啊,首先到底开发几个?这个是一个要点哈,到底开发几个? 你们记住哈,那就一定要开发多个。你想做 c, 我 还那句话,你必须是勇士,你必须要有胆量, 你必须要牛逼,对吧?要不然你要说你就开发一个,你开发一个非常基础的,你做 c 题,哪讲?我就这么说,你再创新也没有希望,因为因为选 c 的 人太多了,高手太多了。老哥这里统计了百分之四十的同学会选 c 了,都是勇士啊。说实话,所以你必须要开发多个, 而且多个模型来估算明白吧,来估算明白吧,你的模型估测关注投票结果是否能得出与每周淘汰结果一致的结论啊,提供一致性的衡量标准就是你要,你要能什么? 你要结果要准确,你不能结果不准确,对不对?确定性如何?每种确定性这个就需要有验证了,就你的结果也有验证,说白了我我告诉大家哈, 真的,这个地方就看谁的模型精度高了,但是你们记住你们的精度啊,很多情况下来大家告诉我,来来,我问一下哈, 我问一下哈,来,这个的话你说老哥,我不单纯的用美赛官方给的数据,我用别的数据来佐证一下,可不可以?老铁们,就是我用一些达人秀,或者我用一些别的投票的一些结果来做,可不可以?老铁们,别的投票的模型来做,可不可以? 可不可以?老铁们,你们跟我说完全可以,反而会把你的模型的这个精度啊,反而会提高的比较高。来这个地方一定要注意两件事一定要注意两件事哈, 一定要注意,除非他明确的说了啊,你可以看了没,你可以自行选择纳入信息或其他数据。看了没?其他数据,但必须要记录数据来,同学们, 我这地方要注意两件事,第一个叫什么过你河,第二个叫欠你河。来,你们觉得哈,你们觉得你们最容易做预测模型的时候最容易出现的一个问题是什么啊?最容易出现的一个问题是什么? 就是你们如果来做这个题目啊,后面会有啊,我会讲到啊,你不用担心啊,啊,你会讲到来 你们容易出现了一些问题是什么?做预测的问题,做回归问题啊,过你河,我告诉你们,你们最容易出现的就是过你河了,真的,所以说你们一定要注意一点,好吧,不要出现过你河 啊,这个很关键啊,很多同学呢,做预测经常会出现过你和还有同学这么这么来做的哈,来,还有同学这么来做的,我们来,来啊,我,我后面会讲到哈,这里有一个完整的看了没?完整的来 看一下啊,来,看到没,他有一个完整的解析思路,第一步,一定要做数据处理。第二步, 观众投票预测构建贝叶斯啊,这是基于概率的模型,以评委得分选手特征周次为自变量,以淘汰结果为约束啊,预测观众投票数,预测知信区间。来这个地方呢,很多同学这么来说的, 我看你们的方案了哈,你们说老哥我预测他的投票得数,那我这样不就行了吗?啊,我,我这样不就行了吗? 来,我直接就是用他每前几个周的得数预测他未来每个周的得数可不可以?老铁们,原来这样来说的哈,我用他前几个周的得数来预测他后几个周的得数 来。老铁们,你们觉得这样的行不行啊?你们觉得这样行不行啊?我刚才有同学在上面是这么说的啊,在评论区留言啊,包括在那个老哥私信我这么说的,行不行?老铁们,行不行啊? 为什么啊?包括你们告诉我为什么?我告诉你是百分之百不可能的,不行的哈, 你别乱搞哈,你记住哈,投票结果是未知的,严格保密的,你不可能说用这个是吧?哦,前一个数据来预测未来几个周的数据,你就你就,你就完整的变成时间序的预测了, 知道吧?你是不可能的啊,你,你别乱搞,你别乱整哈,你别乱整来。 但是我可以构建一个什么样的模型呢?老铁们告诉我,既然如此, 那我就不能用时间虚的预测预测了,对不对?但我可以用什么预测来,我要我现在要做的一个一个参数叫什么?观众投票数,他和很多项数据有关系,包括什么评委的得分打分,包括一些其他的。哎,这地方有哈,包括其他的 看啊,哎,在这地方包括他的年龄,包括行业啊,包括一些是吧?他的这个这个是吧?这个这个选手的一些特征,包括他日常的动态,包括一些其他的淘汰的一些结果。来 来,同学们告诉我来,我相当于我要预测一个指标,它和若干个指标有关系。那你告诉我要构建的是一个什么样的模型啊?啊?要构建的是一个什么模型啊?这是这种预测方案不叫持续预测,这叫什么预测?老铁们, 哼哼,叫什么预测呀?到现在啊,大家都提出了有用 xd 版的啊,随机森林对吧? 这就是回归吗?对不对啊?某一个变量和若干变量有关系,不就是回归吗? 是不是?那不就是回归吗?所以说你这个地方既然构建回归,你们就记住我刚才就要返回来,我刚才提到那个那个逻辑了,不要出现过你河,也不要出现欠你河,好吧,过你河就是你回归的模型,太美完美了。 来,你告诉我这种未知的投票数量的能过于完美吗?老铁们,所以说谁的预测的模型的精度达到百分之百,你反而应该要慎重了,你百分之九十六九九九你都要慎重, 你的精度不可能那么高的。我可以告诉你哈,因为他是未知的,而且这两组变量之间理论上没有什么必然的情况, 不能说他评委得分就高,他观众投票就高,对不对?也不可能说,但是呢,来评委投票高,有没有可能观众投票也高啊,也有关系啊,也有可能啊,那评委投票高,有没有可能观众投票低呢? 也有这个可能,对不对?所以说哈,这里面比较麻烦,比较复杂, 你呢,一定要慎重啊,一定要一定要考虑,就是自变量和一变量之间没有很强的关联度,没有很强的关联性,这个是很关键的哈, 明白吧,做这个做回归理论者是一个大忌,就是自变量和一变量之间没有很强的关联性,我们说这属于大忌,但是呢, 不代表说他俩没有关系,往往会呈现一个啊,就是典型的比如大部分选手可能评委投票比较高,观众得分也会比较高一点,只是说有一个大概的对不对?但是你要考虑极端场景之下的一些情况 啊,因为因为前面说了吗?对不对?来前面说了,以前面已经给你讲了很多了,对不对?说有有可能会出现专家评分高。所以说呢,这个 第一小问啊,我建议你们不要你合的精度太高。好吧,不要你合的精度太高啊,太高了确实会有问题的哈。来 第二小问啊,利用你的观众投票结果估算结果和其他数据比较和对比节目使用的两种投票方法,排名反而百分之在各季产生的结果是吧?就每一季对应的两种结果,如果结果再查也其中一种方法似乎更清,更似乎偏向于观众投票, 对吧?就是比较吗?对不对?和个体产生的结果比较结果的结果,如果,如果结果存在差异,那么其中就哪一种方法可能会偏向接受投票,说白了就是看看哪一种方法和观众投票的相关度更高吗?对不对? 然后考察这两种投票之外存在两种投票方法存在争议与观众或观众意见存在分析的特定选手的拥有情况,投票组组合方法的选择是否会导致这位每位选手的结果相同,是吧?每周什么什么的啊? 然后呢,咱们就那个一考虑一些具体的视力,把你建立的模型,再把具体的视力,然后呢这个考虑进去,然后呢,利用包括投票观众估算结果,在你的数据开发、模型分析、专业舞者以及数据中可用的名人数据的影响 对不对?这些因素对名人在比赛中的影响有多大啊?说白了就是你前面不是估算了一个观众投票的模型吗?对不对?利用观众估算投票结果在你的数据啊, 开发模型分析专业舞者以及数据中可用的名人特征的影响啊,这些因素对名人在比赛中的表现影响有多大 啊?啊,就你那个像年龄啊,特征啊,对比赛影响到底有多大?来评来他们对评委得分和观众投票的影响是否相同,这个也是要建立一个合适的模型哈啊,也要建立合适的模型的 啊。然后第四位提出另一种每周观众投票结合系统认为系统更公平。说白了就是就是啊,提出另一种每周结合观众投票评委的问题,说白了就是你提出一个新的打分方法啊,打分方法不是传统的这两种方法了,提出新的解决方法来哈,这样的话呢,你就需要全新的设计一种投票组合方法了哈, 让我们看一看完整的一个解决方案哈,来第一个啊,第一个来美赛啊,第一,一共四个小问,第一小问预测类题目,第二小问评价加决策类,第三小问影响因素分析,第四小问优化设计类啊,因为第四小问的话,它涉及到 新的投票方案嘛,对不对?所以说需要用到用到这个优化设计类问题哈,优化设计类来每一个小问,第一个问,预测每位选手每周的观众投票数,验证一致性和确定性,说白就验证精度啊,验证投票的这个预测的精度到底怎么样? 评价两种投票方法的优劣啊?分析争议的案例,提出决策建议,就两种方法,他有没有什么两种投票方法啊?选人的方法有没有什么对错优劣啊?这叫是吧?那第三个分析专业舞者和名人特征对比赛结果的影响啊,然后呢?这叫做影响因素的分析吗?对不对? 然后设计新的投票方案,这叫设计新的投票组合方案。系统一般就是优化了,对不对?优化方案找到最佳方案吗?对不对?最佳的这个投票组合方案,来,我们看一下理方法哈。方法 来,第一个用预测类模型,我们说了不能用单纯的时间性的预测模型,这个地方是不适用的,而是要用回归预测的思想,比如 c g c 的 模型加广义县域回归也可以啊, b e s 模型可量化观众投票的不确定性 对不对?然后 glm 能整合评委得分啊,选手特征等预测变量适合小样本高维度的需求,所以这两个模型组合,那个这叫组合创新,类似的组合创新还有很多很多的 好吧?很多很多的组合创新,比如说,比如说你这个地方可以用模特卡罗模拟,模特卡罗模拟来来得到与观众投票的不确定性数据,因为观众投票不确定性数据可以用模特卡罗模拟来做一做, 然后再结合一些预测模型来做,更好了啊,结果更,这样的话更好了好吧。有很多种创新方案,说白了就是你这个地方你不能上来就构建一个基础的方案,比如 igbo 的 cc 零,那这样的话是不太合适的,你要考虑到很多的不确定性因素好吧,而这些不确定性因素反而成了获奖的关键, 明白吧?啊?活跃的关键啊,你这里构建的模型呢?就是小样本高维度的预测数据。因为维度数据比较高,指标特征比较多吗?所以需要构建高维度的啊,高维度不能用基础的什么灰色预测什么的,不可能好吧,不可能的就是老哥老哥我用深度学习神经网络可不可以也可以 深度学习神经网络本身也适合于高维度的预测,但是呢,你的数据量最好大一点好吧,数据量太小的话很容易陷入过你核的现象啊。 啊过你和因为神经网络还有这个这个深入学习很容易过你和。所以说你需要有大量的样本来做哈来做。 还有第二个就是评价了啊,评价两种方案的对比。你可以啊,选择量量化两种方式的多维度,比如说两种方案每一种方案的公平性是观赏性 等等,如何?然后看到系数呢?看到系数用于衡量结果的一致性,这是评论结论,这两个组合起来也可以解决这个第二问啊,就是评价类评价两种方案的一个优劣吗?评价就是是吧,先构建评价指标体系,比如说公平性,观赏性是吧,这个效率之类的效率 啊,成本啊之类的,你可以都把这些特把这些呃,样本把这些指标啊,然后呢构建一个评价指标指标,然后呢再构建这个相关的一个权重 来这个地方你们最好来,你们告诉我啊,权重怎么来确定啊?要用双权法, 双权法能有公平性观赏性能能确定吗?啊?专权法能确定吗?做 a g p, 这是最最基础的一种做法了,因为公平性观赏性这玩意 甚至有模糊综模糊综合评价法,因为里面有很多模糊因素。公平性?什么叫公平?什么叫不公平观赏性?什么叫高傲低啊?较高傲,较低,这有很多大量的模糊因素,所以说用模糊综合评价法, a g b 模糊综合加模糊综合评价法,这个地方是比较适合的。好吧,你用双减法什么的,没有数据支撑压根对不对, 只能用这种模糊综合啊来做啊,来,还有影响因素分析,可以用多元现金回归加随机森林,如果你上面用过随机森林了,在这个地方我建议你就不要再用随机森林了好不好?不要再用随机森林了,你上面如果用了这个地方就不要用了哈,你如果上面没用这个地方啊,第一位也可以用这个地方,就需要换个别的哈,好不好? 影响因素分析啊,你可以用随随随心回归加随心随林啊,回归模型量化限性因素效果。然后呢,这个随心随林捕捉非限性和交互效率,全面分析各行的重要性。说白,用随性回归来评价每限性 量限性影响啊,限性影响哪些因素啊?是限性限性哪些限性因素他的影响影响效益是比较大的,因为这样的话,他的限性限性参数里面的那个参数值参数影响会比较大一点吗?对不对?那么非限性参数, 那么就需要用 c c 森林了,来得到哪些非限性参数啊?来,你那个因素是比较重要的啊,这两个综合来考虑。哎,这个挺好哈挺好啊,营养因素分析用这种两种方法来分别构建限性因素和非限性因素,哪一个影响分别影响是最大的啊?这个反而挺好哈挺好的 啊,还有优化方案的设计第四位你必。你如果想拿奖,整个废题,你不能单纯的就上来就是提个建议或者等等之类的,或者随便上一个方案。你需要构建一个优化模型 啊,你优化模型的话,这样的话是有说服力的啊,不要多目标优化啊,既满足什么?满足公平性又满足观赏性,这样的话两种目标对不对? 然后建立一个优化模型来得到一个最终的一个新的模拟,新新的一个投标系统来做新的一个一个打分系统。来来来得来得到哈。这打分系统既兼顾了观赏性又兼顾了平稳公平性。好吧,这样的会更好一点更好一点啊, 来,这个题目的难度呢?在三点五分左右,我的难度系数呢?中等吧。中等啊,不算高也不算低哈啊,不算高也不算低啊。首先呢比较复杂,就是他不是一个常规的时间训练预测模型啊, c 题就是很多预测都是用时间训练预测来说,但这个题目不是啊,他比较麻烦一点 啊,需要整合很多,又里面又有评价又有预测又有影响又有优化四种题型他完全还改了,你还要做到创新是吧?你没有创新还不行 对不对?你没有创新的话,因为本身原有的方案就有就不好了对不对?你还没有创新,那你怎么能获奖呢?对不对? 所以就是他,他就是要求你创新,他不是说不要求他要求你创新啊,他就数据量工作,数据处理工作量也比较大, 因为题目给了你大量的数据集,你需要做数据处理,你不做也不行,对不对?数据处理比较大,你万一漏了那也不行。而且 c 题百分之百数据是有问题的哈,我告诉大家每赛官方的尿性,百分之百数据是有问题的,你不做也不行哈。 啊,难点啊,刚才说了是吧,投标的间接预测,无直接数据交准是吧?说白了就是你,你需要人为人为的来判断一下一致性,没有数据作为交准,未知的投票结果,观众投票结果都是未知的哈。 两种投票方式你需要兼顾公平性、观赏性这种呢?公平性和观赏性吧,本身就属于模模糊数据级,又要把它变化成量化,所以需要构建成吗?绿水多函数, 这个函数的构建很关键,到底是限行函数还是还是一些其他的非限性函数来,你和这个量化指标,这个就很关键,你要构建一个模糊综合的话,你需要你绿水多函数,这管重要是吧?这个绿水多函数一旦做错了,那就很危险啊。 来,还有选手的特征,评委得分啊,很复杂啊,既有这个年龄行业又有得分,又有主观客观的一些内容交杂在一起就复杂的建模啊,很麻烦哈。还有新的投标系统吧,也比较麻烦,一种条件怎么来设定 对不对?目标函数怎么来制定?目标函数又要兼顾两种,两种内容,这两种内容又不是那种传统的量化那种,他整个题目真的是既有哎,预测优化,模拟。哎呦我的妈呀,我头大,我头有点大了啊。真的啊, 头有点大了是吧,还要脸?数据处理必须要做对吧?零得分啊是吧?控制啊,都需要补充是吧?预测需要明确假设条件,量化不确定性是吧?有很多的不确定性,你还需要量化他 对不对?你不像这个 b 体吧,太空电梯吧,有些不确定因素我们还能知道是吧?异常了,别结果突然变大,结果变小的,这玩意不确定性怎么来量化对不对?比较麻烦 是吧?还有评价指标的确定,指标的确定呢?还都是一些啊,一些难以量化的一些模糊指标, 对不对?也很麻烦对吧?新系统设计还要既要保证效率,还要你不能整的太过于复杂是吧?你整的太过于复杂的话,那就可推广性,可朴实性,就朴实性就比较小了。所以这个题目看着简单,实际上一包子坏水哈,一包子麻烦哈, 来啊,首先解决思路,先数据处理,然后呢啊,选举选手特征,变量,年龄,行业,然后构建观众投票,观众投票预测模型。贝叶斯这样的模型是不是 以什么评,以评委得分,选手特征周期为自变量,以淘汰结果为约束,观众预测投预测,观众投票数,计算预测执行区间 啊,这两种模型来分别构建啊,以什么为质,变量为什么为约束什么的,然后投票方法评价啊,设计指标评价体系,如争议、防范力, top 三偏重等于得分,用 h b 量化权重。然后呢,分析差异, 第四个要因素分析,构建回归和森林分析,专业舞者啊,来来和对投票的一个影响程度啊。然后呢?第五第五种设计多目标优化模型来确定啊,这整个的这个这个思路啊,还是比较比较明啊。思路倒是比较明显了啊。思路第一步,第二步,第三步,第四步该干什么?我们刚才的分析已经比较明显了啊, 要点就是创新,必须要融合多元信息的创新。好吧,这个模型的创新之管重要。这个我觉得这个题目的关键就在于创新,你到底能不能得到一个创新性的一个评价,一个预测模型,一个一个那个,呃,打分模型这个很关键啊,都是逼着你创新, 还有就是量化结果啊,量化结果是吧,给出投票的准执行区间,预测区间,这个说白了,你这你的预测值和预测区间千万不要太高,我建议不要整个百分之百,你说老哥我就等着百分之百,那你这是过你河了啊,一定是过你河了哈。 还有就是这个可制化哎,最好做一下可制化分析,模型检验也最好做一下啊,模型检验啊,然后呢?呃呃,擅长哎,这个题目就比较擅长数据处理。擅长擅长擅长。那个数值分析的题目推荐做, 计算机人工智能的也推荐做,功课的就不要不推荐了,因为里面也没有你能发挥的余地,全都是一些统一建模的东西啊。功课的不建议你做,尽管的呢,也还能做哈,也还能做哈 啊。然后呢,这个零基础的啊,我也不太推荐啊,比较麻烦。中等基础的也可以,高基础,中等基础,基础能力比较好的可以做一做,因为这个题目呢,写的人多,意味着你比较有创新点啊,看着简单,但是入手很麻烦,你看啊,一步一步的很麻烦,你千万不要觉得这个题目简单,我反正做到了,我没觉得很简单哈, 我真是觉得比 b 题都麻烦哈,真的哈,你可以你可以试试啊,你想做的同学,好吧,然后呢,我们一会呢还是会用我们整个的 ai 的 这个这个教程啊, ai 的 教程来给大家全详细的做一遍哈,来把这个是吧,尤其是注重创新,看到没, 我这里面还是会注重创新啊,这个方案二里面会注重创新,然后呢,把整个 ct 完整的从零到一的建模过程,代码调试都给大家做出来哈, 然后呢,我们把相关的代码包括我们的老师也在研发了,到时候相关的原代码都给咱放在这里面,好吧,我们导出的原代码都给大家放在这个里面哈, 好吧啊,大家到时候一定要去领取一下,千万不要忘记领取哈啊,不要忘记领取相关的原代码,相关的参考资料,相关的代码成品那边都给咱放在里面了,你到时候可以比对一下老哥团队做的和你们团队做的到底怎么样,好吧 啊,不一定,我们做的完全就百分之百对,仅供做一个参考哈,相关的源代码资料,每个题目的源代码资料,还有相关的解析文档之类的,就给大家放到我们我们的网盘链接里面去了,大家一定要去领取一下哈。 ok, 谢谢大家。
5七七学姐 10:05查看AI文稿AI文稿
10:05查看AI文稿AI文稿来,我们来看一下这个议题哈,议题的话呢是难度系数我觉得最大的一个题目哈,这个很像 a 题啊,很像往年的数学建模美赛的 a 题啊,这个积累分析类题目哈,所以这个议题感觉出偏了,出偏了应该出到,应该像出到议题里面哈,我们大概的看一看哈,说白了就是设计太阳能方案吗?对不对啊?就相当于当年那个美赛海多 a 题设计浴缸一样啊,是浴缸, 这不是要求第一个就是啊,确定这个设计一个什么校园啊?被动太阳能式设计,减少全年制冷负荷,说白就提高采热, 提高这个热能,热能吗?热能利用吗?对不对啊?设计一个整楼的,呃,学生楼设计改造方案,优化整个学院的供冷和制冷效果,你将采用哪些被动式太阳能策略和建筑的特征啊?如何评估其性能啊?这个就是典型的一个优化模型啊,常规的一个优化模型, 只不过这种优化吧,比较复杂一点啊,他需要考虑的因素很多啊,目标呢?就是这个是吧?这个这个优化目标就是太阳能的制热制热效率或者什么的达到最高啊,由于条件呢,就是很多,是吧?这个场景的限制,比如说建筑物是吧?他的场景,对吧?怎么优化啊?这说就大概就这 角质边呢?就是很多类型啊,就是角质边呢,包括什么啊?建筑物的什么?他的他的这个特征啊,还有一些这个太阳能的一些参数之类的,对不对?然后呢?所以说整这个优化模型的构建吧,还是比较繁琐的。比较繁琐的啊, 然后第二位就是这个啊,这个柏雷种,柏雷大学对不对?也是一样的,为柏雷大学在设计一个太阳能,对不对?也是需要考虑很多的东西,几何形状材料选择,玻璃位置内置体等等之类的,以最大化 冬天的这个吸收啊,避免啊,同时避免暖气的过热,也是要优化几何形状材料,各种材料,对不对?然后呢,达到一个最后的一个效果,所以也是这两个情况应该是差不多的啊,相当于一个是两个不同的学校,可能纬度之类的是不一样的哈, 然后呢,根据不同的这个要求啊来做优化,因为像这个这个学校吧,是吧,那么他这个就是啊, 是吧,这个减少这个制冷负荷最好的,这个呢就是最大化冬季吸热,然后呢,避免暖季的时候过热,就避免夏季过热啊,冬季尽可能多暖和一点,然后呢,夏季也不要太热哈,说他他优化啊,偏向于两方面哈,两方面,一个是冬季,一个夏季的 啊,不能说光考虑冬季的采暖啊,这个的话呢,应该是光考虑冬季的采暖,不用太考虑这个啊,夏天的一个问题哈, 然后呢,还有就这个啊啊,两个训练地点,那么如何把这个模型呢?调整到不拓展到不足的区域啊,比较维度相应的区域啊,怎么来拓展啊,那么就说白了也是一个模型的推广方面的一个考虑哈, 还有就是这个为啊新生会大楼啊设计整个的一个策略了,说白了就是直接把你整个的前面的这个建模的一个约束的一个思路,直接用在这个具体的场景之下哎,如何设计这个?呃,学生会的大楼,然后呢?怎么设计能够达到一个最优的?一个太阳能的一个策略调整的这么影响啊? 啊?大概就这么个内容,我们直接来看一下这个题目,每个小问以及这个啊,以及这个这个,呃,建立什么模型哈,来大概的给大家看一下哈。 来,第一,一共五个小问啊,五个小问,第一小问优化,第二小问也是优化啊,这两个小问只是优化的内容场景不太一样了啊,要求也不太一样了而已哈。第三个叫泛化,指的是一个是高纬度,一个低纬度,那么如何进行推广泛化推广呢?哎, 不同的泛化推广说白了就是改变某一个局部的参数吗?对不对?同样的纬度的,那么可能只需要改变一个局部的环境参数就可以了哈, 然后呢,优化还是优化就怎么设计这个大楼,对不对?第五问,决策建议还是有决策建议对不对?决策建议遇到了就是 top c 和 h p 嘛,对不对? a g b 加 top c s, 你 记住遇到就是这两个模型啊啊,遇到政策就是就是系统物理学啊,这个是逃不开的哈。 然后呢,我们一体的话呢,相关的原代码到时候也给大家放到这个网盘链接里面啊,你们到时候呢拿到这个网盘链接刷新一下,我们把原代码解析文档思路之类都放到这个里面去哈,大家看到以后呢要刷新领取一下就可以哈, 后面的会我们会根据这个提示哈,完整的用我们的超级的 ai 提升词来完整的把它做一遍哈,系统的求解一遍好不好?解答相关的答案结果啊,以及成篇论文之类的,用我们的超级 ai 提升词来做一遍哈,来做一遍, ok 啊啊,没有领到咱们这个资料的啊,可以去领取一下哈, ok, 每小问主要的问题,第一个就是优化啊,三格罗夫大学啊,北楼的被动式太阳能的设计方案,加热制冷复合,这就是主要的问题。还有就是调整方案,适配这个大学,然后最大化冬季吸收热量啊,调整一下你的这个优化方案,然后呢?厂家适让适配这个玻雷大学, 然后泛化模型啊。第四个就是优化行政会大楼啊,整个的一个被动,相当于把原有的这个经验和优化后的模型,然后具体推广到一个完整全新的一个大楼上面的一个给出一个完整的策略分析,说白了叫模型的应用,这个叫模型的推广,这个叫模型的啊,应用啊,模型的应用, 然后呢再个就是实施这个这个这个建议政策之类的,我们来看去这建模的一个思路哈,来第一个优化啊,可以选择 n g plus 模拟啊,这个就是一个模拟工具哈,模拟工具主要就是模拟建筑物能耗的啊,建筑物能耗的,其实主要的建模方法是多目标规划,多目标规划 啊,百分之百两个都肯定用到多目标规划啊,他不可能用到一个目标哈,因为这种复杂的优化类问题的话,往往是多目标的优化哈, 然后呢,这个啊,可以用这个 nj plus 这个工具的话呢,模拟建筑物的能耗啊,模拟建筑物的能耗,然后呢,用这个啊,这个多多标优化模型的话呢,来做哈,来做。然后呢,这个构建一个多标优化模型 里面的参数呢?包括这个挑弦的长度啊,材料啊,角度,这都叫决策变量啊,都叫决策变量,看看它优化到什么场景之下啊,最终要求出来的这个内容哈, 然后呢,第二个就是第二个就是针对博雷大学的,就要就要稍微的调整一下了啊,什么啊?构建的模型是响应面法 i s m 加多标优化模型,比如是 i s m i s m, 就 响应面法来构建热质热质体效果与建筑参数的关系模型啊, 呃,然后呢?快速调整方案,适配高维度哈,然后呢,主要还是用了多标规划模型,这两个其实有很强的相似之处哈,很强的相似之处啊, 然后呢,第三个叫泛化类,用的是地理甲醛回归加情景迁移模型啊,地理甲醛回归就是 d d w 模型的量化维度,气候的热量对模型参数的影响啊,就是这个, 就是这个 j w j w 啊,它能够模拟啊,不同的维度,不同的气候下,我的指标啊,我的坐标优化里面的参数,它到底是怎么来变化的? 然后将变化后的参数再调整,再放回返回到我的坐标优化模型里面去,就能够得到啊,我的这个最优最终的一个方案了, 这就达到一个调整,说白了你只要得到那个参数就可以了,参数怎么来变动的呢?这里用的这个地理甲醛回归这么一个参数,这么一个方程哈,他能够模拟环境对参数带来这个影响, 好吧,然后第四位还是优化了,新建筑物的优化,这个用了一个 b m, b m 呢这个这个还是在建,在建筑里面用的是比较多的哈。 b m 构建三维结构模型啊,这个的话你相你相当于构建一个建筑物的三维结构模型, 然后呢里面包括建筑物的格局大小,形状啊,然后呢再和前面的 整个的建筑优化模型结合起来,那难度系数相当大啊。所以说你适合建筑类的同学,你做这个题还行,只要你不是建筑类的同学,这个题你压根连碰都别碰哈,你碰纯粹找死哈,纯粹找死 呃,一题的话,你除非是建筑相关的同学,纯属的我都我都看不懂哈 b m 我 都我都不明白。因为 b m 这个东西,这个特殊的行业,行业内的行业内的工具哈,工具, 所以这个的话呢,你你你要是能把这个建筑物的模拟轮廓 bm 构建出来的话,这个软件啊不相关的 bm 构建软件,然后呢把这个建筑物的轮廓三维结构图构建出来,那这算是一个亮点,这算是对于你获奖算是一个非常大的一个创新点哈。 决策建议就是从这么一句话叫 to space 了,对不对?每一种法是吧?决策他的这个呃美观性啊,能耗,整体成本,你可以构建一个啊,这样的一个平淡模型,然后呢选出一个最佳的一个政策来啊,就可以了,最佳的一个方案来就可以了。难对系数呢?三点五分啊,这是因为建筑, 因为,因为说白了他他本身来说吧啊,他不是一个比较常规的数学建模题目啊,还是比较麻烦一点的哈。啊,我觉得哈想选择这个同学的同学呢,你最好呢是建筑相关的同学,如果不是的话,我建议你们慎重的选择哈啊,慎重选择 本来说就是就是优化类问题啊,没有什么复杂的,难点就在于建筑的优化,甚至很多建筑参数,材料,角度形状这些都不是常规的。 你们你比较啊,这边的动态调度问题,把机器人动态调度这都还好,比较常规,而且他还要让你建把建筑物做优化,建筑物做优化的话,那么你最后需要给出建筑物的形状轮廓这些信息的话都需要绘图的,那么就需要用的 b m 建筑物的三维模型构建的这么一个方案, 这个方案的话呢又比较复杂啊,比较麻烦哈,这个呢我觉得做 a 更好一点啊,做 a t 的 话其实要更好一点做原来的 a t 吧。 啊,我都是做一题的同学呢,你们要慎重哈,我不建议你们选哈,要选同学呢也也最好悠着点哈,我们有能找到思路代码就放到这个位置。好吧,给大家放到这个网盘链接里面啊,找不到的话那确实也没办法了,因为我们的老师应该 建筑部的专业的老师应该是比较少的,所以大家呢啊可以到时候呢刷新一下,有的话我们就会听给大家好不好啊,听给大家有的话哈。 ok, 这就是我们整个这个议题哈,大家呢可以去好好的思考思考哈,是一种选择。这个题我我不出意外应该会选的人最少的啊,不出意外的话选的人应该是最少的哈。很少很少会有同学会选这个题目哈,应该。
3七七学姐 03:45查看AI文稿AI文稿
03:45查看AI文稿AI文稿下面给大家带来一个二零二六年美赛一体呃 i c m 的 被动式太阳能遮阳的一个赛题讲解啊, 这个题目的话,我们这里的资料的话给大家是一个带来一个初步的讲解,这不是最终版本明天早上,明天早上的话会给大家带来 终极版本的一体,比这个质量更高更全,所以这个的话主要给大家借鉴一下思路想法什么的可以粗略的看一下哦。 我们这个题的话,它是基于多目标偶合优化模型的不同气候区建筑被动式太阳能遮阳策略研究。山药部分, 在这个研究中的话,首先是通过太阳位置计算器获取前天太阳高度角与全方位角动态数据,结合两地的气候参数啊, 然后构建这个多目标优化函数,最后的话采用遗传算法求解模型 啊,这是一些结果啊,全冷降复合降低三十八点六,血光发生率下降六十二点三,冬季的损失减少二十五点一, 好问题,投诉 是子问题,问题分析 二点三点三,模型假设,首先的话要假设内容,室内的环境初熟状态是均匀的,没有额外突发的热负荷,如大型设备持续运行啊,大规模人员聚集, 还有就是太阳辐射按当地的平均数据取取值嘛, 然后蓄热体材料,混凝土啊,石材水啊,那些物理设置不随那个室内温度的变化。意思这个假设内容的话有点多,你们自己可以任选其中的三到四点吧,就可以了, 那这是符号说明, 嗯,解结果此问题二, 直接回应问题。 问题三,没问题的话,我们这里都是构建了有模型的核心公式推导 啊,求解步骤嘛,结果分析,呃,这个是模型的优点。优点评价这里的话我们写的也是比较多的, 然后模型的缺点啊,参考文献,所以这个文章的话还有很多的地方需要优化和补充,比如像配套的代码的话,我们这里的话没是没有选完的,这些代码还要继续写。所以的话 需要后期资料的话,你们可以锁定我那个视频那个里面的企鹅群,明天早上我会第一时间在这里更新呢, 资料的话有需要的就自己加群领取啊。
13牛顿迭代法 01:19:04查看AI文稿AI文稿
01:19:04查看AI文稿AI文稿大家好,欢迎来到数码教学站,那么本次给带来的是这样数码美赛的一个速成攻略,那么本次视频的话,除了我们整个的一个备赛流程之外,还有我们的一个工具合集,特别是我们的一个 ai 的 一个合集,因为我们知道现在这个数学建模这一块的话, 其实 ai 还是用的比较多的,比较典型的,对吧?像我们用来解题的,用来画图的,或者是用来干其他的事情的,那么比如说我们这地方还有一个是 用来排版的,可以给大家大概的去看一下这个效果, 对吧?这个是 ai 生成的一个排版的一个文件, 可以看到,对吧?里面的一些样式的话,它其实已经绑定好了,已经和我们模板的样式是绑定好了的, 这样的一个有序列表,像我们一般用 ai 写的话,它里面都是没有绑定样式的啊,我们这地方是直接给帮样式给绑定好了,而且我们的一个公式也是完全,对吧?按照它的一个 word, 我 的一个公式的一个格式, 那么绑了样式之后的话,我们就可以很容易的干嘛?我们绑了样式之后,我们一改的话,它就会整个的去进行修改,就不需要担心,对吧?我们改了前面之后,后面要一个一个的去修改了, 这个的话就是我们用来用来建的一个拍板的一个 ai, 但的话里面还有一些缺陷,就是它这个序号,对吧?这个序号的话还没它里面原先就有序号,然后加上我们自带的一个样式,这个序号的话就有两个序号,但是的话应该还可以,说的话也是可以帮我们节约非常多的一个时间了。 那么其次的话还包括我们一些画图的 ai, 还有包括我们这样的一个,对吧?这样的一个翻译润色、审教、预审,来看看我们这样的一篇论文写的到底怎么样? 然后包括我们这样的一些,比如说查看文献的一些 ai 对 不对?用来查看文献的一些 ai 里面的话,会告诉我们我们应该去参考哪一些文献, 包括去帮助我们去辅助这样的一个编程的一些 ai, 让我们去快速的学习如何实现这些算法,我们到底用对吧?怎么去调库,怎么去调包,怎么去完成我们代码, 这样的话我们既能够学到东西,又能够快速的去完成整个的一个备赛的一个过程。那么我们话不多说,我们直接进入我们的一个正题,那么首先的话是大概的介绍我们的一个美赛的一个情况, 我们这地方的话一共分了九个小节里面都破坏好我们的一个美赛的基本情况。然后我们美赛近几年用了哪些算法,然后我们各个位置,我们到底要准备哪些东西?我们到底要准备哪些软件,以及我们整个的一个 ai 工具的一个汇总。 还有我们就是美赛里面比较重要的一个点,就是我们的一个绘图的一个专题,还有我们的一个数据,我们如何去进行剪辑,以及我们今年美赛的一个论文和翻译,我们到底应该怎么去做 好?那么我们题目类型的话,其实这个东西在美赛里面它的一个官网上面已经有提到过了,那么的话我们一共分为六个赛题,前三个的话是偏数学的就是 mcm, 后三个的话是偏向于交叉学科,就是我们的 acm。 那 么历年来的一个数据题的话是选的最多的,那么对应的一般就是我们的 c 题和 e 题,去年比较特殊,去年选 b 题的人也很多,但是一般的情况下选择 c 和 e 的 人在往年的情况下是最多的, 这两个的话分别是一个数据科学的一个科目,另外一个是我们的可持续发展的一个题目,他们两个的话都是这种数据性比较强的, 所以说的话可能上手的话就相对容易一点。而我们 a 题的话就偏向于我们整个偏向于一个物理机制,类似于呃,像我们国赛的一个 a 题,对吧?里面会有一些微分方程和动力学方程这些东西。然后 b 题的话是一个偏向于优化的一个题目, 他近些年的考点的话还是主要是偏向于可持续发展和社会科学的一个题目, 主要的用的方法的话就是我们的一个东北语言化,然后 d、 c、 d 题的话就是一个专门用来描述图论的一个题目,里面的话百分之百会考到的数据结构就是我们的一个图结构, 然后 f 体的话就是我们的政治经济学,也是我们一个偏向于刺客的一个内容。然后里面比较常用的模型的话就是政治经济学里面比较常用的模型,比如说 d、 i、 d, 然后的话我们的一个 固定效应啊这些东西,那么的话我们要拿到我们的一个 h 奖以上,我们大概的话只要能够打进百分之前三十就可以了,它的一个整体的一个获奖比例还是比较比较高的,相比于国赛而言的话,因为国赛的话我们要拿国奖的话,比例可能就就百分之 百分之二,百分之二左右,对不对?还可能还不到百分之二,但是的话整个美赛的话,你要拿到 m 加以上的话,它的一个概率的话是能够到百分之三十以上的,所以大家完全不用担心。 那么我们来详细介绍一下我们这样的几个题目到底要考哪些东西。 那么 a 题的话主要是解答的还是微分方程这一块,或者是说更加详细一点,动力学方程。那么近些年来 a 题的一个考点的话,基本上还是围绕着动力学去展开, 呃,像一些其他的东西,比如说像我们扩散方程啊,这些东西的话,其实不怎么考到,基本上的话就是在我们动力学,不管是我们的我们的生物环境,还是说我们这种呃自行车的功率,还是说我们这种磨损,这些东西的话,其实都是和我们的一个动力学相关的。 所以说的话如果说我们要去准备 a 题的话,那么的话我们的一个核心的点的话,其实应该放在我们的一个动力学上面来, 那么比较典型的话就是会考到一个 lot 卡方程, lot 卡的话基本上只要涉及到这种环境类的问题,或者是说呃跟环境这种沾边的,基本上的话每赛的话就会用到我们的那个 lot 卡方程, 这个 lot 卡方程的话在我们的 a 题、 b 题和 e 题里面是出现的频率非常高的,它这一个东西会涉及到三个考点。 lot 卡, 它的话是 logist 的, 它的话是 logist 的 一个扩展型,它的话主要的话是描述它的一个增长率的, 基本上的话也是可以呈现出一个 s 型曲线的一个特点,这个的话也是一个非常老的一个模型,已经是上个世纪提出来的,是美赛最喜欢考的模型之一,常见于 a、 b、 e 三道题。 那么其次的话,像数学建模比赛,近些年来喜欢考的一些比较新的内容的话,就是我们的一个贝爷斯用来做繁衍, 那贝耶斯相信大家都不陌生,那像这这个东西在哪些地方考过?在二零二四年国赛的 b 题,二零二五年国赛的 a 题,然后的话在二零 二四年美赛和国美赛的美赛的哪个是来着?二零幺四年,二零五二五年美赛里面也考过,然后的话同时的话研赛也考过。这个东西,现在的话贝耶斯的话相当于是一个现在这个就考考察的一个趋势,也就是说 他现在不光要求你会正着推过去,还要求你会反着推过来。因为为什么呢?我觉得可能是和我们的一个 ai 有 关, 因为 ai 的 话,他喜欢遇到这种问题的话,喜欢做模拟,而不喜欢去推它的概率,而做模拟的话,实际上他喜欢自己去设值,这样的话其实是很很缺乏积极性的。 所以说一般的时候的话,他可能是用来去仿仿 ai, 用我们的一个贝塞尔来仿 ai, 因为说实话我用 ai 测过非常多的题目, ai 非常非常不喜欢用概率分布去进行模,去 模拟一些东西,虽然他本身就是一个概率模型,但是他特别不喜欢用概率分布,他更多的时候会设置一些值或者设置一些常数, 而用概率分布用的非常非常的少。所以说的话,你可以看到我们近两年来各种各样的比赛考概率分布考的非常多,目前就这两年来已经考过的分布有二项分布,拨通分布、指数分布、 几何分布、正态分布,还有哪些?我想一下,去年啊,去年还考了一,去年有一个贝塔分布,呃,还有均匀分布, 然后还有啊对数正态分布,这个的话也是去年,去年的国赛和今年的美赛里面考过的对数正态,然后还有一个韦布尔分布。 其他的话应该就是这近两年来几个大的比赛里面考过的分布的话,基本上就有这些东西。 都说了。现在这个概率分布的话也是一个非常非常热门的一个考点,尤其是在我们偏数学的题目里面,以及在我们一些统计学的题目上面,这种常见分布是一个非常重要的一个考点。 那么第二个的话是我们那个 b 题, b 题的话它是一个也是关于一个优化的一个问题,那么用的最多的话其实是东边优化以及动力学, 那么你可以看到它现在 b 题的一个处出题的一个趋势的话,基本上也是和我们那个可持续发展相关的。比如说我们油货房制啊,对不对? 什么水电呀,什么保护区呀,什么旅游保护啊,对不对?其实的话很多时候他考的东西的话也是和我们的可学发展相关的,然后的话主要的话也会涉及到一些生态的动力学模型,那么既然有生态动力学模型的话,那么基本上美声的话是离不开这个东西的,洛特卡,对不对?我刚刚说了, 那么其次的话,它里面还有一个是多目标优化,那么的话和我们国赛不同,国赛的话一般不考多目标优化,国赛一般只考我们那个单目标优化,用的比较多的就是我们 遗传魔力退火加智力咨询,对吧?然后的话每赛的话 b 题是喜欢考多目标优化,那么用到的方法的话基本上也很固定, n s g r, 而且一般来说的话,它的一个 b 题的话不会考的 太难,对你的模型要求太高,因为很多时候他的一个难点的话主要是在找数据上面,所以说基本上的话他对于你模型的一个限制没有那么高,就算就像我们之前复现一样,里面可能会有一些明显的,对吧?明显不合理的地方,但是的话, 呃,没有太大的一个影响啊,对吧?对人家评价好像没有什么太大的影响。所以说呢,其实 b 题的话在解析这一块的话是比较容易的,但是的话他的难点的话就是怎么能够找到 能够支撑你去解析的一个数据,你的一个数据来源是不是足够权威,是不是足够官方,那么我们就可以看到有一些同学的话,他们喜欢在什么地方去找数据。简书 c s d n, 知乎 就如这些类似于这种,对吧?这种博客平台,或者说一些贴吧里面这种非官方的一些数据源上面去找数据, 从而导致你整个解决方案的话,他的一个数据,对吧?他的一个基层就没有,就失去了的一个可信性, 那么是从数据上面都出了问题,从机器上面都出了问题,那么你后面的模型你建的再好又有什么用呢?所以说的话,这个的话就是很多同学喜欢遇到遇到一个问题,就是查资料总是喜欢在那一些,对吧?对于我们学术性的一些内容的话,总是喜欢在一些这种薄客平台上面去查资料, 这个的话是非常非常致命的。我们要保证我们的数据,我们的解决方案是足够权威,足够有效的,那么的话,而这些数据的话,它是每个人都可以去写的,它的话是没有 这种,对吧?没有权威的这种背景的,那你不能够保证你的数据是有效的。 那么 ct 就是 我们的一个数据题,数据题的话像往年的话其实考的比较杂,现在的话也开始慢慢的回归我们的一个统计了, 这个的话也是整个数学建模比赛的一个趋势,你可以看一看往年都喜欢考些什么东西,二零幺一一年的巨型狂风,这个的话它当年是考了一个 c b 的 一个题目,对吧?计算机视觉, 然后的话你们会涉及到一些,对吧?一些神经网络、深度的网络的这些理论,甚至还会考到扩散模型 这些比较新颖的一些东西。而往越往后面的话,你会发现他的一个模型是越来越简单,越来越回归传统,不会再考虑那些比较先进的一些东西。二零二二年这种量化的一个问题, 二三年这样的一个关于我们的一个,呃,应该是属于我们的一个自然元处理 nip 的 一个内容, 但是 nip 它没有考的太深,基本也不需要你去去用什么全息薄膜啊,用什么其他的东西去建模,它的话,基本上的话你去用一般的机器学习,它也是可以做的。然后第四第五的话,一个是网球动量效应,一个是我们奥运奖牌预测, 这两个的话就是一个类似于这种序列的一个模型,然后的话加上它的一个贝叶斯 去做繁衍。那么对于数据写的话,它的一个核心的话,现在是越来越回归统计上面的,而不是积极学习,越来越回归传统。那么对于传统问题的话,我们基本上要准备的点的话,就是我们一些比较基础性的 这种计算学模型或者统计学模型,比如说我们回归的现金回归,然后的话我们的决策树,对吧? 然后我们多相似,多相似回归,然后的话我们的 gbt, 然后的话 random forest, 或者说那 gbt 整个算法族,对吧?里面还有什么擦街 boss 的, 什么那 gbm 什么开的 boss 的, 然后要分类模型的话,这个逻辑的,对吧?逻辑的回归,然后的话还有一个 svm 矩阵数,然后的话加上我们整个元素家族,对吧? finn forest, 叉级 boss, gbt, 然后的话我们的来的基本 m 开的 boss, 诸如此类。 当然的话还有一些是比较更加传统的这种分类模型,比如说我们的朴素贝叶斯,那么第三个的话就是我们的一个时间训练,时间训练的话基本上考察的点也是那么几个,一个是我们的 lma, 对 吧? 智慧会叉分移动模拟平均模型,然后的话还有我们的一个 lstm 长短是 gg 网络,然后的话可能对于我们多变量的话还可以用一个我们那个 one 向量智慧微, 那么的话,其实这个地方的话,我们也给大家去准备了那个今天一些比较常见的模型, 对吧?比较常用的 a m a s l t m, 然后 proper hat, 然后一个 one, 然后我们的一般回归现金回归,多向式回归,逐步回归拉索 s o m, 绝对数水就是零 g b d t 分 类逻辑回归 s o m, 绝对数水就是零 g b d t t, 然后剧类的话,目前用的最多的话就是我们一个 k means 和我们的一个 db scan, 所以说的话,其实你觉得这个它里面考的东西很杂,但是实际上的话,你把它归正一下的话,其实也就是那么些东西。如果说你要去准备某一个赛题的话,其实你所要准备的东西没有那么多, 那么第一题的话就是一个永恒不变的一个图论的一个题目了,图论加上我们的一个评价, 那么因为图的话,它本身的话像一些 python 包,比如说我们的 networks, 基本上你只要把图建出来之后,所有的图的一些算法的话,你都可以直接去用一个函数去实现,说实话它不可能只可能那么简单,不然的话你只要把图给建立出来了,那个题目你就解出来了,不管你用什么模型,它里面都要有一个函数去实现, 那么所以说的话,他怎么去增加你这样的一个建模的难度呢?他就喜欢把我们的这个图和我们的评价模型去靠起来。你要建图,你必须要有什么东西?要有节点和边,对不对? 那么边要有什么东西,边是不是应该有权重?那我很简单,我不把这个边的权重给你,或者说把权重啊给你很多个指标,你不知道你选选哪个指标作为他的一个核心权重,你也不知道怎么把它综合起来。那么这个时候我怎么去确定边权呢?我就等于用评价模型,对吧?就会给他们打分。 它的核心的话就是要去量化我们的一个编权,原先的话我们只需要去把我们的节点和编识别出来,然后建立一个图就完事了。现在的话就需要你去自己去计算它的一个编了, 这个的话就是他目前喜欢考的一个点,尤其是像我们那个去年建的一个交通网络,那么我们一个交通,我们一个马路有什么?有它的一个长度,对吧?有车道的数量,车道的数量和长度这两东西决定了它这个地方能够容容纳多少辆车, 然后他的一个限速,限速的话决定他每个单时,每个单位时间内可以通过多少辆车,以及我们当一个节点失效的时候,比如说我们有基本上要维修,对吧?或者说什么像去年可能就是倒塌一个边失效了之后,那么他的一个流量应该怎么去分割? 分割之后会对虾的编权,会对虾的编造成什么的影响?然后的话它整个是一个从静态到动态的一个过程,但是的核心的话仍然是围绕图去展开。好,那么我们来看一下一体一体的话,历年的话都是可持续发展的一个题目。 那么什么食物系统啊,什么碳烊,什么财产保险,什么龙帝,它的一个考法非常非常的多变, 因为我们可持续发展的话其实是一门课,对吧?它是一个很大的一个议题,它没有说专门的去针对某一个特定的领域 所说的话,这个东西是比较头疼的,但是的话里面一些比较典型的一些方法,呃,有我们的一个裸特卡。其次的话就是我们美赛最喜欢考的评价模型,评价模型的话基本上在美赛里面用的就是三个 i、 g、 p、 top、 cs 和商权法这么三个模型。 如果说你想把我们这个一体里面所有可能考的模型全都学一遍的话,那么的话可能就不太可能了,因为你可以可以看看到底是考些什么东西,像我们去年,去年什么玩意,不对,前年 保险里面都考精算,考你的精算这个东西,所以说的话它里面实际上实际上的专业非常非常的多,你很难去完全的准备好,但是的话我们可以把它经常考的一些东西,就是说 这些比较通用的模型给它准备好,像这些专用的模型的话,我们是没办法去一一准备的,我们只需要掌握好它通用模型,其他内容的话,我们到时候现去查文献,或者说现去用我们的 ai 的 话,呃,它的一个效率的话其实也很高, 而且非常节约,我们这个时间我们还是尽可能去把我们整体的一个基石去准备好,而我们其他的,对吧?这个东西的话,我们要去准备的话,它这个性价比实在太低了, 你总不能可能,对吧?还有这么几天的时间,还有十天的时间,你去把我们这么多的专业全部学一遍,这个的话不太现实,也没有那个必要。 那么 f d 的 话就是一个政治经济学的内容了,那么政治经济学这个东西的话,其实应该有相关专业同学,对吧? 基本上你要用的那一个模型的话,就是政治经济学里面那几个 d i d, 对 吧?双重差分面板回归,然后我们的 还有什么来着?那个叫什么来着?那个结构方程 s e m, 然后的话用来去做我们的一个因果的,对吧? 还有呃,固定效应,然后以及我们万年不变的这样的一个平价模型。而平价模型呢,我没有说过每三里面设计的平价模型就是基本上就三个, a h p、 top six 和双转法,然后的话常用组合就是 a h p 加双转法和 top six 加双转法。这个的话不管你怎么搞的话,选择这几个模型是不会出错的,如果说考平价问题的话,选择这几个模型是不会出错的。 除此之外呢,我们评价模型的话,还有一些其他的什么模糊中的评价,然后什么这种数据报告分析,什么字和笔灰色关联,这东西虽然说里面呃也有用到,但是的话你要去看具体场景,你不如这些东西通用的不如这些通用的模型,对不对? 三权法加乘乘乘乘乘乘乘乘乘乘乘乘乘乘乘乘乘乘乘乘乘乘乘乘 乘乘乘乘乘乘乘乘乘乘, 乱七八糟的什么都考一点,但是的话其实模型就是那么些,只是说换了一个场景而已。那么如果说要准备这样 f 题的话,最好还是有这么一点点的去准备一点点这样的一个政治经济学的一个内容, 这的话相当于说一些比较专业的一个领域。但是的话其实模型也我们也说过了 d i d, 然后的话我们的面板回归我们的结构方程 s e m, 然后还有一个是我们这个固定效应 政治经营协议用来用去的话,基本上就是这么东西,然后我让你去衡量一下,对吧?这个用这几个模型去衡量一下这个政策实施对于我们这样的一个东西有什么影响,这个影响是否显著就 ok 了。 好,那么我们来看一看各个位置的一个速成攻略,那么的话这个地方后面的话都是给大家附上这个超链接的,大家可以直接去拿着使用。 那么一般的时候我们在做数学建模的时候,还是会建议大家去用 python, 因为 ai 写 python 的 能力比较强,这个是确实是这样的,目前 ai, 呃, ai 拷定它的一个, 它的一个强项的话,基本上就体现在它的一个 python 和一个 js 上面,因为这两个东西它是开源的,而且的话生态非常丰富,所以说的话基本上我会如果说你是完全小白的话,我会建议你去用 python 来写,它的环境也比较比较好,安, 也不像 maclab 那 么一搞就是二十多个 g, 而且如果说大家不想去一个一个的去安纳第三方库的话,你可以直接去安装一个 l 空的,里面的话基本上就包含了我们这样数据建模里面一些比较常见的库, 比如说我们矩阵预算单派,然后的话我们表格,对吧?数据分析 panda, 我 们的科学计算三派,然后的话我们的统计学 this models, 然后我们的画图 maple 和 c 泵里面的话,已经完全集成了,你不需要再去重新下载。那么除了一些比较特殊的情况啊,比如说你对于 像我们一些素专的同学,或者说数学相关的同学的话,可能还是用 maclab 用的比较多,那么的话如果说你之前没有接触过 python, 你 之前一直用的是 maclab 的 话,那么的话你也没必要去为了这个东西去专门重新学学一门语言,你继续用你的 maclab 也也可以, 这个的话一定是按照自己的一个自身的一个情况来的,不要说对吧?为了追求某一个语言啊,又追求某一个工具,因为工具最后还是为我们人类服务的嘛,对不对?你最后还是要选择自己顺手的一个。 那 my lab 的 话,它主要是在它的一个稳定性和它的一个运行速度上面,它的一个运行速度的话是要比 python 要稍微快一些的,而且的话它不会有很多那种环境的问题,因为 python 的 话, 它的优点就是它的各种各样的库很多,那么缺点的话就是它的各种各样的库可能会有冲突问题,所以说的话 maclab 的 话,它的稳,它的胜呢?就是胜在稳定性,不会有各种各样的环境问题,对于我们这种完全没有搞过计算机同学来说的话,可能还是比较友好的, 因为你遇到的环境问题的话,你可能完全没有搞过计算机的话,可能完全不知道该怎么去修这个东西,它又不像我们这个程序保守它是环境问题。 然后的话我们可以去根据我们这样的一些算法去收集我们的代码包,去准备好我们自己的一个知识库,然后同时确保我们这些代码都可以正常运行,不要到时候我们到了美赛的时候再去 再去搞,结果呢发现啊,你这个当你本地的一个环境出了问题,你这些有些算法你是不能运行的,然后呢到时候去现场修环境,那么你就非常浪费时间说提前把我们常见的算法去准备好,常见的算法的代码包准备好,去一个一个测一遍, 看你到底有没有哪些问题,能不能够跑得通,跑得通的话就没有什么问题,当然的话我们这地方的话也可以去借助 ai 来帮我们完成,对不对?我们可以去告诉他,你需要准备 ai 去, 你需要准备 mcmic 竞赛,作为编程手,你要了解常见的比如说优化算法,或者说统计算法,或者说怎么预测算法,或者说具体分析算法,然后的话以及对应的 api 实现 api 的 话就它的一个编程的接口嘛,然后给它详细的算法,应用场景,适用条件, api 说明,代码视力说明,然后的话整理出来,整理成我们一个讲义的形式, 然后的话我们就知道哦,有一些 lp, lp 的 话可以在我们一个包叫做零 pro, 然后约束是什么? x 一 加 x 大 于等于十,哦,计算于负 x 一 减 x 二小于等于负十,对不对?哦?那就是系数是负一,系数是负一,结果是负十,这个是我们那个标准形式,要化为我们那个标准形式,标准形式的话是小于等于的形式,然后约束公式二 x 一 加一 x 二,对吧?小于等于的形式, 然后约束公式二 x 一 加一 x 二,对吧?小于等于的十六,那么就是二一,然后一个十六, 那么的话这个的话就是我们的一个,我们的一个矩阵就定义完毕了,然后我们就直接调一个库,对吧?把这个函数给调用进来,把我们这些约束条件,我们的目标函数全部都传入进去,然后我们就可以完成一个求结了, 然后还有包括我们各种各样数学题目比赛里面最常见的一类这个混合整数陷阱规划,对吧? m a l p, 哦,要用这个包 p o l p 这个包,然后的话你去完成这样的一个实线, 然后什么约束规划呀,对吧?突优化呀,然后连续非限性优化,然后我们非限性最小而成,对吧?图,网络背包,然后我们插帧净化,然后的话模拟退火, 地方是给了一个文档,然后 ga 啊,这个地方也是给了一个文档,还没有给出具体的代码性,然后我们那个拍末 n s g r 也在拍末里面, 然后哪些东西是我们翻车点,然后的话我们怎么把它写成约束,然后我们验证一下我们是不是真的能够解得好,它会,对吧?全部都给你输出来, 所以说的话这个东西来这个地方就有世界代码了,所以说的话来辅助我们学习的话,整体的一个效率还是非常高的, 比起我们自己去一步一步的学的话,它的一个效率肯定是可以成倍的提高,我们不要去抗拒新工具的使用,对吧?我们要学会把新工具用的熟练,然后的话去加快自己的一个效率。 那么对于剑魔手而言呢?剑魔手就是整个团队的大脑,对于剑魔手而言的话,你必须要熟悉我们常用的模型,熟悉他们常用的场景,然后并且能够有拍板的一个能力,对不对?你要能够确定下来我这个场景里面什么样的模型就是最适合的, 我们这个队伍大的方向是什么?我们必须要朝着这个大的方向走,你也必须要作为我们团队大脑的一个身份,然后的话去推动整个团队前进。那么对于我们数学建模而言的话,常用的算法,常用的算法就是这么四类, 基于分析、运筹、优化去梳理、统计和评价,那么的话,这地方的话,我们前面的话也给大家去展示过这个流程图了,对不对?我们常用的哪些算法? 那么对于我们很多同学来说的话,那么学习这个东西,学习这个 模型去看公式,实际上是非常枯燥无味的,而且很多时候的话,你对于一个背三而言的话,你并不需要去把公式的原理给它扣清楚,你只需要知道它这个模型应该用在哪些地方就可以了?那么比较典型的我们也可以用我们的 ai 去辅助我们, 比如说我们可以用那个 labkin, 那 么 labkin 的 话它就可以,我们怎么去用呢?我们可以首先的话我们去用我们的 gmail 呀,或者说用我们的 gpt 啊,去让它去给你规整出一套。呃,这样的一个模型, 它是用在哪地方的?然后让它用非数学的新的语言给你描述出来,然后你就把这一段语言,然后的话你直接扔给 labkin, 然后的话它就可以去给你生成出一些小卡片, 对不对?比如说什么是正在分布呀?然后我们怎么去分类啊?嗯, 那的话大概的话就是这么样一个效果,对不对?比如说我们的 a h p 每赛里面出现频率最高的一个模型,我们要干嘛?首先的话写清目标,加备选项,然后列出我最在乎的三到五个标准,然后标准之间两两对比算出权重,然后每个方案按照标准 表现评分自动汇总得到排名 啊,在这个地方对不对?然后比如说什么是吉拉斯坦估计啊?哦,我们要通过我们观察到的数据。嗯, 它这个的话是国内访问,国内访问比较慢,它这个是外网的,不挂贴纸也可以访问,但是的话访问速度比较受限, 大概的话就是这么一个效果,可以,你可以让 jimmy 呀这些东西用,让他去用非数学性的语言,用讲故事的语言把你让,让他把一个模型给他,给你讲清楚。 今天这个网是这么慢吗?这谁偷我网呢?这是 好,让他先深层一会吧,这平常按道理来说的话,平常都是秒出的,今天这是发生什么事情了?这是网被偷了 对吧?我们要把一团乱麻的复杂问题拆分成一个一个简单的二选一的小问题,然后的话通过像洋葱一样怎么分析基于内心的真实偏好,哪个选手是这样赢家? 然后比如说我们要去搭建一个金字塔对不对?然后去擂台侧对比较,然后的话加权。 我们的目的就是让我们把我觉得这种模糊的感觉变成清晰的结构,然后的话不忽略主观喜好,如实的计算对于这种结果的影响。比如说把我们的主观变得客观,然后如果团队有错的话,可以分头给权重,最好算平均值,避免吵架。 通过这些方式的话,我们就可以很清楚明了的去把我们这样一些难搞的数学公式,然后的话变成我们比较生动的语言, 但的话我们也不能够只懂原理,我们完全没有实战经验对不对?我们可以去通过我们这样的一些教材啊,对吧?这这个是非常经典的一本书,可以通过里面的这些教材,然后的话去干嘛呢?去做一做里面的题目, 看看我们学会了之后到底能不能够把它给用出来,到底能不能把它用的好。我们需要用实战来进行演练, 然后的话当然我们演练的话也不能够只靠我们自己,我们需要我们三个人来进行协调, 因为你一个人效率高,并不能代表你在美赛里面就可以取得非常好的成绩,我们最后的话我们还是要三个人协同去完成的,当然的话,如果说你能够去单刷的话,那么要当我没说,对吧?单刷的话你应该也不需要来看这个课了, 那么对于我们团队大脑来说的话,你必须要保证,对吧?保持你的一个思维是活跃的,如果说你没有办法去保持你的思维活跃的话,那么你就一定要把工具给用好,确保你能够把握整个团队的一个效率。 那么对于论文而言的话,其实除了写作之外,还有一个非常非常重要的点是画图。虽然说数据格式化是应该由编程手去完成,但是的话 里面我们知道美册里面除了数据格式化还有很多其他东西,比如说我们 ourwork, 对 吧?很多流程图、框架图、示意图这些东西。 而且对于诺言来说的话,你提交的就是你们整个队伍的一个脸面,如果说你的这样的一个排版非常乱,然后的话,你让你的这种图标非常不专业的话,那么基本上你的一个内容的话,对于屏幕来说就完全没有任何吸引力了,因为他根本就不会去细看,他在我们的第一关就把你给 pass 掉了,因为他对你的印象实在太差了, 这个是大家非常要注意的点,至少说你的一个排版看起来不那么乱,至少要要工整一点,不是说你要排的多么的好,多么的专业,至少说你的一个基本项还是要保持的。那么我看到的话啊,就目前我们带过的这些队伍里面有一些非常典型的一些问题, 图表字体不统一、大小不统一、样式不统一, 这个是我们遇到的队伍里面非常常见的一种现象,我们为什么一直强调大家要去用模板去写作呢?因为你用模板刷了之后,你可以强制的保证他们的样式是一样的, 但是如果说你自己去一个一个的调格式的话,你要到时候你有的大,有的小,很乱很乱,让人看着之后第一印象非常非常的差。所以说的话还是不建议大家自己去一个一个的去调格式,尽可能的去用模板去刷格式,保证你的文的样式是一样的, 否则你做的再好,你的模型建立的再完美,你的这个第一关就没过去,那都没有什么用。 那么对于一个论文而言的话,你不能说你只会排版就完事了,你还要去写作呀?你写作的话,你如果说你完全不懂这些东西的话,那你写的出来吗?你不能够完全指望着去复制粘贴吧, 也不能够完全百分之百的去抄 ai 吧,这个东西的话你必须要有带有一些自己的一些理解,否则的话你的这样一个论文那个拼凑痕迹是非常重的, 而且这个东西的话是很容易看出来的,至少说我们拿到一篇这种拼凑痕迹比较明显的论文的话,我们可以很明显的看出来你哪些东西不是你自己写的,和你的这个文风完全不统一。 所以说的话,你一定要把自己的一个这样的一个写作的一个专业性给提起来,当然怎么提的话,我后面的话也会给大家列出一个工具,然后最后的话,我们这一段时间的话,就是尽可能的去协同,尽可能的去合作,尽可能的去加快我们整个团队这个效率。 那么我们数学建模比赛里面会涉及到哪一些软件呢?那么除了我们编程用的 python lab 对 不对?还有的话就是我们的 alaconda 和拍唱或者是我们 vs code 的, 那么 alaconda 的 话就是用来就是一个环境管理的一个东西,它的话自带了一些数据科学的环境,可以去帮助我们,可以包含我们大部分数学建模比赛里面的一些算法 来加快我们的效率。拍像和 vs 刻的话就是写代码的一个工具,那么一般的话,我们追求轻量化的话,我们还是用 vs 刻的用的比较多一点,拍像的话可能相对于而言会更专一点,更适合于用工程环境一点。 然后的话,一般的情况下我们用 g 拍的环节,那么 g 拍的话也是按照 ctrl 自带的,他的话就可以,你他的话就可以让你写多少,对吧?有有一边写边测试,边写边测试,而不是说你一次把一道题全部写出来,到后到时候啊改一改,全部都要改, 那么就很麻烦。所以说我们一般的时候会建议大家去用我们那个主拍的环境去完成。那么我们一般的绘图软件的话,那么 visa 的 话,我相信大家应该都是用过的,这个学校的话应该也会教,对不对? 其次的话 ppt 也是我们一个常用的一个绘图的一个工具,那么的话之前的话,比如说我们一些环状图啊,其实用 ppt 绘制还是比较方便的,我来找一找。 嗯,应该不是这一门, 应该是第三个吧, 比如说一些环状图啊,对不对?这种类型的图片用 ppt 绘的话还是其实还是比较方便的, 无非就是给它加一个什么设限渐变嘛,对不对?然后把大家都给调整,然后到环状文字的话, ppt 里面也有自带的,这个的话就没有什么 挺方便的,只要说你用的比较熟的话,就没有什么太大问题。然后 wechat on 的 话,这种东西的话,它是一个在线网站,它里面的话也是有比较多的一些素材,来找一找 wechat on 在 每个点 wechat on 对 吧,里面的话其实也有非常多的一些素材, 它里面可以绘制的图还是挺多的,各种各样的都有。 再然后的话就是我们的一个 auto cad, cad 的 话这个应该学功课的同学的话都会接触到,对不对?可以画一些这种示意图啊,尽力图啊,特别是几何这一块的东西, 用 cad 的 话应该可以非常方便的进行模拟,而且的话你可以去把它的一个比例给它还原出来。然后的话还有一个的话是我们的一个飞格桌 里面,头面给我们提供了非常多的绘图模板,但是的话它主要的话还是面向于生物科学的,里面有些内容的话我们可以拿来套,但是的话有些内容的话我们不好直接套, 比如说这种我们去掏一些可持续发展的话,可能就没有什么问题,对不对?然后这个的话我们可能要去换一换他的一些样式和底色,然后这个的话我们倒是可以直接拿来用,只是说要把这个,对吧?这些东西换一换就可以用 里面的内容的话其实还是挺多的。 还有个的话就是我们的一个意图图示,那么的话这个意图图示的话我相信大家都已经非常熟悉了,那么比如说我们前面去复现的这项一些 我们之前去复现的一些论文,那里面那些图片就是 overwork 那 一部分的话都是用意图图示去做还原,或者是用 ppt 去做还原。但我觉得意图图示可能要更好用一点, 因为里面的话给我们提供非常多的模板和样式,我们可以直接拿来去套,然后的话 ppt 的 话可能很多东西,很多形状的话要自己去剪,所以说我们尽可能的去加快一下我们的一个, 加快一下我们的一个效率,这个是一个七零五 啊,比如说这个是我们的一个 f 题的, 那么写作软件的话,基本上呢它就是我们那个 lo word 和 laxt, 那 么 laxt 的 话我们一般都会用我们 laxt 加 vs code 的 一个形式。那么前面我们不是给大家展示那个有一个自动排版的吗?里面其实是同样的可以去拍了,我们的一个 laxt 应该在我们啊在这个地方扣子,当然的话这个的话也是基于我们美赛的一个模板,不因为我们 不然的话到时候环境冲突的话会麻,很麻烦。所以说的话,你首先的话要把我们那个美赛的模板和我们他那个模板文件给它传入进去,然后的话再去让他去做生成, 这样的话它里面生成出来的文件的话就可以去完全的去符合我们模板的一个内容, 然后最后的话就会给我们生成出来一份 text 文件,然后我们直接把 text 文件去替换掉我们原来的文件就可以了,还是非常方便的。 那么对于我们 ai 工具的话,那么我们比较头疼的查文献,查文献的话有我们的星火科研助手里面我给看暗度了,我们可以去搜,对吧?可以去搜我们的文献, 然后还可以去生成我们的中数。那么其实美赛的话里面有一个小节的话,是用来写我们的中数的,就是我们那个 layer feature view 那 一个部分, 嗯 啊,这是解锁历史中数列表这个地方, 对吧?它里面的话是可以给我们去生产钟数的,我们可以去根据我们这样的一个比赛里面的一个情况,然后的话去看看我们到底用哪些文献来辅助。 那么除此之外的话还包括我们什么深度研修啊,对不对?比如说我们要研究哪个主题,当然话这个的话一般在美赛里面可能还是不怎么用的到,以及我们论文研读啊,对不对?我们这个论文讲的什么东西?但是我看这个论文研读的功能的话,我感觉还是不如这个网站好。 然后包括我们翻译,当然翻译的话里面有限制,它里面的翻译的话是有,对吧?两千个字母的限制,每次的话只有两千个字母,所以说基本上我们写完一个小节之后,我们就要去翻译一个小节了, 然后包括我们的一个润色,我们怎么让他去更加学术化一点,怎么让他看起来,对吧?高级一点,怎么符合英语的一个说话习惯,我们可以通过这样的一个学术润色的一个功能, 那比如说我们来随便审一篇论文吧, 那么比如说我们前面有的同学,对吧?自己写了论文之后,不知道自己写的怎么样,就可以通过这样的一个审校的一个功能 来看看,对吧?自己到底有哪些缺陷?看看大家我们这个团队有哪些内容是没有考虑到的,就可以通过对吧?这样的一个 ai 评选的这样的一个功能来帮助我们提高整个团队的一个水平。这么慢, 今天这个网络真的不对劲, 好,终于上传出上来了啊,这样一篇论文是干到一个什么东西? id, 哦,老朋友了, 好,优点是哪些缺点呢?模型假设较为理想化,数据预处理细节不足,对不对?模型验证和比较不充分,缺乏与其他基建模型的对比分析, 无法全面评估所提模型的相对优越性。对模型局限性讨论不足,对吧?没有存在扩力、扩力和问题以及泛化能力的讨论 符号和公式没有解释得清楚,对吧? apple shell i 的 具体含义未作详细说明,参考文献引用不规范 对不对?然后改进了建议综合评分。哇,欧奖论文三点五分刚刚集合,所以说的话,这个竞赛论文和我们的学术论文,对吧?看看这个差距还是挺大的,因为欧奖论文的话在我们这里也就是刚刚过几何线的一个水平。 然后其次的话就是我们那个 s c s pace, s c s pace 的 话,这个动画应该之前有跟过我们国赛的同学的话应该知道, 他的话只需要你,比如说你这个地方用的很,用了很多 ai, 结果你完全没有查文献,到时候你要交的时候发现你没有文献,那么的话怎么办?你直接把你的一个专利给它上传上去, 那么的话他就会根据你的个专利内容,或者是说根据你所提的内容去寻找对应的文献,同时的话生成一篇类似于中数的这样一个东西, 然后后面的话就会附上它的一个参考文献,而且的话它里面还可以去做一个分类, 对不对? d p 模型 rostop 文件优化,然后的话 rcf 质量控制对吧?不是质量控制,生产质量,制造质量啊,系统上面的生产质量有个问题, powermad 生产质量问题, scholar 生产质量问题,质量控制, 对吧?有模型也有我们的来源,这个的话都很明确的, 这样的话也可以避免我们这样的一些 ai 去胡编乱造一些文献。 当然的话这些我们也给大家提到过扣子那个智能体 这个又改版了, 这个里面的话就可以根据我们这样的一篇,我们直接把我们的一个赛题给上传上去, 把它的赛题上传上去之后,它就会直接根据我们这样的一些内容,然后的话去对应的去查找文献,去查找我们的一个解决方案,对不对?后面的话也会附上我们的一个文献 啊,这个还是比较少的,这个的话是因为它里面的话在原文里面是给我们提供了一些文件,所以的话比较少。之前我们测过的那个 a t 的 话,它后面附的文件还是比较多的, 那么阿密的话就是我们之前说过的我们这个东西的话,如果说我们要去做我们的一个问答的话,那么的话我们就可以通过我们这样阿密的去来做我们的一个交互, 他会告诉你这个东西哈,我还研究了一个什么样内容,然后的话按那个论文概要,然后的话可以问一问他这个里面到底用的什么东西啊?这个的话就可以加快我们读文献的一个过程, 比如说我这地方提问模型一部分用的哪些方法解决哪些问题,他就告诉我们哦, 首先抽向我们的交通网络,然后的话用双旋法确定我们的边权,然后用流量平衡方程模拟我们的一个桥梁的倒塌,最后用我们的这样的迪迦斯克拉算法去分析他的一个最短路, 然后用 a a d t 去分析它的一个交通流的一个变化,这样的话就可以非常快的,对吧?快速的去过一篇论文,省得我们还要一个的去翻,一个去读,到时候又浪费时间,然后的话还不一定读的明白。 当然的话我们也可以让他去给出我们的一些思路,它里面的话其实是类似的我们一个 glm 模型所制服的一个模型,对不对? 它里面集成了我们制图的模型,然后你可以让他去给你一些这种解决的思路,那么的话一般的还有这种学术专用型的 ai 的 话,他一般给的内容还是偏向于学术性一点的。 那么对于我们编程的话,我们也可以直接让我们的一个 gpt 去帮助我们去编程,让他直接给出我们的一个代码,然后我们直接把代码去跑就可以了。 然后同样的我们的一个 ai 的 话,它里面也有一个画图的一个功能,嗯,这地方好像 ppt 没更新, 那么的话这地方的话一个是我们那个 infamend 的, 一个是我们那个 sora, 这个的话我之前我前面还加了一个 banana 的, 就是我们那个 juma 的 juma 里的,那么 infamend 是 里面可以去有一个科研汇总的过程,哎, 但是问题的话就是它那个中文不太油耗,所以说一般的中文的图片的话,一般还是用我们的一个呃节目来说画,但是的话我们美赛的英文的话可以考虑用我们的 infamend, 那 个有点太卡了吧。今天 so 的 话是我们的一个 gpt 里面的一个模型,然后的话它里面同样的也可以用 gpt 来画图,然后我们也可以去用我们的 啊接下来来画图,那么接下来的话我就帮自己来演示吧。比如说我们把我们的论文上传给他,然后告诉他我们到底应该要怎么画图, 对吧?我们把我们的一个问题上传给他,然后问他,让他去帮我们设计 t 的 十,然后的话去让他去给我们生成对应的 t 的 十,我们就会把 t 的 十直接复制到我们的积木栏里面来,然后的话让他去帮我们去生成对应的图片, 那么的话我们可以来测一测,看看他在这个地方画出来的东西到底是怎么样的。 这个是不是题词有点简单呢? 等一下我们换一个题,他的一个内容比较丰富一点的。 好,他终于出来了,大概的话,画出来的话又是一个这样的一个效果,虽然说题词是很少,但是的话画出来内容的话还是没有什么太大的问题,对吧?内容还是比较丰富的, 而且图标的话基本上也是和我们这样的一个它的一个文本的内容是比较匹配的,比如说钱啊,对不啦? 十亿人民币的知识,然后的话就应该是一个金币的一个图标,然后的话我们这样的一个 teach teaching innovation 科技研究啊,它是一个芯片的一个图标。然后第二个是我们 talent development, uh talent development and edu education, 人才发展与教育,它的话就是一个这样的一个学时髦,对吧?然后 infrastructure and economy, growth, 基础设施与经济增长,它又是一个这样的一个桥梁,对吧?这个的话都是很匹配的。 然后下面的话一个环路数据分析啊,这两个可能好像还有点啊,啊,没有重复,没有什么问题。 data analytics, monitor, policy, adjustment, 政策适应, resource relocation 啊,这个的话可能它下面中间这一块的话有点问题,它的话就会有一点重复,是不是有点重复? 但是的话整体的话,它的一个出错率的话,在我们的一个美观性以及它的一个错率上面的话应该是比较低的, 基本上的话它画出来图的话,基本上可以直接用到我们的一个论文里面来,没有什么太大的问题。现在的一个 ai 深图这个技术的话,还是相对而言的话是比较成熟的, 好,出来了。然后的话,首先的话是数据和处理,有我们的 world bank 啊,世界银行的数据 top, 五百超算的数据, open, alex, 学术数据, patent families, 然后的话, github, activity, gorms, index, 政府指数,然后问题,我们的一个指标系统与我们的一个指标系统里的构建, 那问题二,我们的一个 a c i 的 一个评价和我们二零二五年的一个排名,然后问题三,我们的一个预测,二零二四啊。问题四,政策优化来最大化,我们中国的 a c i 在 二零三五年, 然后这地方还给了一行小字, policy in size 与反 microsoft and scanners, 政策洞察重新来,政策洞察的重新定义,我们的一个 什么场景,对吧?坏了,太久没背单词了啊,不过反正总体来说的话,他的一个生图,对吧?这样一个风格的话,风格风格还是样式的话,基本上还是比较美观的,可能比我们很多同学他的一个画图水平都要好一点,对吧? 所以说的话,这个的话也是我们的一个画图的一个方案,大家也可以拿去用。 那么还有一个比较麻烦的是我们数据网站,那么数据网站的话,我们这地方也给大家准备好了,这里有吗?有这么多的数据网站, 包括我们美团里面最常用的就是我们什么东西呢?世界银行, 嗯,我的世纪银行都跑哪去了?他这个最近,最近浏览器都是罢工了嘛, 改的内容他也没没存进去,我的计算夹还没了。 这个地方的话给大家就总结出来了,我们地方的话比较常见一些数据,这的话都是一些偏比较官方的数据,就不会像我们有的同学,对吧?用什么简书啊,什么知乎什么这种东西到处去找数据员,结果找到了数据的话,他又不是官方的 结果,人家也导致你的一个论文不可信,你做的再好,有一个数据员从根本上就错了,那,那就那不就完蛋吗? 把世界银行的一个公开数据,这个的话是我们美赞里面比较常用的一些数据网站,然后还有包括我们什么卡购啊,对不对?这个的话相信计算机的同学应该不陌生, 那么这地方的话也是把它给大家,把所有的超链接都练好了,大家可以直接链接给跳过去, 当然的话现在的一个 ai 的 话也能够去帮我们去找一些数据,你只需要去干嘛呢?你只需要把它的一个 网页搜索的一个功能给它打开就可以了, 你就可以让它根据题目的内容去帮你去整理一些文件出来,所以说的话,现在的话,对吧?干什么都很方便,只要说你会用这些工具的话, 那么对于我们一些比较喜欢这种古法解题的同学来说的话,对吧?我还是有的时候还是喜欢自己一个人搞搞题目 啊,有的时候但是一个人有的时候搞不过来,因为现在毕业了嘛,有的时候可能无聊的时候可能去单刷一下,但是现在毕业的话没有队友,有的时候而且还要上班,所以说的话时间很紧, 时间很紧的话,有的时候画图的话就不是很想去画,特别是像 python 的 话,它 maclab 现在的一个画图的一个,它原生画图的话就是不去做什么样式修改的话,它的那个图有点看不上,所以说的话我有的时候为了图方便的话,我就会去找一些数据网站, 因为实在不想在我们画图上面花费太多的功夫,因为解析已经够头疼了,还要去花时间挑图的样式,也不想去写 r 语言更麻烦,所以说的话就直接用我们的数据网站直接一一次性搞定, 那么的话这三个的话都是集成了 r 语言的一些网站,它的话是用 r 语言来画图,它里面的出的图的效果是非常好的,只需要你把数据上传上去,它就可以帮你出图。 那么比方我们典型的看看我们相关性的矩阵,我们一般做 p 小 卷四 p 尔曼的,我们是不是都画的方框,他的话就可以帮我们出一些其他的东西,比如说我们的圆块,然后下面的话我们一些字, 当然的话我们也可以去给它调一调,对吧?我们可以用换成四 p 尔曼,然后我们还可以用换成什么,还可以选择椭圆,对吧? 可以显示我们的饼图,可以显示我们的方框,各种各样的, 这个樱花纹还是太丑了,那么椭圆的话就可以表示它们之间相关性的一个方向,是正相关还是负相关。 那么 cs, nova 它也是一样的,来看一下它应该在我们的一个, 对吧?这个里面的话也有非常多的一些图, 非常省事,省得我们自己去写代码,去一个调乱七八糟的格式里面都已经帮我们集成好了, 毕竟现在 a 有 ai 里面 ai 画的有些图的话,我也是有点看不上的,如果说他画个数据格式化的话,我也不想花很多时间去调那个提示词,太麻烦了,要一个一个的调,所以说干脆就用我们的一个在线网站已经给我生成好了,省事 上,毕竟上传,对吧?打开一个网站上传数据,这样的一个时间的话,比我自己挑战码这样的一个时间还是少多了, 里面基本上什么图都有, 然后包括我们这个 high pro 的 也是一样的,也是我们的一个二元 p c a 生成分析,然后的话我们的各种各样的分析的图,什么热图,什么相关性热图啊,乱七八糟的全部都有, 第一次呢是用 map 这些我们比较常用的 p c a 对 吧?有了这些网站之后,我们这样的一个 效率就可以提高了,然后的话省的我们,嗯啊, 省得我们头上自己写代码,对不对?能用工具就用工具,不要重复的造轮子对吧?这个东西 好,那么其他的话,像我们之前给大家说过我们的 weisson, figuero s c i 这些东西,然后包括我们用 sora 去生成图片,然后的话导入我们的 dob library 里面去进行编辑,或者是说我们用我们的 那的 banana, 也是我们 jama 去生图,然后再用我们的一个 lobe illustrator 去进行编辑也可以,但是一般的话应该不需要编辑吧?就像我们刚刚给大家看过的一样,它生图的一个质量还是比较高的,基本上不需要我们再怎么去修改,基本上去应付一个美赛的话,还是没有什么问题的,对不对? 那么对于我们那个整体的时间安排的话,那么的话我们比赛的话在我们那个早上六点钟开始,那的话我们拿到赛题之后三个人就要去干嘛?齐心协力的去找文献,找资料,去确定选择题,确定我们的大方向, 我们到底应该走哪些方向?不管你们是用 ai 也好,还是说你们自己手动去查也好,最开始的话肯定是三个人一起把整个思路给它统一掉的,不要觉得这个统一思路之后,对吧?去搞这些思路会浪费你的一个时间, 因为我们写作的时候越复杂的项目就越要去达成共识,然后的话收敛我们的要素,我们达成共识比我们先干不一定会花花费更多的时间, 因为我们达成共识之后,我们后期的话分歧就会越来越少,同时的话也能够让我们整体的一个思路更加的稳定,对吧? 当然我们不能够在这上面去浪费太多太多的时间,因为我们这个是有时间限制的,对吧?我们只有四天的时间,比我们国泰多一点四天的时间,那么的话基本上我们第一天的上午的话,那我们拿到题目开始 第一天上午的话,我们就要去大概的去明白我们到底应该用哪些模型了,到底应该去 走哪个大方向,然后下午的话基本上我们的一个步骤就要出来了,然后的话我们编程和论文的话就同步进行推进编程,把我们论文的框架给搭出来,然后的话等到我们的论文手跑出了结果就直接填填直就可以了, 然后差不多到晚上的时候的话,就可以去大概的去完成我们第一问的一个写作。然后一般的情况下,我们第一天的话是不建议大家去熬夜的,因为我们四天的时间它是一个拉力赛,对吧?它是一个马拉松, 你在前面花费的精力过多的话,那么你后面可能会影响你的一个效率。我们要保证我们四天的时间每天都可以去高负荷,高负荷运转,不能够因为我们第一某一天而影响到后面那个效率,当然除非说你是干地,那么的话就当我没说。 然后第二天的话,基本上我们来到之后的话也不用起的太早,毕竟我们第一天是六点钟开始嘛,我第二天的话也不用起太早,就像我平时上学一样,对吧?早拔就可以了。然后的话我们继续完成我们的第一问,然后的话准备开始我们的第二问, 那么有了第一问的结论之后,你对于整个题目的一个理解的话,应该会上升一个台阶。所以说的话在上午的时候,虽然说你花的时间比第一天要少,但是的话你在第二天上午的话,基本上也可以把第二问的一个大概思路给弄出来了,然后基本上你第二天的话就可以去 完成我们第二问的一个模型建立了,然后的话根据他的一个结果的话去不断调整优化你的一个内容,因为很多时候你跑出来的结果的话并不一定能够满意。 在很多时候的话,我们第一次见模的时候,我们总会我们的一个结果总会和我们的一个想象是有一点出入的,那么他这个时候你就要去慢慢的去优化迭代的一个过程呢,看看内容里面到底有哪些东西是没有考虑到的,或者说有哪些东西是考虑的太复杂的可以简化掉的, 然后的话去不断的去迭代和修改,然后的话到了晚上的时候差不多的话就能够 拿到我们问题二的一个初稿以及他的一个结果。那么的话第二天的话同样的话不建议大家去熬夜,那么的话基本上建议大家,对吧?十二点多之前睡觉一天奋斗个在早八到晚十二,对吧?十六个小时差不多了, 当然的话现在这个工具这么发达的一个情况的话,一天的话应该是用不到十六个小时的,我觉得一天可能啊十个小时都已经很多了。 那么第三天的话他的一个整体安排实际上是差不多的,但是的话我们基本上第三天的话,我们的一个整个题目的调解都已经要完成了。然后的话下面的话就是灵敏度分析这个部分了,对于每一次而言的话,灵敏度分析是非常非常非常重要的一个板块, 如果说你这个灵敏度飞行做的不好的话,那么很容易就直接降档,因为美赛一般的话都是面向于他的一个现实问题, 那么面向现实问题的话,它里面就会有非常多的不确定性,那么你怎么证明你这个模型是能够用的呢?你怎么证明你这个模型是稳定的呢?那你就只能够通过我们灵敏度分析的方法了,那么现在的现在主要的灵敏度分析的话,基本上也就是说改改参数啊, 然后或者是用什么蒙特卡洛进行模拟啊,看看他们之间那个变化到底是什么样的,整体的难度不是很高,但是的话我们的一个灵敏度分析一定要复图,一定要有图,只有表不行,必须要有图。 所以说为什么总是说美赛是一个跨国大赛,因为它里面对图的一个要求非常高,同时到了最后一天的话,我们不要去 卡点提交,因为美赛那个网站的话是非常拉垮的,如果说你到时候卡点的话很容易容易交交不上去,一般的话建议大家提前两个小时提交,为了避免他那个网站过于拉垮,对吧?然后的话给自己保一个底, 然后交上去之后的话就不要再去修改了,不是说不要修改,不是说我不要修改你论文,只是说修改不要去重复提交,因为它本身的话那个东西就很拉垮,你重复提交的话,你指不定你能够出什么 bug, 所以 说话基本上你交一次就行了,它那里面也没有什么邮件确认的这种功能,就是整个网站还是优化需要优化的比较多, 反正就是至少给自己预留两个小时的时间,不要去卡点提交,然后的话提前两小时把它交上去,然后的话你就可以去休息了。 那么对于我们整个论文的一个编辑和翻译的话,目前我们最好的翻译软件的话还是 d p l, 因为它它里面可以选择你的专业领域的话去去做翻译,但是 d p l 的 话它里面有这种地区的限制,而且的话 翻译文档用需要氪金,所以说的话我们之前的话就可以,我们之前的话就给大家去看过,对吧?星火科研它里面的话也支持这样的一个翻译的一个功能,学术翻译对不对? 只是说它里面的一个这样的一个文本是有限制的,所以说的话建议大家都是写完一个小结就去翻译一个小结,随时翻译,随时随时,那个 大家的话记得给自己留一版中文的底稿,对吧?然后的话后面的话如果说我们要修改的话,那么的话不至于到时候自己都看不懂自己的论文,不知道自己要改哪里对不对?有一版中文稿有留一版,有一版英文稿,最后提交英文稿, 要修改的话要先改中文稿,然后再把修改的那一部分重新翻一遍,然后再到英文稿上面去。同时的话我们之前也给大家看过我们的这样的一个润色呀,审教啊,预审啊这些功能, 所以说的话我们在写完之后,我们是可以去反复的去根据它里面的一个评选意见来打磨我们的一个论文的, 尽可能的让我们的论文的一个考虑的更多,更加的完善,不要让人家挑出毛病,毕竟也不是只有你会用 ai, 人家也是会用 ai 的, 对吧?评文也是会用 ai 的, 就是说可能有的有的评委他甚至可能是懒,直接懒得用 ai 来看你的论文,直接大概的瞄一眼就过去了,但是的话为了避免这种情况,对吧? 我们也可以提前用 ai 来帮我们审校一下我们的一个论文,尽可能的让我们的整篇论文更加的专业化,更加的学术化,更加的 有这种可执行性。好,那么我们的一个分享的话就到此结束,所有的资料的话,大家都可以看评论区置顶进行领取,然后的话希望大家可以在我们的美赛里面取得好的成绩。
49数模加油站 22:58查看AI文稿AI文稿
22:58查看AI文稿AI文稿好,大家好,那么这个视频呢,跟大家讲一下本次美赛啊,我的选题建议以及各题目的这个思路啊,那么我这里已经准备好了一个十一页的啊,这个思路文档,呃,包括 a t 幕和 c t 幕,我个人精准校对之后的啊,这个翻译, 呃啊,我都跟大家去讲,那么在这个思路的讲解过程中呢,我也会把啊大家可能会忽略到的一些关键的信息和雷区注意点,我全部都会跟大家一一讲清楚啊,请大家务必有耐心的把这个视频呢仔细的去看完啊,防止大家在做起过程中呢挖到什么坑。好,那我们首先来看一下这个选择题建议, 那么我们这次选择助攻呢,是 a 题目啊,以及这个 c 题目,那么后续呢,都会完成这两道题目完整原创论文以及相应的代码和结果啊,这个呢,跟我往期的这个比赛都是一样的啊,大家可以继续看我往期的这个视频啊,我现在发布的是这个选题建议和思路视频,那么后面呢 啊,我们预计会在明天,也就是一月三十一号的中午左右就会更新完毕。呃,这两道题目完整的原创论文以及相应代码和结果的这个 教学,那关于这个后续完整成品的说明呢,大家可以看这个视频的评论区啊,这好的不多说啊,我们来看一下这个选择题方面,那么这次这道的六道题目呢, 呃,这个 a 题目啊,是比较硬糙的,加一个智能手机电池的耗电建模,这个呢,题目也明确告诉我们了啊,就要建立一个连续实践数学模型,这个其实就是微分方程模型,这是非常非常经典的啊,大家如果说,呃,你们有受过学校的建模比赛的话,这就是其中非常经典的这种微分方程类的问题。 再一个非常经典的这个题目就是 c 题目了啊,也是往年大家每次都选择最多的这个题目啊,就是纯数据分析类的题目。这次的 c 题目呢,呃,也比较复杂一些,因为它里面有很多规则,包括这个数据说明 啊,这个数据本身呢,也比较复杂一些啊,就是我们或许要去读取和这个处理比较复杂一些,所以呢,在我稍后的讲解过程中呢,我也会把我们在所有的数据读取中啊,可能会出错的地方,我们需要去关注的一些啊,关键的信息和雷区注意点我都为大家讲清楚,好吧, 好,那其余一个题目呢,我不推荐大家去进行选择啊,因为呢,呃一方面获奖率并不高。呃,再就是呢,可能有的题目比较水一点,比如这个 b 题目呢,这个利用太空电机系统建立月球直径。 呃,这道题目呢,估计很多人可能会用 ai 去做这个,呃,就稍微水一点,然后这次的 i、 c、 m 这三道题目啊, d、 f 这三道题目。呃, d 题目的主要难点呢在于我们要去收集一些相应的数据。呃,这个是比较困难的,那再去这道题目呢, 就我们能够采用的模型也比较有限啊,就你想要做的出产的也比较困难啊,比较有限。然后这个 e 题目,被动式遮阳和这个 f 题目啊,这个 e 题目呢, 呃,难度其实并不算高,而且主要是建立这个非稳态的热平衡方程,这个呢,在以往的建模型材里面呢,也比较多一些,但这次这个 e 题目呢,如果我们从横切去从这个获奖角度而言的话啊,眼目图眼大剧进行选择啊,包括这个 f 题目也是一样,这个 f 题目呢,呃, 一方面我们要去收集一些这个相应数据啊,这个稍微能困难一点,再个用这个 i 题目呢,也比较能做得出彩啊。总归呢, 这是为什么推荐大家去选择 d 题目和这个 c 题目呢?因为这两个题目呢,呃,都是大家这次比赛呢,比较容易做得出彩的啊。这个类型的题目, a 题目比较容易做得出彩的地方在于呢, a 题目比较硬核一点啊,我们只要建立合理的违反方程,那么后续呢,我也会跟大家去讲这个啊, a 题目详细完整的建模思路。 好啊,包括一些相应的数据呢,我已经完成了初步的这个收集啊,其这道题目的数据呢,只需需要去收集一些新的参数就可以了。好, 这个呢,做好的话呢,咱们大家这道题目的获奖概率呢,还是很高的好吧,呃,然后就是 ct 目啊,这个数据分析类的题目,呃,我们只要去啊,把各种我们能考虑到的啊,这个数据的参数呢 和注意点我们都落实到位。再一看美国,我们建立合理的注出页模型啊,把题目每一问都解达到位,那么这道题目的扩展率呢,也是比较高的。好,那么选题建议呢,就讲到这里,那么本次的 a 题目和 c 题目呢,我们或许都会完成这个完整的原初论文集现在代码和结果。那关于这个完整的整理的说明呢?大家可以看这个视频的评论区,我们有机会在明天就是一月三十号的中午左右就会更新完毕。 呃,这两个题目完整的原初论文集,现在代码。好,那么废话不多说,我们现在来看一下这个 c 题目的思路。 好,那么这个视频先给大家讲一下这个 c 题目的思路,那么稍后我会再发布的视频去讲解 a 题目的详细思路啊,大家敬请期待。好,我们来先看一下 c 题目。 c 题目呢啊,这也是我人工教对之后的一个精准的翻译版本 啊。呃,因为这样节目的翻译是比较困难的啊,大家容易很多地方出错,如果用 g 翻的话,简直得有一个完整的啊,这样的一个翻译版本。那关于这个, 好,我现在讲解的这个思路,文档呀,包括 a 题目啊, c 题目啊等等的这些人工教对的翻译啊,文档啊,包括这个完整的说明呢,大家都可以看这个视频的评论区。好吧,我来看下 c 题目,那么几乎被讲的我就不多说了。好吧, 他第一位呢,向我们开发一个数学模型。呃,然后呢,为每位参赛者在他们参赛的周四中生成估算的粉丝投票数,那么这个粉丝投票数呢,他是未知的,且被严格保密保守的秘密。就题目给我们的这个数据呢,它里面是只有这个评委的投票数啊,评委的投票数是给出的,但这个粉丝投票数呢,他是完全没有给出的。 然后大家这里面有分了几个子问题啊,一方面是问我们这个模型是否去正确估算了,导致与每周谁被淘汰的结果相一致的粉丝投票啊,提供一个一致性的度量。再一个呢,我们生成的这个粉丝投票数呢,有多大的确定性?那么这种确定性呢,我们要去进行度量。好,我们来看一下这个 ct 目第一问的这个思路, 那么其实呢,整个这个 ct 目呢,它的核心难点就在于我们的粉丝投票数据呢,它是一个未知的引变量啊,我们是只知道粉就是评委的打分和它的输出,输出呢就是谁被淘汰了嘛,对不对? 我们需要根据这两个呢去反向推导出我们粉丝投票的分布,这是我们的这个问题的核心难点所在啊,也是我们必须要去完成的一步,就是我们第一步呢,先把这个完成,之后呢,我们后面呢才有的做,能理解吗?所以我们基于这个推导出的数据呢,才能够进行后续的政策分析和模型优化。 好,我来看一下啊,针对于问题一,问题一呢,这个估算粉丝投票模型呢,这就是一个参数估计和引变量推断的问题啊,那么这里的模式给大家讲这种三种方案,这三种方案呢,首先第一种方案啊, 就是这个用限行规划或者约束满足模型,那么我们这个呢,就是说把每一周的比赛看做一个方程组,那么假如说每位选手某位选手被淘汰了,而另一个选手就晋级了,那我们当时呢,是必然满足当时的规则约束的啊,比如说他的这个得分啊,是比令格高的,我们把这个粉丝投票占比呢作为决策变量来满足啊,所有淘汰约束为条件 去建立一个优化模型啊,我们建这样优化模型啊,我们的目标函数呢,就是去最大化粉丝投票分布的方差啊,或者最大化商议,就是说在没有信息的时候是最随机的,然后我们去做一次性检验就可以了, 就是计算模型生成的这个排名呢和实际排名的这个系数啊。那么这种思路他的优点呢,就是在数据推导上是比较严谨的,而且我们呢能够生成出一个可行解。那么缺点呢,就是在于他对于排名真的涉及到这个主规划问题就求解呢,是比较困难的,而且可能会存在多克几。 那么在针对于这个本次竞赛而言呢,呃,这个竞赛的潜力还是比较高的啊,就是得分潜力,呃, 就针对于以往这种剑魔比赛而言呢,这是一个比较标准的这样一个运球学剑魔的方式呃,结果是比较稳健的。那么另外一种也是我这次推荐大家去选择的这样一个做法呢啊,就创新性比较强的呃,也比较能够呃帮助大家去进行获奖的这样一个, 我这样去打讲吧。那么第一种方法呢,可能竞赛的获奖潜力就是 h 奖啊。那么第二种就是美赛评委比较喜欢的这种创新性比较强的做法,那我们的这个思路呢,其实就是贝耶斯马尔可夫列蒙特卡罗方法, 我们这个时候就是说不由不要求去求一个单一的追优解,而求这个粉丝投票的概率分布啊,我们假设粉丝投票呢是服从某种鲜艳分布的,然后我们根据每一周的淘汰结果呢,作为观测数据去更新我们的后焰分布啊,正是它的这个相应数量形式。 然后我们过去呢,可以去啊,去研究他这个确定性度量,那我们这个确定度呢,度量呢,就可以直接通过后验分布的标准查或者这些区间去回应题目中关于这个确定性度量的问题,因为这个题目呢是明确要求我们啊,要去看一下我们这个粉丝图标总数呢,有多大确定性的 好。那么这种方法呢啊,它的优点呢,就是我们可以去完美的回答关于确定性的提问啊,而且在理论的这个思维程度上是比较深的,这个难点就在于它的计算量比较大一点,然后代码编写复杂,但这个呢,大家不用去管啊,我这个代码呢,我会呃去完成这个十一的编写,然后大家到时候直接运行我给出的这个 python 代码就可以了 啊,还是跟以往的时候比赛一样,我都会给出这个代码和结果的。好吧,那么这个在竞赛获奖前提方面呢,基本上是能够拿到 m 的 o 奖的。就这个思路方面, 这种模型呢,在求解这种不确定性的繁衍问题上面,基本上可以说天花板了啊,就顶级方案啊,当然还有一种思路呢,就是采用奇葩式模拟或者说遗传算法。呃,这个呢,结果是疑心比较大一点啊,这个我们作为一个备选方案啊,就是说假如我们前面两种方法呢,真的要做不出来的话,就根据实际数据学求解啊,很难跑或者跑不出来的话 啊,那么可以作为一个备选方案。好吧,这个就不跟大家多讲了,来看一下他的第二问。待会他就问呢,让我们根据这个粉丝投票估算值和其余数据啊,就说现在我们这个数据已经得出了,对不对 啊?那包括其他数据,然后根据这些数据呢?我们先汇总完了之后往下看一下,开始让我们去比较和对比节目使用了两种结合屏幕和粉丝的方法啊,解决出排名和百分比在各级产生的结果,然后如果能在结果上出现差异的话,那么是否有一种方法似乎比另一种更偏向于粉丝投票啊?当然再就是我们去检查应用于特定领域的投票方法, 那么然后说世界名人身上呢,都存在争议,也就是存在这个分歧,大家问我们的结合评委方法和 vs 投票的方法呢?是否会导致这个结果相同?再一个就是加入评委,选择淘汰倒数两对中哪一对的额外方法会产生影响结果。这个答案看不懂啊。这个后后面关于数据的注示啊,以及投票方案的制定里面, 呃,人家都有跟大家详细讲,当然大家如果这个呢看起来比较复杂一些,大家可能会听不懂,没关系啊,我在后面呢,我有一个汇总了整个这个关键信息,以及每一问里面我们可能要去注意的一些关键的鉴摩点和注意点,我一会跟大家去讲吧。好吧,呃,我们先来讲下这个思路啊。好, 第二问,我们就是做这样的一个交叉验证模拟,呃,其实我们问题一呢,现在已经得出了对不对?我们就是只是根据问题得到这个推断数据呢,去进行反式式的推理就可以了啊。行,我们第一步呢,我们该先做这个交叉验证的模拟,我们建立一个仿真器,然后我们的实验组啊,第一 就说针对于这个,我原来是百分制笔制的这个数据呢,我们去应用排名制,然后针对于原排名制的数据呢,去应用百分笔制啊这样的一个规则。 ok, 这个我们可以解答呢,是否有一种方法似乎比另一种呢更偏向于粉丝投票问题?好,那么关于第二个看一下 啊,就这个针对于特定案例的分析啊。好,那么前面一个呢,我应该跟大家讲清楚了啊,就是要去后面去做一个偏差度量嘛,就定义一个评委友好度的指标,然后去比较一下这两种机制下这种指标的差异啊, 来看一下是否是会存在啊,这个粉丝一边倒去覆盖评分的这种情况。那么另外一个,接下来针对于这个针对特定案例的一个分析,我们先去提取出来这些人的这个数据,然后我们集中在于以下他们在另一种规则之下的这个新生存概率 啊,嗯,针对于这个加入评委选择抛开倒数两对中啊,哪一对的额外方法呢?会如何去影响结果这样一个问题呢?哎,这里呢就是说关于这个评委拯救环节啊,这就这个条件概率问题就是假如说某个人在某个模型中啊,落入倒数两瓶里面, 并且他的评委分呢是高于对手的,那么假设他被救回来,回去分析一下这是否改变了最终的结果就可以了。那么这个问题二的鉴物术呢,是比较确定的,就说只要问题的数据生成好了啊,那么问题二呢,主要是进行统计和进行逻辑判断啊,思路是比较确定的,来看一下问题三, 问题三就是说使用我们的粉丝投票估算值数据呢,去开发一个模型,来分析各种职业舞者以及数据中可用的名人特征,比如年龄啊,行业啊等等这些影响,然后去分析一下这些因素呢,在多大程度上去影响了名人在比赛中的表现,以及他们以相同的方式影响,是否是以相同的方式影响了评委的评分和粉丝投票。好, 这个呢就是一个典型的回归分析和归音分析的问题,那么这里呢有两种方案,一个呢就是这种混合效应分析 好,我们可以把职业五指呢设定为随机效应,然后把明星特征呢设置为一个固定效应啊,然后呢给出具体的模型,我去分析一下啊,来看这两个方程的,这个评委和粉丝两个方程里面呢,系数悲叹的显著性和大小啊, 来看一下这个系统呢,在这两个模型中呢啊,它们的是否显著的这个问题啊,那么这个呢是我比较推荐大家去进行选择的啊,这种混合效应模型呢,是比较能够去啊,比较好的去处理面板数据的,比普通那种心灵回归模型呢是要好一点了。那么另外一种方案呢,就是这个随机森林或者是啊叉子 boss 啊,其实就是基于树的那些模型啊,比如角色树啊,随机森林啊,就是基于呃树啊,对这种模型 积极学习模型。那么这个呢,就比较无脑一点啊,应该大家大家做过数据分析的题目应该都懂啊,就是你直接把它导入进去,然后跑一遍,就可以得出每一个侧重对于结果的贡献度了 啊,这个呢,优点呢,就是我们能够很好去捕捉非现金的这种关系啊,就直接周谷会跑出来一个重要性的排行啊,这个大家做过数据分析类和积极学习的人都懂, 那么这个呢,就是缺点就是它的解释性能差一点啊,就是我们不能从内部的机理和因果关系呢去很好的解释啊,我们只是跑出来这么一个结果,就传用数据进行驱动啊,这个呢,我后续这样的方案我都去做一下吧啊,看一下哪个效果更好啊,当然目前我推荐的是这个,大家去选第一方案是核像也模型好, 那么最后呢,就是要去提出这个新赛制的嘛,对不对啊?提出抑郁症,每周使用粉丝投票和评委评分的这样的一个系统 啊,让这个系统更公平,或者是在某些方面更好,比如说让这个节目更刺激啊之类的啊,我们自己去选择一个目标,然后呢,哎,去提出一个新的系统就可以了。好, 这样呢,大家就比较自由了啊,有很多种方法,比如说啊,你可以采用加卷法啊,这个理由呢,就是说,呃,好处呢,就是我们可以兼顾名次和表现的差距啊,我们保证每一跳都有这个价值, 要么呢,我们就基于等级分的这样一个动态权重系统,哎,我们随着赛季的进行呢,评委评分的权重呢逐渐降低,然后粉丝权重呢逐渐升高,这样的话,只是大家越看越刺激了,越看越刺激,呃,我们的目标就是追求刺激,对不对?那么再就是啊, 我们可以结合这个评委拯救啊,比如说啊,我们的评委分如果说排名前三的话,那么本周啊,那么无论粉丝投多少票都不会淘汰,我们可以保证那些技术最好的选手呢进入决赛,并且呢同时呢剩余的名额呢交给那些粉丝去进行,我们这个投票就是兼顾了这个公正与这个观赏性 啊,这个呢,大家比较自由了啊,这个关于这个新赛季的提议,大家可以再去提出一些其他的方案,我这里呢也只是给出三种啊这个建议啊,那么在整体的建议上面呢啊,呃,我们大家必须要拿下分,是问题一和问题二,我们要去构建一个稳健的将这个蒙特卡洛模拟框架,去解决这个数据缺失的问题。 好,再一个就是我们后面会拉开差距的分啊,就是会让大家拉开差距的分,一个是问题一的不确定分,不确定性分析是比较重要的,然后呢,问题三的这个混合效应模型,这两个呢,我们在过程中必须要去展示非常漂亮的啊,这样一个自信区间图和系数显著性的这样的一个表格图啊。好, 接下来我给大家讲一下这个题目,我们的一些关键信息和雷区以及注意点,你们大家可以看到呢,这个题目呢,呃,这个数据的注视啊,描述,关于数据的这个描述注视啊,然后包括呢各种投票方案的势力,以及一些规则啊,规则,比如说呢他 啊,这个 a 值是什么意思啊?零分是什么意思等等这些东西,这个是非常非常复杂的,所以呢,我把题目中一些比较关键的信息和连续注意点呢给大家提取了出来啊,那么在视频的后面呢,我来相信大家去进行一个补充啊,防止大家容易踩坑的点。好, 首先是呢魔剑魔里面最容易出错的地方就是这个关于规则变迁的时间线,我们的代码呢,必须要能够根据我们这个赛季呢则自断的去自动切换它的计算逻辑阶段一就是这个排名制,它这个使用赛季呢,是第一赛季和第二赛季啊,这个逻辑呢是这样的 啊,排名制他们的淘汰规则呢?是这样的啊,我就不给大家多注注了吧,好吧,据说数值越大的排名呢越靠后,然后呢他数值越大的就会被淘汰,就这个投票排名制的同排名的制,这个题目里面的这个我后面也给大家讲了啊,后面也跟他讲了, 就说排名越大越靠后。好,那么这里呢我们要去注意一个问题,那如果说我们的总排名是平局怎么办呢?这个题目是没有说的啊,我们需要去进行一个合理的假设,这也是大家需要注意的个点,就是如果说排名出现了平局怎么办这样的一个问题。 好,那么另外一个就是基站案也就这个百分比值,这个呢是在第三赛季到第二十七赛季里面去啊,然后这里是他的这个排名的逻辑 啊,就是各自有各自在帮占比的这个百分比。那么啊,评委分是这样的,某选手的评委分,我们这个百分比的设定呢,就是说这个百分比的设定呢,就是说意思就是说啊,评委分的百分比,就是说某选手的评委分除以当中所有选手的评委总分, 当然了另外一个就是这个粉丝的这个百分比呢,就是说啊,这个选手的粉丝票数除以当中总粉丝的票数。好,我们它的规则呢,就是说 数值最小者被淘汰。接待三呢,就是说啊,从这个第二十八赛季到第三十四赛季,这题目是假设从第二十八赛季开始啊,就是具体的是从哪一个赛季开始的,是并没有说的啊,题目里面说的是假设哦, 那么这个呢,是重新回到了排名至区区三,咱们综合排名这里呢,关键差异呢,就是跟我们最开始的这个排名的这关键差异呢啊,就是有一个综合排名倒数两轮,这个选手呢会进入生死 pk, 那 么最终会淘汰谁呢?是由评委现场投票决定的,而不再是由综合排名决定的,能理解吗? 虽然在在我们建模里面会有产生一个影响,比如说在第二十八赛季到第三十四赛季的这个逆向推导过程中呢,如果说某一个人排名综合排名呢,是倒数第二,但他没有被淘汰,这是非常合理的,因为评委把他救了,他能理解吗? 好,那么另外一个问题呢,就是在我们数据清洗和处理方面会存在一些雷区。首先是关于零分的这个含义啊,比如数据中呢是零的,就代表这个选手已经被淘汰了, 然后呢评委人数的变化,有的时候呢可能是三个评委,有的时候呢可能是四个评委,在这个处理方面呢,我们就不能直接用总分了啊,我们必须得去归一化啊。再有个关于这个小数的处理问题, 包括这个 na 值, na 值呢代表的是缺席啊,这个评委或者说休赛周,这个呢,我们在主取出局中呢啊的时候呢,要进行剔除啊,最后呢就是多余一人淘汰,或者说无人淘汰啊,这只是我们相应的处理。 好,那接下来给大家讲一下每一问啊,我们前面的思路已经跟大家讲过了,我们接下来要讲一下每一问的这个注意的点,那么在问题意义里面呢, 前面的思路我们给大家讲过了啊,这点重点就在于我们如何去回答这个确定性的问题,那么有些中呢,这个评委的分叉是很大的啊,粉丝投多少票都破去改变它的结果,那么这种情况下呢,它的确定性是比较低,大家能理解吗? 那么另外一种呢,就是说评委分是比较接近的,所以呢粉丝投票的微小变化就会导致他们的排名会出现很大的变化,那么这种数据呢,就会意思就是说它的吸引力呢是比较高的 啊,这个答案应该能理解什么意思吧啊,就是假如说分差很大,因为咱们是通过这个评委分和排名去逆退他的粉丝投票嘛,假如他分差很大的话,那如果说你这个粉丝投票呢,多少都不改变结果的话, 你偷懒出来这个趋利性可能是比较低的呀,因为你任何值都可以嘛啊?你偷懒出来任何值都行嘛,你高或者低都无所谓的,那你的趋利性当然很低了,就说它的可信比较差啊。另外一种呢,就是说你这个评委分比较低的情况下 啊,他为啥变化就导致他排名逆转,那么这个时候我们再通过排名和评委分综合起来去逆推他的粉丝投票的话呢?哎,这个就是我们趋利性非常高了,大家能理解吗?啊? 所以这个这部分我们的衡量指标就是我们的可行结空间的这个奇迹,或者说我们的卡罗样品的方差啊,去看一下它方差大还是小好。然后针对于问题二里面呢,我们的核心 写就用我们去我预测出来这个票数呢,去套用不同的规则,然后呢去针对于具体的案例进行分析啊,比如针对于这个人,他在百分比之下呢,是赢了的啊,我们要去计算一下,假如说他采用了这个评委拯救规则,他会不会在半路就被评委给淘汰掉, 哎,那么再比如说这个第二个赛季的这个人,他在排名之下是亚军,那么假如说换成百分之十的话,他的这样低的分数呢?会不会被这个粉丝投票给拉回来?大家能理解吧?好, 对着问题三里面的这个影响因素分析里面啊,我们前面给大家讲过了,我们要去做这个回归啊,和这个相关性分析, 这里我有这么几个关键变量啊,首先是这个职业舞者啊,这是非常关键的,因为有些职业舞者呢,他的粉丝是非常多的啊,他们能够去带飞队友去演演投票, 我们需要去把职业舞者呢作为一个分类变量啊,进行编码来,或者说作为一个学习效应啊,一直说三四,最后加一个,在数据表里面加一个判定啊,就是看看他是否是职业舞者这样的个灵异判断啊,可以作为一个变量去导入进去, 或者说把它作为一种学习效应进行考虑。哎,那么另外一个就是他的职业归类,比如他的职业呢,如果说是什么球员呐,什么真人秀明星呐,什么老牌演员呐,哎,这个呢,我们也要把它作为一个变量考虑进去, 能理解吧?就在我们这个分析影响因素的时候,我们哪些变量都需要去进行考虑,我先给大家讲一下啊,关于这个职业问题,我们也得考虑进去。 那么再一个呢,就是这个年龄问题了啊,啊,比如某的老某些老人呢,他可能会有些情怀分啊,他的粉丝票呢,可能会比较高一点啊,那么比如说年轻人呢,可能会呃,票都好,那么就偏位分比较高。哎,这个呢,我们只是最开始的这个初识判断啊,只说具体有没有关系,我们就是看后面的那个回归和相关性分析了吗? 对不对?在我们最开始的这判断的时候呢,我们也先研究一下,大概哪些因素呢,可能都会产生影响,能理解吧, 而且我们在这里呢,不仅要去分析这些影响因素呢,对于结果的影响,还要去分析对于评委分和粉丝票的影响啊,因为这个题目呢也没辙,问了他们对于评委和粉丝的影响方式呢,是否是一样的? 好,那么大致的这个 ct 幕完整的思路呢?和一些啊,这个在我们纠结过程中啊,要去注意的一些关键的信息和雷区啊,以及一些注意点呢。我这个视频呢,应该都跟大家讲清楚了, 那么这个 c 级目呢,完整人生的问题,现在代码和结果呢,预计会在明天就是一月三十一号的中午左右就会更新完毕,那关于这个完整成为的说明,大家可以看这个视频的评论区。好, 稍后呢,我会再跟大家去讲一下这个 a 级目完整的这个思路啊。呃,我们这次呢会选择 a 级目和 c 级目呢,两到几目啊会同时进行,那么 a 级目思路呢,我一会会再出一个视频,那么这个视频呢啊,大家也可以转发到你的队友群里面,和你的队友呢继续商讨一下选题。 呃,以及呢,假如你们队伍选择 c 一 梦的话呢啊呃,给你们队伍呢啊,转到你们队伍群里面啊,可以去一起看一下,你们在休闲课中呢,可能容易踩了一些坑个点, 呃,包括这个题目的赛前思路,大家都可以去看一下。呃,希望能够帮助到大家啊,呃呃,希望大家呢都能够获得满意的奖项啊,谢谢大家。
210数模陪跑保证原创 10:53查看AI文稿AI文稿
10:53查看AI文稿AI文稿好的,接下来讲解一下 f 现在的一个做题的一个情况,现在的话第一问已经接近完成,就是已经主模型的话已经正在正在跑 啊,这是他的一个日制。然后接下来的话我们会去讲解一下这个主模型,然后具体怎么去运行,然后这个因为人数比较多,现在还没运行结束,需要等一会主模型怎么去运行,然后数据怎么去找,然后怎么去画一些图片进行一些介绍。 首先的话我们一个一个来,首先我们在讲 f 题的时候,我们需要去预测一个就是三个职业的去探索三个职业各自的未来,然后的话我们可以去找一些特征,然后去就是我们首先把这个未来要进行一个量化, 这里的话前面说的话我们可以用就业,可以用就业率或者说就业人数,这里的话,因为这个招聘量的话是更好去找一找一些,因为有一个网站的话,等会去讲一下那个网站,那网站的话就是会提供各个行业的一个招聘量,所以说的话 这里的话就是采用招聘量作为这个职业的一个未来的一个发展,一个趋势。这里都选择的是互联网行业,还有电器行业,还有文体艺术行业。因为画家这个行业本身他 太有局限性了,因为他的一个就业形式的话,画家这个行业可能大家可能都是副业,所以说这个不太好说,所以说就是选择了一个文体艺术行业。 然后接下来的话我们要进行,前面也说了两部分,当我们进行一个特征的量化完之后的话,就要去用预测模型进行一个预测, 首先的话我们来说这些指标是怎么得到的?首先这招聘量的话就是在于这样一个心智,这样一个平台,他会去提供各个行业的这样的一个人工,人工智能啊,或者说是互联网啊,或者说你可以选择一些, 比如说,比如说什么文体艺术啊,你可以选择这样这样一些行业,他会给你这些年的一个招聘的一个数据,当然这个数据是要花钱的,就是如果说不花钱的话,只有这两年的一个数据,这里的话我们也是已经买到了他过往的一个数据, 当然如果自身你想还想要其他行业的话,这个就可以自己去购买啊,因为这里这这篇文章的话就是使用的是这三个行业,所以说也只买了这三个行业过往的一个数据, 然后的话这里的话就是经典的。然后怎么去预测?呃,这个和就业相关的一些指标吧,也就是全国的一个 gdp 的 一个发展形式,如果如果说经济很好的话,当然 招聘的肯定会很多,然后还有失业率,可以就是整体的一个国家的一个就业的一个形式吧,也可以说是一个整体形式, 这是这个行业的形式,这是一个整体的一个大趋势。这里的话就是人口数量,如果人多一点的话,国家肯定也会发布一些政策,让让公司多招一些人,所以说的话他也是一个很重要的一个因素, 这些因素的话并不是关键,因为我们本身这篇文章要去分析的是 ai 时代未来的这些职业怎么去发展?所以说更关键的是这两个指标, 这个指标的话就是这个榜单,这个榜单是在二零二二年提出的一个榜单,所以说前面的话都写成六十七了,他也就是在二零二二年的十月份吧,提出了这样这样一个榜单,当时的最佳模型的话,就是拿到了一个六十七分的这样的一个分数。 这个就是这个的话,就是测算的就是 ai 这个人工智能,它的一个综合的能力,包括代码能力啊,什么都有能力。 然后前面为什么不写零的话,就是因为如果零到六十七,它跨越太大了,因为不能说从零直接突然跳到六十七, 这样指标的一个剧烈变化,会导致模型在预测上会出现问题,也就是这个指,也就是这个这个数据它不稳定,所以说预测效果肯定不好。所以说这里的话为了预测方便,所以说前面的话就是全部赋以六十七,这样的话我们用六十七来进行一个替代, 所以这也是就这个指标。另外一个指标的话就是 ai 渗透率。 ai 渗透率的话这里就利用豆包这样一个,每个就是它会有季度发布,或者说有时候会发布的比较勤,它会有每个月,然后发布就是豆包的在线人数,然后占就是总体的一个网民的人数, 然后这里的话它的发布就是因为之前没有豆包,所以说之前都是零,然后当豆包出现之后的话,它的就是它的一个 在线人数的这样一个占比,然后会逐步的增加。这里的话,呃,可我我感觉应该是存在一定的水分所在的,可能是豆包为了吹嘘自己的这样的一个能力,可能现在他可能是稍微的去对这个数据可能做了一些调整,这个我也不太知道,不太清楚,但是 虽然有水分,但是至少经过大家的一个,至少他发布出来了,所以说这个水分其实并不会特别的大,可能会存在一定的, 就是比如说计算,计算,比如说有有一些人的话,他可能计算的分母可能是太,可能设置不太一样,可能是网民,所以说这个比例可能会高一点,当然这这个趋势的话肯定是不变的,所以说我们更需要用的就是 ai 智能的这样的一个变化的一个趋势, 所以说这两个也就是我们在 ai 时代就是量化 ai 对 这个职业的影响的一两个指标,然后所以说我们利用这些指标,然后来对这个进行一个预测,然后我们预测的模型的话选用的就是这个模型, 就是 time s e r 这样一个模型,这个模型的话大家也可以去 github 上自己下载这个原文件,当然也可以下载我给大家就是准备的那个文件,因为我会去改动一些代码, 因为本身它这个这个项目它运行出来,它的预测的结果其实很乱,而它而且它的文件的命名格式也非常非常的乱,它会特别特别长,就是预测结果图的话会特别特别长,所以说不建议大家去自己去下载这个这个文件,到时候我会把这个文件给大家, 这个的话我就是对里面的一些东西的话就会进行一些修改,然后让它的预测会更加的就是好看到一点, 然后这也就是这个东西,然后的话怎么运行的话其实很简单,首先的话你需要去下载一个依赖, 这样的话你首先运行这样一个代码,然后把你的环境配置好,把你环境配置好之后的话,然后进行一个运行,首先的话你需要去给这个,这也就是这个东西的话就是我们要运行的一个指令,就是 python 一个指令的一个程序嘛。 然后的话我们要预设要运行这个拍摄文件,然后要给他,给他其中一些变量进行一个赋值, 这个值的话大家就不要再去修改了,因为这里面的值的话也是有些对应关系的,因为我们有五个指标,加上目标变量的话总有六个六列,总有六列变量,所以说这里的话有一些指标的话大家不要去乱动,然后只需要知道这里的话就是用的就是这样的一个数据, 数据的话就是在这个文件夹下,就是在这样一个文件,文件夹下就放放着这些的一个数据,数据的话就是首先所有的数据的话就是这些,然后因为因为我们还要去做这样一个,就是去解释一下,就是解释一下为什么我们这些指标 他具体有没有用,就是我们选了这些指标,但是我不能,我不能说我选的就一定有用,所以说我们要去进行一个证明,所以说,所以说要进行一个消融实验,也就是把后两列删除掉, 对吧?把这两列一删,然后再进行一个运行,然后来判别两次运行他们的精度是否会会下降,这样的话也就是一个消融实验的一个核心所在 啊,这里的话,这里的话就是用的全部的指标,然后后面这个实验的话就是用的一部分指标,就是把后面的两列删除掉,用的是这样的一个 csv 文件,然后这样去去进行这个问题的一个处理, 然后这也就是第一问的整体的一个处理的流程。当然我们还要,当然我们不能说把模型结果一放,一放上去就什么也不做了,当然我们还要辅以一些图片,就比如说我们可以把这些指标啊,然后做一些图啊,然后去看一看这指标具体怎么变化的,然后我们进行一个分析, 然后接下来的话就是结合模型进行一定的理论分析,这时候我们就已经把这个问题的一个主要的模型给建立出来了,就选用的模型的话就是这个模型, 然后这个模型的话就是在 n i p s。 上进行的啊, a n i p s。 上进行的一个发布,也就是顶刊,计算机的四大顶刊之一,就是这样的一个顶刊, 这个顶刊的话,然后它当时发的很早,就是二零二四年去投的啊,二零二五年才接收,然后最终的话被评为二零二五年的最佳论文,然后也就是这篇模型,也就是这个模型,这个预测模型, 然后的话我们利用这个模型作为我作为我们这道赛题的一个主心骨,然后来进行一个,相当于进行一个呃,一个展现吧,我相当于展现我们个人能力,还要展现我们对这个问题用的一些比较先进的模型,然后我们不仅可以理解问题,还可以应用一些先进的模型来解决这个问题。 就会比大多数人在做这个问题的时候,可能大多数可能就是画一些图,然后去语言分析会来的更更亮眼,亮眼一点会让评委可能会更倾向于我们这些论文,可能会给给一个更高的分数, 所以说这也就是这个问题的一个分析。接下来问题的话,就是这个问题的话,就是相当于第一问的结果出来之后,我们可以起到一个承上启下的作用,就在这个问题中我们可以进行一个呃,结合第一问的结果进行一个分析。 好,第三问的话就是我们要对这个原因,也就是影响招聘量,也也就是影响这三个职业的发展的一个原因。这两列进行一个分析,可以作为一个逻辑回归,然后进行一个分析,然后的话这也就是这一问, 然后第三,然后最后最后一问的话,也就是一个模型推广。这里的话我们就可以去结合 gpt 啊,然后去去生成一些模型推广的一些建议,然后或者说它的一些 他的一些内容吧,然后我们可以去修改一下,然后作为我们的一个模型推广,这就是这篇,这就是这个赛题整体的一个呃处理的一个流程,然后这也就是赛题整体的一个分析吧,然后大约可能在需要五六个小时,然后就可以完成,因为只需要 第二问,第二问的话还是比较快的啊,第三问的话就更不用说,然后当可能在呃半夜的一两点,一两点钟的话可能就会写完,然后的话接下来的话就会去进行一个论文的书写, 然后可能在明天的六点之前的话就一定会给大家发布出来。所以说这也就是这个问题的一个做题的一个情况,就是 f 题的一个做题的情况。好的。
 01:51查看AI文稿AI文稿
01:51查看AI文稿AI文稿好,那么 a 题的话呢,嗯,给大家补充一点这个查找数据啊,首先的话这个数据由于它这个美赛嘛,它是国外的比赛,它所这种, 嗯指的数据集呢,一般来讲呢是这种美国的,或者说是,呃世界性质的,就是我们中国的一些数据网站, 嗯,可能,嗯不太好用。这里的话呢,给大家推荐一个这个卡购,卡购的话呢,呃,他的,他是有众多这种比赛的数据集,还有一些其他大佬啊,他发布的一些这种呃很高质量的数据集,有清洗过的,也有没清洗过的,甚至有的呢,还有一些这种 啊,还有一些这种清理代码,这里告教给大家怎么进行一个搜索啊?首先呢就是我们可以在这个搜索框,比如说我们找找一个想搜索,比如说我们想搜索这个手机的电池水平, 然后我们找,然后我们这里呢可以查找这是它的代码,然后呢这里呢是它的数据集 啊,这之后呢大家可以看到一共有十四个数据集,那么我们可以挨个点进去挑一个这种合适的数据集,对吧?比如说这里啊,我们可以看一下这是它所有的数据集,我们可以看到 我们啊可以看到它到底符不符合我们的要求,比如说它这里可能是这个屏幕大小啊,然后这个设备这个 名称,比如说小米十一啊,我们可以在这里呢根据要求自己搜索数据,自己寻找数据。
68BZD数模社 40:57查看AI文稿AI文稿
40:57查看AI文稿AI文稿好,大家好,欢迎来到数魔加油站。那么本次给带来的是二六年,然后的话美赛的一个历年赛季分析,以及我们的一个考量预测。那么我们知道之前在国赛的时候,我们也做了这么一期的视频,然后的话当时的话是 五道题压中了四道,对不对?整个的一个准确率的话还是比较高的,那么美赛的话作为我们这样的一个比较大的一个比赛,那么的话我们肯定也不能够缺席。我们来看一看这个美赛他到底考些哪些东西, 我们应该怎么去准备,然后整体的一个考察趋势是什么?我们的重点应该放在哪些地方,然后这个地方的话会给大家带来我们六道题的一个整体的一个分析,加上我们的一个总结。 那么梅赛的 a 题的话,我们可以看到它其实考的东西是很乱的对不对?有什么真菌,又有自行车,又有植物,又有什么资源性别,这个是动物, 然后又有什么台阶磨损,看起来的话非常非常的乱,而且的话它的考点也很杂对不对?里面有包含什么东西, 什么动力学方程,然后的话什么作业控制, d p, 然后的话统计空间统计, largest 叉分,然后的话微分方程,对吧?各种各样的分布, 动力学仿真贝叶斯估计看起来的话完全没有规律,完全是杂乱的,完全是乱的不行。那么我们怎么去找到它的一个整体趋势呢? 那么它主流的话主要是考察它的一个这样的一个生态这一块的东西, 对于美赛而言的话,其实生态的话一直是一个非常核心的一个点,六道题里面有两道到三道都是会和我们的一个生态去挂钩的, 所以说在我们之前的一个主要的考点的话,其实就是在生态学这一块,然后里面主要涉及到的方法的话,就是生态学的一些方程,比较典型的就是逻辑,对吧?和他的扩展型逻辑卡 这两个模型的话,在每赛里面的出现频率是非常非常非常高的,而且不仅仅是 a 题里面 a 题、 b 题、 e 题这三个题目里面,这个模型的出现频率是非常非常之高, 所以说的话我们一定要重点关注一下。对于我们要备赛这几个题的同学来说,而现在呢,现在它一个最优化就是它的一个反问题, 那么原先的话只要求你会正着推过去,那么现在的话还要你会反着推回来, 那么反着推回来他有个难点,就是说比如说我们有一个,对吧? y 等于 abc, 那么我我们之前是已知 abc 去求 y, 那 么现在的话我们要已知 y 去反推 abc, 但是的话我把 a 乘以二,然后的话 c 除以二,那么他们得到的答案是不是一样的呢?对吧?是一样的。说实话反着退回来的话,它里面的话不确定性就会更高, 对于我们模型的要求和稳定性也会更高。所以的话可以看到的话不仅仅是美赛各种各样的比赛,在近两年来特别喜欢考的一个点就是贝耶斯, 用贝耶斯的话是不是就是从正着推过去到反着推回来这样的一个模型对不对?那么它整体的一个考察趋势呢?就是动力学是重中之重,是一个非常基础的一项。 在动力学的基础之上,我们要去保证我们模型的稳定性,要充分的去处理模型的不确定性,然后在我们多个指标之下,我们要提出一个可以衡量解决方案,对吧?可以衡量各个指标的解决方案, 整体的话更加看重于你模型的一个落地能力以及它的一个稳定性,因为我们现实生活中是充满不确定性的,而我们的话我们怎么算才算一个好模型?就是能够在我们不确定的现实生活中来得到一个确定的解。 说实话你们主要考的东西就是动力系统,这个是基础,然后的话有多对象进行交互,然后随机性是必考的,然后的话优化和控制,然后近些年的话,对啊,近两年特别喜欢考的东西就反演加推断, 同时我们要保证我们的模型是有作用的,它是可以落地的。最后的话就是我们要干嘛?我们要写类似于那种书信的形式,然后的话去用我们的一个非数学性的语言把它给表达出来。 那么现在他主要考察的东西的话就是这么几个,一个是我们随机环境下面的一个连续系统,比较典型的就是我们去年,对吧?去年的那个楼梯, 然后的话还有一个是二三年的一个自行车,应该是二三年吧,对吧?二三年那个自行车的问题 外部会有各种各样的因素来干扰来影响你,而你要做的就是把这些东西给它梳理清楚,哪些东西是我们需要考虑的,哪些东西又是我们不需要考虑的哪些东西我们应该怎么去对它进行模拟,哪些东西我们应该去找真实的数据, 这个是非常重要的。那么其次的话就是我们的一个多目标策略优化,目前在 a t 里面多目标考的频率不是很高,但是的话会涉及有,偶尔会涉及到一些, 那么基本上对于美赛的多目标问题而言的话,基本上我们用的模型的话就是一个 n s j 二, 那么第三个点的话就是我们的一个繁衍与推断,那么这个是我们近两年来这个数学建模竞赛里面非常大的一个趋势,就是我们的一个繁衍推断,主要是要把我们的一些内容和我们统计学相结合起来,那么统计学的话是现在的一个大的趋势嘛,对吧? 基本上什么东西的话都喜欢带点统计学内容,那么的话现在每次的话也不例外,那么比较典型的话就是用我们的背页式方法去做繁衍。然后最后一个的话就是我们一个具体的一个角色的建议,用非数学性的语言,然后去表达清晰,当发生什么样的情况的时候,我们要做出什么样的决定, 那么我们要去备赛 a t 的 话,我们要去准备什么呢?那么现在对于整个的一个数学建模竞赛而言的话,你去准备单个模型的话是不太够的, 现在的话数学建模的话还是比较考察你的一个综合能力,单模型在我们数学建模竞赛里面已经不是很常见的,那么的话对于 a t 而言的话, 一般的时候我们需要把它作为整个模块来进行考虑,整个系统的话里面可能会有多个模型,我们需要把它们进行堆叠组合,然后来形成一整个模块, 那么这个模块的话就包含了系统动力学,然后的话我们外部驱动因素,然后我们的一个繁衍,然后包括我们的稳定性分析,然后我们的一个模型验证以及我们最终的一个决策。 要保证我们的一个模,我们的一个模块它是一个整体,它是可以连续起来,它是可以拼接起来的,它们之间没有什么太大的缝隙可以插进来,同时的话也不能够直接把它抽出去,抽出去的话就会导致整个模块崩塌,要让它们保证在 要保证我们这个模块在一个比较平衡的一个结构里面, 那么对于 b 题而言的话, b 题的话一样的话也是一个优化的问题,但是的话你可以看到基本上现在考察的东西的话都是跟什么相关, 是不是我们的一个可持续发展呀?对不对?而里面涉及到最多的算法的话,就是我们的多目标优化,也就是我们所说的美赛里面最常用的一个优化模型 n、 s、 g、 r, 专门用来解决我们的多目标优化问题的。 同时的话,其实你们也会和我们的系统动力学去挂一点勾,会去沾点边,但是的话它里面考察系统东西一般考的比较简单,一般就是一个像这种趋势性的一些东西, 比如说增长啊、衰退啊这些东西,它的话一般会涉及到一点系统动力学的一个内容, 那么虽然说我们的一个 e 题才是可持续发展的主题,那么的话,但是对于 b 题而言的话,近五年考了四次,它的一个频率也是非常非常高的。 比如说你可以看到这个可持续发展这个主题的话,其实在我们的 a 题、 b 题和 e 题里面都是有出现的,所以说我们在备赛的时候一定要特别特别注意一下这样一个主题, 那么只要提到了我们这种环境相关的问题,可追相关的问题的话,基本上的话我们有一个模型,它就是逃不开的,就是我们前面收获到的什么东西,对吧?逻辑色,然后的话以及它的衍生和罗特卡, 罗特卡是这美赛里面出现频率非常非常之高的一个模型,这个一定要注意一下, 那么对于整个 b t 而言的话,它还是以优化为核心的,但是的话它里面又会涉及到一点其他的东西,因为我们是要走可持续发展的道路,所以说的话你不能只在当下稳定,你要保证你在未来的一段时间里面也是稳定的。说实话里面有可能会带有一些什么东西,带有一些长期预测的一个内容, 同时的话因为我们未来它的一个变化它是有波动的, 那么我们怎么去把他这种波动的变化率给他模拟出来呢?就需要我们的动态仿真,最后 未来是充满不确定性的,那么我们的这种模拟我们到底能不能够去贴合我们现实,我们的这个误差有多大?他的一个误差区间是多少? 他的一个自信区间又是多少?那么的话我们就需要干嘛去用不确定分析来表明我们的一个模型,他稳定的区间在哪个范围里面去,在哪个区间里面稳定,遇到什么样的极端情况他可能会崩塌,他又能够抵挡什么样的极端情况,这个就是我们要考虑的内容了。 其次的话就是我们要去学会编辑这种非技术性的报告,我们怎么能用非专业非数学的语言能够去清晰的把这个事情给他讲清楚,能够让非技术人员能够看得明白,同时知道我们应该去做些什么东西。 这个就非常考验大家对于自己模型的一个理解能力,对于我们这个场景的一个理解能力,以及我们这样的一个写作能力了。 也就说他现在不完全是要求你只会做一个呃,这种小型肚皮虾只会答题,你现在不仅要会解的出来,而且还能够真正的能把它落到实处去,能够讲还能够把它讲的明白, 这个是我们非常考察我们综合能力的一个点。那么对于 b t 而言的话,主要的话就是要求我们有一个跨学科问题,但是的话现在 b t 的 话基本上也是跨学科比较多, 不怎么再去考考察那种比较纯粹性的那种数学建模题目了,基本上都是和交叉挂钩模型的一个要求不是很高,但是的话对于你这种对于交叉学科的一个要求很高, 那么其实的话就是找数据的一个问题,那么找数据的话基本上就是我们在我们的一个文献政府报告,然后的话我们的公开数据库里面去获得,不要去什么 c、 s、 d、 n, 什么知乎,什么简书这些平台上面去扒, 虽然说它有可能也是引用的某些政府的数据,但是的话整体这个平台,对吧?那个数据平台它是所有人都可以发布的,它的平台的这个数据来源它就不可信。所以说你要去建模,你要去找数据的话,你一定要以官方为准, 否则的话你从数据上面都去都出了错误,那么的话你基于这个数据分析出来的东西,那不都是完全都是乱说吗?对不对? 那么对于 city 而言的话,呃,他可以看到在往年的话,我们说二一年是数学建模竞赛的一个比较有代表性的年份,因为二一年前后它的一个考点的话变得非常的大, 那么二一年的话你可以看他考虑什么东西, cv, 对 吧?然后的话 n、 n, 然后还有什么扩散模型,整体的话考察的东西是比较前沿的,更加的偏向于模型。而到了二一年之后呢?量化, 然后的话预测 what 有 结果?网球动量、奖牌预测越来越偏向于传统性的,偏向于理论测了,这个的话就是它的一个区别所在。 那么二二年的话是关于我们一个量化投资的一个问题,主要的话是包含我们那个时间训练,以及我们对应的一些交易行业里面的一些模型,比如说什么回测呀,对吧? 然后我们要去分析什么 k 线呀,对不对这些东西。然后 word 的 话它是一个训练模型,它是有一个关于文本的一个内容,但是的话它没有考得那么深,所以说你也不需要用什么什么那种 transformer 啊, 那么我们来看一看它到底考下来些什么东西。那么对于我们数据题的话,那么数据清洗肯定是必不可少的, 那么比较常见,对吧?我们缺失值处理,我们异常值处理,我们的多表关联,我们的分组聚合查询,对吧?这些一些比较常见的一些数据清洗的一个内容,然后还有什么,呃,这种编码对不对?特色编码 等等等等,这个的话对于我们数据来说的话是一定会出现的。其次的话会要求你对于我们这样的一个不确定性进行一个评估,因为对于预测模型来说的话,本身的话就是带有一定不确定性的,它本身的话就是一个黑盒的比较模糊的一个概念, 那么你的核心的话就是在我这个模糊里面去找到清晰,从不确定里面去发现确定,确保你的一个预测是可信的啊,比较常见的,我们的 boss, 我 们的蒙特卡洛贝耶斯,对吧?然后去得到你预测的一个自信区间,他的一个位置在哪里。 然后第三我们这个模型性能评估,那么我们比比较常见的我们回归,对吧?阿尔方,我们的 ms 一 ma 一 rms, 一 分类的话,我们的 f 一 分数,我们的准确率、精确率,召回率, 然后剧类的话我们的带维生保定指数,对吧?然后的话我们的轮廓系数 诸如此类,那么有的时候我们还不能够仔细看整体,我们要发现某一个特征之中是否存在一个预值,然后的话当突破这个预值的时候,这个我们的一个预测结果就会完全不同, 那么我们就要清晰的去梳理我们发现这个预值的一个过程,然后的话清晰的说明我们做这个分层的一个依据,然后各个层级之间他们有什么共性,什么特性,你的一个分层的一个理论是怎么样的? 然后其次的话就是我们的一个时间训练,那么的话训练模型是我们非常常见的一个模型,训练状态模型,像我们的这个去年的这个奥运会,前年的网球,然后的话带大前年的我们的 vivo, 其实的话都是在我们的一个训练模型的一个范畴内, 然后优化和决策的话,不太会涉及到这个优化和决策的内容, 只是说你需要用这种思想去衡量,对吧?去把它的一个不确定性给稳定下来,但是的话一般的优化模型是不怎么会用到的。然后还有一个比较核心的一个点,就是我们现在的一个因果和效应的一个识别。在过往的话我们一般做分析的话就只用做一个相关性分析就完事了, 但是现在的话相关性分析的话,他能够得到的一个因果效应太弱了,我们要从我们的相关走向我们的效应,再从效应走向因果去真正的能够深层的发现这个数据背后他的一个规律所在, 到底是什么推动了他这样的一个发展。那么还有一个的话就是我们这个多表关联和层级建模, 那么的话这个是在我们这两年里面用的比较多的,它会给你多个表的数据,然后的话它们里面你要用,对吧?要用外界连接的方式将它们聚合起来, 然后他要涉及到我们的多表查询,而且有的时候他们这个键,他们的一个命名还不是统一的,你还要去进行规范统一。最后一个的话就是我们一个面向非技术人员呢,也是我们所说的我们要去编辑报告,编辑我们的决策建议,那么的话这个东西也是我们现在必考的,基本上是必考的一个点, 我们要用非数学性的语言给他描述清楚,这个的话,他的一个权重是越来越重的,现在的话基本上已经快上升到和栽药一样的层次了,因为的话 从栽药里面可以看出来你的一个权威的工作到底严不严谨,从你的一个报告里面可以看出来你对于什么样的情形会做出什么样的决策,这个决策是否能够真正的落地。所以说这两个东西都是只有一页,但是的话这一页的权重是非常高的。 那么在过往的话我们的一个不确定性是可选项,但是现在的话我们的一个不确定性是我们的一个必选项,那么对于我们不确定性的话,我们的一个概率题,我们的一个统计题,对吧?我们的数据基本上的话就是用的 bootstrap、 蒙特卡路和贝叶斯或者分成, 尤其是我们的贝爷斯,贝爷斯在近些年的一个出现频率非常之高,基本上的话如果说你要去准备出季末季赛的话,你最好还是要去懂一些这个贝爷斯的一些相关理论,不是说你只知道一个贝爷斯公式就完事了,那只是我们的一个入门, 那么相比比之前的话,我们的一个现在对于你的一个模型的一个验证,它的一个要求会更加严格一些, 你必须要保证你的一个模型在当下,对吧?是最优或者是近是最优的,能够放在这个场景下面去稳定的运行。那么怎么证明你的一个模型是比较优的呢?那么的话你就需要一个对照基线有有一个基线模型来和你进行对照, 所以说我们一般都会建议大家,对吧?先比赛的时候先做一套最简的一个架构,然后的话在最简的架构上面去做修缮,这样的话你就能够非常清晰的知道你做什么步骤可以提高你模型的一个能力,你做什么步骤会降低你模型的一个能力,从而的话你就可以理清楚一个非常清晰的一个链路。 那么第二的话就是我们那个从相关性分析,对吧? p h c p r 浏览器, 然后呢或者是说做一些什么分析,做一些那个假设检验,我们就能够得到他们之间是有一个什么企业比较强的一个相关性的,但是的话现在的话他需要进行更加细致的分析,你有相关性,到底相关性体现在哪里?是什么原因造成的这个相关性? 他们的一个变化到底是有一个其中一个的变化会对另一个造成多大的一个影响,你都把它需要把它给量化出来。那么现在的话一些比较常见的一个控制混杂的一个手段的话,就是我们的分层固定效应模型和我们的差分, 那么其次的话还有一个是用在我们的一个因果推断里面,一个非常常用的一个思维,就是反事实的一个推断, 用反事实的方法去作为我们的对照组,看看他到底会有什么样的影响。同时的话我们一个相关和我们的因果之间,他们还是有一个非常强的界限的,所以说的话,你在我们的一个描述里面你就不要说, 对吧?因为他们相关所以说是什么造成的什么那个原因,这个的话是非常不严谨的。那么现在的一个考法基本上就是有三种考法,一种是预测加解释加决策, 比较典型的我们建立一个回归或者分类模型,对吧?那么一般的话就是我们的 g b t t, 然后随机森林 s v m, 然后的话逻辑式的心情回归诸如此类的模型, 然后我们做了之后的话,我们就要去进行解释,那么解释的话我们还要我们比较常用的我们的下铺纸, 对吧?我们之前一直给大家说了,用下铺纸去解释你的模型,尤其是机器学习这一块,然后的话用我们的像我们 bootstrap 呀,对不对?这个是非常常见的,在我们预测模型里面, bootstrap 方法,或者是说你用蒙特卡洛方法去得到你模型的一个自信区间,看看你的自信区间到底有多宽, 你的不自信心到底能不能够收敛,然后基于你的一个模型的结果和你的一个因果的一个推断,然后的话去做出相对应的决策,当发生什么事情的时候,你要去做出什么样的决定? 那么其次的话就是我们的一个训练模型加上我们的一个检验的一个过程,那么训练的话一般会伴随着非常大的一个不确定性,因为的话 一般训练模型的话,它是针对于单个训练而言说的。呃,一般的话在我们的睡觉模式里面很很少会考到我们的一个多训练的一个模型,那么单训练的话你就只能够基于过去去推断未来,然后的话它的话就会有非常大的一个不确定性,同时的话 呃,还会存在一个误差传递的一个过程,那么你的一个核心的话就是怎么可怎么样,尽可能的减少这样的一个误差的传递,同时的话让你的这样的一个单训练能够稳定下来,这是一个非常, 这是非常考验你这样的一个数据处理的一个功夫的一个能力的一个考法。你怎么把这种胡啊杂乱的序链能够处理,能够理清一条比较清晰的链路,然后再选用合适的模型进行建模,这个非常考验你的一个基本功。 那么一般的一个考法的话就是我们的一个状态切换点识别,我们在什么情况下应该去切换我们那个状态,然后的话我们在什么时候,当到达什么值的时候,我们要去进行预警,比较典型的我们的那个量化对不对? 那么第三个的话,我们的一个层级面板加上我们的一个效应分解,那么的话面板数据这个的话也是我们美赛里面非常喜欢考的一种数据类型, 那么比较典型的话就是我们的贝叶斯方法,然后我们的分层拨松,还有我们的固定向与回归,或者是说我们的差分,差分的话在我们的一个因果领域的话是用的非常多的一个方法。那么我们 ct 的 话,到底应该要去准备哪些东西呢?首先的话比较典型的考点预测加解释加决策, 所有的方法的话,就是比如说我们要用一些集成部学习啊,就是我们的一些 gbt 啊,什么收集森林,什么超级 boss 的, 什么来 gbm, 什么开 boss 的, 对吧? 或者说用一些比较简单的模型,心情回归,逻辑回归,然后什么决策树,然后什么贝叶斯朴树,贝叶斯,对吧?然后用我们的 bugstop 方法,然后的话来衡量它的一个不确定性, 最后输出我们的一个决策,并且给出我们决策的一个依据所在。那么第二的话就是我们的一个训练或者说状态模型加上一个检验的一个过程。 那比较典型的话就是我们的一个野马模型,然后的话加上我们的一个置换,或者说我们仿真。那比较典型的应用领域的话,就是我们一个状态切换的一个识别,以及我们的一个预警的一个识别。 那么第三个的话就是我们的一个面板数据加一个效应的一个分析。那么比较典型的方法就是我们的一个分层薄松,或者说用我们的一些贝叶斯方法,或者说我们固定效应模型,或者是说我们的一些差分。 那么像美赛的话,现在这个差分也是考的挺多的,因为的话其实很多有些英国模型的话,他其实也是基于差分的思想去做的, 那么我们可以去给我们的一个 city 去做一个总结,里面的话包含了我们数据层,数据层的话我们要干嘛?趋势处理,异常值处理,分组聚合,对不对?我们说过了我们数据分析这常用的几个函数,对吧?分组聚合查询。 其次的话,我们的一个预测层里面包含了什么?包含了什么持续数据,然后的话比较典型的 lma, 一 般的话是作为我们的一个基线模型,那么除此之外的话有什么呢?比如说我们要预测多个时间序列的,我们一般会用什么?五二对吧? 向量值回归还有什么?呃,比较经典的一些的 prop, hat, l, s, t, m, 对 吧?其次的话我们还有一个用于计数和比例的模型,我们的 glm, 然后一般用于我们的回归和分类的,一般就是我们的一个 logist 和我们的一个 linear regression, 对 吧? 现金回归和逻辑回归是我们比较通明的一个机械模型。然后在不确定性方面的话,我们一般都用我们的 boss, 然后呢摩登卡洛贝尔斯。在分类这一块的话,我们一般用什么方法?我们去给每个类别去设置权重,然后来避免这种不均衡数据的一个影响。 其次的话我们可以手动的去更改这样的一个域值,判别域值,然后的话来减少这样的一个不均衡数据的一个影响。那么对于我们一些概率模型的话,我们还可以用我们的 platt 方法,或者说我们或者说我们的 icotonic 方法去做我们的概率校准, 对于我们训练模型的话,比较常用的我们的划窗模型,或者说我们指数加权回归,然后我们的银码模型辨别检测。那么对于角色的话,我们很少会考到模型,那么是一般考的话,基本上就是涉及到背包和排序,然后的话一个 m l p 就 ok 了。最后我们就要对我们的模型进行验证,确定我们的模型它那个效果是好的。那么我们一般怎么去验证呢?有我们的留一法对吧?留一法留出验证,或者说我们的一些交叉验证,然后对于我们一些金融模型或者时间训练的模型的话,我们有一些滚动回测, 对吧?然后的话对于我们一般的模型的话,我们有一个基线对照,然后确保我们的模型是最简加够,有没有溶于的部分。 那么对于地铁而言的话,地铁的话是一个非常典型的一个图论的题目,他每年的话都是考图的模型,可以看到二零二一年图的一个,对吧?音乐影响力社交图,二二年企业战略数据,这样一个企业图,市场图,对吧?二三年 可持续发的目标环境图,二四年这样的一个五大湖水怪钓位,又是一个环境图,对吧?水位图,二五年城市交通规划交通图,所以说它的数据结构是已经确定下来了,就是一个图, 那么它的考点呢?因为图论的话已经有非常非常多成熟的框架去实现了, 基本上你只要把这个图网络给它建立起来的话,那么里面的各种各样的模型啊,你基本上只需要一行代码就可以实现,所以说的话一般考这东西的话都不会考的很纯粹,但还会把一些其他的内容给加进来,比如说我们的决策对不对? 那么我们知道我们图的话有两个结构,一个是节点,另外一个是边,那么节点的话它是固定的,那么边呢?边是我们需要去衡量它的权重的,衡量它的边长, 那么因为我们图论里面的一些算法是已经相对而言是比较固定的了,他不能他没办法去考出什么新东西来,所以说的话他就只能够去把这个边让你去衡量这个边的权重, 他不会直接把边的权重给你,或者说他给你一个边,给你多个权重,然后让你去最后算出你的综合权重。那么这个时候我们应该怎么办呢?那么比较典型的我们就会用我们的一些评价模型去评,去评价这个边他这个权重到底是多少, 把它给量化出来,这样的话我们才能够把整个图网络给它建立起来,否则的话你拿到数据之后,你会发现它要么就是节点没有边,对吧?要么是节点没有给边的权重,要么就是一个边有很多权重, 那么图的话它是比较错综复杂的,基本上就是迁移法而动全身的这么一个结构,所以说的话对于我们图那么一个模型的稳定性的话,要求会更高一点。 那么比较典型的就是我们的节点失效,或者说边失效的时候,那么我们应该要怎么去动态的去变化,怎么才能够让这个图不会崩塌, 我们怎么去平衡这个图?它们之间的关系,怎么去做分流等等等等。这个是美在对于地题非常喜欢考的一个点, 那么的话基本上它的一个做法的话也比较相对固定,固定的首先的话根据它的给出的数据去构建我们的一个网络体系,然后的话用我们的商圈法,或者是说我们商圈法叫 a b h p 或者是双圈法叫 topase 去定权, 然后的话再去调用这个图论里面的那各种代码包里面的各种各样的模型,什么都最短路啊,最大流啊,对吧?最小费用最大流啊,最小生成数啊这些东西基本上只要我们把这个图给建立出来了,其他的内容的话,所有的算法都是一行代码都可以实现, 那么里面主要涉及到的东西就是有这么些,一个是网络分析对不对?可能会考到我们的网络流最短路。 其次的话评价和角色用来确定我们编的一个权重里面比较典型的 a h p 三乘法和 top space, 然后优化模型,我们一般图论的一些模型, 然后当我们决定和编失效的时候,我们怎么应该去仿真,怎么去模拟它,这个失效之后我们的这个网络会发生什么的变化,它是整个的一个,是一个动态的结构,我们要能够去适应这个现实里面的这个变化,然后的话来进行动态的调整, 然后还包含了一些数据科学的一个内容,那么的话数据科学的话里面的话可能会有什么组成分析呀,具类分析呀、回归预测呀这些东西的。然后去年的话还考到了我们一个 g s 的 一个空间分析,但实际上你不用 g s 做也可以。 那么像现在的话比较典型的很容易考的一个点的话就算了,一个网络的一个韧性,就是说怎么才能够让你整个网络不失效, 不会因为某些变动而直接崩塌掉,这个的话是近些年来考察的一个趋势,尤其是像去年的那那种题目。 所以说啊,他今年的一个考点的话,很可能就是和我们的一个网络韧性相关的,也就是如果说,呃,我们某一个节点或者某几个节点呃他中断失效了, 那么我们应该其他的东西应该怎么变化,才能够去保证我们整个系统它是能够正常运转起来的,而不会牵一发而动全身?全部一个失效,全部失效,我们它能够抵抗风险的一个预值是多少? 我们怎么做才能够提高我们的一个抗风险的一个能力?那么一题啊,是一个关于可持续发展的一个问题,那么的话他考的内容的话就比较杂了一点, 因为可持续发展的话,它是一个很大的一个主题,它里面的话涉及到的内容会非常非常的多 啊。比较典型的二一年你们有什么系统动力学,又有什么供应链?然后又有多信息分析,然后二二年呢?又考到了什么微分方程?又有什么动力学,对吧?然后我们都有多决策模型政策沟通, 二十三年又有我们的这个多目指标模型分类评估决策课。二十四年保险,保险行业的精算,只要说你不是这种保险专业的话,基本上你都不太涉及到这种精算这个东西,对吧? 所以说的话还容易考察的一个内容的话,就非常非常杂乱。如果说你想要去把这种一体可能会考到的模型全部都学一遍的话,这个是不太现实的,因为它里面总会有一些这种偏向于这种专业性的模型,是你平常可能完全都不会涉及到的, 那么这个时候的话就需要我们去查找对应的文献,然后的话去查找对应的资料来进行纠解了, 然后二五年,对吧?又是我们的系统逻辑群,所以说系统逻辑群的话在我们美赛里面是一个非常非常重要,也是一个非常非常常考的一个考点,尤其是我们这个挪的卡模型, 这个是频繁出现在我们的 o 奖论文里面, 那么在过去的话,它里面的话只会涉及到环境里面的某些单纯的情况,但是现在的话需要你考虑整个环境的系统,然后过去的话是我们考虑它里面的一些镜,是对静态的一个系统,对吧?静态的环境进行分析,而现在的话我们要考虑有整个环境它的一个动态的一个发展。 对于模型的选择的话,现在的话也不会考察你单一模型的,更多的是考察你对于组合模型的使用能力,最后要提供一种非技术性的报告,然后的话能够用非数学性的语言能够把它给讲清楚。那么对于一体而言的话, 他的话就要求我们对于整个题目有一个系统性的一个了解,有一个能够对他进行系统性的分析,然后里面会包含多个模块,我们需要根据不同的模块的结果,对吧?我们要把这个模块给他组合起来,然后综合他们的结果去得到一个你想要的一个答案, 根据他的一个输出去提供对应的决策的一个建议。那么里面比较常见的考点的话,就是我们一个第一个是我们的动力学,第二的话是我们必考的这种不确定性的分析。那么现在比较典型的考点的话,就是对于他的一个情景进行分析, 在不同的情景下面会有什么样的一个情况,他是一个理想的,而往年的话一般会考察一些连续性的这种敏感性的分析。 然后第三个的话就是我们怎么去找数据的问题,那么一般的情况下的话,我们都会在我们的世界银行里面去找数据, 或者是说一些这种啊这种官方的数据网站里面去找数据, 这个的话我们也跟大家说过了,千万不要去用类似于这种 c、 s、 d、 n 啊,知乎啊这些平台里面的一些数据,这个的话它的一个是没有经过验证的,这个的话它数据的话你是不能够保证它数据的一个可信性的。 那么 f 题的话它就是一个政策性的一个题目了, 那么 f 一 的话都是和我们政策相关的题目,然后的话一般的话都会用到一些这种政治经济学里面的一些模型啊,跟我们一般用的模型的话可能就不太一样, 而且的话像这种政治经济学的模型的话,一般的话也只会在我们的 f t 里面出现,所以说的话一般的时候的话,我们都没有去,对吧?刻意的去学过这方面的一些东西,因为在其他的比赛里面啊,这东西这些东西的话都出现的太少太少了,只有这个 f t 里面会涉及到这些东西。 但是的话说,虽然说它里面会考到这种政治经济学这种东西,它里面的模型的话一般还是用的比较简单的。 那么对于我们的一个 f t 的 话,虽然说它是一个政策的题目,但是的话一般的时候也会和我们的一个可持续这个东西去挂钩,所以说可持续的话实际上是每一项里面非常非常非常常见的一个考点。 那么对于 f 的 要求的话,它必须要求你使用这种真实数据,因为它是跟政策挂钩的,跟我们的政治挂钩的,你这种的话肯定不能够去编数据啊。像去年的话,它里面的话要强制要求了你使用那个 vcd 的 一个数据据, 用 vcdb 和其他的数据源作为你的一个数据支撑。然后其次的话就是用我们实证分析的方法去衡量它政策实施这样的一个效果, 然后根据我们政策实施效果的话,去给我们提供对应的政策建议,我们到底应该怎么去改良我们的政策到底应该去怎么做? 最后去验证我们的一个模型。那么像这些年来来考到的东西的话,就包括我们的政策法规呀,我们的人力公平啊,我们的国际合作呀,我们的数据安全这些东西 可以看到他基本上什么东西都会沾一点,考的非常的宽泛,对吧?考的非常的宽泛, 那么的话它里面可能涉及到的考点的话,今年的一个考点的话,因为去年的话是 a 建特元年,那么因为它是 a 建特元年的话,所以说它里面可能会考到一些和我们 ai 相关的一个东西。 因为美赛的 f 里的话,一般的话都是和我们实施热点去挂钩的,所以说的话像去年的话,像这么重要的一个年份,这么特殊的一个年份的话,他应该可能会考到这种 ai 治理,或者说 ai 的 一种相关的政策, 比如说根据我们国家的 ai 治理指数呀,对吧?然后的话去衡量各个国家的一个治理水平,或者是说我们的 ai 安全呀, ai 治理呀等等等等。 那么现在的话我们来总结一下,对于我们美赛而言的话,我们到底要干嘛?拿到元素数据之后,我们首先的话要去把我们问题去抽象, 抽象成我们数学语言去表达出来,然后的话再用我们的模型去进行建模,建完模之后我们要去验证一下我们的模型到底有没有用,它到底稳不稳定, 然后总结我们模型的内容,总结我们的输出,总结我们的决策,然后的话把它化为一个可以与非技术人员沟通的一个文章, 然后基于这个文章的内容的话,我们要去反思我们到底应该去遇到的什么样的问题,为什么遇到这个问题。然后的话我们在遇到什么样的情况的时候,需要去做到做出什么样的决策才能够达到一个最好的效果,然后的话最后提供对应的一个决策建议。 而对于我们每赛重中之重的一个灵敏度分析的一个部分的话,我们基本上的话会有这么几种情况,那么我们比较典型的我们要局部灵敏度分析,然后的话它主要是针对于连续参数,看看我们每个变动,对吧?对于我们这个模型会有什么样的影响。 其次的话还有一个是我们理想的情况,我们不同的情况,他的一个变动会对于我们整个模型有什么影响。那么第三个的话就是对于我们的一个不确定性的传播,也是比较典型的,我们要去算他的自信区间对不对? 那么比如说我们如果说输入是随机的,那么我们可以通过我们的大量的模拟,然后得到我们输出结构的一个统计分布,看看他的一个自信区间到底是在哪个位置,他的一个自信区间到底是宽还是窄,能不能够收敛,能不能够稳定。 我们给大家强调了,这个灵敏度分析是美赛的重中之重,一定是要配图的, 就算你的这个地方你只有表,那么也是不够的,我们灵敏度分析一定要配图,这个的话是我给大家是强调过非常多次的,这个是美赛对于这个东西有一个非常严格啊,应该要不, 应该也不算是非常严格吧,就是说他里面评判的时候,其实如果说你这地方灵敏度分析没有图的话, 会给评委,对吧?他们可能会给你这个权重拉的非常低,因为的话这个也是看了很多方面不错的论文,但是的话,呃,没有拿到什么奖项啊?他们里面的话就是没有什么图, 所以说的话美赛他这个会图大赛,对吧?这个外号的话也是没有白交。好,那么我们所有的资料就放在这个地方了,那么大家有需要的可以自行去进行领取。
665数模加油站 13:55查看AI文稿AI文稿
13:55查看AI文稿AI文稿好,那么我们首先来讲解一下这次美赛 a 题的一些思路。首先看一下 a 题的题目要求啊,它要求我们开发一个智能手机电池的连续时间模型, 该模型呢,能够返回在真实使用条件下电量状态作为时间的函数啊,可以用来预测不同条件下剩余电量的耗尽啊。我们就假设啊,手机使用的是锂离子电池啊,这是题目要求的我们,所以说我们不用管 啊。接下来呢,它的要求我们可以看到,首先是一个连续时间模型啊,这是首先的要求,也是最重要的要求,就是它要求我们用一个这样的符合条件的模型来进行一个预测。 然后呢啊,比如说,我们可以扩展一些其他的影响因素,比如屏幕使用处理器附载网络连接 gps 等后台任务,因为它后台任务越多,我们的手机可能用的电量就越大嘛。 之后的话呢,哦,我们这个数据作为支持并非替代,意思就是说呢,我们可以收集啊,使用数据呢,进行这个参数估计和验证哦,如果哦,我们一般这里选的呢是开放数据集,当然我们可以选择一些已发表的测量数据, 但是需要啊,提前引用一下,但是这里呢,我们需要啊,尤其注意的是啊,这个参数呢,是有明确的理由说明和经过理性验证的, 所以呢,这个基于离散取现,你和时间不回归或机器学习而没有连续时间的模型项目 将不满足本期的要求啊,这句话是什么意思呢?其实就是它封死了你用神经网络和机器学习的这个啊思路就是说你不能用这两个思路了,因为大部分的时间序列,比如说 ram 或者是 l s t m 模型都是时间不回归 啊,黑箱基地学习就是叉列 boost 的 那些啊,随机森林啊,就不允许我们再用了。也就说这个题强制我们使用物理的方式啊,和数学的那个微型方程来进行建模。 然后要求二是电量耗尽预测。我们建立好模型之后呢,要使用我们的模型,在这个初识充电水平和使用场景下,计算或者是近似电量耗尽的时间。然后呢,将预测结果和观测到 与观测到或合理的行为进行比较,量化我们的不确定性。这里的意思其实就是判别我们模型的好坏。 然后呢,下面就是一些啊,不是很重要的一点啊,这些点呢,如果大家能实现呢,当然是最好,如果不能实现呢,其实也没有必要强求啊大家,嗯,就是 啊,看自己的这个数据的需求,因为数据不一样,可能能实现的目的呢,也并不一样, 就比如说这个哪些活动导致的电池寿命最大程度的减少,那么电池寿命啊,有没有数据可以标注呢啊,也许是有的,但大部分数据可能没有。然后最后一点呢,就是 这个敏感性和假设检验在这个我们的模型上啊,参数值使用模式波动后,我们的预测呢,有什么样的变化?就比如说我们可能动一个参数,看一看我们的预测是不是有很显著的变化啊,看一下这个模型的抗干扰性如何 啊?然后下面是他给你的一些建议,还有报告的一些书写形式啊,那么我们接下来直接来看一下我们的讲解思路。 首先的话呢,题目要求的是连续时间模型,所以我们需要从能量守恒出发建立这个微分方程 啊,建立的微分方程呢,就是这样一个形式,就这个形式比较简单,主要是我们后面有些扩展,它比较复杂 啊,这是最简单的基础形式,其中呢这个啊微分 soc 呢表示的是电量的百分比,这电量的百分比呢,其实题目中呃说明其实就是我们手机剩余电量和占据手机总电量的百分比是多少, 然后呢这个 p 透透呢是总功耗,也就是它它电池的总功率,然后呢这个 e 呢是电池的总能量, 这里呢是我们这个公式中的一些主要参数。 q 呢表示这个电池容量,然后 v 呢是电电池的标称电压,然后屏幕尺寸啊,手机型号,还有手机年份等。 然后呢第一步呢是最基础的形式,也就是啊我们的基础模型,首先我们就假设我们的工号是横定的,对吧?这样呢就可以得到一个最简单的限行模型, 我们就把右边呢啊变成了一个现行,比如说他叫负 k, 然后呢 k 呢我们这里表示的是啊耗电速率,其实就是一个常数, 然后呢建立一个那个限行模型,其实这里这一步的作用呢,就是帮助大家建立这个基础验证数据质量,理解基本的耗电规律 啊,对啊,对于我们这个模型的建立来说呢,是一个前期的支持和点击的工作,所以大家啊这一步,而且呢这一步呢也能丰富我们的论文,所以这一步大家可以根据自己的需求去做一下啊,最好是有这一步。 然后呢第二步呢,我们要分解一下他的工号组建,比如说我们将总工号呢,其实分解可以分解为多个来源,对吧?首先是这个基础待机的工号啊,这个呢是由手机型号决定的,我们可以查这个手机的具体规格。 然后呢这个是屏幕公号,屏幕公号呢是由我们数据中的一个字段进行推断的,然后呢 st 是 屏幕是否是开启的?然后呢蓝牙公号是有一个啊,蓝牙的信息。 之后呢,这个 b 表示蓝牙是不是连接了啊?可能它是零或者是一啊,零的话表示没连接,一的话表示正在连接。 然后呢这个 p usage 表示的是我们使用的强度功耗啊,比如说它可能这个手机连续使用了三个小时,和连续使用两个小时,那肯定是不一样的啊,这个 u t 呢是我们使强度系数,这个呢是由用户特征来进行预测的。 好,接下来呢第三步,第三步呢,我们加入这个设备参数,设备参数呢,大家这里有很多方式可以去查,就比如说大家可以直接去百度去查,也可以直接用 deepsea 去查啊,当然可能百度啊,可能这两个差不多,但是百度要准一些吧,可能, 嗯,或者是大家如果有条件翻墙的话,可以用谷歌去查,比如说这里 apple 手机牌子对吧? iphone 十五,它的电池容量是多少?电压是多少?功率呢?是多少? 然后这个每一个手机型号对吧?比如说小米,他的充电功率可能有六十七瓦,毕竟国产的吗?他有大家也都知道他的功率比较足啊,这一点呢,可能对于我们后边这个,呃 需求比较差距比较大,比如说啊,我们选了一个国产手机,对吧?想用在一个苹果手机上,让他这个充电功率之间的差异很大,就可能导致我们的数,导致我们的数据,导致我们的结果出现一些很大的差异。 然后呢这里给大家讲解一下这个完整的啊建模步骤。首先是数据预处理啊,数据数据预处理部分呢,我从头开始给大家讲,首先先看一下我们的这个数据,这个数据呢,包括我们这个啊, 包括我们的电池,比如说他这是一个时间训练,对吧?包括我们哪个手机哪个时间他耗费了这个他的电池容量是多少?然后他的这个状态是什么样的? 然后这个呢是我们这个手机之间他的一些,比如说他的牌子,一些型号,然后时间啊,然后使用者的年龄、性别,当然这个可能没有多大用啊,大家去掉就可以。然后这个是手机的使用时间,然后呢这个是,呃, 这个是手机的年限啊,这个是手机使用的,它就就据这个手机生产,它已经过了多长时间啊?比如说这样的数据 啊,这里呢,比如说我们首先啊先用 python 处理一下导包,然后呢将我们的数据读取进来,然后把没用的列进行删掉,因为这我们用的这是一个问卷数据,我们就把用户回答的问题 哦给删掉。然后比如说这里我们就可以看到一些这个数据,对吧?都被我们读进来了,然后呢读取一下他的电池一些啊特征,然后 然后呢接下来是蓝牙他这个用户这个时间蓝牙是否在连接状态, 然后呢这是我们这个用户的一些信息,就是我们手机的一些详细信息,比如说啊它的型号啊,配件什么的,这些都在这个信息里,然后都读取完毕之后呢,我们就可以对这几个表呢进行一下连接,连接之后呢其实就是按照他们的 pid 和他们的时间, 把我们的蓝牙信息和这个手机电池状态啊,还有这个呃手机电池的容量当前剩余的多少啊,给它纳入进去 啊,然后呢再把最后呢再和我们用户的信息进行拼接,这样我们就得到了一个完整的数据框啊,这个数据呢大家呢如果说感兴趣的话呢,可以购买这个我们美赛 a t 的 讲解完整版,到时候所有的数据代码以及完整版的论文都会为大家奉上 啊。那么这里我们继续看,比如说它包括这样一些啊信息,就一个手机这个时间它的电池容量,然后蓝牙 是否是连接的,然后他的电池是什么样的状态,然后手机型号是多少,然后他的手机使用年限,对吧?这些都是我们的信息。然后我们后续可以加上一些这个手机的参数,就比如说这个手机的电池容量是多少,工号是多少,对,我们可以查出来之后把它加上就可以。 然后呢呃,这里呢是我们一些详细的统计,就是包括每一个手机他记录了多长时间,我们可以看到这个二零九七这个手机呢,他有六千多条记录,这里其实数据的选择是很重要的, 就你的数据呢,如果他的行数越多,我们建出来的模型呢,可能是越准的,如果数据越少,比如说他只有六百多条的话,可能我们处理之后他就没有多少了啊,这样的话呢就是差距很大。其实 啊,这里我们可以优先选一个这种比较高的,对吧?条数比较多的,然后呢我们可以看一下手机型号,我们也可以看到这个呃, iphone 还是比较多的,对吧?可能占了一多半,然后呢大部分都是国外的手机,然后哦我们接下来呢 看一下这个具体是怎么处理的,比如说这里我们选择了是二一四六这个手机,然后呢首先我们先把时间处理成正确的格式,然后呢看下一步距上一步我们过去了多长时间啊?计算一个小时时间处理, 然后呢啊还有一些,比如说创建指示变量,然后 看一下他这个,他这个蓝牙连接状态,然后呢算一下这个用户使用的强度,比如说我们根据这个用户他已经使用了多久的时长, 对吧?我们可以给他指定一个啊,映射到一个用户的使用强度,比如说如果他使用时间很短的话,那么他的这个指标也很短,对吧?如果他使用时间很长了,三个小时以上,那么我们给他的指标呢,就非常长啊。 然后呢这里我们有一些电池参数,这里的话就是查询的每一个手机它的一个这个啊 q 啊,电池容量,然后电压呀,这种电池的能耗到底是多少? 然后这个信息的话呢?嗯,大家购买我们这个啊,美赛 a 版的啊,这个题目之后呢,这个完整版我们会给大家啊发过去,然后大家有什么数据上有什么问题呢?也可以购买之后加群,然后向我咨询, 然后呢这里就是把这些指标也加到原始的数据框里,然后呢还有一个老化系数,这个老化系数呢其实就是这个手机,对吧?它的根据它的使用年限,我们肯定要加一些这种老化系数, 就是这个手机使用的年限越长,它电池呢肯定是老化越严重的。这个大家在使用自己手机的时候肯定都有体会,一开始电池的这个健康程度可能是一百,但是我们使用一年之后,它可能就降到啊九十八或者是九十五,甚至更低啊,这个手机使用更长呢,它自然就更低了,对吧? 然后呢我们去除无效的数据啊,这里呢我们就是我们只要因为我们要看这个电池使用时间有多长嘛,所以我们这里保留放电过程就行了,也就说只保留电池减少的那一部分就可以了啊,不需要去关注它充电的这个过程。 然后呢我们处理完成,我们可以发现就剩下这个一千八百多条信息,然后呢用户的强度,然后老化系数等等等等这些信息啊, 然后具体剩余的代码我们写完之后会第一时间发给大家,然后大家购买之后呢可以实时查看,然后可以进行答疑操作。
40BZD数模社