
粉丝576获赞5764
相关视频
 15:00查看AI文稿AI文稿
15:00查看AI文稿AI文稿大家好,今天要分享的是关于 xps 分封礼盒以及绘图方面的内容。 sks, 他作为一种分析元素原子之间作用的一个表征方法 和分析精像以及精约精结晶度的 srd, 还有这个分析形貌以及元素分布的扫描透热电竞可以共称为这个材料学表彰领域的一个三大的基,三大基石。 我们今天来看一下这个 sps 的一个贵图。首先来说可以看这两个图是算是画的比较好 好的两个,他在这个基础的一个 sps 的图谱上对他不同的一个架态进行了一个分封的离合, 而在一般的沦陷中,嗯,我们可以看到像环境催化币,这已经算是影响因子比较高的一个催化类的一个材料。 他们对这种 sps 的分封,你和他虽然进行了简单的你和,但是可以看到这个图其实处理的不是很好看。 无论是这个对银,无论是对银的粘合, 还是对养,这有些太阳,太阳以及清养这个不同这个结合能那个你都是存在一些问题的。尤其来说这 这个 sps 是一个自由度很大的一个表征以及你和的方式。很多文献你其实他对你结合能的标注是有一些错误, 但是我们这里面就不提他的错误了,只说他如何来绘图。首先大家拿到一个 s 七 s 数据,一般是用一个塞牙表,是一个一个塞牙表的形式, 一个 x 轴是他的一个结合能中标标呢是他的一个强度, 让我们直接复制粘贴 sure, 这个选中之后,这个数据我们一般是用 sp 来处理,他不能不能直接导入一个 cel 格式的文件,我们一般选用 这是还这个是来导入,我们今天就先以这个常见的一个氧 oes 来这个分封的操作, 直接复制粘贴到这个记事本里面,记得把最后这个空格这一行要去掉,不然他不能直接读取, 直接打开这个 spsp, 这是一个比较老的一个分松处理的一个软件,现在一些大型的仪器公司,他都有些自己配备的一些更加 简单易行,功能更加强大的操作,但是基本上也都是基于这个软件衍生出来的。 首先导入这个 oes 的数据,选这个第五个音部的 ascii 直接导入,这个时候他就已经导入成功了。这个时候我们首先导入之后我们要给他加一个 background, 这个时候我们他默认的是从头从头做到尾的一个白服装,但是这个时候其实可以看到这段的数据,他是和这个养的分峰是没有关系的,一般在这个最低点和这边的最低点他是一个合适的一个分峰限制, 这个时候我们要把它选定下来的范围大概有五百三十五吧,五百二十五到五百三十五 分手, 刚才是因为五百二十五那没有数据,所以五百二十五点三,这已经最头了, 现在这是画出了他的一个一线,然后我们直接开始添加风,这个养的分风,不管是养的分风还是其他的像银这些个多架态的分风,首先是要看 这个风行,一个正常的风行,他是这种对称的一个尖风,而是多出一块就说明他至少会有两一个,两个风,首先直接在最高点处看 他的这个结合能大概五百二十九点八 啊,这个时候要注意点上 fix, 把它固定在这个五百二十九的位。啊,不对,那是多少? 五百二十九点八,固定在五百二十九点八的位置,别守。 你说一下,你看到他是这个偏差是比较大的,一般偏差在个位数是或者十几是比较好, 就是我们可以看到这个地方是有问题,这个地方超了,我们先不管,因为这个形状他的不对称度主要来自于这样,我们在这先选一个位置,以五百 三十一点六 固定住接受,然后点这个优化,我们看到现在这个偏差是比较大,这个时候我们就要进行一下微调。首先 这个是他的一个结合能位置,这个呢是他一个,呃,应该是半横环一个东西,这个数越大他这个形状会变得越宽。二呢指的是一个积分面积,我们有时候会像在这个里面, 我们计算不同风的一个占比,会有一个占比利用的面积,就是这个埃尔。 最后呢这个是一个相当于,嗯,也不能说是准确度吧,总之这个值在一定范围内六十到八十左右吧,应该是比较好。但是我们为了使它更加贴合原有的一个基础的数据,我们一般是要把它解锁的, 因为现在我们发现他的这个偏差太高,这个解锁,这个也解锁, 同时你和你可以看到,哎,一下只剩二十。一会,我们仔细再看,在这个地方蓝线显得还稍微多了一点,比如说我们这个风,小风 可以像这个 dj 和冷酷再微移一点,我们现在就主要做的工作是微调,比如现在五百三十一点 六改成五百三十一点五,如果他改的正确的话,这个二十会变成一个更小的数, 现在是十七,他的偏差更小, a 就会变了九,证明这个礼盒是没问题的。可以看到原来显得很多出来这一节现在已经完全的贴合了,我们初步来说这就算是一个比较成功的礼盒。接下来我们演示这个导数数据, 导出数据是这个第六个导出的数据是一个 dat 格式的数据,我们还是导出到桌面。 我现在就会面临一个问题,我们在最开始 background 的时候,我们选择的范围是这个最低结合能到一个 中间结合能,如果我们最开始不改这个最高结合能,从这个最低结合能直接到最高结合能的话, 这个数据这个 dnt 数据 就可以直接粘进这个奥运这里面开始用,但是现在我们粘进来看,这个分封他是没有出来的,这个就是因为他有一些数据的错误。我们这个时候呢需要点开这个 dat 格式的数据, 选择打开方式,以记事本格式来打开,嗯,可以看到这个空了一大段,这个 控的范围正好就是我们当时选择的这个上线,我们当时选择的是五百二十五到五百三十五,而不是直接到头,所以我们这时候要把这一段能做表给他删除, 一点痛都不要留。现在保存,我们这回再直接拉进来 就可以看到,哎,这个分方的数据是出来了,我们直接选择 变形,这个标注就大家自己看着标就行,他一般标注是错误的,像 这个 sum 他应该是一个你和后的数据,但是显然这是我们分封的一个主封的数据,我们实际的你和数据是这个绿线 还是有问题,但这个黑线其实反而是一个发线,但他是显示的是 pig, 这是有问题,你就不管了,到时候自己改一下就行。首先这个线 这个波动一般反应的是你你和的一个正确性,如果你是百,你是百分百准确的一个,你和误差之为零的话,他是一条水平的直线,而你误差越大,在某个点上他的波动起伏越高,你看到我们这个其实相当于是很平的,你还是比较成功。 但是现在 sps 里面一般都不会展现这个线给我们这些双击, 这个消失,接下来我们就到终点了,我们前面说是顺风泥巴,接下来我们是要画图,还说前面这种图显得是非常的单调,而且很不美观, 而这图显得很简洁大方,而且一目了然。你就现在双击一下左键双击选择点这个填充,然后选择第二种模式,那现在还是直接到底的肯定不行,而是要把它包起来。 看到现在他已经出现了这个跟风之后的一个颜色,但是黑色肯定是太丑,我们在这个部分选一下其他的颜色, 一般就是深蓝的线下面挂一个浅蓝色的一个填充,同理我们把这个粉色换一个颜色,换一个红色比较好看, 然后把也是红色的线换成比如一个橙色的一个填充,然后 懂得你和线我们改成黑色, 把另一条原始的这个线蓝色已经重复了,换成 绿色,绿色还没有出现好,现在就是一个初步的一个图,那这个时候我们看到他比较丑,他直接遮挡住了后面的颜色,你可以选择给他调整他的透明度, 同样是选择把这个对号取消,然后一般我们可以调一个五十吧, 这个也一样调到五十,这可以看他的调成的效果,你看他现在就是一个半透明的状态,为了好看也可以把这个黑色的前冲 填充出一个灰色做一个基底, 这样的话我们还可以调一下前后,具体的我们就可以直接进行百度一下如何哪个在前哪个在后的问题, 这样话我们就实现了一个比较好的一个分封之后的一个土。
371致我亲爱的二氧化钛 03:39查看AI文稿AI文稿
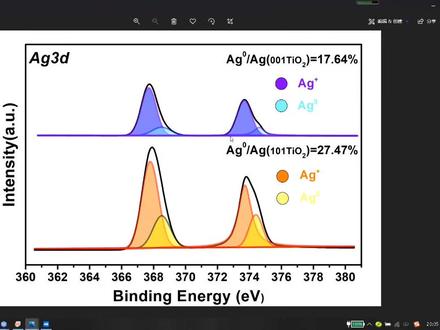
03:39查看AI文稿AI文稿哈喽,大家好,今天给大家分享一下叉 p s 分封礼盒后如何做好归属以及标准结合栏的位置哪里去找? 我们在对叉 p s 进行分风礼盒后,需要对我们所分的风进行一个归属,比如说这个绿色的风它代表什么物质,红色的风代表什么物质,蓝色的风代表什么物质?比如说这个绿色的风它代表了牛二富,红色的风代表牛二富, 蓝色的风代表牛林。那么我们是如何去和标准的结合郎去对的呢?以下介绍三种方法。首先是 a vip 劲, 我们打开 abnt 键,然后点击这个图标,然后它里面有一个元素周期表,我们可以点击我们想要的元素,比如说铁元素, 当我们可以看到左边是化学肽,右边是接二 p m 三的轨道的结合棱,那么它的标准 参照的是探一 s 二百八十四点八,所以说如果你探一 s 没有校准的话,你需要校准到二百八十四点八,然后再看,然后我们可以看到不同坏业态的他的一个 结合,那一个位置,我们可以根据这个结合的那个位置去和我们的分离和结果去对比,这样的话就能得到我们是什么物质。 此外我们可以看到它的一些信息,比如说它的铁的二 p 的这个轨道之间的结合轮差值是十三点一电子负荷,这个可以辅助验证我们分封礼盒的结果有没有问题。 然后这里面还有个信息,就是卫星风的位置,卫星风就相当于是人的身份证一样,那么不同的物质他的卫星风的位置是不一样的,我们可以根据他的卫星风的出现去辅助验证一下我们是这个物质, 然后所有的都是这样,所有的元素都是这样。 那么另外一个就是美国国家标准与技术研究院的一个数据库,它有叉 p s, 有一个结合轮的数据库,我们可以 打开这个网站,然后点击 search menu, 然后我们就是可以点击这个 return data for a select leader element, 然后你可以选结合棱或者动棱,其他的比如说我们选这个结合棱,然后我们找自己想要的元素,比如说铁元素, 然后输入你的这个值,比如说二 p f 分之三,或者是就是二 p f 分之三,或者二 p f 分之一,或者是未清风都可以,然后比如说我们选择二 p f 分之三, 然后我们可以看到铁的不同的二 p m 三的它的一个结合的位置, 然后他对应的一个是什么物质,这里面很全,我们可以根据我们分封礼盒的结果去和这个对。 那么最后一点就是参考对应的文献,我们去和我们比较相似的一些文献的对对,和他们的一个结合能的位置,然后去判断我们是什么物质。 那么本期的视频就分享到这里,谢谢大家。
 00:27查看AI文稿AI文稿
00:27查看AI文稿AI文稿带你全面掌握 xps 数据实力分析。首先讲解 xps 数据分析通用原则,然后结合通用原则,用了 vantage 和 multi pack 软件对 xps 全谱和精细谱进行数据处理, 还有常见的数据分析错误案例和正确的数据处理方法。最后结合实力,手把手教你架,派你和解决你的科研困惑。
1667e测试-科研宝典 05:50查看AI文稿AI文稿
05:50查看AI文稿AI文稿大家好哈,这一节我们给大家分享一下 excel 里边去如何去制作纸方图,以及给它拟核,正在分布曲线。 好,我们有一列模拟数据啊,是一个童话市场的数据,现在我们在数据菜单啊,主菜单右侧找到数据分析,如果你现在这个菜单上没有数据分析呢?你要到文件 选项这边啊,找到左边的加载项啊,点一下加载项之后呢,在右侧最底下啊,管理 excel 加载项,点击这个转到再出来的框里边,你把分析工具勾上就可以了啊,分析工具库也要勾选,点确定就可以了。 好,我们现在呢,还是找到数据分析啊,点开之后,我们找到直方图,这里边就有直方图啊,点确定,这是最省事的办法啊,办法如果手工作会比较麻烦啊。 好,我们现在直接把数据选中,我选中 f 一, shift 下箭头啊,就把所有的数据都选中了,因为我们选了 f 一 啊,选了标题,所以这个地方呢,我们要勾一下这个地方,要去把标志 勾上啊,如果你不勾标志呢,因为 f 一 是一个文本啊,它是列标题,它会报错啊,勾上标志之后呢,那么 excel 就 会知道 f 一 是一个标题啊,它就不会报错。 好,我们在底下把图标输出勾上就可以了,当然这个工具还可以生成帕累托图啊,但是呢,它的效果并不是很好,这个是后话以后再说啊。好,我们点确定啊,这个时候我们就会得到一张啊, excel 自动为我们生成的直方图, 我们可以把它拉大一点,左侧就是它的接收的区间划分啊,这个区间就是柱子的间隔区间啊,还有每一个区间里边的数据的频次啊,都在这里面, 我们其实可以把这个数据给他,尤其是最后一个,其他啊,就是二零七以上的那个数据,这个数据呢,你要对自己的数据有了解啊,我们会知道它最大值的就是二零九啊,我这个数据最大值就是二零九,我直接把这个 其他改成二零九就可以了啊,我们来把它的小时点位给它做一个缩进啊,好, 把小时点位给它缩进来。 text 说这现在就会更加的正常一点啊,这样小时点位太多了,就乱挤在一起啊,现在我们稍微修饰一下它点任何一根柱子, 打右键,设置出一系列格式,在右侧把它的菜单调出来。调出来之后呢,我们把间隙宽度拉到零,我们点一下这个颜料桶啊,在就填充与线条这个地方啊,找到这个边框啊,边框里面选实线,实线里面给他选一个白色啊,这样呢,我们就能够看清楚每一根柱子的轮廓啊, 在填充里边啊,选纯色填充,我们选一个比较啊,正规或者是商户一点的颜色啊,比如说深灰色啊,或者说是浅灰色啊,稍微浅一点啊,这样我们这个纸方图啊,大概的这个样子就出来了。 出来之后呢,我们现在在做什么曲线,我们需要在这个地方,就在它右侧啊,这边这一列紧挨着频率这一列,我们来做一个数据啊,等于稍等一下啊,我们还需要去到 前边的数据里边啊,去做几个值啊,前面数据的几个值,我们首先要做一个均值,这个地方呢,是等于我们回到前边的这个数据, 我们看一下,是从 f 二看,这是下降点, f 四啊,是这样的一个值啊,一百八十点零四九啊,还要做一个标准差,标准差呢,等于 s t, d, e, v 啊, 我们算三泡 e v 点 s 啊,我还是上一页,我们再回到这个数据区域, 再次选中我们这个原始的数据啊,从 f 二开始, ctrl shift 下箭头回撤,这样我们得到它的标准差啊,这两个键有了之后呢,我们在这个地方啊, 等于 norms, 用这个函数啊,用这个函数 normest 啊,它的第一个数值呢,我们取我们接收区间的第一个数啊, a 二啊,第二个数呢,取这个均值 f 二, f 四,把它锁定, 第三个数来取这列差啊,我们取这个 f 三,再把它锁定。最后呢,它是让我们决定是要累积概率的分布还是概率密度的分布, 累积分布的话,从百分之零到百分之百啊,那个不是我们想要的啊,所以我们要选 false, 叫概率密度啊,所以选零就等于 false, 这样我们来回车计算第一个值,填充到底,就把整个的概率密度啊,把它算,计算出来,就针对我们整个的,从最小值到最大值之间啊,把它整个概率密度分布计算出来,计算出来之后呢,我们选中复制,点一下这个图标啊,点一下脂肪图,图标打右键 是粘贴啊,粘贴进来之后你发现已经有变化了,有变化之后呢,系列二已经进来了,但是我们看不到,因为太小了,我们在柱子上打右键啊,更改系列图标类型到这个界面来,把系列二勾到次坐标轴,把系列二勾到次坐标轴,把它的复杂图形图呢改成折线图, 看到这个形状已经出来了啊,点确定?这样其实我们就已经看到了我们的正态的分布的曲线啊,双击一下这条线, 在他的这个线条就是颜料桶这个地方啊,线条与这个边框的设计,这个地方底下有一个平滑线啊,我们勾一下这个平滑线,它就会变得比较平滑,这样更好看一些。剩下的什么颜色呀,这个粗细呀,自己去调就可以了,都在这个菜单上 啊,这样呢,我们就有了植帮图以及他的正态分布的尼克曲线就做完了。好,接下来给大家分享到这。
35数据分析精选 04:03查看AI文稿AI文稿
04:03查看AI文稿AI文稿蜗牛核解决方法让模型告别死记硬背,拥抱稳健泛化简介,在及其学习建模过程中,蜗牛核是阻碍模型落地应用的常见难题。它表现为模型在训练数据上表现优异, 却在新的未知数据上预测效果大幅下滑。本质是模型过度学习了训练数据中的噪声和局部特征,而非数据的通用规律。本问梳理了从数据处理、模型调整到训练策略优化的都维度、过你和解决方法, 帮助从业者快速定位问题,并针对性优化打造泛化能力更强的机器学习模型。在机器学习的世界里,高训练精度往往是见魔者追求的目标, 但如果这份精度仅仅停留在训练级上,就会陷入过你核的困境。想象一个学生为了考试死记硬背习题答案,却无法解答题型稍有变化的新题目,过你核的模型 就是这样一个只会死记硬背的学生。想要攻克过你核问题,我们可以从数据、模型、训练三个核心维度入手,层层递进的优化模型思路是为模型提供更具代表性的学习样本。 首先,扩充数据集是最直接有效的方法,通过数据增强技术,在不改变数据核心特征的前提下,对现有数据进行变换处理。比如在计算机视觉任务中对图像进行旋转、裁剪、翻转,在自然语言处理任务中进行同一次替换、句子重组。 更多样的训练数据能让模型接触到更广泛的特征分布,减少对局部造成的依赖。其次,合理划分数据级也直观重要,必须严格区分训练级、验证级和测试级, 避免测试级数据提前泄露到训练过程中,否则模型的测试精度会失去参考意义。在模型维度,关键是给复杂模型做减法, 避免其过度复杂导致的过你核。第一种方法是简化模型结构,比如在神经网络中减少隐藏层的数量和神经元个数,在决策数模型中降低数的深度结构。越简单的模型学习能力越有限,自然难以捕捉到训练数据中的噪声。 第二种方法是加入正则画像,这是工业界最常用的手段之一。 l e 正则化会让模型的部分权重系数变为零, 实现特征自动选择。 l 二政策化则会让权重系数趋近于零,避免某些特征对模型产生过大影响。无论是 l 一 还是 l 二,政策化本质都是通过惩罚过大的权重参数约束模型的复杂度。 训练策略优化则是从模型学习过程入手,动态调整训练节奏,已规避过你核。早停法 early stoping 是 其中的经典策略,它会在模型训练过程中实时监控验证级的性能指标,当验证级精度连续多轮不再提升甚至开始下降时, 就停止训练,保留此时的模型参数。这种方法能有效避免模型在训练后期过度你核训练数据的噪声。此外,集成学习也是应对过你核的利器, 它通过组合多个基模型的预测结果,降低单一模型的过拟核风险。比如随机森林算法,通过构建多个决策树并采用投票机制,既能保留决策树的非限性拟核能力,又能通过群体智慧抵消单个树的过拟核问题。过拟核的解决没有一招先的万能方法, 需要结合具体的任务场景、数据规模和模型类型灵活选择,有时将多种方法结合使用,能达到事半功倍的效果。比如在深度学习任务中 同时采用数据增强 a r 政策化和早停法,就能显著提升模型的泛化能力。归根结底,机器学习的终极目标是让模型在未知数据上稳定发挥,而解决过你和问题正是实现这一目标的关键一步。 只有让模型从死记硬背转向理解规律,才能真正让机器学习技术落地生根、发挥价值。
0善报推文 00:59查看AI文稿AI文稿
00:59查看AI文稿AI文稿有小伙伴在后台咨询,当有一组 x 和 y 值时,如何拟合出一元二次方程呢?这里介绍一个简易的方法,选中数据区域,点击插入选项卡, 在图标中选择散点图,这里我们选择带平滑线及数据标记的散点图,然后点击图标中的曲线,右键点击添加趋势线, 选择多项式,接数为二,表示二次方程。勾选最下面的显示公式, 显示 r 平方值,可以看到 r 平方值等于一,当 r 平方值越接近一,一元二次方程你合的越准确。哇,你学会了吗?表格问题找小数,欢迎评论区留言!













