Ai订阅完有多少token
是不是我用错了,一百万 token 做不了一个小项目,我买的十五美金的额度,半小时就用完了。呃,我知道了,看来大家对一百万 token 的 概念还是有点模糊啊,我来帮大家梳理一下。一 token 呢,大概是一个中文汉字,或者是四分之三个单词, 一行代码呢?我们按照十个单词来算,大概就是十到三十个 token, 那 一个文件我们按照五百行代码来算,大概是五千到一万五的 token。 现在我们的前端项目都用了 ts, 那 些类型声明其实都是通过杀手, 实际的通过量可能更多。假如我们在操作的是一个中型项目,大概是一百个文件,那就是五十万到一百。五十万的 token。 中型项目 ai 还是能够理解的,如果说是一个大型项目,你想让 ai 理解都理解不了, 上下文就爆了。所以对于 ai 来说,去理解一个中型的项目,一百万 token 啊,其实也就是几分钟的事啊。现在顶级模型的价格,每百万 token 海枯石一刀,骚奈特是三刀,呃,奥普斯是五刀。所以你用 ai 写代码的话,几分钟就有可能会花你个十几或几十块钱。 怎么办呢?也简单吧,就是你一定要用艾特符号,用井号去控制好上下文,遵循上下文最小化原则,也能让 ai 输出的结果更准确。所以平时我们在用 ai 编程的时候,一定要有一个 token 的 消耗意识, token 就是 钱,省 token 就是 省钱。

粉丝1121获赞1.2万
相关视频
 02:46查看AI文稿AI文稿
02:46查看AI文稿AI文稿cloudbolt 这两天全网爆火啊,都在说它是能改变世界的 ai 神器,但是我重度使用了两天之后发现啊,有很多博主啊,有几件事情没有告诉你啊。第一,就是所谓的开源免费啊,仅仅是软件免费,真正烧钱的是 api 的 调用。我们拿 cloudops 最新版来举例啊,每百万的头肯呢,便宜的要五美元,贵的要二十五美元。这个价格确实比之前便宜了不少,但是加上 cloudbolt 这个无限记忆的功能, 你记忆的东西越多,每次掉的头根就越大,成本呢,就会随着时间越滚越高。你偶尔写写文案,回回邮件,可能一个月 几十或上百美元。如果你天天拿它写代码做项目,发早报,一个月可能两三百打底,上不封顶啊。那么这个时候就有人又会说了,那我换一个便宜的模型不就行了吗?哎,这个就是第二点,便宜的模型根本撑不起来。这个用法 像 mini max, 一 块钱一万。 token 是 挺便宜的,但是用过的人都知道,复杂的命令呢,他听不太懂,代码写出来一大堆的 bug, 你 改到第十遍他可能还是不对的。 tipsy, 国产性价比之王确实便宜,但是服务器动不动就排队写着写着他会告诉你,我无法回答这个问题。像豆包通一千问,便宜是便宜,但是能力上限摆在哪里?当个简单的问答机器人还行,但是当一个全职员工,那你想多了, 便宜的模型就像是实习生,能干活,但你一直盯着你省下的 api 费用呢,可能全搭在这个时间成本上了。第三,这个东西其实本质上并没有那么神, 说白了呢,它就是可要的 api, 套了一个电脑控制脚本。很多博主不是推荐工具啊,而是在贩卖这个 fomo, 就是 那种别人都在用,我不用就完蛋了的那种焦虑感。 当然说了这么多,我并不是说这东西没有用啊。如果你是创业者,时间极度值钱,那么这个钱花的值。如果你是内容创作者,并且产出能够直接变现,那么可以考虑。但如果你只是普通的打工人或是 ai 爱好者,想尝个鲜,那么我劝你冷静一下, 现在全网都在制造这个 ai formal 啊,今天 cloud boot 改变人生,明天 max 颠覆行业,后天又来个什么 agent 要取代所有人,等等。上个月还在教你用 curser 写代码,这个月又说 cloud code 才是终极答案。 这些工具底层呢,其实就是这些大模型,你与其天天追热点囤工具复订阅,你不如先搞清楚一个问题,那么就是你到底要用 ai 解决什么具体问题?如果你连这个都没有想明白,你注册再多工具, 买再多的 a p i, 实际上就是在为了博主的流量跟大厂的财报而打工而已。真正厉害的人呢,并不是工具用得多,而是知道什么时候该用,什么时候不用。蜂猫呢,会让你冲动消费,但不会让你变强啊。所以二零二六年呢,最贵的不是 ai 订阅费啊,是你跟风的手速,所以少交点智商税吧。
2920向南(深夜炼金师) 04:55
04:55 01:03查看AI文稿AI文稿
01:03查看AI文稿AI文稿我就纳了闷了,这全网到底是谁一天天搁那瞎吹?这大龙虾我也本地部署了,你甭管它是叫 cloud bot 还是 open cloud, 反正我是本地部署完了偷看,我也充的满满当当的充了 一块钱。飞书我也对接了啊,不信是吧?给你看这前台,这后台, 这是飞叔机器人,电费我也交了,你现在是能满大街拿着手机转悠,然后让他二十四小时能给你干活了?我就问有啥活是能让他直接给你干了的啊?当牛马没够是吧? 你是能让他直接给你审核合同还是给你写个报告?你敢直接交给你老板吗?就问你敢吗?啊? 有这功夫你哄哄老婆孩子他不香吗?一天天的就搁这瞎吹,还我百万头啃撂他。
107硅基流码 00:18查看AI文稿AI文稿
00:18查看AI文稿AI文稿程序员在公司使用 ai 编程产生的 token 费用难道需要自己付费吗?据我了解,不论国内, token 费用一般由公司承担,大模型服务商向企业用户收费。如果需要程序员自己付费,这不真就是自费上班了吗?最后欢迎评论区说一说你了解的情况。
324程序员铭哥 05:44查看AI文稿AI文稿
05:44查看AI文稿AI文稿因为我们现在用的这个叫这个,这个页面就叫做白板啊,所以这个 white 白板它也是组合词,在英语当中非常多这个复合词。好,那么这个是我们说的这个为什么不直接从中文或者英文啊变为现在,而是 通过一个中间的一个 talk, 那 么就是就是这个,呃原因了。好,然后我们来看一下这个 另外一个问题,就是我们怎么计算这个我们输入的中文或者英文变为的这个 token, 它究竟有多少个 token 呢?因为我们知道 token 是 按量计费的嘛。那我们输入一句话的话,比方说我们输入,呃,就是我们我们说的这一段话 啊,使用 u 三的关键生成一个 to do list, 那 我们怎么知道啊?这里有多少个 to do 呢啊?当然模型,当然这个工具 a 工具它会自动帮我们计算去使用了多少个 to do, 但是如果我们想要去测试测试的话,其实也就有方法,我们这里举一个例子,举一个例子是这个 啊,这个是 open open ar 的 一个工具啊,这个是 open ar, 这个吉他,这里有 open ar, 这个是啊,这个陀刻,那么它是一个用于啊这个 bpe 的 分别分词器。什么是 bpe 呢?我们看一下这个下面有个翻译,下面有个讲解, bpe 就是 but peer in code, 它就是 将文本啊,就是将这个文本转化为这个转化为标记的一个方法,就是将文本变为 talk, 就是 将我们就我们刚刚说的将中文或者英文变为 talk 的 这样一种方法,叫做 b p e 啊,感兴趣的,感兴趣的同学也可以去查一下这个 b p e, 我 们这里也总结了这个翻译, but pear 引口的 but, 我 们前面也说过了,字节跳动的 but, dance 的, 这个 but 和字典, 那还有一个是 pair 啊,一对一双,我们通常用来描述一双鞋,呃,一双一双袜子,那不是 pair, pair 一 双鞋,一双袜子啊。 encoding 就是 编码,这个单词的翻译叫做编码,那么字节啊,一个字节,一对字节对应一个编码,那就是,那么就是 bpe 了。好, 那么它这里它有一个方法,它提供了一个方法,当然这里是以这个 python 为例啊,这里是 python 通过 python 去做做的这个, 呃,演示了,我们就不去讲解了,我们大致说一下它怎么怎么去用。如果,呃,我们看视频的同学有会 python 的, 有这个 anacook 的 这个光工具的,那么也可以去玩一下这个啊, tiktok, 那 首先我们通过这个 pib 去安装这个 tiktok, 安装之后我们可以啊去导入这个 tiktok 啊,然后 我们需要在这个 get in code 里面传出一个编码,这个编码哪里来呢?我们可以通过这个 open a cookbook 啊,这个,这个, 这里面去找到这里代码,那这里我也打开了这个东西啊,就这个 in code, 那 么它里面就对应了这个不同的编码啊,比方说 o 两百 k 啊,这个 o 两百 k best, 它是叉 g d 四 o 叉 g d 四 o mini 啊, g d 四 o mini, 没有这个叉的,它对应使用的这个编码的一个名字,然后,然后比方说这个叉 g d 三啊, g d 三,它使用的是 r 五百 k best, 呃,这个 test 啊,这些东西他使用的是 p 五百 k, 就是 不同的模型,他使用的是不同的一个编码方式,那其实这个非常好理解,就是比方说以前的模型,模型他是会不断的迭代更新的吗?以前的模型他可能使用的这个编码方式,可能, 呃,比方说同样是一个,呃,你我他,那他可能变异成的 token, 他 有四个 token, 但是根据这个不断的进化啊,不断的这个更新,那么他最新的这个模型,他可能通过变异之后,他这个 token 就 只有两个啊,能够更加高效的去 减少这个 token 啊,包括增加这个翻译的意思,增加这个向量的含义啊,那么这个事我们也可以这样去理解。好,那首先我们要如果我们是使用这个 gpt 四 o 去做测试的话,那我们转入这个 o 两百 kbs 啊,转入之后我们下面有一个例子啊,这个啊, tom tom test, 就是 转换, 转换这个文本到 token, 我 们可以通过这个方式 token, 这里有个例子,我们可以截下图啊,他这边这个例子就是计算返回这个 token 的 啊,我们回到这里,那其实非常简单,其实非常简单,那同样我们需要导入这个 code, 然后我们通过这个 get encoding 去导入这么一个, 呃,编码,就是我们刚刚模型不同模型对应的这个编码,它是一个参数嘛?啊?就是把这个 o 两百 k 转入这里,转入这里呢?它会得到一个,得到一个结果啊,得到一个结果到一个对象 encoding 啊,就是这个东西,这就是缩写了 啊。然后我们通过这个 encoding, 我 们可以传入一个 encode 啊,传入一个 encode, 那 它会将文字变为 token, 它会将文字变为 token, 然后我们可以调用这个 let 方法。啊,调用这个 let 方法。呃,这边我退,退一下这个 let, let 方法,调用这个 let, 它是一个缩写,它是这个长度啊,长度 要预检测 t h length 长度的一个缩写。应用这个方法,那么它会得到一个结果啊,得到的结果它就是这个 number tokens。 number 是 数字 tokens, 就是 我们需要计算的,那么就得出我们当前这一段文本,它究竟,呃设计算出来多少个 token 啊?比方说我们转出这个 hello world, 转出这个 hello world, 你 好,世界,然后它计算出多少个 token 给我们啊?这些单词我们这边也写一下吧,我这边记录一下。 呃,这个是,还有一个是 length 长度,呃,还有 test, 呃。 test 文本,呃,文本,我看一下还有什么单词,还有什么单词我们是需要记忆的。 应该没有了,应该没有了啊,应该没有了啊? number, 还有一个 number, number, 数字, number one, number two。 啊,这个其实我们尽量能够听到这个是数字啊, number, number one, number two。 好,那么就是它这个,那能够让我们去计算,计算这个文本它涉及多少 token 的 一个方法。
 03:04查看AI文稿AI文稿
03:04查看AI文稿AI文稿目前国内各大平台基本上都是按 token 计价, deepsea 输入百万 token 大 约一元,输出百万 token 大 约六元。这个 token 怎么理解呢?它好像并不是按字母, 也不是按词语,但肯定是跟字母相关,很多人都搞不明白它是怎么回事。简来说, token 就是 大模型理解语言的最小单位, 可以把它想象成我们玩拼图游戏时用的小拼块。当我们给 ai 输入一段自然语言,它不是像我们人类一样直接看懂文字、理解文字, 而是先把这段话拆成一个个头坑,通过这些头坑以及头坑间的联系来理解我们的意思。更具体一点,它可能是一个字、一个词、一个标点符号, 也可能会是一个常见的词组。比如我喜欢喝茶这句话,哎,可能会把它切成我喜欢呃茶 以及句号这五个透坑。此外,不同的语言透坑的切分方式也不一样,英文离动的可能会被切成答案和 t 两个透坑,而中文的人工智能可能被切成人工和智能两个透坑。为什么大模型要用透坑,而不是直接看文字呢? 这里我用非技术的角度来解释一下。这就像我们学一门语言一样,中文常用字才三千五百个, 但是当要表达一个意思的时候,还会有词语、成语、短句、长句等各种不同的组合,最后还有上下文语境。如果让电脑单纯地记住这几千个字,那太简单了。但是如果要理解各种字、词句的组合 以及上下文语境,那常规的思路是不可行的,必须采用新的方式来处理。这种方式的表现形式就是我们现在讨论的 toc, 所以 才说 toc 是 连接人类语言和 aa 智能的那座桥梁。 其实如果用专业一点的技术语言来解释的话,会更加形象,更好理解,更有意思,甚至能让你理解到更本质的东西。那么透看对大模型来说有多重要呢?它直接影响了三方面的问题,第一是能处理多长的文本,每个模型都有透看的数量限制, 超过就处理不了。第二是生成速度,当然是一个透看一个透看的吐出结果的。第三是使用成本, 它是当前主流的计价的基本单位。据说有人开始把透支的使用量加入到衡量 a 经济的重要指标。根据最新数据,中国日军透支使用量已经从二零二四年初的一千亿增长到了三十万亿,一年半时间增长了三百多倍。 最后我做个预测,我们使用手机流量的最小计价单位是 n b, 四 g 和五 g 时代的常用计价单位 g b, 比如一 g e b 流量运营商收费一块钱。或预计未来我们生活中将会多出一个新的计价单位是 t, 现在常用的计价单位是 n t, 也就是百万 t, 未来收费肯定会继续降低,到时的常用计价单位会是 g t, 比如 e g t, 收费一块钱。
11键盘少侠 01:27查看AI文稿AI文稿
01:27查看AI文稿AI文稿这几年大家都在说,想用顶尖 ai, 你 得找 google 或 open ai, 还得交订阅费。但这台机器就是来打脸的,它要证明最好的 ai 不 在云端,而在你的桌子上,它就是英伟达的 d g x bar。 先跑个千问三零 b 模型, 普通电脑跑这模型早卡死了,它却能跑到六十 toky 每秒,比人类的阅读速度快十倍。不管你问什么,答案瞬间铺满屏幕。 最爽的是,这一切完全在本地,不用担心对话被上传。在试下 coffee 外跑 z mega turbo, 也就是喝口咖啡的功夫,五秒一张图就好了,没有排队,没有积分限制,更没有网络延迟,这种随心所欲的生图自由,用过就回不去了。最后是难度最高的视频生成, 跑 one 二点二模型,显存瞬间吃掉三十二 gb, 换做四零九零早崩了,但它还有九十 g 左右的剩余空间,虽然生成一条要八分钟,慢是慢了点,但它真能跑通。 这就是一百二十八 gb 内存的底气。如果用两台链接在一起,那堪比部分服务器集群。 当然,他的售价也不便宜,将近三万。他对普通人来说,可能就是一个性能过剩的电脑。但对开发者来说,他把被巨头垄断的算力重新抢回了我们自己手里,我们重新掌握了数据、隐私和创作的话语权。如果是你,你会买吗?
20太评视野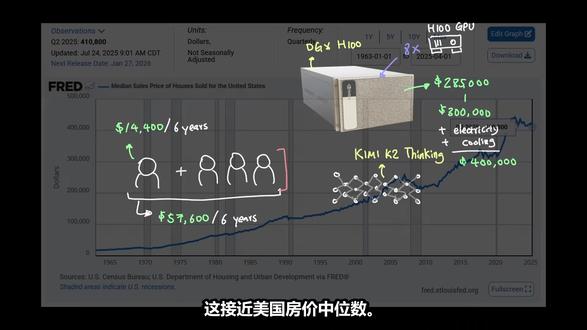 10:10查看AI文稿AI文稿
10:10查看AI文稿AI文稿现在人工智能非常便宜,你可以用不到五美元的价格获得百万头肯输入的城市艺术模型。即使你看订阅费用,你每月也要支付十美元到两百美元不等的费用。 这还不错,但如果我自己来运行呢?我是买自己的硬件,还是直接去 neo cloud 按 gpu 每小时购买算力? 今天我们将研究总拥有成本,看看算下来是否划算。因为智能的成本在不断下降, 而且我们从英伟达最近发布的 ver ruby 芯片中看到,硬件也在显著的变得更好,效率更高。所以关键问题在于,什么时候我们自己运行最先进的模型才真正有意义。 欢迎来到 keto bright 代码世界,在这里每一秒都无关重要。快速提到一下, the computer 稍后会详细介绍。我们先从订阅费用开始说起。如果把订阅费用加起来,比如每月两百美元,六年下来总共是一四四零零美元。 如果你看看像英伟达 h 一 百这样的数据,中星级显卡,这将花费你大约三万美元。所以是的,直接说吧。这笔账算下来对我们不利,因为用每月两百美元的订阅服务,六年会划算的多。 但我们还有另外一个选择,也许我们可以不自己购买硬件,而是直接从 neo cloud 租用 h 一 百。我的意思是这个价格看起来挺合理的,因为 neo cloud 上的 h 一 百似乎大多在每小时二点二零美元左右。 但是一旦你开始累加这六年的成本进行比较,你会发现,即使你每天使用八小时,持续六年,你的成本也会达到三八五四四美元,包括周末, 或者如果只算工作日,则为二七四五六美元。如果这些都不划算,那么前沿实验室的订阅模式是如何盈利的呢? 在研究单位成本之前,让我们更仔细的看看这个场景,比如和四个朋友一起凑钱,看看会是什么样子。既然一个人的订阅费六年是一四四零零美元, 如果你们有四个人,六年的使用费就是五七六零零美元。现在有了这笔钱,你可以做的选择就真的开始变得多了。英伟达 h 一 百显卡零售价约为三万美元,现在已经触手可及了, 但问题是,共享一张 h 一 百卡会不会让他们的体验慢很多?还有,运行 h 一 百的成本又如何呢?难道不需要电费和散热费用吗? 我们先来看看总拥有成本。物料清单显示,假设你已经有台式机,并且能通过 pci 为 h 一 百供电,那么目前的成本仅仅是购买显卡本身的三万美元。 现在根据英伟达的规格, h 一 百的 pci 功耗高达约三百五十瓦,或者为了方便计算,可以写成零点三五千瓦。 现在在密歇根州,平均电费大约是每千瓦时二十美分。由于我们有四个人共享同一个 gpu, 所以 假设这块 h 一 百在服役的六年里会二十四小时不间断运行,那么电费将接近三千七百 美元。电费三千七百美元,总计三三七零零美元。 但我们别忘了散热,由于我们使用的是单 pcie 配置,我们可以保守地将 poe 设为一点五甚至二, 这样冷却成本仍然是三七零零美元,而且这所有加起来仍然远低于订阅的总成本。四年内,四个人订阅六年的总成本是五七六零零美元。但我们还没回答第一个问题,也就是用户体验。 换句话说,四个人共享一张 h 一 百显卡会不会拖慢每个人的用户体验? 我们先来看看单个 h 一 百显卡能装下什么模型。由于我们没有运行来自 open 人工智能、 antropic 和谷歌等前沿实验室的先进模型的许可,我们不得不关注开源模型。 目前我们能使用的最好的先进模型之一是 kimi k 二思维模型。这是一个拥有一万亿参数的模型,它是一个专家混合体,每个 token 激活三百二十亿个活跃参数,并有三百八十四个专家。这种稀疏性现在实际上非常普遍,而且很可能成为未来的常态, 因为它使推理效率更高。但即便架构效率有了这样的提升,为了容纳完整精度的 kimi k 二模型,你至少需要十四张 h 一 百显卡才能装下这个模型。 所以,即使预算上我们四个人共享一个 h 一 百是有利的,但实际上我们无法将这个模型装进单块硬件里。即使我们将模型量化到四比特甚至一点八比特的版本,我们至少也需要三到八个这样的 h 一 百卡才能运行。 现在,你们得和朋友重新集结计划不同的策略了。谢天谢地,英伟达将八张 h 一 百显卡组合成一个名为 d g x 减 h 一 百的拓普结构进行销售。但遗憾的是,购买这些设备将花费大约二十八点五万美元到三十万美元, 而且使用与我们上面相同的计算方法。它们的电力成本和冷却成本将使总拥有成本达到约四十万美元,这接近美国房价中位数。 所以在那种情况下,我们需要二十八个人共享同一台 d g x 减 h 一 百才能达到盈亏平衡。但如果真的有二十八个人注册购买并运行这台 d g x 减 h 一 百设备来运行 kimatico thinking 模型,用户体验会是怎样的呢? 但首先我们来聊聊 zoho 电脑。问题来了,你的文件分散存储在 gmail, google drive, notion, notebook, lm 以及你使用的其他各种应用程序中, 但没有很好的方法能真正将它们整合到一个地方。 zoho 是 一款你可以拥有的私有云电脑,这意味着你可以将所有数据存储在云端,并拥有该实力的所有权。 而且你还可以利用其上的人工智能智能体,这样你就可以使用人工智能来管理你的文件,构建自动化流程,构建应用, 在那里存储你的代码。与锁定你数据的传统应用不同, soho 为你提供了一个持久的工作空间,所有内容都存储在这里。这意味着你可以控制自己的应用和文件。而且因为它是一台云电脑,你可以随时随地访问它,包括发送和接收短信,这是我最喜欢的功能之一, 而且还有其他功能,比如电子邮件,当然还有直接在机器上编辑代码以及自定义构建人物角色的能力,这样你就可以让你的电脑更加个性化。今天就来试试 zoho 吧,他们始终致力于为你提供一台可以简化你电脑需求的电脑 链接。在下方说明蓝。即使专家混合模型能将 token 成本降低到整个大小的近百分之三到百分之四,我们仍然需要将整个模型装入显卡。 所以即便是在 i n t 八精度下,光是模型权重,你至少也要用到五百 g b 的 显存。这意味着一台 d g x 减 h 一 百机器的六百四十 g b 显存只剩下一百四十 g b 用于推理,共二十八个人共同使用。 虽然一百四十 gb 看起来可能还不错,但我们来看看实际的计算结果。如果你去 hugging face, 它会给你更多关于 kimi k 二的思维,模型的实际架构的细节。 我们可以用这些来计算我们可以用什么?你有两倍的层数乘以隐藏层的大小,当然,还有精度推理时通常是 f p 十六。 在代入所有数字后,我们得到每个 token 大 约一点七兆字节的估计值。这意味着在一百四十 gb 的 共享内存中, 理论上可以容纳大约八万个 token。 是 啊,没多少。这意味着,如果我们有二十八个人共享这台设备,那么每个人最多能分到两千八百五十个 token。 而且我们现在只讨论了 kv 缓存,因为我们还没涉及到激活权重和其他相关的开销。所以也许我们该就此放弃了,因为从经济角度来看,这样扩展规模根本不划算。 然后你开始关注推理提供商,并且想知道他们是怎么做到在这种情况下还不亏钱的。总的来说,我的暴论是,按 api 定价的公司可能已经将他们的单位成本计入定价中, 这样他们才不会赔钱。而那些按订阅模式收费的公司每天或按时间段分配一定额度可能是想让你沉迷于他们的平台,因为他们知道人们在 api 定价方面不是很忠诚,但他们更可能为了订阅而留下, 因为 api 除了原始的智能外没有其他好处。但订阅意味着他们正在使用该产品,并且他们希望他们的平台和生态系统上有更多的用户。但这确实让你更加佩服那些推理提供商和前沿实验室。 他们以每百万输入 token 低于五美元的价格持续提供四十万甚至一百万的上下文窗口,以及不错的每秒 token 吞吐量, 而且他们正在为数亿活跃用户这样做,同时还要考虑能源基础设施,冷却和硬件。难怪他们需要那么大的人工智能数据中心, 而且以这种规模运营确实可以实现更高的并行性,从而大大提高效率。这在我之前的视频人工智能中的能源需求中已经介绍过了。 我在其中分解了能源成本以及存在的不同类型的病理性。因此,虽然现在购买服务器级别的显卡可能意义不大,但如果显卡成本进一步降低或者模型变得非常高效,那么它可能真的开始有意义了。 前提是 new clouds 和推理提供商不会相应地降低它们的价格,而它们很可能会这样做。
19声译看世界 01:22查看AI文稿AI文稿
01:22查看AI文稿AI文稿在我了解了这个通会是怎么被消耗的这件事之后啊,我最大的直觉是,我觉得未来的程序员很可能会两极分化, 分为有钱的程序员和没钱的程序员,分为富程序员、穷程序员。你想啊,有钱的程序员,他能够使用最先进的工具,使用最先进的模型,然后去创造出更好的产品, 然后去赚更多的钱。而没钱的程序员,他分为两类人,一类呢是打工人,他使用的是公司提供的免费 ai 工具,一般都不咋地。第二类是创业者,他需要是自负盈亏,如果他的商业模式跑起来了,他就是一个有钱的程序员, 如果他的商业模式没跑起来,那么他需要承担 ai 编程的高额费用,很有可能会入不敷出。 因为 ai 编程和我们平时使用拆一批聊天不太一样啊。一百万头肯,如果你聊天的话,你可以聊个几百次,能用很长时间,但是你 ai 编程,你让 ai 去分析一个功能模块,就有可能会消耗几千到几万头肯, 如果你让 ai 去分析一个完整的项目,全量代码几十万,上百万投坑代码还没开始写,几十块钱就没了,玩不起。我希望我这个直觉是错的,你觉得呢?说说你的看法。
799程序员康健 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿toker 是 二六年算力市场的一切,最近的 ai 圈需求直接炸锅了, ai 编程 ai 对 话全按 toker 算钱。 mini max 智普把程序员加班切成零点零,一元一次,这种降成本的好事谁能拒绝?更加模型厂商干脆甩出包月无限的 toker 套餐,比 视频网站的会员还便宜。互联网大厂连夜改合同, h 一 百 h 两百不租,正期租签意 toker 通行证用多少算多少,闲置是把成本密码给拿捏住了。 现在的 ai 圈需求在狂奔计费,在内卷算力在出租模式玩得越来越溜, token 的 黄金时代已经到来。
7时代华光 03:52查看AI文稿AI文稿
03:52查看AI文稿AI文稿这两天,我把网上爆火的 clubbot 安装体验了一下,一个简单的任务却消耗大量的 token, 效率并没提高多少,但是让我窥见了 ai 的 商业模式。我在创业的时候学到的第一条商业规律就是一定要做管道生意, 就是能源不断创造现金流的生意。这起源于一个著名的管道的故事。一个村子里没有水, 村民要每天花半天时间翻过山去挑水。村长觉得这严重影响生产,就决定雇人专门挑水。 小张和小马接下任务,每天按件计费,一桶水给多少钱?挑的多给的多,小张觉得挺好,每月收入不错,能过上中产生活。小马觉得现在年轻还行,等年纪大了,体力跟不上了, 每天挑水的数量肯定下降,收入就会降低。所以小马就决定未雨绸缪,趁现在年轻,给村里修一条管道,然后就游税。小张觉得挑一天水很累的,不想修管道,而且修管道太难了,管道不仅长,还要翻山越岭, 很不划算。小马游水一圈都没人愿意支持他,他就决定自己干,白天照常挑水,维持生计,下班后花两个小时挖管道。五年后,管道挖通了, 村里要用水接上它的管道,按水的流量收费。小张失业了,小马躺在家里收钱,现在在看 ai 等科技。其实不管如何改善生产力,还是改善生产关系,生产力就是提高生产效率。呃,生产关系就是改变分配形式,所有的赚钱方式都没变。 机器人,很多人不看好,因为很多机器人被人发现是提前写好程序,遥控操作的大玩具, 远没有达成可实用解决复杂问题的阶段。这个商业模式就是做好 ppt, 忽悠投资人的钱, 然后炒高股价变现。再看 ai 大 模型,不管是 agent 还是最近很火的 cloud bot, 我 这两天体验了一下,实际上就是接上各种大模型的 api, 利用家里的电脑或者云服务,变成一个可以在家自动干活的机器人。现在的问题是,不管是云服务还是大模型的 token, 都是现金流的管道生意。 cloud 霸的使用过程中,最大的感受就是养活了很多云服务商和大模型,至于生产力多高,倒是没看到。一个简单的任务,消耗了大量的 token, 还炒火了苹果的 mac mini。 ai 效率没看到,卖铲子的倒是先发财了。 ai 肯定是高科技,但我发现也跟机器人一样,存在低效的问题。 ai 一 些任务的完成度和效率比人还低,有些任务需要跟 ai 反复沟通,甚至浪费大量的 talk 呢,结果还是差强人意。 我不知道这是科技发展必经的低效过程,还是 ai 创造的消费陷阱。 ai 博主一年花费几十万来买各种大模型的会员, 然后制作视频来宣传各种大模型的应用,最后通过视频流量变现各种用户,花钱买会员,消耗 token, 形成了一个商业闭环。但是生产力到底有没有提升,工作效率有没有改善, 没有实际数据支撑,就跟某清华学美术的大 v, 现在摇身一变成了 ai 培训的专家了。因为 ai 商业模式闭环中,他找到了盈利模式。 我们跳开来看, ai 科技似乎是一个精心编织的消费陷阱,大模型企业、 ai 培训师和 ai 博主 共同编织了 ai 的 商业管道,管道里流的就是 tok 啊,这些 tok 有 很多对 ai 焦虑的人来买单,希望这只是科技发展中必经的低效泡沫阶段。最后问大家在 ai 上花了多少钱了,有没有实际的效果,或者有没有获得收益,请在评论区留言。
1879年老登宁叔 03:20查看AI文稿AI文稿
03:20查看AI文稿AI文稿今天我们来聊一个 ai 里面经常被提到的词, talk。 我 们用 ai 聊天、写文章,甚至是看资讯的时候,我相信都听过这个词。比如这次对话用了五百个 talk, 但 talk 它到底是什么呢? 它真没那么神秘,我们可以把它想象成一个 ai 的 语言积木。我们说话和写字是一个一个字来的,但 ai 不 一样,它处理文字的时候,它会把整段话去拆成一个个小的小块,这些小块就是 token。 我们可以想象为搭积木。比如我们要搭建房子的时候,我们可以分为地基,然后是墙体,然后是房顶。我们是用一块块积木搭成的墙体和房顶。 当 ai 也是这样,它是用 talk 来当积木,来搭出一句话、一篇文章,甚至是一首诗。 下面我们来举个例子,如果我们对 ai 说今天天气真好, ai 他 不会一个字一个字的看今天天气,他会直接把这句话拆成几个他认识的积木块。比如今天天气真好, 这四个部分就是四个 talk。 需要注意的是, talk 它不是字,也不是传统意义上的词,而是 ai 自己学会的一种有效率的切分方式。 比如中文里你好经常出现在一起, ai 就 会把它当成是一个 talkin。 那 为什么我们要关心 talkin 呢?是因为 talkin 它直接决定两件事情,第一, ai 能记住多少内容。 现在的大模型,比如支持一百二十八 k 的 tokken, 意思就是他最多能同时处理大约十二万八千个这样的语言积木。我们可以换算一下,差不多是一本中等厚度的小说,所以他能看懂我们前面聊了什么,上下文连贯。 第二就是我们用 ai 服务,比如 api 都是按 tokken 收费的, 比如我们输入文字越长, top 越多,费用就越高。所以聪明的人会优化自己的提问,用更少的 top 来表达清楚意思,这样既省钱又高效。比如我们想让 ai 写一个加法函数, 原句请帮我写一个 python 函数,这个函数要能够接收两个参数,然后返回它们的和函数名叫做 i 的 numbers。 经过优化之后就是 python 函数冒号, 然后接收两个参数,返回它们的和函数名是 i 的 numbers 看起来差不多,但前者可能用了四十五个 token, 而后者只需要二十个,这样省了一半多。所以我们下次再听到 token 的 时候, 我们就能特别清楚地去理解它。我们就想,这是 ai 拼语言用的小积木,每一块都代表它能理解的一个单位。 好了,到这里我们知道了 talkin 是 什么,它不是魔法,也不是黑化,是 ai 理解我们语言的一种方式。理解了它,我们就能更聪明的和 ai 去打交道。如果觉得这个视频 帮助你搞懂了 talkin, 可以 三连一下。下一期我们将聊一聊 ai, 它是怎么看懂一张图片的。好了,本期我们先聊到这里,我们下期再见。
116掌舵者AI实验室






猜你喜欢
最新视频
- 5494朋克周