skill如何快速构建虚拟环境

粉丝7974获赞2.6万
相关视频
 01:20查看AI文稿AI文稿
01:20查看AI文稿AI文稿兄弟们,一分钟让你生成 ai skills, skill six 开源神器,能把技术文档 get up, 代码 pdf 自动转成 agent skills, 并且自动化检查冲突,使用场景非常多,根据对应的网站识别内容生成可以给 ai 使用的 skills。 接下来我们就实际操作一下,首先它需要拍摄环境才能使用,目前比较推荐的方式 使用 python 三点一版本。首先复制下面的指令,打开终端,复制粘贴安装 skillseekers, 返回,这样的结果就安装成功了,这里官方推荐也是使用 paper 进行安装,如何使用,这里也有详细的教程,感兴趣的可以学习一下。接下来我们就来实际操作。在我们开发中,比如要使用这个 tailwindx, 我 们想给我们 ai 有 它的 skills 就 可以使用这个开源项目。这个开源项目主要就是帮我们自动生成 skills, 我 首先准备好了 tailwindx 一 些获取的配置信息, jen 文件, 准备好这些信息是因为需要它会根据提供的这些信息自动化识别页面内容,然后生成 agent skills, 能让我们后续提高开发效率。然后复制粘贴这个指令,根据我们的 config 文件夹下的配置文件去生成识别 skills, 这样它就会去根据我们给的配置文件去自动获取内容生成, 最后生成完成,左边会多一个文件夹 skill 点 m d 文件是主进的文件, references 文件夹下的都是详细内容文档,这样你就生成了 tailwinds 的 skills, 你 也可以运用在比如识别 pdf 或者其他的技术文档中生成 skills, 感兴趣的赶紧收藏,防止找不到!
282蓉漂码农 01:12查看AI文稿AI文稿
01:12查看AI文稿AI文稿从零到一,构建 skills 的 方法和操作流程,这可能是目前来说最落地的操作文档,即便你是新手小白,也能够跟着步骤一步步搭建出来。视频最后呢,你可以直接拿走文档呢,主要分为六大部分。第一部分,什么是 skills? 它的优势是什么?它和工作流有什么区别?有哪些使用的场景?第二部分, skill 的 标准搭建流程,包括本地环境的配置,目录、结构、提示词、模板等等,适用于 cloud code。 第三部分,如何在 tree 编辑器搭建 skill? 相比于 cloud code 呢?使用方式更加简单,而且没有网络的限制。第四部分,如何在 code 平台使用 skill 软件,也不用下载,直接在线使用,彻底摆脱环境的限制。 第五部分,从 ai 落地的角度出发,告诉大家如何正确使用 ai, 如何将自己的行业与 ai 相结合,毕竟啊,工具一直在变,但是变现的逻辑是不变的。 第六部分, cloud code 高级应用开发,这一部分呢,适合高级用户。好,一共六个部分啊,彻底搞懂 skills 的 落地实操,这是我们经过几天的时间来打造的,全部流程都是经过实际的验证。视频下方呢,也可以在评论中跟我们去进行交流。
 01:59查看AI文稿AI文稿
01:59查看AI文稿AI文稿如果你是技术小白,千万不要划走,看完这个视频,你将能够任意创作专属 skill, 甚至还可以变现。上个视频给大家详细介绍了 agent skill, 今天带大家用扣子创建自己的专属 skill, 目前有三种创建方法。第一个方法,先创建技能,再叠带优化。我们进入扣子平台的技能商店,点击右上角的创建技能,进入扣子编程平台,这里可以直接输入需求, 比如说创建一个生成 ai 话题播客的技能,然后扣子会创建一个虚拟环境,然后独立完成这个任务,咱们只需要耐心等待就可以。生成好之后我们来进行迭代优化,可以通过对话让扣子自动修改,也可以直接修改 skill 包中的内容。 修改好之后我们预览看一下效果,欢迎收听 pos ai 拨克。 hello, 大家好!哎,你最近有没有刷到腾讯新出的那个元宝派啊?我前几天看到好多人在讨论,感觉这玩意有点意思,今天咱们就来唠唠。哎对,我也刷到了, 怎么样?这个效果相当不错吧,和真人拨克几乎没有太大区别。创建好技能之后一定要部署,这样我们后面才可以继续调用。 第二个方法是直接在扣子的对话当中让他完成任务并进行优化,最后直接让他打包成一个技能。但是我个人更推荐第一个方法,因为打包成技能之后通常还需要再调整,所以不如直接先创建技能,然后再一起来进行迭代进行优化。 第三个方法是直接上传 skill 包,也许你已经在 github 或者说各种社群里收集了一大堆 skill 包,那你可以直接上传并使用。如果你想把技能公开分享,那可以上架到技能商店,找到刚刚创建的技能,点击上架到商店。 这里需要注意的是,需要在扣子平台,而不是扣子编程平台,然后填写各种信息,上传案例,甚至可以设置付费,然后就可以上传到机能商店了。是不是创建一个 skill 非常简单?那赶快去创建吧,让 ai 来替你完成工作。最后,如果你有一点收获,欢迎点赞、关注、转发。如果有疑问,欢迎在评论区大家一起讨论。
 08:44查看AI文稿AI文稿
08:44查看AI文稿AI文稿二零二六年全网爆火的 ai agent 的 skills 最全操作文档,从 cloud skills 到 open ai skills, 再到 tree skills, 再到扣子 skills, 从收费的到免费的,从配置网络环境,再到一键操作使用,所有的操作步骤我全部都写在这个飞书文档了, 需要的兄弟们说一下,直接拿去来我们看一下我们这个操作文档,从 agent skills 方法论,再到 agent skills 的 配置环境,再到跨平台需要专线上网,再到 吹 skills 免费版,再到扣子 skills, 这个叫傻瓜式一键操作,全部都总结处理好了,现在呢,我们一个一个的来看。 首先这个 a g 的 skills 是 什么?全网都在吹这个 skills, 其实一句话总结,所谓的一个 skills 就是 一个技能, 一个技能呢,其实它就代表了一个智能体,然后呢,我们可以把多个智能体,也就是技能放在一个对话框里来同时调用,而且都是自然语言调用, 就特别方便。以前就比如说我们是润色文案,一个智能体,写爆款标题,一个智能体, 封面文字一个智能体,现在呢,只需要一个对话框,这三个技能呢同时调用,这是它的最牛逼之处。还有一点最强的就是它同时调用 python 脚本, 把外部的事实数据,不管你公司,比如说你如果是官方客服,你做一个 ai agent skills, 有 用户咨询你的货源,那你的仓库事实数据呢,就可以让这个 agent skills 事实调取特别方便。 它呢可以说是集合了以前的 prompt 提示词,再加上 m 四 p, 再加上 api 调用,脚本调用,这样一把它封装成一个一个的技能,让 ai 呢,就是在我们规定的范围内,自然语言一步到位 输出来,我们直接先看效果,你看我们左边这里,这做了三个 技能,第一个技能呢就是 news hotspot, 就是 新闻热点实时抓取的一个技能,然后抓取完之后呢, 再把它新闻热点提炼,提炼完之后,你看下面这个技能呢,根据新闻热点,润色文案,再写爆款标题。这是三个技能,但是呢,我这里是同时一个对话框就可以完成了。以前你的一个智能体,他只能干一件事,现在呢, 直接三件事,一步到位。看这里就一句话,让他帮我总结搜索最近 ai 领域热点新闻,然后提炼总结,生成一篇爆款短视频文案,以及三条爆款标题。 首先先调用了这个热点搜索的这个技能,他实时抓取热点,然后呢,搜索总结完之后呢,再写 润色文案,再写标题,就是三个技能,他会就是一步完成。你看,根据要求,已搜索二零二六年一月 ai 领域的最新热点新闻,并严格按照 这三个技能规范来生成内容。你看 ai 劲的革命爆发,二零二六年被定义为主动智能体元年,下面写的爆款短视频文案 以及爆款标题,要想搞清楚这个 skills 具体怎么来操作,怎么玩转它,我的文档呢,详细总结了 skills 的 一规范和特性, 你看它的方法论。首先呢,它就是比以前的单个智能体呢更省 talk, 也是更省钱了,说白了还有它架构模型,三层原数据 指令,包括它的资源,它包括它生态位对比、 skills 提示词和 m 四 p 工具调用、 ai 交互, 这三者的关系总结的非常清楚,其实最核心的就是它的一个原数据,一个是它的指令,那它这个指令呢?可以理解为就是我们现在的提示词。然后这个资源呢, 可以理解为他的参考文档,他的素材,他的脚本。比如之前我们润色文案的时候,里面要写开头勾子对不对?中间勾子,结尾勾子,那这些东西呢?以前直接写在一个提示词内容里面,他就非常费滔肯,现在呢, 它就把这个提示词给分层了,这一部分分层之后呢, ai 它调用的时候只调用一部分,它不会全部调用。还有一个最重要的更新就是这个脚本,有了这个脚本呢,它就可以打通和外界的数据沟通。就像刚才 我们看到这个例子,他实时抓取 ai 新闻并总结,然后写文案。当然同样道理,如果你是智能客服,问某一个商品库存还有没有剩多少,那他就可以实时抓取到你公司的后台的 erp 系统, 实时调用真实的库存,然后来回答用户的问题,就真正的做到了放手让 ai 去帮你干活。而且你这个技能呢,从指令到参考文档到素材到脚本, 它是一个标准化的封装程序,就像 cos 工作流一样,它是严格按照你这个执行的, 他不会有任何偏差,这就是 ai 进的真真正正的落地的最后一公里,你看适用场景,高频重复,每天每周都要执行的固定流程,多步骤操作是获取信息、处理信息、输出结果和发送通知, 多步骤闭环任务,还有专业的特定的行业标准,如财务分析指标这些等等,包括避坑指南,也给大家总结好了,只要按着操作就行了, 因为当你真正去涉及到一波技能调用的时候呢,它有些可能调用不上去,或者调用了之后呢,它里面规范的技能呢, 它没有完全执行,那这个时候呢,就需要一些约束条件,严格按照你的 skills 的 技能规范来执行。 下面呢,第二部分呢,这个就是 cloud skills 的 需要专线上网,因为这国外的环境配置,具体怎么操作我就不这里就不详细展开了,要有一定代码基础的人才能操作轻松一点呢,一个是扣子,这个是傻瓜式操作,还有一个就是 tree, 这个是安装在本地部署的,本地部署呢,需要一些代码基础才能搞定,要求呢稍微高一点点, 当然也不用担心,我这个文档呢,也详细总结了,操作步骤流程都在这里,包括你如何使用别人的 skills, 比如这个 get 仓库,这代码人员的天堂, 直接从这里面怎么去找官方的 skills, 然后怎么下载,然后怎么部署到你的本地,就这个翠详细的操作文档都在这里 下面呢,我们来说一下这个扣子,你看这里我总结了一个文案润色的技能,你直接一句话跟他说就行了, 根据用户输入的话题,或者对标的文案或者新闻热点进行文案润色,二创成一篇爆款短视频文案扣子,他就会自动给你生成一个 skui 技能,然后这个技能呢,你可以去测试,如果你觉得它测试的不够好呢?你看比如这里开头钩子不够好优化开头钩子爆款短视频文案 最重要的标准就是看开头有没有开好,开好了就成功一半,就是一点点的去 优化你这个技能的输出结果。那具体这个怎么去跟它优化呢?其实我们这里也有一套完整的 sop 流程,都在这个文档里面 写的很详细了,这里我就不展开了。想深入使用的话,扣子平台的 skills 呢,他只能用豆包模型,大家懂的都懂对吧?那想要效果好, 那你必须要懂一点代码技术,可以使用最牛逼的大模型,后边我会出一系列的 skills 具体应用场景的教程。其实 skills 核心就是提示词加脚本, 就是解决了以前的智能体只能处理文案, minus 呢,只能调取数据,这里呢,他直接把这个两方面给结合了,更高效、更规范、更落地。然后需要这个详细操作文档的说一下。
 03:038154程序员三千
03:038154程序员三千 01:46查看AI文稿AI文稿
01:46查看AI文稿AI文稿想用 m c p 和 skills, 但是又被 cloud code 和 code x 的 命令行全退,今天介绍一个让小白也能玩转 ai 的 神器。 cherry studio, 免费开源,中文 下载就能用,不用配置任何环境,一个软件接入三百多个大模型, deepsea、 cloud gpt 随便切换,并且给你配置好了两个免费的大模型。现在 ai 圈里最火的 m c p 和 skills, 它也读知识,我们现在体验一下它的 m c p 功能。比如说装上这个内置的 m c p file system, ai 就 能读取和操作你的电脑上的文件。这里需要配置你要读取文件的目录,不过也可以不配置。但是后面在绘画中,你要说出文件的全部路径,保存安装 m c p。 比如我这里有一个 c s v 表格, 我就用这个 mcp 捕取文件,分析每个交易方共花了多少钱。设置 mcp 和要使用的模型,然后输入指令。从控制台看到它是调用 mcp 捕取文件内容,然后来计算结果,最后完美输出想要的结果。除了 mcp, 最近大火的 skills, terry studio 同样支持添加助手,添加 aint, 选择模型和工作目录。但是这里需要注意的是,目前 aint 功能只有支持 azure rapid 端点的模型可用。我使用的是月之暗面,现在各大模型厂商对于新人都有免费额度设置。完成 show skills, 这里会先去检查 cloud code 下面的 skills, 然后再去查找切尔斯基自己安装的 skills。 我 们这里声明, pdf artefact skills 创建一个内容随意的 pdf 文件,这里不知道是我使用的问题还是设计如此,需要你再输入一遍。 经过一系列操作输出的一个 pdf 文件,但是显然模型不太给力,居然是乱的。当然,大家可以使用内置 skill, skill creator 去创建一个属于自己的 skills。
138东升Coding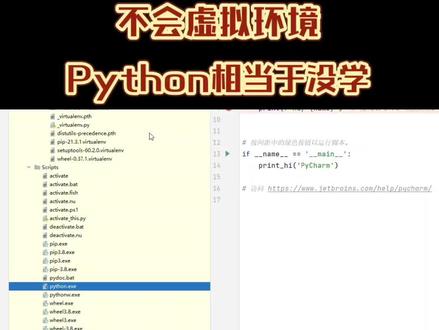 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿不会创建虚拟环境? python 相当于没学,因为我们项目有很多,每个项目的库和版本都不一样,所以需要安装虚拟环境。 如何创建虚拟环境呢?选择文件新建项目,创建项目的时候可以选择一个虚拟环境的类型,推荐大家使用 v to env 点击创建,在创建出的项目当中可以看到有一个 env 目录,这里面就放着他的虚拟环境。有了虚拟环境,我们项目当中所引入的各种酷和版本他都是独立的,不会影响其他的项目。是不是很简单呢?
188喜气洋洋^O^ 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿最近这个叫 remotion best practices 的 agent skill 火爆出圈,关注 ai 的 人估计都被他刷屏了。作为一个实战派,我第一时间去测了,结果太重了。为了生成一个十几秒的动画, 他花了十分钟搭建环境,连代码都没开始写。对于我们这种追求效率的超级个体来说,这完全不可接受。如果我只是想给分镜脚本做个演示,为什么要搞那么复杂的工程? 于是我换了个思路。利用 gemini 三 pro 强大的前端编码能力,我找到了一种极简解法,不用安装环境,一个 html 文件全搞定。 我把本地视频路径给他,让他用 canvas 渲染动画。注意, gemini 很 聪明,他甚至帮我解决了 media corridor 录制开头掉帧的问题,加了预热机制,看这是生成结果丝滑流畅。 扔给他两张素材图,告诉他脚本第一幕的内容,不到一分钟,代码写好,运行网页,它自动全屏,自动录制,自动下载,这效率比打开 ae 都要快。 我们将生成一个纯粹的动画演示视频,不给任何素材,只给脚本和我的配色方案。 gemini 直接用代码画出了这个代码聚合的动画,科技蓝背景、活力橙点缀,完全符合我的账号调性。 总结一下, remotion 很 强大,但在某些快节奏产出下,它太重了。而用 gemini 手搓 html, 虽然需要你手动复制一下代码,或者开个 python 本地服务,但它把制作时间从半小时压缩到了六十秒。 ai 不 应该让事情变复杂,而应该让创意落地变简单。我是 ai 工具猎手,关注我,带你用最硬核的方式挖掘 ai 的 实战红利,下期见!
63AI工具猎手 01:05查看AI文稿AI文稿
01:05查看AI文稿AI文稿最近爆火的构建 skills 完整流程呢,我花了一个星期时间终于整理出来了,包含了从零到一构建 skills 的 详细 sop 流程,内容呢从初级到高级,全部都包括,初级的,比如说使用扣子,直接在线使用, 不用下载软件,不用配置环境,通过自然语言就能可以搭建出我们第一个 skills 的 技能。具体的使用技巧呢,都在这个文档里了, 高级的用法也有,比如说 cloud code, 这个呢,可以使用国际顶尖的大模型,但是对你的网络环境呢有些限制。当然还有一种折中的方法就是国内的锐编辑器, 这个呢也需要你去下载软件,相比于扣子呢,它的数据是保存在本地,安全性更高一点。那么具体如何使用呢?都在这个文档里了。还有更重要的就是第六个部分,这个呢大家可以一定要去看一下,它讲的是如何进行 ai 落地,如何将 ai 与行业相结合, 真正的把 ai 转化成生产力,毕竟我们使用 ai 是 要进行转化的,对吧?需要的说一下,直接拿去。
 06:15查看AI文稿AI文稿
06:15查看AI文稿AI文稿padformers 是 基于百度飞讲框架开发的,让开发者更容易训练和使用大型 ai 模型的工具。我们本地部署 padformers, 并微调了千万零点六 b 模型,下面带大家一起来看一下整个过程。我电脑上的是五十系显卡,十六 g b 显存,酷达十二点八版本。 首先本地部署需要 python 三点一零或更高版本。我整理了一个 python 三点一本地部署教程。我们创建一个独立的 python 三点十环境,避免依赖冲突激活创建的虚拟环境,下载 python 源代码,进入项目目录, 这就是它项目的结构。然后我们安装 padformers, 极其依赖安装适配版本的酷的,安装酷到翻译工具设置库路径和模型下载源,避免运行时错误。我们来看看 padformers 提供的配置文件模板,可以看到这里有七个淹没配置文件,每个对应不同的训练方式。 laura yammer 这是我们接下来即将使用的配置文件。 laura 是 目前最流行的微调方法,只训练模型的一小部分,参数显存需求低,非常适合个人或小团队使用。然后是夫家们, 这是全参数微调,它会训练模型的所有参数,效果可能更好,但显存需求也高得多。这个 f o t p 下滑线 pp 是 多卡分布式训练的配置,当模型太大,单卡装不下时,就需要把模型切分到多张显卡上。 其他还有加入专家并行的版本,以及专门训练函数调用能力的配置文件。根据硬件资源和训练目标,选择合适的配置模板来开始训练。 对于资源有限的用户,推荐从 lara 点 y a m l 开始,大家可以看到这里有四个 json 文件,这是 padformers 官方提供的测试数据集,注意看路径,这个达米就说明了它的性质。 这是一个演示用的占位数据集,我们打开 train 看一下,可以看到只有十二条简单的对话数据,这个数据量在正式场景中是完全不够的,但对于我们测试工具是否正常工作来说已经足够了。真实的微调场景,我们需要准备至少几百条高质量的针对特定领域的训练数据。 准备完训练方法和数据集后,只需一行启动命令,它会自动下载千问模型开始训练,这是训练成果。 train results jason 训练结果统计首先看 progress 是 一点零,说明完整训练了一个 epoch, 最关键的指标是 train loss, 也就是训练损失值,这里是四点一三,损失值越低,说明模型预测越准确。这个数字看起来有点高, 这是正常的,我们只用了十二条数据训练了一轮。在实际应用中,用几千条数据训练几十个 ipad 后,损失通常会降到一以下。训练速度方面,每秒处理二点六个样本,整个训练只用了四点六秒就 完成了真实的微调任务。数据量会大得多,可能需要几个小时到几天的训练时间。内存占用方面,使用了约九 gb 的 cpu 内存, 如果是全参数微调,可能需要几十 gb 甚至上百 gb 的 显存。总的来说,这次训练成功验证了 pad formers 的 完整流程。虽然数据量小,效果有限,但这正是我们测试的目的,确保工具可以正常工作。我们来看 pad formers 训练,日制 pad formers 框架执行了一个完整的 quan 三零点六 bbs 模型 lora 微调任务,从环境初步到模型保存共耗时约四分钟,实际训练仅四点六一秒。 环境初识化模型加载阶段,配置下载,从 model stop 下载昆三零点六 b 杠 bass 配置文件, 下载模型权重文件一点一一 gb 训练配置阶段混合精度 bf 十六训练,训练步数仅三步使用测试数据十二个训练阶段处理速度三点六三样本每秒显存使用峰值二点八 gb, 总耗时四点六一秒。模型仅保存弱弱式配器权重,最终正常退出。整个流程验证了框架基础功能正常。最后用这个对比表格从模型覆盖、训练性能,硬件 支持一百家模型国产化全站方案右边 miss swift 阿里达摩院基于 py torch, 支持五百家模型,社区活跃模型数量 is swift 五百加,完胜 paddleformers 一 百加。但是 paddleformers 独家原声支持 ern i 一 系列, 只有 paddleformers 有 paddle uke vl 官方也发布了公众号说明,模型覆盖全面,包含了 ernie 四点五、 ernie 四点五 vl、 deepseek vthree g l m 四点五系列、千问系列等性能优势。 paddleformers 二零一六卡 h 八零零训练 m f u 达百分之四十七 fullash mask v 三加速一点四倍 deep c k 三优化超越 mag 创 一百二十八卡昆仑芯片就能微调超大模型 mo 模型训练 flash mask dpp, 这 些都是 paddleformers 独有技术。 miss swift 没有大规模训练,选 paddleformers 性能更强,基础的 laura, coolura 都支持,但是新技术 miss swift 全都有, paddleformers 都标位明确,强化学习,对其 miss swift 更全面 专项能力, paddleformus 有 专项支持,各有侧重,硬件支持,这是关键差异。 nvidia gpu 两个都支持,没区别。 paddleformus 支持昆仑 p 八百天数天磊木兮 c 五五零升腾 npu。 miss swift 完全不支持国产芯片,但是消费级显卡 miss swift 优化更好。 miss swift 有 webu i i 界面, paddleformus 没有 选型建议如选 pedophormous 的 情况,用国产芯片正起国产化项目。训练超大蒙舞模型训练 padlow c r n 系列,追求极致训练性能选 miss swift 的 情况,个人学习快速实验,消费级显卡 需要 web ui 界面强化学习,对齐依赖哈根 face 生态。最后总结,两者互补,不是替代。 paddle formers 性能强加国产化加产业级能力, miss swift 模型多家应用强加社区活跃。希望本期视频对您有所帮助,我们下期视频再见!
 05:33查看AI文稿AI文稿
05:33查看AI文稿AI文稿昨天鼓捣了一整天,终于把我的 cloud code 给跑通了,而且配了一个简单的 agent, 那 整个过程其实是花了我除了昨天之外,还有前天大半天的时间。 一开始是怎么样呢?一开始我是通过 b 站的那个免费课程以及它配套的一些学习文档去操作。首先我需要去安装 note js 和 get 这些工具,我以前也是写过代码的哈,所以对于这些工具的安装和环境变量的配置,我没有什么问题。这步没有卡到我, 卡到我的是什么呢? cloud code 安装完之后,它是需要调一个 api 的, 那当时那个免费文档里就有一个坑哈,它没有详细地告诉你 api 的 配置应该在哪个文件里改,它就说你要找 settings 文件, 但是你并不知道这个 settings 是 get 下面的 settings 还是 cloud 下面的 settings, 导致我在这个地方卡了很久,最后我又跳出这个文档,去找了网上另外一个别人的文档,才搞清楚这个事情。 然后我就发现这种免费的教程哈,它给到你其实就是一个钩子,它希望你在学的过程中就是要遇到这些卡点, 遇到卡点之后你才会付费向它去学习嘛,因为你很想学会这个东西嘛。好,然后我解决这所有的卡点之后呢,基本上我也脱离了原来那个教程的框架了,我就寄予第二个教程的框架。我没有去 cloud 的 官网去充值 pro 或者 max 版,而是直接用了一个第三方的 api 工具, 然后我就需要将第三方的这个 url 和 api 接口的代码都配置到我的那个文件里面。做完这一步之后,其实我在 command 里面的那个 cloud 就 已经可以正常运行了,但是我不满足于这样,我希望是通过一个呃编辑器 id 来整体 用 cloud, 然后旁边还能看到我这个项目下的文档,因为我从 get 上已经找到一份人家做的很成熟的一个项目,而且给它克隆到我本地了,所以在这个基础上我又去学习了 vs code。 我 以前代码时候用的是 notepad 加加,其实这次哈,其实这次 cloud 它的安装选项里也写了可以支持 notepad 加加去安装的,但是它的整个运行编辑环境可能就不像 vs code 的 那么更符合代码习惯吧。然后我安了 vs code 之后,问题就出在这儿了。教程,你是说你要搜一个插件,那个插件叫什么?叫 chat for cloud code, 然后我下了那个插件之后, 怎么样搞都搞不通了,你每次把对话框打开,然后输入一个错,而且那个错误是乱码,你怎么调也让那个乱码回不了正常。最后呢,我又找了第三个教程, 找了第三个教程之后我才知道原因是我下的这个 chat for cloud code 并不是 ansorek, 它的一个 官方公司的一个产品,官方公司叫 cloud code for vscode。 然后我又下了官方的这个 cloud code 插件,之后又卡住了,卡住之后又找其他的教程,教程说你要配一下这个插件的环境变量, 好插件的环境变量是有一个变量文件的啊,在文件里面去添加一些东西就行了。然后你只要对应住这里面添加的 u r l 啊呃 token 以及你的 model 都跟你之前在 settings 文件里配的是一样就可以了,然后我配完之后它还是报错,我就卡在这了, 因为我当时已经搞了一整天了,我就说我就说干脆等我老公回来帮我看算了,因为我老公是程序员啊,我觉得他会比我清楚,而且他在我做这个探索之前,他自己已经把那个 tree 啊,然后 coat, body 啊都用了一遍,他基于这个已经成功的做了两个小程序出来了, 所以我觉得他应该比我有经验一些好。晚上我老公回来之后,我就带着他去看,他说你现在什么问题,我就把我的问题说给他听,然后告诉他为什么我两边的 settings 里面设的是一样的,但是会出问题呢?这时候他说你的 settings 里面每一个变量是什么东西,我就告诉他这个是 u r l, 这个是 api 的 这个 id, 然后在自己讲的过程中,我就发现我在这个插件的 api id 这里面填错了两个字母,因为首字母当时复制不过来,我就手打的,然后我就把小写搞成了大写, 然后改成小姐之后马上就通了,就没有让他帮我解决哈。这个通了之后呢,我就基于我的这个 clone 下来的 get 项目去进行了一个 初试的学习,当然一些基础操作我已经会了哈。然后我就是想看它这个项目的重要的 cloud md 这个文件该怎么改来适应我的需求,我的目标是什么呢?我的目标是想把我现在教学的能力中间,每天或者每周固定要做的一些重复化的工作,把它固化成多个 skill, 然后调多个 aint 去实现它的功能,所以我现在只是在做其中一个 aint, 然后现在就是要将它的那个 prompt cloud 的 那个 md 文件里面的 prompt 全部给 转换成我要的这个能力。好,那么下一步就是我要将我个人一个需求或者能力进行一个拆解,来找出目前最迫切或者说最好实现的一个,让这个可拉扣的来帮我实现。总结一下哈, ai 这个东西其实是 你首先要上手去用,然后不断地踩坑,不断地试错,如果一开始抱着心态说,我要先不将所有大模型底层的原理给搞得清清楚楚的,啥是 m c p 啊?哎?啥是这个?啥是那个呀?你要是这样子学的话,其实对于你的使用来说,呃,实际上没有太大帮助哈, 所以这个东西还是要入手去做,而且尽快地去做起来,当你这个事情坐在别人前面的时候,你才可能比别人更快出成果,或者说以后比别人钻研得更深,用得更熟。我对 ai 方面的学习应用的进度就是这样。
549JennyYu的数学专栏 04:4180掌舵者AI实验室
04:4180掌舵者AI实验室 13:00
13:00 00:56
00:56






猜你喜欢
最新视频
- 13.4万爱举铁的大象