你以为浏览器并发请求越多,网页加载越快?错了!限制同域名并发请求数,其实是浏览器保护服务器和网页的关键设计哦。 当你打开网页时,浏览器会向服务器请求图片、 cssjjs 等各类资源。为了避免同一域名下同时发送过多请求,浏览器会设置一个上限。比如 chrome 通常允许六个并发请求。 这就像餐厅限制同时进店的人数,防止厨房忙不过来,导致所有客人等待。需要注意的是,这个限制仅针对同一域名,不同域名的请求互不影响。比如百度和淘宝的请求数是分开计算的, 服务器处理请求需要消耗 cpu、 内存和贷款等资源。如果同一域名同时涌入几十上百个请求,服务器很可能会崩溃或响应变慢。这就像一家小店同时接待一百位顾客,每个都要服务,结果谁都要等很久。浏览器限制并发症是行业共识的保护机制,避免单个用户的浏览器压垮服务器, 从而保证多数用户能够正常访问网络。宽带如同公路,同一时间车太多就会堵车。如果浏览器不限制并发请求,同一域名的请求会占满用户的宽带,导致其他请求,比如其他网站会页面关键资源的加载变慢, 比如家里的 wifi, 同时在看视频、下载文件、刷网页,所有操作都会变得卡顿。限制并发能够让资源分配更加合理,确保 js、 脚本等关键资源优先加载,从而提升页面的整体体验。 浏览器本身也是一个程序,每个请求都需要占用内存、 cpu 和内存。如果同时有上百个请求,浏览器的性能会下降,甚至卡顿崩溃。这就像手机同时打开二十个 app, 后台运行会导致发热变慢。虽然浏览器限制并发症,但可以通过 keepalive 技术附用 tcp 连接,减少重复建立连接的开销。 比如去咖啡店买咖啡,第一次需要排队点单付款之后就可以直接用之前的订单信息快速取餐,不用重新排队。连接附用让浏览器在限制病发的同时提高了请求效率,避免了频繁三次握手带来的延迟。 不同浏览器的病发现值数值有所不同, chrome 和 firefox 通常是六个, safari 可能是四个。这并不是统一的标准,而是各浏览器根据自身优化策略平衡的结果。 比如不同品牌的餐厅,有的允许五人同时进入,有的允许六人,但都是为了保证服务质量,开发者无需过度纠结这些差异。多数场景下,六个并发已经足够。如果页面需要加载大量资源,比如电商网站的商品图片,可以将资源放在不同的子域名下, 比如 img 幺点 e x a m p l e 点 com。 img 二点, e x a m p l e 点 com。 浏览器会把每个子域名当做不同的域名,并发请求数可以叠加。这就像商场里一家店只能近六人,但旁边的分店可以同时接待, 从而提高效率。不过不要分太多子域名,否则会增加 d n s 解析的开销,反而影响性能。即使没有浏览器的限制,过度并发也会带来问题。服务器可能返回五零三错误, 网络拥堵导致请求超时,甚至 isp 会认为是恶意流量而限制待宽,这就像一次性给朋友发一百条消息,朋友可能会忽略大部分或者手机卡顿。开发者应该合理规划资源加载顺序,优先加载关键资源,而不是依赖无限并发。 浏览器的病发限制通常在四到八个之间,这是长期实践平衡的结果。如果限制太少,比如一个页面加载会极慢,如果太多,比如二十个,会导致服务器和网络压力过大。这就像电梯载重,一千千克刚好容纳十人左右,既不浪费空间也不超载。

粉丝6620获赞3.3万
相关视频
 00:59查看AI文稿AI文稿
00:59查看AI文稿AI文稿深夜打开学习网站,正准备起飞的你却被 vip 提醒弄得兴致全无,那有没有办法不开通 vip 也能一块学习呢?一天掌握一个黑客机息,今天我们要了解的是月前漏洞。郑重声明,本视频为正规网络安全技术科普,所有演示均在售前拔机完成,严禁用于非法用途。 首先我们打开 web suite, 然后点击 box 以下的 open browser 按钮,打开 web suite 自带的浏览器,然后将目标网址复制到浏览器地址来,这里我们随便输入一个数值,然后打开拦截开关,再点解锁按钮,这里就能用 web suite 对 数据进行抓包, 然后右键修改响应包,再点击 for 放行,此时我们就可以得到网站返回的数据请求,我们只需要将这里的 files 改成去,再点击 for 的 按钮放包, 即可实现跃前访问。如果还没看懂或想学更多王安工房机洗和工具玩法都已经在老地方打包好了,大家还想学习什么网络安全技术点,可以在评论区留言告诉我。
577白帽小衫 00:32查看AI文稿AI文稿
00:32查看AI文稿AI文稿看好了,朋友们,上次就火爆传这个一个屎量器,直到现在呢?很多朋友爆竹会下载今天的主播三秒教会你,安卓苹果都是可以的。首先我们打开抖音,然后点视频右下角分享,我们点分链接退出来,打开这个应用商店,然后去下这个,我们打开它, 稍等一下,点于爽贴,他会弹出个金元包,立即查看,点进去,看到国外 app, 我 们点进去,然后取消存选,找到你要的选择保存去安装就可以了。
45不是美女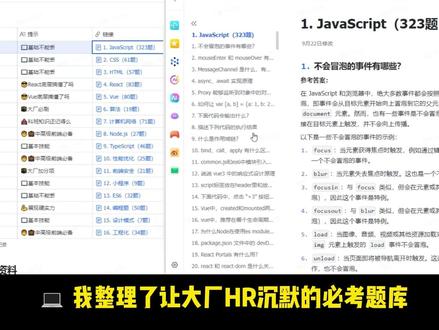 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿面试一个刚独立完成项目的初级前端,我问你们前端运行在 lotlop 三千,要调用后端 lotlop 八零八零的接口,浏览器爆了 q r s 错误,你怎么解决?他很快回答,让后端配一下 q r s 允许所有来源就行。我追问 具体怎么配,如果后端说配了,但依然报错,可能是什么原因?除了 course, 还有哪些方法可以解决跨域问题?在开发环境有没有临时解决方案?他开始翻记忆, 跨域是每个前端避狱的拦路虎,但很多人只知其然,不知其所以然。如果这道题目你也不会回答的话,我整理了让大厂 hr 沉默的必考题库,包含 v o 灵魂拷问、 react 高频陷阱、 j s 十连问点个赞,评论区甩六六六,打包带走 nice, 彻底攻克跨域的本质,同源策略, 协议、域名、端口,三者必须一致,为什么要有同源策略?为了安全,防止恶意网站窃取用户数据。 注意,跨域是浏览器的行为,服务端之间调用没有跨域问题。二、 c o s 标准解决方案简单,请求直接发送后端返回 access control allow origin 头 预检请求,复杂请求前浏览器会先发 options 请求询问带凭证的请求,需要设置 access control allow credentials true。 三、开发环境的临时方案, webcraft dev server proxy 配置,代理将请求转发到后端浏览器插件,临时禁用 c o s 关闭浏览器安全设置。四、其他跨域方案 jsonp 利用标签,没有跨域限制的特性,但只支持 get 请求 postmessage 跨窗口通信, web socket 没有跨域限制。 on jignesh 反向代理在生产环境中将前后端部署在同一域名下,这个厉害。这道题 从简单的怎么配深入到安全原理、解决方案选择、开发、生产环境差异能讲清楚跨域,说明你对网络和安全有了基本理解。最后,你在项目中遇到过最棘手的跨域问题是什么?怎么解决的?
190IT牛马人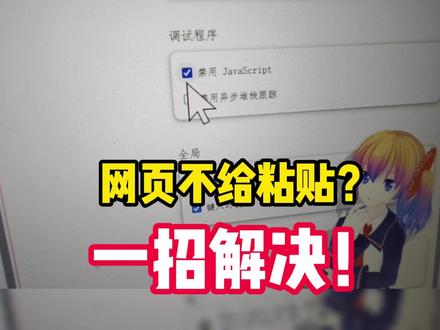 00:43查看AI文稿AI文稿
00:43查看AI文稿AI文稿某些网站会限制用户直接粘贴文本,例如全国幺二三幺五平台的投诉内容栏就不允许粘贴预先写好的文字,这无疑给消费者维权增添了障碍。明明剪贴版中已有所需内容,但无论是右键点击还是使用 ctrl 加 v 快 捷键,都无法完成粘贴。 遇到这种情况,可以尝试通过浏览器的开发者工具临时禁用限制功能。以 h 浏览器为例,一、按 f 十二打开开发者工具。二、点击右上角的三个点进入设置。三、在调试程序一栏中勾选禁用 javascript。 四、返回页面,再次尝试 ctrl 加 v 粘贴,通常即可成功。不清楚网站为何采用这样的设计,导致消费者必须逐字输入,无疑降低了操作效率与体验。
2.1万旅行者北斗Hokuto 18:10
18:10 05:10查看AI文稿AI文稿
05:10查看AI文稿AI文稿大家好呀,我是小安师兄,今天带大家五分钟搞懂 h t t p。 协议和 t t p s。 协议。 大家现在每天都在访问网页,聪明的你肯定留意到了浏览器地址栏里开头的几个英文字母, h t t p 和 h t p s。 这个多出来的 s 代表着什么意思呢?它究竟如何工作?让我们快速的了解下。 h t p p。 协议。 互联网的基础是 http 协议,全程是抄文本传输协议。它的工作模式极其简单、高效。请求与响应。你点击链接,浏览器发送一个请 求,服务器处理这个请求,返回一个响应,里面就装着网页的代码、图片或视频, 就像一个高校的邮差系统。但 h t t p 有 两个与生俱来的特性,带来了巨大风险。第一是无状态服务器,不记得你上次来过。第二也是最致命的, 它是铭文传输的。这意味着你的登录密码、搜索关键词在网络中就像写在明信片上一样,传递。任何一个途径的网络节点,比如一个不安全的公共 wifi, 都可能潜伏着中间人攻击者, 他们可以轻松地窃听甚至篡改你的通信内容。为了解决这个根本性的安全漏洞, h t t p s 诞生了。它的本质是在 h t t p。 协议之下 加入了一个 s s l t l s 安全层。这个安全层的核心使命有两个,加密传输和身份认证。简单说,既要给信件上锁,还要确认邮差的身份。实现安全离不开加密,这主要依赖两种技术, 对称加密、加密和解密。用同一把钥匙,速度快,但如何安全的把钥匙交给对方是个难题。 非对称加密使用配对的公药和私药。用公药锁上的箱子,只有对应的私药才能打开,公药可以公开分发,私药必须绝对保密。他解决了密要分发问题, 但速度较慢。 h t t p s。 安全性建立,和 tcp 三次握手差不多。首先是客户端打招呼,接下来是服务器回应并出示他的数字证书,一个包含工要、域名等信息的电子身份证。客户端接到回应之后, 检查证书是否由可信机构 c 类颁发,域名是否匹配并验证数字签名,以防篡改。当客户端验证通过后,生成一个随机的绘画密钥。对称密钥 完后,客户端用服务器的公钥加密,这个绘画密钥发送给服务器,服务器接到绘画信息之后,用自己的私钥解密得到绘画密钥。此后,双方都是用这个高效的绘画密钥 进行对称加密通信。大家可以明显地感觉到 h t t p s。 的 握手过程是一次精密的协助。它巧妙地结合了两种加密方式的优点, 先用非对称加密安全的交换一个临时的绘画密钥,再用对称加密进行后续所有高速的数据传输。但这里有个信任起点问题,客户端最初收到的 x x 银行, 而不是一个伪装成银行的中间人。这就是数字证书和证书颁发机构 c a 出场的时候了。 服务器必须向受信任的 c a 申请证书。证书就像由公安局签发的身份证,里面绑定了服务器的公钥和身份信息,并由 c a 用它的私钥进行数字签名。你的浏览器内置了可信 c a 的 公钥, 可以用来验证这张身份证的真伪。中间人无法伪造 c a 的 签名,因此无法假冒一个受信任的网站。所以, h t t p s。 的 安全 是数字证书提供信任起点加非对称加密安全握手加对称加密高效通信,这三者环环相扣的结果, 他将不安全的 h t t p。 铭文通道改造成了一条加密可信的私密隧道。对于我们每个用户而言,无需理解复杂的技术细节,但请务必养成一个有关重要的安全习惯。在任何需要输入密码、 银行卡号等敏感信息的网站,请首先确认地址栏是以 h t t p s。 开头,并且旁边有一把锁芯 标。如果浏览器弹出任何证书错误或安全警告,请立即停止访问。从 h t t p 的 h t t p s 不 仅仅是多了一个字母,它是整个互联网卖相更安全、更可信环境的关键一部分。期视频就到这里,我们下期再见了。
20小安师兄 02:53查看AI文稿AI文稿
02:53查看AI文稿AI文稿cookie、 session、 token、 zwpt 咱们一次聊透,先跟大家讲清楚为什么需要这几样东西。因为 http 是 一种无状态协议,用户每发起一次请求,对于服务器端来讲都是一个完全独立的全新的请求。 你是谁?你之前做过什么操作都是一无所知的。就像你去某个电商平台买东西,从商品列表页到商品详情页需要登录一次,从商品详情页把商品加入到购物车还得登录,那对于用户来讲是完全无法接受的,所以就诞生了 cookie。 我们可以将 gucci 理解为存储在浏览器端的一份数据,这份数据是服务器端发送给浏览器端的。在后续的请求中,浏览器端的用户每网服务器端发起一次请求,都会携带这份数据进行身份识别验证,这样就不需要重复进行用户名和密码进行登录了。我们可以看下 gucci 的 详细交互流程, 从这里来看, gucci 确实很好的解决了 lib 之类的关键数据,直接存储在浏览器端,系统就没有安全性而言了。 用户完全可以把 user id 从一二三四五六改成一二三四五七,一二三四五八,这样就摇身一变拥有了其他用户的权限。为了解决该问题, session 也就产生了。 session 直接将用户身份信息,也就是 user id 等于一二三四五六存储在服务器端,然后给浏览器端返回一个自生棚的 session id, 并存储在浏览器端的库体中。 大家可以这样理解,存 gucci 的 方式相当于浏览器端的用户直接说我是某某某,然后服务器端就直接相信了。而 session 加 gucci 相结合的方式则是浏览器端的用户说暗语,服务器端以识别暗语的方式进行确认用户是某某某,这样就大幅提升了系统安全性的问题。我们可以看下 session 加 gucci 的 详细交互流程。 这种方式确实是可以运用在生产环境上的很成熟的方式,但它的弊端在于服务器端需要对 json id 进行存储,如果存储在 reddit 中,那 reddit 宕机,就会出现系统不可用的情况。如果存储在数据库中,高频访问又会对数据库造成压力,因此又出现了仅需要验证签名,不需要进行数据存储的头肯方式。 toon 可以 理解为服务器端给浏览器端先发的数字令牌,浏览器端的用户每次请求都会带上这个令牌,服务器端可以通过它来进行身份认证,就像我们进入公园的时候需要出示门票一样。当然 toon 也是可以存在浏览器端的 cookie 中,我们可以看下 toon 加 cookie 的 详细交互流程。 最后我们再聊一下 jwt json。 web token 是 目前 token 最流行的一种规范,由 header、 payload、 signature 三个部分,以此来实现无状态的身份验证。原始的 base 九十四编码前的编码串,类似于这样,我们可以看一下 base 九十四编码后会变成这样的格式。 由于 user id、 过期时间等数据已经保存在头肯中了,所以服务器端并不需要存储任何数据。当浏览器端的用户发起请求时,拿到头肯直接进行 base 六十四 decod, 就 能获取到 user id 和过期时间,而且进行签名的数据也不用担心被篡改,这样就做到真正意义上的无状态。 讲到这里,大家应该完全理解 cookie、 session、 token、 gw、 t 这四种术语了吧?关注我,拿下更多面试,咱们下期见!
3247托尼学长 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿h 浏览器如何开启兼容模式?现在的 win 十一系统很多都用不了这个 i e 浏览器也下载不了,那么接下来就教大家如何打开 h 浏览器的兼容模式。双击打开 h 浏览器,点击右上方的三个点, 在这里点击设置,点击左边栏的默认浏览器。 internet explorer 兼容性下面有这个允许在 internet explorer 模式下重新加载网站。 ie 模式现在是默认模式,我们需要更改成允许 始终在 microsoft edge 中打开需要 internet explorer 的 网站,这个选项需要打开一下,最后我们在这个选项这里添加,我们需要在 i e 浏览器打开的网址,添加完成后,我们点击这个重启浏览器, 接着我们在这里输入网址,这样这里就显示已经使用 i e 打开了。
127柳州智洋电脑 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿首先打开系统设置,打开隐私与安全性,关闭定位服务追踪也关闭 返回,找到屏幕使用时间, 打开内容与隐私限制,对照着我的选项一一设置, 搞定了再返回,找到通用, 把后台 app 刷新关闭掉返回,点开语言与地区,选择美区,打开代理,返回通用,打开日期与时间,把自动设置关闭 开检测网址不对的重新返回去操作,直到显示没错为止。最后再根据自己的需求把语言调成英文,再打开检测网址,显示百分之一百大功告成。
230出海摆渡人 01:19查看AI文稿AI文稿
01:19查看AI文稿AI文稿h t t p 协议是一种用于在网络上传输信息的规则,主要用于浏览器和服务器之间的通信。 当你在浏览器中打开一个网页时,浏览器会向服务器发送一个请求,服务器收到后会返回相应的响应,比如网页内容、图片或数据。 h t t p 是 一种无状态的协议,意思是每次请求都是独立的, 服务器不会记住之前的交互。例如,你第一次访问网站和第二次访问对服务器来说是两个完全无关的操作。 如果需要记住,用户通常要借助额外机制,如 cookie。 它采用请求响应模式,客户端,如浏览器主动发起请求, 服务器被动回应。常见的请求类型包括获取数据,如打开页面,提交数据,如填写表单等。 http 通常运行在 tcp 连接之上, 确保数据能可靠传输。早期的 http 是 明文传输,容易被窃听,后来发展出加密版本,即 https 通过安全通道保护信息不被泄露或篡改。总的来说, h t t p 是 万维网数据通信的基础,让浏览器和服务器能够高效、规范地交换信息。
 09:07查看AI文稿AI文稿
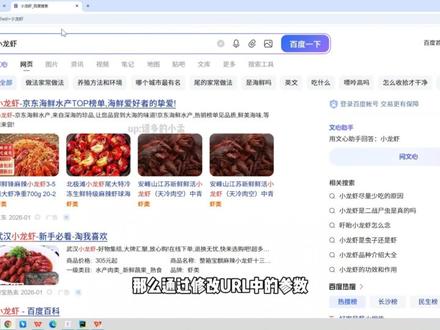
09:07查看AI文稿AI文稿picasa 爬虫教程第五集 url 传餐当我们想要在浏览器中进入一个网页的时候,在地址栏中就会出现一串符号,我们习惯叫它网址,但是这并不准确,正确的说法,我们应该称它为 url。 那 么这个 url 到底是什么?如何在网络爬虫中正确地运用它呢?通常一个完整的 url 长这个样子,包含四个关键的部分,协议,域名 以及路径和可选的参数部分。在 u i l 中,最常见的协议就是 http 和 https。 网络爬虫通常也是通过 http 请求来开始工作的, 而网站中的域名就是网站中的门牌号,例如百度的三 w 点,百度点 com 告诉我们访问的是哪一个网站。 被于域名之后的路径就是访问的网页,它指定了服务器上资源的具体位置。第四部分就是参数,在 u r l 中动态传递信息的关键部分, 以问号开始,紧跟在路径的后面,把这个 and 符号去掉之后,参数部分就变成了这个样子。 在 url 中,参数采用键等于值的形式成对存在多组参数之间使用 i 的 符号连接。为什么 url 中有参数呢?现在我们就进入百度浏览器中一探究竟。 当我们进入到百度的首页的时候,会发现网址中仅仅有两个部分协议以及域名,并没有路径和参数,但是我们抓取的内容绝对不会止步于网站的首页中。当我们在搜索框中输入一个关键词,例如网易云, 然后按下回车键跳转,跳转到对应的页面中,你就会发现地址栏中的内容发生了变化, 出现了刚刚所说的四个元素, http 协议、域名以及路径和参数。 在网站中, url 的 参数并不是每一个都有用的,为了找到有效的参数,我们可以在浏览器中 删除掉一些看上去没有用的,例如这个 w d 等于网易云,网易云是这个网页的关键词,明显是有用的,我们把这个网易云后面的所有参数删除掉, 然后按下回车键,你会发现还是跳转到了网易云的页面中,说明后面的参数都是浏览器后面加上去的一些无关紧要的参数。那么这个关键词前面的参数又是否是有效参数呢?我们来一个一个的删除一下, 再次按下回车还是可以跳转到网易云页面,然后再次删除,这次我删除掉两个, 按下回车还是可以跳转到网易云页面。那如果我删除掉最前面的这一个 i e 等于 utf 杠八, 然后我点下回车键,大家可以看到在这个百度搜索框中,有用的参数仅仅只有这一个参数而已。如果我们在这个 w d 后面直接写上其他的关键词小龙虾, 按下回车,我们也可以进入到关键词为小龙虾的百度页面中。那么通过修改 url 中的参数,我们就可以达到抓取对应关键词的网页。那么现在我们来直接复制这串网页的网址, 还是复制网易云的。当我们直接复制这串网址,然后粘贴的时候,就会发现我们粘贴的内容发生了变化, 从中文的文字变成了一串我们并不认识的符号,这是为什么呢?因为 url 不 支持中文和特殊符号,浏览器会根据编码规则将它变成这串样子。 我们可以在浏览器中进入到开发者模式,进入到网络中,然后我们刷新一下这个页面,进行数据抓包。大家可以看到我们访问的这个网址 也是这样,一串关键词的部分也变成了经过浏览器编码规则而发生了改变的一串文字。 那么我们作为网络爬虫,为了能够更加接近浏览器发起的请求,我们也需要将这一串参数进行编码规则。不懂浏览器中的编码规则也不用担心,爬虫库中的 u r 利步可以帮助我们进行处理。 首先我们可以在代码中导入 urlib 库,并且引用其中的方法 quite 和 unquote。 假设关键词还是网易云,使用 urlib 中的 quite 方法就可以得到这一串文字,和浏览器中转化的一模一样。 想要将浏览器中转化后的变成文字,你也可以使用 unquiet 就 可以重新变成文字了。那么以上的内容你都会了吗?我们在 python 中练习一下吧。那么在正式发起请求之前,我们必须要导入一个库,就是 request 库,写上 import request, 这是我们发起请求关键的一部分。那么导入了库之后,我们来获取包含关键词的网页 url。 在浏览器中我们得到的网址是这个样子的,我们将它复制粘贴到这里,写上 url, 等于 这一串。如果我们想要获取任意对应关键词的网页,那么我们是不是应该对这个关键词进行一些修改。 比如说我使用一个 keyword 关键词,这个变量用来储存我想要抓取哪一个关键词,那么我们需要用户输入 请输入想要抓取的关键词,进行了输入之后,我们这后面这一节就要进行转移, 直接写上 keywords, 那 么我们获得的网页就是 print, 哎,我们打印一下这个 url, 比如说我想要抓取的网页是小龙虾,那么抓取的网页这一节后面就是不被认识的,我们点击进去可以看到并没有进入到对应的关键词页面, 如果我们想要抓取,那么就需要对它进行浏览器相同的编码,那么就需要导入一个库,就是 from, 写上 from u r 列表库中的 quiet 和 unquiet, 这里我们不需要使用了 quiet 的 方法,那么就只要写上 quiet, 写上 q u o t b 进行编码之后,我们再来打印一下这个网址,我们这次抓取,嗯,小笼包 进入到网址中可以看到,我们就可以进入到小笼包对应的页面中啦。那么我们想要将抓取的对应网页的内容保存下来, 就需要使用到写入文件的方法啦。首先发起请求,使用 response 保存抓取请求后的结果,发起 get 请求,向这个 url 发起请求。 同样我们还要写上 heaters, 来模拟为浏览器,在 heaters 里面写上 user agent, 这个 user agent 我 们可以在浏览器中找到开发者模式,然后找到网络,重新加载 好,点击到这里,在下面的请求标头之内,我们就可以找到这个 user agent, 大家记得要把这个 user agent 改变为字典模式,然后粘贴进来,在这里我们再写上 hitters, 写上 hitters 获得到了响应结果之后,我们再将抓取的内容写入到文件中,写入 with open, 写入一个新的文件, 文件名叫做百度,然后加上关键词,告诉我们抓取的是哪个页面,使用 w 模式,并且我们要将 encode 改为 utf 杠八。 那么写完之后,我们再来写上 f, 点 y, 写入到文件中,并写一下这个代码, 请输入想要抓取的关键词。我写一个螺蛳粉吧,螺蛳粉按下回车,在这里我多加了一个 s, 我 们把它删掉就可以了。再次运行这段代码, 还是抓取螺蛳粉,现在我们就得到了螺蛳粉的网页,点击进去,我们在浏览器中打开, 现在我们就抓取到了螺蛳粉网页的页面啦。总而言之, url 是 网络爬虫抓取批量数据的基石。通过这个视频,你有没有学习到 url 到底有些什么可以在评论区说出来,或者你有什么疑问也可以在评论区提出来哦。
940话多的小孟 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿看了全网很火,这个 x 浏览器竟然还有小伙伴不知道怎么去下载以及注册的。今天简单一个视频教会大家,首先点击我视频右下角这个小箭头,然后去找到分享链接或复制链接,然后打开这个手机商城去下载一个这个小蓝鸟,下载好后打开, 然后这里会弹出小框,点允许粘贴,然后下方会弹出文件夹,如果没弹出也没关系。上方可以搜索冬月宝库,点立即查看,点击,然后找到海外软件,取消全选,然后这里有个 x 游戏并保存安装下载解压就可以了。
20湾湾脚脚







猜你喜欢
- 4422惊小蛰
最新视频
- 22.0万西瓜冰a