千问3.5max什么时候发布
什么千万三点五引爆全球产业链,英伟达、苹果、华为、升腾、 amd 啊,全适配,这个数据实在是太牛了,朋友们他们的开发框架乃至这个芯片层啊,都对这个三千万三点五有一个全面的适配啊, 而且这个千万的总参数是三千九百七十亿,目前只激活了一百七十亿,性能是超级牛叉的呀,兄弟, 最最最重要的是,而且每百万 tucker 只需要零点八元,没听错,就是八毛啊,百万 tucker 只需要八毛啊,超级便宜,还有它以 百分之五不到的这个价格媲美兼比你三的高性能。所以说兄弟们,咱们国产的 ai 大 模型已经崛起了,现在跟这个世界顶流的这种 ai 大 模型的话,已经是完全可以媲美了,咱们的这个理解能力,还有这个反应速度, 强烈看好 ai 应用,你觉得呢?开年 ai 应用会不会来一波大的?

粉丝1932获赞8431
相关视频
 03:16查看AI文稿AI文稿
03:16查看AI文稿AI文稿除夕通一千万发布了,通一千万三点五是一个旗舰模型,刚刚他发布四个小时前那通一千万,这次发布的这个模型还是按了按十乘以万。为什么?第一个它是个旗舰模型, 旗舰模型应该是它一千万版本里面是一个顶级的这样的,而且它是开源的,是基于阿帕奇二点零的这样的一个是非常好。 他这个旗舰模型他的能力怎么样?我们大家看一下,这是官方公布的一个数据,一个他对标的都是他的一些。呃,国内的那些旗舰模型,他是 gpt 五点二,最新的 loft op 四点五、 jimmy 三 pro, 包括还有同一千万他们自己的三 max thinking, 这些都是些旗舰模型,你可以看到啊,他跟他们比起来,他有些能力甚至是超过他们,特别是在他跟他们比起来,他有些能力甚至是不如, 特别是。呃,看了一下他指令的遵循,这个应该是 top 最厉害。写代码的能力应该也是跟奥的 ops 还是比较接近的,他多模态的能力,特别是 ocr 的 这种按摩墙应该来讲非常不错的。还有一个三 m u pro, 它达到了七十九分,非常高的一个分, 非常接近于 google 的 germany 三 pro 要与 autop 四点五这个版本基本上跟 g p t 五点二最新的版本是接近了,在有些编辑方面的能力也是超过了像我们前面讲的五点二,对吧? autop 包三, autopcom 在 写代码能力是不如 这次提升比较厉害的是这个叫 terminalbench 二,二的这个主要是智能体写代码,它对于这个终端命令的这样的一个准确率 非常快,原来是比较糟糕的二十二点五,现在达到了十二点五提升费,这是他一个比较大的一个程度, 说明他在写代码能力,目前在挖一个编程这个方面是显著提升了。好,我们可以看看他的这个模型,应该来讲不是很大,大概是三百九十七个 b active 是 十七个 b 是 一个,应该来讲是一个模型,但是他的能力是基本上是达到了,达到 k m k 二点五 e t active 三十二 b 的, 这样 对企业级来讲非常好,是模型能力超强,但是它的模型的大小要比旗舰模型都要小,所以它的效率会要的算力也会更少啊。 这个都是他一些详细的一些评测,重要写代码的,能写多模态的一些不圆的能力,设置 a 境产写通用的智能体的一些能力,这个能力也是比较重要。 f c l 杠米斯,我们经常会给大家讲 u c bookle 的 一个人体调用工具的这样一个停车也是非常重要,推定能力也是不错。 还有一个是长上下文,它这个模型目前长上下文能力也非常强,全身是二百五十六 k, 它也可以扩展到一兆的这样上下文,超长上下文。哦,那这个模型应该来讲在春节除夕晚上发布出来,应该来讲这个模型是对企业来讲非常有价值, 也可以商用的大模型。这个模型跟原来一样,它也是本科架构,跟原来通一千万三 next 这个架构是一样的, 这样效率会比较高,又是个多模态的,原来 next 它是个纯文本的,现在通一千万三点五,它又是个文本,又是多模态,这写代码能力也是不错,所以它是个旗舰模型。好,我们简单就给大家就介绍一下。
73小工蚁 09:10查看AI文稿AI文稿
09:10查看AI文稿AI文稿大家好,我是小木头。在新春佳节之际,首先呢祝大家在马年新年快乐,万事如意,身体健康,马到成功。在新春来临之际,通易千万也发布了他们最新款的大模型千万三点五, 本期视频,我们就来了解一下这款全新的大模型,并且尝试将其集成到 openclock, 从而打造自己最强的国产 ai 助手。 那现在就开始咱们马年的第一期视频分享吧。首先咱们对千万三点五还是来做一番简单的了解,这是通用千万系列最新一代模型千万三点五首发开放权重版本是三九五 b a 十七 b, 这个是整个三点五系列的起点。大家要注意的是,这是开放权重,不是完全开源,但是呢,你可以拿到模型权重自己部署。 这是一套原生多模台模型,他并不是传统的厚接插件式的多模台,而是从训练阶段就做了早期的文和图的融合,基于了原生多模台的架构, 这与过去的那种先训练文本模型在外挂视觉编码器的方式呢是不同的。在原生多胞胎的支持下,信息融合更深,上限呢更高,多语言覆盖从上一代的一百一十九种语言和方言提升到了二百零一种, 这对于非英语场景的开发者来讲是一个非常大的利号。云端版本的千万三点五 plus 默认是支持到了一百万的 token, 这个呢指的是上下文窗口,同时内置了官方工具和自定义的工具调用,官方给到了全面的测评,从分数来讲呢,显然这与过去我们在了解新模型时并没有什么意外,最新的模型在方方面面的测评上表现都非常非常的优秀。 我们来看一组数据,在三十二 k 上下文架,相比于千文塞 max, 它的解码吞吐提升了八点六倍, 二百五十六 k 下更加的夸张,达到了十九倍,相比于千万三二三五 b, 也有三点五到七点二倍的提升, 这把大模型可用性往前推升了一大步。从这张图标可以看到,这个对比效果呢,也是非常夸张的,在过去的对比中,似乎我们还没有看到这么大的飞跃。官方博克还给到了我们许多有趣的 demo, 展示了多模态理解加工具调用、加长链路执行的合体能力。这其中呢,包含了编码 agent、 视觉 agent、 空间理解、图像推理,每一个都并不是一个独立的 demo, 感兴趣的朋友呢可以来一个一个的观看了解一下,非常的有趣。 在官方博克这里也专门提到了在 open clone 中的基层,它能够很好地支撑像编码这类任务的执行, 再集成到 openclo, 并且部署到云端,看起来我们完全可以打造一款自己的国产 ai 助手,并且是最强大的哟。 现在呢,我们就尝试将千万三点五这款最新的大模型集成到 openclo。 openclo 是 近期非常热门的一款 ai 助手,在过去的视频分享中,我们也介绍了如何在本地如何在云端进行部署与配置,还没有做这部操作的朋友呢,可以回看过去的视频分享, 那现在呢,我们就来做集成千万三六模型,在许多的云端平台都提供了支持,同时呢,作为一款开放权重的模型,大家也可以实现本地化的部署,我们今天要介绍的呢,是以 open router 所提供的 api 为例,看看如何集成到 open clone。 我 现在分享的是在腾讯云端部署的小龙虾,大家可以在任何的部署中采用同样的方式来配置。 openroute 是 我常用的一款服务,目前呢也第一时间提供了千万三点五模型的支持,目前有两款,一个是三点五 plus, 一个是三点五三九七 b a 十七 b。 我 们以三点五 plus 为例,在云端 通过 openroute config 来进行模型的配置选择。 model 在 分类中已经有了 openroute, 我 们选择它就好。 因为我已经完成过了 openerer 的 配置,已经添加了 api key, 所以 在这里呢,直接就跳到了模型的选择。我们现在翻到 openerer 所提供的模型列表这里,大家或许会发现并没有前文三点有模型, 怎么办呢?没有关系,我这里呢其实已经配置过老的像 cam 三二三五 b 的 模型,我们可以继续这里的配置选择,继续退出当前的配置。 在目前我已经配置过 api key 的 情况下,大家看起来这波操作呢并没有做什么,那如果大家是初次配置呢,这样呢就完成了 open directory api key 的 配置。我们接下来要做的是使用当前这个命令 openclo model set 来设置 open directory 这一款千万三点五的模型, 设置的这个值,它的格式呢是服务商。以 openerer 为例,在这里呢就是 openerer 斜杠后面带上的就是模型的 id, id 来自于模型页面,我们在这里复制这个 id 就 好, 我正是通过这种方式粘贴过来的。这样呢,就完成了三点五模型的配置。配置完成后,或许大家可以尝试重启 dm, 接下来我们来到 channel, 比如以 telegram 为例,我们来看看配置的情况。在 telegram 中,可以使用 slashmodels 命令来选择我们想要使用的模型或列出当前的模型服务商。 当我选择了 openraw, 会列出其中已经配置的模型。这是我已经配置的几款模型,大家根据自己的情况可能会看到的有所不同。 那我如果点击千万三点五这款模型,理论上期望是将其设置为默认模型,但在这里大家会看到这么一个错误,说这个模型呢,还不被允许使用, 那么该怎么做呢?我们是来到 opencl 后台进行手工的配置调教,还是说通过对话的方式让 opencl 来帮助我们解决这个问题呢? 在 ai 时代,在智能体时代,我们应该尝试避免手工再去做这些事情了,完全可以交给 open core 自己解决。因此在这里我们告诉他问题是什么呢?这个模型三点五不能够被使用,希望他帮助我添加到 open core, 他 会自动的帮我完成这个工作, 它会更新配置,重启网关,并告诉我重启后就可以使用了。那在这里呢,我们来看看。 当然了,在对话中,我还将其切换回了 gpt 三点五 codex, 并且期望 codex 帮我验证当前的配置是否一切正常了。它告诉我是的,一切正常,我们可以开始使用千万三点五了。 那么我们通过模型的配置这里呢再次确认过它的模型呢,已经设置为了铅汞三点五。那接下来呢,我打个招呼,看起来一些工作正常,我们现在可以回到 openclo, 作为开发者,我们还是希望更多的验证究竟是不是正常的工作了。咱们可以使用 openclox dash dash follow 这个命令来实时的监控日制, 再打个招呼吧,看看对话情况。在这里大家可以看看日制的情况,在一个子系统的执行中,它用到的模型呢是千万三点五 plus 零二一五 think 模式是关闭的对话呢,一切正常,我们在这里也能看到它的回复,这表示端到端已经通了。大家如果还不确定是不是使用了三点五的模型,那现在呢,可以来到 open router 后台查看实时的 api 调用情况,我们可以看到最新的调用呢,就是用的千文三点五。 好了,这就是我们如何在 opencl 集成千万三点五。在这次的发布中,我们得到了两个版本,一个是千万三点五 plus, 一个呢是三点五三九七 b a 十七 b。 感兴趣的朋友呢,可以来集成这两款模型,分别在 opencl 中跑一跑,看看它们在功能上究竟有什么差异,在日常的编码任务的执行上,是否能够很好地完成我们交给他的任务。 那么这款模型的能力究竟如何?是否能够成为我们日常工作学习中的主力模型呢?大家在使用后也欢迎在评论区给我们留言吧, 那今天的分享就到这里,感谢大家收看。那么在视频结束前,也再次祝大家新年快乐,万事如意。好吧,那我们就下次视频分享再见同学们,拜拜!
646五里墩茶社 01:29查看AI文稿AI文稿
01:29查看AI文稿AI文稿八毛钱呢,在今天也就是半个馒头的钱,但在 ai 圈呢,现在可是一百万 token 的 价格。今天可是除夕啊,阿里正式开源了新一代的千万三点五系列, 我想这大概就是科技圈最卷的拜年方式了。这次发布的企业模型千万三 plus api 价格呢,直接达到了每百万 token。 八毛钱什么概念啊,这可是谷歌 gmi 三 pro 价格的十八分之一,而且阿帕奇二点零的协议,全尺寸开源,不管你是个人开发者、学生还是中小企业,都能直接免费的商用。 以前我们都知道最强和最便宜的这两个词呢,它是不可能出现在同一模型上的,要么性能顶级贵的离谱,要么是便宜呢,但是能力打折。千万三点五 plus 这次不仅是价格地板价,性能呢,更是直接硬钢了。这俩币源顶流登顶了全球最强的开源模型, 支持的源数量呢,也扩展了两百零一种。就因为这次用上了极致稀疏的 m o e 架构,传统模型呢,是所有参数同时干活,参数越多呢算的越贵。 m o e 的 思路呢,是按需激活,你问一个代码问题, 他就激活擅长代码的那组专家,你问数学题呢,他就切换到了数学专家,等于三百九十七币的知识储量,十七币的算力消耗不熟,显存占用直接降了百分之六十,推理速度快了八倍,这就是省钱的原因。 而且他还是原生多模态,不是后期拼装的视觉模块。从预训练第一天起呢,就是文字和图像混合数据上一起预训练的,天生就能看懂图片和视频,这种就很像当年的 linux, 当一个最好用最便宜最聪明的模型是开源的时候,他就会成为整个行业的空气和水。 以前要花大价钱才能用上,能力呢,现在门槛被技术本身再次拉低。摩达社区哈根 face 千万 a p p 千万披萨呢,现在已经可以体验了。不知道阿里这一波 ai 半年啊, open ai 和 google 看了是什么心情。
122赛脖古 01:51查看AI文稿AI文稿
01:51查看AI文稿AI文稿二月十六日除夕当天,阿里巴巴正式开源全新一代大模型千问困三点五 plus, 性能媲美 jameson 三 pro、 gpt 五点二等顶级闭源模型,登顶全球最强开源模型 千问三点五,实现了模型架构的全面革新。此次发布的困三点五 plus 版本总参数为三千九百七十亿,激活仅一百七十亿。以小胜大 性能超过万亿参数的 quan 三 max 模型,算力部署成本降低百分之六十,推理速度提升八倍,多项精准评测结果媲美超越 gpt 五点二这门 i 三 pro 等闭元第一梯队模型。原声多模态训练也带来千万三点五的视觉能力飞跃。 在多模态推理、通用视觉问答、 dk 文本识别和文件理解、空间智能视频理解等众多权威评测中,千万三点五均斩获最佳性能。相比上一代昆三 max 模型推理效率大幅提升,最大推理存储量已升至十九倍,且上下文越长,速度优势越明显。 在模型部署端,千万三点五通过混合注意力极致显著优化长文本场景的显存占用,并结合高希书猫架构,将每次推理的时机、计算量控制在极低水平,部署显存占用降低百分之六十。 这意味着大模型第一次真正具备了下沉到边缘设备陷入日常应用的工程可行性。当行业仍聚焦于跑分竞赛时,千万三点五已将竞争推向新阶段,谁的模型更实用、更易用、更多人用得起? 不光卷性能,阿里在 ai 应用端也实属卷亡。一月十五日,千问啊发布全球首个消费级 ai 购物 age 的 春节期间,千问 ai 购物 age 的 六天时间帮用户完成了一点二亿笔订单,在全球首次实现大规模真实世界任务执行和商业化验证。 age 的 能力大幅增强的千问三点五,将进一步打开千问 app 在 工作和生活中帮人办事的想象空间。
21甲子光年 07:55
07:55 07:32查看AI文稿AI文稿
07:32查看AI文稿AI文稿各位朋友大家好,今天是农历除夕,当大家正忙着贴春联准备年夜饭的时候,中国的 ai 圈儿却悄悄扔下了一颗重磅炸弹。 阿里巴巴将在今晚的除夕夜正式开源新一代的通用千万大模型 q one 三点五。这可不是普通的版本更新,要知道这已经是阿里连续第二年在除夕夜搞突然袭击了。 去年他们就在除夕深夜抛出了 q n 二点五 max, 让整个 ai 圈过了一个技术年。而今年他们又来了,而且带来的还是实现了模型架构创新的新一代产品。 这背后到底藏着什么玄机?今晚的开源又会给咱们普通人和资本市场带来哪些意想不到的影响?别急,咱们今天就来好好盘一盘。首先,咱们得搞清楚这个 q w 三点五到底是个啥? 根据这几天在 ai 开发者社区里流传的消息,这个模型可不简单,它的代码已经在全球最大的 ai 开源社区 hugen face 上提交了合并申请,这意味着发布已经进入了倒计时。从技术大佬们扒出来的代码看, q n 三点五最核心的突破在于它采用了一种全新的混合注意力机制。 简单来说,传统的 ai 模型就像是一个勤奋但有点死板的学生,不管题目难易,都把整本书从头到尾看一遍。而 q n 三点五这个混合注意力机制让它变成了一个聪明的学生,知道哪些地方需要仔细钻研,哪些地方可以快速浏览。 具体来说,它每四层网络里有三层使用高效的限性注意力,只有一层使用标准的全注意力, 这种设计能让他在处理像一本长篇小说那么长的文本时,速度提升好几倍,同时还能保持很高的理解准确度。这对于需要处理超长文档、代码库或者多轮复杂对话的场景来说,简直就是神器。更厉害的是, q 问三点五极有可能是一个原声多模态模型, 这是什么意思呢?过去的很多 ai 所谓的看图说话功能,其实是把图像识别和语言理解两套系统硬拼在一起的。而 q n 三点五是从娘胎里就具备了同时理解文字和图像的能力。想象一下,你拍一张外卖订单截图,问他这家店还能用红包吗? 它不仅能认出图片里的店铺名、价格,还能结合你的问题判断红包的使用规则。这种能力正是阿里将其融入淘宝、饿了么这些生活服务 app 所需要的。 另外消息还透露, q 问三点五会提供不同规模的版本,包括一个总餐数量可能高达四百七十亿,但每次推理只激活约三十亿参数的混合专家模型。 这就好比一个拥有几十位各领域专家的智库,每次只请出最相关的三四位来回答问题,既保证了答案的专业性,又极大的节省了咨询费,也就是算力成本。 这种在性能和成本之间找平衡的思路,恰恰说明大模型的竞争已经从单纯的堆参数炫技进入了追求实用高效的新阶段。那么阿里为什么偏偏要选在除夕夜这个全家团圆的时候,来发布这么重要的技术呢? 这背后其实是一场没有硝烟的春节党 ai 大 战,不知道大家注意到没有,最近这一周,中国的科技大厂们像是约好了一样,扎堆发布 ai 新品。就在二月十二日,智普 ai 刚刚开源了新一代机座模型 glm 五, 这是一个参数量达到七千四百四十亿的巨无霸,特别擅长复杂的代码工程和长城任务规划。 同一天字节跳动的 ai 视频生成模型 cygnus 二点零也全量上线了,它能根据一句话就生成六十秒带声音、多镜头的连贯视频,效果相当震撼。 而另一家 ai 明星公司 minimax 也推出了为智能体场景专门优化的 m 二点五模型, deepsea 的 新模型也在辉度测试中。你看,从文本大模型到视频生成,从代码智能体到多模态应用,这个春节,中国 ai 企业是在全方位的秀肌肉。 阿里选择在除夕夜压轴出场,用开源 q n 三点五的方式发红包,既是一种技术自信的体现,更是一种生态战略的进攻。通过开源,他们能吸引全球的开发者、创业公司都来使用和基于 q n 三点五做二次开发,快速壮大自己的技术生态圈。 这盘棋下得很大。聊完了技术面和行业面,咱们再来看看大家最关心的,对咱们 a 股投资有什么影响。这次 ai 春节党的混战,虽然主角大模型公司像智普 minmax 主要在香港上市,但它点燃的这把火绝对会烧到 a 股市场, 催生几条清晰的投资主线。第一条主线也是最确定的,就是算力计件,不管模型怎么打,最后都得落在实实在在的算力上,这就好比不管电商平台怎么竞争,物流和仓储都是硬需求。 所以为 ai 提供电力的算力基础设施公司受益是最直接的。这里面又可以细分为几个核心环节, 一是 ai 芯片和服务器,这是算力的发动机,可以关注。韩五 g 作为国产 ai 芯片的龙头,它的产品已经适配了包括 qwind 系列在内的众多国产大模型。还有海光信息,它的深度计算处理器在金融、通信等领域已经有了不错的市场份额。 服务器方面,浪潮信息是全球 ai 服务器的重要供应商,深度绑定国内互联网大厂,中科曙光则在液冷服务器和国产算力集群建设上优势明显。 二是光模块,这是数据中心内部高速传输数据的光纤神经。 ai 集群规模越大,对光模块的速率和需求量就越高。龙头公司像中际旭、创新、益盛都在积极布局下一代一点六 t 速率的产品。再三是夜冷和供电, 这是算力的散热系统和心脏。现在的 ai 芯片功耗巨大,传统风冷已经不够用了。液冷技术成为刚需,因维克是国内液冷技术的领军企业,同时,高功率的 ai 服务器也对供电架构提出了新要求。科华数据、中恒电器等公司在高压直流供电领域有深厚积累。 第二条主线是 ai 应用落地模型能力再强,最终也要变成能赚钱的产品和服务。这就需要我们关注那些能够将 ai 技术真正融入主业,并带来效率提升或收入增长的公司。比如金山办公, 它的 wps ai 已经进入了大规模订阅阶段,当用户愿意为 ai 帮忙写 ppt、 总结文档而付费时,这就形成了一个健康的商业闭环。 再比如一些工业软件公司、金融科技公司,他们利用 ai 优化设计流程、提升风控能力,这些都能实实在在地反映在财务报表上。 不过,这条主线需要仔细甄别,要选择那些有真实场景、有技术壁垒、 ai 业务能带来增量收入的公司,避开那些只是蹭热点的伪 ai 概念。 最后,简单总结一下今天的核心观点,阿里在除夕夜开园 q 问三点五不仅是一次技术升级,更是中国 ai 产业进入效率与生态竞争新阶段的标志性事件。 它和近期其他大厂的密集发布一起,构成了波澜壮阔的 ai 春节档。对于投资者而言,短期可以关注算力基建这条确定性高的主线,中长期则要深耕那些能够通过 ai 重塑生产力、实现价值兑现的优质应用公司。 二零二六年很可能是 ai 从玩具真正变成工具,从烧钱走向赚钱的关键一年。这场由技术驱动的改革,正在深刻地改变每一个行业, 也必将催生出新的投资机遇。好了,今天的分享就到这里,除夕之夜也祝大家阖家团圆,新年都能抓住属于自己的 ai 机遇,我们下次再见!
191妙喵股事局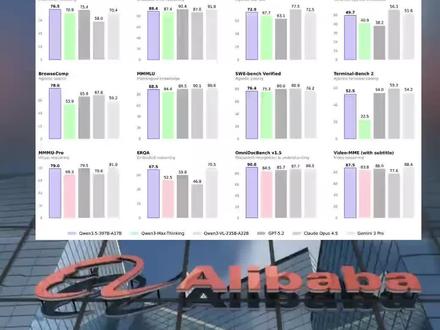 00:27
00:27 01:42查看AI文稿AI文稿
01:42查看AI文稿AI文稿二零二六年二月十六日路透社电阿里发布全新通一千问三点五模型,源哥深度解读阿里于周一发布全新人工智能模型通一千问三点五, 该模型可独立执行复杂任务,在性能与成本控制上实现大幅升级。阿里称,三点五模型在多项精准测试中超越了美国头部竞品模型。阿里表示,通一千问三点五的使用成本较上一代处理能力提升八倍。 同时,该模型新增了跨手机和桌面端应用独立执行操作的能力,也即阿里所称的视觉智能体能力。阿里在声明中表示同意千问三点五专为智能体 ai 时代打造,只在帮助开发者与企业在同等算力下提速增效和拓展能力边界, 为单位推理成本对应的模型能力树立了全新标杆。字节跳动已于上周六发布,豆包二点零为这款目前坐拥国内用户数已接近两亿的聊天机器人应用完成升级。 与阿里的发布动作一致,字节跳动同样将这款新模型定位为适配 ai 智能体时代的产品。阿里在通一千问三点五的发布公告中并未提及 deep seek, 其公布的多项精准测试结果仅显示新模型性能超越了前代版本,以及美国竞品模型 g p t 五点二和 cloud opus 四点五以及 gemini 三 pro。 据 deepseek 预计,将在未来数日 发布其新一代大模型。该公司一年前曾引发美国科技板块抛售潮,此次新品计划也引发了投资者与业内人士的高度期待。
692源头信息哥 00:59查看AI文稿AI文稿
00:59查看AI文稿AI文稿阿里巴巴将于除夕夜开元新一代千问大模型 q w e n 三点五,这是否意味着国产 ai 将迎来新的里程碑?今天是二零二六年二月十六日,距离阿里巴巴计划在除夕夜开元新一代千问大模型 q w e n 三点五的日子越来越近。 这一模型不仅在技术上实现了全面创新,还特别强调了常文本处理能力的显著提升,以及对图像输入的原声支持。 q w e n 三点五采用自主研发的混合注意力机制,结合局部与大局注意力的优势,处理长文本的能力提高了超过百分之四十,同时支持任意分辨率图像输入。 该模型将以双版本形式开源,包括二 b 密集模型和三五 b a 三 b m o e 模型,只在降低开发者部署门槛。 这一举动不仅标志着阿里在人工智能领域的持续进步,也为国内 ai 开发者和企业提供了更多创新机会,预示着国产 ai 技术可能迎来新一轮的发展高潮。
44山林休士 08:5970kate人不错
08:5970kate人不错 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿昨天晚上千问发布了最新的模型三点五,我看了很多评测,业界对这个模型的评价还是相当之高的。 今天二月十七号,据说 deepsea 又要发布他们的最新版本 v 四的正式版上,前两天字节跳动的 cds 刷屏,还有智普的 glm 五刷屏,这个行业真的已经卷疯了,你知道吗?最近卷的都是我们国产大模型,你发现没? 其实在一月初的时候, ansorepic 和 open ai 也发布了新的模型,海外卷的也是一塌糊涂。就我那天看到一句话就说,现在这个 ai 科技行业的从业者啊,从未感觉到如此之焦虑, 包括其实我们投资界就关注这些科技 ai 领域投资的人也是感到非常非常的焦虑,因为这个行业它在以两周为单位去进展。就以前的科技, 你一个月不看,他也没有什么新的东西,对不对?你现在是你隔两天不看,新东西又出来了,你下不了牌桌了,我估计整个二六年还会一直这么卷下去,所以大家勒好安全带吧,我们正处在一个高速行驶的列车上面,正在迈向新的时代。
103蛇口费雪和不二家 00:10查看AI文稿AI文稿
00:10查看AI文稿AI文稿来啦,重磅消息来了,可能跟我们的 debussy 一 样啊!阿里开源千万的最新版本也要开源了,美国 ai 怎么顶?
61书生(爆读消息)







