ai一次对话需要多少token
宝子们来集合了啊! ai 升级系列第三期干货来喽!天天用 ai, 你 们是不是还搞不懂 token 到底是啥? 一句话讲清啊, token 就是 ai 的 语音基本例子就是最小的那个单位啊,是大模型解析文本的最小单位, 他可不是单字或单词标点、表情,甚至一个空格都能算一个独立的 top。 这里有个小小的知识点啊,中文一千 top 约等于四百到五百个汉字。 英文一千个 top, top 大 概是七百五十个单词,因为中文没有空格,分风格同等内容会比英文更贵。 top 哦! 懂 token 的 超重要!它不仅是 ai 计费的核心依据,输出加输入的都按 token 算钱。 它同时还决定了 ai 的 上下文处理长度、体量就会断片失忆。最后教大家一个小妙招啊!问 ai 时删减沉于废话,既能省 token 省钱,还能让 ai 的 回答更精准、更高效!赶紧码住试试啊!

粉丝28获赞219
相关视频
 01:28查看AI文稿AI文稿
01:28查看AI文稿AI文稿是不是我用错了,一百万 token 做不了一个小项目,我买的十五美金的额度,半小时就用完了。呃,我知道了,看来大家对一百万 token 的 概念还是有点模糊啊,我来帮大家梳理一下。一 token 呢,大概是一个中文汉字,或者是四分之三个单词, 一行代码呢?我们按照十个单词来算,大概就是十到三十个 token, 那 一个文件我们按照五百行代码来算,大概是五千到一万五的 token。 现在我们的前端项目都用了 ts, 那 些类型声明其实都是通过杀手, 实际的通过量可能更多。假如我们在操作的是一个中型项目,大概是一百个文件,那就是五十万到一百。五十万的 token。 中型项目 ai 还是能够理解的,如果说是一个大型项目,你想让 ai 理解都理解不了, 上下文就爆了。所以对于 ai 来说,去理解一个中型的项目,一百万 token 啊,其实也就是几分钟的事啊。现在顶级模型的价格,每百万 token 海枯石一刀,骚奈特是三刀,呃,奥普斯是五刀。所以你用 ai 写代码的话,几分钟就有可能会花你个十几或几十块钱。 怎么办呢?也简单吧,就是你一定要用艾特符号,用井号去控制好上下文,遵循上下文最小化原则,也能让 ai 输出的结果更准确。所以平时我们在用 ai 编程的时候,一定要有一个 token 的 消耗意识, token 就是 钱,省 token 就是 省钱。
1522程序员康健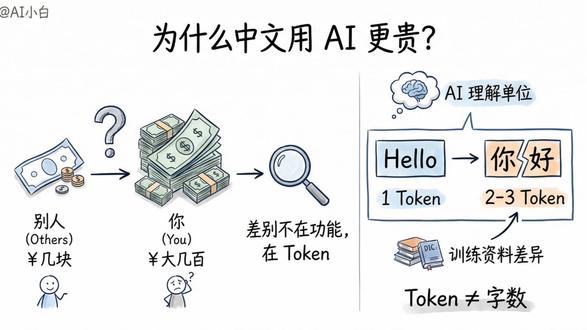 02:05查看AI文稿AI文稿
02:05查看AI文稿AI文稿为什么中文用 ai 更贵?为什么同样用 ai, 有 人一个月花几块钱,有人账单大几百,差别上百倍,差别不在功能,在托肯。 很多人以为托肯就是字数错了,托肯是 ai 把你的话切碎后的最小理解单位。举个例子,你输入 hello, ai, 看到的是一个托肯,但你输入你好 ai, 可能看到的是两个甚至三个托肯。 为什么?因为 ai 模型训练时,英文资料多,中文资料少,所以英文一个词往往就是一个托肯。中文一个字可能要拆成好几块才能识别,这直接影响你的钱包。 ai 按托肯计费,不是按字数,你发一句帮我写个方案,可能是十个托肯, ai 回你五百字,可能是八百个托肯,一来一回都在计费。更要命的是,你每次对话, ai 都要重新读一遍之前的所有内容, 聊得越久,托肯消耗越快。这就是为什么有人用 ai 写代码,一天就把额度用完了。不是因为写得多,是因为每次生成代码, ai 都要把整个对话历史再过一遍。所以怎么省钱? 第一,别废话,把需求说清楚,一次到位别来回改。第二,长对话要分段,别在一个绘画里聊几十轮,该结束就结束,重开一个新对话。 第三,中文用户更要注意。同样的意思,中文托肯消耗可能是英文的一点五到两倍。托肯不是技术黑化,是你每一分钱的去向。 看懂托肯,你才能真正用好 ai, 而不是被账单吓到。下次用 ai 之前,先想想这句话值多少个托肯。
3AI小白 03:35查看AI文稿AI文稿
03:35查看AI文稿AI文稿自己消耗了十亿头肯欧盟 club 国产热门大模型头肯消耗测评我来了,暂停,先看结果, 别着急,表格呢,我也已经整理好放在文档里面了,你们啊,全网都在找一些省钱的模型,我们就日常工作的场景就消耗和交付的结果来对比一下。先看一下这次参赛的选手,热门国产模型三喉结, gim、 mini max 和 dbic, 还有另外一位终极本地免费外卡选手奥莱玛。我准备了一个七千行的员工考勤表,让他去做本地的数据分析,最后产出一个可以汇报的文件发送到飞书。 ipsic 呢,响应时间很长,整个过程经过不停的催促和卡顿,花了挺长的时间。 mini max 挺利索的,五分钟左右吧,可观性呢,也很强。 glm 速度很快,可观性也很强,核心的动产部分展示更清晰, 沃达玛等了半个小时直接报险存,个人更偏向 g l m 五点零模型速度最快, ui 更简洁,观点也更清晰。头克数呢,也看了一下,基本上都是两百万到三百万之间,其中啊, g l m 两百万出头,另外两家都是三百万以上。 我们准备了一个三千字的会议资料,让他呢去提炼会议内容以及建议,并搜索网上的大模型数据进行佐证。生成一个可以汇报的文件发送到飞书。 deepsea 呢,响应时间依旧很慢,且一直有无效的回复。 mini max 呢,还是人狠话不多,直接就是干活。 gim 的 结构非常清晰好读,对比维度呢,也很全面。奥拉玛依旧等待半小时连接超时。在这里啊,已经可以看出 gim 五点零这次新出的模型已经拿出优势了, 在涛哥的消耗上呢,也依旧能省下百分之十五的领先表现。我们准备了一下常识逻辑的脚本题,去试一下他们的反应,看看 ai 们会不会看出零课时不加猫粮的反常识问题的反馈呢。这次很快,理论逻辑环环相扣,但是呢,他好像并没有考虑到常识上面的逻辑。 mini max 呢,由于接口问题,工具代用成功,但是不能回传,不支持本地脚本。 jim 五点零不错,最重要的常识逻辑呢,他会进行一个提示,他也发现了零课时不加猫粮的意图,他执行,但提醒你,这样的设定是不是为了洗猫粮盆 奥拉玛老规矩,连接超时。 deepsea 啊,在单文本任务上的反馈时间终于恢复了,不过呢,也仅仅只是停留在他只是一个还不错的执行者。最后,如果你的使用需求很大的话,需要他二十四小时不间断的工作。不管什么模型,都是推荐扣丁 plan 的, 月费小百元级别,轻松拿捏。 请做一些文员日常数据整理, ppt 内容输出。实际应用上来看啊,一个总结性的输出内容,各家用的 token 消耗都差不多。目前最新的 gim 五点零模型呢,有一点点的小优势。至于模型之间啊, deepsea 还是等四点零出来吧。现在这个状态呢,是不太理想的, 而且呢,也没有月费的制度。 mini max 呢,如果做一些 office 相关的工作的话呢,还是非常不错的,充钱呢,也比较灵活, 还有优惠。对于前面试的两个案例的总结啊,其实整体花费也就一块钱不到,最全能的呢,还是 g i m 五点零,想要一个一直在线的能写项目能聊天的全能助理,就看啊这小百元的月费和你的工作内容能不能匹配的。上了 省钱党的最终模型奥拉玛。这个呢,是真的有点失望了,错了很久啊,几乎是没有办法在大龙虾上指挥他干活。 oh god please no! 都说免费的才是最花钱的,有更多时间的玩家呢,可以继续去跟奥拉玛搏斗一下,想真正提升工作效率的话,找到合适的模型才是正确的选择。好,本期视频就到这里,希望对你有所帮助。我是阿瑞,我们下期再见。
153阿悦很严格 05:37查看AI文稿AI文稿
05:37查看AI文稿AI文稿嗨,大家好,今天给大家分享下基于 openclo 搭建本地 ai 员工的部署教程,不用花一分钱托肯, 这次我们基于汪派能用为面板来搭建搭建完全本地化的 ai 员工助理,核心是部署欧拉曼本地服务以及 gpt 模型,再搭配 openclo 作为交互入口, 数据全程保存在自己的服务器,既省钱又安全,不管是日常办公还是个人使用都超方便。话不多说,咱们直接上实操。整个实操过程分为六步, 第一,准备 gpu 服务器。第二,运维面板万帕诺安装。第三, gpu 资源配置。第四,奥尔玛模型平台安装。第五,完成 gpt 模型加载。第六, open club 个人员工构建。 我们先来完成第一步,基于腾讯云申请一台带 gpu 的 云服务器,这里选择创建一个竞价实力进行操作演示。首先我们保证服务器为 gpu 架构,为本地模型提供算力。其次,磁盘记得设置为一百 g, 方便大模型下载到本地 并开通公网 ip, 方便后续访问。最后记得提前开通应用的默认访问端口,欧乐玛应用端口、 one panel 应用端口、 openquad 应用端口。服务器创建好以后,我们直接登录腾讯云服务器,默认会享 gpu 相关驱动。安装好首次登录需要耐心等待下,登录后,首先我们通过 sudio 命令切换到 root 用户下, 然后到 one panel 在 线文档中获取一键安装命令,直接复制执行即可。进入安装过程时,先检测完成 dawk 的 安装,需要确认安装目录并下载安装 dawk, 安装完成后,开始设置镜像加速器和面板访问参数,其中输入 yes, 完成镜像加速器配置, 面板端口号输入我们已开通的端口号,最后获取面板账号及面板密码即可。登录 one panel, 登录后我们确认下 gpu 卡的驱动情况,紧接着配置好面板访问地址,方便应用直接跳转访问。配置完成后,我们进入终端开始 gpu 资源配置,首先再次输入命令行,确认英伟达显卡驱动,然后逐个输入命令,完成英伟达容器镜像安装 配置 dolphin 镜像使用英伟达的 gpu 资源配置完成后重启 dolphin 镜像,这样我们就完成了 gpu 资源使用的配置。 到这里我们基本准备好了我们的资源,接下来我们开始欧拉玛的安装,我们进入应用商店,选择 ai 就 可以快速看到欧拉玛应用,点击安装输入相关参数即可。 这里我们需要确认好版本,零点一五点四当前最新版本端口号一一四三四开启端口外部访问,最后一定记得勾选开启 gpu 支持,其他保持默认,点击确认开始安装。这里安装包含镜像拉取以及应用安装两部分,大概需要一分钟左右, 这里我们快记下。安装完成后我们到已安装应用中确认欧拉玛已经正常运行, 点击链接地址页面显示欧莱玛 is running 即可。到这里我们就完成了欧莱美开源模型管理平台安装。下面我们急于欧莱玛完成开源模型 g p t 杠 o s 二零 b 模型的加载, 大家跟上节奏,在 one panel 中找到 ai 管理,进入模型管理,点击创建模型,在模型配置页面点击快速跳转进入欧莱玛官网, 输入 gpt 杠 o s 快 速搜索到模型,点击获取模型 id。 然后我们再回到 one pan 面板,输入获取到模型 id, 点击确认开始模型下载,该模型下载大概需要十到二十分钟,这里我们快速跳过模型,加载完成后,我们就为我们的个人 ai 员工准备好大脑了,我们通过模型先验证下能否正常对话,太棒了,可以对话哦, 这样我们就为 ai 员工准备好了大脑。下面我们同样基于 one panel 来安装我们最近特别火爆的 openclaw, 进入应用商店找到 openclaw 应用,点击安装完成参数配置确认,默认端口号已经开通,下拉选择欧拉曼模型供应商并输入相关参数,具体参见如图所示。其中 gptos 二零 b 对 应我们下载的本地模型 a p i t 输入任意字母 base u r i o 对 应我们部署的欧拉姆地址。最后同样记得开通端口外部访问, 其他参数保持默认,点击确认即开始安装。安装大概一分钟左右,我们同样快速跳过,安装完成后通过安装目录获取 opencloud 访问 token, 获取后与 ip 端口 token 等于 token 值,拼接后输入 web 访问地址中, 最后点击跳转,直接选择带 token 的 访问地址就可以体验啦。让 ai 助手帮忙创建一个文件清单,到服务器对应目录查看,完成操作啦。 接着我们让他网上查询一些信息,他也可以轻松帮我们搞定。到这里我们就完整构建了一个本地的 ai 员工啦,大家速来体验呀!完全可以用 one panel 作为 ai 员工的管理员,本地,重点是本地!本地就等于安全! 同时再也不用为 token 着急上火啦!小伙伴们快来快速构建,抓紧体验啦!
3.0万OpenClaw开源社区 05:15查看AI文稿AI文稿
05:15查看AI文稿AI文稿兄弟们,大家最近有没有被这只小龙虾刷屏名字从 cloud bot 到 multi bot 再到 open cloud 火爆全网,你们是不是也想拥有这样一个私人助理,每天早上打开飞书,让他整理 ai 圈发生的大事儿发送给我, 提醒我女朋友生日买花和订酒店,每天帮我关注和整理持仓动态,是否有重大利好利空等消息, 并且能够通过我常用的飞书给他下达指令,这就是 openclaw, 被称为真正能干活的 ai 助手。本期视频给大家带来 openclaw 的 保姆级教程,包含模型选择、安装部署、接入飞书以及如何配置使用 api 聚合平台 crazy router, 节省百分之五十的 token 费用。首先我们来看模型选择 opencloud 实现效果的核心在模型,虽然它支持很多模型,但是官方推荐使用 cloud ops 模型,效果比较好,建议使用。 然而 opencloud 非常费 token, 同时 cloud ops 四点五的官方 api 价格确实也让人生味。本期视频里也会教大家如何配置 opencloud, 使用 crazy router api 聚合平台,实现省钱百分之五十。调用 cloud ops 四点五。 接下来是安装部署,为了避免 ai 误操作导致悲剧产生,这里不建议部署在日常工作,电脑可以选择部署在云主机上,我这里用的是 a w s 送的半年免费云主机,大家可以根据情况自己去薅。 这里我们打开终端,直接登录到 a w s 的 云主机,输入 open c 号官方提供的一键安装脚本进行安装即可。 安装完成,进入初步设置向导选择模型,这里可以先跳过,后面会进行配置,选择 channel, 这里默认没有飞书也可以先跳过,后面会配置 skills 也可以后面根据需要再配置,后面一路 no 和跳过即可,之后根据实际使用情况再进行配置。 这里使用 openclaw gateway status 验证一下状态,再用 curl 看一下状态是不是两百,这样我们就完成了基础的安装配置。如果需要远程访问 openclaw 的 管理界面,还需要安装 x x 进行反向代理,这里可以使用 e r m 进行安装,配置文件可以参考我这个, 重启 n g s 即可。接下去配置 openclaw 信任代理和允许 http 认证, 然后重启 openclaw, 再获取认证的 token, 将 token 拼接在 url 的 后方,即可访问 openclaw 的 管理界面。接下来我们配置 ai 模型,这里使用 api 聚合平台 crazy router 提供的 api key 进行配置,它比官方 api 便宜近百分之五十。 模型使用这个 called open。 四点五,我们点击令牌管理来创建和复制我们的 api key。 接下来打开 openclaw 的 配置文件,找到 model 和 agent, 这里按照我这里面的配置完成 crazy router 的 api key 和 cloud ops。 四点五的配置,重启 openclaw, 完成配置。 最后一步,配置飞书渠道,飞书使用 webbed 长连接模式,无需域名和公网回调地址,配置简单,个人用户也可以免费使用。首先在开发者后台创建企业自建应用,然后获取应用凭证 app id 和 a p c secret, 同时开启机器人能力 开通相关权限。在 opencloak 中安装飞书的插件,设置飞书中我们刚才获取到的 app id 和 app secret 再次重启 opencloak 事件配置中使用长连接接收,同时添加事件和事件权限, 再创建一个版本并发布,就完成了飞书的配置。接下来我们实际看一下效果,看看 opencloak 能帮我们做些什么, 很快就帮我们生成了一份高质量的总结报告。 接下来可以给他布置一个任务,每天早上帮我们搜集持仓股票的动态信息,分析财报、产品发布、监管诉讼、高管变动等重大利好利空消息。这样他每天就会把详细的分析报告发送给我们,方便我们第一时间了解持仓动 态,也可以很全面地分析多个同类产品的情况。 最厉害的来了,可以让他给立即帮我们写一个专业的程序,然后运行这个程序,得到我们想要的运行结果。整个过程我们完全不需要关心代码文件和运行环境。对了,这里要配置下 a 阵字的权限才能使用编程代理, 他会直接把程序的运行结果给我们,结果也完全符合程序的逻辑和预期。 最后总结一下,我们首先进行了 opencloud 的 安装配置,接着配置使用 crazy router 的 api key 注册来调用 cloud opens。 四点五,使用飞书机器人作为接入渠道进行通讯。最后演示了几个常用的应用场景, 像 opencloud 这么全能的助理,每个人都值得拥有。再把我踩过的几个坑给大家分享一下。好了,本期视频就到这里,有问题留言问我。
3749Geek Leo独立开发者 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿别再乱划 talking 了,百分之九十的人都用错了。 talking 到底是什么?其实就是 ai 算字数的计算单位。一句人话讲透,不是你会不会被收费,而是你输入的字, ai 输出的字都会被拆开来计算。消耗不是按对话次数来算,而是按字 词一点一点扣额度。你问的越啰嗦,他回答的越长,消耗额度就越快。所以额度突然没了,不是出错,也不是坑人,是字数堆出来太多了。 这就记住这句话就够了。 talking 等于 ai 用掉你的次数,懂这个再也不会背,突然没额度搞心态,记得关注再走哦!
 00:47查看AI文稿AI文稿
00:47查看AI文稿AI文稿ai 翻译黑化之 tokken, 咱普通人不用懵,什么叫 tokken? tokken 就是 你用 ai 时花钱的一个计量单位。不管你是发文字给 ai 还是让 ai 给你写内容 输出和输入的内容呢,都会被计算成 tokken。 花了多少 tokken 呢,它就会扣你多少米。要想要你米花的少, 首先掌握重点,别啰嗦,说重点不用的信息别发,让 ai 输出也不要太多的内容,精准提要求才能少花 top 我 们就能少花米。关注我,咱们一起用 ai 来提升自己,不花冤枉米。
2明日速成 00:38查看AI文稿AI文稿
00:38查看AI文稿AI文稿ai 里的 token 到底是什么意思?一句话总结它就是 ai 算字数算费用的单位, 你打进去的字,还有 ai 回你的字,全部都要算进去,不是按问题算一次哦,是按字按词一点点的算的哦, 你问的越长,那回的越多, token 消耗的就越快嘛。所以你用着用着哦,就没额度了。真的不是你的问题,纯粹就是字数堆出来的啦。 记住这句, token 等于 ai 用了你多少次?搞懂这个,你就不会被突然没额度哈,撑了对吧?关注马儿,用 ai 快 速提升自己!
 02:50查看AI文稿AI文稿
02:50查看AI文稿AI文稿燃烧了十五亿 tiktok 学了四个月,做了四十五部 ai 漫剧,很多人问我怎么做漫剧,今天我就出一个漫剧速通方案,别信那些卖课教理论的,你就看看我二十分钟从零开始写剧本到分镜生成的视频,最后导出剪映, 我快速讲完,大家可以看一下最后的成片。今天就给你们这些小白一下子点透你们是不是不会用 ai, 我 就用今年春节最火的三个 ai 给你们做演示。第一步,我们先打开千问, 记住打开千问之后要在这选择三点五 plus, 记住了,有最好用的模型就用最好的模型。 在提示词里告诉他帮我完善剧本,然后随便写一段草稿扔进去,你看,这就是我刚写的,等一会他就给我们输出了一个完整的剧本。 好,第二步,我们打开豆包,把刚才千万输出的剧本全部复制进来,然后给豆包说帮我生成一个封面楼提示词,详细的提示词我会放到评论区,你们自己去取就 ok 了,然后你就等就完事了。 等豆包把所有的分镜提示都给你出来之后,我们第三步,打开积木,注意这个地方,我们要选 cds 二点零 fast 的 这个模型, 还是那句话,我们只用当下最好的模型,选择全能参考。然后上传一张你想要的人物图,如果没有就随便生成一张。把刚才豆包生成的分镜提示复制进来,把人物添加进去, ok, 开始生成视频。完事了,到这一步,你的 ai 动画版已经做完百分之九十了, 我们后边把所有的分镜提示词全部复制进来,一个一个生成,生成好之后我们把视频全部下载下来, 你看过程全部是一遍过,一遍出剧本,一遍出分镜头,一遍出视频,我一个都没有抽卡,千问豆包、吉梦都没有抽卡,全部是一次成型。然后我们接下来就是导出剪映,导入音乐,加入转场的特效。 ok, 就 这么简单,我们已经做好了一个成片了。 关注我,下次让你们看一下,我过年期间用了十二亿头更写的一个剧本自动化工具, 哈哈哈,他们都说我疯了,可只有我知道这个世界神明拯救不了, 早晚被神明吃掉。 那就让我来帮你们解脱吧, 鬼神们,我来了。
4512小道道道 02:52查看AI文稿AI文稿
02:52查看AI文稿AI文稿豆包出不了图,元宝回答不了问题。千问加载转圈圈。今年春节这个春运没怎么堵车, ai 大 堵车了,春节前我要交个广告稿,甲方呢心急火燎的催我。文案写的挺快,但是配合文案的这个封面图出不来。 我一般呢就是先写提示词啊,然后让豆包给我作图。那天豆包罢工了啊,估计是玩 cds 的 人实在太多了啊。视频呢,本来就是吃蒜粒和 token 的 大户 啊。海通的研报曾经说 cds 二点零的一段十秒幺零八零屁的视频要消耗三十五万 token, 相当于十万字文本输出的三到五倍 啊。 token 是 ai 处理信息时候的基本单位啊,比如说是一个英文单词啊,或者视频里的一个像素点或者一个特征点。 嗯,不知道几家大厂怎么解决算力问题的。我查了一下,最近全球大模型的 token 消耗, openai 还是 token 消耗第一名,那 chart gpt 几个版本加起来日均要消耗掉一百到一百五十万亿 token。 谷歌的 jimmy 消耗七十到八十万亿, 豆包爬升到了全球第三名,日均六十三万亿。然后后面是 anthropica 的 四十五到五十五万亿。月之暗面 kimi 的 三十五到四十五万亿 啊,千万和元宝也都做到了三十万亿左右啊。 deepsea 二十二万亿啊,最近呢,当红小生 mini max 八到十二万亿,超过了七到十万亿的马斯克的 ai group, 字节的同比日均消耗量增长了三十倍,同比去年, mini max 最近月度增长率是百分之三百五啊。除夕那天晚上豆包的峰值是每分钟六百三十三亿 book 大 厂们搞红包裂变送奶茶下沉市场 啊,春节送祝福!新圈了至少八千万用户,再加上大模型升级最好的视频和图片生成模型,单位用户的 token 消耗量又增长了三到五倍。你拉新再加上多模态,就把 token 搞成了结构性通胀。非限性的算理需求增长了。 按照 scaling law 的 话,透支量增长十倍,算利需求可能要暴涨到一百倍。除夕晚上那个峰值换算为 gpu 的 规模的话,理论上需要两百八十八万张 h 一 百全天满负荷。嗯,国产进口算卡一起上。不知道怎么顶住的,是不是都转冒烟了 啊?真不敢想啊。大厂运维和 a i d c 的 同学,这个春节是怎么熬过来的?这个春节呢,就是 ai 全民普及的拐点,它不再是即刻工具 啊,不再是办公室工具,而是逐渐嵌入了日常生活,变成了普通人过年社交、创作办事的刚需, ai 的 大时代才刚刚开始。
1528桃小仙的碎碎念 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿ai 里的桃肯到底是什么?你是不是也遇到过 ai 用着用着突然就没额度?明明没问几句,额度就见底了, 到底是谁在偷偷扣你的钱?今天一句话给你讲透 ai 里的桃肯,说白了是 ai 计费算次数的最小单位,在以为问一句话算一次费,大错特错。你发给 ai 的 每一个字每一个词, ai 回复你的每一句话每一段内容,全都会拆成掏坑悄悄扣额度。 你输入的越长, ai 回的越多,掏坑消耗的就越快。你的额度不是凭空消失,也不是点错了,全是被字数堆没的。就记住一句话, tock 等于 ai 用了你多少次?搞懂了这个,再也不会被额度清零!搞心态,想知道怎么省 tock 高效用 ai 不 花冤枉钱吗?关注我,带你用 ai 高效提升自己!下期教你一招,让你的 ai 额度直接翻倍!
 00:12查看AI文稿AI文稿
00:12查看AI文稿AI文稿可乐 boss 啊,就把这自动唱歌这个一天五百,你托肯用没了。嗯,也没实现,还到处留着错,还不如用豆包啊哈哈哈哈哈。
 01:11查看AI文稿AI文稿
01:11查看AI文稿AI文稿带你看看我用 oppo pro 两周之内的真实消耗,再告诉你一个技巧,让你的头壳消耗直接减少至少一半,这是谷歌官方的 api 基本系统,我们来看看这个月我是用了十二美元,我使用的模型主要是 java 三 pro、 nano 三 pro 和 sunflash, 我 用它做一切的流程,自动化、视频生成、图片生成、代码生成。再看看我们团队的差不多有三十人,这两周用了七十美元,算下来每天就是五美元,他们用文字、视频、图片的模型做类似的用途。这样算下来,我们每人每天用 java 的 模型差不多就是五到十块人民币, 这个费用远远低于大家在网上说的数字。那为什么我们能做到这么低呢?告诉大家一个技巧,首先打开你的电脑终端,确保你的 open class 是 正确安装的,然后输进去 open class skills, 这里面会告诉你你已经安装了哪些没有安装,哪些打了对号的是安装的。当你认真读清楚你安装的这些技巧之后,在你用旁边和 open class 对 话的过程中,在每次做任务的时候一定要加上一句话,就是用指定的技巧。比如在这里我让他帮我修改 pdf 的 时候,用到了 nano pdf skill, 如果你不指名的话,他会调度多个,一个一个去尝试,所以很多头衔就会浪费在过程中。 如果你已经安装部署的 oppo core, 赶紧去试一试这个技巧,你会看到明显的头壳消耗的下降。如果你还没有安装,或者你不知道怎么去本地部署安装 oppo core 的 话,我们正好有一个 ai 工具小组,里面有手把手的安装教程和进阶的 oppo core 落地应用教学。如果你感兴趣,可以看视频主页介绍,第一行会有专人给你提供更多的信息和介绍。
793硅谷E老师 01:22查看AI文稿AI文稿
01:22查看AI文稿AI文稿在我了解了这个通会是怎么被消耗的这件事之后啊,我最大的直觉是,我觉得未来的程序员很可能会两极分化, 分为有钱的程序员和没钱的程序员,分为富程序员、穷程序员。你想啊,有钱的程序员,他能够使用最先进的工具,使用最先进的模型,然后去创造出更好的产品, 然后去赚更多的钱。而没钱的程序员,他分为两类人,一类呢是打工人,他使用的是公司提供的免费 ai 工具,一般都不咋地。第二类是创业者,他需要是自负盈亏,如果他的商业模式跑起来了,他就是一个有钱的程序员, 如果他的商业模式没跑起来,那么他需要承担 ai 编程的高额费用,很有可能会入不敷出。 因为 ai 编程和我们平时使用拆一批聊天不太一样啊。一百万头肯,如果你聊天的话,你可以聊个几百次,能用很长时间,但是你 ai 编程,你让 ai 去分析一个功能模块,就有可能会消耗几千到几万头肯, 如果你让 ai 去分析一个完整的项目,全量代码几十万,上百万投坑代码还没开始写,几十块钱就没了,玩不起。我希望我这个直觉是错的,你觉得呢?说说你的看法。
828程序员康健 00:22查看AI文稿AI文稿
00:22查看AI文稿AI文稿ai 的 头肯到底是什么?其实就是 ai 统计字数的计费方式。重点来啦!你输入在 ai 里的文字和 ai 输出来的文字通通都要算钱,它不是按照对话次数来计算,而是按照所有的字数来统计。你想,你问的问题越长, ai 回答的就越多,那消耗的头肯就越多。 所以额度用完真不是因为你点错了什么,纯粹是因为字数堆的太多了。记住,头肯就是 ai 消耗字数的计量单位。想要明白这个,你就再也不会被突然用完的额度吓一跳。点赞关注,一起 ai 升级!
 02:43查看AI文稿AI文稿
02:43查看AI文稿AI文稿二零二六,一种狠心的 token 出海正在悄然暴利。不出国不运货,靠家里的显卡做 token 出海,这门生意,今年或许真的能跑通。现在,美国硅谷正陷入一场前所未有的电力饥荒。 一边是 ai 算力的需求爆炸,一边是老旧的电网根本承载不了这么大的负荷。在弗吉尼亚州和加州,很多数据中心想要扩容并网,排队已经排到了两三年后。这种有钱买卡没电开机的窘境,正在推高全球的 ai 产业的底层成本, 而这恰恰给了一种全新的跨境贸易模式留出了巨大的套利空间。它不是简陋的倒卖硬件,也不是复杂的软件外包, 这本质上是一场利用两国资源禀赋差异进行的数字能源套利。我们来做一个最直观的对比,在美国,工业电价受限于能源转型和基建之后,很多核心地带已经涨到两三毛美金一度。 而在国内,一托完善的能源工业体系,我们的电费成本只有人家的几分之一。更重要的是人的红利。 同样一套分布式算力集群,美国聘请专业运维工程师的成本极高,而国内拥有大量懂架构、会调优的自动化和计算机专业人才。这种工程师配置的性价比是全球任何地方都比不了的。 你用最低成本的店,配上最高效率的人,跑的是国产最强的 mini max。 开源模型生成的 token, 通过云端 api 卖给对价格敏感的美国独立开发者。你在境内完成生产,他们在海外完成消费,赚回来的是真金白银。 算力正在变成像煤炭、石油一样的基础商品,美国虽然在芯片制成上领先,但是在 ai 竞争中拼到最后,拼的是单位算力的综合成本。未来,谁能把低廉的电费和高校的人才红利转化为全球通用的 api token, 谁就掌握了印钞机的摇杆。这种分布式数字出口,正在打破地理和政策的边界, 这不仅是技术的较量,更是能源效率和人才密度的对撞。当然,这种路子对一般人来说也是有门槛的,跨海传输的延迟如果控制不好海外客户的体验就会直接崩掉。美国最新的法案虽然复杂,但是只要搞清楚服务贸易和算力租赁的界限,空间依然很大, 更别说还有资金回笼时的合规审查,每一步都得踩准节奏。这门生意是留给一些既懂底层技术又懂国际贸易规则的国际数字玩家的。
1129Lexing聊科技




猜你喜欢
- 6875洛西卡