智谱的大模型干嘛用的
今天最重磅的是,智谱发布了 glm 五大模型,在全球权威榜单中位居开元模型第一,编程能力对标闭源天花板 cloud opus 四点五,超越谷歌 gemini 三 pro。 这太厉害了,国产大模型终于追上来了! 没错,这标志着国产大模型从技术追赶转向价值创造。 glm 五的参数规模达到了七百四十亿,是上一代的两倍,训练数据也增加到了二十八点五万亿, 那实际性能怎么样?在全球权威的 artificial analysis 榜单上, g l m 五位居全球第四,在开源模型中排名第一,在 s w e bench 威慑和 terminal bench 二点零这些专业测试中,都取得了开源模型的最好成绩,这意味着什么呀? 更重要的是, g l m 五完全适配了国产芯片生态,包括华为、升腾、摩尔、现成等七大平台,摆脱了对国外硬件的依赖。 成本方面,由于软硬件深度优化,部署成本大幅降低了百分之五十,单台国产算力节点的性能已经能媲美两台国际主流 gpu 组成的集群,这性价比太有竞争力了。市场反应怎么样? 最让我惊讶的是,智普竟然宣布涨价了! g l m calling plant 套餐价格中国区上调百分之三十,海外版涨价超过百分之一百, 在 ai 行业很少见,说明市场开始为技术进步买单了,供不应求,用户愿意为更好的服务支付更高费用。智普股价在春节后也大涨百分之四十二,市值突破三千两百亿港元。 这确实是一个重要信号,但这个事件对行业有什么影响?首先,它打破了海外开源模型的垄断,证明中国 ai 技术已经从跟跑到领跑。 其次,它推动了 ai 编程范式的改革,将 ai 从代码生成工具升级为虚拟工程师,可以自主完成端到端软件工程全流程开发任务。这是不是意味着以后程序员的工作会被 ai 取代? 不能这么说, ai 更多是作为程序员的助手,提高开发效率。但可以肯定的是,未来的编程方式会发生巨大变化, ai 将成为程序员不可或缺的工具。那对普通用户来说,这个事意味着什么? 对普通用户来说,最直接的影响就是 ai 俗物会变得更便宜、更高效。比如以后用 ai 写代码、做 ppt、 做数据分析,成本会降低很多,效率会大幅提升,这对我们来说是好事啊。那未来的趋势是什么? 我认为未来几年, ai 会像水电煤一样成为基础设施,企业和个人都会离不开 ai, 差别只是用的好不好。而国产 ai 技术的突破,会让我们在全球 ai 竞争中占据更有利的位置。这话说的太精辟了,但这里也有风险吧? 当然有,比如 ai 技术的快速发展,可能会导致部分岗位的替代,需要我们不断学习新技能来适应变化。此外, ai 的 安全和轮历问题也需要引起重视。这话说的对,技术再牛,最终还是要服务人的。要是 ai 只是帮公司赚钱,那没啥意义。 确实,不过总的来说,这个事件是里程碑式的,标志着 ai 行业进入新阶段。说了这么多,我用一句话总结智普 glm 五的发布,可能会彻底改变 ai 行业的格局。 没错,国产 ai 正在从技术追赶转向价值创造,从跟跑到领跑。对,而且我觉得更重要的是我们得学会用 ai, 而不是被 ai 用。这话说的太精辟了,感谢收听今天的 ai 播课,我们下期再聊,拜拜。

粉丝1318获赞10.3万
相关视频
 01:09查看AI文稿AI文稿
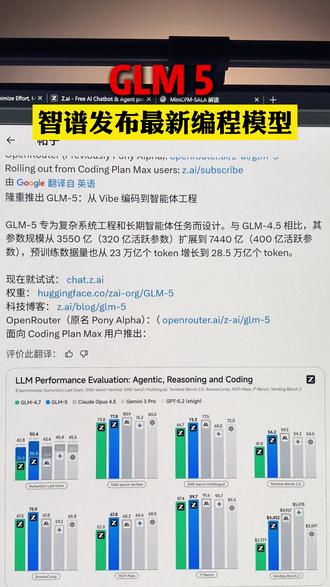
01:09查看AI文稿AI文稿就在今天,智普重磅发布最新编程模型 g l m 五,它专为复杂系统工程和智能体任务而设计。与上个版本 g l m 四点五相比,其参数规模从三千五百五十亿扩展到了七千四百四十里, 包含大约四百亿活跃参数,使用的预训练数据量也从二十三万亿个 token 增长到了二十八点五万亿 token。 其最新 benchmark 结果显示, g l m 五已经能够在推理代码和智能体能力上全面对标国际顶尖模型。 从结果可以看到, cloud opus 四点五和 gpt 五点二虽在部分基础中仍保持微弱领先,但 glm 系列模型已实现了显著的追赶趋势,在综合能力和性价比上形成了有力的竞争格局。此外,从股票投资爱好者最关注的 vending bench 测试结果,也就是测试 ai 商业决策能力的基准测试结果 可以看到, glm 五模型是和比较激进的投资策略。如果你是具备冒险精神的投资者,那么不妨尝试让 glm 五模型成为你的理财投资顾问。 目前, g l m 五已经可以通过欧拉玛的云端模型直接调用,同时你也可访问 z 点 ai 智普官网进行实际测试,欢迎各位分享你的使用反馈。
222杨大哥 02:50
02:50 06:56查看AI文稿AI文稿
06:56查看AI文稿AI文稿在国产 ai 算力领域,硬件性能的堆叠往往只是入场券,而软硬协调的生态适配才是决定胜负的关键。随着智普 ai 最新一代国模顶流 glm 五的发布,这一抠定能力位居全球开源第一、总榜第四的模型迅速引发了行业热议。 与此同时,摩尔县城宣布其 ai 旗舰级计算卡 m t t s 五零零零实现对 g o m 五的迭零发布及适配,并首次批露了硬件性能参数 f p 八精度下单卡 ai 算力高达一千 t flops, 并提供原声 f p 八支持,在显存容量、互联带宽上也与英伟达 h 一 百对标。 从二零二四年推出至今,这款专为迅推一体设计的全功能 gpu 智算卡不仅在纸面参数上对标国际主流产品,更在智研研究院、硅基流动等头部机构的实战检验中显现出挑战英伟达高端算力的统治力。 摩尔县城究竟做对了什么,使其能够从 g o m 四六一路无缝衔接到 g o m 五,让零时差适配成为国产算力的常态 生态的飞跃? g l m 五迭零适配背后的全站协同此次 g l m 五发布及适配的背后,是摩尔县城软硬协同技术路线的集中爆发。 作为定位 agentient engineering 的 旗舰模型, g l m 五相较上一代性能提升百分之二十,对长系列推理和复杂系统工程能力提出了极高要求。 m t t s 五千凭借充沛的算力储备与对稀疏 attention 的 架构级支持,在大规模上下文处理中依然保持了高吞吐与低延迟, 完美承接了 g o m 五在长城 agent 任务中的计算需求,更关键的是, m u s a。 软件战的敏捷性成为了实现对零适配的胜负手。 基于 m u s a 架构的 t o line 原生蒜子单元测试覆盖率已超过百分之八十,使得绝大多数通用蒜子可直接复用,极大降低了移植成本。 通过高效蒜子融合及框架极致优化, m t t s 五千在 g l m 五的运行中展现了极低的首字延迟和流畅的生成体验,特别是在函数补全、漏洞检测等扣定核心场景中表现优异硬实力的底气。 s 五零零零性能逼近 blackwell m t t s 五千性能的首次全面曝光,结实了国产 g p u 在 架构设计与集群扩展上的成熟度。 作为摩尔现成第四代 m u s a 架构平胡的极大成者, s 五千在单卡规格上能力接近国际一流水平,本期现存宽带高达一六 tb 每秒,卡间互联宽带达到七百八十四 gb 每秒, 单卡 f p 八算力更是飙升至一千 tfloops, 在 显存、卡间互联单卡算力上与英伟达 h 一 百基本一致。 此外, m t t s。 五千对 f p 八到 f p 六四全精度计算的完整支持,特别是硬件级 f p 八 tenor core 的 引入,成为了其性能跃升的核心引擎。 据接近测试项目的行业人士透露, m t t s 五零零零在产品精度层面已超越 h 一 百,技术特性更逼近英伟达下一代 blackwell 架构。来自互联网厂商场景的实测反馈进一步印证了其在算理上的优势。 数据显示,在典型端到端推理及训练任务中, m t t s 五千的性能约为竞品 h 二零的二点五倍。分析指出,这主要得益于其高达一千 t f l ops 的 单卡算理。 在绝大多数计算密集型场景中,该卡不仅能提供更强劲的算力输出,也在整体性价比上展现出显著优势。 基于 s 五零零零构建的夸额万卡集群,其浮点运算能力已达十 x f lops 级别,标志着国产算力在超大规模集群层面迈入了世界前列。 在该集群的实测中, s 五零零零展现了极高的算力利用率, d s 模型训练中 m f u 达百分之六十,某一模型维持在百分之四十左右, flash attention 算力利用率更是超过百分之九十五。 这得益于摩尔县城独创的 ace 技术,该技术通过将复杂的通信任务从计算核心卸载, 实现了物理级的通信计算重叠,从而释放了百分之十五的倍占算力。实测数据显示,从六十四卡扩展至一千零二十四卡,系统始终保持百分之九十以上的限性扩展效率, 这意味着训练速度随算力增加几乎实现了同步倍增,有效训练时间占比超过百分之九十。 顶尖模型训练与推理中的实战中,对标 h 一 零零,他说之外,真实的落地案例是检验算力成色的唯一标准。 摩尔县城 s 五零零零在训练与推理两大核心场景中均交出了令人幸福的答卷。 在训练端,二零二六年一月,智源研究院利用 s 五千千卡级群完成了前沿巨深大脑模型 robo brain 二任务的端到端训练与对齐验证,本是其训练过程与英伟达 h 一 百级群高度重合连损失值的差异仅为百分之零点六二, 这证明了 s 五零零零在复现顶尖大模型训练流程上的精准度与稳定性。用户一托 m u s a。 全站软件平台,能够原声适配 pi、 torch、 megatron、 lm 等主流框架,实现零成本的代码迁移,真正做到了兼容国际主流 c u d a。 生态。 在推理端, s 五零零零的表现同样刷新了国产 gpu 的 记录。二零二五年十二月,摩尔现成联合硅基流动针对 deepseek v 三六七 e b。 满血版进行了深度适配与性能测试。 得益于 s 五千原生 f p 八能力与 s g l m musai 推理引擎的深度优化,在 p d。 分 离的部署中,单卡 prefill 吞吐量超过四千 tokens s, daco 吞吐量超过一千 tokens s。 这一成绩不仅大幅降低了显存占用,更在高并发场景下保证了极低的响应延迟。配合首创的细力度重计算技术, s 五千将开销降至原有的四分之一,全方位提升了系统吞吐量,证明了其作为高性能在线推理服务底座的卓越实力。 从 g l m 四点六、 g l m 四点七到如今的 g l m 五,摩尔现成通过一次次发布即适配的实战,证明了国产全功能 g p u 及 music 软件站已具备极高的成熟度。 这种对前沿模型结构与新特性的快速响应能力,不仅为开发者提供了第一时间触达最新模型的通道,也为行业筑牢了一个坚实易用且具备高度兼容性的国产算力底座。
6博宇 01:05查看AI文稿AI文稿
01:05查看AI文稿AI文稿最近中国的大模型集体更新,这一波真的有点猛。先说字节跳动刚发布的 cds 二点零,这是他们最新的视频生成模型,核心能力是多模态视频生成,画面更稳定、人物动作更自然,生化同步更精准,已经不是简单的演示效果, 而是开始往工业级内容生产走。再看智普 ai 发布的新一代模型,在推理能力、代码能力和复杂任务处理上明显增强,智能体执行能力更成熟,已经进入全球第一梯队的竞争区间。还有 deep seek, 这次重点提升的是长文本处理和推理效率,上下文能力大幅扩展,同时把算力成本压得更低,这对企业落地非常关键。很多人还在讨论参数规模,但现在真正的竞争点是推理效率、真实场景应用能力以及商业化速度。 从整体节奏看,中国大模型已经不是跟跑,而是在部分吸粉能力上开始抢占领先位置。如果你是做实体生意、做内容创业或者做企业服务的,今年一定要重新评估 ai 带来的机会。关注我,我持续帮你拆解这一波技术升级背后的真正机会。
24热点宝 03:35查看AI文稿AI文稿
03:35查看AI文稿AI文稿大家好,欢迎收看今日 ai 日报,今天我们将为您带来一系列最新的 ai 资讯,感受人工智能领域的蓬勃发展与创新活力。 首先来关注智普 ai 的 重大突破。智普于二月十二日凌晨正式开源了新一代机座大模型 glm 五, 其底座参数规模达七四四 b, 在 权威编程基础测试中拿下开源模型全球最高分,真实编程场景体验逼近 cloud ops 四点五。该模型面向 agentient engineering 打造,具备强大的工具调用能力和长城规划记忆能力, 可实现一句话输入到完整交付物能,为复杂系统工程与长城 a 整的任务提供可靠生产力。 接着是 entropic 的 重磅融资消息,北京时间二月十三日, entropic 完成了三百亿美元巨轮融资, 头后估值三千八百亿美元,成为全球第二家两万亿级 ai 独角兽。本轮融资由新加坡主权基金、 g i c 等联合领头,微软、英伟达同步加注。此次融资将进一步助力 entropic 在 ai 领域的研发与拓展,其发展前景备受瞩目。 再来看看企业合作动态。二月十三日,沙特阿美与微软签署谅解备忘录,计划基于微软 azure 云平台探索人工智能驱动的工业解决方案,以提升运营效率,增强全球竞争力。 双方将在数字主权和数据 resiliency、 运营效率与数字基础设施等多个关键领域展开合作,推动能源领域的数字化转型。 在政策标准方面,工信部于二月十三日对人工智能关键基础技术、办公智能体应用接口规范等一百六十二项行业标准给予公示, 这将有助于规范我国人工智能相关技术与应用,推动行业健康有序发展,为 ai 产业的高质量发展提供坚实的标准支撑。 教育领域也有新进展。二零二六年春节前夕,由十四五中华优秀传统文化创新教育研究总课题组等机构联合研发的中小学传统文化 ai 智能体启动上线测试。 该智能体一托国产主流大模型矩阵构建,融合知识库,围绕三百个人文教育主题,实现了从知识灌输到能力看究的范式转移,将于三月面向国内第一批传统文化人工智能教学实验基地开放。 最后关注一下太空计算领域。二月十二日消息,三体计算星座实现了新尖组网突破,通过载轨携同完成了十个人工智能模型应用的部署与验证, 探索了深空探测、智慧城市建设等场景的太空计算创新应用。三体计算星座是千星规模太空计算基础设施,目前整体载轨算力达五 p o p s, 是 全球算力规模最大的太空计算星座,正推动太空科研范式改革。 以上就是今日 ai 日报的全部内容,我们将持续为您跟踪报导,期待下次再见!
 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿二零二六年开年刚刚八天,全球大模型第一国正式诞生。这个从北京清华园出发的企业,如今已是中国最大的独立大模型厂商,也是被 opennai 视为劲敌的中国对手。六年前,抱着奔赴 agi 的理想,质朴正式成立比时 transformer 架构。发布刚两年,大语言模型领域还未出现惊世骇俗的产品。二零二二年末, 随着 chat gpt 的面试生成,是 ai 首次进入公众视野,大语言模型迅速成为共识赛道。那一年起,至少有超百个大模型发布。当时质朴已经有了原创架构 glm, 并在二零二三年推出对话模型叉 glm。 百模大战初期的竞争是残酷的,生死局不仅在于大模型的烧钱程度,更在于技术迭代 实在是太快。曾有业内人士感慨,当时的大模型技术一天一个样。在这一时期,质朴则着重投入研发,积攒算力,保持着模型迭代的速率。更大的转折发生在二零二五年, open ai 曾是大模型领域的绝对代言人,但这种领先性在二零二五年开始失效。击溃 open ai, 低到成尺的就是中国大模型。凭借创新的架构与开源的态度,中国大模型在全球市场突出重围。质朴正是这场战役中的排头选手,首次打破海外大模型对 top 三排名的垄断,达到开源能力第一, 布局海外业务。以至于 open ai 在一份官方报告中,将质朴视为了头号中国对手。二零二五年底时,硅谷开始流传一种论调,认为中国模型已经凭借开源拿下人心,性价比是最大杀气质朴的 g l m 四点七, 以 angel pig 的科二的价格,七分之一即可享受到几乎同级别的扣定性能,很快就让海外开发者真香了。至此,全球大模型竞争的格局初步一定。海外是以 open ai 为首的星文计划,国内是以质朴为代表的国产模型底座。这是一场事关国力的全球竞赛。正如英伟达 c 在今年 ces 现场所言,没有人希望在这场竞赛中掉队,但相比中美有字眼底座的实力,更多国家采取拥抱开源模型的态度。船票已定,而质朴抢先登陆资本市场,无疑是为这场更持久的战役补充弹药。资本市场对这场赛事也颇为关注,以用脚投票。质朴的基石投资者是北京核心国资投部、保险 金、大型公墓基金、明星私募基金和产业投资人构成的全明星阵容。上市首日开盘大涨超百分之十。上市只是新的起点。可以确定的是,一场隐秘的算力爆发潮已经开启了,朝着 a g i。 目标前进竞赛刚刚开启。
973凤凰网科技 02:38查看AI文稿AI文稿
02:38查看AI文稿AI文稿大家好啊,春节期间,大家没有等来 deepsea 四啊 v 四,但是却等来了这智普的 g l m m 五,而且智普这个模型呢,在海外这些测试网站上,通过匿名的方式让很多人测试,发现效果极好,已经杀入了前两名啊,这是智普的 g l m 五。 那么在这个春节呢,即将结束的时候,啊浦正式把技术模型的技术报告给大家公开了啊,首次批露这个模型的核心的路径,一个是对于什么所谓套壳啊,所谓蒸馏啊,做了一个真深度的回应。首先,它的被动的推动的编程范式呢,是从 y 的 call 顶就是氛围编程,像 any 顶就是智能体工程跨越的一个下一代的模型。而且呢,这里面引入了稀疏注意力机制啊,能够根据 token 的 重要性来动态分配注意力的资源, 保持上下文理解能力的同时呢,大幅压缩算力的开销进入这个机制。模型参数呢,扩展至七百七十七百四十四个币啊,但训练参数量达到二百二十八点五 万一。训练的技术设施方面,他在他自己的框架上面做了一个全新的异步强化的学习系统啊,将生长过程与训练过程的深度的捆绑,支持大模型的支撑体的轨迹搜寻,而且它是在真实编程场景里这底层的支撑。 而且他在发布之初,他在训练的时候就完全依仗于国产钻力啊,全面兼容华为的升腾摩尔,建成海光、韩五 g、 昆仑星、天柱之心与随缘七大主流的国产芯片平台。据 其报告呢,经过软硬协调优化以后,他在单台的国产钻力节点上性能已经媲美双台的国际主流,也就是英伟达的 gpu 基群长血液处理场景的部成本降低百分之五十以上,他在所有的情况下做了全球的成绩,甚至超过了很多朋 美国闭月模型啊,所以它是一个好用的,而且是开源的,还是国产的,在国产的芯片上跑出最好成绩的这样一个模型。 好吧,简单跟大家说一下啊,你将智普视为我们大模型的对外的一个代表,认为它呢定价是前沿领先的一个信号啊,它提供实时的市场初清的信号 给所有的大模型的持有者,认为这个会影响了更多大模型的发展。我觉得还是很有意思的好不好啊,今天就到这了啊,有很多朋友说,老张,你的那个会员视频压中了很多的热点啊。对,是的,这样的话可以看我们的小程序啊,奥德豆豆与瑞克。老张科普课搜这个就能看啊。咱们的年度会员现在这个 原价幺六九九,现在幺四九九的补贴平台补贴的还有几个名额要,要的话赶紧啊,咱们自己搞的,我们是月度会员,咱们是优惠啊,优惠会员咱们是幺幺九啊, 原价幺九九的,这个是到三月十五号才截止的,月度会员和年度会员就是一个时间的不同啊,其他都一样。月度会员呢,是一个月十到十五个会 员视频啊,然后三二两到三场的会员直播啊,年度会员是一个月一年一百八十个会员视频是吧。呃,这个三十二场以上的会员直播,如果需要可以赶紧下单。好,今天就到这,我是瑞克老张,关注我带大家看中国科技的高度和温度,我们下期拜拜。
428瑞克老张有话说 00:33查看AI文稿AI文稿
00:33查看AI文稿AI文稿朋友们,智普青研正式上线学习搭子功能,随时随地开启学习之旅。学习搭子是智普青研全新打造的 ai 学习伙伴,他能一键将把海量资料变成直观的可识画知识地图,还融入趣味交互设计, 还打造了学、练、册一体化的闭环学习模式,加上 ai 助教,二十四小时随时答疑解惑,带你告别无效统计,实现深度高效的学习智能目标拆解,通过 ai 总结,助力让学习更高效。
1736氪AI测评 00:50查看AI文稿AI文稿
00:50查看AI文稿AI文稿大家好,今天给大家聊一个最近在 ai 圈彻底架场的模型,巨普及。 em 五,也就是之前匿名爆火的 pony alpha, 它总参数高达七四四 b, 实际激活仅四零 b, 却做到了超强向下文,超强推理和顶尖代码能力 接近国际一线大模型水平。二十万字超强向下文能轻松处理文档代码,多轮逻辑推理, 不管是个人学习还是企业开发都非常实用。从匿名内测到政系官宣, g e m 五用实力证明了国产大模型的硬核竞争力。如果你关注 ai 编程技能题或是高效工具, 这波绝对值得重点关注,国产大模型正在快速崛起,未来可期!
0山海遇 01:47查看AI文稿AI文稿
01:47查看AI文稿AI文稿智普和 mini max 今天继续暴涨,从过年前到现在翻倍都多了。我前几天做视频说说这个事,绝对是有基本面支撑的。这俩年前发布的新模型,在编程和智能体上大傻特傻啊,太惨爆了。 token 的 消耗量说明了一切。这俩全都杀进了全球前十五 啊。有网友总结是顶级模型百分之九十的水平只收百分之十的费用。你这不是要砸老美那几家大厂的饭碗吗?你这么玩,那皇冠上最后的明珠还能保住吗? 啊。最近两三个月 ai 大 模型给各行各业带来翻天覆地的影响,编程啊,软件啊,电影啊这些行当日子都不好过,过年还刷到各地都在推艺人公司啊。感谢 open cloud 这些超级 ai agent 啊,让艺人公司跑得飞起来。 所以前几天有朋友问说,这么高将来还有工作岗位吗?那孩子应该学点什么呢?这个打不过就加入呗,做点跟 ai 相关的工作啊,甭管是擅长使用 ai 工具,还是吃 ai 的 信息差。 去年教人怎么用拆它 gpt 的 居然都能迈克发财啊。不过大魔星进步实在太快了,前几个月刚花钱买了 jimmy, nike 的 年费会员,眼见这几个月就要被豆包和 kimi 他 们超过了 啊。扯远了,刚才我几个 ai 相关的帖子被大模型公司的公关们刷屏了。当然是善意刷屏啊,做做甲方的软广啊,估计是有市值管理的需求。准备备战下周了。咱就说,哎,你这个刷评论区的效果很一般 啊,你要不你们就直接投商单给我啊,让我帮你们吹一气价格公道,童叟无欺,效果绝对比刷评论区好。
1924桃小仙的碎碎念 03:13查看AI文稿AI文稿
03:13查看AI文稿AI文稿智普 ai 就 要冲刺港股 ai 大 模型低谷了,作为独立通用大模型的龙头,又是最近 ai 赛道最重磅的 ipo 了,那今天就要好好看一下它的技术硬实力,财务风险等等都要扒清,接上招股数据啊。募资是四十三点四八亿港元,总市值五百一十一点五五亿, 少见的呢是中金大哥,采用十八 c 的 规则,最高回拨百分之二十,最关键的是基石投资者占比高达百分之六十八点六三,这里面有谁呢?有北京国资委,泰康人寿、 广发基金这些一众大佬,相当于长线大资金,给你直接兜了快七成的基石啊,这个基石级别在近期的港股 ipo 里面算是顶流了。可能还有人不太了解这个智普到底是干什么的, 我先简单的说一下背景,二零一九年是由清华团队成立的,从二一年到现在累计是融了八轮八十三点六十亿啊,里面有谁呢?红杉,高领、腾讯这些头部的资本都在里面。二五年 b 六轮融资之后,估值就到了两百四十三亿了,比首轮翻了六十三倍,资本认可度是肯定。 再说说它的硬实力是在哪里啊?它的旗舰机座模型 g l m 三千五百五十亿,参数还是开源的,二五年七月的十二项行业精准测试里面啊,全球第三,中国第一啊,开源模型里面也是稳坐中国第一, 而且它的幻觉率是全球第二低,中国最低幻觉率是什么?大家可以自行科普一下,这个在大模型里面绝对是核心竞争力。要知道大家都不想跟 ai 说一些很傻的话, 其实除了基础模型,还有多模态,还有 ai 准,都很能打,有中国首个支持汉日生成的纹身图模型,还拿过行业精准测试的最高分。这个模型呢,能生成四 k 高清视频,还有智能体,智 能自己帮你定 wifi 啊,定酒店。在斯坦福的 a 和 b 测试里面啊,它比 g、 t、 p、 four 的 某些表现还要更好,任务完成率是提高了百分之二十有多。那市场地位也说一下,按二零二四年的收入来算呢,是全国最大的独立通用大模型开发商,所有的开发商里面是排名第二的,市场份额是百分之六点六。 截至二五年的上半年,服务了八千多家机构客户,赋能了八十多万设备,行业渗透率是没得说。接下来就是大家最关心的财务数据啊,老实说,有亮点也有风险,亮点无疑就是收入增长极快啊, 二二年到二四年,收入从五千七百四十一万涨到了三点一亿,复合增长率是百分之一百三十三点三,二五年上半年更是冲到一点九亿,同比增长百分之三百二十五,毛利也是跟着翻倍涨。但是风险也很明显, 就一个字为盈利。而且亏损还在扩大,二十年的净亏损达到二十九点六亿,二五年上半年净亏损二十三点六亿,同比还涨了百分之九十点八。 现金流方面,虽然现金的储备有二十五点八,但是流动性负债高达一百一十七点二亿,流动负债净额有八十二点八亿,目前就是处在一个高度依赖融资输血的过程中,在不同的小细节,他的收入百分之八十四点五都是来自于本地化客户呢,主要是集中在互联网科技领域,占比于 其他的就是公共服务啊,电信这些领域。最后总结一下,智普 ai 明日里面已经带着 ai 了,亮点也很突出,精华技术背景硬,行业地位也领先, 即使阵容又豪华, ai 赛道前景又广,但是风险不能忽视,亏损是扩大的,负债是高的,当前估值是不低的。那大家是如何看待智普 ai 这个标的呢?把它作为港股 ai 大 模型第一股,会不会有点过分?这样做好了。
143大师兄复盘 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿每年过年的时候就给我们一个拜年的新年礼物,去年是 dipstick, 然后今年呢?就是 glm 五,这一次他是我就是由他是属于一个集团化的,前面有视觉,中间有工程,最后的基座是稳的。那这些 全部的整合在一起以后呢?他又用开源的方式,你可以去使用他,他可以一直不断的增加他的推理跟工程化的能力。税,开源推理跟工程化都会使着他的学习速度跟自我修复、自我改正的速度会越来越快,越来越快。
225台海网 01:59查看AI文稿AI文稿
01:59查看AI文稿AI文稿别再以为中国 ai 大 模型公司只是玩炒作,没干货了,智普即将冲刺全球大模型第一股,这是荣耀,也是无奈。所以长期关注智普的 ai 创业者,很明白智普当年的困难。我们今天来捋一捋智普现在在做什么?为什么非得上市? 大模型开发就像是用信用卡刷爆去购物,每笔短期内能看到更多的是消费,而非投资。 我们先讲业务,智普有两大主营路径,云端 api 按量收费加本地部署企业级解决方案。 智普出身就是清华国家队,现在正在往云端可规模化收费转型。赵虎说显示,二零二五年上半年云端占比占到百分之十五,是为给资本市场更强的未来想象空间。从服务政起的 qg qb 公司逐渐向 c 端发力,毛利更高,平台化的拓展性更强, 包括打造了欧洲 g m 这个世界上第一个通用手机入手。再看能力,他的模型 g m 四点六编程能力在各类评测中世界领先,今年十一月日均四点二万亿透,更消耗量服务一万两千家机构,支持八千万的设备,这说明他是真有用户,不是概念。 现在资金就扎心了,虽然三年来营收从五千七百四十万爬升到了二五年上半年的营收约两亿,但研发、销售、管理加起来亏损约二十三亿, 账上现金只有二十五亿,即使理财和未动用融资在内,储备有八十九个亿,仍就是快烧不动钱的状态了。这就是他为什么要上市,不是为了荣耀,是为了融资补习。 智普当前过了港股的上市,临讯二五年也在 a 股备案了 ipo, 辅导 a 加 h 双轨上市的可能性很大,活下去才有发展的希望。对我们这些 ai 创业者来说,尤其是在 ai 创业融资难的时候,千万别只看吹风,要盯现金消耗速度和收入的可持续性。 普通人看大户型公司也别只看热度,要看钱是不是烧在刀刃上。你觉得智普如果上市,后续发展会如何?评论区聊一聊。
13大卫聊商业财经 02:46查看AI文稿AI文稿
02:46查看AI文稿AI文稿二零二六,中国顶级 ai 模型 top 第五名,质朴青年,大模型届的国家队学霸,刚上市的顶级教辅,二零二六年初正式登陆港交所, 市值稳居千亿俱乐部独门绝技 glm 五架构横空出世,在芯片、算法协同上走出了中国原创路径。 他是 ai 届的清华系老教授,出身名门,自带学术光环。在大家还在卷聊天时,他已经在搞超远距离的认知进化。 如果你需要一份严谨到能写进论文的报告,他就是那个永远不会让你失望的质酷级外挂。第四名,通一千,问大模型界的全能大管家,阿里生态的扫地僧,深度嵌入阿里云百万企业 quan 三 max, 每日处理请求抄摆一次,占据中国开源大模型下载量的半壁江山。他是 ai 界的六边形战士, 就像是你身边那个虽然低调但什么都能搞定的阿里大厨。从写代码到分析财报,从端测设备到云端算力,他主打一个全站接管。他是中国 a 二胜肽的底座,是无数中小企业翻身的数字脚手架。 第三名,月之暗面 pimi, 打工人的数字速效就心软。深读狂魔,二零二六年初完成 c 轮融资,估值突破三百亿人民币,核心很合适,上下文长度卷到一级,能一口气读完一座图书馆的资料。他是 ai 界的过目不忘张松。在无数职场人和学生的眼中, pimi 就是 那个能帮你读几百个文档的最强带薪墨玉大字。他不跟你整虚的。主打一个长河碗, 是生产力赛道里最令人放心的数字脑容量扩容插件。第二名,豆包, ai 界的抖音,承包十四亿人的国民级嘴替月活用户,稳居中国第一,是唯一进入一级俱乐部的 ai 应用。背靠字节跳动,无缝衔接抖音, 统治年轻人社交圈。他是 ai 界的社交天花板。如果说别的模型是在做试验,豆包就是在过日子。他比你妈还懂你的情绪,比闺蜜还会找餐厅。他成功将 ai 从高大上的实验室带到了菜市场和办公室, 是真正意义上的全民数字偶像。第一名 d c, ai 界的蜜雪冰城,横扫全球的效率杀手, 估值突破万亿人民币,成为仅次于字节跳动的中国第二大独角兽。 v 四系列以十分之一的成本跑赢了 g p t 五,引发硅谷集体破防。他是当之无愧的国货之光。他就像是那种家里没矿全靠自己勤工俭学,结果在期末考试把一群富家子弟全虐了的逆天考神。 他用极致的暴力美学证明了在中国工程师面前,算力强不是强,是通往神坛的垫脚石。他是中国科技出海的核武级封面,是全世界 d i。 玩家不得不服的东方神秘力量。
18知识产权资讯 05:10查看AI文稿AI文稿
05:10查看AI文稿AI文稿欢迎收听盘源播客,有趣有料,观点不设限,思想不打烊!咱们今天的话题是港股市场上那些独立的 ai 大 模型公司 在技术上面取得突破之后的快速崛起啊,嗯,以及他们在现在这种算力、资金和生态都被几大巨头牢牢把控住的情况下,究竟面临着什么样的现实的难题,以及未来可能会有什么样的机会?对,这个话题最近确实很火,那我们就直接开始今天的讨论吧。咱们先来看第一个啊,就是港股 ai 大 模型板块的市场表现。 最近啊,这个智普和 mini max 为什么能够在整个科技股都下跌的情况下,还能走出这么独立的这么强劲的行情呢?这就要说到马年的首个交易日那天,恒生科技指数是大跌了百分之二点九一,同时呢,像百度和阿里这样的一些科技巨头,它们都下跌得超过了百分之五。 但是呢,智普它是单日暴涨百分之四十二点七二,市值一下子就突破了三千两百三十二亿港元。然后 mini max 也上涨了百分之十四点五二,市值也占上了三千零四十二亿港元。就这两家公司,它们在短短的一个多月的时间里面,市值都是翻了四倍多呀, 甚至直接就超过了京东和携程,成为了港股里面最耀眼的明星。哇,这涨幅真的是太惊人了。对,那背后到底是什么原因让这两家公司能够获得资本如此的青睐?原因很简单,就是他们的新一代模型表现确实非常亮眼,智普的 glm 五刷新了国产模型在全球的排名, 甚至它的这个编程套餐涨价百分之三十之后依然是供不应求。然后 mini max 的 m 二点五,它是专注在智能体的场景,并且它的海外的收入已经超过了七成。 对,所以就说这波上涨,其实不仅仅是因为技术的突破,也是市场对于整个 ai 行业前景非常乐观的预期。说到技术突破啊,我们再来说说啊,就是这两家公司,他们现在的这个业绩和估值到底是一个什么样的情况? 他们的盈利情况能不能够支撑他们现在这么高的市值呢?从数据来看啊,智普从二零二二年到二零二五年上半年,它的累计亏损是一点九一亿元,但是它的净亏损依然有二十三点五亿元, 就他的研发投入是营收的十几倍。 mini max 更夸张,二零二五年前三季度他的收入是五千三百四十四万美元,但是他的净亏损是五点一二亿美元, 相当于他每赚一块钱就要亏十块钱。听起来感觉他们的盈利压力还是挺大的,那他们现在的这个估值是不是已经高到有点离谱了?没错没错,他们两家公司的市销率都已经超过了七百多倍, 但是 openai 也才六十五倍,就这个估值已经严重透支了他们未来的增长。所以能不能够通过业绩来消化这个估值,其实是市场最大的一个疑问。 那紧接着我们就要讲的就是独立的大魔性公司,他们面临的三大难题啊,和大厂相比,他们到底在哪些方面是处于劣势的?嗯,首先就是算力和资金 这两个方面,他们到底差在哪里?最大的问题就是算力的采购和资金的投入。就比如像智普,他有七成的研发费用都是花在算力上。对,即使他通过 ipo 募了很多钱,他的现金流也只能够撑一年半到两年。 但是像那些大厂,字节跳动、阿里、腾讯,他们都是有自己的算力集群,所以他们的成本是非常低的,而且他们的现金流非常的稳定, 所以他们在这个长跑当中更不容易出错。除了这个生态布局上的差距,对于这些独立的大模型公司来讲,会带来哪些具体的困难?主要是场景落地和用户获取。就是大厂它是已经形成了云加模型加场景的完整闭环, 它可以通过微信、抖音或者说阿里云这些入口,直接把 ai 服务送到大量的用户面前,而且用户都不用去下载一个新的 a p p, 它就可以体验到这个服务。 但独立的公司它基本上只能靠 a p i 去吸引客户,所以它的获客成本就很高,然后用户的粘性也不强,再加上现在大厂又在打价格战,那独立公司的这个盈利空间就越来越小了。我明白了,那技术迭代这个事情,对于这些独立的公司来讲又有哪些具体的压力?这个压力也不小。 虽然说有一些独立的公司在编程或者说智能体这些非常细分的领域里面是有一些技术优势的,但是大厂他毕竟人多资源多,所以他追赶的速度也是很快的。再加上现在开源模型发展又这么猛,那独立公司想要一直保持领先是非常难的,我们最后来看一下这个行业未来的格局会怎么发展, 就是大厂和这些独立的大模型公司,他们会各自占据什么样的位置。其实在接下来的三到五年,中国的这个大模型市场很有可能会出现一个分层的情况,就是大厂会用他们强大的算力、资金和生态去主导通用模型和主流的应用场景, 然后那些有技术特长的独立公司,他们如果可以抓住大厂还没有那么强的一些领域,比如说政企、智能体,海外的一些小众的解决方案,他们还是有机会活得很好的,成为这个生态里面不可缺少的一部分。 所以说那些既没有什么特别的技术,又没有什么钱的通用模型公司是不是就很危险了?对,很有可能会被市场慢慢的淘汰掉,因为未来的竞争一定是一个技术、资金、生态多维度的一个较量,只有那些可以把技术真正的变成产品,并且能够持续的赚钱的公司,才能够笑到最后。没错,我们今天其实就是帮大家梳理了一下 这个 ai 大 模型行业里面大厂和独立公司的优势和挑战。嗯,说白了,最后谁能够留下来,还是要看谁能够真正的做出成绩,实现盈利。好了,那就是这期播课的内容了,然后感谢大家的收听,咱们下期再见吧,拜拜。拜拜。
2盘圆科普




猜你喜欢
- 199小小
最新视频
- 15.5万茉莉bye