ai写prd skill是什么

粉丝5987获赞1.6万
相关视频
 13:51查看AI文稿AI文稿
13:51查看AI文稿AI文稿以前为了让 ai 写个符合格式的周报,我们恨不得要手写五百字的提示词,结果它还能给你瞎编。现在呢,你只需要挂载一个封装好的 agent skill, 效率直接提升十倍不止。 很多人还在傻傻地跟 ai 聊天,但真正的高手早就开始配置 ai 了,从聊天的伴侣到干活的牛马,中间到底差了什么呢?其实就是我们今天要讲的核心, agent skills。 我 把视频内容分为了四个部分。首先第一部分,我们会过一遍交互方式的眼镜, 搞懂了这个源头,你对 ai 的 理解就不只是停留在表面了。接着第二部分,我们就直奔主题, agent skills 到底是什么,我会把它拆开给你看,就跟我们平时用一个万能工具包差不多。 然后第三部分,顺理成章的我们看看 skills 的 工作流程。也就是说,当 ai 真正接到你的任务时,他脑子里是怎么思考怎么挑工具,最后怎么把活干完的。 这个流程你看懂了以后,你调 bug 或者是看系统日制,一眼就能够看出问题出在哪里。最后这一部分绝对是面试和实战中最容易被问到,也是最容易踩坑的地方。我会把 m c p, workflow 这些词拿出来对比一下, 理清了这些啊,以后,再看到外面出了什么新的框架或者是什么协议啊,我们都能一眼看透本质,做到心里有底。好话不多说,我们直接进入第一部分。其实呢,要搞懂 age 呢,为什么能干那么多复杂的活?我们得先往回看一眼,理一理我们是怎么一步一步把大模型调教成现在这样的 这个交互方式的眼镜啊,其实就是一个从结果经常失控到效率高度固化的过程。你看,最开始也就是 level 一 的时候,大家都在研究 prompt 提示词最左边这个图啊,普通的 prompt, 就 像是你随口跟 ai 说了一句,帮我写个简历,结果呢,它可能洋洋洒洒的给你写了一堆的废话,排版也是乱七八糟,重点很明显就是结果根本不可控,对吧? 为了解决这个呢,我们摸索出了右边这种结构化 prompt, 给它设定具体的 role 角色, task 任务,还有 rules 规则。那就像是你平时点外卖,以前你只说弄点吃的,现在备注上写得清清楚楚,扫蜡不放香菜,加个煎蛋, 加上这种结构化的约束之后啊, ai 给出的东西就规矩多了,那马上我们就发现了新的问题,于是进化到了 level 二 come on 的 命令。你看,结构化的提示词虽然好用,但是什么呢?但是它太长了对吧? 我们平时干活总不能每次写需要写简历的时候都去复制粘贴,或者是手敲几百字的要求进去,那也太反人类了。所以我们解决方案是什么? 就是把那些长篇大论的好用的提置词直接封装成一个文件以后再用的时候啊,只需要敲一个快捷指令,比如说图上的,嗯,反斜杠 resume, 瞬间就能调出那一整套复杂的规则。其实呢,这一步就是把我们摸索出来的最佳实践,变成了可以随时调用的快捷键,把效率给固化下来了。不过啊,指令虽然快捷,但如果是长篇大论的聊呢, 这就碰到了 level 三的痛点,所以呢,就引出了 system prompt, 也就是系统提示词。你看平时聊天聊得一长,上下文一多, ai 就 特别容易断篇,把你一开始提的规则全给忘了。 这时候怎么办?我们就得用点 cursor rules, 或者是嗯 cloud, 点 md 这样的文件。你看右边有个架构图, system prompt 永远在最上面,它享有一票否决的最高优先级。不管下面这个灰色的那个用户输入框里怎么瞎聊, ai 脑子里那根弦总是绷紧的,因为它知道头上总有一个系统级的规则在压制着它。 然后我们顺着往下走,等业务再复杂一点呢,我们就来到了 level 四 mate data 原数据阶段。 大家想象一个场景,如果我们的 ai 助手要处理一百种不同的任务,有简历,有周报,有邮件,我们总不能把这一百个场景的背景资料全都塞进他的脑子里吧?那不仅模型上下文称报了,每天消耗 token 的 钱我们也烧不起啊,对吧? 所以你看中间这一个像安检门一样的闸机。我们的做法是啊,给每个文件贴上一个智能标签,贴上一个 tag, 我们只把少量的 mate data 发给模型模型一看,哦,你现在要写简历是吧?行,那我就只把那个简历那个文件给拽过来看看。这就实现了万虚加载。对于我们做这一行的人来说,意味着你系统的扩展能力一下子就被彻底打开了,再也不用抠抠搜搜的去算 toon 上线了。 最后就到了现在的 level 五, references and scripts 参考资料与脚本在这个阶段, ai 的 能力不再是一把抓,而是通过渐进式批录来扩展的。什么意思呢?就是他知道怎么去一步步找答案。 你看图上这个结构,一边是 references 或遇到不懂的,他可以去按需加载产品手册啦,还可以读工程文档。另一边就更厉害了,是 scripts。 ai 现在不但知道你要干什么,它还能直接调用右边这些 python 脚本去帮你生成 pdf, 去跑数据分析。它不仅能动嘴,还能真刀真枪地动手了。 说到这里,你可能发现了,从最开始的一句闲聊,到现在能挂载标签,能跑代码大模型,越来越像一个带着万能工具箱的资深员工了。但是这个工具箱里到底装的是什么呢?它是怎么运转的?这就来到我们第二章节, agent skills 的 本质与构成。 首先,什么是 agent skills? 官方定义叫它被封装的动态能力单元,听着有点绕,对吧?其实说白了,一个 skill 就 像是你手机里的一个独立 app, 或者是一个打包好的标准工作包。 你看,这里有个蓝色的文件夹,比如我们管它叫 resume writer, 简历代写员,它不是一个光秃秃的一句提示词,把它拆开看,里面其实装了四样东西。第一样是最左边的 skill 点 md, 也就是入口,或者是系统提示词。 这就像是技能的岗位说明书,它提前规定好了你现在的角色啊,是一个资深 hr, 你 要按照 star 法则来写,语气要专业。 第二个呢,是 mate data 路由标签,这个特别关键,你可以把它当成这个技能包的门牌号,或者是自我介绍的标签。你想啊,系统里面如果有几十个技能, ai 怎么知道什么时候该掉哪个呢?掉的就是这个。 比如说标签上写着简历、求职排版,那用户一提到找工作,系统立刻就能把它揪出来。第三个是 references 数据素材,这就相当于发给 ai 的 参考资料,比如说你们公司的业务白皮书,或者是标准的简历模板文件。 ai 干活之前,可以先翻一翻这些资料,心里就会有数了,不会胡编乱造。最后一个最右边这个 script 执行工具,这就是发给 ai 的 干活工具箱。比如说给他配一个 python 脚本, 他能上网搜一下最新的行业动态,或者是能直接把写好的文本转成一个漂亮的 pdf。 所以你看最底下这个公式就很直观了, bill 就 等于岗位说明书,加上门牌号标签,加上参考资料库,再加一个干活工具箱, 把它们给打包在一起,就成了一个能够随时能用的独立技能。对于我们平时做业务开发来说,这意味着你系统的能力可以高度附用。你想加一个新功能,不用去改底层的核心代码,直接塞个新的技能文件夹进去就可以了,非常清爽。 好,那么既然技能包已经打包好了,真正用起来的时候,系统是怎么运转的呢?这就到了我们第三部分 skills 的 工作流程, 我们来看一下这个流程图,其实弄懂了这五个步骤以后,不管你是用什么炫酷的 agent 的 框架,你脑子里的主线都是清晰的,排查 bug 也特别快。你看最左边第一步,用户发了一句话帮我写简历, 这时候呢,你看第二步,这个框,我们的客户端 clients 其实并没有把用户的这一句大白话,连同那一堆复杂的工具啊,长篇大论的提示词,一股脑的全扔给大模型,没那么傻,全扔过去,太费 token 了吧,太费钱了。 他其实只是把所有 scale 的 matter data, 也就是我们刚才说的门牌号标签收集起来,发给模型去挑。那就好比老板拿到一个新项目,他不会把你们公司几百号人的详细简历全都看一遍吧,他只会看大家挂在脑门上的技能标签。 接着呢,到第三步, model, 也就是大模型,一看这些标签,秒懂,哦,你是要写简历是吧?这个活呢,得归那个叫做 resume writer 的 技能包来管。于是模型就把这个决定告诉了客户端。 然后第四步,客户端一听好,马上去把 resume 这个文件夹给翻出来,把里面详细的 skill 点 md, 也就是岗位说明书给加载进来。直到这一步,这个简历代写员的这个角色啊,才被真正的激活。 最后一步, execute ai 开始真正干活了,遇到不懂的,去读取刚才说的那个参考资料 references, 遇到需要动手操作的, 去运行代码脚本 script, 一 道行云流水的动作搞完,最后把一份排版精美的简历结果 result 拍在用户面前。所以你看整个流程,其实特别符合我们的直觉。先看标签分发任务, 备上号了,再去加载详细说明书,最后拿工具干活。这是一个非常优雅的按需加载的过程。好,我们趁热打铁,直接进入最关键的第四部分,核心概念变期。 刚才我们看完了技能是怎么一步步被调用的,这时候你可能要问了,他现在外面满天飞的新词,什么 m c p 啦, workflow 啦,那么跟我们今天讲的 skill 到底是个什么关系,是不是一回事儿?其实真不是,这一部分我们必须要理清,不然以后看技术文档或者是做技术选型的时候特别容易蒙。 我们先来看第一组对比 deal 和 mcp, 这两最近经常被放在一起讨论,我给他们的比喻是大脑与手的区别。你看左边这个 mcp 听得很多,对吧? 本质上是什么呢?它就是一套标准化的工具接口,相当于你给大模型配了一双特别灵活的手,或者是丢给他一个极其全面的工具箱。 first, 有 了它,模型能去查数据,能去读本地文件了。 但是这里有个什么问题呢?他手里有工具,但是他未必有经验。这就好比你给我发了一套米其林大厨的定制的刀具,但是我本人根本就不会做饭啊,那我肯定是做不出法式大餐的呀。这时候呢,就需要右边的 agent skill 了。 skill 相当于什么呢?相当于这一本厚厚的操作指南和行业经验,它规定了遇到什么情况该用拿把刀切多厚,也就是何时使用工具以及如何组合工具。 所以你看 m c p 解决了能不能干的连接问题,而 skill 解决的是干得好不好的经验问题。大脑和手,它们是配合的关系,不是替代的关系。 好,那我们再来看第二组容易混淆的 skill 和 workflow 工作流。很多人都喜欢拿 n 八 n define 或者是扣子里面那种连线工作流来做 agent。 你 看左边这个图, block flow 就 像是铺好的铁轨,它是固定编排的,也就是说第一步干什么,第二步干什么,遇到 a 走上面,遇到 b 走下面,这全是你在这个系统设计的时候啊,人为把它锁死的,哪怕跑的过程中呢,遇到点没见过的新情况,它也只能死板的按着这个轨道走, 很容易卡壳报错。但是右边这个 agent skill 就 不一样了,它完全是由模型驱动的,你看它像不像一个神经元的网络?它的执行路径啊,不是写死的,而是 ai 每走一步,看看周围的情况, 及时决定下一步该干嘛。打个比方, walk flow 就 像是你坐地铁,路线早就定好了,到哪站停都是定好的。而用 skill agent 就 像是你打了个网约车,司机知道你的终点,但是前面如果遇到堵车了,它自己会灵活地绕路。 对于我们做架构设计的人来说,这意味着你的系统真正具备了处理复杂、未知异常的能力,不再是那种一碰就碎的流水线了。聊到这里,其实最让人迷糊的概念我们就拆解完了。现在我们把视角拉高,来看一看这个金字塔。这就是我们今天讲的整个架构眼镜的浓缩, 从最底下的 level 一 三八八的提示词,到 level 二用快捷命令固化效率,再到 level 三拿系统提示词去压制聊天的遗忘。接着往上走 level 四,我们引入了原数据 mate data, 实现了给各种文件贴上标签,按需加载。 最后终于到了金字塔间的 level 五,也就是带着参考资料和执行脚本的完整的 agent skill。 你看右边这个箭头,随着我们一步步往上搭,大模型的智能化程度啊,还有它能够处理业务的复杂度是直线上升的。所以最后我们来总结一下, 其实呢,今天我们见证的是人机交互方式的一个根本性的质变。以前我们总觉得用 ai 嘛,不就是在那个聊天框,也就是左边这个气泡里面跟他聊天说话吗? 其实到了 agent skills 这一步啊,对于我们做这一行的人来说,意味着我们不再仅仅是向 ai 发送文字,而是在配置 ai 的 专业能力。你看,我们把提示词,公司的业务数据还有执行代码,像拼乐高一样封装成了一个一个的 skill, 就是 右边这个齿轮。 通过这种配置,我们硬生生的把一个通用的只会讲车轱辘话的聊天伴侣,变成了一个具备你们公司特定领域经验的专家代理,这才是真正的 agent 时代的做事方式。好,那今天关于 agent skill 的 深度拆解就先聊到这里,我们下期再见。
360AI大模型学习 00:56查看AI文稿AI文稿
00:56查看AI文稿AI文稿推荐六个我一定会用的 skill, 都是我一直在用并研究过的。第一个 skill creator, 这是所有 skill 的 鼻祖,官方认证的,直接帮你把跑通的工作流转化成独一无二的 skill。 自动分析工作流程,提取可附用模式,生成标准 skill 文档,一键安装,立即可用这个 skill 我是 认真读完所有文档的,绝对靠谱。第二个, document skills, 也是官方出品, ai 操作文档的天花板,自动填表,写 document, 批量处理 excel 数据,一键生成 ppt 演示,智能阅读 pdf 文档。 装上它,你的 ai 交互能力直接提升一大截。第三个, find skill, 能从几万个 skill 中精准找到适合你的智能匹配需求。场景筛选高评分 skill, 对 比相似方案,推荐最佳选择。做复杂的事,先先呼叫他,帮你找找,说不定有惊喜。第四个, frontend design, 官方出品 前端美化神器,专业级 ui 设计,一键美化界面响应式布局,避免 ai 审美疲劳。安装上你的网页,前端直接起飞。第五个, code simplifier, 使三代码终结者自动简化复杂逻辑,消除笼鱼代码,优化代码结构,提升可读性。安装上它, ai 再也不会给你写使三代码了。 第六个, graph loop ai, 无限打工模式,自动循环执行任务,无限搜索资料,持续迭代优化,直到任务完成。但记得用上包月编程套餐,不然费用可能顶不住。这六个 skill 我 每天都在用,关注大古,分享更多 ai 技巧!
 16:06查看AI文稿AI文稿
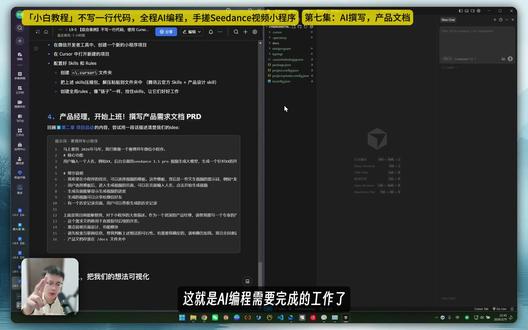
16:06查看AI文稿AI文稿那接下来咱们就进入开发的下一个阶段,我们需要让咱们的产品经理开始上班了,也就是咱们需要去调用我们之前自定义的产品经理 skill, 就是 product manager 这个 skill 去帮助我们把咱们已有的想法变成一个可执行的产品需求文档 prd。 好, 咱们一起来看一下提示词,这个提示词它主要的作用其实就是把我们的想法和我们现在已有的一些考虑给描述清楚。 比如背景,马上要到马年了,我们想做一个赛博拜年的微信小程序,那它的核心功能就是用户去输入一个人名,比如某某后台就会调用 cds 一 点五 pro 这个视频生成大模型, 生成一个专门针对某某的拜年短视频,那这个短视频我们还可以去分享给好友使用。那接下来还有一些细节的说明,比如首先我希望在这个小程序的首页可以选择视频的模板, 也就是说你不可能只生成一种类型的视频,那这里面每一个模板就好像一个卡片一样。比如有的模板他是龙马精神,那有的模板可能是马到成功选择模板后就会进入生成视频的页面,那你再在这个页面里面去输入人名, 那如果我们选择的是马到成功生成的这个视频,那就是祝王总您在新的一年马到成功生成一个类似的短视频,而且最好因为视频生成我们都知道他是比较慢的,那我们希望这整个页面能够显示视频生成的一个进度,我们希望咱们生成的视频可以分享给微信好友, 而且有一个历史的记录页面,那用户就可以查看他生成的历史记录。好,那上面这些所有的是我目前能够想到的,对于咱们这个赛博半年小程序的一个大致的描述吧。 好,那接下来还有我们要求他作为一个资深的产品经理,帮我写一个专业的产品设计文档,这个文档将用于直接指导后续的开发,而且要重点说明页面设计还有功能模块。因为接下来下一步我们还需要用这个文档去生成 ui 设计, 非常明确的指明你这个小程序里边大概有多少个页面,具体的功能模块大概都有哪些。同时这一个也很关键,我们希望 ai 能先帮我们去解锁一下信息,判断我们上述的想法是不是可行。 例如这里边我就有一个比较担心的,就是这个视频能不能很好的在微信小程序里边去分享。那后续呢?我们还可以跟 ai 在 讨论,如果有需要我们确定的, 请明确的告知我,我完全同意后才能开始在执行。而且我们告诉他这些产品文档请帮我放在 docs 文件夹中, 大家可以看到,那因为我们有了这个 product manager skill 咱们的提示词,现在他做的主要的工作就是把我们的需求去说清楚。 那如果在我们之前没有使用到 skills 的 时候,我们不仅需要说明需求,那我们还需要指明当前的角色,比如很多提示词的模板,可能还需要说明它具有的技能,工作流程, 总之很长的一段提示词才能够发挥比较好的效果。那现在有了之后,我们就需要把这个简短的提示词给它复制到科室的界面里边再去执行就 ok 了。同时这里的路径我们记得把它修改成科室里面的路径, 用 app, 然后输入 docs 这个路径好,修改好后我们就点击发送,它就开始帮我们 去纂写这个产品文档了。好,那当然这里边最好不要一步到位,因为里面还有一些具体的细节啊,我们可能没有做到完全的清楚,例如这个视频他在小程序里边究竟该怎么分享,我们可以先跟 ai 再讨论一下,确定一下具体的方案后呢, 再让他帮我们去纂写产品文档,那这其实就是一个类似于头脑风暴,或者说拍板讨论确定方案的过程。这个概念呢,我觉得还是非常关键的, 大家在自己在进行 ai 编程项目的时候,也一定要记得一定要花比较多的精力在和 ai 讨论清楚 具体执行的方案。这个也是目前 ai 编程在工程上应用,就是正儿八经使用的时候一种比较流行的范式, 叫做规范驱动开发,核心理念就是写具体的代码和文档前,先确定好,讨论好方案。好,我们具体来看它,因为网络解锁服务暂不可用,它无法直接看到 cds 一 点五 pro 这个豆包视频生成模型的具体信息。 那这个很简单啊,火山引擎它的官网肯定都会有相关的官方文档,我们只需要把那个官方文档的链接粘贴到这个对话框里,它就可以很好的知道比如这个 cds 点五 pro 这个模型,它的接口应该如何去调用,对吧?它还帮我们分析了 核心功能的可行性。分析,那首先核心的难点就是视频生成,例如第一个耗时问题就是视频呢?通常需要十秒钟或者数分钟,那就远远超过了 微信小程序的默认的超时时间,就是三秒。还有他给我们提供的解决方案就是采用一种异步任务的模式。 好,那这个异步任务我们可以解释一下,其实大多数的视频生成或者图片生成的模型都采用这种异步模式,它的模型调用其实是有两步走的。那第一步就是譬如我们通过 a p i 直接去调用这个豆包的 c 点四点五 pro 大 模型, 那它返回的其实是一个类似于任务 id, 一 般叫做 task id, 那 这个 id 的 主要的作用就是用在第二步上,还是通过 api 去传输这个 task id 来判断当前任务的一个状态,比如状态可能是正在生成,可能是已经结束了。 如果你不想去看这个 cds 一 点五 pro, 比如豆包大模型,它官方的文档还是和刚才的思路一样,我们找到这个链接提供给他,那么 ai 就 能够很好的去理解现在一些主流的视频生成模型,两步走,也就是异步任务模式, 那还有相应的视频的模板机制也是可行的,因为他说了模板本质上就是一些提示词的模板,例如对于不同视频的风格描述,譬如赛博朋克风格,一只机械马,对吧?在霓虹东街道上奔跑,那这是一种风格。 还有视频的播放和存储,需要用到微信云的云存储,那这个也没问题,还有分享功能,他说微信小程序支持分享卡片给好友,但是因为视频文件比较大,通常的做法是分享一个小程序卡片,那好友点击这个卡片,他进入到小程序再去观看视频。 好,那这个方式其实我觉得是比较不错的,因为一方面好友可以看视频,那另一方面还能够起到一种小程序的裂变传播,那我们接下来就可以要求让 ai 帮我们用到这种方案。那接下来他还问我们一些待确认的事项, 比如关于模型的名称,那这一步我们应对措施很简单,我们找到豆包的 cds 一 点五 pro 的 官方文档链接粘贴给他,让他自己去看就好了。关于分享体验,那问我们是否接受这种卡片分享的方式,那肯定最好了。还有第三点,关于成本控制, 那因为一般这个视频生成的 api 的 价格都很高,而且并发量可能也不大,应该怎么去解决?那这个有一个很好的解决方式,我们可以把咱们自己的 小程序做成一个类似于视频生成的工具,用户在这里边去填写他自己的一个 c 带四点五 pro 的 api key, 就 通过咱们的这个小程序,他去调用自己在火山引擎下申请的豆包大模型的服务。好,那接下来我们就给 ai 来进行一定的回复。啊。 好,大家可以看到,那这个就是火山引擎它的视频生成相关的模型一个官方的文档了。 例如这里就写了最近几天特别火的这个 cds 二点零模型,它预计在二月二十四号左右开始能够通过 api 调用,那如果您现在学会了咱们这个视频所有的操作,在二月二十四号之后就可以开发一个基于 cds 二点零的模型了, 你需要做的可能只是把这个,例如有一个叫做 model 的 字段,把它给换成四点四二点零就 ok 了,就很方便。那我们可以简单的来看一下这个文档,我们只要关注一下刚才所说的两步走的过程,比如这里就写了视频的生成,它是一个一步过程,首先第一步 就是调用这个视频生成的接口,它会返回一个任务 id。 那 第二步呢?通过这个查询接口来轮询当前生成的一个状态,譬如每个五秒去调用这个 get 接口,同时传输这个任务 id 来看一看你这个任务它最终的状态。 当这个状态变成 succeed 的 时候,它可能就会返回一个 url, 就 可以通过这个 url 去下载最终生成的文件了,这就是一整个大概的调用过程。好, 那我们就把这个网址给复制一下,再粘贴到歌词里面。好,例如我来回复一下你的问题。首先第一,这是火山引擎对于 cds 一 点五 pro 模型的官方指导文档, 请阅读好,咱们就把刚才这个官方指导文档的链接给粘贴到这了。那第二,关于视频分享,我们就用分享小程序 卡片的方式。那第三就是关于成本控制,我希望的方案是用户有一个设置页面, 用户在里面可以填入自己的 cds 一 点五 pro 模型的 api key, 也就是说 用户使用的视频生成服务是自己的,但是是通过我们的小程序。好, 那这种方式就很好的帮我们去控制了成本,也就是说咱们最终做出来的小程序,它只是一个类似于一个工具,那如果后续你想把它变成一个更加商业化的小程序, 你可以再把这个包装一下,譬如用户去调用模型,只通过你自己的接口,但是每次去生成的时候需要消费一定的资源点, 那如果资源点不够了,你可以让用户去签到,或者说通过分享获得资源点,甚至是去付费,那这就是一个比较标准的 ai 相关的应用,它大致的一个商业流程, 那因为咱们是演示,我们就把它设置成,用户可以用自己的 api 可以 去调用。那这里就有一点需要注意一下, 因为申请 pic 属于一个比较复杂的操作,你可以在设置的地方给用户一个链接,跳转到火山引擎官方的申请页面。 好,也就是说用户点击这个链接,再根据火山引擎的官方指示,就可以很轻松的去申请一个 api key 了。 现在我们把回复的问题再重新发送给 ai, 让他来帮我们看一看具体的效果。那如果刚才的提示词写的比较快,你没有看清楚,我把它放大一下,您可以现在暂停来看一看咱们的回复。好,大家来看,那现在我们这个 prd 文档就已经生成好了, 好,它叫做马年赛博拜年小程序产品需求文档。首先是背景还有目标,这个咱们就先不看了,那它有一个核心策略是采用用户自带 key, 就是 荣耀 o n key 的 模式来降低运营成本,让用户可以用自己的火山引擎 a p i key 来进行生成, 那他基本上理解了咱们所要去创建的这个抢占运的目标。好,还有大致的一个业务流程, 我们可以点击 preview 来看一下。 ok, 这里的默认的格式就是他这个流程图的格式可能出错了,那我们可以把这个复制一下,然后告诉他默认格式出错,无法正确预览。好,那他一边修改这个流程图,咱们一边朝下看, 还帮我们设计好了大概有哪些页面。比如首先要有一个首页,这个首页可能会通过瀑布流或者网格去展示不同的视频模板, 那每个模板可能有相关的预览图,还有模板的名称,像龙马精神,还有马到成功。好,那相关的呢?我们还要有设置页, 那这个设置页就允许用户去输入管理自己的 api key, 还有一些隐私提示,例如明确的告诉用户这个 key 会被声称视频不会被滥用等等。 还有有一个生成页,就是用户去输入一些个性化的信息,例如我们需要祝贺的人,譬如张总、王总点击开始生成视频,那他就开始去触发了这个视频生成的任务。但是一定要记得这时候反馈回来的只是一个任务 id, 因为它是异步任务。 那接下来用一个类似于进度条或者一个 loading 的 图标来显示整体任务生成的状态,那这点其实在 u i 设计中是很关键的,因为用户很可能会随时失去耐心嘛。 还有一个就是视频详情页,一个是结果页,可以展示用户生成的视频,同时提供分享和保存功能,那如果分享就是通过发送一个小程序卡片,那如果保存,将这个视频保存到用户本地的手机里边,再去转发给自己的朋友。 好,还有一个历史记住页,在这个页面用户能够看到自己过往所生成的所有的视频,记录。好,那接下来具体的技术方案,例如前端式小程序,后端式微信云开发,还有 ai 模型的接口,这个他刚才也应该比较熟悉了, 以及对于具体的数据模型,那接下来就是一些比较细节的地方,那同时这里我们来看一下他刚才给我们画的整个的一个业务流程,咱们一起来看一看这个流程合不合理。首先用户第一步他会打开小程序, 那进入小程序之后,他会去判断一下当前有没有存储的视频的大模型的 api, 那 如果有就会进入到首页,用户去选择视频模板,然后进入生成页,用户输入好友的名称,点击生成去调用云函数, 这个云函数他会去在后台调用豆包 c 代四点五 pro 的 服务,那如果成功的提交了这个任务,就会进入等待页,在不断的去轮询状态,然后展示生成的视频,同时可以分享小程序的卡片。好,那这就是一个最常规的使用流程, 如果一开始没有 api key 呢?可能会引导进入设置页,引导用户去输入自己的 api key, 那 同时如果任务提交失败了,那譬如 你的 api key 的 额度已经用完了,那可以弹出相关的提示,让用户去检查自己在火山引擎里边的这个豆包大屏服务还有没有剩余的额度? 好,那这个流程也很清晰,咱们这个产品需求文档就比较符合我们的要求了。那唯一我觉得还有两点需要在 稍微修改一下,因为咱们接下来去进行具体的开发了之后,我们可能要去科室里边去新建对话,那科室有可能会又找不到这个 cds 一 点五 pro 的 官方文档,那么我们就可以要求他把刚才的官方文档的链接把它放到这里,那后续如果再去开发,再去看这个链接就 ok 了。 还有同样的关于这个 ui 的 风格指南,这个我们就先把它给删掉,因为接下来咱们的 ui 设计需要用到 google 的 stitch 这个服务,咱们只告诉这个 ui 开发工具我们需要设计哪几个页面,那关于具体的风格,咱们就交给 stitch 去完全发挥,不要影响它。 那咱就把这个需求告诉他,帮我再稍微修改一下产品。第一把刚才的火山引擎官方文档地址放在合适的地方,以便后续使用。那第二个就是删除对于 u i u x 的 风格指南。好,大家可以看到,那现在这个官方文档就加进来了,同时刚才对 u i 风格指南的一些建议也已经被删除了。好,那现在我们就有了一个很符合我们要求的一个产品需求文档了。
4字符滚烫 14:46查看AI文稿AI文稿
14:46查看AI文稿AI文稿这几个词你认识多少?这几个词你认识多少?这这这几个词你又认识多少?如果你全都不认识,那么恭喜你来对了地方。今天这期视频,我就为你扒开所有这些唬人概念的底裤。你会发现,所谓智能体,就是所有不需要智能的部分构成的部分。 skill 就是 新瓶装旧酒的一场名词诈骗。最后呢,我还会告诉你一个通杀现在所有甚至未来可能出现的新概念的统一方法论,让你瞬间秒懂。哎,这好像是个语病,但这不重要,现在你只需要清空大脑,忘掉你所有知道和不知道的概念,跟我一起进入梦境。 整个混乱的起点就是这个古老的语言模型。小的语言模型,一开始呢,还是个智障,但随着模型的参数越来越大,居然在某个临界点涌现出了智能。那为了和之前这个智障模型做个区分,你在前面加了个大字,这就构成了现在常说的大语言模型,简称 l l m。 恭喜你发明了今天的第一个新词儿。 大模型本身只能做文字接龙,就是不断输出下一个字,但如果只是这么用的话,看起来仍然像个智障。那如果把角色区分一下,人为划分成一问一答两个角色,就实现了第一个有点智能的使用方式对话。 现在呢,我不管你是什么身份,立刻把自己想象成一个老板, l 就是 你的员工,我们就叫他小 l 吧,只不过他服务你的方式有点特别,只能一问一答,然后就结束了。不能追问,不能追问,这个非常重要,后面要考, 那接下来的任务就是你要想尽办法压榨这个只会一问一答的小 l, 榨干它的全部剩余价值。那你会怎么做呢? 不过先别急,你先给自己每次和小 l 的 对话起了个洋气的名字,叫 prompt。 恭喜你发明了今天的第二个词。然后你还发现,这部分内容还可以进一步区分,有的部分是背景信息,有的部分是最终的指示。于是呢,你把背景信息的部分单独起了个名叫 context 上下文。那恭喜你发明了今天第三个词。 同时,有的时候你需要对小娱进行追问,但是呢,刚刚说了他只能一问一答,不能追问。但是你想了个巧妙的办法,就是每次沟通前把你们之前的对话历史放到 context 部分作为上下文信息。 然后呢,再给出你的问题,伪装成多人对话。然后你又迫不及待给这些特殊的上下文信息起了个新词,叫 memory, 意思是大模型的记忆,这些 memory 还可以再次调用大模型进行总结,从而对他的记忆进行压缩,进而减少上下文的长度。恭喜你,一不小心就已经发明了四个新词了。 此时,一个原本只能进行词语接龙的小 l 就 成功被你玩出了可以对话并且可以不断追问的优秀牛马员工了。 当然,不久之后你就不满足于现状了,你发现的第一个问题就是小儿没有上网查阅资料能力,要么就不知道,要么就胡说八道,说的内容都是些过时的消息。不过这很简单啊,给小儿准备一台电脑不就可以了? 不可以!还是那个问题,小 l 本身只会词语接龙,其他任何逻辑都无法独立完成,那怎么办呢?好办,你就告诉小 l, 如果你需要上网搜索资料的话就告诉你,然后你帮忙查完资料后再给他不就行了?但很快你就发现,这样好像显得自己有点蠢,到底谁才是牛马呀? 于是呢,你把上网这部分逻辑写成一段程序,让这个程序去代理你和小 l 进行沟通,并且完成搜索的任务。 在外人看来,你仍然是一问一答就拿到了结果,只不过面向的是这个神秘的程序了。太妙了,这个发明可不得了。这个神秘的程序似乎本身就拥有了智能,而且还是能操作工具的更高级别的智能。你给他取名叫智能体 agent。 你 可能觉得写多段程序不是看起来很简单吗?怎么敢叫这么科幻的名字?哎,千万别有心理负担。一些早期所谓的智能体,其实现逻辑仅仅就是多加了一段 prompt 而已,那从现在的视角回看,当时简直就是一种诈骗。 回到这里,既然这个 agent 能上网搜索内容了,那是不是也可以增加个搜索本地文档或数据库的能力呢?可以的,只不过搜索方式和传统数据库不同。要使用向量数据库把语义相近的片段找出来。 那你给这种通过语义匹配向量化的信息,并将其加入上下文,以增强生成内容的可靠性的办法,叫做解锁增强生成 retrieve augmented generation, 简称 r a g。 那 刚刚这个联网搜索也起个名字叫 web 测试 算了, drop the web just search。 这样呢, scope 显得更大一些,连 r a g 也算是 search 的 一种了,都属于获取模型参数以外的信息的能力。好了,现在看看你造的孽吧,这么一会功夫,已经发明了八个新词了,当然了,好戏还在后头呢。 好了,现在的整体架构就是你和小 l 中间隔着一层 a 阵的程序,并且处理一些小 l 无法操作的东西,包括刚刚的搜索,以及还可能出现的其他各种工具的调用。 但这就有个问题,我们聚焦于 agent 和大模型的对话过程来看,而如果这部分一直用自然语言来沟通,那这个 agent 的 代码可不好用程序来实现呢,鬼知道大模型会怎么描述自己的需求呢? 所以最好有个约定,让大模型按照指定的死板的格式来回复,比如说 jason, 这样呢,程序就能直接很方便的解析了。那你给这种 a 阵呢,和大模型之间关于工具调用所约定的对话格式叫做 function calling, 其实呢,就是个约定罢了,就好像开发的时候前端和后端约定这个接口格式一样。 好了,我们再看看右边这些工具的实现,现在是写在 agent 的 主程序里面的,没有跟核心功能结偶。那如果是单独写成一个服务,那么 agent 的 主程序如何发现并调用这个服务,就又需要一套约定的规范了。比如说约定好 toos list 的 方法就是返回工具列表, toos 框方法就是调用具体的工具等等, 也就是一套约定而已。那你给这边的约定也起了个名字,叫做 mcp, 翻译过来叫模型上下文协议。 而至此,架构就变成了这个样子,此时大模型就像个只会说话不会做的智者,而 m c p 服务就是能提供各种工具的程序级。中间的 agent 就是 个传话筒,把大模型的话转换成调用工具的代码,把工具调用的结果再原封不动的传话给大模型。 同时呢,别忘了还要给你这个老板传话,主打一个,我不生产信息,我只是信息的搬运工。现在我们聚焦于 agent 和你的对话之间。 虽然最底层肯定还是文字,但是交互形式上可以非常丰富多彩,可以是像 c l i 一 样的命令行窗口,也可以是一个编程 ide 工具,还可以是一个更为通用的桌面助手,比如说最近爆火的 cloud bot, multi bot, open cloud, 当然这仨是一个东西。 这里说句题外话,我感觉 cloud code 这个名字起的实在太失败了。一开始呢,好多人认为它是个大模型的名字,但其实它是个编程 agent。 现在呢,好不容易大家接受它是个编程 agent 了,但其实它早就走上了通用 agent 的 道路。我感觉要是名字起好了,就没现在的 cloud bot 什么事了。 当然, collab 的 爆火和它的自身的很多设计有关,如果本期视频的点赞过亿,我将会专门出一期视频讲讲它。不过不论什么形式的智能体,都有一个统一的缺点。假设我们想完成这样一个任务,从一个英文 pdf 文档当中提取内容,翻译成中文,最后保存成 markdown 格式。 当然,你可以直接把这个需求描述给 agent, 让他自己策划整体的流程。但是如果这个流程相对稳定,每次重新让 agent 自由发挥的话,不但不稳定,还非常浪费 token。 比如说,整个流程中,提取 pdf 和保存 markdown 这两步完全可以固化成固定的脚本,中间的翻译直接和大模型沟通即可,整个流程就不需要任何一个中间的智能体插手了。 要固化这样一个流程,你可以通过编程的方式来实现。为了方便编写这种列式的任务,你又发明了一个新的编程框架,起名叫 linchang。 呃,为了照顾非程序员用户,你又发明了一种低代码的方式,就是在页面上傻瓜式的拖拽,上手难度更低。你给他起个名字叫 workflow 及工作流。 但是还有个问题,假如这个问题我们再变一下,比如说处理原始文档,不只有 pdf, 还有可能是 word 文档、 txt 文档、 ppt 等,然后输出的格式也可能是 html、 pdf, 甚至是一张图片。那么难道你要给这些所有的排列组合都写一套工作流吗?这显然是不合适的。 当然了,你也可以写一堆 ifelse 做判断。但如果你仍然希望用户是以自然语言的方式触发这个任务,不牺牲这个体验,这个时候就又不好用程序来判断分支了。那该怎么办呢? 你可以这样设计,准备一个目录,把所有可能涉及到的转换脚本全都写好放在这。然后呢,写个统一的说明文件,把整体的流程描述清楚,并且告诉 agent, 根据文件的格式灵活选举指定的脚本。 然后呢,再给 agent 下达任务之前,加上这么一句话,先读取刚刚我们写好的那一大串要求,然后再按照要求完成任务。这样整个过程就既保证了一定的灵活性,同时呢又变得比较可控。 但是这不就又来了优化空间吗?我可以提前约定好某个指定的位置,然后呢,在 agent 中写死一段程序去读取这个位置的 skill 点 m d, 还是相当于把这句话固化成了一段程序,这样呢,就不用每次都加这么一句废话了。 虽然你也知道这破玩意好像就是把提示词换了个地方存起来,但想想还是给他起个新名字吧,就叫做 skill, 即 agent 的 技能。好家伙,这是往游戏里的英雄方向设计的呀。 好了,现在这个 agent 已经被你弄成这个鬼样子了,你又发现,对于一个复杂的任务,可能 agent 的 上下文会变得非常大。于是呢,你又发明了个新概念叫 sub agent, 对 于一些独立的子任务,可以单独在这个子 agent 中完成,其实本质上就是做了骂上下文隔离子 agent 产生的上下文不会保留在主 agent 中,仅此而已。行了,再好好看看你造的这些孽吧。 最后呢,我想尝试高屋建领的梳理一下这些概念的关系。这里的每一个新概念出来的时候都有大飘的文章,极其夸张的吹捧和营销。但是在我看来,这些概念的设计说的不好听点就是有点拉垮,说的好听点呢,就是技术发展的中间产物。 不过在这之前,我们先看两个经典的容易混淆的问题。在 m c p 刚出来的时候,很多人问方声 call 林和 m c p 有 什么关系啊?呃,其实刚刚这张图就很清晰了,一个是 agent 和大模型沟通的约定,目的是让大模型回答的符合一定的格式,方便程序进行解析。 一个呢,是 agent 和工具服务之间调用的约定,目的是像接口文档一样,约定怎么调用,怎么传餐,怎么接收返回值等等。这俩完全不搭嘎,甚至有人问是否 mcp 能够取代防神拷令呢?这也是无稽之谈。 在 skill 刚出来的时候,也有人问 skill 和 mcp 有 什么区别, skill 其实就是个 prompt 加载器嘛,唯一需要的文件就是 skill 点 md, 其他的不做任何要求,和 mcp 也不是一个维度的东西。 不过 skill 是 否能取代 m c p 呢?我认为是可以的,因为你可以把 m c p 服务中提供的工具通通放在 skill 的 目录下,并且在 skill 点 md 文件中说明是如何使用的,而且特别常用,通用的小工具未来通通都会内化在 a 帧的主程序中,所以目前看 skill 稍稍有些鸡肋。 不过拿 skill 和 m c p 比本身也不搭嘎,不是一个层次上的事,它其实更应该和这几个词作比较。那我把这个顺序成为从刚性到柔性,从稳定到变化, 它们的目标呢?其实都是一个需要多个阶段才能完成的任务,使用 linche 就是 纯编程的形式来实现,全是硬编码,虽然特别稳定,但是也失去了一定的柔性,很难包容一些小问题。而 workflow 只是把程序替换成了 d 代码的拖拽,相对改起来的容易一些。 呃, skill 就是 把 linchang 和 workflow 这种由程序控制的流程走向变成了由智能体自行控制, 但是呢,提前写好了一些说明文档和直接可运行的脚本存在一定灵活调整的空间,同时呢,又不至于变得特别不可控。而最后的纯 a 帧的形式最为柔性,因为它可以随时根据自己的判断进行调整流程,甚至需要的时候自己给自己生成个脚本来运行。 但同时这也造成了容易变得不可控,你不知道它中间会给自己写个什么脚本,把一个原本非常简单的任务变得非常复杂,所以这条线我认为是它们宏观上的一个区别。至于 skill 的 间接式批漏啊,按需加载啊,我认为只是它的一个特性而已,而这个特性也会在未来 token 变得越来越便宜之后变得有点鸡肋。 对于普通人来说, skill 兼顾着灵活性和稳定性,我认为呢,会逐渐淘汰掉 m c p 和 workflow。 m c p 就 像刚刚说的常用的工具,我认为会直接内化到 agent 的 主程序中,或者在未来的基础 skill 包中存在比较积累。 而 workflow 这种既不如 lincoln 一 样适合程序员,也不如 skill 这样更适合我们普通人,也属于一个比较鸡肋的存在。当然, skill 我 认为本身也是个中间产物,未来呢,一定会有更方便的形式出现,让所有人都可以很符合直觉的无脑使用。 然后我想再从最本质的角度说说这些技术,其实所有的这些技术最终还是离不开大模型和我们之间的提示词。 呃,这些技术呢,无非就是帮助我们自动地往提示词里面增加上下文信息,比如说 search, r a g, skill 等等,都是把一堆内容塞进了上下文,或者通过代理的形式帮助我们减少和上下文沟通的次数。 为什么开头我说 agent 呢?是所有不需要智能的地方构成的部分呢?就是说一个流程当中,所有能用固定的程序来解决而不需要问大模型的地方,就是 agent 的 发挥作用的地方。其实就是把模糊的分流逻辑交给大模型,根据语义识别出用户想做 a 还是 b, 把确定的分流逻辑交给程序,比如说 pdf 提取文本,那最终的目标都是节省人类的时间,降低人类的使用门槛罢了。 但是现在还有个最大的问题就是头盔实在是太贵了,越是强大的自己,能默默处理问题的 agent, 背后消耗的头盔就越大。但我觉得这在未来或许不是问题,因为头盔一定会越来越便宜,甚至等到什么时候,一个生产级别的大模型可以轻松部署在一台普普通通的电脑上的时候,头盔就相当于免费了。 由此我又想到了 java 领域的 spring boot 和 python 领域的 uv, 你 会发现这两者都是将开发者的便利完全放在第一位。什么运行速度快不快?包的体积大不大?是不是浪费内存空间或者磁盘空间?这些问题最终和使用的便利性相比,几乎都是瞬间被秒杀了。 程序员尚且这么怕麻烦,而在 agent 的 领域,我认为更是如此,因为他面向的是普通人,不可能让普通人去把什么 skill 放到指定的目录下去,配置什么 m c p 服务,甚至配置哪个大模型的 api key, 这些呢,都会被一个较为便利的产品淘汰掉,比如最近的 cloud bot 为什么这么火啊?除了一些营销因素以外, 难道它和 cloud code code x manage 这些 agent 有 什么本质区别吗?完全没有,就只是因为它能连接社交软件,能够配置定时任务,有个页面能看到 skill 并管理它们。第一次让普通人觉得它像一个智能体,而不只是躺在电脑上的一个服务了。 那未来究竟会是什么样呢?我认为只要是提供便利的方向就是趋势。比如未来我认为一定有一个打包好的超级 a 枕的配置好了,所有常用的 m、 c, p 啊、 skill 啊等等乱七八糟东西,甚至已经不叫这个名字了,普通人啥都不用,配置也能直接使用起来。 好了,本期视频就到这里,看在这么长的份上,能不能给我个三连呀?
7.0万飞天闪客 03:38查看AI文稿AI文稿
03:38查看AI文稿AI文稿哈喽,下班了,今天没带自拍杆,有点黑,就是明天晚上七点半,我会跟张晓宇啊,周五晚上啊,张张晓宇老师一起有一个直播对谈,也在我的视频号直播。 呃,微信视频号直播。那欢迎大家关注啊,我们讨论的主题是 ai 洪流下的个体选择啊,然后讲讲这个浪潮之下,他写了这么多的书,然后他说他最近有一些新的思考,然后大家可以关注一下。 呃,然后我想今天跟大家聊聊,就是说,嗯,最近我写了一个新的 skill 感,我觉我觉得帮助特别大,然后对我的工作提效非常非常有帮助啊,但是我还是这么晚下班,就是感觉工作提效之后,你能做的事情就多了,然后你想做的事情就多了, 你的期待变高了,我觉得这个是核心问题。嗯,但是呢,这个 skill 呢,还是跟大家分享一下,大家可以自己写啊。呃,基本上就是说每天让他跟你一起去规划一下今天要做的事情。呃,怎么来做呢?就是说, 嗯,因为我们每个人每天早晨脑子中的想法是很多的,然后你觉得可以做这事,做那事,然后包括你自己本来其实也是有目标的,但有的时候呢,我们这种现象思维,或者说屁人,对吧?然后脑子里想的事情非常的 美好,丰富,多线条,然后那虽然有规划,然后但每天有新的信息输入进来的时候,你还是想做很多的事情,然后这个时候呢,你就可以让 ai 帮你去对照着你的记忆系统里的那些优先级,然后包括你自己之前的一些文档, 让他去帮你做排序。所以我现在每天上班第一件事就是跟 ai 说开始今日规划, 然后他就说首先脑到空,脑袋到空,就是把你脑子中所有想到的东西全都说出来,然后这个时候呢,他会啊,根据我以往的目标规划, 然后来去排一个优先级,就说今天先干什么,后干什么,然后再干什么,大概怎么安排,哪些是保护时间,就是必须要去做的事情。我这两天还跟他叠带了一版,我说现在我有 multi agent 这种能力,就是多任务并行的能力 啊,有一些不需要我来关注的,那你可以自己去跑,所以呢,你需要把其他一些我就不需要我注意力的事情帮我规划好,然后你来直接跑就好了。 对,好黑呀,是吧?对,天黑了。呃,然后对,用这种方法呢,我就可以同时让五个 agent 帮我开始干活。当然这个过程中还是有很多迭代的事情啊,比如说像, 呃,这个 prom 到底是在哪个窗口写,写多长?它是一次性写的特别清楚,还是在新窗口里让它自己探索?这里面都有很多细节,我觉得这都是根据每个人要去打磨的一些能力,那当然所有的这些我全都是在 cold body 里完成的。呃, 所以这个 skills 呢,就是我当时说的,就是说因为排定优先级这件事,对我们产出,对我们自己目标的对齐非常非常有帮助。所以啊,这个事情我觉得大家可以可以尝试。 我我我改天有电脑的时候再给大家看这个具体的 skills 吧。但我这两天实践下来,我从周周二开始实践吧,开工之后这三天我的效率都超高,每天下班都是精疲力尽,我我我战斗力已经是以前的五到十倍了。我觉得是这样的啊,对,然后 欢迎大家关注明天晚上我跟张晓宇的这个直播对谈啊,他说他有很多新想法啊,然后大家期待一下,拜拜。
1534晓辉博士 03:31查看AI文稿AI文稿
03:31查看AI文稿AI文稿我开源的这个 skill 能够让你用几句话就造出一个完整的废书机器人。这个 skill 覆盖了从需求到交付的完整内容,不用翻文档,不用反复迭代, ai 会一步步的引导你说清楚你要什么,然后直接帮你把代码配置文档全部生成好,最后你只需要在废书开放平台上完成对应的配置之后就可以跑了。 这个视频我会完整演示这个 scale 的 效果,告诉你它怎么用,以及它背后一个可以迁移到任何领域的实现思路。看到最后相信你会有所收获。先说说为什么要做这个东西,近半年来,给飞书群搞个机器人这件事,我重复了十几次场景,其实很日常,每天早上发个热点趋势汇总,或者是做我自己的 open cloud 机器人之类的。 但是每一次构建,我都要让 ai 去重新查飞书的官网,并且就各种失败情况和他反复进行点赞,浪费了非常多的时间。 这样的情况多了之后,我就做了这个飞书机器人 skill, 打包了我在实践中总结的一套详细的 sop 以及需求的挖掘步骤,还有各种情况的处理方法。我现在来演示一下,比如我跟 ai 只说一句话,构建一个飞书机器人, 这时候我们可以看到他读取了 skill 文件之后,并没有直接开始写代码,而是开始问我问题。我们这里选择自建应用吧,因为我们要收发消息,并且会呃跟机器人存在一些交互, 然后具体做什么,我们这里也可以讲的不具体,比如我说每天需要给我通知,我可以和他对话,他有固定指令, 最后 ai 会继续根据我 skill 的 配置来反复的向我们做需求澄清,比如他会问我们通知的具体规则,我们这里选择各发送一次,呃,然后数据的话,比如说我们用外部 api 的 动态数据,然后固定指令,我们随便给一个,比如 today 展示当天天气。 最后呢可以和他对话,我们就是当然是要进入 ai 模型来对话, ok, 然后我们可以看到在我指定了天气之后呢,他会开始问我们天气是通过哪个 a p r 来获取,包括后面我们啊定时的通知方呢?还有我们这里选择固定群聊吧,后面我来配这个 chat id, 然后对话模型啊,我们有自己的平台,所以自己来接。 而历史上下文的话,我们选择保留二十个, ok, 几分钟之后我们可以看到一个完整的项目已经做出来了,而 s r、 c 下面是一些核心的代码, 然后呢, fake 下面是各种的配置,读取的逻辑等等的,然后点 example 啊,点页微点 example 是 我们的各种飞书的配置, 这个也就是我们可能需要人工去做的一些东西了,别的基本上 ai 都能帮我们搞定,然后包括整个的部署,构建的一套全流程, ok, 所以 skill 说白了就是 ai 的 结构化知识包,相当于提示词,文档,脚本、工具等等的集合, 你给他一份 skill, 他 就知道该怎么样一步一步的完成任务,什么该问,什么该做,什么容易踩坑。在做这个 skill 的 过程中,我愈发觉得在模型能力够强以后, skill 也许在中小型任务上的能力要远远的强于工作流, 它更加轻量级,更加灵活,也更加的高效。在 ai 时代,自动化是主旋律,而 skill 则让自动化的工作中多了一层标准化,这是很难能可贵的。如果这期对你有帮助,希望能给我点赞,收藏三年,我是 carl, 我 们下期见。
212卡尔AI工坊 19:18查看AI文稿AI文稿
19:18查看AI文稿AI文稿梅猴王朋友们, agent skill 最近真的太火了,但很多朋友肯定还是很困惑, skill 到底是啥?有什么牛的?没关系,草旅从 skill 大 全它来了。 今天呢,我们会通过一个逐步升级的案例来理解 skill 的 结构和原理,然后我们还会学会定制自己的 skill 这个 skill 呢,只需要我们说帮我做一个促销海报啊,优惠券,员工服装,它就会生成符合我们品牌风格,带 logo 的 物料图片。 另外,我也会推荐给大家一些好用的必用的 skill, 比如说帮你的文章配图,把杂乱的知识变成教学网页,一句话处理表格等等等等。 我还做了个秋之技能生成器,大家只要回答一下 ai 给的选择题,为你量身定制的技能就轻松完成了。并且今天所有的资料链接以及补充资料我都做成了一个网页,大家只需要一步步的跟着做,跟着看,就一定能搞定, 非常值得一个点赞收藏关注哦!来吧,准备好我们 go go! go! 首先,到底什么是 skill skill 呢?翻译过来就是技能呗, 它其实和人类的技能是类似的,比如说你是一个厨师,那你就有炒菜的技能,处理食材的技能,摆盘的技能等等等等。那每个技能里面,比如说炒菜技能,这里面就包含了你的流程,你要先炒什么,后放什么, 还有你的配方,你的油温多高,盐放多少。有了流程和配方呢,你可能还会需要一些工具,需要煤气灶什么的, 甚至你可能还会有一些独家的材料,有一勺秘制辣椒酱什么的。那 agent 的 技能也是同理,它要来做菜,它也得有流程、配方、工具和材料。 所以在 agent skill 的 术语里面呢,它就是 skill 点 md, references, scripts 和 assets 这些东西打包成一个文件夹,这就是一个技能,一个 skill 了。我们先来个简单的, 比如说我们要做一个写作 skill, 那 我们就在 skill 里面可以要求他先去啊这些网站去搜集信息,然后再按这个爆款原则去写个大纲,然后再参考这个语气来写稿啊,最后按照平台要求来审稿等等等等。那有朋友就很疑惑, 那这不就是写提示词吗?哎,本质上还真是的,毕竟啊,我们跟大模型的交互其实都离不开提示词, 但是呢,这并不是 agent skill 的 全部,它在工程上是有很多优势的,能做的肯定比我们拷贝粘贴提示词要多很多。好处我们后面都会说到,那先让我们通过创建一个 skill 来理解它的结构和原理, 我这里用的是谷歌反重力来做编辑器来看文件,然后呢,用的是 cloud code 来做 agent 来处理任务。这俩东西的下载方式呢,我也都放在资料里了,非常清晰简单,大家一步步跟着做就行了。 接着你只要在反重力的这里创建一个项目,比如说我的就叫丘之 project 吧,然后呢,我们调出终端, 输入 cloud cloud code 就 调用出来了,这个界面大家看着会有点复杂,但是不要怕,跟着我一步步来就可以了,之后我们跟 agent 的 对话都会在这里进行。 ok, 那 我们开始创建, 那我们先要做的是一个最简单版本的 skill, 后面呢,我们会逐步升级的哈, 那现在假设我是一家轻食店的老板,那这是我们秋之餐厅的一个品牌 logo, 那 我希望做一个 skill 呢,能够按照我的品牌调性和视觉规范,帮我们去想各种物料的创意,做一个创意生成器。 那按照 cloud 的 规定,我们创建一个 skill, 得在规定的点儿 cloud skills 文件夹里面去创一个 skill 文件,那我们用最原始的方式,直接手动的来创建这些文件夹哈,点儿 cloud skills, 然后我们再创建一个文件夹,这个文件夹的名字呢,就是我们 skill 的 名字,我们叫它秋之创意吧。那这个 skills 的 文件夹里面呢,必须规定有一个 skill 点 md 的 文件,这个大写的文件,那文件里面放啥呢?我已经写好了, 粘贴进来,那就是这么些文字。好了,这就是一个 skill 了,大家先压住脑子里面的问号,我们再来细看一下,那这个文件里呢,上面这两个横线里面的它叫做元信息 matlab, 写着两个东西啊,一个呢是 skill 的 名字,一个呢是 skill 的 描述,这两个东西专门用来告诉 ai 这个 skill 叫什么名字,是干嘛用的,什么时候可以用它,那我这就写着是做创意物料用的啊,当用户说要做个海报什么的物料,他就自己触发它了。 而下面这些信息呢,叫做指令 instruction, 其实就是具体告诉 ai 怎么样做的一些提示词喽。 ok, 那 我这写了我们的餐厅叫做秋之餐厅,品牌的风格有这么些要求,输出的格式让他是这样等等等等,非常的简单哈,那我们保存好一个 skill, 真的 就创建完了?来,我们启动 cloud code 来问问他,你有哪些 skill? ok, 你 看,他现在就已经识别到了我们的秋之创意 skill 了。 ok, 我 们直接问他,我要做一个秋之餐厅的春节促销海报,让他给个创意 好,他这里就开始提示我们,他正在加载这个 skill 了,我们同意 ok, 他 就输出了创意,并且是按照我们的要求和格式来的。 那有朋友就受不了了,哎呀,这一通操作不还是提示词吗?跟我自己写一段这个提示词存着给 cloud code 看有什么区别呢?最大的区别之一在于它是按需加载的, 什么意思呢?其实啊,当我们正常的这样跟 cloud 去聊天的时候,大模型它只会看到我们这个 skill 里面这两行短短的圆信息。 只有当我们说我们要做一个秋之物料的时候,他才意识到,哦,该看具体的指令了,他才会去加载这下面这部分的完整指令,否则这些他都不会看到。 这样的好处就是方便我们可以同时拥有很多个 skill。 每次 a 正的都会看一遍所有 skill 的 简短的原信息,但是只有当 a 正的意识到他要去具体调用一个技能了,他才会去看下面的一大堆指令,而且 ai 的 回答也会更精准, 因为他没有了其他提示词的干扰,那 ai 加载的少了, open 自然也就省了一堆。那这是他按需加载的第一层。 当然了,刚刚这个 skill 实在是太基础了啊,就算一口气把它下面的指令都加载完,好像 token 也不多哈。 但是如果我们的要求变得复杂了呢,比如说我们秋之餐厅的物料其实分很多种, 常规的呢,有海报、菜单,也有比较特别的一些实体物料要设计,比如说餐盒、杯子,员工服装,还有一些社交媒体的物料,比如说公众号封面,微博配图等等等等,他们的尺寸都不一样,配色要求也不一样, 还得符合各平台的一个规范。每一个物料呢,我们都假设它有详细的长长的说明,那这时候我们如果把所有物料的要求都写进 skill 点 m d 里面,那这个文件就会变得巨长。 但是很多时候呢,我只是想做一个,比方说实体餐盒的设计大模型,根本就不需要知道公众号封面的规格,但是 ai 还是得把整个文件都读一遍,那这就造成了 token 的 浪费,也可能会造成一些信息干扰。那怎么办呢? isopec 就 又规定了一个文件夹叫做 references, 我 们呢可以把实体的物料和社交媒体的物料这个两个规格单独拆出来,单独的给它放到这个 reference 文件夹里面去。 那这个实体物料规格点 md, 我 们就写一些线下的工服呀,餐盒之类的要求, 那这个社交媒体物料规格呢,我们就去写公众号封面呀,微博配图这些的尺寸和要求,甚至我们都可以拆得更细。 然后呢,我们只需要在 skill 点 m d 这个总指令里面只留下那几个常见的物料要求,并且我们还需要写上一个指引 啊,告诉他如果用户要做线下物料的话,那就要去读这个实体物料规格点 m d。 如果要做社交媒体类的图,那就要去读社交媒体规格点 m d, 那 现在同样的一句话, 他给出的方案就更精准了。这样当我们只做常规物料的时候,这两个 reference 的 文件大模型压根就不会看。然而当我们说做实体参合的时候,他也会通过 skill 点 md 的 指引,只去看 reference 里面的这个实体规格文件, 那这就是它的进一步按需加载了。那我们可以想象,我们可以有好多种不同情况的 reference, 反正它只会在需要的时候自己去看指定的文件。 但是现在我们的秋之创意 skill 呢,只能输出创意,还得我们自己去做图,所以呢,我就还想让它可以按照我们的品牌规格,直接帮我们把图做出来, 也没有问题。那这就要用到 skill 的 另一种文件夹了,叫做 scripts, 那 这个 scripts 里面呢,一般放的是一些可执行的脚本, 那我这里呢,实际上也就放了一个非常短非常简单的脚本,其实就是在调用 nano banana 的 api 来生图的一个脚本。那有了这个脚本之后呢,我们还得去 skill md 里面在指令里说一声,告诉他,如果用户要求直接生成图片, 那他就得把之前我们想的这个创意转化成生图的提示词,然后按照这个命令去调用这个生图脚本,这样他就能一句话自动去生成精准的图片了。 不然我们还得自己去拷贝提示词,打开软件再粘贴,再生成,再下载保存,现在我们一句话就搞定了。 另外我还有个需求,我希望深层物料的图片能保持秋之餐厅的 logo 不 变, 所以我们还得给他几张 logo 图作为深图的这个参考。那我们就可以再建一个 最新规定的一个 s s 文件夹,我们把两张的 logo 图片放到这个文件夹里,当然我们还要回到 skill 的 md 里面,告诉他参考图在这个 s s 文件夹里面,如果要深图的话,需要把这个图片当做参数给脚本传进去来执行。 好朋友们,现在这个 skill 就是 一个完整的官方完全形态了,其实有点像我们在用自然语言写程序,对吧?那我们先来试试效果,来帮我做一张周六饮料免费的一个实体海报, 你看它发生了什么?它先是加载了这个 skill, 然后它内部可能发现啊,要做的是这种实体物料,它就要去看另一个解说,于是它去检查了这个实体物料的规范。那并且它意识到我们需要的是直接生成图片, 所以呢,它又生成了提示词,把这个提示词和 logo 图片一起给到,并且运行了这个脚本。那最后它输出的图片告诉我们,在这里我们看看结果, 你瞧瞧它这个尺寸,配色 logo 是 完全符合我们这个品牌规范的啊。那为了防止这个是一次性的结果,我还多试了几次,它这个深层的效果都很不错。 然而如果我们的要求还跟之前一样,我们只要创意并不要直接深图的话,那他的这个脚本他也不会被执行。 而且呢,刚才我们说到这个 scripts 脚本,这里面其实还有一个重点,这个脚本里的代码它是写好了的, agent 根本就不需要去看里面写了什么,它只要知道我们在 skill 点 m d 里面写的那些指引,告诉它传什么参数,会输出什么,它只管运行脚本就行了。 所以不管我们在 scripts 里面写了多少行代码,大模型它都不会去读取,一点 token 都不占。 当然了,如果我们在 skill 点 md 里面的那个指引写得不够清楚,大模型不知道怎么用这个脚本,那他有可能也会不得不自己去看一下这个脚本,但他的机智和园艺是不需要去读这些脚本的。 好,那我们来回顾一下,其实创建 skill 就是 在指定的文件夹下去创建一些文件,那最简单的 skill 呢?只要一个 skill 点 m d 就 够了,里面有这个原信息和指令,而完整形态的 skill 可以 加上 references, script s s 这些可选的文件,那这些东西是怎么配合工作的呢?这就是 skill 最重要的设计。按需加载的三层结构,第一层,源信息。 这一层呢,是始终加载的, ai 的 每一次对话都会看一眼所有的 skill 的 源信息,它去看到自己有哪些技能,就像一个目录。那第二层,指令层, 这层是只有当 ai 判断并且决定我要用这个 skill 的 时候,它才会去加载完整的 skill 点 m d 文件。第三层,资源层, 这层包括了 reference 里面的参考资料, scripts 里的脚本, assets 里的资源。只有当 ai 进一步判断任务需要更详细的信息,或者它需要执行某个脚本的时候,它才会去按需加载,并且脚本它是只执行不读取的,完全不占用托克。 好了,这下我们完全理解 skill 的 按需加载,也就是官方定义的渐进式批漏机制和三层结构了。可是对于普通人来讲,这又是写 markdown 又是脚本的,好像创建一个 skill 还是挺复杂的。 no no, no, 现在谁会用手写呢?我是用这个创建 skill 的 skill 啊,秋之 skill creator 创建的。 那这个呢,是我基于很火的 skill 创建器改良的一个更加互动式,更加小白的一个 skill 创建器。那大家把它下载下了以后,放到这个点儿 cloud skills 文件夹里面就好了。那下好之后,我们想要创建什么 skill, 直接打开 cloud 直接跟它说就行, 或者我们也可以斜杠来调用他,那他呢,会开始一步步的引导和追问我们,来帮我们梳理这个需求。而且我特意设计的是这种用选择题的方式来追问我们整个过程,我们就只需要用大白话回复他的问题,以及按一按上下键做一做选择题就好了。 他这个追问的过程啊,到时候大家问题可能和我现在这个不一样,因为他会根据你的需求去做灵活的调整啊,他都是现编的。 然后呢,这个过程中因为我们要做图片,所以我们还需要给他提供 logo 图的参考,以及那个 nano 不 nana 的 a p i 和文档。那我也给他直接拖到了这个项目文件里,然后告诉他了一下这个文件的路径, 他就会自己去参考和把它们放到 excel 文件夹里面。那这两个素材我也都已经放在了我们的课后网页上了,大家可以去用做练习来试试复现它。 那问完这些问题之后呢,他还会给我们核对一下方案,如果我们看着方案没问题,那他就会自动帮我们生成所有的 skill 文件了。 那做好 skill 之后呢,他还会帮你想几个例子来跑一下测试。我们这里其实测了好几个,风格都很一致,很好看。大家在这个调整的过程中,也可以去点开他写的这些 skill 文档来手动的修改一些,反正都是提示词嘛。 所以总之只要你有明确的输出要求,或者有明确的方法规范流程知识,创建器就会指引你帮你来写出一个定制的 skill。 而且除了自己创建,网上也有很多现成的 skill 资料里,我也整理了一些集合网站和 skill 仓库,成千上万的 skill, 大家可以去逛逛。并且我也给大家打包了几个普通人常用的必备 skill, 比如做 ppt, 处理文档, excel, pdf 这些基础的,我们直接把它拖进 skill 文件夹就可以,一句话让它帮你把乱糟糟的表格梳理得整整齐齐。 还有这个官方的前端设计 skill, 这是直接让 cloud code 生成的前端网页,而这个是挂载了这个前端 skill, 做出来的网页,效果明显大幅提升。还有这个动画生成的 skill, 用这么一段提示词就可以做出这样一段演示动画。 当然大家也不用去装一堆自己根本用不上的技能,一个游戏英雄也只需要四个技能 q w e r 就 能杀遍全场。所以最有效的还是把你最最高频做的几件事,打磨成一个你独家的稳定产出的 skill。 尤其是你对结果有明确的要求,你有经验和方法,你验证过的事情。 比如说打工人,你的周报每周都要写,那就做一个让 ai 来主动采访你,然后出周报的一个 skill。 比如说老师每节课都要背课,那就做一个你只要给出课题,就能给你一整套课件习题和 ppt 的 skill。 又比如说,你总是要给你的文章配图,那就做一个给他一篇文章,他就按你的风格做配图的 skill。 又比如说,你总是在审核,那就做一个按照你的规矩自动批阅合同来写备注的 skill。 因为大多数的人都不需要成为一个技能开发者, 我们只要先把自己掌握的小技能交给 ai, 让他替你重复劳动。好了,资料链接都在评论区了,大家动手试试吧!这个时候呢,点赞、收藏、关注的技能就该出发了,我们下次见了!
5.2万秋芝2046 01:29查看AI文稿AI文稿
01:29查看AI文稿AI文稿不会运维,也能拥有自己的 ai 聊天机器人。 openclaw, 一个开源的 ai 智能体框架,能把大模型接入 telegram, discord, 飞书,随时随地跟 ai 对 话。但是安装配置对新手不太友好,配置文件要手写,代理要自己搞, system 的 服务要自己配。踩了一圈坑,所以我做了一个 cloud code skill, 一 句话完成全部部署。 cloud 只问你三个问题, s s h 地址是什么?用什么模型,接哪个聊天工具, 回答完就不用管了。剩下全自动 skill, 会自动检测服务器环境, cpu、 内存、硬盘、系统兼容性全部自动判断,这是实际的环境,检测画面全部达标。然后自动安装 node js 和 opencloud, 写好配置文件,全程自动,不用敲一行命令, 安装完成。自动确认状态模型随便选,智普、 deepsea、 通易、 kimi、 国产大模型都支持。这是部署完成的状态页一目了然。还会帮你创建 telegram 机器人手把手教你怎么建 bot, 三步就创建好了。自动配对,开机自启, 退出, s s h 也不会断。内置十个常见坑的,自动绕过非 t t y 安装报错,代理配置、 system d l g 全都帮你处理好。最后输出验证清单,确认所有服务正常运行。 我用这个 skill 在 树莓派五上五分钟就部署完成了。现在 telegram 里直接跟智普 g l m 五聊天,搜新闻、查资料都行,这是实际的聊天效果。有树莓派或闲置服务器的真心建议试试评论区,告诉我你们想接什么模型。
529Lif 05:09查看AI文稿AI文稿
05:09查看AI文稿AI文稿深度解析 ai 中的 skill, 从工具到同事的进化密码要理解 ai 中的 skill, 光把它看作功能或 app 是 不够的。 我们需要从技术架构、人机交互的进化,以及未来的商业模式这三个层层递进的维度来彻底拆解这个概念。欢迎关注和点赞,下次能够快速找到文章。一、技术视角 skill 是 ai 的 小脑与反射弧。从最底层的技术逻辑来看,大语言模型其实是一个静态的、通用的大脑,它懂得多,但不够手巧。 skill 就是 在这个大脑之上,通过微调提示词工程或外部 api 调用建立的特定神经连接和肌肉记忆。 我们可以把 ai 的 能力分层来理解底层,这是基座模型,它学习了海量知识,但它是通才,不是专才。它知道写诗的概念,但不知道怎么写一首让特定读者喜欢的诗。中层,这就是我们的 skill 层,它的作用是专精化, 通过大量的专项训练或者一套极其精密的思维填提示,让 ai 在 特定任务上表现得极其出色。它的特征是自动化,就像你的手碰到烫的东西会缩回来一样。一个训练好的 ai skill, 当你输入写一封给九零后父母的露营装备促销邮件时,它不再需要思考什么是邮件,而是直接触发一套成熟的、高效的写作反射弧, 快速产出高质量结果。所以从技术上讲, skill 等于特定目标加优化的数据逻辑加高效的执行路径。二、交互视角 skill 是 意图识别与任务封装,这是理解 skill 最关键的视角,也是普通人最能感知到的层面。 skill 本质上是人和 ai 之间的一种交互协议或任务封装。在计算机发展史上,我们经历了三次重要的交互革命。命令行界面,你想用电脑,必须学习机器的语言, 这是人适应。机器图形界面,你想用电脑通过图标和鼠标来操作机器,把功能封装成了可式化的图标,这是机器向人迈出了一步。 a s q 界面,你想用 ai 通过自然语言下达一个完整任务, ai 把一系列复杂操作封装成了一个技能包。 skill 在 这里扮演的角色就是意图识别器和任务封装包。传统做法,你想做个海报,你得打开 ps, 自己会排版,自己会调色,自己会找素材。 ai skill 做法,你对 ai 说,帮我做一张极简风格的读书会海报。 一个强大的海报设计, skill 会自动被激活,它内部可能封装了排版技能,加色彩搭配技能、加版权图库搜索技能、加文案优化技能。你只需要下达意图,它负责调用内部技能包并执行。所以, skill 是 人机交互从操作单元到意图单元跃迁的主体。 我们不再说给我一段代码,而是说整理一下这个文件夹,这个整理就是一个高级 skill。 三、商业与社会视角 skill 是 新劳动力的简历, 这是最具颠覆性的层面。当 ai 的 skill 变得越来越成熟稳定,可被调用,它们在商业和社会中就变成了一种全新的、可租赁的数字劳动力。 你可以把一个个训练好的 a skill 看作是一份份数字简历。简历 a 擅长处理 excel 表格,能从杂乱数据中发现趋势,精通数据可化简历 b 性格温柔耐心,熟悉产品知识,支持七乘二十四小时在线,能处理百分之八十的常见客诉 简历 c 熟悉小红书、抖音等平台文风,擅长制造热梗,能根据热点快速产出文案。在未来,企业可能不再只是招聘人,而是会去一个 a s q 商店里订阅或购买这些技能劳动力。 文章里提到的 ai 人文训练师之所以会出现,正是因为这些数字简历光有技术不够,还得有软技能。 我们需要给这些冰冷的劳动力注入人文素养,让他的简历更漂亮,更像一个得体的同事。所以, skill 就是 ai 在 劳动力市场上的报价和能力证明。掌握了调用和组合这些 skill 的 能力,你就拥有了组建和管理一支数字员工军团的权力。 重级总结,什么是 ai 中的 skill? 结合以上三个维度,我们可以给出一个深度解析的完整定义。 ai 中的 skill 是基于通用大模型能力通过技术手段固化下来的针对特定任务的可自动化执行的高效解决方案。在用户层面,它是我们与 ai 进行意图及交互的任务封装包。在社会层面,它正在演变为一种全新的可被组合调用的数字劳动力单元。 简单来说, skill 让 ai 从那个只会说我知道很多的博学秀才,变成了那个能说这事交给我办的靠谱办事员。而我们每个人正在从学习如何使用工具 转变为学习如何管理和指挥这群各有专长的办事员。欢迎在评论区分享你的想法,我们可以进一步探讨 ai 技能的技术细节和应用可能。
 07:24查看AI文稿AI文稿
07:24查看AI文稿AI文稿随着 ai 的 兴起,新出现的这些名词比你换的女朋友次数还要多,什么 agent, prompt、 react, m c p, 还有大火的 agent skill, 而这个 agent skill 我 觉得是真正可以高效率的执行 ai, 并且可以节省大量 token 的 方案。首先 agent skill 用一句话总结就是把怎么做这一类事情的经验, 从一次用完就丢的 prompt, 变成以后都能反复用,还能随便组合的能力。 在没有 agent skill 的 时候,比如我让 ai 重构一段代码,它完成的效果很可能并不是你想要的。比如命名不规范,注式格式不正确,异常处理也没有使用规定的 code 码,那么就需要写好这些提示, 参考阿里巴巴规范手册,使用驼峰,命名异常要精准补货,从 basecode 获取对应的 code 码,把这些规则再告诉给 ai, 让 ai 再给你重构一遍。这样确实是可以了, 但有个不好的地方,当我以后再让 ai 重购代码的话,还要把这些规则再写一遍发给 ai, 次数多了以后就很麻烦啊。那能不能让 ai 直接就记住这些规则?不用,我每次都要告诉 ai 呢?有的兄弟有的 可以把这些要求写到一个 markdown 格式的文档中,有 kolod 保存这个文档,等我们再让 ai 重构代码时, kolod 会先读取这个文档,然后把文档的内容和要重构的代码一起发给 ai, 这样就不用每次自己来写这些要求了。 但是又有新的问题,如果我是让他干别的,只是简单问问技术问题而已,也不用筹够代码,那他还是要把这些文档的要求发给 ai, 这样 token 用的不就是没有必要了吗? 所以还得有个判断。当真正需要重构代码的时候, cloud code 才会把文档的内容要求发给 ai, 可以变成这个样子,给文档加个名字,知道他叫什么,还要再加个描述,知道是干什么用的。等我们让 cloud code 重构代码的时候, cloud code 会告诉 ai 有 个文档名字和描述是这样的, 如果你要用到的话,我可以给你文档的详细内容, ai 就 会根据文档的名字和描述和用户输入的内容进行匹配。当 ai 发现了这个文档就是要干这个活的时候,他就会通知 kolodok, 把这个文档的完整内容告诉我, 我好按照这个要求来执行重构,这时 kolodok 才会把完整内容发给 ai, 接着 ai 执行重构,返回给用户内容。 因为名字和描述内容本身就很短,所以就不会出现过多浪费 topic 的 问题了。一看这个功能还真的比较好用,那就开始加一些别的要求呗。例如代码重复规范的文档是告诉 ai 如何按照规范要求重复代码。 get 提交规范的文档是用来告诉 ai 如何生成合理的提交信息。单元测试编辑的文档 用来告诉 ai 如何编辑符合团队测试覆盖率的单元测试。当 colocode 与 ai 沟通的时候,就可以把这些文档的名字和描述当成一个缩写目录发给 ai, ai 就 会根据用户输入的提示词来匹配这些文档的名字和描述信息 匹配到了,就会让 colocode 把这个文档的详细内容发给 ai, 然后 ai 按照上面的要求来执行。这样下来, ai 在 干每一件事情的时候,因为是按照我们列出的文档要求实现的,所以完成的效果就符合我们的要求。而这一系列功能的实现就是 agent skills, 这里面的每个文档就是 skill, 这些文档就像使用说明书一样, ai 根据内容来挑选对应的说明书来实现具体的功能。当然了,这些文档也不能随便的乱放,要有个规范来管理起来。 可拷扣的规定,不同功能的文档要放在不同的文件夹下,文件夹的名字就是文档的名字,而文档的名字要统一改成 skill 点 md, 当然到这里并没有完,还是看这个代码重构的例子。 随着后续的一直更新,这个重构规范的文档内容也会越来越长,因为要规范的内容很多,命名规范、异常扣的码规范、日制规范、并发编程规范等等。当要求 ai 重构代码时,可绕扣的会把这个文档的内容都告诉给 ai, 而实际上呢,每次让 ai 重构代码也只能用到文档的内 容,都告诉给 ai。 而实际上呢,每次让 ai 重构代码也只能用到文档的内容,都告诉给 ai。 而实际上呢,每次让 ai 重构代码也只能用到文档的内容,都告诉给 ai。 而实际上呢,每次让 ai 重构代码也只能用到文档了。 这时候就可以进行优化,把每一种规范单独写到一个文档中,然后在之前的这个主文档中,把这些单独规范的文档给整合进来。里面可以这样写, 如果要处理异常相关的代码,就读取异常,处理规范点, md, 如果要处理病发相关的代码, 就读取并发编程规范点 md。 如果要读取日制相关的代码,就读取日制规范点, md。 等。我们要重构一段多现成的代码时,可拷 code 把要重构的代码和 skill 文档发给 ai, ai 根据 skill 名字和描述确实匹配到了,告诉 colocod, 把这个 skill 文档全部内容告诉我, colocod 就 会把文档内容发给 ai, ai 再读取这个主文档的内容之后,再进一步读取到并发编程规范这个文档, 就会让可绕扣的把病发编程规范的文档内容发给我,可绕扣的就会把病发编程文档的内容告诉给 ai, 这样就实现了按需加载,让 ai 只有在必要的时候才会请求对应的内容,这样就可以很大程度的节省掏空了。 其实 scale 不 仅能管理文档,还能实现更加复杂的功能,比如还能让 ai 执行脚本完成一些他本身做不到的任务,比如图片批量压缩这个功能, ai 本身是没法直接压缩图片文件的, 但你可以在 scale 文档里面这么写,当用户需要批量压缩图片时,先确认图片所在的目录和目标,压缩质量, 然后执行下面这段 python 脚本。脚本里面调用 py 库,便利目录下的所有图片,按照指定的质量参数进行压缩,保存到输出目录。你还在 py 文档里面详细说明了,如果用户没装 py 库,先执行对应的命令来安装依赖, 现在 ai 在 可绕扣的配合下,在拿到这个 py 文档之后就知道该怎么做了。 先问用户图片在哪个目录,想压缩到什么质量保存到哪里,然后按照你写的流程执行 python 脚本, 脚本跑完之后告诉用户压缩完成,一共处理了多少张图片,节省了多少空间。到这里 agent skill 的 功能就介绍完了。怎么样,是不是特别的简单?
207阿星不是程序员 02:45查看AI文稿AI文稿
02:45查看AI文稿AI文稿挑战,用三分钟带你理解什么是 skill。 大家好,我是程序员牛肉。最近 skill 这个词在计算机圈子真的越来越火了,所以我们今天出一期视频,聊一聊什么是 skill。 看完本期视频,你将会学会什么是 skill, 它和 m c p v flow 有 什么区别?那什么是 skill 呢?如果我想让大模型把一个英文 pdf 的 内容提取出来之后翻译成为中文,并且最终保存为 mock 格式,那在这个流程中, 其实最大的问题来自于 ai 生成 python 脚本的不稳定性。比如说 ai 生成的 python 脚本可能提取的 pdf 不 符合预期经常性的小提取内容。又或者是保存为 markdown 的 时候不符合我的预期各级标题直接随意发挥了,那这个时候就是纯纯的抽奖了。这种任由 ai 随意发挥的代价是可能会消耗大量的 token。 等你看到欠费信息的时候, 你就知道什么叫做被资本做局了。其实从一整个工作角度看,可能就是两个部分最费力,而且是完全可以附用的经验,分别是提取英文 pdf 以及将其保存为 markdown 格式文档。聪明的你想到了一个办法,我在下一次做这个需求的时候, 直接把这两个部分内容涉及到的 python 脚本固定下来发送给 ai, 让它们不用再重新生成,而是直接附用之前的落地经验不就完事了?那为了让 ai 更好地理解我的要求,我可能要对我发送给他的这两个 python 脚本做简单的说明。 比如下面,我会发送给你两个 python 脚本,当我需要你完成提取英文 pdf, 并且翻译成为中文,最终保存为 markdown 格式的时候,你可以使用这两个脚本。其中脚本一是当你提取英文 pdf 的 时候可以使用的脚本脚本,二是当你将中文内容保存为 markdown 格式的时候可以使用的脚本。 并且我要求你强制优先使用我发给你的这两个脚本来完成操作,不允许自己私自生成脚本来完成这两部分逻辑。当你曾经有过这种操作的时候,那就说明你简单的发明了一个 skill。 所以 什么叫做 skill? 其实就是一个标准的 sop, 让 ai 可以 依照这个 sop 的 流程和工具进行工作,尝试复用已经成功的经验,它把执行方法,工具调用方式以及相关知识材料封装为一个完整的能力扩展包 a 阵的具备稳定可附用的做事方法。但是这个时候你发明的 skill 虽然能用,但是忽略了一个很重要的问题,当你积累了越来越多的 skill 的 时候,你要怎么高效的使用这些 skill 呢?这个时候你有两个选择,要么在问问题的时候一口气把所有的 skill 全部发送给 ai, 要么每一次你手动找一下你需要的 skill 然 发送给 ai。 这两个其实都有一定的缺点,第一个是太消耗偷看了,第二个是太麻烦了,还需要自己手动找。这个时候又有大聪明想到方法,我能不能把所有的 skill 都保存在 ai 的 客户端网站上,然后给每一个 skill 都起一个简短的介绍,之后在每一次提问的时候,我们的客户端会把所有 skill 的 介绍发送给 ai, ai 通过语音识别之后,判断他自己需要使用哪个 skill, 当他需要使用某个 skill 的 时候,就 在向客户端发送请求,让客户端把这个 skill 的 完整内容发送给他,这样他就可以基于这个 skill 来更好地完成任务。这种方式最大的优点就是节省偷看,其 其实就是把找四 kill 的 这个动作交给了 ai, 并且它有一个听着很炫酷的名称,叫做渐近式路由。想到这里其实你就可以发现它和 workflow 的 区别了,虽然它们两个本质上都是逻辑编排,但是 workflow 的 逻辑编排在设计阶段就已经决定好了,而 skill 主要是由大模型驱动,灵活性可以说碾压 workflow。 所以其实不太严谨的讲,我们可以认为 skill 就是 大模型驱动的 workflow。 而 skill 跟 mcp 呢?这两个其实本质上解决的就不是一个问题, mcp 的 主要目的是提供工具,而 skill 的 主要目的是提供使用工具的经验。 ok, 那 今天就介绍到这里了,如果觉得视频有用,不要忘记给小牛点个关注哦,我们下期视频见。
1510程序员牛肉(运动版) 02:212月23日 如何开始写一个高德skill,并且和openclaw一起用在我的租房日常找房子中,不知道有没有什么租房的agent我输入好需求,直接嘎嘎找 #链家 #SKILL #openclaw #AI查看AI文稿AI文稿
02:212月23日 如何开始写一个高德skill,并且和openclaw一起用在我的租房日常找房子中,不知道有没有什么租房的agent我输入好需求,直接嘎嘎找 #链家 #SKILL #openclaw #AI查看AI文稿AI文稿啊,现在 skill 非常火,然后一直在学习怎么用这个 skill, 然后最近正好也在上海这边看 租房子,因为换公司的那个房子到期了,要换一个住的地方,然后经常会找一些中介去问公司附近有没有一些合适的一些地点,然后发现我经常要去打开各的地图去查询我的工作点,然后和公司的地点之间的一个距离,然后我就写了一下这个 skill, 然后这个 skill 也是我写的第一个 skill, 然后整体的思路还是比较简单的,就是说这个 skill 我觉得主要核心的三个点,一个是 who, 一个是 when, 一个是 how, 那 who 就是 介绍这个 skill 是 什么,是干嘛的。然后我这边写的就是这个 skill 可以 帮助你查询地址的一个经纬度信息。 然后第二点是 when, 就是 什么时候使用这个 skill, 就是 当用户查询一个交通的情况,或者查询两个地址之间的一个路径规划的时候,使用这个 skill。 第三个写的是 how 怎么 to 去使用这个 skill, 然后最后一个写的是 go, 就是 我因为我那个高度里面需要修改一个 a p r t, 我 应该加了一句话,就是需要让 用户自己去改一下这个 a p r t。 最后一个是 common 的, 就是这个 skill, 我是 通过封装了一个 python 的 一个脚本去来调用的,然后这个 python 的 脚本大概是这样的 啊,也比较简单,除了改一下这个 ip 之外,其他的都是应该去写,然后整个写这个题目还是比较快的,比较简单的,然后就这样。
34黑加仑&车厘子 04:55查看AI文稿AI文稿
04:55查看AI文稿AI文稿一个 ai 自己生成图片,自己写文案,自己排版,自己上传 tiktok, 结果五天播放量破了五十万,单条呢最高二十三万,其中有四条直接破十万啊,人家呢,只花了六十秒,自己加个音乐,然后就点发布就可以了。 马上过年了,很多人都在想明年该怎么搞钱,怎么搞流量。那今天呢,我就给大家讲一个可能改变二零二六年你一整年效率的 ai 新玩法。但是先别着急啊,这个故事最精彩的部分并不是它的结果有多烂啊。 这个故事啊,是来源于硅谷的一个程序员,他想用 ai 来帮他去做自媒体。但是啊,这个 ai 刚开始生成的图片尺寸是错的,横屏的,而且发到 tiktok 上面全是黑边,文字叠加太小,被 tiktok 的 状态来挡住,用户根本就看不见,写的标题呢,全是自嗨型的 什么?看看 ai 觉得你的房间能变成什么样,结果就有八百多个播放。所以一开始啊,这个 ai 就是 个废物,哎,是不是跟你的感觉差不多啊?我们有多少人都觉得 ai 现在连个 ppt 都做不好,连个视频都做不出来,对吧?但是为什么它现在能从一个废物变成一个比人还强的 ai 呢?答案呢,就是一个东西叫 skill, 中文呢,可以翻译成叫技能, 那 skill 是 什么呢?其实就是一份文档,用来教 ai 怎么来做这样具体的事。你可以把它理解成一份超级详细的员工手册,不是那种好好干活的废话手册啊,是精确到每一个细节的操作手册, 它不是代码,它就是自然语言,中文、英文都可以用。比如说,这个程序员啊,它的 tiktok skill 呢,它就超过五百行。那它里面写的什么东西呢?比如说啊, 图片必须是幺零二四乘幺五三六的,竖屏不能用横屏。比如说啊,文字大小必须是图片高度的百分之六点五,不能是百分之五, 文字位置不能太靠上,否则呢,就会被 tiktok 的 状态栏给遮挡。每条内容呢,必须六张图,不多不少。 标题呢,必须用某个人加冲突加展示,加 ai, 结果加对方改变想法的这个公式,甚至连生成图片的提示模版都写死了, 房间的尺寸,窗户的位置,门的方向,天花板的高度,地板的材质,全部锁定。六张图,只改风格,不改结构。那为什么要这么写呢?其实因为 ai 每一次启动的记忆都是空的,他根本就不记得上次犯了什么错,他不记得哪一个标题爆了,哪一个文案拉了。而 skill 呢,就是他的记忆,就是他的经验,就是他越来越强的原因。 而且这个 ai 甚至自己都说了这么一句话,我觉得呢,非常到位。他说每一次失败都变成了一条规则,而每一次成功都变成了一个公式。这就是 skill 的 本质,它让 ai 有 了复利效应。你想想,一个新员工入职,你要花多长时间去培训他? 三个月,半年,甚至是一年?而且呢,它还会离职,经验直接给你带走。但是 skill 不 会,它呢,永远在那里,每一次的迭代啊,都在原来的基础上叠加。 ai 坏了, skill 还在,而模型升级了, skill 照样用。所以呢,这个程序员的 skill 啊,从第一周 skill 就 改了二十多次,从 图片尺寸的错误,到文字被遮挡,再到标题没人点,每踩一个坑就往 circle 里面去加条规则。那到了后面呢?他写的标题呢,比人写的还好。比如说,我房东说不能装修,我就给他看了 ai 觉得能改成什么样,直接二十三万播放。 我给我妈看了, ai 觉得客厅能改成什么样,十六万播放。我房东不让我装修,直到我给他看的这些十四万播放,全是 ai 自己写出来的, 人只是挑了一下,然后点一下发布。所以你看啊,真正厉害的不是这个 ai 模型本身, gpt 也好啊, cloud 也好,豆包也好,千文也好,模型大家都能用,真正拉开差距的是你给 ai pay 的 skill, 那 同样的模型没有 skill, 它就是一个只会聊天的机器人,而有了 skill, 它就是一个能帮你赚钱的数字员工。而且 skill 的 应用啊,远不止发 tiktok, 也不只是用在某一个平台。你是做电商的,写一个 skill, ai 帮你全自动分析你店铺的差评,提炼出产品的感情方向,还能自动生成客服的话术。 你是做自媒体的,写一个 skill, ai 帮你追热点,写脚本,选择题,甚至自动生成封面。你是做外贸的,写一个 skill, ai 自动监测海外社媒上用户的提问,用当地语言秒回, 二十四小时不停。你是做投资的,写一个 skill, ai 每天早上自动帮你整理行业的资讯,财务的招标,疫情的变化,发到你的微信上面。甚至啊, 你是学生,你可以写一个 skill, 让 ai 自动帮你整理课堂笔记,生成思维导图,并且按照你的薄弱点来出练习题,这都是 skill 已经在做的事情。 而 skill 的 威力就在于它把你的经验,你的判断,你的方法论全部沉淀成了一个可反复执行的文件,那你就不再是一个人在战斗,你有了一个永远不会累,永远不会忘,而且越来越强的搭档。 这就是为什么最近爆火的 openclaw 能帮你干活,因为它有一个庞大的 skill 市场,它可以随时加载你自己的 skill。 当然了,不止于此啊,只要你有了一个 skill, 你 就可以把它上传到 openclaw tree、 扣子,甚至是你公司的每一个虚拟工会上面。 新的一年马上开始,当别人还在手动搬砖的时候,你可能已经有了一个能自我进化的 ai 员工,这才是 ai 智能体。真正的玩法 不是跟 ai 聊天,而是教 ai 干活,而教 ai 干活的核心工具就是 skill。 那 skill 到底怎么写?怎么样才能让 ai 真正的变强?这里面有非常多的细节和技巧,想深入了解的可以预约我春节期间的直播,我会把 skill 的 设计思路,还有实战案例全部拆解给你。我是 c 哥,点赞关注,咱们明年见!
163C哥聊科技 04:13查看AI文稿AI文稿
04:13查看AI文稿AI文稿二零二六年最值得学习的技能呢,就是 cloud skill, 现在 osopik、 谷歌 openai 已经全部支持 skill 了,分享七个。最近一个月呢,在开元社区热度上涨最高的 skill 项目。第一个是 obsidian ceo, 他 自己写的一个 skill, 非常牛的用法是 直接绘制格式化的 canvas 画布。比如说,我让他创建一个 canvas 来解读刻意练习这本书,它会自动识别出需要调用 jason canvas 这个 skill。 大 概呢,花了两分钟啊,运行完成,生成一张 canvas 图,它直接把刻意练习书里面的内容和相互之间的关联化 出来,整本书的逻辑呢,一目了然。以前看书呢,容易迷失在细节和特定章节里面,现在用这种彩色的画布,让你瞬间纵览全书。再比如呢,让它创建一个读书的阅读管理系统,跟踪目前我读书的进度啊,它会自动识别并调用 obsidian faces 这个 skill, 然后生成一套读书管理系统, 显示了每本书的基本信息以及阅读的情况,并创建了子文件夹,对每本书进行总结。你还可以自行进行扩展,添加更多书籍笔记到书籍文件夹里面。地址呢,在这里。 第二个是 ospec 官方 skill, 里面有非常多的 skill, 比如说对 word, pdf 进行处理的 skill, 可以 从 pdf word 里面提取文本。再比如呢,前端设计的 skill, 最重要的是这个 skill creator, 它可以指导你创建自己的 skill。 地址呢,在这里啊。第三个是 gitup 上二点二万 star 的, 它可以指导你创建自己的 skill。 地址呢,在这里啊!第三个是 gitup 上二点二万 star 的 star, 它可以指导你创建自己的 这套 skill。 什么用呢?第一个,他懂得三思而后行,普通的 ai 拿到需求呢,一般直接开干,但是装了 superpowers skill 之后,他会先按住暂停键,会启动头脑风暴这个模式。 反过来问你这个功能的具体场景是什么,有没有边缘情况啊?他会先和你把需求聊透,把模糊的想法呢变成清晰的文档。第二呢,他是一个不折不扣的计划通,需求确定之后呢,他不会乱写,而是会生成一份详细的 实施计划。他会把大任务呢拆解成一个个两到五分钟就能完成的小任务,就像一个靠谱的架构师,把蓝图呢都给你画好了,你点头呢,他才开工。第三,他强制执行测试驱动开发,这是很多高级的程序员才有的习惯啊。他会先写测试用力,如果测试失败再去写代码让测试通。 最后呢,还要重构,这意味着它写出来的代码呢,其实会更加的健壮。这个 skill 库呢,还有很多功能,地址呢,在这里啊,大家可以去进一步的探索。第四个是模仿 manners 的 skills planning with fields。 这个 skills 借鉴的 manners 的 设计理念,将上下文窗口类比为内存,一时 有限。将文件系统类比为磁盘,持久而且无限。而核心的原则是重要信息均写入磁盘,而不是待在内存里面。 针对每一个复杂的任务呢,需要创建三个关键的 markdown 文件。第一个 task pen md, 用于跟踪任务阶段和进度。第二个 finding md, 储存研究内容与发现结果。第三个文件 progress md, 记录绘画日记和测试的结果。这个 skill 非常适合 多步骤的任务,三步及其以上研究类任务,以及需要多次调用工具的任务。地址呢,在这个地方,第五个是自动上传内容到 notebook l m 的 skill。 这个 skill 呢,也可以让你通过 cloud code 快 速获取带有来源引用的打 答案。对于每一个从 cloud 发出的问题呢,会先通过 notebook lm 进行一次答案的综合,然后再用 cloud 进行回答。这个技能借助 notebook lm 的 预处理能力,让 cloud 仅需要发送查询指令,接收精准答案,大幅地降低了 token 的 消耗。地址呢,在这个地方,第六个啊,是 skill prompt 检测 rater。 这个呢,是用来生成图片提示词的,内置了十二个专业领域的 skills, 比如说人像提示词专家,艺术风格专家、平面设计专家等等。它会根据用户的输入呢,自动匹配 对应的专家来帮助生成图片提示词,从而实现精细化生成的效果。比如说我让他生成生成电影级的亚洲女性张艺谋电影风格。使用豆包得到的图片呢,是这样的,而这个呢,是没有使用这个 skill 的 生成结果。我们可以发现呢,如果没有使用这个 skill, 生成的结果呢,更加的发散和随意。第七个是用来做内容营销的 skill, 可以根据多个关键词来生成文章,适用于 s e o 的 场景。地址呢,在这个地方, skill 呢,将 agent 和工作流的门槛呢,又降低了一个级别。二零二六年注定是各行各业 skill 的 爆发年。 现在看完这个视频呢,你就可以立刻去用起来,有什么不懂的可以评论区告诉我,想系统化学习呢,也可以加入我们的社区,下一期呢继续。
2717清华鑫哥讲AI智能体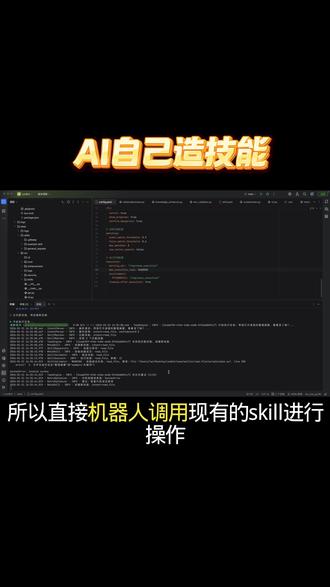 01:11查看AI文稿AI文稿
01:11查看AI文稿AI文稿哇塞,今天在家用 ai 开发出一个智能机器人了,实在太疯狂了。不多说了,看实操。第一步,先把需求生成对应的 p r d 文档,当然这个生成 p r d 文档的也是一个我开发环境的 skill, 生成 p r d 文档后,再以 p r d 生成项目代码。 我使用的是 open code 加 mini max m 二点一的模型,生成代码很快,价格又便宜,一个月才一百一十九米,每五个小时三百次 prompt 调用根本用不完。代码生成完就开始测试,让他给我整理桌面,一秒钟就整理完了, 还生成了对应的整理文档记录。现在我来让他做一个他没有的技能,他会怎么做呢?看到他正在生成新的 skill, 生成后 他会调用这个 skill 做对应的事,做完这个 skill 就 落库,所以直接机器人调用现有的 skill 进行操作。下次如果有一样的情况,他会重复调用这个 skill, 不 会再生成,使用的次数越多,他只会越来越聪明,使用 skill 读取出文档了。 这就是昨天讲的, ai 自己创造一个技能,然后再使用这个技能。需要这个原码的可以免费送啊,但是这个是第一版,后续还会继续接待。
18AI-码上疯 12:57查看AI文稿AI文稿
12:57查看AI文稿AI文稿各位小伙伴大家好,今天带来的是教你自己做一个 skill, 那 么 skill 是 什么呢? skill 是 一个用于为 ai 智能体扩展专门能力的开放标准,它其实是一个标准,而 skill 的 作用是它将特定领域的知识和工作流封装起来,智能体可以通过这些 skills 来执行特定的任务。 skill 从出现到现在已经有一段时间了, 而我对于 skill 的 理解是,它既是一个一个技能或者工作流的实体,而实体就以 skill 来进行命名。 举一个比较简单的例子,上一个视频里面我们介绍了源码学习的新范式,但是有一个问题, 咱们不能每次都复制那么多的提示词,然后给到 ai, 让 ai 帮我们去分析生成我们想要的东西,那有没有更好的方法方便我们做这个事情呢?那显然 skill 是 一个比较好的一个解决方案,我们可以把做这一个事情封装成一个技能, 而这个技能可以在我们的 project 里面去使用,也可以打包给到别的项目或者别人去使用。而这里面 skill 我 认为最核心的点其实无外乎使用了工程化思维的方式,也就是封装和复用。我们把重复的 工作或者流程封装成一个一个 skill 文件,而这些文件其实就是技能的具象化表现,而把这一些文件封装好一个整体给到别人,那其实就是附用。而我今天就是给大家实操一下怎么做一个自己的 skill。 那 首先 skill 的 生成方式,目前我总结下来或者使用的无外乎几种,第一种,如果你使用 ai 编程工具 ok, 那 你是幸运的,你使用的方式其实会比较简单。 那么第二种是用 scale 做 scale, 那 这里面跟为什么再讲一下呢?是因为 ai 工具它使用的方式其实就是用 scale 做 scale, 就是 有网上有一个技能可以下载到,而史劳克他也公布出来了, 就是你可以可以使用这个技能去做你的技能。之前我们说过, scale 也是一个开放的标准,既然是标准,它必然有相应的一个文件结构和文件内容的格式,那既然是这种形式,那必然会有一个工具可以帮助你或者辅助你完成这一个的编辑, 而有一个技能叫做 create skill, 也就是可以用这个 skill 去生成你要的 skill。 而第三点就是如果你懂了原理, 因为它是一个开放的标准,它有自己的结构,你完全可以自己去做一个 skill。 如果你使用的是 ai 的 编程工具,那有两种方式可以唤起这样的技能,斜杠命令和自然语言的唤起。那比方说 call 手这里 我打一个斜杠,我们可以看到这里面是有一个 skills 这样的技能库,我可以去选择它,那比如说我选择的是 create create skill, ok, 那 我如果是斜杠加上技能名称,那会自这个 call 手会自动调用这个技能去帮我们去创建创建我们想要的技能。 那如果是斜杠 create skill 之后,我要需要告诉 skill 说我要去生成一个什么样什么样的技能,它会自动调取 create skill 这一个 skill 的 技能去创建我们想要的技能。那说话说起来其实有点绕,但是确实是这么一回事儿, 但是 coco 有 斜杠,斜杠的一个方式唤起,但是 char 其实是没有的,那所以说 char 这里呢,就只能使用 第二种方式,自然语言的唤起,就告诉他我想创造创造一个技能,然后呢跟 ai, 也就是 char 或者 cos 这样的 ai 的 编程工具,会去调用 create skill 这样的技能,去帮你创建你要的技能。 ok, 我 们接下来进入实操阶段, 我们打开我们自己的 ai 的 编程工具,那我这边今天演示就是使用 char, 因为很多我发现很多的小伙伴使用的都是 char, 而并不像 cloud, cos 这样的。呃,国外的产品,那 char 因为免费,那其实另外一个原因呢,确实也挺好用。 ok, 我 打开的这一个 pro 九的是之前 github 上下载的 openspec 的 源码。那上一节呢,其实是教大家怎么去分析这么一个源码,快速的进入研研究的节奏。 当时是我们输入了一段提示词,就告诉他是一个高级架构师,让他帮我们去分析项目的结构,目录的结构,使用的基础站及如何使用。那如果说我们研究的项目过多,那每次都贴这么一段提示词,其实是挺烦的,所以说我们可以把这一个工作变成一个新的 skill 这样的一个技能, 下次呢直接调用这个技能,就能帮我去分析这一个项目的内容。我们新开一个绘画,告诉 ai 说我想新建一个技能, ok, 我 们看一下它的一个思考过程,其实就能理理解它的一个原理。我们输入的是我想新建一个技能,然后劝他会理解成,呃,他会去根据语义去分析说其实是创建或者添加任何技能时,然后呢需要去调用 skill creator 这样的一个技能,也就是说 我通过自然语言的方式去唤醒了 skill creator 这样的一个技能,而这个技能的目的是帮助我们去创建一个新的一个技能, 所以呢他会去调用技能这一个技能,去接下来去一步一步的完成我们自己想要开发的技能。然后呢,我们可以通过对话的方式告诉 说技能的名称是什么,技能的用途是什么,然后他会自动的去创建我们想要的 skill。 在 这里呢,我给大家介绍一种可塑化的方式去创建,不通过绘画的方式 打开设置,这里有个规则和技能,那这里面会有一个技能的一个功能,而这个功能其实是就前不久券发布的新版才出现的,之前券里面只有 solo 模式下才会有。 那这里面的技能其实分为全局和项目,什么概念呢?就全局的话是我创建的这个技能是以后所有通过券生成的。呃, project 都能适用,那项目级呢?也就说这个项目里面才会适用,那我们这边随便都一样,后面的逻辑都是一样,我点创建, 那他支持几种方式,一种是上传进行智能解析,也就是说我可以从网上下载一个这样的技能包,直接拖拽线进来之后他进行分析,然后构建出我这边的技能名称,描述和指令,这样的话就是自动变成了一个技能,加载到你的 try 这个 id 里面, 然后下次通过跟 ai 进行对话的时候,通过语义去分析的时候,会发现关联到这个 scale 进行调用。呃,那我们这边会去做一个技能名称的一个制定,技能名称我们这边填,随便填。呃, create d o c, 然后指令其实就是我们之前的一个提示词,但这个是比较简单啊,这个,这个写的比较简单,可以后面大家有兴趣的话可以看研究一下其他的 skill, 他 们写的会更专业些。而我们这边是做一个粗俗化的一个呃,技能包, 比如说描述是这一段 ok 确定,然后它会自动去加载好这一个技能库供我们去使用。 我们创建了这个技能之后,我们我们其实可以发现其实这里面会有一个文件夹,而这个文件夹的目录其实是很有意思的。 呃, char 是 代表了我们的 ai 编辑器叫 char, 然后 skills 是 一个标准的一个目录,然后下面就是技能的一个名称,然后这个 skill 是 我们刚才生成的,它会有个名称描述,再加上刚才说的一个提示词,就是刚才一个格式化的一个展示。我们创建了技能之后,我们如何使用它呢?我们先看一个绘画,比如说使用 这个技能主动唤起,精确唤起。但如果说我们在嗯提字词,也就是我们的 skill 里面的描述的提示词里面写的比较 ok 的 话,那它会通过各种语音分析去调用。 a few, moments, later, ok, 我 们来看一下整体的一个过程,我们输入了使用分析这个项目整体架构的这个技能,也就是我们刚才生成这个技能,然后呢,因为是精确的匹配,所以说他会主动去唤起这一个 skill, 那 思考的过程是我会,也就是去他会是使用 collect d o c 的 技能来分析这个项目的整体架构。 呃,然后呢,一步一步他会去做我们刚才让他要去做的这个事情。最终呢,我们后面有一个叫保,把最终的文件是保存到 alt 这个文件目录下, 而且这里其实已经有一个这样的项目架构的文件夹了,也就是说它其实是完全调用了这一个刚才我描述的这个过程,产生了我们这个项目架构的马克当的一个文件,完成了我们一个技能的一个调用和文档的一个输出。 然后这里补充一点,除了这种方式的换取。呃,使用这一个技能的方式的话,还有另外一种方式是我直接拖一个这样的一个文件告诉我应该说使用这个技能 也是进行精确匹配,精确匹配到我使用这个技能,那还有一种方式就是刚才我们演示的,比如说 chart 的 那个 cosuo 这样的 id, 它是支持斜杠进行,也是精确匹配到这个 skill。 而这种方式其实是在整体的你有一堆 skill 的 过程中,或者说我创建了很多的 skill, 而每个 skill 是 专业的去干自己的任务的时候,我们使用的方式是我们会把这一个技能放在相应 id 下指定的目录下,那这样的方式的话, 这个 id 会主动去加载这个 skills 的 技能库,通过这个描述,如果匹配出来,语义分析出来说,发现这一个我用户正在想干的这个事跟这个技能的描述相匹配,他会主动去调用这一个技能,然后再去具体的加载 下面这一段的文案或者叫提示词去完成像类似于专业的技能的工作或者工作流的 工作。而 ai 智能体通过渐进式批录的方式加载这一些 skills 的 技能库,可以有效地降低我 token 的 使用,因为它一开始是加载我整一个 name 和描述,那这样的话它的一个提整个的 token 的 消耗其实是有限的。 然后呢,如果是命中了我这一个 skill, 也就这个技能,它会再去加载我下面的内容,所以整体的设计是还是属于提示词的进阶,进阶的玩法,那我们再回到 我们的内容页,当我们通过 ai 编程工具去生成了我们的 skill, 而且它的原理其实是调用了 skill creator 这样的技能去创建我们这个 skill, 那 也完成了这么一个 skill 的 生成,那这个原理其实大家都已经明白了。之后下一步 各个不同的 id 的 一个目录的一个结构,之前我们选用的是 chart, 那 如果是 coos 或者 code code 其实都一样,也就说它在它的一个目录下,我会有一个 scales 这样的一个标准的一个目录结构,然后再下面才是真正的技能的一个名称 目录,那如果说是放在点下面,也就项目级,那如果是用户级,也就是之前也说过它分为全局和项目级 啊。 scale 的 结构,其实刚才我们只有一个 markdown 这样的一个 markdown 的 一个文件,但实际上它还会有其他的一些文件去辅助完成这个技能,呃,一个是它的脚本,我们可以把一些长的脚本放进去呃 scale 去调用这些脚本还会有一些依赖,比如说一些文档的依赖,然后一些静态资源。 因为我们呃官方也是建议 scale 它最好不要超过五百行,因为这样的话一个文件其实是就非常大了,它可以支持我分分文件夹,然后按照不同的呃文件的类型,分目录的存储, 而 scale 可以 去调用这些不同的文件,而这里的话是运行的一些脚本,而这一个的依赖的文档,比方说我现在要生成一个 ppt, 或者生成一个网页,而网页的格式的一些标准的内容就可以放在这个依赖里面,然后包括一些静态的资源。 而一个完整的一个 markdown 的 一个文件的格式是刚才我们其实已经看到过了,就是头部是一个 name, 也就是我 skills 的 名称,然后是一个描述,描述是它的一个 skill 的 功能,即什么时候会使用它, 然后下面是我的技能的一些描述,使用的一些时机。那所以说标准的一个 skill, 它其实还会有一些,我什么时候会去使用它,然后这个技能会适用于什么?再一次的明确我这一个 skill 的 一个能力。然后再下面是我的一个具体的一些内容,需要让我这一个调用这个 skill 时的时候去做什么事情, 我可以是干一个生成网页的一个一个,一个一个内容,也可以是我几个步骤或者工作流的方式去呈现我的一个能力。 那除了刚才的内容之外,头部信息也就说在这里还会有很多的其他的属性,我认为比较关注的除了最上面这两个之外还有一个,而这一个参数如果设为 q 的 时候,该技能仅会通过斜杠 skill name 的 显示的方式进行调用,而不会说自动根据上下文去调用它 什么概念。如果我这一个设置了 q, 那 刚才的方式自然语义的方式去调用已经不不可能了,只能通过斜杠的方式精确的匹配到这个技能才会被调用。那这个是刚才我们提说的一个提示词,也就说生成技能里面的一个内容, 然后呃,完成了我们这个 skill 的 一个基本的一个概念,再加上实操了一次如何去创建一个 skill, 那 我提问说一声,就是这一个页面的生成,你们看到这一个体系的生成,其实是我也是因为之前做很多的解释用的是纯文本, 那这样的话整体的视觉效果并不炫酷。那我自己也做了一个 skill, 是 专门去做做这一个页面的 skill, 它根据我的一个文案去生成了我这一个演示的 ppt 效果的。呃,网页,那有兴趣的小伙伴的话,下一次我可以专门介绍一下怎么去创建这么一个 skill。
 02:01查看AI文稿AI文稿
02:01查看AI文稿AI文稿这两天把点 ko 一 近五十个视频的啊,底层逻辑以及风格呢,把它封装成一个 skill, 然后能够自动帮我去生成啊公众号的文章或者是视频的脚本。然后呢,它还能够帮我自动配图,是如何做到的呢? 这个 skills 呢,主要包含以下几个部分,那第一个呢,叫提炼风格,在这块呢,我是一次性把点 ko 一 近五十个视频投入给 notebook lm 中,让它去帮我进行分析。 如果不知道怎么样去操作的小伙伴也可以参考我这期视频。然后呢,我在 gemini 中呢,让他分析出 denco e 的 这个整体的它视频的逻辑以及风格,呃,也生成了一套完整版的提示词,有需要的小伙伴呢可以在评论区告诉我。 然后我把这套风格呢,首先呢封装进我的 skills 里面。其次呢,我让他呃去帮我搜索,以及加上我自己提供的素材去生成文章,再让他去帮我去除 ai 位。这里呢,我参考了这个 skill, 大家有兴趣的小伙伴也可以去进行参考。最后一步呢,就是让他为我进行配图, 当然这步如果你觉得花的 token 太多的话,你也可以选择让它生成提示词。然后呢,后期自己去配图,因为本身一篇文章你也不需要配太多图。如果有需要去配图的话,呃,你可以参考我这个 key 的 配置。接下来呢,我把这整个 skills 呢进行一个封装,然后生成一个 md 格式的呃文件。然后, 然后呢我在 cloud code 中呢,首先我建了一个文件夹叫点 cloud, 然后呢在这个文件夹中呢,再建了一个文件夹叫 scuse, 然后,然后呢,我把这个文件呢命名成 wechat writer, 它这是一个一点零点零的版本。然后所有的刚刚我们说到的步骤呢,我都在这里面详细进行了描述。 接下来呢,我就要告诉他,帮我点扣一这个 skill。 然后呢,写一篇四百字左右的文章啊,就关于你怎么去看待 openclaw 这个主题,并且配两张图。然后呢,他就会帮我调取这个 skill 啊,然后完成相关的文章啊,包 包含了这个,呃,文章风格的这个提取啊等等。然后呢,最后呢,他就帮我输出了这一篇文章,我看着啊,我觉得整体还是挺不错的,有图有文。最后呢,我觉得大家可以去参考一下自己工作流中有没有一些重复的工作,把它封装成一个 skills, 快 去试试吧。
2663Alice.X 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿面试官问你, m c p 和目前 skill 有 什么区别?很多人在这个问题上就开始含糊了,什么都往上堆,说了一堆听起来都对,但其实没抓住重点,其实一句话就能说清楚。 skill 定义的是能力, m c p 定义的是连接 skill, 告诉 ai 怎么做事, m c p 告诉 ai 去哪拿东西。展开来说的话, skill 本质上是一组预定义好的指令和处理逻辑,你可以理解为一本操作手册。 比如你写了一个 skill, 教 agent 按照公司的规范去做数据分析报告,先按区域拆分,再算同比还比,最后按模板输出, 这就是一种能力,跟数据从哪来没有半毛钱关系。 m c p 呢?它是一个标准化的开放协议,解决的是 agent 和外部系统之间怎么通信的问题。你的数据库,你的网盘,你的代码仓库,这些东西都在 agent 的 外部, m c p 负责把这些通道打通,让 agent 能实时的去读取和操作这些外部资源,而且它是持续在线的,不是调一次就断了。 打个比方,你是一个厨师, skill 就是 你脑子里的菜谱,记录着每道菜怎么做, m c p 就是 你厨房里通向冰箱,通向菜市场的那条路,菜谱再好,没有食材通道你也做不出菜。食材通道再畅通,你不会做也只能干瞪眼。 这个时候,面试官大概率会追问一句,既然这样,为什么不在 skill 中加入数据获取的 a p i 呢?那不就能取代 m c p 了吗?这个问题其实是个陷阱,听起来很合理, 但经不起推敲。首先你要承认一件事,在 skill 里面写 api 调用技术上是可以跑通的,目前构建 skill 也需要放一些实际的代码,比如数据清洗的代码,格式转换的代码,这些都是 skill 里面很正常的组成部分。所以有人说,那我顺手把调 api 拿数据的脚本也放进去不就完了吗?逻辑上好像很通顺, 如果你只是偶尔调一个简单的接口,确实能用,但问题是能跑和能用好是两回事。第一个问题是认证,真实业务场景下,你对接的系统基本都有健全 off token 刷新,密钥轮换,这些事情你全得自己在 skill 里面处理,写一个还好,写十个你就疯了。而 m c p 在 协议层统一处理了这些事情,接进来就能用, 不用每个数据员单独搞一套认证逻辑。第二个问题是连接模式完全不同, skill 里面的脚本是被触发一次执行一次的,跑完就结束了,它本质上是一个无状态的东西, 但很多真实场景需要的是持续连接,比如监听数据库的变更,比如实时同步文件的更新。 m c p 建立的是一条常驻的通道, agent 可以 随时去查、去写、去监听,这是 skill 里面一段脚本做不到的事情。 第三个问题是扩展性。今天你要接一个 google drive, 在 skill 里面写一套请求逻辑,明天要接 github, 再写一套后, 后天街公司内部数据库又是一套,每一套都要单独处理分页错误,重试、数据格式转换,你会发现你的 skill 越写越臃肿,最后百分之八十的代码都在处理数据获取,真正的业务逻辑反而被埋没了。 m c p 的 意义就在于,它是一个标准协议,数据源那边实现一个 m c p server, 你这边直接连所有数据员,用同一套交互方式,不用重复造轮子。第四个问题也是架构层面最根本的问题就是职责混乱。软件工程里有一个基本原则叫关注点分离。 skill 的 职责是定义处理方法, m c p 的 职责是打通数据通路, 你把数据获取的逻辑塞进 skill 里面,就好比你在一份菜谱里面同时写了怎么养鸡,怎么种菜,怎么搭建冷链物流,能写吗?能,但这本菜谱会变得无法维护。 哪天 a p i。 改了一个字段,你得翻遍所有 skill, 去找哪些地方受影响。但如果数据层和能力层是分开的, a p i 变了,你只用改 m c p 那 一层,所有 skill 完全不用动。 所以结论是什么呢?在 skill 里面写 a p i 调用,本质上是在能力层里面硬塞了一个连接层的活,短期看能跑,长期看一定会疯。 m c p 和 skill 不是 谁取代谁的关系,而是各管一层,组合在一起才是一个完整的架构。 m c p 打通数据 skill, 提供方法通路加能力,这才是一个真正能在生产环境里跑起来的 agent。
439每日AI评论

