motiff可以导出vue代码吗

粉丝3.8万获赞66.0万
相关视频
 07:35查看AI文稿AI文稿
07:35查看AI文稿AI文稿一百行代码实现响应式系统大家好,这里是和前端小组一起学 vivo 三源码系列课程视频,这是第二十二章节,本章我们来带你一百行代码实现响应式系统,从零去理解 vivo 三的核心魔法。我们来思考一下响应式系统是为了解决什么样的问题? 当你在 view 中修改一个数据界面就会自动更新,这看起来很复杂,但其实背后的原理并不复杂。理解原理的最好的方式就是亲自实现一个核心版本。我们假设在有个这样的场景,我们希望当 counter 变化的时候,自动去执行这个 update ui, 那 么如何去实现这个目标呢?我们首先需要知道 响应式系统的本质是什么,它是一个观察者的模式。那么解决整个响应式系统的核心就在于两步,第一步就是一代收集,就是 track, 就是 记录谁在读取这个数据。第二步就是触发更新, trigger 就是 当数据 state 点 com 变化时,通知所有记录下来的使用者,数据变了,该重新进行执行了。 所以我们第一步我们就要去搭建一个核心的数据结构,因为响应式数据系统它需要维护一个依赖关系图,就哪些函数依赖了哪些对象和属性, 那么我们就可以去做一个全举的一个核心的依赖关系图谱。我们是选一个 weakmap 来进行处理,大家可以看到这个 weakmap 其实它它的一个 key 指是什么? key 指就是一个响应式对象, 而响应式对象它的一个 value, 它其实还是一个 map, 而它的 map 是 什么?它的就是对这个响应式对象所里面的一个属性,而属性它所对应的就是一个 set, 一个一个 effect 副作用, 而我们会去定一个 active effect, 这是个全卷变量,就像一个时针,当任何函数去执行的时候,如果它读取了数据,我们就把这个时针指向的函数记录下来。而第二步我们就实现这个以核心就是 track 和 trigger, track 我 们刚说过的,它是一个收集,就是读取属性时调用,然后同时它会去将 active effect 去放到到 dips 的 集合中,我们来看一下这个 track, 在 这里我们就会去首先我们去读 dips map, 就是 从 target map 就 获取这个对象,如果它没有,我们就会进行一个抽象化,我们再去拿到这个 dips 获取的一个依赖 dips 如果没有的话也会进行抽象化,然后将这个抽象的 dips 去添加到,添加进这个 active effect, 那 首先需要注意的是 这个表示什么?就表示没有正在执行的 effect, 就 说明它只是一个普通的读取,那就是不需要去进行个收集。而最后一步的动作是什么?就是将当前正在执行的函数添加到一代集合中。第二个就是 trigger, 就是 触发,在修改属性时去调用它。 核心逻辑就是什么,就取出 dips 便利去执行所有的 effects。 我 们可以看到我们首先我们去读取这个 target, 那 如果它没有 dips, 没有没有依赖,那它们就不会去触发更新,就主称,那它首先它会去获取到所有的 dips, 然后对 dips 来进行一个挨个去执行所有依赖这个属性的函数,有了 track 和 trigger, 那 我们还要去做什么?还需要去实现一个机制,就将函数在执行其执行前把自己注册为 active effect。 这里有个序,有个细节就是 effect 是 可以嵌套的,就比如说副组键去渲染子组键,因此我们就需要在执行完当前 effect 后,把 active effect 恢复成外层的 effect。 那 我们具体来看一个这个视例, 我们首先我们去保存外层的 effect, 就是 保存下来,再重新去设成一个当前的 effect f n 去执行这个函数,而这个函数它里面去做什么呢?这里面它就去触发属性的读起,去重回记录 track, 这就是恢复赋值,就 active effect 恢复回去,然后最后立即执行一次 effect, fn 就是 catch 依赖的一个收集,那我们实现的核心我们就需要去拦截对象的读取操作。六三是通过 pros 来去实现的,那这里有两个非常关键的点,就是地归代理, 就是如果属性值是对象,那就需要地归转化为响应式对象,那同时还有个单例缓存,就如果一个对象已经被代理过,那么就应该返回同一个 pos 实体,保证引用的一致性,那我们来可以看一下这里,首先我们去定义的一个缓存,就是防止同一个对象被代理多次,这里就是如果他已经被代理过了,那直接返回缓存的 pos, 那 这就是一个真正的响应式,一个核就 react 的 一个核心,就是这个在读取时去收集依赖, 然后这里是通过一个懒代理的形式,如果是对象才转化它,而这里就是一个 set 的 一个方法的一个拦截,就是修改属性时进行 trigger 就是, 而它的一个 api 其实就是一个,无非就是 get, 就是 进行 track 并递归代理子对象去进行懒代理 set 进行 trigger 去触发更新, 我们还要去实现 r e f or computed, 就 r e f 它是干嘛呢?它是用来包装基本类型,而 computed 它是用来自动计算的,那具体是怎么实现的?那 r e f 那 其实就非常简单啦,就是通过一个 initial 去定义,然后再里面再去做一个 r 的 一个对象,然后进行一个 get 和 set 去返回这个 r a computed 呢?那其实就是使用 r e f 来去做一个加一个 effect 的 一个组合,这是干什么?就当依赖变了,然后 effect 自动跑去将 resulted value 去进行一个重新的更新,再进行一个重新的一个处理 将,那我们走到这一步,就将以上的代码进行完整的一个整合,我们就得到了一个微型单线功能和核心的一个系统,在这里进行一个显示,大家可以截图保存,来大家去实现一下啊,如果大家想看这个代码,会非常欢迎,大家在评论区啊 点评论一一,那我会去将这个源代码去发送给你们。需要注意的是,虽然一百行代码能够跑通核心流程,但其实相比 real 三真实的源代码就是成千上万行,它在健壮性和性能上还是有非常大的差距,就是以下是我在实现迷你版本时,为了简化而去偷懒了,一个五件的一个非常关键点, 第一个是什么?就是缺乏依赖清理,就在我们实践中,依赖只会被添加,而永远不会被移除,那啊,假设它在 effect 中,这里就是 flag 变成 force 就是 依赖,还会检测 message, 那 其实没有必要去检测 message, 那 这就涉及到一个依赖清理的一个过程,略的做法是每次 effect 运行起来去清理一个旧依赖。 第二个就是缺乏一个调度器 schedule, 我 们的实现其实是大概看是同步执行的,数据一变, effect 就 立即跑,那我们就是有个场景,就当我们对一个 state 点 count 连续加三次的时候,那我们就会去 effect, 就 会被同步触发三次, 这其实是会有一些性能浪费的,那也没必要。而真实的 view 它是怎么做的?它是通过一个调度器和 welearn 对 列,就 microtest 去将多次数据去变更合并,在下一次到我们更新周期中只执行一次 effect。 当 还有就是一个 computed 的 懒执行与缓存优化,还包括像数据与集合类型的特殊处理,在 compute 的 缓存中我们是立即执行的,但是 view 它其实是懒执行的,就读取这一台去算,并且去有缓存就一代不变不重算, 我们是没有去处理 array, set, map 等特殊方法的 push for each, 但是 view 其实重写的这些方法已保持正确的追踪。还有第五点就是一个递归循环保护的一个作用,就是在 effect 内部中修改了自己一代的数据,比如说像这样子去重新去做一个修改, 那我们其实会做一个无限的地归暂回移出,而真实 view 就是 有检测的一个机制,就是如果 trigger 触发的 effect 就是 当前运行的 effect, 则忽略进行一个执行。 虽然上述与是有差距,但是你现在掌握的是 prosc 的 拦截加一代收集图谱确实是 view 响应式系统的一个核心灵魂。这而真实的圆满优化更多是为了处理边界情况,提升性能以及适应更复杂的当情况 就理解了这一百行代码更多是为了处理边界情况,提升性能以及适应更复杂的当情况就理解了这是如何将这个核心设计就是更加贴合业务场景。 好的,这期视频我们就到此结束,欢迎大家点赞订阅以及分享我的频道,如果大家有任何问题,欢迎在评论区啊表达你的意见。对啊,那我们本期视频到此结束,我们下期节目再见!拜拜!
133前端小卒 05:19查看AI文稿AI文稿
05:19查看AI文稿AI文稿大家好,欢迎来到前端进阶课堂 real 三最佳实践。我是前端小组,今天我们来跟着 nt4 去学 real 的 最佳实践,我们去揭秘 real 核心团队成员的代码结闭和最佳实践。在 github 上, nt4 的 名字几乎代表了 real 生态的最前沿,而他最近开源 nt4 scales 的 仓库, 我们今天就来扒扒一下大佬的这个仓库,去梳理一套能让你的 vivo 项目脱胎换骨的规范。我们将从最基础的响应式变量开始,一步步深入到逻辑赋用于代码以组建架构,带你领略什么叫做优雅。而这一第一个章节就是心智模型的大一统。为什么我们只用 r e f? 当我们去开始写一个新组建的时候,第一件事情往往是定义数据,这时候经典的选择困难就出现了,用 i e f 还是 reactive? 在 nt for 的 代码事件里面,这个答案就只有一个,就是 i e f。 很多人为了写不写点 value 而使用 reactive, 但其实在解构 reactive 对 象的时候,响应式就会无声无息地丢失掉, 然后这很容易去出现一个 bug。 比如说我们在这个情况下,我们使用 reactive 去对一个 state state 来进行一个响应式,那我们进行解偶之后, 它这里通过 watch loading, 但其实它其实不会永远不会被触发这具体它的问题的出现,那其实可以翻看我过往的和前头小组一起学六三元码的一个课程视频。但如果我们使用 count 去进行 i e f 的 话,那其实无论是你解 o 之后,它其实都不会出现这个问题。 而 nt4 它的一个 ief first 的 一个策略是什么?就是统一使用 ief, 即使是对象,那这带来了一个巨大的认知常识,就是看到变量就知道它需要点 value, 只要结构就知道使去使用 to ief 的 一个 api, 就 即使我们重置的整个对象响应式其实依然是存在的。 我们来可以看一下。又回到那个例子啊,用 state, 用 ief 来进行处理,哪怕你用 reset 一 点 value 去重新设置,那其实它的响应式依然是存在的,而这个也就是复位,它没法去做到这一点。而第二点就是一个精准控制响应式, 就是将那些庞大的第三方实力不去做一个深度的响应式。 view 的 响应式系统非常强大,但如果不加节制的乱用,那它就会对我们的业务造成一些性能的滥用。那 n n t four 的 代码里面其实就是无时无刻就使用 share ief, 那比方说我们用使用 interest 实力 macbooks 对 象,地图对象,或者成千上万行的纯静态接收数据塞进到 i f 的 时候, vivo 它会去尝试地归地,将每一层属性都穿上 post 的 马甲,这就是完全的性能上的一些浪费啊。举一个例子, 我们去做一个 etht 的 一个啊, instance 的 一个实力的代理,或者说我们对一个 huge justin list 来进行一个代理,那其实它会每一行每一个数据都会被代理, 那这时候我们就去使用 share i f, 而 share i f 就 跟它 a p i 名字一样,就是 view 只监听点 value 的 变化,而忽略 对象内部的一个属性。它适用于什么呢?它适用图表,实体地图对象以及纯展示的大列表,我们可以看这样子,就直接使用 share i f, 然后修改数据,是直接替换引用,然后去发去触发追踪,搞定了内部 状态。接下来我们看组建之间如何优雅地传递数据,就是 purpose 和 model。 在 view 三点四之前,父子组建通信,往往伴随着繁琐的样板代码, nt4 极力推崇利用最新的红来简化这一过程。那我们来看一下这个响应式结构, 我们是通过 define purpose 来进行这个我们就在 watch effect 中直接去使用 message view, 它其实会编辑,会自动地去处理响应式追踪 define model, 它以前为了实现 we 干 model, 我 们需要定义 purpose 在 in map 事件就就是会做一些重复性的工作,那 n t four 就 在新项目中就已经完全全面转换转向了 define model, 我 们来看这个,它直接通过啊, constant model value 就 define model, 然后再修改 model value, 点 value 会自动通知副键,就像 ief 一 样,非常的简单。 那我们组建写好了,但是业务逻辑很复杂怎么办?这时候就需要去提出组建式函数,再去灵活地兼容 maybe ief anti four, 它是 real use 的 作者,它对封装 hulk 有 着近乎偏执的标准,它核心原则其实就只有一个,灵活的兼容。它认为就不优秀的封装就是强迫用户闯入 i e f, 但是优秀的封装应该是同时去啊, 支持普通值 i e f get 函数的时候,它应该是两者通吃。那它是怎么做的呢?它其实是使用 mu 三点三的 to 或者是 use 的 on i e f 去去将输入参数的一个规范化,大家可以看到在这里去接收普通值 i e f 或者 get 函数,然后 to 外头自动去进行一个解包, 然后再进行一个处理,那逻辑复用做好了,我们最后来看一下如何通过工具链和类型系统,就是简化我们的代码。在 nt4 scales 中, t s 不 仅是用来报错的,而是用来自动推导的。它首先第一点就是让组建支持发行,就是不要在组建中去写 any, 就 如果你的组建是一个列表渲染器,那他应该知道 列表像的具体的一个结构,然后同时自动导入,像 ief compute, 像矩阵变量一样使用,去保持代码的一个整整洁。 大家可以看到在这里这里的 item 就 会自动拥有 t 的 类型提示。那我们总结一下 nt4 的 一个风格的路由开发,核心 逻辑就是一致性优先就全员 i f 全员自动导入,然后性能其实无感化的,用 share i f 处理静态大数据,然后包括类型及文档,用范型组建和 t s 推导。好的,本期节目就到此结束了啊,欢迎大家订阅分享以及转发我的频道,我们下期节目再见。
485前端小卒 07:48查看AI文稿AI文稿
07:48查看AI文稿AI文稿大家好,这里是和前端小组一起学 view 三原码系列课程。本章节将讲解 dom 系统的第一章, runtime dom 设计。 view 它其实是一个响异式的一个 ui 框架,开发者描述界面应该是什么? view 负责将这个描述变成真实的 dom, 但是 real 它其实并不仅仅只是一个限于浏览器渲染,它希望能运行在任何的平台。这就引起了一个核心的架构设计,就是渲染什么和如何渲染进行一个分离, 而其中渲染什么就是 runtime core 和如何渲染就是 runtime dom。 runtime core 就是 定义的 diff 算法以及组建生命周期以及通用逻辑等等。而 runtime library 它其实是定义的 dom 操作事件绑定, 这就是浏览器特有的一些行为。这种分离带来了非常巨大的一个灵活性,就是同样的 run time query, 配合不同的平台,实现可以渲染到浏览器的 dom canvas, 原生移动端甚至是终端平台。 而本章节我们将聚焦于浏览器平台,看看 run time dom 是 如何将 view 的 抽象渲染能力落地到一个真实的一个 dom 的。 每个 view 的 应用都从 create a p p 开始,这也就是我们日常最常见的一个 api。 那 么 create a p p 变后代码到底发生了什么啊?我们可以看一下它这个原代码的一个实践。在这一中我们需要注意的是 app 它里面它调用的 ensure, 它是什么?它是它。其实 ensure 它保证了渲染器只创建一次,并且它是一个惰性创建的过程。对,在这它是一个惰性创建的一个过程,只会去创建一次,然后它会返回一个 app, 并且它还会去将 mount 给重写的,就 app 的 mount 好 像是给重写的,它里面去增加了一个容器解析,就 memorize 清空容器,做一些数据属性的一些标题,去做了一些这样子的一个动作。这就是个 create app, 它内部的具体的一个实现。为什么它是要通过 ensure 这个函数去做处理呢?它是它采用的惰性触式化渲染器,只在第一次调用 create app 的 时候创建,它主要是为了一些 tree shopping 就是 如果用户只使用响应式的 api 而不需要渲染层, 那么渲染器代码可以被完全的移除,大幅度的减小了包的一个体积。又提供了两个创建应用的函数,一个是刚刚我们提到的 create app, 一个是 create ssr app。 二者的区别其实非常简单,就 create a p p 使用 ensure render, 它挂载是清空容器, hydrating 就是 force a create a p p 就是 使用 ensure hydration render, 就 保留保留的容器内容,就是附用 h t m 的 hydrating 就是 true。 在 之前我们提到的 normalize container 就是 容器解析, 在这里它其实它 mesh container, 它支持自创选择器 dom element shadowroot, 同时这的 result resultroot name space, 它是会自动地去识别 svg 和 mass massmail, 去确保紫元素在创建时使用的正确的。 create element name space 这里我们需要注意的是,这个 memorize container 自动选择器就是我们最常见的方法,就是井号 a p p 会使用 document script 去查找元素,而 element 是 什么就直接传到 dom 元素,比如说 document 点 get element 百 id a p p, 然后 shared root 是 什么?就是支持挂载到 shared dom 中,而这对于 web browsers 是 非常重要的。 o p s note o p s。 是 run time dom 的 核心,它封装了所有底层的 dom 的 操作,大家可以看到它其实它这边暴露了非常多的一个呃 dom 的 一些方法。 insert remove create element test set element test parent node nest parent data 它其实它只是对一个 dom 的 一个 api 进行一个二次的封装,去结合 view 的 一些内部属性,为什么要去封装它们呢? 这是为了去做一些跨平台的一个抽象能力以及命名空间的处理,还有特殊元素的处理。在这里我们可以看到它其实内部,它 其实内部它去做了一些将平台无关的 carry 逻辑与平台特定的 dom 进行操作。就渲染器它需要两类操作,就是 node op 就是 元素级别的侦查改杀 patch proper 就是 元属性级别的更新,而这两者进行一个有机的一个结合,去将平台无光源 query 逻辑与平台 dom 的 dom 操作去 结合,而这里就是通过 instant 去传递给 query 的。 create render run time query, 它其实根本不关心节点是 dom element 还是 canvas 对 象,它只调用住读的 note a p s 接口, 就是 render, 就是 渲染层,它其实是 core 加 node ops, 而对于 dom 就是 浏览器来说, node ops 其实就是 runtime core runtime dom 在 刚刚我们可以看到 我们是有一些特殊的一些 dom 的 一些操作,那其中这里面会有个非常重要的性能,就是我们性能优化。我们面试中经常问到的就是编辑器,它会识识别模板中的静态内容,就是我我们之前他在编辑器中提到的静态提升的一个作用, 它其实它会去将它们提升为自常量。自创首次渲染就是解析 html, 自创 tabloud 缓存命中的时候,就是后续渲染就直接会刻入 node, 就 大幅度提升了大量静态内容上的性能。 需要特别提到一点, destet types 就 安全策略,而这个一点我们会将下一个章节会着重去讲。现在的浏览器,它其实支持 trace trishtypes, 这是一种防止叉 s s 攻击的安全机制,它要求所有处理 in the html 的 值都必须经过性能处理。在这里我们可以看到 view 它其实做了什么,它其实它是输出 web, 就是 如果浏览器支持的话,它其实去创建那个一个名为 view 的 trishtype 策略。 当设置 in the html 的 时候,通过 serve to trishtype 来去包装值,这里这里返回的 create html 实现 是简单的,返回的原值就是 real, 它其实是假设传输的内容是可信的,就是来自编曲生成的静态内容。如果 c s p 策略不允许创建重复的策略名,它会去捕获到错误,并在开发中去反警告。 real 三中对 reference 它其实有非常友好的支持度,就 define custom element, 可以 将 real 组建转换为文原生的 cost element。 大家可以看到在这个章节中就 it's cost element, 它其实就定义的就是 如果当在 view 中使用第三方 costemaster, 需要配置编辑器,告诉 view 知识原生标签不需要尝试解析成一个 view 的 组建,而这里它有个非常,而这个就是一个缩减器创建 流程的一个核心,那个逻辑就是 create a p p in sharer 不 存在就可以的去注入 node o p s a patch, purpose 等等,然后包括它的 a p p 重写, mount, mount normalized container, 清孔笼器,执行挂载等等的操作。 time dom, 它是位于浏览器 dom 之间的一个桥梁,它通过 node o p s 封装底层的 dom 操作,通过 patch proper 去处理属性更新,将这家平台的相关实现注入到了 runtime core 的 通用渲染器中, 并且它 create a p p 的 延迟模式对程序员非常友好。这些分层的设计其实是使得 feel 具有了跨平台能力,同时在浏览器平台上保持了高效的盗木操作。而下一章节,我们将深入地去做 hash proper, 去看 cast trace 是 如何被高效地进行更新的。 那我们有些思考题就是用什么 create a p p 设计成以延迟创建缓存机制,它是何时失效的 close shared route 的 问题。 好的,那本次节目就我们到此结束了。好的,本期内容就到此结束了啊,欢迎大家订阅分享以及关注我的频道,我们下期节目再见,我是前头小猪。
64前端小卒 04:25查看AI文稿AI文稿
04:25查看AI文稿AI文稿百分之九十九的前端都用过 i e f, 但是没有几个前端能真正的搞懂 custom i e f。 我 们在写 ve 代码的时候,天天在用 i e f 定义成像素变量,那么 i e f 它只解决一件事情,就是数据变了,试图渲染。比如说我们的接口的返回,我这地方是调用一个阿卡克斯接口,在这个生命周期里面啊,赋给这个 u r s 这个显示数据,对吧?调用接口反过来数据,然后这个数据呢?我在页面里面就直接渲染出来,看到没有,那么这样的话,渲染出来的效果就是这样的一个效果,列表,这三个列表,那么这时候我们用显示数据就是用另一层 i f。 还有一种情况就是我们的表单的输入,就比如说在这里面 我定了一个表单,可以输入用户名,在里面输入用户名,页面上实时的显示出来,那么这个 u 的 内部我也是定义成了响应式,呃,在这里面输入,你看我输入 a, 这地方显示 a, 我 输入 a 显示 a, 也就说像我们常见的这种接口的返回啊,表单的输入啊,包括这地方的 low 定的状态啊, 什么时候,比如说我数据变化,什么时候触发更新 if, 等于是 v a 内部帮我们做了 真实的项目里面,我我们也是这么用的,像 custom 它的出现又解决什么问题呢?咱们直接看这个代码,看一下这个页面,我在这里面我可以搜索 a a a, 对 吧?我在这里面搜索,其实按照我们的理解,你不可能说我输一次 a, 我 调用一次后端接口,我输一次 a, 我 调用一次后端接口,那这样的话会频繁的触发,那这时候你可能说想到了是哎,我要做防抖节流,也就说我什么时候让它更新矢图, 什么时候触发更新,这个东西你不能交给内部去处理啊?我们要自己去优化,就比如说在这个地方,我这里面有一个文本框, keyboard 这个文本框, 对吧?它是这种类型的,然后我监听这个数据,也就是文本框里面的数据变化的时候,那么我去根据它输入这个值去调用这个后端的 ip 格式,调用回来之后,然后我这个在这里面去渲染这个 rayout, 这路由是显示的,那么这里面就是一个问题,也就说我这个地方的文本框输入的时候,我什么时候去触发阿卡克时,我不能说你输入一次我就掉一次,输入一次我就掉一次,这样呢基本有问题了。那么在这里面我们在这里面封装了一个 control i f, 这时候 control i f 就 派了用场了,那么这里面有一个 get 和 set, 这个 get check 是 收集,收集,然后 set 是 设置,也就说在这里面我要做防抖减流了,这里面我可以传入,比如说五百秒的时候你给我收集一下,五百毫秒的时候延迟五百毫秒你给我收集。 也就是说在这地方他什么时候真正调用阿贾克斯,并不是说我输的时候他有调用,比如说我在里面输入一的时候,他才真正的去调用,他这地方其实是做了优化的,并不是说我一直输,他一直调用,这时候交给我们开发者了。如果你用 if 的 话, 大家想想,我在这里面每打一个字都会触发, watch 都会触发请求你用 custom, 我 们在这里面可以明确的告诉 me, 等用户停下来五百秒,五百毫秒的时候,那么值变化的时候我再去更新。那么 cost 他 们的一个核心就是说值什么时候变, 什么时候变,我说了算,我在这里面做处理了。在设置里面,包括我们的这种情况也是同样呢,我在这里面也定了一个 这个 custom, 那 么这个是 i f custom, i f, 那 么这个里面我在里面去做了处理,什么时候变呢?根据用户输入的这个这个值,这个值就是用户输入的,也就是说这里面我定了一个问框,就是考这个分数,我自己定义的就是什么时候变 我说了算,并不是说你在文本框里面输入了他就变,不是现在他他没变,看他没有渲染吗?他没有执行这个盗图重选。我输入一的时候,因为我这里定了规则,这什么规则呢?小于零 或者小于十的时候返回输入一,这样,这样,这样就变了,看到没有?这样的话再重新选,但是我我输入小于一的,他不会选的,他不会选,这样的话其实我避免了不必要的 选,也就是说 r e m 是 声明式的响应式,它是可编程的,响应式的 custom 交给我自己去开发了。如果你做这种大型的项目,比如说像这样的搜索,那什么是适合的控制这个输入,输入控制还有性能的敏感区,还有封装后壳式的时候,我们在里面可以做处理。
97大伟聊前端 07:09查看AI文稿AI文稿
07:09查看AI文稿AI文稿c s s。 能把无聊的网页变好看,而一堆又小又简单的 c s s 类,最后竟然改变了开发者做网站的方式。 今天我们来聊 tailwind。 c s s, 它一开始只是个小点子,很快就成了全世界前端的常用工具,几乎到处都能看到它的身影。但关键来了, ai 编程工具进场后,规则正在用没人想到的方式被改写。 接下来几分钟,我会拆解 tailwind 的 崛起背后的设计原则,以及现在正在发生的变化,可能会重塑 web 开发的未来走向,也会影响你写代码的习惯和工作流程。开始吧,我们先从最基础的地方说起。 做网站时, html 负责结构, css 负责好看,你写一堆规则去控制颜色、间距、字体布局等所有视觉效果。听起来很简单,但很快就会变得一团乱。 tailwind 出现之前,网页样式基本都得自己写,你会起一些类名,比如 header、 button、 primary、 large。 过了半年,你自己都不知道它们到底代表啥,别人接手更是一头雾水。 c s s。 文件越堆越大,上千行纠缠在一起,维护成本直线上升。不同开发者起名各不相同,毫无一致性,全是混乱。更痛的是,你改一个小地方,完全不相关的东西也可能崩掉。 c s s 就是 这么不可预测,常常让人心累又抓狂。那 tailwind 做对了什么?它不让你写一堆自定义样式,而是直接在 html 里用现成的工具类, 要那边去就用 p 四,要蓝色背景就用比基布鲁五百,要圆角就用 round 的 料制, 都是小而稳定的积木。每个类只做一件事,而且命名很统一,行为也可预测。 就像自己裁木头和搭乐高的区别,都能盖房子,但乐高更好拼好拆,还能复用,团队协助时也更不容易打架。但 tailwind 的 成功不只是工具类,而是它用上了扎实的设计原则。跟我们天天做系统设计,用的是一套 有条经典规则,组合优于继承。意思是别把东西串成一条互相依赖的链,而是做成小而独立的模块,再把它们组合起来。 tailwinds 在 css 上就是这么干的,每个工具类都独立,可替换可叠加, 互不牵连。 tax center 就 只负责居中, flex 只负责开启 flexbox, 没有隐藏依赖,也不会突然给你惊喜。混搭不易出问题,调试更好定位哪条类再生效,回滚也方便,写作也不易踩坑。 这个思路跟微服务一样,小而独立的单元协作,彼此解偶,又能组合,替换某一块也轻松。再来是约定优裕配置, tellwind 自带默认值,兼具有刻度,配色挑过字号,开箱合理,你不用从零决定,框架已替你做出靠谱选择,用起来省心也更一致, 这也能减少选择疲劳,团队会更一致,这也能减少选择疲劳,团队会更一致。这也能减少选择疲劳,团队会更一致。这也能减少选择疲劳,团队会更一致。这也能减少选择疲劳,团队会更一致,这也能减少选择疲劳,团队就行。 第三个原则,行为的局部性,听起来反直觉,传统 c s s 把东西分开, html, 一个文件样式,另一个文件看起来很干净,对吧?但实际用起来,你总得在文件之间来回跳,才能搞清楚到底是谁在控制样式。 tailwind 把样式直接放在元素旁边,你看一个按钮,就能立刻知道它怎么被设置的,不用找,不用猜,改动也更有把握, 对团队合作来说也更直观。新人读代码上手会快很多。我们用三个核心原则,组合约定,局部性解释了 tailwind, 而这些思路在微服务、数据库、 ai 系统里也到处都是。掌握这些底层原理,学任何新技术都会更轻松。这也是我在 system design master 课程里强调的重点,不只是面试准备,而是建立一套思维模型,让你像资深工程师一样思考。说到底,谁都能做工具类,真的, 你周末就能做个简化版 tailwind, 那 他为什么能赢?因为他们不只是做了个工具,而是围绕他搭了整套生态。 比如 tailwind ui, 一 套专业设计拿来就用的组件库,复制粘贴,改一改就行。 还有 g i t 模式翻译超快,只生成你实际用到的 c s s。 还有 i d e 插件在编辑期里直接自动补全,你敲个 b j, 所有背景色立刻出现,再加上对 react, view and x 点、 g s 等各种技术站的一流集成,怎么用都顺。 再加上庞大的社区,每天都在做插件模板和扩展,生态越滚越大,这在商业上叫护城河。 一旦进了 tailwind 的 生态,换掉它的成本很高。团队会了,代码库依赖了,工作流也围着它转,连招聘标准都会受影响。你会发现,文档组建库、设计稿也都默认按它来。这就像 e、 w、 l s, 很 粘人,不只是一个服务,而是一整套几百个服务串在一起, 然后反转来了。 tailwind 最近裁掉了百分之七十五的工程团队,从四个工程师变一个, 收入也跌了大约百分之八十。发生了什么? ai 来了! get up a copilot 和 catch gpt 这类工具,写 tailwind 的 代码已经强到离谱, 甚至比人更稳定。你让 catch gpt 写一个蓝底白字、圆角带 hover 效果的按钮,它几秒就能吐出一串完美的 tailwind 的 类名,还能顺手补上响应式和深色模式,连命名间距这些细节都能一次到位。 tailwind 的 当初最容易学的特点,比如符号化的类名、可预测的命名、 统一的模式,恰恰就是 ai 模型最擅长的。 tailwind 简直就是模式匹配的天堂,给他例子,他就会举一反三。 当 ai 把这些模式学会后,开发者就不太需要看文档了,直接问一句就能生成。网站流量掉了,收入也跟着掉。裁员百分之七十五的第二天,创始人 adam arson 直接把情况说透了。 他在 github 上写道,现实是我们工程团队里百分之七十五的人昨天失业了,原因就是 ai 对 我们业务造成了残酷冲击。 他还解释,把文档做得更方便, ai 独取只会让网站流量更少,也就更少人发现付费产品生意会更难撑下去。 那 tailwind 就 完了吗?不一定,至少它的生态还在。但依赖文档流量加高级组建,这套商业模式确实正在被挤压,而且压力会越来越大。而这也不只是 tailwind 的 故事,它在提醒所有开发者,工具,如果你的产品很容易学,就也很容易被生成。 对我们开发者来说,继续关注,继续学习就对了,工具进化得很快,先适应的人会跑在前面。好了,今天就到这儿,如果你觉得这个视频有帮助,记得点赞关注,再留言聊聊。
31GenAI动力 00:32查看AI文稿AI文稿
00:32查看AI文稿AI文稿real 团队成员 and 酷又一神作,它就是 real skills 集合,它可以让 ai 输出的代码更贴近 real 社区的习惯,让 ai 按正确方式写 real 代码使用也特别简单,直接在项目里面安装 and few skills, 然后选择你使用到的寄宿站, 再选择你的 ai 编辑器就可以了。我本地测试了下,安装 enterprise skills 生成的微代码,质量和完成度确实变高了,可以让我们在 web coding 时更加得心应手,感兴趣的可以试试关注我,了解更多最新资讯和实用技术。
1588积极的阿灰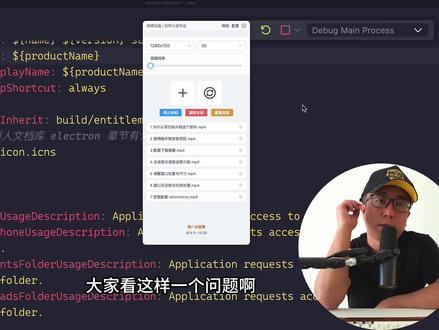 05:11查看AI文稿AI文稿
05:11查看AI文稿AI文稿大家看这样一个问题啊,你在使用以来创还有 fm max 在写这个应用的时候,你肯定也会遇到这个问题,我先把这问题让你看一下,现在呢我正常压缩啊,我点击压缩没有任何问题,他正在压缩,看到了吧?我先不压了,先停掉。 呃,我现在呢是使用开发模式,你看到我这个第八个状态了,在我开发的时候呢,没有任何问题,一切良好。那现在呢?我把这个给关掉,然后呢我回到这里边,在命令行里边,我把它编译成我们的应用,我先把我之前编的先删掉, 然后呢我给他编一下,如果你使用的是 windows 的话呢,你就使用 windows 的命令就行了。好,那现在就开始让他跑,然后呢我们打开那个编译之后的文件夹, 然后呢我们来运行一下咱们这个应用。好,那现在呢,我们来开始压缩。 好,你看这是我压缩的时候呢,他就压缩不成功了,看到了吗?进度条就不动了,不成功。所以这时候我们要分析啊,其实这个以来创他比较的容易啊, 我们有主进程,有序远进程,然后使用的第三方都一些库,很多库啊,其中这个 ui 库啊,包括这个 vivo 三呢,我们都正常运行的,否则我们也看不到这个界面啊。那现在唯一不 ok 的呢,就是我压缩不成功,就是调用这个 ff mag, 它不行, 所以呢这时候怎么办呢?我们回到我们的代码当中。好,那这次 f f max 代码,我们需要这个 f f max 这个命令来进行压缩,所以呢这块有个路径,我们可以先把这路径打印一下。打印怎么打印呢?我们可以使用以来创的 大家 log 来打印,随便找一个,比如说显示错误消息吧,这块就随便写一下。然后呢我把这路径打印一下,这个是咱编辑之后,我先把它关掉,他已经运行不不成功了吗?就没没必要展示他了。然后呢我们还是调取这个开发模式,然后呢观察我们这个任务栏。 好,然后呢这个弹出窗口之后呢,我们把这个路径给复制一下,你可以看一下,这是我们在开发的时候他的路径,那编译之后这路径是不一样的,我们可以新建一个文件,把这个路径呢先放到这里, 把这路径先放在这块啊,然后呢我们这段代码不动,咱们呢?呃,现在再编译一下,看看最终编译之后这个 ff mag 的路径是什么。所以这个时候呢,我再把这编译跑一下。好,现在我们已经编 编译完了啊,那么现在呢,我把这个软件打开,他会弹出一个路径,我把它复制一下。呃,这个路径是谁呢?是我们编译之后的啊,跟咱们刚才开发的不一样。然后呢我再把它放到刚才咱们新建的文件里边啊,其实上面的路径好像没什么用啊。 呃,那你看这个肯定是这个路径不对,也就说找到这我们必须得让他正确找到这个命令,他实际上肯定这个路径不对。那我们怎么怎么找到最 真实的路径呢?我们点击右键显示包内容,然后呢往里边点,双击,再往里边点,在这里边这里边 这里边点,然后找到 note models, 然后这呢我们的命令在这一块看到了吗?在这一块这时 是我们这个命令的路径啊,在这块,所以呢我们这么对比一下。呃,咱们看一下。呃,从这从哪开始看?应该是从 前面不要了,从这个 content 啊, content 没问题,是吧?然后后面到这块没问题。 然后到这块看到了吗?这块就不一样了,我们实际的文件夹目录在这一块,但是我们这个路径呢?是这个,这是不一样的啊。然后接着再往后看,是不一样后看是 note 猫就是没问题,然后这块也没问题,这块 这块也没问题。那最后的就是我们命令所以问题只差这一个位置,差这一块,那我们把它替换一下就行了。我把这目录复制一下,然后回到我们代码里边,咱们要把 这个给替换成他,我们回到 fm mag, 然后在这块我们替换一下搜索他,是吧?替换成他, ok, 那同样下面这个路径也是一样,替换一下。好,那这时候呢,我们这个 dial 对话框就不要了,给他清掉吧。呃,然后呢我们再来编一下,我还是先把那老的先删掉, 然后再编一下就打包完成了。咱们呢再进入到这个打包目录,然后呢再把咱们的软件运行一下。 好,现在启动了。然后呢我再添加一个视频吧,这是昨天晚上八点直播讲的代码,然后呢我执行转转码。好,现在我们看 我们这个,呃,程序已经正常运行了。呃,大家点个关注啊,我会经常分享一些有关于编程的视频,希望大家能够喜欢,再见。
91后盾人 04:55查看AI文稿AI文稿
04:55查看AI文稿AI文稿ps 四,折腾 view 支持五点零五到十三点零,今天来讲解下 view 折腾方式, 这是需要安装的程序,按照顺序安装, 连接网络,设置好 dns 屏蔽, 然后开始 首先用文件管理器复制相关文件到指定地方 发送最新金母机载荷,目前二点四 b 十八点九已经支持十三点零。 接着使用阿波罗, 首先需要离线激活账号, 激活好的账号后面数字是一串代码,反之则全是零。 激活好后重启主机,我已经事先激活 复制文件到主机硬盘 重启主机,因为已经是折腾状态,需要恢复到未折腾状态, 目前是未折腾状态, 和使用 bd 蓝光盘一样,需要开启 hdcp 点击折腾成功折腾, 此方法可以代替蓝光盘,十二点五二以下成功率很高。 为折腾十三点零,机器需要备份还原后,照此方法折腾, 成功率在百分之八十左右。
90往昔时光电玩 17:03查看AI文稿AI文稿
17:03查看AI文稿AI文稿来到和前端小组一起学 real 三元码,本章节我们将讲解属性系统。属性系统看起来非常简单,但实则暗藏玄机, 它里面有处理有一些核心的问题,比如说 class 应该使用 class name 还是 set attribute style? 如何高效地 def this able? 是 设置 dom 属性还是 html 属性? 为什么表达元素需要双重设置?这些问题的答案都会在章节中进行得到详细的解析。 在上一章节我们看到的 render options, 它是由 not apply patch proper 去两部分去组成的,而其中 patch proper 是 负责属性的设置与更新,当 view 需要去更新一个元素的 class style 事件或者其他属性时,都会调用 patch proper。 而这一章节我们就将沿着 patch proper 的 分发路径去从先盼什么后盼什么入手, 把属性系统的关键决策点去逐个拆解。而 patch proper 是 属性处理的路口,它根据函数名的特征,将处理分发给不同的专门的函数,其中我们就可以看到它这里是去 patch style patch class, 然后去处理一个 event 以及对应的一个表单元素的设置,这也是它对应的一个 tag 和 custom element 的 特殊处理。以及最后是一个 patchdom 的 proper。 屏幕看起来就代码有点少, 所以看的不是很清楚,但是没有关系。在接下来章节中,在接下来章节中,我们将会一一去解析这些函数。 patch proper 的 分发顺序是非常有讲究的 啊,比如说它首先对一个 class 是 最常用的属性,它是会优先处理,而 style 第二常用,它需要特殊的 def 逻辑,而对于事件就是 on, 是 以 on 开头的属性去交给事件系统。而对于 dom 属性和 html 属性,它会根据 should setup as proper 去进行一个判断。这里有个值得非常提前记住的点,就事件分支算在 purpose, 你只是转发给了 patchevent, 但它背后决定了事件更新的性能上线就为什么要保存 in worker, 为什么我们尽量避免 频繁的 a, d, d 和 remove。 而这一块我们先按下不表,后面一个章节会将门进行展开。这个模板是支持点 proper 和 auto 修饰符去强制指定属性的设置方式。大家可以看到它是会有这两种修饰符, 而编辑器会将这些修饰符保留在属性名中去运行,通过检手手字母来去进行一个识别。大家可以看到它是运行时通过检查手字母来去识别。 而这里是巧妙地运用了一个表逗号的一个表达式,就比如说是这 key, key 等于 key 的 status 一, 就先去掉修饰符前缀,再返回布尔值去决定走了哪个分支。我们了解了修饰符的处理逻辑,现在我们来进入一个高频分支,就是 class 的 处理。 class 绑定是 view 中最常用的动态绑定之一,而 view 它其实是支持三种绑定方式,就在 templar 上是有冒号 class 自创一个是还有包括一个对象,甚至包括一个数值。就无论是哪种方式,最终都会被规范化为可直接应用到 dom 的 形态。就 模板编辑阶段,会尽量把 class 归一化,运行时也会在需要时去做兜底。例如在 n 的 函数中去闯入一个对象簇时会走 normalize class, 因此 patch class 接受的 value 通常是就是最终的 class 字母串。大家可以看到这就是一个 patch class 的 一个最终处理方式, 它这里有几个关,非常关键的点就是过度 class 的 合并,就是这里有个处理过度动画的临时 class, 当元素处于过度动画时, transition 组间会在元素上去添加这些临时的 class, 比如说 to interactive 这些 class 去存储在 adder, 会存储在 adder await 信息 key 中,而 patch class 需要将它们与用户绑定的 class 合并。第二个就是 classname 和 set attribute, 这对于普通的 html 元素中,它就直接去设置 e l 点, classname 比 set attribute class value 会更快,但 sv 机必须使用 set attribute, 所以 它这里有个判断,就是 is sv 机它会去通过 set attribute 形式来去 做。同时大家可以看到为什么不用 classlist, 就是 通过 classlist 的 a, d 和 remove 需要足够去操作 a class name 可以 去一次性设置整个 class 的 字母创,就当 class 变化较大时去直接赋能会更加的高效。理解了 class 的 整创 替换之后,再去看 style 的 就会发现它的复杂点就来自两个点,一个是它贴呢,是箭指队的集合,第二个就是它还承载了 will, 杠, show 等行为层面的协助需求。因此 patch style 的 核心不只是设置,而是以最小代价去维护一致 style 的 绑定比 class 复杂的多,它支持字幕创和对象两种方式,需要处理 class cs 变量,浏览器前缀或者 unimportant 的 等特殊的情况。 大家可以看到这样子的一个方式,呃,这就是一个 patch style 的 一个智能 def。 首先它对于一个对象形式的时候,它是需要去做一个 def, 就是 旧址也是对象,它会去移除不再存在的属性,而旧址是函数创,它会是解析后去移除不再需要存在的属性, 然后它就会去设置一个新的属性,最后它就是去做一些函数,向量等等。这样的方式是 style 的 def 的 算法, 它其实是采用两步的形式,就当新旧值都是对象的时候,它会去一首先去移除旧属性,就避利旧对象,如果某个属性在新对象中不存在,将其设置为空字母串。第二步就设置新属性,去便利一个新对象去设置所有的属性。而这种算法的时间复杂度是 o m 加 n, 其中 m 和 n 分 别是新旧对象的一个属性的数量,其中 set style 它就是属性设置的一个细节点。首先如果是以宿主形式的,它就会依次地设置去用于 cs 回退值。 其次,如果是使用 cs 变量的话,它是必须要通过啊 set property, 如果它是 important 的 话,它也是必须要通过 set property 去做处理的。 大家刚看到这个 set style 的 一个特殊处理,其实它这里面是有两个,一个是 cs 变量,那 cs 变量它是怎么去做识别呢?就是以杠杠开头的属性是 cs 自定义属性值必须要使使用 set property 来设置,不能直接复制而杠。而 important 的 值也是必须使用 set property, 并将 杠 important 作为第三个参数去做传录。同时数对于数值值的 style 值用于 cs 回退来进行处理啊。请注意它这里有个非常点,就是 autprefix, 刚刚我们看到它会进行一个自动添加浏览器前缀, 那它是怎么做的呢?它首先 prefix 会检测浏览器是否支持某个 cs 路径,如果不支持,那它就会去尝试添加 web webkit mode ms 前缀,它的结果会被缓存去避免去重复的检测。而请需要注意的是, freet 属性会被特殊处理,即使浏览器支持无前缀的 freet 也会去做尝试添加前缀,这是因为某些旧版本的浏览器的 freeet 行为不一致。除了浏览器前缀之外, patch style 还出需要去处理一个非常重要的一个协助, 那就是指定就 vga show。 当元素存在冒 style 动态 style 和绑定和 vga show 的 时候,如果 style 动态 style 设置 display, vga show 显示时应该恢复。这时如果 vga show 隐藏元素 display now 应该覆盖 vga style 这样子一个值。 而这是怎么去实现的?那这是去通过 visual origin display 和 visual hand 这两个标记去做一个实现的。大家可以看到,在这里 visual 的 时候,它去做一个,两个标记去做一个实现。 到这里我们就已经分别看完了 class 和 style 两种最常见的快度镜。接下来进入到一个更加通用,也更加容易踩坑的部分,就同一个键,到底是应该写在到米属性里面,还是写在 html 属性里面呢?而这个就是我们的 should set as proper 该设置哪一个? 需要注意的是, html 元素的属性有两种设置方式,一种是 dom 属性, proper 就是 l 点 value 等于 hero。 还有另外一种是 html 属性,就是 attribute, 就 l 点 set attribute variable 对 应的一个 value 值,大部分 情况两者项目相同,但某些元素属性必须使用特定的方式,而 should set as proper 去决定哪应该去使用哪种,大家一看到它就是对应我们的一个具体的方式,而 should set as proper 去决定哪应该去使用哪种,大家一看到它就是对应的方式,而 should set as proper 就 分为两段。 首先我们来进行一个一对一的讲解,对于 svg 来说, svg 元素大多数属性都必须使用 set attribute, 而对于布尔类型的属性,就比如说 spell, trick, dragon label, a translator creator, 它必须使用 set attribute, 而 i framed setbox 必须使用 attribute, 而 form 属性只读必须使用 set attribute, 而 input 点 list 也是必须使用 set attribute。 test tab 也是使用 set attribute, 而媒体元素,比如说 the west hat 必须使用 set attribute, 那 同时原声事件的再加字母串值也必须使用 attribute。 最有什么呢?如果是盗门属性就用是盗门属性,而刚刚那些只是错掉一看。现在我们来对这些特殊的属性来进行一个讲解。 首先第一个就是每每举值的一个不二属性,像 spin, trick, joy, able, trace, state, out, current 这些属性的到某属性必须是不二值,但 h, t, m, l 属性是每举字母串就 to 和 force 它是一个字母串,那如果是使用到某属性去设置成一个字母串的话,那么会被转为成一个 自创 force 会被转为 true 啊 true 化,所以必须使用 set attribute。 同时 fm 的 sendbox 这个属性去控制 fm 的 安全属性就设置,如果你设置到我们属性为 null, 就 会变成自创 null, 而设置成空自创会使用最严格的杀伤模式,而只有通过 set attribute 和 ensure attribute 才能够正确的处理。下一个就是 input 点 list, input 的 list 它是只关联一个 data data list 属性,而到某属性 a r 点 list 是 只读的返回关联的 data list 是 不能直接复制的,而 form 元素里面 表单元素的 form 属性也是只读的去返回索取的 form 元素,所以这些属性不能直接复制,必须使用 set attribute。 对于一些媒体元素的 words 和 size。 什么是媒体元素?就是 image, video, canvas 和 source 点框高,必须使用 attribute 的 设置。盗墓属性的设置可能是不生效的, 就盗墓属性设置行为不一致而 show set as proper 的 本质是什么?本质是在为后续的两条分支选路。 走到某属性分支意味着更加贴近浏览器对象模型,可能带来类型转换与指读限制。而走 attribute 分 支则更加贴近序列表的 html 表达,就更容易与表单重置,第三方读取逻辑对齐。先把这个选择记住,再看两边的具体时间就比较清晰了。 所以我们来看一下到母属性的设置,就是当 should set as proper 返回 true 时,用 patch down proper 去设置到母属性。大家来看到这是一个 inner html 和 test content 的 一个设置,而下面就是一个 value 属性的特殊处理,对应的这是 这是一些空值处理,以及布尔值就是空字副状场为刚呢,就是我们所看到的一个 value 属性的一个特殊处理, 请注意 value 是 最复杂的盗木属性,因为什么它首先它具有一个比较优化,就只有当新旧值不同时才会去设置,避免不必要的盗木操作。同时 option 处理特殊处理, option 的 value 属性如果没有设置的话会回退到其文本内容,所以是比较时要用 get attribute value 而不是 array value。 同时 check box 的 默认值是 on 而不是空字不串,同时它还会去存储原始值, 非字母串值会被 dom 转为字母串,而 will 会将原始值存在 a r 点杠 value 中去共 v 杠 model 去做实体。 而在上一步我们看到中去设置 in the html 表中, will 会去使用 on serve to transfer html 表包装值去以支持 trusted types 安全策略。而正在上一章章我们就建 已经介绍过了,所以在此我们就不再去追溯了。看完到我们属性的设置,我们来再看看 htm 表的是如何去做处理的,就当 should set as proper 去访问 force 的 时候,我们会去通过 patch or true 来去设置 htm 表属性。首先啊,这是 svg 叉 link 的 命名空间 去做,对那个处理危机中的某些属性必须要叉 link 秘密空间,就比如说啊叉 link, 杠 herf 这些属性必须使用 set attribute n s 设置 set attribute n s 而对于而对于布尔值处理的话, 首先需要注意的是,它存在即表示 true, 不 存在表示 false。 设置值 true 或者空字不算,就是 set attribute key 等于冒号,而 false 或者 null 的 时候属于 null。 attribute key 需要注意它是 including or true 函数,判断一个值是否应该包含不小于属性,而这两种方法需要注意,我们这两种方法的写法是等价的, 走路到 patch or true 这里时,已经覆盖了绝大多数使用需要写入 attribute 的 场景。普通键值,叉令、可秘密空间以及不小于 unk 属性,这是有或者无极帧的特殊语义。但 patch proper 还有一种 不适合直接缩略为字母串的例外,就比如说 real element 需要把复杂值当做属性传递, real 跟 model 相关的 true force value 也需要额外的存储,这就是 real 的 custom element 特殊处理。就当元素是 real 定义的 custom element 的 时候,属性处理是有特殊的逻辑的。在这里我们可以看到 custom element 是 通过 its view c e 标识去识别,对于这些元素包含,它会去做这样子处理,就是包含大写字母的属性值会被转为驼峰形式,非字母串的值会作为盗门属性设置,而不是缩列为字不串。 这使得 view 组键可以通过 custom element 去接收复杂的 purpose 值。而除了 custom element, view 杠 model 在 script 上的真自定义真假值也需要特殊的存储。 在这里我们可以看到六杠 model 在 支持自定义的真假值,这也是通过 achieve variable 等于 yes, force 等于杠 value。 这些值并不是标准的 html 属性,不能通过 set attribute 设置 will 将它们存储在原数的自定义属性上。去 这里我们就可以看到了,它是通过啊 r 点杠去 value elegant 点杠 force value 去存储在元素的自定义属性上。 view 杠 model 指定会在处理 check box 上自动去读取这些值,哎,最后我们来看看表单元素为什么需要特殊的双重设置策略。对于 value, 去 tricked, selected 这三个属性 view, 它会去同时设置 dom 属性。 html 属性为什么需要双龙设置呢?这是因为表达了重置,比如说 input type and reset 会将表达元素重置为 html 属性值,同时为了去做一些第三方库的一个接龙,就比如说某些库或者浏览器扩展 可能会去读取 html 属性,而不是 dom 属性。注意,需要注意的是, custom element 标签名包含杠会被排除在外。最后我们再看一个属性处理流程图。 首先,对于一个 patch proper, 它会去读它的 key, key 是 什么?就是它对应的是 class style, on 还是其他的,那对于 class, 它会进行 patch class 对 于 style, 它会进行 patch style。 对 于 on, 是 v 杠 model 兼容器,它会去做。 如果是否他会去做一个 patch event, 而 patch event 将会是我们下节章节的重点,而如果是的话,请跳过。对于检查修饰符,如果是点 proper, 如果是 attribute, 如果是无修饰符,去分别的去对应它进行下一步的操作。对啊,屏幕有点小,可能看不全。 如果将它当成一个流水线来看,前半段主要负责高频而确定的快捷操作,而后半段主要是负责低频但必须正确的边界接龙,而事件系统 则是一个被单独隔离的出来的高频模块。而下一章我们会去看它为什么需要这样设计,那我们来看一下本章节的一个小结。 patch proper 是 real 属性的核心,它根据属性类型将处理分发给专门的函数 a patch class, 利用 class name 直接复制实现高效的更新。 a patch style 它会去通过智能的 def 去避免不必要的到幕操作。 a should set as proper 会去处理到幕属性与 html 的 复杂边界情况。这套系统体现了 view 对 性能的极致追求,能用盗门属性就不用 set attribute, 能直接赋值就不用 casteist。 同时它还处理了大量的边界情况,确保在各种场景都能够正常工作。下面我来回看一下本章节的深入思考。 首先,一为什么 input list 等于 data list 杠低,必须使用 set attribute 而不能用 dom 属性呢?如果强制使用 dom 会发生什么问题?二就是 patch style 的 diff 算法在什么情况下效率最高,在什么情况下效率最低呢?有没有什么优化的空间? 第三点就是 should set as proper 中为什么 fframe 的 data box 属性需要特殊处理?第四个是为什么 will 为什么要在表单元素上去同时设置 dom 属性和 html 属性呢?好的,我们本章节就到此结束了,欢迎大家点阅、点赞、订阅以及分享我的频道,我们下期节目再见!
83前端小卒 03:23查看AI文稿AI文稿
03:23查看AI文稿AI文稿二零二六年普通人第一个要学的 ai 工具是什么?如果让我选一个的话,我一定会选 cloud code。 为什么去选择 cloud code 去作为普通人的第一个 ai 工具?因为 cloud code 它不仅可以去编辑代码,它还可以去作为个人的第二大脑去管理你的这个项目的所有的知识。 那比如说我是怎么用 cloud code 作为我的第二大脑的?我会把我自己的一些呃关于产品经理的一些经验,然后沉淀到 cloud code 的 里面,作为一个 skill 啊。比如说当我做这个竞品分析的时候,那我肯定会去找到。就说首先第一个找到我需要的这些竞品,就是针对我这些产品,我的竞品有哪些?竞品是什么? 第二个我该怎么去找这些竞品的这些功能网站?第三个我怎么去点击这些系统获取它的一些呃截图以及功能的分析,呃这些都可以用 skill 的 方式去把它沉淀成 cloud code 里。 当我的竞品分析完成之后,我还可以把我的这个 v o e 的 原型代码呃也形成一个 scale, 然后通过我的一些竞品分析报告和我的在里面的需求文档,呃这些 综合的这些信息,然后生成我的原型。因为呃传统的,传统的这个 呃 ai 工具的话,它不会把你的这些竞品的报告,还有这些比如说呃需求文档 啊,以及等等你需要的所有的业务资料沉淀在一个地方。但是 cloud code 它可以做到,就是说把这些你你这个项目所有涉及到的这些文档和资料综合在一个地方, 这样的话,呃 ai 它去获取的这个上下文相对来讲就是比较呃综合全面的,它输出的你输出的这个结果,比如说它输出的原型也相对来讲是更符合你的这个需求的。 所以说当你把你的项目的资料上下文啊这些更多的沉淀在 cloud code 当中,他也会更懂你啊,更按照你的这个习惯以及你 公司的这个业务的知识啊,去输出你需要的这个文档文件啊,一个交付的一个成果。 总之, cloud code 就 不仅可以去帮你去完成你本职的工作,比如说我作为一个 ai 产品经理,他能帮助我完成呃大量产品经理的工作,甚至能啊完成一些之前我做不到的事情,比如说一些前端工程化的事情。嗯,除了呃在 写代码需求分析这方面,它其实也能在其他的方面去呃各项的去辅助你啊,比如说可以在金融领域、法律领域、 hr 领域等多个领域,它都能去呃辅助你的工作,成为你的第二大脑。 点个关注,后续为你带来更多关于 cloud code 的 以及 ai 工具,呃对你个人的工作以及生活真正能起到呃赋能落地的效果,而不仅仅是一个对话的聊天工具。
2AI星河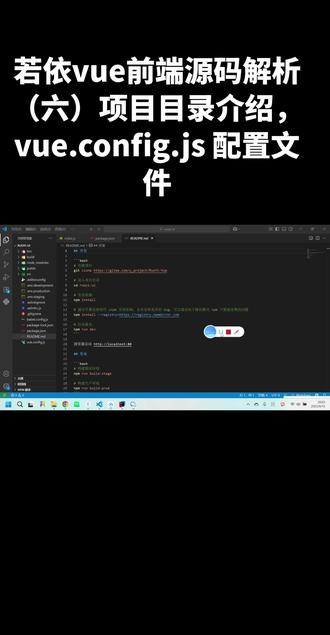 16:29查看AI文稿AI文稿
16:29查看AI文稿AI文稿ok, 我 们继续看这个路由的 v v o e 前端,然后上节课讲解了这个配置文件, 这个 jason 文件它就是配置文件。然后今天我们讲解这个,然后先连贯讲解一下这个,这个的话可以删除,对项目没有任何的影响,它就是一个笔记,我们项目里面的笔记,你看它输入一些命令, 然后你创建这个空文件夹,空项目他也有这个笔记,看到没意思,就是这个文件他不参与项目的,就是启动,或者是那些写业务逻辑,他就是记录一下, 然后今天我们讲解这个唯有一点 config 点。 gs, 你 看我们创建一个空的项目,它就会创建这个文件,而且这个文件它是在根目录下,然后一个完整的项目, 一个正常的完整的已经开发完成的项目,它也有这个配置文件,它里面有这么多,你看到没? 那么接下来我们就有一个问题了,这个配置文件是干啥的?我可不可以把它删除? 那么如果不可以的话,那它里面可以放一些什么东西,然后的话这这就是接下来这个配置文件,我们可以看一下 这个文件,在你创建一个脚手架的时候,脚手架项目的时候它就存在了,然后它是 v o e c o i。 项目的核心配置文件,用于自定义项目的构建、开发服务器、资源处理等各种行为。它的作用你看覆盖或者是扩展 v o e c o i 的 默认配置,这个是核心 啊,不能加粗,你看它都选择不了, 它没有保存,现在可以了。加粗,这个配置文件的核心作用就是覆盖或者是扩展 v o e c o i 的 默认配置, 它是基于 webshop 的 构建,但默默认隐藏了复杂的配置。那么对于这个配置文件来说,它它就提供了一个简洁的 api, 让你在无需修改底层的 webpack, 它的配置文件让你就可以实现这些。通过这个配置文件,你可以修改服务器的端口代理热更新,调整资源的路径, 配置它的选项,配置预处理,然后还有配置构建、优化集成第三方的工具等,好多你都可以在这里面。 所以现在我们就知道了这个配置文件,它是一个核心配置文件,它可以覆盖底层的那些配置或者是扩展底层的配置。 因为整个 v o e 项目,它的底层是啥呢? v o e c o i 项目,它底层就是用这个构建的, 所以核心的我们现在开发这个创建这个孔就是脚手架,它底层就是这个, 然后肯定是这个服务,你可以理解为它有一些配置文件,我们想改底层的配置文件怎么改?人家就给你提供了一个这个配置文件,它就可以覆盖或者是扩展 文件的格式与基本的结构。它是一个 g s 模块,需要导出一个对象或者是返回对象的函数,对象中的属性对应各种配置选项, 它的基本格式是这样, model 导出,然后的话里面是 k 和 value 的 形式,键值对,也可以使用这种形式去导出 接收参数变量。然后以下是一些常见的配置,比如说我们导出,如果我们项目用于配置本地开发时,我们可以配置端口 启动后自是否自动打开浏览器,然后的话是否启动? h t g p s 这是相关代理解决跨境的问题。 项目启动之后,访问这个就可以跳转到访问后端,允许跨域去掉请求中的 api, 因为我们前端调用后端接口的时候, 走这个它就自动跑到这,但是前面多了一个这个,所以但是我们请求后端的时候不要这个就可以把它去掉。 第二个是路径与资源的配置,当前这个配置文件你可以自定义路径与资源,首先也是导出, 就判断一下当前的生产环境是不是开发环境,然后的话输出的路径是不是 diss 的, 你看默认是 diss 的, 就打包之后你把项目放到哪个文件夹下,默认是 diss 的, 这个是静态资源存放的路径,它是相对于这个来说, 这个是整个项目的首页,首页的文件名称是什么?然后这个是文件名称是否包包含这个还是用于缓存控制处。 然后接下来你还可以在这个配置文件中写关于 webpack 相关的配置, 你看方式一直接添加它的配置,配置路径别名如用 at 指向 src 可扩展。 以后你代码中写它就相当于是写这个,写这个就相当于是这个,还可以添加它的插件,还可以用念似的方式 规则访问的, 还有可以限制它的图片的大小。关于 c c s 就是 css 的 相关的配置,就先判断它是不是生产环境, 然后这个是传递相关的信息,然后其他的配置,这是如果是生不是生产环境的话,就开启这个检查,这是入口文件,多页面配置的话是入口文件, 它是一个可选文件,如果项目不需要自定义配置,就用默认的,可以不创建该文件,看到没? 也就是我们的项目可以把这个东西给删了,虽然我们创建初初时创建的时候它有这个,我们可以把它删了。原因是什么?我们不需要改一些默认的东西啊,我们也不需要新增加 配置生效,修改完它后需要重启开发服务器 npm raw 才能生效,然后这是相关的配置文件,配置文档这个, 然后通过它你可以在不不破坏它原有的架构的前提下,灵活的制定项目的各种构建和运行行为,满足不同项目的需求。 ok, 现在我们就知道了,这个是个配置文件, 然后它里面可以配置的东西就是这些东西,看到没?这几个核心经常配置就是这些。 然后啥时候加载?因为我们刚才说了,整个项目的启动需要我们在项目的根部下输入,这个是固定的 n、 p、 m 状,然后后面是什么启动,就看这个文件里面,对吧。 比如说本地系统就输入这个,输入这个之后一按回车,它首先因为它是我们这个命令是在项目的根部下进行的,它首先去自动地找名字,为这个的名字必须为这个, 然后去找后面这个名称对应,去找这个属性里面的名称对应,然后自动执行后面这个脚本,那么在直背后执行这个脚本的背后,他就会去加载这个文件,如果有的话就会加载, 你看在启动项目时或构建这个时候被自动加载,自动输入命令就加载, 输入启动命令就加载这个配置文件,整个项目还没有,还没有干什么了,仅仅是即将要启动的时候,它首先下载的就是这个配置文件, 当你执行这个的时候或 n p m 说它就会在项目过程中会自动地查找项目根目录下的这个文件。这个要知道 我们输入启动命令或者是打包命令的时候,它会自动地查找项目的根目录下,根目录下就是整个,你看我们现在就在根目录下这个去执行项目的命令, 如果该文件存在,它会底层,底层就是就是 v o e 的 这个呃,脚手架,这个 c o i 它会,它就会去读取,如果有的话就会读取这个配置文件, 并且将你项目里面的这个里面的相关的东西去和底层的,你看默认配置配合并, 你输入启动命令,它就会加载这个,然后将这个配置文件里面的东西和底层默认的配置文件两个合并,合并之后用到项目的构建、开发服务器等流程中。 现在就我们就知道了当前我们看的这个配置文件 它是有什么作用,它是在什么时候加载,如果项目中没有这个,就会直接使用它默认的配置,不影响项目的正常运行。 这种自动加载机制是这个约定的一部分,无需手动引入或配置加载路径,只要文件名称正确,你看必须是这个且位于项目的根目录就会被自动识别。这句话要 我们要知道 卡死了, 只要文件名称正确,必须是这个,且位于项目的根目录就会被自动识别, 如果你修改了它需要重新开,就是重新启动才能使配置生效。 现在我们就知道了,什么时候去加载这个配置文件,对吧?项目启动的时候就加载,那么还有一个问题, 项目启动的时候是会加载它,谁会加载它?主要是给极依赖的构建工具使用的,具体调用流程是直接调用者,谁调用它就是底层这个服务, 这个配置文件是底层这个服务的专属配置文件,当你执行启动命令的时候,或者打包命令的时候,底层这个服务会作为入口程序启动。首先自动检测 项目的根目录下是否存在这个配置文件,如果存在就读取里面的东西于底层这个服务 v o v o e。 项目底层 它就依赖于这个服务,它就会与底层这个服务的默认配置进行合并。用户我们在这个配配置文件里面写的配置文件会覆盖它,默认的 合并后的配置会作为最终的参数传递给后续的构建流程, 谁还会进行调用,这是直接调用者,间接使用者是它我们的底层,这个是 voe cio, 它是基于它构建的,所以底层还是它就是间接的使用着配置,最终会转为它可以识别的配置供企业使用。项目的打包、模块处理、代码分割等核心功能全部都依赖于它中的这个等配置, 然后的话相关的依赖端口那些东西, css 还有图片处理这些全部都依赖于这个配置文件,如果你不写的话就用使用默认的。 我们总结一下这个交易关系,用户执行,用户在项目的根目录下去执行一个启动命令的脚本,它就会触发底层的这个这个服务, 然后它就会为什么会触发?因为我们输入这个启动命令之后,它会找 这个文件里面的这个名称,为这个里面的对象里面的你输入的哪个就是对应哪个,就是底层调用这个命令,间接的调用这个命令,它就会加载配置文件, 然后合并将你修改的配置文件。有了这个里面的东西,和底层默认的配置文件合并,然后就传给了底层的其他的那些工具,然后的话底层就会默默的构建或者是启动服务。 简单来说,当前这个配置文件就是用户与 ve c u i 底层之间的一个配置桥梁,所有的配置最终都会作用于项目的构建,开发服务器的核心流程,实现自定义项目的目的。你看自定义 我们就可以自定义一些东西,比如端口,我就想用八零八零,我就想用九九幺幺,对吧?你就可以在这个配置文件里面写, ok, 现在我们就知道了,当前这个配置文件它里面可以写一些什么东西,就在这常用的配置,然后谁会加载它,谁会调用它,什么时候加载?这些问题都给你解答了。
24一写代码就开心 02:58
02:58 00:26查看AI文稿AI文稿
00:26查看AI文稿AI文稿我们开源了一款超好用的可视化编辑器, poly editor view three plus ts 打造,像 ppt 一 样拖拽就能用,文本、图片、表格 svg 全覆盖,智能排版,专业对齐,纯前端,无后端,本地保存, 支持 pdf 导出, mit 协议,可商用,可二次开发,欢迎 star 支持。





