ltx-2.3本地部署硬件要求
l t x 二点三呢发布了,这个呢无疑是开源视频生成领域又一个重大的里程碑。二点三比之前的二点零模型呢,它的视频参数从原来的十九 b 提升到了二十二 b, 它可以更好地支持九比十六的竖屏视频。 并且呢拥有更加清晰的声音,更加稳定的图像,到视频的转换,更加智能的提示词的理解, 以及更加清晰的文本渲染。与之前的二点零版本来讲,它最大的问题依然是模型比较臃肿。在开源社区里边,有各种各样的应用方案,帮助视频的创作者用更少的显存, 更短的时间来创作质量更高的视频。那在这个视频当中呢,我们会给大家提供三种方案,大家呢可以根据自己的实际算力情况来选择不同的工作流。为了让大家更加清楚地看到 这三种方案的不同,那我使用了相同的提示词,相同的参考图片以及相同的种子来对三种不同的方案进行统一的测试。 那在这里边呢,也有很多匪夷所思的问题,比方说针对于这个新的模型,即便你是文声视频,你也要提供一张图片。那大家可以看到新版的 l t x two 二点三 这个版本呢,我们提供的模型是比较多的,那首先呢是我们全量的模型,另外呢,我们这有一个蒸馏板的模型, 那蒸馏板主要是为了加快速度,如果你使用蒸馏板的模型,你可以将 c f g 设成一,然后进行八步裁样,就可以得到一个非常棒的效果。那同样呢,它提供了一个 lora, 你 可以使用这个 lora, 那 配合我们的全量模型来达到蒸馏板模型的效果。那剩下的三个模型呢,就是放大模型。 第三个放大模型呢,有两个是进行空间放大,也就是像素的放大,而另外一个呢则是在时间维度上进行放大,也就是我们说的插针。目前的 confui 呢,已经支持了这个模型, 这是 confui 官方发布的一个簿刻,大家呢可以在这个簿刻里边找到工作流的下载地址,那大家呢,可以将你的 confui 更新到最新版。然后呢,我们可以点击 template, 通过下来列表选择对应的模型。可以看到两个工作流,一个是文声视频的, 一个是途胜视频的。那为了方便演示呢,我将工作流也构建到了 running hub。 在 comfy 领域, running hub 是 一个非常棒的在线工作平台,因为只要有新的模型和新的扩展出现,它都会第一时间跟进。 那下边儿呢,我们就先来看一下 comfy 官方提供的 ltx 二点三这个模型的图声视频的工作流。这个工作流的基本结构呢,和 ltx two 是 非常像的,只不过就是个别的参数呢,有一些调整 好。首先呢,我们需要提供一张图片,这个图片呢可以是横屏的,也可以是竖屏的, 但是呢你要注意就是宽和高呢,尽量的能被三十二整除。另外就是它的总真数一定是八的倍数,然后加一。同时在这个工作流当中呢,它也列出了所有模型的下载地址, 并且呢也详细说明了模型下载之后应该放在本地的哪个目录当中,这有一个文声视频和图声视频切换的一个开关,这个非常的重要,这是我们视频的总帧数,那这个呢是分辨率的设置,下边呢是真频的设置,这我设置的是二十四帧每秒。 下面呢我们看一下主模型的加载,大家注意我现在加载的是一个 f p 八的版本,那这个模型呢是由 l t s 官方发布的,大家看一下啊,它将近三十个 g 全量的 l t x 二点三的模型,它的大小呢是四十六个 g, 所以 说我们有理由相信 f p 八的模型呢,并不是通过简单的数据转换得来的。这个模型啊,我们使用消费级的显卡来跑的话呢, 应该还是有一定难度的。那由于这个模型啊,它本身没有蒸馏功能,那为了提升速度,我们使用了官方的这个蒸馏的 lora 权重,我们设置成了零点五。那另外还有一个问题要注意,在加载主模型的时候,并不是使用 default model loader, 而是用的 checkpoint loader, 那 意思就是说这个模型里边除了我们的主模型之外,应该还有其他的内容,那这里边其实是包含视频的 ve, 所以 说呢,我们也需要把它单独的拿出来,那这是我们音频的 ve。 再往下边呢是我们的编码器,第一个编码器我们使用了和二点一一样的编码三,第二个呢则是 l t x 二点三专门的一个编码器。下边呢是我们的放大模型,这里边呢我们使用的是空间放大, 因为大家呢其实目前更在意的还是清晰度的问题,而不是帧率的问题,提示词呢,一定要严格按照我们的参考图片来写, 那这个提示词大致描述了一个炎热的夏天,一个美女呢,正在从他的同伴的手中拿过一瓶矿泉水。那我们的声音设计是这样写的, i need that。 那 提示词经过我们的文本编码器编码之后, 会进到这样一个节点啊,叫 ltxv conditioning。 那 这个节点其实我们在 ltxtwo 里边就已经使用过了,下边呢我们这儿放了一个自定义的彩样器,那这个彩样器呢,我们使用了一个欧拉的变体。再往下边呢是我们的 sigma, 这个是里边比较独特的一个地方,因为它是一个手动的 sigma, 所以 说步数呢是暗藏在这里边的啊,并不需要大家显示地去进行设置,比较重要的就是这个 latent image date 的 image 呢,和我们的参考图片有关。那我们看一下参考图片的处理。首先呢,我们把输入图片进行一个缩放,让它和我们的分辨率保持对齐。那下边的处理流程呢,和 ltx 二是一样的,先把它的宽边 缩放到了幺五三六,然后呢我们进行一个压缩,压缩完之后呢,我们现在需要将它的宽和高进行减半, 因为呢,我们都知道 ltx 的 工作流呢,基本上都是一个两段式的采样,所以说呢,它是先生成原来的一半, 然后再把它放大成你需要的那个分辨率。下边呢就是 latent 的 生成,那对于音频的 latent 呢,就是直接生成一个空的,而对于视频的 latent, 我 们也是先生成一个空的, 但是呢,我们需要将我们的图片注入到这个 latent 当中去,然后将视频和音频的 latent 进行组合,传递到我们的采样器里边进行采样,这个时候呢就会得到我们的基本采样的一个视频, 那这个视频里边的话呢,声音是已经完全生成了,但是视频呢只有原来的一半,所以说呢,我们要进一步放大视频, 那这个时候会用到我们的放大模型,目前的放大模型有两类,一个叫做空间放大,一个叫时间放大。由于我们现在是进行像素的放大,所以说我们使用的是空间放大, 那空间放大也有两个模型,一个呢是一点五倍的放大,一个是两倍放大,那我们这选择的是两倍放大的模型,下面呢我们将视频的 latent 从音频当中给它分离出来,然后进行放大。那放大之后呢,我们需要做一个事情,就是将我们的参考图片再一次注入这个 latent 当中去,让它保证整体人物的一致性。下边呢是我们第二个阶段的采样,那第二个阶段的采样和第一个阶段大致相同,大家注意这样几个地方, 那第一个呢就是我们的彩样器,这个是不太一样的,第二个彩样步数,也就是我们的 sigma 的 设置也是不太一样的。彩样之后我们还是先把音频和视频的 latent 进行分离,原因是因为我们进行解码的时候使用的 ve 呢是不一样的。那最后呢大家会得到最终的一个效果, i need that。 总体上来讲呢质量还是不 错的,这次采药呢,我用的是两分四十秒,那整体的速度呢也是比较快的,那通过这个简单的测试,大家可以看到 l t x two 二点三的模型,相对于二点零版本来讲呢, 在生成速度上其实有了很大的提升,那从生成的质量上,大家也可以看到生成的人物会更加的自然, 声音呢会更加清晰,但是呢还是有些杂音。那大家如果使用这个工作流,最大的问题就是显存的占用,因为这个呢需要将近三十个 g, 那 如果你的显存不太够的话呢,大家可以尝试一下第二个方案。 那第二个方案呢,其实是由 k 神来提供的,大家可以看到它这呢有一个截图,其实是将我们视频里边的 ve 和我们的主模型呢给它分开了, 同时呢对于我们文本编码器的加载呢,也做了一些优化,那大家可以在它的抱抱脸的仓库里边下载到相对应的模型,那主模型它提供的版本比较多,大家注意啊,带蒸馏这个关键字的就是我们所谓的蒸馏模型,速度会更快, 但是模型大小呢不见得会变小,那模型大小呢,主要看一下模型的精度啊,我们这有 b f 幺六的, f p 八的。 那同时呢大家可以发现这里边呢有其他的一些关键字,比方有的叫 skill, 而另外一些叫做 input skill, 那 这有什么不同呢?那大家看一下这个表述呢,相对来说还是更加的专业一些。那你可以简单地这样认为,如果你是四零系或者五零系的显卡, 可以采用 input skill 版本,那如果你是之前的老显卡,你可以直接采用 skill 版本。那下面呢,我们来看一下 kj 的 这版工作流, 主要的区别呢是在主模型的加载上边儿,由于呢,它现在将 ve 给它分离出来了,所以说呢,我们可以直接使用 load deforge model 来加载这个主模型,这儿需要加载的 ve 就 变成了两个。 下边是编码器的加载,这儿呢,我们依然采用了 k j 提供的那个策略,它这儿提供了一个模型叫做 text projection。 大家呢,在加载的时候呢,第二个编码器选择这个就可以了,放大模型呢,没有任何的变化。好,下边呢,我们运行一下,看一下执行的效果, i needed that。 那 我觉得效果呢,其实并不比官方提供的那版要差,但是主模型的大小从原来的二十九个 g 变成了二十三个 g。 下面呢,我们来看一下 g g u f 的 工作流, 那它的区别依然在我们的主模型加载上边,这儿呢,我们加载的是一个 q 四的模型,而且呢使用 kmeans 进行了量化。 那这个模型是从哪儿来的呢?来自于非常著名的 count stack。 那 大家可以在模型列表里边看到非常多的模型啊,比方最小的 q 二 以及 q 八模型,这儿呢,我们选择的是 q 四 kmeans, 它的大小呢,将近十八个 g。 大家呢,可以根据你算力的情况来选择不同的量化模型。那视频和音频的 ve, 我 们依然使用了 k j 的 加载方式。那关于编码器的加载呢,我们使用了 j j u f 的 双编码器加载节点。大家注意啊,我们这儿加载的 该马三的这个模型呢,依然是一个量化版的,那这个模型呢,来自于 dreamfast, 那 由于这个模型呢,它本身体量是比较大的啊,所以说呢,我们建议大家还是选择一个量化版,大家可以看到我们从 q 三啊到 q 八 fast 都有提供,你可以根据自己的算力情况呢,来选择其中的一个。下边呢,我们来看一下最终生成的效果。 i needed that。 大家会发现啊,这个视频呢,由于人物有一个明显的转头的动作,所以说当人物的面部 重新面向镜头的时候,你会发现它的一致性呢,是有一定变化的。我还没有测试这个问题是不是由量化模型造成的,但是总体上来讲,它视频和音频生成的质量呢,还是不错的。 那最后呢,我们来说一下纹身视频,不管是哪个工作流,你要纹身视频的话呢,只需要将这个部分给它切换成处,那它最终影响到的都是这个节点。其实非常容易理解啊,因为它这儿有一个 bypass, 就是到底要不要把我们的参考图片给它注入到我们的 latent 当中去,如果你选成了 false, 那 也就是说你在这个地方不管传一个什么样的图片啊,它都不会影响我们的潜空间, 所以说呢,也不会影响我们的采样。下面呢,我们使用相同的工作流参数再来生成一遍, 我会发现视频的写实性呢,还是非常强的,包括人物喘气的这个声音。但是你会发现新版的 ltx 模型呢,在细节的动作展现上呢,是有一些问题的,比方说拧瓶盖的这个动作, 那你会发现现在瓶子上没有瓶盖啊,但是他依然有拧的这个动作,所以说逻辑上呢,还是需要去优化的。 那这就是我们今天给大家讲到的四种不同的工作流,其实呢属于 ltx 的 最基本的应用,后边我们会给大家展示一些更加有趣的用法。好,今天呢,我们就说这么多,关注我,做一个懂爱的人。

粉丝8.5万获赞47.7万
相关视频
 04:37查看AI文稿AI文稿
04:37查看AI文稿AI文稿哈喽,大家好,欢迎来到大同的康复爱系列教学视频,今天这期给大家带来前两天刚刚更新的 ltx 二点三视频模型,这是一个本地开源的音画同步音画之初的模型, 次出的二点三这个模型会比之前好了很多啊,至少在很多场景下是可以使用的。这期视频我会介绍一下啊涂声视频的用法,我觉得纹身视频没有什么太多的用处,那我会讲一讲它的使用方式还有优缺点以及使用的一些经验。首先这个工作流和所需的模型我都会放到网盘当中,然后也会尽快的上架到云飞的 镜像上面,让大家可以直接在线体验,因为这个模型所需要的配置需求还是挺高的。我们可能之前在二点零阶段会看到这个模型,说是十二 g 就 可以跑,或者八 g 就 可以跑,然后有人说他又速度很快 都是对的,但是把他们放到一起就是有问题的,显存需求低和速度快是绝对不太可能兼容的,他们都是取一个极端,我给大家看一下实际的占比,我的本地四零八零十六 g 显存加九十六 g 内存, 常规跑的时候基本上就是这样,内存全部都是占满的,第一显存能跑,实际上就是把你的虚拟内存开到极致,这种情况下速度一定是快不了的。那如果你的显存偏大一点,那我们就不需要有这么多虚拟,这个时候我们的速度就能快起来, 我跑一个这样的五到八秒钟的视频,甚至比万象二点二还要快两分钟左右,而且这些速度和显存还是要在你的分辨率,要看你跑的是多少分辨率,要看你跑的是五秒还是十秒还是二十秒,这个绝对是不一样的。 总结一句话来说,如果你的显存也很小,内存也不大,这种情况下即使能跑也是非常慢,所以这是个前提啊,优先还还是推荐大家去云端跑。然后呢,接下来看看它的效果,一些运动幅度不大的,这些带台词、台声音的这些场景,我觉得效果都很不错啊。比如像这个, 你看这棵松树,是我爷爷亲手种的,已经有几十年了,它的清晰度非常高啊。我这里跑的是长边,是九六零的分辨率,最后生成完了之后,实际上就是幺九二零的分辨率,包括这条,女人,不需要别人定义,做自己最美。 像这种呃,镜头运镜幅度不大的,这种情况几乎不需要抽卡,效果都不错。但是呢,如果你想镜头稍微大一点,就会出各种各样的问题呢?我这里还跑了一些,这个声音,我们就不放了,看看其他的,有些还是不错的,总体来说一定是一个可以玩一玩的模型。 另外有一点就是大家千万降低对人物一致性的期待,如果你的图片是一个真人,或者是现实生活当中的人,那传进来一定会非常容易变脸。如果他是个 ai 人,那我们看不出来的状态下,觉得还是不错的,快,他要追上来了, 那生成的速度,中间这几条别看啊,这里显示的一千多秒,这个是我一边录屏一边在跑的时候卡在最后的捷码,卡了很长时间,这 正常来说的话,这个地方的五秒用了一百二十一秒,标准的两分钟,十秒的视频用了四百一十八秒。那 接下来呢,看看这个工作流。首先我的模型是用的官方原版,没有用 kj 那 一套,我觉得官方原版这套好像质量更好一点,用的是 f 一 八模型,满血模型我本地十六级就跑不了了,到时候在云端的话,大家可以用满血的模型去试一下,我感觉效果应该差不了太多。工作流用的也不是官方的在模板里面的那个 l t x 二点三,而是用的这个插件。如果我们要使用这个流程的话,要安装一下插件 l t x video 这个插件它是专门给这个模型所写的,这里面自带了几个工作流,在那个基础上面去改的,我觉得它的效果也是相对比较好,连接已经算是比较简单了,因为这个模型也是先跑初时的,然后再放大,所以这个 流程少不了这部分加载上所有的模型。然后呢,这里是我们之前一直用的这个交换块的这个节点,如果你的显存不是特别大的话,这个是一定要加的。然后后面这些东西大部分是不用动的参数,这里呢我我写成一个,这样我们就不要自己去填宽和高去算你的图片比例了,直接用这个按宽高笔缩放,这里的 分辨率我建议就把它在九六零或者最大是幺零二四,再大就没必要了,因为最终出来的尺寸实际上是它的两倍。然后这个地方我直接做了一个数学表达式啊,我们就不用算什么 n 加一八, n 加一四, n 加一,直接在这里填入描述,那它会自动转成帧数。 提示词是这里面非常非常重要的,网上也有各种大佬分享了自己的提示词经验啊,如果大家不看这个结构的话,给大家几个最基本的标准啊。第一个肯定要是英文提示词输入,因为这是个国外模型。然后第二, 不要写太多的,这个氛围类的,感受类的,一定要写具象化的,有什么动作,有什么展现,一定要具象化的写出来。剩下就是一些标准的质量词,尤其是镜头连贯等等的这些效果。然后我在这里写了一个智能体的提示词,把这个东西给你的任何的大元模型,再输入你的图片, 你可以告诉他你想要的这个运镜的幅度以及预估的时长,我们要跑几秒的,然后把台词给他输入进去,如果你不输入,他就会随机根据你的情况给你生成一句台词,那我建议大家都不要运动幅度太大,因为很难得到好的画面。 ok, 那 内容就是这样,大家可以尽快去体验一下。
191大桶子AI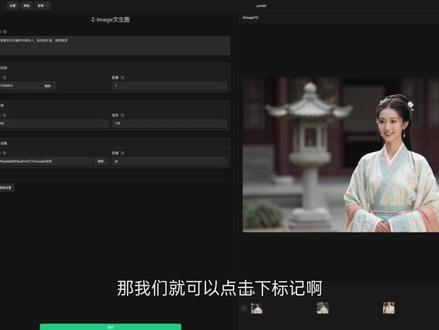 17:01查看AI文稿AI文稿
17:01查看AI文稿AI文稿哈喽,各位同学大家好,欢迎来到数字折叠,那我们之前的本地 ai 视频生成的课程用到的大模型都是万二点二, 但是万二点二的话呢,他就只能到二点二了,他有二点五,二点六也不会给大家本地开源使用了,是要去做一个线上的收费的。就在大家认为这个开源模型将要进入到一个停滞不前的阶段的时候, 咱们的 l t x 啊,这一家以色列的公司给大家开源了二点三的视频生成模型,那 这个模型相比较于万二点二,它有一个比较大的优势啊,它是可以音画同出的,也就是说我们可以出来一个完整的带有声音的 画面的视频,不用我们后期再去重新给它对口型做这个音频的一个合成了,非常的方便,也比较符合现在的一个 ai 的 视频生成的一个趋势吧。那么我们如何去使用它?对于电脑的要求是什么样子的?我们如何在本地成功的去部署它,那这节课我们就要给大家去讲了。 那首先我们来看一下啊,我使用这个 ltx 二点三制作的一个小效果吧, put your hands on the arm here open your legs not too much there you'll see why i like that very much do you want me back? ok, 那 大概就是这样的一个效果,我们可以看到它的分辨率是很高的啊,我在后期对它进行一个放大,但是我们一次就可以直出一二八零乘以七二零分辨率的视频, 并且的话呢,我们这个视频的帧数率是支持二十四帧或者二十五帧每秒的,它的时长也可以达到十秒甚至以上,对显存的要求也没有那么大,我使用的是 四零八零十六 g 的 显存,然后六十四 g 的 内存就可以跑这个效果了。那如果你的电脑比我还好,我相信它可以在一分钟之内就可以跑出一个五秒钟的视频。 如果你是十二 g 的 这个显卡的话,你可以试一下,因为我没有试过啊。那如果你的内存比较低的话,你也可以设置一个虚拟内存,这样子就会让我们的这个跑起来没有那么大的内存的压力。 那我们看完效果之后,我们来看一下怎么样一步一步的把这个效果给它复刻出来。那我们第一节课讲的就是工作流的部署, 如果你从来没有使用过 comui 的 话,你还需要先去下载我们的 comui, 然后再去给制作我们的 ltx 的 模型的工作流。 如果你不想去折腾啊,你不想一遍一遍的又配置环境,又要用这个代码去调配拍摄的各种模块,还要自己去下载工作流,安装插件,然后优化节点, 解决报错,这是所有的非程序员出身的人来去使用本地 ai 的 时候遇到的问题。那么我们数字折叠给大家提供了一套完整的开箱即用的软件,就是 comui 的 整合包,加上我们的这样一个 e f studio 的 工作流操作工具。如果你是我们输入折叠的会员的话,你可以用我们这个工具,如果你不是会员的话,你可以直接用我们的 comu i 自己去部署这个工作流。那么我们来看一下一步一步的一个操作过程。 首先的话呢,我们的 comui 整合包是可以在我们的网站上去下载的,我们首先可以进入到课程这个页面,在我们的课程页面里,我们点进来这个 ltx 二点三的课程的主页,在课程主页里面我们可以看到这边有一个这个配置链接, 首先第一步你就去点击这个 comui 的 整合包,把这个 comui 整合包下载下来,我们现在使用到的是这个零点一六点四的版本, 里边的环境是库达十三加拓十二点九,也就是说你首先要去升级你的这个显卡驱动,能够支持我们的库达十三,然后呢再去安装我们提供的库达十三点幺的这个库达驱动, 那么我们这个详细的部署的视频是在这里的,你可以到这里去下载部署一下,只不过我们这里边是十二点八,你只需要把我们的库达变成一个十三点一就可以了,如果你不是三维用户的话呢,那个侯蒂尼的安装你也可以自动的给忽略掉啊,就前期先去适配一下这个库达环境, 然后下一步的话就是安装我们的整合包,然后把它解压出来,放到指定的位置,就可以把这个软件打开了,下面给大家去看一下如何去打开咱们的这个软件啊?在你没有安装 cd 的 情况下呢,你进入到我们的 comfui 里面, 然后双击我们这个英伟达 gpu 的 bat 脚本命令,就可以把我们的 comfui 给启动起来了, 在启动的时候的话呢,大家可以再继续去下载第二个东西,就是我们的 d f studio, 我 把所有的工作流都配置好放到里面了,那这个 d f studio 的 下载链接的话,也可以直接去打开它 到这里去下载就行了。那它的一个部署的话呢,你可以看我这边这一个县城文学的课程, 这个课程上面的话呢,我们的第二节有一个部署的教程,你只要把这两个东西部署完,后面你就非常开心的去玩我们的 comu i 在 本地可以零成本的去制作各种 ai 的 一个效果了啊,这是我们的一个前期的部署, 如果你是老用户的话啊,你可能之前已经安装了我们的这一个数字折叠的 comui 整合包了,只不过你的整合包目前不是十六点四或者不是扩大幺三的系统,你就根据我们的下面这个部署教程去重新的升级一遍就可以了,你就不用再去安装其他的环境了,只需要去替换一下里面的这样的一个 is embedded, 还有我们的这个插件,还有我们的本体就可以了。那替换完之后,再把你老版本里面的你之前下载的囤积的一些大模型给它直接剪贴到我们新版本的模型文件夹里面去就可以了,这是一个比较方便,不用折腾环境的升级方式。 那现在我们看到 comui 已经打开了,那我们就直接进入到咱们的 df studio 里面去吧,我们打开我们的控制软件。 好的,现在这个控制软件我们就已经打开了啊。首先我们点击这个视频生成,里面我这边提供了有三个 l t x 二点三的工作流,分别是音画同出的图声视频,还有音画同出的文声视频, 在这个声音生成里面还有一个自定义音频的一个 l t x 二点三的图声视频的这个工作流,这三个工作流是我们要用到的, 我们今天先要给大家去讲的是这个 l t x 二点三图声视频,就这个咱们的工作流,那在去使用之前,你要下载 l t x 二点三的模型啊,我们可以直接点击查看介绍, 我们进入到这个介绍页面,我们可以看到这边有一个模型下载的链接,看到没有,你直接点击模型下载链接这边我就提供了我们的这个三个工作流共用的 一个模型,就一套模型系统吧,它的一个文件的路径我也给大家在这里梳理出来了,比如说在 models 里面,然后 different models 里面下载这一个可立普里面下载这一个 ve 下载这俩,是吧?还有放大模型,然后你就直接可以点击这个百度网盘啊,我们这个模型都是 开源的,免费分享的,在别的地方下也是可以的,没有关系的啊,那我们进入到这里面去之后的话呢,那我们就可以看到了啊,这个可立普文件夹,什么 different model 文件夹,给大家说一个技巧,我这个文件夹的名字啊,比如说可立普,就是在我们的这个 comui 的 model 文件夹里面,我们找到 model, 这里面也有一个可立普啊,你就放到同一个文件夹里面去就好了,就把它下载到这里面, 那相同的,就比如说是我们这个 latent app skill model, 那 你就找到我们 comui model 文件夹里面的相同的 latent app skill model 文件夹,然后把它给下载下来就可以了, 按照我的这个方式把这里面所有的模型下载下来,就可以使用它了。那我们首先的话点击使用该工作流,我们在使用的时候可以先创建一个工程,如果你有新的工程就直接打开就行了,比如说我们就放在我们的 l t x 二里面吧,然后这个名称的话,我们就叫做演示吧。 ok, 我 们创建一个演示的工作流,创建好之后呢,我们就选择这个图声视频的工作流,点击使用工作流就可以了。 然后我们可以先创建一个图像,那这个是我们默认的图像,那我就生成一个新的图像吧。比如说我们在工作流里面,我们选择另外一个工作流,图像生成的工作流,我们使用的是 z 妹子的这个纹身图,我们选择它就可以了。 然后我们这个图像我们创建一个古风女孩吧,一个穿着汉服的女生吧,这个的话是可以支持中文的,我们输入一个穿着古风汉服的中国女人 站在院子里,上半身特写, 就这样吧。然后我们的分辨率可以给到一二八零三七二零稍微小一点嘛。那我们这个保存路径的话,也可以放到我们自动创建的这个资产里面,你可以自己写一个文件夹,比如说叫做古风 这边的话呢,我们改变一下他的保存的前缀也行,让我们刷新一下历史记录,这个时候我们就可以执行了。那这个任意美指纹身图也是需要去部署模型的,我们之前已经部署过了,你可以看一下我之前的课程,我们点击一下执行就可以了。 好的,现在我们已经生成了,我们来看一下整个质量还是可以的啊,非常有这种古装剧的感觉。然后我把提示词的上半身特写去掉了啊,改成了面带微笑,因为只有上半身特写,他的面部没有那么完整, 那我就把它改一下,优化一下。那我们就可以点击一下标记啊,把这个图像给它标记出来,作为我们的一个图生视频的手帧图的使用用途。那下一步的话呢,我们就切换到 lts 二点三的图层视频工作流,把这个手帧图切换成为我们刚才的这个 mark 出来的图像就是它了。然后提词词应该怎么写呢?提词词其实是有一些要求的,那这个 l t s 二点三的这个提词词的格式,我们提供了一个反推工作流,就是说你把一些必要的条件给到它,把图像给到它, 它就能够给你一个适合 l t s 二点三出视频的这样的一个题词词啊。不是说你随便去写,可能随便去写出来的效果并没有那么好,那我们可以再去选择一个工作流,你看我们有了这个十六六软件之后,你就不用到处去部署工作流了,你就直接在这里面去选就行了。 那我们可以看一下,在文字生成里面有两个反推的工作流,另外一个是二点三反推的官方版, 这个是之前 lts 二的反推提词词,它的提词词是比较的完整,就是把画面也描述出来了。那这个是官方的 k z 流给到了一个提词词的反推方法,这个可能会更简洁一点,那我们就用这个官方版的,我们点击使用工作流, 如果你没有部署这个反推模型的话,你也可以查看介绍一下,看一下需要去下载什么模型。其实这个工作流里面所用到的那个模型跟我们二点三这个大模型是一样的,用到的是它里面的可立破模型,所以你就不用下载任何的模型了,直接点击使用就可以了。 那我们把刚才的那个图像给到他,就比如说这个图像,然后他的这个前置条件是有一定的格式的,比如说前面这一句是不用管的,就是让这个图像变成一个流畅的动作,然后这个主题你要改一下,动作你要改一下,场景你要改一下,如果自己改的话比较麻烦啊,你可以直接 ctrl 键加 c 键复制一下,然后我们可以进入到 excel gpt 里面去啊,那我们就进入到这里面来,然后把这个题词给到它,就是这个反推的格式,说修改一下这个这个内容 要求,然后我们就可以把下面的这些题目给到它,就是 subject 啊。这个主题是什么呢?一个女女人对着镜头打招呼, 然后再把我们下一个这个 action 再复制过来。说什么呢?说这个女人走到 镜头前,微笑着说,是吧?一日不见,如三秋兮, 这应该是一个文言文啊,就这样子,一日不见如三秋兮。 ok, 然后我们再去回车,然后这个盛世描述一下啊,盛世就是一个呃,古代的院落里, 这里就会触发他对环境或者声音的一些描述,然后点击给我们的这个大模型,他就可以把我们的题词给优化了,我们来看一下,他自动就去写了。 他给了两个版本啊,第一个版本的话他把台词也变成英文了。啊,这个我们要中文的,这个叫什么呀?呃,一日不见如三秋兮,我们复制一下,可以来去看一下啊, 粘贴是吧,让图像以流畅的运动变得生动起来啊。一个女人面对着镜头,然后微笑的说这个样子。好的,那我们就可以把这个反推的指令复制到我们的工作流里面去, ctrl 键加微键啊,如果大家觉得比较麻烦,可能更喜欢做在线的,但是我觉得,呃,如果你想要简单一键的东西可能就没有那么准确,如果你想要省钱,想要做的更专业,你还是要稍微的呃,用一些流程来去规划一下。 那这个最大制服就是说他反推出来有最大的一个反推提示词的长度啊,但是一般情况下是不会超过一零二四的,你就算给到一零二四,他可能反推到几百个就停止了啊。那我们这个路径也可以改一下, 他会给你一个提示词文档的,你后面可以发给别人,也可以自己去学习使用。那我们可以给到这个反推的文件夹里面去就可以了,这个就叫古风吧,然后我们就开始执行就可以了。 好的,我们现在已经反推完成了,我们可以看到这个提示词在我们的右边展示栏里面也展示出来了,我们可以直接 ctrl 键加 c 键,我们回到这个翻译软件里面来看一下, ok, 就 这样子的,你可以看到它又把我们这个中文给它翻译成英文了,这个我们到时候再翻译过来就可以了。 风格他先定义了,然后再定义动作。女人慢慢走向镜头,热情的微笑着,用舒缓的声音说,啊,什么什么柔和的中国传统音乐,然后与鸟儿的呃声音和远处的喷泉融为一体啊,就非常的详细吧。那我们就回到这个这边来, 然后呢我们就把咱们的这个题词给它粘贴过来,只不过你把这个他翻推出来的这个拼音再改一下啊,一日不见如三秋夕, 如三秋兮。好的,现在应该没有问题了,种子值可以随机一下啊。注意,这个是我们刚才那个音化同出的工作流,这个,这个是反推的工作流啊,他俩你不要弄混了啊,先去反推出提示词来,然后再给到我们的工作流, 然后时长五秒,五秒应该可以了,就默认五秒,帧率二十五帧每秒,然后宽度一二八零乘七二零。保存设置,这里就是你保存在我们的 alt put 里面的这个文件夹里面的。这个后面的文件夹和前缀啊,我们就叫做克拉斯演示吧, 这个不是一个绝对路径,大家注意啊,现在我们刷新一下工作流没有问题就开始执行了,那执行之前的话呢,建议大家可以到我们的 comui 里面啊,你可以去清理一下这个内存,清理一下缓存, 如果你再执行多个工作流之后,你再去执行新的工作流,它的内存来不及卸载,会造成这个 comu i 的 卡顿。建议大家可以多去点一下这里,然后保证我们的这个 gpu 还有我们的内存要干净一点,现在没问题之后,我们就开始点击执行,等待它的一个视频的生成吧。 ok, 那 我们这个已经生成了,我们来看一下啊,一日不见如三秋夕, 是不是还是可以的呀?而且我们可以发现啊,咱们的这个嘴型也能对上声音也是这种比较标准的普通话,美中不足的就是有字幕,这个字幕在中文的发音下是比较通常出现的,所以我们后面的课程当中用英文就不会有这个问题了 啊。再然后的话呢,我们接下来要做的这个效果,并不是说光用这个工作流,我们还会用到其他的工作流,像瑞米克斯呀, 像这个 client 啊等等的,所以我们接下来会利用这个大的 ltx 框架,然后再加入其他的辅助模型来去制作。那这节课的话呢,大家只要把它给部署上就可以了,那么我们也可以对它进行接下来的一个放大高清叉撑的处理,我们都会详细的去讲解的, 那下一节课我们再见。拜拜。
203数字折叠 06:54查看AI文稿AI文稿
06:54查看AI文稿AI文稿三千元到十万元大模型家用 pc 硬件方案全解析?上一期社长介绍了纹身视频模型的硬件方案,里边讲了企业或专业工作室的纹身视频模型硬件应该配到什么程度。有不少朋友在评论区留言说,希望社长能够出一期大模型的家用消费级硬件专题, 那么这一期就满足大家专门讲一讲大模型家用消费级的硬件方案。最近 oppo colo 很 火,那什么样的配置能够畅玩 oppo colo 呢?在这一期也有答案。既然是家用消费级方案,也就是个人 pc 方案, 那么 e 五神轿、特斯拉、 v 一 百为代表的老旧服务器显卡就不在今天这一期的讨论范围内了。 ar max、 三九五、 mac mini 的 整机方案由于纹身视频能力弱,也暂时排除在本期之外, 因为毕竟作为家用消费级主机,必然是要兼顾多种需求的,跑跑大模型和智能体,生成一下 ai 视频,做做生产力工作,没事还能打打游戏,甚至新出的三 a 游戏也能尝尝咸淡,这就是本期硬件选型的基本要求。 所以我会尽量选择个人 pc 的 消费级硬件来给大家搭配方案,最低花费三千元,最高花费十万,大家可以根据自己的预算和实际需求,综合考虑自己的硬件配置。 在开始之前呢,先给大家预告一下,在三月十五号,我们会开一期 ar 大 模型私有化部署的小白培训,具体的培训内容在这一期结尾会有展开说明,有兴趣的朋友一定要看到最后。 我们知道,现在的大模型在日常应用上已经分成了上下文推理模型、纹身图或纹身视频模型,这两类不同的模型对于硬件的要求是不一样的,对硬件适应性最广的是上下文推理模型, 它对扩大的要求最低,只要显存达到一定规模,哪怕是好几年前的老旧显卡也仍然可以胜任,这就给了我们家用消费级配置很大的选配空间。 这里要注意的就是如何判断某一推理模型能不能部署,主要是看显卡的显存能不能大于模型的参数,比如三十 b 硬特八的模型对应的就是三百亿参数。按硬特八量化规则,加载到显卡里所需要的显存大约是三十七点五 g, 加上要预留 k v 缓存激活值缓冲区, 因此要运行这个大模型,我们一般是按照模型量化后显存占用的一点二倍计算。那三十币 ink 八模型就需要至少四十五 g 显存的显卡,但众所周知,内存是可以分担显卡的上下文推理模型的加载任务的,比如上面讲到的三十币 ink 八的大模型, 需要四十五 g 的 显存来流畅运行,如果显卡只有十二 g, 剩下的三十三 g 可以 加载到内存中去运行。 当然,因为内存的贷宽远远小于显存的贷宽,如果大部分都让内存来跑的话, tokins 的 速度会大打折扣,所以显存尽量还是要大一些。但对于个人来说,对于效率的要求并没有企业这么高,我相信大多数人是可以接受的,毕竟在性能和成本方面总要找到一个平衡。 纹身视频模型的门槛就要高的多了,他没办法像上下文推理模型那样,显存不够内存来凑,模型必须要全部加载到显卡里。所以如果朋友们想尝试纹身视频模型的话,就要至少满足两条硬杠杠,一是显卡要有 touchcore 支持,二是显卡显存要至少达到十二 g。 为什么呢?我们以 y 二点二为例, y 二点二 t r v 五 b 轻量版模型是一款小型可部署的开源纹身视频模型, 十二 g 以下的显存加载不了这个模型,十二 g 正好能加载,而且能够跑起来。因此呢,显存越大,扩大核心越多,显存待宽越高,视频生成的清晰度、速度、时长就相对更有优势。 于是,基于上面社长针对这两个模型的分析,我们就得出了个人 pc 如果想要同时玩转这两种模型的话,显存要大于等于十二 g。 为保证能够运行纹身视频模型,支持 touchco 的 可选型号为英伟达 rtx 架构的二零系、三零系、四零系、五零系显卡。这样我们就可以定义以下五档家用消费级 pc 的 预算方案了。 第一档,三千元。这一档的核心定位是新手尝鲜,可以进行基础大模型体验加轻度办公加普通网游。具体的配置如下,这套配置的大模型能力是这样的。 第二档,一万元,这一档的核心定位是家用主流,支持中型大模型流畅运行加高效生产地加中高画质三 a。 具体的配置如下, 这里社长推荐了四款显卡,从这一档开始, open club 就 可以畅玩了。下面就贴出这四款显卡结合 open club 加千万最新模型的畅玩区间,供朋友们参考。在这个表格里可以看到,三零九零二十四 g 显卡的性价比相对较高,畅玩范围相对更广。 这四款显卡都能支持纹身视频模型, rtx 五零六零 ti 十六 g 可以 输出七二零 p 二十到三十秒视频片段。 rtx 三零九零二十四 g 可以 输出一零八零 p 六十秒视频片段, rtx 二零八零 ti 二十二 g 和 rtx 三零八零二十 g 可以 输出七二零 p 到一零八零 p 四十到五十秒的视频片段。 第三档,两万元。这一档的核心定位是高阶家用加轻度专业,支持中大型大模型流畅运行,加多模型同时运行,加四 k 游戏加四 k 剪辑、 3 d 渲染。核心配置如下, 这套配置拥有较高的实用性,几乎可以胜任绝大多数主流需求。他的大模型能力是这样的, 第三档说完,接下来的第四档和第五档就进入高端玩家档了,如果只是纯打游戏的话,完全用不到这么高的配置。社长建议大家压抑住所谓一步到位的冲动,先在中低配置上玩熟了,确实有需要了,再上高端配置也不迟。 第四档,五万元。这一档的核心定位是旗舰家用加准专业,支持大型大模型流畅运行,加模型微调加四 k 游戏加专业级生产力。核心配置如下,这套配置的大模型能力是这样的, 第五档,十万元,这一档的核心定位是顶级家用加专业级。社长在这一档破个例直接给他上了英伟达 pro 六千九十六 g 工作站显卡,让他可以支持全类型大模型加大型模型完整训练加四 k 或八 k, 游戏加专业创作,核心配置如下, 这套配置的大模型能力是这样的好,说到这里,五档家用消费级大模型硬件配置推荐就结束了。 最后说说小白模型部署培训的事。最近有不少粉丝朋友跟社长说想要部署大模型,但又不知道怎么开始学起,所以我们打算在三月十五号开一期培训来手把手教小白,零基础上手, 核心内容包含四个板块,一是大模型基础原理与适用场景。二是不同大模型的硬件精准选型。三是本地知识库问答、自动化办公等实用智能体搭建。四是欧门可乐安装配置与私有化部署,有需要的朋友可以联系我哈!
3550单车酒吧搞机社 10:48查看AI文稿AI文稿
10:48查看AI文稿AI文稿蹦出来之后,左手右手接一个慢动作,右边再直接拉到这上面,直接拉到这个轮胎上,上面再接过去之后,然后上面再直接拉到这个位置了,右边再直接这个位置直接倒过去了,再倒一下,然后右边再直接抓着。 ltx 二点三终于正式开源了,而且这次不是小修小补, 它和 ltx 二相比最大的一个提升就是更快更稳。但问题也来了,网上已经有人开始质疑二点三到底是真的升级,明显 还只是官方宣传的,看起来比较厉害。那么这期视频我们就不空讲参数,直接看它哪里做了提升,实测效果如何,以及如何在康复 ui 里面直接跑起来。 我们先说第一个升级点,画面细节。 ltx 二点三这次重新设计了 ve 模型,官方给出的说法很直接,细节更锐利,纹理更真实,边缘更干净。 翻译成人话来讲,就是人物的脸部、头发丝、衣服褶皱以及物体边缘,这些地方会比 ltx 二更清楚, 不容易糊,也不容易脏。稍后我们有实测的案例。第二个升级点是提示词更听话了。二点三这次新增了一个 greedy, attention, text, connector 模块,重点强化的就是 timing, motion, expression 这些提示词的表达。 简单来说,以前你写了一长段的 prompt 模型,可能只听懂一半,但现在呢,它就更容易抓住你真正想要的动作表情和镜头节奏。第三个升级点,我觉得对做短视频的人来说非常的重要, 就是原生做到了竖屏的支持,以前很多视频生成模型也能做竖屏的内容,但本质上还是横屏思维,人物比例、构图以及镜头的空间感都比较怪。但 ltx 二点三这次就直接补齐了这个短板, 他按照 poetry orientation 的 方式去准备了数据集。也就是说,他不再是把横屏直接裁成竖屏完成训练,而是直接按照竖屏的逻辑去完成数据的准备模型的训练。 所以 ltx 二点三这次在竖屏的生成上,支持比 ltx 二提升非常大。第四个升级点是二点三的音频更加干净的,官方提到他们清洗了训练数据, 还换了新的 vocoder, 结果就是音频里的杂音断裂和奇怪的空白片段都会变得更少,文本到视频和带音频条件的工作流里面,对其效果也会更好。所以这次升级不只是画面更强,而是整套试听体验的一个提升。 讲到这里,很多朋友可能会问,这些卖点听起来确实都很香,但到底是官方说的好,还是跑起来效果就不错?那么接下来我们就直接看实测的内容。 这里来看我们的第一个案例是徒生视频给的提示词是一个女生拿着化妆水,旁白正在讲话,同时她用手抚摸自己的脸,表现自己的皮肤状况。这个镜头最容易暴露两个问题,一个是人物面部稳不稳,另一个就是动作细节假不假。 从结果来看,二点三的人物面部清晰度很高,整体画面已经非常接近实拍。而且在人物摸脸的时候,脸部的褶皱和嘴部的肌肉变化也是符合物理规律的。但如果你以为他只是脸更清楚,那还不够,接下来我们看第二个案例。 第二个案例我们给的是人物运动和镜头的一个变化,这里我们提示词写的是一个女生正在街上最近自拍,先用手拉一下裙子,然后向左走两步,再向右走两步展示自己的衣服。这个测试其实很刁钻,因为里面同时包含了人物位仪,裙摆变化,自拍动作还有镜头尺度的一个变化。 特别是人物在手机上进行视频放大的时候,我们整个画面会根据人物的动作去完成一个放大。如果说模型不稳,最容易出现的就是裙子糊掉,或者说人物的手部变形,或者画面一缩放就直接毁坏。 但从当前的测试结果来看,二点三在裙摆动态、人物运动以及整体画面缩放时都能保持稳定, 表现非常不错,没有出现明显的模糊和毁坏,已经非常接近实拍的一个质感。到这里我们来看下一个案例,也就是首尾针工作流。这个案例我们给的提示词是一个女生正在街头逐渐走向镜头,显示出上半身的特写。 首尾针这个模式最容易看出来的就是模型在过度的过程中能不能很好的保持一致性,因为很多模型的手针和尾针都能够做好,但中间如果一旦动起来,就会出现人物漂移,节奏比较僵硬的问题。 而在当前的案例当中,二点三的整体过渡、自然度以及人物的连贯性明显是比较让人放心的。那么接下来还有一些案例大家就自行观看,用不好 l t x 二零三, 那这期视频一定要看惯, 小公子今天居然有雅兴光临寒舍,有失远迎,还请见谅。 壮族自治区爱吃红鲤鱼与绿鲤鱼 与驴的出租车司机,拉着苗族土家族自制粥,爱喝自制的刘奶奶榴莲牛奶的骨质疏松症患者,遇见别着喇叭的哑巴,打败瑶子山前四十四棵紫色栀子树的四十四只石狮子,之后碰到年年恋刘娘的牛郎,念着灰黑灰化肥发黑会挥发走出山头。从上面这些案例看下来,二点三的这次升级补的基本上都是创作者真正会在意的一些地方, 当然它也存在一些固有的问题,比如说视频生成容易频繁的出现字幕低帧率的情况下,剧烈运动会导致整个视频的画面模糊,而且工作流的参数非常的敏感,稍不留意就会出现画面毁坏, 那么二十二 b 的 参数量也会明显的导致显存的压力有所提升。但如果你更在意的是成片的质量,更在意试听体验,那么 ltx 二点三的这次升级你真的值得去做一次尝试。 最关键的是二点三已经完全开源免费,而且康复 ui 也已经获得了完全的支持,那么本期视频后续测试用到的模型以及工作流都在网盘里面有提供,大家可以直接在视频的简介区获取更系统的教程,欢迎大家加入星球学习。那么接下来我们就进入最实用的部分, 如何本地安装,以及在康复 ui 当中完成 ltx 二点三的测试和运行。 好的,那么我们就直接开始本地的安装教程。大家首先就是在小破站找到我任何一个视频,在视频的简介区这里会有啊,也就每一个视频下面会有一个展开更多。点开之后,这里可以看到有个网盘资料分享,打开这样的一个链接,这里会有一个 ltx 二点三模型以及工作流。 点击打开网盘,里面给大家提供了两套模型,第一套是 kj 的 model, 第二套是 models, 也就是 kj 的 官方的。我这里建议大家安装 kj 的 models 啊,因为我们提供的工作流是按照这个来做的,下面这两个 ltx 二点三的 image to video 和 text to video 这两个工作流是基于 kj 的 models 做的, 那么基于 kj 的 这一一套工作流是下面这两个,所以说大家可以直接就下载最上面的这几个就可以啊。每一个文件夹的名字都是按照 comui 里面 models 的 文件夹进行命名的, 大家可以打开自己本地的 comui, 在 comui 里面有一个 models 文件夹, diffusion model 就 放到 diffusion model 对 应的文件夹里面,也就是里面的内容就放到这个文件里面, loris 就 放到对应的 loris 里面。那么一共五个文件夹全部下载,放置完之后呢?然后把这两个工作流也进行下载, 然后呢,接下来就是完成更新,大家要保证自己的网络没问题,才能正常的更新 comfort ui, 大家用的是便携包的话哈,然后在包里面会有一个 update, 这里直接双击这个 update comfort ui, 点 bite, 也就是脚本去完成 comfort ui 的 更新。启动完毕之后,大家还要再做一件事, 点开 manager 管理器,在 custom node manager 当中搜索 kj, 然后找到 kj 的 一个插件叫做 comfort ui 杠 kj nodes。 如果大家本地没有安装的话,就点 install 完成安装,如果有安装的话,要点这个 try update 把它更新到最新,然后大家把下载的两个工作流拖入 copy ui 当中,就可以进行使用了。这里我们稍微讲解一下工作流的一个重点用法。 第一个工作流就是我们文声视频和图声视频二合一的工作流。前面大家正常的加载自己放置好的模型, 然后下面大家正常的加载自己生成视频的宽和高,横屏还是竖屏就在这里设置。 然后这个 lns 指的是视频的时长,这里十秒就是十秒哈,那么 lps 就是 一秒生成的图片数量,我这里给的是六十,那么十乘以六十就是一共六百帧。六百帧我们在显存里面也是可以的,我当前三十二 g 的 显存是可以跑六百帧,甚至可以跑更长到一千帧都是可以的。但是这里呢,大家要注意啊, 如果说你的视频运动状态比较激烈,比如说人物有转身,甚至说是一些汽车的极速飞驰的镜头,那么这里的帧数我建议给高,我测试下来,给到六十是比较好的,如果你给到四十八的话,可能出现重影,给到二十四也能正常生成,但是他画面可能出现毁掉,而且这个 l p s 值越高, 画面的质量会越好,这是我个人测试下来的哈。给到六十,然后这个 list 呢,大家按需去进行设置哈。一句话的话建议就是三四秒左右,两三句话有对话的话给到十秒左右这样,然后在上面呢,我们就是上传图片, 那么在这里会有一个 text to video 节点,这个值,如果你把它打开,就是整个工作流就变成了文声视频工作流,如果你把它关闭,那整个视频就是图声视频工作流,所以说上传的图片它不一定起作用,主要就是看这个点你是打开还是关闭的哈。 然后这里是有个 enhance prompt, 就是 我们提示词的增强,也就是说你打开之后,我们输入的提示词,它会经过本身自带的模型进行一个提示词扩充或者说重写,但是呢它有可能会改变你的语义,如果说大家想更强烈的自己去控制这个工作流的话,建议就把它关闭,然后提示词我们就自己写就可以了。 然后就是点击运行,完成我们视频的生成就可以了。那这个呢,就是我们纹身视频和图生视频的工作流哈,核心点就是这个针数哈,经过测试针率给到六十,效果会更好。然后呢是我们的首尾针工作流,和刚才的纹身视频图生视频基本类似, 只是说我们在这里上传两张图片就可以了,这里上传手针,这里上传尾针,然后在中间写上我们对应的提示词,设置宽高,设置视频时长,设置 l p s, 那 么点运行就可以完成我们视频的生成,其他的参数我不推荐大家更改,那么这个呢,就是我们本地安装和使用的教程了, 如果说大家想要免去这些复杂的安装步骤的话,大家可以在视频的简介区找到云端的地址,然后云端呢后续也会获得支持,大家可以直接在云端完成工作流的运行和测试。那么今天这期视频呢,我们就先讲到这里,感谢大家。
88啦啦啦的小黄瓜 09:53查看AI文稿AI文稿
09:53查看AI文稿AI文稿让我们体验一下 ltx 二点三的效果,也不知道这次 ltx 二点三能有多大提升,心里还是有点忐忑。 let's experience the new ltx 二点三 model together it has made significant progress compared to ltx 二点 o。 春风十里,不如与君共赏人间烟火。 哈喽,小伙伴们大家好,那么刚才片头那些视频呢,全部是 f t x 二点三刚刚生成的哈,那么也是今天开源那个最新的视频模型, 通过这个一段使用呢,就是生成了大概几十组片段吧,也发现了它的一些特征哈, 首先说怎么去使用这个模型哈,啊,第一步呢,就是先更新我们的康威到最新版,那么就支持了这个我们的二点三的 ltx 版本,那么接下来就是要下载我们的模型,那么模型呢,大概有两组哈,第一组就是 ltx 官方给到的二点三, 跟我们之前的二点零的版本那个模型放置非常一样啊,非常类似的。那么 lts 官方这个模型呢,它其实跟我们之前二点零那个模型的放置呢,是比较类似的啊,我们看一下这个模型啊,同样是有一个主模型,是个 dv 版的主模型,然后还有一个蒸馏版的 laura, 然后还有一个蒸馏版的主模型,这两个模型呢,主模型都是四十多个 g 啊,都是四十多个 g。 然后还有就是说我们的放大的模型哈,就是这个放大模型分也分了两个, 还有一个方法呢,就是开架呢,它已经给了一个自己分离的模型哈,就是我们之前的 l t x 二点零也好,它的模型都是包含了 v a, e 和 clip 的 这样一个模型啊,那么开架是把它进行了一个拆分,这两种模型都可以用, 如果用的话呢,就是开架这个版呢,就是要用我们这个呃 diffusion model 这个加载器来加载哈,然后用单独的 ve 还有这个呃 clip 加载器去进行加载。那我这边就用的官方这个啊,用的官方这个。 那我们分了两组测试,一组是这个纹声的,一组是图声的哈。首先说一下纹声的,我个人感受就是它的这个动态,包括这个破音, 破音是解决的哈,就是破音问题已经没有了啊,我跑了这么多组,再也没有遇到过他的音频破音的这样一个现象啊,就一直都是出了正常音频的。 然后就是他这个动态呢,有了大幅度的提升啊,包括我们可以看看这组这个呃,拳击这个哈,他这个动态做的非常好,包括运镜、切镜哈,我觉得在开元里边算不错了,虽然他还是有瑕疵的,但是我觉得已经很不错了哈, 包括我们看一下这个赛车这个也是啊,他这个运镜的一个整个的效果也是非常好,非常合理啊,但是看了他还是有一些小问题,他容易出现那种斑点,就是有点像那种大果粒的一个样子哈,我们之前在浑源上面见过这个东西,那么这组也是哈, 我们看他的一个动态呢,其实在车里边动态表现是非常好的,但是还是说我们这个场景呢,会稍微有点这个大果粒哈,其他的像这个风光的 这组呢,我觉得效果也不错啊,而且画质也很好啊,对吧?画质也很好,都没什么问题,而且十秒的啊,十秒的, 你再来看这个,但是他的二次元呢,我觉得是不太好啊,二次元我们看一下,这个效果我觉得很差了,不建议大家跑这个纹身的二次元哈,我建议如果要跑二次元的话,尽量去跑图什么的。还有就是说这个写实的一个人物在海边,这个哈,他的整个的音画同步做的是非常棒的啊,非常棒的。 然后就是拳击这个还有这个一个大场景呢,我们看一下哈,这个赛博朋克城市风格的哈,也是表现的不错,但是画质就说他的动态稍微大起来,他的画质就会差一些哈,这个我发现无论是图声也好还是纹身也好,都有这个问题。 这个是一个鬼故事的啊,一个偏恐怖风格的啊,这个就运镜也好,他的整个画面的动态也好,我觉得都很好啊,故事型非常好。还有就是这个人物说话这个,这个其实效果非常棒啊,无论说话还有画质都非常好,因为他动态比较低嘛,就非常棒哈, 这是我们纹身的,那这里无论是纹身还是图腾呢,我建议大家注意一点啊,就是说第一点,我们这个蒸馏的 laura 呢,强度给他降低一些哈,就不要给他按一,不然的话他的画质会出现,就是我们人物会容易变老啊,变得 很脸部非常丑陋啊。就是如果你这个 lowra 强度拉成一的话,第二就是我们这个第二步呢,呃,放大这一段呢,我们用普通的 k 太阳去给它接过来哈,然后跑四步, cg 乘以一,然后降噪呢,可以拉低一些哈,比如零点三、零点四、零点五左右, 它的画质会更好啊,不然的话也是一样容易出现那个面部的一种呃,扭曲啊,狰狞感,就肌肉感特别强, 无论是 t 图 a 还是 i 图 a 啊,我建议大家都去这么调整一下。好,这回我们再来看看这个图上视频啊,图上视频的话,这个一个普通的图上视频 啊,就是这个人物坐在这个秋千上啊,我们会发现他其实也是有一点慢动作啊,慢动作,但是他的一个进步的点,我们比二点零时代好的。什么?就是说这种人即便面部占比比较小的情况下,他也没那么崩了啊,没有那么崩。好,我们再来看下一组例子, 这个就是人物说话的就非常自然了,我发现这个 rtx 二点三呢,他也是有概率出这个字幕的话,特别是在什么情况下呢?特别是在你这个视频说的中文的情况下,他就会容易出字幕,像这个视频的说的英文啊,他就没有出字幕 啊,我发现好多次了啊,那我们看看这段视频,他是用的这个出的中文的,他就出字幕了啊,也不知道这次 ltx 二点三能有多大提升,心里还是有点忐忑, 对吧?他就出现了这种字幕了啊,他就出了字幕了,那么这个也是哈,这个我们看看,也是束缚的,就是说这次二点三这个重大提升,就是他对束缚的支持也已经 ok 了哈,我们的二点零的时候,他的束缚支支持的其实不太好的哈, 也是哈,他因为是我们角色说的中文,所以他就出现了这种字幕哈,因为他只要是非英语的,他就容易出现这个东西啊。我们再来看看这种二次元的这个哈, 这个让他的运镜比较大哈,我们看到没有,这个旋转起来,他这个画质就差一些了啊,但是最后他找回来了,最后这个收尾的这个画质还是不错的啊,还是不错的,但是在中间这块我们能看到他的画质,明显是有这种果粒橙这种现象啊。我们再来看看这匹马的一个哈, 这个马在旷野上跑,这个说实话肢体动作呢,我觉得他这肢体动作有点不太合理哈,我们再来看看,对吧?他这个腿配匹配的不太好,而且还是有点慢动作,同样因为他的运动幅度比较大,他的画质呢,就是在草的这地方,这个画质呢,能看到有种颗粒感比较重哈, 但是最后首尾这个动感,整个运镜我觉得还是不错的,这运镜也是一个非常大的一个提升。我们再来看看这个啊,这个人物走在这海边的这个,这个也是啊,就像我刚才说的,他即便是人物的面部占比比较小的情况下,他也没有崩啊,也没有崩了啊, 而且这个说话呢,就是也符合我们这个,包括他最后这个字幕啊,他虽然出字幕,但是他还是非常努力的去写中文字幕啊,大家看到没有,能非常努力的在写中文字幕,他也在尝试去写,但是很多时候写不出来啊,写的字还是有问题 啊。那么这就是这个二点三目前一个应用的一个感受哈,他的基本的架构,包括整个工作流呢,跟我们二点零几乎是一样的,几乎是一样的,包括一些 laura 呢,也能够使用,但是它的效果呢,没有 在二点零上那么强啊,能有一点点效果,但是不够强。同时这次呢,康复腰的官方工作流也增加了这个 他提示词强化啊,就是前段时间康菲尔专门更新了一个这个文本的一个生成的一个强化,专门做了一个优化节点啊,就是用我们这个呃 jama 三这个模型,或者是用我们的千问三的这个模型,就能够对这个提示词进行强化啊,那么这就是整个的一个二点三,一个感受啊,就说他是有一些问题的啊,实话说他很多问题就是包括一些强动态啊,包括这种,我们看一下啊, 这种强动态的支肢体,他还是不够合理啊,对吧?他还是不够合理,脖子又拧了,是吧?但是呢,我觉得,呃, 他在某些在这种就是说运动幅度不大的这种运镜情况下,像这种这种哈,我觉得他的效果都不错啊,就是你只要运镜不够,不是那么强,他就没什么问题啊,一旦运镜幅度特别大的话,他就容易出一些问题啊,这也是目前他的一个限制, 目前它的一个限制,大家一使用的时候也注意一下哈。 ok, 那 么这个也给大家分享到这里啊,模型呢,我会把这个 l t x 刚才那两个版本就是非正流的版本,还有那个 laura 呢,还有呃,它的这个配套的模型都放到那个我们的 网盘上啊, running hub 上也会尽快部署啊,大家也去感受一下。 ok, 那 就给大家分享到这里。
 00:48查看AI文稿AI文稿
00:48查看AI文稿AI文稿其实你现在去部署这个 openclock, 没有必要一定要去买这个麦克迷你啊,麦克迷你的话可能就是部署的时候简单一点,然后他就是省电一点啊,你像这种 呃小的笔记本电脑,只要内存大过八 g 的 都可以去部署。你看我现在就是用这种普通的电脑主机啊,只要内存大过八 g 的, 不管是 windows 或者说是苹果的 os 或者 linux 都是可以的。基本上我现在能用的我家里面那些废弃的电脑,平时以前不用的那电脑啊,都是拿来装好这个 open color 了, 每一个 open color 呢,就相当于我的一个员工。我建议你们就去买这种几百块的电脑啊,去部署一下,去学一下这这些 ai 的 东西啊,真的非常有用。
304梳子哥(正能量) 00:27查看AI文稿AI文稿
00:27查看AI文稿AI文稿这条新闻传达出一个很重要的信息,就是未来职业教育的前途很广阔。这条新闻传达出一个很重要的信息,就是未来职业教育的前途很广阔。国家相关部门已经明确表示,将加强对优秀影片、年轻电影人等的支持力度。 国家相关部门已经明确表示,将加强对优秀影片、年轻电影人等的支持力度。
 03:44查看AI文稿AI文稿
03:44查看AI文稿AI文稿视频我们来看到 l t x 二点三的更新,更新在更强的 t r s 遵循原生的竖屏支持, 想追上我,下辈子吧,音频更加的干净,以及对于图声视频而言更好的一致性。模型的体积为二十二 b, 非常的巨大,我已经几乎在第一时间部署这里优云智算平台上面找到对应的镜像, 点击部署实力,这里的话我们可以租用五零九零,或者说四十八 g 的 四零九零,如果有四 k 需求,可以选择更高的配置说明书往下拉,找到对应的启动指令复制 夜间租用显卡会有一定的优惠,点击立即部署,等待一下,进入猪 peter lab 任意的地方,打开终端, 粘贴启动指令回车,出了地址之后回过来,点击进入康复 y, 我 们先说快速启动,快速启动这个地方我们需要去设置提示词, 设置视频的长度,以帧数为计量,设置视频的帧率多少帧每秒钟,设置视频的宽度高,那么这就是纹身视频的几个必要输入项。 如果我们使用加速的工作流,这个加速二模型会进行前置,如果我们不使用加速的工作流, c f g 将为四反向 t s 呢将会生效。图人视频几乎保持一样的设定,不一样的地方呢就在于它需要多加载一张图像,并且呢是按像素百万像素为计量单位, 真实的宽高是为这个百万像素的二分之一,比如这里是二百万,那么它的真实的视频生成就是以一百万像素为约束的宽高来进行生成,相当于是两个数值的乘积。无论是纹身视频还是足身视频,我们都有一个放大组, 放大组我们需要去加载一个放大模型,那么这个放大模型更新到了二点三的版本之后,除了时间空间放大之外,他有一个一点五倍放大的版本,解码后的话就出结果了,没有什么特别的,我们简单看到一些纹身视频,涂身视频的结果,那么这是纹身视频的结果, 这夜景太迷人了,这杯咖啡的味道让我想起了以前非常连贯。其实这个地方不需要特别的离谱深沉的画面,就是电影级的画面,因为 l t s two 这个地方所使用的训练级,我猜测使用了大量的电影画面, 这场雨来的真是时候,还不是那一种真实的,就是完全从电影当中截取的片段一样。涂声视频的结果,我可以非常明确的说,相较于他的上一代版本,绝对是增强了他的一致性的, 尽管我们看到随着视频的片段播放,到了后面还是调相似度了,但比他的上一代要好太多了。 第二个测试呢,下水,游泳,直到到了最后的部分呢,才掉了相似度,在此之前呢,还是有一个很好的保持的。那么这一切都基于我们使用了大模型,而未使用了正一的多二模型的情况之下, 只要设置当中进行一定的微调,或者说官方版本的再一次迭代开源,我们将获得一个非常好的基作模型。 参数量对于模型的生成是很重要的,参数量这个地方往上去叠加,我认为是非常正确的策略。第三个结果呢,是一个歌手的跳舞,那么怎么说呢,这个人物被拉长到了一个非正常的比例,但他的面部相似度呢,是没有掉的。 黄河之水天上来,奔流到海不复回。 l t x two 的 对口型其实是挺棒的。二点三,这个地方的流还没有出来,我们保持关注。
30AI-KSK 05:41查看AI文稿AI文稿
05:41查看AI文稿AI文稿hello, 同学们,大家好,好久没给大家做教程了啊,最近拍源没什么新东西, 然后这边在视频生成方面补声,视频出了一个 ltx 二点三啊,据说是对这个图像一致性和稳定性有了大幅度提升。然后我们在星狗云上面教大家怎么用这个 ltx 二点三那个宫格瘤啊。 首先我们看一下案例,已经看过了啊,然后我们这边打开星空云的官方网站,这个地址啊,星空云的官方网站,然后打开以后,我们看桌面上有个邀请码,使用邀请码注册可以得到八块钱的算利息, 可以使用四个小时左右,你使用四个小时左右免费啊。然后我们点击开始部署 gmail, 来这里选择推荐镜像里面的第二个蛀牙师兄的镜像,这镜像有三点几个 t r 三点几个 t, 包含了所有视频里的工作流,基本上都是一键置起 啊。我们这边选这边的那个,那个显卡,显卡我们建议选四至八个 g 的 显,这八个显卡不爆显存,因为他这个,他这个的模型实在太大了, 二十四个进贤卡也能跑啊,也能跑,我们这边已经不说好的,然后我们点击这边康复 u i 这个地方进去,如果直接不说好,千万要等个两分钟才能点击啊,要不然会有无法打菜的,就会像这样组法打菜,我们过一会再点啊, 好,真的,三星以后出来了,我们这边点击左边这个地方有个工作流, 然后我们这边有个零三零七更新 l t x 二点三全能宽圆视频生成好,点击进去以后啊,设置一个工作流整体的一个状态,右边散弹一张图片,那里可以 根据这个自动提示词啊,我们是可以生成出来自动提手词,我们把这个拉大一点旁来一次一个,我们登录顺采一个自动提词词的提交的那里,我们上传一个图片 啊,我们就传一个外国女人的图片,这个地方是看提示词的结果啊,对了, 好,我们根据这个图片,然后让它自动出提置词来,出一个动画,我们测试一下效果。在此之前有可能同学会问这个不要自动提置词,要手动提置词怎么办?我们看这里有个文本输出啊,连接到这个地方,好的,我们双击这里搜索 cr, 然后出来一个 prom, prom 特 啊,在地方有一个新的一个节点,然后把这个 problem 连上这个熨索这里啊,在地方就就就实现了。我们手动输入提示词啊,这是一个小技巧,我们现在就使用它的自动提示词啊,我们现在把这个删除,然后直接连接上去。 好,我们点击开始运行,其他地方都不要动啊,都不要动。简单介绍一下它的参数, 也是个 we do set 单词的参数,它是一个不像长宽长宽高的一个 h, size 是 它的 p n p 处理,做几个目,这也都是页啊,功放,不用管它地方一个 nice nice, 这个地方怎么填? nice, 就 着重讲一下 nice, 它就是视频长度,我们这里看到了它的视频长度是二十四帧每秒,如果我们定视频长度是定二十四帧每秒的话啊, 一般就是十秒钟二百四十加一。因为他这个个平针是从零针开始算的,所以我们做针的话一定要写加一多少秒,加一,然后二百四十一啊,二百四十一就是十秒钟的意思 啊。这个功课流还有优化的地方啊,我们因为时间关系,我们没有去详细的给优化这个功课流,有需要同学可以单独联系我做优化啊, 比如把这个地方时间改成秒数那种啊。然后有人问宽高,嗯?宽高在哪地方?宽高?我觉得这个地方它是自动获取图像尺寸,获取图层的那些渐层, 这个图像尺寸把它做成了一个缩放,就是零点五倍大小,就是原来尺寸是七二零看一二八零,哎,他给它缩小成到三六零看六四零。 这地方想用心改的话也很简单,我们不要改变圆图尺寸,要改变圆图尺寸,然后直接把这个 upscale 这地方改成 e 啊,改成 e, 然后然后图像再连上去,或者是直接就取消掉这个额 色方图像这个节点也从图像连到这个地方,这样就跳过了这个色方图像这个节点好,就可以保持圆骨尺寸是处。然后如果你想改变自定义图像尺寸啊,把这两个渐变也给他去掉,然后在这地方显显你要的尺寸,七二零 一二八零,把这个地方头像切上,然后再接下去,这样就显示了你自定义从小尺寸,等他一些技巧啊,同学们记一下啊,我们现在已经开始生成了啊,我们章鱼等会就生成完了。好的,我们这边做完了啊,我们点击播放看一下效果。 好的,今天我们的教程就到这里啊,感谢大家的收看哦,下次教学再见。拜拜。
4猪丫师兄 05:28查看AI文稿AI文稿
05:28查看AI文稿AI文稿l t x 二点三官方设计流程的更新哈哈哈哈哈哈我们就先看到纹身视频和图身视频两个类目,这两个类目呢,又各分为一阶段,采用直接出结果和二阶段带放大出结果, 二阶相较于一阶而言,多了一个放大组。从官方流程的解读看起,已去探索 j u 实现流程来自于 copy y a t x video 插件,也就是这么两个流程。 接着我们来看到详细的地方,视频对应的流程都已经同步部署至线上的任意 copy 当中,均可以在线运行。对于本次的朋友,我也配置了一套量化方案,已放置在剪辑的网盘当中,使用量化的大模型以及 n v f p 四的 jam 三,或者说 g g u f 的 jam 三, 以达成一个低选择用户可用的模型配置。先看到纹身视频的单阶段双轨生成,那么单阶段的意味在于我们在后面会少一个放大组,也就意味着我们生成视频的分辨率,如我们的输入的宽高将会完全一致。 上方为视频的帧率和帧数。设置以下提示词,大模型这个地方对应低选择的用户,我们可以使用 g c u f 的 q 四 k s。 如追求更好的质量,可以使用 f p 八的模型, 那么 k j 已经把分体式的模型做出来了,我们可以拥有 transformer video, v a e audio v a e 以及 jama 和对应的完美编码器。 官方设计流程当中,我们使用的三八四加速六二模型对应的二十二 b 的 版本,那么可以看到我们在使用了加速的情况之下,权重推荐设置为零点五双轨,在它在上一行与下一行分别进行了一个蒸馏与前量的分组配置。 四个码代表着噪声的强度,那么手动四个码值允许我们完全手动指定模型要在哪些具体的噪声层级上进行计算, 可以看到这里走了八个步骤,因为只有一阶段,所以我们直接是从一降噪到零,走了八个步,那么八步的话,我们就生成了结果下方的全量这个地方我们走了十五步,这两者生成的结果之间还是有差异的,你居然活了,哈哈哈, 明显我们走了十五步的这一个兔子活络的结果呢,是更为接近我们提日词的内涵,风格化的表现极尽到位。只是说这个小兔子呢,可能有一些怪异,其他没有什么特别的瑕疵,很有意思。 那么我个人凝念之后得出了这样一套流程,那么这是一个八步的加速生成流,我们可以看到纹身视频这个地方得到的结果有些怪异,甚至说恐怖股相应的出来了,所以如果让我怎么办,我就会选非加速的节点组 来构成非加速的流程,那么在保持了种子所有的变量控制之后的话,我们使用非加速的流程生成的结果是非常的自然的, 哈哈哈哈哈哈。二阶段的流程主要的内容就在于放大组这个地方,当我们在进行了第一阶段的生成之后的话,其实是可以直接出结果的,前面我们也已经看到一阶段就可以出完整的结果。 二阶段呢,会用到一个放大模型,以进行视频倍数的放大,对于纹身视频而言,我们完全可以用它的这个放大组 插入其中,而且这个放大组的质量我觉得还是可以的,这就是我最后凝练出来的纹身视频的流程,导航智能 app 视频相对的流程已经同步更新,可在线运行。那么图身视频这个地方与纹身视频相比而言,多了一张图像以作为收入相,简单的去过一下尺寸的约束。 l t x 二点三支不支持 l t x 二的 laura 模型呢?我的评价是支持,但不是完全支持。比如说之前这个 image to video 的 dapper laura 是 会生效的,但是不是每次生效的结果都是正向增益的,那其实非常不一定,所以我的建议是保留可选,不一定要用 同声视频这个地方。那么我直接就推荐这一个单阶段双轨流程,不需要后面的官方放大组了。为什么这么说呢?我们看到这个二阶段放大流程 后面的这个官方放大组,他同样的需要去进行再次的降噪,前方的雷肯传过来,我们再注入如零点八五的噪声,让模糊的纹理被打破,在清除这些噪声的过程当中,脑补出原来不存在的高清细节 来进行所谓的放大,非常接近于我们之前图像生成当中的图顺图,所以也就注定的变化。如果我们只做单阶段,我们会发现这个人物的一致性会非常的高。 这个视频呢,有什么问题?问题在于动态可能有点太小了,但问题不大。我想表达的内涵呢?是这样的一个内涵图到视频这个地方官方推荐的权重呢为零点七,后面我会在 roundabout 当中标识出我所凝练出来的两个流程,以及部署微调过的官方设计流程。这一个呢,是图到视频二阶段的流程, 左侧被加入了 dota lara, 可以 看到两者都难免的出现了肢体的崩坏。那么中肯的来说, e r t x 二点三到现在为止的肢体表现不如 one 二点二, 但强项也是非常明显的,也许我们只需要一个 lara 的 增幅,一个社区 lara 的 增幅就可以解决这么一些比较明显的弊端。如果让我再去调整垂直面的流程,我会把它做成单阶段,同时呢,这个单阶段呢,也进行是一个非加速的处理。
22AI-KSK 08:52查看AI文稿AI文稿
08:52查看AI文稿AI文稿你现在看到的这些视频全都是四零九零显卡运行 ltx 二点三大模型生成的。 你可曾在雪山上救过一只狐狸?你是那只白狐,我是那只酱板鸭的妹妹。 女士们,先生们,今天做客的嘉宾是当红榨子鸡、小龙虾。 现在我们来看一下 lts 二点三到底升级了哪些地方。第一,依旧开源,配合四零九零显卡就可以尽情的在自己的电脑上运行它。 第二,大幅度的提高了九比十六竖版视频的生成质量,因为我们的手机屏幕是九比十六竖版,所以对移动端的视频更加友好。 第三,画面更清晰,台词配音更准确,配乐和音效更好听。第四,更懂你写的提示词,无论你写的提示词多么的复杂,它都懂你。第五,视频文本渲染更准确。比如你想生成一个 logo 的 视频,它就能准确地把 logo 的 字母写到视频里。 comfui 第一时间就对 lts 二点三进行了支持。现在呢,我就带大家去搭建一下 lts 二点三的 comfui 工作流。在 runnyhub, 我 搭建了四个与 ltx 二点三相关的工作流,我们一个一个的来,先看第一个, 点击运行工作流,你就可以跟着我学起来了。整个工作流你看起来很复杂,但其实需要你配置的参数很少。 首先你要看这个节点,是个开关,开启表示纹身视频,关闭表示涂声视频很明显现在是开启状态,也就是纹身视频 现在来到工作流的左上角,其中 log in mid 节点我们不用管,因为现在选择的是纹身视频模式,我们只要看提示词就可以了。我在这里写的是标志性的电影制片厂的厂头,以航拍镜头扫过雄伟的雪山峰顶,刺破棉絮般的云层,开始 时值黄昏,天空渲染着身子与金色渐变等等等等。这里有一个站位符叫做 replace name, 我 用 test replace 节点负责把这个站位符找到,然后在下面输入你的电影工作室的名字,比如我写的是 emw studio test replace 节点就会把这个站位符替换成你输入的工作室名字了。 下面就是一些常规参数的设置了, length 表示视频总帧数,现在我们设置的视频帧率是二十四帧每秒,然后根据这个公式,总帧数等于二十四乘以秒数加一。因此我想生成八秒的视频,带入公式就能得到幺九三。 一般支持生成十秒以内的视频啊。当然,如果你的显存足够的大,你也可以尝试十五秒时长。 vs 和 hit 表示生成视频的宽和高, 其他参数不用动,包括模型加载,你就用默认的配置就可以了。点击运行,等待两分钟,你就能得到一段运镜效果还不错的 logo 展示视频了。 第二个 ltx 二点三,生成电影公司厂标视频工作流,其中文声视频开关,这里选择的是关闭状态,也就是说这是一个图声视频工作流。那么此时在 lud 编辑节点上传视频的手帧画面,作为视频的开头, 我设计了一款我们工作室的厂标,我直接上传到了这里,然后输入提示词,中景构图,开场画面精准呈现。这张金色厂标, 橘色短毛毛,穿着灰色针织衫,端坐中央,神情威严镇定啊等等等等,写的很详细,其他的参数跟刚才介绍的一模一样,我就没有改,直接点击生成,等待一会你就能得到一段特效相当不错的电影公司厂标视频了。 到这里你有没有发现我写的提示词都很复杂,因为 ltx 二点三这个模型对提示词的要求很严格,你写的提示词需要包含以下几点,生成出来的视频的效果才会好。第一,需要确定镜头的构图, 最好是使用电影术语进行描述你想要的风格。第二,描述视频氛围,比如视频光线、色彩风格以及你要表达的情感。 第三描述动作,将主角的动作按照时间顺序写出来,尽量的自然流畅。第四,确定运镜,说清楚镜头何时切换,包括镜头移动后的主角状态。 第五描述配音,请使用清晰的文案,描述出视频的环境,音、音乐、音频以及主角对话。对于主角对话,请将台词放在引号内,并注明你希望主角要使用的中文还是英文以及其他语言,还有口音等等等等。 讲了这么多,我相信大家已经蒙了,没关系,接下来我就来讲如何在康复 ui 中使用千万三点五来帮你写 ltx 二点三的提示词。现在来看第三个工作流, ltx 二点三配合千万三点五生成宠物播客视频。 整个工作流我只做了一处改变,就是把原来负责写提示词的节点直接删掉了,取而代之的是添加了一个千万三点五大模型节点。 首先我把 ltx 二点三大模型的提示词拷写规则给到了它,然后呢,我只需要把我想生成的剧情用大白话跟它讲一下就可以了,你看,我就是这么写的, 我想生成一个八秒时长的呃,具有皮克斯动画风格的宠物播客视频主持人是一个柯基犬,嘉宾是一个小龙虾。主持人先面对镜头介绍本期来的嘉宾 ladies and gentlemen, 今天做客的嘉宾是当哄炸子鸡小龙虾 现在确实很火啊小龙虾。然后镜头转到可爱的 q 版红色小龙虾,小龙虾面对镜头腼腆的微笑,示意你给我生成出中文提示词,只要最终的提示词结果到这里,大白话就说完了。 然后你看一下经过千万三点五处理之后给你写的标准提示词版本,尤其你来看一下他写的这个运镜镜头脚本,那叫一个专业,是不是写的特别的好,根本就不用再愁怎么去写好 ltx 二点三的提示词了, 其他的都不要动。你来看一下视频效果是不是特别的 q, 特别的可爱。 然后我们来看一下第四个工作流,使用 ltx 二点三配合千万三点五生成武打电影视频。在这里我把纹身视频的开关关掉了,然后在 log 隐秘之节点上传了一张武侠电影的配图。 紧接着我跟千万三点五说,将输入的图片作为起始帧,生成一个八秒的武侠电影片段。 男主和女主的口音是经典的武侠片里的中文配音,那种感觉。女主问,你可曾在雪山上救过一只狐狸?男主回复你是那只狐狸。 此时女主掏出一只特别大的酱板鸭指向男主,然后生气的回复道,我是那只酱板鸭的妹妹。 之后千万三点五就会把你的大白话写成一个很详细且符合 ltx 二点三大模型规则的提示词。再次感叹一下,写的是真好这个提示词,然后你再等个两分钟,就会得到一段对话效果特别棒的武打电影片段了。 最后我们总结一下啊,第一, ltx 二点三这个大模型开源,它可以部署在本地运行,配合四零九零显卡就能跑。第二,生成的视频效果和配音都很不错。 第三,使用千万三点五可以帮你写出很棒的提示词,且符合 ltx 二点三的规则。 最后,有个地方需要注意一下啊,他对中文的文字渲染能力还是不足的,需要继续提升。如果本期视频对你有所帮助,请点赞收藏,支持一下,这里是电磁波 studio, 我 们下期视频见!
737电磁波Studio 13:37查看AI文稿AI文稿
13:37查看AI文稿AI文稿在 open core 横行的二零二六年,可能很多人还不会怎么去电脑安装,要么就是根本不懂,要么就是被一大堆英文配置难住了。现在有了 coco, 让这一切都变得更加的简单。 我们可以先来到 coco 官网了解, coco 是 阿里云通易团队推出的个人智能助理,支持本地与云端双模式部署。现在我们直接进入主题,教你如何本地化部署 coco。 按照官方推荐,我们选择一键安装, 这里会出现不同系统的安装模式,具体根据你常用的系统选择对应命令。视频中我们以 windows 作为演示。首先我们打开 cmd 运行窗口, 把 coco 安装命令粘贴到窗口中,这时候可能会出现运行报错的提示。不用怕,我这里给大家准备了一个备用的安装命令地址,重新输入备用命令,回车进行安装。 看到 coco 已经安装成功了,复制这个命令到 c m d 窗口中,回车, 点击高级,找到下方的环境变量进去,找到 p a t h, 双击打开,点击右上角新建,把这个复制进去,最后点击确定。 接着就到 coco 出使画了,跟着文档命令走就行, 直接回车回车,然后就可以看到出使画成功了。 最后我们就可以启动 call 炮了,复制这条命令,这里启动时间可能会有点久,稍等片刻,当你看到一百二十七点零点零点一的时候,就说明服务已经可以访问了, 这时候我们在浏览器打开这个地址, 看到这个界面的时候,就说明你的 call 炮已经安装成功了。如果默认语言显示的是英文的话,就在页面右上角自己选择中文,接下来我们开始跟 call 炮对话, 啊,不好,我们要先配置大模型的访问权限,这里我们进来后会看到系统已经默认选择了第一个,直接点设置进去,这里会出现一个 api 密钥, 我们打开这个地址去注册获取一个,找到访问控制,另一排就是我们需要的密钥。复制后回来 call 页面粘贴进去,点击测试连接,如果弹出绿色框说明连接正常,然后再回去聊天页面跟 call 愉快的对话。 要命啊,这里又忘了一个设置,记得把刚才设置的提供商勾上,模型呢,随便选一个, 这样我们就可以看到正常输出了。但是这里呢,也只是最简单的 ai 对 话而已, 要注意这里的对话是需要消耗 token 的。 我们差个题外话,可能有很多小朋友还不知道 token 是 什么意思,只要你有用过四 g 五 g 网络,你用过数据流量,你把 token 理解为 ai 数据流量是不是就很容易理解了? 而且这个流量在接下来又用到的的 agent 实力中消耗很快。 为了应对 token 的 消耗问题,我们其实可以搭建一个本地大模型,让 call 炮直接对话我们的本地模型进行服务。这里我们使用欧拉玛来部署本地大模型。进入欧拉玛官网,点击右上角的 download 下载系统程序 安装成功后就可以看到阿欧玛的功能页面了,现在我们去找下我们需要的大模型。回到欧拉玛官网,选择 models, 搜索 p w n 三点五, 不要安装带有 cloud 的 标志,那个是在线模型,需要 token 的, 我们可以找一个体量小一点,适合本地电脑安装的模型,因为正常家用的电脑配置都不会太高。这里有一个支持零点八 b、 二 b、 四 b 的 模型,可以点进去 复制安装命令到 c、 m、 d 窗口中,记得加上你选择的具体模型。所谓的零点八 b 或者二 b, 其中的 e b 表示十亿个模型参数,所以越大的参数量对电脑的性能要求越高, 安装可能要一段时间。本地演示直接跳过, 当看到三 day message 的 界面时候,就说明本地大模型已经安装成功了,你就可以跟欧拉玛进行对话。 接下来回到 call 炮中,找到模型配置去,我们开始配置本地模型,找到 alma 选项, 因为本地尤拉玛不需要密钥,所以我们随便输入一个一二三四,点击保存后会弹出一个报错,让我们安装什么 s d、 k, 太麻烦了,难道就没有更简单的方法?我们找到右侧有一个添加提供商按钮, 这里我们随便命名一个,例如 my model, 然后在默认 base 二中输入,这个妙呢,还是输入一二三四就行。最后点击创建, 找到 my model, 点击模型按钮,把刚刚下载的模型名加上去,最后测试下连接, 最后记得选中刚刚设置的模型保存,然后回到聊天页面, 这里就开始考验你的本地电脑性能了,如果本地电脑配置不好的,不要随意尝试,直接用在线模型就行,花钱买 token 就 可以了。 看来本地模型输出没什么问题,就是速度还是有点慢,为了演示速度之后我们会全程采用线上模型消耗 token 模式。 接下来就进入二零二六年最流行的 skill 介绍,什么是 skill? skill 其实也就是我们常用的技能,这里可以看到 coco 默认已经存在一些技能了, 我们可以来问一下,看下 coco 知不知道它都具有哪些技能, 看来他还是知道的,但是实际应用中可能这些默认的技能不能满足我们的日常需求,这时候我们就可以新建一些自定义的技能了。这里我就来教大家如何创建属于自己的 skill。 比如你现在是一位宝妈,每天为了孩子吃什么而感到焦虑,让 coco 每天推荐一个菜系,并且教你怎么做这道菜,是不是就很方便了? 这里我就简单写一个菜谱的技能,我们可以给技能命名为 cook, 内容呢参考左边我已经写好的。注意,我们在最后有一个输出要求复制进来,技能中的 name 表示当前的技能名称跟刚才命名的 name 一 致就可以。 description 表示当前技能的简介,说明这个技能是干嘛的。 name 和 description 上下有三个短横杠包围起来,这种是固定格式,是给抠炮识别用的,要遵守。点击保存,然后启动我们新增的 cook 技能。 这时候我们打开 coco 运行的 c m、 d 窗口,按下 c t r l 加 c 按钮,当看到终止处理操作吗?这时候继续按一次 c t r l 加 c, 停止当前的 coco 服务,然后输入 coco app 命令启动 coco 服务。 当看到一百二十七点零点零点一的时候,刷新刚才的 coco 网页, 这时候我们继续去问他,你有什么技能? 从输出的内容中我们就可以看到刚才添加的 cook 技能了,现在我们就让 coco 来实现这个技能, 可以看到 coco 识别到了我们的 cook 技能,并且在最后成功输出我们的要求, 灰狼大厨并且带上了祝福。所谓技能其实就是给不同需求的人都可以根据自己的需求创建一个工具,不同的人会有不同的需求, 比如销售,可以创建一份根据客户生成客户喜好的技能,比如牛马,可以创建一份工作日报生成的技能, 比如保险,可以创建一份根据不同职业生成一份合适的保险技能。当然技能完全可以不用自己去写,把你的需求发给豆包,豆包就能帮你直接生成了,加上 call 炮要求的 name 和 description 头部就可以了。 最后我们进入频道的配置教程,我们这里以飞书作为教程演示案例,我们首先要打开飞书的开发者官网, 进入开发者后台,可以看到一个创建企业自建应用的按钮,点它,然后输入应用名称和描述 call pro, 接着全程跟着教程走。 接下来就可以打开飞书应用,无论是电脑应用还是手机应用,都可以直接用飞书跟 coco 进行对话。 到这里我们已经完成了全部教程了。
229羊群中无助的狼





猜你喜欢
- 1275东方红老陈
最新视频
- 2.0万池中之物