seedance2.0参考图重要吗
快看,这个 ai 生的视频好有趣, 快过来做,我们一起试试好不好?欢迎来到倾城 lab, 用 cadence 二点零生成视频时,上传真人图片老是被限制,将图片转绘成素描后又不能和原图达到百分百一致。 其实我们只要将人物图片先转成三个正视图,再将每张人脸分别遮挡一个部分, ai 就 会自动将剩下的人脸进行补全。生成视频后,人物形象基本能够达到百分百还原。我们来看一下生成视频的效果, 好美!视频中的人物形象和参考图片的形象还是非常像的,这个方法不仅在小云雀中进行了验证,再及梦中一样验证可行。 好美!这是另一个人物形象,用这个方法生成的视频,非常完美的还原了人物原有的形象,可以说是百分百对人物形象进行了还原。吹吹风真舒服! 我专门做了一个工作流,只要上传人物照片,就能一键对人物图片进行面部遮挡。使用方法比较简单,来到 runninghub 搜索倾城,来到我的主页搜索真人过审,找到这个工作流。我们打开工作流, 只要在这里上传人物图片,然后点击右上角的运行按钮,就可以生成人物面部被遮挡的正面图片了。 如果是新用户,用我的邀请码注册还能送一千点积分,每天登录还能送一百点,有了这些积分,相当于可以白嫖了。好了,这是今天视频的所有内容,如果你觉得对自己有帮助,点个赞呗!

粉丝2.6万获赞1114
相关视频
 03:30查看AI文稿AI文稿
03:30查看AI文稿AI文稿这两天最让人兴奋的事情就是极梦的新模型了, c dance 二点零一上线直接炸锅,对那些国内外 ai 视频工具完全是致命性打击。大家看一下这个广告熟不熟?喂,你的风油精 是你的风油精?是的,我直接把你的益达广告片扔进去给吉梦参考,然后上传了一张风油精图加男女主照片, 一部广告片就搞定了。这样复杂的打斗场面,你是不是还认为需要永长的动作提示词?还得构思运镜?我告诉你有多简单。我把一个打斗视频画面给了积梦参考,再加上人物图片,跟他说一句在天台打架视频直接完成。 大家猜我做这个黑色星期五活动宣传片花了多少时间?两分钟,我找了一段六幺八宣传片给了季梦参考,然后跟他说一句, 参考这个风格,生成黑色星期五的宣传片,把里面的文字都换成黑色星期五相关的内容。你看好了,这个用 ae 做至少得花两天时间。 为什么这次大家的反应会这么大?因为过去这些视频搭工作流分,禁写题日词需要大半天,但现在不用了,这一切完全变了,以后真的没有什么视频画面是做不出来的了。 cds 二点零把这一切的门槛铲平了, 只要脑洞够大,各种离谱的玩法都能实现。大家应该见过各种短视频主播跳扫腿舞,那你见过你全家人一起跳扫腿舞吗?直接把原扫腿舞视频和全家人合照给寂寞参考,让他把视频里的所有人换成全家人。灯光、运镜、动作等保持不变。 这个模型可以精准捕捉人物动作,并保持新的人物形象,完整身材比例和气质神态都能完美参考。 我觉得做电商的人应该会特别激动,你看我这套衣服图来传进去给他个提示词,大意就是设成一个穿搭博主,把图中的商品都穿在身上进行展示来看一下, 就真的有个模特把衣服都穿上了,一次性非常完美,所有商品上身后都没有变形,你看白底格子衫外套,完全一样,连这么小的表都识别到了,戴手上了。这以后做产品展示视频得省多少时间?而且如果你有想让模特输的话,也可以放进提示词里, 就能提升质感,无论小个子高个子都可以穿。还有这个,看这个水蜜桃的宣传片是不是很专业?我现在把西红柿图片传进去,然后瞬间变成西红柿的宣传片, 就是只要你有参考,你卖的任何东西都可以产出专业级产品宣传片,而且操作简直就是老奶奶都会的程度。还可以把背景换成任何你想要的背景,有没有觉得天亮了的感觉?再也不用 古哈哈。制作视频宣传物料,做电商的就应该专心卖产品,这些产品展示视频就应该交给 ai 去搞,这个功能拿来做慢剧真的不要太爽。过去需要先从分镜图开始,现在几句提示词就能实现衔接流畅,运镜到位的画面。你看我这个提示词有多简单, 选一个预告片,图一的图二在战斗,你看我最后还给了文字图让他定格,他也能完美融入最后的画面,而且保持不变形。是不是有预告片的效果了?不够的剧情还可以续写,注意,不仅能往后续写,还支持往前续写。我就只有一张文字图,他就帮我续写出了完整的片子。 哥,是你吗?这就要命了,以后真的没什么不完整的剧情了。 这是季梦的 cds 二点零模型,很多人都激动的睡不着。这种颠覆性的产能提升,不管是商业广告和营销,或者慢剧、短剧、影视的行业都是前所未有的提升。另外他的图片模型也升级了,一样,是指哪打哪精准升图,这简直是创作的万能钥匙,现在限制我们的真的只剩下想象力了。
1.8万老麦的工具库 02:34查看AI文稿AI文稿
02:34查看AI文稿AI文稿兄弟们好消息,火山引擎的豆包 c 弹三二零的接口已经对外公开了啊,能看到价格了,我们现在价格是包含视频输入的是二十八元百万特刊,不包含视频输入的是四十六元百万特刊啊。然后我们输入的内容是文字、图片、视频、音频都可以输入,输出的就是视频,跟吉梦是一模一样的。 然后我们现在就要去看一下,二十八元包含视频输入是二十八元百万特肯,不包含是四十六,那到底什么算是包含视频和不包含?我自己单纯的理解就是 我们这里面有视频参考,就是按照二十八元百万特肯来计算的,如果你只是图片和参考或者是手帧视频生成的话,那就是四十六元百万特肯,然后我们再看一下百万特肯和我们的五秒视频到底有什么关系来,可以看到 我现在选择的是 c 蛋四二点零, c 蛋四二零官方的体验,然后我选择是图像生成,然后是九比十六七二零 p 五秒一条。可以看到官方进行计价是这样计算的, 呃,视频 top 是 宽乘高乘,帧率乘时长,最后除以幺零二四等于条数,他计算出来的,我们 c 蛋四二点零七二零 p 的 这个消耗了就是十万两千九百六十个 top, 也就是一条五秒视频,大概就是 十万套粉左右。我们让豆包给我们算一下,五秒视频消耗这么多,一秒多少钱?五秒多少钱?一分钟多少钱?得到的结果就是一秒的话包含视频输入是五毛八,不包含是九毛五, 一分钟的话是包含视频三十四块五毛九,不包含视频是五十六块八毛三,所以这个价格你觉得你用的起吗?反正我做精品慢,我肯定是用的起。最后我再给大家看什么叫做视频输入,什么叫做不是视频输入,我们直接看官方案例, 官方在这里面直接给了将这个输入这个视频,然后输入三个图片,输入一段音频,参考人物视频里面的动作和镜头语言,然后根据这个画面打斗背景用这个,然后最后输出的结果是这样的, 那么这个我觉得他就是视频输入包含视频的,因为这里面有视频。来我们看下一个,参考这一条视频的运镜方式,然后参考这个版画风格, 然后给我生成一个马年的视频,他生成的就是这个样子的,所以说这样的视频也是参考视频,那我们可以玩的我觉得就非常的多了,比如说我们去找一些动作,找一些运镜方式,甚至你自己拍一条视频去传上去, 你的价格直接就降下来了,明白吗?好,关注我下一个视频,教会你写视频题词,不需要再写小作文,百发百中免抽卡。
1415小道道道 01:18查看AI文稿AI文稿
01:18查看AI文稿AI文稿这档是二点零,如何使用带人脸的真人猜宝图?先点赞、关注、收藏啊,反正以后找不到了。你看我这这个是一个真人,然后下边这跟他让他生成这个,他就生成了,对吧? 他后面正在生成,如果是你,你用真人的话,就给我这这用了一个这个真人,然后让他给生成,他就说出于肖像保护,这个,这个不支持真人,对吧?下面这个是我用了一个其他的 用了一个千万的,然后让他把这个图给转了一下,然后让他再去生成,他这还是说不行,所以说你简单的用其他的那个 ai 转一下这个图的话,这个还是不行的。那,那我知道这个图为什么可以呢?这个是怎么做的?好?我们用豆包啊,豆包这个 比如说你要你这用图片生成,然后你通过这给他传一个,给他传一个参考图,给他传一个参考图,之后这选风格风格,这往下滑,滑滑,这这往下滑,这有个彩切画好,你就就不用管了,然后这直接 生成,他就会把你这个图真人图给你转成彩切画这个风格,这个风格就是就这样的一个风格,他这个和你的真人度 就可以说是没有任何区别的,然后你就用这个人物形象,然后去做你的这个,呃, c d 二点零的这个真人,嗯,真人参考图,这个就没有任何问题了,好吧。
34五棵松不打虎 01:23查看AI文稿AI文稿
01:23查看AI文稿AI文稿c 的 三点零禁止使用人脸,是不是很多小伙伴都难受了?到底什么样的图能用,什么样的图不能用?而且该如何解决呢?来吧!首先你得知道根本原因其实就是肖像权的问题,其实以前也有类似的限制,但是之前的生成并没有现在这么的真实, 所以以前你可以用这些图去生成视频,而且新的参考功能有可能会滋生很多的作假视频,理解过吗?所以话说回来,只要你的人物是 ai 生成的,基本上不会有什么大问题,哪怕他非常非常的像。比如这样, 那如果你想用到的是一张真人的照片,比如我,虽然我不是明星,但是他也可以识别出来,不让你去生成。但是当我上传了一张我的去掉了背景, 还加了一点美颜,而且清晰度不是那么高的图的时候,它可以了。而当你想用一张明星的照片作为参考的时候,显然是不行的。 所以你一定需要用到某个人物,尽管我不是很介意,但即使你已经把图洗到这个程度了,依然是不行。别给自己找事干了,移架其他平台吧。 综合的来说, ai 生成的人物图片基本上是不会有问题的,而经过精修调整和设计的真人的照片有一定几率是可以的,而名人明星的照片即使你经过洗图和二次加工也有可能不行。当然这不绝对,大家还是可以去试一试。我是樊老师,希望和你共同进步。
737凡老师AIGC 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿分享给你们个 cds 二点零,不用参考视频也能做出媲美原视频效果的方法,能稳定通过平台不让用真人参考的限制,先看效果。 废话不多说,来跟着我操作。比如我想模仿抖音上的这条转场视频,先把左下角的视频标题还有网址栏里的这个视频 id 复制下来,然后用一个能分析视频的 ai, 用折磨奈把转场视频上传上去,用我这套指令让他输出一个包含场景、人物、动作等等要素的结构化提示词,复制下来再打开即梦使用 c 弹四二点零生成视频,不要用 fast 的 模型,要用这个满血版 粘贴折磨奈刚刚给的提示词,你也可以上传一个指定的参考角色,怎么用真人?可以去我主页发相关的教程,然后把提示词中关于人物的描述都替换成你的参考角色。 接下来是重点操作,这一步是实现媲美原视频效果的关键。把最开始我们保存的视频标题或者视频 id, 这两个你用哪个都行, 添加到提示字开头,点击生成,这样就能不用参考视频,也能让它生成类似效果的视频了。不仅不用担心真人的限制,还能节省积分,亲测有效,记得关注我,每天都是干货,带你玩转 ai!
6736赛博小凡 00:37查看AI文稿AI文稿
00:37查看AI文稿AI文稿为什么你用即梦生成的视频一眼假,而我的就像真人呢?趣薄就在于我能上传真人照,而你不行。看下面的案例,你们上班怎么闭着眼打字?我怕工作效率太高。上班要学会止损啊。四千的工资你干四千的活最多算保本四千,你干三千的活有差价才叫赚钱。 那我这种四千的工干一万的活呢?纯亏损。什么?你把销售部都裁了?对啊,安蒙智能系统,一个人带一千个数字,员工获客成交,客服全自动。没错,加入我们一人就是一家上市公司。
24醉语老姜 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿今天我来讲解一下如何用分镜图在 cds 二点零里制作这段,将军一人独守城门,面对百万大军。首先纹身图主要人物,古代将军,这个放心,交给吉梦,不用很长的提示词,创意有保证。 你是不是在搞我。首先纹身图主要人物,古代将军,这个提示词如果交给吉梦,尽量写详细点。好了,话不多说,依次生成主角反派和场景参考图, 然后写个分镜头脚本,如果不会写就描述一下剧情交给 deepsea。 然后把分镜脚本和参考图都丢给 nano banana, 生成多宫格分镜图。 最后把分镜图、参考图和文字脚本都交给 cds 二点零的全能参考模式。注意写清楚艾特关系,点击生成看效果。
3415Theocrasy 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿你用积木 cds 做视频,是不是一传人脸就失败?试了几十次,全卡在审核。今天分享一个邪修办法,亲测有效。现在积木审核有多严?真人不行,长得像 ai 的 真人也不行。 其实底层逻辑他非常简单,就是真实度太高了,他怕侵权。解决方法也非常的简单,就是让图片像人, 但又不像人。把图片做风格转会,保留五官特征,但看着像画的,我反复试了几十种风格,目前最稳的就是豆包自带的彩铅画,跟原图最像, 又能稳定过审。你拿这张彩铅画当参考图,他就不提示包含人脸的违规了。然后再给一段真实视频当风格参考,让他生成真实的效果。两张图一结合,就是你想要的实测相似度在百分之九十以上, 你做视频完全够用。这才是真正的邪修办法。觉得有用点赞收藏,记得关注,不然你找不到我!
119菜芽的AI笔记 00:44查看AI文稿AI文稿
00:44查看AI文稿AI文稿你是不是也发现了,极梦 cds 二点零现在不让上传真人脸了,很多人就直接蒙了,那我的角色怎么固定?我怎么用自己的脸?那我怎么换成指定的人物呢?别慌,我告诉你一句核心逻辑,他根本就不是不让你用人物,而是不让你用真人照片。 听懂这句话,问题就解决了一半,真正的解决方案就是人物 ai 化。那我们怎么去做呢?第一步,上传你的人脸。第二步,点击图片生成 提示词,就一句话,保持脸部特征,保持五官比例,生成 ai 人物定妆照,你可以固定它的表情。关键是什么生成出来的一定是 ai 画出来的版本。 ok, 让我们看看效果吧。
2688Y-AIGC 04:37查看AI文稿AI文稿
04:37查看AI文稿AI文稿这条视频我前后花了一千多算理,整整测了三天,现在你只需要两分钟就能学会我这几天总结的关于 cds 二在电商领域的真正玩 法。 cds 二真的是一个能够重构电商内容生产流程的宝藏。首先它的常规玩法,我们直接快速跳过纹身视频看这里, 徒身视频看这里, ok, 接下来我要讲重点了,真正拉开大家使用差距的是 c 档十二的全能参考模式,它这个功能真的强的离谱。首先玩法一,同款产品换颜色。比如说,哎,你有一件爆款的 t 恤,它有很多种颜色,但你目前只有白色的。实拍视频, ok, 打开全能参考,直接上传原视频,然后告诉他,视频一中模特身上的服装颜色跟后面藏蓝色,其他完全保持不变,他就直接给你生成这个藏蓝色的版本。无论你这款衣服到底有多少种颜色,对他来说就是一句话的事情。做店群的商家看到这里,哇, 天都亮了。玩法二,一键出专业分镜很多人不会拍视频,是因为脑子里没有镜头结构。现在你直接上传一张模特图,然后告诉他,根据电商视频的分镜,包含远景、中景、特写面料、细节、模特走动镜头来生成视频, ok, 直接一键成片,而且效果还非常赞,这太夸张了,哪怕是脑袋空空的小蠢蛋也直接起飞。 玩法三,模特替换。比如说你现在只有一个亚洲模特,你可以告诉他,替换成欧美男模,保持服装版型不变,呈现真实上升比例,他可以在不改变产品一致性的前提下大变活人跨境商家直接被香哭了!玩法四,也是最狠的一个多款式换装视频一键直出什么意思?那这种视频快速切换穿搭的一键直出 怎么操作?直接输入图片一里的女孩分别换上图片二里的衣服,并且整体动作逻辑正常, ok? 城边直接出来了, 是不是很夸张?都不需要做分镜了,直接一键生成换装博主的天都塌了。 我们再看玩法五,视频延长。哎,这个就切中电商视频的一个老毛病了,比如说你的视频太短,然后投流效果不理想,或者说你这段视频里面想要再续几个镜头,但是你又没有办法再去重拍了。 现在你直接上传视频,然后告诉他将这个视频延长十秒,模特继续做动作展示,保持节奏一致,他会直接锁死模特形象,服装结构、场景环境、光影关系、镜头运动节奏,然后在原有时间轴的基础上继续去延伸这条视频效果你们自己看。太离谱 了,这个时候某些聪明的小脑瓜马上就转起来了,哎,他能干什么呢?第一,延长爆款视频的生命周期。第二,将一条爆款视频拆分成多个爆款视频, 怪不得人家能赚钱呢,你瞧瞧这记忆力。再看他的第六个玩法,自动根据音乐卡点生成视频。我不说你肯定意识不到,这是百分之九十九的人都会忽略,但是超适合短视频平台的功能。 看我操作,上模特图,上服装图,上卡点音乐,然后告诉他根据音乐节奏生成模特穿上该服装的卡点展示视频,动作自然,节奏匹配古典,他会自动分析音乐节拍,然后生成跟音乐节拍相匹配的视频效果。你们自己看, 剪辑博主的天都塌了,你还在这苦哈哈的剪辑,人家直接一键生成。讲完了上面这些玩法,你是不是以为就结束了?我再讲三个他更高级的能力,但这些能力已经超出了电商层面了。 第一,环境逻辑与声音联动什么意思?他这个不是简单的贴音效,他是在跟人一样做环境判断,并且附上相匹配的音效,就这种效果,音效师的天都塌了。不管你是干什么的,就这个能力,他都会让你的视频质感提升好几个 level。 第二个我觉得比较夸张的能力,复杂创意动作的执行能力 能复杂到什么程度?我选择了首尾帧模式,并且直接给他来了一篇一千多字的小作文,内容包含了每个分镜的相机参数,镜头角度、景别,运镜方式,场景样式,场景音效,整体色调,人物打光,妆容,服装特效,动作,就这么一整套。不夸张的说,詹姆斯卡梅隆来了都得懵逼, 但你看他的完成度,不说百分之百精准,但百分之九十的准确度还是有的。导演的天都塌了,就这种语义理解能力,不管你的理解你的要求并且完成, 最后再看第三个运镜视频的一个复刻能力,就这种视频节奏好,运镜炫我直接上传,连提示词都不怎么起,他直接附用运镜逻辑节奏节拍动作关系,然后来给我生成视频。运镜博主的天都塌了, 我苦哈哈的拍半天。不如你们直接拿成熟视频做结构参考,然后生成属于自己的版本,说不定你们生成出来的效果比我实拍的还要好。 好了,如果你能看到这里,那恭喜你,在对 cds 二的理解以及应用上,你已经打败了百分之九十九点九的人了。接下来自己去实操和应用就好了。如果说你也对用 ai 去生成电商内容或者说服装内容感兴趣的话,可以给我点个关注。我是牧童,目前正专注于用 ai 为电商以及服装去提供一些解决方案。我们下期视频再见。
1.8万木桐同学 10:58查看AI文稿AI文稿
10:58查看AI文稿AI文稿c dance 二点零还能玩吗?排队降智,动不动就违规。那个一上线就炸裂的王者现在的情况如何呢?前段时间这个吃薯片的女孩很火,我也拿提示词尝试做了一个。 我也想吃薯片。叫妈妈就给你吃妈妈,哎呀,你怎么还真喊呢,好好好了,给你吃就是了,我要你亲自喂我, 我真灌死你。感觉真实感拉满啊,完全没感觉到有降质。本期我尝试用纹身视频制作真人短剧,还有上传角色参考生成视频,尝试去生成角色一致性的视频,看看是否能够突破真人图像的限制。 点上收藏关注,赞我们 let's go! 要生成爽文短句,首先我们要先整一个带有角色描述以及十五秒里所有分镜的脚本,打开 gemini, 手戳一段提示词给他,我要用 cds 二点零制作一个十五秒的短句。 因为不能用真人图像生成视频,所以用纹身视频来生成真人短句,我需要十五秒,里边有多个不同分镜的提示词。 角色一男一女两个人。在中国古代场景,女人是穿越过去的,男的是原来朝代的普通人,没有赛博基甲的特征,人物有对话,有动作,女的穿着古装服装,外表有显露出身体部分的机甲, 手里拿着赛博刀。两人开场对话两句,然后开始打斗,最后女人打倒男人,并且对着倒地的男人说了一句狠话。这里的镜头是女人从上面往下看,对话内容类似穿越爽剧。 请给我纹身视频的提示词,有详细的分镜,两个人物的详细描述,对白符合爽文短句,结果出来有人物的描述,有四个分镜的脚本,也有对白和动作,但是这个脚本内容看起来不够完整, 而且最后的制作避坑指南这里居然说 cds 二点零目前生成的视频没有声音,建议在剪映中使用 ai 配音。 gemini, 你 坏坏,你是来给我挖坑的吧! 于是我打开豆包,看看同样是字节旗下的工具,会不会更了解 c dance 二点零,我发给他同样的提示词,很好,他真的是懂的。他给我的是 c dance 二点零可直接复制使用多帧镜十五秒纹身视频,无真人参考的完整提示词。 重点是这个无真人参考。他第一部分是分镜脚本,第二部分是人物的详细设定,第三部分,这里是帮助你稳定输出的技巧。他告诉你一定要写无真人肖像,人物面部风格化处理,局部机甲不覆盖全身,这才是避坑技巧啊。 为了进一步完善人物一致性,我告诉他加上角色、脸部、服装等所有特征,加上脸部五官的描述,这样更多一致性。然后就得到了第一级的完整提示词。 这个就详细多了,我继续用这个方法生成了第二集的体式词,可以看出他在打斗方面的动作描述比 jammer 要详细很多,并且在一些可能违规的画面,他会出现风格化处理,不血腥深层结果我们也能看到这些风格化处理。 先来看下第一集的结果,这朝代还没人敢拦我,姑娘装束怪异,来路不明, 在我面前古人也敢放肆。这个效果看起来还行, 每个分镜衔接合理,运镜和动作都很流畅。人物也呢,各够完全一致性的,可惜纹身视频没法做到每次生成人物完全一致。我用了同样的角色描述去生成第二集视频,我们看下人物一致性如何,你到底是什么怪物? 怪物,这是你惹不起的底气,再敢多嘴,割了你的舌头。 这里可以明显看到击中人物的地方有发光的染料。这个就是风格化处理,无血腥,还挺特别的。仔细看人物的服装和脸部和上一集是有差别的,特别女机器人皮肤部分增加了,但是第三集之后他出现了自由变化状态, 这个也可以看似一种设定,不过人物没有完全一致性,如果通过角色描述写死他应该可以好一些。最后这个男角色额头上凸起的亮剑,这个招式很特别,提示词中只是写的右手幽兰塞伯短刀抵在他眉心,刀光印在男主脸上。因为短剧都是竖屏的, 之后我把第三集和第四集都生成了竖屏版的,我们再看下结果,我师门不会放过你的 师门,就算你师门来了,也不过是多一具尸体等着瞧,就你这本事还敢提师门,住手, 你们就是他的师门一起上,省的我一个个 结果。看起来竖屏的效果更好,人物也更加真实,应该是直接对应了模型训练中的大量短剧素材,特别是女机器人转身机械的变化,还有这个花式耍刀的部分,这些都是不错的亮点, 整体的打斗也很好。这里的风格化处理,男的嘴角还有番茄酱。这里如果你不介意女主每集换一套衣服,还是有点爽剧那味道的。接下来我们加上字幕和标题,特效和音效,让他更有爽剧的效果。我把他们拖到剪辑工具 feel more 中, 选中影片,点击右键,点击这个语音转文字,这个功能可以给音频转出字幕,也可以翻译成各种语言的字幕,都选择中文,然后点击,生成之后我们双击字幕,可以选择字幕的样式还有位置,确定好你喜欢的样式之后, 点击全部应用,那么全部字幕就完成设置了。我们来看一下效果,我师门不会放过你的 尸门,就算你尸门来了也不过是多一具尸体。因为 cds 二点零生成视频只有七百二十, 我们点击影片,右边这里有一个 ai 增强模型,还有超强的 topaz 画质修复工具,点击产生可以增强视频画质。接下来再给视频加上配乐,为了让它更有短剧的感觉,我们给它加个吸引眼球的标题, 比如 ai 机器女穿越唐朝竟被侠客师门围堵,然后结尾加一个留下悬念的特效,再配上文字。好了,我们看下最后的结果。我师门不会放过你的 师门,就算你师门来了也不过是多一具尸体等着瞧,就你这本事还敢提师门,住手, 你们就是他的师门一起上,省的我一个个。 这种打斗特效对于短剧来说很不错了。接下来我再尝试一下添加角色图像作为参考图, 看下能否生成视频。我先要生成两张角色图,这里用 nano banana pro 生成图,详输入刚才豆包给我的角色描述,然后就生成了两张角色图像。提示词中用到了游戏 c g 和风格化,但还是有些真人效果,不知道能不能成功。趣道即梦, 上传两张参考图,然后在提示词中艾特两张人物对应的参考图,因为这里提示词做了一个指引,所以只要艾特一次,之后的都可以关联上,这样就可以直接生成视频了。很快就有一个好消息和一个坏消息,我们先听下。坏消息 就是生成视频失败了,提示,检查到真人脸部。好消息是点击生成到出来失败提示,中间只有不到几分钟时间,之前可是要排队生成,几个小时之后才知道失败了。 那么也好办了,就调整参考图吧。有人说动漫的参考图也会失败,我就试一下把人物转化成动漫风格,再尝试一下看看结果如何。生成了三个都成功了,看来动漫风格是没问题的,只是效果嘛,大家看一下成品。 警告,空间跃迁异常,已抵达未知古文明区域,何方怪物擅长我女儿国?就这点力道,你们这的战士你等着,有点弱,我这就去禀报国王。检测到高战斗力,女性群体知识库匹配中,国王 城外机甲怪物极强,属下不敌哦,能难住我第一战士,看看有多厉害。没见识,休得无礼看剑,不自量力,来不及了,传侍卫拿下怪物,检测到新增目标,实力微弱。 警告,空间跃迁异常,已抵达未知古文明区域,何方怪物擅闯我女儿国,就这点力道,哼,你们这的战士有点弱。检测到高战斗力,女性群体知识库匹配中,人物一次性是没有问题,只是人物打斗动作和刚才真人比起来 降智了很多,比发誓的效果还差,看来想办法突破真人限制才能好好玩耍。这个影片想要拿来用,得先拿去剪辑一下, 丢进剪辑工具中。因为第一集我生成了两个版本,第二版的前半部分是可以用的,影片都有分镜位置,我们只要点击影片右键, 选择智慧编辑工具里的场景检测,就能快速找到对应的片段,然后不能用的片段去掉,把它们拼接到一起,这样就不会浪费积分再抽卡一次了。 警告,空间跃迁异常,已抵达未知古文明区域。何方怪物擅闯我女儿国?何方怪物擅闯我女儿国?就这点力道?哼,你们这的战士有点弱,检测到高战斗力,女性群体知识库匹配中国王 城外机甲怪物极强,属下不敌哦!能难住我第一战士,看看有多厉害。没见识休得无礼看剑不自量力。来不及了,传侍卫拿下怪物,检测到新增目标,实力微弱。现在的 ai 模型虽然猛,比如咱刚聊的 cds 二点零, 但七二零 p 的 模糊感,不稳定的角色一致性,还有动不动就违规的暴脾气,确实挺劝退,有时就要通过后期剪辑来弥补。即孟刚出了公告说缓解了排队的问题。那我还会继续玩 c dance 二点零,感谢收看,我们下期再见!
261真探玩赚AI 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿你是不是也想生成这种真人的视频?但是一上传真人参考图,系统就提示识别到人脸信息。请调整素材后重试两个办法解决人物上传。第二个方法更能确定人脸一致性。第一个方法, 用工作流或 nano banana 上传你要用的真人图片,生成这种多视角图,再输入单帧图提示词,生成高精度单帧图,然后输入图升视频提示词生成单帧视频,再通过剪辑软件处理输出,最终成片。第二个办法,把真人图片转成彩绘图,用图像处理软件把你的 九宫格分镜图中的人脸用色块挡住,最后把彩绘图和处理过的九宫格分镜图上传及梦 cds 二点零输入提示词,生成视频,搞定一段丝滑到犯规的东方美学视频直接出炉! 请用茶,我是东野,关注我,每期解锁一个 ai 写秀小技巧,小白也能轻松变大神!
383东野Ai分享 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿今天试了一下 cden 赛点零模型,只给一张角色图,合加一段提示词, 再试试徒生视频,只给手帧和提示词, 太超模了。
1.2万不会剪辑的大头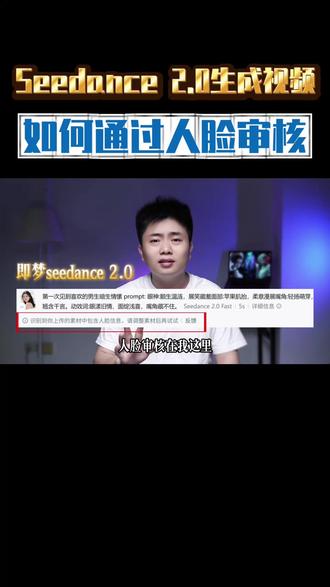 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿用积木子弹十二点零去生成视频,人脸审核在我这是不存在的,打开我的视频,随便截一帧,然后丢到积木里面去生成视频是没有任何问题的。然后用 ai 生成的真人显示图片生成视频也是没有任何问题的,哪怕我们用视频里面的人物制作参考生 成视频也是没有任何问题的。操作方法很简单,注意事项我放到了视频的结尾,像我截的第一张头,我会先把它丢到肚包里面,让它生成这样的三四头,不要直接去丢大头照,全是照的话基本上都能通过我们再用 ai 去生 真人写实图片的时候,你不要去具体的参考某一个明星,大家看这里他写的是不支持真人人脸,反过来说就是用 ai 生成的是可以的,像其他的方法,人脸打网格长废了,然后再还原,他都是基于这一个原理,让 ai 把照片的话重新再生成一次。
 02:41查看AI文稿AI文稿
02:41查看AI文稿AI文稿前两期内容,我用 jimmy 智能体生成二十五宫格分镜图,然后用极梦 cds 二点零根据分镜直接一键生成视频。很多小伙伴对于具体流程还不是很清晰,那么本期视频我会通过一个无人机的案例来详细的跟大家展示一下如何使用 jimmy 做分镜图以及最终的成片效果。 另外提示词和详细步骤我已经帮大家整理好了,可以直接复制使用,以后也可以直接反复观看。首先打开一个 ai 工具,输入提示词,生成一个无人机的设计图, 然后分别把无人机和遥控器放到 jimmy 里面,输入这段提示词,选择制作图片,并改成 pro 模式,点击生成,就可以得到产品的多视角设定图了。 ok, 视频主角做好以后,就到了本期视频的重点部分了,我们在 jimmy 左侧点击这个 jim, 然后点击新建,输入一个你喜欢的名称,说明这一栏可有可无,那我们就随便写一下它的用途。 最重点的部分是指令,这里我们要写清楚他的身份和目标任务,并且要求他严格遵循 jason 格式。输出生图代码 使用 jason 是 为了更好的防止一些不必要的错误。生图指令内容直接从我分享的文档里面复制就可以。最后点击保存,这个分镜智能体就创建完成了。接下来用逗号帮我们写一下提示词,复制以后稍微修改一下。 回到刚才创建好的 gm 分 镜智能体,上传参考图,粘贴提示词,可以补充一下参考图的定义,强调一下输出 jason, 选择思考模式可以有更好的效果。 点击提交,稍微等一下就可以得到一段 jason 提示词了。点击复制,然后回到 jason 主界面,选择制作图片,把参考图和刚才得到的 jason 提示词放进来。接着再补充这样一句话,强烈要求模型生图的时候不要跑偏, 为了得到更完美的效果,可以选择 pro 模式。点击提交,等待片刻,你就可以得到这样一组生动且专业的视频分镜图了。 最后一步,打开极梦 ai 创作类型改为视频生成,这里改为全能参考。为了得到更好的效果,所以选择 c 段十二点零模型,把提示词、分镜以及产品图放进来,并在开头艾特一下每一张图片, 视频比例和时长设置好,点击提交,稍微排下队,等待一段时间,就可以得到最终的成片效果了。
263设计师小海 24:39查看AI文稿AI文稿
24:39查看AI文稿AI文稿目前三代四二点零火的一塌糊涂,很多小伙伴想用它来做慢剧短剧,那么生成视频之前,我们通常要生成人物场景的风景图,而人物场景的风景图又降低了我们抽卡概率,就显得尤为的重要。 今天教大家如何用扣子工作流来生成人物的角色卡和二十五宫格,十六宫格以及九宫格的人物风景图,来保证人物场景的一致性。告别抽卡,后续我们还可以结合 cds 二点零来做慢剧短剧,都是可以的。首先的话我们会去生成这个人物的角色卡, 在这里的话我们需要去上传一个人物的参考图片,在这里我上传的是王林,然后他会根据这个人物图片去给我们生成一个三式图的图片,那么这个三式图的图片能起到一个什么作用?它可以保持我们人物的一致性,在这里的话,他会生成每个场景的表情,然后以及他的动作以及他的这个服装。啊,这个的话是一个炎帝的。 同样的我们去生成一个三式图,然后再去生成他的表情以及他的动作以及各个场景的一些服装, 然后再去根据我们上传的剧本生成二十五宫格的一个图片,这个二十五宫格的图片它主要是保持我们人物场景的一致性。下面这个视频的话,是我根据上传的亡灵和炎帝的图片,然后去联合塞纳斯二点零去生成的一段视频,我们来可以看一下视频效果, 这世间还没我删不掉的因果, 义火焚天斩迹,何为生死逆转?万法归空, 孤身一体,因果尽造。 好,可以看错,他这个人物包括场景的话,完全按照我们这个图片去生成的,而下面这个的话是生成一个十六宫格的一个图片 啊,这个是九宫格的图片,同样的我上传的是一个亡灵和炎帝的一个图片,他会生成一个这样的角色图片, 那么生成这些风格的话,他根据我们上传的参考图片去生成我们这个图像的风格啊,可以看出他生成这些人物包括场景的一致性保持的还是非常好的。那么有了这些风景图片以及人物的角色卡以后,我们可以结合这个 cs 二点零去直接去生成漫剧视频。 关于这个三点四、二点零使用手册的话,我放在这个文档里边,如果说有不会的小伙伴可以去参考一下这个文档。好,那么接下来以后手把手教大家搭建这个角色卡的工作流, 那么搭建之前我们先看一下这个搭建步骤。首先的话我们需要去上传人物的参考图片,这个参考图片的话,你可以去让豆包去给你生成一个文案的内容的话,我们也可以去让豆包去生成,那么搭建的话分为两个部分,第一个先去生成这个角色卡 啊,就是我们先去生成这个人物的角色卡,这个最主要的核心就是确定我们人物的一致性,包括他的表情动作以及他的服饰。 那么第二步我们再去生成九宫格、十六宫格以及二十五宫格的风景图片。那么有了上面这些图片以后,我们再去结合三点四、二点零去生成动漫或者是短剧的一些视频,这些步骤的话可以很高的提高我们一个视频生成的效率。 话不多说,那么跟着我的节奏,我们开始搭建这个工作流。好,打开扣子空间,然后选择这个资源库,然后右边有个资源,这里我们选择工作流,这个地方的话是创建新的工作流,工作流名称这里的话大家注意啊,这里只能输入英文或者是字母, 工作流描述的话可以去描述一下这个工作流可以帮我们做什么事情, 好,点击确认。好,这就来到工作流的搭建界面,首先的话我们把这个搭建步骤先复制过来, 我这个搭建步骤的话,在这里写的比较清楚啊,该怎么去做,然后按照这个搭建步骤去做就可以了。好,下面这里有一个注是我们可以放到这里。好,首先的话这个工作流它定义的参数比较多,所以说呢,在开始的话,我们需要去上传这些参数。 好,先把开始的节点这个编辑好,来第一个节点,这个是上传人物的图像啊,这个变量类型这里大家需要注意啊,我们需要去上传人物的参考图片, 因为麦剧里边的这个角色的话也是比较多的,所以说呢,我们需要去上传多张这个参考图片,那么这个变量类型这里我们首先选择 array, array 就是 数值,数值里边包含了 feel, 为面子,好选择这个就是它数值里面包含多张图片,然后这里的话选择 b 填 好,展开以后可以对这个变量进行描述。 好,还有一个上传故事的文案内容,在这里新增一个变量,好,把这个复制过来, 好,文案的话,这个变量类型我们选择 string, 然后同样的这里展开以后,可以对这个变量进行描述。 好,这里的话是上传文案或者是剧本,还有一个封境的数量。封境的数量什么意思?就是我们会生成一个九宫格或者十六宫格或者是二十五宫格的封境图片,所以说呢,在这里我们去设置它这个封境数量,它会走相对应的一个参数,把这个复制过来。 好,新增一个变量啊。分镜这里的话我们可以去选择这个数字或者是整数,都可以选择这个整数,它输入的是十六九或者是二十五。啊,同样的在这里进行描述。 好,还有一个表色的名称,在这里再新增一个变量。 好,这个名称这个变量类型选择 seed 就 可以了啊,同样展开以后对这个变量进行描述啊,还有最后一个角色的人物参考图片,再新增一下 啊,这里的话我们只能上传单张图片,比如说你对某一个角色进行一个生成描述,那么在这里的话我们需要去选择,这样, 这个和上面这个它是不一样的,上面这个是上传多张,然后下面这个是上传一张图片,同样的展开以后对这个变量进行描述。 好,开始的话需要去设置这些变量。好,现在我们看一下这个搭建步骤,搭建步骤的话前面说过了,这里分成两部分,第一部分先生成这个角色卡之前的话,我们先要去生成这个角色卡的描述词。好,在这里先去添加一个大模型, 好,这个大模型给它改个名称, 把这个模型这里的话选择豆包一点八就可以了。最重要的是我们需要用到模型里边的有一个图片理解,我们会用到这个图片理解,将我们上传的这个参考图片进行理解,然后会生成一个相对应的提示词。 好,那么输入这里的话,我们需要拿到开始的角色名称啊,就是这个角色,然后视觉理解这里的话,我们需要去把开始给到的这个单个人物的角色图片给到他,那么系统提示这里的话我已经写好了, 首先在这里给他定义了这个角色,你是一位专业的动漫人物形象的设计师,能够根据我们上传的这个参考图片 完整的提供其核心的特征,这个特征里边就是发型呀,穿搭气质,标志性的一些服饰,然后再转换为该照片风格匹配的动漫风格。 然后在这里啊,最重要的一点就是生成两行三列,就是我们这个文档里边啊,就是这个图片的一个格式,下面这个技能的话是生成每一个格子里边的一些参数,还有这个是尺寸好,那么用户七十次把上面两个变量引用进来就可以了。第一个是人物的名 称,然后在前面备注一下,好,还有第二个人物的参考图片, 这里大家需要注意啊,引用的时候按住 shift 键不要放,然后按花括号,然后再按一次,好,出来以后我们选择相对应的就可以了,它引用完以后会变成一个蓝颜色。好,那么输出的话保持默认就可以了。那么异常处理这里的话,我们需要去设置一下 这个超时时间,这里是默认的一百八十秒,为了防止这个大模型超时,我们可以选择六百秒,这里有个重试次数,我们选择重试一次,然后备用模型,这里的话我们可以去选择一个备用的模型, 这里的话我们可以选择这个豆包一点六深度思考,它,同样的里边会有一个图片理解, 就是前面上面这个大模型,如果说生成失败以后,由这个备用模型继续去生成这个这个词,把这个大模型这里的话就设置好了。接下来以后我们来测试一下这个大模型,这里一个测试该点点好,这个是我们需要上传的角色图片,先去找一个图片 啊,这个是沿地的啊,名称的话是沿地啊,点击运行,运行结束以后我们可以看一下它输出的数据。 好,这里有个预览,我现在这里话给我们提取到一个核心的风格,然后还有个核心的特征,包括发型,然后再生成相对应的美宫格里边的所有的数据。好,这个大模型这里话是没有问题哈,没有问题,跟着我的节奏我们继续去搭建 好,现在有了图片提成词以后,我们去生成图片就可以了。在这里的话我们需要去用到一个香蕉的生图插件,因为它生成的质量的话是比较高的。好,直接在插件里边搜索 好,选择这个纳尔图片生成 好,直接添加进来就可以了。好,这里给它改个名称。 好,这里有个 k, k 的 话,这个插件它需要算力的,这里的话我们再开始设置一下,再开始新增一个变量。 好,再来到这个插件这里。当然你也可以把这个 k 放到这儿,给大家说一下放到这儿和放到开始的一个区别。如果说我们直接把这个 api k 放到这儿也是可以,但是当你分装成智能体发布以后,别人拿到你这个智能体以后,它会用到我们的这个 api k, 也就是消耗我们的算力, 这就相当于给这个插件内置了我们自己的 api k, 那 么放到开始,它每次运行的时候,它输入的是它自己的 api k, 所以 说我们最好的话是放到开始,那么这里的话我们需要把开始的 api k 给到它。好,这里有个提示词,我们需要把这个大模型输出的提示词拿到。 好,选择 autotune。 好, 这里的话是特别重要的啊,这里的话是参考图片数组,数组的话我们需要去拿到开始的参考图片。 好,这个是人物角色的参考图片。这里有个问题,它这个变量类型不一致,它要求的是 arraystring, 就是 字母串数字,但是我们开始上传的话是一个字母串格式,所以说呢,在这里生成之前,我们先要去转换开始的图片格式。 好,这里的话去添加个代码。 好,代码的话它是运行速度比较快,而且不需要资源。点, 我们看一下这个代码的变量,那么输入这个变量值这里我们需要拿到开始的这个角色啊,选择这个, 我这个变量名的话,需要去改一下 image u r l, 我 看一下代码里面的设置,把初设代码先删掉。好,这个代码这里的话我已经写好了。 好,这里的话就是将单个图片的链接转换成图片链接数字,然后进行合并,把这个返回扣子标准的对象格式,这个的话是我们需要输出的变量,把它复制过来, 把多余的删掉就可以了,那么变量类型这里我们需要去选择数字 frame 指令。好代码这里的话我们需要去把这个图片格式的这个代码, 我们可以看到它现在已经没有报错了。好,那么比例的话我们选择一比一。 好,生成图片的质量的话,我们选择四 k 的。 好,这里的话就设置好了。好,到这一步以后,我们这个第一步就完成了,生成这个角色卡,把结果给到结束,我们来测试一下它生成的效果。 好,结束这里的话拿到这个图片生成输出的数据。好,点击试用,行一下。 好,把开始设置一下,不然的话每个都需要去填好,只需要这三个就可以了,然后点击试用,行, 好,这里的话我们先上传一张参考图片。好,还是这个延地,那么角色名称的话,延地点击生成好。运行结束以后我们看一下输出的这个变量,这个的话是生成的图片链接,直接点开就可以了。 把这个角色卡的话可以给我们生成一个整体的人物形象,这里的话是没有啥问题啊,现在第一步已经完成了,那么看一下第二步生成风景的图片都是九宫格,十六宫格,还有一个二十五宫格的图片。我在这里的话我们先去添加一个大模型,先去生成九宫格的图片, 把这个大模型给它改个名称。好,同样的这个模型这里的话我们选择肚包一点六,这里有个深度思考,关键的这里边它还需要用到一个图片理解的这个模型, 那么输入这里的话,我们需要拿到开始的文本,就是我们需要拿到开始的剧本,它会根据剧本去分析我们这个场景,把这个变量名给它改一下,那么视觉理解这里添加一下,然后把开始的 好,上面这个是人物的数组,就是上传多张图片,把这个给到它,那么系统题词这里的话我就写好了 啊,同样的这里它就有一个角色,你是专业的三乘三宫格风景图片的生成助手,能一键根据故事的内容和视觉的参考图片分成每个风景提示词, 核心的目标的话是拆解并码为九个连贯的场景定位,每个风景匹配精准的风格标签,它这里的话会输出一个节省格式,它里面包含了这些东西。第一个是我们这个宫格的大小,还有一个默认的比例啊,这里的话是要求它关闭这个水印。 好,最后的话它会输出一个接收的格式,里边包含了所有生成的信息,那么用户提示词把上面两个变量引用进来就可以了。好,首先第一个是这个剧本, 还有一个人物的参考图片 啊,同样的这里游泳完以后它会变成一个蓝颜色,那么输出的话保持默认就可以了。同样的这个异常处理这里我们需要去处理一下,那么整体执行超时 这里我们选择同时一次,然后备用模型的话,我们可以去选择这个豆包,一点八,同样的选备用模型,不管哪个都可以,然后最主要的是我们需要用到这个图片理解就可以了。好,防止这个大模型超时。 好,接下来以后我们来测试一下这个大模型,这里上传人物,这里我们需要去上传多张人物。好,上传这个亡灵和炎帝的图片,那么这里的话需要去上传剧本,这里的话我让豆包去写了一篇, 这个就是亡灵和炎帝打斗的一个剧本,把这个复制过来。好,点击试用型。 好,游戏结束以后,我们来看一下他输出的数据啊,他就是根据我们上传的文案,还有一个人物去详细的拆解我们每个镜头所需要的信息。好,接下来以后有了这个图片提日期以后,我们去生成图片, 那么在生成这个图片之前的话,我们先要去给这个图片定义他这个场景和人物的一致性,再去添加一个文本,处理 好文本处理,给他改个名称。 好,这个输入这个变量值,这里的话我们需要拿到这个大模型输出的奇函数,那么字母串拼接,把这个 seed 一 再引用进来。 好,引用完以后,这里后面需要去给它要求一下,加上一句话,这里的话我就写好了,先复制过来, 以参考图片为主体,注意环境的空间布局,空间中人物与所有内容物品的相对应的位置,并且生成不同的角度,符合剧情发展连贯性的风景图。 注意一定要保持与图片美术风格一致,这样的话就定义我们整个图片的风格,人物的一致性和场景的一致性。好,先在这里设置好以后,我们再用这个相框的插件去生成图片。 好,这个图片这里的话我已经收藏过了,直接点开用就可以,大家用的时候也可以去收藏一下,因为这个效果还是比较好的。好,给它改个名称, 同样的这个 k 的 话,和这个 k 它是一样的,我们需要拿到开始的 api k, 那 么提示词这里的话,我们需要拿到这个文本处理的定义的图片要求。 好,这个图片参考数组就是需要拿到开始的啊,它是数字格式,我们需要拿到开始的这两个人物的参考图片。好,这里的话它爆红是没有关系的,这个变量类型它是一样的,可以去生成的。好,这个比例的话我们选择十六比九。 好,同样的这个我们可以选择四 k。 好,到这一步以后,这个九宫格就做好了,我们来测试一下,好,把结果给到结束。那结束这里的话,拿到这个生成风景图片的 u r n, 我 们单独测试这个风景图片就可以了,然后把这个线先拿掉,然后点击适用型,然后这个风景数量这里我们选择九,我们需要拿到 y d 还有五二零的这两个图片。 好,同样的文案,这里的话把刚才这个文案复制过来就可以了。好,点击试用型。好,运行结束以后,我们看它输出的图片 结束这里个链接,我们直接点开,可以看出它生成这个质量确实还是非常不错的,包括人物还有场景的一致性保持的都还是比较好的。 好,现在这个九宫格就做好了,那么接下来以后还有个十六宫格和二十五宫格,这个原理它是一样的,我们只需要把这个大模型换个提示词就可以了。好,把这个大模型复制两个,好给他改个名称,这个是十六宫格, 好,这个是二十五宫格。好,把线连起来, 把这个提示词的话,我已经写好了,直接换掉就可以了 啊,十六宫格的啊,其他东西的话不用去换,然后这个是二十五宫格的, 现在十六宫格,二十五宫格的这个提示词就做好了,点击试用行的时候他们全部会去运行,那么想让单个去运行的话,这里的话我们需要去添加个东西,添加个意图识别。 好,添加这个意图识别这个模型的话,显示已经马上下架了,那么随便去换个模型就可以了,可以换这个豆包一点五三十二 k。 好, 这个意图匹配这里的话,我们需要拿到开始的封境,因为我们开始设置了一个封境的数量啊。意图匹配这里我们选择九, 然后再添加一项,这里选择十六,然后再添加一项,选择二十五。那我们输入九,它会走上面这条线, 当我们输入十六的时候,他会生成十六宫格,当我们输入二十五的时候,他会生成二十五宫格。所以说呢,这个线的话我们这里需要拿掉,这里给到十六,好,这里给到二十五,好,这个线的话这样去连。 好。我们现在看一下这个逻辑,当我们输入九的时候,他会走九宫格,然后当我们输入十六的时候,他会走十六宫格,当我们输入二十五的时候他会走二十五宫格,这里有个其他的话,我们可以去连到二十五宫格,就是当我们不输入这个分界数量的时候,他默认的是二十五宫格的。 我们再看一下这个文本处理这里啊,这里的话我们需要去把线全部给到文本处理,但是这里的话有个问题,当我们所有的数据给到文本处理以后,它识别不了,因为文本处理的话,它只是拿到了一个九宫格的参数,那么现在的话这里我们需要去添加个变量聚合 好,添加变量聚合以后,将这个三个大模型输出的数据给到这个变量聚合进行汇总,汇总完以后再给到这个文本处理,把这个线的话都给到变量聚合 好,那么变量聚合这个参数这里我们首先需要拿到九宫格的图片提热词,还有一个十六宫格的图片提热词,二十五宫格的提图片提热词 就是将这个大模型输出的图片提示词在这个变量聚合这里汇总以后,然后由这个变量聚合进行输出,那么再看一下这个图片处理这里。 好,图片处理这里拿到变量聚合输出的数据就行。那么这个逻辑以后不管是哪个大模型输出的数据以后都给到变量聚合,那么文本处理只需要拿到变量聚合一个数据就可以。好,后面的话这些不用去改 好,到这一步以后我们整个工作流就搭建完了,然后把上面这个线也连起来好,这个人物的角色卡我们也需要给到结束,那么结束这里新增一个变量,把人物角色卡这里用按了,拿到 好整体再测试一下,点击试用型,然后这个分界数量这里我们选择二十五,二十五的话它会走下面这条线。好,然后点击试用型。 好,游戏结束以后,我们看它输出的两个图片啊,第一个是二十五宫格的啊,可以看出来它生成这个效果还是非常不错的,人物包括场景的一致性保持的还是比较好的。 我再看一下它生成的这个角色卡啊,这个是生成沿地的一个角色卡,这个工作流的话我们已经搭建完了,那么这个工作流会给我们生成一个角色卡,还有一个各个风景的一个图片。 好,那么有了这些图片以后,我们再结合这个 sims 二点零使用手册去生成慢距,他这个效率会提高很多啊,因为我们对于这个图片的人物一致性已经保持的非常好,不管你去生成什么样的一个效果,他都是比较快的。关于这个极乐 sims 二点零使用手册的话,我也会放到文档里边供大家去学习使用。
182欢哥AI智能体




猜你喜欢
最新视频
- 4.5万翘翘珊