autoclaw数据导入方法
这一期呢给大家讲一下咱们这个日常作业中这个 cad 图要怎么导到我们这个 r t k, 然后实现一个,我们通过这个 r t k, 然后依据这个 cad 图进行一个方向,那么我们先找到我们的这个图, dw g 格式的这么一个 投币,然后找到一根这个手部可以用用于这个数据传输的安卓线,然后将这个手部和我们电脑通过这个线进行一个连接,连接之后呢我们这个会 有一个这个提示,他是正在通过这个 usb 进行充电,我们给他更改成这个文件传输,这个时候我们就可以在我们的这个电脑上找到我们这个设备名称,然后这里建议大家给我们的这个 文件新建一个文件夹,然后打开这个新建好的文件夹,把我们的这个图拖到我们的这个文件夹里, 然后打开我们的首部,断开我们与电脑之间的这个连接,打开我们的这个首部的这个软件,然后我们这里有专门的这个 cad 功能, 打开,然后这里我们选择这个数据,这个 cad 它里面有一个打开这个选项,我们选择这个打开,返到我们的这个根目录里面,找到我们新建的这个文件夹, 然后选择我们的这个文件,点击确定,那它就会去进行一个图纸的加载,这样我们这个 cad 图纸就加到我们的这个首库里面了。这一期的讲解就这样,然后大家有什么想交流的可以打在我们评论区。

粉丝421获赞940
相关视频
 01:19查看AI文稿AI文稿
01:19查看AI文稿AI文稿今天咱们来聊聊 autoclave, 一个可能会彻底改变你电脑使用方式的新工具。你想不想要一个专属于你就在你电脑上的强大 ai 助手?但问题是,这些 ai 工具通常都太复杂,感觉遥不可及,对吧? 不过智普 ai 出了个新东西,就是要来解决这个问题的。没错,它就是 autoclole, 一个专为你打造的本地 ai。 它的核心就是把 ai 直接塞进你的电脑里,不用老是连着网。最厉害的是,整个安装过程你猜多久?就一分钟。 而且啊,他把门槛都给拆了,不用花大钱,也不用排队,这就等于说你有了个期长,二十四小时在线的私人 ai 助理,功能有多强?这么说吧,他自带了超过五十种技能,开箱即用, 比如说帮你写报告、敲代码,或者快速查资料都行。所以你看,这不只是个 app 那 么简单,它的背后有个更大的想法,这个想法就藏在它的口号里,每个人的 openclo, 说白了就是想让强大的 ai 变得平民化,让每个人都会用。那么问题来了,以后会不会每台电脑都有一个专属的 ai 呢?
1朱亥 04:45查看AI文稿AI文稿
04:45查看AI文稿AI文稿我们今天给大家来说一下,怎么把通达信的数据导入到我们自己的数据库里头。因为我的这个数据库呢是 postgraduate 这个数据库,所以呢我就以这个为例给大家讲一下哈 这个表啊,这个是我们从通达信那个网站上下载的啊,从二零一三年到二零二六年就最近的啊,三月二号的这个数据,他这里头是分了三个市场。你比如这个就是上海的 啊,他是日 k 线的数据啊,你看这个后头写 d 的是日 k 线,这前边的呢是股票代码,那后边的话呢,是这个 八字开头的是这种概念板块啊,你比如说像天然气啊,什么五 g 概念啊等等啊,机器人概念,就这种概念板块的,他的这个 k 线的数据。 呃,那我们现在是要怎么做呢?首先呢我们要把它设计一个表的体系啊,让他让把这些数据全部存到我们自己的数据库里头,这样的话呢,我们后续再做一些量化的一些分析的时候就很方便了。首先我们要建立一个表啊,这个是我这起的名,是通达信,然后是 daily bar, 就是 他的日 k 线的数据, 就是个股和板块的统一,都存到这里头来。因为个股的话呢,就是比如说用我们的股票代码,然后板块呢,我们刚才看到他也有他自己的股票代码,呃,就是通达信给他有有这个股票代码,比如像八字开头的这种八八开头的这种啊,这种呢都是板块的啊,他也有股票代码的啊,他是板块的代码。 在上个视频我们给大家说了,就是现在我们通达信里头下载的这样的这个数据解析完了之后,他是这样子的, 就是日期啊,然后开盘价、最高价、最低价、收盘价、成交量和成交额。但他这里头呢,没有这个 啊,这个股票代码是在这的啊,是在他这个名字上头的。所以呢我们要单独有一个表,数据库里的表是存这个股票的名称的,对不对?他股票代码他的名称啊,他是什么市场啊,什么时候上市的等等,这个表很重要,就这个表是和他是配套的,这个呢是各股的 他的表,这个是板块的表啊,就是这个,比如八八零、七五零啊,这个板块的代码他对应的他的名称啊,比如说天然气这个板块是他这个是这个类型,是这个 概念板块还是行业细分板块。那还有一张表呢,是这个板块的成分股,就它包含了哪些成分?那我们这里头呢?首先啊,从 这个表里头我们只能够解析到这个东西,那具体比如说这个对应的它的简称是什么啊?其实是是在这个里边的。这个,呃,通达信是装在了地盘,对啊,这个通达信地盘里头呢,它有一个这个啊,在这个里边。 那这个文件文件夹里头有什么呢?啊?有这些对应的板块里头,它的名称是什么?它包含哪些成分股?这个呢是各股和行业对应的,这个是各股和板块对应的, 这两个呢都是通达信里头的表,但是呢它是等于是它是二进制的,你需要把它解析出来。 呃,那下边的话呢,是我让 ai 做的一个导入的一个流程。那我们现在这个工作已经在做了哈,给大家看一下, 你看它已经在导入了,它目前来讲已经导入了那么多了,总共是一万两千多个嘛,现在导入了四千多个了。呃,这个,这个前边你看到这个八八零这地方呢,其实是已经是板块了。呃,前头各股的部分已经在 导的差不多了啊,我们就把它做成了一个 python 文件运行,这个呢就能够把这些啊,我们下载到的这些数据给它导进来,运行这个脚本就能够把这些东西呢给我们导入到我们自己的数据库里头来,它会把我们把这个二进置的文件解析成 呃,这样的数据,然后存到我们的数据库里头去,那这个呢?估计再运行个八个小时就差不多导完了。那导完之后呢,还有一个工作需要做,就是,嗯,这时数据有了,你还要给他的名字,他的简称给他匹配上。就刚才我们看到的啊,这几个,这几个表 就是我们需要把这几个表都给它完整了,到时候你在调用的时候才会比较方便啊。当然这几个呢也问题不大,因为它,呃在通达信这个里头,它有相应的这个表,只是我们解析一下,把它存进去就行了。那这个工作做完之后,还有一个工作需要做,就是 我们每天的数据,比如今天三月三号收完盘了,对吧?那我们需要把它这个当天的数据用一个代码给它存到数据库里头去,这样这样我们就能够保证这个数据时时都是新的了。 嗯,那做了这么多,其实后边还有很多的工作要做好,大家如果觉得这个有用的话,帮忙点赞点关注,谢谢大家。
239数分魔说量化 01:58查看AI文稿AI文稿
01:58查看AI文稿AI文稿今天一早,智普科技直接把 openclaw 桌子掀了,它正式命名为 autoclaw 澳龙。 智普科技把小龙虾系统的 openclaw 打包成一键安装的桌面应用,即便你不擅长下载软件也没关系,只需打开官网下载安装登录并接受验证码,一分钟不到,小龙虾系统就部署完毕,轻松搞定。澳龙可不是阉割版, 它的内核与小龙虾系统完全相同,费用同样是零点一一元。打开 app 的 瞬间,龙虾系统就已准备就绪。以往要将龙虾系统接入飞书,那套流程极其繁琐,估计百分之九十的人看到都会头疼。现在只需点击开始配置,后续流程会自动完成。 进入飞书后,在电脑、手机、 ipad 等所有能安装并打开飞书的设备上,你都能使用小龙虾系统。比如回家路上不方便用电脑,但又想查询数据,直接给龙虾系统发条信息就行。半夜突然想起总结报告没写,掏出手机就能让他帮忙赚血。 奥龙功能十分精细,这是智普专门为引擎 n 整场景打造的全新模型,在连续规划、多步执行、反复调用、工具、常常推理和状态跟踪等方面表现出色。当然,如果你不想用这个模型, 它还支持模型插拔,像 check g p t g m i kimi、 mini max 等模型应有尽有。再看只需链接 m c p 服的一个网址就能完成连接 安装技能的操作非常合适化,里面还预装了九十六个工作、生活中可能会用到的优质技能,这些可都是质朴工程师精心挑选, 要是有哪个技能你不想用,才能一键进行更细致的调整,你的龙虾系统可以一键迁移到澳龙,这次质朴的股价是不是也该搜就搜了?
 00:50查看AI文稿AI文稿
00:50查看AI文稿AI文稿以前想养一只小龙虾,门槛真的不低,本地部署、环境配置、 api、 网关、权限设置,光是第一步就能劝退百分之九十的人,但现在,这个门槛基本被清零了。 auto club 刚刚发布,简单理解就是给龙虾套了一层壳。以前折腾半天的本地部署, 现在只需要装一个 app, 一 分钟你的电脑里就能跑起一只小龙虾。里面还预制了 pony alpha 模型,连 api 都不用,配置打开就能用。更关键的是,它不是跑在云端,而是直接跑在你的电脑里,不用租服务器,不用月费数据,也不用离开你的机器。而且它不只是聊天,自动总结群消息、查资料、 写内容、跑网页,系统自带五十多个技能,开箱即用。所以你看到的是一个 autopilot。 但真正发生的是 agent 第一次真正走进普通人的电脑未来。人与人之间的差距,可能不再是谁更会问 ai, 而是谁更早拥有一只真正替自己干活的小龙虾。
 01:08查看AI文稿AI文稿
01:08查看AI文稿AI文稿帮我查一下今天 a 股市场中涨幅超过百分之九的股票有哪一些?列出股票名称、代码、当前涨幅、现价,整理成表格发给 我。很快,奥托夸尔就找到了最合适的股票信息来源,并整理成表格提供给我数据。我核对了证券网站,准确无误,并且我的错别字现价也能被正确理解,智能水平增高。 接下来,我们来让 autoclare 每天给我们汇报股市情况。请创建一个定时任务,每个交易日下午三点收盘后执行。抓取今日 a 股涨幅前五的股票,列出股票名称、代码、涨幅、收盘价、成交量。通过飞书发给我。 autoclare 准确地完成了任务,还在过程中发现配置问题,自动修复。 不得不说, pony alpha 二这款智谱专门为小龙虾研发的模型,智能程度挺高的。并且我们看到第二天的下午三点后也按时收到了 autoclave 的 汇报,真的很省心。
10超级峰 08:29查看AI文稿AI文稿
08:29查看AI文稿AI文稿面试官抛出问题,你们怎么处理向量数据,然后存进数据库的?你脑子里闪过念头,就是把内容分割转成向量存起来呗。如果你是这样回答,这个职位就跟你没关系了。为什么?因为面试官已经听出来了,你没有实战经验。大家好,我是大宇, 今天咱们拆解一下,一个年薪百万的大魔性专家,到底是怎么玩转这套系统的。首先问你个问题,你拿到的文档是什么样的?我跟你说,真实的数据源有多混乱?老旧扫描件、十多年前的 pdf、 o c r 乱码满天飞,页码、水印、页脚全混在内容里,网页爬虫数据、 html 代码、 java script、 cs、 央视第三方追踪脚本一团乱码。办公文档、 word 里面表格套表格合并单元格、隐藏文本 排版。逻辑糟透了,你要是直接拿这些废料去切割会怎样?进来的全是垃圾,出来的肯定也是垃圾,这就是业界的铁律。所以第一步必须清理, 用工具库,比如 unstructure 或者布局识别算法,把格式统一,乱码去掉噪音清掉,整理成规范的结构。但这还不够,最关键的一步,大多数人都漏掉了。打标签。什么叫打标签?就是提取原数据、发布日期、来源、部门、保密等级、业务分类。 有了这些标签,后续搜索就能实现精准过滤用户。问最新的技术方案,系统只返回二零二四年最新的来自技术部的文档。没有标签, 你的搜索就是瞎蒙,在大海底捞针,全靠运气。现在数据洗干净了。接下来第二步就是分割这个环节,这里有个坑,很多工程师都踩过, 最常见的做法是什么?简单,暴力,设定固定的制服数,比如五百字一段,知道会发生什么吗?一个完整的逻辑,一句话, 一个知识点,可能被深深切成两半。我们的优化策略分为三部分,第一是性能优化,第二是 ai 拿着这个残缺的片段去做匹配,怎么可能准确,就像医生只看了患者的半条腿,根本没办法诊断正确做法。智能定位切割系统会聪明的识别 这里是不是句子的分界线,这里是不是段落的转折,这里是不是逻辑的断点,然后才切,加上划窗重叠。 前后两个片段故意有百分之十至百分之二十的重合。比如片段 a 第一到第十句,片段 b 第八到第十七句,故意重合第八和九句。这样形成一个缓冲地带,确保边界信息不会因为被切到接缝处就丢失。但最高级的玩法 叫小块大块架构,这是区分业余和专业的分水岭。理解,小块解锁块,大小控制在两百至三百字,一个单一完整的知识点, 特征鲜明。这个镜像量库,大块生成块,大小控制在一千五至两千字,包含完整的背景,详细的案例,深层的解释。解锁出小块后,把对应的大块送给模型,为什么这样?因为小块的向量特征非常突出,搜索时能精准定位,但生成答案时,模型需要丰富的上下文。 这个架构就是用小块做精准定位,用大块做充分生成,既保证了搜索精度,又保证了答案质量。 大多数公司的 r a g 系统效果平平,原因就在这,要么只优化了搜索结果,信息不足。要么只优化了深层结果,搜索不准。只有真正的高手才能两者都兼顾。第三步,非常重要的一步,文本要变成向量,需要 ingabili 模型。 这时候有人会想,我直接用最强最贵的模型肯定没问题啊!错,这是大坑!我给大家讲个真实发生过的案例,某医疗公司做 ingabili 模型处理医学文献,结果怎样?效果特别差。 用户问,什么是冠心病?系统返回的是什么?是普通感冒的内容?为什么会这样?因为通用模型是用互联网通用数据训练的。 他根本不理解医学领域的专业黑化。在通用模型的向量空间里,心梗、心肌梗死、冠状动脉狭窄这些在医学里完全不同的概念, 都被挤到了心脏相关的同一个区域。模型无法区分。法律领域也一样,合同违约和协议变更在普通人眼里区别不大,但在法律专业里,是两个完全不同的法律问题。通用模型分不清,怎么解决?微调,你不能依赖通用模型, 必须用我们行业的专业数据对模型进行调整。拿医疗的几千份专业文献,对 bgm 三或 m 三 e 这样的基础模型进行微调。训练完成后,模型就变聪明了。他学会了区分冠心病、心肌梗死、心力衰竭 这些词在医学里的真实含义和细微差别。效果提升有多明显?精准度能提升百分之五十至百分之八十,这不是小数字, 这直接决定了整个系统的天花板。记住,通用模型加垂直微调才是王道。第四步,向量有了,要存进数据库。很多人会说,我用 panico, 我 用 milos, 我 用 vivite, 这都是表面真正的核心在锁影算法的选择。 假设你有一千万条向量数据,你能用最朴素的 f l a t 锁影吗?什么是 f l a t? 就是 暴力搜索。每次用户查询,系统要把查询向量和所有一千万条向量都计算一遍,距离 计算量是什么量级?一千万条数据,每次查询都是一千万次浮点预算,你的服务器会直接被烧穿,用户要等好几秒才能看到结果,这完全不行。所以我们用 h n s w 分 成导航小世界, 这是目前最实用的解决方案。 h n s w 怎么工作的?想象一下,不是直接在数据大海里乱翻,而是先构建一个多层级的图结构,这个图像导航地图一样,让你快速定位到最相关的数据区域。搜索时,你不是全表扫描,而是沿着图的边逐层跳跃,逐步逼进最相关的向量。 性能提升有多明显?时间复杂度从 n 级别降到了 log n 级别,也就是说,一千万条数据, f l a t 需要几秒钟, h n s w 只需要几十毫秒,这是质的差别。还有个被百分之九十九的人忽视的细节。批量入库优化,很多初级工程师怎么做的?一条一条的发送请求 入库,第一条限量等待入库,第两条等待入库,第三条等待,这是最低效的方式,数据库完全没办法发挥兵发能力。 怎么做?把数据分批一次性发一千条项链的请求,让数据库能够并行处理,效果有多明显?入库速度能快五到十倍,一百万条数据从几小时降到几十分钟,这就是生产级系统和玩具级系统的根本区别。有人会想好了,数据入库、完成,任务结束,错的离谱, 真正的问题才刚开始。向量解锁最可怕的漏洞是什么?它会产生幻觉。什么叫产生幻觉?用户问怎么开户,系统却把怎么销户的内容解锁出来了。为什么会这样?因为这两句话在向量空间里太像 模型,根本分不出区别。意思完全相反的两件事,被系统当成了同一件事。用户来开户,你给人讲怎么销户?这是什么服务啊?所以需要一个超级关键的机制,混合解锁。什么是混合解锁?不止靠项链,而是同时用项链搜索和关键词搜索。比如用户问怎么开户, 向量搜的角色找所有与意相近的内容,关键词搜的角色找所有包含开户这个关键词的内容。两个搜索结果一结合,开户和销户就再也别想混淆了。但这还不够,我们还要加一个 re rank 重排序模型,这是最后一道防线。 想象这个流程,初选阶段向量搜索加关键词搜索,先塞出前五十个后选。复选阶段重排序模型接手,对这五十个后选重新打分, 用一个更聪明的模型来判断真正的最相关决选阶段,只返回 top 五,最靠谱的结果给大模型。这就像选秀节目的流程,初赛是海选,塞出所有有潜力的,复赛是精选, 从这些人里挑出真正的明星选手。有些顶级公司还会用 h、 y、 d、 e 技术,让 ai 先模拟一个可能的答案,拿这个假答案去做向上搜索,为什么这样有效?因为答案和答案的相似度往往比问题和答案的相似度更高,召回率能直接翻倍。所以 整个向量数据工程的核心就三点,第一,源头要精细。第二,上下文要完整。第三,搜索要精准。 好了,假设明天有面试,面试官问这个问题,你怎么回答才能赢?我给你一个三层级回答框架。第一层,质量意识,我们非常重视源头数据质量,首先用布局分析清理格式,然后提取原数据打标签,为后续精准过滤做准备。 第二层,架构优化,采用低规切分加划窗重叠,确保语音连贯。核心是小块,大块架构,小块镜像量库,保证搜索精准度。 大块送大模型,保证深层质量。引编码模型也是垂直为调的。第三层,工程闭环,用 h n s w 锁影配合 p 处理,保证 性能。入库后用混合解锁重排序和 h y、 d e 技术做多重校验,避免语义错误,持续通过数据驱动迭代优化。你这么回答,面试官听完会怎么想?这哥们真的做过生产级项目?保证他听完直接想给你发 offer, 那 一刻 你就赢了。好了,今天的分享就讲到这儿,点个赞,关注一波,我会持续更新大模型的深度技术内容。
726AI大模型大鱼 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿说一说那个劳伦斯系列怎么导出到数据?那些行点行记的数据怎么导出到另外一个版本呢?我以一年九为例啊,点这个选项 就双叶的,双合叶的哈,那个然后选到存储啊,确定要找到找到行点这个选项,不要去选数据库什么,就直接行点,点下去,然后有个输出, 输出点下去,点下去它要输出版本啊,选输出, 输出到到哪里,那就直接随便确认就行了,它就会显示文件名,文件名你自己取一个,然后就确认确认就 ok 了, 它会提示我这个,因为卡已经取出来了,它可能这个显示会出错哦,也可以,它应该是保存到本地的, 那这样就行了,然后这个你就把这个卡取出来,取出来到这里, 到这里也是一样,选择选择存储哈,这么一个存储 存储,然后选择不用去点行点哈,那点行点是导出的,直接进出哦,直接点你的卡, 然后点到你的这个文件,因为刚才我导出的是这个文件,那就这个直接点下去,点下去就直接可以导入了啊,我因因为已经导入了,我就不重新导入了,就这样很简单啊,希望大家包厢啊。
27三杠_叁鱼会 02:47查看AI文稿AI文稿
02:47查看AI文稿AI文稿如何把旧手机上面的数据导入到新手机上,这个方法你会不会啊?很多人换了新手机之后呢,旧手机里啊有很多重要的数据,像什么联系人啊,通话记录,短信,视频这些,有没有成功传输到你的新手机上呢?其实上传的方法呢,特别的简单, 现在一键就能轻松完成,接下来呢我就手把手给你演示看,只要学会这个方法,以后换手机就不用去麻烦别人了哈。怕看了一遍还记不住的朋友们记得点赞保存这条视频 来,朋友们大家注意看哈,我今天呢专门准备了两部手机,这一部呢是我的旧手机,这一部呢是我的新手机,我现在呢要把这个旧手机上的数据呢全部上传到这个新手机上面, 你们看一下我是如何操作的。那么首先我们要传送这个数据哈,你得先看一下这个新手机是什么样的型号,像我这部手机呢是 oppo 手机,它的传输软件呢叫做手机搬家,这个呢是不需要下载的哈,都是咱们手机自带的,你找一下都能找的到。如果说你的手机是小米 华为的哈,你就对应的去找一下,在这个左上角呢,我给大家贴出来了,像小米手机啊,叫做小米换机, vivo 呢叫做换机克隆, 大家可以对应的去找一下。首先呢咱们打开这个新手机的手机搬家,在这个下方呢,选择,我这个是新设备到达这里呢,你要选择一下你的旧设备的手机型号, 安卓的话,你小米啊什么的,你就选择其他安卓,那 oppo 呢,你就选择第一个,那如果是苹果选择第三个华为呢?选择第四个, 我的这个旧设备是 oppo 的 哈,来,我选择 oppo, 点进来咱们来看一下这一小镇哈,请在旧设备上打开手机搬家,选择这里的旧设备,扫描这个二维码。如果说你的旧手机没有手机搬家该怎么办呢?没关系哈,来,旧设备尚未安装,手机搬家 可以在这个位置去下载安装,安装完成之后呢,来,咱们点开手机搬家,选择这是旧设备选 选择,确定用你的旧手机去扫描这个二维码,那么此时此刻呢,就已经连接成功了哈,那么这个时候呢,你选择你需要迁移的东西,你比如说文档啊,或者是应用啊,还有微信 qq, 对 吧? 还有这个联系人信息,通话记录都是可以的,你也可以把不要的呢给它去掉。然后呢,咱们选择下一步,在这里呢,它会出现两个选项,是否覆盖新设备的微信数据,你可以选择覆盖或者是不覆盖哈,通常呢我都选择不覆盖, 选择确定。那么跳转到这个页面之后呢,来咱们勾选一下,就可以开始搬家了,学会的朋友啊,可以按照这个方式来操作一下,觉得视频对你有帮助,记得留下一个免费小爱心,或者转发给身边需要用到的朋友。
665林江自媒体 03:02查看AI文稿AI文稿
03:02查看AI文稿AI文稿这一讲我们来学习导入文本格式的订单文件。首先我们来看第一种方法,启动 excel 程序,选择打开,选择浏览。 在打开的 windows 资源管理器当中,我们找到我们文本文件的存放位置, 由于默认打开的是 excel 格式的文件,所以我们只需要将这里的文件类型更改为文本文件,然后找到我们要导入的订单文件,单机打开, 这时候将弹出文本导入向导,我们在这里选择文件类型为分格符号,然后单机下一步。 在第二步当中,我们需要设置我们使用的分割符号,那我们这里选择 tab 键,然后点击下一步。 在第三步当中,我们需要设置我们要导入的数据的一个格式,那么我们将我们的订单日期选择为日期格式,那我们选中这一列,然后选择日期格式,并且还可以选择对应的格式的类型。 同时我们需要将 p u number 设置为文本格式,将 line number 同样的设置为文本格式,然后单机完成, 此时我们就将我们的文本文件导入到了我们的 excel 当中。第二种方法,我们将介绍使用导入文本文件的功能进行操作。首先启动 excel, 之后,我们新建一个空白的工作簿, 由于默认的 excel 二零一九没有开启导入文本文件的功能,我们需要先手动开启一下。开启的方法是这样的,单机文件 找到选项,在打开的 excel 选项对话框当中,我们选择数据, 在右侧找到显示旧数据,导入向导,我们勾选纯文本,然后单机确定按钮, 这时候我们将已经开启了导入文本文件的功能,然后我们在数据选项卡当中找到获取数据,然后在传统向导当中选择从文本,同样在 windows 资源管理器当中找到我们的文本文件的存放位置, 单机选中,然后单机导入按钮,同样弹出文本。导入向导,我们按照刚才的操作再来一次, 然后单机完成。在导入数据的存放位置,我们选择现有工作表的 a 一 单元格,然后单机确定,这时候我们也就将我们的订单文件导入到了我们的 excel 当中。
 01:20查看AI文稿AI文稿
01:20查看AI文稿AI文稿对应建模小技巧,这一集教大家如何用,该如何键导出表格,修改数据后再导入来修改足参数, 进入到插件板块里,选择第一个功能,就可以看到咱们所有的构建。主播这里选窗来进行演示,控制窗的主要有高和宽,注意红色的是不能改的,主播做示范就不选太多了,在中间那一栏是所选构建的所有参数,我们勾选上我们需要的参数, 选完之后点击向右的三角,参数信息就会出现在最右栏,最后点击右下角的导出,选好文件位置直接保存就行,这时候导出的文件会打开,我们可以直接在里面修改数据,这里主播把数据都改成一千六百,以便带回咱们查看。 红色的是不可修改的,只有黄色的数据可以修改,修改完成之后保存一下就可以退出赛欧了。 重新回到 refi 里来,我们点击右下角的导入键,选择第一个导入表格文件,找到我们刚才修改过的再导入进来, 等待右上角进度条完成,就算导入完成了,这里关闭这个界面,我们去看看窗的尺寸是否修改, 随即点击一个窗户,在编辑类型里可以看到高度宽度都是一千六百,再换另一个看看,查看数据也是如此,到此算是修改成功。这期视频到这里就结束了,大家学会了吗?
41MoPuBIM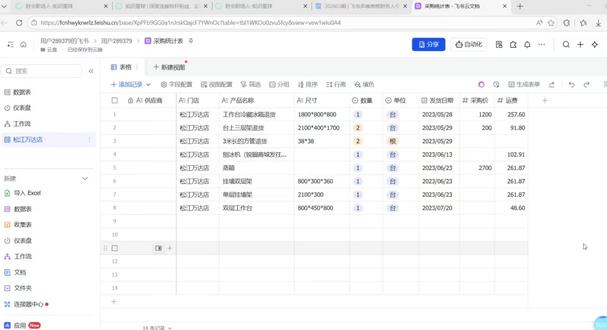 01:35查看AI文稿AI文稿
01:35查看AI文稿AI文稿视频分享一下我学习非输多维表格第二天的内容。那今天的内容主要是包括导入 excel 数据到非输到多维表格里面,然后再对导进来的数据进行公式上的编辑。那导入 excel, 只要点击这里的导入 excel, 点击选择文件,然后导入一个你自己的 excel 或者 csv 文件 就可以了。等数据导进来之后呢,我们可以对这个数据进行编辑。那如果说我们需要计算一下采购总金额,我们只要在这里增加一个公式 标题,我们就写公式,字段类型选择这里的公式。非输的编辑公式和 excel 区别在于,非输他不需要输,等于号,我们只要用数量乘以 采购价,再加上运费,确定这里的字段格式要改成数字,我们这个公式计算出来的结果是数字。数字格式可以保留一位小数,也可以保留两位小数,这里是可以选择的。 那我现在选择保留一位小数,确定这个结果就计算好了。像这个我加一个采购单价五十,他的最终的结果就自动生成了,这里我加一个采购单价五百,那这个金额就生成了 这个。视频分享到这里,下一个视频继续分享我飞书多维表格学习第三天的打卡内容。
20财务谢雨 00:47查看AI文稿AI文稿
00:47查看AI文稿AI文稿你知道怎样在 excel 里面导入这个 excel 数据库吗?我们现在新建一个 excel 文件,然后把它打开,点数据获取数据导入数据点确定,然后再点选择数据源, 选择我们这个 excel 数据库文件,直接双击,然后再点下一步,选择所有的字段, 再点下一步,点完成,点试点确定。这样呢,就把 access 数据库里面的数据导入到电子表格里面了。从数据库导入数据到电子表格,你学会了吗?关注超哥,看更多干货!
21软件开发超哥 01:23查看AI文稿AI文稿
01:23查看AI文稿AI文稿嗨,我是爱汽车的小米,今天教大家一个快速从 gopro 导入视频和照片去手机的方法,只需要一条高质量的数据传输线,用它连接我们的 gopro 和手机, 然后它现在已经自动识别到我们的 gopro 了, 然后我们就可以来查看我们拍过的视频, 然后我们选择要下载的视频 啊,用数据线连接,下载速度非常的快。 好啦,这就完成啦。
56TVstudio






