9b模型openclaw配置

粉丝7获赞207
相关视频
 00:39查看AI文稿AI文稿
00:39查看AI文稿AI文稿中医也是在本地部署了一个 openclock 本地十四零六零肽显卡十六 gb 的 显存,然后,呃,也装了一些 scuse, 也问了一个同样的天气啊,调了一些它这个执行的一过程可以看一下 阿老最后也成功给到了同样的天气,问一下这个搜索的功能也是可以搜索出啊相关的一个情况 啊。最后我本地部署的这个大模型是同一千问的就是三点五九币的一个模型啊,现在再玩一玩。
 06:54查看AI文稿AI文稿
06:54查看AI文稿AI文稿三千元到十万元大模型家用 pc 硬件方案全解析?上一期社长介绍了纹身视频模型的硬件方案,里边讲了企业或专业工作室的纹身视频模型硬件应该配到什么程度。有不少朋友在评论区留言说,希望社长能够出一期大模型的家用消费级硬件专题, 那么这一期就满足大家专门讲一讲大模型家用消费级的硬件方案。最近 oppo colo 很 火,那什么样的配置能够畅玩 oppo colo 呢?在这一期也有答案。既然是家用消费级方案,也就是个人 pc 方案, 那么 e 五神轿、特斯拉、 v 一 百为代表的老旧服务器显卡就不在今天这一期的讨论范围内了。 ar max、 三九五、 mac mini 的 整机方案由于纹身视频能力弱,也暂时排除在本期之外, 因为毕竟作为家用消费级主机,必然是要兼顾多种需求的,跑跑大模型和智能体,生成一下 ai 视频,做做生产力工作,没事还能打打游戏,甚至新出的三 a 游戏也能尝尝咸淡,这就是本期硬件选型的基本要求。 所以我会尽量选择个人 pc 的 消费级硬件来给大家搭配方案,最低花费三千元,最高花费十万,大家可以根据自己的预算和实际需求,综合考虑自己的硬件配置。 在开始之前呢,先给大家预告一下,在三月十五号,我们会开一期 ar 大 模型私有化部署的小白培训,具体的培训内容在这一期结尾会有展开说明,有兴趣的朋友一定要看到最后。 我们知道,现在的大模型在日常应用上已经分成了上下文推理模型、纹身图或纹身视频模型,这两类不同的模型对于硬件的要求是不一样的,对硬件适应性最广的是上下文推理模型, 它对扩大的要求最低,只要显存达到一定规模,哪怕是好几年前的老旧显卡也仍然可以胜任,这就给了我们家用消费级配置很大的选配空间。 这里要注意的就是如何判断某一推理模型能不能部署,主要是看显卡的显存能不能大于模型的参数,比如三十 b 硬特八的模型对应的就是三百亿参数。按硬特八量化规则,加载到显卡里所需要的显存大约是三十七点五 g, 加上要预留 k v 缓存激活值缓冲区, 因此要运行这个大模型,我们一般是按照模型量化后显存占用的一点二倍计算。那三十币 ink 八模型就需要至少四十五 g 显存的显卡,但众所周知,内存是可以分担显卡的上下文推理模型的加载任务的,比如上面讲到的三十币 ink 八的大模型, 需要四十五 g 的 显存来流畅运行,如果显卡只有十二 g, 剩下的三十三 g 可以 加载到内存中去运行。 当然,因为内存的贷宽远远小于显存的贷宽,如果大部分都让内存来跑的话, tokins 的 速度会大打折扣,所以显存尽量还是要大一些。但对于个人来说,对于效率的要求并没有企业这么高,我相信大多数人是可以接受的,毕竟在性能和成本方面总要找到一个平衡。 纹身视频模型的门槛就要高的多了,他没办法像上下文推理模型那样,显存不够内存来凑,模型必须要全部加载到显卡里。所以如果朋友们想尝试纹身视频模型的话,就要至少满足两条硬杠杠,一是显卡要有 touchcore 支持,二是显卡显存要至少达到十二 g。 为什么呢?我们以 y 二点二为例, y 二点二 t r v 五 b 轻量版模型是一款小型可部署的开源纹身视频模型, 十二 g 以下的显存加载不了这个模型,十二 g 正好能加载,而且能够跑起来。因此呢,显存越大,扩大核心越多,显存待宽越高,视频生成的清晰度、速度、时长就相对更有优势。 于是,基于上面社长针对这两个模型的分析,我们就得出了个人 pc 如果想要同时玩转这两种模型的话,显存要大于等于十二 g。 为保证能够运行纹身视频模型,支持 touchco 的 可选型号为英伟达 rtx 架构的二零系、三零系、四零系、五零系显卡。这样我们就可以定义以下五档家用消费级 pc 的 预算方案了。 第一档,三千元。这一档的核心定位是新手尝鲜,可以进行基础大模型体验加轻度办公加普通网游。具体的配置如下,这套配置的大模型能力是这样的。 第二档,一万元,这一档的核心定位是家用主流,支持中型大模型流畅运行加高效生产地加中高画质三 a。 具体的配置如下, 这里社长推荐了四款显卡,从这一档开始, open club 就 可以畅玩了。下面就贴出这四款显卡结合 open club 加千万最新模型的畅玩区间,供朋友们参考。在这个表格里可以看到,三零九零二十四 g 显卡的性价比相对较高,畅玩范围相对更广。 这四款显卡都能支持纹身视频模型, rtx 五零六零 ti 十六 g 可以 输出七二零 p 二十到三十秒视频片段。 rtx 三零九零二十四 g 可以 输出一零八零 p 六十秒视频片段, rtx 二零八零 ti 二十二 g 和 rtx 三零八零二十 g 可以 输出七二零 p 到一零八零 p 四十到五十秒的视频片段。 第三档,两万元。这一档的核心定位是高阶家用加轻度专业,支持中大型大模型流畅运行,加多模型同时运行,加四 k 游戏加四 k 剪辑、 3 d 渲染。核心配置如下, 这套配置拥有较高的实用性,几乎可以胜任绝大多数主流需求。他的大模型能力是这样的, 第三档说完,接下来的第四档和第五档就进入高端玩家档了,如果只是纯打游戏的话,完全用不到这么高的配置。社长建议大家压抑住所谓一步到位的冲动,先在中低配置上玩熟了,确实有需要了,再上高端配置也不迟。 第四档,五万元。这一档的核心定位是旗舰家用加准专业,支持大型大模型流畅运行,加模型微调加四 k 游戏加专业级生产力。核心配置如下,这套配置的大模型能力是这样的, 第五档,十万元,这一档的核心定位是顶级家用加专业级。社长在这一档破个例直接给他上了英伟达 pro 六千九十六 g 工作站显卡,让他可以支持全类型大模型加大型模型完整训练加四 k 或八 k, 游戏加专业创作,核心配置如下, 这套配置的大模型能力是这样的好,说到这里,五档家用消费级大模型硬件配置推荐就结束了。 最后说说小白模型部署培训的事。最近有不少粉丝朋友跟社长说想要部署大模型,但又不知道怎么开始学起,所以我们打算在三月十五号开一期培训来手把手教小白,零基础上手, 核心内容包含四个板块,一是大模型基础原理与适用场景。二是不同大模型的硬件精准选型。三是本地知识库问答、自动化办公等实用智能体搭建。四是欧门可乐安装配置与私有化部署,有需要的朋友可以联系我哈!
4382单车酒吧搞机社 02:59查看AI文稿AI文稿
02:59查看AI文稿AI文稿大家好,我是炎陵,对于群里很多朋友私信我关于 open clone 模型配置的问题,我这边做了一个完整的配置教程,解决他家配置上的烦恼。先介绍一下我们大格力用到的几个大模型,第一个是 mini max 二点五, 智普的 gm 五跟 kimi 二点五,还有最新出的前文三点五。关于 open core 的 一个模型选择,主要就是看它一个视觉推理能力,还有思考能力,以及它的一个长文本处理能力,这些模型的所有数据都可以在这边看到。 这里我们以轨迹流动为例,演示第一种配置方式,让我们切到沃邦图 openclo 页面,然后输入 openclo config, 进入配置页面回车确认,然后再确认,然后选择第二个模型设置, 然后方向键下拉到倒数第二个自定义 api 设置, 然后打开我们的文档,把这一串网址复制进去,回车再回车,然后输入我们轨迹流动新建的 api 密钥, 选择 open ai 接口,再输入我们要使用的模型 哦,回车确认,然后这边它需要一个验证的时间,可以看到这里验证成功。在这边输入我们选择模型的名字,然后回车确认,然后选择 content, 我 们再输入 open curl config, 你 就可以看到我们选择的模型在这边会显示了,然后我们测试一下, ok, 这样就配置成功了。轨迹流动这个平台它有很多模型可供你选择,也有很多羊毛可以薅的,比如它的认证会送你代金券,还有其他的一些送代金券的活动。 刚刚说的是平台配置模型的一个方式,我们再说一下模型本身网站的一个 api 的 配置方式,这里以智普 ai 演示一下,登录我们智普的网页,然后在这边添加一个新的 api 命令,复制一下, 然后跟之前一样输入 open clone com 格,进入配置页面选择模型,在这边跟之前不同的是, open clone 里面本身有设置字谱的,然后你只要选择 cd n, 然后输入 api 密钥就行了。 还有最后一种配置,关于阿里百联的配置方式,打开 open curl, 执行这串命令,执行文档,后面的操作就 ok 了,所有的模型链接地址我都放进了我的文档和它们的配置方式,你在里面都可以轻松的找到, 希望可以帮助到大家,也希望大家可以一键上联支持一下博主。好了,那我们下期再见。
133言灵ru 07:01查看AI文稿AI文稿
07:01查看AI文稿AI文稿很多朋友呢在下载完龙虾之后,非常关心的一个问题,我是不是可以用一些免费的模型,然后去让龙虾进行使用,那这样的话我就可以不花钱了。之前我也给大家介绍了一些免费的厂商,提供了一些免费模型,但是那些免费模型呢,他是会限定一些额度的, 那就会有很多朋友问说,我本地部署模型是不是 ok 的? 那怎么让龙虾去连接本地的部署的模型呢?那这期视频呢,我们就来看一看怎么实现。首先呢在本地模型部署有一个非常牛的软件,就叫这个欧拉玛, 这个软件呢我们可以下载之后,它可以去帮我们去下载对应的一些我们想部署的模型,并且呢在它软件里面可以进行一个启动, 这样的话就不需要我们自己去找对应的模型资源,然后进行一个模型文件下载,然后再去启动对应的模型,所以说这个软件呢非常的方便。那这个欧娜玛的一个安装呢,我们这个地方直接就是给大家提供了下载链接, 就进入到欧娜玛点 com 这个地方,然后点击对应系统的一个下载方式,比如说你是 windows 就 直接点,然后下载完了之后直接安装就可以了。那安装完了之后它是一个什么效果呢?主要是有两个地方,首先呢 安装完之后它有一个文件夹,文件夹里面呢它会有一个 app 的 入口,可以把对应的 app 打开,打开之后呢我们就可以在这个地方跟它进行一个对话,可以看一下它所支持的一些模型,比如说 gpt, 然后 deep sync, 千问的,然后 mini max, 还有一些什么拉玛,然后本期我们就以千问的这个模型给大家进行一个讲解,看对应的龙虾怎么去连接。那我这个地方呢,已经把千问和拉玛的这个模型已经下载下来了, 所以说可以看到如果没有下载的话,他这个地方会有一个下载按钮,然后如果已经下载好的这个地方是没有下载按钮的,大家到时候可以下载一下,一会也给大家说一下怎么去进行一个下载。然后我这个地方就可以跟他在这种格式化的页面进行一个对话,问他你是谁, 那可以看到它现在因为它是一个 think 模型,就是它会思考,然后思考完了之后它会进一个回话,可以看到它的一个速度,在本地的一个部署模型速度还是比较快,当然了这个也是看你本地机器的一个性能,那我当前的这个机器呢,是一个五零八零的显卡,所以说它的一个效率还是比较高的。 然后除了这种方式之外呢,我们还有就是控制台的这种方式,就在这个地方我在文档里面给大家写好了, 就是我们可以在 power shell 里面去执行欧拉玛瑙,千问八 b 就 这个模型, 八 b 这个模型如果我们执行了之后,你本地如果没有去下载对应的这个模型,他会先去当 load 的 把对应这个模型给你下载下来,如果已经下载完了之后,他会直接去启动对应这个模型,那你在这个地方也是可以跟他对话的,你问他是谁, 然后进行一个 syncing, syncing 完之后输出对应一个结果,可以看到还是比较丝滑的,那本地模型呢?已经部署成功了,接下来我们就是要让我们的龙虾接入到这个本地模型。接入本地模型呢,其实也比较简单,那这个地方呢,我给大家介绍的是通过修改 opencloud 的 配置文件, 它里面有一个 open cloud, 点 json, 去把里面对应的一个内容进行一个修改,然后我们先按照上面这个步骤去打开 open cloud, 它对应了一个文件位置,我们就可以先去这个地方,然后 按照我命令执行就行了。先 cd 到点 opencloud, 然后进来之后呢执行这个 start 点,打开对应的一个文件夹,打开之后这个地方会有一个 opencloud 的 json 文件,然后编辑给它,在记事本里面编辑就 ok 了。 那我们可以看到之前呢我们这个地方,因为我是豆包的模型,所以说这个地方会有一个豆包模型的配置,那还有一个 agent, 就是 这个与我们对话的这个 agent, 它对应的模型使用的是什么?可以看到这个地方使用的是豆包, 那我们想去使用本地的欧拉玛模型,其实只需要修改三个地方就可以。首先第一个地方就是我们需要在猫豆子这个里面把我这一段给它拷贝进去, 找一下猫豆,然后与豆包进行一个平行位置, 然后把它删掉,加一个逗号,一定是一个英文逗号,然后加完之后我简单说一下它对应的一个内容,首先它是请求的 url 是 什么?就是本地的 logohost, 然后端口,然后 v e 接口 这个 appk 的 话,实际上它是因为本地模型是不需要这个 appk 验证的,所以说你这个地方随便写就 ok 了,跟我这个一样就可以。然后这个地方模型的话你就是用自己的,我们刚才不是下载的是千万八 币吗?所以说这个地方就是千万三八币。然后配置完这个之后,我们还需要去修改 agent 的 它所使用的模型。首先我们需要在底下去把欧拉玛对应的这个模型添加到它可用的模型列表, 在这个地方添加进去。 ok, 添加完了之后我们还需要替换一下,就是这个地方把这个 primary 给替换成我们下面的这个好的保存完了之后呢,我们这个地方的配置就结束了,就直接可以回到命令行执行一下, 我们把这个地方给关掉,关掉之后执行 open cloud get away。 这个因为我们是命令行之前启动的,所以说我们直接关掉之后呢,就相当于对应的龙虾已经结束了,那我直接执行它重启就好了。但是如果大家是 没有在这个地方直接关闭,它是后台执行的,那大家是需要执行 open cloud get away restart。 大家一定要记住这个点,我们直接启动 可以看到这个地方他有 agent, model 是 欧拉玛的千问三八 b, 那 说明我们这个地方配的还是没有问题的。我们来到龙虾这个地方给他对话一下, 那这个呢?是我之前问他的这个模型使用的是什么,那现在呢?我在问他说你现在的模型是什么?你当前使用的模型是什么? 那可以看到它现在已经告诉我说使用的模型是千问,然后它是通用实验室自主研发的超大规模语言模型, 所以说我们现在就已经切换成功了,这样呢,大家就可以拿龙虾去玩本地的模型了,也就不需要花你一分钱了。但是这个地方大家要注意,一定你的机器性能相对来说会好一点,那这个模型的速度运转会更快一点。然后如果你机器性能非常好的话,因为我这个地方配置的是八 b 的 模型, 八 b 呢代表是它的一个参数量,那三十 b 呢?像这种大参数量的,它的一个效果一定是要比我八 b 的 这个模型的效果会好一点。如果你的机器性能非常卓越的话,那你去下载三十 b 的 这个模型, 当然它需要很大的这种资源,所以说当它运转的时候,它对应的这个思考或者它的一个能力也是要比我八 b 的 强的。所以说这个地方看大家一个机器情况。
295AI Oasis 06:46查看AI文稿AI文稿
06:46查看AI文稿AI文稿部署本地的 openclaw 已经可以剪视频了,大家都知道了吧, 这个让硅谷大佬每日一封的 openclaw 阿月,我呢也是拉到本地试了几天,现在就带大家把本地部署和接入飞书每一步都走明白。为了防止偶然性啊,我呢也是连续测试了四台电脑,确保每一步都可行,接下来你们只要跟着做就可以。点好关注收藏, 我这里依旧用的是 windows 系统来操作,因为 macos 系统呢,环境相对比较简单,不像 windows 这么复杂。首先呢,我们要确认好 windows 的 安装环境,安装的时候呢,全部都点 next, 一 直到完成即可,建议呢,不要去变更中间的安装路径。 呃,安装完成后呢,我们可以检查一下环境,我们在命令提示符的窗口输入这两个指令,如果输入指令后跳出版本号,那就说明安装已经成功了。这里提到的两个环境文件呢,我在文档里面也全部都准备好了。 好,接下来呢,我们就开始全区安装 oppo 卡使用管理员 c m d 指令输入,这个指令安装完毕后呢,再输入这一条指令, 好开始了。 ok, 这一步跳出来的呢是风险提示,我们直接选择 yes。 然后呢我们选择 quickstart, 这一步呢是选择大模型,我这里呢用的是千万,因为他是国内的,如果大家有惯用的呢,也可以自己进行勾选好,然后我们这里模型选择默认的即可。 之后呢会跳转到大模型的首页进行授权验证,大家验证通过就可以了。那通过后呢,这里也同样有一个选项,我们直接选第一个默认的模型。 ok, 下一步呢,这里可以看到很多的应用选项,这其实呢就是指令输入的终端,因为这些都是国外的,所以我们先不管,选最后一个,跳过,后面呢我会给大家介绍如何接入国内的飞书。 ok, 继续,这里会问你需要配置什么 skills? 呃,我们也跳过,没问题,因为这个不着急,后面都可以手动去配置的。 好,这个也不用管我们用不上,直接跳过。好,然后我们稍等一会,会自动弹出一个网页,然后你会发现这个网页是打不开的,没关系,我们这个时候呢,再运行一个 c m d 的 指令, 好,这就是欧奔 cloud 的 兑换框了,我们来尝试和他打个招呼, ok, 他 回复我了,那到这里呢,其实基本上就成功了,还是比较简单的啊。然后呢,我们再来尝试为大家接入一下飞书,很多小伙伴呢,在这一步呢,其实就被劝退了,因为怎么样都接入不了这里,大家看好我怎么操作。 首先呢,我们进入飞书的开放平台,我这里呢用的是个人版,我们来创建一个企业自建应用, 进到这个凭证与基础信息界面,把你的 app id 和密钥保存下来,这个很重要啊,后面会用到的。然后 我们添加一个机器人,再到权限管理这一步,为他添加一些权限。这里的权限列表呢,其实官方呢是有指导文件的,但是呢就藏的比较深,我呢也是给你们找出来,直接放到文档里面了,你们直接一键复制过来就 ok。 好,然后我们需要配置一下这个事件回调功能,在这里的订阅方式选择长链接这一步呢是必须的,而且是绕不开的,也是大家碰到卡点最多的一步,很多小伙伴呢在这里呢就是一直报错,好,不用担心,我呢,已经整理了一份非常长的傻瓜教程,大家直接照做就 ok 了。 然后选择以后呢,我们添加事件,然后添加搜索接收消息, ok, 然后我们就去点击创建应用,然后再发布就 ok 了。 好了,配置工作完成之后呢,我们就要开始给欧邦克劳接入飞速杀键了。由于 windows 的 系统环境问题呢,所以大家的电脑情况都不太一样,所以会出现不一样的报错问题。网上的很多视频呢,也没有把这个问题针对性的讲清楚,我自己呢也试了三到四台电脑来做尝试,都非常有挑战。 如果你手边也报错的话呢,不用担心,我这里想到了一个邪修的办法。好,那既然 oppo klo 可以 控制我的电脑,那为什么他不能自己安装飞出插件呢?我们来试试看吧,直接和他对话。呃,你自己安装一下飞出插件,然后呢,他就会开始疯狂的工作,并自行去验证安装环境和插件配置 啊。五分钟左右后呢,他就会告诉我,他工作完成了,需要我提供给到他飞出机器人的 app id 和密钥。这个呢,其实我们在上一步已经有了,我们直接复制给他,让他呢继续去工作。这里的工作过程当中呢,我们的机器人可能会下线几次,原因呢是他需要去重启网关, 如果呢,你感觉他下线太久的话呢,我们可以用 open cloud get away 这个指令重新把它呼出来。最后呢,他会要求你在飞车上和他对话进行测试,并为你排除最终的一些故障。 ok, 全部搞定,已经可以在飞车上正确回复我了,并且呢,刚才在外部的对话记录他也全部都记得, 呃,我们这里呢,再用手机给他发一条消息试试看。好,他也同样接受成功了。好了,这里欧本卡接入飞书的配置呢,就完全对接成功,基本上都是他自己完成的,我呢只是配合他提供了一些必要的信息, 妥妥的全能小助理。接下来我们来看看他能为我们做一些什么吧。比如呢,我现在想要订一张机票,我就让他帮我查询一下最便宜的航班,他立刻就给我列了具体的信息,包括航班号,价格以及其他的一些航班信息。不过这一步呢,是需要接入 api 的, 大家可以自行去网上找免费的接入就可以。 好,那现在过年了嘛,马上大家呢也会送礼嘛,那我就让他去浏览电商的页面。呃,不过这里呢,需要先安装一个 oppo club 官方的浏览器插件,我们直接从官方渠道进行安装就可以了。具体的步骤呢,已经放在文档里了,大家直接照做就可以。我让他给我打开。 ok, 成功,呃,然后我继续让他为我搜索燕窝。好,也成功了。 好,那我们现在在拿最近小伙伴在学习的 ai 的 线上作业丢给欧本克,看他能不能帮忙完成。 首先我们要让他找到作业的本地目录,并让他完成里面的题目。他立刻就找到了,并且迅速告诉我,完成了。啊,这速度还是真的蛮快的啊,但是呢,人呢,还是比较懒的。如果呢,你抄作业都不想抄啊?没事,直接让他把填完的东西返回给我。好,他已经做完了,我们来看看啊。 呃,代码呢?全部都完成了,不过呢,我也是看不懂啊。看懂的高手可以来说说他完成的这个准确率怎么样。 好了,那这次安装说明就先讲到这里了,关于 open cloud 的 更多能力,有时间呢我们可以再去测一下。好,那既然已经部署成功了,有兴趣的同学呢,也可以再去深度探索一下 啊。对了,现在呢,各大厂呢,也出了针对 open cloud 的 云端部署,我这个呢,也可以跟大家快速的分享一起。好,这里是阿月,希望我的视频能够帮助到你,让你更了解呀,我们下期再见。
1.6万阿悦很严格 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿经过一整天的折腾,不停的调试测试,终于把龙虾和欧拉玛本地部署的大模型链接上了。下面说一下我这次的经验,并不是所有本地大模型都支持龙虾,目前经过我测试,最好用的是千万三, 我本地的硬件最高能支持在欧拉玛里面跑三二 b 的 大模型,但是速度比较慢,所以我下载了一个九 b 的 千万三,先试一下 九臂的千万三在欧拉玛里面可以很快的速度运行,但是在龙虾上反应的速度就有点慢, 而且只能支持本地聊天或者处理文本任务,让九臂的千万三驱动龙虾去打开浏览器都实现不了,也可能是因为我本地部署的大模型太小,有没有哪位部署过比较大的本地大模型的朋友可以说一下使用效果如何? 所以我打算暂时放弃使用本地大模型去动龙虾,去购买二十九元包月的 mini max 的 a p i 来使用 tucker, 量大管饱,关注我,一起交流养龙虾!
34无敌龙虾 03:46查看AI文稿AI文稿
03:46查看AI文稿AI文稿终于弄好了 openclaw 连接奥拉玛, 用奥拉玛部署的本地模型,前吻三点五 看教程不管用。 openclaw 装完的时候外部 ui 打不开, 怎么弄也不知道,最后还是在奥拉玛的官网用这个命令,用这个命令设置重新设置了一下 opencloud, 然后它的外部 ui 就 能打开了。 当然是按照它的这个稍微懂一,稍微读懂一点英语,按它这个一步一步设置完了才行。昨天在没有奥拉玛的时候,在 windows 下 wsl 下装的 openclaw, 直接就能打开 app ui, 这中间出的问题也不知道是怎么回事。 这一步就是用了吗?连接 openclaw, 因为我的电脑主要靠内存,靠 cpu 跑,随便问个问题 cpu 就 跑百分之六十几,风扇呼呼的转,感觉确实也没啥,没啥实际用途啊, 关键是说了话都没带回的, 可能还没配置完, 但是它已经 不运行,也也也占用这么高。 今天就到这了,看来这样也不行,不能用本地的模型跑,又慢又又受不了噪音。回头我再重新连接到免费的 key, 免费的 token, 试试吧。 补充一下,这个 windows 下的这个 open cloud, 这个 web ui 必须得是这个带 to 带 token 的, 带 token 的 这个你才能打开,你要是直接输入这个把地址这个它是连不上的,它这个这个地方会有问题,它只会离线,就是这些东西它都是包含在这个里边的。 然后这个我拉玛里装的模型小,啥事也干不了, 净光浪费 cpu 资源了, 还啥还啥也做不了,还不如,还不如直接在这里聊天呢。
16帅帅的爸爸 07:37查看AI文稿AI文稿
07:37查看AI文稿AI文稿大家好,在你装完 openclip 之后啊,第一件事要做的事情就是去选择一个模型,那模型作为 openclip 的 大脑,它起到一个非常关键的作用,那这么多模型,那他们之间有什么区别呢? 那为什么你的模型只能识别文字,不能识别图片呢?那本期视频呢,就跟大家讲一下不同的模型之间能力的区别,以及怎么去配置模型。那对于一款模型来说,它的能力有接收信息,那信息类型啊,有可能是文字,也有可能是图片, 也可能是视频、音频或者其他就是你发的信息的内容可能包含这些类型。那么大模型在接收到你这些信息之后,他对你的信息进行回复,也有可能有这些类型,比如说他回复文字,给你回复图片,给你生成一张图片,或者说做出来一个视频, 或者说做出来一个音频音乐,那么也有可能是进行一个网页的搜索,你让他调用了搜索的工具进行一个网页的实时搜索, 那么这这两个东西就是一个输入和一个输出,那不同的模型之间的差异啊,就表现在接收和回复这个信息的内容区别上。那么 open core 官方呢, 截止目前也统计了一个模型的一个使用的一个排行榜,那么这个排行榜里面的模型的排名,不是说我们传统意义上那种模型的一个综合排名,它更多强调的是在 open core 里面的任务的完成的成功率和这一个排名,大家可以看一下, 就是平均的一个排名,就是比如说第一的是 gemini flash, 那 么第二的是 mini max 二,二点一,那么对于 mini max 它现在已经发布到二点五了,但是二点五的表现是在这个排行榜是比较差的, 这个也是非常奇怪的。那么前面还有这个 kimi 的 k 二点五,就这些模型在任务完成的成功率是比较高的,所以这也可以作为啊模型选择的一个参考。 接下来我们就来说一下不同模型在接收信息和返回信息之间的差异,大家可以去选择。就是你在完成任务的时候,为什么有些模型处理的不好,那比如说我们 dbisc, 那目前 v 三点二版本它只支持一个文本的输入和文本的输出,那么对于千万三点五 plus 来说,它能接收文本,也能发图片,它也能去理解这个图片是什么。比如说在我的这个 openclip 的 这个非书的聊天里面,我上传一张图片,那模型来识别一下图片中的文字, 如果你的配置的模型它不支持这种啊图片的识别,那么它出来的结果就是跟实际的结果是有很大的差异的, 那么可以看到它识别出来了这个图片里面的所有信息是完全非常准确的。那么在刚刚的演示里面,我们可以看到千万三点五 plus 它是有一个图片理解能,所以大家在用的时候一定要注意自己的业务的场景 啊,选择正确的模型。那么这里边除了图片理解呢,这边还有一个网页搜索,就是说它本身模型它本身支不支持这种搜索这种内容,因为对于模型来说,知识库它是有一个截止时间的,比如说你可能你 模型的训练数据可能只是截止到二零二五年,但是你现在搜索二零二六年的,那就有些模型他是具备这样的网页搜索能力,他就可以调用这种 实时搜索能力,那么有些是不支持的,那就要配置这样的 m c p, 官方也出了这样的工具,比如像豆包系列,二点零最新的模型也是一样支持文本和图片,那么他这边也是可以单独去开通网页搜索的能力啊。 那我们可以看一下,就是啊这几款国产的,比如说 mini max m 二点五、 m 系列和这个智普的五点零,他们这个图片的识别是需要单独去配置 mcp 的, 不然的话他是没办法去识别的。 那 timi k 二点五的话是原生就支持图片识别,那么国外的模型,比如说 colossal 四点六和 jpeg 五点四,还有 jimmy 的 三点一 pro, 那 么它们都支持图片识别,也支持这种啊网页的实时搜索,那算是这个综合能力算是比较好。那其他的比如说你要去让模型去申请个图片, 那基本上我们现在用到的这主流的这个啊主模型啊都不具备,那么你就可以去调用他们专门的图片模型。比如说像千万,他有专门的万象系列的生成图片的,那么都包括有纪梦相关的模型,那么像 jimmy 的 话,有专门的这个深图的模型也是可以的。就是这些 又需要去单独去配置,在你去生成图片的时候去告诉他去调用这个模型去做这个事情,那像这个火山,这个 cds, 二点零系列都是可以去生成视频的,那么这个就是一定要知道,就是一款模型,它不是万能的, 你可能需要不同的模型来配合去完成你的业务的场景,所以一定要一定要弄清楚你的业务场景里面涉及到了文本、图片、视频、音频, 就把这个东西先想明白了,再去找对应的模型配置好,就才能去把整个东西,整个东西串起来。选好模型之后,很多模型厂商都会有两种购买方式,一种叫做按 token 购买,就是 按用量购买,用多少啊你就付多少,这种方式是比较自由的,它是不受任何限制的。那么第二种就是按这种 coding plan, 就是 套餐的方式,那这种套餐是什么样子呢?一般是有 有限制,比如一个月能用多少次,然后一周能用多少次,然后五小时能用多少次,它是有一个这样的一个限制,会每隔五小时会刷新,每一周会刷新,然后总流量是不超过啊,每个月总流量那么像智普啊, mini max, 豆包,还有这个千万 都出了相关的这种啊这种代码的套餐啊,就是可以可以编码,又可以用在 openclo 里面,那每一个套餐这个量是不一样,大家一定要注意去看,它可能在官方的介绍里面会说啊多少多少次请求,但是要换成就是你的一次对话,就是你跟 openclo 对 话一次,可能要 调用很多这样的一个请求,那么这样的次数是没有他说那么多的。最后呢,就是我们选择好了模型之后啊,我们怎么去配置?第一种方法就是啊原声的就是它 openclo, 它本身你在配置的,你在安装的时候它是有模型的一个列表的,比如说你输入这个 openclo config menu, 那 么 到这一步的时候,你选择这个 model, 就是 你需要去配置这个模型这边的话就会选择很多啊,它本身的支持这个 pro i 的, 就是它本身已经内置了这这些模型的链接,那么你点进去之后,你就可以去输入你的 a p i t, 或者说输入你的这个认证授权的一个链接啊,那这能快速的去完成。那还有一,还有一些它可能是不在这里面的,比如说像千万千万的这个 codeplain, 还有一些其他的这种模型的配置啊,那么你就可以使用这种 cc switch, 那 这款软件,那这款软件呢?有一个单独的一个菜单,那么点进去之后你可以去进行配置,也是一个图形化的界面。那接下来就是这种比较繁琐的,就是去编辑这个这个 配置文件,那这个是 openclip 的 一个啊,总的一个配置文件,那这里面的话,你就要去修改这个 providers agents 里面的内容。一般是 如果你选择哪个模型厂商的话,它会提供这样的配置文件修改的,这个啊完整的字幕串,你直接去给它修改掉就行了。那么如果你自己改这个接线文件,因为这个接线文件非常大, 嗯,不太方便了,你可以借助这个 ai 编程工具,比如像 tree 啊,像 cos 啊去帮你去修改它,它这边是可以去给你修改,而且可以去给你修复可能修改出来的问题啊。 那除了这上面的方法之外,那就可以用它自己的这个外部端里面的设置里面找到这个 modus 的 节点啊,但是它这个说实话非常非常难用啊, 我觉得用上面的方法都比它这个官方这个界面用的会可能会更简单一点。那你如果配置完之后啊,最好是重启一下,那么你在页面上可以点去重启,或者说输入这个 open curl, get away restart 这些命令去重启,重启完之后,那么你就可以去使用新配的模型了。 ok, 那 本期视频到这,希望这个视频对你有所帮助。
1434AI随风 03:59查看AI文稿AI文稿
03:59查看AI文稿AI文稿相信大家已经安装好了自己的 openclare, 但是你有没有想过你每一次的 openclare 的 使用都会消耗你的 tokyo, 这个 tokyo 的 话就是需要大家去花钱去买, 那有没有办法能够免费的使用 opencloud? 如果说你也想要免费使用 opencloud 安装 olemma 模型,那一定要点个关注,点个收藏,不然的话你下次就刷不到了。那我们进入正题,我们直接啊百度搜索一下 olemma, 然后在这个右上角位置点击下载, 这边的话选择自己电脑系统,然后点击一下,直接点下载就可以了。 ok, 下载好了之后,我们直接正常安装啊,就会进入到这个页面,然后右下角我们要选择一个模型,正常来说一般是选择这个 gpt 二十 b, 也可以选择千问,三点五千问。 ok, 我 们在这个位置选择好了之后,你发一个消息,你比如说我选一个,我没下载的,我发个一,你发一个消息之后,他就会开始自动下载这个模型。 好,我们直接进行下一步。欧莱玛下载好之后,我们直接通过这个运行安装向导重新把 openclock 跑一遍, 因为之前你们装过 deepseek 的 模型,然后这个配置处理的话,选择更新值, 在这个模型认证供应商这里选择 olemma, 本地本地本地,然后它会有一个模型 id, 例如 deepsea 杠 r 一 比八币,我们再打开你的 olemma, 看一下你的右下角, 就是把这个名字输入进去, 我们用的是这个二十币, 这个的话直接回车就可以了。 这个聊天通道的问题,因为之前已经跟大家讲过了,我们就直接挑过了, 我们把网关打开,等这个 opencloud 的 正常运行。 ok 啊,大家在运用这个 oemma 本地模型的时候,它是不需要花钱的,但是它是基于你电脑来去做的本地模型,那是什么意思呢?就是说它直接消耗的是你电脑的性能, 比如说我们在这个内存 gpu 直接消耗你的电脑性能,比如说你的电脑越好,那它运算速度就会越快,大家这么说能理解吗? 还有就是这个欧莱玛上面的模型,它对应的有一些,比如说它这个二十 b 的 模型,它是 比较推荐八到十六 g 的 这个显存的显卡,然后才去使用,然后有一些是呃,一百 二十币的支持二十四 g 或者三十六 g 的 显存的显卡才能去使用的,也就是说他直接消耗的是你电脑本身的性能。 ok, 如果说大家感兴趣的话,可以自己去装一下试试。
980李琦的AI工具箱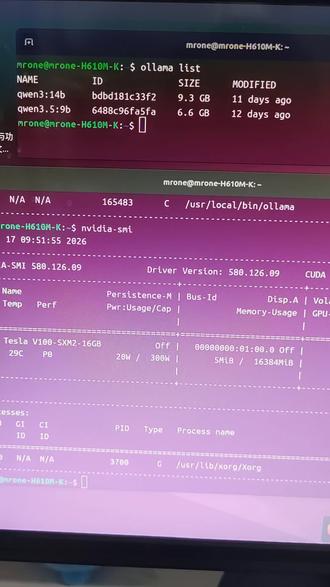 02:22查看AI文稿AI文稿
02:22查看AI文稿AI文稿再来给大家分享一个本地部署的小模型,它的使用的小问题啊,我们可以看到现在本地已经部署了有两个小模型啊,我们使用这个九 b 参数的这个模型来做演示啊,显卡呢只有十六 g 的 显存,然后我们现在来运行这个模型 啊,我们随便先打个招呼, 然后呢我们在这边看,刚刚这个打一个招呼,显存占用呢达到了将近八个 g, 但是呢这里有一个上下文的设置,默认的在这里面运行的这个上下文窗口实际上是比较小的,千万三点五九 b 的 这个模型,它的理论上的上下文窗口可以达到二百五十六 k, 但实际上这么大的,嗯,多数情况下没有什么用,因为毕竟模型太小了, 虽然模型可以接受二百五十六 k, 但是呢在欧拉玛这里面运行的时候,实际上根本就没有使用那么大的这个上下文窗口,那我们可以看一下嗯,他的上下文窗口的设置,嗯,这里也是上下文窗口,这里呢由于只有十六 g 的 选存,那么我们只设置他理论上的一半啊,也就是十二万八千的这个 好了,我们已经设置好了啊,设置好了以后呢,我们可以通过这个参数这个指令来查看啊,我们已经设置好了,嗯,这个时候如果我再跟他打一个招呼,我们再次查看他的显存占用, 这已经达到了十三个 g, 那 如果想要设置他理论上的最大的窗口二百五十六 k 的 话,那么显存就已经超十六 g 了,那么他就会把内容 放到内存里面去了,这样的话会大幅降低他的这个运行速度。这个在呃我们部署小龙虾的时候也会遇到这个情况,我们小龙虾里面设置的呃 agent, 他 如果调用的模型是我们自己本地的这个模型,那么你也要设置他的这个合适的上下文窗口。那如果设置太大了,呃,就会导致刚才我说的一样的情况,他会把它放到内存里面,然后反应就会特别特别的迟钝。 像九 b 这样的模型,一百二十八 k 的 窗口已经足够大了,因为小模型它的注意力有限,你输入的内容太多,尤其是太多的提示词,我们,呃上个视频讲到的前置的工具的使用,这些都会占据大量的这个提示词,那么它会导致模型注意力稀释,然后没有办法准确的 把握你到底想干什么。所以想使用小模型的话一定要把嗯,工具尽可能的节省, skill 呢,也能省,也可以省,然后经常清理他的绘画,不要累积过多的这个绘画历史。嗯,小模型呢也是可以用一用的。
21衡水酷丁 05:11查看AI文稿AI文稿
05:11查看AI文稿AI文稿哎,好的好的,大家好,我们今天手动来带大家从零到一部署在自己电脑上面部署一下最近火爆全网的这个 cloud bot 啊,现在已经改名叫 opencloud, 我 们从零开始,首先我们去 opencloud ai 这个官网,然后往下滑,它有一个 one liner 的 这个 quick start, 非常简单,你只要在复制这个代码,然后开一个命令行,然后把它黏贴进去, 它就会自动去安装这个 opencall, 它会去检测联盟装着 homebrew, nojs 和 git 啊,如果没有的话呢,它会帮你去安装,我这边已经有了,所以它自动开始在安装这个 opencall。 好 的,安装完毕,安装完毕的话,它会自动会进入这个 onboarding 的 这么一个流程啊,它也是非常人性化。首先让你先来先签个协议啊,说这个很 powerful, 但也很 risky 啊。我知道了, onboarding mode, 我 们选 quick start。 然后第一步呢,是我们要接一个模型啊,在后端的模型,它虽然就 open call, 它只是一个中间层吧,你后端的模型还是需要用自己的 a p i 的。 之前呢是我我尝试使用这个 cloud code 的 订阅,可以接入这个 open call, 但是前段时间 cloud code 把它给封了,所以现在就必须只能调用 a p i, 所以美国的模型 api 太贵了,所以我们这里选择支持一下国产。我们使用 kimi 的 模型啊, moonshot ai, 然后 kimi 最近也是浪潮了,自己的这个 kimi k two 呃,二点五的这么一个模型啊,能力上据说是跟 opps 四点五非常相像啊,也是很厉害,然后价格可能只有十分之一,所以我们来体验一下,所以我们这里选 moonshot ai, 月色暗面, 然后把我们之前复制好的一个 api key 给复制进去, create a api key, 然后我们选择一个模型,我们就选 kimi k 二点五。然后呢,我们在这里选的是 在第二步呢,是选这个 channel, 就是 call bot, 呃, open call, 它是可以让你用过用你的这个即时聊天软件,然后来调用它的啊,这里就会去配置一下这个即时聊天软件。我在这里选的是,呃, whatsapp, 然后我们来看一下 whatsapp 怎么 link 啊,它会给你二维码,然后我们要拿 whatsapp 扫一下二维码。 好,我们拿这个 whatsapp 刚刚扫了一下这上面的二维码,然后,呃,现在是可以去继续去设置一下详细的配置。 whatsapp, 它里面有一些 phone, 呃,这个是 phone setup 啊, separate phone just for open call。 我 选择用一个单独的电话号码在 whatsapp 里面,然后这里使用,选择 recommended power mode allow form。 说实话不是很知道是干嘛了。嗯,选择 default 好 了,然后下一步呢,是 configure 这个一些技能啊,这里我先不 configure, 但是我们看一下, 呃,这个 open call 它有哪些技能啊?这些技能本质上来说就是它到底能做哪些事情,你可以看它这里有非常多的集成的这个 integration, 就 你的密钥,密钥管理系统 word 是 可以用来发这个 twitter 的, 然后 bear nose 是 可以用来这个记笔记的一些东西,然后有非常非常多的这个,还有什么 g u g 这种 就是 gmail 啊什么的,非常非常多 open ai 啊什么的很多啊,我们这里今天先不配置了,然后回过头也可以再配置,到时候会问你一些问题,要不要这些 a p i key 有 多选? no no, 如果到时候需要的话呢,可以再单独回过头来配置 好。然后最后一步呢,是这个 hook 啊,自动的这个操作,然后它可以在某些特定的环境下面被触发,然后帮你操作。比如说它这里有一个 session memory 的 这个 hook, 就是说它可以在每个赛季结束的时候呢,自动把赛季的这个你们聊天对话记录呢,保存到他们的这个长期的这个 memory 当中。这里我觉得还是开一下比较好,因为 open call 它是自带这种长期 memory 的 功能的,然后如果每每每一次跟他对话,它会更新长期 memory 的 话,你会发现这个 open call 越用越聪明。 好,然后这些都是系统自带的,我就都开了,然后都开了,然后去设置 gateway, gateway 就是 说是呃呃,如如何去开这个?开个关口,然后让可以让这个你在 whatsapp 里面发送的消息被传递到这个电脑上的 open call 里面。这里我之前已经装过了,所以我们在这里的话就是 reinstall 一下。 好,我们这里的 git 已经装好了,我们现在有有有方法去 hack。 我 的 bug 就是 初设啊,初设的话我们可以推荐是走这个 t u i, 也就是它自己会开一个网页,然后这有一个链接好,然后可以尝试发个消息 啊,很可惜啊,消息没有发成功,我要来 debug 一下。哎,好的,刚刚发现是因为自己的那个 kimi 账号没有充钱啊,现在充了钱就变强了啊,我们现在已经可以 跟他对话了,然后我们在终端呢,可以输入这个 open opencloud dashboard, 然后呢我们来重新进进入这个网页的 ui 啊,然后这里呢我跟他说了个嗨,然后他现在会介绍一下自己可以干哪些事情啊?怎么怎么样,怎么怎么样都是英文啊,太,太烦了,我看他看中文那里边啊, 好,他现在等于说一开始的对话呢,他会让你去呃设置一下他的名字是什么,然后怎么称呼我,然后他是干嘛的?嗯,然后同时呢我们我来就展示一下这个我们这个 whatsapp 的 这个能力啊,就你看我们这边, 嗯,其实 whatsapp 上面是可以给大家直接发消息的,然后在这里的所有的信息呢,我们也都可以在 whatsapp 里面跟他呃聊天,然后他就只要你的这个网关是上线的,他就是可以呃去跑的。 那么今天视频就到这里呢,我们就简单的装一下 cloud bot, 未来的话我们也会在这里继续更新一下 cloud bot 到底能在呃能对我的工作流程带来多大的影响啊?期待可以创造更好的内容给大家,谢谢。
2.6万金黄说AI 01:52查看AI文稿AI文稿
01:52查看AI文稿AI文稿装了 openclaw, 但发现它什么也干不了,甚至有点蠢。除了需要配置各种插件和 skill 之外,它最需要的是一颗足够聪明的大脑。今天来分享我的配置方案,用 mini max m 二点五驱动 openclaw, 性能逼近 cloud 的 up 四点六,但成本只有它的十分之一。走订阅制,每个月一杯奶茶钱,非常适合在 openclaw 中使用。 接下来给大家展示我是如何用 opencll 来提升我的工作效率的。第一个,接入飞书,通过手机帮我剪辑口播视频,现在我直接在手机上发给 opencll, 一 句话就搞定了。帮我剪掉所有停顿重复的地方,然后导出发给我。它会自动调用语音识别,定位无效片段精准剪切。 以前剪一条口播至少要两个小时,现在三分钟出片。装了 opencll, 但发现它什么也干不了,甚至有点蠢。 除了需要配置各种插件和 skill 之外,它最需要的是一颗足够聪明的大脑。第二个,帮我整理文档,自动上传到飞书知识库 ai 时代,每个人都应该建立一套属于自己的知识库,有了 openclaw, 就 可以实现知识文档自动分类,自动入库。 我设定了一个定时任务,每天生成的文档自动识别内容,并根据分类上传到对应的知识库中。比如我今天写了一篇关于 openclaw 闭装 skill 的 笔记,它会自动识别内容,归档到 ai 开发知识库的 openclaw 分 类一下。第三个,帮我打开浏览器,注册各种账号,获取 api k。 当时我需要一个文本转语音的 api k, 正常流程是我自己打开浏览器注册登录,找到 k 页面,然后复制,但我就跟他说了一句,帮我注册 eleven lives, 拿个 api k, 他 就真的自己打开浏览器填表注册成功拿到了 k。 那一刻我是真的被他的执行力震惊到了,为什么每个都能这么顺?两个原因,一, mini max 二点五,自带的任务拆解和工具调用能力,他能真正理解你的意图,拆解有逐步执行。二,题词给的足够清晰,你不需要会写代码,但你需要学会把需求说明白。
3042LIGHT 04:12查看AI文稿AI文稿
04:12查看AI文稿AI文稿你们等了这么久的 open cloud 净化指南终于来了,今天我带你从残血到满血,一条视频全搞定!先说一个残酷的事实,你装好 open cloud 之后,它其实是个残血状态,默认只有二十五个工具,记忆系统是瞎的。每天烧五十到一百美金 a p i 费用, 就像你买了一辆跑车,但是只开了一档。今天我教你怎么把它开到满血。第一步,安装你需要三样东西, 一个代码执行器,比如 tray 或 cursor, 一个大模型 api key。 推荐 minimax, 最省钱,一个飞书机器人,让 openclaw 能跟你对话。具体怎么操作?打开 tray, 新建文件夹,然后把我给你准备好的安装提示词直接粘贴发送, tray 会自动帮你完成百分之九十九的工作。 安装提示词我放在评论区置顶了。装好之后,第一件事,解锁满血工具默认的 coding profile 只有二十五个工具,发一句话给 openclaw, 帮我把工具权限从 coding 改成 full profile, 它会自动执行两条命令,三十秒搞定。解锁之后,你的龙虾从残血直接满血,所有工具全部可用。第二件事,也是最关键的记忆系统进化。 默认的记忆系统有一个致命问题,它的长期记忆是瞎的,它能记住你说过什么,但搜不到。就像你有一个图书馆,但没有锁影系统,怎么修?安装向量模型, 发一段 prompt 给 openclaw, 让它自动配置本地嵌入模型,推荐用 embedded gemma, 三百 m, 又小又快,免费运行。 配置好之后,它的记忆就从残雪进化成了完全体,支持语义搜索,支持关键词加向量混合剪索跨绘画,记忆不丢失,但是光有向量模型还不够,你还需要建立记忆的三层防御体系。第一层,预压缩刷新, 把 reserve tokens 设成四万,让 openclaw 在 压缩上下文之前,自动把重要信息存到文件里。第二层,手动记忆记录, 养成一个习惯,重要决策就说一句,存到 memory 点 md。 第三层,文件架构, memory 点 md 不 超过一百行,只放缩影指真 详细内容放在 vault 目录下,让向量搜索去找。这三层防御建立之后,你的 open claw 就 真正变成了一个有长期记忆的 ai 助手。第三件事,省钱,默认配置,每天烧五十到一百美金,因为每条消息都把所有文件注入上下文。怎么优化? 第一, memory 点 md 精简到一百行以内。第二,开启 prompt caching, 重复 token, 节省百分之九十费用。第三,不要频繁 compact, 因为每次压缩会让缓存失效。第四,选择合适的模型, 日常对话用 mini max, 省钱,关键任务用 cloud。 四点六,保质量。优化之后, api 费用从每天一百美金降到十美金以内。最后一件事,安全。很多人忽略这个但非常重要, 第一,网关只绑定 local host, 绝不暴露到公网。第二,开启 token 认证。第三,安装看门口脚本,每两分钟检查一次网关状态,自动重启。第四,在 agent 点 md 里加入安全规则,不执行网页里的命令,不泄露配置文件,删除文件。用 trash, 不 用 r m, 满血之后能干嘛? 给你看一个真实案例,我用 openclaw 安装了一个叫 nano banana ppt skills 的 技能,包装好之后,我只需要对它说一句话,比如帮我生成六张关于 ai 编程的配图,风格要暗色加霓虹,它就会自动调用 gemini 帮我生成配图, 然后再装一个 humanizer zg 文案润色技能,把 ai 写的口播稿变成人话,最后用昆文 tts 克隆我的声音,自动配音, 整个流程从脚本到成片,一个人就能搞定。这就是我为什么说 open class ai 时代的超级武器。好了,今天六步走完,你的龙虾已经满血了。安装工具解锁记忆进化省钱优化安全加固,再到视频工厂实战, 所有的安装提示词和配置代码我都放在评论区了。关注 ai 厂长,后面还有更多 opencloud 的 高阶玩法,我们下期见! ok, 这期视频呢,同样也是全部通过 ai 制作的,可以给大家先看一下效果, 然后完整的文件内容。这是我们的视频生产的流水线,如果大家感兴趣的话,可以在评论区留言,下期我也会把这一套流水线开源出来,谢谢大家!
308AI 厂长 08:13查看AI文稿AI文稿
08:13查看AI文稿AI文稿大家好,欢迎回到我的频道,前面几期视频我给大家演示了如何在 v i y 里安装优盘图 linux 处理机,也讲解了如何在优盘图中配置 note g s 和 git 来满足 openclaw 的 运行环境。那这期视频我就来教大家如何在优盘图 linux 操作系统中安装部署 openclaw。 在本期教程里,我们将从 github 下载 openclaw 最新的源代码进行安装。如果你下载不下来,也可以在评论区里留言,我把我下载好的 openclaw github 源代码分享给你。 我现在就在 umber linux v i r 训练机里边,我们打开 firefox, 我 看看 github 好 不好。访问今天为车,今天很幸运可以访问,那我们在这儿搜索一下,在搜索框输入 openclaw 车在这个项目 open club, open club 就是 我们要访问的项目。点击一下,打开它,今天速度还挺快,这是咋回事?我们点击这个绿色的扣按钮,有一个 download zip, 我 们还是下载下来吧,避免安装的时候突然访问不了,挺麻烦的。点击下 download zip 就 开始下载了,下载也很快, 超乎我的想象。好,现在下载好了,那这个应该是最新版本的,如果你要是担心这个最新版本里面有 bug, 因为它是刚刚提交的,有的最近的是三十八分钟内提交的。 那你可以下载这个最新的 release 版,你看这有一个 release open club, 二零二六点三点十三,那最新的 release 版是三月十三号的,我们点击这个链接进去,他就打开了这个页面,那这个页面里边就记录了他都修改了哪些问题。在这最底下有一个 south code, 你 也可以下载这个 最新 release 版的源代码,点击这个链接,它就把最新 release 版这个版本给下载下来了。下载好之后,我们来到这个下载目录,那这两个字库文件都在这了,我先修改一下这个屏幕的分辨率,这样屏幕就文字大一点, 我们看一下这两个版本,那我们还是安装这个三点十三,因为这个是 release 版。右键单机点击提取,解压缩到这个文件夹下,我在我的主文件夹下建立了一个文件夹叫 work, 然后把那个解压缩后的 open class 代码拷贝到这个 work 目录下, 我们右键单机桌面,点击,在终端中打开,打开一个终端窗口,我们再确认一下 node 和 get 的 版本,那 node 是 vr。 二十二点二,十二点一,这个是符合这个要求的,那 get 二点五,一点零,这两个版本是可以的,因为我们从 oppo colo 原代码来安装这个 oppo colo, 它需要 p n p m 这么一个呃命令,所以我们先安装 p n p m, 我 们运行这行命令。 soluo 空格 n p m 空格 install 空格横线 g 空格 p n p m 回车,它需要输入密码, 也就是那个哈喽那个账户的密码,他就开始安装 pmpm 了。好,现在已经安装好了,那我们先运行 npm 杠 v 看一下版本, npm 是 十点九点四,那 pmpm 呢?杠 v, 十点三,二点一, 可以,这个 n p m 和 p n p m 我 们都已经安装好了,那现在我们先来到 open k l 源代码所在的这个目录,我们把这目录地址拷贝一下,回到命令行。好,那现在就到这个目录下了,这个就是这个 open k l 的 原文件。在这个目录下,我们先运行一下这行命令, p n p m install 回车,它就会把依赖的或者需要的那些包全都下载下来,并且安装好。当你看到这些信息, 那就证明需要下载的包都已经安装好了。然后我们再运行另一行命令,就是 pmpm 空格 ui 冒号 build, 这个命令运行很快,当你看到这些信息,就证明这个命令已经运行好了。然后我们还需要运行一下这行命令,也就是 pmpm 空格 build 回车,等这个命令运行好之后,这个 open klo 基本上就安装好了。好,到现在为止, 这个 open colo 就 算安装好了。然后我们还需要运行一下这行命令, p n p m 空格 link, 空格,横线,横线 global, 那 这行命令就会把这个 open colo 这个命令设置为可以直接调用的 c r i 命令, 方便你调用,让它出现一个错误,这个错误是什么原因其实也写清楚了,告诉你怎么改。需要运行 p n p m 空格 set up, 先来创建一下这个 global bin 这个 directory, 那 我们就运行一下, 还要运行 south home hello, 点 best i c 现在已经生效了,现在我们再运行一遍 p n p m 空格令格航线 global, 那 现在这个 openclaw 这个命令就可以直接 在命令行里边调用了。然后我们运行这行命令, openclaw, 空格 unbox, 空格航线航线 install 航线 demo, 那 这行命令就开始设置这个 openclaw, 并且安装后台的守护进程,也就是后台服务, 这个 open 卡拉就会在后台一直运行了。我们看这个命令执行之后,就是这个界面第一个配置界面问你是不是继续,那你就通过这个左右键选择。 yes, 然后按回车,然后 unboxing mode, 就是 是 quick start 按回车 model, 也就是大圆模型,你选择哪个?因为我们使用本地的奥拉玛,所以我们选择奥拉玛,那奥拉玛 base url, 也就是我们这奥拉玛模型的 url 是 多少, 我们现在去看一下。我们在 windows 上打开奥拉玛这个应用程序,点击左上角这个图标,有一个 settings, 点击一下,那在这右边有一个选项叫 expose orama to the network, 这个选项一定要打开,否则奥拉玛是不能够被网络上的其他应用程序访问的。 我们再在 windows 里边打开一个 windows power 或者命令行窗口,运行命令 ip config, 那 我们就可以找到我们这台计算机的 ip 地址, 那我们这 id 是 幺九二点幺六八点二零四点幺,我们在浏览器里边输入这个网址 gdp 幺九二点幺六八点二零四点幺,冒号幺幺四三四,回车之后,如果看到奥拉玛 is running 这个页面,那就证明我们这个奥拉玛是可以通过网络上的其他应用程序来访问的。 我们回到这个 uberto linux 这个虚拟机里边,把这个 alama base url 地址改成幺九二点幺六八点二零四点幺,冒号幺幺四三四,回车会让你选择一下 alama 的 mode 是 cloud 加 local, 那 么选择第一个回车, 然后它有提示让你登录进 alama cloud, 我 们就把这个链接拷贝一下,点击 connect, 连接成功了,我们再回到这个命令行, 他问你是否登录进去了。 yes, 我 们回车。现在你就可以选择这个大语言模型,具体使用哪个,那我们就使用缺少的 kimi 二点五这个云端的模型就可以了。按回车,再让你选择那个 china, 就是 你用哪个聊天软件去管理这个 opencloud。 我 们先不用这个了, 我们会在以后讲,我们选择 skip now 回车,选择第一个路由 search, 因为我没有这个路由 search 的 api key, 所以 路由 search 就 不能使用,但是你可以去到这个网址去获取 ikey, 可以 以后再配置,现在它让你选择 skill, 问你是不是配置 skill, 我 们可以选择 yes 啊,回车用上下键来选择,选中之后按一下空格键,这变量就把它选着了。 回车这个 homebrew 我 们也可以安装一下,选择 yes 回车 google api key, 这个我没有,就选择 no, 全都 选中就可以了。 hook, 这个我们也先 skip 它,就开始安装这个 getaway, 也就是这个网关 getaway 已经装好了,他问你想怎么去跟这个机器人聊天,或者机器人互动,我们就选 open the web ui, 那这样他就会打开一个浏览器,你可以在浏览器里边跟他聊。第一个是 tui, 就是 基于文本的那个用户界面,我们还是用外部 ui, 那 现在当你看到这个界面,就说明这个 oppo cola 已经安装好了,这些信息都还是比较重要的,所以我建议你最好把一些重要的信息保存下来, 比如说这 ctrl u i, 也就是我们刚才不是选择基于 web 来管理这个机器人,所以它有一个链接地址,通过这个地址是可以打开这个管理界面的, 那这个地址我们把它拷贝出来,在这个浏览器里边粘贴进去,那这个就是 open k l o 的 这个控制台,当然这个我都跟他聊过一点了, 所以有这些信息。那我跟他说个你好,他巴拉巴拉说了一大堆,我问他现在都能干些什么?他回答了一大堆,好像感觉他非常能干。这些东西都怎么做?以后我可以给大家做视频,来演示一下他怎么才能做到这些功能。
 04:30查看AI文稿AI文稿
04:30查看AI文稿AI文稿openclaw 保姆级安装教程,搭配免费大模型,让你唱完龙虾,十分钟搞定 openclaw openclaw 最近实在太火了,但是自己搭建的时候难免会出现各种问题,比如这样的这样的, 所以很多人已经开始做起了上门安装五百一次的生意。这里教你小白安装法, 包括环境配置、权限问题、下载速度等等,看完不仅立省安装费,你熟练后甚至都可以接上门安装的单了。我们直接开始第一步,安装 no js, 虽然 opencon 官方文档并不要求我们提前安装 node js, 但先把这一步做完,可以避开很多坑。首先来到 node js 的 官方下载页面中,点击 windows 安装程序按钮开始下载。但是由于 node js 的 服务器在国外,所以下载速度会很慢, 也可以通过 node js 中文网来下载,下载速度会有明显提升。下载完成后,你打开安装包, 安装位置可以保持默认,也可以选择你想要安装的文件夹。接下来呢,我们就一路无脑点击下一步, 然后点击 insert 开始安装,这里要稍等片刻,完成后点击 finish 按钮, note g s 就 安装好啦。第二步,安装 get get 并不是必备安装项,但很多人后面遇到的一些报错,本质上都和 get 的 配置有关, 所以安装了 get 可以 提前避坑。来到 get 的 官方下载页面,根据电脑的架构选择对应的下载链接开始下载。下载完成后,打开安装包,点击下一步, 这里同样可以保持默认,也可以选择你想要安装的位置。再往后,如果你不是专业的开发者,不必纠结这些配置,一路点击 install 开始安装, 等待一小会儿。安装完成后,我们可以把这个对勾给取消掉,它会打开 git 的 更新说明网站,对安装没有影响,然后点击 finish git 就 安装完成啦。第三步,安装 openclaw, 在菜单栏搜索 powershell, 这里要注意以管理员身份运行,然后会打开一个大黑窗口。为了避免 powershell 默认策略太严格,等着安装报错,我们要先输入一下这个命令,然后回车运行。 运行后, powershell 可能会出现一个提示,问我们是否确认修改执行策略, 这里输入 y, 然后回车表示同意这一次修改。为了避免 npm 源导致的下载失败问题,我们需要切换 npm 镜像的下载源,输入一下这个命令,然后回车运行。 很多人安装的时候都会出现这个报错,这个错误的本质是 npm 在 执行 get 操作时拉取仓库或者依赖失败导致的国内访问 get help 困难。先把 get 协议强制切换为 https, 输入一下这个命令,回车运行。上面三条命令能避开很多坑,确保我们一次性安装成功。然后我们再输入这个 open cloud 的 官方安装命令,并回车执行。 这个命令可能会运行一段时间,如果中途出现弹窗,问是否允许公共网络或专业网络访问此应用?点击允许。当你看到一句来自 open club 的 欢迎信息,就说明 open club 已经安装成功啦, 不过这还没完。第四步,配置 open club。 open club 会展示一段话,提醒您使用它可能存在风险。问是否继续? 这里可以按键盘上的左方向键选择 yes, 然后回车确认继续回车。 下一步需要选择 open class 背后的大模型服务商有很多选择,比如 open api、 千问等很多。这里教大家使用免费的大模型。我们先选择 v l l m。 第五步,配置免费大模型。
29程序员阿亮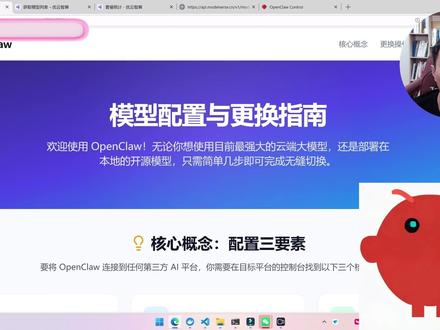 06:22查看AI文稿AI文稿
06:22查看AI文稿AI文稿问你一个问题啊,为什么别人的 open claw 那 么厉害,而我的 open claw 啊,傻的完全没有办法交流啊,背后的原因是啥?以及怎么样去解决这个问题呢?好,接下来一个视频啊,给你讲清楚。那么前面我们说了,龙虾呢,有三大核心组成部分,除了龙虾 本身之外呢,还有大模型以及技能。而在这三个核心里面啊,大模型它充当的是龙虾大脑的时候,那么大概率 一定是你的模型选错了,你模型用的不好,那么整个龙虾就不好用了。好,问题来了啊,那我想让我这个龙虾好用一点,那怎么办呢?那就是使用顶级的大模型啊。好,那问题来了,那我怎么样给我的龙虾去更换大模型呢?接下来一个视频啊,给你讲清楚。好,我们想要给我们的龙虾更换大模型的话, 我们需要知道三个东西啊,第一个 ok, 你 的 api k 啊,你在哪个平台?你的身份标识是啥? api k 就是 你的身份标识, 因为龙虾呢,使用这个模型是要去付费的。好,那么付费的话,我就需要有一个身份标识来标识,张三是张三,李四是李四,这样的话,我才能够成功地去计费嘛,所以我需要有一个 apik, 然后第二个呢,我需要有一个 base url 啊,因为不同的大模型,它的请求的地址是不一样的, 所以这个就是大模型的请求地址,这是大模型的请求密钥。而第三个是谁啊?大模型的名称,因为即使是一家公司的话,他的大模型也是非常多的,那你到底是调这家公司里面的哪个模型, 你要讲清楚的。好,那么接下来呢,给大家去讲一下,怎么样从零到一的给我的龙虾呢?去更换大模型。好,那么首先咱们需要去找到这三个地方啊,通常情况下,不管是哪家平台, 那么它一定是有说明文档的啊,那这时候呢,咱们可以去打开它的说明文档啊,比如说,比如说随便一个平台吧啊,咱们就可以找到了,它里面有啥呀? open ai 兼容模型的这个列表的请求地址 啊,那么这个地址啊, base u l 给大家来说一下,它通常是以 v e 结束的啊,通常是以 v e 结束的,所以, ok, 咱们去调用的时候, base u l 咱们就找到了啊,这个地址有了,那么地址有了之后,接下来呢就是去调用模型了,然后在他们官方里面也给咱们提供了一个接口,然后这个接口呢去访问,你可以得到所有的 模型名称啊,当然因为它们本身是一个集成站,所以在它里面呢,国内的模型和国外的模型都有,比如说 kimi 二点五呀啊, jama 三点一呀啊, gpt 五点四呀啊,包括豆包一点五呀等等等等,还有 cloud 四点六啊,它们家都能用,而且夸张的是啥呀? 它们有套餐,可以让你的成本可控啊,你可以订阅六块九的,你也可以订阅四百九十九的,根据自己的使用情况来选择相应的模型就 ok 了。好, ok, 那 这时候我就得到了贝斯 u l 了,以及 它的模型名称了,那么第三个是啥呀?第三个是我的 api k 啊,那这时候咱们就去访问后台,在后台里面有一个 api k 啊,这时候呢? ok, 我 可以新建一个 api k 啊,比如说这儿呢,我就新建一个 test 啊,然后点击创建。 ok, 那 这时候 api k 就 有了啊,这个时候咱们三个东西都有了情况下啊,当然所有平台都是一样的,所有平台你就去找这三个东西就行了。 找到这三个东西之后呢,接下来咱们就去对接一下最新的 gpt, 五点四。好, ok, 那 这时候啊,怎么样去对接呀?不管你是 windows 电脑还是 macos, 苹果电脑都是一样的,那么 windows 电脑呢?你就点击视窗键, 然后 cmd 啊,打开你的命令行提示符,如果你是苹果电脑的话,在应用里面去找到终端啊,都是黑色的窗体,然后点击它就行了,然后点击它之后呢? ok, 接下来输入一行这样的一个命令, open cloud configure, 然后输完之后敲回车啊,敲完回车之后呢,咱们选择当前本地的配置,然后确定, 然后在里面去选择 model, 因为接下来我要去更换我的模型嘛,所以点击 model, 然后在这个 model 里面呢? ok, 如果你直接是比如说,哎,我就去对接 kimi, 那 你就去选择 kimi 就 行了啊,但是如果我对接这个平台在这里面没有怎么办? ok, 它底下会有一个自定义模型, 所以你不管是哪个平台,你只要拿到刚才那三个东西,咱们都可以通过自定义的这种配置来进行设置了。好,那刚才那个平台它没有内置啊,那我这时候呢,我就选择自定义的厂商啊,因为它符合 open ai 协议的好。敲回车,然后 敲完回车之后,它要你干嘛?输入 base url, 然后 base url, 刚才咱们找到了呀,啊?它在哪啊?它在这儿,对吧?啊?这个 base url, 它是唯一结束的,大家注意啊,唯一结束了,所以咱们复制这个地址。 好,然后回到咱们这边把它原来带的这个东西呢地址呢?给它删除掉啊?粘贴是吧?好,敲回车,备注 u l 有 了,然后接下来输入啥呀? api k。 好, 输入 api k, api k 是 啥呀?刚才咱们登录到后台,这个 api k 复制啊,然后这时候呢给它粘贴,然后粘贴完了之后呢?哎,敲回车, 传回车之后呢? ok, 你 要去选择协议,那我的这个协议呢,就是 open ai 的 协议,所以我选择第一个 open ai 啊,敲回车,然后这时候他让你输入啥呀? model id, 然后 model id 的 话,刚才咱们从这儿哎得到了所有这个 model 啊,我千万三三点五 plus 啊,然后这些都能用的,那我使用啥呀?这一批题四 啊,我使用顶级的大模型,那它的能力一定是最强的。好,那这时候, ok, 咱们去选择啊,这时候不要胡输啊,一定是平台给你提供的这个 id, 不要自己去输入复制,然后粘贴啊,粘贴完之后呢?敲回车啊,敲完回车,这时候他就该干嘛了?去验证你这些信息到底是不是对的?好,验证完之后他告诉你, ok, 我 可以连接成功,到这,你已经成功百分之八十了啊。好,然后这时候呢,他让你去起一个名字啊,给他起个名字,那默认的这个就可以, 不需要去改的啊,这时候咱们去敲回车就可以了,敲完回车之后呢,它需要有一个别名,是吧?啊,那么这个别名呢?咱们就叫做啊有 club。 好, 完了,配置完了啊,配置完了之后呢,咱们继续啊,这时候咱们重启一下咱们的服务就 ok 了啊,配置完之后, ok, 使用 open club 然后 get 位啊,你如果之前你的服务是启动的,这块使用 restart, 如果你之前已经把它关了,所以我这呢 open club get 位就行了。好, 敲回车啊,敲完回车之后呢,咱们问一下大模型,测一下,看它是不是 gpt 五点四啊?好, ok, 那 我设置完了之后呢?哎,我来到网页那边打开我的 龙虾啊,当然龙虾我没有升级版本,现在版本又发布新版本了,那我就问他,我给你更换了新的大模型,告诉我你是什么大模型。好,然后完了之后呢?点击 send, 咱们来看一下它的回复啊。好,那么经过了一段时间之后呢,它告诉我了它是啥呀? gpt 五点四。好,那到这咱们的模型就更换成功了。 所以呢,最后咱们去总结一下,不管你是哪个平台,咱们只要能找到这三个地址之后,然后使用命令的方式,就可以在不改代码的情况下自己来更换大模型了。我是磊哥,每天分享一个干货内容。
420磊哥聊AI 08:25查看AI文稿AI文稿
08:25查看AI文稿AI文稿今天跟大家讲一下这个在小龙虾里面,他这个的模型是怎么切换的,那我当前这个模型是 glm glm 五的模型,那如果说我要切换成呃 glm 四点六 v 的 这种模型,那该怎么切换呢?那切换里面我们有这么几种办法。 呃,先给大家说一下,一种我们先打开一个终端,在这个终端里面呢,我们输入这么一个命令,叫 openclock apple color, 然后呢 o d l 是 model 四,那设置 set j ai, 这是智普的那个前缀 j ai, 然后写杠 g l m 杠四点六 v, 那 这个就是切换成把把这个默认模型切换成 g m 四点六 v 的 版本,然后我们敲回车一下, 敲回车完之后呢,它这里呢会告诉我们模型已经设置成功了,然后呢我们给这个小龙虾呢的网关重启一下, 重启一下,这个可以重启一下, 那重启完之后呢,我们回到这边来,我们去刷新一下这个浏览器,你看它当前呢这一个会增加了,多增加了一个叫 g l m 四点六 v 的 这么一个呃默认模型, 那这个呢是我们切换模型的一种方法,当然大家这里看到的这是一种呃通过它这种内置的这种 p p n 的 一个命令, 呃可以设置的,那如果说呃这里面的那个模型默认的模型不在我们的小龙项链表里面,比如说像 deepsea 这这种模型,那要怎么设置呢?因为 deepsea 它是不能通过这种呃简单的命令去设置,它只能通过自定义的呃 模型去设置,那它这边呢有两种,一种两种命令,一种是直接通过什么通过这种呃非交互模式的这种条命令就可以执行,比如说像这个, 比如说像这种像这种一条式的命令,它这里是什么呢?它这条命令呢?它这个是什么?呃是像这个参数呢?是。呃 执行非交互模式,使用非交互模式。那第二个叫 modelcare 了,这一个呢?按本地模式配置网关,这个是按本地模式配置网关。那第三个是什么呢?第三个是使用自定义的 api t 接入,这个是使用指定 api t 接入的参数。那第四个参数呢?这个第四个就是给这个呢?呃提供商命名为叫 dbseek, 对 吧? 那第五个这个参数呢?这个是什么?这个说明让它兼容 openai 的 协议。那第六个呢?第六个是什么设置?呃, deepsafe 的 这个接口地址。那第七个是什么呢?第七个是,呃设置默认模行为 deepsafe chat。 那第八个这个呢?那就简单了。第八个这个就是填写我们在数据库上创建的这个 api t, 这个就是 api t 的 序号。那第九个这个是什么呢?确认接受非交互模式的风险提示,一定要加这句话,要不然如果说少了这个,它上面的这个就执行不成功,那我现在来给他执行看一下 啊,这里已经告诉我们。呃, justin 呢?已经备份了,然后呢?这里也执行完成了。那执行完成之后我们要记得什么?记得是,呃,我们要给它一个重启网关,网关重启一下。 网关重启完之后我们直接在这上面刷新一下就可以了啊,刷新一下它当前这个 deepsea 的 这个什么?呃,模型已经加载进来了,那我们可以直接什么跟这个呃, 我们直接问用 deepsea 看一下 它,这里会回复我们是由深度求索公司那一个研发的这个大模型, 那这个模式像这种方式呢?都是用一条的命令方式,那还有没有办法用?呃另外一种方法呢?就不用一条命令,我们用那种直接 on 使用的是什么? openclock on board 这条命令呢,就是类似于刚刚安装的时候我们去执行,那我接下来也给大家去演示一下这个呃,我们用这种命令,使用 openclock, 使用这样子的粗俗化的方式去呃配置我们的 deepseek 的 这个呃模型。那首先呢,我现在呢先给它做一个啊,先把这个呢做一下来还原。其实所有我们所有配置的这个 wincore 的 这些配置参数都在这个文件里面,我先把这个删掉, 删掉完之后复原这个文件, 我重命名一下,我复原这个文件之后呢,我们我在这里呢先给他什么,先把它网关 重启一下啊,重启完之后我们确认一下是不是恢复到我之前的呃初设设置,我刷新一下啊, 这已经呃复原到最早的之前的设置了。好了,我现在呢给大家去演示一下这个什么呃通过这个叫做 open, 通过这条命令怎么去呃配置我们的 deepcom 这个模型,那我们执行这条命令叫 opencloud on board 的 这个命令, 那这个执行完之后呢?他就是我们,就像我们第一次安装的时候会告诉我们这个呃一些风险信息吧。完了我们给他确认一下这个选择 yes 啊,这个还是继续选择 quickstar, 那 这里呢告诉我们什么配置,是否继承原来的值,那我们选择第一个就可以了。 use assign 就是 继承原来的值, 那关键就是这些位这个位置了,这个位置这里的模型驱动商呢?有这么多个,那我们要选择哪一个呢?我们选择的是这个叫做 custom, 因为这里没有 dsp 的 那个默认的夫商,所以说我们这里要选择的是自定义的 夫商,那我们选择这个回车,那回车完之后,关键这个位置的 api, 那 个 api base url, 这一个要改成什么?就是我们的模型的接口地址, 这里的接口地址呢?要改成我们的这个叫 deepsafe v 一 的这个默认模型,那我们啊路径改一下,黏贴进来,就一定要改成这什么 a p i deepsafe, 点 com 点 v e 这个 u r 的 地址呢?是兼容 openai 的 接口模式。那我们回车,那这里呢?我们是什么?呃,黏贴那个 api key 的 值,那我们把 api key 的 值黏贴进来, 然后呢这个位置这里有三个参数,是选哪一个呢?我们要选择的是什么?叫做呃,说明兼容和 ai 模式协议,然后我们这里选择第一个兼容 open ai 协议, 那这里呢? model id 又是什么呢? model id 呢?这里呢是设置默认模型,也就是这个提供了哪些的默认模型?然后我们选择呃,输入 d e e p s e k 默认模型,然后显示 a t, 其实就是这一个, 其实就是呃这个位置接口文件里面的这个,其实就是这个, 其实就是这个。这个 deepsafe 提供的这一个叫做什么?推理模型跟聊天模型,然后我现在先选择的是聊天模型,叫 deepsafe chat 的 这个模型。好了,那我们给它 model id 选择了 deepsafe chat, 那这里的是什么呢?那 point id 又是干什么的呢?那 point id 它其实是是模型的一个小名,那我们这里的小名呢?也可以叫让它默认叫 custom api, 这个默认的也行,那我们选择用默认值吧。 那第二个是这个是别名,那这里的别名呢?我们也可以不填,没关系,我们直接敲回车也不填。然后第三个,这什么使用的一些我们交互的方式吧,那这个我们直接跳过啊,这里呢也是直接跳过, 然后这个是配置技能,那技能像我们之前也配置过了,我们可以选择 low, 也可以选择 yes 或者点 yes, 在 这里面跳过也行。我们先跳过,那这后面都是跳过了啊,像谷歌的,国外的这些 a p i 我 们都跳过,目前都没有申请 好了,那这个是不可使的,这个也跳过,那现在最后步呢?这个是什么呢?我们再重启一下就可以了。重启网关, 重启完关之后我们选择的是什么?还是继续选择 open 的 web ui 的 这个方式,然后呢它这里呢?它这里呢?你看它这种方式也可以把这个 deepseek 的 这个模型给它配置进来,那这个就是我们呃默认的这种, 呃自定义的方式,把 deepseek 的 一些那个 a p i 呢?呃配置到小龙虾里面去好了。呃,这个今天呢,呃,跟大家讲的这个第三方的 a p i 呢?呃就到这里了。
218拉灯 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿有很多朋友们在安装之前去问我配置的问题啊,担心说我的电脑能不能装啊,或者怎么样,这个怪我啊,我没有在之前的视频把这个配置说明白啊,给大家说一说配置和模型的问题。 首先在配置方面,如果我们只是单纯的去研究学习入门,我可以告诉大家,任何配置都可以,只要你这个电脑不卡,你自己玩着不卡,基本上都可以,不用看配置。 为什么很多人会说这个 mac mini 啊,或者说必须得苹果电脑啊?我给大家讲一下,是因为苹果的架构以及配置决定了它可以二十四小时不关机,而龙虾 open 可乐这个东西如果长期要使用,它就是要求这个电脑不关机的。所以为什么很多人会假设在服务器上,因为服务器不需要关机, 那苹果也可以做到这个特点,那如果你是一个刚研究入门的,或者说想玩一玩的这种人, 那你不需要特意去选择苹果,或者说特意去买一个 mac mini 啊,或者是 mac 什么电脑啊,没必要,因为你不需要他二十四小时不关机,我们只用只需要用一个 windows 就 可以了,是在 windows 去使用,任何一点问题都没有。然后,然后模型的问题, 我再给大家上门去安装的时候,一般给大家配置的都是国产模型,因为国产模型是很便宜的, 对大家使用或者是研究都是很友好的,那如果有的老板朋友说我就有钱,对吧?我上来就想配置最好的, ok, 我 可以去给你配置国外的模型,我去给你配置中软的啊,第一呢,相对来讲中软的会便宜一点。第二呢,我们不需要去翻墙,降低了大家的操作难度和费用。 而且说实在的,你在我这去买中转的国外 api, 我 会赚的更多。国内的模型你自己去买就可以,我告诉你怎么买,非常非常便宜,所以两种模型你自己去选择,到时候我帮你配置好就可以了啊。最后最重要的是啊,上面安装龙虾。找我找我找我。
7王潜bc 01:46查看AI文稿AI文稿
01:46查看AI文稿AI文稿现在一堆人推荐云版的 open curl, 那 你用过就知道,一到真实场景实在拉胯,两分钟帮你把现在所有的 open curl 形态从哼到拉排清楚。第一种叫本机的 mac mini 部署,这是目前最能打的方案,因为它生态最完整,工具最丰富,而且不会被风控。 现在随着迭代,安全性能也逐渐补上了,可以给到哼。第二种就是像 auto qq 啊这种, 它们都能一键接飞书或者微信,能自动配置 ui 也很友好,一上来就可以给你一大堆的 skills。 但问题是你就模型被绑定,而且能力上限也会被限制,但是仍然可以给到人上人。 第三种就是像 nano curl, zero curl, coco 这种,这种开源的工具是工程玩家最喜欢的,比如说 nano curl 极简可控, zero curl 安全而且是极致性能, coco 多 agent 可以 给到顶级,但是仅限高端玩家。 最后说说各种云部署,其实又分两种,第一种就像 kimi cloud、 max cloud 这种厂商深度集成的。 第二种就是像阿里云镜像,腾讯云镜像的 lighthouse, 还有火山的镜像等等。这两种都有一个非常棘手的问题,就是它容易被封控,它登录很困难,而且非常容易被拣出,云 ip 被限制, 很多高价值的信息都需要浏览器登录才能拿到。要解决这个风控问题,你需要搞代理啊,指纹啊,环境等等,费的劲直接能把我半条命都搭进去。但是看在一键接入方面上,我还是给 kimi cloud 和 max cloud 给到 npc, 最后各种云的镜像直接给它拉就完了。核心结论, opencloud 的 能力上限不只是模型,还取决于两件事,一是能用什么工具,二你在什么环境里运行。
113建斌聊AI