omnibox怎么设置爬虫源
现在我们来尝试一下用 requests 发请求,先新建一个 python 文件。这里注意了,我们这节课讲 requests, 有 同学习惯性就把文件名写成 request 点 p y, 千万不能这样。 import request 的 时候,它会先从执行文件所在目录找模块,也就是我们前面讲的 c 点 pass, 然后一路找到模块安装路径。如果你的文件名叫 requests, 那 完蛋了,相当于你在 requests 里面自己导自己。你看吧,我们用 requests 里面的 get 来请求这个页面,这是我们讲加载流程的页面, 就报错了,说模块 requests 没有 get, 因为你就叫 requests, 你 在导你自己拍枪也提示黄色波浪线了。看到这种深色提示,你就要警惕, 任何第三方库爱上内置模块关键字都不要用来作为文件名或变量名,这里我们还是改一下,就叫 demo。 零一,这个搜索引用不用勾,勾了的话,如果其他地方引用了这个文件会一起被修改。我们这里没有引用,不用勾,可以勾上看一下,点重勾, 看到了吗?这里都被改了,撤销一下,不要勾这个 ok。 请求发出去之后,它会有一个响应来把它打印一下, 这是一个 response 对 象,状态码是两百,说明请求成功了,访问它的 status code, 也可以拿到状态码。 现在我们要拿到它的响应体,因为 content type 是 html 码,所以响应体就是页面源代码,就可以用它点一个 text, 表示用纯文本的方式去读去响应体内容源代码就拿到了, 但还有一些乱码,说明编码有问题。看到 u t f 杠八了吗?之前我们用 url label 需要这样来解码 request 不 一样,我们要在读去响应体之前,把响应对象的 in code 属性改成 u t f 杠八,再来读去, 中文就正常显示了。 ok, 我 们再复制一个 demo。 零二来看小英头,它的 content type 是 html, 但是没有指定编码方式。现在我们换一个网页来看我们第一关的内容,你注意看它的 content type, 这里就设置了编码方式,把 url 拿过来, 不设置编码方式,直接读取响应体,看到了吗?中文正常显示了, requests 会根据响应头里面的 content type 自动识别编码方式,比 url lib 方便多了,对吧?我们也可以通过 response 键 hitters 读取响应头的内容, 不用打开浏览器也能看。除此之外,如果幺二幺里有中文,它也会自动进行幺二幺编码。比如我们随便加一个参数来跑一下,没有报错,说明自动编码了,可以通过 response 点幺二幺查看。这次请求的幺二幺确实被自动编码了。现在我们来看第一关的要求, 它说获取 html 源码的制服总长度,这个长度就是开启下一关的密码,那我们就用内函数获取源码的长度 e 五四五八,那这里就写 e 五四五八提交。 ok, 再来看下一关,他说要抓取所有电影,提取每部电影的评分总人数,并完成哪家来进入靶场,先查看一下源代码, 确认数据都在源码里面,说明是静态页面,再来分析一下它是怎么分页的。你注意看 url, 当我点击下一页之后, ur 要变了,多了两个参数,配几等于二, size 等于十,也就是说分页是靠这两个参数来控制的,配几表示第几页, size 表示每一页的电影数量。那就很简单了,我们只需要用一个循环,每循环一次页码就加一它,这里一共二十五页,那我们就循环二十五次。 刚才第一页默认是没有参数的,现在我们再回到第一页,你会发现第一页也可以带参数。现在我们再来看一下这个 size 能不能改大一点,如果能改大一点,请求就可以少发几次嘛。比如我改成一百,你会发现只返回了二十五条, 说明 size 最大只能是二十五,现在就只有十页了,那循环十次就可以拿到所有电影数据了,这里我们就改成二十五,复制 u r l, 这个我们就改成零一吧, 然后再来一个 number 零二,导入 requests, 来一个 for 循环,从一开始到十结束, url 放进来,这个页面是需要变化的,对吧?所以我们用 i 来代替,然后 requests 点 get url, 拿到 response, 先把它打印一下, 这里我们导入一下 time 模块,用 time 点 snap 延迟零点五秒。对于这种多页数据排序,最好设置延迟,一方面是为了防止请求速度太快被封 ip, 另一方面也是为了保护网站服务器,高频请求会加大服务器压力,如果目标服务器比较脆弱,很容易就给人搞荡机了。前面讲法律底线的时候也说过了,高频恶意请求会有什么后果, 这个你心里应该有数,至于具体延迟多少,没有固定答案,你自己把握。一般零点五秒到三秒差不多也可以在一个范围内随机延迟。不同网站对于频率的限制也不一样, 其实我们现在还没用多进程,多现成也没上一步,代码是完全串行的,上一个请求结束才会发下一个请求,所以就算不加延迟,速度也快不到哪去。但我这里还是把延迟加上,就当给你提个醒。先来测试一下。测试阶段我们就先只爬一页 来跑一下,原码就拿到了,但我们真正要的并不是原代码,而是原代码里面的数据,所以接下来 我们要解析这个 html 源码,从里面提取需要的数据。这里需要用到一个第三方库,叫 parcel, 先把它安装一下, 注意我们现在用的是 uv 管理拍摄环境,所以要用 uv 来安装,如果你不习惯用 uv, 就 用传统方式批量 store 也是可以的。装好之后,我们导入它里面的 selector 类,这里拿到 html 源码之后,就调用它把源码传进去,这就创建了一个 selector 对 象,然后调用它的 css 方法,这里面就要传 css 选择器 来看一下它的结构。由于是静态页面,我们就可以直接看元素界面,当然就算是静态页面,这里也只能做参考,因为内容有可能被 g s 改动。找到这个评分元素,它的类名是 movie rating count, 把它复制过来。还记得类选择器吧前面加一个点,这样就选中了页面中所有类名是 movie rating count 的 节点,把它复制给 item 来打印一下。还有它的类型,可以看到类型是 selector list, 有 点像我们学的列表,对吧?列表的每一项又是一个 selector 对 象,数据就是具体的一些元素,那这里我们就用 for 循环便利它打印一下 item 以及它的类型, 这就是每一个评分元素以及对应的类型。既然 item 也是一个 selector, 我 们就可以继续调用它的 css 方法,用冒号冒号 text 选中它里面的文本节点。两个冒号这种格式的选择器在 css 里叫伪元素选择器,但 css 里其实不存在冒号,冒号 text this partial。 为了方便我们选择文本提供的来把它打印一下,也是一个 select 列表,每个列表里只有一个文本节点,只要是 css 方法返回的都是 select 列表,我们可以用它点一个 get, 获取列表里第一个节点的内容,这样我们就拿到了所有的评分数据。其实可以再简化一下,第一次查询的时候 我们就一步到位,找到这个元素之后,继续往后选中它的文本,这样直接拿到的就是所有的文本节点。只不过这个 item 现在还不是区块,它是 selector 对 象, 我们可以用这个 selector list 继续点一个 get all, 获取列表中所有节点的内容。刚刚的 get 是 获取列表中第一个节点的内容, get all 返回的列表就不是 selector list 了,而是标准的列表。 这样我们拿到的 item 就是 区块链了,可以用区块链切片,切掉最后三个区块,再转成整形。 接着我们在前面准备一个变量 count, 用来做累计,这里每拿到一个评分人数就累计给 count。 最后循环完毕,我们打印一下总评分人数为 count。 循环里面也可以打印一下 d i e。 数据抓取成功来跑一下 没问题吧?第一页跑通了,现在我们来把十页数据全部抓下来,总评分人数就拿到了,这个总评分人数就是第二关的答案,来提交一下, ok, 其实 url 里面的查询参数我们也可以换一种写法,如果参数比较多,这个 url 肯定就会写得很长很长,不好看也不好维护。我们可以这样做,把这一段参数去掉,然后来一个字典就叫 perims 等于 i, size 等于二十五, 然后给 get 加一个参数, perims 等于我们这个字典 perims。 当然这个变量名叫什么都可以,你可以叫 d i c, 我 们一般都叫 perims, 它会自动把这个字典参数用问号拼接到 url 里面去,可以来打印一下 url, 没问题吧?人数也是对的。这个波浪线提示是因为 response 可能没有定义,因为 response 是 在否循环里面定义的,如果没有进否循环, 这个 response 就是 没定义,但我们知道肯定会进负循环,所以你不管它也没关系,你看着不舒服的话,可以在前面定义一下,设置成浪就行,它就不会提示没有定义了。

粉丝5.3万获赞37.7万
相关视频
 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿兄弟们,今天分享一个 openclaw 的 专属黑科技 skills scraping, 帮助 openclaw 实现二十四小时稳定的浏览器数据采集,包括产品信息、行业报告、科技新闻这些互联网真正有价值的数据。 scraping 开源级爆火,迅速暴涨三万星标。 该项目内置 m c p 模式,精简内容,大幅降低数据采集的 api 成本。支持智能跳过验证码和网页改版,支持断点续传,哪怕是突然断电断网, 他都能把他自己爬取的信息和进度保存下来,电源网络恢复后无缝衔接地继续爬取。另外,作者也开发了专用于 openclaw 的 skill, 小 白也可以开箱即用,相较于其他之前的 skills, scripting 更快更稳,可以爬取其他 skills 爬取不到的数据,为你的 openclaw 武装上信息抓取的超能力。全部功能仅需几行 python 代码就能实现,不会使用的朋友也可以直接交给 openclaw 来帮你部署使用。感兴趣的朋友们赶紧去试试吧!
116AI指挥官Felix 05:00查看AI文稿AI文稿
05:00查看AI文稿AI文稿这是某宝的热卖网,怎么样快速的构建一个基础爬虫来实现数据的自动下载呢?五分钟的时间来教大家如何进行工具的一个快速解决。那么像这个网站它到底是采用了一个什么加密呢?我们来看一下啊。首先我们可以打开在下方的开发的控制台里面会有个网络, 会有个网络,如果你也对前端逆向攻防感兴趣,老胡啊,我专门给大家准备了爬虫逆向实战的一个直播课,拆解目前市场主流的一些前端加密技术,还配套录制了全套的逆向入门学习视频,大家记得在粉丝群里面来进行获取,然后在网络界面里面,我们去勾选我们的全部啊,筛选全部,先把暂时把当前所记录的 logo 信息来把它清空 好,那么我们现在在页面当中,你看这里我们是可以直接来进行搜索啊,会有个对应的搜索接口,对吧?我们来直接进行搜索,比如说我们搜索一个女装来进行搜索,那么当我们像在上方去进行搜索的时候,我们像在下面,你看他就会来记录我们当前的客户端跟我们的不计,他们之间的一些数据的一些交互, 对吧?这不都能够记录,看没有都能够记录,那么当它记录的话,我们现在可以看到啊,它里面是有很多接口的,那么我们当前的重点我们是需要来找一下我当前所需要的这些数据,对不对?你看我们是需要当前这些数据,看一下这些数据是在哪个接口里面, 那么我们可以来尝试来搜索一下它对应的关键字,来找到它的数据所包含的接口,你看我们选择把这个点高亮来选中,比如说选中一个名称,然后在这里我们进行搜索啊,比如说我们来搜索一下,是吧?这个是高尔夫夏秋凉啊,什么一个防晒的,一个树干的一个袖子,是吧?来我们在这个里面,你看它这里有个放大镜, 看没有这个放大镜,把这个放大镜给打开,然后进行搜索来搜索,当我们搜索的时候,那么我们像在这里我们就能够快速的去找到。你看我们当前所需要的这个数据,他是不是在这个二点零的一个接口里面?你看 他是不是在这里?朋友们是不是在一个二点零的接口这里面,对吧?这个是一个是这里是一个技巧,我给大家讲一下啊,记住啊,就是我们在很多时候是吧?就是我们比如说是吧很多时候他有 网页,他的一个网络当中记录了多个接口,是吧?在不清楚, 是吧?数据在哪个接口里面,那么我们可以怎么办呢?可以来直接进行内容的搜索,把内容的搜索,通过内容的搜索,我们就能够快速的来找到我们当前的数据所在的一个接口,你看是吧?可以点过去,那么当我们点过去的时候,我们可以看到他这个地方会进高亮,看见没有会进高亮来在这里 收获进行高量,好,那么像在这里我们现在来尝试来构建一个 python 的 一个 request, 那 么像在今天我们将用到很多的一些工具。首先我们今天啊我们会用到一个 ai 工具, ai 工具的话,目前 ai 可以 说是已经算是比较成熟了啊,你们可以根据咱们的自身的一个需求去使用,比如说目前像国内的话,我建议大家可以使用豆包,其实豆包呃,非常的 nice 啊,可以使用豆包,然后其次你们也可以使用像个 google, 或者说像这个谷歌的我们的一个迷你,是吧?都是 ok 的 啊。 那么在这里除了这个工具之外,我们还会有一个工具,这个工具是一个目前用于专门的来转我们的 c y、 l 的 工具,这个是主要的核心,就是通过 c y、 l 的 一个方式来把它转变成各种 的代码,比如说有 c c hop, 以及还有像 go long, 以及还有像我们的 p h p, 还有像 java, 以及还有像我们的 python, 还有像 r 等等等等相关的编程语言,它都能够来把它转变成对应的格式,那非常的方便。 那么在这里你看我们当前请求的这个接口,在这个接口这里啊,右击点击复制里面的 c u i l, 我 们记住复制的是这个 b a s h, 也就是 b s 这个格式,来把它复制好,复制 ok 之后把它粘贴过来,你看那么在下方啊,它就会直接来帮我们来构成一个 python 的 request, 那构成一个 python 的 一个脚本看,没有啊?你看是不是直接生成了一个 python 的 脚本,那么我们在当前在生成的这个 python 的 这个脚本里面,我们可以在我们的代码的投入中去新建一个 js 文件啊,你看我们新建一个文件夹,对吧?某宝热卖网,对吧? 然后来右击新建一个 python 文件,把当前的 python 文件把它复制过来吧,是 ok 的。 好,那么在这里各位请看一下朋友们,我们当前寄予我们的 request, 你 看在这里是不是就是有分别有核心的几个逻辑?首先你看在这个地方,第一个我们的 id, 是 吧?你看这个就是我们的请求头,对吧?用模拟浏览器的请求,然后这个地方的话代表的是我们的 partner, 也就是我们的请求参数, 然后像在这个地方它发送了一个 get 请求,是吧?你看这里是不是有个点 get, 它通过我们的 request 来发送的?对当前的这个某宝热卖网的商品的接口来进行了一个 get 的 一个请求,并且携带了我们的请求参数和我们的请求 cookie, 也就是用户信息,还有我们的 id, 我 们的头部信息, 是不是啊?那么在这里当前请求请求 ok 之后,我们可以看一下啊,当前在这里我们对它来发送了一个请求,对不对?这种就属于无界面的,基于协议来直接进行请求。然后我们可以看一下当前网页,也就是当前这个网站,它给我们所返回的数据是一个创, 看啊,它是一个创创,那么我们在这里直接给它跟上点 t s t test, 然后使用 word 来进行我们的 response 的 打印,那么这样你看我们当前这个程序就能成功的来请求获取到当前的一个页面的数据,对吧?只是说我们当前这个数据还没有清洗,对不对?
 00:50查看AI文稿AI文稿
00:50查看AI文稿AI文稿每天一个知识点,今天我们要学习的是超力爬虫技术,当你半夜突然想发愤图强学习时,五分钟还没到就被提醒,想看完整版请成为人上人, 其实这招就能让你为所欲为。首先郑重声明,本视频仅作为正规网络安全技术科普讲解,所有操作均在受控靶机内实现,不存在实际攻击行为, 将务把技术用于非法用途。首先打开 code, 输入 m s f console, 进入 m e f 控制台,再输入 u s m s f curl 搜索模块,我们选择使用这个模块进行参数配置。再次输入 set roost, 加上目标网站的 ip 地址,回车, 然后输入这个代码,设置现成数,最后输入这个代码,回车,开启爬虫。这时我们已经开始爬取网站的文件了,包括各种隐藏的文件都可以爬取。强调一点,技术无罪,但要正确使用!
102白客叶子 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿这几天终于把甲方的项目搞完了,今天带兄弟们学点简单的基础爬虫技术,看看国内顶级学府清华大学的前端加密是怎么个事。我的天呐,打开这个开放式文件啊,然后呢,可以在这里输一下,输入用户名和密码, 点击这个多动的按钮,来看一下这个文档的界面,里面是有一个 chang, 那 么 你看一下这个载客的讯息,首先这里是你刚才说的用户名下面这个,你看啊,他就是这个加密的数据,很明显吧,不是你刚才说的这个密码吧,所以我们要去逆向分析一下,怎么看到他的真实的密码呢? 我们先去试一下关键搜能不能找到,你会发现这里好像有一个取食的这个位置,打个断念,看一下能不能断在这, ok, 已经是断在这了,第一个是这个密码, 第二步的话呢,是这个密钥其实也在这里,你看到它是一个 sm 二,这是一个国密啊,你看到它的这个方法无法加载的这个问题,没关系,我们可以在下面去搜一下这一个文件叫做 sm 二,哈, 你看到是这个文件给您寄了啊,他的这个姜的方法都在这里面,是说你直接把这个代码把它复制到这个本地中来,你现在是要这个密码的,他的这个姜日为记吗?所以说我们直接把这个代码复制过来, 他到我们这个本地来, ok, 只耍了这个东西,简单的来试一下,你说是张三 啊,这个密钥的话,你可以去复制,这也是一个公钥,因为这个 sm 二这个国密它是属于非对称加密算法, 所以是有公钥和私钥的,让我们对成加密算法哈,就只有一个密钥。好,现在我们可以去看一下这个加密的密码。 ok, 直接出来嘛?
39牛马程序员说逆向 01:23查看AI文稿AI文稿
01:23查看AI文稿AI文稿零基础七天网络爬虫学习计划,每天只需一到两个小时。第一天,打好基础,拍省,加网页常识,学拍省最核心语法,点亮列表,循环函数,看懂 html 标签,知道数据藏在哪。第二天,获取数据, 学会用 read 库发送请求,复制网页 url 一 行代码,拿到页面原码。第三天,提取数据, 用 beautiful super 解析原码,把杂乱代码变成干净数据,不至于眼花缭乱。第四天,批量爬区,分页加循环,学会找分页规律,用循环自动翻页,一次性爬取多页数据,告别手动复制。第五天, 数据保存,把爬取的数据存到 t、 x、 t、 c、 s、 v 表格,然后直接用 excel 打开,爬取 水泥可用三步到位。第六天,基础反爬稳爬不跑错,控制爬距速度,解决四零三跑错应对,简单防护。最后一天,实战项目完整跑通, 整合全部所学,独立完成一个小项目,比如爬取文章、商品信息等,实现真正上手能用七天练完就能独立写基础爬虫,日常抓取公开数据,完全够用了。注意,一定要合法合规,控制爬取频率,希望屏幕前的你都能学有所成!
110校长讲python 49:41查看AI文稿AI文稿
49:41查看AI文稿AI文稿逼自己十天学完拍三网络爬虫,你会发现你真的很牛逼,纯干货,不废话,存下巴真的很难找全了!警告,本视频耗时六个月制作,制作时长六百分钟,陪你系统的学习拍三网络爬虫,这应该是目前抖音具良心全面的入门到进阶的拍三全套教程了,哪怕你是零基础也能听懂。 为了打造这套 python 课程,我系统研究了国内外大量教程,发现普遍存在内容杂乱、节奏拖沓、实践不足等问题。相信大家在之前也或多或少的看过 python 的 系列视频, 但是网络上学习 python 编程的资源太多了,家家都说自己的最好,这个难为坏了有选择困难症的伙伴们。这些视频总结下来就是鱼龙混杂,滥竽充数。 所以我决定摒弃所有的花里胡哨,用最原始、最直观、最纯真的方式呈现出来,能让大家最直接、最快速的吸收,并且最大程度上的活学活用,带大家由浅入深地从零开始学习 python 编程。 除此之外,我把学习 python 的 路上所需要的学习包都准备好了,有搭建 python 开发环境的资源包,还有详细的 python 学习计划表,路线,几十上百记素材,电子书籍和教程等等, 只要你能想到的素材,我这里几乎都有,我都会整理起来放在粉丝群,有需要的伙伴留言打卡学习可一步获取。 相信我,这套 python 系列教程将是最齐全、最详细、讲解清晰易懂的小白专用课。如果看到这里对你有所帮助的话,请给我一个免费的赞吧,让更多想要学习 python 的 小伙伴看到这个视频, 真心希望各位观众老爷们不要白嫖,今天我们学 python 爬虫, 哈喽,各位好啊,那从今天开始呢,给大家来讲解一个关于爬虫的一个教学视频,那在进入到正题之前呢,我们先做一个简单的引入啊 啊,不知道各位在生活当中有没有过这样的一些个需求,比方说我们在浏览到一些个啊,让我们看的特别的爽的一些图片啊,我们总想把它留下来对不对?可以作为日后的我们的桌面的壁纸, 或者说当我们浏览到一些个特别劲爆的一些个视频资源的时候,我们也希望能够把它保存下来,对不对?当当某天你 夜深人静比较寂寞的时候,可能可以拿出来慢慢的去品鉴啊,那还有一种情况呢,就是有些人在我们浏览到一些比较重要的一些行业数据,比方说股票的交易信息 对不对?那我们希望把这些信息呢给他保存下来,对不对?为我以后做投资啊,做一个数据的基础啊。最后一种呢?还有一种情况就是我们有的时候会听到一些比较美妙的一些歌声啊,为了防止这些歌声呢,在 某些特殊情况下,他被封杀掉,或者他被啊雪藏掉对不对?我们还希望能够拿出来再去进行一个品鉴的话,对不对?我们也希望把这些资源给他保存下来, 也就是说我们在平时生活当中经常都会遇到说我们在网站上啊,或者在网络上啊,浏览到一些个特别好的资源的时候,我们想想把它 存储下来啊,希望我们以后的时候哎,能够用到这些东西,那么恭喜你,如果你有以上需求的话,那我们的这门课就特别的适合你 啊,因为咱们所要讲解的这个爬虫啊,他的本质呢,就是通过我们编辑些程序来去爬取或抓取互联网上的一些优秀的资源,那这些资源呢,可以是图片呢,音频呢?视频呢?对不对?等等各各种各样的数据都可以去抓取, 那这是咱们要聊的第一个概念,那第二概念就是爬虫和 python 有 什么关系?我们往往会把 python 和爬虫它们两个呢绑定到一起来数那,呃,有些人会会会会问说爬虫一定要用 python, 并并不是这样啊,我们可以说用 java 也好啊,用 c 也好啊,或者说目前比较啊新兴的一类爬虫可以用 node js 啊,都可以。 就说我们的目的呢是在互联网上去爬取资源,那你用的手段呢是不受限制,就好比说你想吃 啊,吃吃吃饭对不对?那我们可以用勺子,用筷子啊,实在不行你用手抓也可以,但是你要想清楚用哪一种方式吃饭是最舒服的,对不对?那这里面就涉及到一个问题,就是 python 他 去写爬虫的优势是什么呢?就是他的语法特别的简单, 对于小白来说上手呢特别的容易,所以我们啊用用用 python 来去写这个爬虫呢,就是相对来说会简单一点儿,并且啊, python 还有非常多的 第三方支持的库,很多的繁琐的复杂的工作,直接有这些个第三方的库全部都给你干完了 啊,你不就不需要去做一些个特别恶心的一些个准备工作呀,啊,特别恶心的过度工作呀可能,呃,三行五行左右就可以写一个比较 ok 的 一个爬虫啊,所以这是我们选择 python 的 一个很重要的原因,就是它比较简单,而且它 在爬爬虫方向的一个技术支持,第三方库的支持是非常完善的啊,那这个是关于爬虫和 python 的 一个一个一个一个关系啊,然后还有这么一个话题,叫爬虫这个东西它合不合法 啊?这个东西合不合法?这个东西,呃,今年吧,今年好像说他的比较少了,前两年总能听到一些个风言风语啊,说某某某公司啊,他们在去学爬虫,然后呢,这个,这个被警察带走了,对不对啊?进局了对不对?那这个爬虫到底合法?在那个时候就引发了一一 段很长一段时间的一个社会关注。爬虫首先他在法律上是允许的 啊,因为这个东西是存在是合理的,是 ok 的 啊,但是呢,我们写的爬虫呢,是有违法的风险的, 这种各位要注意,就跟我们用这个菜刀是一样的啊,法律上是允许菜刀存在的,但是你拿他来,对吧?干一些个不法的事情,那对不起,对吧?那,那你真的没人惯着你,对吧?所以说我们写爬虫呢,也需要去注意一些个东西,不要说是 就是疯狂的对人家服务器,对吧?疯狂的去寻求,疯狂的去搞人家服务器,疯狂的抓取人家服务器,对不对啊?那这个肯定是对人家服务器会有一定影响的, 对不对啊?所以爬虫这个东西也也会分为善意的爬虫和恶意的爬虫,那善意的爬虫呢,就是不破坏人家原本的网站资源 啊,就是我们正常的去访问他啊,频率呢?就是跟正常人的频率差不多啊,不去窃取人家用户的隐私,不去盗取人家的这个这个这个 啊,资源,对不对?那这个就属于善意的爬虫,那对于恶意的爬虫呢,就比较简单了,就是比方说我们去抢票秒杀 对不对啊?还疯狂 solo 啊,网站资源造成网站当机,比方说我们对着哔哩哔哩对吧?几秒钟啊,一秒钟之内撸他个成百上千次,对不对?这这这这都属于是恶意的爬虫对吧?因为你对人家的网站造成影响 对不对啊?所以呢,这种爬虫呢,就是不太好啊,我们写爬虫呢,还肯定是推推荐个去写一些善意的爬虫啊,不到万不得已,那不要写一些恶意的爬虫 啊, ok, 那 么综上呢,为了就是避免我们进局子,对不对?大家还是安分守己啊,就是没事的把自己的程序呢做一个简单的优化,然后呢,不要去干扰到人家网站的正常运行啊,如果说让人家发现你你你你的这个爬虫是 很过分对不对?那这个时候人家报警了,警察啊,有可能也是会把你给啊带走的,对不对? ok, 那 这是关于爬虫合法化的一个简单的一个讨论啊,然后关于爬虫的一些个毛与盾啊,爬虫的毛与盾主要就是两个概念,一个呢叫反爬机制。 什么叫反扒机制?就是我通过程序去访问你的网站,那么这个时候你你你你,你想想,如果你是一个网站的作者或者网站的拥有人,那你肯定是不希望是程序来访问我的网站,你肯定希望是, 哎,用户来正常访问的网站,对不对?那这个时候我的这个啊,作为网站的服务器管理员,他就可可可以,对啊,他自己的网站做一个保护,使用一些策略,使用一些技术手段来防止 爬虫对你的网站的一个入侵,他会有一个反爬的一个机制,但是呢,你既然能反爬,那我就得想办法去绕过你设置的这些个策略来去抓到你的数据,那这个呢,就是反反爬策略, 对吧?这有点像套玩,是吧?反爬反反爬啊,这就是就是两个对应的一个一个概念,就是他是设置一个 障碍啊,防止你去抓取他的数据。反反盘呢,恰恰是想办法越过你设置的障碍,然后去拿到我们的数据, 然后呢,如果这个网站涉及到一些加密,而且加密加的非常非常严格的话,那很有可能你想窃取或者说想抓取的数据是人家的一些保密的商业机密的数据。那这个时候我就不建议你再去 啊,就是想办法在疯狂的去去去拿人家东西,因为这个时候你很有可能已经,对吧?到了一个恶意爬虫的一个地方 啊, ok, 那 这是爬虫的一些毛语顿啊,就是反爬与反反爬的一个策略,最后还有一个这个东西叫 robo 协议 啊,这个东西呢,它是一个协定,注意啊,是协定啊,就是我我我,曾经我家里面,我,我家里有有有一个亲戚说过这么一句话,就是叫防君子不防小人, 就协议就就大概就是这样的一个东西,就说我们两个约好了,哎,什么样的东西你能爬,什么样东西你不能爬啊?我们约好了,但是说如果你就是就君子协议吗?你小人一下的话,对不对?他的里面的数据其实你还是可以拿到的, 所以这是 robooth 协议,就这样一一个一种规定,就说我这面啊,可以告诉你哪些链接你是不能爬的对不对?这是 days long 对 吧?哪些链接你是不可以爬的? ok, 那 这个时候对于一个呃比较君子的爬虫来说,看到这些链接它就不再爬去了啊,就自动给过掉了, 这个就是一个路由器,但是如果你如果你是一个恶意的爬虫的话,什么路由器协议,什么这协议那协议的你都是恶意的软件了,对不对啊,谁管你那些,所以路由器协议它只是一个协议啊,只是个协议,它并没有说能够防止爬虫入侵的这么一个策略啊。 ok, 那 这是关于爬虫的一些基本的啊,改树啊,爬虫的基基本改树,那么咱们从这一节开始啊,准备就开始进入到咱们正式的爬虫的一些学习阶段了。 ok, 那 本节呢,咱们就说这么多,谢谢各位。 好,那接下来咱们说说咱们这道课里面要用用到的软件啊,首先呢是 python 的 选择, python 呢,我选择的是 python 三点八, 我现在讲课的这个时间呢,最新版本是 python 三点九啊,但是我不推荐各位就是直接上 python 的 最新版本, 因为最新版本它往往会跟第三方的库会有一些个版本上的一些冲突啊,所以呢我这块建议呢是往下降一个版本啊,基本上都不会有什么问题,但是如果你的电脑上已经装好了最新的 python, 那 你就用着。 你你什么时候在装一些第三方库的时候出现了版本冲突的问题,你再把它弄回来,对吧?再再再改成一个之前的一个版本是吧?就没有这个问题了。然后 这是 python 的 选择,再往下呢,咱们就是写代码啊,写代码呢,我是用拍叉,因为我用着比较舒服,也用习惯了啊,那拍叉呢,它的特点呢?就是写代码比较顺, 然后呢调 bug 呢?也比较顺,反正我我用用惯了,用惯了习惯了,但是你注意拍叉嘛,它是收费的。各位,它是收费的,如果你你你你你,你想用一些比较简单的工具呢,也可以用什么呢?那个主 pad 或者呢用 vs code 啊, vs code 都可以,它俩是免费的,想怎么用怎么用, 还不收钱,而且写代码写起来呢也是比较也比较 ok, 也比较顺啊。然后再往下呢,就是 python 的 一个安装问题啊, python 的 安装呢,只有一个点需要你去注意,就是我们需要把 python 添加到环境变量里面去,如果你不加进去的话呢,我们在黑窗口里面去执行 python 的 一些命令的时候呢,会有些障碍啊。 ok, 那 这是拍摄的一个就安装的时候需要的一个注意的一个点,然后呢我我为了防止一些小白啊,在在装拍摄的时候会出现问题,所以呢,我给各位演示一下。好吧, 准备了一个拍三点八点五的这么一个安装包,这个呢,你上官网下载就可以了。好吧,直接下载就可以了,我这呢就直接装了,直接双击, 双击之后它会弹出这么一个窗啊,这就是装 python 的 一个界面,那这个界面里面你需要注意的点就是这个, 看到 a、 d、 d 啊, add python 三点八就 pass, 就是 把 python 三点八扔到 pass 里面去,扔到 pass 环境面板里面去,这样的话我们在用黑窗口的时候呢,就就就直接能用了。好吧,那就把这个勾给它勾上,你把这勾勾上以后你就不用配环境面料啊, 如果这勾你没勾,听好,如果你没勾,那你需要去这地方, 哎,这地方,这地方。然后呢?把那个环境变量,把那个 python 安装路径给它加进去啊?怎么加呢?就双击好吧,然后呢这里面新建,把那个路径给它塞进来啊,把那个路径,比方说 c 盘的什么什么乱七八糟的,叭叭叭叭,一大堆东西啊,把这个路径给它扔进来就可以了。好吧, 这里面是需要你注意的一个点啊,我这块就取消,取消一会回来我们再看这块啊。好,然后呢这个勾勾上之后,呃,你可以选择上面这个,也可以选择下面这个,上面这个呢? 呃,就是直接装啊,就是傻瓜式的,你点灯他啪啪啪就开始装了啊。但是这里面有一个点,你看啊, c 盘 u s s 啊,什么一大堆东西,这路径太深了,对吧?所以我们选择下面这个, 然后呢这个这些玩意呢?别动好吧?过,然后呢再往下这块看,这看这,这是 python 的 安装路径,这很明显太长了,对不对?我们把它变短一点,变短一点好了,用用用这个位置好, insert 就 可以了。 我这块是装 c 盘了啊,你那块你自己选,随便这个,因为我这个电脑它就就一个 c 盘啊,就是个虚拟机。 稍等,等它装完,然后它会对环境变量做一个自动的配置。 come on, baby, come on, 兄弟,不给力啊, 对,这是一个拍叉嘛,这是一个拍叉嘛?这趁它装来说是拍叉嘛,这个拍叉嘛,装就比较爽了,你就一路确定就行。 好吧,一路确定,然后到最后呢,他会要求你去。呃,怎么说呢?要求你去填入一些个激活码,乱七八糟的东西。你,你如果说让你到了,你让你填激活码那个位置,你可以联系咱们的管理员,好吧, 我会告诉你怎么去。嗯,就是就是,搞定这个事,有些东西不能说的太明了, 我电脑比较慢啊,兄弟,这是一个,嗯,虚拟机啊,虚拟机,所以忍一忍吧。嗯, 不给力啊,兄弟,着急的兄弟,可以快进一下啊,快进一下, 你们的电脑现在装它的话应该是非常快的,比方说你现在电脑基本上都是四盒、八盒十六盒,对吧? ok, 好, 你看到这个玩意儿了,哎,你就爽了,那这个玩意儿是什么意思?说 setup was successful 啊,就说你的这个安装已经成功了啊,已经成功,这是个什么玩意儿?被 table pass 了,那个是 limit change operation into a low program。 呃,这个就就放这吧。啊,这个就放这,不管,那你看着它了,基本上就是说你安装成功了,然后回来咱们看一眼啊,它这个环境变量到底是个什么东西?来点属性, 然后高级啊,然后环境变量,然后呢?这个地方我们找一下这个 pass, 看这走看,这就是 python, 这个这个这个安装路径,刚才刚才我我选择的不就是这个这个路径吗?对吧?这 python 路径,然后你再加一个 scripts 啊,加一个 scripts 就是 你你你你如果需要新建的话,你需要新建的话,你把这个 scripts 你 给他打进去,注意这 s 是 大写的啊,它的文件夹的名字是 script 是 大写的啊。 好了,那这样的话,我们就相当于说 python 就 装完了,好吧,然后怎么实验啊?这个其实不应该在这讲,就是 python 就 装完了,好吧,然后怎么实验啊?这个其实不应该在这讲,就是 python 基础的一个问题。嗯, 来,在这,你你你,你弄出来这个这个命令。行了,好了,你这时候输入 python 回车。好,你看到这玩意了,恭喜你,你的 python 安装是成功的,而且环境变量也是配置 ok 的。 如果你啊, 如果你,你在输入拍摄的时候显示的是以下内容,那是这么个玩意,那就是你的环境变量没配置成功。好吧,就是你的环境变量没有配置成功。还有一种情况是最恶心的,各位 啊,这这这这,这种情况极少数人能碰到啊,但是给你们简单说一下,这也是我我我我我之前遇到过的一个一个状况。看着啊, 你们别这么干,你们别这么干,我只是给你们演示。有的时候会出这么个问题,可有意思了,来 c m d 看着啊,走, 你看,你会发现你在这输了个 python, 它哐唧这玩意出来。这是那个那个那个微软的那个商店啊? microsoft store 啊,这个微软的商店。那这是为什么呢?这是因为你的环境变量配置的还是有问题啊,如果你输入 python 蹦出来的是微软的那个商店,那你需要这么干点属性啊,还是这个地方,还是环境变量这个位置,还是这个 pass 里面,还是这个 pass 里面?看着啊,注意 这个点亮啊, windows app。 是 啊,这个文件夹里面就就就就对应的就是咱那个那个微,微软的那个那个破商店。好吧,那,那这里面就有那个微软的破商店。我们输入 python 的 时候,它会 从这个环境变量里面一个文件夹,一个文件夹去找他先找的这个玩意,那就会把 windows 那 个商店给你弄出来, 知道吧?所以我们不能先看他,得把他弄下去,下去他跑底下去了,那么这个时候从上往下再找 python 的 话,肯定先找着你自己个装的这个 python, 对 不对?他就没那个冲突了啊,你看,确定,确定,确定,重启黑窗口啊,每次改环境变量重启黑窗口 来喽,还怎么走?看,这就好使了,知道吧,这个是我之前遇到过的一个奇葩,奇葩现象啊,非常奇怪的一个现象啊,把它改了就好。 好,那这是拍摄安装的时候,你就注意一点,把拍摄加环境变量里面去。好吧,就记着这个事就可以了,然后拍叉把它安装,一路确定啊,一路确定啊,然后装,装到他要求你去输入激活码那一块,对吧?你去找咱们客服啊,会有一个神秘工具啊,为您解忧啊。 好,那这是关于咱们这堂课里面用到的软件啊,给各位去做一个简单的介绍,那么下一小节咱就终于可以去上手,对吧?首任就写一个小爬虫了。好,那本节呢,就到这里,谢谢大家。好, 那接下来咱们来写呃,第一个咱们的爬虫程序啊,那在写程序之前呢?首先我们先回顾一下之前我们聊过的概念,就是爬虫,它到底是个什么东西? 爬虫的本质呢?其实就是我们通过啊编辑程序来获取到什么互联网上的资源,比方说我们拿到图片呐,拿到网页里面的数据,对不对?那这是爬虫的一个本质的概念,那么各位想象一下啊,比方说我现在想拿百度的资源来,我想拿 百度的资源,如果不写爬虫的话,我怎么才能看到百度的东西呢?对吧?我肯定是先打开 浏览器,然后在这里面呢,输入百度点 com, 对 不对?然后敲回车,然后就能看到,对吧?百度服务器返回给我们的这样的一个页面,对不对?这是一个呃,我们我们平时总总操作的一个一个流程, 那么各位现在是我们手工操作的话是这样的,那么爬虫呢?爬虫是一样的,只不过爬虫是用编辑程序的方式来看到这个页面上的这些个内容,那么也就是说我们的程序本质上其实也是什么?去模拟一个浏览器, 对吧?也是搞成一个浏览器的样子,也能输入一个 u l 地址,然后打开这个 u l 地址,然后得到里边的内容, 对吧?逻辑思路应该是一样的,只不过我要用程序来去,哎,干干这件事对不对?不能用浏览器了,得用程序了。那在拍摄里面我想实现这样的一个需求的话,应该怎么做?那首先我们把需求罗一下啊,需求就是说,呃,用程序去模拟 浏览器,然后呢去输入一个网址,并且从该网址中获取到资源或者内容, 对不对?这是我们的本质的需求需求。那用 python 来去搞定这件事的话,到底难不难呢?各位,我告诉你,特别简单,来 python 搞定以上需求,那只需要。呃,也就三三三步吧,大概也就三步啊,那 d 特别简单吧。特别简单 啊,第一件事,我们需要导入一个 python 的 一个包啊,导入 python 的 一个包,哎。 from url lib 点 request 啊,然后导入什么呢? u l open。 来,简单解释一下这个,这,这是拍摄的基本语法了啊。从这个包里面把这个东西给它导进来,那它 u i l 里的 u i l 这是什么? 这就是,就是一个,一个,你可以认为是网址,好吧,一个网址的一个库啊,关于跟网址相关的一个库,从这个库里面找到 request 的 这个库。 request 的 库里边呢?有个东西叫请求。什么叫请求啊? 看着我在这邦叽敲个回车,这这鬼东西他叫请求,也就说我们准备好一网址,一敲回车,这叫请求。那么从请求这个库里面拿到一个叫 u r l open 的 东西, u r l 是 什么网址? open 呢?打开,合起来读,打开一个网址, 好吧,所以我们要把它弄起来,把它弄起来怎么来?用它来? u r l。 我 先准备好我的网址啊, h d p 冒号大哥, 来,我们准备好,我们要呃,去去去抓取的这个啊。网址 u l, 然后我们就可以用这个东西它的,它不是打开一个 u l 吗? u l 也有了,那来吧, u l open 对不对? open? 谁 open? 这个网址对不对?那你仔细看一下,这个鬼东西是不是就可以当浏览器了?这个地方是不是就是那个地址表啊?对不对?这俩玩意就就就就配搭配起来,就打开一个网址,打开哪个网址扔进去,打开这个网址就跟那个网网址,是不是返回给你东西啊?对不对?那返回的东西来,我前面准备一下 response, 好 吧,这就是一个很简单的打开一个网址,然后得到一个响应啊,这能叫响应?那么得到响应里面我们想要的是什么?各位, 你可千万不要被迷糊了,我们得到的响应不仅仅是这个网网页,他还有一些什么响应头啊,还有一些七七八啊,就奇奇怪怪的东西,很多东西都在里面了,那么我们想要的是这个内容, 主体就是说我们想要的是这一篇内容,对吧?这是内容,这想得到内容的话,怎么得到?那么我们需要 response, 点 read, 对 吧?你看这这这玩意,其实你从上到下,你把它英文字母、英文单词翻译一下,其实你就能明白了, 打开一个网址,得到一个响应,从响应里面去读取内容,那不就是读到的这个网址里面的内容吗?对不对?那么读到的内容,各位,这地方有个小坑,来,各位, print response, 点 read, 来,我读出来啊,走, come on, baby, 来看,跑出来了,跑出来之后注意这里面,我给你找个中文啊,找个中文,中文,中文, 哎,看这这这个地方其实都是中文啊,拉到最上面拉拉,拉到最上面,拉到最上面,你会发现这里面有各种杠叉杠叉杠叉对,杠叉,这个东西是怎么回事?再往前看,前面有一个 b 撇啊,一个 b, 然后带一个,带一个带一个。这个,这个 代引号那么熟悉 python 的 小伙伴应该很清楚,这个是字节儿,这个是字节儿,也就是说我们需要把这个字节儿给它还原成我们想看到的字母串啊,还原成字母串,那么各位怎么还原呢?来,这个地方点字节转字母串固定的 d 透, 对吧?一个解码,解码,这里面问题来了,这里面应该放 g b k 呢?还是放 ut f 杠八呢? 哎,看好啊,我们在这里面其实能看到一些东西的啊,什么刀后面的乱码七糟的。来,这地方有个叉赛特 utf 杠八,你看到他了,其实你就应该应该已经很清楚了,这个地方解码要用 utf 八啊。然后我们再跑一下, sorry, 手速有点快啊。走, 来看,往上拉,拉到上面去,走,你看,各位,我们能够看到这种中文的信息,对不对?能看到中文信息了,那现在还是有有问题,对吧?还是有问题? 你你你,现在给我看的是这大堆我看不懂的东,看不懂的东西,那我这面网浏览器里面看到的,对吧?这个东西就很舒服对不对?最起码他他他他他他能看懂,对吧?这玩意看不懂一大堆英文字母啊,一堆一堆怪异的符号,但是没关系,各位, 我们把这些内容给它保存到一个文件里边去啊,把它保存到一个文件里边去。来,我们打开一个文件,可以走 open, 打开一个文件,比方说我叫 my 百度,好吧,点 h t m 这个地方 mode 等 w f, 点 right, 然后呢?哎,把这串东西都给它弄下去,走走。然后最后呢?来一个小提示啊,来个小提示, over 啊,搞定,走, come on, 我 的老 baby, 来, over, 搞定,来,看,这多了一个文件,叫 my 百度点 html, 我 们一一双击,哎,我们发现这里面东西跟刚才我在,对吧?在这个底下看到的打印的东西是一模一样的,对不对?还是那段,那就是那一串子看不懂的东西,没关系,看好啊, 右键,我这地方有个 run, 走,你右键,我这地方有个 run, 走,你 看这,来,我把它拉过来这个拉过来,来,拉过来。你仔细看啊。嗯, sorry, 来,你仔细看,这个是我在浏览器里面,对吧?输入百度点 com 得到的东西来,这个东西,这是我的这个什么?爬虫,第一张 my 百度点 html, 对 吧?爬虫,第一张 my 百度点 html, 也就是说我们现在看到的这个网址 下面这个网址实际上是我们从百度这个网站上抓下来的,你仔细看,是不是一模一样,对吧?是一模一样的。那么接下来 诡异的问题就出现了,就是说,哎,我这面看到的这个这个网站,来看这我们看到的这个网页,哇,这这个啊,虽然丑点啊,反正最起码能看我们看到的这个网页 他的本质。各位是个什么玩意?是不?就这大堆字母串,因为我们已经运行出来了,我们运行出来的这大堆东西和你那百度的这个网网页显示的是一模一样的,对不对?那为什么? 为什么?我们爬虫,各位啊,这个地方多讲一点啊,为什么我们爬虫拿到的是这堆东西,然后呢?浏览器会把它显示成这个样子?各位,我要告诉你一个,呃,你可能不愿意承认的一个一个事实, 我们的浏览器拿到的其实也是这堆东西,只不过我们牛逼的浏览器会把这一堆我们人看的很痛苦的东西把它运行成这个样子,把它运行成这个样子,不信你看啊,我把这个擦掉, 我把这个擦掉来,这个是我们看到的,对吧?这个,这个,百度的这个啊,网页,我们在一个空白位置,右键来显示页面原代码,走,你 来,各位请看,这个是整个网页的原代码。什么叫原代码呢?就是你在输入这个网址之后 啊,你,你这个时候输入完网址,一敲回车,他会找到百度的服务器,然后呢?百度的服务器会返回给你浏览器 这一堆破烂东西,就这堆你看不懂的这堆啊,你可以认为是乱码,也可以是啊,如果懂得知道这叫 html, 对 吧?它会返回给你这堆东西,然后你的浏览器在 在在在在后台默默地把这一堆东西给它运行成了这个样子啊,把它运行成了这个样子,所以我们看到的是 a, 是 这样子,但是它的背后,你要知道它里面其实是哎 多了,他的背后其实是一堆啊,这大堆东西啊,这大的东西,当然你看这个东西不用迷糊啊,你不用迷糊,这个,呃,就就就,百度嘛,搜索引擎嘛,他在这里面的内容可能会稍显复杂一点啊,但是普通的网页可能比这个要舒服一点啊,要舒服一点,所以 我们就成功的。各位,哎,成功的通过 python 的 一个程序,你看这才几行代码呀,对不对?哎,通过 python 的 程序,我们打开了百度的这个 ul, 然后呢得到了一个响应,从响应里面呢读取到了页面源代码这个地方,注意我们拿到的 是网页的页面文案啊,这个地方你要注意一点啊,所以我们成功的,对吧?写成了一个我们啊拍摄的一个爬虫的一个小程序啊,小程序。 那各位你可以去拿着这一套程序去其他的网站上去试一试,也可以自己去呃,去去搞一搞,对不对?然后把这几个单词呢,还有这几个呃每句话的含义呢?简单的去分析一下,尤其是纯小白啊,简单的去分析一下,然后各位给个呃,我要打个广告,下一小节非常的重要,各位 看好,下一小节非常重要。这是这小节的啊,看,下一小节非常重要。下一小节我们会讲 web 请求的全部过程的一个剖析,这一节必须要认真听。然后呢好好的去啊,去去理解一下,在你以后写爬虫的时候,这一节内容直观重要啊,直观重要。 好了,那咱们这小节呢,就说这么多,好吧,各位可以回去去简单试一下,对吧?并不复杂,并不复杂啊,一共就这么几行 time 好 了,那本节呢就到这里,谢谢各位。 好,那经过上一小节呢,咱们成功地使用 python 对 吧?写了一个呃小爬虫对吧?那接下来咱们来对呃 web 请求的全过程做一个 啊,比较详细的剖析啊,这个对我们以后写爬虫呢是特别特别有帮助的,因为我们以后要长时间的跟这个呃外部请求去打交道,所以我们提前把这个东西给他呃学会整明白,然后以后写爬虫的时候呢,我们就能够轻易的去找到一个入口啊。 ok, 那 还是回到之前啊,咱们上节呢是写了一个爬虫,就是爬百度,那爬百度的话呢?我们,呃在输入完这个 网址之后,我们敲了个回车,然后我们就在这等待,等待,哎?服务器返回给我们一些内容,对不对?那在这个过程当中究竟发生了哪些事情,对吧?简单的给各位剖析一下啊,那这是你的电脑对吧?这是那个百度的服务器,我们放近点吧,这是百度的服务器 啊,然后在我们去输入完一个网址之后啊,比方说输入百度点 com 呢?这个时候我浏览器会发送请求到百度的服务器,对不对?那这块我们会输入网址,对吧?百度啊,那 请求到百度的服务器,百度的服务器收到这个请求之后呢?他会返回给我们一个什么 html 的 一个内容,对吧?就是返回页面代码吗?对吧?返回 html 内容,那么各位 在这里面其实还隐藏着一个问题,对吧?我们现在看的只是百度点 com, 那 如果说我想搜一下周杰伦, 对吧?我想搜一下这个某个信息呢?那这时候我们在请求百度的时候一定会带着一个参数,这个参数呢?比方说我搜周杰伦,对吧?带着周杰伦三个字去找百度, 找百度之后,百度第一件事是不得收到周杰伦这三字啊,收到了之后他会拿这三字去做一个他自己内部的一个检测,对吧?把跟周杰伦相关的内容全给我拽出来, 拽出来之后排序对不对?哪条信息放在前面,哪条信息放在后面?他有排名吗?对不对?百度还有个排名。那排完了之后注意啊,整个过程完了之后,他会把 周杰伦相关的信息给他,不是盯在 html 里面,直接写在 html 文件里面,然后统一的进行返回,所以他返回的内容没那么简单,他返回带有周杰伦 的,哎 哎,带有周杰伦解锁信息的 html 内容,把, 把这些内容统一呢返回给你浏览器,然后浏览器啊帮我们运行,帮我们执行,然后让我们能看到,对吧?整个页面的内容,对吧?那这个是啊,一个普普通通的网站,正常的一个网站的一个,正常的一个请求思路啊,正常的一个请求思路。那我们来看一眼这个百度是不是这样来做的?来,在这块, 对吧?来,我们先找百度啊。 来,这是我们进到百度这个页面,然后我搜周杰伦 啊,搜周杰伦,注意我一回车看,我们能看到周杰伦相关的内容,现在是显示出来了,对吧?是显示出来了,但是我刚才说了, 百度是把周杰伦相关的内容直接盯在了 html 里面,也就说 html 里面他的页面源代码里面应该是有周杰伦的相关信息的,对不对?要不然我刚才说那些东西就是就扯淡了,对不对?来,我们来看一眼他的页面源代码里面有没有这堆东西,好吧?来,右键 显示一名人在哪来,往下拉啊,直接搜吧,来搜周杰伦,来,这个不是,这个不是。过过过来看这周杰伦,中国台湾流行歌手啊,然后呢?音乐人,演员,导演啊,百度百科来看这头, 看周杰伦中国台湾流行粤男歌手,什么乱七八糟的,这些东西是不是恰好就在页面源代码里啊?对不对?所以我们说啊,像百度这种网站,或者说我们平时见到的大多数网站其实都是这个样子的,就是他 会直接把相关的内容怼在 html 里面,统一进行反馈。那么在这个过程我们给他起个名字,叫什么呢?叫服务器渲染, 叫服务器宣。什么叫服务器渲染?就是在服务器那边 直接把数据和 html 干嘛呢?给他整合在一起, 统一返回,给什么浏览器统一返回浏览器,所以我们浏览器收到的一定是有什么有内容的,这个就是 tml, 对 不对?那这是第一种啊,叫服务器渲染。怎么叫服务器?为什么叫服务器渲染?因为他是在服务器那头搞定的这个事 啊,在服务器里面就已经把数据跟 hm 结合了,那第二个有第一,肯定有第二个嘛,对不对?第二个叫客户端渲染。来,各位客户端渲染啊,客户端渲染是怎么回事?谁是客户端? 谁是客户端?各位,你用的这个浏览器他叫客户端啊,这个浏览器他叫客户端。那么也就是说有些数据啊,有些内容是在浏览器这头把数据怼进去的,把数据怼进去的,不信你看啊,来我们找这个网站,找这个网 站。这个网站呢,是豆瓣的一个呃,电影的分类的排行榜啊,喜剧片怎么进呢?这块有一个电影啊,这豆瓣的官网啊,豆瓣的官网,然后进这个电影, 然后这块有个排行榜啊,注意在这个之前它都是什么呢?都是服务器端宣渲染,因为这些数据全都是在服务器那面,已经绑到 html 里了啊,就是我们在页面代码里面能直接看到数据的。那来给各位看一眼啊, 走走走走走走,这呢无一之地啊,游牧人生来这无一之地游牧人生,对吧?数据直接是放在页面元代码里面的,然后各位看啊,在这在这,我们点一下这个分类排行榜,我们看一眼这个,呃,喜剧, 来看喜剧片的分类排行榜。那么各位,我们看到有个憨豆先生精选集,来右键元代码看看,这个就不一样了,我把其他的关掉,我们在这搜憨豆 走看,你会发现整个网页里面根本没有憨豆两个字根本没有憨豆两个字,那为什么会这样呢?各位看,我们这边明明是有憨豆的,对吧?你到了这个页面代码里面没憨豆,那这个就很奇怪,对吧?这就很奇怪,为什么会这样呢?各位, 这种网页他是属于客户端渲染,客户端渲染是怎么玩的呢?看好啊,是这么玩的 啊。来这,这也是我的浏览器啊,这也是我的浏览器。然后呢?这是人家的服务器啊,这是人家的服务器。注意, 我第一次请求,我是请求豆瓣的那个,那个那个排行榜的那个网页,对吧?来请求豆瓣排行榜网页,对吧?我是请求这个网页,那这个服务器呢?就比较单纯,你要网页我就给你网页来,看着就给你网页 来给你,给你一个 stm 股票,这个股票里面有没有数据的? 很明显没有,我刚才咱不搜了吗?页面原代码里面它根本就没有憨豆那两个字,对吧?没有,没有的话怎么办呢?我还想显示注意这个时候它会执行一段脚本,然后呢让你的浏览器再发送一个请求,这个请求是干嘛呢?要数据, 要数据,因为你上回只给我一个股价,我没有憨豆,对不对?那这次我要数据,我要憨豆,那我要数据,要数据的话,这边就咔开始去搜索呀,查询呐,反正不管怎么着, 凑吧凑吧,凑出来这堆数据,把这堆数据返回给你的浏览器。那这面呢?是给数据 啊,要响应数据,给数据,给了数据之后,这边的你你,你的这个浏览器是不是就收到数据了?拿着这些数据跟刚才的那个 html 股价他俩一拼, 对吧?哎,我们的韩豆是不是就出来了?所以各位,我们单纯的只看上一次的这个页面元代码里面是不是就没有数据啊?数据是下一次请求才有的数据, 对吧?下一次请求才有的数据。那么这个时候各位你想象一下数据跟 h、 t、 n、 l 的 结合是在哪结合的?肯定不是这头, 肯定不是这头,是不是在这头结合的,对不对?我这边拿到股价,然后再拿到数据,在这边把股价跟数据拼接到一起,对不对?那这个就是,哎,叫客户端选,因为在客户端完成的数据啊,插入,那么这个是 第一次请求,只要一个什么这个 html 股价啊,然后呢?这个第二次请求拿到数据,然后进行数据展示 啊,它的特点是什么呢?就是在页面元代码中, 我把它敲下来,我把它敲下来,敲下来,来,在页面原代码中,我们干嘛呢?看到对不对?上一个特点跟它正好是什么是不相反呢?它是什么在页面原代码中 能看到,所以我们就有了这样的一个,呃,基本上一个恒定的一个,一个一个观点就是说,呃,有些网页在源代码中是能看到数据的,有些页面在在这个源代码里面是看不到数据的,但是看不到数据。你别慌 啊,你别慌,你只要找到他那个请求,因为刚才我不画了吗?这个,这个图存不下来,是吧?这一个,这一个来,我不画了吗?第一次请求确实是没数据,只是个骨架子,对不对?那看不到数据吗?那第二次请求,我只要能够找到第二次请求的这个这个 url, 我是 不就能 就一定能够拿到这个数据啊,对不对?所以我只要有找到这个 url, 我 就能拿到这个数据。那这个 url 怎么去找, 对吧?怎么去找?因为只有他才能拿到数据,他是拿不到数据的,对不对?所以只有他能找到数据,那怎么办?各位,我们要熟悉使用浏览器的一个抓包工具来熟练使用浏览器抓包工具 啊,要熟练使用路由器抓捕工具。什么是抓捕工具呢?就是在这那找找,找,找这个网站吧,来,其他的都关掉啊,来,我们在这个地方可以有右键找找检查,或者说直接按 f 十二。工具呢?就是在这 那找找找找这个网站吧,来,其他的都关掉啊,来,我们在这个地方可以有右键找找检查,或者说直接按 f 十二都行啊,我按 f 十二。 f 十二里面它有什么? elements? 有 console, source, network 啊, performance, 还有 memory 等等一系列东西吧。这里面有个 network, network 叫网络的一个工作状态,那这里面其实就是你在进到这个网址之后 啊,就输入这个网址之后他一共会发送的啊?哪些网络请求?你想看哪些图片?你想看哪些哪些数据?所有东西全都在这里面会有一个显示全都在这里面会有一个显示。那我们来在这个位置敲一下回车,各位请看 来我们一敲回车来,我们往上拉,我们往上拉,拉到最上面看这有个 type rink 是 什么玩意呢?这个 type rink 我 们点一下 来,点一下看这个 h t t p s movie 点豆瓣点 com, 这是我当前这次请求的什么 url, 对 吧? url 在 这呢,你看这个 url 是 不是上面那个破 url, 对 吧?所以这个其实就是拿到的,就就刚才说的第一次请求,我只拿到网页的股价,为什么能看到是股价呢?看这有一个预览,我我我预览一下对吧?预览 来你会发现这里面内容是十分简陋的,十分简陋,但是一部分内容其实是能看到的,对不对?那真正的我想要的这个这个憨豆先生,这里面是并没有的,对不对?并没有这个憨豆先生的,所以再一次证明。看着再一次证明。我的第一次请求就这个玩意。第一次请求,这是你的 电脑,这是人家服务器,你的第一次过去回来的只是一个股价, 对不对?我们看的很清楚了,在这里面它只是一个骨架,并没有数据。数据在哪呢?来,往下,接着看,往下拉,往下拉,往下拉啊,这大堆是 gs, 这个是图片,往下拉,不看图片,呃,看看是不是不是他不是他,不是他,往下走吧, 这有点多啊,找一找,找一找,这呢?这是雷挺,雷挺啊,这是第一个,这也不是他 来,我们找到了,看着啊。看这这有一个请求这还一个请求,也就是说我们输入着完网址之后啊,它不单要加载一些 gs, 它还加载了这么一个链接,这个链接的 u l 是 什么呢?是这个东西 对吧?是这样的东西。什么?呃,反正就就是跟这个不一样,你仔细对去吧,绝对不一样。然后这个链接会返回什么东西呢?来预览一下对吧?看看他会返回什么?他返回了一个这个东西叫 jason, 对 吧?一个 jason 来打开 看,这这里面有什么?憨豆先生精选集来看这憨豆先生精选集,并且你仔细看,这个数据其实是一个规则的啊。 actor count 来看这 actorcount, 对 不对?所以它这个这个数据的格式是固定的啊?格式是固定的,所以它返回的就是我们页面上需要的数据,再一次证明 是吧?再一次证明看到这个网页其实是什么?这是我的电脑,这是人家服务器。第一次请求你给我一个 html 的, 一个一个一个股价,然后我再请求你把数据给我,我真的啵,把数据给你了。哪块是数据?各位 是不是这里就数据啊,对不对?把这堆数据是不是就返回给你了?然后我这面再咔咔咔一顿渲染,对吧?把这个刚才那个那个股价和这个数据倍倍,他俩意思吗? 一怼是不就怼成了我们现在看到这个样子,对不对?所以我们就就知道了,这个这个这个,呃,就是数据在渲染的时候,这是第二种渲染方式,是在我们的浏览器端进行的一个渲染啊,在浏览器端进行的渲染,但是这个概念 不重要。好吧,这个概念不重要,重要的是什么呢?就是,呃,你以后再发现一个网网页里边的内容,对吧?这个内容在英文代码里面找不着找不着,你别慌,他肯定还有其他请求, 对吧?他的数据不是一次性全加载进来的,他肯定是有第二次请求,或者说有什么其他的一些相关操作,对吧?这数据不一定是直接对在 html 里 边的啊,这个是你需要去注意的一个点啊。然后再有呢,就是各位这个地方你一定要去把它啊, 怎么说呢?这个就这里面多熟悉熟悉吧。啊?多熟悉熟悉,如果说啊完全纯的,纯纯的零基础小白的话,这里面都会需要你去熟悉什么啊?需要你熟悉什么?如果之前做过开发这块其实是很容易理解的啊,因为开发天天用着玩啊,天天用着玩啊。对,还有一个题外话,还有个题外话就是 我现在真的想要这些东西,哎,我现在真想要这些东西。各位我用不用去寻求这个这个这个首页这个 atm 股票我一定去 啊,你思考一下对不对?很明显他不用,因为这里面没数据啊,我要的是数据啊,数据在哪次请求呢?是不是下面这个? 嗯?什么?我还找一找是不在这呢?数据是不是通过这个 ul 请求出来的对不对?也就说我以后找数据我找他就可以了,对不对?而且拿回来的还是什么规则数据,对吧?一个规则的 jsen 数据,所以 不见得啊,不见得这种情况就不好啊,不见得这种情况就不好,尤其对我们爬虫而言, 对不对啊?直接拿到数据是最爽的对不对?而如果你把数据怼在 html 里面,我还得从 html 里面的去提炼,对不对?反而麻烦哈,反而麻烦。所以这里面啊,并不说哪种方式好,哪种方式不好 啊。好,那这个是我们呃外部请求的这个过程做一个简单的剖析啊,以后我们看到呃页面代码的时候,你就知道了,这个网页对不对?它的数据到底是啊, 是放在这个 html 里的,还是没放在 html 里的,对不对?哎,你就有一个可以参考的依据了,我们写写起来呢,也会顺手很多,对不对?好,那咱们这小节呢,就说到这,好吧,谢谢各位。
 01:50查看AI文稿AI文稿
01:50查看AI文稿AI文稿今天为大家带来一款操作简单、功能强大、执行顺滑的全能爬虫工具 tikub。 首先,我们打开网址进行简单的注册后,即可进入客户端, 左侧功能栏聚集了目前几项热门的功能性条目,用户可自行选择需要使用的功能。点击 api 管理,创建独属于自己的 t 后,即可轻松访问包含所有主流社交平台的公开接口。 教程中下滑找到查看文档,所有可为你服务的接口蓄势待发。 用户可自行选择具体需要的接口信息 使用代码。视力网站提供不同语言的调用,视力小白也可轻松上手。 网站还同时适配了更为丰富的数据级功能。海量的集合无疑是 ai 时代最为高效的掘金铲。 以某书为例,可选择不同的信息参数,性价比更高,支持客户定制化,寻找独属于客户自己的专用数据集。 最后, tiklab 已接入几个主流 ai 模型,方便客户实时处理、筛选、清洗各位所需要的数据样本。
2爬虫大王 08:08查看AI文稿AI文稿
08:08查看AI文稿AI文稿爬虫逆向实战教学系列第十六期猫眼票房数据采集,我们今天来看的是猫眼的票房数据采集,同样也是一样的右键选择检查,打开开发者工具,打开之后进入到网络面板当中,在这里去刷新抓取数据包,然后 ctrl 加 f 弹出来搜索框之后,再来去搜一下对应的这个数据。 我们来看一下这里的第一个是疯狂动物城二,我们可以搜一下他这个是零四,这个是零一,零一是疯狂动物城二,搜索疯狂动物城二二 搜索发现他在这里都有出现,一二三四五五个数据包里面都出现了,而且他这五个数据包都是一模一样的名字,那也就是说他在不断的去发包,这个猫眼他的确也是实时的去更新的,所以他在这里会不断的去发数据包。我们随便找一个来看, 在这个里面他的确有对应的一些数据,比如说什么上亿六十七天名称,他的一些百分比啊,其他的一些数据,那这个地方其他的数据其实没什么好说的,他都是正常的去获取就好了。就综合票房他是去给他做了加密了的这样的一个建值段里面的一个 number, 这个是做了加密的,所以我们在想象当中能拿到的也是这样的一个数据,你就需要去给他做解密,给他解回来,我们可以先去试一下右键去复制他的一个 c 二幺,在这里通过一个转换工具给它转换成 python 代码去复制一下, 我们这里创建一个拍子文件,猫眼票房好粘贴过来之后, cookie 给他解开,这上面的给他收起来一下,我们先来去测试一下能不能得到正确的数据。 print response 点 json, 它是 json 格式的数据,可以右键去运行,看一下能不能得到。是能够得到正确的数据的,它在这里获取到的数据的确也都是密文值, 那这个时候它其实是什么?就是字体加密,我们在这里的一个元素面板去看的时候,它这里也是不会显示出来的,来看一下这里,它也是没有显示的, 它是一种字体加密,那么字体加密肯定就会有字体文件,我们这里可以看一下,你会发现他这里每次去发一个 movie 的 数据包的时候,下面都会带一个什么?带一个点 word 的 字体文件,那么这个点 word 的 字体文件的 y r y 能不能搜到?我们可以搜一下 这个地方,给它拿过来一点,好给它搜一下这个后缀,其实它是能搜到的,而且它其实就是在什么,在这个数据包当中, 在这里有个 font 这样的一个样式,样式里面包含了这样的一个链接,所以我们也可以去取,可以在文档这里来看一下,它是直接字典去取值就好了。我们这里取一下这样的一个 font style, 这里给大家赋个值,赋个变量, 比如说来个 data, 那 么 data 去取这个链接,我们来去打印看一下。 print u r l 右键去运行,是能够得到这样的一个链接的, 得到了之后,但它这里还需要去做一下处理,是吧?因为我们这里要去取它,它里面还有一些其他的东西,当然你可以通过正直来去取,也可以通过一些字母串的处理方式来去处理,我们这里就可以去用切割的形式,比如这里用它来做切割, 切能切出来三个,我们去取最后一个,那么这就是点 split, s p, l i t。 用它来做切割,去取最后一个,取到了最后一个之后再来去对它做处理,我们把后面的这个给它去掉就好了。点 replace 啊, e p l a c e 去掉 定位替换为空,前面呢需要去给它拼接上 h t t p s, 这里再给它拼接一下,就是一个字体文件的 u r l 了。 h t t p s。 加个冒号吧。好,这里是 font u r l。 再来跑一下,现在这里就得到了这个链接之后我们就给他请求下载到本地,那这里再去给他这个字体文件,我们也给他单独的去带一个 adidas 过去,请求他这里就是一些这样的一个数据,我们来去再转换一下,因为他字体文件和普通的一些其他的文件可能不太一样。请求头我们给他单独拎一个过来。好,这里给大家再设置一个,比如说是放 adidas, 设置好了之后,这个地方收起来,我们就给它请求一下 v 字 open, 这就是猫眼点儿 word 这样的一个后缀。 w b 模式,给它写入 r s f f 的 right, 去写入它的什么静止格式的数据。 get 这个 y y 就 等于放调 y, y 也等于放了 y y, 点 content 去写入它的静止格式的数据。来跑一下,能不能给它下载到本地这个字体文件,这里就多了一个点 word 的 一个后缀文件,我们在本地打开看一下, 打开之后这里可以去双击,用对应的一个软件给他打开,稍等一下,这个字体软件他启动会比较慢,这个时候就可以看到他在这里就得到了这样的一个界面,这个就是他里面那些数字,零一二三四五六七八九,包括一个点、小数点之类的,他也是有的, 就可以去通过这样的一个字体文件,然后去得到他对应的一个印刷关系。那么怎么去获取他的印刷关系?他的印刷关系是什么东西?这里我们可以看到他的一个数据文件里面是这样的一个数据,他这里肯定是一个编码,就对应的是一个数字, 这里应该也不是不叫编码,他这里是一个相当于密文值,就对应了一个数字,那么就需要找什么?就需要去找到。比如说这个密文值他对应的是谁,这个密文值他对应的是谁,他肯定证实是变化的, 我们要去找到他的一个印刷关系之后,再来去把这样的一个密文纸给它替换成明文纸。至于怎么去给他做识,怎么去给他找到印刷关系啊?这里他其实要去用一些识别模块,我这里就有一个代码, 我们就可以去导入这个代码,去教给他识别就可以了。 from import 这个识别导入文件。好,怎么去用?这里就直接用它识别导入文件,去点这样的一个方法。 get 这个方法,咱们这里就得传一个路径过去。好,他这里过去得到一个结果, resuit 结果来打印看一下 print resuit 右键去运行,他会交给对应的识别模块去做识别, 那就得到了这样的一个识别的结果,比如说他把这个识别成了一个八,把这个识别成了一个九,对应的是一样的,这里会得到一个最终的结果字典, 这个字典我们要去给他做一下处理,这个一二零其实看起来好像要给他带上说不定是什么其他特殊的东西。那现在我们这里就可以去给他做一个处理了,这里他是什么?他是一个相当于密文值,对应上的是明文值, 那么你说这个密文值他和我们在想象当中看到的也不一样,他这里是这样的一个形式,是吧?这是因为他在这个地方是显示的实景值, 我们这里要去给它弄成十六帧制的,就需要去循环,循环这个 reset 点 item, 这样呢这个是一个字典,去这里我们可以去给它 for key value, 这里来打印看一下 key 和 value, 右键去运行就能够去得到这样的一个东西。得到这个东西之后我们就再去给它做一个,比如说十六帧制的转换 变成了这种形式,变成了这种形式之后,它这里依旧还是不太一样,但是它后面的位数是一样的,后面是四位,前面的零 x 不 一样。密文就是这样的一个拼接符井号 x, 所以 我们就需要去把这个零 x 给它替换成拼接符井号 x, 假如把零 x 啊替换成这个好, 那么这个就是我们的一个,比如说新的 key, 新 key 这里我们就再来去弄一个,比如说 font d i c 创建出来一个字典,这个地方就是一个 font d i c, 它的一个 key 就 等于这个铭文值,最后我们这里再来去让它得到最终的映涉关键字典得到了之后,现在我们就可以去循环这样的一个数据了嘛, 我们去取这个数据的,这里就没什么太多好说的,这个正常去循环取值就好了,这里直接把它代码给大家复制过来啊,差不多就是这样的一个形式,给大家做循环取值就好了。我们来就先跑一下,其他的没有去打印,就只打印了简单的一些 不需要去做解密的内容,那么现在需要去做解密的内容来打印看一下, print 它好,这个数据我们需要去给它做解密,我们就把这个数据再交给一个函数去做一下处理,我们就给它分成一个函数,就不在这个循环里面去写了。比如这里来个什么替换,他接受一个,比如说,嗯,现在我们这里要去循环这样的一个字典,循环这个字典, four, 这个 key, v, 这个 d, i c, atom 在 这个地方就可以去对 n 来做替换的, n 等于 n 点 plus, 将什么呢?将它的 key 值、密文值替换成什么?替换成对应的铭文值就好了,我们最后循环结束之后给它 return, return 这个 n 就 好了, 把这个数据给它传出去的是替换,这里是传入他接收,比如说就接受一个 n 来打印看一下 print n, 右键再跑一下,那么就能够去得到对应的一些数据了,它中间有有分号呢,咱们在它返回的时候把这个分号给它替换掉就好了。加入 plus, 将分号替换成空值来再跑一下, ok, 就 得到数据了。幺幺三五点三八来看一下这里是不是刷新,他肯定会变化幺幺三五点五一了,这里他咱们再跑一次,他这里是在不断的增长的, 现在这里也在变化,变成了六一了,幺幺三五点六幺了,现在这里六九了,他在这里不断的去加。好吧?这里我们就给他做解密了,下面的零点零,零点零零的也是正确的一些数据,这个就是猫眼票房的一个字体加密的一个逻辑。
66爬虫逆向学习 14:00查看AI文稿AI文稿
14:00查看AI文稿AI文稿拍摄爬虫三十天,从零到精通,今天是表格文件操作于案例实战,我们这里再来创建一个拍摄文件,这里去写个什么 l x、 l x 文件,操作 好要去操作这样的一个文件,我们这里可以通过这个模块,但是他有这个 excel 文件的专属的库,那当然那个专属的库就太麻烦了,到什么涉及到了一些办公自动化的操作了, 这个就很复杂,我们这里来给大家讲个简单一点的,假如这个模块需要去安装这个库,需要在终端去 p i p 安装一下就好了,这个可以执行一下 p i p excel, 执行一下这样的一个命令就可以了,好吧, 好,那么它这个不只是可以去操作这个 x、 l、 s、 x 这样的一个文件,它依旧还可以去操作一些,比如说 c、 s、 v 一 些什么其他的数据库,它都能去操作对应的一些文件,所以它这个功能还是挺强大的。 那我们就只是去单独说一下这个表格后缀的文件,首先导入了之后,我们要去给它实力化这样的一个对象出来,那这里面就可以去传对应的一个文件的名字,比如说叫做表格点, s x, x 是 这个对,好,给它赋个变量,比如说 r, 这就可以去给他设置个什么,设置一个表头,对的,我们给他设置一个,嗯,来一个什么,来一个一样的,比如说姓名换一个 课程姓名日期,再就是对应的网址,好, 现在这里设置好了,表头中我们要去做数据的添加,那我这就把数据拿一个过来,在这个地方就先来一个 value, 如果你也对拍粉爬虫感兴趣,土包将毕生所学都拆分成了这些,从零到进阶全流程,按照八十老奶都能学会的方式讲解。 等于这样的一个列表,我想去添加这个列表,那就可以去通过 r 点 set 和 value, 哎, r 点 a, d, d 啊, a, d, d data 啊 value, 这样就可以去添加数据了。那这里添加数据之后呢,需要去做一个提交,通过这个 i code 来去做提交,提交 这个呢是添加数据,添加单个数据。好,来右键跑一下, 他在这里就会去生成一个表格文件啊,这里是开始写入,切勿关闭进程啊,写入结束会有个提示,这个是他默认的一个提示啊,他底层自己去写的提示。那么来打开看一下呢? 双击打开它,这里是吧,也是能够正常去写入的,而且如果说啊,我这里再去执行一次,它并不会去呃,覆盖,它会继续去做一个追加, 而我们之前所用的那个 c, s, v, 它如果说用的是 w 模式,它会去覆盖,对吧?那这个它不会,它会去追加, 追加,这里就又多了这样的一个数据啊,这里的一个日期也是没有问题的啊,这个就是它的一个追加,并不是覆盖。 那假设你想要去添加多条数据呢?啊,那这个也是一样的,你就直接把它套到一个列表当中,我们来个 values, 那等于这样的一个列表吧。好吧,这样的一个列表,我们再来去做一个添加,那也是用这样的方法, r 点 a, t data, 然后去传一个 values 进去来跑一下。 好,那么再来本地看一下他这个地方有没有去把这多条出去放进去,对吧?也是放了的啊,这里就一共有三个张三,因为我们这里是执行的三次这个添加单条税的逻辑,然后后面这两个呢是,嗯,后面这两个呢是后面做的批量添加的一个逻辑, 那么这个就是我们的通过这样的一个模块啊,来去做的更加简单的 l s x l s x 后缀的啊,表格文件操作。 那接下来我们就来看一个案例啊,这个是豆瓣电影的分类排行榜,这个地方呢有这些数据,我们同样也是去通过右键选择检查,打开开发者工具,打开之后呢,在这个地方去刷新一下这个页面,然后我们这里去搜索一下对应的数据啊,肖申克的救赎, 肖生克的救赎,哎,搜索发现他在这里面,对吧?在这里面的话我们来看一下啊,他呢是一个列表 啊,直接就是一个列表,然后里面的字典,这是一个字典第一条数据,这是第二个字典第二条数据,那我们要去请求这个数据包,请求这个数据包,然后去得到数据啊,给它解析出来之后,给它构造成对应的形式,再来去做一个添加到列表的操作。 好,那么这里就可以去右键复制它的这个 c u l, 复制了之后在本地去打开这个转换文件, 转换软件啊,这里呢给它清空一下生成,然后复制来创建一个豆瓣儿电影,豆瓣儿电影排行榜,好,粘贴过来,那么粘贴过来我们来看一下这个数据 能不能得到正确呢? print response 点儿 json, 它是一个列表的形式,看能不能得到, 好是能得到的,能得到的话这个地方你可以通过普通的字典取值,也可以通过那个 jason pass 取取值,都是没有问题的啊,它这个结构来比较简单,比较简单的话呢,你用字典去取值也可以啊,咱们就不去再套那个导入了。 好,那么现在这里去循环这个 data 的 话,它这里的 i 就 已经是单条数据字,单条数据字典了,对吧?一个又一个的数据字典,我们就再去取它里面的这些数据,比如说它的排名, rank 是 它的排名, 那么这个地方就来一个 rank 排名。呃,这里的话还有呢?是它的什么其他的数据呢?看一下啊,类型是吧?类型的话呢?是 tips 来给它搞一下,但类型它这里得到的是一个列表,我们这里可以去给它做一个拼接,对不对?拼接呢?是用什么 这种方法来做拼接嘛?咱们用斜杠来给它拼接一下,点 g o i n, 给它拼接一下,然后这个呢是它的一个相当于地区,地区也拿过来给它拼接一下呗,它这里好复制粘贴。呃, table 是 它的一个名称,对吧?名称给它拿过来, 名称就不需要去给他拼接了啊,他就是直接取直就好了,他这里不是一个列表,我们再往后面看,还有什么呢?上映日期,上映日期也是直接取直就好了。然后这里还有什么其他的吗?他的评分, 评分在这个位置评分这个人数三二五四六六九是什么东西呢?我们来看一下啊。三二五四六六九三二五四六六九,这个是评价人数是吧?评价人数也可以拿过来一下啊,这个是评价人数 啊,这个地方有一个相当于是演员吧,不是作者啊,是演员。演员的话,我们这里去存储全部的,其实也没有必要啊,这里我看一下, 我们就去取前面几个吧,就取前面两个吧。好,这里取到这,他得到是一个列表,得到列表,我们取前面三个吧,要不 去前面三个,那么这个地方就得去做他做个判断的,因为他有可能是没有包含三个,没有达到三个的,那就得去判断啊,如果说他那个长度要大于三的话, 呃,大于三,那么我们这里就去给他做一个切割切片啊,切片给他切到前面的三个,然后再来去给他做拼接嘛, 啊,这样 g y n 它拼接上,如果说它不大于三的话呢,那就正常去直接拼接就好了,就不需要去做切片了啊,就不用再去做切片了,那么这个就是我们做的一个判断。好,那现在来去打印看一下对应的这些数据, print, 比如这个 rank, 其他的给它都打印一下,右键去运行,是吧?就得到了对应的这些数据。得到了对应的这些数据之后,我们想要去做存储的话,就需要去给它构造成列表的形式,对不对?构造成列表这里我们就可以去给它 来个 list, 等于这样的一个列表,那么存储到本地的,比如说啊, csv 当中,我们现在去写 csv 吧,我们就先导入一下 csv。 哎,这个地方就去给它 把单个数据列表添加到总的数据列表当中嘛,我们就来一个 sumlist, 等于这样的一个列表,我们就给它做一个添加啊,这里就是 sumlist 的 app, 添加进去 好,添加完成之后,最后就可以去给他干嘛呢? with open 呃,去写入 csv 文件,豆瓣儿电影排行榜点儿 csv w 模式。呃,这里的话呢是 encode, 等于 youtube 杠八杠 s i g 然后这里呢是一个浏览为空值。好,第一步呢是创建写入对象,那把这个 c s v 点 writer, 把文件放进去,再来去写入表头。写入表头的话,这个地方我们就来个 w 吧,不然 怕大家搞混了啊。 w 点 right w right l w 啊,这个方法我们去写入个表头,表头可以直接在这里去创建一个列表啊,首先是排名,然后第二个呢是它的类型,第三个是地区, 就我们应该干嘛呢?应该把名称放到第二个,对吧?不然这个顺序感觉有点奇怪啊。名称应该放到第二个那来给他改一下,改成第二个名称, 名称名称类型,地区评分评价人数,作者啊,演员评分 评价人数,然后演员。好,那最后就去给它写入全部的数据,通过 r o w s 去写入这个 zoom list, 右键去运行看一下。 那么现在它就没有报错啊,全都写进去了。我们来看这个豆瓣电影排行榜,它的这个文件双击打开一下, 是吧?数据就全部写到这里面去了。呃,这个就是写入表格的操作啊,那么来看一下,去写入那个 excel 后缀的文件的话,这里就再把这个拿过来吧,我们给大家再创建一个。 呃,零四了。这里呢是豆瓣电影排行榜 x x x。 好, 这里,那这个不要了呗,不要了啊,然后这里我们也不需要去添加到总的数据列表当中的,这个也可以不要了,然后 c s v 不要了,来导入一下这个 data import 的 这个东西。好,那在它这里呢,给它创建出来一个文件对象,出来这里呢,就来一个 豆瓣电影排行榜点 x l s x 啊,这样的一个后缀文件,再来去给它设置表头,塞点 head。 呃,表头那个地方呢?我们可以去复制这个东西过来啊,就不带去写一遍了,浪费时间 啊。把这个拿过来,那现在啊,这里就可以直接去通过什么呢? r 点 a, d, d data 来去写入这个 list, 它会去不断地写入,最后做一个提交啊,这个来提交一下。好,右键去运行看一下。 那么就写入结束了啊,来打开看一下呢,双击 他也是能够正常去写入的嘛。所以这两种方式其实都差不多啊,他都是写入这种表格文件的,你喜欢用哪种,你觉得哪种方便就用哪种吧,这个也没有说强制要求。好吧, 但是我觉得可能相对于这个模块会更加简单一点。他这里也可以通过去写入 csv 文件,你把它改成 csv, 他 也能去按照这样的一个形式去直接写入 csv, 都不需要去做任何的改动啊,不用去导入 csv 模块,直接给他改成 csv 后缀就可以了。 好,那么这个就是我们的两个文件的模块操作以及一个小案例。如果你也对拍粉爬虫感兴趣,土包将毕生所学都拆分成了这些,从零到进阶全流程,按照八十老奶都能学会的方式讲解。
 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿一天学习一个小知识,道友,今天我们讲的是网络爬虫,想知道大数据从哪来吗?秘密都藏在网络爬虫里,你刷到的精准推荐、查的行业数 据背后都有它。今天一分钟带你看懂网络爬虫如何抓取整个互联网。郑重声明,本视频内容仅作为正规网络安全技术的科普讲解,切勿将此类技术用于非法用途。打开卡里进行提权, 输入命令,进入工具,接着输入这个命令,对模块进行搜索,然后使用当前出现的模块,接着对模块进行参数的分配。首先设置需要扫描的网站, 接着设置现成数,最后输入命令执行,这时你就能够看到从网站中输出的各样的文档、压缩包、视频以及图片资源。想学习更多计算机小知识,欢迎大家讨论。
24老五-SRC 00:43查看AI文稿AI文稿
00:43查看AI文稿AI文稿goho 上三点一万星的 scripling 爬虫库,配合 qq 可以 原声调用,一个负责脑力,一个负责体力。以前写爬虫要对着网页 f 十二研究半天选择器,现在 ai 自动写代码,在 qq 巧用 scripling 帮我写个抓取某站房产信息的脚本, qq 会自动调用 scripling 的, 可以几秒钟出稿就出来了。网站改版也不怕,最强的地方在于自适应解析, 即便改了 html 结构,它能靠网页元素的指纹自动找回位置,代码根本不用重写原声。绕反爬遇到 call firs 这种硬骨头,它自带的隐身模式能让脚本像真人浏览一样, 省去了折腾代理和请求头的烦恼。这套组合拳真的能把采集维护成本降到接近零。感兴趣的朋友欢迎评论区交流。
158技术PP虾 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿爬虫学得好,吃饭吃到饱。今天我们用 request 来实现电影自由了。豆瓣排名是非常好的挑选电影的平台,我们可以通过它的网络请求找到数据接口, 然后用 python 高效地实现数据采集。上一期我们了解了 request 模拟浏览器发送请求数据包, 我们用和源请求相同的 get 方法。关键是先穿上男装,在 hide 参数中加上 user agent 头,再传入请求参数,这样注,英台 request 就 完成变装了。 发起请求,我们就可以得到想要的电影名称、评分等数据了。基于这些数据, 我们再加上自己网盘的 ipi, 就 能自动更新自己的影片库了。实现电影自由就是这么简单。大家有什么更妙的想法呢?评论区讨论一下吧!
24行者孙 00:27查看AI文稿AI文稿
00:27查看AI文稿AI文稿想让 ai 去小红书、知乎上收集点资料,是不是被各种反爬虫机制折磨?别折腾了,来看这个堪称降维打击的开源项目, open c o i, 它把任何网站直接变成命令行工具,原生内置了对 b 站、小红书、知乎等平台的二十八种命令支持, 只需要在终端敲一行代码,就能瞬间把热榜和评论拉取下来,并转化为 ai 喜欢的 jason 或 markdown 格式。
158GitHub很棒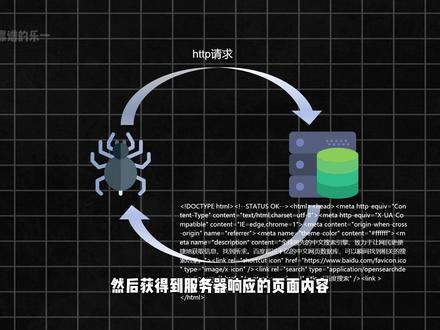 08:31查看AI文稿AI文稿
08:31查看AI文稿AI文稿picasa 爬虫教程第三集 request school 的 使用浏览器向服务器发起请求,然后获得到服务器响应的页面内容。这个过程我们可以想象成去奶茶店买奶茶,奶茶店就是服务器,奶茶就是我们想要获得的内容。 如果我们想用代码模拟这个行为,就需要借助一个非常实用的 python 库 requests 库。接下来的时间,我们就来学习怎么使用 requests 库,并通过它发起请求,抓取并保存百度首页的页面。 request queue 是 一个第三方库,所以我们需要先在终端中以命令的形式安装它。打开终端,在终端内写上 pip install requests, 然后按下回车就可以下载安装最新版本的 requests queue。 安装完成后,如果终端显示 successfully installed requests, 说明安装成功了。如果之前已经安装过,就不会出现这句话,而是显示 requirement already satisfied 表示你之前下载安装过这个第三方库。你也可以在终端用 ppleist 的 命令来查看当前已经安装了哪些第三方库。 成功安装好 request 库之后,我们来看看怎么用它。发起请求使用第三方库之前,除了下载安装,还有一步很重要,那就是在 python 文件中导入模块。 大家还记得之前讲过的三种导入方式吗?第一种是直接导入整个库,第二种是只导入库中需要使用的方法, 第三种是导入库并给它取一个别名。这里我们采用第一种方式直接导入整个 request 库。上个视频我们已经了解了发起 http 请求两种常见方式, get 请求和 post 请求。在 request 库中发起 get 请求就用 request 点 get 方法。 发起 post 请求,就使用 request 点 post 的 方法,当然光写这两个方法还不够。 request queue 不知道你想对哪个网站的服务器发起请求,所以我们需要在方法的括号里传入参数。第一个参数当然是最重要的,也是不能省略的,就是传入你想抓取的网页的网址。 比如我们想向百度首页发起请求,那么就以字母串的形式把网址传进去,告诉 requestcool 我 们想访问哪个地址。现在我们对服务器发起了请求,我们发起请求,服务器会对我们的身份进行甄别。而现在我们是以 requestcool 爬虫的身份发起了请求, 就相当于一个机器人想要去奶茶店喝奶茶,奶茶店老板看到后觉得机器人没有味觉,不想浪费自己的奶茶,就不会给机器人奶茶。那么作为机器人如何伪装自己成功买到奶茶呢?还记得之前我们在浏览器里看到的请求头吗? 浏览器发起请求时,会在请求头里带上自己的身份信息,也就是 user agent 发送给服务器。我们只要让 requests 也带上这个浏览器的身份信息,就能成功伪装成浏览器。那么我们怎么获取浏览器的身份信息呢? 在浏览器里右键点击页面,选择检查,进入开发者模式,然后切换到网络这个选项卡, 刷新页面,然后找到这个蓝色的图标。三 w 点百度点 com, 我 们在右边的标头中就可以看到浏览器发起的请求,以及响应 上个视频学习的浏览器发起 http 请求,找到请求头内会写上的 user agent, 用户代理复制上这一串浏览器的身份,然后在我们的代码里把这段身份信息放进 header 参数中, headers 表示的就是标头, user agent 和浏览器的身份存在对应关系,所以使用字典的形式储存,然后作为参数的值放入了 request queue 发起请求的方法中,这样我们就将 request queue 发起的请求包装成为了浏览器发起的请求。 写好这个方法之后,你就会获得服务器的响应。以 get 请求为例,我们把响应的内容保存到一个变量里,这个变量我们叫做 response 响应。那么我们现在打印一下这个 response, 发现 request 库将响应的内容打包成了一个对象。在这个响应对象里有两个我们最常用的属性,第一个 http 状态码, 使用 response 点 status code 属性,我们就可以查看 http 状态码,通过状态码我们可以知道发起的请求是否成功。第二个 response 点 text, 这个属性里面装的就是服务器响应给我们内容中响应体里的具体内容。 学习了怎么发起请求,怎么获取响应内容之后,我们来通过抓取百度浏览器首页的形式来实践一下如何使用 request cool 成为一名爬虫吧。 在拍唱中,我们需要新建一个项目,所以我们在这个主菜单中选择新建项目,然后在这里写上你新建项目的名字,在这里我不做修改。爬虫项目需要使用到虚拟解释器, 所以我们创建项目的时候需要做出一点修改,我们需要将环境勾选这个生成新的解释器,解释器的类型选择这个虚拟环境。简单来说,你可以把虚拟环境想象成一个独立的干净的项目。专用工作间,你之后可能会同时开发多个 python 项目, 不同的项目可能需要同一个库的不同版本,为了避免版本冲突,所以我们需要使用到虚拟环境。 接下来我们点击创建,打开这个新窗口。大家需要注意的一点是,虚拟环境是独立的,所以在不同的项目中使用同一个第三方库,例如 request 库都需要重新下载,那么现在我来重新下载一下 request, 点击到终端,然后在终端以命令的形式写下 pip install requests, 然后按一下回车。现在终端就开始下载 requesttool 了,成功显示了 successfully installed。 那 么我们使用 piplist 来看是否成功地下载了 requesttool。 在 这里我们可以找到 requesttool, 那 么说明我们已经成功下载安装了 request 第三方库。 接下来我们就可以完成我们的第一个爬虫项目了。在这里我们新建一个 python 文件,取名为 catch。 百度创建了这个 python 文件之后,我们在这里需要做的第一步就是导入 request queue, 写上 import requests。 现在我们已经成功在 python 文件中导入了 request queue, 使用 request queue 发起请求,那么我们需要使用到的就是 request 点 get 方法。 因为我想要抓取的是百度的首页,不需要传递密码和用户名给服务器,那么我直接使用 get 方法输入百度的网址,然后将抓取的内容给变量 response, 复制给 response 之后,我们将响应体的内容,一般来说都是网页中的原始 html 文件,我们将网页中的 html 代码写入到我们自己创建的 html 文件中。 写入文件,我们需要先打开文件,写上 whatsopen, 使用 w 写入模式创建一个百度点 html 文件,并且在这个百度点 html 文件中写上我们获取到的百度的网页 html 文件。 现在我们来运行一下这段代码,可以看到这里出现了报错,这是为什么呢?因为我没有将文字编码形式改为 utf 杠八, 所以在这里我们一定要记住将 encoding 改为 utf 杠八。再次运行这段代码,可以看到在这里已经自动创建了百度点 html 文件,点开这个 html 文件,已经成功写入了一些 html 代码, 那么我们在这里使用浏览器打开,可以看到我们已经成功抓取了一个类似百度首页的页面,但是还是出现了一些乱码。为什么我们已经将 encoding 改为了 utf 杠八,还是会出现乱码呢? 那是因为服务器已经识别了我们爬虫的身份,触发了反爬机制,没有给我们准确的信息。那么我们在浏览器中打开百度,点击检查, 找到网络,然后重新加载数据包,查找到这个三 w, 点 baidu 点 com 这个蓝色图标, 将 user agent 用户代理复制下来,点击复制,然后我们以字典的形式粘贴到这里面,直接粘贴的话,我们需要给它们加上双引号和冒号。成功粘贴好用户代理之后,我们记得在请求的时候,将用户代理写入到标头中,再次重新运行这段代码,打开百度点 html 文件, 现在我们再次在这里打开浏览器运行,得到的就是和百度首页一模一样的内容。大家可以看到在这里是三 w 点百度点 com, 也就是百度自身的网页,而这个是我自己创建的百度 html 文件,网址是这个样子的,我们抓取的页面和浏览器发起请求获得的页面是一致的, 使用这种方法你就可以抓取到大部分网站的原始网页了。不过爬虫的最终目标并不是保存整个网页,而是从网页中提取出我们真正想要的有效信息。所以下个视频我们就来学习如何从这些原始内容中解析出自己想要的数据,我们下个视频再见。
653靠谱的乐一 31:12查看AI文稿AI文稿
31:12查看AI文稿AI文稿二六年最新版爬虫逆向干货教学,今天带大家来实战无框的 wifi 技术,采用纯算的方式来进行爬虫代码的分析安排。 那目前啊,像市场像 wifi 的 话,其实目前主要的话是有分为有两种逻辑啊,第一种是我们最为简单的,我们可以称之为叫做单文件单文件 wifi 啊,然后其次还有个多文件的 wifi, 那 一个单文件的一个多文件的,那么像单文件的 wifi 的 话,其实说白了它是一个什么东西呢?首先我们简单了解一下 ipad, 它属于前端的一个打包器啊,前端的一个打包器,它主要的用途就是来把我们的相对应的一些资源文件来进行打包啊,你可以理解为把它打包成一个模块来进行调用, 这样的话就可以更加快速的来执行它的一个调用啊。老胡啊,我专门给大家准备了爬虫逆向实战的一个直播课,还配套录制了全套的逆向入门学习视频,大家记得在粉丝群里面来进行获取。然后像在这个招标公告里面的话,是有很多的一些标文,然后像在下方的话,我们可以看到它还有一个分页, 我们可以点击下页,那么在这里他可以来实现一个分页,而且我们可以看到在进行分页的过程当中,他的页面是没有变化的啊,只有数据在变,大家有没有发现,你看对吧?是只有数据在变,那么像这种啊,他大多数都是属于我们的动态的一个数据, 那么在这里我们鼠标右击来点击检查,打开开发者工具,然后我们像在开发者工具当中啊,来选择网络来进行监听,我们来看一下啊,他采用了一个什么一个加密,我们来分页, 嗯,朋友们请看啊,在这个地方啊,大家有没有注意啊?就是当我们去进行分页的时候,他会有两个接口,看没有,他会有两个接口,就是我们进分页啊,他会给我们返回两个接口, 那么像这种我们就要注意一下啊,因为像这种如果说他是返回两个接口的,那么也就说我们在我们的数据接口里面可能会使用到上一个接口所返回的一个内容, 那么在这种情况下我们需要来观察一下,首先它里面的第一个接口返回的是一段密文,对吧?然后其次第二个接口,第二个接口的话,我们可以看到它是能够正常的来获取到我们的一个数据,是没问题的啊。 好,那么像在这里我们来把它来构建我们的一个 python 的 一个 request, 来我们把它构建一下啊,然后我们可以看到在这里它的加密好像主要的话是在请求题里面看到没有,对吧?它主要的加密是在请求题里面有一个 permiss 啊, permiss 来做了我们的一个加密。好,我们来新建一个文件啊,来新建一个文件,对吧? 创建一个拍摄文件,我们来看一下啊,那么像在这里的话,我们能够看到在这里的话,我们是对当前的,对吧?来发送的一个 pos 的 一个请求,然后的话它的加密参数是在这里啊,我们可以看到它是属于我们的请求加密,看下有没有其他加密 没了,对吧?就一个请求体加密,然后呢?我们像在这里我们可以看到我们当前所请求,它给我们实际所返回的数据是为一个大括号, 来大家看啊,是一个大括号,那么像这种大括号的话,我们基本在屁股后面,我们是可以直接跟上一个点,比如说我跟上点 ext, 朋友们,这样是对的吗? 一般像我们用的是 test 的 话,大多数啊,可能它是要以基于它的一个文本的一个方式返回,对吧?一般正常逻辑来讲的话,我们应该使用的是点接受,因为它在这里的话,它采用的返回格式是以这种大括号, 对吧?所以我们包是用点接受,你看嘛,用 test 它也是 ok 的, 也是可以就说它返回的是一个文本,那么用点接受的话,我们就可以在后续做取值的时候会比较方便。 但是朋友们有没有发现,当我们在这里使用点接收的时候,他在这里给我们报错了,对吧?你可以看到他不适用于点接收,看没有,对吧?他就报说他不能使用点接收,那我们使用 type, 我 们来看一下他返回非法请求,对吧?我们可以看到我们其实正常来讲使用点接收应该是没有问题的,只是说我们当前的请求是属于非法请求,对吧?然后被他检测到了, 很明很明显被检测了,对吧?被检测了,那么我们像在这里我们来看一下啊。嗯,首先通过我们的观察,我们会发现它在这里面只有一个接收 data 的 一个加密,也就是我们的请求体是属于我们的一个密文,对不对 呀?这有个请求题是一个密文,那么也就是说在这里我们将来分析一下,看一下这个这三 data 它里面是做了什么样的一个操作,对吧?为什么会构建我们的一个非法请求呢? ok, 那 么我们像在这里,我们来到页面当中啊,我们可以来尝试进行关键字的搜索,来搜索一下这个 party, 我 们来搜索一下,看能不能找到啊? 嗯,呃,搜索的话是可以搜的到,只是非常的多,是吧?非常的多,那么也就是说我们通过关键字搜索法的话,其实说实话他还是有一定的问题的,对不对?还是有一定的问题的,那么我们像在这里,如果关键字搜索法不行的话,我们可以使用它的启动器,也就是来调它的一个对战,然后大家来看一下啊。 嗯,其实在这个地方啊,我们会发现它里面会有一个 pomps 点这里的一个异步回调,对不对?是吧?有个 pomps 点这里的异步回调,呃,但是的话,我们可以看到像在 pomps 异步回调执行之后,它后面的话会有很多的一个正常的一个对战的一个执行,所以啊,我们最好的话是先去观察一下我们在 pomps 回调之后的这些逻辑, 对吧?如果说在我们的 pos 点 g 进行一步一步回调之后,在这个里面它,对吧?如果说是在这个里面生成的嘞,所以我们去调以一步的话,可能会比较,呃,浪费我们的时间。熟悉的配方,是吧? 好,所以啊,我们一般像这种情况给大家讲一下,那么在什么情况下我们会直接调 pos 点 g 嘞?就是它的在 pos 回调之后的堆占比较少的情况下啊,比如说我们经常看到像那种进行 pos 的 回调之后, 对吧?他只有那么两到三个对战,那只有两个两到三个对战。那么像这种的话,我们可以直接去分析回调,对吧?直接分析一步,对吧?但如果说在 post 回调之后他的对战是比较多的,那么我们一定要先看一下他回调之后的对战啊,明白吗?因为他有些情况下他不一定是由 post 点 z 来进行它的构成,所以我们点击这个匿名来打上一个断点, 打,打上一个断点,然后我们像在页面当进行分页来点击分页,分页之后我们来观察。呃,不用看代码啊,我们重点的部分是来观察这个中域,然后在中域这一块的话,我们也不用一个一个去调,明白吗?啊?不需要一个一个去调,我们做逆向就是越快越好啊,效率 为主。那么在这里我们就直接来找到我们的最上方,但是我们可以看一下当前的话有个问题,有个什么问题呢?大家有没有发现我们当前他所调用的当前的一个接口的,他并不是属于我们的,这是第一个接口的, 它不是我们当前的数据接口的,所以我们要注意一下啊,你看我们要注意一下啊,因为我们当前的路径的话是这个吧,是吧?一个 o open, 然后是一个 home, 我 们的一个配置,是吧?是不是这个?所以我们在这里我们可以重新把它放掉,对吧?重新调试,你看现在这个才是我们的。那么在这里我们直接推推到 powers, 点击回掉之后的第一个赞, 我们可以看到是处于已经生成好的状态啊,朋友们,大家有没发现,你看那么像这种情况的话,我们就很明显的,我们可以看到我们当前的这个 a 值肯定是基于 pomos 的, 或者 pomos 回调之前生成,对不对?那么跟后面的是不是就没有关系了? 因为当前是处于已经生成好的一个状态, ok, 那 么如果说我们当前是已经处于生成好的,我们可以直接回到,对吧?来到这个 pomos 点这的上一步啊,你看要点一下它啊,你看这个地方,我们点一下它, 点一下它,它没有任何变化,但是我们的 gs 代码啊,它会进行一个对应的一个跳转,会跳转到我们的一个 pos 的 一个位置,然后在这里打上一个断点,打在 pos 点 g 这里啊,位置不要打错了,记住啊,像这种断点的话,我们普遍是打在我们的 pos 点 g 这个地方,因为在这里它才会来进行它的一个毁掉,所以朋友们需要注意一下。 好,然后我们现在可以把后面的断点给它进行释放,我们来进行分页,来分页,来分页的,你看没有断点来放掉,是吧?然后断点, ok, 那 么当他断点之后,我们现在在这个地方,我们也不要着急着就直接快速的去分析我们的异步回调,我们可以先来观察一下在碰死的回调他之前会不会出现我们相对的一些对象或者一些内容,我们可以去看一看,嗯,没有,对吧?没有看,没有啊,没有。 那么通过我们当前为什么我们要去看一下前面的堆栈呢?我去看一下这前面的堆栈的逻辑,我主要是看的我的目的是什么?目的就是为了想要来看一下有没有可能是在 异步之前生成的,对吗?我主要是想去看一下它有没有可能是在异步之前生成的,但是我们通过观察发现在前面没有那么很对吧?我们就可以快速的判断,那么它肯定是基于当前的 pos 点进来进行回调来进过程,对不对? 好,然后我们再来看一下当前的这种回调逻辑啊,其实像现在目前在市场有很多的 pos 都是以这种方式来进行编写,一般像这种 pos 的 话,它在里面是会基于一个迭代的一个条件来进行编写,一般像这种 pos 的 话,它在里面是会基于一个迭代的一个条件来进行编写一个控制流语句, 那一般大多数会,你可以理解为其实就一个 for 的 一个迭代,然后通过当前的一个 for 的 一个迭代去执行当前的一个控制流语句啊,这种记住啊,朋友们要记住啊,这种它是执行控制流语句啊,它跟那个拦截器的话可能没啥关系,打方式会有点不一样啊。能讲讲阿里 vr 的 加密吗?可以啊,可以的, ok, 阿里 vr, 阿里 vr 的 话主要是无感吧啊?主要是无感吧,阿里 vr 的 话我记得好像是,是幺四零吗?啊?是幺四零吧,我记得啊, 阿里维 i 的, 来,我们来看一下,那么在这里我们可以去看一下它的回调的一个情况啊,像这种情况的话,我们直接点下一步就可以了,你看我们在这个调试的工具栏里面来点击它的下一步,你看进目录吧,目录,你看目录,来,目录,你看当前我们去进目录的时候,大家请看,你看,我们都会看到一个这种买个 pos 的 一个实贴画, 对吧?六、我们的 proms, 然后像在下方的话,它在这里会下面这个是异常执行,可以不用管它,它主要的执行是在这个地方,你看它在这里会有个迭代 n, x, t, 是 吧?然后在这里它会具体的进入一个控制流语句啊,朋友们请看啊,它会进一个控制流语句,你看我们往下走, 是吧?来看啊,是吧?它在这里,你看它在这里的话会有个主方法的回调,对吧?也就是它的一个执行,那么你可以看到当前的主体的一个执行是执行的我们一个 r n 点 apply, 然后处理了我们的 this 和我们的一个参数,那么你看这个 r n 的 话,它指向的就是我们这个控制语句, 在下面嘛,对吧?有没看到?你看这个 r n, 它是不是在这里?它指向的是不是在这个地方?你看是不是在这里?下面的话对应的是不是一个。呃, switch 是 不是一个控制语句? 那下面的话是不是就是一些控制流语句啊?你看这些都是一些控制流语句啊,那么一般像这种控制流语句分析,大家请记住几个要点就可以了。控制流语句啊,我们一般重点去看一下每个条件执行之后的返回结果,其实就够了, 明白吗?我们没有必要花特别多的时间去重点关注里面的代码,因为像里面很多的代码说实话我们其实也搞不明白的,明白吗?对吧?比较难处理的啊。嗯,然后我们像在这里我们可以来看一下啊,就是你看,其实我们可以看到当前的这个控制的语句的话,它的主体的话,其实说白了只有两个部分,对不对?是不是只有两个部分? 那么这两个部分的话,我们可以直接在第二个部分这里有个 return, 看到没有?我们在这个 return, 这个 return 是 干嘛的嘞?它是进行了一个 set 接收,接收了上一个迭代下来的结果,也就是说这个 a 点 set 它所接收的是这个 y 执行 e 来返回的结果, 因为上面它有个迭代的条件的指定,是不是指定了一个 i, 你 看是不是指向了一个 i, 然后这个 i 的 话对应的是不是我们下面的这个控制语句的一个条件?这个地方大家看明白不?然后我们像在这种情况下,我们就直接可以在 return 的 前方给它打一个断点,打给大家发个福袋,稍等一下。 好,那我们来看啊,那么在这里的话,我们现在打一个断点给他,我们主体来看一下当前这个内容会给我们返回一个什么样的结果。我们来接收一下,来选中我们的 a 点 set, 那 么你可以看到在这个 a 点 set 当中,它所返回的是不是就是我们要的那个密文?结果你看朋友们,你看 这是不是我们要的密文啊?朋友们,是不是就是它,就是这个 jason data 里面的值,对吧?是不是就是它? ok, 但是我们可以看到它前现在目前已经加密生成,那么通过我们当前的判断,其实我们可以快速地得知当前的 a 点 c, 它所接收的是不是接收了当前的 y, 处理了我们的 e, 也就是它的一个返回内容, 是不是啊?这是它返回的一个内容, ok, 朋友们,你看这就是控制的语句,当然它里面可能还有嵌套啊,给大家讲一下,它可能还有嵌套,所以朋友们你们一定要注意啊,前面这个断点可以不要了,我们只留一个就可以了。 来我们重新进行分页,然后它会进行断点。好,那么像在这里我们可以看到里面有个 e 参数,这个 e 参数的话,它应该就是我们当前被处理的内容,里面应该还有嵌套的啊,我们可以进入这个 y 方法啊,进入这个 y 方法,然后当前的这个 y 方法的话,是不是执行了我们的一个 p 点 apply, 是 吧?又有再次的去嵌套 p 的 话是不是在下面?你看 p 是 在这里,然后我们看一下下面这个 p 方法,在当前的这个 p 方法里面,我们可以看到这里有一个 return, 是吧?有个 return, 然后我们再往下翻,这里还有个 return, 是 吧?这里 return 的 返回的是我们的 s, 我 们打上两个断点,我们分别来观察一下这个条件为零的执行结束之后,会接受一个什么样的一个结果, 然后其次我们向下方向这个地方,它最终的返回的结果又是什么样的?这个网站印象价值值多少?现在这个网站不值钱,这个网站的话目前坐下来的话可能是五百个馒头左右。这个网站比较简单啊,它就是一个简单的 y pad 啊,然后我们可以来看一下啊,就是我们来进行它的一个分页,我们来看一下这个地方来断点所接收的结果是什么? 然后我们看一下 a 点 set, 呃,我们可以看到当前的这个 a 点 set 它所接收的是谁啊?这个 a 点 set 它接收的是我们的第一个接口来所返回的一串密文吧?啊?这个地方应该是一个公钥,对不对?它应该是一个公钥而不是密文啊?你看它是不是由这个接口来返回的, 对不对?是由这个接口来返回的,然后它返回之后,你看它在这里做了三件事情,第一先进行获取,第二取到里面的 beta 的 值,第三把它进行公钥的填充, 对不对?分为了三个步骤是吧?你看获取、提取,然后填充是不?三个步骤,那么我们可以看到,也就是说如果说我们当前想要去构建请求的话,我们首先是不是要先请求第一个接口, 对吧?我们是不是要先请求第一个接口?然后这个接口的话他会给我们返回一个什么?他会给我们返回一个公钥,对不对?是会返回一个公钥给我们,所以我们把它复制一个 c o l。 嗯,来我们把它构建一下, 这个地方大能跟得上不?朋友们,你看一下就是重点的,我们去学这个分析就可以了,你看我们就复制这一行代码,我们在上面进行编辑,那么这个地方它会给我们返回一个什么?返回一个公要给到我们对不对? 当然不一定是公要,我们应该说是密要,我们应该说是密要,因为我们当前的话,我们现在还不能够去确定它是否为公要还是为私要,对不对?我们只能说它这里是返回一个密要给我们,然后这个密要的话,我们在下方做第二次,也就是我们的 json 的 一个加密的时候,我们将会使用到它, 是不是这样的一个逻辑?所以我们可以先执行一下,你看他这里是会给我们成功返回,而且他每次返回应该都是不一样的,可能我们的请求太快了,正常来讲的话,他这里应该每次的返回应该都是会有变化的啊。朋友们,你们要注意一下,他应该每次返回都会变,不然的话他也不会每次都要从服务器返回,对不对?是吧?每次都从服务器返回, 然后我们再来分析它的第二个步骤,第二个步骤在这里是做了一个填充,是吧?把当前的工料去填充到我们的 t 对 象里面去,是不是?然后我们当前的 t 对 象, t 对 象的话,我们可以很明显的可以看到,当前的 t 对 象的话,应该是一个非对称加密算法吧, 是不是?但咱们在座的朋友可能会有疑惑,对吧?有些朋友会想,呃,老师你这是怎么看出来它是一个非对称加密算法的啊?当然其实你看不出来也没关系,你就扣代码嘛,对不对? 看不出来就去抠代码,如果你看得出来的话,那你就直接用嘛,对吧?这个地方我们其实很明显可以看到它当前所输出的结构跟我们在本地的 nordic 里面的 gs in trap 的 输出结构是不是一致的? 是不是?是不是一致的?你们看一下它是不是一致的,所以说我们正常调用的话,我们其实在这里啊,我们其实可以不用抠 ypark 啊,这个文件我们通过分析我们发现其实我们是可以不需要 ypark, 如果说我们不需要 wifi 的 情况下,你看,我们可以先导一个包啊,你看,呃,先声明一个最基本的 word, 等一个 logo, 然后其次导一个包来导入 g s intrap, 对 吧?来,你看,那么像 g s intrap 的 话,它目前就是我刚给大家讲到的一个包,这个包当中所输出的一个对象啊,跟我们浏览器里面所输出的对象它是一致的,你看啊,我们可以打印一下它,我们可以十六划六, g s intrap 我们可以看一下,然后我们向上去翻,哎哎呦,这个地方我们先不要扭,先不要使劲画,我们就正常说,哎,怎么说? c f 已经那个地方没规定,这个是它的第三方源码包的问题, 怎么又抛出一个 c f 的 问题,那么如果说是 c f 的 问题,那么我们上面改一下,把它改成 c f, 你 看这样应该就没有问题了啊,来进行实裂化,好, 呃,讲讲自动土模块,呃,自动土模块非常简单,自动土模块现在在网上都有很多的工具,其实 y pad, 说实话,其实我们在很多时候啊,我们其实不建议大家去抠 y pad, 除了像特殊的,比如说像多多是吧?多多其实及其他的大部分的 y pad, 我 建议大家其实有可能都使用纯撞去进行还原,对吧?用纯撞,因为用纯撞的话,它可能它的并发症的效率会高很多, 明白吗?然后我们来看一下啊,你看各位有没有发现我们当前使用当前的这个 model 一, 它的一个返回的 g s in trap 的 一个对象,它所输出的对象是不是跟网页当中的输出对象是一致的?大家看得清不?这个地方我把移过来一点,怕你们看不见, 现在应该看清一点,对吧?你看有没有发现,就是我们在这里,当前我们所输出的这个对象,有没发现他跟我们在网页当中的输出对象是一致的?只是说我们当前还没有进行公告填充,对不对?那么在这里我们可以把这个公告来进行填充,也就是我们当前的啊值,来我们打个断点, 你看啊,刚刚一半不见,是吧?现在应该可以看到啊。然后你看这个公告的话,是由我们的 python 来做第一个接口的一个请求,然后进行返回的嘛,对吧?我们可以向在下方声明一个阿折,然后声明一个阿折。之后你看我们首先向在下方啊,我们进行一个识别化,比如说我使用一个,呃,随便用个吧,用个 g s in trap, 就这样,然后等于我们的一个六,我们的 g s in trap 的 对象,对吧?然后实调化, ok, 之后我们把它进行供料的填充,你看填充,填充供料之后,然后你看在下面的话,它里面的供料是不是就有了?你看这个地方它是不是就有供料了? 然后我们执行一下,这就有供料了,因为我们当前把供料进行填充的对不对?然后其次我们再来分析一下,就是我们现在的话,就是只搞清楚了一个基本的一个对象的对不对?然后其次我们再来分析一下,就是我们现在的话就是只搞清楚了一个基本的一些处理。 呃,这里有个问题啊,朋友们各位请看啊,我们像在这里它会出现一个很尴尬的情况,有个方法叫做 inhtoken, 是 不是在 t 里面,是吧?里面会有个 inhtoken 的 一个方法,这个方法其实在 gs inhtoken 里面好像是没有的, 对吧?在 gs inhtoken 里面好像是没有的吧?嗯,爬虫逆向算法是用 gs 还原还是用 python 还原?一般前提要求是什么?呃,不管你是用正常来讲,其实不叫 gs 的, 我们一般要么用 node 还原,要么用 python 还原,这两个都是可行的, 它没有特定要求说你一定要用 python 还原,或者用呃, node js 还原。呃,正常来讲,不管是用 python 也好还是用 node js 也好,都是可以的, 明白吗?都是可以的。呃的,明白吗? ok, 那 么像在这里我们来试一下,为什么我会讲到特别把这个 t 点 int 和 null 的 方法拿出来呢?首先,当前这个 t 的 话是谁?当前这个 t 它所指向的是不是我们的 r, s, a, 也就是非对称加密算法?我们的 g, s, int 和对象对不对? 来,朋友们,我们先不要去管其他的,我们就直接来调这个方法,来调里面的 in trap and no, 大家请看,我们对它进行打印,我们来看一下有没有这个方法,你看执行各位有没有发现它其实输出的结果是为未定义。 看到没有,朋友们未定义,那么其实我们通过这种判断其实有两种可能,第一种,魔改的对吧?魔改算法是吧?第二种可能就是在基础算法上额外的给他添加了一些内容, 对吧?两种逻辑嘛,是不是有两种逻辑,要么就是魔改的,要么就是在基础的标准算法的上方,然后额外的去给他添加了一个方法,对不对?是有这种可能性,那么在这里我们有些聪明的朋友就会想到,那我能不能直接也在这个第三方包这个当前十六化的对象上面额外的去增加他的这个 in trap 弄的一个方法嘞, 是吧?有些同学可能会思考,那么在这里我们可以尝试一下,同学们,请记住啊,它有个很尴尬的地方。什么尴尬的地方呢?就是我们在当前,我们如果说我们也想在当前的 g s in track 里面去添加这个方法,它会出现很多的报错啊,朋友们, 你看我们是不是这样去添加是没问题啊?你看我们去执行它有没有发现它会出现很多的报错, 看到没有,对吧?当然有同学说,我们不要这个圆形链,我们就直接这样指向,你看是 ok 的 了, 对不对?我们直接这样指向就 ok 了啊。但是我们现在我们先不管它,因为我们还没有正式加密,我们现在只是说把它的加密方法给它分析清楚了。好,然后其次我们再来看,那么在当前的话,我们可以看到在正确的做加密之前,它还会有一个 a 的 一个生成,是不是还有个 a 啊? 对不对?这个 a 的 话,我们把它填充到我们的下方,是不是还有个 a 啊?然后它将基于我们当前的这个 in trap 和弄的一个加密来,你看执行一个 a 的 一个加密,把这个 a 给它掏过去, 那么像这样的话,我们是不是就成功的来生成了我们当前内容,对不对?这个地方我们是不是就会得到我们的那个参数,也就是接收 data 里面的一个参数, 非常简单啊,其实可以不用扣 ipad, 我 发现这个网站啊好,那么像在这里,如果说我们现在想继续的话,那么我们会发现一个地方会比较尴尬啊,你看首先这里有两个 m, 我 们是没有的,然后还有个 b 处理了,我们这个接收来处理了我们一个 e 值,对不对? 首先我们看一下这个一指是谁啊?看一下这个一指,我们输出当前的一指,一指可以看到是一个名门,对吧?是一个名门,那么我们直接把它复制来进行生成,生成一个我们的这是一个请求体啊,我们的一个接收比特, 对吧?这是我们的请求体,然后我们当前把它全部进行替换,把它全部替换,然后像在下方我们还有个 m 没有,对不对?是吧?还有个 m, 我 们把当前这个 m 也把它取下来,选中当前 m 进行跳转,然后把它直接复制粘贴,把当前的 m 给它复制粘贴拿下来就可以了,我们可以往上去写。 ok, 其实我们不一定说要拿这个 m, 我 们可以去看一下,就是当前的这个 m, 它执行之后的返回结果是什么?其实也可以,你看我教你们一个简单的操作,什么操作呢?就是代码这玩意啊,越少越好,你看首先这里我们会进行一个处理,有没发现这个是我们当前一的值,然后经过处理之后,各位请仔细观察,其实 我们可以看到当前的这个 m, 其实实际上的话,它是没有做任何处理的,对不对? 有没有发现?嗯,这没有做任何处理的, ok, 那 么所以说像这种它没有做任何处理的,那么其实上我们可以不要它都没关系,对吧?当然如果为了我们当前代码的完整性,就是我们如果想要这个 m, 其实也没关系,但是你们要注意在这个 m 里面它会有包含一些 其他的方法,我们是没有的,你看这个 v 以及 note 四,对不对?是吧?所以我们上次在这里如果说你们想要这个 m 的 话,那么你就要考虑到它的完整性,它在这里会有一个 v, 对 吧?这下面还有个 b v b 的 话就分别在它上面,你看这个 v 是 吧?这有个 v, 我 们把它复制下来, 所以朋友们你们要注意啊,如果说你们要硬扣的话,那你一定要注意代码的完整性,如果说你想不要的话,那你就直接把它删掉,明白吗?再一个 b ok, 那 么现在的话,我们当前的这个地方肯定就是能够正常地来进行生成,对不对?你看右键生成没有问题啊?没有问题之后,现在再次地来到了这个地方,这里有个我们的 set 的 一个加 b 括号,处理了我们的 json, 同样我们可以看一下我们的结果,是吧?我们可以看一下我们的结果, 这个地方我们可以看到它其实进行了一次加密,对不对?是不是进行了一次加密?我们把这三 dcep 换成一,你看它是不是进行了一次加密,而且很明显我们可以看到当前它所加密的输出的长度是为三十二位。我们可以进行在线的 md 五加密测试,看一下它是否为标准的 md 五加密,对不对?你看我们加密一个重创一, 是吧?加密自我创意之后,我们找一个在线的 md 五加密,然后进行测试,你看有没有发现其实很多加密其实真的很简单的,各位多花点时间好学一下啊,你看一模一样对不对?加密结果一致,那么也就是说我们当前的这个方法,其实上它采用的其实就是一个 md 五加密, 是不是啊?那么如果说是一个 md 五加密,那么我们像在上方我们直接导一个算法包嘛, c, r, y, p, t, o 加上来等于 require 来导入我们的算法包,然后通过它来直接快速地来实现一个点 md 五加密,嗯, 记得输出乘除数创啊。 ok, 那 么现在我们的加密是不是完成了? 然后这里又再次的给我们抛出一个异常,说 w 已经 note 低,我们也不处理。这个方法是在这里啊,在这个 in trap 这个方法里面打在这个 in trap 弄的方法里面,也就是在这个里面,那么在这个里面有个 w, 哦, w 是 在这里的时候,我看一下啊,当前我们刚刚,其实我们在分析过程当中,我刚好看到 w 了, 对吧?是不是在这里,那么我们把当前这个 w 去给它,呃,这样的话,我们不能直接这样复制,这样复制等一下我们也不对,是吧?来,我们找到这个方法,来,我们进入这个方法来进去这个方法,然后在这个方法里面去找到它的 w, 然后进行跳转,这样可能会好一点啊,来把复制 给它向上填充,直接填充到最上面去。好,那么在这里我们当前的话,你看主体加密基本构成完成,对吧?可以成功得到我们对应的输出结果是没有问题,加密完全没问题了,那么像我们当前的加密没有问题之后,我们现在下一步是干嘛?我们是不是可以把它转变成我们的纯 python 代码, 对不对?而且在这里的整体的处理过程当中,其实像我们的 bvm, 其实实际上它是没有做任何事情的,我们可以再次去进行测试嘛,对吧?我们可以,因为我们用 python, 如果用纯 python 还原的话,所以我们就会考虑到 它的执行的最终返回,明白吗?然后我们来看一下,这里是一个整体的逻辑啊,就是 m 这里有个括号号,是吧?它是为两个部分,大家请看这里面是不是有两个部分?那么当前这里面的两个部分的输出结果分别是我们的一个签名,我们的筛选,然后啊我们的 set 和我们的一个 time, 是 吧?一个时间戳和一个签名,然后它两个再次的进行了 m 的 一个处理,实际上它最终的返回结果也是没有任何变化的 啊,只是额外的做了什么,这个叫什么?拼接对不对?那么其实我们可以看到当前的这个 m 的 方法,应该它的核心就是什么?就是把我们后面的内容插入到前面的这个呃,接收里面去, 是不是啊?朋友们各位,这个代码能理解吧?那么我们像在这里的话,我们现在的逻辑是不是它其实际上做的就是一个插入的一个逻辑 啊?当然了我们不改也没关系,然后我们现在要把这个所有代码来使用我们的纯 python 来进行实现,你看 ctrl c 打进包背上面这个 cf 可以 不用啊,这个 cf 是 因为当前的这个包的一个问题啊,第三方包里面会调到了我们的 cf。 ok, 那 么在这里我们现在把所有段点进行删掉。一般我们现在转 python 也非常简单,以前我们可以还自己手动去转,但现在的话我们基本可以基于 ai 可以 来直接实现啊,非常简单啊。来我们看, 那我们直接在这里,我们可以通过基于 ai 的 一个方式,然后用 ai 来帮我们直接来对它快速的进行转变。好, 你看那么像在下方的话,大家有没有发现,你看它在下面的话将会使用我们的一个纯拍摄来进行实现,但是最好我们就进行测试,就是去测试一下当前这个代码它是否能够进行使用。你看我们来右击新建一个拍摄文件,新建一个 demo, 然后在这里我们把当前代码给它甩进去,甩进去之后进行执行,先看一下代码的执行逻辑有没有问题,我们可以看到在这里是不是有问题,是不是很明显?那么在这里它为什么会出现这样的一个问题呢?我们可以去观察一下当前的 rsa 的 一个公要的一个填充来模拟了我们的加,呃, gs in track, 哎,它这个公要怎么 是吧,对吧?二十四个人有一半同行看笑话的吧。呃呃你呃你随便怎么想没关系啊没关系啊,因为我本身又又做营销或什么的。那你想学就学,不学也没关系啊,反正讲的都是很知识点。 呃,先拿个 ai 好 用一点, ai 的 话你可以根据你自己的需求来用,就是目前在生活这一块的话,我建议各位可以去使用豌豆包 对吧?然后如果说你是在程序这个板块的话,你可以用那个谷歌的迷你,或者说像目前的个 local 啊,如果国内的话可以使用千问,对吧?都是 ok 的 啊。然后我们来看一下这个问题啊,其实像这个的话,目前在对称加密算法和非对称加密算法里面都会出现这种问题,就是当我们使用纯拍摄的话,它里面会有出现比如像编码的一些问题, 记住啊,就是编码的一些问题。为什么会这样讲呢?我给大家回忆一下,你像我们正常在做一个加密的时候,各位有没有发现我们在拍摄里面做加密,我们大多数都会把一个字幕创, 也就是一个思俊,然后会把它进行我们的一个拷扣的,朋友们有没有印象来我们来看啊?所以说朋友们你们注意一下,一般正常来讲的话,我们大多数在进行编辑的时候,一般就是有两种,一种是我们的被加密的内容对不对? 一种是我们被加密的内容,还有一种是什么?还有就是我们的密钥或公钥大多数都会进行相应的一个处理,但是我们在这里的话,你可以看到这个 python 帮我们编辑的代码是没问题的啊,但是你可以看到我们当前的公钥的话,是没有做额外处理的,是不是啊? 是吧?所以我们像在这个地方啊,我们可以来看一下啊,那么在这里的话,我们可以来尝试这个地方,我看下这个调的方法,他在这个里面的话,会进行 rsa 的 一个 公要的一个载入,对吧?搞搞妙妙的一个载入,那么像在这个地方的话,我们就可以尝试对它进行一个拷扣的一个处理,也就是编码,那我们试一下,当我们加上了一个拷扣的编码之后,我发现还是不行,对吧?当然他可能还很多其他的问题,说实话 对不对?可能还很多其他问题,所以你可以看到这就是刚刚我们有位朋友提到用 python 还原跟 node 接口还原它的一个呃,约束,其实没有约束的,就是我们正常来讲,在很多时候啊,因为在 node 接口里面说 实习的一些代码,它的一些编码格式什么的,它可能无需注意,但是在我们的 python 里面,在 python 里面的话,代码的要求是比较严格的,像很多逻辑,你说实话,我们直接使用转存 python 还会耗费我们大量的时间,那么在这种情况下,其实我们一般正常的话,就是直接来进行当前的 gs 文件的一个调用,然后进行结果的生成, 是不是啊?所以我跟大家讲一下,就是不管是用 python 还原还是 node gs 还原,反正只要是做的是纯算,其实都是 ok 的, 明白吗?其实都是 ok 的, 所以没有特别大的约束。好吧,那么这个地方我就不去讲了,好吧,你们进去玩一下,这个地方应该是我们的这个自创,我们也要把它进行我们的印扣的一下,这个自创我们要印扣的一下,如果自创不印扣的话,肯定也有问题,是吧?想都不用想 好,那么在这里如果说我们现在是以这种逻辑来处理的话,那么我们该怎么办呢?首先我们可以现在把当前的这个逻辑进行封装,我把这个代码放到上面去啊, 我们执行一下,看下有没有上下文的问题。呃,它有个上下文的问题在里面,是吧?如果像这种它有上下文的问题的话,那么我们将进行额外的封装。看好朋友们,我们将进行额外的封装。呃,怎么个封装法嘞? 各位,首先这个地方,我们的这个地方是不是纯 python 进行传入的?我们需要把它删掉,我们可以在下面你看我做一个比较丑的一个封装啊,当然你可以封装好之后,然后把它移出去也可以。 你看那么像在这里我们首先第一个,我们先接收一个 r 值,也就是我们当前这个 r 值将由我们的 python 做第一次请求,由它来进行传入,对不对?然后像在这里来进行我们的返回来 return, 返回我们的 parameter。 那 么像在这里有个问题啊,就是当前的 json 在 json 里面它会有个分页参数, 对不对?这是每个分页参数,那么像当前的这个分页参数的话,就需要咱们在座朋友们,你们如果说想把它动态传入,那么我们就要改一下,把它改成一个动态的参数来进行传入, 是不是这样的,没问题吧?没问题之后你看我们现在来到接受文件,那么我们一般啊,在接受文件里面,我们可以直接通过我们的 e s, e c c 接收来执行我们的快速的一个调用,然后就可以了, 我把它连着写的。好吧,朋友们。 open, 打开代码同路径的一个 model e 点结束文件,然后执行 r 读的模式,并且指定拷的编码点 read 的 全部读取。好,然后的话我们在这里我们把它进行, 对吧?执行,对吧?来执行,执行当中主文件点 com 执行卖一二三,并且传入我们对应的参数,两个参数一个是我们当前的第一个,也就是我们的必要 response 第二个分页参数,分页参数我们就随便传啊 啊,你随便给个二三四都可以。好,那么在这里我们现在当前的话,你看他,我们来试一下,看能不能成功接收,是不?没有问题,各位,你们看这都能够成功接收。
 00:56查看AI文稿AI文稿
00:56查看AI文稿AI文稿什么是网络爬虫?爬虫就是用代码写的程序,可以理解为一个工具,通过这个工具可以爬起网页上你能看到的所有东西,不管有无颜色,还是需要付费与否都可以搞定。 优点就是速度快、数量大和自动干活。爬虫能爬视频、音频、图片和文字这四类,在我们的眼里他们就是数据,凡是数据皆可爬起。比如想要某些视频,但是不记起下载,或者要你付钱, 那么爬虫就能解决这个问题,图片和音乐也是一样。再比如系电商公司的运营人员,可以用爬虫去爬起几百个同行的信息,比如销量、销售额和用户评论等等,从这些数据中发现哪些产品卖得好,用户最关心的点是什么?爬虫用什么语言都能做,但是拍档会更为方便快捷。 要是你也想学,但还不知道从哪开始,那这套从零到进阶的攻防视频教程,粉丝可以直接带走,不管是工具使用还是拔枪习剑,都讲的清清楚楚。
56网安黑客MAX 04:01查看AI文稿AI文稿
04:01查看AI文稿AI文稿在爬虫逆向中的堆站分析怎么操作,特别是遇到异步回调又该如何进行堆积?首先任意的输入一个账号密码, 然后打开这样的一个开发者工具来抓个数数包,在这边挪动到对应的位置,有个验证码过了之后,我们直接来分析这样的一个文件,像这个接口发起了一个 pos 请求,带了这么一些参数过去,而这个参数很显然这个赛他是做了一个加密处理的。那如果说使用这个干站的方法,我们可以选择这个启动器,从启动器里面大家可以看到这个是请求的一个调用堆站, 这个请求一个调用一下是往上面去走的这个步骤,我们可以看到最后一个步骤肯定是他,所以可以选择这个位置上去上个断点,点击 他,这是最后的一个请求发过去的时候,在这里当上断点的时候,这是最后一步,那我们要去找参数啊,这个参数肯定属于他发起请求之前就做的一个加密处理了, 待会我们就基于这个点往前面去进行一个回溯,那怎么回溯呢?首先来到这个位置来输入一个密码点,一个登录,来到这个位置之后,大家注意看,我把这块左边这一块右边这块挪过来一点点, 他现在其实从这样的一个作用域的一个当中可以看到他有些参数的一个尺已经出来了,特别这样的一个 h, 这个 h 我 在空台当中进行一个查看,可以看到他里面是有这样一个赛队的一个结果的,加密后的一个结果,那好继续我们继续来查看一下,这下面有一个点,就这样的一个调用对战 这个调一读上就是现在我们这个断点放到一个位置,你看这个箭头直的,就现在这个位置,你点一下之后有这个显示,那其实我们往下面这块是一个回数,我们走往下面走,他这一步直行之前是走的第二这个步骤,那你点击一下之后,点完之后就是我们可以往上面去看点这个步骤,他这个作用域当中可以看到他的一个内容, 这个本地当中有一个 a, 这个 a 取值之后可以看到 a 里面他其实是有这样的一个对塔数值,这个 a 数值我们往后面走,可以这样子来,在空格当中输入一个 a, 把这几个展开之后,他这个后面应该也是,哎,这里我们可以看到 dita 里面不是, dita 里面应该是,哦,没错,这个 dita 当中也有这样一个 set 签名,看到没有这个结果, 那也就是说他现在这个步骤也已经有了这样一个加密结果了。所以我们接着继续往前一个步骤,去这几个维度来点前一个步骤, 点到他之后,我们再可以去观察这样的一个作用的一个当中,作用里面他这个 t 也是有值的,按照类似的一个方式,你看 t 里面也是这个三点,按照类似的一个方式往前面进行一步一步的回数,这样子就 ok 了。那现在我就直接选择下面这样的一个步骤,选择它一点,点开之后好来到对的位置,可以看到这边是有一个外克, 外头就等待它就执行这一块,那我们从这个里面其实差不多已经找到了,可以看到这个赛,因为是一个 c, 而这个 c 当你选择好之后,可以看到鼠标换过来,可以看到它这里面是有值的,但我们没必要在这三个段点,因为你选择这个 c 的 时候,你看到前面是一个赛,所以你取了一个 c, 取了一个 c, 其实我们在这里可以上一个断点之后, ok, 再把这一块给消掉,重新走过去, 我把这个验证码先给过掉, ok, 我 们再重新来一个步骤来,在这边输入一个密码,好点一个登录点,一登录之后可以看到断到了这个位置,那断过来了,此时此刻我们把鼠标放过来,这里面他也是没值的,他也就走了这一块代码,这个代码也可以看到一个等待,等待也就是前面的一个一步,先执行完它里面之后再往后面走,那现在我们在这一块可以把鼠标放过来,直接选择 放到这个位置,可以点到这里面来,可以看到它里面是做了一步处理,点过来之后在这边可以发现它里边又做了这样的一个 c 点, a b, c 做了一个附值,那最终里面这一块可以看到是一个 c, 这个 c 进行了一个,就在这边做了一个附值,给了它是做一个值,用这个赛事取的,从这里完全给推断出来它左这个步骤,我们这里稍到点之后,你在这里再点就往下跑一个 好, ok, 就 可以看到他这个指令已经找到了,那你再往下面走一走一个步骤,好,这个 c 就 有值了。四九 b a 开头的,我们在这空台里面在这一块打印这个大小一个 c, 他 就回车,待会再来做一个对比,好,再来跑过去, 跑完之后其实左键那个 c 发请求,再来跑一个之后,我们可以把这个验证码再挪一下,挪到对应的位置,好,挪过来之后可以看到这边右走的 c 应该是锁定另另外一次的一个教练了,走这个教练了,我们再往下面走一个, 这是 c 的 d 四, d 六四开头,两个 c, 三个回车,两个指是不一样的,好, ok, 已经搞定了,现在我们全部把它走完,走完把这个段子就消掉。走完之后我们选择这样的一个网络模块来搜索,找这样的一个 get 的 名字,那 get 这块对应的就是一个四九开头 b a 的 一个,也就是 d 不 走的那一个请求,拿图片的一个请求,那再来看下面一个,应该是 教练这一块, d 六四开头,对,好,选择公式台, d 六四开头,一模一样, ok, 这就是给大家讲的关于怎么去在网易当中做的这样一个跟正的方式。
35爬虫逆向学习



猜你喜欢
- 30.3万来索思玩编程