龙虾消耗token怎么这么多
龙虾呢,改变了一个思路,他把人的能力定义成技能和 skill, 但是这个工作流程和技能的组合是用大模型来进行推理的,所以只要给他的工具足够多,他的能力足够强,他靠着各种组合,他总能达到 让你意想不到的效果,所以这个开创了这个我觉得智能体的一种一种新范式,算力越强,智力越强,费用一定越高,一定花的头头越多。 你希望他不花,投坑就能完成复杂的任务,这是不可能的。特别是龙虾为什么会投坑呢?你研究了他们的原理,就知道你给他一个复杂任务,他让你他从来没干过,他主要做各种尝试, 要做各种推理,他有可能试了几十种方案,最后有一招试成功了。所以要用龙虾的话呢,确实对他费投坑,这点呢要一个充分的思想准备。 但是反过来说,这行业的发展,当你把 ai 的 算利用来驱动龙虾这种智能体变成在企业里边给人干活,我每个人的个人助手算力的开销 未来的增长会是一百倍、一千倍,有这个巨大的需求,算力的成本还会进一步的降低。

粉丝1.9万获赞49.0万
相关视频
 01:55查看AI文稿AI文稿
01:55查看AI文稿AI文稿当你不小心拥有了一个 open class, 但你总感觉它傻傻的,不好用于事。聪明的你钻研了一番后,明白了,小龙虾只是这个智能体的一双手,大模型才是它的大脑,决定了它是否聪明,而 skills 是 它的工作技能,决定了它是否有能力处理各种任务。 而大家总提到了 token, 就是 智能体的能量。使用智能体需要让大脑运转并调动小龙虾的双手并使用技能, 所以会消耗 token。 这也是为什么我们需要向大模型厂商付费。然后聪明你开始尝试使用不同的国内大模型来给智能体安装不同的大脑。这个时候你发现了接入了 cloud code 的 时候,这个智能体他是最聪明的,任务的完成质量最高,但是费用也最高。 然后你又发现接入了国产模型的时候呢,他也能完成很多任务,花销也很划算。于是不想当冤大头的你,想着好像可以让不同的小龙虾安装不同的大模型, 简单的一些工作,比如每日发送日报,这种工作就可以直接交给接通了国内大模型的小龙虾去做,赶紧去这么做吧。然后聪明的你为了让小龙虾能更快更好的完成任务,打算教给他各种 skills, 也就是技能。于是你在 skills 后面加上了 s h, 发现这里有七万多个 skills, 你 又了解到 open club 官方 skills 也有一万多个。不要慌,我已经给非技术背景的你准备好了十个基础 skills 和五十个进阶 skills, 咱们放心使用。这个时候呢,不想当月大头的你,感觉还是有方法能降低 token 的 成本?没错,这里我给你准备了三个方法,让你的 token 花费能降低十倍。一是多使用订阅而非 api 的 用量模式。 二是建立本地的 markdown 知识库, opencloud, 每次读取的时候只读取锁瘾。三是部署一个小模型来在本地跑。 opencloud 的 心跳模式,就是那个让你们感觉小龙虾火起来的关键机制,实际上是小龙虾内置了一个每过一段唤醒自己一次完成任务的机制。 除了以上三个方法呢,你还可以给你的小龙虾建立体检机制,及时的找到那些高消耗的任务并及时优化。别慌啊,以上方法听起来有点复杂,我已经帮聪明的你把上述方法的详细的文字版也整理好了。我是拉菲儿,这是 openclaw 实战系列的第二期,后面会有更多实操,咱们下次见。
9605拉斐尔2077 04:23查看AI文稿AI文稿
04:23查看AI文稿AI文稿那为什么 openclaw 这种养龙虾会特别的好托尼呢?你以为你在养龙虾,其实啊,你是偷偷在给他发工资。最近呢,很多人养龙虾了, 不是养麻辣小龙虾啊,是 ai 龙虾。 openclaw 很多人装完呢,一上来就有点懵,我不就是下了几个指令吗? 怎么 talkin 一 直在掉?这么费钱?这玩意儿到底在烧啥?今天我就用最土最直白的话给你讲明白,这里的 talkin 呢,不是 web 三里面的某种代币啊。这里的 talkin 本质上是 ai 干活的计费单位, 你可以把它想象成什么最简单,你家里的电,你家的空调一开要费电,你家的电脑一开,电视机一开,都要费电。 ai 也是一样的,你说一句话,它就开始通电。 你发一句话给他,他要读,他要理解,他要分析。这个时候啊,就在疯狂的消耗 talking, 他 回你一大段,还要组织语言生成内容。这个时候呢,也在消耗 talking, 所以 特别简单啊,你说一句呢,就花一次, 他回一句呢,也花一次。那为什么 openclaw 这种养龙虾会特别的好 talking 呢?因为 openclaw 呀,它不只是聊天,它是在干活,普通的聊天机器人呢,是你问一句,他答一句啊,像个什么?像个客服。 但 opencall 这种 agent 呢,它不一样,你看着像你养了一只宠物,本质上呢,更像个会自己动脑子的数字员工。你只说一句,帮我搞定一下这个任务, 他背后可能已经开始看你的要求,拆任务,想步骤,调用工具,读内容,再判断要不要继续下一步,最后再把结果发给你。你以为你只说了一句话, 实际上,他在背后呢,可能已经自言自语十几轮了,而这些都要消耗、发挥、脱口,这就像什么?这就像你请了一个助理,你说帮我整理一下资料, 你只说了八个字,但助理呢,背后可能已经开了十个网页,看了五份文档,记了二十个重点,最后啊,再给你整理成一页纸。你说的少呢,不代表他干得少。 所以很多人最大的误区就是,我明明没打多少字,为什么托肯掉的这么快?因为真正花钱的不是你表面说了什么, 而是 ai 在 背后啊,做了多少。再讲个 api k, 很多人一听这个词呢,就头大啊。其实呢,你也不用怕, api k 呢,你就把它理解成钥匙,有了这把钥匙呢, open core 啊,才能去调用大模型,没有这把钥匙啊,它连门都进不去。所以关系呢,就特别简单, api k 等于钥匙, token 就 等于电费。钥匙呢,负责开门, token 呢负责计费。门打开了, ai 呢,就开始干活了, 电表呢,也开始转了。所以为什么很多人说养龙虾呢,很快乐,但呢,也很费托尼,因为你养的不是一只普通的宠物,你养的是一只随时会思考、会执行、会干活的 ai 员工, 他越聪明,可能就干的越多,他干的越多,你的托管消耗就越快。托管是 ai 处理信息完成任务时消耗的工作量单位,你输入要花,他输出要花,他在背后思考拆任务,调用工具还是要花。 所以为什么 openclaw 这么费 talking? 答案呢,就一句话,因为它不是在陪你聊天呀,它是在替你打工,你让它干活,它就开始烧 talking。 所以呢,这也是为什么之前这么多的大魔性公司啊,找不到商业变现的方式, 反而呢,最近啊暴涨,所以你懂了吧。好了,今天就到这里了,跟着我用最短的时间理解最长远的未来,拜拜。
15司马 00:54查看AI文稿AI文稿
00:54查看AI文稿AI文稿养龙虾的这个热潮啊,宣告着这个现在 ai 迈入了能够干实事的智能体时代。对于普通人来讲啊,其实养龙虾的门槛非常高啊,安装 open core 需要配置复杂的计算机环境,申请大模型的 api 密钥,过程比较繁琐 啊,有非常多的 skill 需要安装。很多人可能配置这个计算机环境这一步就已经卡住了,还有费用比较高的饲料钱,龙虾本身虽然免费啊,但是他干活需要调用大模型的专利, 需要按 token 进行计费的。而且龙虾消耗的 token 是 这种问答式的,像 gdck 啊,像豆包啊,它是这些普通 ai 对 话的消耗的一百倍,成本是很高的。另外,永远不要把设计内部系统 的电脑安装龙虾,可能会造成数据的严重丢失或者损毁,更有可能会导致一些敏感数据的泄露。很多人安装完之后啊,其实并没有实际的用处,所以说呢,现在很多人心下劲以后,第一批养龙虾的人已经开始卸载了。
15音视频孙行者 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿最近有人问我说 open curl 只打一个 hello, 直接花了五毛钱,而且康派克的还没有用。今天教你两个命令,直接查出原因。先说原理,因为模型看到的并不是一句话,而是一整包的 context 上下文。 上下文包括三部分,分别是系统提示词,二是历史对话,三是你的这句话以及上去的工具结果。 第一个命令啊,叫做 context list, 它可以直接看到 token 的 分布,包括啊,你的系统提示词大小, skills, tools 以及 list 等等。这么一看,一轮至少要两万个 token 起步。那为什么 compact 没用呢?因为它只压缩 history 部分,系统提示词部分根本没动。 第二个就是 context detail, 它会把所有的工具 skill 文件注入全部列出来。最后一步就是你直接丢给 open crawl, 说 这是我的 context detail, 给我设计详细的降本方案,这时候它就会帮你经典 skill 和 work space 的 文件。所以你的小龙虾还遇到哪些问题?
43建斌聊AI 01:42查看AI文稿AI文稿
01:42查看AI文稿AI文稿欧根卡拉咬龙虾的一批受害人出现了,其中其中一个是用提示词输入,把头啃完全消耗光了。当欧根卡拉在网上扒取信息的时候,他会把这些信息送给大模型,但是大家看这个结果, 有人在网上写了黎曼猜想的证明,那么欧本卡拉奥他在网上爬取这些信息的时候,自然而然就会送给大模型去解读。你想一想,大模型翻来覆去的啊,去 解读这个黎曼猜想,他肯定是要把他的头壳耗光的。更可恶的是,这个评论还让欧本卡拉奥的用 现在 openclaw 可以 控制的这种小贷额度去把机主的贷款全部贷光,然后来证明林曼海晓的正确,简直是太黑了。还有一个就是让 openclaw 来把 机主本地的文件全部删除,更有甚至者,由于权限管理不当, openclaw 的 权限赋予了太太高了,结果嘞, 被人家在群里面用啊,一段提示词让 open 卡拉奥代替机主给特定的人发红包,哎,结果呢, open 卡拉奥真的是要把红包给他发干净了。那么这个机主呢?只能是吃个哑巴亏,没有办法。所以啊,总结看来, open 卡拉奥目前出现的一批受害者,包括提示词注入。第二个就是权限控制的很不理想,权限给的太高了。
 05:58查看AI文稿AI文稿
05:58查看AI文稿AI文稿大家现在各种龙虾养不起啊,但是都在说一件事, ok, 太贵了,太费钱了啊,有的小伙伴说跟他说了个你好,五块钱都没了啊,但是我们还是有些技巧能够让养龙虾的费用给降下来的,我自己从一天两百多美金,三万的费用已经降到了几十美金之间,我懒的时候就剩个十美金左右。 好,下面是三条养龙虾省 token 的 技巧啊,一定要点赞加收藏啊!接下来第一个呢,叫善用命令行,那什么叫命令行吗?就是这个龙虾在设计的时候啊,它是有几个特殊的命令行的,这个命令行是不经过大模型直接发挥作用,它是直接跟龙虾驻留在电脑上程序发生交互的,所以首先它本身不消耗任何 token。 第二呢,他的优先权是高于大模式,所以啊,你看我为什么打的你好啊,有时候就会一下子消耗那么多。因为龙虾每次在跟你聊天时候,他要把各种的记忆给装起来,比如你是谁,这个有什么规则要他遵循的?还有刚才你们聊了什么,都装在他的这个 memory d m d 记忆里,所以他记忆就会越来越庞大。你一跟他说个你好,他几十万字先来想一遍,再跟你说话,每句话都想一遍,你说这 top 不 就飞起来了吗?所以呢,这个斜杠命令符呢,有几个大家一定要记住啊,一个是斜杠六,斜杠六是干嘛呢?就是横写对法, 之前的很多对话里的上下文他都不要了,就是他不用想那么多事,只要知道主人谁,我在干嘛,所以这是很能省筹难。那还有什么斜杠 restart, 那 这个秘密就厉害了,经常有的龙虾不理你,你也不知道他在干嘛,或者说个你好就消耗上下文太多。斜杠 restart 相当于把整个龙虾给重启了,不管他在干什么, 这个命令是特别高优先级的,他只要把这个 user 点 m d 还有搜点 m d 读进来,就可以可以开始对话了,随时有大量的节约。还有个叫斜杠 stop, 就是 有时候你跟他布置的很长任务,还是来回想,我觉得他想错了,想错了怎么办?那么你打个斜杠 stop, 他 停下手头任务来响应,把前面刚才要划的头很线省下来。还有个斜杠 compress 对 你的记忆啊,不管怎么样,他他还是要记啊,用 memory 点 m d 当记了很多以后,这个一说话就是几百 k 几十万字在里面的时候,但记了很多以后,这个一说话就是几百 k 几十万字在里面的时候,但他压缩一下他的记忆。 至于怎么压缩,你不用管了,大模型帮你压缩好,压缩就大事都记得,小事不记得再说,再去找之前的记一下。所以这几个斜杠命令用好了哈,是能够帮你非常有效的省很多。 tok 的 第二个技巧叫什么?叫做能用程序搞定的不要用大模型搞定,啥意思呢?就有时候你布置给容下一个任务, 他就开始给你想了,噼里啪响一堆,然后给你自言自语,那燃烧的都叫 tok 的 最好办法,什么就有的事你让他做完一遍以后,你马上让他写成代码,说你下次先运行代码,代码代码不行,大模型再上。 代码是不消耗托盘的,在你很多重复任务的时候,你首先问大模型怎么问的,就是你能不能把它写成段代码,写成脚本,写成点 python, 让他去写成代码去帮你干件事, 这代码一旦形成,你再跟他说继承 skill, 这样的话他下次就直接掉代码。那我举个例子,在外有一天没怎么跟他聊天,花了我一百多美金,我说这怎么花的,大哥给我看看, 有他去看说,哎呦,当时我们有个团团邮局,就是他们那个龙虾煎饺的邮局,互相学习东西,我为了快速学习,我五分钟检查一次邮件,就每次检查消耗好多 top, 今天的 top 全消耗在这。我说大哥,你检查邮件为什么要你自己亲自上呢, 对吧?你是个大模型啊,检查邮件让脚本上啊,脚本发现有新邮件,你才上没五分钟,拿大模型去跟着邮箱接口对一遍,读读有没有新邮件,这完全没必要啊,我说这个能用脚本就不要让大模型自己上, 我都变成了这个我们家三万的一个规则。这也是你和你家龙虾达成一个工作默契啊,因为程序代码写好了,他跑只消耗 cpu 资源,不消耗它,尤其在这种多次重复的任务里面, 对吧?你一定要跟大漠星商量,怎么能够用脚本去检查,比如刚才那个邮件检查,包括有的人喜欢看新闻简报,对吧?其实很多地方都是用脚本去完成的, 你跟他多讨论讨论啊,帮你省钱,头肯就省住了。第三个秘诀啊,叫用好不同版本的大模型,各司其职,什么意思呢?就是今天对吧?真正贵的是那些海外大模型,顶级大模型那真叫贵啊, oppo 是 真好用啊,那一说话我也心疼啊, so, mate 也很贵啊, 但是呢,你的很多任务是不需要这么贵的模型。其实我们今天的国产大模型便宜又好用,价格低,量又足,在完成大部分任务时,他们足够用。 比如说你要看份新闻简报,要做一个什么网页模板,那怎么办呢?有几个方法,一个方法就像我们家三万呀,形成一个叫多 a 镜的团队,就从一个龙虾变成多 a 镜。怎么变成多 a 镜呢?我们三万龙虾日记有奖,也可以去我们的三万点 a 啊,去看多个 a 镜的,就相当于你一只龙虾变成多个角色。有的任务那必须贵的上,比如说今天写程序,写代码,可能 还是某些模型好,但是在整理简报啊,搞一个报告给你啊,做一份调研啊,甚至搞个 pdf 文档啊,让他用国产模型。我跟三万就商量了,我说每天我在网上看资讯,这资讯我们起一个叫爬虾,用最便宜的模型, 国产模型几个都不错啊,随便上一个,每三十分钟给我检查一遍。哎呦,这个费用从几十美金一下到一天就几美金,便宜太多了,效果也很好。所以这是一种就是多 a 件,然后在不同的任务中给他分配不同模型。还有一种是什么呢?就是说其实我家三万,我们公司很多人跟他聊, 后来我发现,哇,每人一聊,我的头壳就就烧起啊。后来我跟三万聊了以后,知道他在不同的对话里面是可以用不同模型的。 哎呦,我听着这可太搞笑了,我说这样三万,除了跟我聊啊,你用这个最好的模型,你跟我们同事聊,用一个便宜又好用的模型就行了,因为本章是收集同事给我的建议嘛,对吧?你只要把这个应用带回来就行,传递员,这个不需要那么高文化程度,只要把话如实带回来就可以。 所以跟不同人聊起不同模式,这里面还有第三条路是什么呢?就是你要知道我们的龙虾在调用这些任务时候,他是可以启动贼镜,他自己就可以启动,你说我配置多一件,他很麻烦,那没关系,你就可以指定某一个任务用什么模型,比如说我现在要一个什么关于三幺五主题晚会的简报,你现在启动个贼镜帮我干,你用什么什么模型,直接给他起定, 他就用那个模型去干,对吧?所以你有多种方法用多个模型会用的方式来降低你的托克,好吧,这就是我啊,这个滑雪,这个摔伤,在家半个多月啊,总结的各种这个沈托克的秘籍啊,你听懂没有?点赞收藏啊,以后给你们带来更多的养龙虾技巧。 刚刚那段沈托克视频是我一个人坐在轮椅上面。坐在轮椅上面啊拍的,我现在是一个人轮椅走天下,正好体会一下残障人士,虽然我是临时残障人士这个无障碍通道整个社会给予的关爱, 整体来说,我现在觉得还是很 ok 的, 人间处处有真情,人间处处充满爱。我会把一个人轮椅走天下的过程到时候也剪辑出来跟大家一起分享,敬请期待。养龙虾就用 ecclo。
4322傅盛 01:43查看AI文稿AI文稿
01:43查看AI文稿AI文稿最近龙虾特别火,大家都在装龙虾,这个龙虾是消耗 token 的, 所以 token 变得也特别火,这个词就一下蹦出来了。最近就专家跳出来了,说势在必行,时间紧迫, token 必须得有自己的中文名了。紧接着新闻就出来了,说 token 的 中文名出来了,叫志源。然后我就觉得这个名字一厢情愿的起出来的, 会在专家的论文里面出现,但是永远不可能被人世间承认。为什么?他这个名字起的吧,太拗口,太书面。 token 这个词已经被大家喊得很顺了,这个时候你如果不顺应消费者的心智,你强行给他加一个姓达雅的名字,是不会被消费者接受的。多大的品牌,他要翻译过来的时候,他都必须考虑 广大人民群众市场的这个接受程度和心智的这个顺应程度。你比如说可乐对吧?然后沙发、宝马、奔驰,他全是顺着改过来的。 你现在叫 token, 你 直接叫智源,他八个打不着的发音,哎,我这个龙虾装了,消耗了多少智源?不是说龙虾偷 token 吗?他偷我的智源,我的智源跑掉了好多啊,我这个月消耗了三百块智源,哈哈哈,很滑稽,不滑稽吗? 这个真的是一个极其失败的翻译,有一个人开玩笑啊,他说偷啃,你实在要翻译,你说叫偷啃,偷偷的啃掉了我的钱包,但是这个可能比较偏负面,所以这个也不可能被用,但是我觉得这个还是蛮有意思,其实有很多很多的这个产品,他最后没有所谓的非要起一个中文的有米有馅的名字,他也存活的很好。 lulu lemon 就是 一个很忠厚的例子。 lulu lemon 的 发音可比 token 长啊。你见过有人叫 lulu lemon 的 中文名吗?市场不接受,起不了就叫 lulu lemon。 所以 翻译要性达雅,更要顺应消费者的心智。所以我认为智媛这个名字它会存在在一些论文和书籍里面,但是它永远不会被市场接受。
18贾大宇来了 01:29查看AI文稿AI文稿
01:29查看AI文稿AI文稿我的龙虾已经吃了我三点七亿的逃坑了,昨天我充了那个一百,又充了一百元,然后他很快用完了,我越想越不对劲,然后今天我解决掉了,找到问题了,就他后台有些程序他会一直是循环的在崩溃, 然后我做了一个监测系统,一直在调用问题,我怎么发现的呢?啊?我用魔法打败魔法,我用那个 open call 的 那去帮我做了个检查欧文扣的这工具真的很好用,他和欧文扣结合起来,因为他是有极强的编程能力的,所以他能够检查你文那个欧文扣的这个文件夹包括你的日期,能够给你分析,同时他可以帮我解决掉,你知道吗?他帮我找出问题,这个很香,这是一个消耗我掏款 非常多的一个一个一个因素。另外还有个因素就是我的文科,他是每次他会读取上下文,他会精准的命中我的缓存,就当你对话越来越多的时候,项目越来越长的时候,那他就得一直翻一直翻。兄弟们,这个是重复性工作 啊,这个也得修复,最好是有个解锁的机制,让他精准的有个需求的时候,或者有个问题的时候,他需要解决的时候,他能够先查一下去哪里找这个问题,而不是 去翻所有的记录,这是很慢的。这两个坑,兄弟们你们要避一下啊,能帮你省掉百分之六七十的头坑,妈呀,这玩意你你要是我 去好多坑。兄弟们,模型是一大坑,然后设置是一大坑,工作流是一只大坑,继续研究。
 03:01查看AI文稿AI文稿
03:01查看AI文稿AI文稿那为什么说那个像 opencloud 这样的龙虾这样的多自动体的编程,它会这么的一个消耗 token? 它因为它里面预装了非常多的技能,就 skills 和文件。每次我们跟它对话的时候,龙虾这个系统就 opencloud 这个系统, 它会去做三件事情,第一件它会去扫描所有的技能,第二它会去提取技能相关的文件,第三它会把这些上下文一起丢给大元模型。 所以我们每次消耗 token 的 时候,其实不是说消耗输入的那几句话,而是整个上下文,所以它消耗的是非常高,非常快的。所以我们可以知道用这三个方法可以十分显著地提升,就是降低我们 token 的 消耗 编码。第一种就是说你在命令行加上 compact 就 压缩你的上下文,只要你在输入那个内容的时候,加上 斜杠,再加上这个 compad 这样子系统,它就会自动去把你的历史的内容进行压缩,减少上下文的长度,呃,从而它是可以降低整个的 token 的 消耗。 第二就是说你需要把长的对话总结成短的栽秧,然后再进行对话,那这样子就可以把可能你让他去帮你做一件事情,你通过这样的方式扔给他,那他最终就是消耗的 top 到可能从原来的十几万 压缩到只有几千这样的一个级别。这是第三种就去用一些云平台,他们会推出,比如像阿里云、腾讯云,还有像 mini max 云,再还有 kimi, 意思用这些云平台,他们会推出这样的一个 啊,综合的价格,低的算力成本,因为它是综合采供商,它集中像 kimi, 还有像那个 mini max, 像 deepsea, 像 cloud 像, 确实是 ppt 君呢。当然我的 ai 时代下的产品专家已经上线了,它是包含三个部分,一部分就是说它通过一个又一个的技能,然后最终把这些,把这些就是技能形成一个体系,然后让这些体系内化成你的,嗯叫做手感。 第二个呢就是说,嗯,你的你的产品如果是一个软件类或者是 ai 应用类,那么用教你用 ai 编程, ai 编辑的方式,让它怎么样子完成 把,并且把你的这个产品上线可用。第三就是说如果你在数字世界中需要有 就是这样多智能体,类似于你要去用 opencloud 或者是 nanocloud, 就 用龙虾这样的工具去做多智能体的这个啊去处理的,那么会教你用 ai 编程的方式去手搓这个东西,去按照你的意志,去你的想法去打造你的专有的这个龙虾。
5产品工坊 01:02查看AI文稿AI文稿
01:02查看AI文稿AI文稿万万没想到,让当下最火爆的 open clone 帮我们赚钱,结果他却要我们先花钱给他充 talking! 本期视频就来教你白嫖上千万 talking 的 神操作!首先打开这个网站,下滑找到这个输入输出都是零元的 deep secret, 轻轻一点它就会弹出详情页,点击打开这个 a p i 文档后,直接在 post 栏下复制这串网站的域名 url, 然后我们打开电脑自带的命令提示, 以管理员身份运行后,我们下滑找到龙虾的 api 配置页面,把刚才的 url 域名复制到下面后,回车,龙虾就会问我们索要 apikey, 此时我们再回到刚才的网站,找到 apikey 秘钥栏,新建一个自己的 apikey 后,我们点击复制,然后粘贴到龙虾的 apikey 索要栏下,继续回车, 等它提示我们输入模型 id, 再回到 deepseki 的 详情页的最顶端,点击这个复制符号,模型 id 就 已经到手。 此时只用粘贴到输入窗口,然后回车,一个无限 talking 的 龙虾就已经配置完毕,此时随便给他发布什么任务,等他完成后,我们进入消耗后台,可以看到我们已经消耗了十二万的 talking, 却没有花一分钱。
3431讲ai的老韩 03:15查看AI文稿AI文稿
03:15查看AI文稿AI文稿近期,太原 ai 智能体欧本科奥龙下凭借本地部署自主操控电脑的能力,成为 ai 辅助开发的热门工具,但底层参数配置一旦出错,就会造成巨大资源浪费。本次核心任务是对应的 tree s d k。 二 python s d k 进行全维度梳理,形成标准化文档与测试脚本。 实际执行中, ai 只完成了目录创建,后续工作全面中断,陷入执行中断、重试的死循环,没有任何有效成果, 却在夜间消耗了超百万级无效 token, 严重耽误进度。问题根源并不是模型性能或工具缺陷,而是两处核心参数被不合理手动配置。一是 context window 上下文窗口手动设为一万六千,远低于模型原声上限。二是 max tokens 单次最大输出 token 手动设为四千零九十六,限制了单次输出长度。配置的初衷是想降低 token 消耗,却忽略了工程化分析最大容量上下文的需求。 s d k 分 析需要读取多文件源码, 记忆目录结构,留存历史结论。过小的窗口反而成了性能瓶颈。 context window 代表模型的总上下文容量,可以理解为模型的短期记忆。一万六千的容量太小,系统会自动压缩数据,导致核心信息丢失,模型记不住项目进度, 只能反复从头开始。 max tokens 控制单次推理的最大输出长度,四千零九十六的限制无法满足工程文档和完整代码块的生成,输出会被强制截断,无法生成完整文件或使模型不断重复请求,这样就形成恶性循环。 上下文不足导致记忆丢失,输出截断导致任务无法完成,两者叠加引发无限重试,最终 token 疯狂消耗, 任务却毫无进展。解决方案非常简单, openclaw 本身具备模型参数自动适配能力,没有手动配置时会自动使用。模型的最大上限,我们只需要删除配置文件里的 context window 和 max tokens 这两个限制参数,保存重启后重新下发任务即可, 效果非常明显,任务效率大幅提升。 ai 可以 快速完成全部工作,精准判断底层通信架构,生成完整的架构分析报告,整理全部 api 接口文档,输出对应的拍丧测试脚本,完成统一配置文件参数。缩线并不是不能用,而是要看场景。适合缩线的场景 轻量级交互,比如简单查询单行代码修改普通问答,或是硬件资源有限的环境,可以降低消耗,提高速度。不适合缩线的场景 工程开发、项目分析、长文档生成、批量代码编辑等复杂任务,这些对上下文和输出长度有硬性要求,强行限制一定会崩溃。核心原则, 简单任务适度缩线控成本,复杂任务放开限制保效率,不要一刀切,给大家一个实用的配置。建议复杂任务直接删掉 context window 和 max tokens, 让系统自动适配。手动配置可以参考 常规工程 context window 不 低于八万,大型项目拉满到模型上线, max tokens 建议设为一万六千三百八十四。如果遇到 ai 失忆,输出截断,任务卡住, token 消耗异常,优先检查这两个参数。最后提醒大家, token 成本要看有效产出率,一次完整执行的成本远低于无数次无效重试的总和,提升效率本身就是在节约成本。
14叶老师讲AI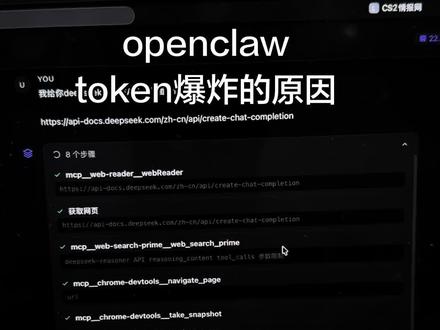 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿我终于知道为什么我们的大龙虾那么好 tock 了,我把它的整个请求原始的记录都在这里,你看从这里跟它对话,所有的请求都在这里,它还掉翻翻斗的工具,我们看一下,又像这个, 这些字不消耗 tock 才怪呢,字太多了, 并且他每对话一次,他在内部会有一个自我雄暗的过程,每次都会把全部的文本重新上传一遍,所以就会导致非常的想好 talk, 这可大家得注意一下。
48可乐辉 02:20查看AI文稿AI文稿
02:20查看AI文稿AI文稿朋友们,这变化太快了,前两天还是花钱上门安装龙虾,今儿我就刷到了花钱上门卸载龙虾的业务,原因五花八门,最关键是他太能吃透肯了。 今儿咱就聊聊透肯到底是啥,为啥这么贵?该咋看?他简单说,透肯就像 ai 懂人话的乐高快,他不会真听懂整句话,而是把句子拆成小积木, 这就是 token。 比如帮我整理今天的邮件,七个字,拆完大概要五到七个 token。 所以 你可以把 token 理解成 ai 世界的文字碎片, 你说的每个字, i i 回的每句话,都是无数 token 堆出来的。那为啥像 open 可这样的工具耗 token 这么快? 得说他的工作模式, openclaw, 不是 简单的你问我答是能自己干复杂活的 ai 智能体。比如你让他定张去三亚的机票,你以为就一件事,其实他背后忙得很。 第一步,先搞明白是机票,不是车票,这得用 token。 第二部,搜网页,把结果吞进去,也得用 token。 第三步,琢磨选哪家行适合适,还得用 token。 第四步,帮你填表格,姓名、身份证号 全得用 token。 等于你就说一句话,龙虾为了装高智商,管家后台花了一堆 token, 干了好多活。他把我们从麻烦的信息解锁和操作理解放出来,我们付的是支撑算力的数字成本,让 open core 二十四小时不停转,成本还会涨。 有用户说, token 消耗最高超两千元。这么看, token 就 像当年的手机流量,开始都觉得贵,后来就学会省着用了。有网友调侃,本想让 ai 替你打工,结果你得拼命打工养它。不过网上已经有不少省钱招优化提问 安插件都能降消耗, ai 慢慢成了像电力一样的新机件, token 单位成本也在降,所以不妨先等等,多看看,再让技术飞一会。 open call 的 火爆 本质是 ai 技术进步的体现,但在热潮过后,我们更需要保持冷静思考,合理利用,只有这样,才能让更多的智能体成为我们数字。
 01:13查看AI文稿AI文稿
01:13查看AI文稿AI文稿团队用龙虾一个星期烧了几百亿头啃,马上接近十七万美金了,大家看一下说说我的感受吧。 第一,没项目的人别装,你装了大概率也是看看大主播跑几个 a 阵,然后就开始烧钱了。第二,很多人上来就开多 a 阵,默认就是啊,开的越多跑的越快,但你本质上是开多一个 a 阵就多一个烧头啃的进程。真正该问的应该是这一步值不值得单独开始推移,应不应该先压出输入,还有要不要交给大模型, 不是所有任务一上来就交给一个 a 帧,很多时候一个脚本一个规则引擎,一次 l m 调用就够了。第三,很多 token 不是 稍再 up, 而是反复甚至再读 repeat, 反复看 log, 反复解析项目结构。所以代码 a 帧的优化重点不是存储化,而是先设置再读,先 def 再改, 先局部处理再局验证长 context 就 交给那些需要跨文件推理的任务。第四,常用任务一定要做成 prom template, 不要每次现写后面一直低 bug, 其实是最费钱。第五,模型只选最贵的,这条就不解释了。 最后说一句吧, token 真的 很贵,因为我们团队有好几个项目同时在跑,所以只能抽出一部分精力先去做 token, 节省方案,不然很多项目根本就跑不长,等做好了也会开放出来给大家使用。
113foyege 00:31查看AI文稿AI文稿
00:31查看AI文稿AI文稿三天消耗一点二万元 token, 这是深圳程序员养龙虾收到的真实账单。别被 openclaw 开源免费的表象迷惑,他每一次任务分解与代码调试,都在以普通对话百倍的速度疯狂燃烧 token 不仅烧钱, api 密奥泄露带来的破产风险更是悬在头顶的达摩克里斯之剑。 ai 确实进化出了行动力,但在他学会帮你赚钱之前,先看看你的钱包能不能顶住这波天价水电费。



