openclaw私有化部署 效果
其实龙虾平台它的本质是什么?它的下面的底层的本质,其实就是我们现在在经常讲的欧本扣的这种东西,一体积有前景,我觉得没有前景,你自己去回想一下,当时你去想当欧本 ai 的 那个 chat gpt 出来的时候,它那个模型, 大家在外面套一个壳就能赚钱。但是你看看现在这这些人还赚钱吗?你自己去看,我觉得这个肯定是不行的,这个太薄了,没什么价值。 你赚钱的本质是什么?赚钱的本质是你产生的价值,产生的价值就是你为这个社会产生的价值。你不要去做一些现在我们称之为信息不对称的事情,现在没有了信息不对称很少了,这个生意做不了, 只有你知道,别人不知道的事很少,这个东西很快就会普及了,因为现在这个世界舆论信息发展太快了,比如说前面中东打仗了,是根本就瞒不住的,马上你就得到了一个视频,你就去看一下这个人被炸死了, 或者这个东西被炸了,谣言又起来了,官方马上又辟谣了,根本就瞒不住了你这个事情。所以你在龙虾这么薄的这样的一个市场里面做这个肯定是不行的,我觉得大家还是要花点力气去学一下。什么我最近讲的那个课,我觉得大家去可以学学一下你怎么通过自然语言去写代码,我觉得这个你是可以学一下的, 这个对你来讲是有长期价值的。其他我觉得这个价值不是很大,你还是要想办法,就是自己去创造软件,而且你创造软件的成本已经非常低了,你要把你的思想变成一个软件,再把这个软件去卖掉。

粉丝4.5万获赞32.5万
相关视频
 07:09查看AI文稿AI文稿
07:09查看AI文稿AI文稿一说到最强核显, amd 粉丝, yes 七八零 m 八九零 m 八零六零 s 都是真能打级别的核显,但是在非牛的玩家里, amd 的 核显硬解一直没有适配。作为非官方非牛代言人提前透露,非牛马上发布 amd gpu 加速的适配,并且会一锅端的推出一键部署。非牛 open club, 咱们今天先来尝尝馅儿,为什么总是你仰仗各位,那不得开香槟庆祝一下吗?然后去薅了一台三九五的机器, 飞牛官方合作伙伴,林克 gtr 九 pro、 amd amx 加三九五插电开机。 咱们先来看一下林克这台 aimax 加三九五的系统信息。 amd ryzen ai max 加三九五内建八零六零 s 的 核显十六核三十二现成。我这台是一百二十八 g 的 统一内存,八千兆赫的频率, gpu 识别正常,双万兆的网卡啊,这都是免驱的啊,直接识别,我现在给它装了一块四 t 的 硬盘。 ok, 咱们先来看一下这个包升级的地方。第一,支持了 amd gpu 的 硬件转码播放视频, 支持了 amd gpu 的 相册人脸识别和智能识别,也就是 ai 相册的全支持,全硬件加速需要安装 amd 的 rocm 七点二驱动和非牛自研的 ai 引擎。安装飞牛 ai 引擎和 amd rocm 七点二驱动, 飞牛影视的设置已经自动打开了 gpu 加速。咱们来播放个视频给大家看,四 k 蓝光史比特 hdr 杜比全景声走起,我们让纳斯端应解启动, gpu 应解成功,咱这三九五你就说是啥解不了吧,随便拖。 接下来咱们来提升一下难度啊,这是杜比世界版本的 hdr 视频,颜色对应,牛,注意看啊,也是服务器端硬解杜比世界四 k 杜比全景声,这就是典型的全杜比,所以即便你的电视或者你的设备不支持杜比世界,他也不会出现色彩映射错误, 惨绿惨绿的。在 ai 相册里面也可以识别出这块和弦, ai 设置里面下面就多出了启动 gpu 计算的按钮,咱们启动 gpu 设置成功,咱们先看机操啊!人脸识别情况走起!一共是五百四十五张,计点计用,然后我们来看资源管理器,但愿让大家还能够看到 gpu 占有率只有轻轻松松的百分之十四, cpu 根本就不带动的啊,所以 gpu 人脸识别, ok, 这负荷有点太轻了是吧?哼,分分钟你看就识别完了,接下来上强度智能识别走起,你看直接就几十几十张的跑, 用 cpu 的 时候大家懂了吧,都是一张好几分钟 gpu 硬解,直接拉满 c p u, 非常轻松。五百张哇,智能识别秒没 amd 玩家,你就说狂喜不狂喜,但这只是基础操作。 amd 粉丝飞牛玩家第二部,欧拉玛 本地大模型,在飞牛 amd 的 平台上部署欧拉玛,我给大家看有多简单,直接输欧拉玛。 最新版本的欧拉玛已经升级为一点一的版本,已经可以直接对接 lcm 的 硬件加速,你只需要安装然后就可以了,一键打开欧拉玛,牛皮,我已经给大家下好了,千问三点五,一百二十二 b q 四量化的模型 gptos 一 百二十 b q 四量化的模型,塞进显存的容量分别是七十六 g 和六十一 g, 哎,正好适合咱 aimex 加三九五,咱们来调戏调戏 ai, ok, 这生成速度还可以哦,大约二十点五六, tokens 每秒 amx 加用户进阶玩法。第三步,一键部署 openclaw, 直接调用欧拉玛的本地 ai 模型。所以你看你家什么机器,二十四小时开机啊, 你的纳斯,你家什么机器算力过剩啊,你的纳斯,我说你要累死纳斯。所以你看你在纳斯上部署 本地大模型,部署 openclaw, 资源的利用最大化。所以之前好多次老张直播的时候都告诉大家,我一直认为 nas 才是 ai 的 最好平台。好,接下来咱们一键部署 openclaw, 这个很快会给大家推送啊,推送之后,你直接在应用中心就可以找到一个叫做非牛 openclaw 的 应用,然后它依赖的应用都会直接部署,所以真的就是一键部署。 yes, 一键启动,我们是本地模型,所以直接选择欧拉玛自动识别本地模型,包括 ip 端口号,一概不需要懂,自动读取出现有的 本地大模型,然后啥也不用管,保存, ok, 恭喜你, openclaw 配置完毕,然后这大家说这怎么用啊?非常简单,你看这打开 openclaw 图形化界面了啊,远程访问网页版就可以和你的 openclaw 互动了,咱们问他,你是什么东西? 恭喜你打开新世界的大门,再也没有 token 焦虑了。 在小龙虾给大家生成的第一个文件屋缝对接飞牛啊,来大家看吧, 很多小伙伴玩小龙虾是希望在即时通讯工具中能够直接对接的飞牛的,这个 open claw 直接内置了飞书的对接, 企业微信和钉钉的对接一键安装。一个意外发现啊,因为是在非牛的应用中心中直接安装了一个非牛的官方应用,所以你根本不需要管什么端口映射、外网穿透这些技术的问题。因为非牛纳斯自带 f n connect, 你 可以随时随地在你的手机 外网访问你布置的 open club, 一 键打开移动端,直接无缝连接之前的对话。所以在飞牛上玩龙虾,事实上,你根本不需要去对接 实时通讯工具,这事变得更简单哦。依然是老规矩,明天中午老张直播间大家准备了很多好东西, ro 明天中午不见不散!
4860老张是大佬 04:37查看AI文稿AI文稿
04:37查看AI文稿AI文稿哈喽,大家好,我是你们的小伙伴思摩图。那画面上的这只小龙虾啊,相信大家都已经不陌生了吧,他就是大名鼎鼎的 open core, 他 能够通过 ai 为我们自动完成不少电脑上做的一个工作。那早在过年之前呢,我们就爆干给大家出了几期相关的教程,教大家在不同的平台上进行这个部署。 但是这个啊,实话实说吧,哪怕我把这个步骤拆的再细了啊,那卡在这个环境的一个配置中 啊,那确实啊,因为这种 ai 项目,它原生安装的是比较复杂的各种依赖项目,经常会打架,很多这个非开发者的普通小伙伴跟着敲这个代码也会犯迷糊,那直接呢就被挡在了门外,难道普通人就不配玩前沿的这个 ai ai 准了吗?那当然不是啦, 那最近呢,绿联那是搭载的 u g s pro 系统,就直接给我们提供了一个快速接触前沿技术的这个捷径,一键安装 open crawl。 那首先我们来看一下这个一键安装所支持的范围啊,那目前 dsp 系列,已切换系统的这个 dx 四六零零系列,以及这个 dh 二六零零都能够直接支持 open core 的 一键部署。那今天我们又来演示呢,依然是那台高配性价比的这个神器啊,绿联 dsp 四八零零 pro, 我们只需要在系统里面点一下应用中心,在里面点一下 open core 的 这个图标,点一下安装,然后输入你让他能够访问这个目录,然后再设置一个加密令牌,接下来几分钟他就全部自动安装完成了。 安装好之后,我们点击系统里面的小龙虾图标,然后输入你的令牌,就可以直接进入网页的控制台,然后你就可以跟你的这个龙虾助理开始对话,然后安排工作。 那玩过 open crawl 的 小伙伴应该这里会发现有点不同啊,那我们是不是还没有部署这个模型呢?哎,那这个炸裂的来了, 玩过 a 卷的小伙伴应该都知道,那这玩意一旦跑起来是极度消耗这个 api token 的, 而绿联这次呢,直接联手国内头部的这个 ai 企业 mini max, 只要你用绿联一键安装,那连这个 api 都不用买,直接送你免费的。这个高性能 mini max 大 模型算力, 那除了能用以外呢?相信很多小伙伴也关注着这个 opencore 的 一个安全性问题,那其实大家在这一点呢,也是完全不用担心的,那绿联 u g s pro 里面的 opencore 呢?它默认被安装在 dos 之中, 除了它自己所在的这个容器以及你映色的目录以外,它无法直接对外部的文件以及你的电脑进行直接的操作,这也代表它最多自己玩崩自己啊,而不会对你的这个电脑那上的文件产生破坏。 而且由于 u g s pro 所使用的这个文件系统,它能够支持快照的保护,我们可以定时对这个目录进行快照备份,随时让文件回到之前的状态,那这也可以避免因为小龙虾对需求理解偏差所导致的这个文件错误修改。对比你直接在电脑上安装小龙虾,那这样的方式要安全很多。 那接下来呢,我们也简单分享几个我们在这台机器上的 open crawl 使用案例,那安装好 open crawl 之后,我们可以通过国内的 skillhop 网站为它安装一些常用的技能。安装完技能之后,我们就可以配置飞出的一个通信连接,直接通过飞出客户端与 open crawl 进行这个通信。 在这台那上,我创建了一个头脑风暴的 a 卷团队,那团队由四个不同的智能的这个 a 卷构成。他们可以每天早上十点为我发送由最新消息筛选而来的这个数码相关选择题。 那接下来呢,他们可以根据这些选择题进行自主的一个搜索完成。头脑风暴为我提炼每一个选择题中的看点。大家看,现在画面上就是我用飞书向他提出需求得到的反馈。那最终呢,他们会通过这个 o c d 的 一个技能为我在我的笔记中生成多个选择题的这个看点汇总。 那另一方面呢,他也可以对我存放在工作目录中的每月消费发票进行一个汇总,我只需要告诉他目录所在,他就可以按我需要的这个格式生成报销的清单。如果你愿意花时间调试的话,他还可以通过浏览器自主的为我们在购物网站上获取订单的一个发票,然后进行整理。 那除了前面一些日常的工作以外呢,我还让他接管了我的这个 copy ui 和 lm 推理的服务器,我可以通过一句话控制它下载模型或者是切换模型。也可以控制服务器直接调用工作流生成素材。生成的素材 open crawl 会直接从服务器拖回 nas 本地,我们在网页端也可以直接打开查看, 那它还可以用于控制我的这个语音下载系统,我只需要一句话来操作 open crawl 就 可以为我下载指定的电视剧,或者直接进行剧节的追踪。 那其实现在在电脑上基本上一些花时间费脑子的这些任务,我都会尝试用 open crawl 给跑通,那这些呢,都是实打实的为我节省时间,也能够更多的完成工作。好了,这就是我们视频的全部内容,希望大家能够养好这些龙虾,那我们就下期再见喽,拜。
665司波图 05:11查看AI文稿AI文稿
05:11查看AI文稿AI文稿哎,好的好的,大家好,我们今天手动来带大家从零到一部署在自己电脑上面部署一下最近火爆全网的这个 cloud bot 啊,现在已经改名叫 opencloud, 我 们从零开始,首先我们去 opencloud ai 这个官网,然后往下滑,它有一个 one liner 的 这个 quick start, 非常简单,你只要在复制这个代码,然后开一个命令行,然后把它黏贴进去, 它就会自动去安装这个 opencall, 它会去检测联盟装着 homebrew, nojs 和 git 啊,如果没有的话呢,它会帮你去安装,我这边已经有了,所以它自动开始在安装这个 opencall。 好 的,安装完毕,安装完毕的话,它会自动会进入这个 onboarding 的 这么一个流程啊,它也是非常人性化。首先让你先来先签个协议啊,说这个很 powerful, 但也很 risky 啊。我知道了, onboarding mode, 我 们选 quick start。 然后第一步呢,是我们要接一个模型啊,在后端的模型,它虽然就 open call, 它只是一个中间层吧,你后端的模型还是需要用自己的 a p i 的。 之前呢是我我尝试使用这个 cloud code 的 订阅,可以接入这个 open call, 但是前段时间 cloud code 把它给封了,所以现在就必须只能调用 a p i, 所以美国的模型 api 太贵了,所以我们这里选择支持一下国产。我们使用 kimi 的 模型啊, moonshot ai, 然后 kimi 最近也是浪潮了,自己的这个 kimi k two 呃,二点五的这么一个模型啊,能力上据说是跟 opps 四点五非常相像啊,也是很厉害,然后价格可能只有十分之一,所以我们来体验一下,所以我们这里选 moonshot ai, 月色暗面, 然后把我们之前复制好的一个 api key 给复制进去, create a api key, 然后我们选择一个模型,我们就选 kimi k 二点五。然后呢,我们在这里选的是 在第二步呢,是选这个 channel, 就是 call bot, 呃, open call, 它是可以让你用过用你的这个即时聊天软件,然后来调用它的啊,这里就会去配置一下这个即时聊天软件。我在这里选的是,呃, whatsapp, 然后我们来看一下 whatsapp 怎么 link 啊,它会给你二维码,然后我们要拿 whatsapp 扫一下二维码。 好,我们拿这个 whatsapp 刚刚扫了一下这上面的二维码,然后,呃,现在是可以去继续去设置一下详细的配置。 whatsapp, 它里面有一些 phone, 呃,这个是 phone setup 啊, separate phone just for open call。 我 选择用一个单独的电话号码在 whatsapp 里面,然后这里使用,选择 recommended power mode allow form。 说实话不是很知道是干嘛了。嗯,选择 default 好 了,然后下一步呢,是 configure 这个一些技能啊,这里我先不 configure, 但是我们看一下, 呃,这个 open call 它有哪些技能啊?这些技能本质上来说就是它到底能做哪些事情,你可以看它这里有非常多的集成的这个 integration, 就 你的密钥,密钥管理系统 word 是 可以用来发这个 twitter 的, 然后 bear nose 是 可以用来这个记笔记的一些东西,然后有非常非常多的这个,还有什么 g u g 这种 就是 gmail 啊什么的,非常非常多 open ai 啊什么的很多啊,我们这里今天先不配置了,然后回过头也可以再配置,到时候会问你一些问题,要不要这些 a p i key 有 多选? no no, 如果到时候需要的话呢,可以再单独回过头来配置 好。然后最后一步呢,是这个 hook 啊,自动的这个操作,然后它可以在某些特定的环境下面被触发,然后帮你操作。比如说它这里有一个 session memory 的 这个 hook, 就是说它可以在每个赛季结束的时候呢,自动把赛季的这个你们聊天对话记录呢,保存到他们的这个长期的这个 memory 当中。这里我觉得还是开一下比较好,因为 open call 它是自带这种长期 memory 的 功能的,然后如果每每每一次跟他对话,它会更新长期 memory 的 话,你会发现这个 open call 越用越聪明。 好,然后这些都是系统自带的,我就都开了,然后都开了,然后去设置 gateway, gateway 就是 说是呃呃,如如何去开这个?开个关口,然后让可以让这个你在 whatsapp 里面发送的消息被传递到这个电脑上的 open call 里面。这里我之前已经装过了,所以我们在这里的话就是 reinstall 一下。 好,我们这里的 git 已经装好了,我们现在有有有方法去 hack。 我 的 bug 就是 初设啊,初设的话我们可以推荐是走这个 t u i, 也就是它自己会开一个网页,然后这有一个链接好,然后可以尝试发个消息 啊,很可惜啊,消息没有发成功,我要来 debug 一下。哎,好的,刚刚发现是因为自己的那个 kimi 账号没有充钱啊,现在充了钱就变强了啊,我们现在已经可以 跟他对话了,然后我们在终端呢,可以输入这个 open opencloud dashboard, 然后呢我们来重新进进入这个网页的 ui 啊,然后这里呢我跟他说了个嗨,然后他现在会介绍一下自己可以干哪些事情啊?怎么怎么样,怎么怎么样都是英文啊,太,太烦了,我看他看中文那里边啊, 好,他现在等于说一开始的对话呢,他会让你去呃设置一下他的名字是什么,然后怎么称呼我,然后他是干嘛的?嗯,然后同时呢我们我来就展示一下这个我们这个 whatsapp 的 这个能力啊,就你看我们这边, 嗯,其实 whatsapp 上面是可以给大家直接发消息的,然后在这里的所有的信息呢,我们也都可以在 whatsapp 里面跟他呃聊天,然后他就只要你的这个网关是上线的,他就是可以呃去跑的。 那么今天视频就到这里呢,我们就简单的装一下 cloud bot, 未来的话我们也会在这里继续更新一下 cloud bot 到底能在呃能对我的工作流程带来多大的影响啊?期待可以创造更好的内容给大家,谢谢。
2.6万金黄说AI 26:49查看AI文稿AI文稿
26:49查看AI文稿AI文稿openclaw 系统构架底层原理好?大家好啊,这节课是咱们这个 openclaw 的 这个公开课,之前听过我课的同学在这个 vvip 课上听过我课的同学啊,知道我是主要做科研的啊,简单自我介绍一下吧,我是硕博毕业于海外某高校的人工智能专业,师从海外工程院硕士。 呃,国内的大长江团队啊,现在是博士两年毕业,现在是该领域上最年轻的全职助理教授啊。据我了解,反正是这样的啊,大概就是些这样的发文情况, 现在呢,也是主要做大模型 opencloud 它现在特别火嘛,那咱们也是趁着这股东风,那我们一起来看一下这个 opencloud 到底是个什么玩意儿? 好,咱们这堂课呢,主要会分三节来讲。第一个,我们会详细的去讲一下这个 ai agent 是 什么啊?我们都知道 openclaw 它很火, 但是 openclaw 它其实也只是 ai agent 的 一种而已啊,那它在这个普通的 agent agent 上,它有什么样的改进啊?或者说它到底是做了什么样的操作, 可以让他这么出圈,可以让他摆脱大大众对这个 ai agent 的 这个认知啊,可以进入到我们普通人的视野里面啊。第二部分呢,我们会讲一下这个 open code 的 底层架构啊,咱们既然来了这个课嘛,那就是知其然,我们更希望知其所以然啊, 现在网上有很多的教程啊,路客啊,大家应该都刷到过啊,大概就只会讲一下这个 openclaw 怎么用啊,大概是个什么玩意儿啊,但是它底层工作是怎么进行的,它怎么运行的?它用了哪些框架,用了什么样的技术 啊?这个可能一般涉猎的会比较少一点啊,这样,了解了底层之后,对咱们这种不管是做开发的同学,或者说做科研想用到这个 open code 的 同学,我相信都是会有点帮助的。最后呢,可能也是大家比较关心一点,我们做一下本地部署啊,链接一下推书。 好,因为咱们这个是个直播课啊,大家如果有问题可以发在这个弹幕上,我这边看到的话,会跟大家解答的。好,话不多说,咱们发车吧。好,我们先讲一下什么叫 a i a 阵的啊, 大家也知道,大概呢,在年前开始啊,就选选起了一个全民养虾热潮啊,左边是腾讯大楼, 腾讯大楼下面免费装虾啊,大家都看过新闻哈,说一代人有一代人的鸡蛋要领啊,那我们这一代人的鸡蛋是什么?去领一个小龙虾过来啊。那右边呢,是抛开我们这个现象不谈啊, openclaw 在 这个 github 上,它的新数啊,从二月一月底二月初开始就一路飙升啊,可能大多数原因呢,是得益于咱们国内的宣发能力啊,还有一些比较出圈的操作啊。那在这个这么火的一个现象后面, 我们不禁要思考一个问题啊,大家为什么非要来养虾啊?你拿到这个虾的时候,你知道他是干嘛的吗?或者说你能知道他能对你创造一个什么样的价值吗?你就去领啊,你鸡蛋囤多了还会放坏呢, 对不对啊,我,我个人觉得呢,现在大多数人啊,养龙虾主要还是以猎奇心为主啊,更多的呢,我觉得可能是我们家的哎, f o m o 在 作祟啊,就是 fear of missing out, 你 是怕错过这个技术啊,可能觉得哎呀,这是是不是一个像 g p t 一 样出来的技术,我如果不提早入局的话,我就要被淘汰啊,大多数人可能都是情心理对不对啊, 那也因为这个给他蒙上了一个非常神秘的一个面纱,那他到底是不是这么厉害,是不是这么神秘啊?我们其实只要理清这里面的结构原理就会发现啊,他其实还是一个很好懂的一个东西啊,对于我们个人来说, 要不要去部署这个 open klo, 或者说我们学这个 open klo, 我 们需要学到一个什么地步啊?我觉得要从它部署难度还有成本啊,还有一个呢,就是它安全性这三个方向来考虑一下啊。好,这个是前话。 好,那我们正式进入今天的课啊,讲一下这个 ai a n 的 以及到这个 open klo 的 这个发展历程啊,实际上已经落地的阴影,感觉没有那么强大,哈哈,这个我们到后面说啊,好, 我们说这个 agent 啊,其实在 agent 之前啊,它的前身其实还是大模型,就是我们最早熟知的这个 gpt 啊,以切的 gpt 为首的是一个传统的大语言模型啊, 说早不早啊,那个时候呢,大家其实对这个大模型最主要的概念呢,就还停留在问答上,就跟大家现在用用豆包一样啊,打开一个手机问个问题,他告诉你一个答案啊,那个时候还是以这个叫什么,以问答为主的大大语言模型时代啊, 但是呢,发展到 g p d 四的时候啊,三到四它其实是一个很大的跨越啊,那个时候呢,就已经出现了早期的这个大模型 agent 的 框架雏形了啊,大家那个时候可以发现,这个大模型好像不光只是简单的问答那么简单了 啊,他会用上一些。我们听过我之前的课的同学都知道,有个叫 react 的 框架啊,他会推理了啊,并且会做一些相应的操作啊,这个是早期的大模型 agent 的 啊,但是呢,那个时候他叫什么?他还是主要停留在类似于在大模型上做一个拓展能 力部部署的地方呢?还是服务器?还是云端?还是大模型厂商,我们的可操控性还是非常低的啊。后来呢, 再往后发展,大概有个半年到一年左右啊,这个时候呢,就有类似的推理模型框架出现了,我们在之前的 vip 课上也讲过啊,这个 v i m 啊,它的作用是什么呢?简单一句话就是可以搞了个框架出来呢, 帮你非常简单的可以把这个大模型给部署到本地啊,并且呢,他不光是一个问答,他还有操作的属性在里面啊。 那当然呢,你既然部署到本地了,那你就只能用一些开源的模型了,比如我们的拉玛,还有谦问以这个为首的代表模型啊,这个是本地大模型 agent 的 时代啊。那从这个之后呢,其实也没有过多久,大家就看到了现在的突然有一夜爆火的这个要 opencloud 的 东西啊, 这个东西他到底是个啥啊?大家可能了解的知道啊,他是一个欧美一个退休的程序员啊,他闲着没事一个小时搓出来的一个东西,目的就是为了让他在外面的时候也可以用手机操控他的电脑,电脑黑奴来帮他干活 啊,就是一个这么简单的东西啊,但是他突然就火起来了啊,他为什么火起来啊?他相比于之前的本地大模型啊,他做的无非第一就增强了这个 g u i 的 控制能力啊。之前这个本地的大模型,大家可能需要用到一下命令行或什么样的东西,会需要稍微有一点点的基础 才可以去完成这个东西啊。那个时候大家觉得搞大模型,用大模型这些可能还是稍微专业一点的基础才可以去完成这个东西啊。那个时候大家觉得搞大模型用大模型这些可能还是稍微专业一点的就可以了啊。 open cologne 呢,在我看来它是走了最后一公里的路的啊,就把它给带到了大众的视野里面,用一个相对于比较傻瓜式的操作就可以去干到某些之前我们想不到的事情啊。再来一点呢,它有一个非常关键的改进呢,就是它 大胆的开放了权限啊。刚刚有个弹幕同学问这个 open klo 为什么没有被认定为病毒啊,很简单啊,还没到时候啊,哈哈,他如果一直这样发展下去的话,肯定是会有相应的限制措施出来的 啊。现在大家从新闻上已已已经能看到啊,可以有很多的学校已经开始明令禁止在这个学校的电脑里面按 open klo 了, 并且呢,有些国家啊,比如说我现在在日本,他们对这种对这种数据安全是非常的在在乎的啊,所以在这个实验室的电脑上去部署这种 opencloud 也是不太现实的啊。 好啊,我这里放了两两张图啊,大家一看这个画风就知道 ai 生成的啊,但是我发现啊,它生成的非常好啊, 这个我们先看看一下左边那个图,从左边那个图我们可以看成三部分,第一部分就是 ai 是 怎么工作的,这里我们啊先不细讲, 左下角呢,是这个 ai agent 的 现在有哪些类型啊?这个我们也先放在这不讲啊,右下角这个 ai 系统在部署的时候啊, 我们知道大家可能看新闻也看到了有人说什么一人团队一个人养了一群龙虾啊,养了一个池塘的龙虾,什么意思呢?就是一个 multi agent, 就是 一个做代理的一个过程而已啊,它其实就是一个二个这种 ai agent 的 实力 啊,这就是所谓的多个 agent。 好, 那我们再回到上面再看啊,上面这个 ai 是 怎么 walk 的? 我们现在先不讲它的流程是什么样的啊,我们先主要理解一下这个 ai agent 它有哪些东西啊? 首先右边啊,它啊有一个工具,比如说什么我如何去访问互联网,对不对?我怎么样可以写代码呀?我怎么样去调用这个 api 的 接口啊,对不对啊? 还有一个很关键的 memory, 这个是大模型就有的啊,那 agent 里面的 memory 跟大语言模型里面的 memory 有 什么不一样? a i agent memory 跟我们 openclaw 的 memory 又有什么不一样?大家先留一个小小的疑问啊,它其实是这个是 openclaw 比较创新的一点改进啊,在它的 memory 上面。好,这里我们先不讲,我们下一页会讲到,我们先再看一下右边这个,右边这个 中间这些组件啊,大家可以先不管啊,可以先看这两个标识啊,第一个我们一个 wifi 画了一个叉,还有一个就是锁了啊,什么意思呢? 没有 skills 吗?有 skills, 这里 ai 没画出来。我们后面会讲啊,这里意思呢,第一就是在本地,你可以部署到本地啊, 部署到本地之后呢,你的数据就非常安全了啊,那这两个属性叠加在一起会产生一个什么效应呢?首先在本地之后啊,你就可以自我玩的很花嘛,我们常说的 可以随心所欲的去改它呀,去操控它呀,你的数据全部都在你的本地。我们之前讲那个 v l l m 框架的时候,我们就提到了,这个框架对于公司或者企业来说 是非常友好的啊,因为很多公司和企业,它的数据不可能说我放到我调用的这个 api 的 云端上,不可能放到 openai 那 里,我不可能放到 google 那 里啊,这是我公司的私有数据,所以在很多业务场景下呢, opencloud 它是 叫什么?是一个非常好的选择的啊。好,那我们具体来看一下这个 ai agent 是 个啥玩意儿?我们说到 ai agent 啊, 其实可以拆成两块来看,第一叫 agent, 第二才是 ai。 有 同学如果了解过,强化学习啊, 应该知道啊,这个 agent 呢,是里面的一个概念,一个最基最基础的概念。它的定义呢,就是说一个实力啊,可以通过观察环境啊,做出行动 啊,为什么做出行动呢?为了达到某一个目的啊,这样的一个实力呢,就把它定义为 agent, 在 强化学习里面,那 ai agent 无非就是说可以用 ai 来提升自己的性能,这就是 ai agent 啊, 这就是它最基础的定义,没有什么太难的地方啊,我们看框框架这里啊,先看左左边,我这里写了三个模块啊,第一个是输入模块啊,输入模块的作用呢,就是从外部环境中来获取信息啊,它可以是多模态的, 在传输系统当中呢,这个输入的可能只是文本数据而已啊,但是呢,在我们今天这个 ai agent 呢,包括 open code 现在用的这个环境里啊,它其实已经是多模态的啊, 也就是说不光包括文本,还可能包括图片啊,语音啊,还有视频啊,或者说是来自于各种 api 的 结构化的数据,都是有可能的啊。 那我们如果想把它应用到科研领域,或者说应用到一些比较专业化的垂直领域的时候,可能就会需要这种 api 的 结构化数据了 啊。我讲的尽量稍微概念浅一点啊,因为咱们直播间里会有很多对这个 ai 基础会稍微薄弱一点的同学啊,希望大家都是可以听懂的。 蛋白质结构能不能详细介绍一下?那行,我们最后会有十分钟的答疑,如果你感兴趣的话,我跟你讲一下。好啊,我们继续回到这里啊,我们说第二个模块呢,叫思维模块啊,这也是 ag 的 系统中最核心的部分 啊,也就是这个大模型发挥作用的地方啊,这个模块呢,通常是由这个大模型来驱动的啊,他负责对我们前面说的这个输入模块获取到的多模态的输入进行理解推理啊,以及决策 啊。具体来说呢,大模型可以根据当前任务啊,先对问题做一下分析啊,对任务做一下分解,去规划一个策略来解决这个问题啊。 所以我们说这个大模型在 agent 系统中呢,其实就扮演的是一个大脑的一个角色啊,用来负责思考和决策啊。那我们现在获取了输入,有了小龙虾的钳子了 啊,有了思维模块,小龙虾有了大脑之后啊,我们需要进行交互啊,这就是我们的交互模块,当 agent 完成思考之后呢,我们就需要采取行动。 什么东西?左下角有个小窗口遮挡,是否关掉?我这里看不到哎,这个很影响吗?同学们,我这里啥也没有啊,哈哈,问问题不大啊,那我先讲了,因为咱们咱们时间比较紧啊,我准备的内容可能一个半小时讲不完啊,有个思维导图啊, 好, ok, 这个让我们助教老师去解决一下吧,我这里控制不了。好,我们接着讲。刚刚这个思维模块讲哪来着啊?对,我们这个小龙虾就需要采取行动了 啊,这些行动呢,其实没什么高大上的,他就是通过一些现有的工具啊,你看我们这里画的图里面啊,工具啊,其实你比如说 我们这个小龙虾遇到一个需要计算的任务了,他干嘛呢?他又去调用一个 calculator 啊,他可以根据他的角色,他自己去写一个小小的这样的方法去计算一下。可以啊,他如果觉得累的话,他也可以去调用一下。你这个计算机里面自带计算机的程序啊,小程序他来去计算一下都可以 啊,具体怎么做就看它自己来判断了啊。再有像 search 啊,其实呢,我们一般把它叫 websearch 啊,但是呢,因为 search 比较高大上嘛,所以现在都是把它叫 search 的。 大家看到这个其实就是一个搜索网页的过程,但是相比于搜索网页来说的话,它还有一个 就是综合和整理的过程啊,如果单纯只是搜索网页的话,他其实就像爬虫嘛,你爬虫下来的数据啊,那全部喂给这个小小的龙虾里面,当然也不合适,所以呢,需要有一个稍微一个整理的一个工作在里面的, 用什么代码写的可以有这么高的权限?是这样的,他有这么高的权限不是因为什么什么代码,而是因为他的端口啊,他在端口开放的这个过程当中啊,是给予了他一个非常高的权限的,再来就是很多端口他本身就是具有很高的权限啊, 超级用户对当前里面讲的 agent 的 比较像,对,当前这个其实叫什么,也是大模型的一个框架嘛,其实 agent 所有的东西,不管是什么,最终就是一个 基于大模型作出的拓展而已。大家记住这一点啊,现在你们看到的所有东西啊,它的底子啊,都是切了 gpt 一 手的这种大模型,只不过呢,我们因为受到这个 scanning log 啊,尺度规模 法则的这个限制,大家在堆叠基础能力上,大模型本身的基础能力上,目前是现金陷入了一定的瓶颈啊,所以呢,之后从 g b t 四开始,现在所有的大模型厂商开始把这个大模型从这种堆参数砸钱,把它往大了去搞, 从这个思路慢慢去转向了一些工程化的一些改进和落地,就比如 ag 的 就是其中的产物之一啊。 好啊,我们再看一下右边这个模块图啊,我们刚刚讲了有输入模块、思维模块和交互模块分别对应的。哪输入模块没有啊?我们这里 工具 pos 刚刚讲的有这么多我们这个智能题啊,他可以直接去执行操作,也可以调用这个工具来执行操作,这个取决于你给他的任务难不难啊,如果你只是简单的问答,他本身的大脑就可以告诉你了啊,他就不用去拿计算器了 啊。右边是他一个决策的过程啊,如果你的给他的任务非常难啊,他首先会触发他的这个决策过程,去判断一下他需要通过什么样的操作才可以去完成你指定给他的任务啊。这里面会有一个思维链, 这个也是一个说老不老,说新不新的概念啊,在大模型里当然老,但是按年份来算的话,还是一个比较新的概念啊。我们这个 vip 课里面也是之前详详细的讲过两节关于这个 c o t 的 内容啊,它也是当前这个 a j 的 能出现的最主要原因之一 啊,让那个大模型可以像人类一样进行思考啊。当然呢,它现在变成小,变成小龙虾了。好,那我们看完这三个模块会发现我们还有一个什么模块没有讲呢? 这个 memory 啊,刚刚我也说了,这个 agent 里面的 memory 跟这个大模型里面的 memory 有 什么不一样的啊?我们知道大模型里的这个 memory, 我 们通常指这个上下文窗口,对不对啊?上下文窗口? 那在 agent 里,它分成一个 short term and long term 的 memory, 有 有一个长期和一个短期的 memory 的 区别啊,那它到底是个什么东西?好,我们仔细看一下这个记忆模块儿啊,前面可能稍微会枯燥一点,因为给大家讲的是从发展历史开始啊,去讲这个 open code 出现的这个原理 啊。但是希望大家还是可以好好理解一下这一块的内容啊,因为现在网上 openclaw 的 视频这么多,你看了他们也会看,大家都会看,你的同事也会看,那你跟他们相比,你的特性在哪里啊?对吧?你的特性就在于你可以跟他讲出这些底层的架构上的不同啊,对不对? 他的决策和能力是通过调用的大模型能力决定的吗?对,根本来讲就是大模型进行思考的啊,包括你要不要用工具,怎么用工具这个东西也是大模型里面的思维链来进行决定的,是不是和 lstm 相似啊?不是,完全不是一个东西啊,我们仔细看一下。 好,我们说一下这个最关键的记忆模块啊,我们在理解这个 agent 的 时候,很多人会觉得你的大模型怎么这么厉害,好像那啥都记得啊,我昨天跟你说的话,你怎么今天还记得呀?我明明都关机了,对不对啊?但实际上呢,并不是这样的, 大模型本身呢,他并不具备真正意义上的持续记忆的能力啊,大模型是没这个玩意的,他的本质还是代码啊,那他如何去获得这种能力的呢啊?他的工作主要是依赖于这个, 大家都知道叫这个上下文窗口啊,因此呢,我们可以把这个大模型的上下文窗口理解为一块儿面积有限的一块儿黑板理论啊。所谓的黑板理论, 他的核心思想就是大模型,在每一次推理的时候,你只能看到当前上下文理的内容,也就是说,推理的时候,这个模型会把所有输入的信息全部写在这块黑板上, 基于他黑板上写的这些版书啊,去进行思考啊,进行推理来产生结果啊。但是有个问题,什么这块黑板它的面积大小是有限的啊,比如几千 tok, 几万 tok 啊,甚至在一些大的模型里面会有几十万的 tok 啊, 无,不管多大,他始终都是一个有限的资源啊。一旦信息容量版书的内容超过了个黑板的大小, 那新的内容就必须要覆盖旧的内容啊。我板书写不下了,大家上学的时候都看过,老老师一开始从左边写板书写到右边写满之后啊,再跑到左边,问大家这边抄完没抄完,我擦了啊,大模型也是一样的,如果内容太多的话,就会导致信息丢失啊。 因此呢,在这个 ai 智能的系统中,就需要专门设计这个叫什么一个记忆管理机制来解决这个问题啊,弹幕啊,主持人的屏幕,哈哈哈,这个我没有办法,看看那个助教老师他们那边有,有没有办法解决啊? 没事,人类是一个适应性的动物啊,你多看一会就适应了。好,我们刚刚说这个大模型需要专门设计一个记忆管理机制来解解决我们刚刚说的黑板理论的问题啊,我们没有办法把所有的历史信息都无限制的堆在这个上下文窗口里, 而是呢,要有策略地去管理哪些信息应该保留,哪些信息呢?应该压缩或者删除啊。这里就涉及到两个非常重要的机制了。第一个机制叫这个 system prompt 啊,叫系统提示词, 它是什么呢?我们可以把它理解为啊,就固定在黑板顶部的一段指令啊,这段指令呢,通常用来定义我们这个 ai agent 的 它的人设, 给他一个身份啊,给他一个角色以及一个行为轨,一个行为规则啊,比如我们可以规定在 a 证呢,它是一个金融分析助手 啊,或者说你是一个科研助理啊,甚至呢,你是一个超级牛的一个 p 十级别的这个代码生成专家啊。由于这个 system prompt 它的是位于这个整个上下文的最前面啊,所以,并且它在整个对话过程当中,它通常是保持不变的, 因此呢,它可以持续地影响这个模型的行为啊,不会发生改变啊,相当于给我们这个 ai agent 锁定了一个叫什么稳定的人设和任务目标啊,这个是 system prompt 啊。第二个呢, 叫 contact 呃, contact management 啊,一个上下文管理在真实的这个 ai agent 的 系统中啊, 这个对话往往会持续很长时间啊,如果你把所有的历史对话都保留在这个上下文当中,那很快就会超出这个上下文窗口的限制了。但因此呢,系统常常会针对这种大量的历史信息进行压缩摘要或者筛选啊, 什么意思啊?就比如说我们可以定期的对我们之前聊过的内容历历史对话进行一个总结 啊,因为大家很多时候用大模型上来来来一句你好对不对?像这种就属于废话,在大模型看来,而且也额外消耗你的 talk 啊,也占用你这个上下文窗口的这个限制大家以后用的时候可以不写了啊, 没有必要跟 ai 那 么礼貌啊,谢谢也不用说你好跟谢谢都是废话啊,那我们说了,把历史对话压缩成一短一段简短的这这种摘药,或者说只保留与当前这个任务相关的重要信息啊,把不重要的内容删除啊,这样就 能够在有限的上下文空间中来保留最关键的信息啊,从而保证模型在推理的时候既可以看到前面的知识啊,也有空间来理解当前的这个任务啊。 这个是他的一个记忆模块,主要有两个关键的机制啊,第一个我们回回顾一下,就是固定在那整个黑板的最顶端啊,就比如说这这堂课的内容, 他通常会定义了你一个大模型的一个角色行为和准则啊。第二个我们会对历史的大量的这种记忆进行一个记录、优化、结论总结,把那些废话全部什么 ok 剔除掉,我会感觉到正在进行社交互动,哈哈。啊,这倒是啊,这是一个叫什么?这个是一个情绪价,情绪价值的体现啊。我那小侄女啊,天天我, 我问她你懂不懂 ai 啊,她说我懂,我说你懂 ai 什么?她说我每天都会跟豆包讲话。哈哈,谢谢可以作为奖励算法的关键词啊。 那不一定啊,比如说你没有得到答案,你也有可能会跟他说谢谢嘛,对不对?那只是出于你礼貌的一种表现。你在淘宝问这个商家的时候,他没有货了,你不会跟他说一句谢谢吗? memory 点 md 啊,这个同学了解的比较多啊,这个我们在这个 opencloud 里面会讲。好, 那我们刚刚了解的这个记忆模块,基本的 agent 的 记忆模块是什么东西啊?我,我们看一下它具体实现方式是怎么样的啊?我们上页说到大模型本身的上下文窗口,它是有限的啊,因此这个系统必须通过一些机制来拓展这个记忆能力。 那么在实际的 ai agent 的 系统当中呢?最常见的一种实现方式呢?就是这个东西,我们说叫 rap 啊,外部记忆系统,或者说知识库或向量向量数据库啊,是 rap 的 一部分啊, 大家如果之前上过这个大模型的课啊,应该会了解这个 r a g 啊, rap 解锁增强生成记忆机制啊,它其实分为两块啊,它既有解锁和增强生成记忆机制啊,它同时它也是一个记忆模块 啊,整个流程就可以拆分为这几步。首先用户提问,用户向这个 a g 呢输入一个问题,那这个时候大模型就会把你输入的问问题 embedding 之后进行解锁啊, 跟什么东西解锁呢?你给他的一个知识库啊,这个知识库是什么?你自己来定义啊,他会把你给他输入的问题啊,和这个知识库里,他觉得在向量空间中最相似的那个东西做一个 match 啊,把知识库里给的答案 做一个增强跟这个大模型它本身的能力生成的这个回答,去做一个 enhance 的 一个操作啊,这个就是你最终的答案啊,简单来说就是让你在考试的时候让你啊带一本参考书, 你做一道题,你可以翻一下那本书,你看跟哪道题比较相似的,你就去抄吧啊,当然也不能全抄对不对?因为他毕竟只是例题,跟你这个题跟你考试的题可能不太一样啊,所以就要把这个参考书里的内容和你自己本身的 题目的内容去做一个修改也好,改进也好,拼接也好,反正就是一种以 hands 的 操作,这个才是你的最终答案啊, 这个就是我们常说的这个 reag, 它现在是一个主流的 agent 的 记忆,一个记忆模块 啊,这种机制机制的核心优势在哪呢?就是它可以突破大模型参数知识的限制啊,能够有效的解决这种上下文窗口有限的问题啊,为什么?因为知识库在外部的。
469跟余七水学大模型 22:40查看AI文稿AI文稿
22:40查看AI文稿AI文稿有一个二十四小时帮你办事的 ai 助手 openclock, 还有一个最强的开源模型调用工具 comui, 两者结合就能这样你通过手机发送需求, 然后 ai 在 你自己的电脑上自动加载模型,完成图片、视频、音频的生成,并最终将成品发送给你。 那就可以把 aigc 做到完全私有,本地部署,并且免费不限量。本期视频演示的就是真正意义上可落地的数字员工和数字生产力。 openclaw 和 comui 的 联动就是给极致的大脑装上了最强的开源模型,从会说变成会干活。它可以根据要求自动生成图片、克隆声音、合成数字人口、播跑首尾帧视频, 还能批量执行工作流,把原本需要坐在电脑前一步步点击的操作,变成你随时随地发消息就能完成的自动化流程,这就是最有价值的实战方向。那么本期内容我就会带你从实际演示出发, 看这套联动到底能做到什么程度,又能怎样接入你真正的生产流程。接下来的很长一段时间,我将会陆续开始在星球更新 openclock 教程以及最新的 comui 教程。 想要从零开始系统入门并逐步进阶提升的小伙伴,欢迎加入小黄瓜的知识星球。 open call 和 complain 联系起来之后,它的过程是非常稳定的, 就是它能稳定调用我们使用到的那些工作流,而且它可以稳定的去设置相应的一个参数,能够正常的按照我们的要求去完成图片或者视频的生成,然后以及音频、数字人,这些都是可以的啊, 可以看到我们这后台呢,已经在运行了,我们的硬件呢,现在可以看到已经开始有活动了哈,内存在逐渐的上升,就是在加载对应的模型, 然后图片生成,我给他配置的是用的 z image turbo 的 模型哈,所以说内存现在在上涨的阶段,说明模型正在往内存里面加载, 加载完毕之后呢,我们的 gpu 就 开始运行,也就是开始完成我们正常的图片生成。生成完毕之后呢,这个 openclaw 就 会通过飞书把消息给我们发送过来啊啊,可以看到这里已经生成了,也就是这个生成的过程是他自己做的, 然后生成完之后呢,他就会把这张图片发送给我们,然后包括人物的着装姿势,配饰背景,然后包括姿势形象,这些全都是他自己给我设计的啊, 可以看到这里已经生成了,那等待他把消息发送给我哈,可以看现在已经给我生成了,在飞书里发送给我了,这就是他给我生成的一个男生哈,然后我们把控制台打开哈,把 com 约的后台打开,能够看到他运行的过程哈, 然后显存呢,就是我们的性能占用还放在这边,我建议你能时刻的观看自己的硬件占用状态,了解模型现在运行到什么样的过程,然后这里给我们生成了,我们就可以让他再给我们生成一段音频啊,用小黄瓜的声音生成一段音频,小黄瓜。再说 这里是广州市中心,大家向后就能看到广州塔,欢迎大家来广州游玩,然后说天气比较热,建议多往室内有空调的地方去。 好吧,就这样,那么这两句话大概也就是四五秒的时间吧,然后我们发送一下,现在呢,我们是让他用本地的 com 给我们生成音频,然后等待他把音频给我们生成完, 生成完之后呢,我们让这个男生用我的音频再生成一段视频,也就是数字人哈,可以看到这里,我们的音频已经生成了,我们来听一下啊, 这里是广州市中心,大家向后就能看到广州塔,欢迎大家来广州游玩,天气比较热,建议多往市内有空调的地方去, 可以吧,这个声音没问题吧,跟我的声音是一致的啊,我们再听一遍。这里是广州市中心,大家向后就能看到广州塔,欢迎大家来广州游玩,天气比较热,建议多往市内有空调的地方去。好的,这个音频也没有问题啊, 我们说用刚才生成的这个男生形象,根据小黄瓜的声音做一个数字人的视频,视频时常控制在十秒钟吧,每秒二十四 fps 吧,然后视频分辨率呢 为一二八零乘以七二零吧,好吧,就这样。然后呢,他现在就开始给我们做一个数字人的视频啊,这里面我给他配置了七个工作流, 这就是我给他配的,所以说大家如果要用的话,你想给他配什么就配什么,我这里配了一个首尾,真的配了一个数字人的,配了一个声音设计的,还有一个声音克隆的,就是让他可以用我的声音去生成音频,声音设计的话就是他可以自己设计声音去生成音频, 然后还有 ltx 二点三的图声视频的,然后以及一个图片编辑和一个纹身图的,就文本到图片生成的那纹身图的模型,你配置完之后,你就可以让他给你做一些,比如说封面设计,然后 其他的内容哈,可以在上面看一下。我有做封面设计啊,你就像这个,在最开始你跟他交流的时候,比如说我这里说给我设计一个视频封面,关于 openclaw 和 compui 的, 然后想把它做成我的封面,然后是十六比九,主要是国内人看,所以说我们的封面标题呢要用中文,然后这是他给我设计出来的第一版封面啊,很明显这是不醒的,对吧?然后呢就给他做了一些个额外的干扰,我说要有标题, 然后呢标题写的清晰一点,有设计感。然后这是他给我的第二版封面,这个也不行,然后我说文字都粘到一起了,要有排版,然后这是他给我的第三版,这版其实还行,但是受限于大模型,也就是我本地部署的这个图片生成模型的能力, 所以他后面的很多文字呢是毁掉的,然后呢就给他说封面文字有误,然后让他重新修改,然后这是他又修改完的一版,看起来还行哈,然后呢我就给了他一张图片参考,我说你把这张图片给我复现出来,当然了 这个生成图片的能力取决于你部署的那个模型,就像我给它配的是 z image turbo, 所以 说这个能力并不是因为 openclock 不好,或者说因为 comfui 不好,只是因为这个模型我们目前用的不好,但是呢模型它是会进步的, 对吧?你像最开始我们用 sd 一 点五叉 l 的 时候,那个时候生成的图片质量是很差的,但是呢,随着模型的进步, comfui 甚至可以什么都不做,就只是适配一下这个模型,它的功能呢就会提升, 因为 comui 的 能力不取决于 comui, 它取决于模型。然后这是他给我的第三版哈,也就是参考刚才的图片生成的,然后发现文字都毁到一起了,然后又让他给我改, 最后生成了这个,所以说限阶段,如果你想用可以,但是他并不会到非常智能的程度。我这里接的是拆的 gpt 的 五点三的模型,所以说能力还是很强的。这里视频生成了,我们看一下哈。这里是广州市中心,大家向后就能看到广州塔,欢迎大家来广州游玩。天气比较热,建议多往室内有空调的地方去, 后面因为音频没了,所以说就没声音了。在这里是广州市中心,大家向后就能看到广州塔,欢迎大家来广州游玩。天气比较热,建议多往室内有空调的地方去,可以看到它调用的是我本地的,而且我们的显存呢,确实刚才有在运行啊,然后内存的占用现在还在这一百多 g, 这是演示的一个小功能啊,还有我们的首尾针什么的都可以。 之前的话,我们是需要在 cfui 里面跑工作流的,对吧?现在跟 openclaw 配属完之后呢,我们可以你拿着手机,任何时间,任何地点,你只要给它发送消息,它就可以给你制作。主要是这样的一个过程,而且呢,它可以有自己的设计,比如提示词当中可以让大模型自己写,也就是让 openclaw 接的这个大模型自己写,不用我们写,你 甚至可以让它批量的生成图片。以前如果说你在 cfui 要批量生成图片,是需要自己搭建一些工作流的,对吧?比如说设置种子值自增, 然后让他一个一个的生成。现在我们可以直接让他生成哈,比如我们这里给他说让他生成二十张真实男青年的照片,然后人物配饰、长相、背景,让他自己设计分辨率,在这里写一下。比如说我在一盘哈, 给他重新创建一个文件夹,叫做男生,然后粘贴到这里,然后二十张图片放到这个文件夹,然后名字从零一开始到二零结束。好吧,那这个时候呢?我们就等他给我们生成就行了。 你像以前我们还需要去处理工作流,对吧?然后自己或者说一张一张生成,但现在我们不需要了,批量给我生成了二十张,大家可以在这里看到哈,我们来看看这些图片哈, 怎么都是这种呢?他是他生成的是这种合集,好吧,他生成的是这种合集,我再给他说一下算了,我说把刚才的二十张图片删了, 我要一张图片只有一个人物的,就这样让他再给我做一下哈,可以看这里,我们二十张图片已经生成完了哈,大家可以大概看一下二十张这些还像同一个人啊,对吧? 他是给我们生成了五次啊,这是第一批,第一批当中像是同一个人,第三批像是同一个人,对吧?可以看一下,还挺帅的,对吧? 我们让他这样用第五张和第八张图片,把这路径复制一下, 给我们生成一个视频啊,生成一个五秒的吧,五秒的首尾帧视频,让他用一二八零乘以七二零的分辨率,每秒二十四帧吧,然后让他给我们生成一个首尾帧视频啊,看一下视频啊,这是我们做的首尾帧视频,六秒, 好吧,这个质量还是可以的,这个质量取决于 ltx 二点三,也就是我们给康复 ui 配的这个模型的能力。好吧,这点大家能理解,我们让他给我们做个海报吧,但是海报的话,我们可能需要让模型有一些提示词哈, 或者说写一些比较详细的提示词,我们去搜一个海报的案例的这张吧,这张好看,我们让他说给我设计一个罐装可乐的海报,可以参考这个提示词,文字内容你自己考虑加什么分辨率,我们要个一零二四乘以一五三六的,就这样 我们试一下哈,让他给我们设计一个海报哈,然后给他提供了一些参考提示词,如果直接用这个提示词生成,你生成的就是这样的内容。但是呢,我很明显不对啊,因为我们要做一个可乐的海报嘛, 所以说你自己要去想这上面的字我们改成什么,这两个字改成什么,哪些字要改,哪些字不能改的,现在我们交给大圆模型,让他去想,我们就不想了,不动脑袋了。这他给我们设计的海报哈, 并没有出现可乐哈,但是文字、排版这些都没有问题,画面的质量也没问题,这个质量呢,是因为 the image turbo 的 质量比较好哈,所以说这个呢,不行,我说再给他说一下, 就说图片里要出现可乐,这是一个产品海报这样的这一个产品海报对吧?看起来还不错,但是我们可以让他加一些英文文字,设计一个标题,大字标题, 白色文字啊,手写体最好,然后文字内容为 c o o l, 就 这样,然后放在图片的最上面,我猜测它可能会用到编辑模型的,因为这张图片的话是用 z 生成的嘛。 这里你看它已经在思考了,并没有直接生成,所以说它应该会切换工作流哈,切换到 flex clean 模型,当模型的能力再一次提升的时候,我们现在流程的能力就会再一次提升哈。 所以说现在大家其实可以去接触 open club 了,我觉得因为他们的能力不取决于他们本身哈,取决于他们用到的模型。模型的能力提升呢,不取决于个人, 取决于那些走在前面的那些大厂。好吧,所以说你现在学和以后学都是学一样的。稍微等待一下哈,不知道他现在思考到什么程度?我看一下哈,我们能在 open club 的 后台看到他 思考到什么样的程度啊?哦,他已经加好了吗?我们看一下。靠,他加了一个这样的文字哈,可以看这个,这俩基本上没问题啊,这两张图片除了文字之外的没区别啊。这个文字是他自己加的, 如果说我们有自己的提示词的话,让他去做海报就更简单了哈。比如说像这个,我们直接把这个提示词给他,用这个提示词给我制作一个海报,就这样直接把提示词给他就行了,然后他就会自动给我们生成哈, 等待一下,我推断他加的这个文字啊,是他自己通过脚本加的,并不是用了我们的模型哈,看一下,这是在后台啊,我们跟他交流的过程在后台都能看到。我们看看刚才说的让他加文字这件事情上,他做了什么,哈, 它用了一个工具调用哈,然后在这里可以看到,它是通过代码给我们加的文字哈,并不是用模型给我们加的,它这里用了一个 python p i l 库哈,这个是对于图片设计的,用了一个 image, image draw, 还有 image font 这几个类哈,然后去做了一个图片上面加文字的操作, 所以说呢,它并没有调用我们的 comui 哈,它选了另外一种方式,然后就生成了,所以说我们的 comui 呢,也没有运行。 然后这里他还下载了几个字体文件, ttf 是 字体文件哈,然后就加了几个文字哈,这是他的一个刚才加文字的那个过程,并没有用我们的编辑模型哈, 这里生成了哈,这个怎么说呢,文字排版不太行啊,这个海报如果把这么多中文直接交给模型生成,基本一定会出现错字、粘字、排版乱,所以我还是按更稳的方案来, 先生成了海报底图,然后再把文字排版进去。我说不要这样,直接用提示词生成就行,你看,这就是他自己的一个思考,但是他的思考是不对的,如果直接用提示词生成就会更好,反而他自己写的排版乱了, 对吧?所以说他自己想的,他先生成了一个底图,然后自己又加了一些文字,但是自己加的文字明显排版是乱的,还不如直接让模型生成,所以说这个呢,没办法,你在跟他交流的过程中就会遇到这些问题啊,所以说大家装完之后,最主要的是跟他的配置和交流的过程,可以看这次就直接生成了,这就没什么问题啊, 对吧?这次这个海报就没什么问题,所以大家以后用的时候,你想啊,当你看到了这个问题的时候,你能不能分析出来这个机器人他是在哪里出了问题, 然后让他给你改成合适的。如果说对康复 ui 了解不多的同学,可能看到这里就觉得康复 ui 的 能力也就那样了,对吧?其实是因为模型在中间做了一些事情, 然后导致了这个海报不太好。好吧,现在他的能力确实是有的哈,但是取决于我们给他配置了什么样的工具以及工作流,我来配置一个哈,这里有个图片放大,我觉得是需要的,我们让他直接给我装个插件哈,看这个工作流是不是这个 see the vr two 高清放大我搜一下哈, 我们一定尽量的把指定的插件路径给他哈,让他确定是装的这个插件,比如我们复制给他,然后说帮我安装这个 comui 插件,然后重启 comui, 然后把地址给他就行了,接下来他就会自己帮我们装了哈,可以看一下哦,还是在这里看哈, 一会的话,我这个网速的话就会开始提升啊,说明他已经准备下载了,下载完之后呢,他会处理环境,然后把环境装在 comui 对 应的环境里面,然后呢再给我们启动,可以看现在网速已经上去了,就是在给我们下载插件啊。好吧,他说重启了,我们试一下哈,我们看看这个插件有没有装上啊, 可以看,这里已经有了哈,这个节点没问题。所以说前面的这些呢,是 c 的 vr two 的 插件哈,看一下。所以说还得再装一些插件啊。已经给我们成功装上了一个插件,然后我看一下那个工作流哈,他好像把我的康复 ui 装到了 c 盘里面哈,看一下这个插件里面的视力工作流哈。 插件比较少, seedvr2, 然后找到对应的工作流,这里面缺失几个节点,然后我自己给他装一下吧。手动装一下吧。这是什么?有两个插件装失败了吗?我们重启一下看看啊,好像没问题啊,这几个都是装上的,现在在重启 comui 哈, 这些操作大家应该不陌生了,如果说啊 comui 已经学过一段时间的话。好的,有个插件没有装上,不对,应该不是没装上哈,是这些节点应该过时了哈。 get image size, 这是 c 的 vr two first pass, 不是 这个节点哈。看来这个插件还是没装上,选择最新的版本,看一下后台有没有在下载哈。哦,现在是在正常的下载,等一等吧,我把这个图片放大的工作流也给他,给他之后呢,他就可以批量的去完成图片的放大了哈, 我们刷新一下。好的,已经启动了,我们看看有什么报错哈。哦,载入成功的哈。插件在这里啊, see the vr two video upscaler 在 这里哈,这个节点。所以说把它替换掉啊,这里是 block swap。 然后这个呢,不管它了哈,直接把它从中间给它替换一下就行了。第一个阶段的放大, 这是第一个阶段的图片,第一个阶段有个 block swap 参数,现在不需要了,我们把这个删掉就行了。然后 d i t 就是 它的模型哈,我看看我本地的模型有哪个哈工作流要提前给它配通哈,配通之后再让它去运行 seed v r two 在 这里哈,本地有七 b lp 十六的模型,我是有的。那就直接选这个哈, 选完之后选我们的库达林 block swap, 直接在这里可以设置哈,给个二十吧,不给太多哈。然后这个也连过来 v a e 模型,这是 c 的 vr two 的 v e 模型,然后选上,这是分块放大,我们就按默认参数就可以了,把这个也连过来 v e 模型,那这个时候就相当于我们配置好了模型, 然后来测一下这个工作流的运行哈。等一下啊,我把这个工作流先保存一下,重新命名,然后把刚才这个工作流拖入进来。拖入进来之后呢,我们看看它是怎么做的,参数是怎么连的,做一个替换哈。 open floor 里面, 把 the vance 拖进来看一下哈,这个节点就连出来了一个最短边的参数哈, shortest side longest 最短边的参数应该是连到了这个 resolution 上面啊。好的,那这个工作流基本就没问题了,我们上传一张图片,让他给我们放大一下试试啊,我们就用刚才他给我们生成的这张男生的图片吧, 复制一下,粘贴到这里 set, 因为就给他连过来啊,把这个节点删了,然后第一阶段的话,放大到两千就可以了吧。第二个阶段呢,我们放大到四千吧, 这个指的是它的最长边哈,我们把它的最长边放大到四千,就相当于做了二点多倍的放大哈,二点五倍的放大了基本上,然后我看一下这个参数哈, seed 给它改一下 tailing upscale 放在这里, 然后看一下他的参数有问题啊,也就是插件更新导致了节点出现了问题,所以说我们是需要把节点删除重建一下的,原来他的过程呢,做一个替换就可以了,连到这里,所以说这个节点可以看他已经没有输出了,所以说这个节点对我们当前工作流没用,删掉就可以了, 现在应该没问题了。 new resolution, 把连上放在这里吧,运行一下试试啊。运行吧。好吧,现在这个呢,就是图片高清放大的工作流哈,这个节点有错啊,我们看一下错误是什么? block swap 是 无效的哦,我懂它意思了,它的意思是呢,你的模型放在了显卡,如果你做 offload 的 话,也就是显存卸载,做 block swap, 你 需要把它卸载到另外一个设备上,所以说这里呢,我们得选 cpu, 不 然的话它卸载不了哈,我试一下不做 block swap 它能不能跑哈,因为我想让它尽可能的把我显存占用多一点嘛, 如果我的显存不够的话,那我就去做 block swap。 现在的话可以看在做第一阶段的放大,然后我们的显存占用只有九个 g 是 没问题的,九个 g 占用很少哈,但是等到第二阶段放大就开始大了哈,图片放大对显存的占用很多,所以说这些工作流的配置你一定是要清楚的,不然的话,你没办法把它交给 openclock, 让它给你运行, 因为你需要选择其中的参数,让 openclock 去修改的。你比如说这里的模型的名字,你肯定不能让它修改,因为这个模型是你自己固定好的,放在本地的。还有这些呢, device 这些它没必要修改,所以说你就不要暴露给它,如果你暴露给它了,它就可能给你改,一改的话,工作流就跑不了了, 那个时候问题就大了。但是这个呢,就取决于你康复 ui 学的怎么样。如果说拿到一个工作流,你都不知道提示词在哪写,或者说都不知道你在哪里设置图片的尺寸,那你怎么去让模型配置呢?对吧?所以说这个呢,可能需要就是你学完了康复 ui 之后呢,你再学 openclip 加康复 ui 会更方便一点哈。 好的,放大完了,我们来看看,右边是原图,左边是放大之后的,大家可以看一下哈,看看他的衣服哈,还行吧,衣服质量还不错啊,看这个扣子, 这个扣子原来是扭曲的啊,现在已经到正常了。还行,这个放大质量不错的哈, 对吧,他多少会有点修改哈,百分之九十九相似。还行哈,这个质量没问题,工作流也没问题,那我们就直接把它 导出开始封装吧,导出一下,但是要把它导出成 api 格式哈,图片高清放大命名一下。 api 命名完之后呢,我们就把这个工作流导入进来哈,然后这里有个描述,说明我们要给它写上哈,就是图片高清放大可以,这应该就行了, 这俩节点我们不用管,所以说主要给的就这仨参数就可以了,一个是一百四十八号节点,一个呢是一百零四,一个是一百二十五。 我们先把一百四十八号节点给他暴露出来哈,一百四十八号在这里打开,然后描述一下,就是需要被放大的图片位置,然后生成必须给他勾选上,然后呢还有一百零四和一百二十五啊, 你找到一百零四,一百零四,一百二十五,这俩都给他打开啊,一百零四的话,这是啊 number, 也就是第一步放大的最长边长度 建议在两千以内,然后这是我们的第二步哈, number 二,给他起个 number 二吧,就是最终图片的最长边的长度建议大于第一步放大图片的最长边, 就这样,一个两千,一个是四千,这样的话就应该已经够了哈。第一步放大的最长边长度建议在两千以内,不要超过 number 二的大小。好吧,就这样保存一下, 我们来试一下哈,就像现在我们就已经配置完了,你可以问问这个 openclock 你 现在可以用的工作流都有哪些?可以看到他已经给我们说了他现在可以用的工作流这有八个,然后再加上我们刚才给他配置的这个图片高清放大的, 然后他说刚才装的插件已经装成功了,那我们给他,让他生成一个真实人物,女生在二十五岁左右吧,然后衣服风格,背景装饰,长相你自己设计, 然后分辨率呢在一五三六零二四左右,然后再把这张图片放大到,我们让它放大小一点嘛,不要太大了,最长边放大到三千,不改变原始比例。我们先让他把生成的人物发给我,然后呢再放大发送给我, 然后呢再把这张图片最长边放大到三千,不改变原始比例,放大后再把放大后的图也发给我。 好吧?就这样这个时候他就会去做了哈,然后现在可以看我们的图片已经生成了哈,这个是一五三六乘以一零二四的分辨率吗?然后这是他设计的给我们生成的一个真实的女生,然后包括他的长相啊,然后以及穿着啊, 然后装饰包括背景全都是自己设计的哈,他用提示词设计的。然后设计完之后呢,现在就开始做图片放大了哈,等他把图片发给我了哈, 这确实是放大后的图片啊,这是我们放大前的,这是放大后的 是吧?确实是啊,是放大后的图片。
409啦啦啦的小黄瓜 06:46查看AI文稿AI文稿
06:46查看AI文稿AI文稿部署本地的 openclaw 已经可以剪视频了,大家都知道了吧, 这个让硅谷大佬每日一封的 openclaw 阿月,我呢也是拉到本地试了几天,现在就带大家把本地部署和接入飞书每一步都走明白。为了防止偶然性啊,我呢也是连续测试了四台电脑,确保每一步都可行,接下来你们只要跟着做就可以。点好关注收藏, 我这里依旧用的是 windows 系统来操作,因为 macos 系统呢,环境相对比较简单,不像 windows 这么复杂。首先呢,我们要确认好 windows 的 安装环境,安装的时候呢,全部都点 next, 一 直到完成即可,建议呢,不要去变更中间的安装路径。 呃,安装完成后呢,我们可以检查一下环境,我们在命令提示符的窗口输入这两个指令,如果输入指令后跳出版本号,那就说明安装已经成功了。这里提到的两个环境文件呢,我在文档里面也全部都准备好了。 好,接下来呢,我们就开始全区安装 oppo 卡使用管理员 c m d 指令输入,这个指令安装完毕后呢,再输入这一条指令, 好开始了。 ok, 这一步跳出来的呢是风险提示,我们直接选择 yes。 然后呢我们选择 quickstart, 这一步呢是选择大模型,我这里呢用的是千万,因为他是国内的,如果大家有惯用的呢,也可以自己进行勾选好,然后我们这里模型选择默认的即可。 之后呢会跳转到大模型的首页进行授权验证,大家验证通过就可以了。那通过后呢,这里也同样有一个选项,我们直接选第一个默认的模型。 ok, 下一步呢,这里可以看到很多的应用选项,这其实呢就是指令输入的终端,因为这些都是国外的,所以我们先不管,选最后一个,跳过,后面呢我会给大家介绍如何接入国内的飞书。 ok, 继续,这里会问你需要配置什么 skills? 呃,我们也跳过,没问题,因为这个不着急,后面都可以手动去配置的。 好,这个也不用管我们用不上,直接跳过。好,然后我们稍等一会,会自动弹出一个网页,然后你会发现这个网页是打不开的,没关系,我们这个时候呢,再运行一个 c m d 的 指令, 好,这就是欧奔 cloud 的 兑换框了,我们来尝试和他打个招呼, ok, 他 回复我了,那到这里呢,其实基本上就成功了,还是比较简单的啊。然后呢,我们再来尝试为大家接入一下飞书,很多小伙伴呢,在这一步呢,其实就被劝退了,因为怎么样都接入不了这里,大家看好我怎么操作。 首先呢,我们进入飞书的开放平台,我这里呢用的是个人版,我们来创建一个企业自建应用, 进到这个凭证与基础信息界面,把你的 app id 和密钥保存下来,这个很重要啊,后面会用到的。然后 我们添加一个机器人,再到权限管理这一步,为他添加一些权限。这里的权限列表呢,其实官方呢是有指导文件的,但是呢就藏的比较深,我呢也是给你们找出来,直接放到文档里面了,你们直接一键复制过来就 ok。 好,然后我们需要配置一下这个事件回调功能,在这里的订阅方式选择长链接这一步呢是必须的,而且是绕不开的,也是大家碰到卡点最多的一步,很多小伙伴呢在这里呢就是一直报错,好,不用担心,我呢,已经整理了一份非常长的傻瓜教程,大家直接照做就 ok 了。 然后选择以后呢,我们添加事件,然后添加搜索接收消息, ok, 然后我们就去点击创建应用,然后再发布就 ok 了。 好了,配置工作完成之后呢,我们就要开始给欧邦克劳接入飞速杀键了。由于 windows 的 系统环境问题呢,所以大家的电脑情况都不太一样,所以会出现不一样的报错问题。网上的很多视频呢,也没有把这个问题针对性的讲清楚,我自己呢也试了三到四台电脑来做尝试,都非常有挑战。 如果你手边也报错的话呢,不用担心,我这里想到了一个邪修的办法。好,那既然 oppo klo 可以 控制我的电脑,那为什么他不能自己安装飞出插件呢?我们来试试看吧,直接和他对话。呃,你自己安装一下飞出插件,然后呢,他就会开始疯狂的工作,并自行去验证安装环境和插件配置 啊。五分钟左右后呢,他就会告诉我,他工作完成了,需要我提供给到他飞出机器人的 app id 和密钥。这个呢,其实我们在上一步已经有了,我们直接复制给他,让他呢继续去工作。这里的工作过程当中呢,我们的机器人可能会下线几次,原因呢是他需要去重启网关, 如果呢,你感觉他下线太久的话呢,我们可以用 open cloud get away 这个指令重新把它呼出来。最后呢,他会要求你在飞车上和他对话进行测试,并为你排除最终的一些故障。 ok, 全部搞定,已经可以在飞车上正确回复我了,并且呢,刚才在外部的对话记录他也全部都记得, 呃,我们这里呢,再用手机给他发一条消息试试看。好,他也同样接受成功了。好了,这里欧本卡接入飞书的配置呢,就完全对接成功,基本上都是他自己完成的,我呢只是配合他提供了一些必要的信息, 妥妥的全能小助理。接下来我们来看看他能为我们做一些什么吧。比如呢,我现在想要订一张机票,我就让他帮我查询一下最便宜的航班,他立刻就给我列了具体的信息,包括航班号,价格以及其他的一些航班信息。不过这一步呢,是需要接入 api 的, 大家可以自行去网上找免费的接入就可以。 好,那现在过年了嘛,马上大家呢也会送礼嘛,那我就让他去浏览电商的页面。呃,不过这里呢,需要先安装一个 oppo club 官方的浏览器插件,我们直接从官方渠道进行安装就可以了。具体的步骤呢,已经放在文档里了,大家直接照做就可以。我让他给我打开。 ok, 成功,呃,然后我继续让他为我搜索燕窝。好,也成功了。 好,那我们现在在拿最近小伙伴在学习的 ai 的 线上作业丢给欧本克,看他能不能帮忙完成。 首先我们要让他找到作业的本地目录,并让他完成里面的题目。他立刻就找到了,并且迅速告诉我,完成了。啊,这速度还是真的蛮快的啊,但是呢,人呢,还是比较懒的。如果呢,你抄作业都不想抄啊?没事,直接让他把填完的东西返回给我。好,他已经做完了,我们来看看啊。 呃,代码呢?全部都完成了,不过呢,我也是看不懂啊。看懂的高手可以来说说他完成的这个准确率怎么样。 好了,那这次安装说明就先讲到这里了,关于 open cloud 的 更多能力,有时间呢我们可以再去测一下。好,那既然已经部署成功了,有兴趣的同学呢,也可以再去深度探索一下 啊。对了,现在呢,各大厂呢,也出了针对 open cloud 的 云端部署,我这个呢,也可以跟大家快速的分享一起。好,这里是阿月,希望我的视频能够帮助到你,让你更了解呀,我们下期再见。
1.6万阿悦很严格 04:11查看AI文稿AI文稿
04:11查看AI文稿AI文稿使用 openglue 呢,如何让每一个 token 都花在刀刃上?先问一个问题啊,就是你用 openglue 一个月花了多少钱?有的人可能花了六百美金,有的人呢,花二十美金,但是他们干的活有可能是差不多的。差距在哪里啊? 差距就在于你有没有让每一个 token 呢,都花在这个刀刃上。今天这条视频,我把社区里面验证过的是, token 就是省钱的方法呢,全部浓缩成三部,看完你立刻就能用。我们先说一个真实案例啊, reddit 上呢,有一个老哥跑了一个自动化新闻分析的 agent, 他 以为呢,每天的消耗呢,是很低的,结果呢,外部 a p i 返回了一个异常数据, agent 开始无限循环重试,结果一觉醒来,账单已经 一万两千八百四十七美金。所以 opencube 的 透视消耗呢,有一个最大的坑,就是上下文累积。你每发的一条信息,它会把之前所有的当前的筛选的对话历史,系统提示工具定义,还有 skill 的 定义,全部重新发一遍。注意啊,这里面系统提示词可不是说几句话或者几段话的。这种事我之前有个视频详细讲过 opencube 的 五大配置文件,那里面也提到了,就是我们每次对话开始呢,这五个文件呢,全部内容 都会加载到系统提示词里面,包括这个 agent, m d, sun m d, u s m d, heartbeat m d 以及 open clue 点 jason 这五大文件。 现在你对话一百轮之后,光 token 输入呢,就是两万多 token, 一个月下来几百美金就这么烧掉了,那我们要省钱怎么破呢?三步走啊!第一步,做模型的分层,不要用大炮打蚊子。 open clue 二零二六年最近的一个重要更新,就是支持了 自适应的模型路由。简单说呢,就是我简单的任务呢,我用便宜的模型,然后复杂任务呢,我才上贵的。给大家一个社区验证过的五层方案啊。第一个就是心跳检测,简单分类这些,用 gemna flash 这个模型,一百万 token 才一毛钱。第二个呢,你做日常分析讨论,用 kimi k 二点五或者是 deepsea v 三六毛钱,一百万 token 呢,不到一块钱。第三个,你做内容创作,内容创作呢,对表达是有要求的,那你上 cloudsonet 这个模型啊。第四就是最难的决策,采用 cloud operas。 那 从开源社区的反馈来看,用户呢,就靠这一招,月份呢,就可以从八十七美金降到二十七美金,省了百分之七十。 第二步啊,砍掉隐形的浪费。三个最容易忽略的 token 黑洞。第一个呢,就是 send 点 m d 文件太长了,很多人写了这个两三千字的系统提示,每次调用都要重新发,我们要把它砍到三百字以内,这样历省百分之三十到百分之五十, 怎么来压缩呢?首先,你得懂 sao m d 的 构成,可以看我往期的这个视频,或者看我们的蓝皮书。第二呢,有可能你没有开 prompt capture 的 提示词缓存功能,能够把重复内容的费用呢,降低百分之九十,通过 catch retention 这个参数可以一行配置的。是呢,很多人却不知道。第三个,心跳任务用了贵模型,那 open cool 呢?这个心跳任务呢,是每半个小时它就要触发一次的,如果你用的是 opengool, 那 一个月光心跳,那就得烧几十美金。 所以我们要把心跳模型呢,单独设成着 hico 或者更便宜的模型,这笔钱呢,你就省下来了。那还有一步呢,就是设安全网,防止翻车。大家要记住这个三道防线啊。第一个就是 opencloud 的 层面,设置,单独的请求上线,每小时上线和每天的上线。第二呢,还可以在 api 平台层面来设置,比如说 osmic 或者 openai, 或者第三方的中转,比如说 apprutor, 他 们在后台你都可以设置使用的上限的限制的。再一个呢,就是支付层面,用预付费的账户可以充多少呢?用多少,不要透支。前面讲的那个一晚上烧了一万二的脑壳呢,就是因为这些防线呢,他一道都没有做啊。 所以最后我们总结一下,第一个模型分层,第二个砍掉浪费,第三个设好防线,这三步做完,社区的平均数据呢,是这样的,月费呢,能够从六百美金降到 五十美金左右,不是省一点,而是省下了一个数量级。 opencube 的 核心理念是让 ai 帮你干活,帮你赚钱,但前提是呢,你得管好成本对吧,这样你才有利润,虽然它有收入,但是呢,你成本太高,可能你利润没有了,所以呢,只有你的 r o i 大 于百分之百,那这个 token 呢, 挖的才值, ok。 以上这些完整的配置方案和踩坑的清单,都更新在了一百八十九页的 open clue 蓝皮书的最新版本里面。如果这条视频呢,对你有用,可以点赞收藏,我们下个视频呢,继续聊,当然最重要的就是你看完得马上用起来。
107清华鑫哥讲AI智能体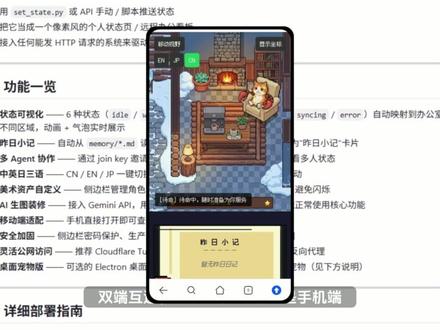 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿给 openclaw 下大任务之后,不知道 openclaw 在 干啥?这款开源项目帮你实时监控 openclaw 的 工作状态, 它在 github 上有近六千 star, 双端互通,不管是在 pc 端还是手机端,都能查看 openclaw 的 状态。它不仅能帮你实时监控 openclaw 是 在干什么,在工作还是在待命。 每个状态都有单独的模块, a 阵切换状态时,办公室里的像素角色会实时走到对应的区域里, open klo 的 状态一目了然,还能生成。昨日笔记告诉你昨天你的 open klo 干了什么,相当于一个可视化日记。 不仅如此,它还是一个实时协助仪表盘,支持多 agent 的 协助,通过 johnkey 邀请其他 agent 加入你的办公室,实时查看多人状态。安装十分简单,直接到 github 上复制命令发给 openclaw。 这里我是用 one panel 控制面板安装的 openclaw, 需要在容器中开放端口,点击容器找到 openclaw 的 容器,点击更多,进入编辑页面,找到端口,填入 star office ui 的 端口之后点击确认 star office ui 的 默认端口为幺九零零零,等待更新完成。然后点击智能体,找到 openclaw, 点击 web ui 端口,跳转到 openclaw 面板,把命令给 openclaw, 让 openclaw 完成部署, 再切到 github 复制这条指令,回到 one panel, 找到智能体。在智能体这里进入工作目录,然后找到 workspace, 点击文件夹,找到 so, 点 md 文件,点击文件进入编辑,将我们在 github 上复制的代码填在最后, 点击保存后输入访问地址,就可以进入你的面板开始体验了。在界面中可以看到我的 openclaw 正在待机,回到 openclaw 给他一个任务,开始执行任务, 回到 star office ui 的 界面,发现从待机转变成工作状态,像素风还蛮可爱的,感兴趣的话就试试吧。
158IT塔台 02:07查看AI文稿AI文稿
02:07查看AI文稿AI文稿大家好,我是南哥, oppo 壳到底能不能用于全自动量化交易呢?以及它的效果具体如何?今天南哥哈特意在我们这个电脑上也安装了一个 oppo 壳,那安装这个小龙虾我们大概 花了半小时左右,它的安装步骤其实比较简单,但是它后期的一些配置我看了一下应该会比较麻烦。 oppo ql 在 我们这个量化市场上有一个很著名的案例,在国外有一个叫 markey 的 二零八克的一个 预测市场,利用这个 open clone, 利用这个价格的一个时间进行的一个套利,仅仅经过四十八个小时,它的收益翻了五十八倍。那大家也可以查找一下相关的一个新闻,那么我们今天把这个 open clone 刚刚安装好, 那因为我做的是人体是跟量化相关的,所以说我在问他你能干嘛的时候,他给了我们的一个指令,他可以协助了我们进行策略的一个开发哦, 因为大家都知道蓝歌是用金字塔跟 t p 开拓者的,所以说我这个字整体直接说了,它可以协助我编辑金字塔的一个策略跟 t p 开拓者的一个策略,不仅仅是回测,还可以优化我们相关的一个 在策略上的一些问题,那我这个字整体我把它取名为叫蓝歌量化。那么我也是简单的 问了几个跟策略相关的一些问题,我我这个自人体呢,他也确实给了一些比较专业的一些回答哈, 那这个东西我目前哈还在研究中哈,到时候呢,就是我让这个自人体就是协助跟优化我们的一个量化策略,那大家如果说如果有思路、有成熟的一个想法, 要,要实现这种量化的话,也可以去借助这种 open core, 因为这个目前是最先进的这种智能体啊。
27量化南哥 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿openclaw, 一 款能接管你的电脑,真正自己动手二十四小时替你干活的 ai 工具。因为 claw 这个单词有龙虾钳字的意思而被国内网友戏称为 ai 小 龙虾。为了用上这个小龙虾,有人甚至花几百块找人上门安装 openclaw, 腾讯还专门搞了个线下活动,免费帮你装龙虾。这期视频手把手教你学会 openclaw 的 本地步数。 一、前期准备工作,硬件要求不高,一台能联网的电脑, windows、 mac 系统都可以,只要不是特别卡都能流畅运行 openclaw。 如果你的电脑里有重要文件资料,建议把 openclaw 部署到虚拟机里运行。软件方面,我们需要先在电脑上安装 nodejs 和 git 这两款软件。首先来到 nodejs 官网版本,建议选择 vr 二 lts 稳定版,点击获取 windows 安装程序, 下载后打开软件安装包,勾选同一软件安装协议,然后一直点击 nex 的, 再点击 instyle 开始安装,稍等片刻, note gs 就 安装好了。然后进入 get 软件官网,点击下载,没反应的话可以到评论区看看安装选项,全部保持默认即可。 最后把这个 view release note 取消勾选,点击 finish 完成。二、安装 openclaw, 点击左下角开始菜单,输入 powershell, 选择以管理员身份运行,然后输入这一行命令,按下 enter 键运行, 系统会询问我们是否确认执行策略,更改输入 y, 按下回车键表示同意,然后再输入 openclaw 官方安装命令并执行, 剩下的就是耐心等待 openclock 完成部署。安装过程中你可能会遇到各种各样的错误提示,直接截图问 ai, 根据他们的回答逐步解决问题, 期间会有一个弹窗提醒,选择允许访问,随后会来到这个界面,表明你成功完成了 openclock 的 本地安装。接下来我们还需要对 openclock 进行配置,按下键盘上的左右方向键,切换到 yes 回车,确认出石化模式,选择 quickstar ai 大 模型。这里支持使用 gpt、 mini max、 kimi、 豆包、火山引擎、阿里千问、百度千帆等。这是国内主流 ai 的 api, 使用费用大家可以自行选择。 这里以 kimi 为例,依次选择 kimi apikey, 点 c paste、 apikeynow, 然后打开浏览器,搜索 kimi 开放平台,确保账户有余额。点击 apikey 管理,新建 apikey 名称,输入 opencloud 项目,选择默认复制这串密钥,并粘贴到刚才的窗口即可。 如果你喜欢用豆包,就选择这个火山引擎 pass 的 api k, 然后进入火山引擎控制台,点击这里的 api k 管理,创建一个 api k, 粘贴到 power shell 窗口中,返回 timi 的 配置界面, 按下 enter 确认执行模型版本,选择默认的即可。这一步是配置通讯频道,我们选择最后一个 skip, 包括后面的配置,搜索引擎配置、 skills、 自动化脚本全部选择,暂时跳过,等跑通了再回来配置即可。 最后一步选择 opens web ui 系统,会自动调用浏览器,打开 opencloud 的 聊天窗口,如果小龙虾可以回复您消息,恭喜您完成了 opencloud 的 本地部署。下期视频我们具体了解小龙虾的使用方法。
4919从头学电脑 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿不懂代码的普通人怎么不熟 oppo clone 呢?根本不需要花几千块钱去买一个 mac mini, 今天看了我的这条教程呢,直接让你白嫖一百万。 talking, 咱们打开阿里云的官网,在这里点产品,然后选到清亮应用服务器, 然后呢,在这里可以选这个啊, open club 啊,然后一个月啊,一个月大概是这个二十多块钱,一年大概六十多块钱,咱们选个二十多的直接付款啊,付款之后呢,可以看到我们这个实力马上准备好了,咱们点我这个实力,点进去有个音乐详情啊, 因为详情一共有三个步骤啊,第一个步骤啊,就执行这个命令啊,可以放通这个端口啊,第一个已经成功了,第二个呢,就是配置这个 oppo 的 这个 mate 啊,咱们这里呢,直接使用这个百炼 callinplay 啊,确认开通就行了, 免费赠送一百万 token 推理额度啊,这个是阿里云旗下的一个百链平台。然后呢在左下角有个蜜柚管理,创建 a p o a p i k, 创建一个 a p i k, 然后呢勾选用户名称描述一下,随便填一把啊, opcode, 然后确定, 然后大家可以看到啊,这个庙已经生成了。然后呢,右上角有一个地区啊,我们现在是在华北啊,就在北京地区,然后复制这个,然后复制 api k, 然后在上一个页面,然后回到上一个页面,粘贴我们的 api k, 然后呢选北京。那就可以看到奥鹏哥老配置成功。 然后呢就是第三步了啊,就直接呃,可以给我们一个网站,让我们去访问我们的这个龙虾机器人, ok, 点开我们的龙虾机器人,直接问他用中文介绍你自己 啊,你看他已经回答了,下一期我会让 oppo cola 自动帮你干活,大家有遇到部署的问题可以随时问我。
877Yapie程序员哥 05:40查看AI文稿AI文稿
05:40查看AI文稿AI文稿哎,你有没有想过拥有一个完完全全属于你自己的 ai 助理花的钱呢?可能比你每天那杯咖啡还少。今天啊,咱们就来揭秘一下,怎么轻松把它搞到手。 这么说吧,如果我告诉你,每个月就花个二十九块钱,也就是一顿午饭钱,你就能拥有一个超级强大,七乘二十四小时线上,而且还不用翻墙的 ai 助理。你是不是觉得我在吹牛?哎,这还真不是幻象, 有一个叫 open cloud 的 开源项目就能让这事变成现实。今天啊,我就把这个独家秘籍分享给你,整个过程啊,简单到你不敢信, 是不是已经有点迫不及待了?好,那咱们就别光说了,直接上手跟着我六分钟,就六分钟,我们就能在云端把它跑起来。准备好了吗?我们开始 第一步特别简单,就是给你的 ai 在 网上安个家,你去阿里云这种地方买一台清亮应用服务器就行。哦,对了,记得啊,一定要选那个已经预装好 opencloud 的 应用镜像,这样最省事。 哎,这个有个重点听好了啊,这个服务器的内存啊,至少得是二 g, 这一点你可千万别省,不然你的 ai 跑起来可能会卡,那就体验不好了。记住,二 g 是 最低门槛。 好了,服务器买完之后出场就更简单了,人家云服务商都帮你把路铺好了,你只要点进应用详细页面,跟着那个一二三的步骤,点击下鼠标,这事就办完了。 ok, 最后一步,也是最关键的一步,就是给咱的 ai 大 脑加燃料,也就是配置一个 api 密钥。那问题就来了,上哪找又便宜又好用的燃料呢? 别急,这就要说到咱们今天的独家秘籍了,一个叫做 coding plan 的 神奇玩意儿, 你可以把这个 coding plan 想成什么呢?嗯,就好像是给你的 ai 大 脑办了一张手机卡,还是那种无限流量的月度套餐。这么一说,是不是一下就懂了?按月付费,本地直联,没有漫游费,想怎么用就怎么用。 那用这玩意儿的好处简直不要太明显!首先,便宜,便宜到什么程度?一个月二十九块钱起。其次,快,不用开什么 vpn, 国内网络嗖嗖的,延迟超低。 最后,选择还多,你定一个套餐,好几个 ai 大 模型就能随便你换着用,简直太爽了! 你可能会想,听着,这么好,设置起来肯定特麻烦吧?完全不会!我跟你说,不管你用谁家的服务,来来回回就这么三步,买套餐,拿到密钥和地址,然后把这两东西填到配置文件里,最后选个你喜欢的模型搞定。 那么市面上这么多家,到底哪家的手机套餐卡最适合你呢?来,我们快速对比一下几个最热门的, 来看这张选购指南。如果你喜欢尝鲜,想玩遍各种不同的 ai 模型,那阿里云有八个以上模型绝对是你的首选。 如果你像我一样有点懒,希望系统自动帮你搞定一线,那火山引擎的 auto 模式就是为你准备的。当然了,如果你追求的是一个极致性价比,那没得说, minimax 二十九块钱包月,闭眼入就对了。 这句话真的说的太对了,你仔细算算每个月省下来的那点 ipi 费用,跟你每天被那些重复无聊的工作浪费掉的时间比,哪个更重要?这笔账啊,其实咱们心里都清楚。 当然了,再厉害的技术,有时候也难免会闹点小脾气。不过别担心,万一真出问题了,我这也给你准备了一份快速排错指南, 如果你辛辛苦苦把 api 秘笈都设置好了,结果一运行,诶,报错了,先别慌,也别砸电脑,十有八九就是下面这三个小问题之一。 来,跟着我检查一下。第一,那个 base url, 你 看看最后是不是带了杠勾定杠这个小尾巴,大部分服务商都要带的。第二,模型名字你是不是从官网一个字儿一个字儿复制过来的?差一个字母一个大写都不行。 第三,也是最多人犯错的那个 api 密钥前面的 s k space 杠这部分你是不是给漏了?赶紧看看。如果你是个高级玩家啊,还想玩点花的 opencloak, 甚至允许你再配置一个备用的服务商, 这样以来啊,就算主力的偶尔罢工,备用的也能马上顶上,保证你的 ai 永远在线。 好了,说到这,你发现了吗?拥有一个私人 ai 助理的门槛,现在基本上已经可以说是没有了。 二十九块钱,你想想现在二十九块钱能干嘛?可能就是两杯奶茶的钱,但现在呢,你可以用它换来一个全年无休七乘二十四小时待命的 ai 伙伴,帮你写邮件,做研究,处理各种烦人的工作,这简直太划算了! 好了,方法工具,所有的钥匙今天我都交给你了,现在就轮到你了,你会用这把钥匙去开启一个怎样的新世界,去创造点什么好玩的东西呢?我很期待以上,你 get 了吗?
19秋忆 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿经过一整天的折腾,不停的调试测试,终于把龙虾和欧拉玛本地部署的大模型链接上了。下面说一下我这次的经验,并不是所有本地大模型都支持龙虾,目前经过我测试,最好用的是千万三, 我本地的硬件最高能支持在欧拉玛里面跑三二 b 的 大模型,但是速度比较慢,所以我下载了一个九 b 的 千万三,先试一下 九臂的千万三在欧拉玛里面可以很快的速度运行,但是在龙虾上反应的速度就有点慢, 而且只能支持本地聊天或者处理文本任务,让九臂的千万三驱动龙虾去打开浏览器都实现不了,也可能是因为我本地部署的大模型太小,有没有哪位部署过比较大的本地大模型的朋友可以说一下使用效果如何? 所以我打算暂时放弃使用本地大模型去动龙虾,去购买二十九元包月的 mini max 的 a p i 来使用 tucker, 量大管饱,关注我,一起交流养龙虾!
43无敌龙虾 07:20无限Token版OpenClaw龙虾 运维教你:Windows 本地部署无限 Token 版 OpenClaw 龙虾,稳定不崩!
07:20无限Token版OpenClaw龙虾 运维教你:Windows 本地部署无限 Token 版 OpenClaw 龙虾,稳定不崩!
#openclaw #无限token #龙虾 #windows #ai查看AI文稿AI文稿呃,大家好,今天给大家带来的是在 windows 上可以直接部署的一个无线拓客版的 open curl, 大家也可以看到这是我当前的一个拓客消耗的一个使用情况,基本是没有花钱的。然后这边其实也是前天就已经部署好了,最近部署好在用了,但可能 工作上比较忙,所以没有时间去更新旧使用工具以及去做那个教程的更新。 这边的话我先会先讲一下环境的一个要求,就或者硬件要求的一个情况啊,以及会讲一下那个啊将架构是怎么去实现的。 最后的话可能会讲一下啊,参数里面就这边是使用多款去部署的参数的一些啊,配置是如何去配置的?首先说一下那个环境的要求和那个硬件的要求,在使用那个本地部署的话,其实 如何做到那个无限拓展,其实就是用本地的那个显卡去做那个大模型的一个部署。嗯,本地模型呢,我这边是用的啊,千万的那个三点五九币的一个模型,然后使用的话是使用罗马的一个框架去做一个这个模型的部署。 嗯,这个模型的话是需要那个四点五到六 g 的 一个显存,所以这边建议是需要八 g 以上的一个显存的一个显卡才能去做到一个使用 啊,这边本地部署了是用那个啊 windows 去做部署的 v 十一去部署啊。其次给大家讲一下这个方案的架构是怎么实现的,因为 open core 它其实本身与 我们的 china 就是 频道去做那个通信的话,其实是依赖于公网的一个端口 webshop 的 这个协议端口来去实现的,所以本身是需要有那个公网的一个能力,这边在本地的公网的话,是通过去购买了一个阿里云的服务端, 呃,清江应用服务器部署了一个 mps 的 一个服务端来实现公网的一个端口转发,然后,呃将我们 windows 机器的一个端口进行 open code 这个幺八七八九的端口进行转发。 呃,首先的话就这边也大概说一下,就是本地都可部署了三个服务,对应的话就是这个是用做端口连接服务端并做端口转发以及转访问到对应的那个 open curl 的 一个 getaway 容器, 以及这边部署了一个参数的一个搜索引擎,用做 open curl 的 去做搜索,默认搜索不用那个,呃,默认的那个搜索引擎,因为那个还需要那个 api k 以及它也有每月的一个调用次数的一个上限。 呃,这边的话,呃对应的话是欧朗玛的话是部署到那个宿主机,也就是 windows 当前环境下去实现的。呃,可以大家可以在这边叫 这种方式直接去部署实现的,然后,嗯,这边端口是要改一下的,然后一会也会给大家看一下,就这边其实也对应你需要将那个环境变量去做一下修改,因为需要去实现跨域的一个访问配置, 这个的话是通过环境变量这边的话有一个叫欧拉玛的一个参数, 允许跨域的一个配置以及那个 host 的 绑定, host 需要修改一下,然后它才能对应去啊,让那个 open curl get away 去直接能访问到 啊。最后呢就给大家说一下整个方案中关于那个参数的一些配置以及需要注意的点吧,像简单的那个啊应用的安装我这边就不做介绍,像多壳的这些安装,大家选到 对应的进入官网,进入对应选对应的版本,直接下载,然后点点点的方式去安装就可以了。这饿了吗的话是也是通过那个 pro shop 直接用命令安装也行,通过那个下载那个离线包 安装包的方式来进行。点点点你是一路往下点就行了,用默认配置不需要去做外的一个配置。然后像那个注意一下,就是刚刚说的需要改一下那个 roma 的 那个监听端,监听地址加和端口,监端口可能不用变,就主要是监听地址要改成零点,零点零去 监听所有的那个地址以及的话啊,大家需要一个轻量应用服务器,这个的话就不局限于说阿里云,就各个厂商的都可以,大家自己看下哪个便宜点就可以,自己去购买就行了。主要用做部署那个 n p s 的 一个服务,这个服务的话,嗯 啊,这边也有对应的一个啊,文档说明就使用文档,这个是开源的,就大家可以用其他的软件去实现,也可以,就反正链路流程是通的啊。这边最后的话就给大家说一下整个配置啊,我这边打开一下, 就首先啊多个 compose 的 一个配置,是当前是这样子的一个配置,然后目录的话,我这边是分了三个一个目录啊,对应的话是这样子,首先第一个就 opencode 的 这个服务, 这个的话我们这边做端口映设,这个端口需要跟自己的那个启动命令对得上,启动命令的话是在这里面就这个多个 file, 这里面啊这个端口跟这个端口对应上就行了。 然后以及呃这边的话,大家新进一个 open color data 的 一个目录去保存,就做那个呃映设目录映设,然后以及方便本地去做直接修改。比如说这边当前的一些配置,可以直接那个在本地就直接去修改实现, 到时候直接重启一下容器,就能实现配置上的一些更新。然后这边的话以及第二个服务,就 npc 就客户端连接那个清凉饮用服务器用于转发端口的一个配置。这个的话,呃我我把这个包也直接放上来了,然后通过它让它直接实现多个 friend, 里面直接实现自己复制解压以及对应的安装执行去实现那个呃自动启动 以及打印日期。这个的话需要大家填一下,自己填一下这个啊,那个 k 跟搜物端口,这个的话大家参考这个在服务端去做配置就可以了。这边是 web 端管理里面 进入相应的 web 服务器里面可以去做那个查看到对应的那个 vk 以及搜我 ip 加端口,这个搜搜我的 ip 一 般就是你对应的尽量应用服务器的一个公网 ip, 这个大家自己根据自己的去做配置就可以了。 然后以及这边的话,呃这个这个是不需要去做任何修改的这个插入的一个配置, 然后这边的话,呃或者这个如果大家有需要的,可以那个关注我,那个我给大家新建一个,提供一个我们当前我当前在用的就尽量拥有服务器啊,在资源没达到上限啊,就我贷款没到上线之前应该大家都可以自己先用着,没什么关系, 先跑着用,然后这边的话整体的方案就这样子,其他基本没有什么特别需要注意的。
108咕咕嘎嘎(运维&开发)



