turboquant对存储芯片影响

粉丝169获赞898
相关视频
 01:46查看AI文稿AI文稿
01:46查看AI文稿AI文稿你敢相信吗?关键就藏在这三个细节里!存储芯片巨头突然集体暴跌?关键就藏在这三个细节里!最近美光 m u、 西部数据、 w d c、 闪迪 s n d k 等存储芯片股集体下跌,原因直指谷歌推出的一项新技术, turboqant。 这究竟是什么技术,能让存储芯片市场风生鹤立? turboqant 本质上是一种数据压缩和量化技术, 简单来说,它能让 ai 模型在运行时占用更少的内存,从而降低对高性能存储芯片的需求。 谷歌声称,使用 turboqant 可以 将 ai 模型的体积缩小好几倍,同时还能保持甚至提升模型的性能,这对存储芯片行业来说无疑是一个潜在的利空消息。 如果 ai 模型不再需要那么多存储空间,那么存储芯片的需求量自然会下降。尤其是在 ai 大 模型时代,存储芯片是算力的重要组成部分, turboqant 的 出现可能会改变这一格局,但事情并没有那么简单。 首先, turboqant 目前还处于早期阶段,实际应用效果还有待验证。其次, ai 技术的发展日新月异,未来可能会出现对存储芯片需求量更大的新型应用。此外,存储芯片的应用场景非常广泛,除了 ai 之外,还有消费电子、汽车、工业等领域, turboqant 对 这些领域的影响可能相对较小。所以,存储芯片的未来走向取决于多方面因素的综合作用。 技术创新是推动行业发展的关键动力,但市场需求、政策环境等因素同样重要。你认为 turboqant 会给存储芯片行业带来颠覆性变化吗?欢迎在评论区分享你的看法。
198老张说半导体 03:37查看AI文稿AI文稿
03:37查看AI文稿AI文稿不知道大家今天有没有被这个消息给吓到啊,反正我是被吓得够呛,导致今天存储芯片全体下跌。其实今天的下跌肯定有被错杀的,不是说这个技术的出现就会导致所有的存储都不行了,最主要的我们需要去研究这个技术具体原理和应用。 为此,我特地到谷歌官网找了一下关于这个 turboq 技术的相关论文,其实它本质就是一个超厉害的 ai 压缩算法,专门解决大模型运行时的内存瓶颈问题, 巴拉巴拉的,我一开始也不懂,后来我用 ai 了解了一下,现在用传统的个人计算机给大家打个比方,让大家能搞懂这个技术对未来存储的影响有哪些。大模型平时思考处理长文本, 就像咱们用电脑办公一样,会把正在处理的历史信息存在电脑的内存里。从专业角度来说,内存全程随机存取,存储器也叫 ram 内存,属于一次性存储,就相当于临时工作台 通电时才能存储数据,负责临时存放正在运行的程序、打开的文件和实时处理的信息,方便 cpu 快 速调用,断电后里面的内容会全部丢失。 而硬盘属于持久性存储,常见的有机械硬盘 hdd 和固态硬盘 ssd, 就 像长期仓库,不管通不通电,里面存储的文件、软件、系统等数据都不会丢失,主要用于长期规章和存放非实时处理的内容,和大模型临时运算的操作没有直接关联。 但这个内存工作台空间有限,处理的文本越长,需要临时放的信息就越多,内存很快就被占满,就像工作台堆满了文件,电脑会变卡,甚至打不开新文件一样,大模型也会变慢,跑不动。 turboq 就 相当于给这个内存工作台装了一个无损整理压缩神器,分两步帮你腾空间,还不丢任何有用的信息。第一步是换个整理方式,以前往内存里存信息,就像把文件杂乱无章堆在工作台上,占地方还不好找。 他就像把文件分类、叠放、压缩、打包,体积变小了,但里面的内容一点没少。就像咱们把电脑里的文件压缩成压缩包,占的内存变少,解压后还是原文件。第二步是做小修正。压缩整理难免有一点点小偏差,他用特别小的空间就把偏差修正过来, 保证整理后的信息和原来的一模一样,不影响大模型正常使用。但有了 turbocharger 之后,未来就不一样了,它不用咱们再盲目追求超大内存这个硬指标,就像不用再强行换超大工作台,而是把现有工作台的空间利用到极致。 短期来看,它会让普通内存就能满足大部分 ai 使用需求,不用再花大价钱买高端内存。但从长期来说,它会让 ai 应用越来越普及, 比如以后咱们的手机、家用电脑都能轻松跑复杂大模型,这反而会带动小型高效的存储类型需求增加,比如更轻便、更节能的内存,还有适配端侧设备的小型存储芯片,而不是一味追求大容量的存储设备。 可能有人会担心,这会不会让大容量内存硬盘被淘汰?其实完全不会,就像以前大家觉得压缩软件会让硬盘没用,但反而因为压缩省了空间,大家存的东西更多了,对存储的需求反而变广了。 未来高端大容量存储还是会用在服务器、专业 ai 设备上,但普通设备的存储需求会更偏向高效轻便,不再是单纯比大小。这就是 turboqant 给未来存储类型需求带来的最大改变。 总结一下,目前 turboqant 还处在谷歌内部实验室阶段,不会对存储价格有影响。走出实验室至少要到今年年底。 当 turboqant 进入商业化的时代,每个人都能本地化、低成本部署 ai, 这反而会推动存储行业进入一个全新的阶段。 想一想世界上第一台计算机 e n i a c 到家用的微型计算机,你就能想通这个事情了。所以,今天的下跌快点有错杀的。未来端测存储,如手机、电脑、 ai、 眼镜、汽车等等,需求量会越来越大。
21Louis_Lú 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿最近科技圈和股市彻底炸了,谷歌发布的 turboqant 算法一夜之间让全球存储芯片市值蒸发几千亿。很多人都在问,这项技术到底是真是假,又会给行业带来多大影响?今天用最通俗的话给大家讲明白。 首先,这项技术是真实可靠的,并不是概念炒作。谷歌已经发布了专业论文,并且在英伟达高端芯片上完成了实测数据全部公开。 它的核心作用就是针对 ai 大 模型运行时的缓存数据进行极致压缩。简单来说, ai 运行的时候需要临时存储大量数据, 这就非常占用内存。以前需要六份存储容量才能支撑的运行需求,现在用这个算法一份就够了,不仅能节省超过百分之八十的存储空间,运行速度还能提升八倍。最厉害的是完全不影响模型的精度,也不需要重新训练。这项技术的出现直接冲击了整个存储行业。 这两年 ai 飞速发展,高宽带内存存储芯片一直是供不应求的状态,而一旦这个算法普及, ai 服务器对存储芯片的需求会大幅减少。这也就意味着像三星、海力士、 美光这些头部存储企业,业绩会受到直接影响,股价暴跌也是市场最真实的反应。整个存储产业链都会面临短期的需求调整,但大家要明白,这并不是存储行业的终点,而是一次行业洗牌。 算法再先进也离不开硬件的支撑,不可能完全替代存储芯片,而且技术落地需要时间,产业链也会有适应和升级的过程。总的来说,谷歌这项技术是一次真正的技术革新,它短期重创了存储市场,长期会重构整个 ai 算力行业。 对于普通人,未来我们用到的 ai 产品会更便宜、更流畅。对于行业而言,这是一次大浪淘沙,只有不断创新才能不被淘汰,科技进步的速度永远超出我们的想象,这一场存储行业的风暴才刚刚开始。
13龙城新视野 01:12查看AI文稿AI文稿
01:12查看AI文稿AI文稿来来来,我知道为什么谷歌要干这个 turboqant 这个技术了,美光完全就是人在家中坐,祸从天上来,因为今年谷歌就是存储不够用,所以他前段时间干外挂,现在要干那个存储缩减的事情, 记不记得当时谷歌还因为这个事情把那个一个采购经理直接裁掉了,那么主要原因就是英伟达、欧盟 ai 这几个哥们 去把这个存储包圆了,包了美光的一年,然后二九年把三星跟海力士给包了。然后呢?你让人家谷歌无路可走?然后谷歌咬咬牙就搞了这个技术, 据说这个 k v cash 减少六分之一的这个用量,那么在呃英伟达的这个 h 一 百的 g p u 上,直接帮人家实现了高达八倍的 attention 的 这个计算速度的提升,哈,这你不让大家瑟瑟发抖? 哎,这是离谱他妈给离谱开门,离谱到家了。然后最离谱的是短期看单任务的这个内存流量跟 gpu 的 确需求是下降的, 但是朋友们长期受杰文斯贝勒的驱动,更低的头肯成本必将催生更大的这个需求的,这个规模和更长的上下文的需求,最终对硬件存储形成更旺盛的需求。大水冲了龙王庙,一家人不认识,一家人散会睡觉,晚安。记得关注我。
1206黄小勋 07:51查看AI文稿AI文稿
07:51查看AI文稿AI文稿谷歌 turboqant 炸翻美股存储圈儿?别慌,这波恐慌纯纯是虚惊一场,家人们!二零二六年三月二十五日晚,美股盘前,科技圈和股市直接炸锅了。谷歌突然扔出个王炸,官宣了一项叫 turboqant 的 k v 缓存压缩技术, 张口就吹,能让 ai 推理速度狂飙八倍,内存占用直接砍到原来的六分之一。这消息一出来,科技圈直接炸开了花,美股市场的反应更是快的离谱,主打一个即时应机。 美股一开盘,存储板块四巨头直接集体低开跳水,场面堪称大型翻车现场。 sandisk 狂跌五百分之七, western digital 跌四百分之七, sig 跌百分之四, micro 也跌了百分之三。 更离谱的是,另一边纳斯达破一百,指数还在蹭蹭往上涨,合着这波是精准打击存储板块,直接给他定向爆破了, 妥妥的股市版区别对待。不过这恐慌来得快,去的也快,盘中各家跌幅嗖嗖收展,收盘时平均跌幅就回落到百分之三左右。这走势明摆的就是市场先是被虎的魂飞魄散,冷静下来一想,又赶紧往回拉。那问题就来了, 谷歌这波技术官宣,对存储板块到底是动了根本的利空,还是单纯被高大上的技术名词糊住的噪音闹剧?今天咱就用唠嗑的方式把这事掰扯的明明白白。先搞懂 turbo quant 到底是啥, 别被专业词糊住。一看到 k v 缓存压缩、三比特量化这些词,是不是瞬间头大,觉得不明觉厉,下意识就想跟着恐慌?大可不必, 咱用个超生活化的搞笑比例,一秒给你讲透想象你是一家爆火餐厅的服务员,忙得脚不沾地,每来一桌客人,你都得拿随身的小本本记满菜品。这个小本本就是 ai 的 k v 缓存, 相当于 ai 聊天时的短期临时记性,随用随记。但问题来了,同时招待的桌子越多,每桌点的菜越复杂,你的小本本越系越厚,口袋都塞不下,只能放慢速度,甚至不敢接新单,效率直接拉垮。那 triple kwon 干了啥?相当于给你发明了一套无敌速记法。 原来一道菜要写十六个字详细描述,现在三个字就能搞定,关键信息还一点不丢。这么一来,同一个小本本,能记的桌数直接多六倍,记菜速度还快八倍,主打一个高效开挂。但敲黑板这三个关键点千万别搞错,搞错就容易瞎恐慌。第一, 它压缩的只是服务员的零食,小本本可不是厨房里的食材库存, ai 训练需要的海量内存该用多少还是多少,半毛钱不受影响。 第二,它不是减少餐厅需要的食材总量,只是让一个服务员能同时伺候更多桌客人。说白了就是一块 gpu, 能干更多活,但不代表需要的 gpu 总数会变少,该买的硬件还是得买。 第三,这技术现在还在实验室摆着呢,下个月才在 iclr 二零二六会议上正式发表。谷歌连官方代码库都没放,想大规模商用,落地还早得很,远水解不了近渴,根本没到影响实际生意的地步。市场到底在慌啥? 主打一个直线型脑回路市场这波恐慌的逻辑,简单到让人哭笑不得,纯纯是不动脑子的直线思维。内存用量少六倍,买内存的人变少,存储公司要没生意,股价赶紧跌。这逻辑看起来顺的像一加一等于二, 实则漏洞百出,跟小学生做算术题一样,完全没考虑现实世界的复杂情况。而且咱说实话,这剧本真的一点不新鲜, 之前已经演过两次一模一样的戏码,堪称股市照妖镜,一照就看出市场有多盲目跟风。历史同款道具, 这俩前车之鉴还没忘呢。剧本一,英伟达 gpu 性能翻倍,有人喊着要滞销,每次英伟达发新 gpu, 都有一群人跳出来瞎分析,新卡性能是老卡的十倍,那以后买十分之一的卡就够了,英伟达要凉。结果呢?现实啪啪打脸, 新伟达连续多年营收创新高,每一代新卡都供不应求,抢都抢不到。为啥?因为算力变强变便宜了,大家根本不会省着用,反而开始折腾之前算不起的事,做更大的 ai 模型,跑更复杂的推理,开发更多新应用, 需求根本不是固定大小的蛋糕,而是越做越大的超级蛋糕。算力越多,需求越旺。剧本二, deepseek 说算力减百分之九十,算力股暴跌后反转。二零二五年初那波更夸张, deepseek 横空出世, 说完成同样任务,算力需求降百分之九十,市场直接吓懵,集体喊算力要过剩了。以英伟达为首的 ai 硬件股集体暴跌,结果这波下跌就撑了三个月,之后直接强势反弹。 deepsea 确实让行业效率变高了,各大模型都跟着优化,但效率提升带来的是 ai 更好用。这就是经济学里的杰文斯辩论,说白了就是一种资源,用的效率越高越便宜,大家反而用的越多,总消耗量不减反增,新需求直接被彻底释放。这可不是纸上谈兵, 是过去两年反复验证的铁律 triple quant 的 真实影响。别再被恐慌逻辑带偏了,咱把市场的恐慌版直线逻辑和现实版正常逻辑放一起对比,差距立马就出来了。 恐慌版效率提升,单位内存需求减少,总需求变少,存储股利空。现实版效率提升,一块硬件能干更多事, 云服务商成本降低, ai 服务更便宜,更多人用得起, ai 更多新场景诞生,更多 ai 任务要跑,总需求反而暴增。存储股长期利好。还有个超级搞笑的点,市场连基本概念都没分清就下跌。 turboqant 压缩的是 drm 里的 k v 缓存, 可存储四巨头里的 sandisk 和 sig 主营的是 nid 闪存。这就跟发明了高效快递分拣法,结果仓储物流公司的股价莫名其妙跟着跌,纯纯是张冠李戴闹了个大乌龙。存储板块基本面变了吗?压根没动。答案很干脆,半毛钱没变。 今年二月,摩根士丹利直接把美光的目标价上调到四百五十美元,还把它列为半导体板块首选。核心原因就是 ai 带动的存储供需失衡越来越严重。 d r m 价格第一季度环比狂涨百分之六十到百分之七十, n a n d 合约价也一路走高。大魔预计美光二零二六年 e p s。 能超五十二美元,比市场预期还高一大截。 再说这四大存储巨头,去年直接包揽标普五百成分股涨幅榜前四,今年以来涨幅也依旧靠前, 现在本来就处于前期涨太多需要消化估值的技术性回调阶段,跟谷歌这消息一点关系没有。谷歌 turbo quant 的 消息说白了就是个背锅侠,刚好撞上回调窗口期,给那些本来就想卖出的人找了个看似合理的借口而已,根本不是存储板块的基本面出了问题。 结论这就是噪音加借口,搞不好还是买入。想想看,更省油的车,发明后,加油站不仅没倒闭,反而因为开车成本变低,更多人买车,更多人上路,加油站生意直接更火爆。放到这事上也是一样, 短期来看,确实是个利空借口,存储股顺势回调一波,完全在预料之中,没必要大惊小怪。中期来看,纯纯的市场噪音,跟之前 deepsea 那 波冲击一样,市场用不了多久就会反应过来,效率提升根本不等于需求减少, 这波恐慌很快就会消散,长期来看反而是利好 ai 推理成本下降,会释放海量的新需求, 杰文斯辩论会再次应验,存储总用量只会不减反增。所以别跟着瞎恐慌了,与其慌慌张张卖筹码,不如想想,等这波恐慌彻底散去,你是想拿着存储龙头的股票稳稳躺平,还是后悔在这场闹剧中卖飞筹码拍断大腿?
41极客舟 01:33查看AI文稿AI文稿
01:33查看AI文稿AI文稿现在的存储圈正在面临历史上最诡异的剪刀厂。今年三月二十四日,百威存储砸出一百零八亿去锁金元才能,这其实是典型的重资产防御,我预判了物理才能会稀缺,所以我提前去买断生存权。但在同一天,谷歌发布的 cherry queen 却在告诉全世界, 物理容量正在贬值,算法效率正在膨胀。那你可能会问,哎,这个算法那么牛,存储是不是会降价的? 错,效率越高,欲望越爆。当 ai 成本降低六倍, ai 的 应用场景会增加六百倍, 短期因为这个消息,市场可能会发生震荡。但长期来看,存储市场不是在萎缩,而是经历一场从卖斤两到卖性能的权力总共。而这场博弈落到咱们国内的市场,最扎心的其实是鲜货商和贸易商。如果你还在按以往的逻辑觉得大容量即是正义,那你就危险了。 算法强了,普通大容量的颗粒的溢价空间就会被迅速的挤压。未来硬通货不再是容量,而是贷宽能跑得动,顶级压缩算法的极数量才是未来五年的刚需,那些傻大黑粗的旧模组可能会变成无人问津的 负债库存。对咱们国内的终端工厂而言,如果你没有钱像大厂那样锁一百亿的货,那你的出路我觉得只有一条,采用国产替代芯片,配合国内研发的暴力减负算法,用十二 g 的 成本跑出三十二 g 的 性能。 这不叫缩减开支啊,这叫规格降维打击。你们怎么看?关注我,了解最新行业的资讯!
702芯片资讯-Jax 01:39查看AI文稿AI文稿
01:39查看AI文稿AI文稿小曾告诉我,美股上演黑色星期三,存储芯片巨头集体暴跌,美光西部数据闪迪全线跳水,一天狂蒸发上千亿。 到底发生了什么?罪魁祸首竟然是谷歌!一篇还没正式发表的论文,谷歌刚发布的 turbo quant 压缩技术,直接炸翻了科技圈和股市。这项技术有多狠? 一句话,它能把大模型运行时最吃内存的 k 飞缓存,在几乎不损失精度的前提下,直接压缩到原来的六分之一 内存,开销砍六倍,推理速度还能狂飙八倍!简单说就是,以前跑一个大模型,得要六台服务器的内存才够,现在一台就绰绰有余。 市场瞬间慌了, ai 服务器的内存刚需逻辑被直接动摇,万亿存储芯片市场的底层逻辑遭遇了前所未有的冲击。所以,哪怕这只是一篇技术论文,还没真正落地,美股资金就已经开始恐慌性抛售了。 毕竟大家都怕以后 ai 不 再猛堆内存硬件,转而靠算法省空间,那存储芯片的需求岂不是要断崖式下滑? 但说句公招话,这波暴跌更多是市场情绪的过度反应。业内大佬都在说,这项技术主要影响的是推理阶段的缓存,并不影响模型真正需要的高宽带内存。 而且 ai 越发展,对数据的需求只会越大,长期来看,存储芯片的需求还是稳的,所以别被短期的波动吓住了。 技术进步是好事儿,能让 ai 更便宜更好用,而存储芯片作为 ai 时代的基建核心,长期价值依然在。关注我明天带你看,这波技术浪潮下,谁才是真正的赢家!
 02:11查看AI文稿AI文稿
02:11查看AI文稿AI文稿朋友们,谁能想到,谷歌昨天发布的一个新功能啊,却让美股的存储板块集体闪崩,美光闪迪,西部数据啊,全部收跌,而且呢,是在纳斯达克整体啊涨了百分之零点七, 而且占稳了五日均线的情况下。谷歌刚发布的这个黑科技呢,叫 turbo count, 简单说啊,就是一种 ai 内存的压缩算法。我大致了解了一下啊,就是以前跑一个大模型可能需要六块内存条,现在呢,用它这个算法啊,可能只需要一块就能跑通,内存的占用呢,直接是原来的六分之一。 那么市场的逻辑很简单啊,软件变强了,硬件的需求呢,是不是就减少了?哎,但是大家也要冷静下来想一想啊,这种冲击性很强啊的这种标题式的消息,哎,他有时候往往是暂时的, 那虽然单位的存储需求减少了,但是 ai 的 门槛呢,也降低了,那以后人人如果都能跑模型,那总需求真的会跟着降吗? 目前呢,可能谁也说不清,总之市场对这一点呢,目前可能是有些担心,所以我就想到啊,巴菲特为什么喜欢投那些传统行业,尤其是那些技术轻易改变不了的公司 啊,因为这些前沿技术他迭代太快了,尤其是现在我们所出的这个 ai 时代,那颠覆性的技术呢,可能还会层出不穷。 哎,就像前段时间啊,市场担心呢,就 ishtropic 那 个 cloud 大 模型啊,对很多美股的萨斯软件公司有可能造成降维打击, 像什么 photoshop 之类的啊,都跌了很多,就连最稳的全能选手微软啊,我们看它从高点都跌了百分之三十多,这也是我们如果选择啊,投资高科技行业的一个潜在的风险。 好,那回到存储的问题啊,谷歌的这个新技术啊,到底是技术红利还是行业利空?大家怎么看?评论区可以留言聊一聊。
67Z探聊投资 06:27查看AI文稿AI文稿
06:27查看AI文稿AI文稿各位观众朋友大家好,今天我们来深度解读谷歌最新提出的 turbo quant 压缩算法对大模型算力、成本、云厂商存储和硬件产业链的影响。先讲三个结论, turbo quant 让大模型推理用六分之一的内存跑出最高八倍的速度,而且几乎不掉精度,不用重新训练模型, 它只压缩 k v catch 注意力里的临时记忆本,不碰模型权重,但等于是同一块 g p u 能接四八倍的对话长度或请求数量大幅提升,单卡产出 k v 开始可以理解为模型在对话中记住历史内容的备忘录, turbo quint 就是 把这个备忘录高度压缩。对投资层面,短期对 g p u 存储是效率提升,但不一定是需求下滑。长期更像 deep sea 时刻是改变 ai 部署成本曲线的技术。立好云巨头与模型平台 对计算与存储需求偏中长期正面,那 tropos 究竟是什么在解决啥问题?先讲背景,大模型推理时,真正的瓶颈越来越不是算力,而是 k v cash。 内存,也就是注意力机制里存历史 token 的 那块缓存,随着上下文窗口变长, 这个缓存空间是限性往上涨的,直接吃掉大量 gpu 显存,导致单卡能接的并发症,上下文长度都被卡死,推理变慢,成本变高。 tropos 针对的就是这块 k v cash, 他把原来三十二比特的向量压到大概三比特,也就是内存占用缩小约六倍,同时把注意力计算本身的速度最高提到八倍,而且在多套基础测试里,几乎看不到精度损失。 这里特别强调,他只改推理阶段的 k v cash, 不 动模型权重,不改训练流程,相当于一个即插即用的推理加速组建。对现有大模型来说,集成门槛低, 我们再看看它是怎么做到六倍压缩加几乎无损。技术上, turboqant 是 一个两阶段的向量量化方案,目标是同时做到两点,一是压得足够小,二是保持注意力里内基运算的精度,不能把模型的理解能力压坏了。第一步叫 polarqant, 可以简单理解为换一种坐标系来压缩它先对向量做一个随机旋转,然后把传统的直角坐标转成极坐标形式,一个角度一个半径,这里角度更多的承载羽翼方向半径,承载信号强度。在这个坐标系下,大部分有用信息可以被更 高效的编码进有限的 bit 里,而且省掉了传统量化里很多昂贵的归一化操作,直接减少了额外算力开销。第二步是 ebit qgl, 也就是 quantize johnson london straws。 第一步之后多少会有一点压缩误差。第二步就是用一个低维随机映射, 把这部分残差压到只剩下加一或负一的一位符号,相当于给每个向量打一个很轻量的纠偏标签,保证内基估计不被系统性拉偏。研报强调,这一步几乎不增加额外内存开销,因为这一比特的校正被吸收到总比特预算里,在相同的比特数下把误差又往回拉了一截, 从信息论角度看,已经接近理论压缩极限。所以 turboqant 不是 简单的多压一点看看效果,而 是在有明确师生上届证明可用的前提下,把压缩做到极致,同时仍然适合在线推理场景,这点是很关键的。从算力经济学角度,摩根式单利的核心观点有三点,第一,这是一次结构性的推理成本下降, k v cash 已经成为大模型推理中成本增长最快的部分, 六倍内存压缩,八倍注意力加速,直接把每个 token 对 内存和算力的占用往下拉。相当于同样的 gpu 集群可以服务更多请求,单次调用成本明显下降。第二,它扩大的是有效 gpu 产量, 未必立刻砍总 gpu 需求。研报判断,短期看,更多是利用率提升,而不是绝对需求下滑。云厂商很可能把腾出来的资源重新投入到更大模型、更长上下文、更大 bug 以及更严格的延迟 s l a 上。换句话说,同样一笔 kpx 可以 支撑更强的模型,更好的体验,推理端的 r o i 被明显抬高。第三,典型的 jevens belloon 会放大总需求。报告里直接引用了 jevens paradox。 当效率提升、单位成本下降时,总体需求往往会上升,而不是下降。每 token 成本降下去之后, ai 服务可以更便宜更大杯很多原来算不过账的应用会更便宜更大杯很多原来算不过账的应用会更下去之后, ai 服务可以更便宜更大杯很多原来算不过账的算力和内存。 同时, turboqant 降低了部署门槛,部分原本只能云上跑的大模型有可能压到本地服务器甚至高端终端上运行,这对私有化部署边缘侧 ai 都是明显利好。那这对云场 gpu 存储和软件的产业链有什么含义? 对云巨头模型平台明确证明,因为每单位质量的长上下,非推理成本大幅下降, roi 明显改善,更容易把大模型做成高毛利、可规模化的基础设施。 同时,像 turbo quant 这种压缩会被直接嵌进平台底层,对上层应用开发者来说是透明的,意味着平台护城核继续加厚。对 gpu 计算芯片报告判断,短期是中性偏正 单任务的 gpu 需求下降,被更大模型、更长上下文、更高 qps 虚收掉,整体 gpu 需求不一定下降。从中长期看,如果长上下文,解锁增强场景爆发,反而会因为更便宜而更普及。对高端加速芯片的总需求拉长周期。对内存与存储,短期看是效率提升, 单位 workload 只改 kvatch, 不 动权重和训练, 整体算内存效率提高,而不是内存用量腰斩。长期同样受 jevens 辩论影响,更多模型更多实力保持在线,更长的上下文和更高的迸发可能反过来推高总体 drm per hour bm 存储需求。 研报定性为中性到长期正面对软件上层应用,这里研报给了一个有意思的角度,因为压缩被做到基础设施层部分做推理优化,压缩工具的软件价值会被平台内升吞掉,在利润池上可能略偏负,但对真正以业务逻辑和数据为护城河的应用来说,这是纯利好。 底层推理成本下降,提高毛利与用户体验。如果我们把 deep seek 看作用更聪明的软件,把同样硬件炸得更干的一次示范,那 turboqant 则是直接针对大模型推理中最核心的 k v cash 瓶颈给出了接近信息论极限的压缩方案。 ai 基建的估值不能只看当下的单次推理成本, 而要看到像 turbo quantum 这样一代又一代的底层技术进步,会不断把成本曲线往下压,同时用 jevens bellun 把需求再拉起来。在这个过程中,云场、 gpu、 内存以及高质量的模型平台都是相对更有定价权的长期受益者。以上就是今天的解读,关注我,带你看懂科技趋势!
 02:17查看AI文稿AI文稿
02:17查看AI文稿AI文稿我们继续上期视频行业影响上,首先就是推理成本大降, ai 普惠加速到来。 tableqant 算法的出现将大幅降低 ai 推理的成本。 据谷歌官方数据,使用 tableqant 算法后,大模型推理的内存需求降低了六倍,推理速度提升了百分之三十。 这意味着企业和开发者可以用更低的成本部署大模型,加速 ai 技术的普及和应用。 ai 推理成本的降低将为各行各业带来新的机遇。 例如,在医疗领域,医生可以使用大模型辅助诊断,提高诊断效率和准确性。在教育领域,教师可以使用大模行为学生提供个性化的学习辅导。在金融领域,银行可以使用大模型进行风险评估和欺诈检测。 这些应用场景的实现将进一步推动 ai 技术的发展和普及。但与之伴随而来的是,硬件格局深变,存储产业面临新挑战。 tabocont 算法的出现也将对存储产业产生深远的影响。由于推理内存需求的降低,存储芯片厂商可能会面临订单调整的压力, 尤其是 d i m 内存厂商,由于推理服务器对 d i m 的 需求占比较大,可能会受到一定的冲击。然而,从长期来看, turbo quint 的 算法的出现也可能会为存储产业带来新的机遇。随着 ai 技术的普及和应用场景的拓展,存储芯片的总需求可能会持续增长。 同时,存储芯片厂商也可以通过技术创新提高存储芯片的性能和效率,以适应 ai 时代的需求。 至此一托,软件架构重构将推动大模型应用场景爆发。 tabocont 算法的出现将推动大模型软件架构的重构。由于推理成本的降低,开发者可以更加灵活地设计大模型应用,开发出更多基于长文本处理的应用场景。在法律、学术、文学等领域, 开发者可以开发出能够处理超长法律文书的大模型应用,也包括阅读和分析那些超长学术论文和文学创作。 这些新的应用场景的出现将进一步推动大模型技术的发展和应用,为用户带来更加丰富和便捷的 ai 体验。下期我想分享一下我是如何看待这次技术突破对产业的影响。
 00:56查看AI文稿AI文稿
00:56查看AI文稿AI文稿三月二十四日,谷歌研究院发布内存压缩算法 turboqant, 可在不损失精度的前提下,将大语言模型推理时的 k v cash 内存占用减少至少六倍,并在 h 一 百 gpu 上实现最高八倍的注意力计算速度提升。该成果将于下月 i c l 二二零二六会议正式亮相。消息引发全球存储芯片股剧烈震荡。 三月二十五日至二十六日, s k。 海力士、三星电子、美观科技等巨头市值合计蒸发超九百亿美元,闪迪单日跌幅达百分之十一。华尔街分析师普遍认为市场反应过度。摩根士单利指出,该技术仅作用于推理阶段的 k v cash, 不 影响训练需求和 h b m 市场, 且效率提升可能因杰文斯备乱反而刺激更多需求。目前全球内存供应仍高度紧张,也曾预计 q 二 d r a m 价格环比上涨百分之五十一。业内将这一成果称为谷歌的 deep seek 时刻通过极致效率优化拉低 ai 运行成本,但存储芯片长期需求逻辑尚未发生根本性转折。
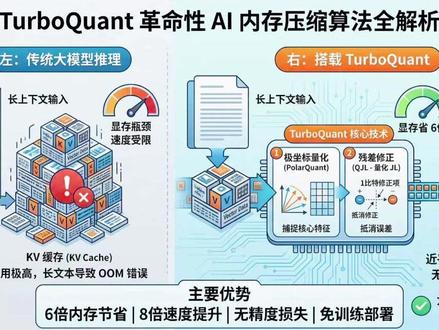 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿今天 a 股存储板块出现明显调整,和昨晚美股存储板块的下跌形成直接联动,核心原因就是市场对谷歌最新 k v 缓存压缩技术的预期冲击。谷歌这项技术通过 turbo quant 量化压缩算法, 在不重新训练模型的前提下,将 ai 推理核心的 k v 缓存从常规精度压缩到三倍,同时基本保留模型效果。在开源模型上可实现约六倍的内存压缩率,在 h 一 零零芯片上推理性能最高提升近八倍。 这一技术一旦成熟落地,会直接改变 ai 算力对存储硬件的需求结构。当前 hbm 高带宽内存、 nnd 散群都是 ai 大 模型训练与推理的核心支撑, 缓存压缩技术大幅提升存储利用效率,会直接虚弱市场对大容量、高带宽存储的增量预期,进而压制整个存储产业链的固执逻辑。 后续重点观察两个关键点,一是今年四月谷歌在国际学术会议上公布的真实落地效果,二是国内主流芯片与模型厂商的适配进度。
58财论社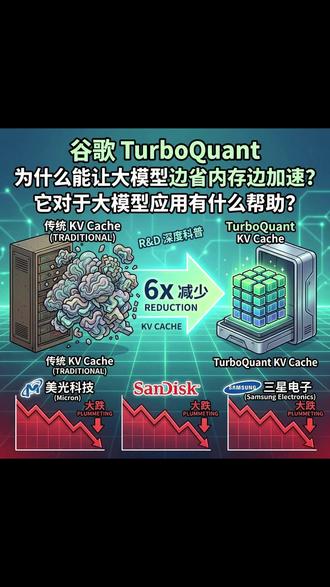 07:34查看AI文稿AI文稿
07:34查看AI文稿AI文稿上周科技投资界很火的一个话题就是谷歌推出了特步矿的技术,它号称可以能够将大模型运行时的 k v cash, 也就是键值内存值减少六倍啊!这个技术一推出,存储 这美观科技啊,闪迪啊,三星电子的股价都大跌。今天我们就来介绍一下特步矿到底是一个什么样的技术,它到底厉害在哪里。相信了解了这些后,你就会明白他对于 ai 大 模型到底有什么作用。如果你是做投资的,对你的投资决策也会有帮助, 那我们先从大语言模型推理中最头痛的内存杀手 k v kash 讲起,这也是特博矿的诞生的核心背景。 而在大语言模型生成文字字的时候,其实它是逐个字蹦出来,为了生成下一个字,模型需要回顾之前已经生成的所有字。简单的来说, k v kash 这个键值缓存其实就是大模型 l a m 的 短期记忆。在没有 k v kash 的 情况下, 大模型每生成一个新字,都要把之前所有的字重新读一遍,有了它,模型就能记住处理过的内容,从而实现极速的推理。 那为什么它是瓶颈呢?虽然缓存能够加速计算,但它也带来两个致命的问题,一个就是限性增长,对话越长, k v k 使用的空间也就越大。如果你在写长篇小说或者分析长文档,显存就会迅速被填满。 第二个遭遇的问题就是内存强。现在的 gpu 算力其实很快,但是显存里边读取的数据的速度、带宽相对较慢。当 k v cash 变得巨大时, gpu 大 部分时间都在等数据传输,而不是在计算。 举个例子来说,想想你在读一篇啊,一本很厚的推理小说,如果没有 cash, 每读到新的一页,你都要把前面的章节全部读一遍,才能理解剧情,这个就太慢了。那有了 cash 呢?你把之前的关键线索记在了笔记本上, 但是呢,你也会遇到瓶颈,随着你这个书越来越厚,你的笔记本就被填满了,也就是说显存易出了。而且你翻阅笔记本找线索的速度也开始跟不上你阅读的速,这就所谓的待宽限制。胳膊框的出现呢,本质上其实就是发明了一种超级微缩胶卷, 把你的后笔记本压缩成一小片,但又不丢失关键线索。这个 point 使用了量化技术,就是所谓的 quantization 技术。简单来说,就是把高精度的大数字,比如说像 f、 t 六零这种十六位的浮点数,压缩成低精度的小数字,比如像四的这种等数。 但这里就面临一个巨大的挑战,那就是精度损失。如果你强行把所有的数字都压缩成呃 int 四这种整形数,模型就会胡言乱语,逻辑变得混乱。特步矿腾呢,发现了一个神奇的现象,叫异常值,就是说, 他认为就是 tv cash 中其实百分之九十九的数据都很平庸,数值很小,即便压缩了以后也没有什么关系。但是呢,有极少数的所谓的异常值,它的数值非常大,承载了模型最重要的记忆和逻辑。 那这样呢,就特步矿的它采取了一种保命策略,它就不像传统的压缩方法一样一刀切,而是采采用的就是异常值感知量化,它会先像雷达一样扫描这个整个 k v catch, 识别出那些极少的异常值,给它们分配。高精度啊,保留原来的这个精度啊,类似于 f p 十六这种。 对剩下的绝大多数的这个普通纸呢,进行高倍压缩,压缩成 excel 甚至更低。当然这里面牵涉到一个比较复杂的一个叫随机旋转,还有一个 one bit 的 这种机制来做具体的操作。这里不假拍讲,太复杂了,我相信普通的读者可能也并不关心。 虽然这种方法逻辑上看似很完美,但是在计算机底层却有一个大麻烦,也就是 gpu, 它喜欢整齐划一的数据类型。 想象一下,如果一个盒子里面既有巨大的石头,也就是十六 bit 的 这种异糖纸,又有细小的沙子,也就是四 bit 的 这种整形普通纸。那搬运工也就是这个 gpu 算子,它处理起来就会非常手忙脚乱, 如果解压缩的速度太慢,那省下的内存贷宽就会被计算延迟给抵消掉,我们也无法为了一个算子就去重新设计生产成千上万块 gpu 芯片。那这个时候最聪明高效的方法就是在软件层面进行优化。那其实在 turbo 框子中,这种优化主要体现在如何解决既要快又准的矛盾上。 那特步矿的做的一件事情就是在算子层面做了融合,就是在普通的推理过程中, gpu 先要从显存读起,压缩的数据放入缓存,然后再减压成原始数值,最后再进行计算, 这个每一步都要产生数据搬运的开销。那特步矿的呢,就编选了专门的扩大算子,它让 gpu 在 读取数据的一瞬间,直接在积存期,也就是 gpu 内部最快的地方完成了减压和计算。这种边读边算的方式呢,就极大的减少了数据在显存和核心之间的往返次数。 另外他用到了一个所谓的叫未包装的技术,就是让四比特数据在三十二位或者六十四位的英俊通道里边跑的顺畅,包括矿的。使用了这个未包装技术呢,就是把八个四比特的数字打包进一个三十二位的整数计算器里,这样的 gpu 就 可以一口吞下整个的数据量,包含的信息密度就是原来的四倍。 第三个就是使用异步处理异常啊, double quantum 的 算子设计也比较巧妙,它让 gpu 在 处理大量四倍的数据的同时,通过一个并行的极小通道去读取和还原那些高精度的异常值,那这两者在计算核心中会会合,这样既保证的速度,也掌握在精度。我们知道 gpu 的 瓶颈往往不在于算的够不够快, 而是在于数据运不过来啊,主要就是由于内存带宽的限制。假设原本我们从显存里搬运一百 g 的 f p 十六数据的 gpu, 那 现在通过 turbocharger 压缩压缩成了四个倍,也就是说只有原来的四分之一大小。 但在这种情况下, gpu 在 相同的时间内能处理的对话长度也就是吞吐量啊,其实理论上最大可以提升到原来的大约四倍。 我们来总结一下,其实突破框的这个要解决的核心痛点就是 k v cash, 随随着上下文自数限行增长,这就把那个整个文显存给撑爆了,那它采用的什么策略呢?就区别对待异常值和普通值,用四倍的换空间,用高精度保留智商。 那实现的方式呢?就是通过底层算子优化,让解压和计算同步,把理论上四倍贷款红利变成现实。 当 kvmatch 不 再是就是紧箍咒的时候,大模型的这个能力呢就发生了质的飞跃。最值得改变的其实就是两个维度,一个就是突破健忘症,也就是有了更大长的上下文,那比如说原来是一个 mini 的 上下文限制,那其实相当于现在变成了四个 mini 的 四个四兆的上下文限制, 那以前受制于这个现存模型可能只能处理五十页的文档就断篇了,那现在有了这个特步框的以后,同样的硬件可以处理两百页甚至更长的。 就是第二个就是告别打字机,这也就是更快的推理速度,因为数据搬运的话,瓶颈被打破了,这个模型生成文字的速度,也就是 token per second 会显著提升 啊,交互管会像真人一样,就是使得对话这个更加流畅。了解了 turboq 的 这个技术原理和作用以后,其实我们来聊一聊啊,就是对资本市场那个内存股的这个影响啊,就是从表面上来看这个有了这个技术以后, turboq 可以 使得大模型推理 使用到的这个内存大幅下降,感觉像是对这些内存公司的一个利空。但是个人来觉得这其实并不是,打个比方就是说其实就像车子卖便宜了,那其实车子的销量会更大, 那有了这个特步矿的技术,其实大模型的这个推理成本会大幅下降,那因为推理成本里边很大一块是内存的价格。倒,那既然推理成本能够大幅下降,那大模型的这个应用的潜力和空间也会大幅提升,用的人会越来越多啊。其实短期看上是一个利空, 但是我个人觉得长期可能是一个利好,因为大模型用的人越来越多,使用的成本也会越来越多啊。当然这个是我个人的一些潜见,仅供大家参考。好,谢谢大家。
24阿雨的视频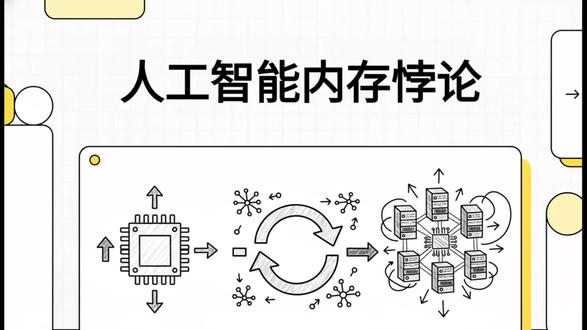 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿咱们今天来聊聊 ai 硬件里一个特别有意思的悖论。谷歌发布了一个叫 turboqant 的 新算法,所有投资人都在问, ai 内存的好日子到头了吗?大家的第一反应都是,太好了, ai 的 内存问题解决了以后,能省一大笔钱了。 你看,市场反应非常快,内存股马上就跌了,因为大家担心需求会减少。这个技术针对的是一个叫 kv 缓存的东西,你可以把它想成是 ai 的 短期记忆一个很大的瓶颈。 以前呢,这里面的每个数据都需要用十六位来存,但 turbo 宽的厉害在哪呢?它能把数据压到差不多三位,而且精度一点都没丢。 所以你看这个结果,内存占用直接少了六倍多,性能反而还快了。表面上看,这不就是省钱吗?对吧?但故事可没这么简单。 要想明白为什么,咱们得先搞清楚 ai 服务器里这两种内存。重点来了,缓存压缩后变得特别小,就能从昂贵的 gpu 内存搬到便宜的服务器内存里。 这样一来,服务器就能用上二 tb 近至四 tb 的 巨大内存池,同时处理海量用户的请求。 这就带来了第二个效果,吞吐量暴增,一个 gpu 能同时服务比以前多得多的用户。但问题也来了, gpu 效率高了六倍,那服务器的其他部分跟得上吗? 答案是, cpu 那 边需要更多的系统内存,也就是 dram 来给这个超强的 gpu 位数据。 这个现象其实就是经济学里一个很经典的杰文斯贝洛。就像摩根史丹利分析的, ai 变便宜了,用的人只会更多,市场反而变大了。 你看这个逻辑链,效率高了,成本低了,结果就是 ai 的 用途和需求都爆炸了。 所以这么一圈看下来, ai 的 内存瓶颈其实根本没消失,它只是换了个地方,从 gpu 上昂贵的 hbm 转移到了对服务器 dram 的 巨大需求上。这就留给我们一个问题,效率越高,需求越大,那未来的数据中心得建成什么样?
10全哥AI日记 03:29查看AI文稿AI文稿
03:29查看AI文稿AI文稿周三美股存储芯片巨头美光闪迪在英伟达、特斯拉和谷歌等科技股反弹的背景下,却走出了明显的下跌走势。同时,周四韩国股市在三星和 s k。 海力士的下跌带动下也出现了明显下挫。到底发生了什么? 是基本面反转还是情绪带动?下面我们来做下深入解读。三月二十四日,谷歌推出了一款全新的 turboqant 内存压缩技术,这款技术专门针对大语言模型和向量搜索引擎研发,主攻 ai 推理环节的核心瓶颈,有望让 ai 推理效率实现跨越式提升。 这项全新的 ai 内存压缩技术在科技界掀起了一场关于底层算力效率革新的热议,同时也让美股存储芯片板块迎来了剧烈的估值重估。 而华尔街机构却在这场市场波动中看到了布局良机。周三当天,受该技术可能大幅削减 ai 硬件需求的预期影响,美股存储芯片板块盘中大幅走低。截至收盘, 存储芯片与硬件供应链指数下跌百分之二点零八,闪迪、美光科技等行业头部企业股价均明显收跌。 市场对 ai 硬件需求前景的担忧带动资金做出防御性反应。一时间,科技圈将这项突破性技术称作真实版 pad piper, 也有人将其比作谷歌版 deepseek, 认可它对 ai 算力效率的提升意义。 但与之不同的是,华尔街各大投行却保持着冷静,认为市场的反应有些过度。 turboqant 的 发布被业内视为解决大语言模型高昂运行成本的重要里程碑, 它专门攻克 ai 系统中的键值缓存瓶颈,核心亮点是能将占用大量空间的缓存数据压缩至三比特,大幅释放内存空间。谷歌采用了两步压缩的思路,先通过 polarqant 技术将数据向量转换为极坐标,省去额外的归一化开销, 再借助量化算法 qgl 消除残差误差,兼顾压缩效率和数据精度。在 gamma、 mister ro 等开源模型的测试中,这项技术实现了六倍的内存缩减。在英伟达 h 一 百 gpu 上,推理性能较未量化的三十二位方案最高提升八倍, 亮眼的测试数据也让他迅速走红。面对二级市场的抛售潮,多为华尔街分析师直言,这项技术的实际影响被市场过度计价。有分析师指出,当下主流推理模型早已广泛采用四比特量化, 谷歌公布的性能提升是对比老旧的三十二位模型得出的结果,相关报道存在一定夸大。 多家机构认为,这类先进的压缩技术只是用来缓解算力瓶颈,并不会撼动未来三到五年内存与闪存的需求基本面。 毕竟当前 ai 硬件供应依旧偏紧,内存需求依旧坚挺。摩根士丹利更是从经济学角度给出解读,远引杰文斯辩论说明技术效率提升会降低使用成本,反而会激发出更庞大的市场需求。 terbit 指,作用于 ai 推理环节的键值缓存 不会影响模型训练,也不会冲击高宽带内存 h p m 的 需求。它只是提升了单 g p u 的 吞吐量,让 ai 规模化部署的门槛进一步降低,从而激活更多受成本限制的 ai 应用场景。 综合来看,这项内存压缩技术并不会摧毁存储硬件需求,反而会成为推动 ai 行业扩张的催化剂,对算力与内存市场的长期影响并非立空,反而偏向中性、偏正面。
12财经土拨鼠 01:17查看AI文稿AI文稿
01:17查看AI文稿AI文稿处理器厂商已经成为 ai 经济推手受益最大的群体,这一波铺天富贵深刻改变了存储的业态。为了降低存储依赖,谷歌二十五日无预警发布全新 ai 内存压缩算法 turboqant, 宣称能大幅优化大语言模型的运算效率。 turboqant 技术锁定了生成式 ai 推理阶段最耗资源的键值快取。在英伟达 h 一 百 gpu 的 精准测试中, 该技术能在不牺牲精准度的前提下,将快取内存需求缩减六倍,并让运算速度暴增八倍。消息导致一众存储厂商的股价大幅下跌, 引发市场恐慌情绪。另一方面,这波存储缺货潮已经展现出颠覆传统存储 bug 周期波动的迹象。科技巨头为求稳定供货,甚至愿意承担溢价风险,与存储厂商签署长期合约。 三星电子正与 google 及微软磋商内存长期供应协议。可能的合约架构为固定供应量,搭配与现货市场联动的价格机制,客户需预付大笔款项, 若未在三至五年内采购承诺数量,预付款将被扣底。同时,若现货价格波动,合约价格也会同步调整。这种全新合同模式帮助存储器厂商避免崩 pass 的 出现。产能过剩后价格大幅下滑的可能,宣告存储期产业将进入一个全新商业模式。
12电子产品世界 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿你见过一篇论文直接把整个内存行业的股价粘崩了吗?股哲把他们即将在 s l r 亮相的论文拿出来先修了下,结果找的美妆、西部数据这些存储巨头股价大跌。他们找了这新压缩算法,叫做 turbocharger, 把 ai 推理过程中最吃内存的 tvx 压缩了至少六倍,而且精度零损失。消息一出,市场一下就慌了,因为这意味着,以后做长上下文推理,可能根本不需要那么多内存了。有业内人士评价,这就是谷歌的 deepsea 的 时刻。还有人展彩,以后十六 gb 的 mate mini 也可以用来跑大模型了。 甚至不少人第一反应是,这不就是美剧规则里的 pad pad 吗?当年那个近乎无损的极限压缩算法,竟然真被谷歌做出来了,那 turbocharger 到底厉害在哪儿? 简单来说,大梦性推理的时候,会有一个叫 kpi 叉式的东西,专门存临时信息,方便下次调用。这种东西已经成了 ai 推理最大的瓶颈,上下文一长,它占的内存就疯涨。谷歌的优化思路是不硬省,直接换一种更省空间的表达方式。具体有两步, 第一步,把原本的坐标系表示换成距离加角度,信息没少描述仍剩。第二步,用一个比特做残差纠正,把前面压缩完剩下的那点误差,用几乎不占空间的方式磨平,两招配合下来,最终实现三比特量化, 无需任何训练或微调,精度零损失,效果也很可观。不仅内存占用直接产到六分之一,而且在 h 一 百上四比特, turbocharger 的 计算注意力速度比三十二比特基线快了八倍, 连项链搜索的召回率也直接占过现有最好的方法。不过冷静一点看,新算法现在还只停留在实验室,没真正上线,而且它只解决推理阶段,训练环节不受影响。如果这种级别的压缩真才是普及,你觉得未来会怎么洗牌?
765量子位 07:12
07:12


猜你喜欢
- 415云山