opencode 修改配置文件 覆盖主题
大家好,欢迎回到本频道,今天想向大家介绍一个非常实用的 github 仓库,如果你经常用 ai 代理开发前端, 它就是 vote agent 开发的 awesome design md。 乍一看,它似乎只是又一个资源列表,事实也确实如此, 确实是一个精心整理的合集。但我认为这个仓库的价值在于,它切实解决了 ai 生成 ui 时的一大痛点。大多数 ai 代理都能写代码,这早已不是什么新鲜事了。 问题在于,生成的界面虽然结构没问题,但视觉上却显得非常割裂。手屏或许还凑合,但紧接着兼具混乱,卡片样式也怪异,按钮也像是从别的网站硬搬过来的, 最后整个页面就像是用五个不同的提示词拼凑出来的,而这正是这个仓库想要解决的问题。那么, awesome design md 究竟是什么?它汇集了一系列精选的 design md 文件,灵感均来自真实网站,尤其是开发者常用的那些, 比如 virtual linear、 stripe 和 raycast 等等,还有 superbase、 notion、 vote agent 等等。我去看了一下,里面已经收入了五十多套设计方案,内容相当丰富,而且每项内容都不只是简单的文字记录,每个设计都配有规范的 design md 文件, 还附带了 preview html 和 preview doc html, 方便你在使用前预览视觉风格这方面做的确实不错。另外,如果你还没关注 google stitch design md, 本质上是一个描述设计系统的 markdown 文件,能让 ai 智能体轻松读取并理解。它包含了视觉基调、配色方案、排版规则等,以及组建样式兼具布局原则, 还有层级深度响应式规范和设计准则,这正是它最有趣的地方。你无需再给智能体丢下一句模糊的指令,比如做的简洁现代一点,而是提供了一份完整设计参考,以模型可直接调用的格式。 readb 文档对此也做了清晰的界定。 agent smd 用来定义项目的构建规范, design 调 m d 则决定了产品的视觉与交互体验。这种分离直观重要,因为很多 ai ui 偏差都源于 试图把架构、行为、样式以及文案要求一股脑塞进同一个提示词里。说点实际的,这个库并不是什么魔法工具,我也不建议直接拿它来偷懒做克隆更好的做法是借鉴其设计准则,并将其适配到你自己的产品和品牌中。好了,现在我们来看看 verdant, 因为接下来的工作流程才是精髓所在。如果你在实际项目中使用 verdant 这个仓库,能完美融入你的工作流。在 verdant 中打开项目,将 design dmd 放入根目录,随后让 verdant 进行构建,并以该文件作为唯一视觉精准 基本设置就是这样。另外,需要提一下费用问题,我来演示一下如何进行配置。首先,创建或打开一个前端项目, 无论是 next white astro 应用还是其他任何项目都行。 burden 的 工作方式是围绕项目文件夹展开的,关键就在于这一点。先打开工作区,然后克隆 awesome design system 仓库。 version md 是 version 的 全局规则文件, agent star md 则用于定义项目特定的实施规则。只要理清这三者的区别,配置起来就非常简单了。文件准备好后,在 version 中打开项目,使用桌面版应用的话,直接登录并打开文件夹即可。 如果是用 vs code 的 插件安装后登录,然后在项目里打开 verdant 面板即可。这时我习惯在提示词里把要求写清楚。即便 verdant 能自动识别文件,我还是会明确指定 为 shipstar 开发工具。制作一个响应式落地页,并以根目录下的 design e 作为视觉基础,创建一个 hero 区、功能、网格代码势力区、 定价板块、客户图标以及最后的引导操作。保持文案简洁并遵循间距与排版,并严格遵循设计文件中的视觉质感。这是一个很好的起始指令,因为它明确了 verdant 的 构建目标,并指明了需要遵循的视觉参考。如果项目规模较大, 我会先启动规划模式。如果是小型着陆页,直接用代理模式通常就够了。接下来演示一下具体流程。我在 verdant 里打开了一个简单的前端项目,很基础, 我还把 verso design 的 md 复制到了项目根目录下。打开这个文件后,你马上就能明白它为何比通用提示词更有效。它定义了具体的设计准则,而非模糊的审美,包含排版间距、强调色、边框处理、 组建样式及响应式规则等,这些全部都有明确规范。现在我发送提示词让 verdant 开始工作。他通常会先检查工作区并读取相关文件,包括 design d r m d。 随后他会分析需要创建的组建,并结合项目技术站确定所需的页面。 稍等片刻, verdant 便会开始生成页面,通过第一轮生成结果就能看出配置是否生效。只要文件规范,提示词清晰,生成效果会协调得多。比普通的 ai 界面输出投图区域显得更有章法,间距排布也更加规整,按钮和卡片也不再显得杂乱无章。 这正是我们要追求的一致性。很多 ai 生成的前端页面虽然没坏,但就是感觉太普通了,而 design dmd 就 能解决这个问题。那么一次生成就能达到完美吗? 通常不会,几乎都需要进行二次优化,所以我通常会再发一条优化指令,精简首屏文案,删掉不必要的装饰元素,将功能卡片做的扁平些,并让最终的行动号召按钮与设计中定义的视觉语言保持一致。顺便检查一下移动端布局, 提交运行一下,看看这是否能让工作流变得可靠的多,远胜于反复发送零散提示词。因为设计文件存放在项目根目录, verdam 会不断回溯,同一个视觉员不会再因后续的提示词而跑偏。 所以我认为这个项目比初看时更有用,它为设计生成提供了可附用的精准。我还喜欢的一点是,因为它提供的样式都是开发者们熟知的网站风格。比如你选择了 version, linear, recast, stripe or super bass, 你心里就已经对目标风格有数了。这让写提示词更容易,也更容易判断生成的结果是否达标。另外,我认为这种设置如果配合项目里的 agents, md 文件,效果会更好。 agents 到 md 定义实现逻辑, 而 design 呢? md 定义视觉表现,这样提示词更简洁,可附庸性也更高。那么这有什么缺点吗?确实有几个缺点。首先,生成结果不一定完美,即使文件写得再详尽, 质量最终还是取决于智能体提示词和项目结构。其次,有些设计风格过于鲜明,如果不加注意页面,容易显得千篇一律。所以我建议一定要调整内容结构、产品框架和品牌细节。 第三,如果你只是做简单的内部工具,那这套方案可能显得有些繁琐。但对于落地页、精美仪表盘文档以及网站演示及各类面向客户的 u i, 它非常适用。我觉得这套工作流非常完善丝。总的来说,我的评价是, awesome design md 属于那种 默默解决了 ai 辅助前端开发中核心痛点的项目。他把那些原本只存在于脑海,散落在截图或模糊提示词里的设计语言转化成了 ai 代理能真正理解并附用的文本格式,配合 word 使用时,整个流程会变得非常顺手。 只需打开项目,放入 design 点 m d 文件提示 verdant, 将其作为视觉参考标准,生成初稿,再在此基础上进行优化。这套流程简单实用且易易复现。如果你厌倦了 ai 生成的页面,虽然开头看着还行,但往下一滑就惨不忍睹, 那强烈建议你试试这个仓库,这绝对是个很棒的选择。总的来说,非常赞!欢迎在评论区分享你的看法。

粉丝3213获赞2.2万
相关视频
 18:12
18:12 04:13查看AI文稿AI文稿
04:13查看AI文稿AI文稿哎,你有没有过这种感觉,为了追求更强大的功能,装了个叫 oh my open code 的 插件,结果用起来总觉得哪儿不对劲儿,好像反倒是被悄悄降级了。 别急,今天这个快速指南就是来帮你找回 open code 原声代理的,那份轻便和高效的。 你看,你以为自己是升级了对吧?但问题就出在这儿, oh my open code 插件在末月安装的时候啊,会悄悄地用它自己的代理换掉 open code 里头两个本身就特别好用的原声代理。这背后到底是怎么回事呢?我们一起来看看。 这个隐藏的代价就是你失去了两个非常强大的原声代理给顶替了。 当然了,新代理肯定也很厉害,但是在处理一些日常任务的时候,你可能会特别怀念原来那两个小而美的工具。 那么问题来了,我们有必要费这个劲把它们找回来吗?答案是,绝对有必要!这可不只是怀旧哦,找回它们对你的工作效率和灵活性来说,好处是实实在在的。 好处主要有三个,首先呢,就是省钱,原声代理非常清亮,处理简单的日常任务消耗的 token 会少很多。其次,执行速度呢,叫一个快。对于一些简单的请求,原声代理几乎是秒回,能给你闪电般的响应。 最后,也是我个人觉得最酷的一点,就是灵活性。你可以根据手头任务的复杂程度,自由地在功能强大的新代理和轻快高效的原声代理之间来回切换,这样一来,你才算是真正控制了自己的工作流,对吧? 好消息是,想把他们找回来,操作起来超级简单,我们只需要两步,一个非常快速,任何人都能轻松搞定的修复过程。来,我们马上开始, 那就是屏幕上的这两步,第一,咱们去修改一个配置文件。第二,重启一下验证成果。听起来就很简单,对吧?我们先来看第一步,这也是最核心的一步, 你需要找到这个文件路径,我已经给你打在屏幕上了,就在小砰点 config open code, o my open code 点 json, 这个是 o my open code 的 插件,它自己的配置文件,我们所有的小魔法都将在这里面发生。 好,找到文件之后,用你的编辑打开它,然后把屏幕上这段 json 代码整个复制粘贴进去。放心,下方的字母区我也放了,纯文本,你可以直接复制。 你看这两行代码意思很直白, replace plan false, 就是 告诉插件,嘿,别动我的 plan 代理。而 default builder enable true 呢?就是让那个默认的 builder 代理继续保持起用状态。 好了,代码添加完了,现在最关键的一步来了,记得一定要保存这个文件,然后把你的 open call 完全退出,再重新启动它。这一步就是为了让你刚才的修改能真正生效。 ok, 重启完成了,那我们怎么知道刚才的操作到底成没成功呢?别接,咱们得验证一下,接下来就看看如何确认你已经重新掌控了你的代理。 验证方法超级简单,在你的 o ping 扣端中里,直接输入这个斜杠命令 agent, 然后敲回车,这个命令会把你当前所有能用的代理都给你列出来, 看效果是不是立竿见影。这张对比图就非常清楚了,在修复之前,你的代理列表里是找不到 plan 和 opencode builder 的, 但是现在你再运行命令,看看它们俩是不是已经稳稳地回到列表里了,这就说明我们的操作大功告成。 所以你看,有时候就是一个小小的配置修改,就能让你的工作效率和灵活性获得巨大的提升。这也给我们提了个醒儿, 在你用的其他各种工具里,是不是还有很多默认设置是,你从来没有质疑过,但它可能正在悄悄地限制你的潜能呢?嗯,这个问题真的值得我们好好想一想。
18忘记 02:52查看AI文稿AI文稿
02:52查看AI文稿AI文稿我啊,最近用 cloud code 泄露的代码干了个大事,很多人也就是了解一下那个代码的思路,但是不知道和自己有什么关系,我就把微信找了个分析的文章, 加上这个源码文件,让 ai 分 析了一下。然后我让他根据我的需求把 open code harness 环境给搭建出来了,当然同理也可以用来完善小龙虾的 harness 环境。 这 harness 大家可以去查一下,意思就是如果 ai 模型是发动机,那 harness 就是 整个汽车的其他零部件系统,车机系统不搭好,发动机再牛也发挥不好。你看啊,我先让他分析这些代码分别是在干什么的, 哪些值得我来学习的。可以看到他给我做了一大堆的这个分析,对吧?包括这些总开关和启动器,以及它的干涉,很像机场的总调度等等, 做了一大堆的这个分析,但关键的是什么?他告诉了我该如何学习,学什么是适合我的?他告诉我哪部分是值得学习的?首先怎么自己做自己的 ai coding 的 harness, 他 建议先学这六块。 然后呢,我又让他告诉我的 coding 和写作的 harness 有 什么可以值得调整和建议呢?他给我做了这样的一些分析, 可以看他说基于你现在的 coding harness or writing harness 应该做哪些调整?我现在已经有双 harness 体系了,那么我之前因为也配置过一些嘛,那现在他该做哪些调整和升级?他给我做了各种各样的分析和建议,包括小修小补, 或者说来做一个共享的这个 run time 的 这个内容。这个 run time 啊,我也是之前没有接触过啊,那接下来我来问他这个多模式的 run time 是 怎么来理解的? 好,这个就有意思了,他告诉我这个多模尺的 run time 呢,是同一套底盘,不同任务切不同的工作档位,不是做四个独立机器人,而是一个模式。如果说再像我刚才举例子把它比喻成一辆车的话,那 run time 呢,是底盘和发动机, 然后呢,剩下他给我配置那些模块,其实都是整车上面的那些相应的一些零配件和系统,可以理解为一台引擎加多套工作方式加明确的切换原则。那么因为我有写作和开发两个需求,那它就需要两个模式来回的切换。然后呢, 我在一边学一边理解和它的推荐,下面慢慢慢慢把我的 open code 的 整个一个 harness 的 系统给完善出来了。 后来呢,我就觉得非常的好用,非常的智能。这次的经历让我发现什么呢?首先我们学习的方法可以把比较有深度的文章和内容让 ai 来协助你升级你的系统和认知, 很多时候我们能看懂,但不一定知道自己该怎么用。然后就是 agent, 虽然现在很火,但是到底怎么用,根据不同的应用场景还是有很多不同的解决方案的,应该和 ai 多讨论,手托出更适合自己的工作系统, 我称之为 vibe walking。 具体下次我详细来分享这个内容,因为我目前啊已经跟很多企业团队做了培训了,今天就到这里关注我, ai 时代,我们一起前行。
73雷厉AI观 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿兄弟们,你应该听说过 colada code, 但是 open code 不知道大家听过没有? open code 是 最近比较火在终端里运行的 ai 助手,并且是完全免费使用的,接下来带大家安装下。首先电脑配置 note 环境, 安装好后输入 node v, 检查 node 版本,打开官网,这里有多种安装方式,我们选择 npm 的 安装,复制这个命令,打开 cmd, 右键直接粘贴,安装好后我们输入 open code 的 就可以用了。 然后输入 models, 选择免费的模型,目前使用下来 mini max 还是可以用的。现在我们让他帮我开发一个贪吃蛇小游戏,采用 html, 稍等片刻来看下,最终效果还是非常不错的,在免费的模型里面,可以日常帮我们处理一些简单重复的工作。 好了,本期视频就分享到这里,记得双击点赞加关注文档,我放粉丝群。
311程序员Mars(创业中) 02:10查看AI文稿AI文稿
02:10查看AI文稿AI文稿大家好,我是你们的荷兰瓜,嗯,在上两期视频中,我们介绍了 windows 电脑上面和在苹果 mac 电脑上安装和使用 cloud code 最简单的办法, 不到三分钟就能搞定,不需要自己手动安装任何依赖包,也不需要搞复杂的环境变量配置,直接点点鼠标就能够使用。 cloud code 能够这么方便,都是因为使用了预打包好的克劳德克的启动器。这个神奇的克劳德克的启动器在 linux 电脑上一样可以用,甚至我觉得比在 windows 电脑上更好用,因为 linux 的 文件系统更科学, 所以我们甚至可以用这个启动器来自动化管理我的电脑。这是我们以后的节目,会给大家做详细的介绍。好了,现在我们先来看看如何在 linux 电脑上三分钟就能安装,用上克劳德 code, 小 白新手一样能轻松搞定。 第一步,打开你的浏览器,在地址栏输入这个神奇的网址, c l a u d e c o d e 点 z i p, 然后按键盘上的回车键。第二步,看到页面中间那个下载运行按钮了吗?点它把克劳德扣的启动器下载下来。 第三步,打开下载目录里的克劳的 code, app image 浏览器下载的 app image 默认是没有运行权限的,所以我们要给这个文件授予运行权限。鼠标右键点击文件图标,打开文件的属性面板,然后打开作为程序运行这个开关。 现在双击运行克劳的 code 启动器。好啦,安装完成,就是这么快,就是这么轻松! 怎么样,这个神器是不是超级赞?现在我们已经成功的把克劳的扣的跑起来了,但是他具体怎么用呢? 怎么让他帮我们自动改 bug, 快 速搞定项目呢?别急,下期视频荷兰瓜就来手把手教大家怎么用克劳的扣的,如果觉得视频有用,记得给我神奇三连哦,咱们下期见,拜拜。
13飞翔的荷兰瓜 06:39查看AI文稿AI文稿
06:39查看AI文稿AI文稿哎,是不是看觉手里的 api 密钥越来越多,各种模型接口乱七八糟,简直要抓狂了?别急,今天咱们就来个一劳永逸的办法,把所有这些头疼事都给搞定,让所有模型都听你一个人的指挥。 你是不是也觉得,哎呀,每思想换个模型试试就得折腾半天,密要管理乱成一锅粥,访问官方 a p i 呢,又老是卡的不行。说真的,这可不是你一个人的烦恼,咱们开发者圈子里,这绝对是个大痛点。 但如果我告诉你,有办法把这些乱七八糟的线全都理顺,而且操作起来还挺简单的,你信不信?没错,今天咱们要聊的核心技巧就是这个自定义 api 的 base url, 说白了就是用它来给你自己打造一个煮熟的 ai 模型调度中心。 行,那咱们闲话少说,直接开干。今天的内容安排是这样的,咱们先搞明白为啥要这么干,然后再一步步带你上手,看看具体怎么操作。相信我啊,学会这招,你的开发效率绝对能上一个新台阶。 好在咱们卷起袖子开始敲代码之前,我觉得吧,咱得先聊明白一件事,为啥要费这个劲去自定义 base url 呢? 因为啊,一旦你真正理解了它背后带来的那些好处,你就会觉得,哎呀,这事做得太值了。 这么做的好处可以说是立竿见影的。你看啊,首先就是统一管理,你再也不用被那一堆 api 密要搞得头大了,用一个平台,比如 one, api 就 全搞掂了。 其次呢,是成本控制,你可以接入一些按量付费的代理服务,用多少算多少,非常灵活。还有就是访润加速, 这一点咱们国内的同学肯定深有体会,网络言渠问题能得到特别大的改善。最后,如果你有自己部署的 l l m, 比如用 v l l m 或者 olama 搞的,那通过这个方法也能轻松地把它接入到 open code 里来。怎么样?是不是挺香的? ok, 道理咱们都懂了,那接下来就该上真个的了,咱们来动手操作一下。这第一步也是最关键的一步,就是要找到那个核心的配置文件,一切的魔法都将从这个文件开始。 你要找的文件就叫 open code jason, 它一般会藏在两个地方,一个呢,是在局的配置目录里,改了它,你所有的项目都会受影响。 另一个呢,就在你当前项目的根目录下面,这样就只会对这一个项目生效,你根据自己的需要来选就行。 记住,这个文件可是咱们今天的主角。咱们先来看第一种方法,也是最简单粗暴的一种,直接覆盖现有的提供上。如果你就想图个块,不想搞太复杂的,那这个方法绝对是你的菜。 这种方法的应用场景特别清楚,说白了就是把你平时在 open code 里用的那个默认的 open ai 接口给它来个偷梁换柱,悄悄地指向你自己的那个中转服地址。嘿,别看它简单粗暴,但效果是杠杠的。 你看啊,代码就这么几行,它的精髓就在于简单,你只要找到 provider 下面的 open ai, 然后在里头加上一个 options 的 配置块儿,接着把你自己的 base, url 和 apk 往里一填,啪,搞定。是不是觉得就这儿? 对,就这么简单?好?如果你觉得第一种方法虽然简单,但不太够用,那别急,咱们还有第二种方法,这个方法呢,就要灵活的多了,能应付一些更复杂的场景。 那这个方法好在哪呢?它的核心优势就在于,你既能保留官方的 open ai 那 个通道,又能再加一个你自己的新通道,这样一来,你就可以在 open code 里头随时随地来回切换了。 比如说你想对比一下两个通道的效果,或者根据当前的网络情况选一个最快的,都非常方便。 行,咱们来看看这个配置,它看起来是比刚才那个复杂了一点点,但其实逻辑很清晰。首先咱们在 provider 下面自己起个新名字,比如这里叫 my api, 然后注意这个 npm 字段,这个很关键,它是在告诉 opencode, 嘿,用这个兼容包来处理我的请求。 再往下就是咱们熟悉的老朋友了, options 里面填上你的 base, url 和 api。 最后也是很有用的一个部分,就是 models 字段,你可以在这里把你这个渠道支持的模型都列出来,甚至还能给它们起个别名,这样在 opencode 的 下拉名单里,你一眼就能认出来,特别方便。 ok, 两种方法都看完了,估计你现在对着代码里的那几个参数心里可能还有点低估,这都啥意思啊?别急,咱们就把最重要的几个参数拎出来给你掰扯明白了,这样一会你自己动手改的时候,心里就有底了, 咱们再来捋一遍啊,这几个参数是核心, n p m。 这个决定了用哪个 ai s d k 的 包,你要是用 one api 这类服务,就用这个 s a i。 先按的 line s d k 看 open ai compatible b s u r l 就是 你的代理地址。这里我得再强调一下,地址末尾通常都要带上 v e 这个小细节可别忘了 apk 好 理解,就是你的密钥。最后 models 就是 把你这个渠道能用的模型列个清单,就这么简单。 好了,到这里配置工作就差不多了。那么你可能会问,忙活了半天,咱们到底得到了什么?我跟你说啊,这个不仅仅是改了几行配置文件那么简单, 你现在得到的是一个真正属于你自己的强大的 ai 模型。中书就在 opencode 的 里面, 从现在开始,所有的模型调用都由你说了算,你想用哪个就用哪个,想怎么切换就怎么切换,还能加速访问,统一管理密钥。这种掌控感对咱们开发者来说简直不要太爽,你的开发效率和自由度都会大大提升。 行了,现在这个强盗的模型路由控制权已经交到你手上了。那么问题来了,掌握了这项新技能的你,第一个想去构建点什么好玩的东西呢?别犹豫了,赶紧动手试试看吧!
15忘记 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿open code 的 插件想必大家都用的不少,确实让其在 vs code 的 内部启动变得更方便,但是其启动端口号的修改功能似乎还没有具备,所以我就自己增加了一个端口号修改和固定的功能, 可以打开修改后的 open 扣的插件,发现了里面多了一个设置功能,点开之后就能设置和固定端口号了。设置完固定端口号之后,重新打开 vs 扣的之后,就能使用插件启动其在你所固定的端口上了。 在固定端口之后,其实还有一种用法,就是启动 open q 的 g u i 版本,但是记住是纯 g u i 界面,然后在这个服务器设置里可以固定你修改的端口,你就会发现能够正常使用 g u i 界面了。 我们先去 vs go 的 插件市场上下载一个原本的插件后,再进行模改插件的安装。如何安装修改后的插件呢?你可以去我的 github 上下载 zip 包后,点开 vs code 的 这个用户文件夹,找到 expansions 文件夹,点开找到 s t d v open code 的 这个文件夹,然后点开,把下载好的 zip 文件里的文件全部覆盖后,重启 vs code 就 行。
13不知名人 02:59查看AI文稿AI文稿
02:59查看AI文稿AI文稿open code 的 怎么配置第三方的模型接口啊?我们一般是这么配置的,首先呢,我们进到啊,如果你是 windows 系统,进到这个用户的点 cf 目录下有一个叫 open code 的 这么一个文件夹,然后呢,你进去会发现有个叫 open code 的 点 json 什么文件,如果没有的话,可以手动创建一个,我们用记事本或者其他编辑软件打开它, 打开它之后你会看到,呃,这里这个是我已经配置好的。呃,在 provider 这边, provider 就是 模型的供应商的意思,然后在下面配置一个,这个是第一行是 provider, 是 provider 的 名称,供应商名称你可以自己起一个。然后第二行比较重要, npm 这里呢, 它应该是表示我使用哪个接口去兼容你的 api。 我 们这里采用 open ai 兼容模式,大部分的第三方模型供应商都会提供 open ai 兼容模式的接口。 后面的这个 name 就是 你在呃我们 open code 的 打开之后,它的页面界面上显示的那个 provider 的 名字,我们可以跟这个 provider 起的一样。呃,然后它的选项我们要把 options base url 填上,这里是一个我已经创建好的一个 接口地址,然后下面 models 中是填入你的模型名称,我这里有两个模型,一个叫豆包 c 的 一点八和豆包 c 的 一点 六,然后这两个模型怎么来的?我们我在后面继续讲。下面是另外一个 provide, 等你把这些东西配置好了之后,我们就可以打开 open code 中去用这个 provide。 我 们来看一下 啊,我们打开了 open code, 然后在这里配置第三方模型接口的时候,我们先要选择 provider, 这里输入斜杠 c o n e c t connect, 在 connect to provider 这个界面中,我们可以往下找找找找找,大概在最后你可以找到呃你新配置的 provider, 我 这里选择 open ai 豆包,然后填入 这个呃 provider, 它需要的 api key 我 输入一下,然后按回车, 此时就会列出你配置的两个模型的名称。我们选择一点八,如果你的一切配置都正常的话,这个时候输入你的问题,你够能够得到一些反馈。 好的,看到有反馈的话,就是说明你的,嗯, key 啊, provider 啊以及 jason 啊都是配置对的。
67小闲AI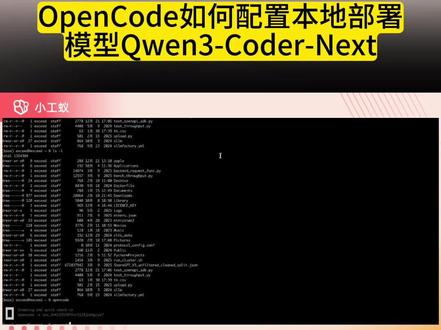 02:47查看AI文稿AI文稿
02:47查看AI文稿AI文稿给大家来演示一下用 open code 的 这样 ai 生成代开源工具,用那个通一千万三扣的 next 这个模型, 我们配置了一个独立部署的模型,给大家看一看,前面我已经跑过了,已经跑通了,给大家演示一下,因为它应该还是可以跑的。它这个给大家看一下,这个是我服务器上面的这样的一个环境,这个服务器上环境我是四块 rtx 四零九零起了一个通一千万 三 ko 的 next f p 八的一个模型,这个模型目前只能跑的是上下文是四四万八千,目前还是能够跑的,应该算是跑通了。我们给大家详细介绍一下这个模型和如何配置独立部署的模型,好吧, 首先我们先来看一看那个通一千万三 ko 的 next, 这个模型性能应该是不低的,因为它是技术白皮书发布出来,我们看了一下,它这个应该是我们企业独立部署的小模型,里面应该算是比较优的。它这个 你可以看到它对比了 deepsea v 三点二, v 三点二要将近六百多个币,所以是非常大的,包括 g l m 四点七、四点七也是非常大的一个模型,也要将近五百四五百个币。 mini max m 二点一也是一样,都是三个非常大的模型。那么相对来讲, 通一千问的这个扣的 next 的 这个模型差不多只有八十币左右,八十币左右,但是你可以看到它的编程性能来讲,其实跟其他模型比起来相差不是太大,水平差不多,它应该是这样,所以它这个模型对我们企业独立部署一些 私有化的模型,做这个代码生成的应用来画这个模型,应该是目前是比较优的一个模型。那这个模型也是我们之前跟大家介绍过,它跟通一千问三 next 八十币有点类似,它也是属于混合的这种架构是 member 架构,再加上 transformer 的 这种架构,混合的一种架构,也是 mo 一 的这种方式,它是总参数量是八十个币, active 的 这个参数是三十,是三个币,它等于是这样, 专家也是有五百十二个, active 的 专家一共是十个。谢尔的专家是一个,它等于是上下文,它只要达到二百五十六 k, 我 因为我的内存还是比较小的,所以我目前是用到了四万八千,相当于四十八 k, 它等于是这样。 好,呃,这是一个。接下来我们给大家简单介绍一下它到底是如何来配置的这个模型,因为我们现在跑了本地的,我们给大家来介绍一下它到底是怎么来配置它。其实最核心它是有一个配置文件的,它这个地方是有个配置文件, 大家看一下,在你的根目录下,用户目录有一个点 config 的 这样一个文件,文件里面有个 open source, open source 里面 它是有一个,我们打开给大家看一下,那么这个文件主要是配置我们独立部署的这样的一些大模型。你可以看到我们用了一个 provide 的 这样的一个 提供商, light a l m, 它是默认它是用了 open ai 的 兼容的 api。 我 这里面是配了一个通用千万三 code next f p 八的一个模型,这个 base url 就是 你本地的那个 url 的 名字就可以了。
102小工蚁 19:42查看AI文稿AI文稿
19:42查看AI文稿AI文稿hello, 大家好,我是 d p, 欢迎来到我们的 codex 系列视频,这期是这个视频的第一期,主要讲的是新手入门相关的内容,主要包括 codex 的 安装,一些基础的配置和一些基础的使用指南。好的,我们来进入 准备环节。首先你需要做的第一件事是打开 d p r t 点 lab 零零点 com, 在 这里搜索 codex, 然后找到这篇文章。打开到这里,你需要知道的是, codex 这期视频相关的所有内容你在这个文章里都可以找到。现在我们把这个文章放在一边,下面我们需要新建一个文件夹, 我用的是 d p 下划线, codex 下划线一零一主要是,呃为这期视频做演示做准备的,你可以使用任意的名称以及任意的位置推荐放在你的那个项目文件夹目录里面去。 好的,这两样都准备完了以后,我们下面进入安装环节。好的,我们首先回到刚刚的这个文章,然后第一部分就是安装指南。我们先大概的来看一下目录架构,分别是四种安装模式,其中两种是命令行,第一种是 npm 安装,第二种是 codex app 安装,第四种是 codex vs code 的 插件安装。我们将逐一来看这些安装方式。 首先是两组命令行的安装方式。呃,先介绍一下命令,第一个命令一点一是检查你的 npm 环境里有没有安装。呃, codex 用这行命令 list 就 可以看到下面这样的输出结果, 像我这里就有一个 codex 零点一一二点零这个版本,这就代表安装了,如果你没有的话,你就可以继续。 第二步,一点二就是用这条命令安装,然后第三步是检查 codex 版本,就是你安装以后用这个命令就可以看到这边的这个输出,就是 codex 的 版本,就代表安装成功了。 然后如果在你使用的过程中需要升级,就用一点四用这个命令来升级,然后 homebuil 是 一样的,首先是查看它的列表, 可以使用这行命令来查看,那么查看的结果就会输出一个 codex, 如果你不用后面的这个过滤条件,它就会把你本地的所有的呃 homebrew 安装的内容都列出来,然后在这边就可以看到有一个 codex, 然后 如果上面的检查就是二点一这个部分,你的机器里没有任何的安装,那么你就可以在这边使用二点二的命令来安装, 然后安装以后相同的版本检查,然后相同的升级。我这边在 mac os 上用那个命令行安装了一个 homebrew 版本的 codex, 给大家看一下过程。首先我打开我的命令行,然后我用这个 codex 杠杯来查看,它告诉我这个机器上没有 codex。 然后我尝试做了一个 list, list 的 操作,这边也没有后 codex, 然后我尝试用了那个就查找关键词的 list, 没有任何输出。然后我做了一个额外的测试,我用 sqlite 做测试,因为这里显示了 sqlite, 所以 它这个能有输出就代表一切都没有问题。 然后我这边用了就是二点二这个命令来做安装,然后它从这里开始跑,一直跑跑,反正跑的挺多的, 然后到下面他就给我一个反馈,就是 codex 零点一一七点零这个版本他就开始安装,一直到安装完成, 呃,然后到这里就是安装结束,然后接下来我用了查看的命令做了一次确认他有 codex, 然后我又做了一个全局的查看,就没有过滤的查看有,然后我用了 codex v 这个命令查看的版本。零点一,一七点零是我当时录视频时的最新版, 这就是命令行的一个安装方式。下面我们来看三那个 codex app 安装,这个就是打开官网下载一个 app 就 好,我在 macos 上我下载的就是这个 codex, 点 dmg 打开以后就有这么一个文件,这个文件是这样 四百七十三兆,然后我如果安装把它拖过来就行,我这边已经安装过了,因为所以就演示一下这么一个过程。然后我们来看一下 codex vs 插件的安装,我这边整整理了一下,你需要做的是第一步打开 vs code, 第二步在插件市场搜索 codex, 然后找到这个插件进行安装。好的我们去那个 vs code 里面看一下,首先插件市场在这儿,然后你在这边搜索 codex, 我这个已经安装了,但是我给大家演示一遍流程,然后这个时候就会找到这个是 open a r 官方的这么一个插件,然后打开以后它的名字就是 codex 杠 open a r 的 code engine agent 在 这儿和这个名字啊,这样看这两个名字是一样的,然后这边会有一个安装,你点安装就行,安装完了以后,那个你在这儿就能看到一个 codex 的 标志,然后我一般是在这儿去使用的,它其实没有太大的一个差别, 就是在侧边栏上这个是 copilot, 这个是 codex, 放在这边有可能要拖动一下,但我不记得不太清了,反正是有相关位置的。好的,作为最后的建议,一共有四种安装方式,我建议大家把三和四都安装上,一会我们在演示的过程再解释为什么。 好的,这就是安装相关的所有内容。 ok, 接下来我以 codex app 做一个演示。首先我打开了 codex 这个 app, 它会要求你登录,这个时候你只需要点击这个按钮,然后它就会跳转到一个登录的页面,这个就是 open i r 的 页面, 你在这个页面里完成你的账号的登录,然后它就会跳转回来,然后这边就会有相关登录完成的一个状态。 ok, 花了点时间完成了网页上的授权,然后这个 app 就 会自己自动跳转到类似这样一个页面,这就是 codex app 的 主操作页面。 其他三种登录方式都是相同的流程,这边我们就不额外的演示了。登录完了以后,按道理说我们可以直接呃输入一些命令来完成相关的任务,但是我们先不着急,我们先进入一些重要文件和配置的讲解。 首先你需要知道的第一个概念是 codex, 它在你的本地是有一个配置文件夹的,在你的用户根目录下有一个点 codex 这个文件夹,里面就是配置的所有的内容。然后我这边用编辑器已经打开了, 这里面一共有好多个重要的文件,我们一个一个来讲,首先讲第一个就是 author 点接收,这个就是你的所有的 talkin 都在这边。我这边跟大家演示的是我进行了脱敏的一些数据,你实际跟我看起来应该是差不多,但是我这些呃 d p i t 这些你肯定是没有的, 分别有获取信息的 talkin 和用户 id, 然后 talkin 的 id, 然后什么 refresh, 就是 刷新 talkin, 然后时间,这就是 open a r 给你的一个 key, 然后这个 config 点 t o m l 是 什么呢?就是一些你使用过程中的一些记录,比如说我用的模型是 g p t 五点四,然后思考强度是 x high, 然后一些信任的目录像这个这边就是五点四,和 x high 和这边是对应的,这就两个配置文件。 为什么要讲这两个文件呢?这两个文件在稍后我们讲账号切换的时候是非常重要的两个文件,如果大家对账号切换有兴趣,可以点个关注,我们后面的视频里会讲 好的。然后我们下面进入一个呃全局配置的一个环节, 首先就是全区的配置,就是你这个本地的所有的 codex 相关的项目,你想让它遵守的一些规则是什么呢?我这边给出了一个 demo, 首先文件是在点 codex 文件夹下有一个 agents, 点 md, 这里我写了一些规则,就什么遵守用户的需求啊,中文呀,回答呃 case 原则啊这些,这个写的比较长,这个东西在哪呢?在配置指南就第二部分的第一点里面 就是目录是用户目,文件夹下点 codex index, 然后你把这个粘进去,就可以作为你的一个项目的开始。 然后还有一个目录,就是说如果你不做全局级的,你这个项目想设置的话,那么你就需要做一个项目级的目录,那么它就是说在 d p 下划线 codex 一 零一这个项目文件夹下新建一个这么一个文件就行。那么我们现在来新建一个右击 新建,这,哎,他为什么没有给我新建?好奇怪哦, 这样,是这样,这样新建的好,这样就新建进来,然后这边你就是比如写全程使用中文和我交互 类似这样,然后这条文件它的那个规则就可以写入进来,你也可以简单的把这个东西给它复制过来,也就是说你这里给它的这个规则是这个 codex 零零一这个项目级的,而不是说这个放在全局级的,你把全局级这里给它删除掉就可以了。 好,这就是两种配置方式,如果你是想让所有的 codex 都能遵守,那我建议你就像我这样配置一个全局级的一个规则,让他们遵守一个默认规则。然后如果你想让某一个项目,比如说这个项目去遵守,我们就可以在这里面写一二三, 告诉他这个项目单独的遵守规则,首先他会遵守这个,然后把这个再附加上就是这么一个配置关系, 像稍后会有像 scales 呀、 workflow 呀这些,我们会单独用视频来讲解,这个也不算基础的内容,如果有兴趣就 稍微等一等,再讲一下。 c 部分相关资源,这边我把常用的一些链接放在了这里,如果有兴趣的话可以来用。这边是 openair 的 官网,这是 codex 的 官网,这是 codex 的 开发者文档,这是 codex 的 github, 以后有相关的链接我会继续往后面去加。 ok, 我 们现在进入 实际操作环节,我这一期的实际操作先用 codex app 来做演示,首先它这个给我们默认打开的只有一个 playground, 就是 一个测试环境。然后我们刚刚新建了一个目录,还记得吗?我们需要把它加载下来,点这边这个加号,然后找到你的这个目录, 把它加载进来就可以了,这样你就有了这个目录,然后在这边选择这个目录,开始一个新对话,这里就可以开始一个新对话,然后你可以选择模型,比如说我们选呃 codex 五点三,然后呃思考强度,我们就选 high 就 好。 然后我们给他一个简单的对话内容,然后这时候你会看到他在这边会新建一个对话,然后这边是我们说的,然后这是他思考,然后稍后给我们回复的内容。 这边你可以把把它变成任意一个内容,比如说你给我写一个贪吃蛇的游戏存放在什么位置,什么,就这么一个流程。 当然我们这边只有一个简单的演示,然后这时候我们接着来演示斜杠命令,它和我们常用的命令好像一样,你只要出入斜杠,它会有很多的命令。最重要的我想给大家讲几个命令,首先是 status, 你可以看到你的,如果你是那个付费套餐的话,你可以看到五小时限额和七天限额,还有一些呃,上下文长度啊这些信息,然后相同的内容在这边也可以看到,也是配额的一个信息。 然后斜杠命令里面还有一些命令,我们来看一下,比如说这边有一个 fast 的 模式, 呃,当然五点三开不了 fast, 你 只有五点四来行,然后到五点四以后你可以开那个 fast, 看到吗?现在 fast 的 模式就被关闭掉了,然后 这边你在敲就可以把 fast 的 模式开启。提醒一下, fast 模式只有五点四可以用,只有这个小闪电开启的时候才是。然后 fast 的 模式大概是消费两倍的 talk, 得到一点五倍的速度, 然后智力不会有所下降,只是优先给你处理任务,就是说类似于 vip 通道的那种感觉。好的,这就是 codex app 里的一些功能,至于其他的一些命令,那么稍后大家自己再来看就好。 ok, 接下来我们回到那个 codex vscode 的 插件,这边我想给大家演示我最近做的一次 html 任务。首先我们先来看呃,两个 html 页面, 我首先用那个 ar 设计了下面这个 index 派去的 html, 然后我让他用 bootstrap 进行一个改写。 首先我们来看第一个,第一个是就是一个 ar 点 lab 零零点 com 这个页面,我想做一个新手页面,然后我用 ar 做了一些设计,但是它做完了以后有一些问题,像这些点击啊,这些呃 type 的 切换,这些 card 的 折叠,它都没有做,它只是做了样式,像这边这些搜索它都没有,但样式是做好了,然后是这个样子,然后我让它做的就是对这个页面百分之一百的用 bootstrap 进行了一个重写,然后把这些点击样式, 这些 card 的 呃这些 type 的 切换,然后这些 card 的 折叠都给它做出来,然后像这边搜索也都给它做出来,这边的搜索也都做出来。 是做成这么一个状态,其实改动不是很多,但是最主要的就是遵守这个设计稿的一个方式,然后给大家看一下实际的操作过程。首先我调用了一个 walker, walker 就是 定义了一个上下文,这个 walker 不是 为这个项目准备的,但是差不多能用,我就用了,就是一个 html 设计的 walker, 然后告诉他是一个特殊的任务,然后是根据这个设计稿的页面,也就是这个由 ar 生成的原始页面 来让它把一些呃功能用 butstrip 进行重写,然后让它严格遵循这个规则,然后其他我们在 word 里定义的什么 p r, d 线框图都让它忽略,然后它给了一个 反正就读一些文件,然后进行思考,然后它给了一个方案,这个是我这个项目定义的一个格式,但实际上只要看 执行方案这边就可以看到。他是对那个 css 用 bootstrap 五重写,然后调整了一些间距,用把 bootstrap 尽量应用下来,然后 抽离了一个项目级的慢点 css, 然后什么这些该不动的都不动,然后补充了一个慢点 gs, 然后他就让我确认,我说确认就可以修改,然后给他一个要求,就是我怕他把那个原始文件替换掉,我就说让他再同 就同级目录下建一个新文件,所以就有了这两个文件的差别,然后他就完成了这个文件,这个文件就是大家看到的这个页面,就是刚刚演示的这个就相关的功能,该有的都有 这么一个页面,然后他就告诉我修改已经完成了,然后这个过程还挺长的,他做了很多的事情。呃,对,然后中间还经历了一次网络异常,我记得是, 哎,没有看到,没关系,然后他给了一个总结,告诉我修改的内容,然后这时候我验证了一下,发现了一些小问题,总共就是三点, 让他再去做修改,这时候他出现了一个小小的网络波动,就我们用的是正常的,然后呃一些交互, 然后在过程中好像还有一次,啊,对,还有一次大的网络波动,原因未知,然后我就因为遇到这个网络波动,我就直接把它暂停掉了,然后我就告诉他好像有网络问题,让他重试,然后他又花了五分多钟把最后一个点 g s 写完, 到这时候我才想起来,哦, codex 有 点慢,我差点把这个事忘了,所以他前面可能不是网络波动,只是单纯的在等待,我以为他卡住了,然后他把这些东西都弄完,然后告诉我交互已经补完了, 然后就给出了一个最后的一个答复,包括修改的内容是什么。最后我就在这边测试了一下,该有的功能都有了,后期大家也会看到这个 ar 点 live 零零点 com 这个页面上线主要的功能就是 一些基础工具和命令和一些基础知识的展示,然后一些关键的视频和文章的一些链接, 然后对应热门的 github 资源的链接,还有一些热门链接就是做一个一站式的导航,这么一个页面,算是一个工具书的页面,大概就是这么一个,我希望用这个页面就是我实际操作的过程,向大家展示就是 codex 其实 在 vs code 插件里更接近我们的编程习惯,为什么呢?因为就像这边一样, 我的任它改的任何一个文件,我可以点开看,然后在这边像这个改动,这个在 codex app 里有,但是它没有这个编辑器这个功能,也没有快速导航和快速选中这个功能,甚至我可以把这边这一段话直接给它添加到 codex 这个上面, 做一个快速选择。然后在对话的过程中, vs code 这个插件会把我们打开的这些页面的名称传递给 codex, 作为上下文的一部分。所以我觉得从如果很多用户跟我一样是从那个 cloud code 过来,后来进入 anti gravity, 然后再到 codex 的 话, 我觉得这个方式是比较合适的。好,最后我跟大家说一下,为什么我建议 vs code 以外还要有 codex app 呢?因为我在使用的过程中有时候会遇到一些奇奇怪怪的问题,遇到这些问题的时候就需要用 codex app 来做一个兼容性的工作。 比如说有个项目运行的突然卡住了,你用 codex app 打开,把任务运行完,然后再回到这边,这个问题就得到了解决,而不需要去死磕 vs code 的 codex app, 当然我百分之九十的工作是在这边完成的。哦对,还有一个点,有用户说,呃, vs code 的 codex app 会比较卡顿,但是我在实际的使用过程中没有遇到这种卡顿的情况, 就是这是我的程序,然后这个 ip 呃 codex 的 应用,我装的也是最新的一个插件。好的,我们做一个比较简单的总结。首先我们介绍了四种 codex 的 安装方式以及一些基础的配置方式,特别是这边的这个全局级的配置建议大家就是照我的抄,然后在基础上去改,随便用,不用跟我客气。 然后接下来我们讲了两种应用的使用方式,分别是 codex app 和 vs codex 强,强烈建议大家这两种都尝试一下,并且尽量把你的常用工作方式固定在 vs code 的 codex 插件上。 好的,这就是这一期 codex 新手入门系列视频的全部内容,希望这期视频对大家有帮助,如果可以,请帮忙点赞和转发,如果你有相同的经验想要分享或者遇到了相关问题,欢迎留言, 稍后我们会发布更多的 codex 相关视频,有兴趣的话欢迎关注,谢谢大家!我是 d p。
225DP_IT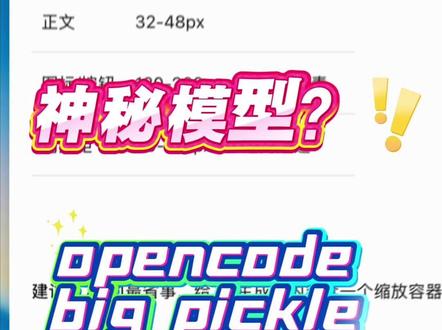 00:38查看AI文稿AI文稿
00:38查看AI文稿AI文稿谁能告诉我这个 open code 里面这个逼格 pick 这个模型是哪一家放在这里的?套壳模型啊,效果还不错,我觉得可以 比那个黑名单的三 flash 差不多一个水平。我感觉和这个 gbt 五拿诺也差不多,我感觉这两个差不多是一个水平的。这个迷你 max 二点五它是来搞笑的,这个东西千万别用,完全不可用。 下面这个的话好像说是欧本扣着自己出的某种套壳模型,但是套子也是一个不怎么低的模型,所以我下面两个基本没用。上面两个我感觉挺好用的,有的时候会排队,排队的时候我就用上面这个 gpt 五 noto, 不 排队的时候我就用 gpt 五 noto, 大家可以试一下。
 03:39查看AI文稿AI文稿
03:39查看AI文稿AI文稿今天上午 openai 的 研究员发了一条推特儿,他说从今天开始你可以在 cloud code 里面使用 codex 了,就是他帮你的 cloud code 扩容了。原来因为 cloud code 它的额度很少嘛,哪怕是你买了二十美元的 pro, 仍然不够用, 没做几个项目就已经没有额度了,多的时候连本周的额度都会用光。但是配置好以后,一个是可以扩容,再一个就是 codex, 它可以从另一个视角去审查你 cloud code 编程的过程啊,代码呀,有没有问题。它这个审查还有标准审查以及严格审查。标准审查的意思就是它只看它不动代码,严格审查就是挑刺儿的那种审查。 然后今天这个视频给大家分享一下怎么安装,我把安装所需要的所有的命令行放在这里了,大家可以保存一下,这也是我们安装的步骤。第一步,如果你电脑里没有 open ai 的 codex 的 话,你得先安装一下,把这一行复制到你的终 端去,打开我的 cloud code, 把安装 codex 这条指令直接复制到 cloud code 里头就可以, 然后等一下他就会帮你自动安装了。在过程当中他问你是否允许,你就点允许,或者是允许这一次以后不要再问了的那个第二个选项,他就说安装成功了。那接下来我们就要来到第二条,就是登录还是复制这个,到这里面 他就会跳转到浏览器里,让你授权你点一下谷歌登录,他这中间会经历一些报错,不断的尝试一下他就可以了。点继续 好,已经登录到 codex 了,接下来我们要进入到第三步,就是一条一条的输入这个指令第一条就是在 marketplace 里面加 open a i codex 的 这个插件,我们还是输入到这里面,它就是说,呃,成功加入,然后我们把第二条粘过来, 他告诉我们等一下,然后我们选第一个,就 codex plug in, 在 这里的选项我们也选择,第一个的意思就是说虽然安装了,但是先让他别用, 然后现在就安装好了,安装好以后我们试一下是不是可以啊?我们打一个斜杠,然后出现了一个 codex setup, 我点一下设置,呃,已经可以了,然后这个也有权限了。那么最后我们来介绍一下如何使用。在 cloud code 里面点斜杠输入 codex, 然后你会发现有一些选项可以让你选,这些选项刚好是使用 codex 的 方法。 我在这里面总结了刚刚我们在这看到的所有的功能,它可以分为四大部分,第一块就是代码审查, 这个普通的审查它只是说读一遍你的代码,很常规很惯例的去回顾一下,而这个挑刺式审查,它要它是用一个质疑的眼光去挑战你的架构设计, 代码的设计质疑有没有风险啊?它这个设置呢,主要是看你这个 codex 是 否安装,是否授权登录的,看它状态。 这个 codex rescue 指的意思是甩活给 codex, 比如说你的额度不够啦,或者需要让它来去调试代码去修补的时候,就用这个选项, 那最后就是工作管理,那像查看状态呀,保存最后的输出啊,以及取消后台的任务啊,就用的是这三个选项。今天视频就到这里,欢迎大家给我留言,一起交流一下这个新闻的看法,然后我们下个视频再见,拜拜啊,拜拜。
1078一枚卓子 06:53查看AI文稿AI文稿
06:53查看AI文稿AI文稿今年 ai 的 大趋势还是 agent, 不 过跟去年的 agent 不 太一样,我打个比方啊,去年我们是在用镰刀收割玉米,还很初级, 那到了今年,我们将开上联合收割机,成为农场主,不是盯着一个 agent 写代码,而是管理十到十二个 agent 并行工作, 十几个 agent 在 后台跑,咱们就喝着咖啡等着验收,大概就是这样的画面。多 agent 编排一定是今年 ai 领域最大的趋势。而在这个趋势下边,我认为还有一件事情一定会发生,那就是针对这些 agent 定制化。 因为在生产环境当中, agent 的 上线除了跟模型的性能有关之外,还有一个非常重要的决定因素是它是否能够按照你的工作方式来运行,对吧?这就是为什么 open code 和它的插件 omocode 最近人气这么高的原因。 这套组合提供了一条全自动的 a 卷流水线,你向主 a 卷下达需求之后,它会自动分析拆解,交给不同的子 a 卷去执行,在后台跑着一大堆的任务。而且这套东西可以随意更改,你可以通过配置文件做一些小的改动,也可以把整个项目放下来重新设计。 我还是打个比方啊, clock code 就 像一辆配置很好的量产车,它很舒适很顺手,上路就走,也提供了一些改装的选项。 而 open code 则是一个彻底的改装平台,它给你提供了一个非常扎实的底盘,你可以根据需要把它改装成最适合你的赛车。使用 open code 和 omaco code 插件,从模型的选择到 a 卷的配置,甚至创建,全都向你展开了, 只要你有动手能力,你完全可以把它打造成最最适合你的 ai 操作系统。比如我就在欧曼 opencode 的 插件基础上,专门针对内容创作场景重新设计了八个 agent, 把它们打包成了新的插件分享出来。 本期视频我会介绍如何进行配置,以及我是如何彻底改装插件,让 ai 操作系统完全满足自己的需求和习惯。 哈喽各位好,欢迎回到我的频道。谦虚的说啊,我是国内少数几个能把关于 ai 的 y 和号讲明白的博主,我提供的东西远比教程更值钱,记得点一波关注, 如果想链接我就来我们 new type 社群,这个社群已经运营超过六百多天了,有超过两千位小伙伴付费加入啦。如果你是国内用户,可以从知识星球加入。 如果你是海外用户,可以从 substack 加入我的第一套课程,日常的 newsletter 以及专属视频在社群内都可以看到。回到今天的主题, open code 定制化。在开始配置之前,你需要理解用户级的配置和项目级的配置这两个概念。 当你安装好 open code 之后,在 config 文件夹下边会有一个 open code 文件夹,这个就是用户级配置的文件夹, 也就是说,除非你在项目里特别设置,否则的话默认就是按照这个配置来走的。而在每个项目里边,你还可以在项目的根目录下边创建一个点 open code 文件夹, 这个就是项目级配置的文件夹,它的优先级会高于刚才的用户级配置。所以如果你想单独为某个项目做一些设定的话,可以在这里进行配置,在这两个文件夹里边都会有这两个文档,一个叫 open code 点 jason, 一个叫 omaco 的 点 jason, 从名字你就能看出来,他俩一个是配置本底的,一个是配置插件的。总结一下,大家可以看我画的这张表,逻辑很简单,两个层级的配置,项目级优先级更高。 两个层级的配置里都各有两个文档,分别对应本底和插件。理解了这个逻辑,你就可以开始动手了。比如我在用户级层面,通过 open code 点 jason 来设置使用什么插件, 那在项目级的层面,通过 omoneq 的 点决策来设置每个 agent 调用什么样的模型,以及我会通过 mcp 点决策来设置这个项目里要添加哪些 mcp 服务器。 我所举的例子只是一小部分的设置本质和插件可以配置的地方太多太多了。比如你可以通过 prompt append 对 某一个 agent 最佳系统提示词,那具体的配置方法,大家可以去看官方的文档,或者你直接问 ai 也行, 这个是通过配置文件进行自定义的方法。但是啊,这个方法还是有局限的,在 o my open code 插件里边,它的 a tag 都是硬编码的,都已经写死了。比如它们的名称不能修改,它们的基础提示词也不能修改。 如果你像我一样追求更深的自定义的话,那可以把项目 fork 下来,把里边的 a tag 全部都给它改了。 比起开发项目,我平时做的更多的是内容。所以就像前面说的,针对内容创作的场景,我对 opencode 插件做了重新设计,我创建了八个 agent, 它们完全都是为了内容而存在的, 其中主 agent 除了会自动给子 agent 派任务之外,它还会自动切换两种模式,探讨和执行。 这个就是对应编程场景下的 plan 和 build, 只是针对内容场景做了调整,并且改成了自动切换。这个自动切换很关键,你跟他聊想法的时候,他是你的讨论伙伴,可以帮你梳理思路。 你说开始写的时候,他会立刻变成项目经理开始派活,都不用你动手去切换模式。举个例子,我问 ai, 我 看到一个说法,英伟达的双利卡故障率大约是百分之九左右,请问这个结论数据是从哪里来的?真实吗? 注, a 卷接到需求之后,他会首先判断出需要的是探讨而非执行,所以他自动进入探讨模式, 接着判断出需要调研和验证,尤其是搞清楚这个观点的上下文是什么。最后再派两个词, a 卷去后台干活,一个查来源,一个验证,那这个过程会去调用它为你 m c p 进行搜索,最终给出结论。 我最满意的是,他不是告诉我这个观点或者数据是真是假,而是告诉我上下文或者场景是什么,以及引发讨论的原因是什么。 这只是一个小例子,在日常工作内容创作当中,会有很多类似这样的情况,需要多个 a 卷的配合起来,去完成一大套的写作。 这个内容插件名叫 newtype profile, 我 已经发布到 github 上了,也在社群内做了分享。目前这样的配置我用起来最顺手,生产力比之前用 clock code 的 还高,所以我建议大家可以试一试。记住啊,安装 open code 之后,一定要安装 o my open code 的 插件? 如果你的项目不是编程而是内容创作的话,那可以试一试安装我的插件。 ok, 以上就是本期内容,想了解 ai, 想成为超级个体,想找到志同道合的人,就来我们 newtype 社群。那咱们下期见。
795黄益贺 06:05查看AI文稿AI文稿
06:05查看AI文稿AI文稿我来完整介绍一下 newtype os 的 安装和使用方法。 newtype os 是 我今年做的新产品,我看到很多人,包括以前的我使用 cologold 来做支持的消化内容的产出,那 newtype os 就是 专门干这个的, 因为它是定制化的,所以它会干得比 clockcode 更好。现在我的 ai 主力工具就是 newtypeos, 我 日常有百分之六十的时间都在使用它,那百分之三十是使用 perplexity, 剩下的百分之十使用 grog 和 gemini。 它已经帮我产出好几万字的内容了,所以大家如果用了觉得不错的话,记得去 github 上帮我加个星, ok。 先说安装和配置, 安装很简单啦,只需要在终端里输入一行命令, n p m install 等等等等,这一行等个几秒钟就搞定了。 这一步基本上不会有问题,如果安装不了,那很有可能是你的机子里还没有装 note g s, 那 你去官网下载一个就好。当安装完毕之后,你在终端里输入两个字母 nt, 也就是 new type 的 缩写,那 new type os 就 启动了。 第一次使用一定要先做好配置,这个是很多人会卡住的地方,其实很简单,你就做两个动作就好。第一,连接模型供应商,要么你直接走 api, 也就是输入你的 api key 用多少花多少,要么你去走订阅。 在输入框里输入斜杠 connect, 就 会出现一个列表,市面上主流的模型供应商都在这个列表里边,比如国外的 openai, 国内的智普, mini max 都在里边。我用的是 github copilot, 虽然上下文窗口有限制,但是主流的模型都在,没那么多的破设,用起来很省心, 我在列表里选择这个,然后根据引导完成账号的绑定就可以了。第二,给 a 卷配置模型。 newtype os 的 底层是一套多 agent 编排系统,我特意按照内容创作场景设计了八个 agent, 每个 agent 都有不同的角色和分工,那很自然的,它们也有最适合的模型。并不是每个 agent 都要用最好的模型,那就太浪费了,而且可能速度也不够快。 所以给 a 卷配置模型,你有两种方式,一种简单的,也是我最推荐的,你直接在输入框里输入斜杠 a 卷 models, 你 会看到 a 卷列表以及它们现有的模型。 然后你选择其中的一个 agent, 就 会看到可以分配的模型。你看,我在上一步连接的是 github copilot 这个模型供应商,所以在可分配的模型列表里,我可以选择的范围很大。 那当你给每一个 agent 都配置好模型之后,这一套系统就可以正常运转了。 ok, 安装和配置完成之后,接下来就是使用了。 new type os 是 一个在终端里运行的 ai 工具,那理论上你可以用系统自带的终端去运行,也可以用 vs code 之类的工具。 我的选择是 dead, 有 三个原因,第一,它可以正常渲染 t u i, 我 之前用 v s code 就 遇到了渲染的问题,界面要么卡顿,要么不连贯。第二,在运行 new type os 的 同时,我还需要浏览文档以及做一些手动的修改编辑, 我肯定不会让 ai 做所有的事情。第三,它好看,大家所看到的界面就是我在在里边运行的。这款软件是免费的,大家可以试一试。 那么当你用 new type o s 打开你的内容仓库之后,该怎么使用呢?我建议你先做这两步。第一,在输入框里输入斜杠 i n i t 横杠 deep。 这是一条内置的命令,它会让 ai 去读取你整个仓库的所有文档,了解这些内容的方方面面,然后创建一个 knowledge 点 md 文档, 这样一来, ai 就 知道你项目的基本情况。第二,在输入框里输入斜杠 i n i t so, 这也是我内置的命令,它的作用是创建一个叫做 so 点 md 的 文档。如果你用过 opencl, 就 知道这个文档是用来定义趣否的性格的。 我给 chief 也就是主 agent 设计了两层人格,里人格属于底层人格,用户不可更改,有一些基本的行为规范需要始终保持,那表人格就是四二点 m d 里定义的, 用户可以根据自己的偏好进行编辑。这两个命令都属于对项目的初步化,让 ai 知道项目的情况以及你个人的偏好。接下来就是实际使用了,其实很简单啦,你完全不需要去考虑调用哪个 agent, 你 就跟 chief 对 话就好, 它会根据你的需求进行判断和拆解,让相应的 agent 去干他们最擅长的事情。除了多 agent 编排之外,我还内置了好几个 skills, 用来增强某些方面的能力, 比如需要深度分析的时候, chief 就 会自动使用 super analyst。 除了 skills, 我 还内置了几个 mcp, 这个我就不多说了。 最后我再讲两个可能会很有用的,一个是连接微信,我把爱豆比做的 vcl 项目整合进来了,所以你安装完之后,在终端里运行 ntwechat set up, 用微信扫码连接,然后再运行 ntwechat start 就 搞定了。 另一个是支持别的 a 卷调用,比如 opencl, 我 之前特意添加了一系列命令行,就是为了让别的 a 卷可以通过命令直接调用 newtypeos, 这相当于是配了一个专业的内容团队。如果你在使用 openclaw 的 话,可以试试运行 nt i n i t 这条命令,会自动把命令行的用法以 skill 的 方式注入到你的 a 卷当中。刚才我介绍的这些在 github 仓库里都有, 大家如果还有不明白的地方,可以去那边看一看,如果还有什么问题,或者建议到星球里跟我说, ok, 以上就是本期内容, 想了解 ai, 想成为超级个体,想找到志同道合的人,就来我们 newtype 社群,那咱们下期见!
276黄益贺 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿下面是安装介绍,我这里提到的是欧根扣的和欧根科尔的双线合力。现在装科尔这个东西很多啊,不是收费吗?其实这个就是怎么说不懂, 不懂也不是不懂,可能没有接触过这些东西的人,他的一个一个吧,信息差吧。其实去装欧空扣的这种 coding agent, 他 就是完全免费的,你如果自己没有模型的话,他也会有一些模型是可以用的。你直接下载这个东西, 你去跟他说,你帮我在电脑里把 openclaw 装好,或者说你去搜索这个网站,你不告诉他这网站,你叫他去联网搜 openclaw, 他 也是能找到的, 你让他去找,找完了以后他自己就去装了。这里就说了用 openclaw 的 搭建开发环境。 这装 oppo 壳其实也很简单,反正 windows 或者是你有 note 包的,你去 note g s 去拉一下,就去一句话告诉他查询一下 oppo 的 官方文档,帮我在 wsl 上安装一下。我是装在那个 windows 的 虚拟机上面就是 wsl open call, 它里面也是可以再去装这个 calling agent 的 open call 的, 可以再让它去调动这个 open call 的 帮我去开发项目。但是目前来说的话,它还是有一点问题,我之前试的 最好还是你自己就用 open call 的 去做开发就行了。 open call 上面可以去部署一些就是它持续能干的活,你给它装一些 skills 去干什么就可以了。 这个就是我的一台那个 windows 的 小主机下面装的装的 wsl 的 那个,我今天大概下单了一台 mark mini, 之后的话我也想试一下 mark 的 能力是不是会更好一些。
 12:59查看AI文稿AI文稿
12:59查看AI文稿AI文稿最近几天 andrew carpercy 分享的他的个人知识库工作流的帖子爆火。 受到他分享的工作流的启发,最近几天 github 上有很多开源的知识库项目诞生,今天就为大家介绍并且演示一款最具代表性,而且真的能提升生产力的知识图谱项目 graphify, 它的产品定位就是 ai 编程助手的 skill, 而且我们可以在 cloud code codex, open code 甚至 open cloud 中来使用 graphify。 graphify 这个项目基本可以看作是对 andrew capacity 它分享的知识库工作流的一个产品化、图谱化的实现。 capacity 它的铁子核心是把原始材料都放进 raw 文件夹, 用大模型持续把它们翻译成可维护的知识库,而 graphify 则是把 raw 文件夹直接翻译成知识图谱。而且我已经在 opencloud 还有 cloud code 中来测试了这个项目,测试的效果还是非常理想的。本期视频就为大家深度讲解并且测试 graphify 这个项目。 在演示之前,我们可以先详细看一下这个项目它的优势有哪些,以及它是如何将 corpus 的 工作流变成了知识图谱的。 首先我们先看一下 graphify 它的架构全景,它会将任何语料包括代码、文档、论文、图片转化为持久化,可查询带审计轨迹的知识图谱。 这里我们看到的就是我用我的开源项目,在 cloud code 中用 graphify 将它转化为了这些知识图谱,而且我们可以详细查看这些代码之间的关系。 然后我们看一下它的架构,它的架构包括输入层,还有核心处理层,还有分析层以及输出层,还包含基础设施层,在输入层包含文件检测, url 摄入,还有羽翼缓存。 在核心处理层包括 a s t。 结构提取,它能对代码文件进行确定性的 a s t 解析,在这一步是不需要大模型调用的,所以就不消耗 token。 然后就是羽翼提取,它支持文档、论文、图片,通过 cloud 并行,此代理提取实体和关系。 然后就是图谱的构建,它能合并 a s t, 还有羽翼提取结果分析层,包括社区发现,还有结构分析以及 token 精准测试。 然后就是输出层,它能输出审计报告,而且支持多格式导出,还能实现 vk 生成。然后我们再看一下它是如何从 android capacity 分享的知识库工作流中实现了工程化与图谱化的引进。 我们看一下这两个流程对比,左侧是 capacity, 它的流程,右侧就是 graphify, 它实现的这个流程首先是原始数据收集, carpathic 的 思路是将文章、论文、代码、仓库、数据集、图像等全部放入 raw 文件夹。然后 graphfile 它是自动检测,还有 url 摄入,包括地归扫描、目录,自动分类十三种代码,还有文档、论文、图像等。然后 carpathic, 它是通过大模型来编辑 wiki, 翻译成结构化的 markdown wiki 包括摘要、反向链接、概念分类、文章转写等,用大模型来维护所有 wiki 数据。而 graphite 它是通过知识图谱来构建,它会构建成 network x 图谱 corpus, 它的查询是通过大模型自动维护所有文件和摘要 输出, markdown, 换灯片等内容。而 graphify 它是实现了图便利查询,所以使用 graphify 能够实现从 wiki 到图谱的三个飞跃,能从扁平 wiki 到关系图谱, 从大模型缩影到 a s t, 还有羽翼双通道,从人工维护到算法发现。好,下面我们就可以看一下为什么我们要在 cloud code 或者 codex 或者 opencloud 中来使用这个项目。首先 cloud code 它自带记忆系统, 但 cloud code 自带的记忆系统是一个限性文件驱动的对话记忆系统,而 graphfile 它是结构化的知识图谱引擎, 使用 graphfile 就 可以为 cloud code 注入持久化的知识图谱能力,让 cloud code 从传统的 glob 还有 graph, 如文件搜索进化到按照图谱驱动的结构进行导航。 像这样的话就能大幅度提升 cloud code 或者 codex 它们的代码理解能力,而且还能大幅度节省 token。 使用这个项目就可以快速上手陌生代码库,从而将代码库来生成知识突破, 而且还能实现精准回答框架问题,还能发现隐藏藕合,还能实现跨模态混合语料理解。我们可以将代码设计文档、相关论文全部纳入到同一张图谱中,像这样的话,我们就可以快速上手新项目,还能精准实现问题定位,甚至还能发现我们所不知道的事情, 而且还能实现可量化输出,还能实现工作区变更后,知识库能够同步更新为 cloud code 集成 graph 后,就相当于在 cloud code 的 记忆层之上叠加了一个结构化认知层, cloud code 从直文件阅读到文本回忆,进化成了图谱导航。还有关系推理 好,下面为大家实测 graphify 它的效果。首先我们可以为我们的 cloud code 或者 open cloud 或者 codex 来安装这个项目,在 read 命令这里已经给出了这条命令,我们只需要复制命令,然后打开终端命令行, windows 用户打开 cmd 直接执行这条命令就可以。 然后大家如果不想手动安装的话,也可以直接打开 cloud code 或者是 codex, 让 cloud code 或者 codex 帮我们安装。我们只需要复制这个仓库链接,然后回到 cloud code 或者 codex, 然后我们只需要输入自然语言,让它为我们安装并且配置这个项目,在这里跟上仓库链接就可以。 安装好之后,下面我们就可以来测试 graphify 它的效果,然后我可以从我的 github 来找一个项目进行测试,然后我就用 memoryless db pro 这款为 opencloud 开发的记忆插件进行测试,直接将这个项目克隆到本地,然后我们回到中端命令行,用 cd 命令进入到这个项目路径, 然后启动 cloud code。 在 cloud code 中我们就可以直接用斜杠命令加 graphify, 然后再加一个点号,这就相当于在当前的根路径,然后我们直接运行这条命令, graphify 就 会从我们这个项目的根路径开始来扫描所有的文件,还有所有目录下的这些文件。 像这样的话,它就会按照下面的流程去执行,包括文件检测与分类,然后 a s t 结构提取,羽翼提取,还有合并 a s t, 还有羽翼社区检测与分析,然后社区标签命名可示化生成,精准测试与清理。 在这里我们可以看到 agent 正在执行羽翼提取,因为目前我们这个项目的代码量已经非常庞大了,所以在这里它运行的速度要慢一些,这里我们要稍等一下, 在等待了几分钟之后,这里运行完成,下面我们可以查看一下它生成的这些文件,在这里生成了这个图谱文件,我们可以点开查看一下这里在浏览器中自动打开了这个项目的这些图谱,然后我们可以找一个节点,这里就是我们这个记忆项目的它的 index 文件, 然后我们可以详细地查看它们之间的这些关系。好,下面我们就可以在 cloud code 中来测试一下它对我们这个项目是否有了更深入的理解。 在 cloud code 中我们还是使用斜杠命令加 graphfile, 然后我们这里输入 query, 也就是进行查询,我输入的查询内容是 b m 二五的代码在哪个文件,我们直接发送 这里,他很快就查询到了 bm 二五的代码分布在两个文件夹中,包括这一个文件,还有这一个文件,而且他还详细给出了代码的行号还有作用。然后这里他问我们是否想深入某个方法的具体实线,然后我们就可以测试一下这个方法,直接输入这个方法名 好,这里他提到这个方法是一个十二阶段的评分管道,然后这里给出了这一些关键设计点, 然后我们还可以在我们这个项目的代码库上继续去测试,可以让 graphify 解释一下我们这个项目中智能提取是如何实现的。 我们回到 cloud code, 然后输入替式词,这里是 graphify 命令,在参数这里是 explain, 让它来解释解释这个智能提取是如何实现的。我们直接发送 这里,他开始输出这个解释,这里画出了完整的这个流程图,而且还给出了关键设计决策,包括这六种记忆,还有两阶段去重复。然后紧接着他还追问我们是否来看这个评分逻辑,或者看这个 prompt 设计, 然后我们这里就输入看这个评分逻辑这里他给出了这个评分逻辑,包括核心公式, 可以看到它给出的解释非常详细。在这里还给出了流程图,然后我们可以继续测试查询,我这里还是用 graphfile 这个斜杠命令,要查询的内容就是问它 geminiambani 这个模型是多少维,我们看一下它能否从代码中准确查询。 好,这里精准查找到了 geminiambani 这个模型,它是三零七二维,这里还给出了具体的代码。 下面我们还可以继续测试,我们可以找一个 pr, 然后让它合并到我们本地的这个项目中,然后用 graphify 这里给出的更新命令来测试下在我们当前代码库上新增了内容之后更新的效果。 我们就找这个 pr, 然后我们就复制这个 pr 回到 cloud code, 我 输入的提示词就是将当前 pr 合并到我们本地项目中,然后直接发送,让 cloud code 自动将这个 pr 合并到在本地分析的这个项目中。 好,这里已经完成合并,而且测试全部通过,下面我们就可以用 graphify 它提供的这个更新命令测试一下。我们回到 cloud code 这里,直接输入斜杠命令,加 graphify, 再加这个点号,然后再加上 update, 直接运行,让它针对我们刚才从 pr 中和编的代码进行更新。好,这里提示图谱已经更新,而且这个 pr 的 改动已经反映在图谱中。然后我们可以测试一下,然后我们还是输入斜杠命令,这里我输入 explain, 让 cloud code 来解释这个实线逻辑。 好,这里输出了这个具体实现逻辑,这里还给出了对比表格,这里给出了修复后达到的效果。然后我们还可以继续问这个 pr 的 价值。 好,这里是他对这个 pr 的 价值分析,他说这二十七行代码修复了一个数据泄露和一个永久故障。可以看到我们使用 graphify, 让他分析我们的代码库,以及分析 pr, 这个效果还是非常不错的。 然后我们还可以测试一下,让它来新增论文。我这里从 archive 搜索一篇 a m a c 相关的论文,然后我们进入这个 archive。 好, 这里就是与 agent 记忆相关的这个论文。然后我们直接复制这个论文链接。我们回到 cloud code, 然后输入 graph 命令加 add, 然后再跟上刚才复制的论文链接。我们直接运行, 看一下它能否将这篇与 agent 记忆相关的论文增加到这些图谱中,因为这个记忆的论文这里包含这个 a m a c, 而且我在之前也为这个项目加入了 a m a c 相关的这些功能。 好,这里它已经完成,而且这里还给出了论文中提到的五个因子,与本项目的实线完全对应,这里是论文中的,这里是权重,而且这里还给出了关键发现, 包括最有影响力的因子与代码完全吻合。然后这里我们还可以用这条命令来追踪论文节点和代码实现之间的图谱路径。我们就直接输入 printf 命令,加上 pass 让它追踪论文节点和代码实现之间的图谱路径。好,这里开始输出图谱路径, 这里还给出了具体分析。下面我们还可以测试一下 graphify 它的其它命令,比如说我们测试一下让它生成 obsidian 的 库,我们就用这条命令进行测试。然后回到 cloud code, 我 们直接输入这条命令, 这里生成。完成,这里还给出了文件结构。下面我们就在 obsidian 中打开查看一下效果好,打开之后我们就可以在 obsidian 中进行查看,可以看到这个效果还是非常不错的, 我们可以直接点击,在这里我们就可以具体来查看这一些内容。像这样的话,我们就实现了用 graphify 导入到 obsidian 中进行查看和管理, 而且它还支持非常多的命令。但是由于时间有限,本期视频就先为大家演示这些。通过我们的测试可以发现这个项目效果确实非常不错, 使用这个项目可以让我们快速上手各种陌生的大型代码库,并且实现对代码的精准分析,而且还能实现对比代码与论文。好,本期视频就做到这里,欢迎大家点赞关注和转发,谢谢大家观看。
396AI超元域 03:52查看AI文稿AI文稿
03:52查看AI文稿AI文稿现在我用手机也能连上我的 ai 操作系统了,这套系统跑在我家的 mac 上边,当我出门在外的时候,只要打开 discord, 就 能像跟却 gpt 聊天一样跟它对话、查文档、联网搜索、改文章,它都在后台悄悄帮我搞定。 先介绍一下这个系统,很多新来的小伙伴可能不太清楚,它由两个部分构成,第一, open code 加 newtype profile 插件。你可以把 open code 理解为是开原版的 clock code, 而 newtype profile 插件则是我专门为了内容创作和日常思考而定制的多 a 卷编排系统。 它里边有我的方法论,有我的工作流,还内置了五个我专门创建的 skills, 所以 这套东西是我 ai 操作系统的框架。 第二,在这个框架之上,我把自己沉淀了好几年的内容仓库给接进来了,我所有的产出都在这个仓库里边,包括笔记、视频脚本、 news letter。 对 于 ai 来说,这些东西既是参考也是约束,这样它才能成为我的系统。这一整套的 ai 操作系统已经完全承包了我日常的所有输出。但是啊,这个系统还有一个限制,它只能跑在桌面端, 当出门的时候,我只能在 iphone 或者 ipad 上面使用 gemine。 这种割裂就导致我面对的其实是两套系统, open code 和 gemine, 它们分别存储了两套数据,两套记忆。 这是违背我整体的原则的。我认为对于用户来说,在 ai 时代最有价值的是你的记忆资产,这个必须抓在手里,并且长期积累。 我之前特意给 newtype profile 插件添加了记忆系统,分成了长期记忆和短期记忆两套机制,把它们全都传成 markdown 文档就是为了这个。不过好在前两天这个问题被解决了,手机上的 discord 和 mac 的 open code 彻底打通。 而这一切的实现都要归功于两点,第一, opencode 的 服务器模式。一旦开启这个模式之后,它会把 opencode 的 核心功能包装成一个后台的 http 服务器,你直接通过端口调用, 简单来说就是把你的 opencode 变成了一台服务器,完全不需要走前端的操作,全都走后台的处理。第二, discord bot 这个机器人其实是一个传声筒,一方面它在前端,也就是 discord 频道内跟我交流,那另一方面,它在后端,也就是在 opencode 服务器内边进行数据的传输。 也就是说,机器人接到我的需求,拿给 open code 的 处理,然后再把结果拿回来给我。就像职场里的很多人一样,假装功劳都是他的,都是他做的。但其实啊,都是后边团队搞的,他只是面向老板的一个交互界面。要创建这样一个机器人非常简单,我全都是让 ai 帮我写的, 我只需要到 discord 开发者后台去创建一个 application, 然后把权限都勾选上,把 token 复制下来就好了,剩下都让 ai 去处理。为了方便使用,我还让 ai 帮我写了一个脚本,双击运行之后,它会自动把 opencode 的 服务器模式开起来,然后把机器人给运行起来。 以前出门的时候,我只能用通用的 ai, 它跟我的系统是断开的,那现在不一样了,我的方法论,我的记忆,我的工作流,走到哪里都能调用,这才是我想要的 ai 操作系统,不是某一个 app, 而是一套跟着我走的基础设施。 在这套系统的帮助下,我的内容生产效率至少翻倍了。这个是我每天都在用的东西,也推荐给大家。 ok, 以上就是本期内容,想了解 ai, 想成为超级个体,想找到志同道合的人,就来我们 newtype 社群,那咱们下期见。
338黄益贺 02:20查看AI文稿AI文稿
02:20查看AI文稿AI文稿嘿,欢迎来到这期视频,今天我们来聊一个让很多小白头疼的话题, open core 的 配置文件,别怕,我保证讲完你也能搞定。 首先, open core 的 配置文件叫做 open core 点杰森,默认藏在你电脑的用户目录下,路径是 open core 斜杠。 open core 点杰森拨浪号代表你的家目录。 这个文件用的是杰森 five 格式,比普通杰森更友好,你可以在里面写注是末尾,多一个逗号也没关系,而且这个文件不是必须的,如果没有 open class 会用默认配置自动运行。 配置文件主要分四个模块,第一是 agents, 用来配置 ai 助手的行为。第二是 channels, 配置接入渠道,比如飞书 telegram。 第三是 gateway, 配置网关的端口和认证方式。第四是 session 管理绘画策略。 重点来了,模型配置在 agents 里面,你可以设置主模型和备用模型格式式,提供 entropic, cloud senate 四五, 还可以配置一个模型白名单,只允许用户切换到指定的几个模型。注意, api key 绝对不能写在配置文件里,应该用环境变量,比如设置 andropic 下划线 api 下划线 key, 或者运行 openclaw configure 命令来安全的存储密钥。 opencloud 支持热加载,也就是你改完配置文件不用重启,大部分改动会自动生效。但如果改了端口号这类关键配置,还是需要重启网关,运行 opencloud gateway restart 就 行。 修改配置有四种方式,第一直接编辑文件。第二用命令行,比如 openclaw config set 来改某个值。第三,打开控制台界面,访问本地一万八千七百八十九端口。第四,运行 openclaw config 交互式向导最适合新手, 如果你要同时运行多套配置,可以用环境变量 openclaw 下划线 config 指定配置文件路径, openclaw 下划线 profile 指定环境标识,这样状态目录会自动隔离。 好啦, openclaw 配置文件的核心就这些,记住配置文件放在斜杠, openclaw 斜杠用杰森 five 格式, apikey 用环境变量大部分改动热加载生效有问题评论区见,我们,下期再见。
173阿宁的AI生活实验 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿你有没有觉得啊, open code 在 复杂工程里特别慢,还容易返工?原因很简单啊,它本质上是单的 agent 顺序执行的。 最近啊,我试了一个升级版叫欧麦 open code, 他 做了一件关键的事情,就是他把单的 agent 变成了多 agent 的 并行安装,非常简单,直接复制一句话,然后进 open code, 他 会问你有没有 clode, code, 叉等等的模型,你如实回答就好了,没有的话就告诉他全部用当前的模型, 我用的就是 kimi。 二点五装好之后,你就会发现左下角从 build 变成了希奇福斯,这是规划和调度执行的 agent。 接下来在你的任务前面加一句, u l w, 正式进入多智能体模式,它会自动拆解任务 多个 a 阵的并行执行,边做边叫验,减少反攻,对复杂的改动化文件的联动,重构场景速度和稳定性的差距会非常明显。一句话总结啊,单县城的程序员和多县城工程团队的区别。
118建斌聊AI
