ollama不能安装到有空格的路径

粉丝149获赞945
相关视频
 07:13查看AI文稿AI文稿
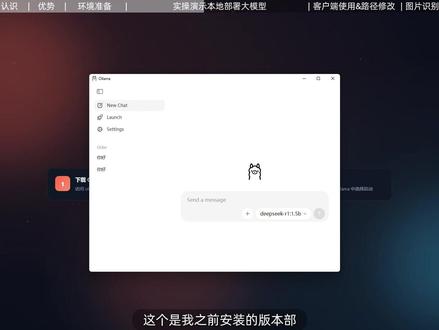
07:13查看AI文稿AI文稿大家好,本期内容我来分享如何在本地部署谷歌新开源的多模态 ai 模型代码四,我会分享命令行和格式化界面两种安装方案,零基础也能轻松搞定。 最后我还会教你如何修改部署的路径,彻底解决大模型占用 c 盘的问题。本地部署的优势就是你的数据可以完全保存在自己的电脑上,隐私安全有保障,而且支持模型微调, 可以打造专属的 ai 助手。但是他也是有缺点的,就是我们需要稍微懂一些技术,还有就是硬件的支撑,如果电脑配置高,自己可以部署折腾一下。有了本期视频,就算你不懂技术,跟着视频操作也可以部署成功。 本期演示我只分享入门版本,主要就是参考部署的方法和流程。接下来我手把手带大家用欧拉玛一键部署。 首先我们先来了解一下 jam 四到底是什么,它是谷歌新发布的开源多模态的 ai 模型,与 jimmy nay 是 同源的。 简单来说,谷歌就是把自家的 ai 技术打包成了一个免费开源的版本,让每个人都能用上。它的能力是非常全面的,支持文本交互、图像识别、音频处理,还能生成代码, 基本上覆盖了所有的 ai 应用场景。下面我们再来看一下它的核心优势。核心优势它有三个,第一个就是多模态能力,文本、图像、音频代码,一个模型全部搞定。 第二个就是完全免费,它没有会员订阅,没有暗次收费,可以随便的去使用,甚至用它去开发商业化的产品。第三个就是比较重要的隐私安全保障,本地部署模式下,所有的数据处理都在自己的设备上完成, 敏感信息不会上传到云端,这是三大核心优势,就是在我们安装之前,需要我们了解一下这个安装环境。首先系统兼容性 demo, 四是支持 mac os、 linux、 windows 三大主流操作系统,基本上覆盖了绝大多数的用户。 然后就是内存要求,如果你的电脑小于三十二 gb, 推荐安装四 b 版本,自己安装体验折腾一下就可以。如果你的内存达到或超过了三十二 gb, 那 就可以选择二十六 g 或三十一 g 的 版本。 在这里有一个小提醒,就是如果是 mac 电脑 m 系列的芯片,它的显存和内存是合二为一的,大家直接看内存就可以。如果大家不是 mac 电脑,比如 windows 或者 linux, 那 么就优先看显存,显存不够再看内存,这是关于这个配置的查看。像这个本地部署也非常简单,仅需两个步骤即可完成。第一个就是安装欧拉玛,这个欧拉玛就可以理解为是本地大模型的一个容器, 它是装大模型的,有了它才可以运行。第二步就是我们容器安装好之后,我们需要给它把模型放进去,就是部署模型,两个步骤即可搞定。下面我们直接进入实操环节,我们来一起看一下部署的全部流程。 在这里第一步我们就先要有这个欧拉玛,他是一个大模型的容器,就是我们打开之后选择右上角的 download, 这时候我们就需要选择匹配自己系统的版本,在这里我这是 windows, 然后我们选择 download for windows, 在这里选择 download for windows 之后就会弹出窗口,我们选择路径直接保存就可以,当下载好之后,然后我们就安装即可,安装好之后打开就是这样的主界面,这个是我之前安装的版本,部署着一个一点五 b 的 zip, 然后下一步就需要我们去选择大模型,我们还来到刚刚乌拉玛的这个界面,在这里我们选择左上角的 models, 然 然后在这里我们可以看到该马四,然后我们选择进来,它提供了好多个版本,在这里我就选择一个入门的版本,主要就是演示安装的流程,比如我们选择 e 二 b, 然后我们选择,这时候我们就看到了这个安装命令,选择右边的这个两个方框,然后选择 copy, 然后下一步 我们就按键盘上的 windows 加 r 键,这时候出现运行窗口,然后在这里面输入 cmd, 然后直接回车, 回车之后就出现了这个命令窗口,然后我们刚刚复制了直接鼠标的右键,可以看一下,这个命令就粘贴过来了,然后我们直接 回车好了,这时候它就开始部署到本地了,在这里我们需要等待一段时间,好可以看一下出现了 success 这个提示,就证明安装成功了。现在我们在这里可以直接和它对话,比如我们输入你好当前什么模型,然后我们发送 可以看一下,他现在回复我们了,我是一个大语言模型,我叫 jama 四,这时候我们就在本地已经部署成功了, 然后我们再回到欧拉玛的客户端,在这里在这个对话窗口右下角这里,这里可以选择模型,然后我们找到刚刚部署到本地的 jama 模型好了,这时候就切换好了。同样在这里我们也可以直接和他对话,比如我们输入你好,然后发送, 这时候他就回复我们了,你好,很高兴和你交流,请问有什么帮助到你的?到这里我们就已经部署成功了。前面我们分享的是使用命令行 c l i 模式去部署,其实还有一个简变的方法, 在这里我们还可以选择模型后面对应的这个按钮,也是可以直接部署的,这个是非常方便的。好,最后我再分享一个大家比较关心的问题,就是我如何设置这个本地模型的一个部署路径, 在这里我们也不用去改环境变量了,这个客户端是直接支持的,我们选择左上角的设置,然后在这里选择这个 model location, 在 这里我们就可以去设置模型的一个保存路径,在这里大家自己设置就可以,是非常方便的。 好,下面我这里演示的是上传了一张图片,就让他识别这张图片,我们一起来看一下他给我们的结果,好了可以看一下,我们给了他一张图片,我们问他这是张什么图片,他给我们的回复, 这是一张符号或者是图标,然后他还分析了主要包含的元素,还有用途预测等等,能够精准的识别内容,并生成详细的描述, 表现还是可以的。好了,现在我们本地部署成功了,然后刚刚我们也做了一个功能测试,第一个就是我们和他对话,就是文字处理,第二个测试的就是这个图像识别,他也是可以精准识别的, 他虽然是多模态的,但是目前我们用的这个容器不支持多模态的输入,我们暂未测试音频和视频的识别。好,最后我再补充两个细节,就是第一个欧拉玛的拓展性他是非常强的,除了可以部署这个 demo 四, 还支持比如通用签问或者是 deepsafe 等众多的开源模型,部署方法也是完全一样的,一条命令就能去部署。第二个就是本地部署的真正价值不仅仅是隐私保护,更重要的是支持模型微调, 可以用自己的数据去训练模型,打造一个完全专属的 ai 助手。好了,这就是我们本地部署的所有内容,大家感兴趣的可以自己折腾一下,探索更多的玩法。好了,我们本期内容分享就到这里,可以留下你的想法,我们下期再见。
152掌舵者AI实验室 05:55
05:55 04:13查看AI文稿AI文稿
04:13查看AI文稿AI文稿上期视频发布后,有玩家表示奥拉玛推力有点慢,想看看怎么在 c c 中通过拉玛 c p p 调用本地模型,本期视频我们就一起来看一下。首先我们来看一下拉玛 c p p 的 安装与配置。在 github 上找到拉玛 c p p 这个项目,根据 red 中的描述,从 release 记录中找到自己系统对于的软件包进行下载,主流操作系统都支持, 比如我自己就是安装的这个 windows 叉六四库达十三点一的版本软件,下载好后将其安装到磁盘中。 接着需要将软件安装目录添加到系统环境变量,确保使用命令行工具时能正常找到软件提供的 lama clea 和 lama server 等可执行命令。接下来添加环境变量,点击开始打开系统设置, 点击左侧系统菜单滚动到底,找到系统信息,打开后继续点击高级系统设置,弹出窗口中即可看到环境变量设置入口,点击环境变量,将软件安装路径添加到用户变量的 pad 变量中即可。 此外,你也可以直接在此电脑图标上右键选择属性,直接进入系统信息界面,这样会更快捷一点。 环境变量配置好后,打开命令行工具,通过运行 lama 颗粒 version 或者 lama server version 命令确认配置结果。如果正常输出版本信息以及你的显卡信息,则说明安装成功。接着我们来实际运行一下模型试试。 我这里已经下载好了一个千万三点五的 g g u f 模型,大家如果想用可以前往摩搭平台下载搜索视频展示的模型名称即可。我使用的是 q 五 k m 的 量化版本,此外还需要下载这个 m m p r o j 的 文件, 这个文件的作用是多模态场景下处理视觉张亮和文本张亮之间的映射关系。回到文件目录,右键打开命令行工具 运行视频所示命令就可以在命令行中与模型对话了。试试让模型帮忙写一个简单的加法函数,并且要求他用 python 语言来编辑 回车发送模型立刻就有了响应。这确实比欧拉玛要快很多,过程就不给大家展示了,快进看一下结果吧。实现了函数,还主动添加了测试用力。 但是如何才能在 cloud 中调用呢?我们先回去看看拉玛 c p p 的 说明文档,向下滚动,找到拉玛 server 这一小节,这里明确说明拉玛 server 命令可以启动一个适配 openai 规范的大模型 http 服务,这应该就跟欧拉玛的本地服务是一回事了。 回到命令行,按照说明运行一下,看看是什么效果。服务启动后,果然得到一个带端口的 http 服务地址。不仅如此,根据文档所示,我们还可以通过 port 参数指定服务端口,记住,这个服务端口后面配置 cloud code 会用到。 现在我们继续配置 cloud code。 cloud code 的 配置文件通常在用户根目录下的点 cloud 的 目录中 先备份一下,然后打开 settings json 文件,没有的话直接新建一个就可以,这里 autoken 随便填。本地没有较验,被 c u i l 的 端口改成刚才我们设置的四个九即可。模型配置没有用,随便修改一下也会用于确认配置是否生效。 保存后,随便进入一个目录,右键新开一个命令行,输入 cloud 命令,启动 cloud t u i 界面,如果遇到安全检测提示,信任一下即可。通过这里的模型名称可以确认配置生效了。同样,先让它写个加法函数试试, 比在命令行中使用的反应要慢一些。好在还是正常响应了,可以简单检查一下生成结果,再进行一次普通的对话试试,没有问题。托肯正常跑起来了,但怎么确认调用的是拉玛而不是奥拉玛呢? 我是这么验证的,切换回 lama server, 启动窗口,停止 lama server 服务,然后回到 cloud 的 交互界面,再次对话,可以看到 cloud 的 明确给出了无法连接 api 的 提示,至此可以确认 cloud 控制中通过 lama c p p 调用大模型成功了。点赞关注,下期更精彩!
67遇见AI 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿olam 的模型文件都是比较大的,以 g 为单位。官方文档说明模型文件默认都装在吸盘当前用户的 olam 目录下面。 由于吸盘安装操作系统和应用程序,很可能装几个模型文件,空间就不够用了,所以建议更改默认的模型目录。 olam 通过 olam models 环境变量来设置模型的存放目录, 打开 mindows 的设置,找到系统, 点击系统信息, 点击高级系统设置,点击环境变量新建环 镜,变亮变亮名填入 olam models, 选择你想要设置的目录, 重启电脑后生效。下载模型后,在新目录下可以看到 blobs 和 manifests 两个目录,说明模型目录设置成功。
253T锅侠















猜你喜欢
- 1250基地