qoder 可以挂skill吗

粉丝2.1万获赞3.4万
相关视频
 01:14查看AI文稿AI文稿
01:14查看AI文稿AI文稿公司最近给配了一个月的 cursor, 我 之前主要使用的是阿里的 coder, 使用下来我觉得 cursor 还是要稍微更好用一些。 首先在 tab 补全上面, cursor 在 你多个文件切换之后,基本上还是能准确预测到你要补充的字段或其他信息, cursor 就 要稍微欠缺一点。在智能提问上面, cursor 的 响应速度以及处理速度都会快一些,特别是在一些细节的处理上面, cursor 会更精准一些。然后 cursor 还会时不时的能预测到你下一个要跳转的文件。 cursor 在 我之前使用过程中几乎很少能预测到文件。 此外, cursor 再启动大型 java 项目时,出实化速度会快很多,然后在后续的使用过程中也会更流畅一些。这个确实是我比较喜欢的一点,不过国内的 coder 以及 tree 等这些智能编辑器 更新频率很高,也越来越优秀,希望能早一点跟上国外的水平吧。
14一昂杨_ 03:56查看AI文稿AI文稿
03:56查看AI文稿AI文稿u z 这里变为了零杠三百钢铁侠 windows 端如何去使用?从头带着大家来一步一步的操作一下。首先我们下载官方最新版本的扣,我们电脑上这个扣的版本是零点二点二,三是比较旧的版本,先来更新一下扣的,安装的时候一定要安装在 c 盘, 使用默认路径去安装,其他的字盘不可以。安装好以后打开扣的看一下版本号,目前版本号是零点一、四点二,然后看一下 id 里面的账号,已经登录了一个 uzi, 这里是一个 free 的 状态, 积分是零杠零。好,我们先将它关掉,接着打开下载好的文件,只有一个 exe 文件,右键管理员身份运行, 注意啊,一定要右键管理员身份运行,否则一些操作可能会被拦截。软件打开以后就是桌面上看到的这个界面路径,这里看一下这个扣的的路径,是我们刚才安装的最新版本的 扣的点 exe 文件。然后我们的操作有两种方式,如果是基于自己去注册,那么就使用绿巨人启动,如果想使用现成的账号来快速切换, 就使用这个红色的呼叫钢铁侠按钮,这是两个按钮的区别,使用两个按钮之前 再强调一下,注意看那个 ip, 当前的 ip 是 这个,我们在切换账号之前一定要想办法将那个 ip 改变掉,不会换的话自己可以百度,百度去问问豆包如何更换公网 ip 方法有很多, 大概有三种方式,手机热点魔法光猫重启查询自己公网 ip 的 网站,可以通过 ip 幺三八点 com 在这里进行查询,不要访问其他的,比如 ip 点 s b ping 零零那种网站,一定要使用这个幺三八的网站,它的查询是最准确的,可以看到这个 ip 是 跟我们的 软件上的 ip 是 对应,确保自己拿到的是一个新的 ip。 以后点击呼叫钢铁侠,好,我们点击它有这个提示,不要紧,是因为我们刚才就已经换了一个 ip 了,直接点击试,需要等待一段时间,让程序自动跑完。 好,跑完以后有一个提示,注意看一下这个弹窗里面的提示的文字,然后我们看一下这个扣的的界面,变成了初使的界面, 这个时候我们选择一个风格,一路 continue, 注意这里不要点 second, 要点跳过点 second 又会登录全新的账号,这里一定要点击跳过,因为这个账号已经切换进来了,可以看到右下角变为了 pro trail 是一个 pro 的 状态。 u z 这里变为了零杠三百,点击人头,点击 coder sighting, 也可以看到账号的信息,有一个绿光,点击 harp 和 bot, 可以 看到 coder 的 版本号是最新版本,使用的时候 可能会遇到一些问题。 uzi 这里没出现三百积分,没出现 pro 有 几种情况,网络延迟,网络还没有过来,所以没有收到这个三百积分。还有一种情况,公网 ip 没有更换,或者公网 ip 比较脏,已经被别人使用过了, 是这种情况。那么如果遇到这种情况的话,我们只需要更换好自己的公网 ip, 再次重启 code, 重启以后点击 uzi 这里 再次观察他的积分变化,注意一定要点一下 u 地址去观察。然后我们可以打开自己原来的项目, 历史的项目,打开原来的项目以后,里面的记忆还会保留,不会丢失。如果想使用绿巨人启动按钮自己去注册的话,可以访问泊客地址,加运点赛道到用户名这里来升级天数。艾瑞曼 w 可以 通过给视频三连, 通过我们的博客地址查查密点上栏找到钢铁侠这篇文章,在里面自助下载,或者点击右上角免费获取。
 02:34查看AI文稿AI文稿
02:34查看AI文稿AI文稿来了,兄弟们今天给大家分享四个办公必备的 skill。 先说 skill 怎么装,一分钟搞定。我们打开永冻虾七二四 claw, 打开后点击右上角的兑换码输入三三三,输入后即可免费使用。接着我们点击左边的技能,就可以看到所有的 skill 了。然后就是第一个必装底线技能, skill vader 安全审查卫士。兄弟们每天在 claw up 上面敲代码、挂插件,最怕就是碰到恶意宝马龙虾社区早先就爆出了 claw havoc 供应链事件,一夜之间炸出三百四十一个恶意插件。 你必须得让 ai 有 个看门狗,这个技能相当于给你的龙虾雇了个二十四小时不休息的门卫。你后续每装一个插件,它就会自动去 virus total 给你做个全身扫描,只要发现可疑权限,恶意代码,当场拦截标红。 这是办公电脑的最后防线,必须第一个装上,所有用户都给我焊死在 skill 列表里。第二个办公大杀器, heavily search pro, 全能实时搜索! 咱们办公做 ppt、 写报告最烦什么?最烦搜出来的全是百家号广告和过期资讯。这个 skill 跟某度不一样,它是专门为 ai agent 优化的实时搜索引擎,返回的全是结构化数据,没广告,准确率特别高。 你只要在对话框里说,帮我找二零二六年直播电商核心数据,顺便看看竞品最新财报。龙虾立马在全球范围内把最新的论文报告全给你扒下来,哪怕是刚发布十分钟的消息都能捞到,这速度比你开十个网页手动扒快多了。 第三个,懒人狂喜 agent browser 浏览器自动化,有了数据还得干活啊!这个技能一装上你的龙虾就解锁了操控电脑的能力。 以前你上班是不是得手动填十几次报销单?每天定期去后台点签到,或者手动去某眼查吧企业信息。现在不用了,你直接在对话框发指令,去某网站抓取前二十条标题,保存成表格,或者帮我把这些报名信息自动填了,龙虾自己就能打开网页 模拟,点击自动翻页抓取数据。全程不需要你写一行代码,主打一个意念办公,让鼠标自己在屏幕上飘,这在以前想都不敢想。第四个,自媒体和打工人都给我焊死! humanize a text ai 文本优化,龙虾靠联网和抓取整理出来的东西,很多时候像个没有感情的念稿机器,一股子 ai 塑料味。你拿这种稿子去汇报或者发视频,老板一眼就能看出来是 ai 干的。 把这个 skill 一 开,它能把深印的汇报秒变人化。比如整理完的数据总结发给他润色一下,瞬间带上你的个人风格,变得生动自然,有血有肉。最关键的是,处理好的东西能云端同步,你在地铁上拿手机就能发给客户。到了公司,打开电脑,继续无缝衔接,这才是真正的办公闭环。
 01:57查看AI文稿AI文稿
01:57查看AI文稿AI文稿大家好呀,我是秋姐。接下来一段时间,我想给大家开启一个关于 ai 智能体的实战课程。今天的第一课的主题是什么?是 skill。 在 整个课程体系,我们将从底层逻辑出发,最终带大家完成一个完整 skill 的 开发与部署。首先我们要明确什么是 skill, 它呢?最早是由 ansypic 提出的,它被定义为扩展智能体功能的模块化密封装。它的核心逻辑在于一个通用的 a 型的作为大脑,通过挂载无数个可附用的 skills 模块来实现从想到到做到的跨越。 大家可以看图中的逻辑结构, skill 就 像是给 a 型的装上了精准的肌肉,让它能够调用外部工具处理特殊格式的数据。这种模块化设计极大地增强了系统的灵活性和可维护性。 很多同学会问, skill 和传统 api 插件有什么区别呢?来我们看这张对比图, 它最核心的区别在于, skill 强调自然语言交互与自主逻调用逻辑。它不仅是一个接口,还包含了怎么使用这个接口的描述和逻辑判断,使它的分装深度和灵活性都远超传统插件。 在深入学习开发细节之前,我问一个问题,就是这种自然语言交互的特性会怎么改变我们以往使用软件工具的方式呢?以前的软件呢?我们是学习他们的说明书, 那以后呢?是软件理解我们的意图发现了吗? skill 是 让交互从点击驱动变成了目标驱动,你只关心,只需要关心结果,过程将由 ai 来调度。
74木火相助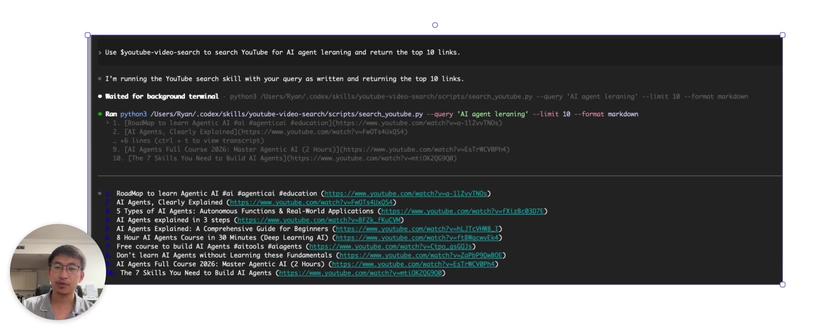 04:23查看AI文稿AI文稿
04:23查看AI文稿AI文稿最近我用 cortex 写了一个 skill, 它可以帮我在 youtube 上拿到我感兴趣的视频内容的前十个链接。 写这个 skill 本身并不复杂,我这里想说的其实是另外一个好东西,我在 github 上偶然发现的一个 工具,这工具叫做 nyxid, 它具体是做什么的?它就是相当于给我们的 ai agent, 可以 访问任何 api, 做任何事情的功能,而且它还非常的安全。 它到底是怎么做到的呢?其实只需要跑这么几个命令,第一步肯定是安装,第二步就是登录,登录之后你需要把它的 m c p 挂到 cloud 或者 codex 上面,之后它自己本身有一些自带的一些服务, 你可以用这个 ai 的 方式去跟他聊。另外如果你有一些私有的个人 a p i, 你 也可以用一个命令行的方式,把你的 a p i 可以 加到这个 nyxd 里面, 剩下的事情就是交给 ai, 你 跟他说你想做什么事情,他就能帮你干。下面我给大家展示一下我是怎么用这个工具生成这样一个 skill。 那 首先第一步跑这个安装的命令, 装完之后我就跟他说,你能用这个 n o x d 去帮我利用我的 youtube api 去做一些搜索吗? 把你的所有结果告诉我,他就开始检查。 ok, 后面我发现我实际上还没有搞这个 youtube api key, 我 问他说你帮我先弄一个,然后他告诉我详细的步骤怎么样去生成这个 youtube api key, 我 就去弄了一个, 弄完之后他就告诉我说你需要走这个 custom 的 方式,告诉我用什么样的指令,我就做了,做了之后让他看试一下,他发现 ok, 我 的加进去的这个 custom api 是 可以用的,他现在可以去跑一些搜索了, 然后我就跟他说 ok, 那 你现在就用这个 ai agent 去给我一个十个视频链接的结果把它做成一个 skill, 这样我每次想去做这个搜索的时候,我就去调用这个写好的 skill, 然后 call the c l i 就 开始调用它的 skill creator, 去尝试去做这么一个东西,它还有它的 play, 做一个 skill folder, 再写一个 script 去要 to discovery, 再去写这个 skill instruction, 最后 validate, 然后他把这个骨架已经搭好了,然后他开始写这个 python 的 代码,最后他说这个技能写在了什么地方,有一个 script, 然后他试了一下下面这个是他试的结果,他告诉我说下次再用的时候就直接这么说,他就可以正常工作了,我相信没有这个 n y x i d e 我 们也可以写这样一个 skill。 但是我们这里的问题就是,你在写的过程里面,你需要每换一个不同的 api key, 你 就需要 重新走这么一遍流程,去把这个 api 放到一个什么地方,告诉他怎么用,你都需要很多的 prompt 的 交流,但是有 nyxid 这个工具,你只需要把 api 加到里面, 剩下时期你只需要交给 ai, 让他去读 api 相关的文档,然后他自然会发现这个 api 是 怎么去用的,有多少 api 可以 背调,然后你描述你的需求,他自己就会去 把这些事情全部搞定。而且它这个工具也说了是安全的去管理 api key 的, 它不容易暴露给外面的人,所以这个工具最大的好处在于它可以帮我管理我所有用到的 api key 啊,不需要我自己去花时间搞一套管理工具来维护。我都有多少 apikey, 我 都用它来干什么?当然这个工具目前来说唯一的一个不太好的地方可能是它对 windows 系统完全不支持,这个地方可能是有待改善。
33大白不跑调 04:10查看AI文稿AI文稿
04:10查看AI文稿AI文稿大家好,我是瑞克老张。说个有意思的新闻啊,今天四月三十号,阿里 qr 的 正式发布了,移动端和数字员工在聊。这之前呢,我先说说真实的感受啊,都知道我已经养了五只龙虾,并且有龙虾养的时间还很长了。当然,我也是通过 i m 工具,类似 qq 和钉钉才跟龙虾实时对接的。 但其实这里面有很多的问题是用龙虾这种工具无法真正解决的,只能想尽一切办法绕路大龙虾的接入。 qq 和钉钉干活的方法很简单,你把他机器人拉进群,或者跟他单聊,你艾特一下说帮我看完这段日记,他过一会丢一段结论,你要是放个长假,想让他半自动半夜自动跑个自动化任务就更痛苦了,你根本不知道他在干嘛。 有一次凌晨先生服务报错,我艾特大龙虾去查,他说好的正在分析,然后我就只能干等,群里偶尔蹦出一条查询 command 中啊,又过一会儿查询日期中,最后甩给我一大堆的文字。结论中间他思考了啥,为什么走这条路,遇到什么报错,全是一团黑。 更关键的是,你想中途拉他一把不行,你想在某个决策顶上说别走一条路,换个方案做不到。因为在 qq 钉钉里,底层就是聊天信息流,你发给他一条,他回你一条,一切都是限性,时间限。这种产品形态本来是设计给人和人聊天的,不是给人和 ai 远程协助的。 很多时候,我们希望大龙虾换个思路走,但换来的只能是前面的任务还在执行中,等任务执行完了,哎,我再来回答您的问题,这样的回答 不光白白浪费了 to 肯,还确实浪费了时间。说实话,大龙虾接 im 这个法,你用来查个天气,写个文案还行,但凡一跑几个需要十几步推理几十次工序调用的正经任务, im 就 完全扛不住刷屏刷到你怀疑人称关键的四个过程全被淹没了。 那么,对于真正享用大龙虾这类自成体公寓提升效益的人来说,有没有真正好用的解决办法呢?这回阿里就带来一个阿里新发布的 qaltair。 移动端的做法完全不一样,他不是把 a 枕塞进钉钉,而是单独做了一个移动端的 app, 整个产品形态围绕 a 枕在跑你的判断重新设计。 打开 app, 你 看到的不是挑聊天列表啊,而是一组任务卡片,一眼就能看清楚啊。哪几个任务在跑,哪几个在等你确认哪几个已经跑完,需要你看结果。 点击一个任务,啊里里边是这次绘画的完整结构啊,当前的执行计划就是 plan 还有 agent 的 思考列啊,他每一步怎么推理的,用过哪些工具以及每一个决策点。最牛的是,每一个决策点你都能展开看依据,然后选择放行修改或者直接退回去重来。 底层呢,是任务制,而不是无限滚动的时间线。一个绘画,就是一个有声有色、有尺有中、能被复盘的工作单元,这才是人和 ai 合作的设计的产物。 说说我今天实际体验啊,我们团队现在最近正在修正一个新的预警分析模型,我让 q o d c l i 跑一个数据清洗和特征工程的活。这个任务不算小,涉及到多轮数据预处理、特征筛选、模型参数调优,中间好几个环节都需要我的确认方向。 哥,以前在钉钉里,我只要一直盯着电脑,消息一多就找不着北。今天我试了下 q o 的 移动端,体验完全不一样。我出门办事的路上,打开手机,任务卡里一个红点, a 站呢,已经跑完第一轮数据清洗到了特征选择这个关键点,直接弹窗问我筛选出两组的动两组特征方案, a 组方案的精度高,但计算该开销大, 一组方案清亮,但可能就有一些长尾信号,附带每种方案的详细依据和引用数据。我在地铁上两分钟看完思考链,选了 a 方案非洲依据先跑小曼要么验证啊。 agent 接着往下跑,后来又卡在了模型融合策略上,又弹窗问我权重分配的事,我在咖啡厅扫了一眼,直接开板。 整个过程我没开电脑,我没在群里边翻一条消息,就把这个模型的关键环节全部确认完了。而且 agent 每一步的思考链、 play 工具调用,手机上都看的清清楚楚。这种掌控感跟之前在 im 里面翻消息完全是两回事儿。 整个过程不用切回桌面,不需要在群里翻消息。没人帮我转述上下文,这是不是应就是移动端 agent 应该有的样子呢? 现在 q o 的 移动端已经率先支持 q o 的 c i 啊,你可以去啊这个哎,下面这个链接啊,就在直接就可以使用了啊。而且呢,抢先体验近期全面支持 i o s 和安卓,未来还会打通 q o 的 ide q o 的 worker, 到时候你可以早上在手机上给数字员工派个活啊,他干完后在弹窗让你确认真正实现一个人带着一个 a s 军团,然后 一句话把 a 忍的塞进 i m, 那 是偷懒的过渡方案,为移动端从头设计一个任务卡片加思考链加决策点,才是真正啊把让你选择远程干活的产品。好,今天就到这,我是瑞斯老张,关注我,咱们投资的视角,看科技背后的精彩,我们下期见,拜拜。
183瑞克老张有话说 01:02:12
01:02:12 10:32145William说
10:32145William说 24:49查看AI文稿AI文稿
24:49查看AI文稿AI文稿呃,那个,各位朋友大家好。呃,我是阿里云智能兽医库团队的袁鹏,负责 and native db, my circle 产品相关的工作。那个非常感谢这个雅纯的邀请啊。 这个他刚才还问我就是为什么下午专门为了这个分享请个假,我说, 呃,这个下午没法干活,他问我为啥没法干活了,我说我这个月扣的的考勤已经用完了,呃,不光标准的套餐用完了,然后我的资源包也用完了,我下午没法干活了,我只能请假来给大家讲一讲啊。 然后今天我分享的主题主要是就是这个 code 专家团落地的一个实践啊,我是怎么用 code 这个专家团的模式来构建一个 open class 使用行为观测系统的?嗯,这个系统啊,其实很简单,但是我为什么要讲这个东西呢? 因为他是这个前端这个东西啊,我是完全不懂的,就是我在做这个系统过程中,就是那些前端的代码我一行都看不懂,然后在专家团团的这个鼎力合作之下,然后这个最后的呈现的效果还是非常不错的, ok。 呃,然后再说一下我们为什么要做一个 open cloud 这样的一个可观测的系统,就是我们就是我们自己团队也部署了大量的 open cloud, 然后有一些我们自己的客户啊, 也部署了大量的这个 open cloud, 有 的客户他部署了上千个这种 open cloud 的 pod 在 里头。然后这个部署了之后 就存在这样三个问题,就是就是我们就什么都看不见,就第一个就是成本的黑箱啊,就是账单就是一直在涨,然后也不知道这个钱花在什么地方,然后老板就就问你这个到底都干什么?这个 昨天的这个钱是这么多,然后今天突然怎么又涨了这么多啊?然后第二个就是行为未知,就是这个东西大家到底用 open klo 在 干嘛啊?你到底是在写代码做数据分析还是在聊 a 股是吧?我们就有个客户用这个可观测发现之后,他的员工 上班的时候在炒股啊。然后第三个就是这个能力的盲区,就是大家的这个在用 ai 到底每个人的水平到底是什么样的程度? 那有的人能力可能高,然后有的人能力可能低,那有的人发送过去的指令,那个 ai, 然后不断在重试,发现重试的多了之后任务没有解决,然后这个偷看烧了很多,这是一个问题,那这个归结到一句话上面,就是没有可观测,他就没有这个管理的能力。 那在解决这个问题的时候,我们定义了一个非常关键的东西,那就是任务链,那这个任务链是什么呢?就是从用户发起一次指令到 agent 最终输出的这个完整的结果啊。那我们看这个右边这张图,就是用户输入指令之后,那这个 agent 先会用这个大模型去了解用户的意图啊,了解完用户的意图之后,他会去调用不同的工具去拿到他那个想要的结果,然后再经过这多轮的反复之后,他再会把这些工具的结果给他汇总,然后输出给用户。 那有了这个任务链之后呢?我们才可以做一些成本的归因以及性能的分析,然后再加上这些 我们定义的任务链,然后我们可以做一个坠死的下钻啊,下钻就能看一看清这个每一步的这个耗时的 token, 它到底都是在干什么,然后它调用哪些工具,然后这个任务链就是我们整个可观测系统的一个原子单位。 呃,就基于这个任务链,那我们搭建了什么呢?就是这个东西也是非常简单的,就是我们把 opencloud 的 所有的绘画呃采集过来, 然后做一个任务量的聚合,然后完了之后我们就构建了我们四大分析模块,可能我不知道有的同学有没有了解过,就是了解过 open core 它的这种原理,就是可能你如果去扒它的呢 ches 那 个绘画文件的时候,就能看到它详细的对话过程。然后我们就做了这么一个事情, 这这个是从零到一的。然后呢就是我们四大分析模块有这么几个,就是一个是系统的概览,这个就是你能看到这个活跃的用什么,然后任务量的数量有多少,然后成功率什么样的,然后总的成本是什么样的, 然后状态分布是什么样的,这就是。呃,老板看这可能就是一眼大观就能看出来具体的消耗的成本。然后第二个就是具体的成本分析,我们会按照用户的维度,然后模型的维度,以及按照任务量的归因啊成本效率去做一个 分析的排名。那第三个是智能分析,这个是我们呃做的我觉得是不错的一个点吧,就是我们 做了一个用户提词质量评分的,呃,一个东西,就是按照六个维度,然后第二个就是用户意图的识别,再一个就是任务复杂度,嗯,然后最后一个是性能分析,这个我们会分析他每个 a 阵的那个工具调用的成功率以及耗时的分布的统计。 嗯,这个我我给大家展示一下,就是我们做的智能分析的一个系统啊,就是这个我们是基于大模型去做的全方位的一个分析的平台啊。大家看上面这个 这个表格啊,就是我们做了一个用户偷看消耗的排名,在这个表上就能看到每个用户他到底都花了多少钱,就是你可以一眼看出来哪个用户花的这个偷看最多,花的钱最多。 然后在这个列表的右边我们有三个分析的按钮啊,一个是那个提示词的评分,就是对应下面左边那个提示词的评分,这个我们构建六个维度,那在这个维度里头,我们把用户最好的提示词和最差的提示词 都给他提取出来,然后呢话在这个提示词我们可以点击这个提示词做一个详细的下段的分析。 第二个就是意图识别,就是我刚才讲的就是这个会按照你这个任务的类型去做一个这个饼形图的分布,就是看到你到底是在写代码,然后解决复杂任务,解决工作的呃问题,还是再去吹水。然后最后一个就是这个任务的复杂度, 我们可以看到这个装装头,就是,呃,比如说有的用户他这个任务极高的任务的复杂度,他这个占比比较多,那我们就会去看一下这个任务的复杂度,到底是你是在做具体的解决具体的工作中的复杂的任务,还是做一些其他的东西。 嗯嗯,那说到这里就是我们做的这个东西,那我们为什么去选择这个专家模式呢啊?因为因为我们这个系统啊,虽然是个小系统,但是呢 他也涉及到很多模块,就比如说那个数据的分析啊,最核心的就是任务链的建模,以及一些分析的算法,还有后端的服务,再加上前端的可化这个五个技术领域。那我看那个专家谈他因为分的那个角色比较清晰嘛,然后我就试用了一下这个东西。 那对于执行方式来说,就单个一层呢,他可能串行执行一个任务,做完一个再分析下一个。那我们的专家模式, 他这个任务会先分分给这个 team leader, team leader 然后去创建这个依赖图,然后分成三到五个专家去并行的这个执行任务,那这个效率比较高,而且这个 团队角色的分配也比较合理。那第二个就是任务的分解,任务的拆解,你单个一程呢,需要用户去拆的,然后你再用专家模式的话,这个 team leader 他 自动会给你拆分,然后拆分带依赖关系的这个子的任务,然后再去执行。 第三个好处的点就是它的这个质量保证,那单程模式的话,它做完可能就交付了。那有的同学可能会在 agentmd 里头写一个这个 啊校验的要求,然后让 ai 每次改完这个代码之后,去做一下这个单测或者是集测啊,或者是其他的这个构建的测试。 但是在专家模式里头,它自动就构将这个 q o 的 q o a 的 能力,它自动会去检查这个 nant, 然后再加上类型检查,然后再去做一个一投一的测试,这是我觉得它比较好的一个点。 然后第四个就是这个上下文的理解,那单人 a 站他了解的话,他就是一个单一视角的,而且是全剧模式的。那在专家模式下,他会派出一个调研员去探索,然后每个专家会先读很多的文件,读完文件之后然后去做分析,分析完了之后他 再去做这个写代码或者是构建系统。那第五个就是错误的修复啊,这个单程模式下你需要用户去爆 bug 去修,然后在专家模式下,这个 timothy 就 会直接去抓这个你构建的对战,然后直接诊断根音,然后把这个任务分发给 对应的工程师去解决。然后我们的我这个系统中一共是有一百零七个专家的绘画,待会我给大家看一下那个绘画的图, ok, 然后看完了,就是看完了上面的我们看这个专家团的写作的机制啊,就是 这是我自己通过专家专家团的那个对话发现了,就是这个任务会首先发给 team leader, 然后 team leader 接受了任务之后,他会去派出调研员去做调研,调研完了之后他会去做一个 plan, 就是 做一个规划, 等到这个规划完了之后,他按照这个系统的模块分配给不同角色的专家,就包括后段专家或者是这个前段专家以及通用的工程师,然后去解决这个问题。解决完了之后, 每个专家把自己的工作完成之后,这个时候会交给测试的专家,然后测试的专家测试完之后再去交付结果。 在整个这个写作的机制机制中啊,我我发现这个整个专家团的能力有三个就比较可以讲的点啊。第一个就是技术的诊断力,就是我们是有一个 功能,就是按用户去筛选,我发现这个筛选之后,他那个,呃每次用户对话他那个步骤都变为一了,然后把这个问题发送给专家团之后,他就精准定位到就是 呃,他在做这个搜索查询的时候,把他的 sendid 放在了未 条件里,而不是 sendid 条件里头。那这个在 opencode 对 话里头就是我们发现就是当 user 的 那个当 user 的 时候才会有这个 sendid 的 当入,等于那个 assistant 和那个透的时候,它是没有散打力啊,它通过这个过滤之后,那相当于是把中间的很多数据都给它丢掉了啊,然后这个专家团就能诊断得到。然后第二个就是依赖编排的能力,它会自动识别这个呃前后段的依赖。 比如说我现在任务,任务一先去做调研,然后任务二去做这个编排,编排完了之后 ok 啊,然后他他做完之后他会告诉我,他说 ok, 我 现在任务二已经完成了,然后我现在去解锁这个三四五,然后变化去执行任务。然后第三个比较可讲的点就是这个质量的闭环能力, 他在每次的交付前他都会去构建这个检查,然后去做类型的检查,他会把他所有写的文件都去检查一遍,然后发现了一些错误,然后他就会立马去修复。我觉得这这个在我们的开发过程中端到端的正确性还是比较重要的,不是说 ok, 我 开发完一个功能,然后就交给你,那 也不知道这个到底是对还是错。嗯,他这个就是不是一个简单的多 a 阵的同事干活,他是一个有技术判断力的 team leader, 然后在管理一组遵循这个先理解再动手原则的专家去做这个事情。 这是我这次这个任务里头专家团的一个阵容啊,就是最最上层就是 team leader, 然后最左边呢就是一个通用调研工程师,专门去分析文件,分析问题,然后去做调研, 然后中间的这三个都是开发工程师,包括后端的前端的,然后通讯公司调研员调研完了任务之后,我会把任务呃结构反送给 team leader, team leader 再把任务下发下发给这三位技术专家,然后技术专家在开发完任务之后,最后的右边的 q a 会去做一个测试。 嗯,呃,然后我具体的说一下,就是我整个任务是怎么完成的,就是从零到一, 这个是从需求输入到最终的完成,是经过三次的这个架构演进。嗯,初试的 prom 就是 我截了一部分啊,这个不是完整的,就是我说我现在有一个需求,就是要开发一个可直观的这个,呃, windows 系统,然后让他去先调研一些方案, 然后我说这个系统要能展示我很可靠的日制以及三省的绘画数据,然后主要是用来做可观测分析的,然后我告诉他要指定时间范围的用户数,然后范围内的绘画任务个数啊,以及指定范围时间内的 token 的 消耗。然后另外在这里有一个关键的点,我是把 我的这个任务链的定义是写在我的 a 整数 md 里头的,待会我给大给大家,给大家看一下我 a 整数 md 的 写法,然后我告诉他,你在做整个分析的时候要一定要严格遵循我的任务的任务链的定义。然后另外的话, 我在做这个时候,我是把我的这个 open cloud 这个三省的所有采集数据的表的结构是喂给他的,就是把这个东西要给他的上下文,你有这个上下文之后,然后 ai 才会知道去怎么去做分析。 然后整个过程是经历了三个阶段嘛,就第一个阶段是三月二十七号,应该是个周五,这个任务是周五下午开始的,因为这个需求就是突然就来了,然后也是我我不懂了,一个前端的一个领域, 然后这个下午就是但是报的家人托管分析这些都都完成了,然后大概一个小时吧,一个小时过去之后,这个整个系统的雏形就有了, 然后我去跑了下测试,然后看了一下他整个的呃,系统是怎么展示的,我会发现他那个成本分析再加上系统概念,他有些东西是重合的,然后我就告诉他,呃,你去给我检查重重复的东西在哪里,然后给我重新去设计这个架构 啊,呃,这个最后他是完成了,然后这个周五,呃,完成了之后我就跑了一下,我就没再管,然后到了周一的时候,周五下午我六点下班之后就走了,就没再管,然后周一的时候早上来, 然后我就让他再去做一下智能分析的,这个这个东西就就相当于是整个系统就是完成了。 然后我说一下在这个过程中我经历的真实的坑,以及一些真实的判断吧,待会我会给大家看这个整个专家团这个对话的东西啊,就是这个模型,这个,这个,嗯, a 站呢还是比较犟的啊,就是他把我数据库的配置他给换了, 我明确要求他用就是 mac 口,因为我的 adb mac 口他是适配 mac 口协议的,然后他去给我接的那个 starx, 嗯,这个就说明这个关键配置还是要在 promax 反复强调的。那第二个就是任务链的状态反复出错,这个是修的五四啊,我我告诉他就是 当那个 stop rate 等于 stop 的 时候,就整个任务才算成功的,然后 stop rate 呢?是这个 balti 的, 就是任务是反复才是失败的,然后他一直不理解,然后我告诉他五次,然后他再给我修好。 然后第三个就是功能的架构要当天当天重构,嗯,这个是因因为 a a i 本来就干的比较快嘛,然后干完之后你完成重构就 ok 了。然后第四个就是它有一个我们就是相当于是业务逻辑的判断嘛,这个东西你不告不告诉这个 ai 的 话,它是不知道的。 呃,他把任务量显示的步数就是,呃显示为一了,然后他平均的时长算成一百三十四个小时。我觉得这个是一个非常细节的点,尤其是大家在做 erp 一 些系统的时候在计算, 呃,包括财务啊或者是人力成本之类的,这个点是要非常注意的,你要在你的 protool 或者是你的 agent m d 里头把你的计算逻辑要写得非常的清晰, 尤其是业务逻辑,你如果不写清晰,那 ai 他 自由发挥发挥的话,他就不知道他会到底会给你干出什么事情来。 这个是非常严重的一个错误。对,因为你明显能看出来这一个任务我不可能花一百三十四个小时去执行,因为你发一个任务,机器人发完之后我可能过一会就给你返回来了,然后他计算出来这明显是个错误。然后第五就是让专家团是去自主探索 啊,因为我在最开始的就是把整个三审绘画的这个结构给他了,然后结构的定义也给他了,所以他会去自己去探索,然后看他能做哪些分析。然后第六个就是一个缓存失效的机制。 呃,就是这个东西是,呃,在那个做智能分析的时候,我会让他做那个提示词和意图识别嘛?那这个东西 我是按照周去分析的,每周去分析一次,但是在放分析当前周的时候, 呃,用户可能已经产生了新的绘画,但是他还是使用了之前的缓存。为什么要做个缓存呢?因为这个东西他数据都已经固定了,你再让这个 ai 每次都去分析,这个时候,那你相当于是多花的偷看吗?这个钱是没必要花的啊。那就是 就是有缓存的话就让他用缓存,没有缓存的话就是让他去更新,然后这个时候就是他因为没有做当前周的这个呃更新,导致这个缓存失效,这个就需要你去。嗯,手工去提示一下 ai, 就是 ai 现在执行的很快,但是对于判断力这件事情,我觉得还是人要去执行的, 因为你自己的判断力我可能当过程序猿都知道,你这个很多次的这个排查任务的经验还是非常重要的,有 ai 可能他不知道你到底在这个现实的场景里会出什么问题,然后你自己会 嗯做什么的判断,这个是重要的。然后总结一下,就是在这个过程中我做到了什么,我已踩到什么坑。然后这个左边是第一步就是我会把表结构贴近这个 program, 然后这个专家就是在第一时间就能理解整个的数据模型,这个是很重要的。 然后第二步是上要调研,调研员先去探索一下,然后看当前的系统有什么数据,然后我们能做什么东西,来啊,让他先去先去发挥一下啊。 然后第三个就是要把问题描述清楚,尤其是你的系统的核心概念,那你这个问题的描述的越精确,然后他会修复的越快。 然后每次的就比如说你在编辑过程中遇到的,呃,系统在执行过程遇到的问题,你需要把完整的异常的链都给他,或者是对于这种 u i 系统的话,你最好把截图给他, 然后他就能很快的失去了。呃,识别的这个问题就是信息提供的越多,他修复的越快。之前那个 orc 做过一个测试,就是他他们对比了一下那个 a 站四 m d 和 skills 执行的 这个准确率,他们经过多轮测试之后发现 ags m d 的 准确率,呃几乎都在百分之百。然后 skills 这个自动加载的时候,因为 skills 描述的准确性的问题 以及 ai 识别的问题,它可能会出现呃,各种意想不到情况,它最后的准确率,呃,就在加了各种的措施之后,它准确率也只有百分之九十五 啊。然后踩了什么坑呢?就是就是我的马斯克配了,但是他被换成这个 starbucks, 这个,这个,这个就是刚才那个同学问的,就是模型,他有时候啊,刚才啊这边那个同学他好像已经走了,就是模型比较犟,你跟他说了之后他还是那么干, 这还是有多次强调的。嗯,模型的幻觉,这个我们是必须要承认,他毕竟是传播吗?这注意力,注意力不到的时候就会有这个问题,这个人的注意力也是一样的,就是有时候需要多次去提醒的是 ok 的。 然后第二个就是任务链状态分判断五次,然后 底层这个就是我们 adb 的 特性,他才会被完全理解,因为他模型训练的时候他可能 a d b, 它不是一个就是通用的产品嘛。嗯,他可能知道一些 my circle 的 一些语法,但是不知道 ad b 的 一些语法,所以他迟迟不能理解我的意图是什么。 然后就是出版的架构,要先做功能架构 review。 嗯,第四个就是计算逻辑,不能只看你这个系统工作是不是 work, 是 不是正常的,你还要看它具体的业务逻辑是不是对的,计算逻辑是不是正确的 啊。第五个就是缓团设计,要考虑数据的时效,然后必须有这个时效的机制。嗯,这个就是你不要把这个整个的过程想的太完美啊,就是有坑有重构,有反复,这是才是真实的写作, 毕竟现在模型也没有那么强,即便是太强的就是非常强的,他有可能也会因为算力不够。呃,就是出现降质的问题。呃,大家之前前几天可能会知道那个 os 四点六降质比较严重, 那个就是那个,那个那个就是因为可能是因为 os 四点七要上线,他就有一部分算你给他下架了,我觉得我猜猜是这样的啊,昨天晚上他给我限流就比较厉害, 我 max 的 套餐呃,一个小时就给我用完了,然后我今天早上在用 os 四点七的时候,我发现他这个额度又上上来了,这可能是在发布的过程中一个切换, 所以就是这个 ai 的 能力,他有时候不是不是稳定的,就所以我们要接受这个现实,因为本身数据中心的建设他就有一定的滞后性,要包括这个农能源的建设也有一定的滞后性,所以我们现在还是需要有一些东西还是需要人去介入的啊 啊。最后我们再说一下,就是什么时候该用这个专家模式啊?就是,呃,推荐使用就是系统横跨多个技术域,然后包括采集分析啊,后段前端的这个就是大家可以用一用都试一试, 就是 ai 这个时代这个潮流已经来了,就是大家要紧跟上,就是多用啊,多用了之后你才能培养你那个 ai 的 sense。 然后第二个就是你要有明确的数据基础,要快速建立这个分析的体系啊。第三个就是你需要去端到端的交付,然后不只是写一个啊,简单的功能, 那不不推荐的就是你的需求还没有想清楚,想清楚,然后是纯探索,然后第二个就是单模块的小改动或者 bugfix, 那 你用普通的模式就可以了。嗯,就是不用太多的去消耗。 tocan 这个就是占权团,他就是不是让你去偷懒,而是让你把精力放在这个更值得思考的问题上啊,你要去定义问题的这个边界,审视输出的质量,然后做出这个呃最终的判断吧。 呃,然后这里,呃借抠点场子给我打一个小广告啊,就是我们是做售货部产品的,我们有一个 adb 可乐,然后这个是搭载了我们呃, adb micro 资源的 ai 的 数据分析引擎,然后深度融合的这个海量的计算能力, 然后可以让业务人员无需编辑的 circle, 然后你就可以通过对话完成专业的数据分析。对,大家可以扫码进一下这个群啊, ok 哦,这是自己打了一个广告,然后另外一个广告,就是我觉得大家可以多去用下 coder 啊,就是我现在的工作就是 啊, coder 和 coderwork 都用,包括现在所有的日常的数据的整理啊,包括 ppt 的 制作全都用 coderwork, 代码也全都用 coderwork 去写。 当然呢,我分享一个就是比较实用的经验啊,就是我自己在写代码的过程中,有时候一些大的工程的话,我会先用千万的模型,然后搭配可拉的扣子去探索整个工程,探索完了之后 再让这个 code 去写。为什么这么做呢?就是因为你在做大型工程的时候,你让 code 去读代码库,然后了解这些东西,我觉得是非常好 token 的。 呃,然后, 呃你用千万这种小的模型用可乐扣的他本身可乐可乐扣的,我觉得他的工程能力还是比较,就是从目前的层面来说,可乐扣的他,呃, a 站的做的肯定是断档领先的吧。呃,大家用过的可能都知道,所以我会让他去探索整个代码库,然后把整个 我需要了解的功能啊,或者是我要了解的整个的流程,或者一些核心的设计,我会让他先给我写出来。嗯,有时候我会让他画一个架构图,然后有时候我会让他写成 md 文件,然后写完这个 md 文件我再用 code 去开发,因为 code 毕竟 呃钱是很贵的啊,然后也经常不够用啊,千万的话还可以还够用啊,所以我会去这么做啊。然后这个就是我今天的一个整体的分享,然后感谢大家。
23Qoder 00:06
00:06 16:07查看AI文稿AI文稿
16:07查看AI文稿AI文稿呃,很高兴过来给大家分享我们抠的的一些一些设计和一些理念啊,然后我叫陈安,呃,就这我花名,我真名叫夏小文,然后主要是呃参与去做抠的上下文相关的一些,呃技术上面的一些开发, 嗯,然后呢?这是我今天想要分享的一个主题,就是,呃,刚才那位老师,老师也也讲过的,对吧?就是现在 啊 ai coding 它已经不只是一个 coding 了,它已经是在一个往更大的一个 scope 去发展了,就是 它从辅助到自主,就是嗯,它除了写代码,我们还还能去帮你做很多研发产品,下面研发产品整个大环节里面的其余的部分,嗯,这是现在 ai 的 话,正在,呃正在往这方向去去发展。 然后呢?呃,讲这个主题呢,就是,呃,主要还是想要先有一个影子,就是给大家看一下,就现在 ai 的 话, 嗯,对,对于我们行业的一个冲击,就包包括这两部分,一部分的话就是影视行业,对吧?然后还有就是我们现在这个软件行业,然后他们的本质其实都一样的,就是 ai 的 话,它已经把整个行业的这么长的一条线路都通过一小部分人的话就可以做到了。 像影视行业的话,像有编剧、导演、演员化妆、道具、场景后期制作,然后包括发型,包括特效之类的。现在啊 sit down 或者 happy house, 它一次性帮你直接生成了,跳过了这么长的一个复杂行业的一个链路, 就直接帮你端到端生成了,这是 ai 最可怕的一点。所以现在软件行业的话,它也是一样的性质,就是我们软件行业的话中间内容也很长,有产品、有设计、有运维, 这个整个团队下来的话也是有五十五十多号的以上。那现在呢? ai 的 话他帮你做到整个环节内所有的事情,也是一个端到端交付,这是这是一个必然的一个趋势,也是的话现在就我们扣的一直在做的一个呃范式,嗯, 这是这是一个趋势啊。然后所以的话我们现在的话就在讲,就扣的就在讲我们现在要做的一个流程重塑。 嗯,然后呃了解我们 q 的 ide 的 话,背景的话我估计大家估计也比较清楚,我们以前在二四年的时候,我们就已经在做一些辅助编程的一些事情了,然后我们有个内部项目叫 cosy 的 话,也是做这种蛋白补全相关的一些,呃, ai, ai 体校, 然后后面的话我们推出了通用领马,通用领马也是我们扣的一个呃呃兄弟产品,然后主打的也是一个协同编程,然后那个 然后呃先补全,然后现在的话就是主推领马,就主推还是协同那一块,就是我们能去生成,告诉 ai 去生成代码,这是二四年到二五年的这个呃这个趋势, 然后现在呢?现在呢?大家的一个宏观趋势,就是 ai 的 话他自自主的去编程,自主的帮你完成这个呃研发任务的一个伪派,然后那个呃帮你做好测试部署,然后包括验证,包括发布部署相关的一些事情。 这是这是一个图啊,就是也想要想想要去借着现在比较火的一个概念,就哈尼斯 engineering 的 一个事情去讲,就是怎么让 ai 去提升我们十倍的一个研发效率,就是 这个图也很明显,就是呃它就像一个自动驾驶的一个大环,这个是跑道,跑道就是我们呃呃,我们想要给 ai 定义的这些边界, 然后 ai 这这些一一点一点的就是 agent, 他 这个 ai agent 在 这个呃大环里面可以高速运行,但是,但是呢 只要在这里我们有人参与的话,有人参与的话,我们就可以把我们就会导致这个效率急速的下降。所以我们怎么让 ai 能够提升这个识别的效能呢?就是尽量在定好 ai 的 安全边界之内,让它高速的运行,然后不要有人参与, 就不要有人去参与,因为有人参与的话,他的协同场景是会有很大的流程损耗和摩擦的啊。 然后呢是这个就还是说的这个 honey's engineering, 然后呃我们有,我们以前的话,二二五年的时候,嗯,我们着重去建设这个 contest in 链链的事情,我们是给他做多轮迭代,然后模型,然后工具反馈提示词之类的,然后现在的话我们正在做这个架构约束,然后多智能体的一些,多智能体的一些架构, 然后专业场景啊,端到端交付, want shop 就 一次性帮你做好一整个链路的事情,所以我们现在就这个方式在转变,就是我们已经从,我们已经从从抠定这个场景走向端到端交付,嗯, 然后呢我们,呃,我们现在是以 s w e agent 和回合为核心去重铸我们这个软件研发流程, 然后之前的话,我们整个软件研发流程的话,链路上是有一些痛点的,包括上下文过程,然后 human in the loop 就 需要有人参与,需要有人参与,然后呢?嗯, 然后呢?我们需要有一个更好的 honey 式来去解决我们这个端到端的人交互,包括我们多智能编排,多智能体编排,然后包括我们重点去建设的这个三角形,三角形引擎,然后一些自星引擎,然后我们现在是呃,我们大概是 年后我们就推出了我们这个多智能体的一个架构,就熟悉的人的话应该也比较应该,可能已经试过了,就是我们有一个专家模式,就一个多智能体的一个模式,帮你实现这个端的端交付,然后然后呢? 好,然后呢?我们这个多智能体将我们我们这边叫那个专家模式啊,就是我们会有一个 leader, 我 们会有个 leader, 然后我们还默认内置了很多的专家,然后有调研的,然后有前端编码、 ui 交互设计师,然后还有后端编码,然后测试。呃,前端测试包括验证啊,就是有一些并 并不是一些外部场景的话,我们也有一些呃端到端测试的一些产呃 agent, 端到端的一些 agent 去做,然后还有就是这个评选专家,然后我们通过这个专家这么多专家帮你做好整个端到端交付的一个流程。就下面的话,就是 一般情况下你去用的时候,我们都会先调研,然后做呃 ui 设计,做好 plan, 然后有如果说 plan 模模型还不知道应该怎么做的时候,我们也会让他去呃 ask user question 的 方式,就让 呃,让你去补充更多信息上和上下文,然后让你做好 plan, 然后就往后去执行,然后我们这个特点的话就是,呃,我们能跟这个多智能体架构去 跟这个专家模式模式去交流的时候,我们是通过这个 leader 去做交流的,我们不不直接对话这些专家,通过 leader 的 话帮你安排好所有的事情。 然后另外的话就是我们这个专家模式的话,还是一个异步的一个方式,可以你可以随时打断或者纠篇的方式去呃去提出更多的问题。然后这是我们的一个模式,可以给大家看一下啊, 就下好 code ide 的 话,我们在这边的话就有个就能去使用这个专家模式。 然后我们这个流程的话是,呃会先好先写好 plan, 然后再去呃 plan 的 过程中的话也会去描述好这个需求应该要怎么做,做成什么样子,然后最终是怎么验证的,端到端验证。嗯, 然后我们这个模式的话也是多并发的,你刚才看到了,就是我们一次性拉起了四个专家去帮你做同一个事情,但是他话他的分工是不一样的, 这也是我们一个比较好的一个特点。我们啊把一个事情拆成若干个,然后让他们并发去做,然后这个可以大大的减少你这个啊我们这个工作的一个时间。 然后另外的话就是我们还会,我们还设计了,嗯,我们还是一个越用越强的一个团队,我们帮你去持续的沉淀这个,呃, skills memory 还有一些可以附用的一些路径,然后让你的写作效率逐步提升。嗯, 然后,嗯嗯,然后就是我们这边有一个效果优化的一些策略, 我们做的内部的端到端的一些评选,然后我们从质量、成本和周期上面来讲的话,都是比精品比较好的,然后嗯, 像这个质量提升的话,我们是领先精品百分之十六,然后我们这个呃,嗯上下文上面有做过很好的优化,然后也会去再按照任务 的难度系数来去分配 b r 的 模型,然后那你达到这个酱本的一些一些一些策略。当然我们还有一些上下文压缩的一些策略也也是比较好的,然后也能把,然后还有还有就是能把你做好,这个更能缩短这个端的端的一个交付周期。 而我们我们为什么能做到这个嗯,这么好的一个效果呢?这是我们几个比较关键的一个技术因素。 一个的话就是我们工程的这是引擎,我们有我们有很多的上下文一些策略,我们包括 ripper、 ripper wiki, 我 们包括那个 呃上下文引,呃那个语义解锁、关键字解锁,然后还有一些记忆的一些沉淀,还有 skills 的 一些沉淀,我们可以做到这个呃 token 下下架百分之十的情况下,我们还能把准确率给它提升上去。 还有就是我们也在着重这个,这个自动验证这一块的话,也是我们目前 call 的 话比较着重去做的一个事情。就是我们呃现在 ai 生成代码的话,它那个效果已经非常好了,但怎么让 ai 去做下一步的事情?就是一定要做好这个自动化验证 啊?然后所以我们有一个验证的一个环节,就是就比如说我们有 browser agent 的 话去验证我们外部场景,外部场景,然后还有就是我们有 code review 的 agent 的 话,也能比竞品做得更好一些。 然后然后是这个安全安全的防火墙,就我们本地的话是有三三层的一个防护体系的,像 mac、 windows and 上面我们都有一些内合集的一些纱窗隔离。然后呃, 用的时候如果说他执行一些高危的一些高危的一些命令的时候,我们是可以让用户去选择啊,是要在沙县环境去跑呢?还是说你就直接不要让他跑了? 这是一些安全上面的一些策略。另外的话就是我们还有一些可选项吗?就是呃用 ai 去读的一些文件,他不允许是仓库外的项目外的。 然后我们工程知识引擎呢?就是这是我们的一些嗯, 一些一些一些一些架构级的一些东西,然后像 viki 啊,加货加太代码啊,然后我们去年的话也做好了一些 commit 的 一些缩影, 就是根据用户的一些仓库级的一些历史地理历史,我们去给他去做一些召回,然后就能去让他让 ai 知道呃历史的一些代码块和一些经验啊。 然后另外的话我们还做建好的一些图谱,图谱的一些缩影,呃,我们在呃我们最好的就是用,呃, 我们会给整个仓库库的贝斯建好一个图缩影,然后通过关系的一个方式,这种准确的方式来 ai 去调用,调用这个类似于 slp 的 slp, 就 让位于 server 的 一个呃功能去拿到一个准确的一个符号信息, 而这样的话就补全或者或者 ai 生成代码的话会更加的一个准确。 然后我们这边也做了一些评测,包括我们线上的一些一些 a b test, 或者说一些呃离线的一些离线的一些对比评测。我们相对于呃, 我们相对于普通的模式的话,我们有些提,有大概百分之十一的一个提升,然后还有 token ok, 这是一个比较泛的一个事情啊,就是现在的话,就流程的话已经不再是,就刚刚才讲的就是 ai 的 话,它已经不再是一个写代码的一个事情了,或者它已经不只是擅擅长于写代码,它现在是擅长于去 重塑我们整个传统的产研流程,就它已经从生成代码从变成了去干做事情的这个这个过程了,就帮你做好整个链路上面那些事情。像是我们这个验证,其实它不是一个代码 或者呃验收或者部署,它不是一个代码,它是一个呃做事情的一个过程,就 ai 的 话它现在非常擅长于做事情,嗯, 然后呃,然后讲到最后呢,就是嗯, 呃以前的话有很多人跟我讲过,就是 ai 它会不会淘汰程序员?所以这,这也是我这个嗯,今天想要讲的一个比较,呃,比较想有想法的一个事情啊,就是想跟大家讲一下,就我觉得我个人觉得是 ai 的 话它不会淘汰这个程序员, 而是让需求呃大爆发,让大家的想法能够做的更快更好这一个过程。然后比如说按照以前那种交通出行的一个方式,大家以前的话都是 在以前我们都是人力车,然后后面有马车、有自行车,有有汽车、有火车、有飞机,就大家对这个速度的追求,或者对速度的一个需求,他从来没有消失,反而是因为我们这个效率提升了,然后爆发起来了。我觉得 ai 在 我们这个软件行业的一个,呃,眼镜,啊,啊,叫错了,在 ai, ai 在 软件行业上面的一个眼眼镜,我觉得也是如此,就让大家不需要再去做这个非常细节的一些代码生成了, 但它能够让我们把某一个想想法很快的就能落地出来,马上就给它做出来,这就是我们 ai, ai 对 我们的一个呃,比较好的一个帮助。 ok, 然后我给大家演示一下那个我们在内部的用的一些场景啊,然后内部研发的用的一些场景,然后还有也几个小游戏,就是我做的一个小游戏,给大家看一下。
58Qoder








