大家好,我是麦东。 hermes 零点一四版本终于带来了一个大家期待了很久的更新, hermes engine 终于原生支持在 windows 上安装了。 之前想在 windows 上用 hermes, 我 们必须先通过 wsl 搞一个 linux 子系统,对于很多技术小白来说,这个门槛儿就把它们给挡住了。 现在零点一四版本开始,我们通过 cmd 或者是 power xl 运行一条命令就可以直接安装 harms 了,不再需要 wsl 了。而且这次还多了一个更简单的安装方式,通过 pip 命令即可安装,对于本地已经有拍摄环境的朋友来说还是非常友好的好。下面我们来看一下具体怎么安装。 首先第一种方式,通过 power 线安装脚板,我们只需要打开 power 线,运行如下这条命令即可,这个脚板会自动帮你装好所有的依赖,包括 uv 包管理器, python, node js, rip group, ffm pack 等等。如果你电脑上没有 get, 它还会自动去下载一个。 这是第一种方式,通过一键脚本进行安装。第二种方式,我们还可以通过 p i p 安装,如果你电脑上已经有拍摄环境,那么我们直接运行 p i p install harmony engine 即可完成安装。 安装完成之后,所有的 harmony meaning 跟之前都是一样的,这个方式呢,更加简洁,适合本地已经有拍摄开发环境的同学。好,下面我们打开发校给大家演示一下完整流程。 我们还是使用官方的一键安装脚板进行安装,直接将一键安装脚板粘贴至发光效果,按下回车可以看到它在检测系统环境,然后依次安装各个依赖。这边需要注意的是,如果你的网络环境不太好,可能需要稍微多等一会, 只要安装脚板没有报错结束,那么就不用管它,耐心等待即可。 安装脚本自动帮我们启动了触式外的配置。首先第一步依然还是会检测你当前电脑上有没有装过 openclaw, 如果有,它会提示你是否需要导入 openclaw 相关的配置, 我们可以输入 y 确定导入。 ok, 接下来开始配置 harmony, 这边我们直接按下回车,选择 quick setup, 到了选择模型这一步了, 本次演示我们就以大家用的比较多的 dsp 为例,这边需要注意一下,之前我们无论是在 wsl、 macos 或者是 linux 安装在这一步配置模型的时候,我们都是可以通过方向键上下切换模型进行选择的,但是 windows 原声安装的时候目前是不支持这样设置的, 我们需要手动输入模型供应商前面的编号,再按下回车。可以看到 dsp 这边前面的编号是十七,我们输入十七 按下回车。接下来输入 deepsea 的 api key, 这边要注意一下,之前很多朋友在配置 api key 的 时候都会搞错,在 power 七二里面粘贴的动作不是通过 ctrl 加 v 完成的,而是通过鼠标右键, 鼠标右键一定也不要多点,点一下就行了,然后按下回车。接下来第二步配置 v c u r l 这个一般是不需要改的,直接按下回车。第三步就会让你选择默认模型了,我们这边选择 deepsea vs flush, 按下回车 ok, 模型就配置完成了。这一步是让你选择在哪里执行,后端我们直接默认回车即可在本地执行。 下一步就是配置消息对接平台了,这一步我们在本次视频里面就不做演示了,国内主流的消息平台对接我们在之前的视频里都有讲过,大家可以回过头去翻一下我前面的视频,我们选择二,暂时不配置消息平台,按下回车, ok, 配置完成。下面我们最好关闭当前的 power 界面,重新开启一个新的 power, 输入 harmony, 按下回车,打开对话界面,下面我们跟 harmony 打个招呼, ok, 可以 看到 harmony 已经给我们响应了,到这边我们的基础配置就已经完成了。需要注意的是,目前 harmony 的 原声 windows 安装还是处在早期 beta 阶段,可能还是会遇到一些小问题。官方在这个版本里面也修了四十多个 windows 相关的 bug, 但是呢,毕竟是第一个正式支持的版本, 遇到一些问题我们也可以去 github 上给官方提一些英雄。好了,本期视频到这边就要结束了,最后总结一下,如果你之前因为 wsl 的 门槛没用上哈密斯,那么现在可以去试一试了, 只需要通过一条命令即可完成安装。如果你本地有派生开发环境的话,通过 p i p 的 方式安装会更加的方便,不需要你再去折腾 linux 环境了。大家如果有在 windows 上已经安装了的,可以在评论区反馈一下体验怎么样?工具会变,但方法更重要,我是麦冬,下一条继续。

粉丝8709获赞2.2万
相关视频
 05:19查看AI文稿AI文稿
05:19查看AI文稿AI文稿opencloud 中如何让你的 ai 智能体自己对话,自己写作呢?不用你挨个发指令,它们自己就能自动的沟通分工,甚至开会讨论。今天我就把 opencloud agent 之间的通讯机制讲清楚。 在 opencloud 中, agent 是 不能够直接对话的,而是要通过 session 绘画功能来进行统一的调度。我们来看一下帮助文档进入到 opencloud 的 web ui, 点击左下角的文档,来到 opencloud 的 官方文档, 我们首先把它调成中文,点击代理这里的绘画工具。可以看到 openclaw 为智能体提供了跨绘画工作的这些工具,其中主要的就是 seson 和 seson 这两个, seson, seson 是 将绘画发送到另一个绘画,并可选择性的等待回复,然后 seson 是 启动一个子智能体,创建一个隔离对话,主要用的就是这两个。 我们来看一下实力是怎么做的。首先是来到 opencloud web ui, 点击左侧的代理,我们来看一下当前的代理, 我们看现在已经设置了三个代理,分别是 coder, manager 和 writer, 那 分别代表着一个是程序员,一个是管理,一个是写作。我们来看一下它们各自的设置,在这里我们就不讲了,我们主要看一下它的绘画部分,点到 manager 它的 tools 这里可以看到在这个快捷设置里,它的设置,我给它点到了 messaging, 中文翻译过来就是消息传递, 这样的话它读写,编辑这些权限都没有,它只有 session 这里的权限,也就是说 manager 只是把任务分配给其他的 coder 和 writer 来进行执行,所以只需要把它的 session 这里打开就可以了,最重要的是这个 session send 和 session sport 这两个一定要打开,就是点一下这里的 messaging, 设置完了之后,我们点一下保存 save, 其他的 coder 和 writer, 它们可以设置的宽松一些。下一步我们还要修改一下 opencloud 的 配置文件,找到它的配置文件 opencloud 的 json, 然后点击打开。 首先我们要到工具里边 tools, 首先要设置 session 的 可见性 with ability with o, 所有都可见, 这样的话方便我们可以查找对应的 session。 然后要打开 agent to agent 这个工具, agent 之间可以相互对话,这样的话设置 enabled 为 true。 然后 allow 是 允许哪些 agent 进行对话,我们把我们 可以进行对话的这些 agent 打到这里,然后同时还要什么呢?还要给这个 manager, 这个 agent 进行授权, 它的这个 sub agents 里边有这个 low agents, 就是 manager 有 权限可以对话的 agent, 我 们可以把 writer 和 coder 这两个授权给他,其他的你可以看你将来要做什么,在这里给他增加授权。下面我们用飞书来给大家演示一下,我们这个飞书的大总管已经绑定了 manager 这个 agent, 我 们跟大总管说一句,列出 所有的主 agent, 可以 看到他已经把我们授权给他的三个 agent 列了出来,还有一个麦是没有授权的,所以不在这里显示。那么下一步呢?我们 告诉这个 manager, 也就是大总管如何把任务拆分,并且交给其他的代理来进行执行。我们在这里告诉他,你不用做任何工作, 只需要我把安排给你的事情进行拆分。编程类工作 交给 code, 文案写作类工作交给 writer 来执行。好打个回车, 他已经回复我们了,明白了,那现在我们来让他做一个任务,编写一个 python 的 小程序九九乘法表,并写出写出一篇这个应用的使用方法 的小红书文案打回车让他去执行。提示我们任务已经分配给了两个子代理,分别是 code 来负责编辑程序, writer 来负责拣写小红书文案。 现在小红书的文案已经写完了, python 程序也写完了,我们看一下在 workspace, 我 们看一下 code 里边这个就是最新写的九九乘法表,九九乘法表 再进 workspace 的 writer, 它没有保存,直接就给我们返回来了这个文案,运行一下这个程序, python t y 这个求救乘法表也已经完成了,文案也已经给我们返回来了,证明还是比较成功的。今天就到这里了,感谢大家的观看,再见!
1016波哥的AI课 01:23查看AI文稿AI文稿
01:23查看AI文稿AI文稿看看我的 agent 团队们,有写图文的、网站运营的、监控金价的、记账的,还有提供情绪价值的,后面还要增加一个视频剪辑的 open cloud 小 龙虾 用上多 agent 的 模式了吗?但像我这样每个 agent 对 应一个机器人的配置是有点广泛。在飞书上其实有一种更简单的方式,就是通过拉群,实现一个机器人多个 agent 多个群聊分别管理的模式。我们来以选择题、写作和神稿三个事情为例,完整的配置一遍, 一共三个步骤。首先用这样的命令创建多个 agent, 分 别负责不同的工作,然后给每个 agent 的 职责拉一个飞书群,并且把我们的唯一的这一个 飞书机器人添加到群里面。接着把每一个群聊和 agent 绑定起来,在这里查看群的 id, 通过这样的 bindings 配置把两者映设起来。最后不要忘记给飞书 channel 增加这两张配置,开放群聊和群聊中,不需要艾特机器人也能回复。 配置完成之后,在各个群里和 agent 对 话,给他们安排好职责和身份,让他们记录下来,你就可以在不同的群里指挥不同的员工工作了。像这样的流程,先选择题再写作,审稿,审完再改, 最后得到一篇完整的内容就可以发布了。这样做配置简单,效果强大,快来把你的 agent 军团也安排起来吧!关注我,带你玩转 open club!
1010唐斩AI编程 05:58查看AI文稿AI文稿
05:58查看AI文稿AI文稿玩 open 可乐、养龙虾最害怕什么?一旦发生了系统崩溃、误删除或者需要更换电脑这些特殊情况,如果没有一个完善的备份机制,那就意味着一切努力全白费了,都得从头开始。今天我用一条视频来给大家讲清楚 如何使用 open klo 官方的备份功能,以及如何还原系统备份。首先第一点我们要知道的就是 open klo 它的数据都存放在哪里?我们来拿 windows 系统举例,它的数据都存放在 c 盘 用户你的用户名我们往下找,找到点 open klo 这个文件夹。 open klo 所有的数据都存放在这个文件夹里,包括配置文件、 api, 密钥, agent 机 e 安装的技能,还有 历史绘画等等等等。备份它就等于保住了所有的数据。那么该如何备份呢? opencloud 已经给我们提供了相应的命令,我们进入 opencloud web ui, 点击左侧下方的文档, 我们就进入了 opencloud 的 官方文档,选择中文,然后我们点击参考。在重置和卸载里边的第一个叫做 back up, 这个就是 openclaw 提供的官方备份命令,我们可以看它的最简单的一记用法就是 openclaw backup great。 我 们来运行一下这条命令看一看。首先在运行这条命令之前,我们要把 openclot 的 gateway 停止,因为如果不停止,在运行期间产生了新的数据,那么就会产生数据上的错误,所以我们要做的第一件事就是把 openclot gateway 停掉,所以我们要用 openclot gateway stop 来停掉 openclot 的 网关。 出了这个界面,代表着 openclot 已经停止了,我们来验证一下,用 openclot gateway status 来查一下现在网关的状态,可以看到现在已经停掉了,状态是 final, 然后我们开启一个新的窗口来运行这一句 open club back up great, 来运行一下, 可以看到提示,我们已经生成了一个备份文件,放在了当前用户目录下面,生成了一个带时间戳的文件,我们来找一下这个文件 用户这里我们找一下这个文件,就是这个,它是一个压缩包,我们打开看一下, 就是这些备份文件全都在这里,他是把我们整个的点 open 可乐全部备份到了这个压缩包内, 也就是说到时候我们还原,只要还原这个文件,就可以把现在所有的状态全部带过来。备份已经完成了,我们还有一件事情要做,那就是确认这个备份是完整的, 是成功的。那该如何操作呢?这个就需要使用到 openclaw 的 备份验证,这个命令就是这个 verify 命令,我们打开命令行工具,运行 openclaw back up verify, 然后输入文件名,打回车,看一下它的验证结果,这里显示 ok, 就是 代表着这个验证已经通过了。 back up 还有很多其他的参数和用法,比如说可以自定义输出的文件夹,可以自定义需要备份的文件等等,大家可以针对自身的需要来对照,帮助文件进行 自己的尝试。了解完了 openclaw 如何备份之后,我们再来了解一下如何还原备份。很多网站给出的解决方案是使用 openclaw backup restore 命令,我可以明确地告诉大家,在最新版本里 是没有 restore 这个命令的,这里是帮助文件,大家可以看没有 restore, 然后我们再用命令行工具来验证一下到底有没有这个 restore 命令。我们来运行 openclaw backup help, 我们可以看到它的命令只有三个, create help, verify, 这三个命令是没有 restore 的, 所以用 restore 命令是无法还原 openclaw 的 备份的。那么该如何还原呢?我们先把 openclaw 卸载, 我们来找 openclaw 这个文件夹,可以看到已经没有了这个文件夹,我们再来安装一遍 mpm install 已经卸载完了,我们来看一下 openclaw 的 版本是二零二六点五点一二,再来看 openclaw 它有哪些 agents, 它就只有默认的 mac 这个 agents, 我 们也没有对它进行初步的安装。我们现在来看该如何还原这个 openclaw 呢?我们还是回到当前用户的目录,刷新一下,可以看到 open 可乐已经在这里有了他的文件夹,但是没有设置,因为这里,因为这里只有两个文件夹,其他什么都没有,那么我们返回找一下备份文件,双击打开,然后我们顺着文件夹往里找一找, 这就是点 open 可乐这个文件夹,我们把这个文件夹整体拖到这里,覆盖原来的文件夹, 然后选择替换目标中的文件,这些错误我们先跳过,然后我们来运行 opencloud getaway, 看看能不能启动 opencloud getaway 往关,我们来访问一下 opencloud web ui 试一下,等会等会一八七八九, 这是已经启动了,把原来的这些信息都已经带过来了,那这个还原工作就已经完成了,这次给大家带来的是 opencloud 的 备份与还原,今天就讲到这里了,谢谢大家的观看,再见。
85波哥的AI课 03:44查看AI文稿AI文稿
03:44查看AI文稿AI文稿大家好,我是麦冬。今天我们来聊一个很多人问过的问题, promise 能不能对接 obsidian? 答案是可以的,而且配置非常简单。在正式开始之前,我们先简单介绍一下 obsidian。 obsidian 是 一个本地流行的 markdown 笔记软件, 所有笔记都是以 dmd 文件的形式存在你的电脑上,不依赖云端。它最大的特点呢是双向链接,你可以把笔记之间相互关联起来,形成自己的知识网络。很多人用它来做读书笔记、项目管理以及个人的知识库。 因为数据全在本地,所以天然适合跟 harmless 这种本地 a 境的进行对接。并且呢, harmless 安装好了之后,自带了 obsidian 的 skill, 你 不需要装任何 obsidian 的 插件,你只需要告诉 harmless 你 的 void 在 哪,它就能直接读写你的笔记,读笔记,搜笔记,建笔记,改笔记,它全部都能做。 那么具体怎么配呢?首先第一步,你需要找到你的 obsidian void 的 路径, void 就是 obsidian 里面笔记库的意思, 其实它就是你电脑上的一个文件夹,所有笔记都存在里面。在你第一次安装 obsidian 的 时候,它会让你配置这么一个文件夹作为它的笔记库。如果你不确定你的 word 在 哪也没关系,我们打开 obsidian, 将鼠标移动到左下角,稍等片刻,它就会悬浮显示出你当前的笔记库路径。比如我的就是在 d 盘下的 obsidian 文件夹。好,下面我们打开 hermes, 给大家演示一下如何让 hermes 连接上你本地的 obsidian。 我们打开 harmony 的 聊天界面,只需要跟他说一句话,帮我把 opposite void pass 设置成杠 m n t 杠 d 杠 abc, 写到你的点音频文件里面。这边有一点需要注意,因为今天演示是以 windows 电脑为例给大家做讲解的。 windows 电脑上有一点需要注意一下,大多数情况下,我们的 harmony 是 跑在 w s l 里面的,它是没有办法直接识别 windows 的 路径的,所以我们需要将 windows 的 路径转换成 w s l 的 格式, 就是把盘符改成斜杠 m n t 斜杠盘符的小写,比如说我的地盘 obsidian, 对 应过来就是斜杠 m n t 斜杠 d, 再斜杠 obsidian, 好, 直接按下回车, hermes 会自动打开它的环境变量文件,并且把这行配置加进去,你不需要自己去找文件,手动编辑让它自己去搞定就可以了。配置完成之后, ctrl 加 c, 关闭当前绘画,然后重新运行。 hermes 打开一个新绘画就可以测试了。 我们先来试一下,我们跟 hermes 说帮我搜一下 word 里面关于 document 的 笔记, 可以看到它直接列出了所有包含 docker 关键词的笔记、文件名和匹配内容。这个搜索是基于文件内容的权威搜索,并不仅仅是文件名,所以搜索还是相对比较准确的。下面我们再试一个帮我写一篇 docker fire 编辑指南的笔记,存到 void 里面 好了, hermes 跟我们说已经写好了,下面我们打开 ocd 看一下, 可以看到这边已经多了一篇 docker fire 编辑指南,并且 hermes 自动帮我们将它跟之前的两篇笔记关联到了一起,点开关系图谱也可以看到。 好了,今天的演示到这边就要结束了,最后还有一个小 tips 要提醒一下大家, hermes 操作 obsidian, 它是不需要 obsidian 本身在运行的,因为它是直接读写文件系统的,跟 obsidian 的 app 是 没有关系的,所以你关注 obsidian 也完全没有任何问题。 大家平时都在用什么工具管理自己的知识体系呢?欢迎在评论区聊聊。工具会变,但方法更重要。我是麦冬,下期继续。
315麦冬AI实验室 05:45查看AI文稿AI文稿
05:45查看AI文稿AI文稿大家好,我是麦东。很多朋友吐槽 hermes 自带的网页界面没有对话功能,界面也不好看。我去 github 上翻了一圈,找到一个大佬写的第三方面板,叫 hermes web ui, 实测下来确实比官方自带的 ui 要好用一些。 这个面板基本上把 hermes 的 所有功能都搬到了网页上,像模型配置、定时任务、渠道管理,全部都能在浏览器里操作,不用再去改配置文件了。安装非常简单,只需要在命令行执行 npm store 杠 g hermes web ui 就 可以了。 安装完成后,只需要运行 hermes web ui start 就 跑起, 服务启动完成后会自动打开网页界面。下面我们就来看最基础的聊天功能,这个就是非常多的朋友想要的,能够在网页上和 hermes 直接进行聊天。而且你的 hermes 本身通过 profile 创建了多个智能体,我们还可以直接在左下角进行智能体的切换,切换完成之后,相应的绘画界面也会随之刷新。 除了切换用户之外,你在系统里面配置的模型也可以在这边自主进行切换。另外, hermes web ui 还有一个比较有意思的群聊功能,我们可以通过创建群聊,把多个 agent 拉到一个房间里面,在群聊里面可以通过艾特方式指定某个智能题给你回复。下面我们演示一下这个比较有意思的功能, 点击新建群聊,输入你的群聊昵称以及房间名称, 点击创建房间。创建完成之后,在右上角我们可以点击加号添加智能体,在这边可以选择不同的 profile, 将它们加入群聊。我们首先将 default 加入群聊,再添加一个 coder 或者编程助手, 下面我们来尝试一下在群聊里面艾特它们,跟它们进行对话。我们同时艾特两个智能体,让它们介绍一下自己, 可以看到两个智能体分别都给了我回复,这个还是比我们在命令行里面操作要方便很多。当我们想跟不同职责的智能体进行对话的时候,我们不需要去不停地切换 profile 了,直接在这个网页群聊里面去艾特它们就可以了。 当然了,如果你已经将这些智能体接入到了实时通讯工具里面去,那么也是一样的体验效果。下面我们接着往下看。 搜索功能就是对绘画的解锁,解锁到相应绘画之后,我们可以直接点击进入当前绘画,接着跟智能体继续往下聊。任务功能则是管理我们 hermes 里面的定时任务,我们可以在这边去创建定时任务,也可以对已有的定时任务进行管理。 频道功能则是用来对接各个实时通讯平台的,目前内置了八个平台,我们国内常用的通讯工具在这边也进行了集成。他这边比较方便的一个点是每个平台相关的配置参数都可以直接在网页上配,改完他会自动重启消息。网关 技能菜单可以查看你当前智能底下所有的 skills, 并且可以对这些技能进行开关。记忆菜单则是对你当前用户的所有点 md 以及 memory md 的 一些管理,我们可以在页面上直接对这些文件进行编辑。 模型管理也做得比较完善,我们可以直接在页面上去添加相应的模型,配置模型的时候,也可以在页面上看到相应的 api key, 这个对很多新手朋友来讲还是非常友好的。之前我们讲 hermes 模型配置的时候,很多朋友在配置完模型之后去跟 hermes 进行对话,都提示四零幺,基本上都是因为 api 可以 配置错误了。 除此之外,我们还可以在页面上看到 hermes 的 一些日制,看到你当前 token 的 一些使用情况。工具这边还提供了终端功能,你可以在这边直接输入相应的命令,跟你打开命令行输入是一样的。 除此之外还有文件管理功能,你可以在页面上直接对文件进行编辑查看,或者是下载上传都是可以的。再往下看网关这边则是管理我们的消息网关的,也就是管 harmis 跟外部的一些通讯平台通讯的。这边提供的功能比较简单,我们可以对某个 profile 的 网关做停止开启操作, 不需要再去命令行里面敲命令执行了。再往下是用户菜单,用户其实就是我们讲的智能题,看过我前两期视频的朋友应该知道,当时的这几个智能题都是我使用在命令行通过敲命令的方式去创建的。而现在我们可以直接在页面上点击创建配置, 就可以非常快速的去创建新的智能体了,并且创建智能体的时候同样可以使用克隆功能,还是非常非常方便的。最后一个菜单设置,设置里面我们可以给当前的 hermes 网页设置一个密码登录,可以配置当前网页的一些显示主题 配置我们跟 ai 对 话时候的一些显示信息,比如流质响应、推理过程、显示费用等等。除此之外,还有对智能体记忆、绘画、隐私的一些设置,这些配置都比较好理解,我们就不一一去讲了。不过最后这个模型我们还是要跟大家去说一下, 这个地方我们可以修改当前已经添加进来的模型的 api key。 大家应该有注意到,刚刚在配置模型的时候,对于已经存在的模型,我们是没有办法对它进行编辑的,那么如果你模型的 api key 发生了变更,我们就可以在设置这边对其进行调整 好了。 hermes web ui 完整的功能介绍到这边就差不多了,关于 hermes web ui 的 一些基础英文命令,我这边整理了一个手册分享给大家,希望对大家有帮助。总的来说,如果你觉得 hermes 原声界面不够用, hermes web ui 是 我目前找到的最完整的第三方面板, 像渠道管理、模型配置、使用统计这些高频操作全部搬到了网页上,对于新手小白来讲还是非常友好的。大家目前都在使用什么 hermes 的 面板呢? 体验怎么样?欢迎大家在评论区聊聊。工具会变,但方法更重要,我是麦冬,下条继续。
515麦冬AI实验室 06:36查看AI文稿AI文稿
06:36查看AI文稿AI文稿大家好,我是大叔,只说真话,只做实在事,只给干货。上周有个创业团队找我,说他们公司有五个开发人员在用 hermes agent, 每个人都在自己电脑上配置了一遍,结果每个人的 agent 行为都不一样,代码审查标准不统一,文档风格乱七八糟。最麻烦的是,每次有人更新了 skills, 其 他人都要手动跟着改。他问我有没有办法能让整个团队的 a 键的配置保持一致,还能自动同步更新。我说 profile distribution 这个功能就是为你们这种场景设计的,它能把整个 a 键的打包进 get 仓库,一条命令就能让所有人都用上最新的配置。 今天我就把这个功能做个详细讲解。先说说以前的做法有多麻烦,你要手动发送搜点 md 人格文件,还要分享坑费点淹没配置文件, 记得手动删除里面的密钥架,再描述 m c p 服务器连接配置,说明定时任务设置,告知需要设置的环境变量,最后祈祷对方能正确组装所有配置。 每次版本更新都要重复这套流程,简直是噩梦。更糟糕的是,团队成员配置不一致, a 键的行为差异大,手动复制文件容易遗漏或出错,无法追踪配置变更历史,回滚到旧版本几乎不可能。 现在有了 profile distributions 这个革命性方案,它能把所有配置打包成一个 get 仓库,一行命令搞定。这个方案有四个核心特点,第一是完整打包人格 skills 配置, m c p 定时任务全部包含。第二是一键安装 hermes profile install 一 条命令完成部署。 第三是自动更新 hermes profile update, 拉取最新版本。第四是安全隔离, api 密钥和记忆数据完 完全独立,不会泄露。它的核心优势也很明显,零构建步骤,直接推送到开源 get 代码仓库,无需打包上传。 get 原声版本控制 tag 分 支 commit 就是 版本系统增量更新,只拉取变更,不是重新下载。整个包透明可审计,可以浏览代码,查看差异,提交 issue, 私有仓库免费支持 ssh 密钥 get 凭证自动认证。一个完整的 distribution 包含以下文件,首先是 distribution 点 yammo, 这是清单文件,包含名称,版本,环境变量要求。然后是搜点 md, 这是 agent 人格核系统提示词。 接着是 confid, 点 yammo, 包含模型、温度推理工具,默认配置,还有 skills 目录存放捆绑的 skills, 随 agent 一 起分发 chrome 目录存放定时任务配置。最后是 m c p, 点一上 m c p 服务器连接配置。 distribution 点 emo 是 这个结构的核心, 它定义了 agent 的 名称、版本描述、作者、许可证等信息,还声明了必须的环境变量,比如 one api i key 和 sapkey key, 只有 distribution 点 emo 是 必须的,其他文件根据需求添加。作为作者发布流程只需要四步。 第一步,创建并调试 agent, 使用 hermes profile create 命令创建新 profile, 然后进行 set up 配置 编辑,搜点 md, 安装 skills 配置 mcp, 设置 crown, 最后用 chat 命令测试直到满意。第二步,添加 distribution 点 emo 清单文件,在 profile 目录下创建这个文件,定义 agent 的 基本信息。 第三步,推送到 git 仓库,进入 profile 目录,执行 git n i t 初步化仓库。然后 git a d 添加所有文件, git commit 提交并打上版本号标签。 最后 git push 推送到远程仓库,记得加上 text 参数。第四步,版本更新,修改 distribution 点 ymail 的 版本号编辑,搜点 md 或添加新 skills。 再次 git edit git commit git tag git push 完成更新。对于用户来说,安装只需一条命令,执行 hermes profile install 开源 git 代码仓库斜杠 u 斜杠 resport 加上 alias 参数, 安装过程会自动完成七个步骤。克隆仓库到临时目录,读取并显示 manifest 信息。检查必须的环境变量标记已设置或需配置请求确认可以用 y 参数跳过复制 distribute 信息。检查必须的环境变量标记以设置或需配置请求确认,可以用 y 参数跳过复制或模板。最后创建别名包装器。 它支持多种源类型,开源 git 代码仓库,简写完整, h t t p s s a h 都可以。还支持自托管的 gitlab, gititer 以及私有仓库。甚至可以直接从本地目录安装,方便开发测试。安装完成后,需要配置 api 密钥。复制 invi 点 example 模板位 invi 文件, 然后编辑填入真实密钥。更新机制非常智能,只需执行 hermes profile update research bot 一 条命令, 它会区分哪些文件属于 distribution, 哪些属于用户。 distribution 拥有的文件包括搜点 md skill 目录。 chrome 目录会被新版本替换。用户拥有的文件包括 memories 目录, sessions 目录。 off 点 jason 英 b 文件永远不会被触碰。 covari 点 e m o 默认保留用户的修改。如果想重置,可以用 force config 参数。你可以在 distribution 点 e m o。 中自定义 distribution on 的 列表,精细控制哪些文件会被更新替换,什么时候应该用 distribution? 适合的场景有四种,分享给团队或社区的专用 agent, 部署到多台机器,避免手动复制迭代开发,并希望用户一键更新,将 a 键作为产品发布。不适合的场景也有三种,仅备份自己的 profile, 应该用 export 和 import 功能。想分享 a p m 要这是故意排除的。想分享记忆或绘画历史用户数据,不打包。实际应用案例很多。合规监控 agent, 全公司统一配置,确保合规标准一致。代码审查 agent, 团队共享编码规范和审查逻辑研究助手 agent, 学术界分享文献解锁和分析流程。客服机器人 agent, 企业统一部署客户服务标准,核心价值就是标准化,可附用、易维护。 这里有几个高级技巧。技巧一,自定义 profile 名称,不同用户可以用不同本地名称安装同一个 distribution, 比如 alice 用 supporters, bob 用 support u, 但都来自同一个仓库。技巧二,精细控制所有权在 distribution 点 ymail 中指定哪些文件属于 distribution, 可以 只替换特定的 skills 指目录,其他安装的 skills 保持不变。技巧三,强制重置配置,如果想让用户的 confag 参数也更新到最新版本,使用 forceconfig 参数。 技巧四,本地开发测试,无需推送到远程,直接从本地目录安装即可。测试安装流程,推荐做法是每次稳定版本都打 tag, 方便用户选择特定版本。总结一下,为什么选择 get distribution, 它有四大优势,极简工作流,无需构建、打包、上传、 get push 及发布成熟版本控制 tags branches commits, 天然就是版本系统高效增量更新,只拉取变更, 不是重新下载。整个规章完全透明,可查看代码对比差异,提交 issue fork 定制 profile distribution 就是 agent 分 发的终极解决方案,快速开始只需要四步完善你的 agent, 包括搜点 md skills config 创建 distribution, 点研某清单推送到 git 仓库并打 tag 分享给团队,让他们执行 hermes profile install 命令。感谢观看,我是大叔大,下期见。
42大书大 06:45查看AI文稿AI文稿
06:45查看AI文稿AI文稿大家好,我是大叔,只说真话,只做实在事,只给干货。大家好,昨晚本来想着早点睡觉了,结果看到后台多了几十条私信,大家都在问同一个问题,就是怎么在同一台电脑上运行多个独立的 hermes agent。 如果用同一个配置,很容易搞 appme, 互相干扰,记忆和绘画历史也混在一起。 hermes agent 提供了 profiles 功能,可以完美解决这个问题。认真看完这篇教程,你将学会创建和管理多个 profile。 三种克隆方式,命令一 p 标志年性默认值的用法, 配置独立网关和机器人令牌,还有更新、导出、导入和删除操作。咱们直接看内容来。先了解一下什么是 profiles。 简单来说,就是一个独立的 hermes 主目录,每个 profile 都拥有独立的配置文件,包括 config 点 emo 点 inviso 点 md, 还有独立的记忆数据库、绘画历史 技能库和状态数据库,这样就能为不同目的运行独立的 agent, 比如变成助手、个人、机器人、研究 agent, 它们互不干扰,完全隔离。最方便的是创建一个叫 code 的 profile, 马上就能用 code chat、 code setup、 code gateway start 这些命令。好了解了概念,咱们看看怎么用。快速开始非常简单,只需要三步。第一步,执行命令 hermes profile create code, 这会创建一个名为 code 的 profile, 同时自动生成命令别名。 第二步,执行命令 coder setup, 按提示配置 api 密钥,选择模型提供商,设置默认模型。第三步,执行命令 coder chat, 就 可以与 coder 这个独立的 a 键开始聊天了,就这么简单,一共有三种,满足不同场景需求。第一种,空白 profile, 执行命令 hermes profile create my bot, 这会创建带有捆绑技能的全新 profile, 然后运行 my bot setup, 配置 a p i 密钥模型和网关令牌。第二种,紧克隆配置,执行命令 hermes profile create work 加 clone 参数, 这会复制当前 profile 的 config 点 emo 点 n v 和搜点 m d 共享相同的 api 秘钥和模型,但拥有全新的绘画和记忆。第三种,克隆全部内容执行命令 hermes pay profile create backup 加 cloneout 参数, 这会复制所有内容,包括配置, api 秘钥、个性、所有记忆、完整绘画、历史技能、定时任务插件、相当一个完整的快照备份。你还可以从特定 profile 克隆,比如, 比如执行命令 hermes profile create work 加 clone 参数,再加 clone from code, 这样就能从 code 克隆配置到 work。 创建好 profile 后有三种使用方式,第一种,命令别名,这是最方便的,每个 profile 在 波浪线斜杠点 local 斜杠被斜杠名称目录下,自动获得命令别名。 比如你可以直接用 code chat 与 code agent 聊天,用 code setup 配置 code 的 设置,用 code gateway start 启动 code 的 网关,用 code doctor 检查 code 的 健康台,用 code skills list 列出 code 的 技能。第二种,使用 p 标志,这是最灵活的执行命令 hermes 加 p code 再加 chat, 或者执行命令 hermes 加 profile 等于 code 再加 doctor, 甚至可以在查询时指定 hermes chat 加 pcode 加 q。 后面跟 hello。 这种方式适用于任何命令。第三种,粘性默认值,最适合长期使用。执行命令 hermes profile use code 之后执行 hermes chat 就 默认针对 code 执行。 hermes tool 也是配置 code 的 工具,如果想切换回默认执行命令 hermes profile use default 这类似于 quebeco configuruse context 的 使用方式。另外, client 会实时显示哪个 profile 处于活动状态, 提示符会显示 code 加右键头符号,启动时会显示 banner。 执行 hermes profile 命令会显示详细信息。 接下来讲讲如何运行 gateways。 每个 profile 可以 作为独立进程运行。自己的网关拥有独立的机器人令牌,每个 profile 都有自己的点音频文件,可以配置不同的电报 discord slack 机器人令牌最棒的是安全令牌所机制。如果两个 profile 要意外使用相同的机器人令牌,第二个网关将被阻止,并显示清晰的错误信息, 这样可以避免冲突。启动不同 profile 的 网关很简单,执行命令 coder gateway start 启动 coder 的 网关。执行命令 assistant activate taway start 启动 assistant 的 网关,它们是独立进程,互不干扰。如果需要持久化服务,可以执行安装命令。执行命令 coder gateway install, 这会创建 hermes gateway system d 或 launched 的 服务。 同样,执行命令 assistant gateway install 创建 hermes gateway assistant 服务。支持的平台包括电报、 discord, slack, whatsapp 和 signal 都支持令牌锁定机制。 每个 profile 都有自己的配置文件,主要包括三个文件,第一个是 config 点 emo, 这里配置模型提供商,工具级以及所有设置。第二个是点硬币文件,存放 api, 密钥和机器人令牌。第三个是 c o 点 md 文件定义个性和指令。配置模型很简单,执行命令 code config set model, 点 default antropics 斜杠 close on the four。 设置个性的话,可以用 e q 命令。执行命令 echo 后面跟双引号 u r a focus coding assistant 点双引号, 然后从定向到波浪线点 hermes profiles coder 目录下的搜点 md。 如果需要设置工作目录,执行命令 coder config set terminal, 点 cwd, 后面跟上项目的绝对路径。这里有个重要提示,搜点 md 可以 指导模型,但不强制执行工作区边界, 如果需要可预测的起始目录,请显示设置 terminal 点 cwd。 最后讲讲如何更新和管理 profiles 更新非常简单,执行命令 hermes update 这会拉取一次共享代码,然后自动同同步新捆绑技能到所有 profile, 用户修改的技能永远不会被覆盖。管理命令也很丰富。执行命令 hermes profile list 执 行命令 hermes profile coder devbot 显示一个 profile 的 详细信息。执行命令 hermes profile rename coder devbot 可以 从命名 执行命令 hermes profile export code 导出为 c, 点 t r, 点击 z。 执行命令 hermes profile import code 点 t r, 点击 z, 从规章导入。 如果需要删除 profile, 执行命令 hermes profile。 delete code 需要输入 profile 名称确认,也可以使用加 yes 参数跳过确认。删除操作会停止网关移除 systemd 或 launch 的 服务, 移除命令别名,并删除所有 profile 数据。另外还支持 tab 补全。对于 bash, 执行命令 evo 后面跟双引号,美元符号 hermes completion bash 双引号。 对于 zsh, 执行命令 evo 后面跟双引号,美元符号 hermes completion zsh 双引号。好了,今天的分享就到这里,咱们回顾一下核心功能。第一,独立运行在同一台机器上运行多个独立 agent, 每个都有独立的配置 api 秘要记忆绘画技能和网关状态。第二,灵活创建,支持空白创建,仅克隆配置克隆全部内容三种方式满足不同场景需求。第三,便捷使用,提供命令别名、 b p 标志、年性默认值三种使用方式,克莱实时显示活动 profile 状态。 第四,安全管理,每个 profile 独立运行网关,支持令牌锁定机制,防止冲突。提供完整的更新管理和删除功能。如 你需要在同一台机器上运行多个不同用途的 groupon agent, 比如编程助手、个人机器人研究 agent。 强烈建议使用 profiles 功能实现完全隔离,这样可以避免配置和状态混乱。我是大叔大实测验证并整理,后续会持续革命性 session 的 相关内容,感谢观看,咱们下期再见!
70大书大 04:15查看AI文稿AI文稿
04:15查看AI文稿AI文稿如果你已经把龙虾下载到了电脑上,那么你的第一个要完成的一定不是说你给他一个什么具体的任务,而是你首先需要对他进行初步化的一个配置,那这个配置的话,我简单的把它分成三个方面来讲,这每一个方面都非常重要。 首先第一个你需要给他一个标准的文件规范,这个文件规范有可能是比如说 word 文档,或者是 excel 表格,或者是 ppt, 或者是你在做的什么其他的工作,总而言之它输出的规范一定要标准, 那这个的意义在于什么呢?就是在于你可能会用它,你跟它要伴随很多年,那你的文件越来越多之后,你最后 自己去加工处理这些资料的时候,你会面对非常大的一个困扰,然后他有可能还会给你产生每一个文文件,给你产生很多个版本,那可能会更加的混乱。所以的话,我的建议是你先花一点时间先形成一个 呃,文件规范,你这个文件规范,你比如说你可以规定他的题目应该怎么取,前面的日期怎么排列,然后你的内容应该遵循什么样的一个输出规范,甚至你字体你都可以给他进行一个具体的要求。 那么你越具体之后,龙虾给你生成的这些东西,它就会越规范,你后面的加工调用的时候就会越简单和流畅。那第二个是这个性格描述, 因为你不管是采用什么样的龙虾,你需要的是一个靠谱的一个实事求是的工作伙伴,你不是要的一个电子舔狗, 所以说你给他的执行纪律就很重要了,那你很多龙虾或者是 agent, 他 都要求他都会有一个底层化的一个设置,是倾向于让用户感觉流畅,然后或者说顺着你的方向去说, 那这个的话你有可能你的考虑点已经距离事实很远,但是他依然是顺着你去,或者是产生各种各样的一个幻觉,那这个对你的工作结果肯定是难以实现保质保量的一个交付的。所以在这个方面的话,你可以也是要花一点时间形成一个 ai 的 执行执行纪律,比如说第一条实事求是,然后第二个你可以要求他 要输出的答案,要求质量,而不是以这个流畅等等这些。当然如果说有的兄弟可能不想在这上面就是搞的太复杂,那你也可以关注我,后面我会把这些标准的文本,我可以搞一个通用的版本发在评论区,大家可以直接复制去用就行了。 然后第三个方面也是非常重要的,龙虾为什么需要养?因为你一定要从这个角度来理解这个 ag 呢?他就好像是你公司新招了一个天才的实习生过来,他可能是一个通用型的专家,他可以通过调用大模型或者是其他的一些 skill 来去 充实他的知识库以前所未见的效率去学习。但是他终究不能理解你这个行业内在的那些可能不会上网的一些知识这些东西,而这些才是决定他能不能够变成你所从事的本领域类的这个专家的这个 高度,或者说它的深度。而这些东西就来自于你喂养龙虾的这么一个过程,所以我们叫做养龙虾,比如说你开会的会议就要那么你们每今年每月积累下的经营数字 啊,当然你在保证安全的前提下啊,然后再比如说你的这些营销策划案,再比如说你的其他的一些呃形成权益的文件等等,这些对于龙虾帮助了解你都是至关重要的。也就是说在这个 agent 这个时代, 你个人非但没有因为这个龙虾导致个人事业,相反他是会让那部分善用 agent 的 人的个人的能力得到无限的一个放大。 也就是说你复制一个归机版的你,那你需要把你的这些过去沉淀的这些知识,然后灌输到他,让龙虾了解你,让他成为一个 敬重的你,然后让他去替你干成那些。以前你可能需要去驱动、激励、管理别人来完成这些工作,而现在你只需要一串简单的提示词和约束词,你就可以让他帮助你高效的完成了,这个才是龙虾最重要的一个意义。
 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿如何在 hermes 当中配置多 agent, 实现不同能力的 agent 讨论同一件事情或执行同一件事情,类似于这个样子,比方我建立一个产品方案讨论时,我在里面创建了四类角色,当我去发布一个事情的时候,我可以艾特指定角色进行回复, 也可以让其中有一个角色调动其他人,这样就很具想象力的。那怎么设置?总共分为三步,第一步,在这个页面里面我们去创建用户,相当于就创建一个 agent, 点击这个地方, 你只要去定义他的名称就好了。第二步,很关键的事情,你需要去定义他能做什么,比方说我定义第一个产品经理,他的身份是什么样子,他能做什么已经不能做什么。 第三步,我们就只要在这个群聊里面去建立这样一个场景,把不同角色的人去拉进来,类似于这个样子,你把刚才创建好的这个身份去把它添加进来,这样一个群就创建好了,很简单,对了。
423智简 AI 09:00108大厂吾师兄(AI篇)
09:00108大厂吾师兄(AI篇) 05:39查看AI文稿AI文稿
05:39查看AI文稿AI文稿哈喽大家好,欢迎来到今天的解析。今天咱们要聊点齐齐用核,同时也绝对会让你眼前一亮的东西, hermes agent。 它可不是市面上那种普普通通的云端工具,而是一个能直接在你本地电脑上运行,并且会随着你的工作流不断自我进化的全自主性 ai 助手。 如果你一直在苦苦寻找一个能真正成为你左膀右臂的数字员工,那么今天的内容绝对不容错过。接下来几分钟,我们会来一次纯干货的零基础到高阶演练, 内容包含了 hermes agent 简介、环境检查与安装、首次启动配置、核心工具演示、进阶的技能提取与定时任务。最后是一个快速的总结和资源分享。咱们直接进入第一部分,先来聊聊 hermes agent 的 核心承诺,看看它到底凭什么与众不同。 大家可能用过像 openclo 这样的框架对吧?他们基本上采取的是一种网关邮件的设计,主要就是帮你连接到各大平台。但是 hermes agent 采用了截然不同的架构哲学,叫做 agent 循环邮件。这意味着什么呢?也就是说,它其实是一个闭环的学习系统,它不仅仅是个指挥死板、执行命令的机器, 它是真的能记住你的工作流,利用底层的持久化记忆系统,你每使用它一次,它都会在暗中学习,变得越来越聪明,越来越懂你。 第二部分,咱们得打好基础,一起来做一下环境检查和安装。在咱们真正敲击键盘运行代码之前,你得先确保电脑上准备好了这几样基础组建。首先排版必须是三点幺幺或以上的版本,其次是 note g s 的 v 二版本,当然还有不可或缺的 get。 这里要特别给用 windows 的 朋友提个大大的醒啊,原生的 windows 环境是没法直接跑的,你必须得提前配置好 w s 幺二,也就是那个 linux 子系统。这是硬性要求。 把前置环境搞定之后,安装其实特别轻松,简直就是秒级部署。你只需要在终端里跑一下官方提供的这行科询告脚本,它就会极其聪明地帮你把所有依赖都搞定。 不过呢,这里有个新手特别容易踩的坑,装完之后千万千万记得运行 source c capture, 刷新一下你的使用环境,不然的话,你的系统压根就不认识这个刚安装的新命令,直接给你甩的报错,那多扫兴啊! 环境就绪,咱们趁热打铁进入第三部分,首次启动与配置。在选择背后的大脑,也就是模型提供商的时候, hermes 给了你可以说是随心所欲的自由度。 想省事的极其推荐走 open routing, 只要一把 api 密钥,就能在各大顶尖与模型之间智能穿梭。当然,你也可以直接连 anthropic 的 cloud 训练。 但最爽的其实是,如果你自己本地算力扛得住,或者你对数据隐私有极高的要求,你完全可以通过填一个 base url, 无缝接入欧拉玛或者是 vlm。 知道这意味着什么吗?这意味着纯正的零 a p i 成本,纯本地运行,就算你把网线拔了,它照样能跑。你的数据永远安全地锁在你的硬盘里, 那怎么启动呢?完全由你做主。如果你是个急客,喜欢敲命令,直接输入 hermes 秒进一个纯命令行的交互界面。但如果你跟我一样,有时候就想点点鼠标图个直观,那你就敲 hermes dashboard, 它马上会在你本地的九一一九端口弹出一个极简美观的 web 面板。在那个网页里,什么模型、网关啊, api 密钥啊,点几下鼠标就全都配好了。 第四部分,到了真正见证魔法的时刻了。核心工具演示说真的,很多人刚开始用这种能操控本地电脑的 ai 时,心里都在打鼓,我直接用大白话让 ai 动我的文件系统,这真的安全吗?万一他脑子一热,敲错个命令,把我系统文件删了怎么办? ai 到底是怎么做到把咱们随便敲的一句聊天指令,安全无误地转化成终端命令或者文件修改的呢?其实这背后的定海神针就是智能审批系统加上隔离容器, hermes 绝对不会像无头苍蝇一样乱敲键盘。比如说,你让他执行个简单的 ios 命令,看看目录或者更复杂的文件,读写 它内部的语言模型。辅助评估机制会先像个安检员一样,对你的命令进行极其严格的安全审查。更绝的是,这一切都是在一个完全隔离的沙盒容器里执行的。它能精准做事,但绝对跨不过雷池半步,所以你完全可以把它当成你双手的一个极度安全的数字延伸。 接下来进入第五部分,这也是他真正的杀手锏,进阶的技能提取与定时任务。我们来看看这个所谓的技能自我提升闭环,到底是怎么颠覆工作流的。 这个过程有点像你带个徒弟,首先, hermes 会去执行一项复杂任务,跑完之后,他会自动评估自己干得漂不漂亮。一旦他确认任务成功了,最精彩的来了,他会自动把刚才摸索出来的操作提取成一套标准流程,取个名字,然后存成一个 markdown 格式的技能文件。 下次你再让他干类似的活儿,他直接秒调用这个技能文件,完全不需要重新摸索。这就是他越用越懂你的底层秘密。 那么,如果你把这些他自己摸索出来的武功秘籍,跟 chrome 这个 unix 系统里的定时任务调度神器结合起来,会发生什么?这就相当于你给他排了个班表, 你可以让 hermes 在 后台全自动完全独立地去跑那些极其耗时的复杂任务。无论是半夜偷偷备份,还是每天早上准点拉取最新数据,写好日报,他全包了,你彻底解放双手。 不知不觉了了这么多,咱们进入最后一部分总结与资源,咱们快速盘一下今天的硬核干货。它的安装几奇几简,一行课本全搞定,模型选择异常自由,本地云端通吃,而且自带 f t s five。 持久化记忆,是个真正能陪你一起进化的闭环 ai。 在节目的最后,我想留给大家一个真正值得思考的问题,如果有一天,你最依赖的生产力工具,它不仅能秒懂你的命令,还会主动观察你的操作习惯,甚至自己给自己编辑操作手册,那你每天的日常工作流会被重塑成什么样? 这种每天都在悄悄进化的 ai 写作者,你准备好迎接它吗?非常感谢大家的收看,咱们下次解析不见不散!
55古法编程-小周 08:02查看AI文稿AI文稿
08:02查看AI文稿AI文稿大家好,前几期大家对 hermes agent 已经基本入门了,今天要跟大家讲解一下系统性的东西,也是它的核心点。内容包含主配置的关键配置,从 hermes slash 目录结构到 config org org md 的 核心设置, 一次性给大家讲透,咱们直接进入正题,先看看 hermes 的 配置目录结构,所有配置都存在波浪线斜钢 hermes 斜钢目录里,方便访问、管理和备份。这个目录下有几个核心文件,第一个是 config dot emo, 主配置文件管模型、终端 t t s 这些设置。 第二个是 ib 文件,存 a 片密钥和敏感信息。第三个是 author jon o o 凭证,比如 news portal 的 认证。第四个是 so dot md a 键的身份定义占系统提示的第一位。第五个是 memories 文件加持久化记忆,有 memory dot md 和 user dot md。 第六个是 skills 文件加管,定时任务 sessions 文件加管,网关绘画 logs 文件加存,自动脱敏的日制。 记住一点,所有配置都在波浪线斜杠 hermes 斜杠目录里,方便统一管理和备份。目录结构清楚了,那具体怎么管理这些配置? 接着看 hermes 的 配置管理命令,很方便。想看配置,在终端输入 hermes config 就 能看到当前所有配置。想编辑的话,输入 hermes config editor。 想设置配置,用 hermes config set kz 为 vl, 比如设模行为 anthropic 斜杠 cloudops 是。或者设中后端为 docker, 检查配置有没有缺失,跑一下 hermes config check, 想交互是添加缺失选项,用 hermes config me great。 设 api 密钥时,输入 hermes config set open router api k y k r 会自动存到 in v 文件里,这里有个很实用的特性叫智能路由。 hermes config set 命令 会自动把值存到正确的文件 a p i 密钥存到因微其他设置存到 config 的 emo, 这样就不用担心把密钥物写到配置文件里了。配置管理命令讲完了,那这些配置的优先级是怎样的?往下看。 hermes 的 配置优先级从高到低分四层, 第一层, client 参数优先,即最高,比如跑 hermes chat model enterprise, 斜杠 cloud sonit 四,这次调用会覆盖其他所有配置。第二层, config 到 emo 文件组,配置文件管所有非秘密设置。第三层, indiv 文件环境变量回退存必须的秘密信息向 api 密钥,令牌密码。第四层,内置默认值,啥都没设的时候会用硬编码的安全默认值。有个经验法则要记住秘密信息,比如 api 密钥, 机器人令牌密码放 indiv 文件,其它设置像模型终端后端压缩设置内存限制,工具级放 config 到 emo 文件,两者都设了的话,非秘密设置以 config 到 emo 为准。 另外, config edu 里可以用美元符号大括号 var name 引用环境变量。比如 auxiliary 的 vision 配置里 api key 设成美元符号 google api key base url 设成美元符号 custom vision url。 注意,只支持美元符号大括号 var 的 语法,不支持裸美元符号 var 优先即清楚了。接下来看看终端后端的配置。 hermes 支持七种终端后端决定 a 阵的需要,命令在哪执行。 第一种是 local, 直接在你机器上跑,没隔离,适合开发和个人用。第二种是兜客,在兜客容器里跑,完全隔离安全。沙乡环境。第三种是 s s 区,通过 s s h 连远程服务器, 跨网络边界,适合远程开发。第四种是 model model 云,沙乡云端虚拟机,适合临时计算。第五种是 dayton 的 dayton 的 工作区托管的云环境。第六种是 versa sandbox versa 沙乡云微虚拟机,支持快造词久化。第七种是 singularity 容器,适合高性能计算集群和共享机器。拿 docker 后端举例,你可以在 config dot emo 里配 docker image, 指定用 nicole 斜杠 python node js 冒号 python 三点一一 node js 二零镜像,还能配 docker forward env 转发还变量像 gitupoken 配 docker volumes, 把本地目录挂到容器里,还能设 container cpu, container memory 以及 container persistent, 要不要持久化?容器终端后端选好了,接下来看看记忆系统怎么配。 hermes 的 记忆系统得先分清记忆和技能这两个概念。 记忆存的是事实,向你的环境偏好项目位置, it 学到的关于你的事。技能存的是过程向多步骤工作流工具、特定指令可附用的配方。 简单说,记忆管是记忆性能或者什么。记忆系统有两个核心文件,第一个是 memory dot md 持久化记忆文件, memory enable 设为 true memory char limit, 设呃两千二百字,大概八百个 token。 第三是两千 dot md 用户档案文件 user profile enable 设为 true user char limit, 设一千三百七十五字符,大概五百个 token。 有 几个记忆管理技巧要知道,第一 记忆容量有限,大概两千两百字,幅满了 agent 会自动整合。第二,你可以跟 agent 说清理你的记忆或者替换旧的 python 三点九笔记,我们现在用三点一二。第三, productive session 结束后跟 agent 说,记住这个已被下次使用。第四记忆是冻结快照, session 里的改动要到下一个 session 才会在系统提示里出现 记忆。系统讲完了,接下来看看最重要的 so dot md 文件。 so dot md 是 agent 的 主要身份定义,占系统提示第一位,完全替换内置默认身份文件,位置在波浪线斜杠 hermit 斜杠 so dot md 或者美元符号 hermit home 斜杠 so dot md。 如果 so dot md 没了,空的货架再不了, hermes 会退回内置默认身份, hermes 会在文件不存在十自动生成默认的 so dot md。 你 可以编辑 so dot md 来自定义 a 键的身份。比如,你是个专业的 ai 助手,专注软件开发和技术咨询。性格特点包括耐心细致, 善于解释复杂概念,注重代码质量和使用实践,乐于学习和改进。专场领域包括 python、 javascript、 type script 开发、 devops 和云计算系统架构设计。 hermes 用两种不同的上下文范围,第一种是 soul md, agent 的 主要身份始终独立加载。第二种是项目上下文文件,像 hermes md 或 hermes md。 项目特定指令优先级最高。还有 agent start md 也是项目特定指令和编码约定,会递归便利目录以及 cloud dot md clock 的 上下文文件只在工作目录生效。注意,项目上下文文件用优先级,系统只加载一种类型,首 次匹配获胜。 so dot md 讲完了,最后看看技能系统,技能系统用来存过程性知识,什么时候该建技能,如果你发现一个要五步以上还会再做的任务,就让 agent 给他建个技能。比如你可以跟 agent 说,把你刚才做的纯成名叫 deploy staging 的 技能, 下次只要输入斜杠 deploy staging, agent 就 会夹在完整流程技能的位置。在波浪线斜杠、 hermes 斜杠、 skill 斜杠目录下,每个技能是个文件夹,里面有 skill dot md 文件和 scripts 子文件夹 技能。用 skill manage 工具管理, agent 创建的技能会自动存在 skills 目录里。技能有四个好处,第一,程序性记忆, agent 创建并附用的流程。第二,跨 session 持久化,所有 session 都能用。第三,自我改进, agent 用着用着会优化技能,一键调用书写纲, skill name 就 能快速执行。 核心内容讲完了,最后总结一下,回顾一下 harmony agent 配置的核心要点。第一,目录结构,所有配置存在波浪线斜杠、 harmonies 斜杠目录里包括 config comfy 等文件。第二,配置管理,用 hermes comfy 命令查看编辑和设置配置智能路由到正确文件。第三,优先级规则, client 参数优先级最高, 然后是 config comfy, 再是 in v, 最后室内自默认值。第四,七种终端后端按需选合适的。第五,记忆系统, memory dot md 存时是 user dot md 存用户档案,容量有限,但能管理。第六, stored md 定义, a 证的身份,占系统提示第一位,可完全自定义。 第七,技能系统纯过程性,支持五步以上任务键,一键技能支持一键调用。如果你再用 hermes agent 或打算部署 ai 助手,建议仔细看看官方文档,合理配置各个模块, 用起来会更稳定、更个性化。我是大叔,大实测验证并整理。如果你觉得这个配置指南有帮助有用,请点赞收藏,后续会持续更新 hermes agent 的 相关内容,感谢观看,咱们下期再见!
141大书大 02:01查看AI文稿AI文稿
02:01查看AI文稿AI文稿口袋终于实现国产模型自由了, dc 切问质谱随便切,重点是绘画记录还能够完整保留,这下真的不用再整天盯着额度了。这次使用的工具是 echo ball, 你 可以理解成 给口袋加了一个模型切换器,上次我们连接 dc 的 时候还要配 cc 叉和 cc switch, 这次更加的简单,模型都放在同一个面板里面,想用哪个直接切?安装包我都已经整理好了,下载之后直接运行就行。 我们先来打开这个 echo board, 左边点击我们的模型中心,这些模型呢都是可以直接链接的,只要符合 open a 的 协议就没有问题。点 击模型,然后添加我们的模型 id 还有 api key。 接下来我们再点击右边的应用管理,这里可以看到有很多的 ai 工具,但这期我们主要讲的是 code, 所以 我们先找到 code, 点击我们已经配置好的 d c 模型,点击启动就会自动弹出我们的 code, 看已经切过来了,我来测试一下,让他解析一下 echo ball 这个项目。 ok, 没有问题。重点来了,直接回到我们的 echo ball, 切换千问,点击启动就会自动重启我们的 codex, 看刚才的聊天记录都还在继续追问,刚才那个项目他也能够接的上。模型都放在同一个面板里面管理,不用反复去配置,这可比以前舒服多了。最后再给大家补三个坑,第一个我测试的时候发现先换回默认的 open ai 反而会丢失他的绘画记录,检查后发现原来是工具里面的一个小 bug, 不过包里面的版本已经是修复好的。第二点是部分的绘画可能会出现模型切换之后不能继续对话的情况,因为不同的模型对话里加密信息和工具调用状态他不一定能够兼容的。建议切换模型之前呢,先总结一下上下文,然后新建对话,再继续项目。 第三点,很多朋友也反馈过, a p i 模式下没有办法正常的去使用插件,但是我最近看到一些解决方案,这两天我会再去实测一波,到时候再给大家分享,不过目前又是不影响的,是可以正常使用的。今天的分享就到这了,我是木马,每天一起玩 a 的 赛博大志,咱们下期见,拜拜!
4573木马_MUMAI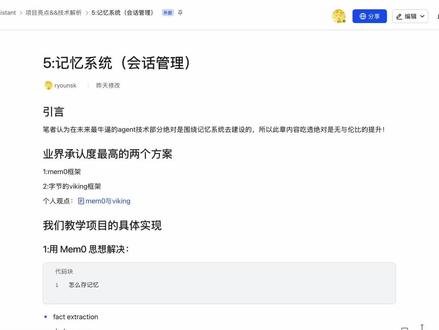 12:58查看AI文稿AI文稿
12:58查看AI文稿AI文稿hello, 大家好,这里是永泽,我们今天来讲我们这个 a g i s c t, 也就是我们这个知识问答项目的记忆系统, 因为我们觉得我们这个项目的核心也就是这个记忆系统嘛。嗯,我朋友花了大心思做的三层记忆架构, 读者认为在未来最牛逼 a 阵的技术部分绝对是围绕记忆系统去创建的,所以此上内容吃透业绩承人最高的两个方案,一个是命令框架,一个是字节的这么一个框架。然后首先来讲我们教学项目的这么一个具体实现, 一,用这个思想解决呢?怎么存记忆,而用 vk 思想解决,怎么组织上下文? 嗯,这是一些常见的一些解决方案。实验方案。我们的机系统呢,是分了三层架构,短期记忆、长期记忆以及用户偏好。嗯,短期记忆是滑动窗口,维持最近的多轮对话摘药。 长期记忆呢,是存入呃,两个这么一个限量库,然后混合解锁,保证这个精准性和语义。 长期记忆管理有驱虫合并重要性,衰退机衰退机制使用的记忆是为怎么阻止上下文呢?这么也有对应的这么一个方案。实验方案一驱虫 就是双轴驱虫,一驱虫是哈西驱虫和相对化驱虫。相对化驱虫本本条记忆如果去长期记忆表中检测到一条相似度大于零点九二就放弃存入长期记忆表,比如说已经有对相似度大于零点九二就放弃存入,然后就合并, 第一呢就是召回相似的记忆。第二,相似度判断如果大于零点八五,我们就进入这么一个合并,合并有对应的这么一个提示词。 第四呢,也就是更新,呃,更新 memory, 也就是更新记忆嘛,然后再到过期和重要性,这是一个简单的介绍,然后我们从 个人观点以及对应的这么一个,呃,我们具体的一些实现来具体的深入。第一个就是这两个,呃, am memory 思想流派这么一个对比, 最终母校都是让 a 帧的长期记住东西,中间件思想,模拟人更偏中间件思想。另外一个是操作系统运行时不是简单的对呃态态关系。 那么他们有个核心的这么一个对比,麦布林呢,是基于这个独立记忆层, viktor 是 基于 a 阵的 run time 的 内置记忆, 优势分别是宽远了,然后工程化强。这个对比我们就不详细说了,我们来讲讲麦布林的核心思想。麦布林最核心的一点就是不要存聊天记录,而是存事实。那传统麦布林是把所有聊天都存进去,下一次呢?全塞给这个 prom 的, 那么问题就是 tiktok 爆炸啊,噪声巨大等等。 那木木林思路就是从对话中征留记忆,例如用户说我喜欢 go, 我 在东京,我在做 a 着的,那么木木林不会存整个对话,而是提取用户喜欢 go, 用户在东京,用户正在开发 a a 着呢,这叫做基于事实的证明,记忆就是它的核心创新。 我们再来看木木林的这一个架构,它本质上已经不是这个向量 d b 了,而是证明 memory 的 public library, public library 就是 流水线嘛, from conversation 到 memory acceptation 等等。关键点第一个就是 only memory, 不 覆盖旧记忆,例如已经有了旧记忆,我们不会删,而是同时存在,因为记忆时间太短,再到向量搜索, memory 不 只是向量向量搜索,而是联合抓回,从这个事实还有这个关键字等等。 micro 链后面发现 micro 写入不能阻塞响应,所以用用户响应先返回 micro 后台一步写,这是生产直接这么优化,这是我们后端也会做的一些嘛,就是去做这么一步的流程,那么它最大优点就是工程结构做的非常好,它不像 long graph 一 样必须绑定 write tom, 它可以用这个 memory 点 i 的 和 set 就 能接,所以很适合作为中间件,所以现在很多的 agent 也都接这个 memory 这么一个记忆系统。那么最大的缺点也就是它是外挂的这么个 memory, 就是 我们在 agent run time 里头,它需要去调用,也就是我们所说的 memory i service 嘛。所以 memory 不是 run time, 有 时候会导导致 contest 的 不统一, 很多时候是分割的。那么第二 g 一 直是解锁 or run time stand。 曼曼林更像长期事实的这么一个数据库,也就是说曼曼林是把所有长期事实存在它对应的项链数据库里头。那么 agent 呢?真正需要的是一个运行时这么一个状态, 例如任务做到哪一步,工具执行,执行状态, work for change point 等等,那么这些曼曼林不擅长。 那么第二个我们要讲的也就是字节的这么一个记忆系统的这么一个架构,那么 memory 是 context infuture, 而不是一个外挂的这么一个系统。那么 wiki 呢?更偏向于统一上下文,引擎是整体的一个架构, 统一进入这么一个上下,统一进入这么一个上下文,而毕竟不是需要时候,我们再去调用它那个中间键进行这么一个 search, 所以 两者最本质的区别呢?这是对应的两者最本质的这么一个区别。 v k 是 一个上下文的这么一个编排,也就是记忆存在上下文里头,那么麦五零呢?需要我们记忆去呃,需要,需要记忆的时候,我们需要对进行对应的这么一个解锁,那 v k 优点就是更适合 a 阵的,因为 a 阵呢,不是了解记性, a 阵呢,需要状态,任务,流程规划, checkpoint, 而并不是只有这么一个用户事实, contacts native, 也就是说 memory 并不是外挂,而是这个 promote 构建的一部分,不是我们外挂,一个向量库等等去进行这么一个搜索,那么更容易,我们去做这个复杂的这么一个工作流,比如分成 planner 啊, execute 啊, reviewer 等等。 那 vk 第一个也就是藕荷重,它像一个完整的这么一个 run time, 而并不是一个 sdk, 所以 改造的成本高等等,那么不够通用,莫雷呢,接啥都行,那么 vk 呢,更偏字节这么一个 run time 的 直选。第三就是开开元盛代弱, 再到现在的记忆性,第一代 memory 呢,就是存条记录,第二代就是 in booting 这么一个项链这么一个搜索。 第三代 micro 零,就说不仅存项链,而我们更存的是基于记忆的这么一个现实事实。再到第四代,就是 wiki, 也不再是数据库,而是 a 阵的 runtime 的 一部分, 那现在的方向也更偏向于 wiki 这么一个架构,现在都在做呃,都在做这么一个 runtime memory 嘛。 那么他的建议借鉴这么一个 micro 零的这个基于记忆的事实,再采用 micro 的 统一上下文, 用 microsoft 思想解决怎么存记忆,然后用 git 思想怎么组织上下文啊,这是相当于统一,把这两个架构的这么个优点进行这么一个对应的统一, 正如未来的方向, memory 不 再是数据关联的 context 硬件,未来 a 阵的 pick 的 核心不是模型,而是上下文调度能力,谁能用更少的 togg 输入更准的上下文,保证长期一致性管理 runtime state, 谁就更强, 这是业界承认度两个最高的方案,一个简单的一个介绍以及对比。嗯,这个当对应文档的大家都可以私信我进行这么一个获取, 这是另一个呢?如何组织这个记忆上下文?嗯,这有对应的这么一个图片。那么我们这个项目呢,最优质的也。呃,我朋友介绍啊,他最优质的这么一个设计呢,也就是他的记忆系统的这么一个设计, 在我们的,我们已经放在 get 上,在我们的 get 上有对应的这么一个,呃,整体的这么一个加固图以及流程图, 这是整体的一个,呃,一个加固,一个加固图吧,这些基础设施等等。 然后长期记忆,就是以固定的语音向量,然后用户偏好,然后短期记忆,这是我说三层这么一个记忆记忆这么一个架构。 咳,以 run 等等。那么来介绍一下核心流程的这么一个数据图,那么最简单的就是用户输入一条信息,然后选择对应的工具,那么我们进入这个,通过这个 chad, 然后进到这个智能智能路由,智能路由里头, 然后加载 s t m l 历史,加 l a t m 加偏好,也就是加加载这个用户存储的三层记忆,然后放在我们上下文消息列表里头,然后进行这么一个 chad, 就是 system prime, 也就是说它系统提示 si, 加上这么一个呃,挥发力,挥发历史,加上当前信息,然后通过自然自然语言进行回答,这是无无工具的,然后一步提取这个偏好,然后存储到长期记忆,有也是回答之后,我们会一步提取这个偏好, 这么工具偏派,也就是运用了 agent react 这么一个范式,这么一个思想,然后分析 query 加关键词列表,执行成为这么一个执行计划,然后进行这么一个 tour promise reason 这么一个执行, 执行对应的拓根据计划嘛,执行对应的这么一个拓工具,然后调用具体的这么一个工具观察结果,然后这就是 react 的 经典思想,也就三层思考动作,再到观察,然后保存对应的快照,合成所有的 over observation, 也就是观察达 到最终答案。通过自然语言呢,进行这么一个回答,然后最后一步存储长期记忆加提取编号,嗯,具体的它的架构时间呢?在利用前一个视频我们已经有讲,然后再到记忆系统的这么详细流程图, 主要分三层记忆,就说短期记忆,长期记忆和用户编号,那么 load preface, 然后进入这么一个历史片号,根据从历史片号取了啊,然后恢恢复片号到内到内存里头,然后再呃 load load, 也就是说拉取这个长期记忆,然后逐条恢复到这么一个内存缩影,重重建这个 tf 词库,恢复这么一个项链啊,这个长期记忆呢?还是这么一个项链库, 那么每轮对话会呃,会呃每轮对话的读写阶段,那么输入啊这么一个一条消息之后,然后窗口大入 maxthon 乘二,也就是说这么一个短期记忆这么一个会窗口会淘汰,根据这个限流,限流淘汰这个超过窗口大小的这么一个消息, 然后再去取它的长期记忆,通过这么一个把对应的快锐进行这么一个向量化,然后去取对应的长期记忆快锐向量,然后辨辨别所有的这么 l t m 目录,也就是我们所有的长期记忆长期记忆目录,根据它的鱼线相似度了等等啊我们, 然后我们取出对应的长期记忆,那么这里有个降级,也就是 tf 向量啊这么一个搜寻,然后召回对应的记忆,然后我们 照回记忆之后进行这么一个上下文的这么一个呃,存储上下文的这么一个构建,然后再去取对应的用户偏好,然后把呃 system permit 也是系统提示词加上偏好上下文,加上这么一个长息记忆呃和偏好记忆,呃和那个短息记忆, 然后以及当前的这么一个所有历史的所有消息,然后返回给用户,也就是说 证明每回对话会有一个启动阶段,就说把对应的这么一个回答内容,然后存储到呃用户信息等等,然后存储到我们这么一个长期长期记忆里头,然后通过这么一个把学习内容进行这么一个向量化, 然后驱虫检测等等,驱虫检测在刚才记忆系统,系统我们已经有对应的这么一个判断嘛,就比如说大于大于九点五了等等,会有这么一个驱虫 存储长期记忆,然后再到存储最后的这么一个,呃,最后这个就是历史,呃,就是数据库层嘛, 然后有一个降级,就是 t f 磁带,然后一步的话就是 l m 会进行这么一个片号提取,然后从从我们这么一个输入的对话,然后进行这么一个片号提取,然后批量的去存入到我们用户的这么一个偏量,呃,偏后偏后,然后同步会有一个规则这么一个兜底,这也就是我们都会 兜底,那么这些兜底也就是我们所说的这么一个哈尼斯这么一个思想嘛。然后合并触发每五条新记忆的时候,然后我们会进行这么一个驱虫加合并,就是首先重要性会有一个衰减,然后再到驱虫合并通过,呃,比较相似度了啊,然后会进入这么一个呃 驱虫,然后进入进入这么一合并,然后以及过期这么一个淘汰,然后再到最后绘画结束。这么我们一个记忆系统这么一个设计是详细流程图,那么这是我们整体这么一个 项目的这么一呃记忆系统,也就是我们的核心的一个设计。然后上一个视频也讲了我们这个 项目的整体架构,我觉得这个项目包括它对机器系统的一些设计,以及它的整体一些架构图,包括对 rag 的 一些 i g 的 一些设计,我觉得是可以写到你简历上,如果大家有需要的话就可以私信我来获得。
683永泽 07:08查看AI文稿AI文稿
07:08查看AI文稿AI文稿大家好,我是大叔,只说真话,只做实在事,只给干货。上期视频大家已经学会安装 hermes agent 了,但是装好了之后还需要对接通信渠道才能真正用起来。 今天这期我们先介绍一个比较简单的微信接入,也是大家日常使用场景里最容易上手的。后续如果大家有需要,我们可以再出一期接入飞书或者 qq bot, 看情况。先说清楚这个是什么? hermes 信件的微信接入是通过腾讯官方的 iink bot api 来实现的,专门针对个人微信账号 划个重点。企业微信要去找 wecom, 那 个是配器,这个是专门给个人微信用的,别搞混了。简单说就是通过 iink bot 接口,把你的微信账号变成一个可以接收发送消息的 bot, 不 需要你有服务器,不需要开端口,也不需要配置 webbook。 整个接入过程只需要三步安装,依赖扫码登录、启动网关,没有复杂的配置,没有坑。不过在开始之前有个重要限制,必须先说清楚, 这个搞不清楚后面功能用不了,别怪 hermes。 扫码登录之后,你的微信账号会绑定到一个 i link bot 的 身份,不是你原来的微信号本身。这个区别非常重要,直接关系到你能用哪些功能。 i link bot 无法像普通联系人一样被拉进微信群, ilink 通常也不推送普通微信群的消息给 hermes。 即使你在群里提及你扫码的那个微信账号,也不等于提及 ilinkbot, 它们是两个独立的身份群,相关的配置只有在 ilink 真正推送群事件时才生效。如果 ilink 本身不推送,设置什么都没用。说白了,微信群消息这设不是 hermes 的 问题,是 ilink 本身有限制。根据官方文档和社区反馈,个人微信账号接入后私信对话是最稳的 群消息。如果 i link 不 推事件过来,那就真收不到。所以如果主要想在一堆聊天,完全没问题。想玩群聊机器人,要先测试 i link 是 否给你推群事件。 git 会启动时,如果 waxing group policy 不是 disabled 的 日子里会打 warning, 提醒你注意这个限制。 如果设置了策略蛋,群里完全收不到消息,就是 i link 那 边的限制。别死磕配置了。好了,限制说完了,开始。第一步,安装依赖。开始之前确保你有一个个人微信账号,然后安装两个 python 包, 就这些,第一个是 a i o p, 用于网,网络通信。第二个是 cryptography, 用于微信媒体文件的解密。微信的文件传输走的是 a s one twenty a d c p c 加密。这个包必须装,命令行 跑一下 piping store, aotp cryptography 两个一起装。如果想在终端里直接看到二维码渲染,可以额外装 hermesign messaging, 这个是可选的,不想装也行。扫码链接会打印出来。 aotp 和 cryptography 这两个包,微信和 telegram 这类平台基本都要用到,装一次以后都省事。 依赖装好了,现在第二步,扫码连接最简单的方式是用官方提供的交互式向导,全部流程自动化,你只需要拿手机扫个码,运行 hermes gateway setup, 向导会提示你选择平台,选择 wixin, 然后向导会自动请求 i link bot api 的 二维码,二维码显示在你的终端里,或者打印一个 url 给你。用微信手机端扫这个二维码,手机端确认登录凭证自动保存到指定目录,扫码并确认之后,终端会显示 account id, 这个 account id 后面配置环境变量要用,记不住也没关系, 已经存在文件里了。在 hermes slash dot f 文件里加上 waxen account id, 等于你的 account id, 如果想限制谁,可以私聊 bot 加上 waxen allowed users 群策略默认式 disabled, 保持默认就好。三步都走完了,来看看微信接入具体支持哪些能力?第一个,长轮询接入消息,通过 http 长轮询拉取,不需要服务器开放端口, 不需要配 web 家秘。微信媒体文件走 cdn 加密传输,自动加解密,全程透明,不需要你手动处理。 第三个,完整媒体,支持图片、视频文件,语音消息全支持语音,有文字稿的直接拿文字,没有的保留音频。第四个, markdown, 保留发出去的 markdown 消息,微信里能原声渲染,标题、表格、代码块都能正常显示。 第五个,智能消息,拆分消息,超过四千字的才会拆分,没抄的保持一条发出,不破坏阅读体验。第六个,输入状态只是 ai 处理消息时,微信里会显示对方正在输入,体验更自然。 第七个,自动重试,遇到临时的 a p i 错误会自动退币,重试偶发的网络抖动,不会丢消息。第八个,上下文词久化对话,上下文 token 存在词盘上,重启网关后对话连续不丢上下文。第九个,去从机至五分钟滑动窗口内相同消息 id 不 会重复处理,防止网络抖动导致双头。不知道你最感兴趣哪个功能?我 个人最关注媒体加密和上下文词九画这两个最实用功能。看完了,现在看第三步,启动网关。配置好了之后,一行命令启动网关,微信接入就完成了,跑 hermes get 为网关,会读取保存的凭证,恢复微信连接,连接 l p i 开始涨轮询,拉取消息并发分发给 ai 处理。最后来说说常见问题, 列了十个最常见的,对号入座就行。第一个,运行 hermes get 为启动报,缺少 a o, t p 和 cryptography, 解决方法是 pip install aop cryptography。 第二个启动报, token is required。 解决方法是重新运行 hermes gateway setup, 完成扫码登录。 第三个启动报, account id is required。 在 一点一 n v 里加上 waxing account id, 等于你的 account id。 第四个提示另一个网关正在使用此 token, 先停掉另一个 hermes 网关,十例同意, token 只能同时被一个,十例使用。第五个 session expire 错误码负。十四,登录太过期,重新 hermes gateway setup, 再扫一次码。第六个二维码过期,二维码会自动刷新,最多三次, 如果持续过期,检查网络连接。第七个 bot 不 回私聊消息,检查 vaxindian policy。 如果设置的是 allowist 确认发送者在允许列表里。第八个 bot 完全收不到群消息,见第二页的限制说明。 ilink bot 身份本身不支持普通微信群消息,这是 ilink 测的限制,不是 hermis 的 问题。 第九个,媒体文件上传下载失败。确保 cryptoography 包以安装,检查网络能否访问微信 c d n 域名。第十个终端二维码不显示,从新安装 hermes agent messaging, 主键 十个问题基本覆盖了。如果还有其他的评论区留言,遇到问题先看 get 位日制。如果设置了群策略弹,日制里完全没有收到过群消息的,原始事件基本就是 i link 这边没推过来,可以排除 hermes 策的配置问题了。日制会告诉你一切排错的。第一步永远是看日制,不是反复改配置, 配置改来改去,日治里末收到消息就是平台测问题,改配置没用。好了,本期内容就到这里来,快速回顾一下今天学的三步。第一,第一步,安装依赖运行 pip install aotp cryptography, 把两个包装好。第二步,扫码连接,运行 hemi skytwo setup, 选择 vixen, 用手机扫码确认。 第三步,启动网关,配置好 wixin account id, 然后运行 hermes gateway。 整个过程没有复杂的配置,记不住命令没关系,用到的时候回来翻就行。如果对你有帮助,欢迎点赞转发收藏,你们的支持是我持续更新的最大动力,有问题欢迎在评论区留言,看到会尽量回复,我是大叔大,我们下期见!
7大书大 11:40查看AI文稿AI文稿
11:40查看AI文稿AI文稿今天聊一个很多人都在问的问题,怎么让 ai 写出来的代码真的能上线?你可能已经用了很多代码, agent 写项目,体感上确实快了,但如果你在一个真实的企业级项目里面对十几万行代码, rpc 框架、流程引擎、配置中心、分布式缓存、全套中间件,你大概率遇到过这个情况。 agent 写出来的代码语法完美,风格统一,但业务逻辑有微妙的错误。这种错误在编一层面没问题,但是实际运行却错漏百出。 为了修这些错误,形成恶性循环,不仅耗费金钱,还让代码仓库变成了一座屎山。比如价格字段用了 double, 而不是 long, 单位搞错了。比如改了主链路,但漏了国际化链路的同步修改。比如调用外部服务,没设超时和降级。这些错误有一个共同特点,它们不是模型不够聪明导致的, 模型的单步推理能力已经很强了。问题出在模型,不知道你项目里那些从来没被写下来的规矩。今天分享一下阿里团队的一个存量 java 项目上,用一周时间搭了一套 harness 体系, 把 ai 代码率从百分之二十五拉到了百分之九十。不是换了更强的模型,仅仅是根据 harness engineering 的 定义,搭了一套外部的约束和反馈系统。今天我就来拆这个实践,不讲概念,讲操作,你听完之后能直接在自己的项目里开始搭。先说一个背景, ai 工程实践正在经历第三次范式跃迁,第一次是 prompt engineering, 两千零二十二到两千零二十四年。核心是怎么写好一条指令, fewshot chain of dot 角色设定都是在优化单次交互。第二次是 context engineering, 两千零二十五年,核心是给 agent 看什么动态构建上下文窗口。 agentreg 解锁工具定义 shopify ceo 的 比喻是给邮件附上所有正确的附件。第三次是 harness engineering, 两千零二十六年,核心不再是一次对话或一次上下文窗口,而是设计跨越多个绘画、多个 a 阵角色、多个执行阶段的完整系统架构。 本质上来说,由于大模型的不确定性,每次你发现 a 阵犯了一个错误,你就需要花时间工程化地消除它再次发生的可能性。注意,不是修 prompt, 不是 加一句,请注意不要犯这个错,是工程化地消除, 意思是你要把这个约束变成一个文件、一条规则、一个自动化检查,让它成为系统的一部分,而不是一次性的口头叮嘱。为什么需要这么做?因为 agent 有 四种典型的失败模式。第一种,试图一步到位, 拿到复杂需求后, agent 倾向于在一个上下文窗口里完成所有工作,上下文填充率超过百分之四十之后,输出质量快速衰退, 开始出现幻觉循环、输出格式错误的工具调用。第二种,过早宣布胜利, agent 完成部分工作就说编码完成,但实际上翻译都过不了。 第三种,没做端到端验证就标记完成。 agent 认为功能实现了,但没跑过完整的测试部署后才发现关键路径不通。第四种,冷启动问题。每次新会话都要花大量 token 重新理解项目结构,真正用于编码的预算被严重挤压。这四种失败模式的共同根源是 agent 缺乏外部的结构化约束和反馈机制。 anthropic 在 他们的工程薄册里说得很直白, agent 无法准确评估自身产出的质量,你不能指望 agent 自己审查自己。好背景讲完了,现在进入实操。这个团队的做法是,在项目根目录下建一个 harness 目录, 里面放四样东西,规则、技能、知识库、变更记录。我一个一个讲。第一个规则体系,三份文件,工程结构开发流程规范、项目编码规范。这三份文件告诉 agent 标准是什么,不随需求变化的稳定约束。 比如工程结构文件里写清楚项目分几个模块,每个模块的职责是什么?分层架构是 controller、 service、 domain、 dow、 adapter 五层。比如编码规范里写清楚,价格字段必须用浪,类型单位为分,禁止 double 和 float。 外部服务调用必须设超时和降级。流程编排组建内不写大段。业务逻辑必须委托 service 处理。这些规则的特点是,它们不在代码里,但所有资深开发者都知道,以前靠口头传承,现在写成文件让 agent 也能知道。本质上讲就是给 agent 看详细的文档,进行软约束。 第二个技能体系,九个 skill, 每个 skill 是 一份结构化的 s o p。 最核心的是 coding skill, 里面有八份分层编码规范,从 controller 到 dow 到 adapter, 每一层怎么写都有明确的模板和约束。 a 阵的编码的时候不是凭感觉写,是按规范一层一层实现。 另一个关键 skill 是 expert reviewer, 这是一个评分 skill, 它定义了两种评分,循环计划评分和执行评分。 每条评审意见必须包含问题描述、修改建议和优先级分级。还有一个 unix right, 体现了改动驱动测试原则,改了哪个接口就测哪个接口,不是一刀切测最上层,而且要求优先,用线上真实请求的出入餐来构造测试数据。第三个知识库, 放在项目根目录的 wiki 文件夹里,列路梳理数据模型、核心业务流程,这些是 agent 理解业务上下文的素材, 但注意,知识库不会主动加载到上下文里。 agent 根据任务需要自主查找,这是按需获取,不是全量贯入。 第四个,变更管理每个需求,创建独立目录,从需求分析、文档、任务拆分、清单、编码报告、评审记录、 c i 结果到部署验证、全流程留痕、审批文件用版本递增,旧版本永远不删。这四样东西组合起来就是 agent 的 完整工作环境。但光有这四样东西还不够, 你还需要一个大脑来串联它们。这就是 agent 角色定义文件。这个团队定义了一个叫 application owner 的 agent 角色,它是整套体系的编排。中书定义文件大概四百行,包含五个模块。第一个模块角色和项目背景,二十到三十行,提供刚好够用的项目视野。第二个模块配置。中书缩影 用结构化表格列出 rules、 skills、 wiki、 mcp 四大组建的路径、职责、触发场景。这就是 anthropic 说的 index and map, 不是 百科全书,是地图。 agent 通过这张缩影表,在任意阶段快速定位到需要加载的知识。 第三个模块,七项核心职责,需求理解、任务拆解、任务分发、任务验收、质量把关、文档管理、知识问答。每项都有具体的行为准则。 第四个模块,工作流程调度指令定义了十个阶段的完整调度逻辑,每个阶段有出发条件、 skill、 加载指令、产出物路径、质量门禁条件、失败回退路径。 第五个模块,沟通原则和硬性约束必须做到和禁止做的两张清单。这个 agent 的 定义文件的本质是什么?是把一个资深开发者的工作习惯和决策逻辑编码化。 agent 不 需要学习怎么当一个好的项目 owner, 它只需要严格执行定义文件里的每一条指令。接下来是整套体系里最重要的设计。十阶段,开发流水线需求分析、需求审批编码实现编码凭证单侧编辑、单侧凭证代码推送、 ci 验证、部署验证、用户确认。 每个阶段都有三要素,触发条件、 skill、 加载质量门禁阶段之间有精确的回退路径, c i 失败但测试为零,回退到单侧编辑,编辑错误,回退到编码实现 需求不符,回退到需求分析不是出了问题,从头来是精确路由到该修的环节。审批环节有循环上线,需求审批最多三轮,编码审批最多两轮,超出后升级到人工决策,防止 agent 陷入无限的自我修改循环 流程里嵌入了五个人工确认点,需求代决意确认、计划评审后确认、编码评审后确认、部署环境参数确认、最终交付确认人始终掌握关键决策权。 这里有一个关键设计,分离执行和评判编码 agent 和评审 agent 是 分开的, anthropic 反复强调这一点,将做事的 agent 和评判的 agent 分 开是一个强有力的杠杆。 在这个团队的实践中,评审 agent 发现了编码 agent 遗漏的渠道判断逻辑,一个潜在的线上故障还在另一个需求中检测到 agent 试图跳过评审阶段并强制回退。 评审 agent 不 需要更聪明,它只需要用一套不同于编码 agent 的 检查视角来审视产出物。再说上下文管理,这个团队把项目知识按加载时机分三层,第一层, 绘画常驻 agent 定义文件,加三份 rules 文件,提供大局视野和基本约束,总量严格控制。第二层,阶段,触发进入需求分析阶段,加载 request analysis skill 编码阶段,加载 coding skill 和八份分层编码 spec。 评选阶段,加载 expert reviewer, 每个阶段只加载当前需要的知识。 第三层,按需查询 wiki 知识库,不主动加载 agent, 根据任务需要自主查阅。核心原则是让 agent 在 任何时刻都拥有刚好够用的上下文。不多不少 好实操部分讲完了,现在说几条关键经验。第一条,在拿真实需求使用之前,用一个虚拟需求完整走一遍全流程。这个团队在空跑中发现了四个缺陷, ci 门禁只检查状态码,而忽略测试用力数为零的异常 审查报告,在简单需求下不生成文件摘要文件因 agent 的 追加倾向出现重复行,部署参数被 agent 错误预测。这些问题如果在真实需求中才暴露,每一个都会导致严重反攻。 第二条,质量门禁必须可程序化验证。 open ai 百万行代码项目的核心经验,如果一个约束不能被机械化的执行, agent 就 会偏离检查 ci 是 否通过。这种自然语言描述不够, agent 可能认为状态 success 即通过,却忽略测试用力数为零, 改成三个可程序化验证的条件, status 等于 s u c c e s s total tests 大 于零, past 等于 total。 问题彻底消除。一切不可被机器验证的约束在 agent 执行中都是无效约束。 第三条,流程一致性优先于流程效率。一个仅涉及两个文件六行代码的小需求依然走完了完整的十阶段流程,一轮评审即通过,过程很流畅。 好的流程不应该给简单任务增加显著负担。当需求足够简单时,每个阶段的执行时间自然缩短。但流程的一致性保证了不会因为这次改动很小就跳过关键环节。在企业级系统中,小改动大事故的案例不胜枚举。 第四条,规范式活文档需要持续迭代,每次实战发现新问题都立即 patch 到 harness 中。规范的每一行都对应一个历史失败案例。 当你觉得某条规则多余或啰嗦的时候,那往往是因为它背后有一个真实踩过的坑。最后说效果,项目维度的 ai 代码率从百分之二十四点八六跃升到百分之九十点五四,个人维度从百分之十四点二四跃升到百分之八十七点八五。 这不是某个特殊需求的偶发峰值,是包含多个不同复杂度需求的常态化产出水平。但更重要的是,这百分之九十的 ai 代码经过了完整的需求分析、编码评审、单元测试和 c i 验证流程,每一行都通过了 harness 体系的质量门禁。高 ai 代码率本身不是目标,在质量可控前提下的高 ai 代码率才有意义。 最显著的效率收益不是 agent 写代码更快了,而是返工大幅减少。以往 agent 裸写代码后,人工 review 发现问题,要求返工的循环可能迭代三到五轮。有了 harness 后, agent 对 agent 的 审批闭环在内部就完成了大部分质量纠偏到人工确认时,通常只需要一轮。 一个意料之外的副产品是知识沉淀。 harness 目录下积累的规范文档、编码、 spec、 审查记录和变更历史,实际上构成了一份活的项目开发手册。 新人加入团队时,不再需要靠口头传授,无论是 agent 还是新人,都可以通过相同的阅读路径快速理解项目全貌。一句话总结, harness 的 价值不在于让 agent 变得更聪明,而在于让 agent 的 错误变得可控、可发现、可修复。 这和传统的软件质量保障思路一脉相承。我们不指望程序员写出零缺陷的代码,而是通过 code review、 unit testing、 c i、 c d 来确保缺陷被层层拦截。 harness 做的事情本质上完全一样,只不过拦截对象从程序员变成了 ai agent。 如果你想在自己的项目里开始搭,最小可行方案是三步,第一,写一份编码规范文件,把你项目里那些所有人都知道但从来没写下来的规矩写下来。 第二,写一个评选 skill, 让 a 镇在提交前自己审一遍。第三,加一个 ci 门禁,用可程序化验证的条件来卡质量。这三步做完,你就已经比裸用 a 镇的强了一个量。
1470每日AI评论 07:03查看AI文稿AI文稿
07:03查看AI文稿AI文稿这几天有小伙伴反馈用千万三点六呃,追买四,用了一段时间,大模型的响应就越来越慢,然后 agent 开始失忆,紧接着 tos 调用异常,最后直接卡死。 这种情况啊,大部分是不是模型不行,而是常对话的 token 爆了。大家好,我是根谷,今天教大家用一套本地的模型配置方法, 简单的调教好参数,从根源上控制头肯的消耗,让你的本地模型能稳定长时间运行。为什么你的这个长对话会爆头肯呢?不是你的模型不行啊,是上下文被撑爆了,是因为第一个就是每轮对话 都会追加上下文。 n 轮对话以后啊,这个系统提示加全部的历史,最后的新提问,头肯只会呈指数级的增加, 可以大家用一个公式去计算。二十人对话的话大概是会到五万,这个头肯直接会超限,所以说还有第二的话,就是你的兔耳是会输出炸弹,因为 m c p 啊,就是模型上下文的协议,他默认的是我这里配置的,默认是五万这个头肯,所以说一次就能占满上下文,这个地方我们可以通过配置文件去解决。 第三块就是 memory 无限堆积,因为有些人他用的是这个 skills 啊,特别是那些比较好的 skills, 他 会把所有的记忆体给你塞到上下文,所以说你的任务越长,他 token 累积越来越多。第四块就是 cost 啊, cost 这样一个隐形的消耗,也就是反思 是推理这个玩意,也是也是大量吃透根,却不产生直接的价值啊。解决的思路就是用四种方法去防止他的这个透根膨胀,第一个就自动的压缩这个历史对话,第二的话就控制这个拓式的输出长度,第三就是防止这个曼曼的无限堆积,最后就长时间稳定的运行。我们通过限制的轮数,包括这个最大的透根的 的限制,包括关闭这个这样一个 cost 啊,好,然后呢,我这里给大家举的例子就是我用的是这个呃 呃,这个 j m 四二十六 b a 四 b 的 it, 它是 f b 这样一个十六位的一个全量模型,大概是消耗我的内存,应该是二十六乘以四,大概是八十 g 左右,八十 g 以内的这样一个显存啊,其实这个模型已经非常强大了。首先我找到这样一个配置文件,这个配置文件就是在加载目录下 hammers config yum yum 这样一个文件,这个文件的话首先我要输,找到这个模型啊,我这里有三个模型,一个是 j 满四,一个是千问,还有一个是这个 gpt, 是 吧?这个模型为什么我设置六五五三六啊?这个你,你不设置这么多,你这个你这个嗨马斯就运行不起来,正常情况下我们应该设置一万二千个头啃, 所以说这第一步是骗这个 hammer 的 啊,这个倒没关系啊,好,这个是第一个配配置,第二的话就是在这个 a 检测里面有个叫 master, 默认的话,这个系统默认的话它是二十轮,二十轮其实有点大了,然后我们每轮配置的这样一个是这个就是最大的头啃啊,就是一万二,一万四都是可以的,如果他的这个 这个模型的参数最大的这个上下文累计到二十五万的时候,它就会爆头壳,所以说你一次性一万四的话,大概是要十次接近十次啊,就会把它撑爆,当然你说其实每次都没这么大,大概是几百个头壳嘛,所以说大概是两两百人左右,那它才会爆是吧? 所以说 max 的 pro mode 设置为一万二到一万四都是可以的,千万不要设置为两万三万啊,这个就会出问题的。那是第一个,第一个地方, 第二的话就是这个刚刚说的这个没有价值的东西,卡斯特,怎么怎么卡斯特了,这个玩意得给你关掉它去啊。这个这个玩意,这个玩意很恶心啊,就是我之前是没关掉他比较好。这个头肯 啊,就这个玩意,这个 enable, 把它变成 force, 默认他是 true 啊,这个没什么卵用啊。这个。然后第三个是最最关键的,就上下为压缩,如果这个系统发现我快要达到这个二十五万的时候,它会自动启动压缩,我们这个预值默认的是零点三或零点五都可以。当达到一万十二万的时候,它自动的启动压缩, 然后这个一个这个目标这个率的话默认的是三零点三,我们把它设置为零点一八,还有这个轮数我们设置为六轮,那就不要设置为二十轮,二十轮的话有点有,有点太长了,对吧? 好,这个地方这个配置是最最关键的。第三个就是我们把这个记忆体关掉,因为我这里用到了一个样式,就是我记忆体其实其实可以看的跟古老师的上一堂课啊,就是设文件啊,慢慢的这个文件去做记忆体配置,先不要在这里去弄啊,这个把它关掉,甚至你是自己去外接一个存储,这个,这个这个数据库都是可以的,把它关掉啊。 第三块就是这个拓式的 alt put, 这个也很恶心,因为你肯定是用了一些这个,呃,外外部的样式吗?对吧?他这个这个这个 输出他五万,那五万就直接把你五万还是五十万吧,应该默认的是个十百千五万,五万也太大了,因为设置为一万二千吧,对吧?五万的话你杀差不多三到四次调用这个工具的样式,你这个你这个内存啊,你这个透坑就承包了。好,你设置完了以后,这个 hammer 你 重启一下,就是 hammer, 是 吧?然后重启一下, 哎,这个就是可以了,对吧?好,可以了。以后我要假设我要做一个这样一个比较长的任务和一个比较比较复杂的任务,就是我用这样一个样式查询最近三天的 ai 新闻啊。它之前我没有做这个配置的话,它很快,大概是一两分钟它就会, 他就会承包。你可以看一下这里,我这里有一个这个 hammer 式的这样一个,是吧?然后到仪表盘里面,我把它变大一点,啊,这个你看到吗?他请求过来了,是吧?一个请求我可以把它放到这里来,是吧?哎,他已经调用了这个这个样式, 大概会到百分之七八十的时候,他就会输出这样一个新闻,是吧?他第二轮已经出来了,大概是 现在是六百七十四个头款,美版也是非常快。我,我这个这个电脑应该非常快,给大家看一下我的显存消耗,我这里显存消耗的话应该是,哎,五十七个 g 是 吧?接近六十个 g 了,六六十个 g 的 显存,所以说大家显存低的话还是玩不起这个追满四,那只能去老老实实的去用这个,呃, 千万三点六是吧?他当超出这个上下文的话,他就会去进行压缩啊,进行压缩, 如果不进行压缩的话,基本上这个就卡到这里就会死掉,基本上就会死掉。好,然后再回到这个这个 ppt 来。 好,这里也就是告诉二数人是非常大,大概率就叫爆,是吧?所以说我们设置为一万二千是比较合适的。还有地方去设置是这个玩意,这个地方有一个这个全局的设置,这个地方在 这个地方也需要设置一下啊,这个三万二千最大的上下网窗口,还有这个最大拓展,这里设置为四千多就好了,就这个是那个 ml, 是 这个,这个推力框架的配置啊。好,然后其他的地方这个都说了,是吧?压缩,这个把它关掉是吧?然后这个也关掉是吧?然后具体把它关掉。 有些人说我这个这里关掉了,会不会让他这个失忆啊?我觉得不会啊,因为你的失忆核心不是他核心的是我们的三个文件是吧?一个售文件,一个是 mami 的 文件,还有一个优者文件,这你可以翻一翻跟我老师的前面的课程,这个也是一定要一定要去设置的,这个不要设置太大,不要设置太太大, 最后就是在这里面的完整的这个地方,大家可以截图保存啊,把这些,这是针对 jama 四的这样一个二十六 b 的 模型的配置啊?就是我尝试调了很多次这样一个配置,像是比较好的,比较好的啊,其他的地方就应该没有什么了, 哎。然后这个地方可以大家看一下,刚刚这个东西它已经出来了,是吧?这是查到最近三天的这样一个新闻,它其实里面大概耗了也是有几万个 token 了,对吧?几万个 token 这堂课就分享到这里,你学会了吗?
99根谷 05:42查看AI文稿AI文稿
05:42查看AI文稿AI文稿你 hermes 装好后是不是跑得不稳?这十个进阶配置让你从会用到好用。先看三个最常踩的坑,默认配置能跑不等于跑得稳,最常踩的就是这三种坑。第一种, agent 开始复读, 聊着聊着就原地打转,根源是上下文压缩没调对。第二种,长任务卡死几十分钟一点动静都没有,因为默认 get 位没配兜底。第三种, token 烧得快,辅助任务也走主力,贵模型子任务又开一窝,压缩太急还会丢细节。进入第一组 hooks, 意思是在 agent 干活的某个时间点偷偷插一段你的代码。 hermes 提供四个挂点,第一个 session start 绘画,刚开始可以加载环境。第二个 pre l l m call, 调模型之前可以注入上下文。第三个, post l l m call, 拿到模型回复之后可以自动上后。第四个 session end 绘画结束,统一收尾。先看 pre l l m call 这个挂点的用法, 在调模型之前自动把当前 get 分 支塞进去,先做个判断,只在第一轮塞后面,每轮直接跳过分支,不常切,塞一次够用,不重复浪费 token。 然后抓当前分支,返回成 context 模型,每次都知道你在哪个分支干活, 不会乱改命。最后用 register hook 把这个函数挂到 pre l l m call 的 钩子上,每轮自动跑一遍。第二个用法, post llm call 模型回复之后自动给当前改动做一次存档。先把用户原话截前几十字,再清洗一道,里面可能带密钥不能直接进。 commit message, 然后 get add get commit 自动留一个 wait 节点,意思就是 work in progress, 出问题随时能回退到任意一轮。同样用 register 挂到 post llm call, 每轮自动存档一次都不漏。第二组,改 config 三个参数。 第一个,把思考强度拉到 high, 在 agent 下面写一行 reasoning effort, 等于 high。 就 这一句,一共六档,从 non 到 x, high, 复杂任务给 high, 简单任务调回 medium token。 第二个参数 致 agent 嘴上答应,其实没真去调工具的毛病。 tool use enforcement 设成 true, 所有动作必须真走工具通道,也可以传 auto 或 force, 或者只对那几家爱敷衍的模型单独打开。第三个参数,压缩, 意思是对话变长后, agent 会自动总结老内容,腾空间,这就是压缩。我们把策略调保守一点, threshold 从默认的零点五调到零点六,晚一点再压, 保住的原文多一截,再加一行 protect last n 等于三十。最近三十轮永远不压 代码重构,这种近处细节多的场景特别有用。第三组, so mid, 这是 hermes 的 全局规则文件,各家 agent 都有类似的设定,它不是写人设,是写 agent 默认怎么处理歧义。比如你说修一下登录 bug, 没写 default, agent 会自作主张把 srcos 重构, session 改 radis, 六百多行被改大半都不该动。写了 default agent 会先反问你指的是 office 下的 login 还是 api 目录下的 login text, 问清楚再动,只改十二行。第四组, skill hermes 的 skill 是 分三层按需加载的,装一堆也不报上下文。第零层只读所有 skill 的 一行描述,初时才几 k token, 第一层真要用某个 skill 时才展开正文,一到三 k。 第二层, skill 里引的子文档按需再读, 所以装几十个也不卡。第二个 skill 用法,让 agent 自己把流程存成 skill, 你 跟他说把刚才修这个迁移的流程存成 skill, 他 直接调 skill manage 函数,本地落文件,不用去官方 skill 市场翻。下次遇到同类问题, agent 自动附用这条 skill 的 步骤, 不用你再讲一遍。第五组,并行和调试,独立的子任务,可以一次丢三个出去。比如第一个任务,把 office 模块重构成 j w t, 带终端和文件,工具,默认一次最多三个,可以调高主线 context 基本不动。第二个任务,给 building 加单元测试也带终端和文件, 子任务里 delegation, 记忆消息这些工具会被关掉,不会乱套。第三个任务,读三篇 os 文档总结给我,只要外部工具,三个并行跑完,结果回来由你省, 合不合你说了算。并行还有一个关键搭档 work tree, delegate task, 派三个任务出去 work tree, 让它们各占一个 get 工作区,各改各的,不打架命令行,直接加 dash, dash work tree 临时开一次, 或者写进 config 全局开。子任务跑完没改动会自己删,有修改才留不堆垃圾,结果合不合主分支由你点头。 agent 卡住了怎么办? 这三招都备上,挑着用。第一招, verbos all, 打开详细日制,能看到 agent 每一步的内部调用,出问题先看现场。第二招, debugshare, 一键把日制和系统信息打包成分享链接,密钥会自动脱敏,方便上报和求助。第三招, getaway 超时,这个是平时配好长时间没回应就自动断,不至于一直挂在那。最后说一下,本周官方动态,新出了三个内建 skill, 直接可用。第一个 architecture 描述你的系统,一句话出架构图。第二个 infographic 丢一个网址进去,长文直接变信息图,原作者宝玉,官方移植收入。第三个,官方和某 ai 厂商联合的开发挑战赛,为期十六天,奖金池可观。详情看官网。 今天的十条要点全在这页,可以截图存下来,装好 hermes 之后挑两三个先调 agent 就 能稳一个量级。我是曲奇,一个 ai 练习生,让我们一起记录 ai 时代的个人进化。
1615曲奇(AI练习生)


猜你喜欢
- 7404林亦LYi