
粉丝4270获赞8.6万
相关视频
 01:52查看AI文稿AI文稿
01:52查看AI文稿AI文稿一、 tenne ten 查中规则与中文论文查中的检测原理有所不同,外文的语法上面还是和中文语法有所差异,查中原理主要是语法上面的查中,所以和单词的重复没关系,只要使用不同的语法逻辑表达相同的语义, 那么 tennetten 茶中是检测不出来的,这其实是茶虫的原理。二、 tennetten 检测标准 对于每一个句子的重复率而言,其实是对比了很多论文来计算出来的重复率,比如有一个句子的重复率是百分之六十,那有可能他重复的来源文章有十个。 对于整篇文章的重复率又是每个句子的重复率计算起来的,而整篇重复率的计算是一重复率低于百分之 值的,一般是常见的短语或者文本匹配得来的,每处的重复率不高,所以是在 sci 期刊投稿或者毕业论文合格标准范围内的,我们可以忽略不计。二、重复率达到百分之十到五十之间的, 很多学生或者投稿这第一次查重都是在这个区间。这种一般存在一定的借鉴和摘抄,我们需要注意重复率高的句子进行修改后再次查重。三、重复率达到百分之五十以上的, 这个可能是整篇文章和数据库的其他文章很类似,有大段的与句相同,这种一般会认为是严重的抄袭,我们需要大幅度的修改。四、重复率很高,但是全部句子重复率都很低,那么这样简单修改一下就可以了。 五、重复率很低,但是有几个句子重复率很高,那么那几个句子一定要全面修改,不然重复率低也会算抄袭。
 01:05
01:05 02:26查看AI文稿AI文稿
02:26查看AI文稿AI文稿理工科论文查虫避坑指南家人们,理工科写论文的注意了,你是不是以为论文没抄代码和图表就能随便用?别天真了,现在查中系统早就不是指定文字的老古董了。代码、图表、公式这些你以为的安全区,其实全是隐藏的雷区。 今天这条视频直接帮你拆掉这些雷,避免被误判抄袭,赶紧点赞收藏!先说代码,你以为改了变量名加了注式就万事大吉?错,现在的查重系统能识别代码的股价抽象语法数, 就算你把负二循环改成 y o 循环,只要底层逻辑和开源代码一样,照样会被标红。更别提那些直接从 github 上扒下来的热门算法,简直就是自带身份证的抄袭。 那怎么办?记住两点,第一,核心代码一定要深度重构,别只改表面,要改变算法的实现路径,比如把地归改成迭代,这才是真正的换骨。第二,非核心的展示性代码直接转成图片插入, 注意是彻底转成 jpg, 别留任何文本痕迹,这样能大大降低被匹配的概率。再来说图表,你是不是觉得把别人的图截下来用就没事了? 醒醒吧,现在的系统能读图,尤其是 vcu matelab 画的矢量图,里面藏着原数据,就像图片的身份证系统,一扫描直接就能找到原始出处,更别提那些从 pdf 里直接截图的,连排版代码都带着,简直是自投罗网。 避坑方法很简单,所有图表导出时,一定选不保留原数据,或者用画图版过一遍转成纯炸格图片。如果是复现别人的数据,建议稍微调整下图表形式,比如把折现图改成柱状图, 数据点做微小扰动,在误差范围内,这样既合规又安全。最后是公式,别以为用公式编辑器生成的图片就安全,系统能直接识别 latex 原码, 你写的积分上下线变量关系和文献里一样,照样标红,怎么办?要么改变推导步骤,要么换个数学符号,比如用 simon 代替 s, 实在不行截图插入。前提是学校允许 家人们查证的本质是保护原创,不是故意为难我们。了解这些技术细节,是为了让我们的真实成果不被误伤。 最后再送大家一个自查清单,代码要重构,图标清源,数据公式换符号。赶紧转发给身边写论文的理工科朋友,祝大家都能顺利毕业,我们下期见!
 02:14查看AI文稿AI文稿
02:14查看AI文稿AI文稿这是一个真实的案例,一篇重头的英文论文,个人使用特纳井进行 ai 检测, ai gc 率为百分之三十, 觉得不高,稍微修改后投稿到出版社后,论文的 ai gc 率飙升到了百分之八十五,然后不仅被拒稿,还被刊拉黑了。就上面的客户的情况,我总结了他的两点失误,希望能给所有的后来者警示。一、 定稿检测的内容和提交出版的内容存在差异,很多人觉得只要政文部分没问题就行。就重复率检测来说,这样操作问题可能不太明显,但对 ai 率检测影响很大。 因为 ai 检测是通过识别 ai 生成指纹,结合上下文关系进行判断内容不同、字幅数不同小的内容修改等,都会影响检测系统的切片和分段,而切片和分段的变化会带来关键词权重比的变化,进而导致之前没有识别的内容被标记。 确保个人提交查重的内容和提交出版的一样。嗯,确保个人提交查重的内容格式和提交出版一样。 确保个人提交查出的文档格式和提交出版室一样。二、论文修改后没有再次进行定稿检测。 定稿检测是什么意思?就是你明天准备投稿,今天检测完后重复率合格,然后明天一字不动、一个空格不加地把论文发过去。你可能觉得百分之三十的 a、 i、 g、 c 率或重复率不高,随便改改没有多大影响,但可能就是这里的不重视给你带来麻烦。 只要修改了,一定要再次查虫,确定效果,定稿检测后再提交。你可能还要说,难道就不能是查虫网站的问题? 上篇文章已经说过了,进行了仔细的比对,本次出版的内容可指系统是一样的。总的来说,要想得到出版一样的查虫检测结果,除了选择出版一样的检测系统外, 个人定稿检测一定要提交完整的论文内容,包括作者个人信息、基金图表、参考文献、致谢等内容,确保内容格式、文档格式与出版一致,且个人查重检测的时间和出版审查的时间不能相隔太久。
0微研微学 01:03查看AI文稿AI文稿
01:03查看AI文稿AI文稿很多同学看到 turning 重复率高,就开始一句一句的换词,结果改完之后重复率可能下来了,但文章逻辑也乱了,甚至英文变得更奇怪。降重不是简单的同一次替换,也不是把句子改得越复杂越好。 真正有效的降重是判断重复来自哪里。第一种是引用格式没有处理好,比如直接引用了原文,但没有正确的引用。第二是表达过于接近原文,虽然换了几个词,但句子的结构还是一样。 第三,句子中概念性的内容太集中,导致重复率偏高。正确的方式应该是首先理解原文意思, 再用自己的逻辑进行重新组织。比如你可以改变句子的结构,合并并拆分信息,加入自己的分析,而不是机械的替换单词,尤其是从百分之三十降到百分之五,不能只靠软件改写, 必须结合论文内容,引用格式和学术表达一起调整,不再核妙。留学还有 six next time enjoy!
 00:21查看AI文稿AI文稿
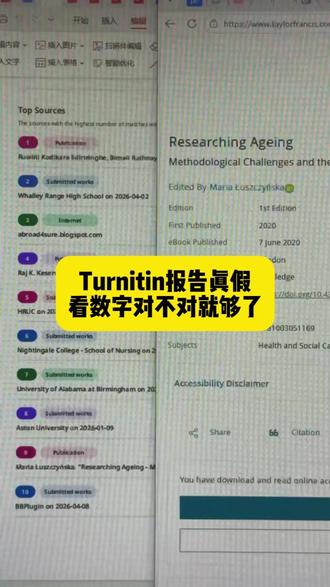
00:21查看AI文稿AI文稿我买了三份报告,两份是假的,今天教大家看数字对不对?假报告表面百分之十八下滑,一看百分之七十,数字直接崩了。放大看百分之十八这个数字是 p 上去的, 边缘模糊。真报告数字对得上来,缘能点开一分不差,真假对比一目了然。买报告前先验数字,还有别的判断方法吗?评论区补充,一起避雷。
2雪梨梨 00:55查看AI文稿AI文稿
00:55查看AI文稿AI文稿评论区问的最多的几个问题,嗯,现在反 ai 工具很强,无论你提交什么格式,老师要查写作痕迹。其实很简单,就是不用工具老师也能一眼看出来。比如平时用 help, 写作的时候用 facilitate, 平时用 use, 写作的时候用 unitize。 第二就是 ai 写作格式,分段也特别的模块化,整篇文章经常会出现三段式或者是两段式固定的排版,所以不要再纠结这些问题。 在这种老师已经默认了所有人都会用 ai 的 情况下,那安全的 ai 使用方式是把 ai 当做辅助工具,整理你的思路,修改语法,但最后生成的内容一定要用你的表达方式写出来。我做的这个网站重点也不是单纯的把这个 ai 率给降下来。第一, 语言风格要统一,不要很突然的从普通学生水平变成学术大神。第二,文章逻辑要合规,不能像套模板一样每一段都过于完美。第三就是写作要有痕迹,避免老师产生误会,尤其是教授印象不好的同学们。
49BeiBei 02:26查看AI文稿AI文稿
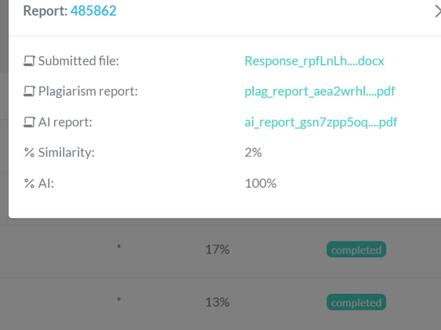
02:26查看AI文稿AI文稿turn attent 检测报告中都有三个文件,一个 pdf, 两个 h t m l, 两个 h t m l 的检测报告中,一份排除了参考文献,还有一份是不排除参考文献报告。 turn at 的检测报告以哪份为准?哪份更重要? 答案是,在 tournatin 的检测报告中,其相对重要性依赖于具体的使用场景和目的。个人使用 tournutin 进行查中的时候, 根据个人需要和学术要求来决定不排除参考文献的报告。报告将包含全部文档,内容包括参考文献引用部分以及其他文本。 他的优点是可以全面的评估文档的整体相似度,并显示所有涉及的相似部分。这对于评估论文的整体原创性和学术成性非常有帮助。 教师和学术机构可以使用这份报告来全面评估学生的研究和写作能力,并确定是否存在不当的引用和抄袭行为。排除参考文献的报告报告会从检测过程中排除掉参考文献和引用部分, 只关注论文内容本身的相似度。该报告适用于需要评估研究论文核心内容的原创性和独创性,而不受引用和参考文献的影响。 这在某些情况下可能更重要,例如,评估学生在特定课程或项目中的研究质量和独立思考能力。 同时,排除参考文献的报告也可用于论文出稿的重要反馈和改进。 turnitan 是一种用于检测文本相似度和抄袭的软件工具,它通过比较所提交的文档与其广泛的数据库中收录的文本进行比对,并生成 相应的检测报告。 turnet 的算法会将所提交文档与其数据库中的文本进行比对,把相似部分标记出来并提供一个相。这个报告以及是否涉嫌抄袭还需要由处理该报告的教师、学术机构或相关权威决定。 需要注意的是, tonit 本身只是一个工具,他直接判断文章是否习。对于检报告的解读和判定需要借助于专业人士、教师或学术机构的判断和评估。这些专业人士会结合 tonit 的检测结果,综合考虑文本相似度、 引用规范、原创性等因素来评判论文的情况。 check 于 vip 论文查状降重系统。感谢您的关注!
6微研微学 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿家人们还在用 turniton 查论文的 ai 律吗?其实啊,现在有不少更适合咱们学生党用的工具的 turniton 虽然名气大,但有时候检测结果可能不太 超高。比如有些平台会专门分析文本的逻辑连贯性,用词习惯,就像老师批改作业一样,一 眼的工具,最重要的还是咱们自。
 01:50查看AI文稿AI文稿
01:50查看AI文稿AI文稿辛辛苦苦做了大半年的实验,论文刚投出去就被秒拒,连审稿人的面都没见着。先别急着怀疑人生,赶紧去查一下你的 chandler 报告。 现在的 sci 投稿,光看查重率已经不够了, ai 生成率正在成为拦在你面前的隐形杀手。以前我们只知道盯着查重率,觉得只要低于百分之二十就万事大吉。但现在 chandler 升级了,它能精准识别你是不是在用 catapatch 写论文。 虽然基康没有明文规定死数字,但行业内默认的双重红线是,总重复率最好控制在百分之十五到百分之二十以内, 而 ai 生成率强烈建议控制在百分之二十以下。一旦 ai 率飙红,编辑会直接认为你缺乏原创思考,甚至怀疑学术不端,直接去搞媒商量。那用了 ai 任色就一定会挂吗?也不是,关键在于你怎么用。 查询的其实是文本指纹, ai 写的文章往往太完美、太顺滑,句式整齐划一,而人类的写作会有长短句的跳跃,会有独特的逻辑转折。 所以,千万不要直接把 ai 深沉的段落复制粘贴。你要做的是用 ai 搭建框架,但必须填入你具体的实验数据、独特的文献观点,把那些工整的排比句改成更有你个人风格的表达。还有一个保命的小技巧,做好合规声明。 现在很多刊都要求陈世交代哪里用了 ai, 是 用来润色语言还是整理文献,大大方方地在投稿系统里申明,这反而是你学术诚信的体现。记住,工具是用来提效的,不是替你思考的。 ai 可以 是你的超级助理,但你永远是那个掌舵的船长。你的论文 ai 率是多少?有没有因为这个问题踩过坑?欢迎在评论区聊聊,关注我,带你了解更多 sci 发表的实战干货,我们下期见!










猜你喜欢
- 4319爆爆吖