谷歌seedance3.0上线时间
ai 视频又炸了,吉梦的 c 蛋三点零内测直接是从十五秒钟干到十分钟以上。很多人啊,现在二点零还没玩明白,三点零已经开启内测了, 从十五秒钟的短视频一步到位,这是十分钟以上的长视频,这完全是颠覆级的升级, ai 视频不再是只能做那种短频快的,什么短剧啊,剧情啊,以后长剧情 ai 慢剧长口播都能够一键生成。 ai 的 迭代速度实在是太快了,今天十秒钟,明天十分钟,下一次又不指定是什么样子,不跟上真的容易被甩开。

粉丝1223获赞5627
相关视频
 02:27查看AI文稿AI文稿
02:27查看AI文稿AI文稿笔画完全跟随动作,写出来的公式也完全正确。谷歌全新 ai 视频引擎金布莱奥米首爆视频版香蕉来了!谷歌这次是瞄准了 siri 下架窗口搬上来的新品。 那么面对一代视频强者,七代是二点零,又有怎样的表现呢?两分钟带你了解这个即将上线的全新 ai。 首先,奥米到底是什么模型?在哪用? 目前它正处于大规模推送或内测阶段。如果你是 g m 两高级定员用户,可能会看到推荐使用选项,这是别向大众发布,应该在五月的谷歌 i o 大 会后就能看到了。为什么要叫它视频版香蕉?因为它继承了当年 nano banana 那 种即插即用,极度精准理解人话的特质。以前出片结果还是抽盲盒,全看概率。 在奥尼,标志着 ai 视频进入了逻辑生产时代,他不再是单纯的在模拟像素,而是在模拟这个世界的运行逻辑。大家最近可能在网上刷到了谷歌爆出的几个演示视频,教授在黑板上写公式和吃意面喝奶油汤。这一段视频展示了奥尼最核心的两个能力,极致的致富精准度和动作逻辑。跟随兄弟们,你们细品 视频里那个老教授在黑板上飞速书写粉笔碎屑、手部关节的自然扭动,甚至写字时的力度感都极其真实。但最让我感到头皮发麻的是,那个公式本身,它是完全正确的。 这种逻辑一致性目前在整个 ai 视频圈是非常领先的。它证明了奥秘不只是在画画,他真的看懂了这段公式。所以,如果你问我,他能带来什么表现?他能让 ai 教学课件复杂的科技演示,精准的产品说明视频从不可能变成一键生成, 但是它并非完美。当设计那种超大幅度极高爆发力的物理动作时,它的表现力确实没有另外两家对手那么激进。 或许你想知道它和苏拉二现在是二点零上比到底谁更强?首先是 opalion 的 苏拉二,它的强项在于它的物理引擎画面冲击力依然是很强悍的,但现在关闭了使用,无论是网页应用还是 a p i 都没法调用了。 然后字节的吸氮是二点零。他最强的地方在于他的饮用系统和角色一致性。你给他一张照片,他能保证在深层的视频里人脸几乎不崩,这对于短视频博主和短剧团队来说是非常棒的。在动作的表现上来说,我们也有目共睹,虽然还没有正式发布调用价格,但目前测试段效果非常恐怖。 正式价格让我们拭目以待吧。以前我们或许觉得 ai 视频就是图个娱乐,但 jamie 阿莫里告诉我们, ai 已经可以处理极其严肃的内容了。虽然他在动作爆发力上还有提升空间,但这种极致的准确性,这是目前专业创作者最缺的东西。那么问题来了,面对这个不仅会拍片,还会算微积分的视频相交,你会用它来做什么呢?
1.4万高尚的AI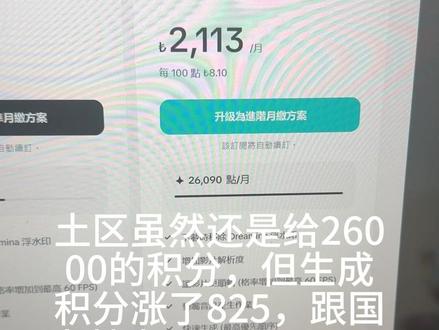 00:24查看AI文稿AI文稿
00:24查看AI文稿AI文稿天塌了呀,昨晚国际版极梦全面涨价,家区的从三万七千积分变成一万一千六百七十积分,土区虽然还是给两万六千的积分,但生成积分涨了八百二十五, 跟国内基本没有区别了。今早我还看了日区、印区月区阿区全部调整了,想玩国际版的兄弟不用考虑了。
95谢先生Aigc 05:13查看AI文稿AI文稿
05:13查看AI文稿AI文稿全球搜索之王,世界最塌视频平台的亲爹, transform 框架的奠基人谷歌终于发布了它的最新视频模型 wilhelm。 但是没想到啊没想到, wilhelm 上手一侧,像个鹿鞭一样拉完呐。 那 vivo 给我的感觉不是下一代视频模型,而是上一代视频模型。戴了个新墨镜,说自己刚从硅谷进修回来。什么东西啊?你说它不能生成吧?它能生成还能自动分镜,但你真想把它当做一个视频创作工具,那你可遭老罪了。这下 cds 又可以美美涨价喽! 哎,算了,开始测试吧。本次 vivo omni 可以 在 gemini 的 官网和 flow 进行使用。我这里做了几组对比,主要是看四个维度,分别是指令完成度、动作逻辑流畅度、一致性。 零分代表不及格,一分代表及格,两分代表满意。那第一组是文声图,题词如下,我们先来看 vivo omni 的, 我们再来看看 simon 的。 你们觉得这两个片段哪个好一点? 虽然这两个片段都是槽点满满,但是从情绪渲染和动作流畅度上, sentence 还是要强上不少的。不像 vivo omni 这个动作设计啊,完全的放弃治疗。那这是我对这相册时的打分,两个逻辑性都不及格,但是 vivo omni 它的流畅度也不及格,没救了。 刚刚是动漫高动态场景,那我们再来看一组偏静态的真实场景。先来看看 real 欧美,看什么看?不必声张,对我们如同对寻常百姓,即刻大人方幸,对付百姓小的拿手。嗯? 看什么看?哈哈哈哈哈哈,这个纯大爷啊!这巴掌轻飘飘的不够凶,还突然愤恿大笑,操,你们都干嘛呢?妈的,哎呀,我最知名的是中间的台词念错了一句,直接这个片段就是报废的。我们再来看看 sentence 的, 不必声张,对我们如同对寻常百姓即可, 大人放心对付百姓,小的拿手。嗯,看什么看,你吼那么大声干什么嘛?这个情绪就到位了,但是没有完整的挥手扇耳光的动作,而且这一巴掌下去,关羽脸上竟然凭空出现了一道疤痕。 这个物理逻辑零分啊。掌上附魔了说一声,这是我对这一项的打分。那测完了纹身视频,我们测试一下图身视频,而且我们之前测的都是多分镜画面,你说有没有一种可能会有 all night 单场景稳定呢?于是我让 eevee 帮我生成了一张很复杂的图片,让人物在这个场景跳舞, 最后再弄个更花的大翅膀,看看谁能压得住。先来看看 cds 的, 除了中间转反了一下,其他的没什么毛病。再来看看 vivo omnit。 嗯,停停停停停,不是谁拉这了,你直接处理不了,给我简化了。什么意思?本相零分啊,这个就无需比较了,那一目了然。 我们再来看看多图融合表现。这个是参考人物,这是参考场景。先来看看 vivo omnit 的 表现。 不是,哥们儿,这照片是你吗?是我是吗?是,那时候我还很瘦。再来看看 sentence 的 表现吧。 i said, 我 还能说什么呢?直接上评分吧。最后一个测试是九宫格分镜测试,这是用 emoji 做的一张九宫格分镜图。先来看看 vivo omnit 的, 感觉还行是吧,但是它很多镜头跟我的九宫格分镜图完全不一样。我们再来看看 status 的 表现。 status 它也不是百分百对,但是大部分镜头都是跟着九宫格走的。剧组测试下来,我只能对 vivo omni 说, 你不是我的星,你是路人。很失望啊,兄弟们。没出之前都说是自洁杀手,自洁被他逼的要出新模型了,结果呢?端上了一道菜,菜名叫做,敬请期待下一代视频模型哦。 我还能说什么呢?让我们进行 pro 的 发布吗?我相信这个 flash 绝对不是你的真正实力。那也希望你不要跟每次世界赛的 lpl 一 样再藏。但藏的是什么呢?回家的机票。那么本期视频就到此为止了,我是二级之标同学,我们下期再见。拜拜。
86二进制喵同学 02:44查看AI文稿AI文稿
02:44查看AI文稿AI文稿三千块钱,十天时间,一位中专生把好莱坞的名导演给炸出来了!这位自称野鸡,中专毕业,来自云南玉溪新平的小伙,网名叫 m x l。 刘子瑜,非科班出身,本职工作是房地产公司的宣传,同时还有婚庆摄像的业务。 在家十天, ai 手搓了一部三分钟的短片丧失。清道夫从国内火到海外,短短几天,播放量已经超千万了。你在评论区可以看到英语、日语、西班牙语,来自世界各地的观众,大家一致评价就是,这是我见过的最炸裂, 最具类型强度的 ai 电影。于是外网就在疯狂找这位神秘创作者。然后这个事情的转折点就是在 ai 影视领域的现象级大神 pjs 留言了,他 说这是他看过的最好的 ai 短片,必须把他签下来,或者要跟他合作。五分钟之内,我要知道这个男人的所有信息。最后这句话是我加他,原话是,我猜他是一位来自中国的抖音创作者。没过几天,人就给找出来了。刘子瑜果断婉拒了好莱坞的高薪邀约,决定扎根在国内,目 目前已经跟广东的一家影视公司达成合作。大家估计很快就可以看到升级版的丧尸。清道夫激动,他们一开始设想是六十分钟,但是因为现在越来越火了,将来很可能会登陆院线大荧幕。 这件事离谱就离谱在第一,三千块钱,三千块钱他没花钱,他用的是 cds 二点零的积分兑换,折合成三千元人民币的 toc 成本。 三千元你要放在一个剧组,一天的盒饭钱你都不够。现在所有人都在把它对标爱斯基,但你要知道,每一集的爱斯基都是各大顶尖动画工作室及大成制作,当时每一集的成本是一百到两百万美元起步。 整个团队包含导演、编辑、美术、分镜、动画、音乐各个领域的大神。刘子瑜用的是啥? cds 二点零市面上最主流的图片和视频生成模型。 离谱的第二件事是刘子瑜今年一月份才接触的 ai, 二月份手搓高达跳级动画,五月份掏出神作,没有分镜图,没有首尾,真纯纯是文本生成的画面,手搓文案来实现视频里的专业运动。说白了他就是在写作文。那以前我们说电影或者说短片吧, 都是大公司或者专业团队的特权,那现在有了 ai 之后,就打破了这种资源限制内容门槛,反而其实这个门槛非 非常的高,这个门槛就来源于 ai。 工具给了他翅膀,但是真正决定飞行高度的是他多年来积累的综合审美。音乐人的节奏感就让他对画面配乐的把控特别精准。摄影师的镜头感让他在无师自通的情况下,设计出了非常专业的运镜逻辑。 他本身也是美剧续世的超级粉丝,让他在没有剧本的情况下,依然可以编织出引人入胜的故事。这也是为什么现在越来越多的 ai 大 厂开始招文科生和哲学生了,因为当工具越来越聪明,人类有灵魂力的审美会愈发的弥足珍贵。
1724我想静静了 01:14查看AI文稿AI文稿
01:14查看AI文稿AI文稿今天我来教大家如何免费无限使用 cds 二点零。首先我们选择浏览器的无痕模式,我们直接复制链接进去,这里可以领两万个积分。点击领取,点击注册,注册成功即可领取两万积分。我们制作视频来试一下,选择 video, 我们选择文本转视频,这里我们可以选择很多模型,有极梦二点零,可零千问 v o, sora 等等,我们直接选择极梦二点零,复制一下提示词,打开自动认色,生成一个试一下,时间比较久,我们直接看成片。 两万积分,虽然只可以生成六个一零八零 p 十五秒的视频,但是大家不要担心,主播已经挖掘出了能够无限获取积分的方法,我们只需要更换 ip, 关闭无痕窗口,重新打开,再进入链接,使用新的邮箱注册,就可以再次领取了。主播已经领取五六个邮箱了,大家速度领,不确定有多少。关注主播,获得更多 ai 羊毛资讯。
968UPUPUP! 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿谷歌今日凌晨发布了 gemini, 在 底层逻辑上简直就是一次史诗级的进化,瞬间引发了轰动,我们一起来看看实际的测试效果吧。哈喽,各位小伙伴们大家好,今天给大家演示一下最新的视频模型 omni flash 的 使用方法。 好,这个的话呢,它支持使用十秒啊,然后三十个积分这种方式操作好,那么怎么来操作呢?假如说我们要做这样的一个漫剧效果 好,那么首先第一个我们可以使用分镜啊,这个是我之前做的分镜。好,那么我直接把这个分镜的话呢,放到我的这个提示词里边啊,那么我可以直接到这里艾特一下就可以了。好,我艾特一下分镜,点击确认。好,然后的话呢,我可以直接说 啊,使用啊,根据分镜,或者我把它删掉啊,根据分镜生成动画。 好,然后我艾特一下这个分镜,这个分镜好,可以了。好,然后人物参考,使用这一个人物。好,然后场景参考,场景参考, 再使用一下这个场景。哎,我的场景也有了。好,这样子的话呢,那么就直接就 ok 了啊,然后我们直接来生成好生,呃,动画流畅,然后运镜流畅 就可以了。好,那么就直接点击生成好,这个的话呢,大家就可以看到一条非常运镜流畅的,并且呢有音效的这样的一个画面呢,就可以展示。 嗯,而且它的准确度是非常高的啊,就是没有脱离我们的这一个分镜,所以的话呢,这个是一个非常好用的功能。
279AIGC创意教育坊 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿用 ai 做带货视频啊,昨天谷歌更新了啊,新更新的那个视频模型是那个欧米,然后呢,今天我们测了一下,测下来啊,他应该是也是拉了多大的,他就是怎么说呢,他只有 c 档三点零百分之七十的能力吧,七十到八十左右我觉得。然后呢,他整体做下来,做一些简单的,其实也还行啊,他唯一的优点就还是那句话,还是那个优点,就是便宜啊, 别的优点好像也没见到啊,怎么说呢,看来看来,将来啊,将来有可能真的是 c 档三点零一家独大。本来我想的说的是,你只要是能关键你这次更新也就算了,你只更新个十秒的,你好歹更新个十五秒的,最长十秒的,如果去发墨西哥和巴西也够用啊。我说实话真的够用,因为今天我测了几套题石模板, 但是就是确实挺让人失望的啊,真的是拉了一坨大的。大家看一看他做的视频啊,做的视频其实还行,肯定是不如 c 档子啊,就是说的过去,主播是期望太高了啊。
71小辉跨境 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿朋友们早上好啊,今天的 ai 圈又炸了,十五秒带你看完三条关键动态!第一条,谷歌 vivo 三点一现在可以免费用了,所有谷歌账户,用户每月可以获得免费的 vivo 三点一十条的升成额度。那熬炒会员呢?每月可以做到一千条,平均每秒两毛二的佣金的成本,真的是香蕉鸡蛋便宜 太多。第二条,谷歌正在内测全新的奥林匹克争争模型,据说呢,实力是非常的强悍。继快乐马之后,金链子又迎来一个强劲对手,五月十九号的谷歌大会呢,会正式发布,可以期待一下。真的,现在想充 ai 免费会员的先别冲动, ai 更新实在太快了,可能你这个月充的,下个月他又过时 了。第三条,中国测恒星 ai, 推出全球首个影视级的 ai a g 的 star film, 一 次性能写三万字的 一等片。现在大多数 ai 都是只能输出个 数出五分钟。最后说个数据啊, facebook 预测二零二七年,超过百分之三十的数字视频将由 ai 生成。这场内容过滤并不是会不会来的问题,而是你上不上车的问题。 ok, 那 么以上就是今天的内容了,我是陈越,关注持续更新 ai 变现的实战策略。
56陈越讲AI变现 04:20查看AI文稿AI文稿
04:20查看AI文稿AI文稿谷歌刚刚发布了 jimmy 三点五 plus, 同时还把他们的编程工具 antigravity 升级了二点零,那这次就很明显了,谷歌的话这次是要全面提升它的这个抠点能力。之前不管是在 coi 还是 ide 还有模型, 其实给我的感觉就表现很一般,那这一次的话,这个模型最大的亮点官方说就是它的这一个速度啊,是前模型的四倍, 所以这一期我们就测一个最关键的问题,这么快的速度,它整个的一个代码质量会不会缩水?那我直接会拿两道真实的一个编程任务,把它和 cloud op 四点七, gpt 五点五放到同样的项目里面,同样提示时看它大家的一个表现情况。那下面的话,我们大概去扫一下它官方改出来的一个奔驰 mark 评分哈, 在编程方面的话,主要就看这一个 terminal, 奔驰二点一,还有这一个 sw 一 奔驰 pro, 从这个评分看的话,这一个 jimmy 三点五 plus 这个评分还是可以的哈,但是基于我之前对于谷歌模型实测的结果来看,就是评分不代表一切,因为之前就感觉它在这个编程方面挺拉的,这次我们就看整个的一个三点五 plus 表现到底怎么样。那这一次的话,我们的整个测试题目哈,就是沿用之前测试 cloud of 四点七,还有就是 gpt 五点五的两道真实的一个编程任务。第一个的话就是我们这一个 skills agent 嘛,需要把它从一个 c o i 做成一个 web ui。 第二个的话是希望他从一个已有的比较复杂一个项目里面把这个认证登录给它迁移过来,这一块也比较复杂,需要支持啊, get 谷歌,然后还要做一个落地页。好,我们来看一下这两个实测项目哈,左边的话,就我刚刚说的这一个 skill is a 镜头嘛,第二个的话就我们图片生成 a 镜头,那这次的话,我们是用了这个 anti gravity 它的一个 c o i 终端工具, 整体这一块呢,它的交互的话是跟呃卡扣的很像,那我这边测试下来,他的速度是真的快,相当相当的快,他说四倍,一点都没夸张。 那大家看一下它这个交互的一个情况啊,其实还是感觉挺挺好的。这个交互,那至于整个模型的能力怎么样,那这两个任务我这边实测下来,它都没有一次性的去完成,它或多或少都有一些小问题。那同样的这个提示值,在同样的项目,我给到了 gpt 五点五 以及 calloff 四点七,它都是能够一次性完成的,不管这两边哪一个项目都可以完成。但是 gmail 三点五 plus 它除了快,但它其实还是会有一些或多或少的 bug 嘛。好,我们来看一下它整体的一个表现情况。 好,我们来看一下这个是 jimmy 三点五 plus 帮我们完成的 skus agent 的 一个 ui 界面嘛,它可以去执行一些操作,比如说我给他一篇文章,可以让他帮我们去总结,它就会去加载这个的 skus。 就 我之前有一期视频 专门讲了这个 skills 的 一个工作原理嘛,那这是它完成的一个效果,整体上 ui 这块还 ok, 那 这边的话是 g p d 五点五给我们完成的,左边也是有我们的一个的一些 skills 是 哪一些?那右边的话就是它整个的一个操作的一个过程嘛。怎么说它这个 ui 的 一个结果的话,我觉得就是呃 g p d 五点五的会好一些。 那关于图片生成这个项目,让它去做一个落地页,以及让它去做一个就是谷歌 get 五的认证登录嘛,那这块它也是完成的,但是不是一次对话完成的。 u i 这块的话就是谷歌还是可以的,就是相较于 g p t 五点五的话,我觉得还是会好一些,就 u i 这块的话,我们还是优先选择就是谷歌的模型嘛。 好,下面我们来看下整体这个评分结果哈,那这个评分的话,还是跟之前一样,我们是把所有的模型生成代码通敏之后,然后改到模型去做 review。 那 这边的话 g p t 五点五是要胜出的,它的分会高一些。 第二个的话就是 cloudoff 四点七会辞职,那 gpt 三点五 plus 的 话,它整体评分效果会低一些,也就是它除了快,那代码质量上的话是会差一些。那这边的话也有些解决方案,比如说你可以用 cloudoff 四点七做设计,或者 gpt 五点五做设计,然后再用呃 jimmy 三点五 plus 去做执行。 那这块儿它还不是还发布了这个 anti graphic 二点零嘛。那这个 id 的 话,你就把它等同于 codex 吧,跟 codex 一 模一样。那我这边的话 现在还登录不进去,不知道啥问题。好,下面我们来进行一个总结。那这次他的整个编码水平的话,就是速度上确实是领先很多,但是在交付的一个结果上来看的话,跟国外两家模型还是有差别,尤其是在一些复杂项目里面,他还是会有偷懒的情况。 如果你是需要去做一些原型啊,或者做一些 u i 啊,我觉得这个 jimmy 三点五 plus 真的 是有比较有吸引力,因为它整个速度比较快,而且它的价格也比较便宜。那如果你是需要一些复杂的项目啊,多文件呀,那阶阶段我还是更推荐大家使用 g p d 五点五,在 codex 里面 你运行起来也非常的快。扣袋子这个 app 我 强烈推荐给大家用,我已经最近用了一个多月了,真的非常非常的好用, card 的 话就是封号真的特别严重,我已经放弃了。 ok, 那 这就是这期视频所有内容了,如果大家觉得这期视频做的不错,可以跟我一箭双雕,我是阿江,我们下期见,拜拜。
 12:33查看AI文稿AI文稿
12:33查看AI文稿AI文稿ai 漫剧赛道的大结局终于来了, cds 二点零加 cammi 三点零的出现,直接宣布了比赛结束。只需把小说丢进去,大模型就能自动接管一切,推理剧情,生成脚本,自动处理提示词,无需手动拣写,智能分镜指令,它能直接生成连贯的电影级分镜剧本。 最关键的是,它彻底解决了人物一致性的千古难题,一键生成人物三式图,场景以及各类道具,让主角从片头到片尾长相始终保持一致。 做慢剧再也不用求人,也不用四处寻找各类软件了,附带保姆级教程,手把手带你零基础出片,你也能制作出这样的大片效果。 使用工具已经全部整理好了,感兴趣的小伙伴六六六直接分享好,我们刚才给大家讲了人物形象的一个设计,那我们接下来看一下这个分镜头图片的一个创作。 呃,那我们为什么要创作这个分镜头的图片呢?对吧?大家知道我们在生成视频的时候,基本上我们百分之九十五以上啊,选择的都是图声视频的一个方式,对吧? 然后再把这个视频啊,经过咱们的剪辑后期处理啊,最终形成我们这个完整的一个作品。那所以说我们分镜头的图片啊的质量,直接决定了最终视频的一个效果。 所以说分镜头啊,我们的每一个分镜啊,每生成的每一个图片啊,他其实都是最终会影响我们的一个效果, 对吧?那我们视频制作的流程就是有了剧本之后,然后我们来写对应的分镜头,对吧?生成高质量的故事的图片的啊,这个分镜头图片,然后我们再用图片呢来生成视频啊,这个我们后面也会给大家讲, 然后接下来的话,其实就是剪辑和后期啊,把不接生成的视频片段呢,把它组成到一块,最终呢就是一个完整的一个作品。 好,那我们接下来看第一个分镜头图片创作的一个方法啊,就是脚本描述画面啊,直接生成这种方式的话,其实比较简单, 我们直接准备 ai 生成那个脚本,然后包含啊警戒和画面描述,对吧?在提示词中输入对应的一个指令,然后我们就可以等待啊分镜头的一个图片的生成,这个相对来说比较简单啊,我们来给大家演示一下, 我们还是拿之前的这个糯米啊,糯米的这个故事来给大家举例啊,那我们先有一个分镜,对吧? 故事有了之后的话,我们啊要求他生成十个分镜啊,因为这个故事比较短,所以说我们让他生成十个分镜, 用你生成的这个故事生成脚本,然后要求十个分镜呢,不要有画面景别的切换,这个咱们之前给大家说过 是不是?那接下来的话他会生成啊,这个短篇的一个分镜的脚本啊,一共十个,然后单个呢是小于五秒。那第一个啊,呃,老象杂货铺,然后奶猫糯米卷在这个 腾一边腾一边,然后歪头望香港啊,这没什么问题,然后小满蹲身啊摸糯米,然后指尖蹭小猫的软毛,这个大家可以分别来读一下。那接下来就是有了这个分镜头的一个脚本之后啊,那接下来的话,我们就把它生成出来,对不对? 好,那接下来我们给他一个身份,你是一个 ai 视频创作大师,然后现在请根据脚本中的景别和画面描述啊,生成前五个分镜头,画面比例呢?十六比九。 那大家看看生成的这个画面啊,第一个对吧?这个小猫是一个写实风的,然后第二个呢?哎,大家发现啊,第二个这个画风有点不对,对吧?而且啊,他的描述,他这个画面生成的也不对, 你看小猫摸啊,蹲身,小满啊,小满啊,不是小猫啊,小猫小满蹲身摸糯米啊,这块,然后呢指尖蹭小猫的一个软毛,对吧?但很很明显这个 ai 理解错了, 糯米才是这个小猫,对吧?并不是真的去摸这个真的糯米,然后你看下一个啊,下一个就更离谱了,对吧?小满抱着糯米落泪啊,眼眶通红,这个也不对,是不是因为它生成的都是什么? 他把这个啊,最最后啊,最后这个糯米就完全跑偏,对不对?他没有理解这个上下文啊,所以说我们在用豆包来生成的时候,呃,他有这种他的画面啊,他是有这种上下文的话,很容易啊,就出现这种情况,画风呢完全不对,对不对? 这个时候我们怎么办呢?啊?可以借助吉梦,他有一个参考图片啊,非常的好用。我们先把什么,我们先把这个小满 的猫的这个图片啊,就是糯米的图片呢,生成出来这几张图片,对吧?大家选一张啊,然后呢,同样的,大家把那个风格给他去掉啊,把那个风格给他去掉,因为我们是参考的这个风格来做的, 那这张图片的一个风格来去生成的,对不对?那接下来的话,我们把这一句啊,比如说小满蹲身摸糯米,然后指尖蹭小猫的软毛啊,对不对?那这里啊,大家注意看, 我给大家使用一下这个提示词,你看小满的话,他这块有一个参考,引用,就可以引用这张图片啊,引用你上传的这张图片,然后蹲身摸这个糯米,对吧?那糯米的话,这张图片我们也把他这个直接拖进来就可以啊,你想参考的话直接拖进来就可以了,看这样就可以了 啊,然后他这块呢,我们也选这个引用,引用这张图片,然后指尖蹭小猫啊,这里,那这样的话他就理解了哪个是哪个,对吧?他要参考的图像的一个生成到底是什么?是不是?你看你这样再去生成第三张图片的时候啊? 同样的小满我们还是去引用这张啊,然后爆糯米,好,那我们再让他去生成, 这样的话,他的就理解了,谁是谁,对吧?不会不会像豆包这样,豆包在生成图片的时候,他就是拿着这句话来去生成的,而且他在做图像生成的时候,他是没有办法做到像吉梦这样啊。就是,呃,你的每一个角色呢,都可以去有一个参考图片啊, 这样的话我们在生成的时候效果就会比较好,对不对?这张就这几张图片,基本上是把我们的这几个题词给他复现出来了。 小满蹲身,然后呢摸糯米,对吧?这个糯米是在椅子上,如果说你不想让他在椅子上,在地上也是可以的,就是我们加上一句啊,糯米坐在地上就可以了,好吧, 然后这里啊,你看,呃,小满抱着糯米落泪,然后眼眶通红,这个基本上也都是符合的,是不是?尤其是这个吧,这个画风就基本啊符合我们的一个要求。前几张的话,你看这个小猫啊,可能抱的姿态可能不是特别好, 这个还可以,对吧?这个我觉得这个效果是比较好的。然后我们后面在生成视频的时候,其实就可以用什么,那用咱们的这张图片来去生成,对吧? 那这是第一种方式啊,这个就是我们的第一种方式,直接用咱们的提示词,对吧?啊?当然提示词的效果呢,并不好,也给大家看到了,咱们最好用这个吉梦,是不是? 然后第二种方式的话,我们来看第二种方式啊,第二种方式的话就是我们可以让 ai 学习你的口吻啊,呃,我们刚才看到了,他那个题词写的并不是特别好, 对不对?那我们可以怎么样呢?啊?就是给一个优化的一个视力,然后让 ai 模仿这个视力呢?从新的来写这个角位,然后我们再从新的生成这个分镜头。这块给大家举个例子啊,比如说我们原来的,呃,这个分镜头是这样,混沌天空裂着巨大的缝隙, 五色石光芒从缝隙边缘溢出啊,这是他原先的这个题词,那我们可以把它做一个优化,比如说天空出现一条黑洞, 对吧?你这个混沌天空裂着巨大裂缝啊,他 ai 很 难理解,对吧?你就直接说,啊,天空出现一条黑洞裂缝,然后裂问啊,裂这个裂痕啊,之中散发着彩色光辉,然后画面比例啊,十六比九,然后呢我们把这个 这句话写上之后的话,然后我们再加一句啊,就请模仿上述的一个口吻,重新的精简编排脚本里的所有的画面描述,然后要求言简意赅,直白可观。 这样的话他会按照你这个写的,把之前写的所有的脚本呢重新的都给来写一遍,对不对?那他可以干嘛?首先第一个啊,就可以消除一些词藻的对策,对不对?你比如说什么混沌天空啊,这个 ai 很 难理解, 对吧?第二个就是它可以提升我们的一致性啊,所有的分镜头的描述呢,保持统一的一个风格,然后可以降低我们的一个出错率。这个的话大家就根据自己一个的一个描述啊,你生成的那个画面描述,然后大家自己去改就可以了。 好,那接下来的话我们再看一下这个分镜头图片的一个修改方法,我们基本上就是啊直接通过大模型来去进行一个修改。 当然如果说,哎,老师我会那个 made in, 或者说我会 ps 啊,可不可以呢?也可以啊,就是大家可以用 ps 来去改图也是可以的,但是这个 ps 并不是呃,每一个同学都学过,所以说我们这里啊还是跟大家说一下怎么去修改。呃,这里如果说你觉得这个 呃你要做一些局部的一些修改,对吧?比如说刚才生成这个猫猫的这个猫的这个鼻子啊,来,比如说那你可以做一些什么?做一些这个哎,比如说细节修复啊,或者说局部重绘啊, 比如说我们放大一些,你把这个猫的鼻子给他做一个重绘啊,这样在这里就是直接通过这个自然的提示词啊,就可以,比如说猫的鼻子改成什么,改成其他的颜色啊,直接发,然后他就会把这个猫的这个鼻子的颜色呢给你改掉, 这样的话我们就可以做一个局部的重绘,对吧?就整体的这个画风,哎,我是我是满意的,对吧?但是,呃,可能是吗?可能里面只有什么,只有这个猫的鼻子,这里我不是特别满意啊,它的颜色我不是特别满意,那大家就可以用这种方式来去做一个局部的修改, 对不对?你不用说重新的把整个图片呢全都给生成,我们只需要去做一些局部的修改啊,就省去了 ps 的 一个麻烦啊, 因为啊, ps 并不是每个同学都会,那这样的话啊,我们在用这个局部重绘的时候就比较简单对不对?或者说大家可以啊,如果说觉得整个呃图片不是特别清晰的话,那咱们可以把它变成超轻的, 或者说做一些细节的修复,但这个我们一般也不会去做,我们一般就是用来局部重绘啊,比如说他哪里不合理,我们就把这一块啊给他做一个修改就可以了。 那我们接下来再来跟大家总结一下啊,分镜头图片创作的三种方法,但其实我们只给大家讲了两个,那还有一个是什么呢啊?就是结合自我想象,自主来生成这个对于大家刚刚接触咱们的 ai 短剧的同学啊,这个方法并不太适合,当然这种方法 肯定是吗?肯定是效果最好的,就是他是参照故事原文,然后加入画面的一些构思啊,就是加入一些自己的一些想法,然后呢再去生成我们的分镜头的图片。但是大家一开始刚做的时候应该是没有什么思路,所以说我们更多的可能还是用 第二种方式,对吧?就是先优化一个分镜头的描述,然后呢再让 ai 生成你的这个描述,对不对?模仿你的描述重新再来生成一遍啊?那接下来就是一个图片修改啊,图片修改的话,我们就基本上就是用它的局部细节的一些微调, 对吧?那这个就是我们分镜头图片的一个制作啊。好,我们刚才给大家讲了分镜图片如何来生成。
 06:57查看AI文稿AI文稿
06:57查看AI文稿AI文稿谷歌的欧米尼视频生成模型上线了,我们可以在这个 flow 平台上进行体验,同时 flow 平台也上线了很多的视频和图片编辑小工具, 那么本期视频我就给大家测试体验一下欧米尼模型还有这些小工具。首先我进行测试的时候,模型只开放了 fresh 模型, 目前最高能生成七二零 p 十秒的视频,每个视频消耗三十个点数, umi pro 会员一共有一千个 ai 点数,而且我在使用的时候,它的首帧参考功能还没有上线,所以我就简单测试了几个纹身视频的例子, i will send you back to the dark abyss。 好,提示词所要求的东西都有,但是动作,电影质感还有音效都差很多,可以看一下 c 带是二点零的, 而且在 flow 这个平台,我们可以在下面这里输入提示词,直接对视频进行二次编辑。比如我直接输入一条金枪鱼跳上船,我们来看一下效果, i will send you back to the dark abyss。 他 这添加的内容太生硬了,几乎是不可用的。当然有可能他是 fresh 模型的原因。我们再多看几个例子, 这条视频的话,飞机驾驶是还不错,女主的紧张感和节奏也还行,但最后飞机仪表盘反向了,而且多了一个人。下一个我们试一下著名 ip 加想象力 why won't this stupid code work? 暂停一下,这里电脑里表现的内容太棒了,连代码的说尽都像那么回事。 i refuse to do this? 直接切镜头换风格 anymore why won't 他 这条真人路飞生成的其实挺棒的,这是就中间莫名其妙多出来一个动漫风格的镜头,下一个是变形金刚的镜头, 这个表现就太差了,别说跟 c 站十二点零比了,连快乐马都比不过。 下面是一个著名 ip 加动漫风格, anya will defeat all the villains, 这个表现其实还算可以了,介于 first 和 cds 二点零完全体之间, 下一个是香港电影。如果记忆是一个管头,我希望他永远不回国。起 这个案例就表现的很差了,无论是中文音还是镜头都不符合要求。如果记忆是一个罐头,我希望它永远不会过期。来一个九比十六的变身镜头, 那就再来一次, 感觉能比快乐马好上一些,但是这种动作和特效还是 c 大 师您的拿手好, 再试一下科幻镜头, 这个表现太拉胯了,完全没有电影质感,比快乐马都差远。 总结一下就是 omni, 它的表现肯定是不如 cds 二点零的,但它毕竟还是 flash 模型,不知道它有没有正式版,如果有正式版还是未来可期的。它还有一个优点就是足够的便宜,性价比还是很高的,目前生产速度也快,而且目前还 现那些著名的 ip。 今天除了欧莫尼这个更新之外, pro 这个平台还上线了巨多的图像编辑和视频编辑小工具, 我也帮大家测试了一下,总结一下就是很鸡肋,就是看起来很厉害,实际上就是一些常见的开源项目整合而成的图像和视频编辑工具, 比如说编辑文字动画的呀,还有说像什么手绘转图片,从各个仕图和角度去查看原始的图片,这个就是千问的技术吧,我记得还有什么视频跟随音乐动起来,这样的就适合整活。 还有一个是上传三 d 模型,然后再转化为二 d 平面图片, 它的视频小工具还有一个印象比较深刻的是一个抽帧加抠图加重叠的技术, 其他的图像小工具的话,要不然就见太多了,要不然就完全没什么意义。总结一下的话就是 omni 未来可期,图像工具的话作用不大。 那么以上就是 jimmy 在 本次 flow 上的更新的测试结果了,我个人是比较失望的。好,如果本期视频对你有帮助的话,麻烦帮我点个赞。
759实验式 01:32查看AI文稿AI文稿
01:32查看AI文稿AI文稿看来好莱坞打不过就要加入了, ai 视频终于迎来 c dance 的 重磅挑战,谷歌即将激出最新的 ai 视频生成模型 where for。 看到视频的最后呢,我会展示一个所有想做视频的人都能受益的案例。首先, where for 在 视频输出的能力上全面追平 c dance, 终于有人能把现在视频生成价格高、速度慢的问题解决一下了。 而且呢,已经有人开发出了针对电商广告和各类市场内容团队非常有潜力的玩法,只需要通过一个商品视频和无限多的模特视频,就可以完成更多的内容组合式创新,这将是对内容生产释放的重大利好消息。 之前 luoma 等模型吹过的牛,现在也被 will for 实现了。只需要通过自然语言就可以完成视频编辑。例如直接提出把盘子里的意面换成南瓜汤模型就能针对局部内容进行修改而保持其他部分不变。即使是这种飘忽不定的水印,它都可以去掉。过去这类需求往往需要非常复杂的调整, 而如今正被转化为口喷的编辑方式。这次谷歌呢,不仅是占频 cds 这么简单,还在解决一个所有不会做视频的人的痛点。我只有一个想法,但是我不是专业人士,如何转化成视频呢?比如为给他一段乔布斯生平的故事,让其生成不需要你操心,就可以直接生成长达三十五秒的视频。 也就是说, vivo 不 只是生成看起来像的画面,而是能够围绕某个主题组织出更符合常识和语境的内容。这类任务都体现出他试图把视频生成和知识理解结合起来, 对于所有想做视频自媒体的人来说,这会是一个很值得关注的方向。所以通过这次 vivo 的 更新,我预测未来的 ai 视频模型将会成为每一个故事讲述者的智能导演,而你只需要一个好的想法。
220AI熊厂长 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿就在昨天呢,谷歌正式发布了全新的 ai 视频大模型谷歌奥尼,这不仅是一次更新,而是一次改变视频创作规则的革命。首先呢,给大家一句最核心的理解啊,奥尼就等于从任何输入创造任何输出, 什么意思呢?也就是说,他可以把一段文字,一张图片,甚至一段音频合成完整的视频。他打破了传统 ai 的 边界,把文字、图片、音频甚至视频全部融合到一个系统里面。 从此以后呢,你不再需要复杂的剪辑软件,只需要一句简单的指令,就能够让 ai 编辑画面,修改场景,调整动作, 用自然语言呢,也能够做出像电影级的视频内容,创作效率呢,呈几何级的提升。目前推出的首款模型呢,叫做 gemini omni flash, 已经开始在 jimmy 的 各个平台,包括谷歌 flow 等平台中可以去使用了,让普通用户呢,也能够体验一下用嘴来创造电影的时代。大家呢,可以点个关注,下期呢给大家带来实际的测试效果。
 01:58查看AI文稿AI文稿
01:58查看AI文稿AI文稿一口气看完谷歌 i o 大 会七大更新,先看明星产品 gemini 三点五 flash, 几乎所有机型超越三点一 pro 主打更强的 a 帧能力、更强的抠定能力和更快的速度,速度四倍于同级模型,价格比三 flash 差不多贵了三倍,但比三点一 pro 便宜百分之四十。三点五 pro 推迟到下月发布, 值得期待。第二, gemini 一 款世界模型,能根据图片、视频、音频、文字任意输入生成高质量视频, 创作出来的视频完美卡点。还可以通过跟他对话来编辑视频,换环境、换角度、换风格,多次优化也没问题。而且他对这个世界也很懂,短短一行提示词就能生成黏土动画,讲清楚蛋白质折叠。 第三,谷歌把 antigravity 打造成一个完整生态桌面版。二点零是目前主力入口,中端 c l i 适合快速脚本化清亮场景,自己造 agent 就 用 s、 d、 k 还有企业接入, 实现无缝配合。谷歌这波的核心方向就是专注于多 agent 协助异步任务和更广泛的知识工作,而非仅限于编码。 第四,你的私人 ai agent gemini spark 由 gemini 三点五和 google ant gravity 技术提供支持,在谷歌云上的专用虚拟机上运行,甚至注入了智能编码能力。第五,智能购物车。不论你是在刷 youtube 还是看 gmail, 都能直接添加商品,它还会自动比价向你推荐更加方案。 第六,一些好玩的更新,谷歌的 ai 选映技术,官网里又将会圈一下就能查这张图是不是 ai ask map youtube 把搜索框变成直接对话的窗口, 还有 dog's life, 以前让 jimmy 写东西得字斟句酌的输入提示词,现在直接说就行, jimmy 会自己整理,最后提一嘴谷歌的音频眼镜秋季上市,不得不说这届 i o 大 会信息量真不小。你最喜欢哪个? 关注机器之星,探索 ai 世界。
128机器之心 02:20查看AI文稿AI文稿
02:20查看AI文稿AI文稿沉默了十几年的谷歌眼镜终于复活了,这一次明显是冲着 matter 来的。就在今天的 google i o 二零二六大会上,谷歌正式展示了新一代安卓 x 二智能眼镜。美国科技媒体 cine 的 现场体验完后,记者的反应非常真实, but i did get to see your demos on prototype glasses, which look even better than the last time i checked them out what's really impressive? 体验下来最离谱的是 jammin, 简单说,他现在已经有点像真人版 james 了。记者随口问了一句世界杯相关的问题, jammin 直接在眼镜里语音回答, i've saved all of bosnia's world cup games to your calendar。 翻译功能更夸张,现场有人说法语,有人说葡萄牙语。眼镜会自动识别语言,然后直接把实时字幕显示在镜片里,甚至还会跟着说话人的语速变化进行同 声传译,传译的声音也会根据说话者的性别进行调整。 abitong tong tong canada a vegemoman mad emma shah because i lived in ken hida with my mother and my cat all right wow, that's cool! 那 在拍照方面呢?用眼镜拍完照片后,内容会立刻同步到手机和智能手表,而且微软手表甚至还能反过来当眼镜的取景器。 最抽象的是,现场还演示了 nano banana。 记者刚用眼镜拍完一张照片, ai 立刻把它改造成一种灵奇漫画加寿司的诡异艺术风格,而且生成结果会先出现在眼镜里,然后再同步到手机 另一边。 xreal 的 project aura 甚至已经开始搞空气操作了,直接用手势隔空捏合滑动控制应用, 看是不是已经越来越像钢铁侠里的 tony 操作 jarvis 的 界面了?总体体验下来的感觉就是谷歌这次终于学聪明了。当年 google glass 最大的问题是什么像个赛博神棍。而现在的新版本开始疯狂去即刻画 谷歌,直接拉来三星 warby parker gentle monster 一 起做外观,说白了就是先让它看起来像正常人会戴的眼镜。当然它也不是没有槽点, 比如 jamming 和同声传译会有略微延迟,比如 project aura 还得外挂算力设备。但现在这些已经不算什么大问题了。你觉得谷歌 mate, 苹果到底谁会先把手机这个终端从你口袋里彻底干掉?评论区聊聊。
53AI普瑞斯 07:52查看AI文稿AI文稿
07:52查看AI文稿AI文稿今年谷歌 i o 大 会有哪些看点?对国内的产业又有哪些影响?我们一个视频说清楚。首先是 token 方面,到了二零二六年,现在的月度处理量已经飙到了三千两百 t, 单平台的 token 日处理量都超过一百 t 了, e p i 每分钟处理一百九十一亿 token, 这个消耗速度确实是有点吓人。顺着这个 token 的 消耗,它们模型的迭代也挺有意思。这次发布的是 jimmy 三点五的中监态系列产品, 偏推理方向,那个 gemini 三点五 flash 版本的性能直接超越了三点一 pro, 速度比其他 sota 模型快了四倍。然后 gemini 三点五 pro 预计是在二零二六年六月发布,听说是要在 coding 和 coding agent 领域有比较强的加强。 还有一个很关键的动作就是谷歌首次在推进 world model, 也就是世界模型。紧接着他们还发布了原生全固态模型 gemini omni, 整合了图像、视频还有世界模型这些技术。这可以说是谷歌 ai 体系的核心,贯穿系统。说白了,这就标志着谷歌的 ai 愿景正在从组织全球信息转向模拟并代理物理世界。说到代理, 他们这次明显在聚焦 code agent 和 agent 的 生态。谷歌推出了一个叫 universal commerce protocol, 也就是 u c p 的 协议,摆明了是对标 andropic 的 m c p 协议。然后他们还发布了一个 agent 产品,叫 spa r k, 这个东西可以在谷歌云上七成二十四小时运行,目前它只支持谷歌自有的工具, 不过后续也会接入第三方工具。整体看下来,未来的 agent 将会把搜索引擎从一个单纯的信息入口,直接升级成交易和任务的执行平台。 你看,在搜索和电商业务的升级上,这个逻辑就体现得很明显。搜索端那边,他们推出了由 gemini 三点五驱动的 ai overviews 智能搜索框,支持上传图文和视频,还能开启对话式搜索, 甚至还能代替用户去和商家沟通。这种主动代理功能,电商端也是个大动作,他们推出了 universal cart, 也就是通用购物车,能支持跨平台的商品聚合、 ai 自动追踪、降价,还有补货提醒这些 a 政功能。其实前面提到的那个 u c p 协议,已经接入了 shopify 等主流平台,甚至还支持酒店预定等服务。 他把 a p i 支付协议打通了,用户可以通过 agent 进行有限额的信用卡消费,基本上就把发现、决策到支付的全链路闭环给做成了硬件和端测。他们也没落下,这次宣布了和三星合作, 基于交通平台去开发 ai 眼镜,这里面的产品包含了带显示功能和语音交互的两类。就在二零二六年秋天,他们会先推出语音交互款,功能上支持听音乐、拍照、通话以及调用手机 app 等, 未来还会继续向 ar 智能眼镜的方向去发展。当然,这背后全靠算力在撑着。谷歌此前已经公告过,二零二六年的资本开支是在一千八百到一千九百亿美金,它们第八代 tpu 的 算力比前一代直接提升了三倍。这次第八代 tpu 分 成了两款,一款是八 t 训练芯片, 专门用于大规模预训练,支持跨数据中心训练,能完成超百万卡集群的部署。光模块标配一点六 t, 另一款是八 i 推理芯片,这是谷歌历史上首款推理专用的芯片,特别强调低延时,最大能支持一千一百五十二张八 i 芯片的集群互联。而且你会发现 谷歌的 tpu 正在从自用转向外公。他们和黑石成立了 e t u cloud 的 合作公司,黑石出使就投入了五十亿美元, 目标是在二零二七年上线五百兆瓦的数据中心容量,来提供谷歌的 tpu 算力服务,整个投资预计会达到两百五十亿美元。关于 tpu 的 出货量,预期他们二零二五年出货量还不到两百万张,二零二六年预计就会有大约四百万张, 二零二七年预计能达到一千万张,到了二零二八年预计会达到两千万到三千万张。既然芯片出货量上去了,集群和网络架构肯定也得跟着升级。它们的最小 pod 的 计算单元提到了九千六百张卡,同时还首次推出了可以商用的 scale out 网络, 最大支持三万四千四百张卡的集群训练。这么一来,光模块的用量就大幅提升了,训练端和推理端都在加单,同时 ocs 交换器的用量也在提升, 训练端和推理端都有明显的增配需求。聊到这,咱们来看看整个产业链上那些正在受益的公司。光模块产业链这边,你可以重点看看谷歌的光模块供应商, 像中际旭创、力迅精密、联特科技,还有美股的 f i n i s a r。 上游的光芯片供应商里面有原结科技的厂商,比如光库科技、德克利福金科技、藤井科技、 海泰星光也都值得留意。再往深了看,半导体产业链的变化也很大。 t p u 制造相关的有台积电,他们负责了 t p u 的 全部流片和 koloss 封装。还有博通 作为 t p u 核心设计供应商,和谷歌签订了长期协议,一直到二零三一年,同时还供应数据中心网络组建。联发科也参与了部分的 t p u 设计。存储相关的有美光、海力士、三星, 随着 tpu 出货和 token 消耗的增长,它们 hbm 和 dram 的 需求都在跟进。而且随着视频和图片生成以及 agent 任务结果的存储需求增长, enfinash 的 需求也在动。 pcb 相关的有沪电股份、深南电路、彭鼎控股、圣虹科技、广核科技、东山精密,它们都是 tpu 回到 gpu 主板的核心供应商。服务器和交换机组装这边有天弘科技,负责服务器和交换机组装,力迅精密和东山精密则负责光模块组装。 甚至连数据中心基建产业链都在变。受这种百万卡集群和跨数据中心合作需求的影响, d c i 也就是数据中心互联的前景挺广阔的,像诺基亚电力企业,还有数据中心厂商都卷在里面。最后就是应用端产业链了, ai 营销里面有一点,天下、汇量科技、蓝色光标, ai 电商里面有值得买。焦点科技,视频深层领域则有中文在线、昆仑万维这些,大家伙都在跟着。
40正经的阿干




猜你喜欢
- 4259军武知识局
最新视频
- 1263蓝鲸TMT