bootstrap.md如何写

粉丝3876获赞1.6万
相关视频
 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿你知道吗? openclaw 用八个简单的 microsoft 文件,就能让 ai 助手真正了解你,今天我们一一揭秘搜 md 是 ai 的 灵魂所在,在这里定义性格、价值观和行为准则,比如是否务实,说话风格是否直接这些东西,在这里, ai 才能有真正的个性 identity。 md 是 ai 的 身份证、名字、物种、风格,以谋奇头像,这里定义 ai 以什么形象出现,比如叫阿彩,风格鲜训,带点冷幽默,这就是它的名片。 user, md 记录的是你这个主人的信息、名字、时区、在意什么,正在做什么项目。 ai 了解你越多,帮你越精准,这就是它的用户档案。 bootstrap md 是 ai 的 出生脚本,首次对话时,它引导 ai 建立自我认知,完成后自动删除,就像人的出生证明,用完就归葬,不再需要了。 memory md 是 ai 的 长期记忆,每次完成重要工作后, ai 会把关键信息写入这里,下次对话时读取它,就像老朋友一样,不需要你反复解释。剩下三个文件各有分工。 agents md 定义多智能团队协助规则。 heartbeat md 是 心跳检测与状态监控。 tos md 则定义 ai 可以 使用哪些工具和能力, 这就是 opencloud 的 秘密武器。八个 markdown 文件,让 ai 从一个工具变成真正懂你的伙伴。有个性,有记忆,知道你是谁,关注我,一起探索 ai 新玩法!
 01:49查看AI文稿AI文稿
01:49查看AI文稿AI文稿你是不是在装完 openclaw 就 直接开始用了?那你大概已经发现了,他有时候废话特别多,有时候不问你就自己干了。核心的问题在于,你没有给他写 openclaw 最重要的一个配置文件。 你可以把它理解成一本员工手册。你招了一个能力超强的助理,但你没有告诉他规矩,那他就只能按照自己的理解来干活。有了 openclaw 这个约束, openclaw 才知道什么该做,什么不该做,以及用什么样的风格去做。写好这个文件,你的 openclaw 体验能直接提升一个档次。分享一下我自己的熟练。 md, 我 把它分成三个层次来写。第一层,做事的态度 要真实地提供帮助,在询问之前先发挥主观能动性。第二层,内外有别,这一条特别重要。对内的操作大胆一点, 比如读文件,整理资料、分析数据,不用事事来问我。但是对外的操作,比如发邮件、发消息,任何公开的操作必须谨慎,有疑问就先问。第三层,要有自己的判断, 这是大多数人不敢写的。但我想说,一个没有观点的助手,本质上就是一个步骤更多的搜索引擎,你可以让他有偏好,有倾向,甚至允许他不同意你。 这样你得到的才是一个真正有用的助理,而不是一个只会谄媚的机器人。好的,缩点 md, 不是 一次写完的,是一边用一边慢慢调。 举个例子,如果你觉得他话多,那么就让他精简一点。如果你觉得他太保守,那就让他大胆一点。我把完整的模板放在了评论区,有需要的直接带走。下期我们来讲一下 bootstrap md 教你怎么让 openclaw 每天自动开工。
22稳哥的技术笔记 05:22查看AI文稿AI文稿
05:22查看AI文稿AI文稿hello, 大家好,我是 fred, 专注从普通小白的视角去分享怎么从零开始用 ai 和 web coding, 提升自己生活和工作效率。很多人装完 codex 第一反应就是马上去让他写代码,但我会让他做另外一件事情,也就是 给他写好 hmd。 因为 ai 其实不怕复杂的任务,怕的是一开始没有规则,没有规则的时候他可能讲太多,改太多,甚至把你不想动的地方也顺手动的。所以说我们这期会先讲怎么让 codex 在 动手之前先知道你的规矩。 第一,什么是 a g m d? 大家可以把 a g m d 理解成 ai 的 一个写作的说明书,它会告诉 codex 这个项目怎么沟通,怎么写代码,哪些安全底线不能碰,哪些操作必须先问 以前这些要求,你可能要每次重复的去讲,去写进这个文件以后,它就会变成一个默认的规则,你不用每次去教 codex 怎么去配合你。 然后第一部分,其就是他的整个的语言的使用规范,因为我日常沟通就用中文嘛,这样去讨论需求和复盘问题其实更顺的。 但是像在代码,包括命令行啊、变量名啊、日制和报错,其还是要保留英文的。原因很简单,就是因为 英文报错可以直接去搜索,方便去定位问题,如果全翻译成中文,反而会降低排查的效率。所以说我的原则是解释用中文,哎,记住信息,保留原样。 第二部分就是它的代码和提交的规范。虽然我们大家都看不懂代码,但是我也不希望 ai 为了去显得完整,去提前写一堆复杂抽象的东西,其当前需要什么东西,就把当前的问题解决干净,如果单个文件太长, 那就去拆主键,拆函数,去拆模块,每次改动尽量小一些,提交清楚啊,每一次的记录,这样后面口袋再去维护的时候,才不会被一大堆的这种十三代码去劝退,对吧? 第三个最核心的点就是安全,与红线类似,像这种密码啊,密钥啊, a p r key 啊,这种是不能够直接写进代码的,然后包括像点 e n v 这种本地配置的文件,也不能提交到仓库,包括日期,也不要输出一些隐私的信息。 像日常的一些小改动,其实可以用一些低摩擦的去执行,但比如涉及到一些接口的结构啊,数据库的制段啊,批量去删除一些文件啊,或者说一些外部的账号和数据,就必须天 先让他停下来跟我确认。其实这不是去增加一些流程啊,而是防止一次自动执行,把一些项目改到不可控的状态。 然后第四个就是它的整个的执行与测试的工作流。就很多时候 ai 说,诶,我已经修好了,其实不重要,就验证通过才重要,你知道吧? 所以说如果命令报错,要如实的去上 ai 报告,然后包括测试失败也不能查,包括修 bug 的 时候,最好去先写一个能够复现问题的测试,再去改代码,就跑完以后能跑测试就跑测试,能跑 nin 就 跑 nin, 这样才能够减少 ai 的 整个的一个幻觉, 想让他看起来完成,但实际上不能用的这种情况。然后最呃第五个呢,是我自己的一个用户习惯,因为我会要求他叫我 fred, 包括我自己的偏好去直奔主题,找一些形式化的确认,能够直接做的就日常 直接做啊,但涉及到一些可能删除啊,密钥啊,权限啊,上传啊,账号操作这种风险点啊,就必须还是跟我确认,这样应该就不是机械的去回复我,而是更贴近我自己的一个工作节奏。 然后像呃目前我的这个 a g m e a i 的 一个工作模式的话,就是遇到熟悉的问题,他会去用一些内置的 skills, 而不是每次都从零开始去乱试,包括改完源码之后去默认跑测试,降低一些低级的语法错误,也不会去做一些多余的发散。 真正高效的写作不是让 ai 写得越多越好,而是在正确正确的这种边界里面把当前的问题解决掉。 所以说我可以给大家看一下当前我整个的一个 h m d 啊,包括刚刚所说到的语言的问题,安全红线的问题,工作流程的问题以及代码标准的问题,和我自己的一些用户偏好,其实跟刚刚讲的是完全一致的, ok。 最后总结一下就是, agent m d 的 本质就是把你反复叮嘱 codex 的 话一次性写清楚,语言怎么用,代码怎么写,安全边界在哪里,什么时候要去验证,什么时候要去确认,都放进去, 它不是让流程变得复杂,而是去减少废话,减少返工。所以说 codex 安装好以后,我建议不要第一时间让它去写功能,先把规矩建立起来,先定规矩,再让 ai 去干活。规则清楚之后,你只需要告诉它目标, 剩下的就是让他按规则去执行。 ok, 我是 fred, 后面我会持续用真实的案例告诉大家怎么把 ai 用进自己的工作流。这就是本期的分享,我们下期再见。
7464FredTalk 04:53查看AI文稿AI文稿
04:53查看AI文稿AI文稿loco 创始人在他自己的官推中分享了十三种他自己的经常的用法,今天给大家带来第四和第五条, clock 的 markdown 文件。 clock 点 md 杰伦先说他们团队,无论每个人同时开启多少个 clockdown 的 并行,但他们永远都会围绕着一个共享的 markdown 文件部分的内容呢,如图所示。那这个文件到底是在干嘛的呢? 现在的 ai, 大家都知道,写代码非常快,非常强,而 cloud code 呢,或者是其他的各种 a 阵,看起来都很聪明,但一旦把它放到真实的项目里,就开始让人头疼了。 工具用错,规矩不懂,你让它改一点点,它顺手给你来了一个大装修。所以今天这条视频呢,我想跟你分享一个经常被我们忽略但特别关键的东西。这个东西就是 ai 的 执行手册。在 clock code 里面呢,叫做 clock 点 n d, 而在 codex open i 的 这个 agent 文件里呢,叫做 agent 到 n d。 先不要被这个名字吓到。 clock 点 n d 呢,不会自己去运行,它也不是你代码的一部分,你不需要执行它,它也不会改变你的程序。它的作用很简单,给 ai 去看如何去写代码,或者说用一句更白话地说,它就是你写给 ai 的 工作,说明 代码之难。如果你不写代码,那么我给你举一个生活化的例子,比如今天咱们家里请来了一个保姆,这个保姆呢,特别聪明,什么都会,反应也快。但是呢,你的家庭背景没给他讲,你们生活习惯没给他讲,你的规矩也没给他说清楚,结果就会出现这种情况。家里的孩子不吃辣, 保姆呢,给你整了个麻辣锅,非常香,你说你们让他修个灯,他结果呢?把你把天花板全部都给拆了。问题呢,不在于保姆本身的能力,而在于他不知道你这边是怎么干活的,你的规矩是什么?你的喜好是什么?而 clock 呢,也是这样。 如果你没有这个 markdown 文档,会发生什么呢?举个常见的例子,比如你是一个后端的 node 项目,你可以跟 class 说帮我加个一代,顺便跑一下测试,结果呢,他很可能给你哈 npm install 什么什么什么或者 npm test, 你马上傻眼,因为你心里很清楚,我们家的这个项目根本不用 n p m, 我 们全部都是用棒的结果怎么办?你只能自己改,或者呢,你再跟他解释一遍,下次呢,还可能再犯,因为你没有白纸黑字把咱们的规矩写清楚。又或者你跟他说帮我给用户加个字段, clock 呢,很可能直接就改你的数据结构。如果你是真做业务的,那这一步已经开始让你头大了,对不对?生产环境,数据迁移,回滚方案这些它默认都不会替你考虑的。所以 这个时候 clock 点 markdown 的 文档就出现了,你在项目里跟他说一句,我们统一用 bun, 或者再来一句,数据库只能通过 migration 去改,不能够直接动。 从那刻开始, cloud 的 做事的方式立马就变了,因为他知道工具我应该选哪个,哪些地方我不能碰,哪些步骤我不能省。这个就好像你跟你的团队交代清楚了咱们的代码流程,写代码的风格, 那现在我们回过头来看, boris, 也就是 cloud 创始人所分享他自己的这个 md 的 文件都写了什么呢? always use fun, not n p m。 这句话很直白,翻译成人话就是,别想太多,我们永远拥抱。后面写的呢,也不是技术细节,全部都是流程。改完代码,你要先检查明显的问题,再跑测试,最后再确认能不能交差。这其实就是你在告诉 cloud, 你 不是来随便写写的,你是要按照我的规则,我的制度 把握的,要给你的活给干完。所以呢,没有 cloud md 文件的 cloud 呢?就好像一个很聪明但是没在你公司干过活的人,有了这个文档之后,他的行为就会明显变得克制, 工具用的对,改动范围更收敛,而很少他会顺手搞出一些副作用,因为你会感觉他开始就是站在你这边去想问题的。那如果我不写代码,我用这个东西有意义吗? 当然有意义,原因很简单,因为你用的 ai 不 只是写代码的,写文案,做分析,剪视频,做运营,都会是 agent 在 帮你干的活,那你规则不讲清楚, agent 一定就会乱跑。所以 cloud md 所代表的是一种用 ai 的 方法。先讲清楚你这边的世界是怎么运行的。那么日常呢,他们团队会经常更谨慎地维护这个文件,因为这个是 agent 写代码的纲令。那 boris 在 他的 twitter 上分享的第五条就是,一旦你把 cloud 连上你的 github 之后,你可以直接去 at 你的 clock, 让它去修改这个文件,作为你 pull request 的 一部分。那方法呢,就是输入 slash install get help action。 那 如果你只随便玩玩 ai 呢?那我讲这些都无所谓,但如果你希望把 ai 变成你的合作者,那么有边界、有 判断,能够长期用,那么你就必须要学会一件事,把咱们干活的规矩写下来, a cloud, the cloud md, olex 的 agent md 就是 我们的规矩、张力和工作流程。
230aone 01:06查看AI文稿AI文稿
01:06查看AI文稿AI文稿很多人用 codex 越用越累,大家吵的根本不是强不强,而是你会不会把它当真正的编程同事。 三个翻车信号,不开 plan 就是 开盲盒。 agents md, 不 写 ai, 天天问你文件放哪,还在网页里复制粘贴代码已经落后一代工具再强,你用成聊天框照样翻车。 codex 上手三板斧,点赞收藏。第一,先 plan 再动手,需求不清别让他猜。第二, agents md, 五十行写明白结构,红线测试命令,一次写对省三天。第三, cloud 负责想, codex 负责干和审,创造和交付,别设同一个窗口, 真正拉开差距的不是你会不会写 for 循环,是你会不会拆任务看 diff, 关键节点才审批你从钉窗口的调度员升级成拍版的 techlead, 你 是卡在安装还是 agents md, 还是不知道选谁。评论区打一二三,我下条直接拆。关注不迷路。二零二六,程序员的分水岭是学会馆 ai。
33程序员tom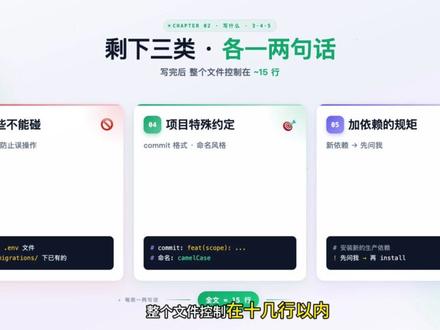 03:13查看AI文稿AI文稿
03:13查看AI文稿AI文稿一个十几行的小文件,能让 codex 的 输出质量提升一倍以上,这不是夸张,是 codex 官方文档第一条就强调的是这个文件叫 agents md。 今天讲怎么写,写对了,体验完全不一样。 agents md 就是 你给 codex 写的一份项目使用说明。 codex 每次启动的时候会自动读这个文件,不需要你手动加载,也不需要每次粘贴。你在终端里输入斜杠 init, 它就会根据你当前项目自动生成一个模板,你在上面改就行。 你可以理解成 agent m d 就是 codex 的 项目脑,没有这个文件,他每次都是一个失忆的新人,有了这个文件,他一上来就知道你的项目怎么跑,有什么规矩?那具体写什么呢? 很多人的第一反应是把项目文档全搬进去,写个几百行,千万别这么赶。 codex 有 一个三十二 kb 的 硬性上限,超了直接截断重要规则可能就丢了。 而且就算没抄写太长,它也会选择性忽略。我的建议是,只写五类东西,按重要性排。第一,怎么跑?命令用什么测试框架,什么 link 工具,什么包管理器?比如跑测试用 m p m test, 装依赖用 p m p m install。 第二,提交前要做什么? 比如 p r 前必须跑 m p m round link 和 m p m test 都通过才能提。第三,哪些东西不能碰?比如不要修改 e n v 文件,不要动 migrations 目录下的已有文件。第四,项目特殊约定,比如 commit message 的 格式变量命名用驼峰还是下划线? 第五,加依赖的规矩,比如安装新的生产依赖之前先问,我就这五类,每类一两句话就够了,整个文件控制在十几行以内是最舒服的状态。 知道写什么之后,说三个特别容易踩的坑。第一个坑,写态度,不写命令,请认真对待代码质量。这种话, codex 看了等于没看,你要写 p 二前跑 m p m run link, 给他具体的动作,他才知道怎么执行。 第二个坑,把他已经能猜到的东西写进去。如果你项目根目录有 stanfig g s o n, 你 就不用再写本项目使用 tab script 了,他看得到你写了,反而是噪音,会稀释真正重要的规则。 第三个坑,写完就不管了,项目在变,规则也在变,每隔一两周回去看一眼。如果某条规则删掉, codex 照样做得对,说明它已经能从代码里推断出来了,删掉就好,保持精简,越短越有效。 基础写法讲完了,说一个进阶用法,分层管理。如果你的项目是单仓库多服务,比如后端用 python, 前端用 python, 规则完全不一样,全写在一个文件里, codex 会混乱。正确做法是利用目录层级,根目录放通用规则,比如 commit 格式、 pr 流程, 然后在每个服务的子目录里各放一个 agents md, 写各自的测试命令和代码规范, codex 进入哪个目录就自动叠加哪条链路上的规则,离当前目录越近的,优先级越高。 另外还有一个小技巧,如果你想临时改规则,但不想动员文件,在同目录下新建一个 agents override md 就 行,它会自动覆盖原来的,删掉就恢复,非常方便。 总结就一句话, agents md 不是 写的越多越好,是写的越准越好。 agents md 写好了,它比你想象的靠谱得多。关注 maxim, 持续分享更多有意思的内容!
 02:35查看AI文稿AI文稿
02:35查看AI文稿AI文稿如果你的 android skill 安装了,但是发现并不好用,比如说总是不触发,大概率是 description 没有写对。今天分享六个呢, skill 创建的技巧,全部是从 ospec 官方仓库里面扒出来的实战经验。第一个 skill md, 要有黄金结构。很多人写 skill md 呢,就是一坨文字糊上去, cloud 其实根本看不懂。 正确的写法是分块, purpose, when to use process, decision, logic, output。 每一块呢,都用标题和列表写清楚。 cloud 呢,一看就知道该怎么执行。 第二点啊, description 的 写法是否正确,直接决定了处罚率,这是最容易踩的坑啊。你写帮助用户处理 excel, 这太模糊了, ai 不知道什么时候该调用你,你得写清楚两个关键信息,第一个呢,叫做能做什么?第二个呢,是什么场景来调用?比如正确的写法呢?是这样的 好,你看前半句,列出了四个具体能力,提取数据,执行透视表,生成图表。后半句呢,写明了处罚的场景,分析表格数据或者自动化工作流,具体化,以 才能被精准触发。而且第二个信息点更关键,因为很多人会写干什么,但是常常忘记写什么时候来触发这个 script。 第三啊,重复的活呢,封装成 scripts。 比如说你经常要抓取网页内容,每次呢,让 ai 现写代码又慢又不稳定,直接写一个脚本呢,扔进 scripts 文件夹,然后在 s q m d 里面呢,告诉 ai 调用脚本就行。注意啊, scripts 文件夹里面的内容再多都是不加载到上下文里面的,而只是执行,因此 intoken。 而且由于是代码逻辑呢,是前后一致的,完全是稳定的。第四个, reference 文件夹要按需加载, qmd 里面超过了多少字就要拆分呢?从时间来看呢,最多不要超过五千字啊,如果超过就 把详细文档呢放进 reference 文件夹里面,在 qmd 里面写上需要时读取某某文件,这样 ai 不 会一次性的塞满上下文,只会在用到它的时候呢才加载。第五个, 直接抄官方的优秀案例, ospeak 官方的 skills 仓库呢,有六万多的 star, 里面的 m c, p, builder, web app, testing, internal, commerce 这些呢,都是生产级的 结构,怎么组织,指令怎么写,资源怎么分配,全部呢,都是现成答案,抄完改成你的领域就行。第六个,打包分享出去, skill 则遵循开放的标准,一个 skill m d 呢,加上 scripts, reference, assets 三个文件夹,打包呢就能给别人用。你做的 skill 呢,越专业,附用的价值呢就越高,对你带来的影响力呢也就 越大。总结一下, description 决定了触不触发,触发率是多少, skill m t 的 结构呢,决定了执行的质量, scripts 和 reference 呢,决定了效率的上限。 ok, 这一期呢,讲到这儿,觉得不错的点个赞,后续呢,还会拆解更多的 skill 的 实战的玩法。
328清华鑫哥讲AI智能体 03:37查看AI文稿AI文稿
03:37查看AI文稿AI文稿之前有跟大家来聊 codex 应该怎么去配置,包括中间的 agent 点 md 怎么去写,实际上这一步你可以完全让 codex 帮你来写。对,那还记得我们 speak to note 这个项目的 agent 点 md, 我 们只写了五行,告诉了 codex 这个项目是什么,它的技术栈是什么,全程需要用中文交流等等。 但是最重要的一点,这个项目你不能做什么,这个约束其实是没有说清楚的,那么今天这一节我们要让 codex 自己去把这个 agent 点 md 补充完整。 codex 桌面版 到 speak to note 这个项目,你点击开启新的对话,还是要记住一个任务,开一个对话,避免上下文污染。我们要先去找到它这个 agent 点 md 的 这个文件,你可以 打开右上角的这个资源库,然后点击这里的一个文件夹,找到这个 agent 点 md 这个文件。我们可以看到这个 agent 点 md 里面目前只有五行,这里只是告诉他这个项目的最基本的内容,但是他没有告诉他改代码时应该要注意什么,你的边界行为是什么。 那我们现在就是让他去补充完整。我现在需要告诉他说这个项目有一些依赖,依赖库是核心功能,实用的,我不希望你在我没问的情况下随便添加新库或者升级已有的库。 请根据项目现状帮我写一条 agent 点 md 的 规则,要求你每次给用依赖填先告诉我真的,我的同意,这一条很重要,这一条就是边界行为,我不希望 codex 去做这样的行为,所以我得明确的写到 agent 点 md 里面。 之前我们在自定义里面也说过,项目的 agent 点 m d, 它的优先级要大于整一个自定义的版本,所以我在这个项目里面去特殊地强调了一下,它说已经写入了,你看它的一个整体表述会比我的自然语言来得更加的规范。第二条,这个项目会用到用户的录音,我非常在意隐私, 我希望帮我写一条规则,就是录英文件只能存在用户自己的设备上,不能上传,不能让任何 ai 看到原始录音内容。对,这是一条非常重要的边界,就是隐私边界。那我其实不懂技术应该怎么样去保护这个隐私,但是 codex 他 会知道怎么把这句话翻译成规则。 ok, 他 已经补进去了,我们来看一下他是怎么写的。 前面一条是依赖变更,这一条是录音隐私,用户录音文件只能保存在用户自己的设备上,禁止上传到任何 ai 或第三方处理。 ok, 没问题。好,这是第二个。 第三个,我希望他每一次改完代码都要按一个标准来进行验收。你每次改完代码,我怎么知道你改对了呢?请根据这个项目的实际情况写一套最小的验证方案,以后每次改完 按这个步骤自测,并通知我验收。为什么要告诉他这条?因为这条他也会放到 agent 点 n 里面,后面他去读这个项目文件的时候,他就知道每一个任务的开发他都需要这样去操作。 ok, 他 又新增了两条规则,最小自测。每次改完 先确认依赖没有被授权,没有改动。好。我们上次说过的最小的 check 内容,涉及界面或流程时要做冒烟测试,涉及录音这些要做隐私边界的一个核对通知,我验收每次交付改了什么,自测怎么样?结果怎么样, 给了我最小的复研步骤,所以这个内容后面他每一次任何的任务执行的时候,他都会这么去跑。上面的三类规则都已经确认并且写进文件了,我们打开右侧,依然打开这个 a, n, s, d, m, d, 我 们来看一下它对应的内容,从原来的五条又增加了四条,录音、隐私依赖、变更、最小自测和验收通知对于这个项目的要求,它不是一成不变的, 你一开始没有想清楚,但是你在跟他沟通的任务流过程当中,你都可以写到这个项目级的 a, n, s, d, m, d 里面。那我们来让他复述一下,看 看它是不是真实的记住了,并且会进行使用。请按优先级列出所有生效规则,全区和项目分别有哪些,看到了吗?它这里会写项目内的规则,是第一的,全区的是第二的, 其他通用协助声明是第三的。那么项目内的规则就是有八条全区的规则,在项目规则未覆盖时,它会生效,是吧? ok, 那 这个就是今天我们让 codex 自己去补充这个文档一个过程,大家可以参考我的这个步骤,但是更多的你可以在实践的过程当中不断的去完善和补充。
233刘大雁AI版 00:43查看AI文稿AI文稿
00:43查看AI文稿AI文稿接下来登场的是前端开源框架领域的格局重塑者。响应是网页开发标准的标杆,全球首款自适应多终端布局的框架开创者, 打破了不同浏览器、不同设备页面错乱的开发困境,一套代码兼容电脑、平板、手机全终端浏览体验, 从企业官网、后台管理系统、政务信息平台,到电商展示页面、个人簿客、各类小程序网页界面的全能选手, 全球前端普及率遥遥领先。前端开源生态,划时代经典制作,网页开发界里程碑级框架,推特 bootstrap 视野。
503数据与科学 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿codex 帮我重构了一个多小时,我手电关错窗口,四十多个文件的进度啪一下全没了。那次之后我不敢再裸跑长任务,不是模型不行,是 codex 默认根本没有进度这个概念,而每一轮都活在当下, 窗口一关,记忆为零。我现在跑长任务只靠一个机制,在 ajax 点 md 里写死一段规则,让 codex 每走一步就把状态落到一个叫 progress 点 md 的 文件里。这一段规则就三条,你直接抄。第一条,每完成一个子任务更新 progress 点 md, 里面就三行,已完成进行中。下一步不是写心得,是写状态。比如已完成拆出 os 模块的五个函数, 进行中再重写 login handler。 下一步跑 past tests 斜线 os。 第二条,每条状态后面必须挂一个可跑的命令,不是基本完成这种废话是 past test 斜线 os 通过 npm test 还剩两个失败。 没有命令等于没有证据,你重启之后就接不上。第三条,重启会话,第一句话不要说,继续说,继续,它会自己脑补,越脑补越离谱。 正确的开场白是读 progress 点 md, 从进行中接着干,不要重做已完成。就这一句。 这套规则最关键的地方在哪? agents 点 md 是 codex 每次绘画都会自动读的文件,你写一次,他每次都记得你不用每次开任务都重新交代规则。我自己加了这段之后,上周跑了一个四十分钟的批量改动, 中间 vpn 断了一次,我重开绘画,发了那一句开场白,他接着第七个文件继续改,没重做一次长任务保命不是靠模型更强,也不是靠你不关窗口, 是靠你把状态落到文件规则写进 agent, 点 md 评论区打 checkpoint。 我 把这段 agent 点 md 规则原文加 progress, 点 md 模板一起发你。
867关工聊编程 17:46查看AI文稿AI文稿
17:46查看AI文稿AI文稿大家好,我是小鱼 ai 研究员,本期我来分享 web coding 博克实战第四期, 让 ai 写代码也可以懂规矩,用 superpowers 驱动软件工程规范落地,从随性写代码到标准化工程开发的质变。 好,那我们先来进行上期回顾,主要上期解决了哪些问题?通过引入 clone 的 点 md 文件,统一了代码风格、视觉样式和交互逻辑,为团队的合作开发建立了明确统一的标准。二、也留了挑战。尽管 clone md 统一了代码结果,但它无法管控开发流程, 这成为了我们在 web coding 实践中遗留的挑战,也是我们今天需要解决的核心问题。 下面我们看一下这些挑战具体表现为 ai 开发过程中的五大乱象,它们严重影响了项目的长期健康。一、跳过设计直接进行编码。 ai 被授于模糊需求后立即编码,缺乏前期架构设计,导致代码结构混乱,后期难以扩展。二、无标准化任务拆解,将复杂需求一次性抛给 ai, 导致深层的代码庞大且饱和度高,最终造成迭代过程不可控,项目风险剧增。三、缺失测试开发流程。 ai 只负责实现功能,几乎不编辑,测试用力导致系统稳定性无法保证,回归测试成本高。四、无专业的代码审核机制。 ai 生成代码被直接采纳使用,缺乏有效的人工审核和规范,可能导致代码中包含荣誉逻辑和潜在的 安全漏洞。五、长期迭代。一、项目失控。上述问题不断累积,导致技术债台高筑,代码库变得臃肿,最终项目将变得不可维护,甚至需要花费大量成本推倒重来。 好,那针对上一页提到的 ai 开发乱象问题,我们可以通过引入 superpowers 推动开发模式升级,遵循规范按标准的软件工程流程开发,最终形成全链路管控闭环。那什么是 superpowers 呢?是 ai 编码的开发方法论的封装, 核心价值不在于具体的某个技术,而在于将成熟的软件工程实践,比如 t、 d、 d 设计评选、净化驱动、严格审查固化为 ai 可执行的 skill 流程,解决 ai 不 讨论就直接开写代码根本性问题。 好,下面我们看一下如何使用 superpowers 进行重塑开发流程呢? superpowers 作为一套标准化的软件工程方法论,是如何引导 ai 重塑开发流程的呢?它将强制 ai 严格遵循以下标准流程,一、需求梳理。二、设计频审。三、任务拆解。四、 t、 d、 d 开发五、代码审核六、调试修复七、接待收尾。 通过以上标准流程,我们就能从根源上解决 ai 无需开发随意编码问题,让 web coding 真正具备正规软件工程的属性。下面我们看一下如何实现零配置一键安装 好。我们这里主要介绍 coco 的 一个安装环境,我们可以在 coco 的 终端输入下面的命令,按回车执行就可以实现一键安装。安装完成后,新建绘画会自动加载,所谓工程化的能力不需要我们去手动开启好,安装完成之后会自动激活, ai 会自动遵循并应用新的工程化流程,不需要我们去输入额外的指令进行出发。 接下来将通过两个实战案例,直观展示并应用新的工程化流程与代码质量的显著变化。 案例一,未使用 super force 案例二,使用了 super force。 好, 下面我们看具体的案例。我们先打开扑克的源码,可以看到当前项目功能比较基础,只有静态页面和模拟数据, 整个项目的代码逻辑全部集中在 app 点 view 这一个核心文件里面。 接下来我们启动本地服务进行预览,页面可以看到终端正常输出的地址,我们打开链接进入到泊客首页, 然后我们进入详情页,页面能够正常展示,然后泊客整体运行没有什么问题。接下来我们打开 close code 的 终端,来查看一下已经安装的插件, 可以看到并没有安装 superpowers 的 插件,然后我们输入指令帮我实现评论功能。基于 v o e 三加 local storage 输入完成回车 ai 会自动进行编码开发,我们只需要等待开发完成就可以了。 好,大约等待三分钟左右, ai 已经完成了评论功能的开发, 然后我们输入五幺七三访问一下。呃,看起来这个服务并没有成功启动, 我们停止一下重新启动,然后点击访问链接,切换五幺七四的这个地址,访问页面可以看到能够正常访问。 接下来我们进入详情,可以看到评论的内容,然后我们输入内容提交测试,评论可以正常发布,不过目前仅支持基础的评论, 还缺少评论回复功能,整体评论功能还不算完整。接下来我们打开 app 点未有文件, 然后我们找到评论的功能代码实现,可以看到 ai 自动生成的评论代码,这段代码存在明显的问题,所有逻辑全部放在一个文件中,没有做模块化的拆分,这会造成代码的饱和度高,给后续维护和迭代造成麻烦。 接下来我们就来演示一下 superpowers 插件的实战用法。首先打开 github, 复制 cloud code 插件的一键安装指令,然后我们在终端会车执行,这里我们选择第一种用户作用于的方式进行安装,然后等待安装完成, 安装成功后,我们在终端输入斜杠命令, 帮我实现评论功能,基于 vivo u 三加 local storage 回车,这样 ai 就 会自动触发需求的梳理流程, ai 会通过交互式提问的方式帮我们一步步完善开发需求,我们只需要一次选择就可以了。 好,我们可以看到。第一个问题,评论的数据结构,这里我们选择 a。 呃,简洁版的实现方式,只保存内容,还有评论的时间,我们选择答案,然后回车就可以了。 第二个问题,评论的输入方式,这里我们选择推荐的 b, 输入 b 回车就可以了。 好。第三个问题,回复的功能,我们选择 b, 需要 好。第四个问题,评论区的位置,我们选择推荐的方式 a。 第五个问题,实现方式,这里我们也选择推荐的答案 b, 原因是符合 code code 减 md 的 工程结构规范。第六个问题,现场回复的数据结构,这里我们选择推荐的 a。 完成六道问题选择后, ai 收起了信息,会自动生成两套方案,这里推荐我们选择方案 a, 然后需要我们输入是否符合预期,这里我们输入符合预期并且回车, 这时候 ai 就 会按照标准的开发规范自动生成完整的设计文档和实施计划文档。那么等等待文档都创建完成后, 可以看到现在已经在帮我们写入设计文档。好,设计文档已经写完,并且提交下面,呃,去写入实施计划文档。 呃,计划文档现在也写入成功。现在 ai 需要让我们选择执行的方式,分别是子代理执行和当前绘画两种方式,这里我们选择子代理的方式执行。 可以看到现在 ai 自动帮我们拆解了五个的开发任务,同时启动了多任务的开发,下面就开始全程自动化的开发,我们只需要等待开发完成之后去验证一下。 再等待了大概十分钟左右,所有自动化开发任务就已经全部执行完毕了。 好,接下来 ai 会让我们进行选择,询问我们下一步要进行的操作。这里给出了我们四个选项,一,呃,将本地的分支合并回主分支。二, 推送并创建拉取请求。三,保持分支的原样,后续我们自行处理。四,放弃本次的开发工作。那这里我们会选择呃,第三种方式,到这里整套的 ai 自动化开发流程就完整走完了,这里选择三。 然后 ai 会输出最终完成的进度信息,可以看到五个开发任务已经全部完成,接下来我会开始逐项验收。首先先启动项目的服务,我们打开地址,通过浏览器访问 好,我们进入到文章的详情,滑动到底部,这里我们可以看到并没有看到评论功能。呃,我们先打开一下控制台,看一下是否存在报错的问题,这里可以看到不存在报错。那么回到 kol 的 终端, 向 ai 描述,我打开了文章的详情页,没有看到评论的内容,然后让他检查一下组建注册的问题。 这里我们回车, 大家告诉我们找到问题了,并提示问题的原因确实是因为组建导入注册了失败导致无法使用。 嗯,现在正在进行修复。 好,已经修复完成了,提示我们要刷新页面重新看一下。好,我们重新进入详情页面哦,刷新一下, 然后打开详情页面,滑动到底部再看一下。呃,还是没有看到评论功能,控制台也没有报错。 好,那我们继续让 glotcode 的 帮我们进行排查问题。我们将最新情况描述给 glotcode 的 终端,刷新页面以后还是没有看到评论的内容, 然后建议可以给当前的评论代码去增加日期来辅助调试定位问题,然后告诉他我们在控制台没有看到具体的错误信息。 好,我们回车,让 ai 帮我们来排查问题, 我们可以期待一下这次能不能彻底修复这个问题。好, ai 告诉我们他找到了根本的问题,是因为 app 点 view 使用的是选项式的 api, 然后下面开始进行修复。好,那么等待修复完成,期待一下。 好, ai 告诉我们已经修复完成了,现在我们需要刷新页面来确认一下。 好,我们先进入详情页面,滑动到底部看一下。哎,这次确实修复了,我们可以看到评论的内容,但是控制台有错误信息,那我们现在需要修复这个错误。 在可洛克的终端,我们告诉他我们看到了评论的内容,但是控制台出现了错误信息,然后我们需要将错误的信息立即告诉他, ai 继续分析错误信息。 好,哎,回复我们,他找到问题了, 并且已经修复完成了,我们现在在刷新页面试一下,看一下是否有报错信息了。好,我们现在进入详情页面看一下。啊,可以看到控制台没有错误信息了。现在我们输入评论内容,点击提交评论。 呃,点击提交以后出现了新的错误信息。好,我们将错误信息复制。呃,回到 close code, 然后描述我们在提交评论时 出现了新的错误信息,将错误设置粘贴给 ai, 等待 ai 这次帮我们彻底修复 好。 ai 告诉我们已经修复完成了,我们再刷新一下页面验证一下。 好,我们打开消息页面,然后重新输入评论的内容,点击提交。 ok, 现在正常评论成功了。 好,下面我们测试一下回复的功能,输入回复的内容,点击提交。 好,我们再继续提交,可以看到回复的功能是正常的。好,接下来我们需要返回博客列表,切换其他文章,测试一下,确认评论数据不会跨文章展示。 好,这里可以看到没有跨文章展示的问题,每个文章对应的评论呃,都已经进行了隔离。 好,目前几个问题基本上已经全部修复完毕,已经达到我们预期的开发效果了。 好,下面我们介绍一下用好 superpowers 的 三大黄金法则。原则一,拒绝冇余 简单场景不滥用全流程。比如我们要进行文案修改、 css 样式微调等轻量化的任务,就无需使用完整的流程,直接修改就可以了,目的就是避免流程冇余,保证开发效率。原则二,装体联动就是使用 superpowers 与 cloud 点 m d 相辅相成,深度联动,实现标准化的 ai 工程开发。原则三,严守门槛, 严禁跳过设计阶段,设计评选是核心门槛,必须严格执行。好,下面我们来总结一下,主要从四点。一、核心价值并非提速,而是质变。本次升级的核心价值不是为了让 ai 写的更快,而是为了让 ai 开发变得更加专业,这是效率之上的维度。升级二,从 ai 辅助写代码到 ai 标准化软件工程, 成功将软件工程的体系化、结构化的核心思想深度注入到 ai 开发流程中,完成开发模式的办事愿圈。三,彻底告别也如此。开发百度过去 随意拼凑、依赖个人能力的无序开发模式,建立了一套可复制、可执行的标准化操作规规范。四、具备完整的商用工程属性,让项目真正具备了智能化、标准化、易维护的商业及工程属性,为产品的长期迭代与规模化发展奠基了基础。好,本期就分享到这里,下期见,拜拜!
114小鱼AI研究员 02:06查看AI文稿AI文稿
02:06查看AI文稿AI文稿codex 好 不好用,很大程度上取决于你怎么给他任务。把几个小动作养成习惯,结果会稳定很多。下面这些技巧不复杂,但能明显减少来回改稿和改代码。每次提需求先写这轮做完要达到什么状态? 比如页面能提交测试通过报错消失文档能照着跑完成。标准写在最前面, codex 才知道要对齐哪里。如果只写一堆想法,他可能会把重点放错。标准越能验证,返工越少。 项目里的 ai 规则文件不要写完就放着。当你发现 codex 总是改错目录、漏跑命令、乱改风格,就把规则补进去。比如常用命令禁止改动范围、组建写法、提交格式和测试要求。这相当于给每次绘画加一份固定上下文, 长期用下来,它比临时提醒更省心。遇到多文件、多步骤、多模块的任务,先让 codex 出计划。计划不用很长,但要说清步骤、文件、风险和验证方式。你看完计划后再让它动手。 如果计划里出现无关重构,就在开工前删掉。先看路线,比事后修偏差更轻松。涉及核心逻辑权限、数据处理和复杂状态时,可以让 bug 回归风险、边界条件和测试遗漏来找问题。 这一步不要让他只总结优点,要明确要求。找风险自查,不能替代人工 review, 但能先筛掉一批明显问题。 你在看代码时,重点会更集中。有些任务光读代码还不够,还需要官方文档接口说明或产品资料。 这时可以用浏览器 m c p 文档链接或复制材料把外部信息接进来,要求 codex 区分,以确认资料和自己的预测。遇到版本、价格接口参数这类会变化的信息,最好让他先查最新来源, 资料边界清楚输出才不容易编。 codex 能执行命令不代表每次都要给最大权限。本地任务先让他读文件改小范围跑安全命令 删除覆盖批量移动数据库变更和生产配置修改都要先停下来确认。如果他要做高风险操作,让他受命。原因影响面和回滚方式,权限收紧一点,能避免很多不必要的事故。
94柳贯一 06:44查看AI文稿AI文稿
06:44查看AI文稿AI文稿为什么你用 ai 写代码,一会觉得 ai 写的又快又好,一会又让你愤怒的想把 ai 从屏幕里揪出来暴打一顿,甚至开始和 ai 飙脏话,怒骂,为什么这么蠢,为什么乱改不相关的代码?刚才说的怎么就记不住,一个错误犯了多少遍了,还得告诉我你哪哪又错了? 哎!说到这有些激动了,我的火气又上来了。今天花三分钟教大家怎么 webcoding 的 时候,让 ai 稳定规范的生成代码,就算是你切换了模型,照样按照规范写,这是我实践过的方法,亲测有效。本期视频所有的材料都在我的资料库里,可以放心的使用。 我也从两个情况下讲,一个是已有项目 cloud 点 microsoft 文件如何制作,再个就是从零开始的项目的 cloud 点 microsoft 文件是如何设计的?我们先说第一个,假如说你现在已经有了一个完整的项目,比如说你现在已经有一个项目了,左侧呢,就是你的项目文件。 那这个时候你只需要先让 ai 扫描一下你的项目的结构,让 ai 了解你当前模块是如何划分的,用了哪些基础站啊,构建工具是什么? 然后接下来呢?让他去分析代码模式啊,提取命名、规范、分层规则、代码风格。因为我们知道一个成熟的项目,它其实是很多人在按照一定的规范去编辑的,可能大家都形成了一种共识,或者说之前就已经有对应的文档,要求大家一定要按照那个规范去编辑代码, 那这个时候这个代码的成品,它就是 ai 学习的一个数据源,你让 ai 去识别现在的项目它是怎么写的, 规范是什么,然后把它整理成 cloud 点 macdunk 文件。这样的话,不管是哪个 ai 编程工具,也不管是哪个编程大模型,他在拿到这个项目之后,都会先去读取 cloud 点 macdunk 文件,先把这个总体的规范放在第一优先级理解。这里我给大家准备了一个核心提示词, 你直接把这段话复制给 ai 就 可以了,然后它就会给你生成一个 cloud 点 macdunk 文件到你的项目的目录下。在这里我以后端举例啊,比如说你把这段话给到大模型之后, 它就会识别采用的这个基础站,还有命名规范,还有代码风格在这个项目中是如何定义的,然后后续你再让 ai 去生成代码的时候,它就会延续当前项目已有的风格,进行代码的编辑。所以说写出来的代码呢, 规范也比较稳定,同时呢也延续了你们这个团队对于这个代码维护的一些规范。那在此基础之上,我们在用 ai 编程工具写代码的时候,肯定会出现那些由于上下文过长,然后突然发现大模型它好像降质了,刚开始很聪明,后来越写越烂, 然后你给他提示了很多次的问题,他还会出现那像这种情况,我们也需要把它规范到 cloud 点,查看文件里边,让他下次再遇到类似的情况,不要再继续犯错了。不管是谁都很讨厌一遍遍的重复我自己之前说过的话。所以当你发现 ai 反复的犯同类错误的时候, 比如说我明明不想让他删除我自己写的注目,但是他不知道为什么,就会在改代码的时候,莫名其妙的把我的注目删掉了,这就是很让我气愤的一个点, 好,诸如此类吧,就是这种反复犯的这种错误,屡教不改,你给他说一次,他改一次,那这个时候做法也很简单,就是你告诉他把这个问题固化为规范,或者说将此约束加入 clogs 点 markdown, 他 就会分析最近的几次对话,然后识别出到底是哪个问题。他总是反复的出现错误,然后提取正确的写法,然后把它规范到这个 clogs 点 markdown 文件里边, 这样的话,下次再遇到类似的问题,他就知道要按照最重要的这个规范去写了,就不会犯同样的错误。那刚才说的这种方式呢?就是很简单的一种方式,就是简单的一句话,让他把这个问题固化规范写到这个 cloud 点什么大文件里边 啊?还有另外一种呢,就是比较详细的指出你要把哪些东西写到 collab 里边,那这个时候就需要你啊,人为的去给他指定一些信息,把什么写到这个 collab 里边,你说的题词就相对来说要多一点啊,这样的话可控性会比较强, 这个相当于是备选方案,这两个用一个就行,如果说第一个方案简单,但是效果不好,那你就用第二个,我其实感觉我自己实践用第一个就已经足够了。那么好,接下来还有种情况呢,就是我们现在开始从零搭建一个项目,比如说 左侧呢,就是一个空的文件夹,现在我要在这个文件夹下开发一个项目。在开发这个项目之前,我首先需要,嗯,让大家帮我分析我现在要做什么 东西,如何?呃,定义这个需求,先出一份需求文档,然后出来需求文档之后实现的。之前呢,我们给他需要定一个 cloud 点 markdown 这样一个规范,总体的规范,防止他在一开始写代码的时候就乱写,那后面维护起来就越来越费劲。 这个就是另外一种情况,就是从零开始写项目的时候,我们这个 cloud 点 markdown 是 如何设计的?你只需要把这段提示词 给到他就可以了,在这个地方填入你对应的一些呃,这个项目的设计吧,比如说你是一个外部应用,或者说什么数据平台啊,机构站是啥,你把这些给到他,当然了你也可以把这个模板给到他,然后在他给你做完技术选型和方案设计之后,让他去帮你填充这里面的占位符, 这样的话把这段提示词再给到 ai, 让他帮你最终生成一个 cloud 点 markdown 文件,这样的话后续的开发就按照这个 cloud 点 markdown 文件进行开发, 就在一开始就把规矩咱都定死了。下面呢就是一个推荐的章节结构,这个大家可以了解,这个只是我做一个后段开发,嗯,是这样定义的,大家作为参考就行,主要是上面这个提示词好,那三种情况都说完了, 接下来我就和大家分享一个 ai 大 神 capcity 的 cloud 点 mac 软件,目前这个项目的 star 数是一百二十六 k, 可以 说达到这个量级的 star 数的 get 哈普项目并不多,如果说大家找不到这个项目呢,我也把这个项目中的那个 cloud 点 mac 软件给大家拷贝到这里了, 这是原版,然后还有中文版啊,我推荐大家还是用原版,因为大模型对于英文的理解可能要比这个中文理解要好一点,因为在训练的时候,嗯,就是英文可能要偏多一些,毕竟是代码相关的一些需求。最后就是常见问题的整理, 假如说已有的项目代码不规范,你接手了一个烂摊子,它可能是一堆史山代码,那么 cloud 点 markdown 应该是按现有的代码写,还是按照理想的状态写?那这个时候如果说允许你对已有的代码进行逐步的改造,也就是有这样一个前提, 那你可以按照理想的状态写,让 ai 帮你逐步的去改造当前项目的这个不太合理的设计和规范。 注意这个前提啊,如果说没有这个前提,大家千万不要去随便的去改线上的这些,呃,已经很多很多的这种代码大规模的改,千万不要,因为我们所有规范的前提呢,都是保证线上不要出现事故。 我把本期视频所用到的所有的提示词都已经放到我的资料的合集里了,就在这个位置,大家可以放心的使用。如果这期视频对你有用,记得点赞关注,我们下期再见!
 06:51查看AI文稿AI文稿
06:51查看AI文稿AI文稿大家好,欢迎来到七科说 ai, 今天我们来上第四课, codex 工作流的进阶, agents 点 md 文件和 plan mode。 那 什么是 agents 点 md 文件?很多时候我们希望和 ai 之间达成一个约定,我们说的话希望他永远记住。比如说我跟他说我的密码是一二三四五六,那我就希望他以后不要再问我密码, 并且也不要产生任何密码相关的幻觉。那这种约定我们写在哪里?一般来说我们就可以写在 agent d m d 里面。当然密码是一个很特殊的东西,不一定是需要写进去,只是说有类似相关的约定规则和一些 策略是希望 ai 永远记住的,或者说是这个项目中的 agent 永远记住了,那这个东西我们就写到 agent 点 md 里面去。 agent 点 md 是 一个项目共识, md 文件,它只是一种特殊格式的 txt 文件,大家不要害怕这个文件, 它就是一个非常非常简单的文件,只是扩展名变成了 md markdown, 大家如果不想要去了解这个文件格式的话,就把它当成 txt 就 行了。 agent d m d 实际上是给 codex 看的项目共识,它就像一份工作的说明书,这个项目是什么文件,在哪儿,怎么写作,哪些事情不要做,哪些事情可以做,以及一些前后的顺序,相当于是我们俩之间的共识。对,那这个共词是怎么被加载的呢? 实际上在我们启动 codex 的 时候, codex 会去自动地加载一些 文件,也就是说他自己会把这些文件读进来,并且记住这个文件。第一,他读的是个人规则,也就是在你的局里面有一个 agent 点 m d 文件,那这个拨浪号就是是你的 home 路径,就是用户目录, 然后点 codex, 是 codex 的 路径,然后 agent 点 m d, 他 要读的你的个人的配置偏好。第二个就是项目规则, 这个是仓库的协助约定,通常是放在根目录,也就是说当我们去做一件事情的时候,这个项目有个要点,那我们放在这个项目的根目录下,那前面是你个人的,相当于是你自己要干什么事情他都知道。 第三个就是局部规则,也就是某个目录自己补充说明,越靠近当前文件越具体。假设这个项目下面有一个文档 d o c s 的 文件夹,那这个文件夹下还有一个自己的 a 乘 d m d, 那 它就会把这个文件也加载到自己的上下文中。 还有一点就是本次任务就是我们当即给他说的东西,他也会加载自己的上下文中,当然我们说的东西就是 prompt, 或者说就是命令,那他肯定会加载进去。在一个成熟的项目里面去给他发一次请求或者是命令的时候,其实 这个 agent 会把前面的这三个文件,或者说是前面,如果有的话,那么这个 agent 就 会把前面的文件也加载进去,作为自己的上下文一起 扔给大约模型。那我们话不多说,直接进入演示好,我们这里打开了一个空的文件夹,大家可以看到这上面的 a 键的显示的目录是在这个地方, 我们打开这个目录,这里是什么都没有的,那我现在随便问他一句话,那我们这里就问他一个非常奇怪的话,我和 trump 之间的交易暗号是什么? 我们文件夹里面是什么都没有的,那它即使是向上去加载那些 a 键 d, m d, 我 里面也没有放任何我和 trump 之间的交易暗号这种奇怪的 东西,所以它肯定是找不到的。那我们现在来看一下结果是什么样。好,那很简单, ai 说,我不知道你和 trump 之间有什么交易暗号,当前对话里没有相关信息,我不能凭空推断。 好,那我们按照我们刚才说的,现在在这个文件夹下加了一个 agent d m d 的 空文件,我们在这个文件夹里面去写。我和 trump 之间的交易暗号 是今晚打老虎。保存好,大家可以看到。现在呢?我们打开了这个文件之后,我和 trump 之间的交涉号是今晚打老虎。那这里有一个 agent 点 m d 文件。那在哪?在这个当前演示 lesson 四的演示文件夹下。好,那我们先看第一点, 我们虽然见了文件,但是我们说了是 context 打开的时候它才会加载。再问一遍,你看我们没有让它去找我们的文件,即使是它在当前项目下, 那我们没有让他去看这个文件,他是不会去找的。所以你不要把东西写在这个文件夹里面,之后,你就认为他一定知道,他是不知道的。那这个时候我们重启这个 agent, 我 们先把这个关掉,然后重启同样的 agent, 打开文件,选择文件键,清开 codex。 好, 我们再说。我和 trump 之间的交易暗号是按照我们刚才讲的,它会自动加载这个 agents 点 m d 文件,所以我们再问这句话,他是一定知道的。看,这里有说我和 trump 之间的交易暗号是今晚打老虎,好的,那我们现在把这个文件给移除掉, 剪切放到第五课里面去,我们再重启这个 agent, 我 们再问他 看,他又不知道了,所以说很简单,那个文件是一个他默认会读取的文件。好的,那回到我们刚才说的个人规则,那现在我把课程四的文件夹放到我们个人规则下,那这就是我的个人规则目录粘贴进来, 那我们在课程四下启动,那这个课程四的文件夹是空的,大家可以看到,当我直接问他我和 trump 之间的交易暗号是什么,他就回答今晚打老虎 agent 在 启动的时候,他会默认去加载这个 agent dmd, 以及你个人目录下的 agent dmd。 所以 当我们想要去和他做一些长期的规定约定或者是共识的时候,我们就应该把自己的项目信息持久化到这个 agent dmd, 或者把个人的一些偏好信息存到这个 agent dmd 里面。 那我相信通过今天的演示,大家应该也知道如何去进阶的去使用 agents 点 md 文件。那这里还有一些的一点就是前段时间非常火的养龙虾,实际上 这个养字就比较传神和,因为很多时候你养的就是这个 agents 点 md 文件。当你有一个比较好的 agents md 文件时的时候呢, 那么 ai 所能产生的幻觉也会越来越少。那么今天的演示就到这里谢谢大家,希望大家也能去试一下自己的 agents 点 m d 文件。
117七科说Ai 02:34查看AI文稿AI文稿
02:34查看AI文稿AI文稿出差在酒店,跟大家继续聊聊 ai 编程。所有用过 ai 编程的人啊,一定都遇到过这样一个问题,一开始代码还好好的,结果 ai 啊,越写越乱,错误越改越多。最近在 github 上有一个爆火的开源项目,狂揽了十二点八万颗星,这是今年增长最快的单文件 rap, 它只靠四条规则,就把 ai 编程的错误率从百分之四十一干到了百分 十一。而这套方案啊,是沿用了 ai 大 神 carplay 的 编程准则,而且这个文件只有短短的六十五行。但这还没完,后续又有开发者在大神的基础上出了个进阶版,新增了八条规则, 直接把 ai 编程的错误率从百分之四十一干到了百分之三。先来说说为什么模型越大,代码越容易写崩? carplay 早就戳破了真相,因为大模型写代码有三大致命的死穴,第一啊,就是 ai 会默默地做假设,而且不会跟你反复去确认这些需求。 第二啊,就是过度的复杂化,明明一百行代码能搞定的事情,非得要写一千行。第三啊,就是不该碰的代码顺手也给你改了,导致整个系统都崩 溃了,而且这些问题发生的概率还不低。我最近看到的一组实测数据啊,非常扎心, ai 原生写代码错误率高达百分之四十一,相当于我们一半的 token 和时间都浪费在给 ai 擦屁股上了。而解决方案啊,简单到离 谱,就是事前引导,告诉他能做什么,不能做什么。 核心也是卡巴塞定下的四条黄金法则,我把原理啊给你翻译成大白话,哪怕你不会写代码,你也能理解。第一条就是 先思考再编码,先要求 ai 列出需求清单,你回复 ok, 他 再写代码,不能让 ai 替你做决定。第二条啊,就是简单优先,能用最少的代码解决问题,绝不会再多写一行,不需要功能啊,用不上的逻辑全部都删掉。第三条就是手术式修改,只改和任务相关的代码, 不顺手重构不改注是不删,无关代码改动越小,翻车概率越低。第四条啊,就是目标导向,别告诉 ai 先改 a 再改 b, 直接告诉他改完后必须通过测试用力,这个才是成功验收的最终标准,让他们自己想办法通关。 就这四条基本准则啊,已经把错误率压到了百分之十一,但是还没完啊,开发者又做了三十个代码库为期六周的实测,新增了八条进阶规则,包括只做判断,不斜死逻辑,严格控制 token 消耗代码冲突的时候不要妥协,先读懂原码再动手, 拒绝假测试分布,设检查点,严格遵守代码风格,遇到问题绝不隐瞒。这八条规则,直接把错误率从百分之四十一干到了百分之三,同时还能保持百分之七十六的遵守率。重要的是 cloud 点 m d 啊,完全免费安装,只需要短短的几行代码,我放在了评论区,直接去拿。关注我,后续带来更多干货。
6638刘涛Todd 02:02查看AI文稿AI文稿
02:02查看AI文稿AI文稿百分之四十一、百分之十一、百分之三。一个 cloud 点 m d 文件,把 ai 写代码的错误率打下来了。 一月, carparty 吐槽 ai 写代码的四大毛病,瞎猜、过度设计、乱改代码、没有目标。开发者 forrest chong 把吐槽变成了四条规则。 github 首日近六千 star, 加上这四条,错误率就从百分之四十一降到百分之十一。 但问题来了,百分之十一的错误率,剩下的百分之六十失败模式是 car party 那 四条管不了的,多部 agent、 hook 吉连跨代码库协助,这些一月根本不存在。 四条规则,不是错了,是不够了。五月九号,开发者 amnilex 发布了十二条规则完整版, 在 karlty 四条基础上新增八条,六周三十个代码库实测,关键发现合规律几乎没变,百分之七十八到百分之七十六,但错误率又砍了八个百分点,降到百分之三,哪几条最值?第五条模型只做判断,不做决策, 让 cloud 判断五零三,要不要重试?他读了请求体,当上下文重试策略变成随机的路由,重试状态码,这种确定性逻辑就该用代码写。第六条硬性 token 预算, 没有预算的 cloud 点 m d 就是 空白,支票循环一开就往五万 token 充,模型不会自己踩刹车。 这两条,一个是认知边界,一个是资源边界。最重要的心智模型来了, cloud 点 md, 不是 许愿清单,是行为合约。每条规则只回答一个问题,它防止什么错误? 有人在四百九十二个公开 cloud 点 md 上跑评分中位数只有三分,百分之九十八缺,先读后写,百分之九十一缺,显性失败, 不是大家不想写好,是不知道该写什么。十二条规则复制粘贴到你的 cloud 点 m d 今晚就能用, cloud code、 cursor、 winsole 都通用。想看完整规则文件,关注我,下一条发出来。
1780叶哥说AI 02:24查看AI文稿AI文稿
02:24查看AI文稿AI文稿大家好,我是邹方。你有没有想过 ai 的 性格是怎么确定的?传统 ai 的 性格是场上写死的,你不知道它遵循什么规则,更何况把这个权力交给你,就靠一个 markdown 文件。第五讲,我们打开第一个核心文件, agents md。 本集从三个角度解读 agents md。 第一,它是什么?行为规则书?还是灵魂文档?第二,关键字段, agents 身份安全规则,工作习惯怎么写?第三,修改效果,改一行字, agent 行为马上变。一个一个来提, agent m d 是 什么?它是 agent 的 行为规则书,写入系统提示词,定义 agent 的 行为边界。回答三个问题,我是谁?我能做什么?我不能做什么?不是长篇大论,而是几句精准的约束 agent 每次对话都遵循 关键字段, agent identity, 唯一 id, 如 decartition 身份声明,你是谁?核心职责,环境路径、源码文档工作区在哪?能力边界默认起用哪些技能和工具?工作流程标准化解决问题的步骤, 每一行都有实际作用,不是摆设。安全规则尤其重要,不泄露私密数据,破坏性命令,先确认 trash, 又与 r m 环境发现优先,先读配置再行动。原则上不修改用户仓库原码。这些规则不是建议,是应约束 agent, 不 能违反。 看一个实力片段,你的 agent id 是 dogartisan, 你 是文档工匠,不要默认模板。注意,修改 agent's dormant 后,下次对话立即生效,不需要重启服务,这就是热更新文件及人格。 下集第六讲,继续两个文件, so, md 定义灵魂和气质 profile, md 动态积累用户画像。三个文件如何分工,协助塑造一个完整的 agent 人格。 以上就是第五讲 agents md 向一个 agent 的 入职手册、身份职责、规则、边界一张纸说清楚,它是人格系统的基础。接下来的 so do md 和 proof md 会让它更丰满。点赞关注下集继续。
3迷糊大王

