google 昨晚发布了新的视频生成模型 omni, 他 宣称自己在多模态融合和物理模拟上都有明显提升,那我们就拿它和 cds 做个简单对比测试。

粉丝8.0万获赞42.7万
相关视频
 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿上期分享的当 ai 结合实拍视频,有很多小伙伴问教程和提示词,话不多说,直接开始,这是使用到的 ai 工具以及提示词。 首先我们需要一段实拍的原视频,因为视频编辑模型是按秒来算,所以把原视频多余的画面剪掉,然后导出视频和视频的第一帧图片,找一张场景参考图,使用图片编辑模型 hello banana pro 输入提示词。 然后将原视频和新生成的场景图使用视频编辑模型克隆三点零安利或 sims 二点零,输入相逢提示词。
2.9万华生AiFilms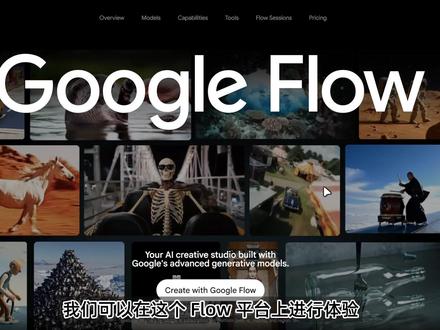 06:57查看AI文稿AI文稿
06:57查看AI文稿AI文稿谷歌的欧米尼视频生成模型上线了,我们可以在这个 flow 平台上进行体验,同时 flow 平台也上线了很多的视频和图片编辑小工具, 那么本期视频我就给大家测试体验一下欧米尼模型还有这些小工具。首先我进行测试的时候,模型只开放了 fresh 模型, 目前最高能生成七二零 p 十秒的视频,每个视频消耗三十个点数, umi pro 会员一共有一千个 ai 点数,而且我在使用的时候,它的首帧参考功能还没有上线,所以我就简单测试了几个纹身视频的例子, i will send you back to the dark abyss。 好,提示词所要求的东西都有,但是动作,电影质感还有音效都差很多,可以看一下 c 带是二点零的, 而且在 flow 这个平台,我们可以在下面这里输入提示词,直接对视频进行二次编辑。比如我直接输入一条金枪鱼跳上船,我们来看一下效果, i will send you back to the dark abyss。 他 这添加的内容太生硬了,几乎是不可用的。当然有可能他是 fresh 模型的原因。我们再多看几个例子, 这条视频的话,飞机驾驶是还不错,女主的紧张感和节奏也还行,但最后飞机仪表盘反向了,而且多了一个人。下一个我们试一下著名 ip 加想象力 why won't this stupid code work? 暂停一下,这里电脑里表现的内容太棒了,连代码的说尽都像那么回事。 i refuse to do this? 直接切镜头换风格 anymore why won't 他 这条真人路飞生成的其实挺棒的,这是就中间莫名其妙多出来一个动漫风格的镜头,下一个是变形金刚的镜头, 这个表现就太差了,别说跟 c 站十二点零比了,连快乐马都比不过。 下面是一个著名 ip 加动漫风格, anya will defeat all the villains, 这个表现其实还算可以了,介于 first 和 cds 二点零完全体之间, 下一个是香港电影。如果记忆是一个管头,我希望他永远不回国。起 这个案例就表现的很差了,无论是中文音还是镜头都不符合要求。如果记忆是一个罐头,我希望它永远不会过期。来一个九比十六的变身镜头, 那就再来一次, 感觉能比快乐马好上一些,但是这种动作和特效还是 c 大 师您的拿手好, 再试一下科幻镜头, 这个表现太拉胯了,完全没有电影质感,比快乐马都差远。 总结一下就是 omni, 它的表现肯定是不如 cds 二点零的,但它毕竟还是 flash 模型,不知道它有没有正式版,如果有正式版还是未来可期的。它还有一个优点就是足够的便宜,性价比还是很高的,目前生产速度也快,而且目前还 现那些著名的 ip。 今天除了欧莫尼这个更新之外, pro 这个平台还上线了巨多的图像编辑和视频编辑小工具, 我也帮大家测试了一下,总结一下就是很鸡肋,就是看起来很厉害,实际上就是一些常见的开源项目整合而成的图像和视频编辑工具, 比如说编辑文字动画的呀,还有说像什么手绘转图片,从各个仕图和角度去查看原始的图片,这个就是千问的技术吧,我记得还有什么视频跟随音乐动起来,这样的就适合整活。 还有一个是上传三 d 模型,然后再转化为二 d 平面图片, 它的视频小工具还有一个印象比较深刻的是一个抽帧加抠图加重叠的技术, 其他的图像小工具的话,要不然就见太多了,要不然就完全没什么意义。总结一下的话就是 omni 未来可期,图像工具的话作用不大。 那么以上就是 jimmy 在 本次 flow 上的更新的测试结果了,我个人是比较失望的。好,如果本期视频对你有帮助的话,麻烦帮我点个赞。
1479实验式 01:33查看AI文稿AI文稿
01:33查看AI文稿AI文稿本视频为我们本地化 ai 智能画布可零三点零欧米尼的功能介绍,我把视频效果先给大家展示一下, 那我们正式开始点击左侧的 ai 视频加载视频功能主键。 首先可零三点零欧米尼支持最多七张的参考图,这样我们就再也不用担心人物转身的时候靠模型去猜你的衣服背面是什么样的, 能更好的实现服装的一致性。不仅仅是参考图片,而且它可以参考图片的同时参考视频,拖入参考视频和参考图片, 参考视频的运镜和人物的动作,生成图一不二的服装展示,点击执行这个模式就可以非常容易的一键去复刻爆款视频,靠视频的电商卖家应该会非常喜欢这个功能。 第二个功能板块就是视频编辑,可以对视频中的内容做修改,或者说可以让视频中的人物使用上你的产品,例如 拖动视频,拖动图片,输入视频中的人物带着图一的帽子点击执行,然后这样就可以生成一个视频中的人物带着你的这个帽子的这样一个视频。 以上视频功能模块儿一托可灵三点零系列的模型,集合了简单操作的可灵三点零和更加强大的控制能力的可灵三点零 omni 模型比官方更便宜,逻辑更加的清晰,视觉更加的优雅。
11AI智能画布 02:05查看AI文稿AI文稿
02:05查看AI文稿AI文稿哈喽,今天一分钟使用欧盟尼生成三十秒的长视频来看效果, 现在这一个视频用的是谷 歌最新出的欧盟尼来生成的,测试下来视频的编辑能力非常不错啊。这里我是分别生成了三个短的片段,然后拼接在一起, 整体效果还是不错的。接下来说一下完整的思路。我们来到 google fold 的 主页新建一个项目,这里我已经创建好了。接着从左下角的加号进来,可以去上传我们的图片、视频或者音频。 这里我上传了产品的不同角度图,还有拼图。因为欧尼的视频编辑功能最多支持上传五张图,所以我就把一些服装的细节图拼成一张,接着再上传我们的参考视频,那我的原视频是二十多秒,所以我就剪成了三段,这里也需要添加视频到多少 框。接着再说这段贴纸,这里我要欧尼把视频中的服装替换成上传的参考图,也可以补充服装的材质、细节等等,然后开始生成。 在右侧我们可以看到它调用的就是 omni 来生成视频,一个视频跑下来差不多两分钟,稍等一会,我们来看一下输出结果。 这里有一点要注意,如果我们要做长视频,那么在第一段生成完之后,需要看产品整体是否一致,如果有问题就需要去检查上传的产品素材是否足够,以及提示是否有问题。如 如果素材和提词都没问题,那么我们就可以继续去生成第二个、第三个视频,这里还是上传相同的素材和提词,有需要的可以参考我这个来。那目前测下来,我觉得欧米尼的视频理解能力真的不错,不管是产品的一致性 还是画面质感都非常在线,后续可以考虑探索其他产品的玩法。最后在视频片段都生成完后,我们打开编辑话布, 可以去把刚刚生成好的视频添加到轨道。那这里还有个点要注意,如果生成的画面个别真的有问题, 那么大概率是参考视频画面衔接的间隙太短影响的,所以这个在前期剪片段的时候也要注意一下,不过整体的效果还是不错的,基本的思路就这样。好了,以上本期视频呢,觉得有用的话不用点赞关注,咱们下期见!拜拜!
176棒棒闲不住 15:43查看AI文稿AI文稿
15:43查看AI文稿AI文稿刻印三点零终于来了,我简直激动坏了,把它跟 vivo 三点一这类工具比比看到底谁更胜一筹?还有,跟之前的刻印老版本和 sora 二相比又如何?首先要使用这个功能,请点击这里的视频模块。 进入后,这里就会显示 ai 三点零模型。你也可以直接在这里选择模型或者切换到 ai 标签页。然后你会看到可供选择的模型,包括 ai 三点零和 ai 三。 ziramni 这个新推出的 ai 参考功能允许你上传一个视频或其他元素作为参考素材。此外还提供了 ai 编辑功能。 现在让我来为你一步步演示这些功能。首先,这个三点零版本很可能就是你最常使用的通用模型。在这里你可以设置起始帧与结束帧,并且使用多镜头拍摄功能。 多镜头是个关键功能,因为它能让你在一个视频里融入不同的场景。我来操作给你看就懂了。 new model just dropped it's clean they just dropped 3.0 and it's insane。 看到了吧,这就是多镜头功能的效果。上面那个视频我是这么做的。如果我复制这个项目的设置,你就能在这里看到多镜头选项。 看界面左边,这里列出了镜头一、镜头二和镜头三,而且你还可以继续添加更多镜头。说白了,你可以把一个十五秒的视频拆分成若干段,每段最长五秒。 因此你可以自由设定每个镜头的时长,但最长不得超过五秒。接下来,你可以对每一个镜头都进行同样的操作,而且每个镜头你都可以设定一个起始画面。你还能添加各种元素,甚至亲手打造专属元素。 举个例子,我自己就做了一个元素,就是这个红牛罐,我拿它来测试,看看整个流程效果如何。那么当你点击添加按钮时,你还可以去引用那个起始画面、红牛罐,或者你添加的任何其他元素。关于使用这个多镜头功能,我最好的建议就是像平常聊天那样去写提示词。 具体来说,我用的就是这个工具。这绝对不是广告,这只是我日常都在用的一个工具,叫 whisper flow。 它的功能很简单,我只要按住一个键就能开始说话。 我来给你演示一下。你看,我现在就按着这个键。如你所见,界面底部正在录制我的麦克风声音,然后我一松手,它就会开始描述或转写我刚说的话。我写提示词的时候用的就是这个方法,这能帮我省下大把时间。 再强调一遍,不是广告,纯粹觉得这个写提示词的小技巧很有用,分享给大家。说白了,每个镜头你都可以描述成不同的拍摄类型。比如我第一个镜头就从特写开始, 接下来是一个过肩镜头,接着再来一个特写镜头。你应该把每个镜头都视作一次微剪辑,如果觉得某个镜头太长,直接像这样缩短就行, 这样镜头的时长也就随之改变了。这样一来,你基本上可以制作各种时长一两秒的镜头。此外,你还可以添加多个不同的镜头。 我记得上线是六个箭头,也就是说,你在提示。此例最多可以描述六个不同的场景,每个大概两秒左右。创建方法就是这样,接下来选择分辨率,支持七百二十 p 或一零八零 p。 在 我看来,眼下这个功能很可能是你玩转柯影三点零时最常用的功能了。下面我给大家看几个我生成的例子, 比如这个一只大熊猫,我们来看看。 哇,看完我觉得这也太可爱了吧,现在我来试试看它能不能搞点破坏。大家可以看到,我这里生成了两个不同的镜头。我们先看第一个, 看这里就用上了多镜头拍摄手法,现在这个镜头效果可能会更好一些。 好了,展示完毕。你可能一直梦想着看大熊猫如何大闹成事, 现在角色对话也变得更自然了。目前唯一让我有点头疼的就是口型同步还差点意思。我来给你演示一下具体是什么问题,我们来看看这个镜头。这是一个由多个镜头合成的画面,具体到这个镜头,我用了四个不同的分镜来合成,我反复生成了好几次才得到满意的效果。 我先用了一个广角镜头,接着是一个中近景,然后是一个特写,接着又是一个特写,我们来看一下效果。 you know why i'm here i want my money now give me more time i'll get it you don't have time anymore。 这里面部的一致性保持的相当不错,我见过有些案例部特征在过程中会有些变化,但总的来说,眼前这个已经是最差的情况了。就我们目前看到的效果来说,这简直不可思议。 在我看来,用这个工具完全可以生成高质量的内容,而且还能一次性生成多个不同的镜头画面,仅凭一个提示词或一次生成就能做到,这简直太牛了。不过现在让我再给大家展示几个其他的功能,这些都是你现在可以用全新的 kine 三点零来实现的。 首先,大家可能没注意到,如果你把这个开关关掉,那么你就会看到一个普通的提示词输入框,这样你就可以像往常一样操作了。 你可以输入提示词,然后生成最长大约十五秒的视频。所以能生成十五秒视频是这里的一个新特性。通常你只能生成十秒的视频,而现在我们可以生成十五秒的了。我喜欢这个十五秒时长的地方在于,现在你可以创作更长的连续场景了。 通常我看到的所有 ai 生成的电影,每隔五到十秒就会出现一次剪辑切换,那是因为之前只能生成五到十秒长的视频片段,而现在你可以生成更长的视频了。唯一的问题是,正如你在这里看到的画面出现了一些变形, 理想情况下你最好把那段剪掉,所以你可能得重跑一遍,或者多试几次,这可能会让你多花点积分。 说到积分,咱们来聊聊这个模型到底有多烧钱。所以目前来看,生成一个十五秒的视频需要花掉三十积分。如果拿它跟颗印二点六比的话,价格其实差不多。这边是花二十积分得十秒,这边也是花二十积分得十秒,所以换算下来,每个模型都是每五秒十积分,所以价格是一样的。 所以从使用额度来看,它和刻印二点六一模一样,但它的实际表现到底比二点六强在哪里呢?别急,我稍后就给大家演示一下。咱们先来深入聊聊它的几个新功能。接下来的另一大亮点就是刻印三点零安尼功能。 通过这个功能,你可以在视频里添加最多七张图片或各种元素。比如你可以添加图片,什么格式的图片都行。也可以添加元素,比如像我这样的虚拟人物,也可以是其他类型的元素。 再举个具体例子,比如我手边这本红色的书,就可以把它作为元素来使用。然后再输入提示词的时候,你还可以通过输入特定指令来标记这些元素,然后在提示词里直接调用它们,无论是图片还是其他任何你想放进视频里的东西。 这样一来,你对视频内容的掌控力就大大增强了,能更精准的决定视频力呈现的内容。可惜我最近遇到点小麻烦,所以还没能把它完整的测一遍。不过我还是生成了几个其他的样例,想跟大家分享一下。首先,据说它的音频效果有所提升,那我们就用这个视频来实际测测看。 emily, if you see this then i'm sorry, i love you and please, please don't look for me the infection is spreading everywhere and it's too dangerous to go outside remember that mama loves you。 我是 说这个效果明显不如之前那个。不过话说回来,这个听起来还挺不错的,但我们要真正比个高下,对吧?就是拿它跟科隐二点六比一比,还有 google v o 三 one, 那 咱们就来比一比。我用了相同的提示词和参考图,这是科隐二点六生成的效果。 emily, if you see this, then i'm sorry, i love you and please, please don't look for me the infection is spreading everywhere and it's too dangerous to go outside remember that baba loves you。 说真的,这个版本比上一个差远了,上一个也就是三点零版本简直强太多了。咱们来比比看它和谷歌微 dior 三点一谁更牛? emily, if you see this, then i'm sorry, i love you and please please。 效果还不错,但那谷子谷歌微 dior 的 味儿太冲了。怎么说呢,我基本上一听就能分辨出来,就算你把各种视频摆在我面前,我只听不看角色,一开口你就能听出那是谷歌微 dior 三点一的动静,这个视频也不例外,一听就是它。 出于好奇,我也试了试用科影零一来生成会是什么效果,就想看看有没有区别,毕竟它也是新出的模型。 emily, if you see this, then i'm sorry, i love you and please, please don't look for me infection is spreading everywhere and it's too dangerous to go outside remember that mama loves you。 光从刚才这个测试你就能听出来,我觉得科影三点零是所有这些里面听起来最棒的。 不过如果你有不同看法,一定要告诉我,我还在摸索阶段,我试了不少提示词,但还不足以得出最终结论。咱们接着测,顺便也和 sora 两比一比。接下来就精彩了,因为我在跑这些测试的时候,我有个奇怪的感觉,就是 sora 二在多镜头处理上其实也挺牛的。 sora 二唯一的短板是,你没法真的丢一张人像进去,让它动起来,或者用它生成视频,因为它在这方面就是有限制, 而柯影则打破了这层壁垒,所以现在用柯影就能实现这个功能了,而且它生成的视频最长能达到十五秒。那咱们就实际来看看效果吧。要想公平的比较柯影和 sora, 唯一的方法就是跑文本生成视频,因为这样才能绕过所有限制条件, 所以我就从情感测试的角度来看看它的真实感到底有多犟。打头阵的是柯影三 zero, 我差点就信了,这要是段真视频我绝对信,以为真效果太顶了,好到让我都有点难过了。再来看看 sorry 二的表现, i don't know how to stop feeling like this。 背景音乐有点拉胯,但配音、演员、角色声音,还有那些细微之处,听起来都超级真实。不过现在如果你看看我们给的提示词,就会发现,我们压根没要求它生成任何对话, 所以这些对话全是它自己发挥的,这就是它们最真实的情感流露。看来 sora 二是这么个感觉,现在咱们来和 vivo 三点一比一比,顺便也听听音效。 说实话效果不赖,但他眼角那滴泪真是让我有点猛,怎么说没就没了呢?他这是在倒着哭啊,这操作是怎么实现的? 没错,要我说这选择其实很简单,就拿这次测试来说,基本就是 sora 和科影二选一,但我感觉科影这边选择更多,因为他的玩法更丰富,你可以上传自己的图片,这在 sora 二里对人类可不行, 咱们再试一个,现在咱们还在测纹身视频,不然就没法和 sora 二作对比了,所以我现在主要对比这些模型的动态效果, 我用的提示词是这样的,让这些模特为镜头摆姿势,我想看看他们对提示词的理解和执行力怎么样。动作是慢慢将头转向左侧,再转向右侧,然后微微抬起下巴。基本上就这些动作要求就是动作要轻柔舒缓,看看他们表现如何。先看科影三 zero 看起来挺自然的,现在轮到 sora 二, sora 二似乎不太清楚该怎么摆弄下巴,不过他多少还是跟着指令做了。现在来看看 v o 三一的表现。 要我说,你确实可以认为他遵循了提示词,这跟我预想的不太一样,但他确实是先往左走,然后向右转了个身,最后抬起了下巴。平心而论,虽然我不想显得偏心,但我觉得在这里柯映的表现最佳。而且我也给了这个模型公平的测试机会。我进行了多次生成, 并从中挑选了效果最好的一个,免得你们好奇我是怎么选的。接下来这个镜头动作更丰富一些,同时我也想对生成过程有更强的把控,因此我想重点考察一下它遵循提示词的效果到底怎么样。 我这里设定了一个起始针和一个结束针,画面里是两个劫匪正在撬银行的门,结果进去发现里面有一群人,然后还有个保安,他本来在睡觉,然后惊醒过来。 我去,什么情况?那咱们就直接开看吧。这里我特别想对比一下所有的 ai 模型,因为 sorry 二不让我生成这段视频。我遇到点问题,可能因为画面里出现了枪。至于 ai, 我 目前还是所有模型都在用,像 ai 二点一和 ai 二点六这些版本我都还在用,来我们看看。 先看 ai 二 one, 这个没声音,它没按我提示的那样把门踢开, 而且这家伙已经坐在那了,所以这个算是翻车了。那我们接着探 can 二 six, 同样门也没踢开,不过这家伙在睡觉,但他身体在 moaning 行变,接着他醒了,然后抓起枪。 还行,但行变还是太多了点。现在来看科影一,我是说这一脚踢得没劲儿,对,这个镜头全是行变,这根本没法用。最后是科影三 zero, 这个镜头不错,像这样踹门才是我想要的,而且我喜欢摄影师从这两人中间穿过去的运镜。这家伙在睡觉, 我们的注意力会集中在其他人身上,然后焦点会慢慢从他们的眼睛移向这边,就好像在问,右边这哥们在干嘛呢?太离谱了,真是绝了。好了,我还有一个最终镜头, 想拿来跟 y o 三点一和 sora 两比一比。可惜的是这对比不太公平,因为镜头里有人,而我没办法在 sora 二里用带人物的镜头来实现它,所以我尝试用文本提示 prompt 来生成它。不过从可引三点零开始,我们就能做出这个镜头了。我们从这个镜头开始,然后我往里加了四个不同的镜头。 首先是一个定场镜头,一个从屋顶拍摄的白色调定场镜头,接着切到一个侧面的中近景,他的头轻轻转了一下,然后一个硬切,直接给到他脸部的特写。最后再一个硬切,以从背后拍摄的白色镜头收尾。现在咱们来看看他到底有没有按提示词来。 哇,这太牛了, ai 能真的听懂你的提示并照做,这才是我喜欢的这个操作。我也用 y o 三点一试过,毕竟视频里包含多个镜头也不是什么新鲜事了,这效果比不上你亲自操作那个多镜头功能的时候。接下来我们来看看 y o 三一, 我们从一个白色的定场镜头开始, 这里他跳过了那个镜头,感觉就像是镜头切换时,他的头应该跟着动一下,接着应该切到一个特写镜头, 然后是一个从背后拍摄的镜头,但这个镜头系列不是。总的来说,我对刻印三点零的整体感受是,那就是这对于 ai 电影制作人、广告商、营销人员来说,将会是一个巨大的利器。
157云桥网络 11:49查看AI文稿AI文稿
11:49查看AI文稿AI文稿哈喽各位小姐,我用了半个月的时间读了一点文献,试图把这个框架做的更加的结构化,但是呢,我意识到相比于板正的书面语,大家应该还是更想听一点人话,所以今天呢,请假设我是一名你的女性好友啊,带你去一次健身房, 那在此之前我们都要经历哪些流程,做哪些决策和准备呢?那么首先第一件事情是,很多人在去健身房之前,他不会去思考,但是一定是非常重要的一件事,你做任何事之前,你的目的是什么? 在这里我们把它分成三类啊,男的女的都一样。首先第一点就是肌肥大,就是练肌肉嘛,练线条。 第二点呢,是增强你的绝对力量,比如说我下次坐高铁的时候,可以把自己的行李箱单手这么提溜上去。第三点呢,减脂,它其实跟力训并不是直接挂钩的,但是它是很多人去健身房绕不开的一点,所以我们也把它 拎出来讲一下,总之就是你一定要想清楚自己的目的,才可以不绕弯路的实现。举个例子,现在很多人鼓励女生去做什么小重量多组数,这在增肌这方面是行之有效了,但是如果你的目的是下次坐高铁能拎起四十斤的行李箱, 那就很难卷北折了。所以明确目的之后,我到底该如何挑选适合我的方式呢?我们可以简单粗暴的划分一下,如果今天我就是追求 练出肌肥大的效果的话,那我就去做小重量多组数,用它来雕刻自己的肌肉线条,因为肌肉的生长它是取决于你每次训练的容量就是你的 volume, 它等于你训练的次数乘你的组数,再乘你单次举起的重量。 所以发现了吗?它不取决于你的绝对力量,它取决于你一共练了多少,这才是肌肉生长的逻辑。如果你想增强自己的绝对力量的话,我们就要考虑大重量中或者 低次数,它才是一个行之有效的方式。那有没有发现,既然肌肥大的效果取决于总的容量,那我去做大重量中低次数是不是也可以达到练出肌肉线条的效果呢?当然 当然,在总的 volume 一 致的情况下,你用这两种方案所实现的增肌效果其实是一致的,那我就会觉得其实还是。呃,第二种方案好像更划算一点嘛。那你如果说郑老师我去健身房就是为了减脂呢? 那我依旧给一条效率最优的方式,我们去做三十分钟以上的纵吐有氧好吗?他从效率上一定是最优,而且从心情上也是最愉悦,最不累的。那你说现在我们解决完了第一个问题,可以进健身房了吗?不可以,因为我们要先干嘛?先吃饭饮 食。在力量训练这个领域,我认为是占比可以高达百分之五十到百分之六十的,所以我今天不拓展,我只想给三条我认为非常有效的意见。 首先就是女性不要去做任何的空腹训练,特别是空腹的力量训练,不要看男的在健身房不吃不喝,拿一杯冰美式框框就是干就去学,没有任何的参考价值。因为我们处理能量可用性的方式是不同的, 空腹的训练更容易让女性的身体进入一种压力模式,就是生存模式。在这种情况下,我们的皮质醇会升高,那皮质醇升高会带来什么副作用呢? 我们的血糖会波动很大,我们晚上睡觉会睡不好,那我们就会疯狂犯猪炎,想吃一些高油高糖高脂的东西,那么我们的肠胃消化,他们的压力又会进一步的传递到我们的大脑, 那我们的大脑把多余的神经都分到这方面了,我们训练的恢复能力又会变差。所以发现了吗?这是一个循环,在这种情况下,高强度的训练他反会成为我们的负担。所以不要空腹训练啊。那既然不要空腹,我们吃什么呢? 一般来说,如果我去健身房的前两个小时,我有吃一顿正餐的话,我就不会再额外的吃东西了。但你们知道我都是早上去健身房,那我就会把我的早餐掰成两份吃,保证每份都有大概。呃,三十克的碳水加十五克的蛋白质,其实就是酸奶加燕麦, 呃,吐司加奶酪,然后三明治那些有的没的。那么说到蛋白质了,又有人会问我到底一天应该吃多少颗蛋白质?我这里给你写一个标准答案好吗?就是把你的体重乘一点六倍,就是等于你每天要吃的蛋白质的数量。 那有的小姐会觉得我是真的吃不了那么多肉怎么办?没关系,你可以去喝蛋白粉的。呃, 它的形式不重要,重要的是你每天要有这么多食脂蛋白质的摄入。那我的第三条建议就是多吃还原型的食物。 每天我都能看到有评论区在下面问我金老师,金老师到底是怎么每天看起来这么有劲的?答案就很简单啊,多吃还原型的食物。那么什么是还原型的食物呢?一言以蔽之,就是你拿到它的时候,你要吃了,你一眼就可以看出来它是什么做的。 那 which means? 能吃卤牛肉就不要吃牛肉丸,能吃大馒头就不要吃小饼干,少吃,也不能说完全不吃吧,少吃那些精加工的,然后你根本就看不出来是什么东西的 零食。在你一天的饮食结构里,你吃到的还原型食物的占比越高,那么我们的身体消耗它,处理它所需要耗费的精力就越小。 那根据能量守恒定律,剩下的精力会到哪里?就在自己身上吗?对不对?好,第二个问题说完了,但是不好意思,我们还是不可以进健身房。 为什么呢?因为我们是女的,有生理周期的呀。今天你怎么知道今天适不适合自己锻炼对不对?什么月经第几天不能练,什么黄体期不能练,这样那样。网上的图大家肯定都看到过很多,但我个人的观点就是,在目前这个领域的研究是非常的薄弱的, 他的说服力很弱,而且不同的人他往往有着不同的理论,甚至还有研究表明,就是这个生理周期,他对实际的训练效果,包括训练水平根本就没有影响的。 那我们该怎么办呢?不办,我更想教大家的是如何去根据自己当日的状态去调整自己训练的侧重点。你大可以忽略掉所有的这四个因素, 在没有病理性反应的前提下啊,我们来考量这三个指标,这是我自己总结出来的,首先呢就是你绝对的力量, 举个例子,今天可以举起来多少重量?那么第二点呢,就是考虑我们的神经中书,浅显一点,就是今天我的脑子转的够不够用, 我做这些动作的时候顺不顺,我的四肢协调不协调,特别是我们在做像深蹲硬拉一些的复合动作的时候,我是盲目的做,我还是我是有意识的在标准化自己的动作,带着脑子做的,这一点非常重要,这是由我们的神经中枢纽来决定的。那么第三点非常重要的是恢复能力, 我今天完成了这组训练之后,我今天这一天,剩下的这一天我还有电吗?我还能不能就是正常的运转下去?考虑这三点是非常重要的,我拿我自己结合这四个时期给大家举一个例子好了。 在我月经的开始的第二天到第十三天,十四天,也就是排卵期前面那几天,我的恢复能力,力量还有神经中抠 三点都是拉满的,我觉得自己像一个超级赛亚人一样。所以我的关注就是两点,首先是给自己上重量,其次是增加一些辅助的心肺能力的训练。 但是一旦过了十四天这个节点,一旦过了排卵日这个节点,我整个人就不行了,接下来一周我都像被炮轰过一样,我的恢复能力和力量在此时此刻是奇差无比的, 但是我的神经中枢纽好像还在线,那我在这段时间该怎么办呢?我听起来挺惨的,不怎么办,很简单,就是听自己身体的声音, 饿的话就多吃一点,累的话就少练一点,然后去专注动作的细节。举个例子,我平时深蹲做组的话,大概是六十公斤做组,但是我在这个时期我可能就做 四十千克的组,但是我会调整占距,我还会每蹲一组做的慢一点,我来复盘一下刚才那组动作质量怎么样,而且我也会在这个时期用一些小重量去解锁,去学习一些新的动作, 这都是非常行之有效的。就是在我们非常虚弱的时刻,并不代表我们的时间被浪费了,我们还是可以利用他们去做更多有意义的事情,一切只是测重点不一样而已。 而且你整个人状态不可能一直是非常燃的,一直燃肯定也有问题,在这种时刻让自己冷静下来也是非常非常有意义的。那么到了下一个阶段,到了我的黄体期,特别是黄体晚期,我的状态是什么样子呢?就在这个时候,我的力量其实是非常在线的,有时候我自己都惊讶, 但是呢,我的恢复能力非常的弱,而且我的神经中风能力只能说是一般般吧,其实也没那么好,就有时候我做着做着,可能力量我还在线,但是我脑子突然荡机了,那在这个阶段呢,我一般就会考虑啊,维持自己正常情况下的力量水平, 并且巩固自己在之前那段时间学到的一些新动作,这对我来说也是一个非常好的方式。总之,我举自己的例子是想说明一件事情,就是 所谓的健身,所谓的力量训练,到了最后,其实不是在把自己往一套科学的模板上面推,不是那样的,其实我是在做更加个性化、更加定制的内容,我要 听我的身体要跟我讲什么。摸清这个规律,最简单的方式其实就是记录,你拉一个表,就记录每天自己睡了多少小时,你早上起来睁眼的时候,你启动的状态是怎么样的。 然后你今天处于生理的哪个周期,你做了什么训练?你的练后反馈是什么?今天一天大概吃了多少东西?我的还原型食物占比是多少?然后我的精加工食物占比又是多少? 你坚持两周以上,其实就已经可以从自己的身体反馈中挖掘出来一些非常有意思的规律了。然后我觉得这个也是非常值得的。反正今天就是先讲这么多吧, 讲太多我怕我剪不完了。然后我有点想笑,叽里咕噜讲了一仗,讲这么一大堆,结果我们连健身房的门还没进呢。呃,接下来这一部分可能会讲一些 我们的器械选择,比如说你是做孤立器械还是自由重量?你该怎么选?我看经常有人问的问题,几分化的问题。私教还是自己练?我练到什么程度可以去脱离私教?我先提前说吧,一句话总结,这不是一个可以拿时间衡量的事情,这是一个要考验衡量自主学习能力的一个事情。 然后还有就是我已经被催了很多次的补剂。呃,就很多人在评论区问啊,郑老师,你每天都吃什么补剂?我一直没做这视频是因为,哎呀,我一做这种理论化的视频,我就有点压力,我好像老是想把这种东西写成文件综述一样的东西,但是, 哎,没必要吧,反正,呃,大概就是这样。对,最重要的还有最后后面则声明, 首先我不是专业的,我不是健身教练,我也,呃,甚至现在目前都还算不上资深的健身爱好者。我只是一个初期的爱好者小白吧,但本人就是不才,特别擅长呃信息解剖,看文献,还有就是对各种的方法论和理论,结合自己的身体经验进行一些 评述,就像我今天给大家展现的这样,所以这个东西大家可以看作是百分之八十 我的信息搜集所得。然后百分之二十是基于我自己经验的一个感知。如果你觉得你和我的体会不一样的话,那也很正常,毕竟每个人的体质都不一样。那么先这样吧,我要回家睡觉,再见。
8.7万Gin 02:27查看AI文稿AI文稿
02:27查看AI文稿AI文稿哈喽,早上好,现在是早上的七点,其实我五点钟就起来了,因为今天欧迷你上线,我就想看一下我的账号能不能有幸的去使用上它。在拍这个视频之前我已经嗯简单的探索了一下了, 所以现在的话呢,可以给大家拍一个视频。首先我准备了一段大概十五秒的一个脚本,脚本里面是包含了创意,然后就设计元素,因为早上试的时候呢啊,放了一个真人参考图上去是不过审的,那么我就把这个形象人物形象的 这些描啊特征我都用文字去让 ai 给我描述出来了。我试过有大概两个渠道是可以用上欧迷你的,详细的话我就视频里面不能讲了,你们自己看就好了。然后,呃,然后的话选择十秒,竖屏参数都是一样,然后把这个内容放上去,我们点开始 一次就呃生成两个哈,这一边是 c 档是二点零的,同样的 c 档是二点零,我们选十五秒,这边可以选十五秒哈,哦, ok, 呃,然后欧米尼这边的效果已经出来了,我们看一下哈,唤醒你的不该是喧嚣,而是对深度的渴望,掌管你的种熟时区 deep moment 咖啡。 然后这一次,呃,点进去之后呢,是要有一个像进度条的一样的东西,就是我可以随意拖动,随意拖动到每一帧的一个地方,然后刚刚我尝试一下这个,这个挺有趣的,就是我拖动到男主角的这个地方,然后跟他说把男主角的衣服改成黄色,其他 五遍,然后直接发送给他。这个就有点像我们在啊制作制图的时候啊,对话框的一个形式,告诉他我在哪里修改修改什么地方,然后就跟我昨天发的一个前三是很相似的,哎,你看他就把这个男主角的衣服改成黄色了。这时候我们回去看一看, c 档是二点零的,还在排队。好,现在 c 档是二点零的效果也出来了,我们看一下哈。 唤醒你的不该是喧嚣,而是对深度的渴望,掌管你的专属时区, deep moment 咖啡, 专注每一滴。然后两个模型对比下来的话, c 档子二点零的运镜还是比较优秀的。然后欧米尼的话呢,它就是中规中矩的一个感觉,在实际应用上面的话呢,它的效果也已经不错了。 呃,今天演示的这个还相对比较简单的,动作幅度小,场景简单。呃,那么在后面的话,还会在实际应用上面去看一下动作幅度大,场景切换的比较丰富的情况下,它的一个表现是怎么样。 讲的再好,实际应用上面的体验感是非常重要的。那么在后面的一个广告片的时候,我也会融入到,如果使用 omini 的 话,它的效果会是怎么样?那么我们下期见啦,拜拜。
199花花AIGC研究室 03:00查看AI文稿AI文稿
03:00查看AI文稿AI文稿大家好,我是外工作室的幕后大 boss, 很 荣幸的告诉大家一个好消息,短片纸手机成功入围嘎纳国际电影节。我们做纸手机这部影片主要想通过我们中国人传承了几千年的纸扎文化 表达对故人的思念。整部片子没有过度渲染悲伤,小男孩的视角也让片子显得没有那么沉重, 相反用克制和留白方式来表达反而产生了巨大的情感张力,也给观众留下了充分的共情和想象空间。这部短片的制作由二位团队小伙伴耗时三天共同完成, 能有这么高的制作效率,主要归功于视频生成模型。可零 ai 角色一次性一直是创作中的重难点问题,本次创作主要运用了可零三点零 omni 的 主体参考功能,交出了完美答案。 通过参考主体资产场景图关键的分镜图加分镜提示词,就能自定义分镜生成一段最长十五秒的富有电影质感的戏,人物可以保持高度一致性,让主角本色出演。那么怎么做到让人物表演细腻呢? 其实重点在于角色情绪状态的把握,比如我们想表达小男孩因为钱不够有些尴尬的把握。比如我们想表达小男孩因为钱不够有些尴尬的把握。比如我们想表达小男孩因为钱不够有些尴尬的特写。 这是基于我们对小男孩这个角色的深刻理解和带入,并且在提示词描述上也并不是单纯的描述动作,而是把他心理状态也一起带上,让模型更易于理解。 另外,在这次的音色设计和一次性保持上,是挑选了可灵音化同出的音色,并且通过可灵主体库进行锁定,这些地方口音放到情节里,让大家听着更亲切,更有代入感。 还有很多人好奇影片最后的长镜头是怎么做的,其实是用可灵三点零模型的首尾针, 通过在提示词里描述小男孩的表情动作、车内车外的环境,让原本单次最多十五秒的镜头衔接丝滑质感,真实实现两分长镜头的历史性突破。 我们探讨死亡并不是为了传递悲伤,而是想传递对亲人的思念。 中国人表达情感一直比较含蓄,通过烧纸钱这些习俗,我们想说的是,逝去的亲人一直活在我们的思念里,并没有真正从记忆中消失。爱你哦!
4641FOS 01:25查看AI文稿AI文稿
01:25查看AI文稿AI文稿用 ai 做视频到底有多简单?首先找个数字人模特,用提示词给模特穿上这件婚纱,并佩戴耳饰和头纱。再用提示词生成人物的多视角参考图。 然后把人物多视角参考图丢给豆包,让他帮我们生成人物穿着婚纱的婚纱大片脚本 生成完成后,我们打开界面内,用界面内来为我们生成这段脚本的二十五宫格风景图。 jason 把脚本和人物多视角参考图粘贴进去,让他帮我们输出 jason。 接着我们打开 level, 把 jason 粘贴进去。参考图,选择之前生成的人物多视角图,用 nano banana pro 帮我们生成二十五宫格分镜图。分镜图生成完成之后,如果你觉得不好,可以多生成几次,选取你喜欢的分镜 图。最后用 kling 三点零奥尼生成个视频,一起来看看。
35CHonor 00:26查看AI文稿AI文稿
00:26查看AI文稿AI文稿五哥新发布的奥尼模型,有人吐槽效果很差,那是你使用方式不对,这个泰国特种兵一日游视频就是奥尼生成的,只需打开这个无线画布,先用 g p t 一 米至二生成故事版, 然后为给奥尼做参考,生成视频,一个画布就能完成所有操作,生成的效果就很好,赶快试试吧!想要获取画布工具的小伙伴,评论区打一哦!
5谁懂 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿你能看出来这些电商广告视频其实是 ai 做的吗?人物动作自然,商品拿在手里也很稳,连口型、反光这些细节看起来都挺像真的。而这些视频其实来自字节跳动新搞的一个专门做人和物交互的 ai 视频模型奥利兽,我们直接看几个演示,只需要给他一段文字描述, 再加上人物参考图和商品参考图,它就能生成质量非常高的电商广告视频。而且你会发现,不管是人物的表情、动作,还是人物和商品的一致性,都做得非常不错,已经有点到以假乱真的程度了。商品拿在手里非常稳定,没有明显变形,甚至连反光和质感这些细节都很自然。 再加一段口播音频,它还可以直接生成带讲解的视频,而且口型同步的效果看起来也不错。 experience soothing relief with this rich fast absorbing cream perfect for calming tired。 如果你想让它参考一些动作,它同样也能完成。奥姆尼兽可以很好的跟踪运动轨迹,同时保持人物和商品交互时的真实性。动作姿态加进去之后,整个电商视频会更生动,也更有吸引力。如果再把图片、姿势、音频这些信息同时输入,让它生成视频时的稳定性还会更高, 整体效果也会更真实。某些场景已经有种可以代替部分电商广告实拍的感觉了。 discover the power of nature with this all in one organic supplement 通过这些演示能看出来,这个模型在人脸一致性、商品一致性、物理理性表现力,还有口型同步这些方面,整体表现都相当不错,并且它最长能生成十秒的连续视频, 非常适合用在电商产品演示里。当然它也不只是适合做电商内容,拿来做一些动画或者数字人口播内容也很合适,通过人像加音频输入就能做出比较生动的说话唱歌效果。不过目前代码还没有正式放出来,还在内部审核阶段, 距离开源应该也不远了。最后我们来聊个题外话,如果以后越来越多电商宣传视频都变成 ai 来做,你会买这样的视频里展示的产品吗?欢迎在下方讨论。我是 ai 那 些试作者搞设计的花生人,我们下个视频再见。拜拜!
 01:13查看AI文稿AI文稿
01:13查看AI文稿AI文稿小米最狠的竟然不是画质,而是他竟然会自己剪辑成片!注意,这绝对不是后期剪辑,而是纯提示词控制的多镜头快切!比如你写全景特写、侧面跟拍甚至俯视镜头,他就能在同一条视频按节奏严丝合缝的切出来。而且连人物状态、动作方向、空间关系竟然全能接上!这个逆天的能力, c 单三目前真的不具备, c 蛋斯尔更擅长稳定的单镜头,而 omni 已经开始真正理解镜头之间的关系了。第二个升级能力是提示词控制更准,你要车门上有 pop 字样,你要军靴踩碎木板,甚至要红光扫过人物面部。 omni 明显更容易把这些机器聚 细节执行出来。他早就不仅是做氛围了,他开始完美适配品牌视频产品演示和技术可化。第三个能力是人物质感,更像工业级的引擎渲染。千万别误会,这可不是脸更清楚,而是皮肤、汗珠、眼球、光线之间的物理关系变得更加完整。所以我对欧米的最终判断是,他绝对不是单纯的更会生成视频。 他是在把 ai 视频从一个普通的出片工具,强行推向了视频引擎的硬核高度。多镜头快切解决视觉精准控制解决工业可控,人物质感 彻底解决角色真实。我把这次硬核测试用到的已经整理成了一套现成的模板,包括多镜头快切、人物质感、物理交互这几大类。想直接附用抄作业的老地方自取。我是关关,每天带你硬核玩转 ai。
90上班时间打酱油 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿谷歌今日凌晨发布了 gemini, 在 底层逻辑上简直就是一次史诗级的进化,瞬间引发了轰动,我们一起来看看实际的测试效果吧。哈喽,各位小伙伴们大家好,今天给大家演示一下最新的视频模型 omni flash 的 使用方法。 好,这个的话呢,它支持使用十秒啊,然后三十个积分这种方式操作好,那么怎么来操作呢?假如说我们要做这样的一个漫剧效果 好,那么首先第一个我们可以使用分镜啊,这个是我之前做的分镜。好,那么我直接把这个分镜的话呢,放到我的这个提示词里边啊,那么我可以直接到这里艾特一下就可以了。好,我艾特一下分镜,点击确认。好,然后的话呢,我可以直接说 啊,使用啊,根据分镜,或者我把它删掉啊,根据分镜生成动画。 好,然后我艾特一下这个分镜,这个分镜好,可以了。好,然后人物参考,使用这一个人物。好,然后场景参考,场景参考, 再使用一下这个场景。哎,我的场景也有了。好,这样子的话呢,那么就直接就 ok 了啊,然后我们直接来生成好生,呃,动画流畅,然后运镜流畅 就可以了。好,那么就直接点击生成好,这个的话呢,大家就可以看到一条非常运镜流畅的,并且呢有音效的这样的一个画面呢,就可以展示。 嗯,而且它的准确度是非常高的啊,就是没有脱离我们的这一个分镜,所以的话呢,这个是一个非常好用的功能。
375AIGC创意教育坊 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿这就是我的个人网站,是否有一种电影奇幻和硬核科技完美融合的质感呢?而这个网站从前端页面到后端的部署,再到最吸睛的这个动画效果,整个制作过程我没有写一行代码,也没有手动编辑过一条视频,全都是我用 ai 生成的。 那今天我就花一分钟左右的时间,手把手教大家如何制作这样一个动效视频,并且把它嵌入到你的个人网站中,实现如此质感。第一步,我们打开可零,进入 omni 模式, 输入准备好的参考图以及我们的提示词,一键生成动效视频三点零 omni 模型打破了模态的限制,可综合理解我上传的这张照片以及我描述的提示词,精准生成视频的各种细节。 大家看我生成好的视频,比如在这里,人物的皮肤上叠加了琥珀色的呼吸光晕,就像内部的能量正在涌动, 悬浮在城市上方的水晶正在围绕他的轴心自转,散发着金色的光芒。 山谷中呢,也有连绵不断的云雾正在缓慢的翻腾飘动。而画面最下方坐着的程序员,双手正在敲击键盘,就代表着我的职业。而两块电脑屏幕上滚动着这样的一个蓝色的代码, 与画面上方宏大的金光形成强烈的冷暖对比,呈现出一种赛博朋克与古典史诗的碰撞感。第二步,我们打开 ai 编程 ide, 输入刚刚下载好的视频,以及事先准备好的提示词,选择优秀的编程模型。 那经过几轮和 ai 的 交互和修正,我的个人网站就支持了主题切换的功能,可以从原先的极简模式一键切换成现在的动效模式。 ai 时代,这种酷炫的网站页面不再是动画设计师的专属,大家也快去可林尝试一下吧,体验 omni 模式下视频生成的生命力!
17秋阳Chris 01:11查看AI文稿AI文稿
01:11查看AI文稿AI文稿大家好,今天我们来聊一个在 ai 圈掀起巨浪的新家伙,谷歌的詹姆斯奥姆尼,我们对这个模型进行了一些视频测试,接下来我们看一下测试结果。首先我们打开谷歌的阿米视频生成,选择制作视频后上传人物参考图, 然后根据剧本复制画面内容, 然后再去修改优化我们的提示词,输入完成后点击发送。我们来看一下生成的效果,生成的效果很好, 然后这边也是了真人写实风格的,完全符合我们的预期。然后我们再试一下视频编辑,首先给出一段视频,然后我们再给出替换的人物图片, 我们就会得到一条新的视频,人物的形象和表演一致。总的来说, tommy 奥姆尼的出现标志着 ai 视频创作又向前迈了一大步。关注我,下期继续分享 ai 创作干货。
6上融老苑



