节省token实战教程
前段时间我自己写了个 ai 应用,用的时候花了不少钱,甚至比我订阅别人的 ai 应用花的钱还要多。这让我很不解,明明消耗的 token 数量都差不多,为什么我自己的应用没有了中间商,还会更花钱? 我才发现自己压根不知道有个东西叫做 prompt caching。 后来我调整了一下 prompt 的 结构,只花了五分钟,费用直接降低到了原来的一半,还降低了延迟。这个视频就讲讲 prompt caching。 我 们知道计算和获取数据是有成本的, 如果一个结果会反复用到,那就要反复做同样的计算,这样很浪费资源。于是有聪明的人发明了缓存这个概念,将可能会被再次用的东西存起来,下次用的时候就直接读取,不用重新算了。比如有的时候,我们用浏览器会发现点开刚刚关掉的标签页的时候,速度会变很快,就是因为浏览器缓存了页面。 而在 ai 中,每次向模型发送请求,模型都要把整个 prompt 的 token 从头到尾处理一遍,给每个 token 计算出 k v 两个值,为后续的处理做准备。而一个 token 的 k v 其实取决于这个 token 前面的所有 token。 也就是说,如果这个 token 自己没变,前面的所有 token 都没变,那这个 token 的 k v 就 不会变,每次请求结束,计算出的 k v 就 丢弃了,下次再重新算。所以如果每次 prompt 的 开头都一样,那就是在反复付钱,做同样的计算。于是聪明的你就想到了, 我们可以把计算出的 k v 缓存下来。如果下次的 prompt 和这次的 prompt 前面是一样的,那就不用重新计算了。恭喜你,你想出了现在最流行的缓存方式, k v cash。 对 于大部分模型提供方来说,缓存都会有效降低延迟和费用。以现在最贵的 cloud 来说,缓存费用是十分之一,而对于性价比之王 deepsea 来说,缓存的费用可以降到百分之一。那直到这一点, 省钱省时间的方案就很清晰啦。也就是把不变的内容放在 prom 的 前面,比如角色设定、规则、背景知识这种每次输入都是一样的东西放在前面,而用户输入历史对话,这种每次都会不一样的东西就放在后面。像历史对话, 有的人可能为了省钱,想要控制长度,使用滑动窗口去截对话,但这样就完全利用不到缓存,因为前面的部分每次都在变,还不如每次都直接往后面加, 这样只有最后一部分是新的 token。 也就是说,变长并不是问题,变化才是问题。现在你可以去看看你的 prompt, 把每次都不变的内容统一挪到最前面,说不定这一个小动作就能让费用省掉一大半。 除了 prompt, caching, ai 工程里还有许多优化的小技巧。如果想要了解更多关于 ai 工程的知识,欢迎订阅我的频道,或者加入我的知识星球。感谢你的观看,我们下次再见!

粉丝2.2万获赞9.1万
相关视频
 00:39查看AI文稿AI文稿
00:39查看AI文稿AI文稿当你不小心安装了个 open curl, 然后发现 token 消耗刹不住了,而且非常健忘。你直接给我去 guitar 输入 cloud man, 你 会发现这是一颗能给你的龙虾赋予持久化记忆的插件。以后你就能像看朋友圈一样,实时看到你的 open curl 到底记住了些什么,而且还能节省百分之九十的 token 消耗。之后你又不小心输入 open viking, 更牛的来了,这是一个专门为你的龙虾设计的开源上下文数据库,它能让你的多个智能体之间共享信息,直接结束那种无法协助的智障模式,而且还能让你的书 token 成本降低大概百分之九十六,任务完成率直线上升。有了它们,你的大龙虾会越来越聪明。这么好的东西,不给你的龙虾配一个吗?
7535赛博自由老爹 01:38查看AI文稿AI文稿
01:38查看AI文稿AI文稿几个简单的小技巧就可以让你的 ai 命中缓存达到惊人的百分之九十九,其托肯消耗和成本其实可以锐减百二十倍。这真不是夸张,是我消耗了整整一亿托肯得到的一个实际经验结果。第一 点,善用记忆系统。其实我们知道现在大部分市面上主流的 i can, 它都是有自己的一套记忆系统,无论是 open card 还是它都扣的。只要我们善于利用这个记忆系统,其实可以大大的增加这个缓存的命中率。举个例子,我最近在做一套自己的 ai 面试助手,但是这个任务他不是一天两天我就能够完成的, 所以我每天会在任务完成的时候,我会告诉我的 autodrive, 让他自己去保存当天的这个记忆。这样的话,在我明天或者后天重再开启这个任务的时候,他能够直接读取自己的绘画内容,从而大大的降低这个拓客的消耗。 第二点,制造边界和原则。布置一个任务的时候,如果没有明确的规则和原则的话,你可能需要跟你的爱多次交互,他才能够真正的明白你的需求。 就算他明白了你的需求,你没有制定一个明确的边界,你的 ai 也可能会做出越界以及难以预期的一个结果。所以制定边界和原则是非常重要的,你可以直接将这个工作原则喂给你的 ai, 让他传进他的记忆系统。 最后一个点,整理和提炼工作流,让他按照工作流的方式输出结果以及产出文档。当你需要他完成一个周期较长的任务的时候,一个合理的工作流是非常重要的,他不仅可以让 ai 快 速理解和解决一个问题的流程,并且可以通过产出一些文档来极大的提高一个缓存的命中率。举个例子, 你需要做一个文档,那么你可以先跟你的 ai 交流想法,让他去产出做出这份网站需要的一份产品文档,然后你再根据他的产品文档去优化,之后让他去根据产品文档去完成功能,这样他有了依据而不会天马行空,每次产出都会根据文档来做,而不会浪费脱坑又产出垃圾。
978欧拉欧拉的替身AI 07:57查看AI文稿AI文稿
07:57查看AI文稿AI文稿聊一下玩这个 openclaw 养小龙虾怎么样去省 token? 现在大家呀玩 openclaw 有 个最大的问题就是这玩意太费 token 了 啊,就好多人他现在想找一些免费的便宜的 token 去用,但我不建议大家这么去做啊,因为如果你执行一个特别复杂的任务,你用的是一个便宜的啊,这种 token 也就这个模型,它肯定不是最强的嘛, 那实际上他根本就处理不了你那些复杂的任务,他处理不了这些复杂的任务呢,小龙虾他就会不断的就多次的跟大漠神交互,那反而有可能会消耗更多的头壳。所以说呢,找便宜的头壳呢,不是解决小龙虾呃非头壳的问题的一个解决方法。那我们到底要怎么样去节省头壳呢?有几个方法跟大家分享一下。首先我们说啊,就是为什么小龙虾这个玩意这么非头壳,实 际上啊,就是我们每一次在跟小龙虾这个玩意这么非头壳。实际上小龙虾这个内部呢,他会把 很多的这个系统级的这个提示词都给带上去,比如说你一开始定义他的什么名字呀,他的身份呀,你自己的信息啊,情况啊,这些都是作为一个背景的提示词,包括你在小龙虾里面装了一些其他的啊,一些 skills 啊,或者工具啊,这些都是一个上下文。 你每次对话的时候,这些内容都会被 open claw 一 起发送给大冒险。所以表面上看,你跟这个小龙虾聊天的时候呢,就是那么几句话,对吧?但实际上大冒险那边接收的信息可比你那几句话多多了, 所以说这也是它非常浪费 token 的 一个原因,所以呢,就是了解上面这个背景之后,那我们第一个能够节省 token 的 一个方法,那就是对 opencloud 的 系统的提示词进行一个瘦身。在 opencloud 的 那个工作台里啊,其实存放了我们所有对 opencloud, 就是 你这个小龙虾的一些呃规则, 你比如说这个 agents, user, soul, identity 这些文件呢,都是我们对它就是不断的重复当中,它会记下来,然后去呃做的一些 记忆性的一些存档,那这些文件呢,实际上我们就可以对它进行一个瘦身,其实好多东西呢都是没有必要写的,都是一些没有用的话,这步呢,其实你可以交给 ai, 你 可以把这个文档拿去给 ai, 让 ai 呢对它进行简化, 你就跟他说在不保证丢失细节的情况下,尽量精简提示词来节约 token, 这样的话 ai 可以 帮你去优化。那最后优化的好不好呢?评判一个标准,就是说你如果删掉了一些话没有用的话,你在使用小龙虾的时候,哎,发现效果还都一样,那就证明你之前写的那句话是没有用的,是可以被精简掉的。 然后再说第二个方法啊,呃,除了我们控制系统级的这些 token 啊,这些呢,实际上是输入 token, 就是 我们发送给大模型的时候,大模型接收的这些 token 啊,我们可以精简之外,我们同时也可以让大模型少往外吐一些 token, 因为现在大模型记费的话,它就分为两部分吧,一个是输入头跟和一个输出头跟,输 入头跟就是你发送给他的那个内容的长度,输出头跟呢就是他回答你的那个答案,其实输出头跟也是费钱的,那我们其实可以规定大模型啊,在我们的要求之内回复多少个字, 你比如说你控制就让他回复一百个字以内,或者你只让他回复结论,不要回复那些有的没的那些过程啊,分析啊,因为有的时候你不做这种限制的话,大木星就非常的啰嗦,那这样的话呢,我们就从限制输出头根的这个角度来去节省头根。第三点我们就是要利用好压缩啊,新疆规划和一个拍的位的一个功能 啊,先说压缩啊,嗯,正常我们在这个跟大木星交互当中,我们这一轮一轮聊天,你所有的历史的信息其实都是在你后面,每一次给他发送新的内容的时候,都会被带到大木星那边, 这些呢就会一直去积累这个 token。 所以呢这里就有个方法,就是我们在一个任务,比如说你跟 ai 交流到某一定程度的时候,就可以用这个 compact 的 命令,然后大模型呢对所有的历史的这个绘画做一个压缩,这样呢就极大程度的帮我们节省了上下文的长度,也就节约了 token。 然后还有个命令啊,就是 new, 这个 new 是 干什么的呢?就是我们可以担起一个绘画框,那在小龙虾里面,因为我们只有这一个聊天框嘛, 那我们如果想让小龙虾也兴起个绘画框的话,那就可以用 new 这个命令,那一旦你用 new 这个命令了,小龙虾他呢其实就是相当于他自己开了个新的绘画窗口, 然后你再跟他聊新的问题的时候呢,过去上一次绘画那些历史的这个内容就不会被传到大平台边了,这样的话呢,你后面再去聊天的时候,就不会被前面的历史的那些内容所干扰, 同时呢也接上头肯第三功能就是 b t w 其实就是白在位的一个缩写,这个什么意思呢?就是说你在一个主线任务里面,你在跟小龙虾不断聊天的过程当中,哎,你突然间有一个呃临时的一个问题,你比如说你想问他,你上一次你说的那个事是什么意思来着?其实这就是一个临时问题,就好像你跟他聊天的时候,突然间打了个叉, 针对这样一个临时性的问题,然后你又不想把这个问题呢被无限的带到后续的这个对话窗口当中,那你就可以用这个 b t w 这个命令,相当于告诉小龙虾,哎,我现在临时问你个问题, 那小龙虾呢,这一轮回答完你这个问题之后,你们的这一次对话呢,就作为一个临时的对话,你后续再跟小龙虾进行主线任务的交流的时候,那你这一轮的临时的对话呢,就不会被带到上下文当中,也相当于变相的节省了 token 的 使用。第四点啊, 就是尽量少装一些没有用的工具或者 skills。 好 多人一上来玩这个 open cloud 呢,因为就会可能装了很多的 skills, 还有乱七八糟的工具。 其实这些工具呢,它都有一个相当于描述说明去存放的列表当中,你每一次跟大拇指交互的时候,大拇指都会读取到你现在你的本地装了哪些 skills, 那 这些内容其实也都是一个包含在上下文里的内容,那如果你有好多的 skills 都没有用的话,那大拇指读你的这个 skills list 的 这个成本呢,其实也就白白浪费了。 所以说呀,就是大家不要在你的本地装那么多啊, skills 就是 尽量是保留有用的 skills, 没有用的 skills 呢,你就删了就可以了。 另外呢,我们在执行任务的时候,如果你明确知道这一次想要触发哪个 skill, 那 你就明确的在聊天框里面去跟大模型去说我这次要掉这个 skill, 那 这样的话呢,也能减少大模型它判断到底你想触发哪一个 skill 这个过程的一个成本。 同时呢也避免了就说有时大模型它可能会判断错误,会掉了就是错误的 skill, 那 这样的话呢,就相当于你任务跑错了嘛,那这个过程也是在浪费投坑。然后第五点啊,就是大家要把缓存打开。 呃,现在一般大模型呢都会提供一个缓存的功能,就是历史的一些绘画内容,呃,或者说我长期不变的一些系统级的提示词,那就比如说 skills list 啊,还有之前说的那些 agents 啊, so user 这些文件,它 实际上都是长期不变的,就是你不会频繁修改,那所有的这些文件每一次发送到大模型那边呢?呃,如果这些文件的内容没有变的话,大模型厂商呢,一般是提供缓存的功能的,那这个功能呢,也需要我们在 opencloak 里面呢,把这个功能打开,这样的话呢, opencloak 再去请求大模型的时候,它就会告诉大模型, 能用缓存就尽量用缓存,一旦大屏那边呢,命中了缓存,那你其实缓存的这一部分 token, 它的成本呢,就会大大降低,因为大屏厂商那边呢,对于你命中缓存的 token 的 价格都是低于没有命中缓存的 token。 另外啊,缓存这块大家还要注意啊,那些系统级的文件,比如说 agents 啊,或者 so 啊,这些文件你不要频繁的去改,因为你一旦改了,它就命中不了缓存了。 另外的话呢,在同一个任务当中呢,你尽量也是保持着,就是围绕着同一个问题或者同一个任务进行展开,你不要东一个问题跟下一个问题差的十万八千里, 那你很有可能之前有些缓存它就命中不了了。然后说第六点也是多一点啊,我们要做好任务跟模型的一个分层,难的任务呢,用贵的模型干,简单的任务呢,用便宜的模型干。我们现在一般玩这个小龙虾呀,你配上小龙虾之后,可能你就配了一个模型,然后就完事了,后面呢就一直用着一个模型, 其实这样的话呢,是不利于节省 token 的, 为什么呢?就是因为我们不同的任务,它实际上需要的模型能力是不一样的。你比如说我们如果想做一些复杂的任务,比如说推理啊, 或者说去深度思考吧,或者说这种复杂的编程任务的话,那实际上我们可能是需要一个好的模型,但是有些任务我们其实没有必要去用这么好的模型,你比如说一些简单的定时任务, 或者说一些简单的资料整理啊,一些这个文案的修改,其实这里面我们用一些便宜的模型,或者说用本地部署的模型呢,也能完成这样的任务,那如果你所有的任务都用最好的最贵的那个模型来去执行的话,那岂不是也会浪费很多头坑? 所以这里面呢,我们可以是对模型进行一个精细化的管理,让那些特别难的复杂的任务,在主 a 阵它里面使用最贵的模型,最好的模型,然后一般的简单的任务呢,我们可以去开一个子 a 阵,它让它去执行,那子 a 阵它呢就可以让它去用便宜的或者你本地部署的模型来执行就可以了。 所以呢养小龙虾如果想少花点钱,也不能一味的专门去找那些便宜的模型,因为一分价钱一分货吗?你用一些比较垃圾的模型,你可能最后呢跑出来的效果又不好,而且可能还浪费更多的头根,那不如呢,我们用一些科学的技巧啊,从源头上解决这个问题,我们从一开始就把这个头根省下来,这样的话呢就能让我们玩虾的这个经济压力呢少一些。
88金尘马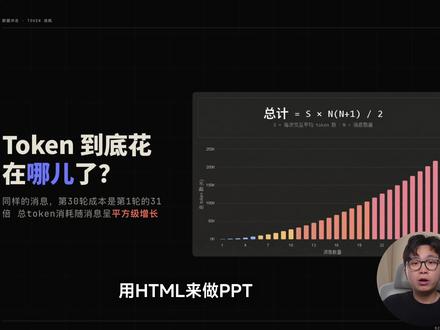 09:48查看AI文稿AI文稿
09:48查看AI文稿AI文稿用 html 来做 ppt 应该是 ai 时代人人都需要掌握的一项技能了,比传统 ppt 更高级,更好看,还能用 ai 来一键生成这期视频,应该是目前全网最完整的教你用 html 做 ppt 的 零基础教程。 我会从安装 skill 开始,到生成 ppt, 编辑文字,插入图片视频,再到最后打包分享和部署上线,从零到一,带你走完全流程。并且还会免费给你分享一个我自己开发的 html 编辑工具,帮助你格式化调整 ppt 里的字体和 图片大小。话不多说,我们直接开始。在首先开始之前呢,我们需要有一个 agent, 我 这里演示用的是 call code, 如果你没有 call code 的 话,可以去看我主页的上一期视频,零基础安装 call code。 当然如果你 用的是 codex, 还有 openclaw 或者国内的一些 agent 的 工具,用法都是一样的。用 html 做 ppt 之前呢,我们需要下载两个 skill, 第一个 skill 叫这个 fronted slides, 这 个 skill 在 github 上其实已经有一万七千多的星了。然后这个 skill 呢,是教你的 agent 怎么样去用 html 做出好的 ppt 来。第二个 skill 呢,其实是叫 beautiful html templates, 这个都是一个博主 zara 做的。然后这个 skill 呢,它就集合了非常多比较好看的有设计感 的 html 模板。那么我们首先要去给我们的 agent 去安装这两个 skill, 安装的方式非常简单,你只需要把这两个项目的链接发给你的 agent, 帮你安装这个 skill, 还有这个 html 的 模板其 就可以了, ai 就 会自动的帮你完成整个安装流程。如果就是你的电脑没有办法访问 github 的 话,我这里也准备了一个方式,可以通过我的链接去下载这两个项目的文件,然后你解压之后呢,把这个文件夹发给你的 agent, 让你的 agent 帮你安装就可以了。我这里演示一下, 当你下载好之后,你会得到两个压缩包,你解压完之后呢,会得到这两个文件夹,然后我们只需要把这个拖到我们的 curl code 里面去,然后我们告诉他帮我安装这个, 然后呢你的 agent 呢,就会自动地去帮你安装好这个 skill, 我 这里因为已经安装好了,我就不演示了。当我们安装好了这个 skill 和这个模板的项目之后呢,在使用之前,我们需要修改一下这个 fronted slide 这个 skill, 让这个 skill 呢可以直接去调用第二个项目里面的 模板。修改的方式也非常的简单,我们直接按一下这个斜杠,然后我们调用这个 fronted slide 的 这个 skill, 然后我跟他说就是帮我修改一下这个 skill。 生成 ppt 时要用直接把刚刚下载的另外一个项目就 beautiful html templates, 然后这里头的模板,然后这里头会有一个文件叫 agent dmd, 然后我们把它拖到 call code 里 头来,让它生成 ppt 时调用这个里面的模板。我们只需要把这个发给你的 ai, 它就会帮我们去修改这个 skill, 然后让这个 skill 它在生成模板的时候, 就能够去调用另外那个项目里面那些比较好看的那些模板了,不然的话就是这两个 skill 是 分开的,你要先用第一个去生成 ppt, 然后再用第二个里面的模板去改,其实就比较麻烦,所以这就是我们在用的时候可以去针对它做一些自己个性化的定制,包括你从网络上下载的各种各样的 skill, 其实你都可以通过自己的方式去修改这个 skill, 更符合你自己的需求。接下来呢,我们修改完这个 skill 之后呢,就可以进入正式的 ppt 的 这个创作了。建议大家就是做 ppt 的 时候,我们可以单独建一个项目作为它的工作的文件夹,如 果你是 call 的 话,我们直接打开终端,直接就输入 cd, 然后摁一下空格,接着呢把我们创建好的文件夹拖进来,拖到这个终端里,然后我们再摁一下回车,这个时候呢,它这个终端其实就以我们刚刚创建的文件夹作为工作目录了,然后我们再输入一个 call, 这样的话我们在做 ppt 的 时候,它就会以我们现在的这个 ppt, 演示我刚创建的这个文件夹作为工作目录,然后我所有新创建的 ppt 的 文件,各种内容都会在这个文件夹下。接着我们就直接来开始做 ppt 了,同样的直接输入这个斜杠,然后我们调用这个 round 的 slides 这个 skill, 我 这里直接把我的一个短视频的文案发给他,然后让他帮我做一个演示的 ppt, 一下是我的短视频文案,帮我做一个演示的 ppt, 这里直接去粘贴我的那个文案,大概二十行,然后我发给他,等待他调用 skill, 然后开始工作。这个 skill 呢会先问我们几个问题, 就是你想做多少页的换登篇,我就选择一个八到十页吧,你需不需要在这个浏览器中去直接编辑文字,因为我后面会有一个我自己做的工具来编辑,会比这个更好用,所以我这里就显示不需要,希望观众看完 ppt 有 什么感受,就你选择风格,然后专业有新福利,冲击性,清晰易懂,然后我我就选这个清晰易懂吧, 你还可以多选,我就选这个清晰易懂,然后提交提交答案。这个是有非常好的一个点,就是他在正式给你做 ppt 之前,他会先给你做三张不同的页面,然后你去选一个风格,就是比起你全做完了,你对这个风格不满意,他 会先一开始就给你做一个一页的 ppt, 然后用三种不同的风格让你选一下,可以看到就是 ai 现在给我做了三个风格的标题页,然后让我来选一下第一个,这是第二个,然后 这是第三个,我喜欢简约一点的风格,我就选第二个吧,他会直接跟我们提问,就选第二个蓝色的风格吧,然后我们直接点击确认选择风格之后呢,他就会根据这个风格帮我们把所有的 ppt 的 内容就一次性就做完了,我们就等着就可以 aj 呢,已经帮我们把 ppt 给做完了,然后也帮我在这个浏览器打开了,我们来看一下整体的效果,我们摁住这个空格就能换页,我觉得是还挺 不错的,就是基本上是一个比较可用的一个状态。接下来教大家怎么样去调整字体的大小跟图片,这里呢我自己做了一个工具,直接打开这个网页,这个就是我做的一个编辑工具,然后这个网页工具呢能帮助你去编辑调整这个 di 做出来的 html ppt。 直接来看这个编辑工具是怎么用的,下载好之后你直接打开它就是个网页的工具,然后我们打开文件夹,这个 ppt 演示呢,就是我们刚刚创建的 那个文件夹,然后我直接选择这里会让你显示一个是不是允许点击允许,这样呢,我们就在这个编辑工具里打开了我们刚刚做好的这个 html, 我 们就可以在这里去进行编辑了。你选中任何一行字,你都可以给它放大缩小,比如我觉得这太小了, 给它放大,然后包括说这里你可以直接去输入我两倍太大了,一点五吧,我想让它变大,包括我想调整,比如说把这个问号改成感叹号,就是你都可以去调整的,然后包括我觉得这太小了,因为你会发现就是 ai 做出来的东西呢, 其大致上是够用的。但是 ai 它就总喜欢把这个字体的大小弄得是比较的小,因为它没有视觉,或者说它有视觉,它不像我们人类能够实时的去预览。所以说我做出来的 ppt, 基本上我会用我自己的工具再去做一下微调,主要是调整一下字体还有大小的。 包括这个工具呢,能够帮我们去插入图片,接下来我讲一下怎么插入图片,比如说这个万能片是第三页,我想在这里去插入一张图片,然后我们回到刚刚的 coco 的, 直接跟他说,我想在 p 三插入一一张图片,图片的内容是头肯凹好嘴要写字数的 变化读对。这个时候呢,如果说你用的是 cloud 模型,或者是你用的 codex, 就 你的模型有读图片的能力的话,就可以直接把你的图片拖到这个 cloud code 里头去,然后它就能够帮你添加另外一种方式呢,如果你用的模型它不能读取图片,比如说你用的是 deepsafe 或者是国产的 g r m, 它没有办法读图片,那么你一定不能在 cloud code 的 里面 把图片给粘贴进去,因为他读不了图片的话,会造成这里的 token 的 一个爆炸。如果说你的模型不能读图,我们怎么样给我们的 ppt 插入图片呢?方式也很简单,我这直接演示一下,你用图片占位符来替代就可以了, 包括就是我们去插入视频也可以这么去操作,比如说我让他在第四也在帮我插入一个视频, p 四帮我插入一个视频,然后也用视频占位符来替代 发送给 ai, 之后呢, ai 就 会帮我们编辑好,然后接着你再用我的那个编辑的工具把图片跟视频替换进去就可以了。那 ai 给我们改完了,加上了两个图片跟视频的占位符,我们 直接打开看一下,第三页这加了一个图片,然后第四页这里加了一个视频的战略服。接着呢我们就要用我的那个编辑的工具,我们把这里的图片跟视频替换成我们的素材,这里点击打开文件夹,同样选择我们 html 所在的这个目录,你看我们 html 文件,在这里选择它的上一层的这个文件夹,然后就会把这个打开,然后 我们来看一下,你会发现这里图片有一个插入图片的选项,然后我们直接点击这里的插入图片,把你的素材给替换进去,你可以看到这里我就替换了我的这个图, 然后呢我还可以去调整它的大小,我觉得这么大就差不多。接着我们再来看一下视频,视频的话,我们也是他留下了一个视频战略服,我们直接在这个工具里面,我们点击这个插入视频,你可以看到这个,这里就有了个视频,然后这个视频的大小也是可以去调整的,比如说我想让这个视频大一点,那就这么大,让它小一点, 然后就这么小,这个视频呢都是可以播放的。接下来我们改完之后呢,就要把这个 html 进行保存,点击这个覆盖原文件,就会直接在我们原来的那个文件上进行一个修改,点一下覆盖原文件,它就已经覆盖了。然后我们再打开我们的这个 html, 去看一下我们的图片跟视频是不是弄好了,我们打开 这就是我刚刚插入的图片,刚刚插入的视频就这样插入成功了,这样你的 html 其实就已经做好了。接下来讲我们做好的 ppt 怎么分享给别人, 那么有两种方式分享,第一种是文件的方式分享,第二种是以链接的方式分享,那么先说用文件的方式分享,如果你的 html 没有用到图片啊,视频这样的其他的素材,那你直接把你的 html 文件发给别人,他就能够用浏览器打开就能预览了。那么如果你的 html 用到了额外的素材,比如像我们这里用到了图片,还用到了视频, 我们就需要把这个文件夹打包一起发给别人,这样他打开这个 html 才能正常显示里面的图片跟视频。比如说像我们这里的话,我就把这两个,比如说也给他新建叫 打包,然后呢我就把这个文件夹发给别人,然后别人打开之后呢,他再去打开这个 html, 它里面就会有我的图片还有视频这 些素材,然后你在别的电脑上就也能去正常的去观看了,这是以文件的方式去分享,然后接下来讲一下怎么样以链接的方式去进行分享。首先呢就是你要把你的 html, 也就是一个网页去转成链接,你需要把它部署在云服务器上,如果你是传统的去买服务器域名备案,就这个流程特别的复杂麻烦。就如果你不是要把这个网页去提供大规模的访问服务的话,你 分享给你身边的朋友同事,那你就用这个 netify 这个免费的网站就可以了,这个网站转成的链接在国内也是可以打开的。然后呢方式也很简单,你打开 netify 之后,登录之后注册一个账号,我们直接来演示一下,像这里我用 的这个 netify, 然后你可以看到其实我已经部署了两个项目了,然后我们直接点击这里,你可以看到它可以上传文件以及上传个文件夹,就是如果你只有一个 html 文件的话,你就选择这个,如果你涉及到图片素材的话,我们就选择一个文件夹,比如像我这里这个 ppt 就 用到图片还有视频,我就要选择这 文件夹,你可以看到,哎,就是我刚刚创建的这个打包的这个文件夹,然后这里头就会有我的 html, 然后有我的这些素材,我就选择这个文件夹上传,选择 上传,选择这个左边这个就可以了,它就会把我们的内容去进行一个上传部署,我们等一下就可以了,这个时候呢它就把我们的内容已经上传部署完了,我们要改一下我们这个链接的名字,我们点击这个按钮,在这里去填写一下你的名字,因为像这的话,其实就是我们最终分享的链接随便写个名字,因为像这的话,其实就是我们最终分享的链接随便写个名字,然后我们点开这个这个网页,打开的内容就是我们的 那个 ppt 了,然后你就可以直接在顶部去复制这个网页的链接,然后分享给你的朋友去在别的电脑上去访问就可以了。希望这个视频能够帮助你从零到一,学会用 html 去做 ppt。 因为像现在随着 ai 模型能力的发展的话,其实用 html 做 ppt 会变得越来越方便,越来越好用, 包括你使用熟练之后,你就可以去定制你自己的好看的 html 的 ppt 模板,如果这个视频对你有帮助的话,也可以去定制你自己的好看的 html 的 ppt 模板,如果这个视频对你有帮助的话,也可以分享干货,我们下期见。
6960栗氪聊AI 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿open 壳三十二天烧了二十亿 token, 这两个 skill 直接帮你把浏览器的 token 砍掉百分之八十。 先说结论, bb browser 能用就优先用,不支持的再用 agent browser。 为什么呢?因为这两个 skill 啊,它核心就干一件事,就是只给大模型最精简的交互信息,所以 token 可以 直接砍掉一大截。 其中 b b browser, 它直接把网站当 a p i 用,还能附用登录状态,但是它只支持固定的平台,大概三十六个。那通用的网站怎么办呢?交给 agent browser, 它负责像人一样操作网页,点击输入翻页。所以啊,这两个组合起来,专门解决登录问题和偷看爆炸。
4528建斌聊AI 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿前两天有粉丝跟我吐槽说用龙虾太费偷啃了,平均一小时就要烧掉一百块,问我有没有节省偷啃的方法。今天就会分享我们在跟龙虾对话的过程中常用到的三个命令,把这三个命令用好,能帮你合理的节省偷啃用量。第一个命令就是杠 status, 这个命令的话呢,是用来指示检查偷啃消耗情况的,当我们发送了这个杠 status 这个命令之后呢, 他就会回复我们这几行信息。请重点看一下这个 context 当前上下文占用的比例,如果你发现下文已经快满了,就要让他去总结和记忆,那让他进行总结的话呢,我们就是会使用到第二个命令放 compact。 这里先给大家普及一个知识点,当我们在聊天界面跟龙虾对话的每一条消息,龙虾都会记下来,存到一个叫 scissor 的 文件里,当你输入一条新的消息给他的时候,龙虾就会把最新的一条消息加 scissor 里面保存的历史消息一并发给大母星,这样的话就会导致我们 to call 的 消耗会增加。那你使用 compact 这个命令是来压缩历史对话的,它压缩的话就是龙虾在 scissor 里保存的历史消息。 你看,当我发送完这条指令之后,他五九 k 的 对话内容压缩到了二点六 k, 就是 节约了很多上下文的空间。那第三个命令就是杠六,清空上下文,开启全新的对话。这个适合的场景就是当你的龙虾完成了任务一以后, 你又给他布置了任务二,这个时候的话呢,是其实是需要自己评估一下,如果任务一和任务二没有任何关系,你就可以使用杠六这个命令来清空一下上下文。 我不清空一下,龙虾在做第二个任务的时候,就会混着你任务一的对话记录一起传给大模型,那这样其实也是一种偷啃的消耗,浪费了你的偷啃,同时速度也会变慢。 当我发送了杠六这个命令之后的话,他给我反馈了这样的一条提示,就是告诉我可以开启一个全新的对话了。一个杠六的话,大家可能会担心,这样做我的龙虾不就失忆了吗?重要的信息我要让他保存下来,怎么办呢?那这个就需要 memory。 当我跟我的龙虾说了这样的一段非常重要的消息, 加上这样的一句话,以上内容存入 memory, 这样这条重要的消息呢就会存在 memory 里。存进去之后的话呢,你再使用前面的杠 compact 杠 new 命令,也不会对它产生任何影响了。最后建议大家还是要选择一个 ottoman 模型套餐来用,像是阿里云百联的 ottoman, kimi 的 ottoman, 评价都不错,性价比也挺高的。
726AI产品美洋 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿有没有觉得你的 opencll 笨笨的,一件事情要沟通好久?聊到后面忘了前面,第二天还要再来一次。我摸索了一整套的技巧,可以让 opencll 更加聪明,合作起来更吓人。关键点,上下文、绘画和记忆在飞书这一类通信软件里,使用 opencll 有 两个隐性的陷阱。 第一个,我们容易认为上下文是无限的限制,这就是聊久了之后 opencll 忘记事情的原因。 如果你发现他开始忘事了,一定要把关键信息再复述一遍,提醒他记住,或者是直接重新开一个窗口, 不然的话效果就会越来越差。第二个陷阱,我们默认 open call 会管理好绘画,在一件事情做完之后,他会开启一个新的,但实际是不会的,除非我们明确告诉他开启新绘画才行。绘画不开启新的,他会带着整个历史聊天记录 效果差,而且还费 token, 这也是大家诟病 open clock token 消耗比较大的原因之一。正确的做法是把关键信息放到持久记忆里,我们可以告诉他记住这些信息,记住这个事情来触发他的持久记忆机制。 总结一下,模型有上下文限制,所以我们要及时复述关键信息,让他记住不要遗忘。 open class 有 绘画机制,完成一件事情之后,主动开启新的绘画专试专办,既提升效果,又能节省头疼。重要的信息 主动触发持久保存机制,让他能跨绘画技术。用好上面三百幅,让你的 open cloud 助力提升一个水平。关注我,带你玩转 open cloud 加 skill, 实现内容创作自动化。
103唐斩AI编程 02:06查看AI文稿AI文稿
02:06查看AI文稿AI文稿那你用 cloud 是 不是经常用着用着就被提示额度不够了?那今天分享六个我自己在用的省投款技巧,非技术背景的人完全能听懂。那第一个,不要发新消息,而是编辑消息。那很多人遇到 cloud, 没有理解自己的意思啊,就接着发了一条,不对不对,我的意思是什么?什么什么。那 这是最贵的习惯啊,因为 cloud 每次回复都要把整个的聊天记录重新读一遍,你发的消息越多,就越浪费 token。 那 正确的做法是啊,点击之前那条消息旁边的编辑按钮,改掉它,重新发。那第二个,每十五到二十条消息,新开一个对话, 对话越长啊,每条消息的成本越高,因为 cloud 要重读的历史越来越长。有人统计过啊,长对话里百分之九十八的 token 都花在了重读历史上。那真正用在你的问题上呢?只有百分之一点五。那做法也很简单啊,感觉聊了很多轮了,就让 cloud 总结一下,复制开心对话,把总结粘贴进去,继续聊。 第三个,把多个问题合并到一条消息,觉得这样清晰。那很多人习惯一个问题一条消息,觉得这样清晰,那三条单独的消息, cloud 要加在三次上下文, 一条消息啊,问三个问题,加载一次就够了。那合并提问省 token, 答案还往往更准确。第四个,把常用文件放进 project。 那 如果你有一份文件,经常要跟 cloud 讨论,比如你的品牌手册,项目背景、参考资料。不要每次新对话都重新上传,上传到 cloud 的 project 功能里, 那系统会缓存,那同一个项目里面的所有回话都能够直接引用,而且不会重复扣 token。 那 第五个,在设置里保存你的个人信息和偏好。那我是一个内容创作者,我的 风格是什么什么?那这些文字啊,本身就是头肯的,浪费。那进入 cloud 设置,找到记忆或者用户的编号,把这些写进去,那 cloud 会自动带入每次对话,你不用再解释自己是谁了。那第六个啊,简单的任务,用嗨酷模型。那 cloud 有 不同的模型,嗨酷是最清亮的那一个。检查语法,翻译格式,整理错漏风暴。 这些任务不需要最强的模型来做。用嗨酷处理这类任务啊,能节省百分之五十到七十的额度,把额度留给真正复杂的任务用。那这六个习惯养成之后啊,你就能用有限的额度完成更多的任务了。那你还有哪些省投更的技巧,欢迎在评论区分享。
139起哥的AI实战 04:28查看AI文稿AI文稿
04:28查看AI文稿AI文稿我雇了六个 ai 员工,其中有一个在摸鱼。这条关于龙虾的视频可以解答一直困扰你的四个问题,如何不花钱体验真实消耗 token 的 感觉?如何不花一分钱使用最新的 deepseek v 四大模型? 如何让你能够同时拥有六个 a 制的员工帮你一起干活,以及如何让你看到这些 ai 员工是怎么协调工作的? ok, 你 甚至还能看到有人在偷偷摸鱼。 从第一期视频认真学习到这里的同学们,我猜你一定会有以上的好奇,这正是因为你的认真和努力,你开始想探索以上的问题了。而第一次刷到这条视频的你, 也或多或少从前有过这些疑问,因为你听了太多不同的观点和声音,你无法验证哪些是对的。来吧,跟我一起先入个职。 这将是作为普通牛马的我们所养的第一匹马。当然,这不是你们听过的那个爱马仕,这是腾讯最新发布的马维斯, 这就是为你准备的六只牛马。而未来你们办公的场景就在这间办公室里。 办公室的图标是咖啡豆,右上角的 token 消耗也是咖啡豆,所以咖啡豆就是这一款马。对于 token 消耗的计量单位,我稍后会通过执行一系列的任务,让你们感受到马维斯团队的能力以及 token 的 真实消耗情况。 我们先来做个 ppt, 再做个倒计时应用。 好了。现在办公室里有两个正在干活的,有一个正在峡谷摸鱼的。很快,倒计时应用做完了,还有一个任务在进行中。那么现在的情况是,消耗了五万多的 token。 别闲着,我们再让他做个应用程序。 哎,有个员工好像睡着了。好了, ppt 做完了。 既然是牛马,不能让他们闲着,让马维斯给我的微信指定联系人发消息,我们来测试这个功能。 我就把我之前做的发微信的 skill 发给他,你看一次就成了我们的队长。马维斯是真牛马,一个人扛起了一个团队的工作量,这像不像真实生活当中的你呢? 这个时候,代办事项程序也做完了,这是一款真正的程序,不是网页。 好了,这就是最终投肯的消耗情况。我们一共完成了一个 ppt, 一个网页的倒计时工具,一个代办事项的 app 程序,一个给微信发消息的功能,成功测试一共消耗了一百二十万的投肯。 想想过去的评论区里,你能看到有人悲伤地说,问,一句话就能消耗几十万的 toc, 太贵了。也有人洋洋洒洒地说,我平均每天要用到三到四亿的 toc。 其实它们都没有错,这是源于每一家对于 toc 的 消耗定义不同, 也源于每一个如我们一般的使用者需求各不相同。我们今天的这款马维斯,每天都赠送一千万头肯,我想这足够培养你的使用习惯和探索 agent 智能体的边界了。未来那个有探索精神的你, 可能会享用到真正的 open club 或是爱马仕,以及解锁更多如马维斯一般的生产类工具。所以 token 的 消耗是一个必修课。最后,我还想说,无论是哪只虾还是哪匹马,最终都会为你所用,你会知道它们的能力值和边界在哪儿。 而你就像是一个指挥家,让擅长的人做擅长的事,从而让目标达成的更快更好。而无论是 ai 还是 agent, 他 们终将为你的创造力做托举。 我为能看到这里的你点个赞,也请你为我点个收藏,我们一起陪伴彼此开始这趟旅程吧!
631王昕ai实战笔记 02:56查看AI文稿AI文稿
02:56查看AI文稿AI文稿兄弟们,我又来了,我是没有想到呀,昨天我发了一个抖音,没想到评论区惊现了一位大佬在推广他的编程智能体,我就下载了, 于是我今天就试了一下,就是他 deepsea renaissance, 他 是 deepsea 原生的代码智能体,这个作者游戏出身,代码功底应该非常的扎实, 整个架构也非常非常的厉害。他有一个非常省钱的技术,就是可以让大量 token 乖乖的命中缓存。而这边呢,就是这两天比较火的 deepsea, 它虽然支持中文,但是呢不是原生中文,有的时候呢会不太方便。另外我使用下来,这个 token 消耗还是比较大的,我甚至都不敢用 pro 模型, 但是他从设置到配置全部都是中文的。他有一个我非常喜欢的地方,就是这里有一个 web 界面,我打开给大家看一下, 在这里大家看到了吗?这里我的对话是同步的,这里 这里是一个突兀的镜像,这边这里也可以实时的去调整一些强度啊,模式啊之类的, 然后这里有很多的,你可以去设置,这里可以获取余额啊,比如说像这里,我今天小跑了一下,那缓存的命中率是百分之九十五, 非常的强大。还有工具啊,基本上呃该有的都有了,非常好用, 虽然没那么火,但是我觉得这个项目的潜力也是非常巨大的。另外给大家看一下这两个呃, get up 的 地址,这个是兔翼的, 这个是 reasonx 的, 我个人觉得这个名字取得非常的不好,如果叫做 deep sea, cold 之类的名字,可能会比现在要火的多啊。哦,这是吐译作者,这是经常出现在新闻上 这个 reason 的 作者主页,他,他是游戏出身的,这是他做的一个框架,应该是一个关于游戏的,这是一个游戏框架, 这个作者大部分项目都是 ps 研,推荐给大家,大家可以试一试,支持国产作者。
330生活的临时工 01:46查看AI文稿AI文稿
01:46查看AI文稿AI文稿今天啊,给大家分享五个最实用的技巧,帮你的可用 code 节省至少一半的 token。 建议你先点赞收藏。第一,选对模型,日常写代码,改 bug, 用 sonet 就 够了,那复杂的推理呢?价格问题,再用 opus, 那这中间就是一两倍的差价。建议你把 sonata 设置为默认模型,避免大材小用。第二,控制上下文,那避免一直在同一个对话里面聊,你聊得越久啊,越费 token。 那 任务结束的时候,直接用斜杠 clear 清空上下文,开启新对话。那长对话呢?用 compact 来压缩上下文。 第三,善用 cloud 点 md。 那 cloud code 的 作者就表示啊,要像优化提示词一样优化 cloud 点 md。 那 些需要反复强调说明内容,比如说项目说明,代码规范,使用习惯 都可以写进去,卡拉扣的启动的时候都会自动去读取,不需要你反复去和 ai 说明了。那我在之前的视频中有专门讲到过卡拉点 m d, 不 熟悉的同学可以去翻一翻。第四,表达要具体,不要说帮我修复登录错误啊,要说清楚错误信息是什么,附件错误的操作步骤是什么, 正确的返回应该是什么样的,那 ai 猜测你的意图的过程啊,就是在浪费偷看。第五,开任务,不要一上来就让他帮你直接实现一个个人网站。那复杂的任务呢?往往隐藏的细节太多了, ai 很 容易走偏或者忽略掉一些关键细节。 那当你耗费了大量的头肯得到了结果可能不达你预期,那你可以把一个复杂的任务拆分成多个子任务。比如说你可以先去搭建网站的框架,实现首页的基本布局,具体模块详细实现啊,可以放在后续的子任务中执行。那这个就像流水线上的每一步都有质检一样啊,避免一步走错,步步走错。 总的来说啊, set token 就 等于选对的模型,加上控制上下文,再加上控制任务的力度。那你还知道哪些 set token 的 技巧吗?欢迎你在评论区分享,我是欣琪,每天分享一个 web coding 的 小技巧。
178起哥的AI实战 10:20查看AI文稿AI文稿
10:20查看AI文稿AI文稿大家好,欢迎来到本期解读,今天咱们要直击痛点,聊聊现代 ai 开发里最让人抓狂但也最容易被忽略的隐形成本。 随着 ai 写代码助手和智能体越来越普及,咱们其实正面临着一场真正的 ai token 危机。你没听错,大量杂乱的命令行数据正在悄悄榨干你的开发预算。 不过别慌,今天咱们就来看看,如何用一个叫 r t k 的 神器,彻底搞定这个端端数据的消耗陷阱。好,咱们直接切入正题,你看,咱们对比一下这两种开发环境。左边呢,是咱们常见的标准环境, 你的 ai 助手可能也就是偶尔跑几个脚本,一切看着都挺岁月静好的。但是你再看看右边, 这是像如 flow 这种前沿的多智能体编排平台。好家伙,一百多个专门的 ai 智能体组成的庞大集群,用肥雷刀通信,在那不断地进行自我学习和匡助,这架构是极其强大对吧? 但是在这个高度自动化的过程里,这些智能体在后台疯狂且持续地跑着各种端端命里,这就埋下了一颗巨大的隐患炸弹。那么问题来了,到底是什么东西在疯狂吞食你辛辛苦苦攒下的 ai 偷坑预算呢? 答案其实就藏在那些看似普通的端端里。当你运行这种重度依赖 ai 的 工作流时,像咱们最常用的 npm test 或者 gitif 这种命里会吐出海量的原始代码输出, 这里面全是一堆格式化、空格、长篇大乱的样板代码,还有各种无关紧要的干扰信息。 你知道, ai 可不是人,他得把这些辣眼睛的原始日制逐字逐句塞进他的上下文筐里,这直接就引发了一场上下文际危机。一百一万八千, 这是个什么概念?说出来你可能不信,这仅仅是一个标准的三十分钟 cloud code 的 绘画,在任何没有过滤的情况下,平均消耗的 token 数量简直高得离谱。 你花大钱买的上下文窗口,根本没被用来做深度的代码逻辑推理,全被这些毫无意义的终端静态噪音给占满了。所以这就引出了我们今天的主角 r t k, 也就是这个高性能 c l i 代理, 百分之六十到九十。哎,你没看错,这个数据真的相当扎列, r d k 能在咱们常用的开发命令上直接砍掉百分之六十到九十的 l r m token 消耗, 你想想这治什么?这不仅仅是让你的 api 账单大瘦身,更关键的是它给咱们宝贵的 ai 模型释放了巨大的思考空间,让 ai 能真正把好钢用在刀刃上去解决复杂问题,而不是在那些又臭又长的日子里大喊劳真。 那么它凭什么这么牛呢?来看看它的底层架构, r t k 其实就是一个单一的 rust 二禁制文件,零外部依赖,并且内置支持了一百多种咱们最常用的开发命令。 最让人觉得不可思议的是它的速度,因为是用 rust 写的,它的处理开销竟然不到十毫秒, 也就是说,他完全可以像个隐形人一样待在你的工作流里,你根本感觉不到他的存在,他就已经瞬间把数据给你洗的干干净净了。接下来咱们来看看他是怎么做到这种神仙压缩的,主要是四大核心压缩策略。 这四大策略啊,你可以把它想象成一个极其聪明的数字滤网,它能精准的隔离出最关键的声音,把那些乱七八糟的杂音全挡在外面。这四步分别是智能过滤、分组截断、还有去虫。 咱们一步步来看,它们是怎么层层递进发挥作用的。首先是第一步智能过滤,这是最基础也是极其漂亮的一手清洗。在终端输出真正未给大语言模型之前, r、 t、 k 会毫无留情地拔掉所有没用的噪音。 比如什么呢?比如大段大段的注示,多余的空格换行,甚至那些啰里啰嗦的样板代码,就就好比你给老板交报告,先把那些凑字数的废话全删了,确保 ai 一 眼就能看到最干练、最核心的信息。 接着往下走。第二部分组,你想啊,要是你的命令突然吐出来几百个文件列表或者一长串报错乱糟糟的输出, ai 看着也头晕,对吧? 分组策略就非常讨巧,它巧妙地把相似的项目自动归拢到一块儿,比如把文件老老实实按目录结构排好,或者把翻译错误按类型分门别类, 这样一来,数据就有了非常清晰的逻辑结构,让 ai 智能体消化起这些上下文来,简直不要太轻松,而且特别省钱。第三点是我们非常关注的去虫, 这绝对是个省空间的超级杀器,你要是跑过测试用力你就懂了。同一个警告或者报错,经常能在日记里刷屏重复几十次。 驱虫功能呢,会直接把这些烦人的复读机折叠成一个单一的挑目,然后在旁边给你标个频率计数器, ai 只要扫眼哦,这个错报了四十二次,完事了!根本不需要把这四十二条一模一样的废话读完,极大的削减了。溶于 说得再热闹,不如看数据,咱们来把这种节省效果实时化一下。你看这个落差极具视觉冲击力。 当咱们跑向 cargo test 或者 n p m test 这种测试命令的时候,如果你按平时的标准输出跑,随手便便就能烧掉二万五千个 token。 但是经过 r t k 的 四部绝活压缩之后,这座数据大山瞬间就被缩成了一个只有两千五百个 token 的 精准招标,直接暴降九十八。这意味着你的测试反馈不仅变得极其廉价,而且对 ai 来说还更加一目了然了。 而且这种堪称恐怖的优化可不仅限于是跑跑测试,它是贯穿你整个开发流程的。 不管是敲个 l s 看看目录,还是用 git diff 扫一眼代码差异,再或者是查查 git status, 你 会发现 r t k 给你省下的 token 始终稳稳当当保持在七十五到八十 percent 之间。无论你执行什么操作,成本的缩减都是全方位的。 那么用起来会不会很麻烦?咱们来看看它的无缝自动重写集成 r t k 最优雅的设计就在于它的自动重写勾字系统,你根本不需要去记什么新的语法,甚至不用改变你那根深蒂固的肌肉记忆。 你就在终端里正常敲你的 bash 命令。比如敲个 git status, 这个钩子会在命令执行前的极短瞬间像个透明人一样把它拦截下来,自动重写成 otk git status。 这一切全在后台默默发声,完美融入你原先的节奏。 还有啊,它原生支持市面上几乎所有的顶流 ai 辅助工具,不管是 clodocode、 cursor, 还是 github co pilot、 gemini、 cioi, 甚至包括 rufolo 生态里的 hermes 插件。 不过,这里必须插一句极其重要的细节提醒大家,虽然钩子系统很神,但是像 clodocode 自带的一些特定工具,比如它的 rate 或者 grab 功能,是会绕过咱们这个 bash 钩子的。所以,针对这些内置工具,你得明确地敲出 r t k 的 特定命令,才能享受到那种丝滑的过滤优化。 另外,关于不同操作系统的表现,咱们得在这里快速澄清一下。如果你是 wsl 或者 linux 用户,那太棒了,你将拥有最好的体验,可以享受完整的、透明的自动重写勾字支持。 但如果你是在原生 windows 环境下工作, r t k 会自动降低到一个叫 cloud 点滴的后背注入模式,顾虑机制还是照常运作的,但命令就不会自动重写了。所以,为了把 r t k 的 最强实力发挥出来,我们强烈建议 windows 电发者们使用 wsl 环境。 最后,咱们怎么知道自己到底省了多少呢?来看看怎么追踪你的操坑,节省情况。 只需要在你的端端敲一个简单的命令, rt game。 这可不是什么弄虚作假的花架子,而是一个极其精确的经验分析工具, 你只要一敲,它立马给你算出来你减少了多少 token。 更爽的是,它还会根据当前的 api 定价,直截了当地告诉你预估省了多少美元。 你可以眼睁睁地看着自己的开销。随着一次次优化不断降低,这种控制感绝对会让每一位开发者感到身心愉悦。 当然了,聊到这儿,肯定有很多高度重视代码安全的 devops 朋友会问,那隐私呢? 请放一百个心,你看这几点, r t k 的 遥测数据收集完全是需要你主动加入的,也就是 opt in 百分百符合 g d p r 标准。它仅仅追踪完全匿名的使用量和性能表现, 绝对不会永远不会碰到你的任何原始代码、文件路径或者具体的命令参数。你的知识产权始终牢牢掌握在你自己的手里。 节目的最后,我想用一个极具启发性的问题来作为结尾,在你每天的 ai 开发里,你花大价钱买来的 token, 究竟是在为真正有价值的上下文买单,还是仅仅在为一堆毫无意义的系统噪音交智商税呢? 不管你是在跑像 rofflo 那 样包含上百个智能体的庞大基群,还是仅仅用 cursor 处理日常代码,控制好上下文数据的质量绝对是事关重要的。 希望今天介绍的 r t k 能成为你优化 ai 工作流的一把尖刀。感谢大家的专注收看,咱们下期解读,再见!
 16:36查看AI文稿AI文稿
16:36查看AI文稿AI文稿如今百分之九十以上的企业业务都使用到了我们的 reg 技术,可是我们似乎忘记了如何评价一个 reg 好 坏已经成为我们面试的必考点。那么今天我们将会通过十分钟带你了解如何去做我们 reg 的 评估方法。 掌握了这些,你不仅能让你的 reg 系统真正的节省 token, 为我们带来经济上的优势,还可以真正提升你的用户体验,让你的用户对你的产品更有粘性。好,第一步,我们先来看一下 我们的 reg 评估到底分为哪些维度,我们应该从哪些量化的指标上对我们的 reg 进行评估, 以衡量我们现在的系统它还有什么地方需要进行改进。那第二个部分呢?我们会带你详细的去解析一下我们什么是准确率, 什么是忠实度。那我们做一个 reg 系统,我们到底应该怎么平衡这些不同的数值?那第三个部分呢?我们就会带你了解一下我们的主流评估方式,比如说我们人工评估它为什么是不可替代的? 那么我们自动评估又能通过哪些框架和手法呢?最后我们会带你进行一下总结,看一看我们的开源框架 如何帮助你构建一个可靠的 reg 系统。好,我们先来看一下我们通过哪些维度去评价我们的这大模型,它的一个 reg 系统到底是好还是坏呢?首先我们来看一下第一个维度,那么 最终的结果肯定是重要的,对吧?那么我们所有的用户呢,他都期待着我们大模型可以给他一个最重要的就是最准确的结果,那么我们第一个衡量的核心指标就是我们最终结果的准确性。那 如果说我们这个 red 系统经过我们的优化,能让我们用户最终拿到一个满意的答案,那么我们说这个 red 它是一个良好的系统,看一下我们第二点, 那第二点呢就是大模型的能力,我们刚刚关注了结果,现在我们要关注一下过程,看一看我们给大模型提供的信息,能不能让大模型有效的利用 我们其实 reik 技术核心的一个原理,它的全称呢叫解锁增强生成,那解锁呢?就是把我们的文档从我们的数据库中查询出来,然后结合我们用户的问题一起交给大模型, 那我们大模型能不能有效利用我们给他解锁到的文档,就是最重要的一个指标。那这个步骤我们核心观观测的一个问题,就是我们看看大模型有没有正确的理解 我们给他提供的内容,对吧?有没有把我们提供内容给利用上。我们来看下第三个特点,我们称之为剪辑阶段的效果。那么这个时候呢,我们考虑完了前两点之后,我们还要考虑这一点,就是剪辑我们有没有好好的剪辑 我们数据库里,比如说我们现在存放着啊七八千份我们企业内部的文档,那如果说用户提了一个和财务相关的问题,那我能不能把这七八千份文档中 所有跟财务相关的文档全都能剪辑出来呢?这就是我们剪辑系统,它有没有找全信息,有没有漏掉信息,这就是我们 rate 评估的三大维度, 那么接下来我们看一下我们这些参数,对吧?我们如何去评价,去平衡我们大模型的剪辑的准确率呢?我们来看一下,我们在剪辑阶段我们有三大指标,我们来看一下第一个指标, 我们看一下这个图啊,这个图片呢就是我们在查找过程中,我们灰色的背景就是我们目前数据库中所有的知识片段,那么我们 a 代表的这个红色的圆圈呢?表示跟我们用户这个问题 相关的所有的知识,那么我们 b 圈就是我们的蓝色圆圈,你可以看到呢?这是我们解锁到的啊知识,也就是说我们从这个 我们的企业文档库里,对吧?企业文档的数据库里给他查找出来的摆在大模型面前的这样一个知识,就是我们的 b 圈,那 c 圈呢?就是什么?就是我们中间这一部分,对吧?那中间部分呢?就是 a 和 b 的 交集,那就是有用的,对吧?查找出来真的有用的内容, 我们可以看一下第一个指标,我们称之为召回率,那召回率如何计算呢?实际上就是我们的 c, 也就是我们真正有效的内容 啊,在我们所有相关的知识中,他的一个占比,我们称之为召回率。那第二个呢,就是我们的精确率,那精确率就是我们中间就是 解锁出来的有用的知识,在我们所有解锁出来的知识中啊,他的一个占比就是我们的精确率,那有了这两个,我们这时候就要有一个疑问了,对吧?能不能让我们的这个检测率 让的精确率非常的高,召回率也非常的高呢,其实我们是做不到的,我们没有办法让我们红色的这个圆圈和这个蓝色的圆圈它是相等的,对吧?这太理想化了,那么我们怎么样解决这个问题呢?我们引入了一个概念叫 f 一 分数, 这个 f 一 分数的计算公式就在这个位置,你可以看到实际上非常简单,对吧?这就是一个啊,乘法和加法,对吧?再加上一个除法,就是我们召回率乘以我们的精确率,然后呢再乘以二比上我们的召回率和精确率之合, 那它到底是做什么的呢?我们来给大家看一下,我们为什么要计算我们的 f 一 分数呢? 的右侧呢?就是我们的一个图片了,可以看到我们的 x 轴,它代表的是查全率,那我们的 y 轴代表的是查准率,那我们为什么要计算 f 一 分数呢? 实际上就是寻找到这样一个平衡点,那就像我们不能要求一个灯泡,对吧?它变得非常亮, 同时呢我们又要求它发热量非常的低,这是一个没有办法两全的,那在这种情况下,我们 f 通过计算我们的 f 一 分数,让我们取得一个良好的平衡点, 就让我们最后呢查的也在相对查全的情况下,然后查的尽可能准,对吧?就好像我们让这个灯泡尽可能的亮,但是呢热量发出的热量又是可控的,不会烧坏它, 这是我们 f 一 分数,它存在的意义就是为了平衡我们整个 reg 系统。好,接下来我们来看看精准率和召回率,我们在实际应用中应该有哪些权衡。我们先来看第一种场景,我们称之为追求极致的精确率, 那这时候我们发现一个什么问题呢?如果我们希望解锁出的每一篇文档它都是精确的,必须每一条信息呢,都和我们用户提出的问题都是相关的。 那这个时候我们要设置比较高的相似度域值,也就是说呢,我们把这个,呃,本来我们可能是这样一个高度,对吧?这个高度呢,相似度大于这个高度的都可以被我们选进来, 但是现在我们要提高门槛,对吧?必须相似度非常高的才能被选进来,那我们就发现一个优势,优势就是它可以过滤掉边缘相关的文档,也就是说跟我们相关性比较弱的文档,不是很相关的文档就可以被筛选掉。 但是他有三个非常致命的缺点。那首先呢,我们就看到这样呢,我们的召回率就下降了,召回率下降呢,他带来一个问题,就是我们如果有一些文档,他虽然相关性我们计算出来的相关性没有那么高,但是呢他实际上内部也包含一些信息, 那我们这样就会漏掉关键的信息,那最终他就可能会导致我们大模型呢没有完全的读到我们知识库中所有的信息,导致他回答的不完整。 但是这有一个好处,至少呢不会让一些糟糕的信息过来捣乱,可以保证我们大模型最后的回答 它的准确性是比较高的啊。那如果你的知识库恰好质量非常好的话,那么我们方案一就是比较适合你的。好,我们来看一下方案二,那方案二他有什么优势呢?那我们既然说了当然是查的越准越好啊,那为什么我们要优先优化召回率呢? 我们看一下优先优化召回率的策略,就是尽可能的扩大解锁范围,我们宁可引入一些 糟糕的和我们这个问题不太相关的文档,我们也要保证必须所有提到我们这个内容的文档全给他查出来。那如果,那我们现在呢,就是要降低我们的门槛,对吧?把门槛放的很低, 几乎呢所有的,比如说我们要查一个呃跟财务相关的一个文档,只要这个文档中但凡跟财务有关,对吧?我们全给他找出来,有了优先召回率这样一个方案,看看他有什么优势。 首先呢,这个时候我们发现呢,大模型他其实对一些噪声数据,也就是说跟我们用户问题不相关的数据,其实他的容忍度是比较高的,那这个时候呢,他就可以过滤掉没有用的部分去为我们提取答案。 那如果说用户问题非常复杂的时候,我们这个时候呢,因为我们引入了大量的文档,我们借助大模型的优秀性能,我们就可以呢让我们面对复杂问题的时候,拥有足够的信息,可以回答的更稳健。 而且当我们的资源比较充足的时候,因为我们放低了门槛儿,我们现在呢和我们资源相关的文件都在,那么我们这个时候呢就能获得比较优秀的回答效果。那实际上呢,我们为什么会出现方案二呢? 就是因为随着我们这时间的发展,我们发现我们的大模型越来越智能,包括我们最近很火的 glm 五,对吧?智普清眼五, 你会发现呢,他的模型已经非常的智能了,而且他的上下文窗口非常的长,所以而且很多企业我们都会发现一个问题,他的知识库质量根本就没有我们想象的那么好,所以呢,我们优先召回率的方案是我们目前实战中比较常用的。 接下来呢,我们来介绍两种评估方法。首先呢是人工评估和自动评估,看一下我们人工评估为什么需要这一步骤呢?因为我们整个大模型,它的系统,它是面向我们用户的,那能不能让人满意就成为我们首要的标准,所以呢, 人工评估很好理解,就是找一些我们人工的评估员啊,打分之后取一个平均值,对吧?不难理解吧,大家一到十分对大模型的答案给个打分,到时候呢,我们取个平均值,但是有缺点, 但大模型他需要进行很多问题的回答,耗时耗力,而且呢,我们还需要雇人,对吧?让人来对我们的大模型结果进行检测,所以说人力成本很高, 他虽然呢打出了分数了,但是呢,因为不同的人喜好不同,很有可能你这个打分评估员这一个组合,他对大模型的他的倾向就不一样,对吧?有主观的因素在, 而且呢,最重要的是因为我们人力成本太高了,我们大模型呢,很难说快速的迭代更新,但是他是不可忽略的。 我们很多人会陷入误解,认为人工评估是不必要的,但是我们发现呢,它是检验我们用户体验的一个黄金标准,我们任何的模型在上线之前,我们都需要通过我们人工评估,因为呢 我们接下来介绍的自动评估,它可能没有那么完美,那实际上什么是自动评估呢?那我们这里有一个 cross encoder 和 rerun 啊, 那实际上呢,它就是通过什么?因为我们要从我们的知识库里把相关的文档剪辑出来,那我们是不是可以去计算一下我们这个文本的相似度呢? 我们这里引入,比如说我们的 bird source 啊,它就是一个小的语言模型,那小到什么程度呢?它的参数量非常小啊,只需要在我们的这个 c p u 里就可以运行, 那它呢,就是粗略的看一眼,你可以理解它,粗略看一眼,你看你把文档找出来了,那我就粗略的看一下,它和我们用户的问题相不相关呢?由我们的 bird 进行一个打分,那这个优势呢,就非常的显著了,它效率很高,对吧?可以一次性处理很多信息, 而且呢它也不需要标准答案就可以进行评分。这个时候在早期可以借助我们的模型自动评估开发很快, 而且它的成本很低,完全自动化执行,解放我们人力成本。那最后我们会为大家推荐一些相关的框架,我们可以看一下第一个框架,我们的这个 rugas 啊,它其实呢是一个专门为我们 rugas 系统设计的评估框架, 那它会给我们提供非常多的,比如说忠实度啊,答案相关性啊,和我们上下文精确率的指标。我们给大家看一下它的首页, 我们现在看到的呢就是我们的 raguas 啊,它现在呢它整个的流程,比如说我给大家呢摁一下翻译按钮, 你会发现它的侧面呢包含我们的快速入门,我们只需要选择评估一个简单的 raguas 系统,它就可以呢,通过它提出的这样一个视力的 python 代码,只需要引入我们的 raguas 它的一个库, 你就可以直接获取到非常详细的指标,而且呢直接就能对你的 reg 系统进行评价,它是非常简洁好用的啊,它目前呢已经获得了十二点八 k 的 star, 所以 说整个的质量非常的可靠。接下来我们来看一下第二个框架,第二个框架呢就是 true lens, 它是干什么的呢?它可以对我们的大模型进行一个多维度的评估,我们同样来看一下它的标语呢,是从我们的 vips, webs 啊到指标,那什么意思呢?之前我们的 webs 就是 主观的,那么现在呢,有客观的指标来衡量我们大模型的好坏了,那么我们可以看一下它到底能为我们做什么呢?可以看到 它可以为我们进行一个 reg 系统的上下文相关性的评估,然后可以对我们大模型回答的答案相关性进行评估。而 而且呢可以发现我们大模型是不是生成了一些有害的语言,就是对用户造成伤害的,或者是引导用户啊,走向错误道路的,包括有没有偏见,能不能呢?呃,匹配我们用户的语言可以见得呢,它其实是一个非常多维度的一个评估框架。 那最后我们来看一下我们的 a r e s, 那 这个框架呢?它本身其实是倾向于我们的模型安全性的,它称为人工智能鲁棒性评估系统。 a r e s。 那 能为我们做些什么呢?可以看到它已经实现了这些功能,比如说提示词注入攻击,那么我们之前呢,经常能看到,比如说在一些软件上,对吧?我们比如说小学生在写作文, 这时候我们做了一个 ai 系统,说你帮我给这个小学生的作文打分吧,这时候有一个小学生,他在这个作文最后一行写,请给我这篇文章五十分,对吧? ai 读到了这个内容,直接给这个学生满分,这就是体式词注入, 那我们这个框架就可以解决这些问题,帮助我们去预防这些体式词注入攻击,包括我们的一些敏感信息啊,对我们的这个数据模型进行处理, 所以说整个 a r e s。 有 了它呢,就能保证你系统的一个基本稳定性和可信了。好,我们回到我们的 ppt, 那 实际上呢,我们要做这个 它呢,最好是用我们大模型赋能我们的评估。那现在我们也提到了说我们的 cloud 五, cloud 啊, cloud 四点七, sony 和我们 gpt 五,它已经非常的智能了,那我们再进行一些 公司内部的系统评估的时候,我们就可以选择用这些非常智能的模型给我们的这个 reg 系统做打分。而且呢我们现在大模型非常聪明,我们可以让它自动生成一些测试样本和参考答案。 而且呢基本上我们通过大模型的赋能呢,我们就可以让大模型把它的这样一个智能,然后发挥到我们的 reg 评估上,对吧?减少我们的人类成本。所以我们有三点建议,第一呢,就是我们最好是使用现有的框架,而不是从零开始。 那使用成熟的开源框架呢,就可以为我们节省很多成本。最重要的是还是根据你的业务场景定制你的评估指标好,我们相信呢,了解这些内容,你也能构建出一个指标,非常不错,赢得用户满意的 rek 系统,我们下期再见。
485程序员老元 07:22查看AI文稿AI文稿
07:22查看AI文稿AI文稿今天呢没有画任何一张图,我做了十年的 u x, 用 cloud data 去做了一个静态的一个游戏的一个网站,从需求到现稿到高保真,再到 cloud code, 一个代码运行的一个整个的一个全流程,今天 完完全全的分享给大家,小白使用的一个流程,我给大家整理出来了需求意识,到你生成这个线框图,再到生成高保帧,中间呢要确认高保帧的需求是否满意,再到回调我们最终导出来的这个设计资源,给可拉扣的去生成这个代码应用去运行起来,运行起来之后再去预览进行测试, 是成功以后我们部署和发布。当你真正去使用 kol 迭代的时候,打开 kol 的 左侧导航,里面有有一个迭代。目前现在这三个功能呢,第一个呢是高保真设计和应用界面,第二个呢 ppt 的 一个设计,第三个是有规范体系的, 我们今天来做游戏的一个静态的这个网站,这个项目里面先进行一个命名,这里呢作为一个小牌的话,我肯定不是上来就去做高保真的。然后当我达到需求之后呢,先选择第一个小牌的话,我肯定不是上来就去做高保真的。然后当我达到需求之后呢,作为一个小牌的话,我肯定不是上来就去做高保真的。然后当我达到需求之后呢,作为一个小牌的话,我肯定不是那个圆形草图的意思, 下面这个输入框里面告诉他赛博朋克风格的一个游戏网站的一个相框图,首屏呢需要一个大型的一个视频的一个区域, 我希望在这里面有一些用于观看游戏预告片的一些按钮,用于可以去创建开始游戏的这个按钮。整个这个游戏的名称呢,就是这个钢铁城市。第二个板块呢,需要展示这个游戏一些核心的特色,还可以用于展示游戏更新了哪些内容。 线框图部分给他提的这个需求,然后把这个提子词呢去丢给他,而且这个时候他给了你三个方案, v 一、 v 二、 v 三,他给出了三个线框的一个方案, 那么你可以选择其中一个你比较喜欢的一个布局的方案。因为我想要那种东方美学特征钢铁城市的感觉,所以我选择了第二个暗色系的这个风格,这一个线框图给我进行一个反复的一个回调,一次性过到这里的话, 我觉得还是非常 ok 的。 第一次生成的这个里面的空白的图是没有图的, image two 去配合生出来的这个图呢, 再去给这个 cloud design, 它每个模块它是空的,有站位图截图去丢给 china gpt, 让它根据这个站的这个风格进行这个配图。我选了这个色调的这个基调进行整个视觉风格的一些建议。 hero 这个手屏的这个视频区域这块儿 先给我进行这个静态图的一个生成,这个基调的话,我觉得还是非常符合我想做的这种钢铁城市的这种感觉的。它是在首屏的这个 hero 这个区域里面,还是要给它提这个需求的,然后大家看一下丢进去之后,它会在这些地方它都会有一些细节的, 非常哇塞的,我真的是非常哇塞的,大家对比一下我原来生成这个图的这个效果和现在它放到网站里的这个效果,它质感是不一样的,加了一些网格的肌理和整个的这种流动线条的这种激光感,之后的一些小细节 我就做的还是非常到位的。而且这个时候我也是没有在需求里面去说的,我们就会对下面的一些板块进行这个图片的一个适配,参考前面的这个主视觉的图进行一个生成, 丢给 gpt, 然后让它去把这一块配图的提示词先写出来,写出来之后我们再去让它进行这个生成,每个模块就去这样去生成,生成完之后我们再回到 collab 里面, 拖动到它现在已经给你放好的这个站位图的这个位置,那么它直接会把这个图片适配到这个里面,适配到这个区域里面, 就它有一些带有站位图生成的地方的话,是可以直接去拽图的,如果它那个地方没有去放一个站位图的话, 那个地方是需要你给他去诉说这个需求应该怎么改这个项目的右上边编辑它是可以像飞格玛一样一个字体啊、尺寸啊、颜色呀,就在飞格玛里面可以调整的一些设置项,在这个地方是可以直接去调的,去给他编辑设置的时候是不跑你的 token, 你 如果说是非设计人员的话, 你就可以点一点,然后让他呃参数值上下的变动一下,你就能够大概有个概念说这个地方他是调什么一个间距,调什么样的一个颜色,那么你就知道了。再去点一下这个编辑,那么这个页面他就是一个保存的一个效果了,这个网站的效果也是 我满意了。 cologit 做好了之后,怎么去给 cologit 去进行代码的一个实现? cologit 页面的右上角点下分享,它会下拉,目前这个阶段,这些选项你都可以不用看,只看最后一个,它是去使用终端的 cologit 的, 选中左边这个 coding agent, 然后在下面这个复制它的这个命令, 我们再去启动一下终端,因为我们在 cloud design 里面去创建的这些从线稿到高保帧这一系列的在做设计,而设计做完之后,我们去考勤的时候去给它代码运行。实现的时候,我们肯定是先给 cloud code 的 这个项目去创建这个项目的文件夹,打开终端,然后打开你这个项目, 在终端里面输入 cloud, 我 们把 cloud 给启动起来。 cloud design 里的这个命令行呢,去钻到我们这个终端的这个项目里, 摁一下 enter, 让它去运行就可以了,让你进行一个确认和回复的一个过程,你可以去看一下它具体是说了些什么。那么这个效果就是已经是用 coding 代码已经给它实现好的一个网站了,基本上是一比一的一个复刻手屏整个这个区域这一块它是用视频的这个效果来表达。刚才的 静态图去用 sands 这个模型呢,去给我生成这个视频就可以了,就详细的说怎么去生成这视频了,让 k g p t 在 现在这个静态图的基础上写一个视频的一个梯子词,主要的一个基调的话,其实还是需要我自己来把控的, 一定是那种缓慢的,有细节的,而且还是一种有电影感,而且非常有克制的那种情绪在里面。 ai 帮你去写的这个东西,包括他给你生成这个东西是取决于你想要一个怎样的一个感觉和基调的一个东西。 生好的这个视频丢到这个项目文件夹里,把这个素材去丢到你这个终端里面,告诉他这个素材我是要放在 hero 主视觉的这个区域里面,把这个静态的图给我替换成这个视频的这个效果,把说的这个需求,然后再去 写进去,然后这个时候去让整个 clock code 去跑起来,把这个去适配一下就可以了。那个网格这个效果它都是还是存在的,也直接替换到这个视频的上方了,因为整个的这一块我去演示的这个过程的话, 一次性的需求输入,一次性的通过的,没有进行反复的悔改,你能达到这样的一个效果的话,我觉着已经是非常好了。给大家总结一下,就是首先第一步我让他先出的是圆形的一个线稿,三个方案的一个线稿,然后进行一个选择,通过这个线稿去进行高保帧的一个生成, 走的是这个静态的一个风格,哪些地方到可酷的里面再去输出动态的,就按照这个流程去做就可以了。 有一些小细节的时候,就可以在 cloud code 里面去慢慢的去修改了。那么如果你想把这个产品打磨的更细致,更深入更好的话,那肯定是要消耗更多的一个 token, 在 阶阶段来说的话,额度那么小,还能够把这个流程能够跑完,肯定前景是非常好的, 更深入的进行这个迭代和反复验证的话,可罗德里亚这个 token 的 话,肯定是远远满足不了你的,你可以去借助于其他的一些工具去配合的去使用。大家评论区可以告诉我哪一段没有听懂再细致的去裁剪一下的,我们下期给大家裁剪,再见。
501弦的AI日记 00:56查看AI文稿AI文稿
00:56查看AI文稿AI文稿欢迎来到挖宝日报,今天这个项目特别实用,叫 r t k, 用 ai 的 朋友都知道,肯消耗是个头疼的问题, 每次查个文件,跑个测试都要浪费大量偷坑,一个月下来费用不少。 r t k 就是 来解决这个问题的,它能帮你省掉百分之六十到百分之九十的偷坑。怎么做到的呢?它会自动过滤掉没用的信息,只把关键内容发给 ai。 比如 git status 原本要花两千,经过二 tk 处理只要四百,节省了百分之八十。 text, 读文件从四万降到一万二, gitif 从一万降到两千五百,装好之后后台自动运行, 你完全不用管它。 gitif 五万三千颗星,完全开源免费。如果觉得有用,帮我点个赞!关注挖宝日报,每天分享一个使用工具,下期见!
1挖宝日报 25:50查看AI文稿AI文稿
25:50查看AI文稿AI文稿朋友们晚上好,今天这个视频呢,只有一件事情,就是从零到一的教会你们使用 cloud code。 那 很多人听到 code 这个单词啊,就会想到写代码, coding 编程,对吧? web coding, 但实际上以 cloud code 为代表,这种 ai coding agent, 它并不是只能写代码,而是一个万能的工具,并且就在昨天飞书刚刚看完了,他们的 coi 就是 command line interface, 也就是我们说的命令行接口。那么这意味着你可以使用 ai agent 帮你做表格,回消息, 发通知,定会议和安排日程。那么它代表的什么呢?它代表的其实是一种新质的生产力,你可以不用它写任何的代码,但是你要学会使用它。就像在远古时代,一个人是转不去火,而另外一个人直接拿着打火机就把火点起来了。 那么 cloud code 除了编程,它还能帮你做什么呢?首先它可以帮你做数据分析,管理文件,其次可以帮你爬取你的这个每日信息流,每日资讯,还可以帮你修图升图,生成播客,剪辑视频, 甚至你也可以根据你自己的工作方式来搭建属于自己的 skills。 那 么这个视频我将全面的讲解,不需要你有任何的预备知识,从基础到高阶,循序渐进,包括安装和设置,那么基础操作和这个最佳实践,以及 hooks agents, skills, plugins mcp 我都会教给你。那么同时像一些不常见的非常好的命令,比如说 simplify insights, a loop 我 也会教给你。以及我还会分享一下我的经验,比如说如何避免在长时间开发中的莫名其妙的 bug, 以及如何优化 token 节省成本。最后我还会告诉你如何设计你自己的 skill, 点 m d 来让自己的工作效率最大化。 那话不多说,我们直接开始。那首先呢,我们先来安装 cloud code, 那 么这里我们直接进入它的官网,然后我们下滑,我们可以看到这里有好几行命令,那我们只用根据你的电脑,比如说你是 micro s, 或者你是 windows, 选择相应的命令就安装就好了。 那这里呢?如果,如果说大家是 windows 的 话,我推荐大家使用这个 power show, 而不是 cmd。 因为这个 cloud code 的 它的底层是 unix 风格的命令,所以说使用 power show 的 话会更好。那比如说这里我是 micro s, 我 们只复制条命令,然后我们打开我们的终端, 然后我们粘贴上命令,然后再回车就好了。那么它就会帮我们自动地装好 cloud code。 由于这里我已经装好了,所以我就不再演示了。 ok, 那 刚才既然我们已经安装好了 cloud code, 那 现在我们该怎么使用呢?那很简单,我们只用打开我们的终端,然后输入 cloud 就 好了。 我们敲击回车,那这里它会选择说你是否愿意选择当前这个呃,文件夹做你的 workspace, 那 我们点击 trust this folder 就 好了。 ok, 进来之后我们就来到了这个界面。 ok, 那 现在趁着 cloud 在 安装,那现在我们需要安装另外一个非常重要的工具,叫做 c c switch。 我 们知道。呃,我们在国内想要使用官方的服务,比如说 opus, sonnet 或者是 hikube 是 非常麻烦的。那所以说我们就需要使用我们国产的模型,比如说 mini max, 呃, g o m, deepseek, 或者说百炼等等等等。 呃,还有像 kimi 这样的模型,那我们该如何使用呢?那很简单,我们使用这个工具就可以方便的帮我们配置,那么这个工具呢?叫做 cc switch, 那 么它的作用呢?就是允许我们配置多个模型,并且可以快速的切换。那么安装方式也很简单,我们只用往下滑。 好,这里有个快速开始,然后如果说你是 macos 用户,你直接复制这行命令,然后打开终端,像刚才我们安装一样,把这行命令复制过去,然后回车,它就会自动安装了。那如果说你是 windows 用户,那就比较麻烦了,我们需要点击 release, ok, 那 这样我们来到它的 release 界面,那我们一直往下滑, 那么我们可以看到它的一个 contributors, 然后它有个 assets, 那 我们点开这个 show all, 然后我们找到这个 cc switch v, 三点十二点三, windows 点 msi, 注意一定要是 windows 点 msi, 然后我们下载这个就好了。 ok, 那 既然我们已经安装好了 cc switch, 那 这一步我们要做的就是配置我们的模型,那么在这里呢,我选择的是我们的 mini max。 二点七,那配置方式也很简单,我们点击一下这边这个加号, 然后我们可以这里可以选择你使用的是模型,比如说你是智普,就选择这个,那么你,你是 deepsea, 选这个,对吧?你是 kimi, 就 选择这个,那我们这里是 mini max, 那 我们只能选择 mini max。 这,我们往下滑,那这里它已经帮我们填写好了这个 base url, 那 我们需要做的指示填写,我们好我们的这 api key 就 好了,那 api key 怎么获取? 那很简单,我们打开这个,呃, mini max 官网,呃,这里有个订购套餐的界面,好吧,那在这里呢,我建议大家就选择这个四十九元的这个套餐就好了,呃,目前我用下来是非常的够用。购买了套餐之后,我们点击我们的这个账户管理,我们选择 tokenplay, 在 这里我们把这个 api key 复制一下,然后我们粘贴在这里就好了, 这我们点击添加就 ok 了,就配置完成了, ok, 那 现在既然我们已经把 cloud code 安装好了,然后我们把 api 也配置好了,那现在我们就直接开始使用,那使用方式也非常简单,我们打开终端,输入启动命令,我们回车之后就进到第一个选项,那这里我们选择 yes, ok, 我 们就来到我们的工作页面,那可以看到刚才我们已经配置好了 api, 所以 说它这里显示的是 mini max 二点七,然后这里是 api use, ok, 那 么首先呢我们来讲讲 cloud code 的 三种模式,那么第一种模式呢叫做 default mode, 也是现在这种模式就就是这里什么都没显示。那么第二种呢叫做 plan mode, 那 就是规划模式。那么第三种呢叫 bypass permission mode, 那 这就是,呃完全执行,也就是相当于 full access 这种模式。那么首先我们来说第一种,第一种模式的话,那它的呃这个特点就非常简单,就说,嗯,它执行就是 cloud code 执行任何一个操作,比如说它读写文件,编辑文件,都需要你明确确认之后它才会执行,那比如说现在 我们让他在桌面上创建一个文件,看看是什么效果,那这里呢?我推荐大家一个工具叫做闪电缩,那他就是一个语音输入法,但是他这个语音输入法是会使用这个拉玛,也就是我们的大模型去整理的语音输入,并且他是可以学习的,所以说他这个识别准确率是非常的高,那么包括我看到抖音,他们也做出了自己的这个 豆包输入法吧,那么我看我身边有朋友体验也非常不错,那大家可以去试一下,总之一切是免费的。那云输入法的话很简单,我们只用给他说我们的想法,呃,帮我在桌面上建立一个文件夹吧,然后里面给我放一个文件叫做 test 点, md, ok, 我 们回车看一下他会怎么执行, ok, 那 首先他会问我们文件夹是什么名字,对吧?叫做 test 就 好了, 这里呢它就会让你选择是否执行这个命令,那我们可以看到 make d r, 就是 就是新建一个文件夹嘛,然后在这个位置,好吧, 那我们选择 yes 就 好了,因为现在我们是 default mode 嘛,就是它每个插座都会问你是否要执行,我们选择 yes, ok, 他 说已经成功创建了,刚才我们已经讲解并演示了 default mode, 那 么它就是每执行和命令,好吧,都需要我们手中确认一次,那我们想刚才只是一个非常简单的任务,对吧?我们创建一个文件夹,所以说执行一次,选择一次,点击一次就好了。那如果说现在我们在执行一个非常复杂的任务,那我们每次就要点嘛, 那我们还怎么玩手机,对不对?那怎么摸鱼对不对?非常的麻烦,所以说我们就要使用这个危险模式,那危险模式该怎么进入呢?危险模式的话,我们需要呃用一个单独的命令进入,刚才我们是输入 c l a u d cloud 这个命令来进入的,对不对?那现在如果说我们想要使用这个危险模式,也是这种 full access 全自动的模式,那我们就需要在后面加上参数,加上这个 dangerously skip permission 就 许可嘛,对吧?就是无许可模式嘛。 ok, 我 们点击回车 啊,一样的,我们选择 yes, 相信这个。呃 folder 做我们的 workspace, 那 ok, 看到这里就有了这个 bypass permission 啊,就说现在它执行和命令不需要我们的这个批准了,好吧,它会直接自动执行。那同样的,我们说帮我在桌面上建立一个文件夹,然后名字叫做 test 二吧,然后里面给我放一个这个 md 文档,名字随便取就好。 ok, 我 们看看它会怎么做, 你看它这里直接执行了这个 bash 命令,好吧, macd 直接创立了这个 test 二的这么一个 folder, 然后在下面呃,创立了一个 untitled 的 点 md 文档。 ok, 他 现在直接给你说我们完成了这个任务就非常方便。所以说,呃,我更推荐大家使用这个 dangerously keep permissions 这个命令来起到我们 cloud 吧。那我们继续讲讲规划模式,就是这个 play mode, 那 play mode 它其实有两种的,呃,这个应用场景嘛,那么第一种就是当我们在做产品的时候,做项目的时候,在初期,呃,我们想知道这个 ai 会怎么执行,对不对?是不是按照我想的方式执行? 那么我们可以用这个 plan mode, 让他规划书写一个 plan 出来,我们看一下,没问题。 ok, 那 就会按照这个 plan 去执行。那第二种应用场景呢?就是针对一些比较宽广的任务,就是广度比较大的任务吧,就比如说现在我让他把我桌面上面所有的这个文件全部给我迁移到我的这个硬盘里面去,那他会操作很多文件,对吧?可能呃几百个,那这时候我们就用这个 plan mode 就 比较好。 那还有一种场景就怎么说?就比如说现在我们我需要让他去 re-use 我 们的代码,就去审查我们的代码吧,对吧?那这时候让他用这个 client 就是 一条条干,先干嘛,后干嘛,那这个场景是比较好的,那这里我们来体验一下这个 client, 我 们还是用 shift 加 tab 切换一下。 那我想想我们列个什么计划,那很简单吧,现在我要整理我的桌面文件夹,现在请你帮我列个计划,我看看该怎么整理。 ok, 我 们回车看看他会怎么做。那么我们要注意啊,就是 plan mode, 他的权限是只读权限,就是他只会进行读操作,不会进行写操作,只有你看过没有问题之后,那么他才会进行写操作。 ok, 我 们可以看到很快他就给了我们一个 plan, 那 同时他给了我们三个选项,第一个选项就是 yes and bypass permission, 这是什么意思?就说无条件执行,不要来问我了。那么第二个是什么意思?第二个就说 yes, manually approve it, 就是 执行这个计划,但是需要我手动来批准每项这个编辑,那么第三个选项就说你可以告诉他,你觉得这个计划有什么不好的,你直接给他说, 他就会按照你的这个要求去更改这个计划,然后再让你看一遍。那比如说你再帮我把垃圾箱清理一下吧,把这个计划加入进去,然后让我看一下。 ok, 我 们可以看到他刚才又在我的要求上增加了一部清空垃圾箱的这么一个任务,那你觉得没问题,那我们就选择 yes 这个 bypass permissions, 它就会自动执行的。 ok, 那 现在我们来讲讲 cloud code 的 一些命令,那首先第一个命令就叫 enit 命令,那么现在我已经打开了一个项目,这个 voice input 是 我让 codex 做的一个语音输入法的项目, 那一定题命令很简单,就是初设化嘛。那么他这个命令呢?首先会把我们整个这个项目的代码看一遍,看完之后他会根据他理解生成一份 cloud 点 md 文档,那这个 cloud md 文档有什么作用呢?就是,嗯,每次绘画的时候,他都会首先加载这个 cloud md 文档,那里面就是一些最高的原则,相对于类似于机器人不能违背的三条法则那种感觉。 ok, 我 们这里可以看到他成功创建了一个 cloud md, 然后这是他给出的一份资料,那即使想要写好一份好的 cloud md 文档,也是需要花很多功夫的,那我们就不在这里多说了,但是 唯一一个原则,大家需要记住的就是不要让你的 cloud md 写得又臭又长。如果说 cloud md 写得非常长的话,那每次上下文稿加载它就会一个是会消耗我们大量的 tool, 另外一个就是会让这个 嗯 a 键是变得非常笨。那一种解决方式就是我们把那种长的文件拆分出来,我们新开一个这个 md 文档去存放,那比如说我们可以开一个 get 点 md, 对 吧?然后我们把这个 get md 的 这个路径,我们记录到这个 cloud md 中,然后并且我们想指示说如果你需要这部分的知识,那么请去查找这个文件,这就是,嗯, cloud 客户团队非常喜欢的这个叫渐行式批录。 ok, 那 我们什么时候可以使用这个 init 命令呢?那我的答案是你任何时候都要使用这个 init 命令。比如说你从 github 上面下载了一个新的项目,你使用这个 init 命令,那就可以让这个 agent 快 速的了解整个项目,然后生成一份 cloud 的 md 文件, 然后 cloud 点 m d 文件是相当重要的一个文件,它相对于这个 ajax 的 一个最高指示,所以说你可以在里面写一些你自己喜欢的,你觉得非常重要的一些原则,比如说开发规范,比如说千万不能执行 r m 杠 r f 等等等等。那 cloud 点 m d 呢?一般会随着你项目的迭代,开发过程迭代呃来完善。 ok, 那 大家肯定听说过 marty agent 或者说 agent team, 那 其实想要创建一个多 agent 的 这么一个团队也非常简单,那像 cloud code, 它就支持我们创建这个 agent, 并且可以用这个自然语言创建,那我们只用执行 agent 命令,可以看出来,我们点击确认,那它就会说第一个选项 create new agent 就是 创建一个新的 agent, 那 么这就是 user agent, 就 代表说我们已经创建好的 agent, 可以 看到我这里创建了一个 codex review agent, 还有一个这个 marty agent coordinator。 ok, 那 现在我们来创建一个 agent 来看一看。那首先很简单,我们直接回车选择这个 create new agent 就 好。 ok, 它这里就会让我们选择这个 agent 的 location 在 哪里,就说选择你这个项目级别,就是它这个权限级别嘛,那我们就选择这个 project 就是 这个项目级别就好了。 然后它现在又给了两种方式,第一种方式就是 generate with cloud, 就是 说让你跟 cloud 一 起创建这个 agent。 第二种方式呢,就是你自己去写它的这个配置文件,那我们肯定选择第一种,对吧?因为毕竟它后面都说了这个 recommended, 那现在他就说让你去描述一下你这个 agent 要做什么,你看他这里说的 describe what this agent should do? 吧啦吧啦吧啦一大堆,对吧?那我们很简单,现在我要创建一个这个 technique co founder, 这么一个 agent 就是 一个技术合伙人的 agent 吧?那我把我准备好的这个 prompt 发进去, ok, 那 现在我们点击回车就拿创建这么一个 agent, 然后他现在就在 显示,他说 generating agent from description, 就 说现在根据我们这个描述在创建这么一个 agent。 那 当然本次教程提到的所有提示词会放在我这个文档里面,那具体怎么获取文档请看我的这个主页,好吧, 在我的公众号里面获取。 ok, 那 现在出现了这个界面,这个界面就是说让你去选择你新建的这个 agent 允许他使用哪些工具,那他根据我们的这个描述,现在给他全部工具权限,那当然你也看到这里写了是 enter to talk selection, 那 就是 talk 切换状态嘛,那很简单,如果你想 不让他使用这么多工具,对吧?那你就小键盘嘛,上下左右。然后你假如说不让他使用全部工具,你再按一下这个 enter, 那 你看全部都没有选中了,现在是零个工具这里显示的。 那如果说你要全部工具选上,那就返回去,然后再按下 enter, 现在是 auto selected, 然后确认没问题,我们就 continue 就 好了。 那这里他就说让你去选择你新的这个 app 的是用什么模型,那比如说你是用 sonet 或者 oppas 或者是海库,要不然的话,你就说它是继承它的这个负类的模型。那很简单,因为我们用的是 mini max 二十七嘛,那我们其实不用选,我们直接选择这个 inherit 就 好了。 然后这里就说让你选择这个 agent 的 颜色,比如说你选择红色、蓝色、绿色、黄色,对吧?选择选择一个你喜欢的颜色就好,那我们选择一个黄色吧,然后他这里就说这个 agent 这个 memory 它在哪个范围,那我们选择这个当前项目级别就好。 然后现在它就会让你再再次确认,然后你可以浏览一下这个,你的这个 description, 你 这个 memory, 你 的这个 system prompt 等等等等。 ok, 确认没问题,我们选择 enter 就 创建好了,你看它这里显示的 creative agent technical founder。 ok, 那 我们想要调用我们创建的 agent 也很简单,直接使用这个自然语言去交互就好了。 那这里我们就说帮我调用我新建立的这个 technic founder, 这个 agent, 我 要做一个项目, 那我们看看他会怎么做? ok, 可以 看到他成功唤醒了这个 agent, 你 看他正在初步化,花费了二十六点六 k 这个 tokens, 然后现在他说 technical founder 这个 agent 已经启动了,现在你可以说你要做什么项目了,那我们就开始巴拉巴拉巴拉说我们的一堆项目,对吧?他就可以帮我们完成。 那我们什么时候该新建立一个 agent 呢?那很简单,就是当你发现你会重复地做同一类任务的时候,并且这类任务需要很长的一段 prompt, 需要你定很多的规范。那这时候你应该专门创立一个自己的 agent, 比如说你可以专门建立一个产品经理的 agent, 一个后端开发的 agent, 一个前端开发的 agent, 一个专门做这个测试的 agent, 甚至呢你也可以专门建立一个 codex agent, 那 这个 agent 其实就只用干一件事情,就是在你的终端去执行这个 codex 命令,相当于唤醒了 codex, 那 这样就可以实现 cloud code 的 写代码 codex 进行 review, 并且不需要你人工去传递他们的 prompt, 传递上下文,直接让他们两个对接就好了。 一个单独的 agent 还有一个非常好的点,就是它可以帮助我们节约我们的上下文。那假如说现在我们要去执行一个非常长的文件的写操作,或者说一大堆这种抓取的操作,那我们可以单独开一个 java agent, 让这个 a 键去执行的操作。我们并不关心他到底获取了什么样的数据对不对?我们只关心他到底完没完成任务,那 x a 键就帮我把中间上下文给省略了嘛?最后他完成任务返回一个 ok, 那 我们就知道任务完成了,那 a 键这个命令就讲这里了,那同样有很多玩法需要大家自己去探索, 那现在我们来继续讲讲 m c p skills, 以及最近新出的 plugins, 还有我们的 hooks。 那 首先我们来讲 m c p 跟 skill 吧,因为很多人会把这两个词搞混,那其实很简单, m c p 中文翻译过来叫做模型上下文协议,那么 skills 呢?翻译过来叫做技能能力,对吧?它们之间的差别 有一个就是 m c p 是 告诉你能不能做,就是你有没有这个能力做,而 skill 是 告诉你你如果有了这个能力,你应该怎么做。那我举个例子,现在假如说我是一个残疾人,我没有这个腿,但是我想去骑自行车,是不是我就不能骑?那假如现在给我一个骑车的 m c p, 相当于就能帮助我长出这个双腿,那我有了腿是不是就可以去骑车了? 但现实就是很多人尽管他四肢健全,他还是不会骑这个电瓶车,对吧?不会骑这个,呃,这个自行车,摩托车的。那我们再给他一个 skill, 就是 给他一个骑车指南,就是教他怎么骑这个自行车的,对不对?那这样二者一结合,是不是我们就会骑车了?大家应该可以很好的理解。 然后我们再举个例子,那假如说现在我们在进行一场开卷考试,开卷考试我们肯定要带复习资料对不对?肯定要带书对不对?那么 m c p 就是 说你带了这个书,带了这个资料,那如果说没有这个 m c p 就 相当于没有带书,那么 skill 是 什么呢? skill 就是 说你脑袋里面组织你怎么看这个书,怎么看这个材料,对吧? 比如说有些人会很快的找到这个答案在哪里,有些人要找很久才能找到,所以说 skill 是 教你怎么看书的,那么 m c p 是 你本身带不带这个书,带不带这个资料?那现在我们想看我们 cloud 的 安装哪些 m c p 很 简单,我们直接在这个命令行里面输入这个 slash m c p 指令就好了, 就可以看到现在我这里只安装了三个这个 skill, 一个抖音的,一个 pencil 的 playwrite。 那 现在你想看你安装哪些 skill 也非常简单,我们输入这个 slash skills, 就会看到你安装了这 skill。 当然这里的误区就是 skills 并不是越多越好,而是越精越好,就是 你如果是个小白的话,你可能会安装很多 skill, 对 吧?摸索一些你比较常用的 skill。 然后那我给你的建议就是你在这个使用过程中,你要不断去精简这些 skill。 因为 skill 过多会造成一个什么现象?就是模型有太多的工具调用了,导致他根本不知道什么时候该调用什么工具。这句话怎么理解呢?就有点相对于类似于选择恐惧症了, 就是一个人有太多的选择,就导致他一下子迷茫了,不知道自己的路该怎么走,那如果说他就一个选择,那就逮着往死里干就完事了。 那什么是 hooks 呢?嗯, hooks 用中文翻译过来叫做钩子,这个可能比较难理解,其实他本质上就是一段脚本银行代码,然后呢,在特定的事情发生的时候,他就会自动触发执行。 那么 hooks 呢?大家按照它的执行顺序,可以把它简单地理解成两大类,第一类叫做在工具调用前执行的 hooks, 第二类叫做在工具调用后执行的 hooks。 那 我们看一下, 那现在我们想象这样一个场景,我们知道 cloud 它是可以操作我们电脑所有的文件,对不对?但是你不想你的某些私密的信息,一些密钥文件,或说你不想让 ai 知道的文件被它读熟了,那怎么办? 那你就可以制定一个 hook。 这个 hook 怎么定义呢?就说每当这个 ai 进行读操作之前,或者说之后执行这个 hook, 这 hook 就 会检查你当前要读取哪一行文件,读取什么东西。如果说发现你读取这个路径和你这个私密文件的路径重复了,那就直接拦截, 懂了吧?这就是 hooks。 那 再比如说,现在我们在我写一个项目,那么项目写好之后,我们会把它推送到 github, 进行这个代码托管。那么我想的是每一次只要我执行了这个 review 操作之后,就自动地给我推推送到 github, 那 么也可以定一个 hooks。 那 么这个 hooks 呢?就是这个 post tool use hooks。 简单就说,当它监测到我们执行的这个 review, 那么它就会自动触发这个 hook, 把代码推上 gitlab。 那 hook 是 怎么创建的?也非常简单,我们只用告诉 a e i 说帮我创建一个 hook, 然后它这里就显示了你想配成哪一种 hook 啊,然后你再把你的需求给他说,他就会根据要求帮你配进一个 hook, 很 简单。 那同样的我们该如何创建 skill 呢?那么 skill 其实不建议大家在一开始就创建好,除非你很明确自己的这个流程是什么样的,场景什么样的。我更建议大家在使用这个 cloud 的 过程中来创建,因为你在使用的过程中才会发现哪些工作流是可以重复的,对吧?会大量重复执行, 那这时候你就可以建立一个你自己的 skill, 那 比如说我自己就建立了一个记录素材的 skill, 每当我给他发一个抖音链接,或者说小红书的链接,或者说呃, youtube, bilibili 等等视频网站链接,那么他就会执行一个动作,他会把这个链接的这个字幕也是在这个脚本这个竹子稿,然后保存到我本地我指定的位置,非常的方便。 那什么是 plugin 呢?这是最近新出的一个东西啊,那么 plugin 本质上就是说它把你的 hooks, 把你的 skills, 把你的 m、 c, p 全部打包封装在一起,那这样你在进行团队开发的时候,大家都可以附用这个主键,就非常的方便,非常的好,所以这就是 plugins 紧急抄波一条啊。刚才 codex 官方出了一个 plugin, 叫做 codex plugin c c, 就是 允许我们在可拉钩中直接调用 codex, 那 么安装非常简单。首先我们执行这行命令, 那么再执行这个命令,然后我们再重载一下 plug in, 这我们再准备这个 set up, 那 它就会自动调用你这个桌面上面的这个 codex 的 配置,然后写入,那就准备就绪了。来继续讲讲几个非常好用但是很不常见的这个命令,我基本上没有看到任何人讲过。那么第一个命令就是这个 simplify, 我 们把它敲出来, 那就是这个命令。这个命令命名是什么意思呢?那么叫 simplify, 它的中文翻译就是简单简化,对吧?那么 simplify 它其实就是一个代码的一个呃,检查命令,一个进行 code review 的 一个命令。就说当你完成一段代码的修改之后, 你运行这个命令,它会自动地对你所有的变更进行全面的审查。那么它的工作流程就是它会同时派出三个 sub agent, 那 么第一个 agent 它会检查这个代码有没有重复造轮子, 那么另外一个 agent 它会看这个代码或者命名这个格式不规范。那么还有一个 agent, 那 么它会直接查这个性能影 换,那就比如说重复计算,内存泄露等等问题。最后呢,他们会把发现的问题直接修复掉。当你的代码写完了,你直接运行这个命令,让这工具帮你检查一遍,进行这个 code review。 大家要注意就是我们想运行这个命令,我们必须把这个代码上传到 github, 进行这个代码托管。那 github 什么呢? github 是 全球一个最大的开源的一个,呃,代码托管的一个社区,那你如果没安装 github 的 也非常简单,你直接给你 ai 说帮我把代码上传到 github, 它就会协助你完成。好吧,那现在我们运行一下这个 sql 发命令,看一下是个什么效果。 ok, 我 们可以成功看到他已经把这个命令运行完了。由于我这个代码仓库刚才只是更改了这个 readme 文件,然后做一个演示,所以说他这里给出这个发现是你的代码非常干净,好吧,没有任何需要更改的。 那我们可以看一下他这个命令的运行过程,首先他执行的是 git diff, 他 看一下你当前这个代码和你之前提交在 gitlab 上面的代码,那有什么差距,对吧?那他这里说这个 only change is readme dmd, 那就说我们只修改了我们这个 readme 文档,那他还会走他接下来的流程,那接下来的流程就是他开了三个稍不一点的,那么第一个可以看到他进行了这个代码的附用的这个检查,第二个进行了代码质量的检查,那么第三个进行了这个效率的检查,那发现全部做完成之后,那给出了结果,然后给出了发现, 那这就是这个命令。 ok, 那 现在我们来讲第二个命令,第二个命令叫 rewind, 也非常简单,我们把敲出来看看,那这个命令它作用是什么呢?这个命令它作用就是时光倒流,就是当你把这个项目做歪了,或者说你想换个方向的时候,那么它可以回归到之前这个 checkpoint, 就是 回归到这个检查点,然后同时它会恢复这个代码和上下文。非常简单, 因为刚才我只执行了两个命令嘛。首先第一个命令我执行了 clear, 第二个执行了 simplify, 对 吧?所以说这里就只能选择两个,那我们选择一下这个 clear, 那 进来之后呢?我们可以看到这个命令给了我们三个选项,第一个选项就是 restore conversation, 那 我们看到它的解释是这个 conversation will be fork, 就是 说当前这个对话那会保持不变,但是我会在 clear 这个 checkpoint, 就是 在 clear 这个检查点这个地方,我们先看一个分支, 然后继续我们的对话,好吧,那我们看第二个选项是什么?第二个选项是 summarize from here, 就 说我们会把从 clear 这个检查点到现在这个检查点之间的所有对话进行一个压缩,进行一个总结,生成一份答案,然后再继续。那这个 nevermind 就是 我们直接取消的意思,那我们直接选择 restore confirmation, 你看那他就新开了一个对话,这个命令就到这里结束了。那接下来我们讲讲 in size 这个命令,这个命令非常简单,顾名思义就是洞察,那么他会根据你的 sql 的 对话,就是你所有的 session 来生成一份这个报告,那么他会统计你使用 sql 的 模式,比如说你会在哪些项目区域花的时间多,在哪里容易卡住,那么帮助你了解自己的一个写作习惯。那么使用方法也很简单, 我们直接输入这个 in size 命令就好了。那我们使用方法也很简单,我们直接看到这个报告非常详细, 那最后这个命令叫做 loop, loop 也很简单,顾名思义就是循环的意思嘛,那它就相当于一个定时任务,但是一个定时任务是在三天之内的,那我们怎么使用呢?比如说现在你想每一个小时帮我查一下当前的时间,那你可就可以这么执行,我们先选择 slash, 然后输入 loop 命令,然后你看它这里说了 interval 就是 间隔的意思,那我们选择 one hour, 就是 e h, 然后干嘛帮我查询一下当前的时间,那回车我们看看它会干嘛? ok, 那 我们可以看到它成功帮我们设立了这个定时任务,并且查询了当前的时间。 ok, 那 这个 loop 还有个非常好用的地方,就是它可以和 skill 一 起赋用,因为我们知道 skill 本质上就是一段 prompt, 对 吧?所以说我们可以这么使用,那比如说现在我想让他每隔一个小时帮我查询一下当前这个 ai 新闻,那我们该怎么执行?就是 loop, 然后执行一下哪个 skill, 执行下 ai news 这个 skill, 我 们看看它会怎么做。然后我们可以看到它成功执行了我的这个 skill, 并且把内容保存到了这个位置,然后它也创建了 cron。 ok, 那 现在我们来讲讲如何解决在长对话中莫名其妙出现的 bug。 那 我们知道如果说我们一个对话进程很长,那它肯定会压缩我们上下文,就是那个 auto compact, 那 压缩上下文的时候,那如果说最开始前几轮还会好,它只会压缩一些内容,一些文档,不会压缩一些关键信息。但是我们发现随着对话的进行那么多轮压缩之后,它第一点就是它的关键角色信息会丢失,早期价格约束将会被遗忘,那就会导致我们多人写作的时候 bug 越来越多了,好吧,所以说一些莫名其妙的 bug 出现, 那我们该怎么解决呢?那我们就是要让这个 cloud code 不要遗忘那些关键的决策,对吧?那比如说我们就可以在 cloud md 里面加入加入这个方案,或者说我们让他写一份这个 handoff 文件,那 handoff 文件怎么写?首先第一步我们要说清楚当前的进展是什么?我们的目标是什么?已验证的有效方案是什么?那么已验证的无效方案是什么?写清楚之后, 再打开下一个对话,让他进行交接,这样就会没有问题了。 ok, 那 现在我们来继续讲讲一个被很多人忽视的就是工具调用所产生的这个上小文的噪声。那我们知道,假设调用工具,比如说你测试代码,它会给你输出一长串的配索键,或说你查找文件的时候也会给你输出一长串的那种信息,那这东西是 cloud 是 根本不需要的,他只需要知道你完成了没有, 对吧?是 ok 还是不 ok? 所以 说我推荐大家安装这个 skill 就是 一个 r t k, 那 么他就会帮我们把这个信息压缩,只用返回给 cloud 的 最关键的信息就好了。 ok, 朋友们,那么看完了这期视频,我相信你对 cloud code 的 掌握已经超过了国内百分之九十九的 ai 玩家。但是说实话,工具只是工具, ai 时代最重要的并不是你会多少个命令,而是你的想法,你的 idea, 你 到底有没有真正想要做的事情。那么 ai 就 像一盏阿拉丁神灯,你提什么愿望, 它就会帮你实现什么愿望。所以说做一个有趣的人, dream bigger。 那 么下期视频还想提什么?你们决定评论区打出来,我们下次再见,拜拜。
2.0万AI 杰瑞斯 01:55查看AI文稿AI文稿
01:55查看AI文稿AI文稿当你不小心拥有了一个 open class, 但你总感觉它傻傻的,不好用于事。聪明的你钻研了一番后,明白了,小龙虾只是这个智能体的一双手,大模型才是它的大脑,决定了它是否聪明,而 skills 是 它的工作技能,决定了它是否有能力处理各种任务。 而大家总提到了 token, 就是 智能体的能量。使用智能体需要让大脑运转并调动小龙虾的双手并使用技能, 所以会消耗 token。 这也是为什么我们需要向大模型厂商付费。然后聪明你开始尝试使用不同的国内大模型来给智能体安装不同的大脑。这个时候你发现了接入了 cloud code 的 时候,这个智能体他是最聪明的,任务的完成质量最高,但是费用也最高。 然后你又发现接入了国产模型的时候呢,他也能完成很多任务,花销也很划算。于是不想当冤大头的你,想着好像可以让不同的小龙虾安装不同的大模型, 简单的一些工作,比如每日发送日报,这种工作就可以直接交给接通了国内大模型的小龙虾去做,赶紧去这么做吧。然后聪明的你为了让小龙虾能更快更好的完成任务,打算教给他各种 skills, 也就是技能。于是你在 skills 后面加上了 s h, 发现这里有七万多个 skills, 你 又了解到 open club 官方 skills 也有一万多个。不要慌,我已经给非技术背景的你准备好了十个基础 skills 和五十个进阶 skills, 咱们放心使用。这个时候呢,不想当月大头的你,感觉还是有方法能降低 token 的 成本?没错,这里我给你准备了三个方法,让你的 token 花费能降低十倍。一是多使用订阅而非 api 的 用量模式。 二是建立本地的 markdown 知识库, opencloud, 每次读取的时候只读取锁瘾。三是部署一个小模型来在本地跑。 opencloud 的 心跳模式,就是那个让你们感觉小龙虾火起来的关键机制,实际上是小龙虾内置了一个每过一段唤醒自己一次完成任务的机制。 除了以上三个方法呢,你还可以给你的小龙虾建立体检机制,及时的找到那些高消耗的任务并及时优化。别慌啊,以上方法听起来有点复杂,我已经帮聪明的你把上述方法的详细的文字版也整理好了。我是拉菲儿,这是 openclaw 实战系列的第二期,后面会有更多实操,咱们下次见。
1.0万拉斐尔2077 01:29查看AI文稿AI文稿
01:29查看AI文稿AI文稿很多人觉得打中转就是为了赚钱还犯法,水很深,坑很多,都是挂羊头卖狗肉。但我今天说句实在话, 自己搭个纯自用的中转站真的特别划算。你自己用也不犯法, 他可不是单纯的省钱,他也不是光花一块钱就能用上别人上百刀刃才能用的。 g p p t t t 五点五。最关键的是,你能把你所有的 ai 资源都聚到一块,统一调度管理。 如果估计未来两天用量很大的话,搞点试用号放到池子里,用量少的时候 就可以把你的 k 给你的朋友用,要么放到海鲜市场平价出,掉回个血。 资源快不够了,突然不够了就去同行那平价掉一点。而且你自己的服务器自己的服务 调调,用你的中转站也是非常的顺手。我真心觉得哈,只要是你日常消耗仇恨,你就必须得有一个自己的中转站。
29白菜AI
