Qoder开发的功能如何回退
大家好,我是抠的那个呃,那个 agent 的 一个技术同学,然后叫卓志鹏,然后我们最近发布的专业态模式啊,今天是一个非常好的日子,今天前段时间其实我们北大发布了允许一部分小部分的同学来跟我们一起共创,然后内测 就是测试了一把,然后今天我们会全量的,然后给大家发布,所有同学就只要是我们的会员都可以使用。另外的话我们今天也会全量的,我们上了一个 auto 模型的选择,到时候大家的成本也会得到一个比较大提升的一个优化。好一会我会给大家演示一下这个模式 啊,我们可以简单前面先先聊一下整个的 ai coding, 其实这这几年 ai coding 变化真的很快,前几年的时候我们 最开始的 code lab 的 出来的时候,我们可以看到啊,还是辅助编程嘛,大家可能用过,就是说我敲了点代码,然后呃他帮我补全一点点的东西嘛,就比如说帮我我写几个字母,帮我补全一个函数嘛,那时候 可能对我们有一点生产力提升,大概百分之三十吧。然后在前两年的时候,我们有很多人协同式的编程,就是说我给呃 ai, 然后开发一个小任务或者几个文件,让他编辑一下,然后 生产力得到了进一步提升。现在我们包括我们的专案模式,我们在倡导 ai 自主式平等,自己互相写作的,把一个非常大的任务帮你端到端到完成好,这个的生产力提升是非常高的,未来的上限可能有十倍的生产力。 对,这里我没有用到体校词啊,我就用的生产力,我觉得 ai 能让大家,比如说以前你能做,比如说你一天能做一个软件,现在真的是一天可以做十个或者上百个,就是整个的生产力,包括整个公司的生产力都会提升到一个非常高的水平。 这是我们抠的一个产品的全景图,我把它稍微放一下,对,我们针对于不同的开发者,其实提供了多种形态的产品。对于 vs code 的 开发者啊,我们现在有呃抠的 id, 就是 我们现在主要的产品 and native id。 还有对于有很多同学,国内嘛有很多同学还在用呃 jade breeze 系列嘛,包括拍叉吗? go down 的 呀,还有一些 java 用户,我们也是有提供呃 jade breeze 整个系列的产品, 嗯,包括,嗯,终端。还有大家可以把呃用我们的 code c l i 把它集成到你的各个研发环节里面去,然后做各种自动化的事情,嗯,也可以,大家也可以体验一下我们的 code c l i, 然后今年,今年我们呃把我们整个嗯 code 的 一个生态版局扩扩充到整个的日常办公。 很多非研发的同学现在也可以享受整个呃 ai 的 红利的,就用我们 codewalk, 大家比如说日常的办公,去做一些 ppt 啊,做一些定时的任务啊,然后去做一些数据分析啊,处理啊,我们 codewalk 在 呃发布的这 一段时间以来,其实获得了非常高的好评,大家也可以体验一下啊,下面是我们呃,那我们有这么多产品,然后怎么样保证我们 整个的呃这么多的产品,智能体,它效果又好,速度又快,然后大家拿到成本又低呢,就是由我们的多智能体架构,还有我们的丰富的上下文的引擎,我们每个工具级都是经过我们金金条的,还有各种的 memory 自动化的记忆,然后承载了我们所有的产品。 还有我们帮大家做了自动化的,比如说啊页面,呃整个市场上会经常会出非常多的模型吧?大家有非常焦虑就是一段时间会出一个新的模型,一段时间会出一个新的模型,到底怎么用呢?其实不同的场景 其实是可以用不同的模型的,然后以达到一个最好的效果以及最好的性价比的。然后我们内部其实自建了一套比较非常完善的一套评测集,然后来帮大家去呃去选择更好的模型提供给大家。 对,还有呃还有一项就是说这下面在技术设置层面,其实我们应该是呃提呃全球顶尖模型,提供最全的就是各种顶尖的模型,全球最好的模型包括我,我们这里面都有,我们也 针对于呃扣定场景自训练的,我们啊各种尺寸的模型,包括大家之前看到我们的呃昆,嗯扣的昆扣的这个模型,还有包括我们各种补全模型,其实我们全尺寸的模型都有在训练。 对,其实企业里面啊有非常多的问题啊,就是我们其实是为了解决企业里面的真实软件的问题, 而做着这一套 ai coding 的 产品。就比如说企业里面的工程其实比较大的很多,因为我之前接触过一些代码,可能都运行了十几年了, 对,其实非常大。那那怎么 ai 的 窗口大家也都知道 ai 的 context 一 共就那么点大吗?怎么让 ai 能拿到更精准的上下文呢?其实我们在上下文工程做了非常复杂,复杂的包括我们 运用了各种,比如说语域剪辑、图谱剪辑,然后还有我们的 vk 记忆等各种方向,然后让模型在更针对你的需求,每一次都能拿到最精准的上下文。 然后我们还解决一个非常大的问题,就是呃隐性的知识显性化,就是之前的时候基本上大部分企业呃像像传统的时候,大家都懒得去维护文档,就你写个需求,大家都催你上线嘛。其实这个也能理解,就是比如产品催着你上线,你老板催你上线,那就很难 去呃去更新和沉淀你的文档吗?然后有新同学进来的时候,有很多的知识其实都是对不起的,因为之前都没有被记录下来,我们现在做了呃呃隐性知识显化这个东西,就是说我们把可以自动的帮大家去生成这个 vk, 大家用我们的呃 i d e 可以 一键就可以生成整个你文档的这个呃知识。 当你有需求,就随着你在我们这个平台上不断的对话,不断的去输入你的知识,然后呃 我们可以把你历史这些所有的经验都自动化的沉淀下来,然后自动化的记录到你的知识里面。对,然后我们也提供了就是 select 这样的方式,就是说让大家在 呃开发开始的时候,你先把所有的需求先跟 ai 聊清楚,聊好规范,聊好我怎么验证,然后再去让 ai 实现,这样可以减少非常多反攻的问题,然后呢?呃最终的校验的呃结果也更加的可控。 对啊啊,上面是对整个行业还有我们一系列产品的介绍,接下来讲一下我们最新发布一个专家团,我可以给大家先看一个视例哈。 呃,大家可以看到我今天呃这这个分享这个网页像 ppt 这个效果啊,其实其实就是我用我们这个专家台模式来做出来,就完全像 ppt 的 一个这样的效果一样。对,还支持这样的啊,整个的 缩放啊、跳转啊什么之类的,我们可以看一下我们的专家团长什么样子,对,可以。呃,我跟他做一个需求,就是现在大家可能有非常多的啊, a 阵他哈,然后我就让他做一个 a 阵的协助面板,然后我就发给他一堆的需求,然后他会 呃我,我们会自动去帮你做这个意图的澄清和计划生成。可以看到前面就说他执行了一个 啊,一些执行建议,然后这里还有就是说啊,就可能会问我一些问题,然后然后跟我澄清完之后,然后顺便了解完整个仓库之后,然后会生成完整的这个 呃计划实行的计划包括就说我要我要怎么选技术的选型,然后我项目结构是什么,然后我要怎么验证,会帮你生成整个的计划,然后如果你觉得这计划你不满意,你就可以跟他继续的对话,直到这个计划 啊满意之后你就可以批准这个计划。在这里我们会有一个,但我这已经点了按钮,这里会有一个 build 按钮,点完之后我们的所有专家团就会就开始逐步的拉起来去帮你执行完所有的计划,可以看起来我们这前面 我们会动态的生成呃,很多专家一起来帮你做成事,比如第一个他会去生成啊,我们这个脚手架就基座搭建,接下来我们大家可以看一下 我们这个功能是 nick 已经在搭建的项目架构,然后它完成之后才会进行后端和前端的一个并发的执行。可以看到它执行完之后, 然后它就是说啊,我那我前后端并行的开发整个的这个任务的这个呃调度机制、协调机制,都是由我们的这个呃呃 leader agent, 然后它来完成所有的调度和协调。可以看到我这里有呃这么多任务,我们可以看一下 有这么多的专家,就是呃就是全部都是由我们这个一点一的自动生成的。就是比如说 呃我们前面会做整个项目的呃呃图纸化搭建,包括后面我们的集成验证代码的审查,然后浏览器的呃验证,然后中间出了问题,他会自动的修复,然后最终给你端到端的一次性就会产生一个可以运行的一个项目。我们可以看一下我,我这个跑出来一个样例, 大家可以看到他写的都是浏览器的这些全部都是浏览器自己去调用我们这个 chrome 去跑测试产生,然后最终他跑成功了,然后会把测试报告给我,然后这就是 呃一次性就完事的运行出来一个项目。对,这就是我们专家团模式,我们可以来了解了解一下为什么我们要做这个模式,这个模式能给大家带来什么好处? 其实的时候就是之前的时候,我们大家可能只有一个 agent 嘛,它是其实有很多的问题,就比如说我只能串行的执行,我可能最开始的时候我我做完呃前端,然后等后端改,然后还有测试,这里好像还有很多的角色的 呃呃存在里面,我要好多角色一起来做才能把这个事情做完。第二呢就是说因为我角色多了,然后我的上下文也长,然后呢我角色之间也有沟通成本,所以我的上下文是非常容易迷失的。然后一个 a 阵呢,其实很难去做完所有的事情, 然后大家就可能要去找非常多的 agent 同时来去呃做这个事情,这个成本其实也非非常高的一个 agent 大家也知道模型有幻觉吗?单一个 agent 其实呃很容易出现一些,比如他幻觉了之后啊质量,不把质量呃不好啊什么之类的,就没有人管他最终可能说你要花大量的时间跟他 呃协助,然后去帮他把质量给提升上去。然后在我们这个模式下的话,你呃对于我们用户来说就就是你只要说一句话,我们可以把整个呃我们研发任务这个调度系统全部 交给我们这个 leader 呢, leader 呢是一个非常聪明的超级大脑,他来筹筹所有的事情,他可以去调度啊,我们的前段专家、后段专家、调研专家,还有测试专家、评鉴专家啊,他会安排好你们几个该怎么做, 然后你们几个的病情顺序是什么样子的?然后如果中间比如说出行出现了任何的问题哈,我们这个最强大脑会全程的协调,然后我们会呃这个最强大脑,如果你中间出了一些 呃,比如说呃进度上的问题,或者需要确认的东西,我们这个啊最强大脑都会来去介入进来,然后去帮帮帮这些子的专家,去解决好所有所有的问题。比如说呃前端,后端如果同时改了一个呃呃文件,然后他们冲突了怎么办?然后我们这个最强大脑啊,全部 都会来来来来做出这个仲裁和解决方案。大家可以看到,因为我呃这个模式和大家之前那种协调模式不一样,大家,呃这个由于我们的最强大脑来承担了大部分的事情嘛,就怎么和和这么多 a 呢?对齐,如果是以前的话,你一个人 可能要和这么多 a 人才对齐嘛,所以你可能要花百分之九十的时间,就你平时工作啊,可能要花百分之九十的时间和这么多专家来对齐。现在的话因为有有超级这个大脑的存在,你可能只要花百分之十的时间了,你的时间就会大量的被释放出来了, 你就可以去做更多的事情了,你就可以去找好几个这样的超强超级大脑,去去去去给他派更多的这样的任务,然后你的生产率就会得到非常高的提升,而且在我们这个情况下,因为我们默认内置了, 呃就是调研专家呀,测试专家啊,评审专家,你一次性拿到的质量也是非常高的,就是不用你反复的去跟这么多 agent 打交道协调了,就是减少了非常多心心累的历程。 对,我们呃其实之前的时候也有一些用户问啊,就我们和呃有些同学会用一些 setup agent, 我 们和一些普通的一些多 agent 有 什么区别呢?刚才看到的所有的专家哈,每一个都是 我们呃经呃精心调过的,就是我们每一个专家都在,比如说业界公开的评测集上,还有我们自己的评测集上,然后呃在成本啊、效果啊,都是呃 比较领先的一个水平。对,然后我们的呃和普通 safari 呢,还有一个很大区别,就是我们这里所有的专家都是一步携手运行的。 之前的时候你调一个多 a g 的, 你比如说我同时调了三个,三个 a g 的, 他可能说我三个一起做完之后就三个三,三个方阵扣嘛,然后回来之后我可能才会进行下一轮任务嘛。现在我调了三个专家,然后他就干活,比如说前端干完,我就可以说 呃解锁了前端后面的验证任务,然后这时候我的效率就会高很多,然后其他两个专家他他谁干完,我就可以呃可以进行下一步的伪派了,就不用等所有的专家一起做完, 嗯,再进行下一步。另外就是说用户其实可以随时插话的,就以前的时候你交给 a 阵的,其实做一个活嘛,就是说啊,我可能就说要打断他,就是你说你之前之前的时候,你说 帮我写一个网页,然后你这时候插话,你可能说我要先停一下,然后我再给他插一段号码,现在不用了,在我们这种情况下,因为所有的 a 证都是异步运行的,你可以随时随地跟主说话,我现在做这个 ppt 的 时候,我就会跟他说啊,你帮我把这个 ppt 第一页改,然后我然后我继续给他插话,第二页改成什么样,第三改成什么样子,我可以给大家看一下, 就整个今天整个 ppt 我 就会给他就是这样一直不断的给他派任务,就这个你干一下,这个你干一下,其实别的一阵的可能都还在干活,但是我可以不断不断不断不断跟他去调调调调,去干更多的活,然后不断随时的去给他插话。 对,然后在我们这个机呃呃多一些的模,在我们这个专业台模式下,我们自己帮大家做了记忆的机制,我们可以实现 呃个体和团队团队的双重进化。这个怎么理解呢?就是说我们不是有很多专家吗?每个专家我们其实都有自己的记忆,都有自己技能,我们可以根据他历史执行的经验,他自己去迭代成长吗?就比如说,呃,你的前端专家, 你可能就是说呃,会,会不断的学习你的偏好,还有你的仓库的偏好,学些前端知识,然后这是对于个体来说,就是每个专家其实都会学习自己的技能。另外我们整个团队也会进化,就比如说整个我有那么多专家,他凭他怎么去更高效的去委派这些专家,怎么样? 我去伪派这些专家的时候,能让他啊出错的频率更低,然后呢?然后返工的频率更低,然后其实我们也会自动沉淀整个团队的这样的一个学习的经验, 对,这就是我们整个的记忆知识,就是你在我们的平台上,就是我们不仅有,就是 啊,你的仓库的知识,你的个人偏好的知识,然后你们团队的知识,然后我们都会不断的去记录下来,学习下来,然后包括就是刚才提到的有沉淀,我们整个的,呃,就是每个专家的技能,然后我们整个团队的技能,整个编排的技能,然后最终你你用的多一点,然后就会成为一个, 呃,我,我们这个整个的专家团就会成为一个非常和你配合非常默契的一个搭档,然后你用的越多,然后你的生产效率也会越来越高。 x 模式,然后刚才分享了一下这个模式,那对大家来说寓意我是什么?然后可以帮大家,呃。就是带来什么,然后呃,因为现场可能有很多超越个体啊。就是, 呃,因为,因为我知道,就是之前有很多同学可能都呃呃,也听说过,就说 web coding, 其实可能交付来代码是不都是玩具,呃。在我们这个模式下可能可以尝试去打破这个 啊限制,就是说啊,第一个就是说啊,因为我们这个 lead, 呃。如果,如果你之前你想要交付一个比较啊,质量比较高的代码吗?你可能需要同时学会按这个前端怎么写, 呃,至少你要学会怎么跟前端这个专家沟通需求,你要跟后端专家怎么沟通,你可能不需要说我具体前的代码怎么写,但是你要知道他的他怎么做算好, 前端怎么做算好,后端怎么做算好,测试怎么做算好,频审怎么算好。那现在的话由我们的一个超强大脑来和这些专家协调,其实你不需要学那么多技能了,你不需要去学前端后端测试频审, 然后还有还有什么页面测试都不需要了,因为我们有个超强大脑,你需要学的只需要瞄政治需求,跟我们这个超强大脑去协调就行了。所以我是觉得在我这个模式下,然后每呃全站的这个成本其实 得到了非常大的一个降低,然后高质量的门槛然后也降低了,因为我们自动会帮你做好各种各样的审查测试。 你一次性拿到的代码啊,就是一个质量比较,就是比传统的那种斜通模式质量会高很多的代码, 然后,然后当然带来好处,就是说你一次性可以也交付更多的代码了。就就是有两个方面,第一个就是说呃我们的多专家是并行开发的, 他们可以前后端一起来做。第二就是说你其实可以去呃同时指挥多个军团了,因为以前的时候你只能一个人和一个 a 阵的交流,现在你一个人可以和十个甚至二十个这个军团去交流了,你一个人可能带几几十个军团去呃作战了。你可以并行推,不同的项目,不同的场景都可以去做了。 对,其实整个产研不同的场景都可以去做了。对,其实整个产研都可以去做了。对,其实整个产研都可以去做了。对, 整个产业合作可能也会发生一个比较大的变化。之前的时候想想我们传统的研发产业流程,其实其实是一个非常串行,效率非常低,然后功能成本也非常高的,就比如说 pm 去写需求,然后再开始技术评选,再任务拆解的开发编码、 自测、 tpr 等等非常长的一个流程嘛。现在的话,因为我们把所有很中间的很多环节一起打包,都给我们的超级 agent 来推, 来协调和推进了,大家可能需要做最重要做的,就是说我前面描述描述清楚好需求,然后我们 delete 呢,去把所有东西拆解好,然后去协调好,去执行好这个东西,然后最终你来做一个最终版本的验收,验收就行了。对, 然后其实其实昨天有同学来问我,就产品经理可能有没有什么变化,然后我来分享一下,就是说其实,呃,在我们这个产品里面,我们这里有很多这样的事,图嘛,其实都是我们的,呃,产品啊,设计啊,先把这个原型给做出来, 然后我们的前段同学,然后再来做一下最后的审核,然后上线。其实那那未来的话,前端经前端的这个产品经理是不是, 呃,也可能有些变化,就是说比如说前的,呃,我们的产品经理有些想法,他可以用我们整个的产品去快速的做出原型,然后他看看好不好, 这个交互好不好,然后这些功能好不好,可疑性好不好,然后最终交付给研发的时候,上线就非常的快了,就不用再等前面啊,我要等,哎,我写了,我有个想法,我要等前端帮我去做一下 demo, 然后他可能要前端同学可能要排期,然后整个流程就非非常的长,大家可以看一下,就这里的很多东西,就包括我们这里的仕图呀, 然后啊我给大家切到这个 express, 就 我们这里的页面那些彩蛋啊,很多同学都是我们的设计啊产品同学,然后来自己搞的,等我们这个画布也很有意思,大家也可以去玩一玩。我们在我们这个呃画布是一个无线画布,大家可以在里面打开, 每个都可以看到每个 agent 的 东西,当然大家如果想看单个 agent 的 执行的情况,也可以点开这个,我们也有大屏,也有一个汇总的 xbox covers 来给大家玩。对,这些都是由我们的产品设计和端子同学一起来写作去搞出来的。 对,我们也是在用这个专家团模式迭代我们的专家团模式,那我们刚刚介绍了我们这个呃这个模式能给大家带来什么样的好处?适用的场景,那我们这个模式怎么做呢?我们会简单分享一些,呃我们这的一些技术的实现和一些思考。 呃首先呢就是,呃在在大家看得到层面哈,就是我们的应用层上面,然后其实我们就是有一个主控的 agent, 就是 我们的超级 agent, 它会协调所有的专家,大家 就是其实我们的主,呃这个超级大脑其实它是用的一个确实用的一个非常好的模型。然后其他的几个专家呢?我们都是经过啊经调的模型,就是可能不是,呃就它它在这个领域,比如它在调研领域 非常好就好了,那成本也很低,速也非常快,然后达到一个综合,呃比较性价比比较高的一个版本,然后每一个专家都是经过我们的一个特调,然后我们的主任呢,然后会进行各种,比如说,呃这种流程啊,一代编排就说他可能说啊,我先 我先去调研,然后其他有几个可以并行,最终可能是不是有些专家可以去做这个集成测试,然后中间就是我们这个整个的中台层,我们 的整个的上下文引擎啊,搜解锁服务啊,通信服务啊,还有我们的文件编辑服务啊,有一大堆的能力来支撑起了我们的呃整个上面应用层的扩展。 然后在我们这个模式下,所有的 a 阵呢,都是异步并行的去做的,就是我们这个这个 experts 这个 leader, 然后他会,他就是会异步的去派一个任务,派完任务之后他就会进入一个轮询等待,就说谁干完了,然后我就去看看谁啊的一些工作报告, 其实真的很像人,就很很像一个就是呃一个技术 t l, 就是 发现,呃,就是我派活派完之后你们谁干完了,他会通知一下这个 t l, 然后说我干完了,然后 你来看一下我成果,然后他干完之后他就会去呃评估,然后然后评估,哎,你干的怎么样?你干没干的好?如果没干好,然后我再找一个人干,或者说是你再去修一修,然后如果说啊你干好了,你后面是不是还有别的流程?你去干,然后我就会呃重新的去派遣新的专家去做后面的事情, 对,然后所有的呃专家都是一,都是一步不堵塞的。对,然后我如果中间的话,比如说我们的专家有些问题我们是支持, 比如说我们这个后端工作室,他发现哦,他拿的上下我们不够,我们是有个机制,他会自己的去找我们的这个 lead agent 去要信息,就说,哎,你这个任务是不是没有给我全啊?然后他就会,他们俩就会自我自己协调啊?然后他就会说,哦,我是,我是有个东西可以 没给你,然后我就给他,还有一些东西,我们可以把一些高级的健全放在我们的主页这层里面,有时候我们会发现哈,就有时候我们的前端工程师发现啊,他有些健全没拿到,他去找这个 lead agent 的 去拿,然后他可以授权给他。对,然后如果 lead agent 的 发现他自己也没有这些东西,然后他再去找用户, 对,然后最终人啊,我们的用户和我们整个的系统交互,只需要和我们这 leader 交互就可以了,对,所以 leader 就是 我们整个的中疏系统,然后我们其实所有的 agent 之间都是通过我们这个啊一个信箱的机制来实现的,就是 其实不管比如说用户怎么和怎么告诉我们这个呃,立德 a 呢?有什么事情,我们就是给他发了一条类似,大家可以理解,我发了一条消息给他,然后然后他会不断的去轮询,看看,哎呀,这时候有没有用户发来的消息啊,然后就他就自己看自己的信箱,然后他他有时候会看看啊,有没有 别别的专家说向我寻求帮助啊或什么之类的。他就是大家都是就每每个 a 制呢,其实都有一个自己的信箱,然后我们去管理维护了所有的信箱的这个 呃状态,然后其实有些同学会问我们为什么啊?不让这几个专家之间自我对话啊?其实我们觉得就是这就牵扯到一个问题,就是 呃整个 a 证的自制问题啊,就有些 a 证的一个架构,其实其实呃在走长这样路线,但我们觉得当前这个阶段,如果让所有的 a 证的自制啊,其实自制需要每个每个 a 证的,比如说呃呃,我浏览器 a 证的调研的,他们其实都要 稍微有一点大局的概念,另外就是他们也需要一个比较强的大脑,他们才能理解啊别人干的事情,然后理解整个团队要一起摸摸啊,往下一个阶段, 然后因,因为我们想给啊,因为因为我们觉得这样子的话啊,我们每一个子的 agent, 其实啊我们子专家都要分配分配一个比较好的模型,其实在当前阶段对大家来说成本是不划算的,可能带来的效果也比较差。 当然我们支持的这个能力,未来会逐步的随着我们的眼镜会逐步逐步的把这个自制能力开放给大家, 对,这就是我们的自净化机,如果大家呃呃,如果大家用的过程中会发现右下角会有个卡片,然后我们就会呃,其实就意味着我们整个的系统给大家学自动学会这些技能出来。 就比如说呃大家任务完成后,其实我们会呃触发一些信号,触发信号之后呢,我们会呃经过我们整个的呃记忆引擎去去把这个技能,比如说我们看看你这个这个东西啊,是你这次的对话有没有些经验可以提取啊?有没有些 你以后可以附用的啊?然后我们就把它呃呃做一些打分,然后呢经过,当然我们这个打分机制也是很复杂的,存储机,然后然后如果觉得它还是个质量比较好的,我们就会把它存储下来,然后面推给用户。当下一次,比如说你,你又提了一个新的任务,比如说你呃上一次提了一个 什么呃什么呃支付模块的,后面你又提到支付模块了,那我们就可能就可以把这个记忆给你召回出来,然后给你后面的整个的专家团和编排团啊,一起去用,对,然后指导你这个下一次那个呃专家团更好更快的完成。 可以简单认识一下专家团,就比如说我们有调研专家团,然后他其实可以去做方案的,调研一些问题的 bug, 然后还有些业界方案调研,比如说你可以让他去做一做啊,最近很火的什么小龙虾啊,业界有几个呃方案啊?然后啊我,我之前做了一个案例,就是说啊, 大家现在不有很多小龙虾,我想做一个自己小龙虾,我就跟我的这个整个专家团说,你先你帮我去研究一下业界这个整个的小龙虾实现有很多开源项目嘛,他就自己去 并形成了好几个调研专家,帮我调研好之后,然后自动的去帮我去把它实现出来,就整个调研到实现,我们整个专家团可以一次性帮你做出来。还有我们的编码专家,他可以去做这个功能的实现啊、 bug 修复啊,呃重构啊、文件操作啊,然后各种各样的东西, 还有我们的这个 q a 专家,他可以去做,呃,你的需求有没有完成啊?你的完成功能度有没有?呃,有没有?是不是全全部覆盖了呀?然后你的单册能不能执行啊?然后你里面是有没有些翻译错误啊?有没有些回归的问题啊? 还有我们这个呃呃评审人家,然后我们会检查你代码里有没有一些嗯 漏洞啊?有没有些问题啊?我们都会帮你做出来。然后我们我们这些呃专家,呃呃,就是,呃,其实底下你看到是一个专家,其实下面都是由我们整个的这个上下文引擎来支撑起所有人,比如说大家改了一个代码, 是吧?你改了一个片段,传统的一些啊代码 c code review 可能就是说,哎,我拿你个地方问问模型有没有什么问题?那其实它可能是不是有一些影响到其他模块了?有没有一些调音调用链?就是你你调一个函数,它会不会影响到呃你的一些依赖函数什么之类的?其实我们整个的这个 占位引擎会帮你去呃拿到所有的调用链,所有的场景,然后进行啊非非常一个详细准确的一个分析。 对,然后还有就是我们的一个呃浏览器专家,然后我们可以去通过我们的这个浏览器的一个专家端到端去帮大家完成这个呃交互的验证啊、 u i 的 检查呀,还有一些 呃测试啊,然后它关键的一些节点,就比如说你这个页面没有完成,或者你页面有什么问题,它都会自动帮你去截图作为一个凭证,其实真的很像一个,呃,就是前端的一个视觉呃验收的一个同学。然后我们也和业界的一些 m c p 方案进行对比,其实 呃能能比业界的一些你纯用 m c p 的 方案可以省百分之六七十的一个呃这样一个 talk 的 一个消耗。 然后我们其实也和我们元欧的 agent 的 模式啊,还有拷扣的最近也出了呃那个 agent 的 teams 模式,进行了一个 对比嘛。然后我们的整个的呃质量其实相比于我们原来的集成的其实可以大幅的提高,就一次性的质量就不用你返工,然后我们的比呃业界的一些产产品的话成本也是更低的。然后其实呃最后是谈谈时间哈,就是 我觉得大家评估时间的时候,之前大家可能会看,哎呀,我一次对话时间,其实其实我觉得一个更合理的口径是你完成你这个需求所需要的时间。 之前的时候如果你用传统的 a 证的模式,你可能是通过啊多次跟他对话,多次跟他盯正,多次修改,当你追尾很多次之后啊,返工很多次之后,其实那个时间其实可能比我们这个专业的模式要长非常的多,你要不停的呃介入去配合他去返工。 对,所以所以综合周期来说,我们这个模就是完成。从一个需求的维度来说,我们这个模式下的时间应该是更短的, 就可以推荐几个场景啊,一个就是说比如说做一些前后端啊,全站的开发,还有些复杂的问题的定位与修复啊,还有一些技术方案调研 啊,技术调研,刚才我讲一个龙虾例子吗?其实我现在我就我我就有点我感觉,呃,我已经全部就是在技术调研方面,我已经全部用这个模式,因为他可以启动非常多的专家,我从多维度的帮我去找,另外就比如说有些专家他可能找的东西有问题,我们的整个的最强大脑会帮他去 自纠篇,然后去,然后可能还会去派一些新的专家,从别的角度去验证一下。哎,你调研的对不对?最终拿出来报告都是一个啊,质量非常高的报告,一会给可以给大家看一下。 对啊,那我们现在有两种模式,一种 a 阵的模式,还有一种 x 模式,那那他怎么去?什么情况下去用哪种模式呢?就你如果有一些非常明确啊,简单的一些 啊啊,小功能修改,你就用我们的 a 帧的模式,其实啊很快,然后你也因为你也不需要协调,你也不需要返工,你就让他去做就好了。如果你涉及一些比如多模块的开发呀,你需要去研究之后才能实现,然后你还要做测试, 还有一些非常重要的功能,你需要非常高的质量,尤其大家企业级代码都非常要求质量。就是呃,我们可以推荐一下用我们这个专家团模式, 然后有些 moment 呢,可以分享给大家一下。就就比如说就是呃,关于呃,就是我们呃,就是这这整个字协调这个体系带来一些 呃,一些一些我我觉得还还还比较不错的时刻。就比如说大家看左边那个图,就是说有一个研究员 tina, 他 觉得是版权问题,拒绝的任务当然是他,当然后呃这个问题我们实实际排查下来,发现啊,是他的幻觉问题 啊,你看主任都说用于调研参考完全合理,然后如果像传统的模式下,可能说,哎,我人要去跟他说,你到底能不能调研?你能不能帮我去再试一下能不能调研?但现在这个模式下,我们的 leader agent 呢?直接就说啊,我评估了调研完全合理,重新派了一个 agent 去替换了那个专家,直接去做了。 对对,然后我们这个 leader 的 自求编辑是,呃非常好的,还有就是动态任务的分发。那看到这个我画红线的点啊,就是说 啊,我们前面有个审查员呢,然后发现了,发现了别人,呃有有些问题,然后,然后,然后,然后他就会发现,哎,这里有个工程师正在干活,好,那我就直接给他,他自己去,嗯,修,让他一定去修了吧。对,然后他这个动态动态任务分发能力也是非常强的,这样这样这样效率也是非常高的。 有些最佳实践的和玩法,因为我们这个模式就是,呃,呃,其实是你做好,呃,希望是 呃有用户,呃和和我们整个的 lead agent 先对齐好你的需求,然后把整个的计划玩好,之后我们会有多个专家来来帮你去呃对齐,呃,就是完成你这个需求嘛,就包括去实现这个东西,然后去 呃去做自动化的审查验证,那前提就是说你可能需要有一个比较正确的方向,正确的目标给用户。 我们在我们专案模式下内置的这样的一个 plan 工具,它会自动的去识别你的需求,如果你的需求复杂的话,我们会自动去调调起这个工具。当然呢,如果你觉得啊,他有啊,他有时候积极性没那么高,你可以自动的去用我们这个杠 plan 的 命令, 可以随时进入规划模式,就是大家可以试一下我们这个斜杠 mini 这样内置的一些智能体啊,就比如说我们这浏览器啊, code review 啊,还有这个执行计划,大家都可以也可以用过用,用过用用我们的这些内置的一些技能去创建你自己的智能体,创建你自己的技能,对,你只要跟他说就可以了。 以前的时候啊,其实大家的,嗯,就是我觉得有用了这个模式之后,大家的工作的模式可能也会发生一个一些变化。以前的时候你可能是要告诉 a 技能你要怎么写代码,怎么写代码你要怎么做怎么做,接下来时候你可能还还可能会升级一下你的技能,就可能是说你要告诉你这个 非常强的这样一个大脑,说你要怎么编排你的这个团队,这样后面也可能会成为一个一个大家比较重要的一个技能。 呃,那怎么样去定制专家?就我们内置了很多专家团啊,但有些呃大家可能有自己的业务啊,有可能有些自己的 呃专家呢,比如说有人要做金融,要做文档,其实我们也是可以呃去把你的内置呃大家自定义的专家团, 呃自动内内置进来,大家可以用,要么就是说用我们刚才演示那个斜杠的命令 create agent 去创建出你自己的状态。如果大家已经有一些呃呃指的一些 agent 可以 直接放到我们这个命令下面,我们会自动的帮你去加载进来。当然如果你想说有些场景我就是要用某些专家来做, 可以在我们的命令中就直接斜杠,然后输呃,换起几个专家就可以了,就是,嗯,就比如在这里,然后我直接换起来就行了,我们会优先使用你的专家,这些所有的调度过程都是自动的。 然后,呃,这是,这是几个我自己时呃实践中的场景啊,就随时追问派活。大家看到这里是个 in progress, 就 它还在运行中嘛,就是上面这个专家还在干活,然后我,我另一个页面页面我就给他一说 啊,这个稍微大一点,他就又派一个,这样就是你可以,呃,以前的时候你可能说,哎呀我,我派一个任务,我要等个几十分钟,等他干完了,他现在你就可以随时不断的,你就一直丢活给这个主任就行了,你就一直一直丢,丢给我们。就这样的说,你再给我加几个活,再加个加,你一直跟他说,行,他自己会卸掉所有的活,然后不断的去 拉新的人,然后你这个团队就是无限大的。就是,呃,比如说你就是,就是,比如说你有你,你先给他派一个活,后面你可能说我要拉,再拉一百个测试同学,然后你,然后他,然后你再给他丢个任务,他就可能去拉一百个测试同学来帮你干活,然后是可以无限扩大,无限自动扩大的。对, 然后啊,我这里还有一个话,就是说如果你发现比如说他们有些干活干偏了,或或者说是 啊,你有更好的方法,你可以直接告诉我,你的主 a 阵的,他会自己去告诉他的员工,就是他带拉起那些专家去自动调整。大家可以看到我跟他说,你告诉运行中的 a 阵的你不要怎么样,你要怎么怎么样,他就说,哎,我已经通知了 这个利益和他的啊,只用什么做,不要重写这个东西,他非常的聪明,他会和他拉起那些专家去进行沟通和写作 啊,还有一个非常好的玩法,就给专家起个名字,这时候,这时候我们同学呃就内部就会会把自己的同事, 然后名字,然后放到我们这个呃褥子里面或 memory 里面,或者 hdmi 里面都可以,然后你就会发现你甚至还可以把你老板的名字写进来,让你老板帮你打工,大家可以看到我这也就是说,哎,有什么张三李四啊,奥特曼啊,王五啊,王大锤啊,对,这是一个非常有趣的玩法, 但我们的编码工作也可以变得非常有趣,对,可以把自己的同事们都加进来玩一玩啊。最后呢,我简单介绍一下扣的这个企企业版,就是我们呃扣的有个人版和企业版, 然后然后我们的企业版,嗯,简单介绍一下我们的这个核心能力,嗯,一句话总结就是说我们提供了全球呃这个整个最完整的最顶尖的大模型,大家看到的就是听到的,然后所有顶级的大模型我们这里前面其实都有,然后我们企业级的知识引擎啊,知识库啊,然后还有我们的多智能体能力啊 啊,我们都是帮大家内置进来的,对,然后我们其提供了全套的这个研发全家桶,包括我们的 ide 插件,还有我们的办公的智能体 codewalk, 集成的智能体 cci, 然后也可以去把我们的 code review agent 去集成到大家的这个研发流程里面, 对,然后我们期望是呃跟大家一起融入,然后融入到企业里的每个环节,帮大家去办公,写代码,省代码,跑测试,还有自动化上线,然后整个流程都跟大家一起去呃共创, 对,然后我们也也给大家支持的自迭代的这个知识引擎,然后大家自由呃私域的企业知识,然后也可以内置进来,然后让我们的这个 a 阵呢,更懂你的企业,更懂你内部的一些呃业务,对, 然后在这个安全效率方面,我们其实是支持大家在企业用户啊,支持大家给这个代码仓库分级打标的,然后允许你根据分级打标去呃选择你的一些比如说合适的模型啊,然后我们接下来也会对我们整个的 呃呃规则啊, role 啊,然后 mcp 啊, skill 啊进行管控,然后针对于企业级特性会有很多的能力会开放出来,大家也可以通过我们的企业级报表去看到大家的一些,比如说代码的产出啊, ai 生成占比啊,然后还有一些呃分析数据啊,对, 都是可以来做的,对,这个大概是我们的一个价格,就是然后这里换成人民币了哈,然后两百二,每席位每个月,然后会有两千的 credits, 然后两个席位就可以呃去呃去购买文企业版,然后也是可以支持开发票的, 对,然后接下来上面就是我的分享,然后欢迎大家体验我们这个专家台模式,然后最后一句话就是呃希望大家呃我们这个模式能更快的助力大家成为这个超级歌体吧, 就是我们这个模式能帮大家去真的能提升十倍的生产,利用十倍的 talk 换来十倍的产出。对,好,谢谢大家,嗯。

粉丝2.6万获赞4.3万
相关视频
 39:39
39:39 07:53查看AI文稿AI文稿
07:53查看AI文稿AI文稿最近阿里旗下的 a i d e q 的 更新到了一点零正式版,相较于之前零点几的版本呢,这次更新增加了很多实用的功能,而且体验十分优雅,今天大家一块来品尝一下。 我们打开 q 的 你会看到一个非常熟悉的 id 页面,可能有朋友说了,哎呀,这也没有变化呀,一点都不酷,甚至有点平庸,你看你又急, a i d e 不 都长这样吗?但是当我们点击右上角的这个快捷按钮,打开任务模式, 你会看到一个全新的页面,全新的设计。在之前的版本呢,快捷的只是一个模式,它跟这个编辑模式呢是互斥的,你要么使用编辑模式,要么就是任务模式。但是这次更新的 qd 一 点零版本,它做成了一个独立的窗口,你可以同时打开你的编辑器,和快捷的模式 并行的去操作。这个设计风格呢,有点像 codex, 简约刻制,你可以注意一下, 稍微有点难崩,但是它的功能更加的丰富。左右两边呢是各有一个侧边栏,中间是一个对话框,我们可以在左侧新建任务,或者直接打开本地的工作区。当然你也可以直接在对话框的上方,在这块去直接切换。 如果你愿意的话,甚至可以用 s s h 去连接远程服务器,让 ai 直接在服务器上去进行开发,对于一些把项目跑在云服务器上的朋友呢,比较友好。 剧情模式这里呢有两个选项,一个是本地模式,一个是 walkthrough 模式。本地模式呢就是 ai 直接在当前的机器上去进行更改代码跟传统的 ai 定义是一样的,代码都是实时修改的,那这个 walkthrough 模式呢,就是 ai 在 一个独立的 get walkthrough 工作目录中 去认真的工作,改完之后呢,再通过合并的方式回到我们的主分支里,那它到底有什么用呢?为什么要这样去做呢?最大的好处呢?其实它可以并行的去开发任务,更方便团队协助,每个任务都是在自己的隔离目录里去跑,主分支永远是干净的。在选择模式这里呢,我们注意到有一个 agent 和这个专家团模式,就是一直由多个专家组成的团队进行分工协助,这也是目前 a 业编程主流的一个做法。那值得一提的是呢,当我们选择 agent 的 时候,可以自由的去切换模型,包括去使用自定义的 api key。 当我们选择这个专家团模式,后面的模型就不再能选择了,是 auto 和极致这两个选项。 这个极致模式呢,就是有更加深度的推理思考,效果呢会更好一些,但是额度消耗呢也是更高的。那接下来我们就在这个目录下以本地模式开启一个新的任务,打开规划模式, 然后我们直接在输入框里去输入提示词,懒打字的话也可以直接用语音制作一个 ai 导航网站,风格参考苹果公司官网。这个时候如果我们觉得自己的提示词实在是过于简单,过于潦草,那么可以试一下这个优化输入。 ai 呢会简单看一下我们本地的代码,然后呢给我们规范化提示词,毕竟 ai 更懂 ai。 ok, 我 们发送我们的任务发出去之后呢, ai 会先派出一个调研员,专家先来调研我们的项目,然后他会问我们几个关键的问题, 比如说你想要使用什么技术站,想要什么设计风格,等我们填写完毕之后呢,他会再次开始规划,给我们一个全新的清单,根据这个任务的具体需求呢,去动态的分配出一只专家团来执行这个任务。在工具的设置里呢,我们可以看到有五个内置的专家, 但很明显他不是那种死板的配置。比如说我跑的这个任务,因为模块比较多,他直接梳理划出了五个全站,工程师并行的开始工作,加上调研员测试、 u i 操作、代码审核,一共是九个任务,他可能就派个两到三个。这个呢应该就是所谓的弹性团队的设计 啊,班位非常好。我们回到当前的项目,点击这个概要,那在这一块呢,我们就能看到他的任务的实时进展,以及每个专家现在都在干什么。那如果你觉得这个还是不够清晰,那点击这个在专家团全景图中查看,这个时候呢,又切换到了一个格式化的看板式图,就可以更加方便的去查看每个专家他在干什么, 写到了哪一步。那相信各位也注意到了,他分配的任务呢,实在是过于详细,我们实在是等不了这么长时间,没有耐心去盯着这个项目,直到他完成, 那现在其实是完全没有问题的。快速的现在支持多个工作区,或者是多个项目并行的操作,比如说现在我进入了一个新的工作区里,然后我们输入一下斜杠,这个就可以快速调出命令, 可以使用浏览器执行,或者是进行代码审查,也可以让业帮我们创建技能,创建智能体,用在专家团里。那我个人觉得这个代码审查还是比较好的, 你写完代码在提交之前呢,让他先审一遍 ai, 帮你过滤一下,他会指出潜在的问题,给出改进的建议。你可以注意到他的审查呢还是比较详细的,每个代码呢,他都看过了,只不过他好像有点小脾气,意识到我在耍他了。 如果以后你把这项目真的用 get 管起来,再来让我对具体的提交挑刺,我会更开心。现在这种全量审查还真是对你有点太宽容了。我靠,我心里一紧,怎么感觉像领导审我的代码似的。 好消息,代码审核员把你这套视频管理系统从头到尾扒了一遍,结论是没发现什么立即需要修的致命问题,逻辑错误、安全漏洞、灾难性一个没捞着。 不过话说回来,菜,不管我们在做什么其他的项目,原本的那个项目呢,仍然在运行,他没有停止,这个呢就是真正意义上的并行开发,就是多个任务呢去同步的进行。这个专家团队呢,一共分配了十二个专家,每一个呢只专注自己的任务, 然后最后呢来进行合并。里边呢内置了一个浏览器,当它运行之后呢,我们可以直接在这里去进行查看啊,比如说我们的这个一页导航网站, 如果哪个地方觉得不对劲,我们直接用这个选择工具选择一下这个元素,它会自动添加到输入框里,这个时候也可以非常精准,非常快速的帮我们来进行更改,同时这一块呢也是非常严谨,他依然会询问我们确认之后呢再开始工作,避免一些不必要的投更消耗。那下面我们打开设置, 可以在这里更加详细的配置我们前面提到的一些功能。智能体。这里呢除了内置的五个专家之外,你还可以自由的创建或者导入本地的智能体, 而且呢可以选择是把它创建给整个用户层用,还是说只在某个项目里去用,那这个分层其实还是挺好的,把你自己的工作习惯放到用户级里,团队的规划呢直接放在项目里,跟着 get 走,技能和指令呢,也是支持这样去配置,它是一样的逻辑 模型。这里呢如果你有其他厂商的 a p i 或者是头根 plan, 可以 直接在这里去进行接入。不过我不确定的是扣的这个海内外版本是否有差异,我这里呢是没有发现有自定义端点的入口,只有一些内置的渠道, 那如果你有这个需求的话,可以自己下去去确认一下。最后呢我们来说一下这个知识中心和这个插件市场。在知识中心里呢,我们可以选择已经导入的项目,一键快速的帮我们生成一个项目的说明书, ai 直接从我们的代码里去读出来。 大家这个微信呢是自动导入到我们项目的目录里的,也就是团队里的所有人呢,都可以共享这套知识,跟着代码一块 get 提交。旁边呢还有一个记忆功能, 默认的是开启的,他呢会对你以往的对话或者是项目的操作做智能的持久化记忆,理论上来说你用的越久,他越懂你。那至于这个插件市场,目前的话只是一个雏形, 里边打包了 skill 和 mcp, 可以 一键安装,比如说这里边就有这个烧饼饭, mango db 以及这个 contact 七这些内容呢,基本上就是给我们的 ai 智能装垂直端能力包生态确实看起来不是太丰富,但后续应该会越来越多。我们现在回到刚才这个任务,可以在右侧看到有变更文件以及一些产物。 那其实最有意思的就是这个测试工程师在任务的最后呢,跑完了另一个检查和 bug 构建,不管是通过了还是失败了,会告诉你具体的原因,然后去查相关的源文件。说实话,这套自动验证的机制呢,我觉得应该每个 ai 第一里都标配一下,一页写完代码不应该直接交付,而是自己先跑一遍验证,总不能让我们用户一个一个去试吧。 最后呢,简单做一个总结。那说实话,以前的 qq 的 我感觉他在对标 qq, 现在这版感觉走的是 qq 代码的内容,简约克制,但功能又丰富了一些。我好像看到了很多身影。高情商,一点集百家之所长, 低情商,跟之前的零点几版本相比,这个一点零的更新力度确实是大太多了,完成度也非常高。如果各位感兴趣的话,可以到 qq 的 官网去下载体验一下, 至少目前我个人是比较喜欢这个设计和功能的。那以上就是本期视频的全部内容了,如果对你有所帮助,或者觉得视频做的还不错的话,欢迎给个一箭三连。有什么想看内容呢,也可以在评论区留下你的足迹。最后祝各位玩的愉快,我是段峰,我们下期再见,拜拜!
589神烦老狗 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿钢铁侠二的使用非常的方便,看一下我们的积分,三百,杠三百已经用完,接着我们打开钢铁侠,呼叫钢铁侠二,点击一下,有一个漂亮的动画等待科技感十足的进度条, 让他将那个进度走完,非常快,已经成功了。接着会自动重启 ai 软件,按 uzi, 这里马上就变为了零杠三百 是一个 pro 的 状态,然后看上面的记忆完全没有丢失。选择 ultimate 极致模型,我们就可以将开发的外部项目一些报错的问题发给极致模型。
33达文西 24:33查看AI文稿AI文稿
24:33查看AI文稿AI文稿呃,各位好,我是来自高德大模型平台的开发工程师,我叫王树新。然后大家可以看到,其实我今天分享的主题主要是围绕 harness 和 s d d, 然后我们是如何集于 coder 在 我们团队进行这个呃实践的。那呃, 其实这个在开始之前吧,我想先说一下,就是去年九月份,我当时呢受邀在云溪大会呃 koder 的 分论坛上,然后分享了我们团队在呃基于 koder 进行研发提效的这样的一些实践经验。 其实当时我们的分享都是基于像 propt, 然后上下文工程在技术方案的环节和研发环节进行的一些呃,这个提效,然后我们当时对外暴露的一个出码率是百分之五十三, 然后其实在当时我们能看到这个数字啊,它背后可能说对于 ai 在 编程这个方面会有巨大的潜力。 呃,我先回顾一下当时我在云集大会上分享的一些核心内容。首先呢,是在当时那个场景下,我们识别出了 ai coding 存在的三个主要的问题。 第一个就是自由发挥的问题, ai 胜任代码常常是种天马行空的啊,原因就是因为他业务理解不足,或者是说规范很缺失,然后你让他写一个功能,他可能给你三种不同的实现方式,每一种都能跑,但每一种都跟我们现有的架构是格格不入的。 第二个原因,第二个呢,就是这个效率低下的这个问题。我们听起来好像很矛盾, ai 我 们用了 ai 难道不应该是提效吗?为什么啊?我们这里边反而会说到这个效率低下的问题, 其实在实际的使用过程当中,如果我们的指令不够清晰,你会在多轮对话的过程当中呢,需要反复的去和 ai 进行拉扯,你说改一下,他改了,然后你说不对,还要再改,他又改了,经过这么来回几次,很多人就说还不如他自己写, 那第三呢,就是这个关键信息丢失的问题。我们在这种多轮对话过程当中, ai 呢,它常常会忘记之前的一些重要的约束,在任务的这种颗粒度非常大的时候啊,开头说的一些架构的要求,到后面它就完全忘记了。 所以针对这些问题,我们当时是使用 coder 进行了一些系统化的一些实践方案,比方说通过这种 reprieve memory 和 roles 来约束 ai 的 这个自由度, 然后通过这个提示词工程来改善它的效率问题,我们通过这种上线工程快速模式,避免一些关键信息的丢失, 那当时其实在分享,最后我还表达了对于 ai 编程的未来充满了期待。未来呢,开发者只需要去做定义需求验验证结果这样的事,像文档编码测试这种体力活,我们完全可以交给 ai 来干。 ai 呢,可以从一个生产工具转变为新的研发的基础设施,开发者呢,也能够从编码者转变为一个 ai 的 架构师,但 这是半年前的一个愿景。但其实这个半年多过去了,情况是什么样呢?刚才有一位 cto 啊,他说的这些我很有共情,因为我觉得我们当时暴露的数字是百分之五十三。 然后现在啊,我们经过很多的访谈,包括 pmo 的 一些数据告诉我们说,我们现在整个团队的出马率百分之八十到百分之九十都是由 ai 来生成的,并且都能采纳了。 但实际上其实我们会发现呢,即使呃我们的 ai 写了非常多代码,但是开发者的工作量并没有减少, 出码率提升了,但是整个项目的交付周期并没有明显的缩短。所以说呢,我们基于这样的一个现象,我们就不得不停下来认真思考一下这个背后的问题是什么。 所以为什么出码率的提升他没有带来真正的这个提效呢?那我其实呃花了很长时间去思考这个事情,然后并且团队做了大量的实践,最终我们是归纳了三个核心的原因。 第一个,研发是一个全链路的过程,它不仅仅是写代码,我们其实来看一个需求,从提出到上线,但这是我们在呃高德内部要经过产品的提需,然后缜严的去做对需求的审,然后方案的设计,开发代码的审,测试连条上线, 每一个环节都有沟通成本,都等待时间,都有可能犯错。其实在人月神话里边有一个这样的一个理论,叫做没有银弹,为什么没有银弹呢?就是因为软件开发过程,它其实不仅仅是编码, 更多的呢?他还要涉及到沟通、协助决策,你把编码环节优化了百分之五十,但是他其实整个的在整个链路当中编码可能只占百分之三十,那我们来看全链路的话,其实他整体提效就只有百分之十五。所以说我们呃 用 ai 在 生成代码的时候,可能还会再去引入更多的 code review 的 时间,更多的调试时间,然后更多的对话,更多的返工的时间。所以这让我意识到,如果说我们要真正提效的话,必须要打通从需求 p r d 的 生成到部署这样的一个全链路, 而不仅仅是优化一个单个的这个环节。所以啊,接下来我可能会跟大家去交流一下,就是怎么让 ai 啊跨越这种环节的边界,从需求到部署形成闭环。 第二个原因呢,就是存量的应用进行 web 抠定风险非常高。呃,其实刚才我听到同学们很多问题,还更多的是一个新的应用啊,从零到一的去实践,去生成。但其实在阿里内部,我们大多数的都是存量的大型的项目, 那对于这种存量的大型项目,我们用 web web 定这种方式呢?其实风险非常高。什么是 web 定?就是氛围编程,我们随口给 ai 几句提示词,然后让它几秒钟就生成几千行代码。 那这种方式呢?其实在新项目或者是一些小的脚本小需求上可能还行,但是在这种存量的应用当中,风险非常高。 存量应用的特点呢,就是有历史包袱,有隐性的依赖,还有很多的这种隐性的业务知识沉淀在代码里边。你让 ai 去氛围编程,那他可能给你一个呃,看起来很完美,但是和现有的系统完全不兼容的方案。更可怕的是这些问题他可能等到上线之后我们才会发现。 我们曾经就遇到过一个案例,就是说在我们用 ai 生成了一个代码,他修改了一个核心接口的这个参数的顺序,然后我们去跑单测,发现单测全通过了,然后上线之后 很多下游的服务就找过来告诉我们,下游服务啊,三个下游服务都哐哐的报错了,然后我们排查了一整天。其实这就让我们深刻意识到,在存量的应用当中, ai 的 去编程必须要从氛围走向规范, 必须要有明确的一个验收标准。那其实这个也正是我们去引入了 sdd 的 这样的一个原因。 sdd 呢,它其实核心思想就是说在 ai 去写代码之前,将人类的这种模糊的想法 转化为清晰的、没有歧义的这种结构化的规范,让 ai 呢能够在可控的这种轨道上去运行。 第三个原因就是大型项目复杂的这种轨道上去运行。第三个原因就是超出了 ai 单次的这种对话的能力边界。 我们曾经呃有这样的一个需求,就是它涉及到前后端,然后十几个模块的这种重构的任务,那不可能在一次对话里边就让 ai 去完成,因为 ai 的 上下文是窗口,是有限的,注意力呢,也可能分散, 所以说对于任务这么大的任务来说, ai 它在生成的过程当中可能顾此失彼。那我们其实看 这三个原因,它其实都指向了同一个结论,就是 ai 编程要想从个人技能转化为团队级的这种工程能力,必须要让它从氛围编程走向规范驱动工程治理的这种研发方式。 那明确了问题,所以我们就开始寻找解法。我们目标呢就是让 ai 不 仅在研发写代码这个环节去提效,更多的是要打通从需求的 p、 r、 d 到直接部署的全流程,然后我们就把这个视角放到了 s, d, d 和 harness 的 啊这个核心的思想上。 我这里快速的讲一下这个 s, d, d 和哈尼斯啊, s, d, d 呢,其实它的核心思想是很颠覆的,呃,最早其实在软件工程里边有 at d, d 的 这种思想,那 s, d, d 呢?其实呃,我理解它本质上呃这个思想是差不多的, 就是 s, d, d 呢,就是说规范不再是给人看的,而是结构化的,给 ai 来看的,能够让 agent 去精确理解和执行的这种意图的代码。 在传统开发当中呢,我们说 prd 或者设计文档,它更多的可能就是一个指导书,代码呢,才是呃真正的这种真理之源, 这会导致文档我们沉淀出了很多的文档,但是在这个迭代的过程当中啊,会经常的这种出现过期啊,和代码脱节这样的一个问题。而 sdd 呢,它颠覆了这样的一个结构,规范是唯一的这个真实的来源。 需求变更的时候,那我们开发者首先修改的是这个规范,然后让 ai 的 工具根据这个规范呢重新生成验证并更新这个底层代码 s, d, d。 它的工作流呢,主要就包括,呃四个阶段,我们能看到像第一阶段就是这个 specify, 就是 去做规范的定义, 开发者和 ai 去探讨,然后输出一份这个结构化的规范,定义好用户的故事,然后验收的标准,系统的一些约束,这就是一个原始的需求阶段。 之后呢,我们要开始制定计划, ai 呢,就会去像这个编辑器一样,把规范编一成详细的技术方案和这个任务的拆解的列表,这就是一个技术文档的呃这个阶段。 然后呢,第三步呢,就是 ai 智能去逐个地执行这个任务列表,然后自动地去生成高质量代码,它会去进入到这个软件开发的阶段。 最后呢就是呃 sdd 的 一个核心思想就是验证,它会根据这个规范自动化的去生成,测试、用力并执行,保证我们最终生成代码呢,能够和规范完全的契合。 那 sdd 其实它解决的是做什么的问题?那哈里斯其实它解决的是如何让 ai 能够可控的去做这样的一个问题。 harness, 其实这个词呢,它比较形象。呃,我们可以把这个大模型比作一匹野马啊, ai 大 模型它其实是拥有无穷的这个力量的, 但是呢,没有马具你根本骑不上去啊,甚至可能会被这匹野马给甩下来。 harness engineering 呢,它的核心的思想就是不是去改变这个呃模型本身的能力,而是给这个模型去设计一套精密的控制系统, 它包括这四个核心的支柱。首先呢就是这个上下文工程,不再是简单的刚才我们提到的 ig 啊解锁增强生成,而是通过这种结构化的信息的投喂,维护一个单一的事实来源,然后让 agent 它能够知道当前项目的目录结构,当前的执行计划是什么,以及呢哪些文档是最新的。 第二个就是哈尼斯,一个非常硬核的部分,就是这个架构的约束,通过这种物理的手段来强制 ai 去遵守规则,比方说我们规定 ui 层的代码绝对禁止去访问数据库层的这个呃,代码,那 ai 试图去违反这个架构分层的时候,代码呢,就无法通过这种语法的检查,在这个提交之前啊,就被拦截。 第三呢,就是这个反馈的回路和商管理,就是 ai 一定会犯错,那关键就在于我们如何去提前发现并修正,建立这样的一个呃,自动化的一个测试沙箱, 让 agent 去写代码,之后呢,自动地去跑测试,跑完测试我们发现测试失败了啊,把这个错误的日制给 agent, agent 呢去读这个错误日制,它进行自我的修正。呃,然后呢,之后呢,再不断地去重试,把这个代码给提交,同时呢,它会把这些人类去修复错误的这个经验 沉淀为这种可以服用的规则,保证呢 ai 它不会相同的错误犯两次。最后就是人类的监督。其实人类呢,从写代码的这样的一个角色就转变成了审核员和环境的一个设计师, 职责就是定义复杂的这个业务边界,然后处理那个百分之五 ai 没有办法去判断的一些复杂的业务逻辑,以及优化这个 harness 本身的一些规则。 那其实,呃,我们可以看到,从最早的,从去年我们一直在强调提十四工程,然后再到这个上下文工程,再到我们今天去提哈尼斯工程,其实它是一个范式的转移, 就是说我们其实是一直在思考我们怎么去和 ai 说话,然后到现在 ai 应该看到什么啊?最后再到今天就是 ai 如何在这种受控的环境下去运行。 那基于上述这两个思想呢,其实我们就开始在这个 coder 上进行了一个实践,接下来我先请大家看一段视频吧,这个视频是我最近用 coder 呃端到端的去完成了一个比较大的一个需求。 首先呢其实我们是把这个需求它会涉及到大概三个核心的项目,然后我会把它放到一个工作区里,之后会用这个 quest 的 这个模式,呃,然后这个 quest 里边它有一个 spec 驱动这样的一个能力,然后我们会把这个需求的 prd 贴到这个文本框当中, 然后当然如果说这个需求会涉及到一些这个多模态的一些图片啊,或者是呃 prd 里边会有一些图片,我们也可以直接粘啊粘贴给它,然后这个时候啊快速模式它就会开始启动这个任务, 它会不断地去探索这个需求的 prd, 然后仓代码仓库,然后一些知识库,这过程用了一个十倍的加速,大家可以快速看一下。 然后其实这个就是 spike 一个非常核心的一个能力,就是它分析完之后呢,它会让人工去澄清一些我们 prd 里边没有说清楚的一些问题, 之后,我们把这个问题澄清之后,它就会开始呃去做这个执行,然后它会生成一份呃完整的这个技术方案 啊,这个技术方案其实就有点类似于我们说 openspec 里边那个 design 点 md 的 这样的一个设计文档, 可以看一下它生成完成之后,其实它这个里边是包含比较详细的数据的模型,然后接口的规范, 然后最重要的是它最下边最下面是有这个 sdd 的 一个验收标准,就相当于是呃我们这个需求,最终呃如何让 agent 去自我验收这个他完成这个任务,他的这个验收的标准是什么? 会包含这种详细的这个前后端的一个验收的标准。然后我们拿到了这份 spec 之后,我就会切换到 coder 的 一个专家团的这样的一个模式,把需求生成的这个 spec 文档呢给导入到这个 规划框里边,然后告诉他基于这份 spec 去进行呃这个开发。然后最后呢你要完成这个测试,并且帮我自动化的部署到我们的这个日常环境,而这也是因为我们现在这个生产环境的要求不能直接去做生产的上限,所以我们现在打通全流程是到日常 然后这个专家团模式,大家可以看到其实他会呃去委派啊,并行的去委派不同的这个子 agent, 他 开始比方说去做任务的调研,调研完成之后他会制定这个实施的呃这个计划,然后之后会有前后端的这个工程师的 agent 来编辑这个代码, 这个中间过程就不给大家看了。然后到部署的时候,阿里内部其实它后端是用的那个 a one 平台,前端是用的 o two, 然后这个里边我们会把它这个官方平台提供的 m c p 工具给接入进来,然后这个 agent 呢,它就会自动的去调这 m c p, 自动去打通这样的一个部署的全流程, 然后它会调起一个运维的 agent, 帮我们创建新的迭代,把代码推送到远程的分支, 然后它部署完成会给我们一个部署的一个详情的链接,我们点开这个链接之后,其实就能看到它,呃,在触发了一个这个部署的一个流水线啊,然后部署完成,其实整个的端到端流流程就被打通了啊, 那视频就看到这里,其实我们大家可以看到啊,就是整个的过程,从需求的 p、 r、 d 的 开始,到 spec 的 生成, 再到任务的拆解,到呃代码的生成、测试、验证,到最终的部署,其实整个的过程是全自动化的。然后开发者呢,在这个过程当中其实就扮演了一个需求的澄清者,最终结果的验证者,而不是再去做实际的操作。 接下来我会详细的去拆解一下这个整个的实践过程,那其实整个实践的里边最重要的核心的基础就是这个知识库,我们现在呢,其实经过实践来看的话,知识库更多的是用这种三层的结构来组织我们内部的知识。 首先呢是这个项目层,项目层它主要就包括我们当前的一些核心应用的项目概述啊,技术选型,这个是 ai 去理解这个上下文的一个基础。然后根据这种, 呃,我们后面还会介绍到啊,我们会根据按需加载的这个思想,维护一个顶层的 readme 的 这样的一个文件,作为 code 的 一个单一的事实来源。 然后之后就是技术层,技术层主要是一些通用的技术知识,编码的一些规范啊,包括还有就是一些三方库的文档,最佳的一些实践,呃一些问题的解决方案等等,然后这些知识可以跨项目附用的。 呃,之后呢就是这个资产层,资产层呢主要就是一些可附用的代码的片段组建,包括一些历史需求的 prd 基础方案,还有一些规党的测试 case, 这些是团队多年积累的一些这个最底层的砖块,然后 ai 就 可以利用它去构建新的功能。 然后在实际的项目当中,我们文档是就是按照刚才看到的这三层的这个结构去进行这个分层的设计的。然后其实我们用到了一个 skill 里面的一个思想就是按需加载,我们可以看到在 呃最下边我们是有一个 readme 的 这样一个文件,我们会在这个 readme 里边呢把所有的文档做一个锁引,然后这种锁引的机制呢,就能够保证我们知识的一个结构化的组织,然后同时也能够让 a 阵的去做这种按需的。呃,加载,按需的去获取, 那这个里边其实提到知识的这个体系,肯定还不能离开这个 memory 的 这个概念,其实 memory 呢是 coder 的 一个内置的一个能力。呃,它就是把我们的一些这个知识做结构化的组织和存储。嗯, 然后执行的这个过程,其实我们有了知识库之后,下一步就开始处理这个需求的 p r d。 那 我们其实是使用的呃 design point markdown 的 这样的一个文档, 那这个过程其实不是自动化的,而是需要人工干预,就是我们现在经常提的 human in the loop, 其实为什么还需要人工干预呢?就是因为当前的这个需求文档当中其实是有很多隐性知识的, 很多产品经理提了一个 p r d 啊,它里边会有很多的知识会认为是研发同学理所当然的啊,应该知道的。但其实是需要我们使用 ai 开发的过程当中,需要 ai 去澄给 ai 澄清的。 比方说我们想做一个用户登录的这样的一个功能,那它背后其实啊需要去告诉 ai 啊支持哪些登录方式, 然后要是否要记住这个登录态密码的强度是怎么设置的,登录失败怎么处理等等。那么通过 spec 的 这种模式呢, ai 就 会主动主动地去提问,然后引导开发者去澄清这些隐性的知识,逐步地去补齐一个完整的这个呃 spec。 那有了这个 spike 之后呢, ai 其实就相当于有了一个明确的呃施工的图纸,就不再是一种氛围编程的模式 之后呢,就是进入到这个执行的阶段,执行阶段我们为什么使用 code 的 这个专家团的这样的一个模式呢?就是因为我们其实呃在思考我们当前所有的人类的这个组织,组织的呃设计我们分成了有前端工程师、测试工程师、后端工程师等等这样的一个角色。 而专家团的这个核心思想呢,其实也是不同的任务交给不同角色的这个 agent 来完成,然后像一个真实的这个开发团队一样, 那 ai 就 会根据这个 spike 去生成具体的这个执行的计划,然后把一个大型的任务拆解成一些可管理的小任务,然后每一个小任务呢,都有明确的这个输入的输入和输出,包括验收标准。然后之后呢,再把这些任务分配给不同角色的 agent 来执行, 然后这个里边像他的这个专接团,呃专家团呢?其实是内置了很多 a 阵的,比方说调研的专家、编码专家、 q a 评审,还有浏览器专家, 然后这个里边其实除了专家,我们说一下呃,用户在使用这些专家的时候,呃其实不仅仅是一个观察者,更多的是我们也能够参与进去。 比方说在专家团他在执行的过程当中,我们发现有一些问题,我们可以随时地去介入,然后和这个专家团有一个 leader 的 这样的一个角色,跟他去让他去调整任务的方向,或者是取消不再需要的这样的呃一些任务。那 基于这样的话,其实我们角色就变了,就不再是这个一个观察者或者是一个执行者,而是能够和 leader 去澄清意图,对齐方向,审核计划、验收结果,就像我们带了一个有经验的这样的一个研发小组一样。 然后之后就是到了这个部署阶段,其实我们是打通了通过这种 m c p, 打通了整个的这个呃阿里的内部的这个 a one 的 呃 c i c d 的 平台,然后我们通过这种 m c p 可以 让粤维的 agent 帮我们去触发 c i c d 的 流水线,执行部署的脚本,然后去看部署的状态,查询一些这个部署的异常,然后帮我们把这些异常给处理掉。那其实这样的话就相当于把整个的从需求的 p r d 到部署全流程就打通了。 然后这个里面其实也可以通过一些 skills 的 方式去扩展。比方说其实我们在真正的实践过程当中,我们会发现的除了工程代码啊,我们还要去操作一些底层的数据库,那么可以通过这个呃数据库查呃操作的这个 skills, 直接的让 ai 帮我们查询修改这个数据库,这样的话其实整个的呃端到端的开发,然后测试验证,这样的流程就完全的可以自动化掉。 最后呢就是回顾一下今天的分享吧,就是我们从我从最早的这个云溪大会出发,然后去发现了出马率提升,但是提效不明显的这样的一个问题,然后分析了三个核心的原因,并且基于这些原因呢给出了一些具体的解法。 那其实我们能够看到整个的这个过程,其实我们是实现了从这个呃氛围编程到规范驱动工程治理这样的一个范式的转变,然后我们通过种 harness 呃去让 ai 在 约束下变成了一个可靠的工具。 那在未来呢,我认为我们其实有三个方向可以去探索,首先就是更智能的这个 spike 的 生成,其实当前 spike 生成还需要更多的人类的去干预,呃,我们其实希希望呢这个未来能通过更智能的对话的方式啊去做需求的澄清。 第二呢就是更强大的这种 agent teams, 我 们当前这 agent teams 的 协助模式,呃还可以去更多的啊去探索,比方说一些更复杂的一些场景。 然后还有就是最底层的这个基础就是知识管理,我们如何去做整个知识库的啊?这个体系如何去构建?然后知识如何去更新,如何去复用?其实这些东西我觉得我们都可以在未来去呃实践,去探索。那以上就是我要分享的全部内容了,谢谢大家。
9699Qoder 05:51查看AI文稿AI文稿
05:51查看AI文稿AI文稿那接下来和大家分享一下整个经验教训一些事情,我们到底怎么样踩过的坑?这里西施想强调一下,虽然我们叫胡代码,这是我们在下面我们开玩笑发明这么一个词, 但是胡代码并不等于就完全不看代码了,刚才提到了我们要看 spec, 我 们要 review 整个 commit, 那 这个就是一个过程,胡代码依然要看的第一个就是 spec 质量没有问题。其实这个问题刚刚写过,包括也有些人说,哎呀 ai 老是跑偏,为什么这个 ai 写出东西,你们在这各种吹,这个不好,那个不好, 那我刚才前面其实给大家看的都是真实的我们的截图,那为什么我们能够用 spec 去把这个东西做出来?其实刚才我也强调了,本质的核心就是前期不能偷懒,前期一定要仔细地去看这个 spec, 让这个 spec 能够起到真正意义的指导作用。如果你的指挥棒你就指挥错了,你指挥的方向都错了,那 aj 呢?再聪明他也干不好。 所以前期当你有个需求,有个意图的时候,一定要和这个 pest 一 起共创 spec, 然后仔细地去阅读这个 spec 是 不是跟你想要的是一致的,如果是一致的就让他去做, 那有些时候大家觉得特别烦,让他去做,那这个时候其实 ai 可能是跑偏了。今天随着 ai 能力的逐步增强,其实我们写代码的整个范式已经发生了非常大的一个变化,那如果传统的开发的话,我们写代码其实就是右侧这个灰色这个框的方式就是人去想, 想完了之后去写,写完了之后我们测试,测试有问题我们就改一行行编写手工调试每个细节。那整个过程我们今天把它类似于叫手艺活,这是传统编程,或者开玩笑说叫古法编程,这是我们传统的开发模式。 那随着 ai 从代码片段到 compiler 到 agent 等等这一系列的方式,其实整个 ai 在 写代码这个过程中,它的占比已经越来越高效了。所以就是因为这样,我们看到了这样一个趋势,所以去年我们率先推出了 quest, quest 是 coder 里面一个非常特色的一个能力,那这里面有个问题,就是说 写 p r d, 其实产品经理也知道这是也很痛苦的技术,写技术设计文档也很痛苦,那这个过程我们能不能也让 ai 来这个帮我们完成呢?所以我们整个研发过程就变了,左侧这种人去想 人大概写一个 spec, 其实这个 spec 是 非常简单的,类似于 webcode 里描述一个想法, ai 去理解这个意图,理解这一说,他来帮我写 spec, 但他写 spec 有 很多这种是基于他的理解做出来东西,那这里面可能就会出现幻觉,所以我们叫人机共创 spec, 人基于这个 spec 要去改写哪些跟我想的不一样,哪些一样, 几轮交互过程中,最终就是大家共同人机共创写一个 spec。 那 写的过程中,其实无论人和 ai 都已经对这个需求本身有了一个比较深刻的理解。 那接下来的事情其实就比较明确了,只要把这个 style 交给 ai, ai 就 能把代码写好,写的非常好,一个完整颗粒度的模块,他都能够把这个东西搞起来。那如果有些人说我给他一个大的需求,让 style 太长了,我不想看那么长,太烦了。那这个时候其实你可以采用另外一种方式,你可以再把 style 再拆细一下,这个需求再拆的细致一点。 所以你是希望花大量的时间去 review 一个 stack, 然后把这个 stack 交给 agent 去多执行一段时间,还是说你愿意把这 stack 需求再拆得细致一点,让这个 agent 少执行一段时间?所以说取决于你的这种工作模式,你更喜欢哪一种,我们就来做哪一种。 举个例子,这个东西就像比如说你有个同事,休职的同事和你一起做事情,那刚开始其实你是把一些事情交给他,你可能交的时间短一点,他做个半个小时,一个小时就来找你问你,那时间长一点之后,你们更了解的时候默契了之后,其实你再交给他任务,你可能说交给他一天的任务他就搞定, 那再后来时间长一点之后,他可能变成了一周的任务。所以说这个是取决于我们和 ai 相处的模式,在这里面我们是如何相处的, 选择最适合你的模式就好了。那就回到了第二个问题,就是我们的任务颗粒度到底有多大?所以说这里面我们有个最佳经验,就是说快速约等于一个可测试的功能单元,这样子和整个 test case 能够做好一个比较好的一个关联。 这是像刚才我前面截一个图都是一个小的一个功能点,那这个功能点这个这个 q a 同学他去验收的时候也能验收 a 证,他验收的也很好验收,那这样子就相对比较方便,大家提代码也不会说颗粒度特别大,这是一个。 第三个就是 review 不 能偷懒,前面 spec 已经保住质量了,往去做我们也难免会有漏网之鱼,所以这个时候我们还是要去做 review, 虽然代码量太大了,我们人没法一行二行的全都看过来,那么除了 ai agent 帮你把这个事情搞定,那么人就要去做 review。 那 这个时候其实 线上的小伙伴们,估计有些企业或者是个人,你这个代码库里也没有去配置对应的这个 review 的 能力,那我也强烈推荐你可以用 code c l i 去在代码仓库里去配置好整个 review 的 一个能力,然后提交代码之后,我们就会自动的去帮你去做代码的 review, review 出来问题我们已经跑了大概是半年左右了,这个能力 其实现在我们所有 review 出来能力,我们都是要改完之后才能上线的,它 review 出来能力都是真实有效的。那 最后一个就是合并冲突的管理,所以刚才讲了一下,就是说为什么我们前期的时候,我们不是一个人只会多个 quest 在 本级工作,而是前期的时候一个人就只会一个 quest, 然后小步快跑地去提交代码,因为前期大家都在做基础的功能设施, 那这个是属于代码的公共模块,那这块其实合并冲突是非常高的,所以我们主张大家是要快速地提交,快速地解决冲突,这样子就不至于是后面整个冲突点会比较多。 然后第二块就是后面垂直了之后,整个代码冲突相对会少的时候,我们就开始主张一个同学在他本机跑多个 quest, 通过 bug 来做本机的一个隔离和合并,合并完之后提交的时候就可以做一个大的一个合并,那这时候因为这个模块比较垂直,所以说冲突相对会少一些,所以这个时候是解决就相对方便一些。 同时整个代码冲突的解决啊,今天我们也不是纯靠人来解决,我们也是依赖于 ai 来解决,你直接遇到冲突了之后,你就直接告诉 啊这个 agent, 你 直接跟他聊,你说现在遇到这些冲突,你帮我去解决一下哪些问题,当他遇到了这个不可缓解,必须人来做决策的冲突的时候,那么他会告诉你哪些什么冲突,来去看就可以了,还是尽最大的所能遇到所有问题。第一直觉应该是 ai 能不能来解决,如果 ai 能解决,千万不要用人。
54Qoder 15:44
15:44 00:2871Qoder
00:2871Qoder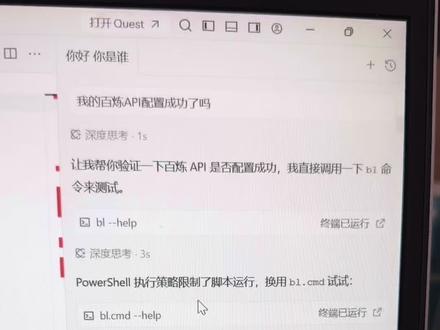 01:32查看AI文稿AI文稿
01:32查看AI文稿AI文稿今天把阿里百炼的 api 诶调同了,然后让 api 让大模型, 这是阿里百炼的 api 自定义,然后今天用百炼重新分析了一下,这是百炼的 阿里百炼的模型还可以,跟上次分析的差不多, 然后他一下检查出了几个问题, 然后让他根据这个他提供的优化建议又重新优化了一下, 然后显示效果没有本该还是原来的样子, 这是阿里百炼上的大模型用量用量的显示, 然后这是百炼了 api api k, 然后是模型。
2醒困💤 01:22:53
01:22:53 02:06查看AI文稿AI文稿
02:06查看AI文稿AI文稿然后就会发现 coder 使用它的 auto mate 极致模型开始在网页端正式的工作了,分析速度非常的快, coder 的 更优雅的使用 桌面上这个文件夹的项目就是我们这个风车油箱系统,但是它里面有一些 bug 需要我们去修复,所以我们来使用网页端的扣的来操作这个 windows 上的项目,可以看到这个项目已经挂载到了网页上,就是这些文件夹 是和这个文件夹相对应。接着我们来在终端里叫出 code, 输入 code clone, 将这个终端最大化一下,然后我们来选择一个模型,输入杠 model, 一 般我们就用这个 ultimate 一 点六叉 翻倍的这个模型。然后这个账号的状态是 pro available, credits 是 九十四,还剩余九十四,积分稍微有点少了,按 esc 键可以退出,按一下 uzi, 的 确啊,还有二百零六,我们需要将这个 这个账号得换一下,要不然积分太少了不够用。先将这个账号退出啊,接着呼叫一下钢铁侠,这个钢铁侠是在加运典赛的这个 ai 工具箱抠的钢铁侠这篇文章。然后我们继续回到这个项目里,将中单打开对应的这个目录,没有问题,接着输入抠的 blank, 我们来重新登录一个新的账号,选择 log in log in ms browser 是 用浏览器登录,直接复制这个链接,右键一下就会跳转登录界面,点击 continue, 这样直接就登录成功了,按一下 u z, 这个积分又变为了三百积分。好,这个时候我们就可以描述我们这个 bug 的 问题,将总结好的 bug 历史问题复制一下,然后粘贴到网页上, ctrl v, 然后就会发现抠的是用它的 alt mate 极致模型, 开始在网页端正式的工作了,分析速度非常的快,给出了修复的指引,我们接下来就可以分析一下他的修复是否正确,然后继续让他去实施这个修复。
14达文西 10:32144William说
10:32144William说 02:46查看AI文稿AI文稿
02:46查看AI文稿AI文稿是用阿里那个最新出的那个 ai 工具识别的单片级项目,能够正确识别出单片级的型号编解器 以及程序当中的广角定义啊。程序的框架。 然后需求的话,我是把一些需求都给了它,包括 管脚定义、显示屏的驱动方式、驱动芯片、电流采集芯片。 框架,让它写一个程序的状态机。框架分别是驱动程序和应用程序要分开,包括显示的内容,它,然后它自己生成了一些整个的过程, 然后在这个罐汤当中第一次生成的,算是比较 框架没问题。但是显示内容有点乱吧, oled 显示是乱码,汉字显示不出来, 它在思考了很多,但是一直没有成功。哦,它显示的效果是这个样子的, 然后我的理想的状态应该是这种样子的。 最后没有办法了,我将我原来写的一些正确的程序驱动程序喂给了他, 他解决这个问题通过新程序解决了,更新以后就解决了, 然后这是他写的一个过程, 最终显示的效果是这个样子的,效果还不错, 是还是有待提高,底层定义的话还是理解不了,需要提供给他书记员。
20醒困💤 00:24
00:24 00:43查看AI文稿AI文稿
00:43查看AI文稿AI文稿各位技术负责人,你们有没有算过一笔账,企业自建 ai agent 应用,三到五个人干几个月,光人力成本就烧掉多少钱,最后还可能踩坑重来?今天这条视频直接帮你省钱!阿里云库德 c l i 一 点零重磅上线五大实用强势功能,一、百万级超大上下文,吃透全量代码库。二、 目标驱动长城任务, ai 自主高效推进。三、语音直书编程,洞口就能写代码。四、一键生成团队知识库,数据安全不外泄。五、云端离线运行,提交任务做等成果, 帮你跳过沙箱,调度模型、路由等重复工作,直接附用阿里成熟生产级技术,省去繁杂搭建流程。想要完整资料、部署教程与专属报价,欢迎来聊!
3乘云科技 41:09
41:09 01:18:16查看AI文稿AI文稿
01:18:16查看AI文稿AI文稿呃,大家好,主持人好。呃,非常高兴能收到可乐官方的一个邀请,呃,我是富有致富的恶建。 呃,今天呢来给大家做一次就是关于 ai coding 的 一个,呃,简单聊一聊,就是关于 ai coding 我 们是怎么去落地的,然后关于有哪些地方我们需要去配置, 然后让我们融从费用 ai 到用好 ai, 怎么去让 ai 能够更稳更更好的一个节奏?帮我们去做那个编程编码, 我们需要通过哪些配置,例如 scale 啊, mcp 啊,还有规则或者提词优化,还有就是怎么去节省我们那个可疑地址啊,嗯,让 ai 能够更好更稳的,然后在工作中真的能够帮助我们。 首先今天呢分享,呃,分享的主题的话就两个,两个章节,一个是我们一个基础篇,嗯,从我们的一个上下文, 呃,上下文管理怎么去写题字词,然后怎么去选模型,怎么去,嗯,写指令,然后还有就是我们关于我们的一个最佳的一个实践,然后可理解是一个怎么去用一个用了一个好的一个总结这种,然后 主要是这就是注重我们的一个基础能力的一个构建,让我们先熟悉 ai, 然后才能说去用好 ai。 第二篇的话就是我们从进阶篇,然后讲就从怎么从啊, skill mcp 啊,或者 hok 指令啊,或者是规则,还有就是我们的一个嗯嗯,规则为怎么去配置,从这些角度,然后不同的角度去,嗯,让 am 能够更好地去服务我们。 第一篇的话就先把,就是先把基础功练扎实,就就是我们的一个上下文,首先如果没有,呃,打个比方就是我把 ai 的 上下文,呃,就是如果没有刻的,那我们直接在官网对话的时候,我们需要写哪些东西? 第一步我们先把我们的一个项目的一个引路写进去,对吧?我们项目的已知条件,还有我们一个项目目录,然后包括我们的一个系统题词,就你是一个资深的编程官,编编程专家,然后还有就是我们的一个,嗯, 还有就是我们一个规则啊,我们的一个约束条件,然后就是我们一个目标要求我们 ai 能达到什么,就是我们想让 ai 帮我们做什么目,做什么,写什么代码,就我们需要去引入哪些地方,你需要参考哪些代码去帮我去实现这个逻辑, 然后这是整一整套的 ai 的 一个上下文。当然现在有了有了 ai 的 这个 ai 的 一个工具,像刻的,我们用刻的的话,就我们只需要在对话框里面只需要输入输入一句提示词,然后 ai 就 能帮我们去把这一整套的呃上下文全部理清楚。 嗯,像我们那个科乐内置的一个系统题词,然后用 m c p scale, 还有就我们一个记忆,然后项目结构,包括我们那个项目约束,像规则文件什么之类的这些东西全部帮我们整理好,我们只需要一具体,只需要写我们的一个目标,然后 ai 就 能自动帮我们去完成这些。嗯,输入输出。 之所以把 ai, 我 把 ai 叫做一一次对话,因为我们所有的内容,包括就是我们在输入框输入一句话的时候,并不说只是输了一句话,它会把所有的信息全部当成一个完整的上下文扔给 ai, 然后我们在下一次跟 ai 对 话的时候,它会把所有的历史对话,包括我们之前说的一些输入输出 啊,历史的一些啊,输入输出信息,包括我们那个最开始提的一些系统题词啊、规则啊,什么后壳文件啊,就是 style、 mcp 啊,这些东西一一次性在下一次对话里面也是完整的一次性全部扔过去, 所以说每次基本上都是全新的全完整的数据,这叫一次性就是。嗯,完整的上下文, 它只有 ai, 只有说读了我们的三下文就是完整的三下文,知道我们需要写哪些东西,有哪些信息,它才能参照我们的一个目标要求,然后参照我们那个代码去帮我们去,嗯,更好地去实践这个写好我们的一个编程,做好我们的编程, 然后完整上下文是第一铁律,你像左边这个错误的一个视力啊,这部分代码有问题,你帮我改一改。但是你这这句话,你说实话,你说给其他的技术开发人员的话,他可能也不懂你要做什么,对吧?也不知道你要改什么,你,但何况扔个 ai, 对 吧? 你我们肯定要说给,就是哪一块,哪一行代码有问题,哪一行报了空子在,然后是因为什么原因导致的, 这个才是一个完整的一个题词词的一个内容,你要告诉他原因,告诉他结果,告诉他出现什么问题,然后才能帮你去解决,对吧?我们那个输出了一个 ai 的 一个输出质量,也跟我们那个完整度也是成一个正相关的, 所以说题词写的时候我们肯定也要注意一下,嗯,文件引用了一个正确知识, 像打我之前的话就是写题词词,因为在那个对话框,哎呀,刻在的一个对话框里面,可能是直接去写题词词的话,因为这个框是有一个限制的,对吧?和上下宽度是有个限制,有时候写很长的一个需求的话,就写个一两百字的时候,可能就来回去看,可能就不太方便。所以我习惯的话就是打开一个记事本, 然后在记事本里面先把我的一个嗯,需要这一次本次需要实现的一个目标先描述清楚,然后中间的话,如果需要嗯,用一些, 嗯,引用一些文项目中的一些内容的话,我会使用一些占位符的方式,然后把我们那个需求,嗯,先占位,把我那个文件先占位住,然后再接着描述我们那个许完整的一个需求描述, 然后最后描述完之后把我们那个,嗯,然后加上一个参考的你就是你参考哪个文件帮我实现这个需求,然后最后把所有的写完之后,然后拷贝到我们一个对话框里面去,然后最后再挨挨个去艾特我们的一个文件,然后让 ai 去帮我们去做很好的一个输出。 如果就是现在的话,我看刻到了,刻到了一个插件,在 id 二里面有个插件,它这个插件右下角其实也内置了这个功能,也应该也最近上新了一个功能,这功能其实挺好用的,它是点了,就是右下角有一个 啊,有一个这个方框小箭头,对吧?你点一下之后,它会在你那个嗯 id 的 那个打开一个新的一个文本对话框,然后在这里面我们去描述我们的需求,就避免我们在外面去打开一个记事本去写,这这个点还是其实挺好的。 然后也可以就写完之后我们让 ai 帮我们去做一下提示值优化,提示值增强,我们点一下这个右下角一个小四角星,让 ai 去帮我们做一下提示值的一个增强提示优化,帮我们组织好我们这个语言 结构化的输出的话, ai 可能会输出的质量会更好一点,如果我们写的内容就是输入的内容质量会更好一点,如果我们写的内容写出来的质量可能也不是特别好。 嗯,这是要分享一个,就是简单举个例子,分享一个就是我们在探索行一个,探索一个新那个项目的时候,嗯,我加了一个提示词, 就请用给习晓成大爷讲明白的一个方式,假设这个项目最终失败,然后回答最早是什么时候出现问题,然后哪一个关键决策走错了方向,对哪个风险应该最早应该能识别,为什么被忽略了? 当时是如果时间能倒回,项目刚开始的时候只允许做一件事情,那你们会,你会做什么?你会先改什么? 为什么要用给习晓成大爷讲明白这个,嗯,习晓成大爷来举这个例子呢?因为我们跟 ai 对 话的时候,他不知道你那个就是他不知道你的一个水平什么样的,也不知道你的一个技技能什么样的,但是他知道习晓成大爷是什么样的,对吧? 他的一个水平是什么样的,所以说他写的时候就是给你输出的时候就会用一些大白话,或是你能很很清晰很明白去理解的一个方式去给你输出, 然后这个提示词,嗯,的一个目的的话,就是让 ai 用事后护盘的一个方式,先提前帮我们预料我们这个项目实际在落地过程中可能会有一些一些风险,然后提前帮我们发现这些风险,然后识别一些潜在的一个问题, 然后上下文管理。就我们在对话框里面经常可能会遇到,嗯,有一种情况,就我们在对话框里面跟 ai 去对话,然后第一次我们让 ai 去帮我们改个控制帧,然后 ai 输出了之后,然后输出了一个错误的话, 然后继续在上面去改,然后我们指出问题之后 ai 继续调整,但调了之后还是按照这个错的话,错误的话继续去,嗯,去调就多多轮纠缠还是没有用。 这种情况下 ai 的 上下文其实已经被污染掉了,因为它因为每次跟 ai 对 话,它都会把我们那个去完整的上下文,就是我们包括我们的历史,包括我们最开始扔给它的一个规则,系统题词啊,还有 scale、 mcp 等这些东西全部都一次性扔给 ai, 帮我们历史 ai 回复,回复的一个历史内容,输出的一个内容,对吧?这些东西其实已经在 ai 的 内存里面已经被污染掉了,他已经觉得这个方案是对的,所以说你多次再再跟他纠缠也是没什么用,不如新开一个窗口, 嗯,避免在原对话里面跟他反复进行就是纠缠,因为这样的话可能改到最后不但浪费了我们可疑历史,而且还效果还不特别好。 而且不要在一个逗号框里面去愤怒多个无关的话题。嗯,尽量在一个窗口里面,我们就聊当前这这一这一个需求, 因为聊聊得太份乱的话,可能 ai 也不太明白你当前要表达什么,对吧?还有一个就是我们不要在一个逗号框里面去艾特,艾特,艾特七八个文件,我们打个比方,一个文件大概有六百行或者一千行,那么七八个文件大概有接近于上万行的 三万行的代码, a a 的 上下上下文其实实际是有限的,两百 k 三万行三万行的代码其实扔进去就已经占了很多了。 这样的话,我们可能一个代码框里面 a a 还没改完就已经需要压缩,但是压缩的话就会带来一个问题,就压缩的话 ai 不知道它的重点,不知道你的一个重点是什么,它可能会就是给你自动去做一些压缩,但这个压缩可能不是你想要的,所以它会有一些问题,就是它可能在压缩之后你跟它原来说的话,然后后面它给你跑偏了,就是输出的内容可能更不合适, 所以建议就是在对话过程中不要触发压缩。嗯?重开窗口,我们什么时候重开窗口? 第一次就是我们在迭代超过三次之后, ai 的 输出结果并没有什么改善,就是还是有一些问题的时候,我们去重开一下窗口,然后如果我们的话题更换了,就我们想去本来想修个控制针,然后后面想修一个缩水键,对吧?我们需要就是换一个窗口去让他去修,不要在一个窗口里面去跟他对话, 这样的话他不单可疑是占用的比较多,因为上下文占用的也多嘛,对吧?而且他的一个,嗯,因为当前之前聊的话题跟现在话题犯了,然后他可能会理解的时候还会按照第一个话题去给你输出,可能会改了,越越改越乱, 然后就是模型重复,重复之前的内容,或者是模型跑偏了,然后话题没有关系,所以我们就建议重开一个新的窗口来去,嗯,做这个新的一个对话,来保证我们的一个 ai 的 一个输出质量。 然后模型的选择的话,我们现在,嗯, qq 里面有有很多种选择,不同的选择。 嗯,我总结的话,因为我常用的话也就这四个总结了一下,现在就是用了一些情况,用了一些场景 极致模式的话,就擅长在架构设计,十八个文档整理,还就是代码重构,然后复杂逻辑的一个编写,从零一到一个,一的一个文档的一个编写设计,就他的一个架构思维比较比较好,写文档或是梳理梳理整个计划用它是比较合适的。 还有个性能模式,性能模式的话用就是改 bug, 嗯,一些紧急问题修护,你排查问题可以用一些性能模式。 嗯, iot 模式, iot 的 话就是在我们通用编码,日常编码的时候,我们可以去用一下,就它简单的需求编辑,日常的话,日常的一个需求编编码都可以用用 iot 啊, grm 五点一的话也可以,就在它是一个常识,我们利用我们做测试啊,我们做,呃自动编啊,或者是做一些,嗯, 不是特别重要的一些。嗯,代码的一个编辑,不是逻辑特别深的一个代码,编辑时候我们可以用一下 gm, 五点一,它的效果也是挺不错的。或者是套件不足的时候,我们也可以用一下 gm 五点一就选不同的模型,选对不同的模型,不但节省可递式,而且我们的一个效果也会更好一点。 嗯,关于编码的选择, code 是 提供了三种,一个是默认的话是 editor, 就 我们 agent 人工交互的一个方式,嗯,还有一个就是 quest, 它有先且计划,然后再去,嗯,动工。 最后一个是按专家,专家团的一个模式,就它会给你招一个开发团队,对吧? id, 它的话是你相对你开车, ai 帮你看路,就你你,我跟 ai 是 协助的一个方式,适合于在你去主要是写编码的时,写代码的时候你就常用的一个功能, 然后觉得 ai 有 时候不是特别靠谱的时候,也可以用 id 它,因为这个时候它会跟你去写作,一起去看,一起看问题,一起去写代码,有问题我们可以及时纠正。 然后 quest 的 话是类似于它是,嗯,先给你做计划,计划你确认,先给你确认,确认完之后你觉得没问题,然后给你输出一个计划文档,然后文档里面,嗯,输出完之后最后你再去 嗯,让他去按照这个文档去做,然后后面你就不用去管,他会做完之后先先给你做规划,规划完之后然后给你执行这个文档,执行编码,编码完之后给你自动跑测试,跑变异,然后最后给你一个结果验证,这种话就比较省心一点, 然后增加团的话是就是类似于你招了一个开发团队,嗯,有人帮你干,对吧?然后适合多智能体去并行写作的一个方式, 但是呢不同的选择,编码选择的话,它的一个 crease 的 一个消耗量也是不同的,我们嗯,大概就是用了一段时间实测了一下,嗯,专家团或是 quest 模式的话,它它的消耗量大概是 edit 一个 n 倍很多倍,可以去去试一下。然后那个智能问答的话,有时候我们去做一些就是嗯,不是编码任务,我们可以去用一下智能问答,它那个消耗量其实很小。 嗯,指令,指令这一块,我把指令分成两部分,一部分是叫做交互性指令,一部分是开发指令。 什么叫交互指令?就是你你问一句,他答一句,然后你就是 ai 问一句,你去执,你去执行一下,然后把执行结果切给 ai, 然后 ai 再去问一句,就我们我们协助去交,协助去排查问题的一个场景,用交互性指令, 就我告诉 ai, 我 当前嗯有个环境问题或者部署问题,有个问题你帮我去排查一下这个问题怎么去解决,然后让 ai 去就是一 嗯一次输出一个命令,然后我去执行,然后把执行结果贴给你,你看到有你看的话之后,然后你帮我去嗯去分析一下这个问题出现在哪里,然后或者是嗯如果找不到,你可以继续在多人交互,对吧? 还一个就是除了交互性指令的话,就另外一个就是开发指令,就我们把一段常用的一个快捷的一个命令,你在输入框里面就直接通过斜杠去调用, 把一些任务的一个标准化的一个写法,就可以直接在这里面去通过斜杠就能调动,而不用说每次都会都会写一遍。 例如某个需求,我们需要加载某个,加载某个 scale, 或者加载某个 m、 c、 p, 或者是用,嗯,用某一个,用某一个规则,然后我们就可以把这些东西整合到一个指令里面去,然后每次在写这个需求的时候,我们就可以用直接用这个指令去执行就行了,就很方便很便捷。 嗯,还有一个就斜杠指令的话,还有一个就是 play 模式, play 模式,然后它是先做规划,然后再去执行,就先给你写计划,写完计划之后,然后再去做实际的落地, 然后什么时候去用它就是你你的需求可能不是特别明确的时候,或者你的任务描述,然后超过一句话, 嗯,超过超过很多就超过一句话,然后我们可能是要拆分,拆分出很多个小任务,子任务的时候我们可以用一下 plan 模式,那先去规划,规划过程中有问题可以是随时提问,对吧?我们去补充,补充没问题之后,然后最后确认之后,然后让 a h 直接 b o 的 去执行就行了。 它跟快速的模式有一点区别,就是快速的是也是先做计划,最后它是自动执行,这个跑单模式的话需要你去先做计划,需要你手动去执行,手动去点 bu 的。 我一般就是单文件的一个小修改,或者是简单的 bug, 我 也不一般不用,就直接去在 a 帧里面直接去对话就行了。 嗯,这个就是考勤的一个占用优化,嗯,最近的一个总结就怎么去省我们一个考勤, 怎么去让我们那个,嗯,考勤能用的时间更久,对吧?因为我们默认的话是有两千考勤的,但是如果用专家团模式,可能一天或者两天可能就用完了。 嗯,第一条就是 add in, add in 点 md, 它是导航地图,尽量不要超过一百行。这个 add in 点 md 的 话是放在项目的根目录下面去的, 嗯,它跟我们那个规则文件是有一点区别,因为它,嗯,例如,例如我们打比方,就我们的一个项目下面会放一个 readymessage md, 一个瑞德明, m d 的 话是给人看的,给同事看的,对吧?嗯,介绍这个项目的一个框架,然后项目是有哪些东西,呃,怎么去就怎么去起的,因为项目这个架构是怎么样的? 然后 ipad, 嗯, a 镜是点 m d 的 话,它是给 ai 去看,让 ai 去熟悉整个项目的一个架构,熟悉整个项目的一个文件文件的一个分布。你告诉他我们那个 vk 在 某个地方,在哪个文件夹下面,我们的一个 doc 文档在哪个文件下面?我们括就建表语句,我们在哪个文档下面去, 嗯,包括我们那个规则,什么时候用,什么规则,对吧?我们都可以写在 a g 四点 m d 里面,它只是做地图导航,尽量的话不要超过一百行,因为太多的话可能会影响到我们一个,呃,上下文的一个占用,而且还不一定遵守。 嗯,第二个是细划规则,我们请分类放到我们的 control row 下面去,就我们 control row 下面是放我们的一个实际的一个规则规则内容的,我们根据编码规则,我们架构规则, circle, 呃, circle 规则,或者些部署测试规则什么之类的,我们把这些规则然后全部写到我们一个 row 下面去, 然后按照不同的类型去分类好,然后把规则的一个生肖,生肖的一个设置改成模型角色,然后他在实际去执行的过程中发现我们这个这段代码需要去测试,然后他会去根据关键词的缩影,然后找到这个规则去执行。 之所以要改成模型决策,是因为那你如果改成始终生效的方方式的话,就会在每一次提示词它都会就你用到,用不到它都会把它把规则内容加载进去,这样的话会也会占用我们的一个上下文内容。 第三个是记忆配置,我们增加记忆这个延时策略在用到的时候再去加载,不要每次就是提示词一写进去,然后我一提交,然后 ai 就 把我们那个项目的一个记忆全部加载过去了,那这样也是占用了一个上下文内容, 然后就生成了 repowerk, 嗯,刻的有一个,有一个比较好的一个地方,就是它一个 repowerk 可以 去点一下,然后去整帮我们的一个整个项目架构去整理成,嗯,最佳最佳的一个 md 文档, 这个文档的话我们自己自己可以去读一读,它里面是帮我们规划好,总结好了,就是每一个文,每一个流程的一个调动电路是怎么去用的, 然后这个文档也是可以也可以去看的,他在实际在编码过程中也可以根据一些关键字搜索去读到这个文档,然后去找一下里面的一个最佳实 践,省得再去每次去根据编码的一个嗯,相关性,然后去缩影对应那个文件,这样的话效率会更快一点,而且效率更更好一点。 但是呢生成的 v vape, vape 它也有一个问题,就是它会生成有一些就是我们用不到的,有的话它会把部署的一些 啊,部署的一些方案最佳实践,然后生成的 v k 放到里面去。但是这些东西我们可能部署方式不一定是按它的规,按它的生成的来走的,然后就是我们那个测试, 嗯,自动化测试什么之类的,然后这些文档的话实际放在就生成出来,我们也不一定需要,需要,所以在这种文档我们建议就是生成完之后,我们把整个 api 仓库去检查一下,如果有没用的,我们可以直接删掉,或者是把内容直接调整一下。 然后就是项目的一个根目录下面加一个那个刻的一个 excel 文件,然后用来排除一些无用的一些目录。你像我们这个 together 和一个 build 文件,然后这种的话不用去扫描到项目里面去, 然后在规则的要求,要求 ai 输出的总结,然后在一百字以内。因为有时候我们在对话过程中可能会有一个问题,就我们跟他说完之后,他可能对话给你,最后给你回复了很长的一段总结,然后包括就是 我要按遵守某某规则,然后实现了某某需求,然后我的一二三四,然后一堆的总结。但这个总结呢,我们大部分情况下是不看的,所以建议就把 ai 的 输出一个总结内容控制在一百字以内, 这样的话我们让他精简一下,只输出出来你当前改了哪些需求,改了哪些问题问题,然后加上你就是改了哪些文件,这样的话我们看起来也更方便一点,对吧? 第七个就是重开窗口,重开的话就是重置嘛。然后第八个就是按照我们那个需求选择模型那个等级以及编码那个模式,它不同的编码模式占用那个消耗量也是不一样的,包括模型等级也是 啊,对话框里面明确你的需求,明确你的输出,然后减少自动化跑测试,然后写总结文档,嗯,等占用过量的一个头看, 就对话框里面我们去描嗯,去描述好你的输出,他应该输出什么改什么哪些地方,然后不让他去自动跑测试,因为他跑起来可能跟我们那个项目不一定合适,不一定切合,有可能跑的时候还会报错,然后最后编辑,编辑时候也可能也可能会有问题, 所以他尽量就不让他去跑,这些东西你尽量疏明确一下,我们要让写完就完,写完就为止就行了。 然后第十个就是 ai 跑偏了,我们就要立即终止一下,重新描述一下,然后再新开个窗口,重新去纠正一下方向, 然后就是全局替换。我们在嗯,实际编码过程中肯定会有一些,就是可能哪些地方用到一个场量,然后这个场量或者是有一些地方用到一些变量,这个变量的话可能要全局去改一下, 然后这种的话或者是有些搜需要全剧搜索一下,从这种情况下呢,就避免我们直接用 ai 模型,可以用一些传统的方式,对吧?直接去 ctrl f 或 ctrl r, 直接去搜索替换就行了,也避免用杀鸡用牛刀。 然后呢, mcp 的 话也不是越来越多,越多越好,因为超过太多的话,它 mcp 跟 sky 不 一样, mcp 的 话它是每次会把所有的内容全部加载到嗯,你的上下文里面去扔给 ai, 嗯,太多的话它会占用你的上下文会很长,所以说不建议,因为 m c p 它是有工具嘛,工具调用就每个指令它这个工具怎么用的,它都会跟它描述清楚,嗯,不,不建议,就是太多,尽量不要超过八个, 你可以按照我们实际的一个对话的一个实际情况我们去呃做开启和关闭。 然后就是合理利用好我们一个大模型那个官网,你像我们一个千万的千万那个官网,你可以在这上面去把我们的一个已知条件或者什么一个规则,或我们一个要求目标,我们都可以组织好,然后扔到官网里面,让他去写代码也是没问题的。 然后而且它还是免费的,而且还不限量,而且输出的效果可能比磕到一根还要快。 还有就是我们刻到底下有一个语音模式好的思路,不应该被手速限制,对吧? 我们可能想的很多,然后说的很快,然后最后呢?说完之后我们可以用那个梯子词优化,帮我们去组织成嗯,好的一个梯子词,分结构的一个梯子词,然后再去整个 ai, 这样的话我们就也能节省一部分效率,输出更快一点。 然后境界篇的话就是主要是讲我们的就是通过 scale、 mcp 啊,或者 hulk, 嗯,然后定规矩,让 ai 去遵守,然后让它从一个就是通用了一个大模型,通用了 ai, 然后变成了一个私人的开发助手 m c p。 m c p 的 话,嗯,应该大部分人应该都清楚 m c p 是 什么,就我们经常会用就它让 ai 能够去访问外部的一些接口,去访问一些,上网去搜一些资料,对吧?然后 可以做一些浏览器的自动化,然后 m c p 的 话,配置这个数量的话建议就是不要太多,嗯,可以小于八个。 然后下面推荐两个 m c p 啊,比较好用一点的。嗯,因为经常也在用,一个是 ctrl 七,就他会搜索一些最新的一些文档,就我们在用一些, 嗯,打比方就是用阿云的一些文档去去做 o s s 的 时候,你可以去直接用在对话框里面,然后用 ctrl 七帮我们搜一下,然后他会找一下最新的一个文档,然后就帮我们实践 比我们直接贴文档地址,然后直接贴贴片段代码片段要更合适一点,更好一点,更系统一点。第二个是做复杂推理的时候,有让 ai 能够按照深入思考的一个方式,第一步一步,第一步先做什么,第二步先做什么, 那最后一步先做在做什么?然后按照步骤的方式帮我们一步步去梳理这个问题,帮我们拆解问题,让它仔细思考我们这个需求,然后再帮我们去实现, 然后 scale, 就 scale 的 话是跟 m c p 啊,什么提字词啊,我们是一相辅相辅,相辅相成的,每一个都有不同的作用。 scale 的 话,它就是类似于一个操作手册, 我告诉你,我应该就是在里面,我们,我把一系列的工具啊,把一系列的,嗯,就是我们一个操作方式,我们把它给封装好,告诉你怎么去用, 然后打个比方,就做个 ppt 吧,我们用题词告诉一下我们先需要,需要做什么, 然后 ai 知道之后,然后 ai 去掉我们这个 style, 嗯,调我们一个 ppt style, 然后它去看里面内容,然后去知道了,知道我应该调哪个 gs, 去整理文档,调哪个 python, 去把 gs 把 html 转成某一个 ppt 格式,然后怎么去排版, 那怎么去?呃,如果我需要一些图片,我怎么去?通过 m c p 去连接文档去获取一些图片,然后插入到合适的位置,那这样就这样一个流程,它们是相辅相成的, 然后网页访问的话,推荐这边也有,也有三个 skill, 一个是第一个是网页做网页访问的,然后一个是 notbook, 你经常用的话应该知道这个是做知识库还是比较合适的。你写需求可以把需求文档传进去,然后直接在代码里面让他去连连接这个知识库,然后去根据知识库内容去帮我们去生成专业的、合适的,就比较精准的一个分析, 分析结果, ai 输出结果最后一个 pua 嘛,就是让 ai 去 pua, ai 让它输出的效果更好一点,就不让它说我做完了,我变异通过了,实际我一群一运营全部都报错,对吧? 让 ai 自己去检查自己。嗯, openstack, openstack 的 话也类似一个,嗯,也是一个 scale, 它类似一个就是一个工作流的一个方,它以一个工作流的一个方式去帮我们实现我们的一个需求。它跟 plm 模式的一个区别, 就 play 模式,还有一个 quest 模式,对吧?我们刚刚讲了一个 quest 模式, quest 模式的话它也是先建 spec, 然后最后再嗯,执行我们这个 spec, 它跟 quest 模式也很像, 就我们先去探索,我们先用这个指令,然后嗯,加上我们的一个提示词,让 ai 先去先去探索我们的一个需求, 去分析调用一些技能,然后去分析去去探索我们一个需求,探索完之后他觉得没有问题了,然后再去。嗯,通过这个指令,然后听通过提案这个指令去帮我们去发布提案。我们生成对应的一个落地的一个 m d 文档, 包括我们那个任务,还有个提案内容,包括我们那个设计,还有整体的一个嗯,拆解的一个需求,怎么去拆的,怎么去实现的,包括风、风险和标注,包括我们中间一些澄清的,就他在探索的过程中也会跟我们进行交互,就怎么去澄清这个文档, 澄清完之后,然后他觉得没问题了,然后会我们可以去执行这个提案,去让他去只根据提案里面的内容去帮我们实际去落地,去编码。 对,然后这个编码写完之后没问题,测试的话他不会自动帮我们执行,然后需要我们自己手动去执行,就测试没问题之后,然后我们觉得验收通过了, 让他再去进行规档。他一个好处就是你提案发发布完之后,你可以新开窗口,或是今天写完写个提案,我明天再再开,再开一个窗口重新去做,他可以持久化到你的一个项目仓库里面去,就不会说你开个窗口你就废话就断了,就刚刚说过的东西,我就忘记了, 它不会,这样就会有个持久化的一个过程,会好一点,就适合我们做,在平常日常编码过程中适合做一些,就是一些小需求啊,多个任务的一个拆解,多个任务的一个开花。 嗯, at database, at database 这个是我们那个 idea 一个插件的一个功能,我们可以在嗯电话框里面通过艾特艾特符类方式把我们那个数据库嗯引入链接,直接 skimmer 直接链接嗯艾特出来, 然后它艾特这个字链,拿到这个数据库链接之后,它也可以去连接你的数据库,然后访问你的一个表,访问你的一个字段,嗯,还有你的一个数据都可以帮你查,对吧? 然后生,然后你可以在多少框里面告诉一下,然后你连到这个税库,然后帮我读一下,像我的加,加上我们的一个项目架构,然后一个项目规则,然后去帮我直接生成对应的一个实体类啊, 还有就是每个 control 还有帮我们实现加上再加上我们一个 notbook 知识库里边,我们可以直接让需求从需求到数据库,然后到我们的一个到落地,直接帮我们把整个代码全部生成。 但是效果的话可能要跟你的根据你的一个需求的一个内容,一个实现的一个细节来的。 然后第二个就是我们可以通过就是做 bug 排查,嗯,在测试过程中,然后遇到了一些问题,然后可以通过让 ai 去帮我们去找一下这个接口,它的一个实际的一个实现,一个路实现的一个路径,对吧? 先就找到这个逻辑之后,然后他会去读一下我们那个 circle, 读完之后,然后直接把这个 circle 拿到数据库去执行,然后把你的参数也塞进去直接执行,执行结果看还是数据问题还是我们的业务逻辑问题,就全流程自动化去去排查了, 咳咳,还有一个就是,嗯,比较实用的一个就是 s s 去远程一个排查一个功能,就我们传统的一个流程的话,我们是先登到 s s 去服务器,对吧?然后先去嗯,根据命令去搜索一些搜索, 搜索网址,查一些服务器的一个配置,查一下当前的一个运行环境,然后查到之后我们把网址内容切回来,然后扔给 ai 对 到框里面去聊,然后让 ai 去给结果,给结果之后 ai 拆出来一个结果,然后我们去执行,然后再扔给 ai 再去拆,这样来回反复去服务器验证, 这样的话效率却很低,有可能排查一个小问题一两个小时就过去了。现在的话我们可以直接通过 s o 去连接, 嗯,就在我们那个嗯 ide 工具里面,它有一个叫做远程资源连接的一个一个图标,你通过这个去连接到我们一个 s 去,直接在我们那个服务器端去去访问 ai, 让 ai 可以 实时去读我们的一个服务器的一个配置,读我们的一个日,读我们的一个日子,包括我们。嗯,他在遇到问题他排查的过程中有哪些?就是执行的一个结果,他可以自己实时去看,对吧?看到有问题他就去改,减少很多的一个排排查问题的一个时间。 但是 s 去呢?嗯,用的时候我们也要注意一下,就是尽量是用最小的一个权限账号去登录,因为 ar 的 话毕竟是不可控的嘛, 它有可能会给给我们执行一些比较不安全的一些命令,然后可能会把我们这个服务器环境搞坏,所以说尽量就是用最小权限的一个账号给他一个止读了,然后去帮我们排查问题就行了, 然后操作的话就便于最终一下,然后有些高风险面临的话,不要让它就不要改成自动执行。嗯,改成手动执行,人工确认之后再去执行,生长环境的话就慎用。 嗯, hock 就是 让 ai 去守规矩的,守规矩怎么就在我们的一个 cut 里面去有一个 hock 文件夹就可以去配置这个东西, 让 ai 去,就是他就配了后壳,之后我们可以让 ai 在 我们输入提示词之后发送给 ai, 然后 ai 的 话就会检,就是首先它会触发我们一个后壳命令,检测到我们这个提示词里面有没有敏感信息啊,有没有什么,就是不需要执行那些指令啊? 嗯,这些东,这些东西,然后我们就嗯让 ai, ai 就 就会自动帮我们连接掉,就不会说把这些内容发给大模型。你记得最开始的时候我们可能之前也遇到过, 就是有些人在有些用户在大模型里面去问 ai 要一个什么,嗯,微软的一个 windows 的 一个秘密要,然后 ai 大 模型发出来了,然后结果还是真能激活的, 因为这种可能就是别人扔,扔到大模型里面,然后当成了个语料,然后又被另外别的人获取到。也会有这种问题, 我们的一个代码里面的一个 k 啊代码一个密钥是不连接的一个方式啊什么之类的,这种你可以通过后壳来去拦截掉,不用就是让直接发给发给大模型, 然后一些敏感的一个敏感的一个操作啊,删除数据的一个操作,尽量也也可以通过后壳然后去拦截掉,自动拦截。还有就是还有就是我们就是有时候 ai 说它已经写完了,代码 它写完了,但是我们实际在跑的过程中,我们去测试的过程中去翻译的时候,然后全是报错。这种的话也可以在那个后壳里面去配一下, 然后去配一下编辑的一个指令,让 ai 在 写完之后它去自动去执行这个指令,然后编辑有问题,然后也可以自己继续去改,还不需要我们人工去介入, 然后也可以去配一下,就是嗯,配一些就是外部的一个服务,我们可以把嗯,我们当前的一个 当前 ai 执行的一个内容全部配进去。 ai 的 一个输出内容,包括包括 ai 的 一个什么 sky 技能、 mcp 啊这些东西全部执行了一个, 执行了一个结果,执行了一个过程,包括最最终输出的一个内容。总结,我们可以通过服务发给另外一个平台,然后去做一些就是知乎的总结,经验总结,对吧?也可以去做这些控制。 ai 那 个后壳的话,它就类似于我们在 java 里面,类似于我们那个漆面,还有个前置增强,后增强 这种。然后在提提交题词的时候,它可以去做一些敏感拦截,密钥提示,增强密钥拦截啊,调用工之工具之前呢,它可以去做一些就是命令的一个拦截,哪些命令不应该执行,哪些命令是危险命令,然后调用工具之后呢?然后就可以去, 嗯,去跟踪一下我们哪些文件做了变更,哪些文件做了调整,然后我们改了哪些文件,改到哪些地方?工具调动了一个结果都可以做一些输出,对吧? 然后还有就是 aint 完成,最后完成那个响应的时候,我们做了哪些技能啊?然后经验了一个总结沉淀。输出到文件里面去,可以输出到一个外部的文件,或是输出到外部系统里面去。 它的一个配置的优先级,一个是首先从用户个人配置开始,然后到我们那个项目配置,然后最后到我们那个,嗯,本地的一个个人那个配置,你可以通过附件文件去配置,这个就它的优先级是从低到高开始的, 如果是项目级的或者用户级的,我们就放在用户目录下面去,这样的话就每个项目都会通用的 啊,就然后剩下的就是我们一个规则的一个配置,规则的话应该都知道我们扔给 ai, 让 ai 去写好代码,怎么去写好代码肯定要有规则,有陷阱,对吧?我们陷阱它去怎么去输出,然后 写的代码一个语法加我代码的一个语法怎么去实现?哪些是最就我们一个编码规范,嗯,都要扔,都让它按照这个去遵守,对吧?然后我们目前的话大概就有这几种项目,一个是新项目, 嗯,新项目的话,新新项目的话我们就直接通配一个规则就行了,像编码规则啊什么之类的,我们可以从其他项目直接拿过来去用就行了。那迭代项目的话,我们是先生成一个 replay, 根据 replay 的 生成的一个结果, 然后我们再去让 ah 帮我们总结一下当前这个规则。我们项目那个编码规则,因为它根根据我们当前项目里面那个编码,那个风格代码的一个写法,然后就很轻易帮我们识别出来,然后先帮我们整理一版,就是最初的一个规则, 整理完之后我们自己再去检查一下,有问题我们再去调整,对吧?还有一个就是我们一个多个项目子项目的这种情况,作为一个大项目里面,我们可能有呃多个弧去调用的, a 调用 b, b 调用 c 这种多个弧的,我们可以把这些大的项目就多个子项目放在一个大的项目里面去, 然后大项目里面我们放一个地图导航,就 a 进四点 m d, 对 吧?然后在 a 进四点 m d 里面我们可以指定, 我们可以指定,嗯,嗯,就是我们可以指定,嗯,每个,嗯,每个每一个项目子项目,它的一个对应的一个文档的目录啊,嗯,一个子项目的一个规则的一个位置啊之类的,你可以把这些指定好,就把地图的一个路径做好,目录的一个路径做好, 然后让 ai 自动去识别,去找到对应的位置,然后就帮我们去处理,然后它在写多个项目的时候,也会根据这个规则的要求,然后找到对应的一个项目里面去,然后再根据这个项目再去实际帮我们去改对应的代码,然后尽量保证我们的一个风格统一,对吧? 但是规则的话有,嗯,规则的话是有几种生效方式的,一个是使用生效所有的就是每一次废话都会自动加载的。 还有个就是手动引入的方式,然后它会通过就是拍摄录的一个方式去手动去引入进去,就有些特定的就针对某个 g s 的 一个文件编码,我们需要通过这种方式去引,对吧? 还有始终生效了,你就所有的当前这个加号项目,我们所有的编码规则都要遵守,每次写代码都要遵守的,你可以去按照这个来,也可以就是指定文件生效,指定某一种就是 python 文件啊,或者是 js 文件。这个写这种文件的时候我们去生效或是配置模型决策, 让 ai 的 话根据我们那个在实际,嗯,就是在输出过程中,在实际调用过程中,根据关键字,然后看它是在写文件的时候,还是在去查文件的时候,你可以去去决定它要不要调用这个规则。 规则的话配置有几个原则,第一个我们是 a 印字做地图导航,嗯,这是在项目根部下面, 然后我们那个刻到点 zero 下面有一个,就每一个细具体的一个项目规则,我们可以再添加,先添加一些核心必要的一个规则, 先把规则添完善好,先添加进去,添加完之后根据对话的反馈,我们在对话框里面就跟 ai 进行对话的时候,根据它一个反馈的一个结果,输出的一个结果,让我们再持续去更新, 有问题我们去调整,对吧?然后单文件的话,单个规则,规则文件的话建议是小于两百行,因为太多, 你规则文件太多,你相当于你就打个比方,规则太多相当于是没有规则,对吧?你立立的规则太多的话,就相当于没有立足之地,他就没法去给你写,所以规则太多可能就相当于没有规则,尽量不要写太多太长、太容易的规则, 容易的时候我们就,我们就大胆的去删除一些,然后每隔一段时间呢会进行一次重构,把规则重新整理一下, 然后 color 也有一个记忆系统,让 ai 越用越懂。你的这个我们可以在记忆里面去配一些,就是相片号啊,或者是我们让在实际对话过程中,它会每次会帮我们整理更新的, 你可以,嗯,记录一些相片哈,嗯。然后沟通了一个风格,例如我们连接数据库需要用哪些数据源,嗯,需要去查哪些哪个哪个数据库的,哪个 scanmail 的, 对吧?我们编码的一个风格,我们用命令的时候, python 命令的时候,我们是用 py 还是用 python 三这种, 那我们可以把这些记到我们那个记忆里面去,在实际使用的时候记得项目规则,实际使用的时候他会去根据自动加载的时候,自动去输出的时候,会去自动帮我们缩影这个规则,缩影到规则,然后缩影到这个记忆,然后帮我们去加载,然后里面的一个就是调用的方式, 但是记忆呢?嗯,也不要配太多了,一个全局记忆,因为全局记忆的话,他是嗯每次对话你跟他聊天的时候,他都会去加载进去,所以会会影响我们的一个上下文的一个占用。 而且我们在配的时候也尽量配一些,就是记忆加载延迟的一个策略,就是在按需使用,在我们实际用到的时候再去去缩影,去加载,不要每次都去直接就把所有的规则全部所有的记忆全部扔过去, 核心价值的话是用的越久它也就越懂你,对吧?然后嗯,我们一个进阶的一个总结,规则文件的话,尽尽可能的话简洁一点,然后一切都重要的时候换,一切都不重要,因为规则太多,反而就相当于是没有规则,也可能就不一定遵守。 然后知识内嵌我们看不到的 a 就是 ai 看不到的一些东西,它可能就不存在,你尽量把我们那些知识啊,我们些啊,文档那个 circle 啊,是建表 circle 什么之类的,我们扔到一个项目项目里面去, 而不是说放到一个其他的一个目录,它看不到这些东西,它就没法去帮你写好代码,对吧?它不知道你表结构什么样的,它就没法跟你去实修项目的一个逻辑, 然后机械验证,而会人工验证就尽量配一些,就是工程化的一些检查, 而不是说让人人工去一个去扫,这样的话写更有效一点,让 ai 去。在嗯,写完之后,我们可以用工程化的一个检查方式进行一些命令,然后去帮我们自动编页,自动去检查,检查通过之后,然后再,嗯,再提交,对吧?不,不通过的话让 ai 继续改 那多工具备用。嗯,尽量我们可以用一下。就是,呃,千万弄一下官网,弄一下领马,对吧?每个工具他都有自己一个特长,一个领域,然后可能刻的解决不了的,我们在领马里面能解决,然后刻的解决,我们在千万里面也能解决,对吧? 然后频繁提交啊,不要批量啊,就是一次性提交,你写完就,嗯,立马就去验证,然后没有问, ai 写完之后立马就去验证,没有问题的话我们直接提交,提交可以查,然后降低我们的一个回滚的一个成本, 然后多开废话工资的,就我们每就可以多开几个废话,因为每个废话它上下文是独立的,我们可以在每个废话里面去聊,不同的废话里面去聊, 然后使用 hock, 有 时候我们这些敏感信息啊就可以。嗯,通过 hock 去拦截,对吧?然后最后一个就是我们新工具如果不会用的话就是先用,用熟了之后再慢慢配,对吧。大概就是这样一个情况 啊。然后最后呢?最后的话我们再做一个,就是我们的一个简单的一个 case 的 一个演示,包括我们分享里面提到的一些啊, is data base 啊,或者是 s h 啊,或者是我们的一个 hook 的 一个拦截, 我切一下屏幕啊。 呃,主持人那边有什么问题吗?呃,您可以先进行项目演示,然后之后有问题的话,然后我再给您进行反馈。嗯,好的好的。 嗯,我们先演示一个基最基础的一个 hook 的 一个配置,对吧?嗯,我做了两个,就是敏感文件拦截的,一个是敏感文件拦截的,嗯,随便演示一个,就做了一个小 demo 啊。配置 hock 的 话,就是在我们的一个 color 点下面, color 点 color 下面,我们配置一个 hock 文件夹,然后加一个 setting, 点 jason 文件,然后在文件里面我们把 嗯,对提,每次提交的时候我们去拦截,然后就会执行我们的这个规则,就我们这个敏感提示词的一个教验文件,然后遇到我们这个遇到拦截的,遇到我们的一个就是敏感信息了,它就会自动拦截掉,然后帮我们直接退出,就不再发给 ai 了。 打个比方啊, 啊,随便说一段密钥是吧?说一段密钥,然后让 ai 帮我加到我们的配置里面去 啊。调动被 hok 阻止,如需解除,需要在 hok 中文件中调用啊调整,就我们在有一些敏感信息的话,我们就可以在这边去配置,配置一个 hok, 你 可以把这个提交到 git 里边,每个团队都可以去用。 然后遇到一些敏感的一些制服啊,敏感的信息,身份证号或者这些密钥什么之类的,你在提示里面去说的时候,它立马就可以,就不会传到大模型里面去,直接就阻止掉了。 还有一个就是我们那个 as database, as database, 嗯,简单做个演示, 它是我们在那个 id 里面一个插件里面一个功能,因为在 id 里面它是在我们那个 id 里面是没有这个功能的,它的 id 里面是没有这个功能的,因为后续官方应该会去加。然后现在在那个插件里面是有这个功能,可以直接通过插件去对话的一个方式 有这个我们通过 id 啊,然后 data base, 呃,把我们的一个数据库的一个连接,嗯,就直接去艾特出来,我们直接在这里面去对话,让他帮我查一下有哪些表,对吧?帮我们新建一个, 我这边就随便写了一个,然后我们根据实际的情况我们自己去调整。就是在用的时候可以去调整 啊,他已经查到我有一个商品表了,然后就不不用帮我们建了,让他帮我们建一个订单详情表, 因为连接数据库随时是有很多好处的。第一个在排查问题的时候,我们可以直接把接口路径贴给他,然后把入参贴给他,那么这些东西我们都可以从网页上去获取,对吧?获取完之后我们直接把这些内容贴给他之后, 然后让他自己去找对应的接口文档,找找对应的接口接口的一个逻辑,然后自己去梳理,梳理过程中如果发现哪些地方需要连接数据库去查看数据的,然后他也可以自己去查,查完之后然后告诉我们到帮我们分析具体是我们的业务代码有问题啊?还是我们的一个数据问题。 然后他是先帮我们新增了一个,在我们的一个嗯, circle ddl 文件里面帮我们新增了这个表,先加了一个建表的一个 circle, 加完之后,然后帮我们实现了我们那个实体类,对吧?然后单子表有没有执行到数据库呢?应该去查一下直接问嘛。 呃,我这个电脑可能配置还不一定能执行这个命令,你买售后连接这个命令,它要执行通过之后才能进去, 可能我装的那个需要脚板不?不太不太合适, 我们可以试一下,就是用我们的 ide 的 方式,然后去帮我们去处理,看能不能行 啊。命令好像执行不了,可能是我这个 id 二版本不太合适啊,可能不支持这个执行这个命令,但实际工作实际功能是可用的 啊,在我们的 id 里面还是很强大的。帮再帮我们直接执行了,然后数据库连接成功,然后没有这张表,然后帮我们直接执行命令,帮我们新建了,然后建完之后,然后告诉我一个结构是这样的, 我们去查一下 啊,确实有这张表, 然后让我帮我们往数据库里面插一些数据, 现在表是空的,它直接插入三条模拟数据, 速度还是很快的,一会儿就抄完啊。确实数据也在, 然后我们在实际排查过程中或者照数据啊,也可以通过这种方式让他直接帮我们执行,他会写一些脚本帮我们照数据,然后跑一些数据,就是代码排查的时候,也可以让他去帮我们连数据过去查数据,对吧?是代码问题还是数据问题?都挺好用的。这两个, 然后就我们刚 ppt 里面分享了一个,嗯, s h 去连接,就是在这个这个图标, 这个图标点开之后的话,它里面是有一个就是你需要配置,配置一下你的就是主机,还有你的用户名,对吧?配完之后,然后你去通过这个图标去连接,连接完之后它会让你去输密码, 因为我这个配的是因为有些地址不太方便演示,所以这里没配啊。还有 配完之后他会打开,就是在我们那个新窗口打开,打开完之后我们这个对话框也是也是可以在里面在服务器上直接去这边这侧边去打开这个对话框的,可以在服务器上直接去问他,让他帮我们去交互,查一些那个服务器配置或查一些问题。 然后就是我们那个 scale 的 一个 scale, 我 们刚刚 p e d 分享里面有一个 open spike, open spike 的 这个 open spike 这个技能,你演示一下这个技能怎么去用的? 你可以直接通过斜杠指令把它给艾特出来,艾特出来之后你可以再告,直接告诉他那个我们写一个简单的需求,帮我开发一个。 嗯,订单退款,呃,需求,那直接告诉他我们的目标就好了,然后他会先帮我们做澄清,先帮我们梳理, 先解锁我们这个项目结构,解锁完之后然后再帮我们去编辑, 先探索,探索过程中可能会用到很多,查到很多文件,很多实体类,很多表, 那订单状态现在已经完成了,有没有退款的?没有退款的借口,他帮我们去梳理一下,然后先问几个问题,就是退款场景触发,谁能退?然后什么时候能退? 只要有订单进格是吧?都能退。退款方式先退到哪度 就原路返回就好。直接退到余额 啊,需要记录的退款记录表 订单的一个状态,你可以加一下扩展,就他在实际帮我们探索过程中会先去帮我们审视整个搜索整个项目, 然后需要我们澄清的,他会先就会告去问我们,然后澄清完之后他再去帮我们再继续澄清,继续探索,这款是我需要审核,暂时不需要吧? 哎,何老师,您当前的这个画面还是在刚刚的那个插入那个数据表的那个画面?是不是需要切个图,切个屏 我看一下啊?啊?我当前还在 idea 里面啊,不好意思 啊,对,这个是正确啊,对, 然后最开始我是通过这个指令的方式,然后去让他先帮我们去探索这个需求,对吧?探索完之后他会问了我几个问题,然后这几个问题呢?我确认确认回复之后, 然后下面他又帮我重新梳理了一下,整个一个探索流探退款的一个流程,然后帮我们就设计了哪些表啊,退款设计表啊,还有一些对应的接口啊,然后怎么去做?包括我们一个项目,一个架构,然后怎么去,在哪一层怎么去写,对吧?帮我们梳理清楚,然后最后再跟我再去澄清几个问题, 就是确认所有问题都澄清完之后,然后才去帮我们编辑退款,是扩展到订单给我们还是新建? 是我需要退款查询接口审核人制段 使用 c 档吧。 然后再次澄清完毕之后,它会再告给我们一个最终的一个总结, 然后总结生成完之后是问我还有有没有必要继续探索,要么就是直接发布题案,对吧?发布题案就直接到生成那个 spot 文档那个地步了, 你直接发布题案,等它提交变更到我们的一个落实到我们的一个文档, 他在写的过程中也会去先去看一下我们现有的一个题啊,就有哪些十八个文档,嗯,需要去没有没有完善的,或是没有没有规章的,也可以帮我们去检查、 添加订单、退款,帮我们新建了一个情节, 然后他会创建三个,三个文档,一个是题案变更文档,还有一个开发任务文档, 然后记录它那个文档,那个时间创建时间, 这就我们一个提案内容,为什么要做这个接口,对吧?然后哪些地方需要改,然后新的变更,有哪些东西,然后修改哪些地方来帮我们就是一步步记录清楚, 有这个,有这个题案,有这个文档之后,你就可以再直接掀开窗口,或者是明天再来写,都可以,因为他没有规章之前都会这个清洁下面去,然后明天再去,接着让他去查到我们当前未完成的一个规章文件,然后让他接着去写,都是没问题的。 这个是我们一个设计文档, 就会澄清了几个问题,他也会在这里面去记录啊,最终要怎么去做,然后包括我们那个项目的一个规则怎么去,在这里面也会去遵守 啊。这个就是我们那个实际的一个任务文档,就是我们开花第一第一天应该做啥,第二天应该做什么,对吧?他也帮我们细节到非常小的一个颗粒度啊。第一步先先改哪些?第二步先改哪些,帮我们非常细化, 这样的话就保证 ai 去在实际落地的时候不会不会跑偏,对吧? 就很细,每个时段,然后在哪个对象里面新建,哪个时段新建哪些东西?第一步、第二步、第三步哪一层新的 app 跟一层,然后另一层每一层需要建哪些东西, 然后写完之后我们可以就是退出我们的一个嗯探索模式,但现在应该是就到我们的一个嗯应用模式了,因为刚才的题案已经发布了,现在到我们一个应用模式,直接让它应用当前这个 嗯题案去帮我们去实现这个逻辑,开发逻辑 可以先查看我们有哪些已经存在的一些文件,然后再接着这些文件进行进行,帮我们去编写去改。那创建了十几个很小的一个突突任务, 因为它的突突的任务它都都是颗粒度很小的,具体到很很细的一个点,这样的话就是 ai 的 话,它肯定不会跑偏,对吧?你大的方向肯定会容易有问题,但是越细的点它越容易自信。 一个退款结构他写了很多,写了十几个,嗯,十几个就代办思想,二十二十三个, 在很细的点上帮你去做开发。 二点几时间效率还是很很快的啊,一会就帮我们写到二点多, 生成了这么多退款,退款的一个,然后基础的一个 resource map, 然后搜索, 然后查询退款查询,然后订单查询,根据条件点查询插入,还更新的,后面生成了很多一些基础的基础的一些那个代码文件, 而且用到了我们一个就是实体类转换的一个一个工具并转换的一个工具也是比较好的一个时间, 然后生成了实体类,生成了 map, 七到三点五了, 然后帮我们新建了一个返回程的一个对象,还有入仓的一个对象, 你帮我们加新加了五个接口啊。申请退款的审批退款,审批通过退款,还有个审批拒绝退款。嗯,长信订单详情,那个长信订单列表的,长信退款列表 新帮我们新建了一张表,嗯,退款单号关联订单号用户 u i d 退款金额 退款了。一个整体的一个逻辑帮我们完成了 整个退款流程还是很长的,我们实现了接口,实现了五个逻辑,一个退款查询、 退款列表,退款详情, 这边也有一个进度,一直在加载中 变更了二十四个文件, 我们在写的过程中也可以去看一下这个上下文的占用量, 如果用如果是用嗯,这个 openstack 的 一个方式去写的时候,它虽然压缩了,但是不影响 ai 的 一个输出, 因为他的一个实际的一个计划编码的一个流程,他已经是落实到我们的一个文档中去了,他就按步骤去完成就行了。做完他就会更新,然后下次再检查从哪些没做完,哪些做了 啊,最后是帮我们跑翻译,翻译我们就不让他跑了,因为有可能是跑跑不通过了。我就是做了一个单冒型项目,可能环境不一定能跑的通啊。我们先直接终止掉, 然后让他帮我们去做规档, 规档完之后的话,当前这个嗯需求就开始写完了,然后下一次的话他会去检查,再去写的时候他会检查有没有没规档的,如果没规档他会继续帮你填写,如果有规档的话,就不用不会再去检查了,就直接跳过了。 我们一般是在写完之后就是确认检查没有问题之后,我们再去归档,因为他在写的过程中,没归档之前,我们可以去调的,就可以跟他继续对话,让他去更新文档, 尽量保持我们那个文档的一个最终,是最终的一个正确的一个决定决策,然后在正确的决策上去归导,因为我们他这个文档是做了增量的,增量的更新增量的文档,下一次再改同一个地方的时候,他会在里面去做一些小的变动, 每次都是增量的 啊。归导完成的这个编辑有问题,你环境问题吗? check。
94Qoder


猜你喜欢
- 1014南风情感支招