AI翻唱音乐怎么生成不了
哈喽啊,大家好,欢迎来到我们的 solo 国际版的操作课程,这个课程适用于任何无乐理基础的同学, 但是想创作一首属于自己的音乐作品,为了防止大家在实操时卡壳,我把这三个月测试出来的 solo v 五点五爆款曲风中英文提示词词典和人生高阶调试参数表打包成了一份内部实操手册。这套资料非常关键, 但因为篇幅太长,平台发不出来,想要配套,边看边学的同学老规矩,懂的都懂。本套视频我就带着大家了解最新的 ai 音乐制作攻略。那接下来的三分钟内,我将手把手教你如何用 solo 实现这种歌曲的翻唱。我们话不多说,我们现在正式试开始。 那首先呢,你需要准备好你要翻唱的歌曲人生文件,那我们接下来呢,就直接打开 solo 的 主页,我们点击 create 来到创作的页面。那这一次我们需要用到的核心功能就是顶部的这个 audio, 我 们直接点开 这里呢,有一个叫做 upload, 是 可以直接上传人声文件,上传完之后呢,直接点击继续,那在这里呢,我们直接点击这个翻唱,直接点击提交,而且呢我们也可以直接点开这个网页的翻译。上传完成之后呢,我们接下来就是填写歌词, 我们直接复制原曲的歌词到达这个歌词栏当中。而且呢我们复制完成之后,我们可以看一下它顶上的一个歌词,像一些生僻字,我们可以用到同音字来替代,这样呢,可以去替代我们苏诺的一个咬字不清晰的一个概率。那第三步呢,就是填写风格提示词, 在底下的风格栏当中可以直接去输入你想要的曲风或者感觉,那这里呢,依旧是用到我们上一期视频讲过的提示词公式, 不会的朋友呢,可以再去翻看一下我们上一节课的内容。那第四步呢,其实就是高级选项功能了,我们可以直接调节高级选项当中的人生性别,与这个提示词当中去保持一致。 比如说我提示词当中是书写的女性,那我们就可以直接给它换成女性。那么重点来了,就是底下的这个滑块,那第一个滑块呢,尽量我们向左,那这个呢,是 sora 它即兴发挥的一个程度,那我们这里呢,一般就给它控制在百分之十到百分之二十之间, 尽可能地去保留这个歌曲原本的一个旋律。那第二个呢,其实就是提示词遵循的程度,那我们这里呢,可以调在向右, 那一般来说,我们在设置这个滑块,我们就给到百分之七十到百分之八十之间就可以了,那这样新的编曲呢,会更加按照我们想要的风格去进行呈现。第三个滑块,其实这是代表着原声音频的一个参考程度, 那这里呢,会有很多人有一个误区,认为呢翻唱就要尽可能的高参考原声音频,那其实可以不需要这样子,因为呢,我们上传的参考只是原曲当中的人声部分,并不包含任何的编曲, 所以呢,我们只需要保留百分之二十到百分之三十左右的一个源曲参考,就能够保证人生的节奏和旋律的框架基本不变,并为我们新的一些编曲风格留出足够的空间。那全部设置好之后呢?我们直接点击底下的一键生成。那现在呢?右边这里已经跳出来了两个版本,我们可以来试听一小段。 怎么样?是不是超级简单, 而且你不需要任何的阅历,你三分钟就可以完成你自己改编的翻唱,我还整理了一些不同风格的翻唱提示词。那最后如果你觉得这期视频对你有所帮助的话,不妨点赞收藏起来,我们下期再见。

粉丝313获赞1158
相关视频
 04:37查看AI文稿AI文稿
04:37查看AI文稿AI文稿ok 啊,你的 solo 上传翻唱是不是出现各种各样的报错?有的是艺术家报错,就有的是歌词报错,那今天一个视频告诉你这报错的原理,以及怎么解决这报错,把歌传上去。那在正式揭秘方法之前,请允许我讲一下这个原理。那首先 solo, 它是根据 sportify 的 歌曲去判断 你的歌词有没有违规,你的音频是不是与现有艺术家相同?那这里拿我二四年的一首纯 ai 的 歌曲举例,二四年 纯 ai 那 个时候还是 v 三的时候, v 三点五的时候。那我其实不算什么知名艺术家,那我的歌我给他唱的是 superstar 的 解析版本,稍等一会,他依然会报错。这一首歌 无名之辈也是二零二四年,而且没歌词,这个时候你上传整首上去,你发现它也报错了,这种没有赞的歌,并且也是 ai 的 歌,它都传不上去,包括歌词,你想翻唱的时候用它的歌词也不行。那搞懂了原理,歌词他也是找 superstar 的。 我们对 superstar 的 举例, 你在这里搜,如果能搜到你想上传的歌,那你大概是传不上去的。那有没有办法解决?也有。那众所周知, solo 上传的音频最短支持六秒钟, 最长支持三十分钟,最短的只有六秒钟的片段。目前的检测算法还不足以说我六秒钟能判断出一首歌,对吧?所以能做的方式就是你把你的歌切成六秒钟,六秒钟,六秒钟往上传,你六秒钟,六秒钟往上传,你再用九九 把它一个还有两个三个这样子给它拼起来,最后导出一下成品。那恭喜你,你就把你的歌给它传上去了,那根据历史的发展规律来看,不管是 ai 文字也好, ai 图片也好, ai 音乐也好,视频也好, 或多或少的都会有侵权的这个事的。隔壁吉梦前段时间不才火吗?为什么人脸上传这么难?一样的,咱们音乐有的苦恼 cover 翻唱不了,人家视频隔壁是脸传不上去。 也有一种方法叫转会啊,或者给这个脸拆成很多缝啊,或者是各种各样的餐式图一样的,那音乐也有各种各样的解决办法,除了这种切分的方式,那你视频里面切人脸,把它左半边脸右半边切开来传它也能识别生成, 那音乐也是一样的,你给它切开来,这边拼到一起也行,甚至说我们音乐的你可以哼唱唱拉也可能也行,但听说修复了,因为我自己不怎么做翻唱,我们做原创比较多。翻唱在我看来只是一个短期的事,你想跟着平台发展,你最终肯定还要成为一个原创音乐人的。翻唱音乐人大概只是一个 叫什么商单类型的。那我真的想靠音乐去做我自己的 ip, 做我自己的品牌,打出我自己的名气,那肯定还是原创才能做出来,你光做翻唱很难让别人记得你,还是得有一些真正能打动别人的原创作品。所以翻唱这条路子从二五年那么 大的时候火了,咱也没有接触过,所以翻唱这一块目前更加正规了,是个好事,逼迫大家更多的去做自己的原创,说不定就发现好像做原创你做出来了, 你翻唱再怎么火,那也只是老歌给你带来流量,可能不是你自己的,那如果你做原创做火了,那就是你自己的东西了。好,那最后你可以用随便一个 ai 的 编程软件, cursor 也好,去也好,或者 code 也行。 你跟他说我要用拍摄写一个小工具,要 g u i 页面,可以把上传上去,音频按十秒切成一份一份的放在一个输入文件夹里面,这个模型尽量选择这个聪明一点的大模型,它跑出来的效果就还不错。这个输入音频的选择,目标文件夹 时长的选择,输出格式的选择,也是一遍成功,这里很重要,你如果隔以前,那可能就不止一遍了,包括什么变速变调,他也能给你加上,就跟他说一句话,加个变速变调功能就 ok 了。这个就是 ai 带来的一些科技屏权。你以前可能不会做音乐,现在用 solo, 你 可以自己去做音乐了。 以前可能不会写代码,但是有这种 ai 写代码的工具,你很轻松的,可能两三分钟就能写出来一个马上就能解决你办法的一个工具。你可能不会拍电影,但是你也可以通过自然语言的形式,像最近很火的机器人那些骗子, 他可能也不会拍电影,但他有自己的想法,他也能把自己的想法通过 ai 视频变成一个产出的成品。所以这是个最好的时代。也不用质疑说这个 ai 视频变成一个产出的成品,所以这是个最好的时代。也不用质疑说这个 ai 视频变成一个产出的成品。所以这是个最好的时代。也不用担心苏诺倒下了。 国内还有很多虎视眈眈的,像什么 mini max, 柬埔寨海绵音乐,他们现在其实已经都不差了,已经类似于大概 solo v 五左右的水平了, 最好的可能倒了,那我们还有退而求其次的选择,但是 ai 带来的科技进步是不会说往回退,还回到原始的手工生产的阶段, 大概率是不会了。所以大家不用那么焦虑,把 ai 当成一个能快速实现自己想法的工具,就是我认为在这个时代最好的解法了。那我是 l g y, 对 感兴趣的可以关注我八八六。
 00:49查看AI文稿AI文稿
00:49查看AI文稿AI文稿ai 翻唱歌曲有版权吗?肯定有版权。 ai 翻唱歌曲本身在 ai 生成的平台上面就已经卡了一道关卡,如果你直接上传那首歌, ai 是 不让你去生成的,环球跟索尼现在在跟他 打官司,就你会严格到我们哼唱的或者用乐器演奏出来的有版权的歌曲,他都能够识别,让你去制作。那这个时候怎么办呢? 你用一些非服务器的 ai 软件分轨旋律自己做,让 ai 去给我们提供,这个过程也是我这堂课里面的核心。 怎么教大家去做这件事情?因为以后翻唱歌曲的版权会越来越严格,除非那首歌已经不具备版权效应了,一定要超过七十年就已经没有版权了。一些老歌或者一些公共歌曲,就是什么生日快乐啊,可能这些还是不用担心版权的问题。
18嗨嗨音乐社 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿solo 翻唱不能上传,今天三步解决,以这种素颜为例,第一步,咱们首先把歌曲去标签进行波形改造,等待处理完成好。第二步,现在找到输出文件夹这首处理过的歌,把它拖进宿主软件进行变速处理, 记住这里改为零点五,也就是降为半速。接着准备选择导出,记住不要导出,整首选择到副歌结束就满足需求了。第三步,打开 solo studio, 在 这里点击上传音频,等它检测完上传成功后,就在这里把速度调整回来。接下来就导出到歌曲库, 然后就可以正常的进行翻唱了。以上少了任何一个步骤或操作,就基本上传不上去。好了,翻唱和原创都要玩,你的歌曲才会有流量,关注我,让你的 ai 音乐少走弯路。
192小头围 00:47查看AI文稿AI文稿
00:47查看AI文稿AI文稿不懂乐理先别划走一首歌。五步,直接改词翻唱。 第一步,先把人物图准备好,后面对口型全靠它。第二步,把原歌词丢给豆包,按指令直接改成新歌词。 第三步,打开我整理好的歌词工程文件,把歌词贴进去,选一个声线就能出完整音频。第四步,用通用万象做数字人,对口型图片加音频,直接生成视频。 第五步,把视频和伴奏放进剪应对齐节奏,稍微剪一下就可以了。整个流程不需要阅历基础,具体操作方法和歌词工程文件我都已经整理好了。想少踩坑的评论区打翻唱,老粉都懂,资料都是直接给,不绕弯。
138屿幻AI 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿怎么用 solo 做翻唱保姆级教程?因为最近呢一直忙着去更新各种工具,各种处理逻辑,所以说呢,很少在更新这种比较基础的一些教程啊。最近呢也有很多人在问我们啊,这个翻唱到底怎么做? 其实很简单啊,就像我们先把音频处理完,我们经过工具出加工以后呢,我们一个一个的导入我们的 solo studio 啊,打开 studio, 然后把音频一个一个的导入进来,导入进来以后,我们直接点击导出,点击前往歌曲。然后呢还是老规矩,找到卡本功能,然后把我们准备好的歌词粘贴,然后这呢可能会用到 deepsea, 比如说加点神秘代码, 或者是我们改改同音字,选择好男生和我们下边的参数,直接点击开始生成。 然后在做翻唱的时候呢,给大家一个建议啊,就是我们的人声建议,大家还是同意一下,比如说你要做原嗓的, 或者说是 dj 的, 或者是是怎么怎么样的,我们一定不能说点一下,我们直接就上传,至少我们自己听着,要是合格的作品以后我们再去上传。 然后我们歌曲下载完成以后呢,还是老规矩,来到我们的妙想,也就是以前的抖音创作实验室。同样的我们来到 ai 编辑器, 把我们刚刚下载的成品导入进来,导入进来以后呢,你也可以先混一下音,做一下基础的一些调整,然后我们直接点击导出,导出完成以后,我们直接点击 发行全曲,这要注意啊,咱们一定要去选择翻唱或者是 remix, 不要去选原创啊,然后根据步骤直接去发行就 ok 了。
24山野音乐徐老师 20:32查看AI文稿AI文稿
20:32查看AI文稿AI文稿ai 翻唱零基础保姆级教学 service svc 四点一 g u i 版软件完全免费!大家好,我是佳音。这条视频将从盘古开天辟地讲起,电脑小白也能轻松掌握 ai 翻唱的全流程。在此之前咱们先听效果,然后我们再开始教学。打开软件后, 我们第一步首先加载已经跑好的模型,然后紧接着往下翻,放入原唱的干声音片, 再点击下面的音频转换,这里需要稍等片刻, 转换完成后,打开右侧的输出路径,这条通过声音模型转换出来的跟声,那么就是我们自己的声音。好,我们打开混音工具,十六六万, 把刚刚我们转换的音频放做人声轨, 然后紧接着把提前分解好的伴奏再放进来,好准备开始试听。不想听效果的兄弟可以跳过这里直接观看后面的教学内容啊。为了对比 ai 的 音色还原度够不够高,然后前面的部分 由我本人唱,然后咱们再衔接到 ai 上面,看看区别大不大。 ai 唱 ok 试听完毕,下面正式进入教学。首先大致介绍一下所需工具, 第一个就是我们的主角 service svc 四点一增音克隆工具,用我们的声音唱歌就是通过它所实现。第二个 most 人声伴奏分离工具, 还有一个 uv 二,我们把它放在旁边,这个也是分离工具,他们的区别在于一个是自动挡,一个是手动挡。本期教学针对于零基础小白,所以将以默扫作为人声伴奏分离演示。 第三个十六六万混音工具,用于后驱混音,那么同样这个 au 也是混音工具,区别在于十六六万需要专业调试,一般建议有外置声卡或者直播需求的人使用,那么 au 的 话它是安装即可使用的啊,没有那么多要求,所以根据自身情况选择使用即可。 第四个就是我们的跟声素材,也就是我们本人的唱歌录音作为模型训练素材,所以需要无伴奏无混响的纯净人声。最后一个就是我们今天教学的示范歌曲搁浅。 ok, 下面操作正式开始。首先第一步 我们右键解压 svc 部署包,为了方便教学操作,我们就解压到桌面这里,我们稍等它解压完毕。 ok, 解压完成后,打开 service svc 文件夹往下翻,这里有一个 svc 四点一,这个就是我们的启动按钮,为了今后使用方便,大家可以右键创建一个快捷方式,把它放在桌面,下次打开双击桌面那个图标即可,不用再到文件夹去翻找启动器,是非常耗时间的。 好,接下来我们双击图标,打开这里弹出个窗口,需要稍等一下,然后打开过后请大家看一下免责声明,如果有不遵守者,请自动放弃使用。 然后第一步我们要点击这里的工具,给杆身做一个切片,然后我们看到上面需要输入一个音频的路径,然后我们回到桌面,把我们的杆身新建一个文件夹, 然后把杆身放到文件夹里边,双击点开右键属性,把这个位置复制下来,然后紧接着回到我们的操作界面, 把我们刚刚复制的路径粘贴到这里,然后点击加载原始音频,这里显示成功加载了一条,然后下面有一个输出路径,我们打开 s o c 的 文件夹,然后我们点这里再点进去, 好把这个路径复制下来,然后回到我们的操作界面,把刚刚复制的输出路径粘贴到这里。好的,现在开始点击切片, 好,这里已经显示切片完成,然后我们回到文件夹看一下啊,这里面就全是干生切片文件,那这个就是作为一个训练的数据集,要是也就是说我们的模型是通过这些录音片段来学习的。好,我们回到操作界面, 点击这里的训练,然后点击识别数据集,这里的编码器、预测器都是默认的,已经设置好了,大家不要去更改,然后默认点击数据处理就可以,这里需要等待他处理完毕, 大家可以看到这里是有进度条的,等他到百分百, ok, 我 们能看到这里已经百分百了,处理完毕了,然后我们继续往下设置一下参数,这里一千默认,这里三默认, 然后这边批量大小,我们一般根据自己的显存来设定啊,一般六 g 设定为四啊,我这里的话是十六 g 的 显存,我可以改成十二,然后大家根据自身的 显卡配置,然后根据这个数字去换算就可以。好,我们继续往下把这里打勾, 然后我们继续往下翻配置一下扩展模型的参数,然后这里打勾,打勾打勾,然后这里的扩展模型的批量大小,一般我们就是建议不超过数据级的四分之一啊,这个就根据你自身的 这个数据机的大小,还是要根据自己的显卡而定,然后这后边这里改成十,那这里改成一千。 好,改好过后,我们点击下面左侧的保存配置,然后接着点击右边的协助配置,我们往下翻,这里有一个从头开始训练,这个就是训练我们的主模型,点击开始啊,这个时候会弹出一个窗口,我们等待一下。 好,我把它放大一下吧,大家看得清楚, 我们这里做教学,我就快进一下,让他跑到一千。 好,大家这里已经能看到了啊,我框住的部分,这个就是证明我们已经跑了一千步的模型了啊,他已经等于说我们已经保存了一个一千步的模型, 但是这个模型我建议是跑到两万步或者三万步以上啊,然后我这里是做教学,我肯定就不继续跑了,大家明白我的意思就可以,然后这个我们进行下一步,把这个窗口关闭, 咱紧接着看下边有一个从头开始训练扩散模型,我们点击好,同样会弹出一个窗口,我们等待一下。 好,这个就非常快了,大家能看到,我们看下面这个数字,他跑的非常快了,那这个跟上一个不同,上一个我们要求是两 w、 三 w 以上,这个的话我们跑一千就可以了啊,所以说我们就等着他到一千就 ok。 好,跑完了过后,我们关掉这个窗口,然后打开我们 service svc 的 文件夹,找到 logo 文件夹,点进去一个四十四 k, 再点进去, 然后把我选中的这几个文件给它复制,一个是 g 杠多少,然后一个是配置文件, 然后上面那个是里面存放的是扩散模型,所以说我们把它全部复制,然后回到我们的根目录, 然后它下面有一个文件夹,我们点进去把我们刚刚复制的所有东西粘贴到这里好,然后再回到我们的操作界面,然后选择推理,我选择一下模型,你们看能看到已经有个 g 杠一千了,这就是我们的模型。好,我们试着加载一下, 哎,这里是能看到已经成功加载的啊。 好,然后我们就继续下一步操作了,下一步我们用 mouse 来分离原唱的跟声跟伴奏,把这些我们暂时用不上的先关闭,然后回到桌面, 右键解压我们的 mouse, 我 们还是为了方便解压到桌面。好,这里等待它解压完成。 好,解完成后,我们双击打开文件夹,然后还是一样往下翻,找到启动器还是一样啊,我们可以在这里右键创建一个快捷方式,然后把它放在桌面,方便下次使用。 好,创建完成过后,我们双击打开,这里依然会弹出一个窗口,大家稍等片刻。 打开过后,我们点击这里的绿色使用,然后选择这里的正常分离,然后把我们之前准备的这首歌曲直接把它拖进来, 点击输入音频分离等待即可,这里我就加速了。 好,解压完成过后,我们点击这里的打开文件夹,我们所分离的歌曲就全部在这里边,然后第一个是伴奏,我们来试听一下。 ok, 伴奏试听完过后,我们来听和声,和声在我们的第三个, 然后原唱的干声在最后一个,我们双击打开试听一下。 ok, 这里的还是比较干净的,然后我们需要用这一个原唱的干声通过我们的声音模型来转换成我们本人的声音演唱。好,打开我们的 service svc, 打开过后这里选择一下模型,还有配置文件。好,这里我们说一下扩展模型,这个扩展模型的话,如果说是翻唱出来没有特别就严重的回音的情况下,咱们可以不用去使用它,所以说默认不要加载,然后往下翻,点击加载模型,稍微等一下, 好,加载完成过后,我们把刚刚分离的原唱干声直接拖进来,然后往下翻,翻到最下面一个音频转换,点击 好,转换完成后,我们点击打开文件夹,这里面的干声就是我们通过声音模型转换的我们自己的声音。好,我们来试听一下。 好,由于时间关系,我们就稍微听一点啊,但这首歌我是完整去做过的,里面是稍微有一些瑕疵啊,我最后我已经把瑕疵给修改掉了,所以说我们直接就听成品听结果,然后打开我们的四六六外, 把伴奏单独来一个轨道,然后再把和声单独来一个轨道, 然后再把我之前哎修好的这个根深我们再放进来,然后大家先不要着急走,视频的过程中我会用文字的方式去演示,咱们去用 au 来做一个回忆,好开始播放。
39ai音乐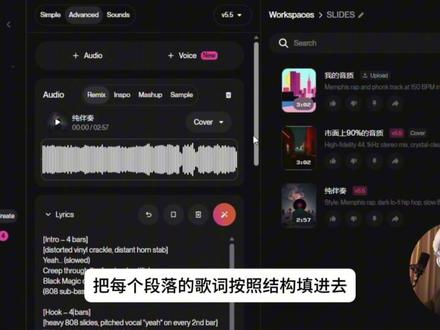 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿这是目前市面上百分之九十 ai 音乐的音质, 这是我生成的 ai 音乐的音质。 如果只听伴奏,它们的差别是这样的, 天差地别,而且这歌没混,可以直接发。 所以为什么 ai 歌曲总被人一耳的听出 ai 尔?首先就是音质问题,我的工作流是这样的,第一步,先使用 solo 生成一段纯伴奏。注意,这个时候我在歌词栏里填入的只有每个段落的编曲原标签,没有任何的歌词, 提示词中也不包括任何对于人生的描述。并且我会在提示词里再强调一遍我的歌曲结构段落。像这样生成 solo 会把所有的算力都投入到制作伴奏上,出来的音质自然就会好。 ok, 我 们先把它下载下来。然后第二步, cover 这个伴奏。 这一次要在歌词栏中填入歌词了,注意,保留之前的编曲原标签,在已经定型的伴奏骨架上,把每个段落的歌词按照结构填进去,拍子一定要对得上。如果你之前的伴奏给副歌部分留了四个八拍,那你新填写的歌词不管是几句加起来这部分也得是四个八拍。记得这一次要在提示词中加入对于人生的描述, 然后点击 create 生成歌曲。现在生成这版并不是我们要的成品,但我们需要其中的人声部分。所以第三步,音频分离再重组。我们点击右侧三个点,选择 get stems, 然后选择右边这个 vocal 加 instrumental, 下载完之后拖入到数值软件里。那这一轨分离出来的伴奏我们就不要了,现在只需要把最开始生成的纯伴奏和后来分离出来的人声放到一起,就有了视频开头的成品, 像这样做出来,歌曲乐器分明、人声干净,结构完全可控,后期的混音空间也直接拉满,快去试试吧!关注我,解锁更多 ai 音乐爆款技巧!
1491白帽子(AI音乐研究中) 04:44查看AI文稿AI文稿
04:44查看AI文稿AI文稿今天喜修教你一招 ai 音乐生成大法,要是学会了,所有类型的歌曲都轻松拿捏,记得点赞加收藏起来。首先最重要的就是选对平台,每个 ai 音乐软件都有自己独特的曲库以及生成模型,如果这个平台的模型比较弱,那么不论你输入的指令有多优秀,它生成的音乐品质上线就在那边。 不同的生成平台有自己擅长的风格,想做短频快的热歌,可以使用 music ai 海豚音乐、触摸 ai 音乐中文极速版对音质有要求,首推还是国外版的 suno 瑞卡以及乌迪奥,详细的评测可以看我之前的视频哦。选择完平台之后,来聊一下 ai 音乐的生成原理。每当使用者输入指令 软件,在曲库中搜索有关指令标签的歌曲,将搜索到的歌曲进行拆解以及重组,进而生成歌曲。所以输入 ai 看得懂的指令,才能生成理想音乐。生成指令大致可以分为四种,按重要顺序排列。第一种,音乐风格,明确你要生成的音乐风格,其实 歌曲就完成了一大半,因为风格会包含歌曲大部分的信息,像是速度、节奏、演唱技法、编曲、配器和声音色等等。此外,一首歌不限制只有一种风格,可以包含多种风格。我们看个例子,像是 i u 的 celebrity, 很 明显是一种 hip hop, 也是有强烈电子音乐风格的 dance pop, 同时还融合了 chubby go house 的 节奏。懂大懂大懂大大懂大。 所以如果我们把这三种风格同时输入到指定框里面,可以生成一首情感跟 celebrity 很 像的歌曲。 第二种,歌曲基本设置可以包含演唱者的细节、调性以及速度。 是给男生唱的,给女生唱的是青年音呢?低音炮还是甜嗓御姐音?欢快歌曲可以设定成大调,小调则听起来哀伤一些。速度的写法以 d p n 为开头,也就是 bit per minute, 一 分钟打几下,如果六十就是一秒钟的速度, 一百二是半秒, 以此类推,此类指定的优先级低于音乐风格。如果我们写一首华语的抒情流行,配上 b 片两百的速度,那这条指令就直接被 ai 无视,因为大部分的华语抒情速度都在七十到一百之间。 第三种,心情与场景可以简单描述一下,歌曲的场景会影响伴奏、编曲、配器以及合声进行。现在是开心难过晴天天这些都可以包含进去哦。 四种配器,你想要这首歌包含哪些乐器呢?打在指定栏,让 ai 帮你生成。但我的经验是,太细节的乐器指定 ai 不 太好 执行,而且配器的层级也低于音乐风格。比如说在一个民谣风的歌曲中加入狂暴的电吉他,那 ai 大 概率就不会低于。所以明确音乐风格之后,大部分的内容大概率都可以覆盖到这边。给大家一个模板,每次生成前可以检查一下还有什么东西想要补充。 不是每一个框都需要输入内容,有时候让 ai 自由发挥,也会有意想不到的结果呢。像我就不太建议新手去输入结构类的生成指令,需要对音乐又比较深刻了解再去上手。 如果已经有歌词的话,简单标一下段落即可。介绍了那么多,已经深受同学一头雾水了吧,我也不懂音乐风格配器要怎么输入正确的指令呢?这时候就需要协修了,找三首听起来跟你心中的成品很接近的歌曲,记住风格不能差太多。假设我今天要写一首类似李荣浩的模特, 把歌名丢到任何文声 ai 里头,让 ai 帮你分析歌曲风格特色,甚至可以直接用 ai 帮你写提示词,再直接套回刚刚提到的模板里面就行。一起来听一下成品 虽然听起来一点不像,但是我们写这个也不是要抄袭,只是 借用它的音乐风格,这首歌的风格听起来是到位了,接着我们就可以针对这个提示词做相对应的修改, 重新生成,去达到我们想要的效果。只要掌握正确的方法,做一首好听的 ai 歌其实比想象中的简单呢。最后聊一下,我们应该要怎么样看待 ai 歌曲呢?无论是首出的原创音乐人还是 ai 创作者,最重要的还是要回归到创作者本身对音乐的理 解,提升自己对音乐的认知,建立对风格的审美,才有办法掌控自己的创作,写出让其他人也能喜欢的音乐。大家都赶紧去试试吧!有什么疑问欢迎在评论区讨论哦!
921音乐诗人秀华 03:26查看AI文稿AI文稿
03:26查看AI文稿AI文稿ai 音乐确实让不少人都挣到了钱,但是六月份将会迎来史上最严打击 ai 音乐的规则更新,目前呢,全平台统一收紧了创作审核,作品如果说包含 ai 生成内容, 必须主动报备,并且承诺核心的创作环节以人工为主。如果说刻意隐瞒未声明的 ai 作品,查实后会直接取消原创标识,并且呢限制流量分发。 同时呢,相比于之前禁止 ai 编曲来说呢,这一次呢,又新增了不能把旋律及歌词这种核心主体也用 ai 生成。那么也就是目前来说,所有的歌曲,只要你的 环节里面用到了 ai 作词、作曲、编曲、演唱的任意一个环节,必须要主动标注,如果说隐瞒不上报啊,就会下架限流,严重者甚至直接封号了。但是这个里面又存在一个非常影响收入的东西,也就是 ai 歌曲,它是拿不到官方的版权登记,也没有 正常的这个版权收益。但是呢,把话说回来啊,不要就觉得这个东西没有收益了,怎么怎么样,现在在各大平台呢,都会有相对应的 ai 歌曲生成的活动,那么这个收益呢,它并不是版权,而是更多的体现于一种什么流量的激励金形 式。这个其实是官方在推的啊,官方的意思很明显,就是说我可以给你钱,但是你要告诉我你这首歌是真的原创还是 ai 生成。那么说实话,这个规则呢,它其实并不是在这几天,甚至是六月份以后才有它。其实呢,在四月份开始,我有一些专门 做批量生产 ai 音乐这么板睡的工作室,老板都跟我有在吐槽之前端控走原创渠道发行的那些新歌呢,发行之后马上啊就会被打上 ai 标签,甚至是在去年发布的歌曲都被打上了标签, 那么这些呢,都是 ai 平台呢,开始维护自身发行权益以及保护音乐人的行动信号。目前呢,各大平台呢,已经陆陆续续清理了几十万首 ai 一 键生成的歌曲,未来呢只会越来越严格。 但是这里面大家一定要搞清楚,如果说你用 ai 做的,你标注的是 ai 了,它并不会下架你,它下架的都是那些以 ai 生成去冒充原创的歌曲啊。此次的广公,不仅仅是规则的约束,音频检测技术也迎来了全面的升级,只要你的作品是 ai 生成的,那么这个里面就会存在 ai 的 隐 形特征,隐形水印,那么这个呢,就会直接给你去进行一个 ai 的 标记,并且呢不支持申诉附和。那么限阶段平台呢,其实对于 ai 编曲和演唱的技术呢,已经非常非常成熟了, 但是呢,对于这个旋律创作和文字歌词的生成来说呢,目前是做不到一个有效的可溯源排查的。但是所有平台啊,都在想尽一切办法去把这个歌词和旋律的检测技术啊进行升级。但是说实话,如果说你是通过 ai 辅助,然后人工主导 去制作的歌曲,那还是检测不出来的,因为这个基本逻辑就是不要让 ai 直接参与到你的创作过程中间。那么我其实从去年到今年,对于 ai 音乐这个东西呢,我的角度一直都是以这个辅助的角度去出发的,因为说实话,一个好听的音乐,最终呢它是需要通过踏实创作,用心制作的音乐人去操控这个流程的, 那么这种方法相比于以前没有 ai 辅助这种传统模式来说,其实它是已经做到了,大大的节省了时间以及人工成本的。但是呢,我一定要告诉大家,就是目前来说并不是在禁止 ai 音乐或者是打击 ai 音乐,而是说平台只是积极的推进, 把 ai 和人工创作进行一个完整的切割分流,不能再出现 ai 冒充人工的事情了。如果说你一直在玩 ai 音乐,然后呢一直都是非常本分守规则的,在合理的规则内去挣那些 ai 音乐的激励金,那其实对于你来说没有任何影响的,影响最大是哪些大家应该也清楚,所以对于本次新规的落地,你们有什么看法?
233律动盒子音乐工作室 06:16查看AI文稿AI文稿
06:16查看AI文稿AI文稿今天我们来学习这种用喜欢的角色翻唱,其实雨也没多大,好了,我们先欣赏一下效果视频, 我们来到剪映的主页,点击这个 ai 创作, 直接把我们的要求发过去,生成一张城市夜景,比例十六比九,稍等一下,等图片出来我们导出保存就可以,这样我们的背景图就做好了。然后我们做一张角色拿着话筒唱歌的图片,先上传我们要做的角色, 再让他拿着话筒陶醉歌唱, 等图片出来导出即可。 然后我们回到主页,点击开始创作,把我们刚才做好的背景图导进去,然后点击背景图,长按尾部,我们发现可以拖动,于是我们拖动到三十秒处,这样我们的视频时长就变成了三十秒。然后我们点击画中画, 把我们要翻唱的歌曲的视频上传过来,歌曲的视频随便可以在抖音下载来,我们先听一下, 然后下方任务栏一直往右边滑,找到这个声音效果,点击歌曲换音色,在这里克隆你要做的角色的声音就可以,主播已经克隆好了,就不再演示,我们点克隆好的音色, 我们来听一下效果,有点噪音,那我们接着任务栏往右边滑, 找到这个音频降噪,打开音频降噪之后,噪音基本没有了,来我们接着听一下, 到了这里你看它基本就够了,我们点击分割,把多余的歌曲视频删除,然后我们退回来,点一下歌曲视频,找到这个混合模式,把进度条拉到零, 这样画面会隐藏起来,只能听到声音。然后我们点击新增画中画,把我们做好的角色上传过来 一样的长,按尾部把它拉到和背景齐平,然后点击我们的角色图,任务栏往右滑, 找到抠像,点击色度抠图,把取色器拖到角色旁边的白色区域,这时白色区域消失了,然后我们把角色拖到合适的位置,再开头打个关键针,然后滑到五秒,轻微往左旋转,角色就会自动打上关键针, 然后继续往后滑五秒,往右旋转,角色如此往复,到最后把角色转正, 这样角色会一直慢慢地来回轻轻转动来,我们看一下效果, 感觉还可以,然后我们返回来,在主页的任务栏往右划,找到特效,画面特效 搜索模糊。 第一个就是我们添加过来,把它拉到和背景一样长度, 然后点击返回,接着点击画面特效, 这次我们搜与 d 这些特效都差不多,随便添加一个,然后按照感觉调整参数, 老样子把它拉到和背景一样长度, 然后任务栏往左边回拉,找到文本进去后往右边画,任务栏有个识别歌词, 点击就可以把歌词给识别出来,我们看一下有没有错字,然后我们返回主页,找到贴纸搜索音乐背景, 用这个, 然后放大拖动到最底下,老样子,把它拉到和背景一样长度,然后我们点击新建文本,把标题写上去就可以了。 好了,减场安静,我们欣赏音乐。 好了,你现在会做熊二翻唱,其实鱼也没多大了,那么用其他角色比如王者英雄,懒羊羊等等翻唱其他的歌,你也是手拿把掐了吧。
2334烛灵AI研究员 02:27查看AI文稿AI文稿
02:27查看AI文稿AI文稿一招教你用自己的声音唱 ai 歌曲,不需要训练自己的声音模型,轻松实现用自己的声音唱 ai 歌曲。点击创作中心,点击歌手人设创建人设。在这里我们上传一段提前录好的音频, 可以是唱歌,也可以是朗读,时长二十秒左右就可以,电脑有麦克风的也可以现场录制,点击保存,大约两分钟就可以了。 这是我今天训练的人设,并用自己的人设写了一首歌,大家来听一下效果怎么样? 这个效果还不错吧,我们下载歌曲做一个简单的处理, 这里需要用到生物提纯和 ai 远标签净化两个功能。 ai 歌曲处理好之后就可以发行原创了。这首歌我已经通过审核发行原创了,想听全曲的可以去听听,别忘了个小红心哦!
 04:28查看AI文稿AI文稿
04:28查看AI文稿AI文稿现在网上流行很多有趣的歌曲,怎么做的呢?很简单,打开剪映,点击音频,然后选择 ai 音乐,选择人声歌曲,在输入框里写下你的需求,例如早晨上班路上的小趣事,轻松 rap 风格,如果需要,还可以在下面自定义歌词,增加个性化效果。 点击生成它生成了三首曲子,我们听一下 第三首纯音乐也是一样,点这里的纯音乐输入要求,点击生成即可下期分享 ai 翻唱。
6小A 03:24查看AI文稿AI文稿
03:24查看AI文稿AI文稿今天来操作如何通过 ai 制作音乐编曲伴奏,打开 ai 编曲软件,然后选择根据哼唱主旋律添加伴奏模块,这个模块是来操作如何给清唱主旋律添加完整的音乐伴奏并导出完整伴奏。我们接下来开始操作。第一步, 导入清唱音乐。导入的参考音乐要求为清唱干音为歌曲的主旋律,特别注意的是导入的音乐不能超过十五兆。还有,如果想要确保能生成前奏、监奏、尾奏,那么要求上传的清唱干音在前奏、监奏、尾奏位置留下空白片段。如果想指定前奏、 监奏、尾奏的旋律,可以自己用乐器演奏,然后拼接到清唱干音中。我们现在先听一听导入的音乐,哈喽酷狗。 第二步,选择演唱音色,这里只提供两个音色, 男声音色和女声音色,但生成的音乐演唱音色软件会尽量参考上传的清唱音色。第三步,输入编曲伴奏风格,这里是控制生成音乐的提示词,可以用系统内置的提示词,这里提供了多个风格提示词,总计上百种。提示词也可以自己输入生成要求, 也可以让豆包根据你的音乐歌词来写对应的音乐创作提示词。第四步,设置歌名。上传参考音色的时候,这里会自动填写音乐歌名,如要修改可以在这里改。第五步,输入歌词要求歌词必须和你演唱的干音一一对应, 歌词一行一句不能有标点符号。第六步,点击生成音乐,等到三到十分钟, 默认生成两首音乐。生成音乐后,可以点击播放音乐试听, 如果选择其中一首音乐,然后点击人声伴奏分离按钮,等待几分钟便可生成人声和伴奏。 生成人声伴奏后,点击下载伴奏即可,从而完成整个操作流程。现在伴奏下载中,最后我们听听生成的伴奏。
 02:46查看AI文稿AI文稿
02:46查看AI文稿AI文稿看到一首十万家收藏的歌,甚至能卖钱了,我想着我怎么模仿他呢?大家先听一下我模仿出来的一首说唱,待会我直接上教程, 怎么样?兄弟们是不是非常带劲?这个我到底是怎么解决的呢?呃,咱们先来到网页版,然后呢点这个傻瓜模式, 呃,傻瓜模式大家可以看到呢,在这个地方可以输入你的主题啊,主题你可以随便写啊,比如说你想要一首这个呃,一个人,呃,经历失败 啊,又成功嗯的故事啊。然后呢,大家可以看到这个地方还有个随机主题,你可以随机生成啊,但重点,其实下面的这个地方 啊,就是可以看到呢,有个 ai 选风格的一个东西,你比如说流行,你可以看到下面上面直接有很多英文啊,就是 ai 直接帮你选好了,那摇滚的话就是 rock 啊, electric guitar, 对 吧?说说唱 hip hop, 我现在意识到呢,你要写一首好的 ai 音乐,这个风格体式词是最重要的啊,但是当然呢,如果你对风格有自己的要求,你可以自己选,但这个很复杂很麻烦啊,比如刘派 啊,刘派有很多哈,流行二二的 b, 对 吧? edm, 古典,独立,中国风,摇滚,民谣,哎,情绪呢?什么悲伤啊,欢快啊,都很多哈,很多 啊,乐器啊,钢琴,古筝,什么吉他,贝斯,你看这全部都有啊,也是几百种人生呢,有男生女生,还有那个男女对唱,对吧? 然后你还可以在这填写你自己的一些特殊的要求,对吧?特殊的要求,咱们重点就是说的这个风格标签啊,就是 ai 选的这个你不用选了,你不用去这个自己选的去选了,你直接在这啊,比如说我现在就想要一个说唱, 刚刚我给大家听的那一首歌就是点的这个说唱。然后呢?就这么简单啊,一个人经历失败又成功的故事,然后直接呃点击这个生成音乐就行了啊,然后等待这个功能目前只在网页上有,小程序还没上,今天这个版本我称为史上最强版本。
181Yapie程序员哥






猜你喜欢
- 3377小泽剪辑
最新视频
- 5744一趴