DeepSeekv4读论文贵吗
前两天 deepsea 在 官方平台宣布一条消息,外网这次真的坐不住了,原来是搞活动到五月三十一号的二点五折,现在变成了永久的正式价。想当初 deepsea 是 只花了三百万美元就训练出来的模型,而 chat gpt 花费了八百万至一个亿, 东方神秘力量暴打华尔街,国内全免费使用,逼的 chat gpt 原本两百美元一个月的费用干到了免费,国产 ai 一 出场就是人民的 ai 啊!现在 deepsea v 四又来一波永久打折,直接把电费他在告诉全世界, 中国的算力价格就这个价!你以为这是降价内卷,其实不是,他这么疯狂降价还赚钱的原因藏在他的 m v 架构里面,这个结构极大降低了训练推理的成本。中国大模型周掉用量已经连续四周超过美国,并稳居全球首位。国产 ai 把曾经外流的赔款全捞回这集你知道我等了多久吗?

粉丝20.7万获赞42.3万
相关视频
 01:49查看AI文稿AI文稿
01:49查看AI文稿AI文稿我跑了八天,一点二亿头肯账单只花了九块钱。众所周知,克拉的扣对对中国用户来说,最难的不是会用,而是能不能稳定的用。他访问受限,有魔法,成本还高,很多人帮刚把工作流打起来,就卡在账号网络额度的问题上。 但我这几天发现了一个可以替代的方案,就是克拉的扣的壳还可以继续用,但是后面接的是我们的国产 v 四。我不是说理论上能用,我是真的拿它跑了八天, 这八天不是只跑了几百个对话,是从需求拆解,页面结构、接口逻辑等,还有报错修复,全程再跑。 那九块钱是什么概念呢?以前你用海外模型写代码,心里一直在有个计算器在跳,现在我终于敢把这个长期在线程序员当程序员用了,而且他不只是只能聊天,我真的把它做成了一个小程序第一版,第一个可用版本就是他帮我打出来的。 我的小龙虾项目呢,目前也是接这个的模型在跑,体感明显有一点就是他不一定很完美,但是你可以放心大胆的用他,便宜到你可以反复的是,这才是关键的变化。所以 ai 编程真正门槛从来不是你知不知道某些神级提示,而是你可以让一个模型在持续的在你的项目可以。 以前我们怕没有 cloud 的 就不能写代码,现在我发现真的只写的不是魔性名字,而是你能不能把这个工作能跑起来,多次错多次错才有机会。如果你也把 cloud 访问的成本卡住了,可以试试这个方案, cloud 当前的工作台,然后第一步是当后面的发动机。 所以说我说金宇公司梁文峰这波真的是活菩萨,不是因为他完美,而是真的把价格打下来,太好用了,成本太低了。
2.7万何小黑(普通人学 AI) 04:11查看AI文稿AI文稿
04:11查看AI文稿AI文稿好,我这几天深度体验了一下,用可老的接上这个 deepsea v 四 pro 之后的效果给我的感觉呢?怎么说呢,在之前最开始时候我用 tree, 我 觉得它非常好用啊,后来的时候我用 vsco 的 里面的 copec, 然后觉得那个非常好用,但是它现在已经出现限额了, 然后后面我用去了,用了 codex, 但是用的是中软战,给我的效果感觉也是一般化吧。直到最后,也就是最近一段时间,我接触到 deepsea 威斯,加上我的可乐扣的我这个组合真的是, 反正给我的感觉就一个字,太便宜了吧,真是太便宜了,可以给大家看一下。我这边的话,这场使用下来啊,就今天一天整整用了三千万头啃, 平均下来是三块四毛九,因为它有这个缓存命中跟未命中缓存吗?啊,有这个命中缓存跟未命中缓存 只用了三块九。三块四毛九,这个价格呢,平均下来每块钱可以换到八百五十七万的头根,这个价格我只能说真香,太香了。这你要是去用 xpt 五点五啊,或者说用 oppo 四点七,这个价格肯定是 太太香了,真是太香了。而且我实际应用下来,包括用克拉克的座椅,下来之后,我发现真的这样之后还挺好用的。当然他也有一个自己的问题吧,就是说他的那个 没有这个图像识别能力,但是我听说后续好像也在开发了,等到后面有这个多媒体功能的话,可能会更好一点,那基本上我感觉就相当于是我们的平替了。 然后这个用下来给我感觉呢,就是现在的算力啊,可能 g p c 公司他们自己想做的,就是去把这个算力打成跟我们以后电费一样的价格吧。我估计以后会这样子,因为他最后的时候不是用深层芯片吗?在下半年的时候大规模的投产,到时候这个价格肯定还会可能还会更便宜点。对, 看看我这边让他做的这个的话,做这个想法集吧,大概是用了十几二十分钟啊,包括前面的前啊前端设计,我是让那个吉米奶三点一 pro 给我做的,然后前段设计好之后,后端功能包括数据库啊,全部都是让这个这个 vc 来做, 然后整体做下来的话,基本上一遍就跑通了,然后你要有问题给他的话,他还能帮你改,基本上不会超过两遍, 而且你后期要什么功能他都能给你加上去。包括你把这个东西移植到我,把我现在做这个页面移植到我之前的那个项目里,他都是可以用的,而且 识别的非常快,然后做的非常准,所以实际体验下来还是非常不错的。我感觉跟我之前用 gbt 五点四差不多,但是你要说有五点五或者奥克斯四点七这种强度吗?应该是没有的,但是他真的便宜啊,是吧?这么便宜了还考虑那么多干嘛呢? 然后包括我这个坐下来这个想法集坐下来之后,是吧?谁可以输入你的想法?你好,把你的想法记录下来。你好,我是 叉叉叉啊,这些东西包括啊这些前端的话都是,呃,基于在三零一 pro 做的,但是后端这些功能包括它有个 ai 整个分析,还有 ai 表达优化,然后还有这个关联想法,这些 啊都是让第四个 v 四来做了,整整体做下来的感觉都非常好好,包括你后面接这些 a p i 啊什么的,他基本上都能帮你完成,也不会出现什么太大问题。如果这东西丢到车里面做,哼,丢到车里面做,那你这个提示词工程能力得非常的强大才行。对,提示词工程能力得非常的强大才行。 可以看到我们这个现在用这个扣的加 v, 呃,第四个 v 四我感觉是 比较适合那种呃自己搞个人开发或者说在方面感兴趣的人去使用。当然如果你大公司是吧,有些公司它会有这些 呃报销的,那你就去用 g p t 五点五 off 四,四点七嘛,反正公司有报销。但对于我们个人来说,平常如果只用用玩玩的话,我觉得 d b c v 四加上可洛克的真的是一个非常好的一个方案。
7152arkjack~AI学习版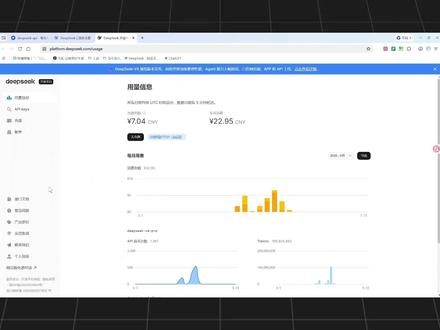 01:42查看AI文稿AI文稿
01:42查看AI文稿AI文稿刚才我查了一下账单,发现自己用 deepsea 写代码花了将近二十三块钱,三千多次调用将近四亿 token, 同等量级扔到 gpt 上,一个月少说几百十几倍的差价,而且用起来说实话没感觉有什么区别。这就是我今天想聊的东西, resonix, 一个专门适配 deepsea 的 本地编程助手。先说清楚,这玩意儿不需要外网,装起来也很简单。 github 搜 resonix 小 白直接下桌面客户端,双击打开即可, 首次启动会让你填 a p i 密钥,据 deepsafe 官网注册一下,领个密钥粘进去一两分钟的事。界面就是个聊天窗口,有两个模式需要注意, review 和 auto 模式会申请工作区外的文件访问权限,而我日常电脑没什么重要的文件,所以一般直接开 ulog 模式,省事方便。 来实际带你们体验一下。比方说我想知道 ai 热点,用这个 ai 热点的 skill, 直接跟他说帮我搜今天 ai 圈有什么新闻,整理成精简文案,他自己就去抓信息了,不用写任何代码。 等了大概几分钟,结果直接出来了,可以看到这都是最新的资讯,时刻紧跟热点。我做自媒体内容的时候,给他搭了一套完整流程,从八视频素材提文案到改写预判数据表现,一条指令走通, 花费一两个小时搭建,就能节约以后我找素材的时间。而且如果你完全不懂代码,也能用它搭个人网站。 我试过用了开源的模板,借助 deep c 转化为我想要的样子,可以给大家稍微看一下成品纯前端,自己图一,乐呵乐呵的。当然运行中间报错了也别慌,它会自己看错误信息 自己修,修完继续跑。对新手来说,这体验确实可以。原作者我在评论区 a d 出来了,感兴趣的可以关注。下期的话,看评论区问的最多的问题,我挑一个话题继续深入。
5498既白真摆 00:44查看AI文稿AI文稿
00:44查看AI文稿AI文稿什么不花钱就可以用 deep six v 四了?现在国家为了让普通人都能用得起 ai, 门槛都降这么低了。以前用这种大模型 ai, 你 得买会员吧,你得翻墙吧,你得翻译一下英文吧?现在国家直接把这个 ai 模型直接挂到网上,所有人都可以用, 意味着什么呢? ai 不 再是什么高大上的东西,就跟我们平常用的网络自来水电一样的普通,但是很多人往往看到免费的东西不懂得珍惜。今天这条视频 来挑战一下你的执行力,直接打开这个网站实操一下,你只有自己真正去体验一下,你不玩他一下,你怎么知道他有什么用呢?对吧?你实在不知道 ai 能帮你做什么,你把你的职业打在评论区,我帮你看一下。
66齐悦AI破局 00:55查看AI文稿AI文稿
00:55查看AI文稿AI文稿一部是一个微视,这波升级真的太狠了,本来以为升级了给个真实的参考文献已经很牛了,没想到他将 ai 也有一手。你先从初稿里薅出一段正文糊进工具里, 这里有个死命令,必须切到专家模式。默认模式那是给上古神兽用的。再把深度思考点亮,把那串提示词往里一丢,等个两三分钟,一段内容就被他戳的干干净净。 偶尔遇到戳不动的,多来几次,跟开盲盒似的,总有一款能中。但有一个毛病,就是一段一段的复制粘贴太耗时间了。 等你撸完别人都答辩完了,所以直接上终极大招,把整篇初稿一口气全扔在这,再选好你们学校指定的那个查重平台。然后你该干嘛,等你回来。一篇原文意思一毛没动, ai 率却低到老师无话可说的初稿就已经乖乖站好,等你拿去交差了。
 02:11查看AI文稿AI文稿
02:11查看AI文稿AI文稿最近这个是一个 v 四永久降价百分之七十五输出价格啊,直接干到了六块钱一百万 token。 六块钱一百万 token 是 什么概念呢?粗略计算下来,你写一篇一万字的论文,成本只有六分钱。你和 ai 聊一千轮,每轮一千字才六块钱。 但网上还有一大帮人天天忽悠你买显卡装服务器,说本地部署大模型,数据安全,不用联网,永久免费。我今天把话放在这里,凡是不问你的实际需求,就让你本地部署大模型的,非蠢即坏。 为什么这么说呢?我给你算一笔账,首先能流畅运行七十 b 大 模型的本地部署,至少需要什么配置呢?显卡至少两到四张高端显卡吧,还有主板, cpu, 内存,硬盘散热,一套下来至少两三万,还没有算电费。 两三万能买多少 bitcoin 的 token 呢?六块钱一百万,三万块钱就能买到五十亿 token。 五十亿 token 是 什么概念呢?你每天和 ai 聊十万字,能聊一百多年?你每天让 ai 写十篇一万字的论文,能写一百多年? 而且一百年以后啊, bitcoin 早就更新到 v 五十 v 一 百了,模型能力翻几十倍,你当年花三万块钱买的显卡早就淘汰了。 有人说我数据敏感,必须本地部署,那你告诉我,你那些所谓的敏感数据比银行、政府、医院还要敏感吗?这些机构啊,用的都是云服务,你的那一点数据算什么呢?而且现在啊, deepsea 都有企业级私有化部署方案,比你那几万块钱自己折腾靠谱的多。 还有人说我一个月要用几亿的投坑云端太贵了,你一个月用几亿投坑?你的业务规模还差那一点 api 费用吗?真正跑大规模的企业早就有定制化方案,不需要瞎操心。 最可笑的是一堆卖硬件的卖课程的,搞 ai 创业培训的,天天骨锤本地部署私有话说白了就是卖铲子的人。 deepsea 这次降价六块钱一百万投坑,比你花两三万买硬件,然后过几年就淘汰划算的多。我再说一遍,凡事不问你实际需求就让你本地部署大模型的非蠢即坏,要么是卖硬件要么是卖课程,要么啥也不懂跟着瞎吆喝,别再当韭菜了,清醒一点。
14冯言微语 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿五月三十一日深夜,一条 api 文档更新,让技术圈集体愣了一下。 deepsea v 四 pro 宣布永久降价,直接打到原价的四分之一,不是限时促销,不是阶梯折扣,就是白纸黑字,从此就是这个价。很多开发者反应过来, 之前那波限时原价自己还真赶上了。笑归笑,大家真正好奇的是,这种降法凭什么还能玩得下去?核心底气来自两层。第一层,算力测的一次静默升级, v 四 pro 从训练到推理,全面绑定 f p 四精度, 而更适配这套路线的升腾,九百五十完成了大规模交付。原生 f p 四算力发挥出来,等效利用率冲到百分之八十二点五,远超此前 h 两百上的表现。带宽对贸易模型的通信瓶颈格外友好, 同样的钱买到的是多倍的实际计算量,单偷看成本应声而落。第二层,缓存架构抠出来的巨大空间, deepsea 的 上下文缓存不及这清热数据,在 hbm 温数据自动落到 nvm 一 盘上,冷数据还能压缩持久化,命中率高得惊人。真实文本类百分之九十二点七,代码类百分之九十八点四。 大部分请求只需计算增量部分真实算力需求彻底变了,第三方数据已经出来。 高频缓存场景下, v 四 pro 每百万 token 综合成本约四块钱, gpt 四 o 同样场景要烧掉近六十八块。差距不是缩小,是直接被撵到了他人的零头。已经有头部企业把客服系统切过去, 月账单直降七成多,首次延迟反而还少了一半。消息传开,压力瞬间转移,文新的阶梯报价开始吹风通一内部邮件传出要重效成本模型 降价,眼看要变成一轮洗牌。最后说句实话, v 四 pro 现在被全球开发者顶着用,靠的不是免费送 token, 是 硬跑出来的成本优势。把算力做成水电这件事有人真的在做,也别忘了底下撑着的是一块加速成熟的国产算力土壤。
 01:03查看AI文稿AI文稿
01:03查看AI文稿AI文稿同样让 ai 写一百万字, g p t 四 o 收你十美金, deep seek 收你不到一块,便宜十倍。 deep seek v 四,上个月刚发的一点六万亿参数,但只激活百分之三,什么意思? 相当于一个公司有一万个员工,但每次只派三百个最合适的人干活,省钱还快,降价百分之七十五,直接把 ai 价格战打到地板。但争议也来了。 第一, anthropic 公开指出 deepsea 曾用大量账号获取竞品模型的输出数据,引发了 ai 行业知识产权的讨论。第二,数据存储在中国服务器,部分海外企业用户有合规顾虑。 便宜十倍是真的,争议也是真的。一句话, deepsea 证明了算法比算力重要,但过程是否经得起审视?还在讨论,你用过 deepsea 吗?体验怎么样?评论区说说。 下一期我们聊 ai agent, 你 的 ai 不 再只是回答问题,他开始自己做事了。关注我,下期见。
 00:38查看AI文稿AI文稿
00:38查看AI文稿AI文稿如何评价 deepseek v 四降价的事?就这么说吧,腾讯涨百分之四百六十三,智普连着涨三次,阿里百度全在跟 deepseek 呢,直接宣布永久降百分之七十五,输入价只要二点五分钱,扎百万 token。 有 网友算过,你跑一堆请求,成本可能还不够一瓶矿泉水。 我当时看到这价格愣了一下,要说离谱了又好像挺合理。我有个做 a p i 的 朋友,看完价格表直接说,这不就收个电费吗?群里有个更逗的,充了二十块钱,敞开的照,照了大半个月,一看账单两块七分,然后搁那发感慨,还是用的太少,以后要对得起 deep seek。 真不是段子,群里当时就刷屏了。有意思的是,彭博刚爆出来, deep seek 再搞一轮七百亿融资,他拿资本的钱撑研发,研发把成本 压下来再反馈给用户正循环,别人都在赶紧回血,他反而杀价抢用户圈生态。所以圈里现在都在猜,这种降法持续下去,后面谁还顶得住。
22林宇论Ly 01:03查看AI文稿AI文稿
01:03查看AI文稿AI文稿最近 deepsea 微四刚上新,那我必须第一时间去试水凑个热闹啊!不得不说,这新版本是真有两把刷子,配合指令,居然能直接把初稿的 ai g c 率压到零!先拿老朋友豆包整一段文稿 拿去检测一下,那好家伙, ai 率直接飙到九十多,红彤彤的,忒吓人了,赶紧换 deepsea 微四新英雄救场,输入提示词, 再粘贴要修改的内容细节,使用专家模式开启深度思考,关闭联网搜索,这样才能把新手实力发挥到最大。整完后再去复检一次 ai 率,直接干出零,你说离谱不离谱?不过毕竟 v 四刚出生嘛, 还不够稳定,下一次再试就只降了一点点,很拼运气。这个时候就该我们的老玩家上场带低手了,可以选择知网在内的几家主流平台,根据学校要求来, 然后把需要降 a i g c 的 文档丢进去,等几分钟就完事。还得是老玩家,虽然不至于降到零,但是试了几次不一样的结果,都很稳啊!
102小磊师兄 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿为什么建议用 deepsea 微四降 ai? 因为它是真的牛,今天带你们实操展示下。 首先来到 deepsea, 这里一定要勾选专家模式,不然还是之前的老模型。然后把深度思考打开,智能搜索关闭,先让它给咱生成一段内容出来, 生成完了去跑一下原始 ai 率,可以看出来是非常高的。然后进入降 ai 环节,我们先开一个新的对话窗口, 这里一定要切到专家模式,把这段特别好用的降 ai 指令发给他,等他领会了改写要求之后,再把刚才生成的内容发过去,稍微等一下就有了。 然后拿改写后的内容再去测一趟, ai 率明显已经降下来了。咱们这套降 ai 指令加上 deep seek 的 专家模式,效果确实不错,但同时也存在几个问题,这种方法很容易改变文章的原意,导致文章过于口语化,而且降 ai 也不是很稳定, 有时候能给你降到个位数,有时候 ai 率怎么都降不下来,这时候你可以把文章丢到这里面,它可以在不改变原意的基础上做到这种效果,你就学吧。
150番茄拌芒果 04:08查看AI文稿AI文稿
04:08查看AI文稿AI文稿很多人都在问 deepsea v 四到底强不强?我今天不吹参数,不看跑分,也不复读发布会我直接告诉你, 普通人到底该不该用。因为现在很多 ai 发布最大的问题不是不够强,而是你看完一堆宣传,最后根本不知道它能不能真正帮你干活。而 d e e p s e k v 四这次最关键的其实只有五件事。第一件事, 它不是那种一夜图榜的模型,你别指望它刚发布就把所有顶级闭源 ai 按在地上打,但重点是它重新回到了第一梯队。什么意思?以前很多国产模型最大的问题是不稳定,有时候很强,有时候像失忆。 但这次 deepsea v 四明显开始往稳定生产工具走了,这很重要,因为真正能进入工作流的 ai, 不 一定是最炸裂的,而是你敢长期依赖的。第二件事,这次真正被低估的不是跑分,而是百万级上下文。 很多人还把 ai 当聊天机器人,但现在已经进入智能体时代了, ai 不是 陪你聊天,而是开始帮你读文档、拆任务、调用工具,连续执行。这时候上下问一短,问题就来了,任务做到一半直接断篇,前面说过的话,后面全忘。 所以 deepsea 这次把长上下文做起来,本质上是在铺 ai 工作流的基础设施,你现在可能感觉不到,但未来所有自动化协作 ai agent、 长链路任务都会越来越依赖这个能力。第三件事,很多人看模型只盯着 api 价格, 什么一百万偷啃多少钱,但真正做项目的人都知道,单价根本不是重点,重点是同一个任务, 你到底要改几轮?有些模型虽然便宜,但你改十次他都理解不了,最后头肯越烧越多。真正该算的不是调用成本,而是任务完成成本。 这也是为什么有时候贵模型反而更省钱。第四件事,很多普通用户最容易犯一个错误,所有任务都开最强模型,其实完全没必要。如果你只是写文案、做总结、整理数学、 多步骤任务、 pro 版本,差距就会慢慢出来。真正聪明的玩法,不是无脑上最贵,而是普通任务用快的关键,任务在用强的,这才是 ai 时代真正省钱的方法。第五件事, 也是最关键的一件事。 deepsea v 四真正值得测的,根本不是网页聊天框,而是智能体工具,比如代码助手、自动整理资料、知识库问答、 pdf 报告生成、自动化工作流。因为只有到了真实流程里,你才能真正感受到长上下文 工具调用、中文表达能力到底有没有价值。但这里我要提醒一句,很多人现在对 ai 最大的误解就是觉得模型升级以后就能全自动驾驶,其实并没有。复杂任务里, ai 依然不一定会主动选最合适的工具, skill 插件、外部调用很多时候还是需要你自己判断,所以它更像什么,像一个效率极高的协作者,而不是一个完全不需要人类的大脑。最后说一句, 这次 deepsea v 四真正重要的可能不是超越了谁,而是它在持续开源,持续降低门槛,持续推进国产 ai 生态。 这意味着国产 ai 开始从跟随慢慢进入,共同探索下一代智能。如果你平时经常写内容、读长文档、做代码、搭 agent、 跑工作流。我建议你认真试一下, 不是为了追热点,而是看看它到底能不能让你的任务更快完成。但如果你只是偶尔聊天,也不用焦虑,你不会因为没有某个模型就错过一个亿。记住一句话,模型排名只是参考,能不能进入你的工作流才是真正的关键。我是 ai 知识博主麦克飞 k, 后面我会继续用普通人的视角拆 ai 模型,拆 ai 工具,拆 ai 工作流。别迷信单个模型,真正的红利永远属于会把 ai 放进流程里的人。
23迈克菲K 01:08查看AI文稿AI文稿
01:08查看AI文稿AI文稿我为什么一直不太建议直接用豆包 deepsafe 去整初稿?原因很简单,它们本身没有文献数据支撑,说白了,参考文献这一块,它是编的。有些人很聪明,知道这一点,于是就开始换玩法了。先去织网找文献,然后找升级后的 deepsafe 微四版本, 最后自己一段一段粘贴,看起来很聪明对吧?但你忽略了复制粘贴的 ai 痕迹。等你花几天时间改完,你会发现一个问题, 清除 ai 痕迹并不会降低 ai 率。你让他总结研究思路,归纳大纲,确实是有惊喜的,毕竟也不是白升级的哈。我教你一套更顺的方法,把只网找的文献丢给 dixon, 但注意别让他整全篇。那让他干嘛?给你整理研究思路,拉一个三级大纲,这才是他该干的活。你还别说, 不管是逻辑调理还是整体框架,都挑不出毛病。研究思路、文献大纲都有了,接下来你以为我要手敲出稿了? no no no! 别太高看,我把刚才的真实文献和完整大纲一股脑丢进去整合,再选上你学校的格式模板,几千套模板对号入座,从这一刻开始,格式问题跟你没关系了,需要图标公式代码的右边勾一下, 剩下的就很简单了。等结果一篇格式排版整整齐齐,内容逻辑也很顺畅的出稿,直接就成型了。说实话,是时候准备和豆包绝交了。
45小八要毕业 01:47查看AI文稿AI文稿
01:47查看AI文稿AI文稿我们今天来聊两个问题啊,第一个问题是 deep stack v 四的收费情况,第二个问题呢,就是我的电脑上有哪些工具已经接入到了 deep stack v 四?首先看一下收费情况, 像我这个月的话,其实已经使用了九块四毛五分钱。那么使用 token 的 话,首先第一个是 pro 模式之下,我大约是消耗了两百七十万 token, 然后是在 flash 模式之下呢,我大约是用了一千万,这样 token 加起来是不到一千三百万 token, 花了不到十块钱,那么合算下来的话,其实就是每百万 token 不 到一块钱,性价比其实很高的。 那么第二个就是我有哪些工具已经接入到了 deepsafe v 四。那首先的话,其实就是最适合我们普通人用的 workbody, 大家可以看一下,在这里的话,其实直接去配置到 我们的 deep deepsafe v 四就可以了,那这是我的第一个,其最也是最常用的。那么第二个呢?其实是我的龙虾 opencloud, 那 么我所接入的模型也是 deepsafe v 四,再有的话就是 cloud cloud code, 那 么我用的模型依然是 deepsafe v 四,是一个 pro 版本啊。 那么很多人会说我不会用 cloud code, 也不会去用 opencloud, 那 这种情况之下应该怎么办?那我可以给大家看一下我刚才的指令啊,我们以 cloud code 去举例子, 那我直接输入的第一个指令就是打开我电脑上的 cloud code, 那 么这个时候它会自动打开,但是我遇到问题它是没有用的,那我把问题复制到了对话框当中,让它自己去修复,并且接入到 tipsy v 四的大模型,那么它自己就会去运行了,那么所呈现的结果就是我可以再去自如的去使用这个 cloud code。 那 所以说就像昨天所说的,如果大家真的不会去用,那很简单,你就下载一个 work buddy, 然后把你所有不会的问题去问他,让他自己去解决了,这就是我们普通人去用 ai 的 唯一秘诀。
12眉毛李 01:31查看AI文稿AI文稿
01:31查看AI文稿AI文稿呃,非常吓人家,人们,昨天我用 deepsea 开发了一个量化策略网站,只花了三块钱人民币,便宜到荒诞,有感觉吗?给你们看一下网页和代码,这就是我做的量化平台,首页的话就是各股的股价,点进去呢,可以看到 k 线图,还可以放大哦, 还有它的主要功能就是这个策略实验室啊,可以进行一个回测的运算,我们随便输一个, 随便选一个,这些我都不懂,我随便选给他一百万吧, ok, 看到这边会展示他的收益,年化收益,最终的资产现在变成三百多万了,然后底下的话是资金取现,还有下面他做的交易的记录, 这些所有的内容都是他自己设计的,我一个字都没参与过。这个是他给我的一个产品文档,这是一个面向 ai 投资者的 a 股量化,然后这个就是代码前后端, 后端用的是 python, 前端用的是 vue。 当然其实用大模型做开发早也不是一个。呃,新鲜事了,就实话实说, deepsea 能写出这个网页来,我完全是很意内,但是真让我震惊的是,居然只花了三块钱, 那我想如果要我自己去做这个开发的话,怎么也得半个月到一个月啊,因为我都完全不懂量化嘛,有很多知识要自己去学习啊。但是 deepsea 的 话呢?哎,它只需要三个小时,三块钱。 最后看一下我 dp 的 消费记录,这一天我是写代码的,花了两块钱,昨天花了一块钱,今天花了二毛九。
7235不好惹人士 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿不是 dbz 微四 pro 永久百分之七十五折扣了,那就是永久二五折,那就不是促销了,是新定价呗。 你算一下,除完了之后,每百万偷看输入是零点四三五美元,输出翻个倍,零点八七美元缓存命中的话,价格是零点零零三六。不是你这么糟的话,我跟你讲,如果是一个比较复杂的任务, colodsonnet 按照十五美元百万输出 gpt 三十,那 vs pro 是 零点八七,输出端便宜的倍数还要更多。 那其实现在它的作用就很清晰了,你老说这个东西,你,你天天诟病 vs 四 pro, 你 说它比不过 oppo 的 四点七,没有超越 g b d 五点五 x high, 但是它是十五分之一到三十分之一的价格,那做一点终端的编程代码审查对不对啊?你把活先干了,把那个累活先让它干出来,然后到了一个非常重要的节点,比如说挑出问题,真要改,这时候你再派出 oppo 四点七大神不完事了吗?在成本质量的帕累托曲线上,只要在最前沿 有意义,也就是说在这个成本下,我们是最强的啊。谷歌其实也是追求帕累托曲线,比如说他前几天发布的 flash 三点五都是一样的。所以 deepsea 现在就来了这招,就是对标你 c c, 对 标你 cologne 的, 但是主打十五分之一的输入价格和三十分之一的输出成本。
1.1万口罩哥研报60秒 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿太狠了, deepsea 微四永久降价了,一年能省多少钱?我给你算笔账,微四 pro 输出降到六块钱每百万 tokens 什么意思? 我平时写一篇万字长文,以前花三块钱,现在七毛五,一天高频调用,一年能省下两千五百块钱。第一类,最刚需做 api 接口,批量生成素材,还是系统接入 ai 高频号 talking, 这次降价直接把成本砍到底,随便调用不心疼。第二类,本地装机跑自动化脚本,像我用迷你主机搭环境写爬虫,做定时任务,批量处理脚本。 v 四,编程能力拉满, 不用再依赖高价海外模型,成本直接省九成。第三类,玩 a r 智能体的一定要看 deepsea v 四,适配各类本地 agent, 搭配 open club 这类工具做任务拆解,多步骤推理知识库问答逻辑和响应速度完全够用,性价比直接拉满。我是张 sir, 下期教你们更狠的玩法。


