两个指标联合roc曲线绘制步骤
lc 曲线常用于评价诊断试验的判别效能。由于单一指标判别能力可能有限,临床实践中常采用多指标联合分析以提高灵敏度或特异度,从而增强对疾病状态的区分能力。 联合诊断通过整合不同指标的互补信息,有助于降低误判风险并提升整体诊断性能。在 roc 分 析当中,可采用 latest 回归或其他机器学习方法,将多个指标整合为预测概率,并基于该预测概率或者 roc 曲线, 从而与单项指标的诊断校准进行比较。本问重点介绍基于 lodis 的 一个回归构建联合 r o、 c 曲线的方法,并比较 s p s s 软件与 g p t 实现路径的分析过程。 我们先来看具体的案例,对三十例受检者,分别采用新方法 a、 b 及传统方法 c, 也就是均标准进行疾病诊断,表意为部分数据,其中 disease 为金标准,结果零是未患病。一是病变 a、 b 分 别为两种方法测得的生化指标,研究只在比较方法 a、 方法 b 以及基于 a 和 b 构建的 logistic 回归联合模型的 o、 c 曲线及其诊断效能。 接下来是案例分析。本案例属于典型诊断性试验,以传统方法 c 为金标准,评鉴方法 a、 方法 b 及基于两者构建的联合模型,在区分患病与未患病个体方面的诊断效能,并采用 oc 曲线进行分析。 然后是软件分析。我们先来看 s p s s 为评价 a、 b 两种检测方法的联合诊断效能,构建二元 logistic 回归模型,以两种检测方法作为自变量,疾病状态作为应变量, 计算联合预测概率,并基于该预测概率绘至 r o c 曲线,计算取线下面积 a、 u c, 以评估联合诊断的准确性与判别能力。我们一起来看 spss 的 具体操作步骤。 首先是二元 logistic 回归模型建立,第一步是回归模型调用,在 spss 当中选择分析,然后回归,选择二元 logistic 回归。 然后是参数设置,将 disease 放入因变量框中,将自变量 a、 b 放入斜变量框中。方法选择进入,也就是将 a、 b 一 次性同时纳入 logistic 回归模型进行分析。 接下来是联合预测概率的生成,点击右侧保存,然后勾选概率以生成个体预测概率,点击继续,最后点击确定。 此时数据式图中将新增一列由 logistic 回归模型计算得到的预测概率值数列,基于 a、 b 两项指标的取值生成,反映两种方法联合后的诊断效能。 以该预测概率作为检验变量,即可绘制 r o c 曲线,并计算取线下面积,用于评价联合诊断的判别能力。 接下来是 r o c 曲线分析。首先 r o c 分 析功能的调用,在 s p s s 菜单栏中依次选择分析,然后选择 r o c 曲线。 接下来是参数设定,将 disease 置入状态变量,并将状态变量值设定为一,表示患病组将 a、 b 及预测概率置入检验变量。 勾选下面的 o、 c 曲线,带对角参考线、标准物和执行区间 o c 曲线的坐标点,然后最后点击确定。 最后就是 oc 分 析结果。与诊断效能比较, oc 曲线分析结果显示方法 a 的 曲线下面际为零点八五,百分之九十五,执行区间为零点七三到零点九八八。方法 b 的 曲线下面积为零点七七二,然后它的百分之九十五执行区间是零点五九四到零点九五零。 联合预测概率的曲线下面际为零点九五一,百分之九十五,执行区间是零点八八三到一。 我们可以看到联合模型的曲线下面际最高,提示基于 lotus 给回归构建的联合预测概率较单项指标具有更优的诊断效能和判别能力。 图八,嗯,就是它的一个 r o c 曲线。接下来我们再用 g p t 重新绘制上面的 r o c 曲线,来看 g p t 统计分析的一个准确性怎么样?我用的 g p t 是 五点二版本的, 首先是点击这个加号上传原始数据,我已经提前上传好了。然后呢,就是在这个对话框当中输入我们的统计分析要求啊,这个呢,我也已经提前输入好了。 原始数据中的 zeros 为因变量, a 和 b 为自变量,在一张图上分别会指 a、 b 以及基于 largest 一个回归的二者联合 osc 曲线,并计算 aoc 值及百分之九十五之性区间。输入好了之后,我们点击这个向上的箭头, 这样呢, gpt 就 开始进行数据分析绘图,这个过程呢,需要稍微等一会。分析好了,我们可以看到 gpt 不 光绘图,它还给出了 python 的 这个代码,这个代码本色就不细看了,我们直接看最后面的这个凹 c 曲线。 单向指标 a 和 b, 也就是蓝色和黄色的这个 r c 曲线,以及它的曲线下面积与 s p、 s, s 基本一致,但是在 a 和 b 联合诊断的 r、 c 曲线及曲线下面积,也就是绿色的这个 线,我们可以看到与 s p、 s, s 结果存在较大差异。因此,目前 g、 p、 t 在 绘制较为简单的统计图及进行基础计算方面表现尚可,但对于涉及联合模型等相对复杂的统计分析与图形绘制仍然存在一定的局限性。

粉丝2768获赞7496
相关视频
 04:57查看AI文稿AI文稿
04:57查看AI文稿AI文稿已经经过临床检验确诊他已经是患了某种疾病,那么你选取了某些数据,然后呢?你通过这些数据的检测啊,分析啊,你就可以得出来 这个这个指标对这个疾病诊断的意义和价值。那么当以后类似的患者,他的某个指标达到了一定的值的时候,那么他就很有可能患这种疾病 啊。所以我们这个状态变量,也就是我们在我们今天的这个示范的数据里面损伤情况,他就是要么损伤了,要么没损伤,那么隐身到你们的研究里面,就是 他要么患了某种疾病,要么没有患某种疾病,是不是好损伤情况就是状态变量,然后状态变量的值就是我们以一为参考哈,就是 发生了器械性损伤的患者,就是一嘛,我们刚才这里对这个就是一,对不对? 然后我们的营养评分啊,白蛋白、血糖、气血作用时间等等其他指标,你的一些生化指标啊,然后就是我们的检验面量选项卡里面的,基本上就是默认的,不用管啊。然后我们把这个对角线, 然后标准物还有那个曲线的坐标点勾选上,点击确定就是发生的器械性损伤的,大概有一百零三个人 啊,没有发生气性损伤的有七十九个人,这个没有什么意义哈,就是看一下,让你看了解一下本次数据的具体情况,那么具体的就是我们这个 ioc 曲线图这个蓝色的这条线,这个是蓝色吧,我应该不是色盲, 蓝色的这条线是营养评分,营养评分,哎,为什么没看到?他可能就是和某条线重合了,他估计就是没有诊断价值吗?那么我们看这个白蛋白就是这条绿色的线,绿色的线你看到没有?就是总的来说,我先给大家看了的哈,就是说 我们的这个线越靠近左上角,那么就说明我们的诊断价值越大。如果在这个对角线的右侧啊,就是在右下角,那么说明我们的这个指标对我们的诊断没有任何意义啊, 没有太大的价值。所以你看我们的这个白蛋白,他基本上就是在这个黄色的对角线右下侧,是不是好,他基本上就没有什么意义了。器械作用时间他也有一部分在这个黄线,就是对角线,这条黄色的是参考线,看到没有?我们的这个 细节作用时间他也在我们的这个左左上角啊,有一部分,右下角也有一部分,所以他对我们这个 是否发生器械性损伤啊?只只能因为这个数据我改了的哈,就是说他没有任,没有意义不是很大,但是这条血糖的话,他相对来说,相对来说他在这个参考线的,那么他相对于其 几个指标来讲话,那么他对于这个器械性水啊,有一定的参考意义,但是 越高越好。第二张表哈,就是我们这个曲线下面积,你看我们这个营养评分是零点零零零好,他可能就是和这条线重合, 应该是这个样子啊。然后我们的这个白蛋白他有他,他是这个面积,是曲线下面积吗?就是他这个曲线下面积, 白的白是绿色的,这条线看到没有?我们的这个一半面积哈,是零点五是不是?那么你看他很明显小于这个一半的面积,他的曲线面积他年他只有零点四一六啊,这个零点四一六是什么呢?也就是说他有百 百分之四十一点六的概率可以预测,就是通过白蛋白有百分之四十一点六的概率可以预测出这个患者是否会发生器械性损伤啊,同样这个血糖就是有百分之六十四点二, 你如果只观察血糖这个指标的话,你可以有百分之六十四点二的这个概率,能够预测出这个患者 会发生器械性损伤啊,至于他的血糖大达到什么什么指标呢?他他可能会发生器械性损伤,这个就是我先给大家说的阶段值 啊。嗯,关于这个阶段值还有这个约灯指数需要配合,这个约灯指数还有特异性敏感,敏感度有关啊 啊,如果有想要了解的朋友呢,你们留言啊,我后面会给大家分享,今天主要就是给大家讲解一下这个 ioc 曲线图的绘制啊,以及结果解读啊,谢谢大家。
393spss数据分析帮 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿在一些医学诊断研究中,经常会绘制 off 曲线作为辅助判断诊断方法准确性的指标,用 spss au 轻松三步就能绘制完成。登录 spssau, 选择可视化 roc 曲线,将产妇体重、产妇年龄放入检验变量矿中,将低出生体重而放入状态变量矿中,分割点设置为一级数值等于一为阳性。点击开始分析 即可得到 off 曲线图。分别绘制出两条 off 曲线,可根据图形结果进行比较。诊断准确性如何?如果要具体对比两种临床诊断的效果,可使用下方的比较检验表格,输入对应的 aec 值和标准物 即可得到结果。具体操作过程可点击小灯泡查看帮助手册中的案例说明。
234SPSSAU 10:36查看AI文稿AI文稿
10:36查看AI文稿AI文稿今天教大家用这个麦卡来制作 oc 曲线,那么我已经把数据准备好了,分为是指标 a 和指标 b, 指标 a 和指标 b 在我这里是通过实验测出来的数据, 这个第三列的是主别主别,我分为零和一,其中零表示正常组,一表示疾病组, 所以我们先要把数据像我这样准备好, 格式不要错了,要分成几列。 就是要注意的是分组作为 单独的一列,最好用零和一表示,而不要用其他一或二表示。我们现在开始分析,点击这里看到下面有个 oc 曲线, 然后点第一个 oc 曲线分析, 然后在变量这里选入我们想要分析的指标,比如我们先看一下指标 a, 这里选入分组的情况,下面有个蓝色字体,这里点开, 他默认就是零和一,所以我们刚才建议是要用零和一,他这里也说了,一表示阳性 的或者异常的、病例的,零的是阴性的,健康的或者正常的,我们点击 ok, 默认,其他的选项也是默认,就可以点击 ok, 这样他的结果就出来了,分为两个框,一个框是具体的数据,一个框是图片的展示。 我们先来看一下这个详细的数据,这里可以看到他的 auc 是零点六八一, 然后这也是他的百分之九十五自信区间,他的批值 是小于零点零零零一的, 这个是他的最佳的一个预知, 然后这个最佳的玉值对应的灵敏度是百分之六十五点八二,特异度是百分之六十五点四三,我们最常用的就这几个数字, 然后我们再看一下图片, 这个指标 a 这里可以,我们可以删掉, 有这些横坐标、重坐标,他都是给出了默认的注意在这里,因为他的横坐标 是二十、四十、六十到一百这样的,有的文章他是用零点二、零点四表示, 所以我们这里也是一百减,这个退一度 建议要加个单位,也就是百分号,同样这里也加个百分号, 这样子就会更加严谨一点,因为比如二十,这里有个单位表示百分之二十, 如果这里是零点二、零点四,那这里就应该是改成一减退一度, 有这些数字的格式都是可以改变的,我们双击一下, 这些都是可以改的。如果想改变字体的大小,不用双击,单击一下就选中他,然后这里可以选择,字体的大小就会变了,不要加粗也行, 这里也是可以改的,这里可以进行修改内容, 比如我想加上 灵敏度、特异度, 他这里就会展示出来,当然我这里就不加了。 然后这个 蓝色线条跟红色线条的格式也是可以改的,双击他有改成这种蓝色, 要不要那么粗,你看就会改了。同样的操作,点击红色的, 比如换一种颜色,把它弄粗一点,这样就可以了。 我们可以在这里输出图片,这里有好几种格式,可以选 tf、 f 或者 jpg, 或者是其他的格式, 这里我就不示范了,这些操作都是非常简单的, 那么我们再回到这里,那么如果我想把两个指标在同一个图片里面, 就是把这两个指标放在一张 oc 曲线的图片里面,怎么做呢? 我们还是选中这里,然后倒数第二个有个凹凸曲线的比较, 我们这里可以同时选用多个指标,把指标 ab 都选进来,这里同样是把分组的情况选进来,点击 ok, 这样就会出现两个指标的哦,是曲线的,而且 这里数据可以看到,指标 a 的 auc 是零点六八一,指标 b 的 auc 是零点六零九。那么显然从图片也可以看得出来,蓝色的是指标 a 的, 他的曲线下面积要比指标低的要更好一点。 具体的这些修图我就不一一介绍了,刚才已经讲过了。还有一种情况就是我要把指标 a 和指标 b 合并结合成一个新的指标,作为预测的一个指标。怎么做呢? 我们先在 这里选择 logistic 回归分析, 这里还是选用分 分组的一个情况,那这里选入指标 a, 指标 b, 这些也是可以选择默认的就可以了。点击 ok, 我们直接拉到最后面,可以看到把这两个指标合并成一个新的预测指标之后,他的 auc 稍微提高了一点点,是零点六九五, 这是他的百分之九十五之间区间。然后我们点一下这个左边的蓝色字体保存, 这里可以重新命名, 你看这里就会自动生成新的一列,就是一个新的预测指标,这个新的预测指标是综合了 a 和 b 的 形成的一个新的预测指标,如果你只是想单独展示这个新的, 那就直接在这里选入就可以了。如果我想把 a 和 b 还有新结合的这个新的指标三个放在一起, 那还是用刚才这种方法,用 comprove, 是这里 选用指标 a, 指标 b, 还有这个两者结合的指标 i'm okay, 这样子他就是有三条曲线,包括指标 a 的、指标 b 的,还有两者结合的。当然 其中的细节我就不一一再重复说了。好,今天的视频到此为止。
297飞猪Doctor 07:41查看AI文稿AI文稿
07:41查看AI文稿AI文稿哈喽,大家好,我是宋哥统计,今天呢在公众号的后台有一个人呢问了一个 roc 曲线诊断的一个问题,我觉得非常有意思,所以呢特别呢录制了这一个 roc 曲线的番外篇。那么 roc 曲线呢,我们在前期的课程呢都已经讲过了,它是非常简单的一种诊断线 诊断一直发现的一种方法,我们再演示一遍给大家开来看一下。我们点分析去寻找到 lc 曲线啊,松哥用的只是二十六点零,二十六点零的 lc 曲线已经不在分析里面了啊,二十六点零的 lc 曲线已经不在这个主菜单里面,在分类里面 里面啊,他有个叫 lc 曲线,并且他还增加了 lc 曲线的一个分析功能啊,比较强大一点点,可以进行的一个组间的比较。以前呢, lc 曲线呢,只能够做出他们的曲线的曲线,下面的一个 lc 和他的百分之九十五可以区间,但是对不同指标的 lc 之间的面积啊,没有办法来进行比较,我们通常是借助别的软件做了,但是呢, hps 在二十六点零呢,可以实现了 lc 曲线,不同的 lc 曲线呀,面积的直接那个比较 ok。 话不多说,我们来看这么一个案例, 比如说我们来诊断一个身高和一种疾病状态到底有没有什么关系,我们把 多一点,让大家感受深一点,把这个疾病状态呢,他定为一,一是疾病,二是没有疾病,所以状态值呢是一。 然后我们把相应的三个值勾选中之后了,我们直接点确定了这个 lc 曲线就做出来了。我们发现身高和体重对于这个疾病的诊断的一个消毒还是挺好的,是不是?而且身高呢,他这个曲线的面积应该比体重要更大,哎,这是我们通常所做的,但是 啊啊,顺便再把这个解释一下吧,我们可以看到你看身高和体重,他们的曲线下面积,哎呦细 哎,就是艾尔瑞亚昂德克五啊,他是身高是零点九三六,哎,体重了零点八幺幺啊,然后呢后面是他的一个什么标准物,我们知道这两者有一定的相差,但是差别到底有没有同居异议呢?哎,这个 是不太清楚的,然后可就可以通过下面这个灵敏度和意见特异度了,我们去计算出他的一个正确指数 对不对,然后就可以进行一个 lc 曲线,找到正确的一个诊断机制,貌似没有问题,但是呢,有一天啊,突然有一个问题, 就是后台啊有个问这样的一个问题,就是他说了说完描述这个问题之后呢,我就随机模拟了一个,就为了实现他讲的这样的东西,我又模拟了一组数据,他是研究艾滋病和 cd 四的啊, 如果你没有这个技术了,你也很好,你看啊,让我们来分析一遍,带大家看会出现什么样的结果。我们做 lc 曲线,然后呢把这个二疾病的状态,艾滋病状态是一啊,然后呢把 cd 四呢作为一个减 指标,是一种细胞印子检验指标,我们把相应的值给他,勾选中之后,我们点个确定,立马就会做出他的一个 lc 曲线,可是 我发现这个 lc 曲线他是什么,他是这个曲线都已经在这个下面 这一半了,我们讲的话,这是中间的参考线,是不是?然后肚子越大,肚子越大越往上面飘?意思是我们通常前面见到 lc 曲线是不是都是这样的,对不对?上面这样肚子越大,说明这个这个指标的他的一个诊断能力是不是越好啊? 可是我发现这已经降到这下面了,连他的正确率连百分之五十都没有,所以很多人看到这样的指标,直接就把他否定掉, 指标太差了,肯定不可以啊,肯定不可以,但是大家想想,有些指标他是越小越有诊断价值的指标,哎,我们刚才讲的那个身高啊,体重啊,都是什么?越大越能够诊断这种疾病,越大越能 血压一样,那就是越大越好,越大越好。可是呢,我们知道 cd 四呢,他是一个免疫功能细胞,当你 cd 四含量越少的时候,越可能这个人诊断为 lds, 是不是这样概念,所以他就和我们前面的套路不一样了。那么这时候进行 lc 曲线可以怎么办呢?哎,我们适当的先看一下,然后进行相互前后比较,你看这个 lc 曲线是到的是不是?然后我们发现他整段的概率只有多少?零点幺幺二,大家记住这个值零点幺幺二, ok, 好, 而且呢,下面给的这个是什么?大于或等于此之时为证。也就是我们在选他戒指的时候,那么选好了之后,比如说这个二点七五,我们就是大于等于这个二点七五,那么那就没有解决方案了吗?哎,我们知道 cd 四这个指标他是越小越好的,我们前面所研究的很多疾病都是越大越好的,血糖越高越危险,是不是高血脂?越高越危险,是不是高血糖、高血脂、高血压?一般来讲,我们体内的 某一种物质浓度越高,说明越有问题,可是有些东西是越少越有问题,比如说,哎,就像我们刚才讲的一个例子之外啊,比如说我们讲的那个血红蛋白含量越少,那是不是越容易贫血呢?红细胞含量越少,是不是也越容易贫血了?那对这些越小越 有诊断价值的指标怎么办呢?其实我们以前在讲的时候都忘了跟大家讲一个东西,就是在这个选项里面,他有个功能叫做什么呢?叫做通常默认的就是越大越代表更加肯定的检验,那么下面是这个就要 小的结果,代表更加肯定检验。我们只要把勾选那个较小的结果当做更加肯定的检验就可以了。当我们勾选他之后,点继续再次点确定,你会发现他立马就翻转过来了,是不是这样概念? ok, 你还记得上面我们讲的这个值是多少了吗? 是不是零点幺幺二?零点幺幺二,你看下面是多少?零点八八八。 那么零点八八八总共缺一样的面积呢?是多少?是不是一啊?一减去上面零点幺幺二就是零点八八八,是不是这样概念?而且他的百分之九十五肯定是零点七七六到零点九九九,我们再看上面的百分之九十五的减值是多少呢?是零点 零点零零一,对应的是不是零点九九九,然后是零点二二四,是不是零点七七六啊?零点七七六。所以对这些越小越小 好的指标,其实大家一定要注意一点,就是要勾选越小越好那个选项,同时我们也可以得到什么他这个绘制的 lc 曲线里面这个坐标值是什么?是小于等于此之时为正, 小于等于此之时为正。哎,上面我们这个是什么?是是大于等于此之时为正。 ok, 好,这就是越小的指标, 越小越好的指标,如何来去做他的一个 lc 曲线一个缝隙。 ok, 这一天呢就给大家简单补充这么多,大家也非常感谢呢, 公众号后台有这么一人问这么一个问题,真的一个好的问题啊,非常有意思,也欢迎大家继续来。嗯,问一些问题,宋哥跟大家一起来进行一个学习或者分享。
555松哥统计 05:59查看AI文稿AI文稿
05:59查看AI文稿AI文稿l c 曲线,也就是受试者工作特征曲线,是评估灵敏度和特异度的综合指标,其纵坐标为灵敏度,也就是真阳性率。横坐标为一减特异度,也就是假阳性率,通过连接各个数据点形成曲线。那么如何确定 l c 曲线上的最佳截断值呢? 通常我们通过约单指数来选择最佳点,我们将以 s p s s 软件 g p t 介绍如何会至 l c 曲线并计算最佳截断值。下面我们一起看具体的案例。 对三十名就诊者,分别采用新方法 a 与传统方法 b, 也就是新标准进行某疾病诊断。表一展示了部分结果,其中 disease 表示新标准判定的患变状态 零为未患病, e 为病变, x 为新方法 a 测得的某生化指标为评估该生化指标对该疾病的诊断价值会至 x 的 o c 曲线,并确定使诊断效能最大的最佳截断值。 接下来是案例分析。本研究指在评估生化指标 x 的 疾病诊断价值,通过会至 o c 曲线并确定最佳截断值, 以直观判断其诊断效能。 r o c 曲线越接近左上角,诊断准确性越高,其中最接近左上角的点对应错误率最低的域值,即假阳性与假阴性之合最小。接下来是软件分析,我们先看 spss。 首先在 s p s s 当中完成变量及其水平的设置,我已经提前设置好了,就是 zeros 和 x 这两列。然后呢,在菜单栏中依次选择分析,然后 roc 曲线图。 接下来就是参数设置,我已经提前设置好了,我们一起来看一下。检验变量选择自变量 x 状态变量选择应变量 disease 状态变量的值设置为一,表示病变 输出的这四个选项我们都全部勾选,然后点击确定,然后这样就得到了一个 r o c 曲线,还有它的曲线下面积为零点八五零百分之九十五,执行区间为零点七三到零点九八八, 以及它的曲线的坐标最佳的截断值对应 l c 曲线上最接近左上角的零一的那个点。然后呢,呃,我们将这个曲线的坐标 这里面的这三列数字,然后我们把它复制到 excel 表格当中,我已经提前啊复制好了,我们一起来看一下,就是前三列的数据, 通过计算并排序,月单指数已确定最佳临界点,而月单指数最大时对应的临界点为最佳临界点。 跃登指数呢,是用于评价诊断方法,区分患病与非患病个体的总体能力,它的计算公式是灵敏度减去括号一减特异性,也就是第二列减去第三列。 经过计算呢,啊,我们得到了就是第四列的这个结果,然后把它进行一个降序的排序,这个我都已经排好了,这行对应的就是最大的约等指数为零点六四三, 那么他对应的这个最佳临界点呢,就是五十八点五,敏感度呢为一,特异度就是一,减去零点三五七, 呃,为这个零点六四三。然后呢,我们对 spss 得到的结果进行一个总结, 就是 rc 曲线下面积为零点八五零百分之九十五,执行区间为零点七一三到零点九八八。以约端指数最大为准则,确定最佳截断值为五十八点五,此时约端指数为零点六四三,对应的灵敏度为一,特异度为零点六四三。 接下来我们看 gpt 的 结果怎么样?我用的 gpt 是 五点二版本的,首先在 gpt 对 话框当中上传原始数据,上传 原始数据, 然后呢,输入所需的统计分析要求,我已经提前输入好了,原始数据中的 disease 为阴性量, x 为自变量。绘制成线,并计算取线下面积, 灵敏度,特异度,跃灯指数最大值,以及根据跃灯指数最大时选出的最佳临界点,然后点击向上的箭头。 呃,它的这个分析过程呢,可能需要稍微等一会,等了大概三十秒钟。呃,它的结果出来了,我们一起来看一下。这是绘制成的一个 l c 曲线,下面呢是相应的一些数值, 曲线下面积呢是零点八五,呃,最佳的截断值是五十九,敏感度是一,特异度是零点六四,最大的跃灯指数呢是零点六四。 我们可以看到 c p t 得出的结果呢,与 s p, s s 基本一致,并且呢操作更简变。所以你认为统计师和统计软件会被 ar 取代吗?欢迎在评论区分享你的看法。
94婷好看 06:12查看AI文稿AI文稿
06:12查看AI文稿AI文稿大家好,欢迎继续本讲内容的学习,现在是第四部分多项指标的 r o c 分析。 首先介绍适用类型。在实际临床工作中,往往是根据多项指标综合判断病情的,如心梗愈后, 根据年龄、性别、心电图参数等多个因素综合判断,因此需要对多个指标共同作用的结果进行综合分析。 下面我们举实例加以说明。某研究者预判断中性粒细胞总数、白细胞总数、 年龄对孕妇绒毛膜牙膜炎的综合预测能力部分数据库简截图所示,变量复制绒毛膜牙膜炎一为否,二为是。 首先需要计算总体预测概率,因为此时是三个因素综合考虑的,总体预测概率的计算使用澳元 logist 回归,具体操作请看演示。 打开数据库,在任务栏中分析,下拉菜单,选择回归,进一步选择二、元老橘子的回 回归。将要分析的中性粒细胞总数、白细胞总数和年龄共同放入斜变量对话框。将绒毛膜阳膜炎放入阴变量对话框, 在方法中选择向后 l a 法,在保存中 选择预测之下的概率。选择完毕,点击确定运行。 以下是 s p s s。 给出的结果窗口,具体请看 在这张表中给出了澳元老 gister 回归的步骤,经过了两步澳元老 gister 回归筛选变量, 最终进入回归方程的是中性粒细胞总数和白细胞总数,说明二者共同作用可预测绒毛膜牙膜炎,而年龄则无异议。 根据回归方程中中性粒细胞总数和白细胞总数对应的 bata 值,可计算每个样本的预测概率。当然,在 s p s s 下,系统已经 自动计算出概率,生成了这个新的变量。请看 数据库中可发现二元老 g s。 的回归程序运行完毕后,每一个个体都有综合预测概率,下面就用综合预测概率进行 r o c 分析。 任务栏中,在分析选择 roc 曲线, 将总体预测概率作为检验变量选入对话框。将卢某某羊膜炎作为状态变量选入对话框,手工录录状态变量值为二。 在显示栏选择带对角参考线、标准误差和秩序区间以及 r o c 曲线的坐标点,点击确定预行, 这是 spss 给出的结果窗口。 请看这即是整体预测概率的 r o c 曲线。从曲线上看,这条蓝色的曲线均在红色的 对角线的左上方,因此我们猜测其预测结果具有统计学意义。进一步检验发现, roc 区线下面积为零点七八八, p 值等于零点零零零, 因此得到本研究的结论。本研究判断中性粒细胞总数、白细胞总数、年龄对绒毛膜牙膜炎的综合预测能力。 二元老君子的回归显示,中性粒细胞总数、白细胞总数联合作用对绒毛膜牙膜炎具有预测价值。 将中性粒细胞总数、白细胞总数的总体预测概率进行 roc 分析,曲线下面积为零点七八八,百分之九十五,致性区间为零点 六五零到零点九二五, p 值等于零点零零零。 因此,中性粒细胞总数、白细胞总数联合作用对容嬷嬷牙膜炎具有预测价值,预测程度中等,而年龄无作用。
175贰壹壹项目数据分析服务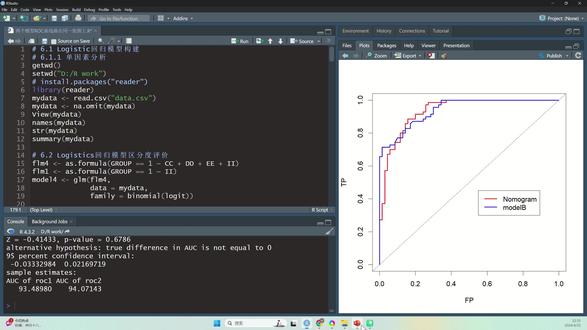 04:47查看AI文稿AI文稿
04:47查看AI文稿AI文稿好的,朋友们,我们跟师姐合作了一个课题,画了一些简单的表,呃,机械资料表,逻辑回归,先单后多,然后又画了一个逻辑回归,先单后多。中文版投稿格式的一个要求,中文格式的一个表格,然后画了一张拉错的两张图。 呃,通过组建差异单因素逻辑回归和 vn 图去交集确定。我们需要建建模型的基。 呃,这个是单因素逻辑回归的森林图,然后通过相关性矩阵检查这个,呃,我们的特征的 x 之间的多重贡献性。 画一个立线图, r o c 曲线,交轮曲线和绝色曲线。呃,这时候师姐希望我们,呃,就是 画把两个模型的 r o c 曲线画到一起。呃,第一个 r o c 曲线呢,就是最终纳入的四个变量的那么图,然后另外一个模型的话,就是一个单一变量的一个 r o z 曲线。我们来解决这个问题, 设置工作路径,读入数据,查看数据。呃,第一列是我们的结局二,分类的结局 group 零和一,然后从 b, b, c, d, e, f, g 这八个变量是我们的自变量。 x 都是连续性的变量。 嗯,内部词一下, turn 一下,三模一下。好了,我们首先建一个模型,就是我们四个最终的四个月亮的一个模型。 呃,我们命名为 f m 四,然后接下来这个单个变量呢?我命名为一。呃,你和这个四个变量的模型,一个变量的模型,然后预测一下加载包。呃, 训练结 u c 和 r o c, 啊,不存在啊,就是四变量。呃,四个变量的 model, 我们把它命名为 model a, 它的这个,呃, a o c 值是零点九三四,制性区间是八九六到九七四。 好的,我们首先画画一个这个 r o z 曲线,但是现在它这个 x 轴竖直是反的,要想顺过来,要加上这个。呃, legency x 的 tea。 好的,然后第二个第二个格式的这个 l c 曲线。然后第三个风格的 l c 曲线。啊,接下来展示一个变量模型的 u c 是零点九四一。 呃,它的直径区间是零点零点九零七和零点七四七七四。好的,画它的 r o c, 还有的轴仍然是反的,要把它顺过来,现在它的横轴是一点特一度。 呃,第二个风格的 l c 曲线,第三个风格的 l c 曲线。好的啊,这里还这里,我们可能后面需要把它或者用那个加一个 type 参数,把它的执行区间和它的 a o c 值给它加上去。 这里我就不再赘述了,重点要讲的就是绘制多条 l c 的多条 l c 曲线。首先第一个 l c one 是我们的四个变量的,呃,那么土,然后 l c two 的话是个单个变量的, 把他的图例给他加上去。好的,现在就画完了。嗯,但上面呢,我们其实已经得出来他的他们两个模型的 a o c 纸和置顶区间了。看一下第二个风格的。 好的假设,我们需上面的是第一个风格的,下面的是第二个风格的。好的假设,我们需要把对角线改为虚线, 就是在这里加上 l t y 等于二,它为虚线。 let me, 马上给它插上去。好了,接下来比较这个, 呃,两个 r o c 曲线,这里我们可以看到就是第一个模型的,就是四个变量的时候,它的 a o c 值是零点九三五 啊,单个变量的时候他的模型 auc 只是零点九四一,所以四个变量还没有一个变量的 auc 只是高。然后我们查询了一下资料,说这种情况是否合理。 呃,然后亲爱的 gpd 告诉我们是合理的,就是你四个变量,假如说你要更纳入了无关的变量的话,还不如一个变量对他的预算效能比较好。好的,我们学到这里。
 00:23查看AI文稿AI文稿
00:23查看AI文稿AI文稿想看三个标志物联合起来的诊断效果,别把三个 r、 o、 c 曲线简单叠加,要用逻辑回归 logistic regression 建立一个联合模型,算出预测概率,再用这个概率画 r、 o、 c。 通常联合模型的 a、 u、 c 会比单个标志物高很多,这叫组合权,是提高诊断准确率的标准做法。
11啾啾师姐聊生信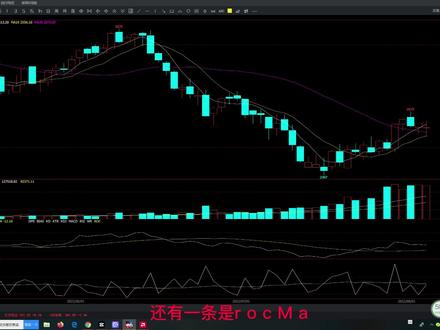 01:14查看AI文稿AI文稿
01:14查看AI文稿AI文稿大家好,今天给大家讲解一下二欧 c 指标。二欧 c 指标呢,总共有两条线,一条是二欧 c 这条线,还有一条是二欧 cna, 这相当于二欧 c 的一个移动平均线。那我们来看一下他的公式啊, 那二 oc 这条线呢,就相当于他收盘价减去 n t 前的收盘价,处于 n t 前的 一个收盘价的一个比例。 rson 呢?就是啊, roc 的一个算数平均,一个 mt 的算数平均啊,那他的一个一个波动幅度呢?是不是连到一百的?他是一个 以零为中心的上下政府,无限的一个波动啊, 那他的应用信号也是一个交叉,你看这个这个位置啊,这个位置,你看下穿的这个环线,说明他是一个下跌趋势,上穿的一个环线,他是一个上展趋势啊。
37期缘










猜你喜欢
- 2.6万龙一侦探
最新视频
- 2774光导的菜