jmp如何导出cpk分布图

粉丝448获赞1449
相关视频
 05:21查看AI文稿AI文稿
05:21查看AI文稿AI文稿欢迎观看三分钟玩转数据分析系列。本期我们的主题是过程能力分析。 过程能力是指一个过程满足客户要求和工程规范的能力。过程能力以该过程产品质量特性的公差与过程输出总体变异的覆盖程度来表征。 有能力的过程是这样的一个过程,其过程质量特性输出的分布中心与目标重合,且绝大多数过程输出位于微割线之内。 过程能力指数是衡量过程能力的一个定量指标。在大家耳熟能详的过程能力指数当中, cp 与 pp 的区别主要在于总体变异估计的方式不同, 而 cpk 和 ppk 相对于 cp 和 pp 而言,考虑了过程输出中心的偏移,这为广大用户 提供了多过程能力分析平台里边用户结合不同的业务和分析场景来灵活选举。下面我们仅就最常用的过程能力分析平台来加以说明。对于一个按批次记录的单一过程质量特性的抽样数据而言,当我们对质量特性的变量赋予了规格性的隶属性之后, 通过点击分析质量和过程控制图,生成器在生成均值极差控制图的同时, 在报表的右侧同时生成了与之对应的过程能力分析报表。在过程能力分析报表当中,所谓组内 cn 能力是指基于 子组级差的均值估计的总体变异与之对应的过程能力指数是 cp 和 cpk 在很多教材中又被称之为短期过程能力指数。而所谓的总 c 管能力是指 基于二十五个子组一百二十五个观测的标准差来估计的总体变异与之对应的过程的力指数是 pp 和 ppk, 在很多教材中又被称之为长期过程的力指数。 基于当前过程能力分析报表,我们可以看出 cpcpkppppk 的绝对值都不高,因此当前制成的过程能力较低,而 cp 与 cpk 相差无几, pp 与 ppk 相差无几。结合输出的图形,我们可以看出,当前 前制成的过程能力较低不是由于过程输出的中心偏离目标导致的,而是由于过程输出的变异较大导致的。因此,后续改进应首先着眼于减少过程输出的变异程度。 而对于同等监控机制下的多过程质量特性的抽样数据,则提供了差异化的过程能力分析平台。以 drop 自带的 sammi conductorcompubilet 样本数据即为例, 当前数据表中的每一列表示的是一个单一过程质量特性。我们通过点击分析质量和过程过程能力,将这些裂变量纳入点击确定, 软件会自动提示当前设置逻辑异常的质量特性。裂变量我们点击确定,选择跳过,不予以修 修正。在众多的输出报表当中,以目标图为例, 其所表彰的含义是,这里的每一个方形标记表示的是原始数据表中的一个怎样特性。 由于这些质量特性的量高和尺度不同,因此目标图的杭州表示的是规格标准化的均值,越靠近两侧的质量特性,其过程输出的中心越偏离目标值。目标图的纵轴表示是规格标准化的标准差, 越靠上的质量特性,其过程输出的变异越大。而基于我们当前设定的 ppk 谕旨,一,粉红色的着色区域表示是过程能力小于一的质量特 性,需予以改进。绿色区域表示是过程能力大于一的质量特性,需予以保持。而黄色区域则表示是过程能力介于一和二之间的质量特性,需予以关注,防止恶化。 因此其可以一览众山小事的帮我们审视当前众多质量特性输出当中那些过程能力的平静和薄弱环节。 我们可以通过蜻蜓标签交互向下赚取更多细节,也可以通过单向详细报表逐一审视查阅, 还可以汇总报表的形式将这些量化结果进行 汇总出出。 好了,以上就是我们本期所要介绍的全部内容,需要试用 job 或想要了解更多,欢迎联系我们,谢谢!
660JMP数据分析 04:29查看AI文稿AI文稿
04:29查看AI文稿AI文稿欢迎回到 jump 的教学指南,我们会透过简易好懂的教学带您快速了解一个使用 jump 的技巧。今天我们要分享的主题是如何利用 jump 的的水,比如选平台,做初步的资料分析及探索,快速的了解资料的轮廓。 在 jump 的的士兵选平台或称分布平台上提供互动式联动直防图,让我们快速了解参数间的关系。我们也可以利用的士兵选平台观察有兴趣的参数统计量,或是找寻适当的统计分配,提供后续的统计分析参考。 打开 help 选单下的 san potato library, 并且在资料库中寻找 big class 点 jump 资料,并且打开 big class 点 jump 资料。您可以在 jump 平台上点击 dissolution 小图饰, 或是由上方工具列中的 analyze distribution。 打开 distribution 平台,接着摆入您有兴趣的分析参数到 ycallins 区域蓝位这边我们放入 six height weight 的参数。 想要快速的了解参数间的连接关系及资料轮廓,可以勾选下方的 historygrounds only 选项,按下 ok, 完成联动直方图的制作。 在底速评选报告中点选 six 之方图的 m 或 f, 轮流切换,可以观察男生的身高分布状况,叫女生来的高。 利用壮普互动式选择图形功能,在 hit 直方图上动态选择资料,相对的 waiter 的资料也被选取。利用此联动功能,我们可以快速了解 hait 和 wait 存在一种正向相关。利用此 功能,我们可以快速的了解资料间的联动关系。接着再次打开 discussion 平台,摆入 hi weight 参数,按下 ok, 可以按下 disfubu 选旁的红色三角形,选择 stack。 将报告转为堆叠呈现, 观察 disco 优选报告,发现报告预测带出值方图,百分为统计量以及统计量汇总表。利用值方图的 box plug 可以确认是否有离群值,以及资料的分布是否有偏移的状况,且透过状态互动性探索功能,可以观察选定的资料跟资料表的对应关系。 百分位统计量及统计量汇总表提供统计量值。若想要增加统计量值,可以点选 summary statistic 旁的红色三角形,选择 customized summary statistics, 选择想要观察的统计量。想要对害参数寻找适当的统计模型做后续的统计分析,可以点开害旁的红色三角形的 continus feet 或 discoyfeit。 根据想要确认的统计模型检验适配或是不适配, 也可以选择 continues fit 下的 fit o。 对所有的连续型统计分配做检验。 jump 会根据 aicc 的结果排序,建议您最适当的统计分配,并提供相关的参数估计结果。 选择的预估统计模型会将预估线放入相应的脂肪图。若宁想检验参数 head 长太信,可以点击 headpond。 红色三角形下的 continues feet, 点选 fit normal。 打开 fit normal diss 普选报告,并点选 fit normal dissort 的红色三角形,选择 goodness of feet。 若小 pirate weeks 值大于零点零五,则表示资料符合常态性。也可以点选害旁的红色三角形下的 normal contel plus。 若资料点在上下线范围内,则代表资料符合常态性。 以此例,想要储存参数害预估的常态统计模型,选择 fit normal digital 选旁的红色三角形下的 safe collins 选择 safe dancert formula, 将公式储存到资料表。接着可以去 gravefield 将 high 放置 x 轴,将 normal dancet high 放置歪轴,选择 formula 图形形态,绘制统计几率密度图形。 对所有工作上会需要对数据做分析的使用者。 jump 的的是标准平台,让您快速了解参数的叙述、统计 量、资料轮廓以及资料间的关系性。非常建议在做其他统计分析前,运用此平台对资料做快速的诊断及了解。想了解更多壮婆数据分析技巧吗?欢迎在底下留言或一秒给我们,我们下次影片见!
201JMP数据分析 03:09查看AI文稿AI文稿
03:09查看AI文稿AI文稿欢迎观看账三分钟,玩转数据分析系列。本期我们的主题是绘制控制图。控制图是统计过程控制的两大核心之一,绘制控制图可以帮助我们分辨过程中的异常是偶然因素还是特殊因素, 并帮助我们对特殊事件展开调查。通常我们绘制的统计量符合正态分布,因此仅有百分之零点二七的数据会落在控制线外。根据小概率原则,控制线外的点被判定为异常点。 控制图的类型有很多种,按照数据的类型被分为计数型控制图和计量型控制图。现在我们来到账,我们可以通过分析质量和过程下的控制图生成器来绘制控制图, 也可以通过控制图下的此处来选择我们想绘制的控制图类型。下面我们来看一个例子,这组数据是典型的计量型数据,数据中记录了某工厂生产螺母的日期,螺母的直径以及不同的生产阶段。 打开控制图生成器,把螺母的直径拖拽到绘图区域当中,这样就会根据数据的类型自动生成相应的控制图。 我们也可以把日期纳入到词组当中,并生成不同类型的控制图。选中图中的点,点击右键警告检验,选择所有检验 就可以轻松的看到异常点违背了哪种判议原则。同时我们也可以通过定制检验来设置个性化的判议规则。如果把 阶段也纳入到控制图当中,我们可以轻松的锁定异常来源于制造的第一个阶段。在面板的左上方,我们可以看到数据中所有的变量。在面板的左下方,我们可以对控制图进行调整,例如添加镶嵌图、 加入警戒线以及对警戒线所示的区域进行着色等。在面板的中央下方的控制图用于确定控制线,上方的控制图用于根据控制线打点并发现过程中的异常。 在面板右侧的线值汇总报表中,记录了控制图的红色控制线和绿色均值所对应的具体数值等信息。下面我们来看另一个例子,这组数据是典型的计数型数据, 数据中记录了某工厂生产二极管的工作日不合格品数量以及当日抽样的样本量。由于每日抽样的样本量相同,我们既可以选择绘制 p 图,也可以选择绘制 np 图, 选择质量和过程平台控制图。下拉菜单下的批控制图子醋,将工作日纳入子组,将不合格品数量纳入 y, 将每日抽取的样本数量纳入 n 次实验, 我们就可以得到不合格品数量的批控制图。需要试用账或想要了解更多,欢迎联系我们,谢谢!
359JMP数据分析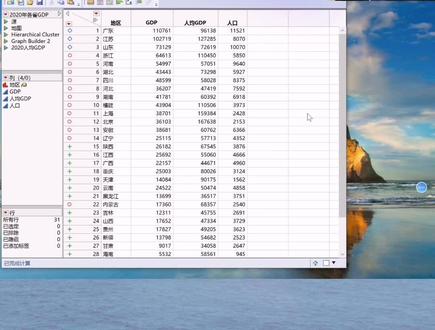 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿这样子的图形生成器可以灵活的生成各种图形数据表,记录了大陆三十一个省市、自治区二零二零年 gdp 和人均 gdp 数据。在图形灿烂线的图形生成器平台,把地区拖动到地图形状, 单击选中显示缺失形状复选框,在图形区域单击右键,选图形菜单下的背景地图,然后选择精心地球,单击确定 把 gdp 拖动的颜色按钮,就可以对各省以 gdp 着色。单击撤销按钮, 再把人均 gdp 拖动到颜色按钮,就可以对各省以人均 gdp 进行着色。从图中可以看出,除北京外人均 gdp 高的都是东南沿海各省,单机完成按钮就可以生成最终出行。
182制造学习联盟 11:40查看AI文稿AI文稿
11:40查看AI文稿AI文稿质量人经常需要对一些数据进行分析,有时不一定需要实际测量的数据,只需要一些符合条件要求的数据进行模拟分析,这些数据不仅要符合尺寸要求,可能还要服从正态分布,甚至是特定的标准差或 c、 b、 k, 如果只能自己手动一个一个编,那就太费事了。这期视频就分享如何快速的生成一些符合特定条件的数据组,不多话进主题,其实要生成符合特定条件分布的数据并不难, x 或一些专业的统计分析软件都能做到。 这期视频分成有钱的跟没钱的做法进行说明。先说有钱的做法, mini tab、 jmp pro、 spss 等专业软件都有提供生成随机数的功能,就以 mini tab 来说,假设要生成一组随机正态数据,只要到功能区中的计算 功能找到随机数据,并选择正太,然后在对话窗口中输入相关的条件设置即可。 先来生成一组有三百个数据且平均值五点零,标准差一点零的随机正态数组,来看一下这组数据的正态检验,其实这有点多此一举,身为专业软件,生成的数据如果无法通过检验,岂不可笑? 另外,看到基础的序数统计均值五点零五,标准差零点九七,并不会完全与设置条件相同,只能做到尽量靠近, 顺便看一下过程能力的指标。 cbk 是零点六五,如果没有特殊用途, cbk 的值并不重要。但若要特定 cbk 值的数据组进行模拟分析时,那要如何处理? 假设现在有个五正负二的尺寸规格,所以规格上下线就是七跟三,希望生成的样本分布中心跟规格中心重合,也就是样本平均值是五,那标准差该设置多少才能生成一组 c、 b k 符合要求的数据? 这是大家已经很熟悉的 c b k 公式,公式里面共五个未知数,规格上线 u s l 规格下线 l s l 样本均值 x double bar 标准差估计值 sigma 以及过程能力 c b k。 值刚刚的假设规格上下线 让本君值都已知, c、 b k 则是看要求给定,因此只剩下标准差是未知数。这样只要简单的把公式进行推导,就可以知道标准差的公式。先讨论双边公差的部分,为了方便 推导公式,再假设样本均值无偏移,就是样本均值 x double bar 等于规格中心,这样的话,规格上线减样本均值就等于样本均值减规格下线令它等于 s l。 所以 c b k 的公式就变成,但是要除以三倍的标准差。接着等号两边都乘以三。再来是把等号右边的分母与分子的三倍上下相消,就变成三倍的 c b、 k。 等于,但是要除以标准差,然后等号两边都乘以标准差, 就可以把等号右边分母的标准差消掉,变成三倍 c b k。 乘以标准差等于 s l。 接着把三倍 c、 b k 移到等号右边,就可以得出结果,标准差等于 s l, 除以三倍 c b k。 所以在样本分布中心无偏移的条件下,标准差等于 s l, 除以三倍 c b k。 最后看到,若样本均值不等于规格中心时,把 s l 换回来,就是 s l 等于规格上线减样本均值,或等于样本均值减规格下线,因为计算 c、 b、 k 只有用到这两个其中一个较小的值,所以就可以写成最后这样。 假设需要一组 c、 b、 k 一点三三的随机正态分布数据,就按这个推导出来的公式来计算需要的标准差,只要使用 many 函数套用公式即可。 计算的结果,标准差零点五零一二,改变一下,样本均值为五点二零,其他条件不变之下,标准差需要变成零点四五一一三。接着用这个结果到 mini type 生成一组随机正态数据, 再用这组数据进行过程能力分析,可以看到,平均值标准差 cbk 虽然没有与要求的目标值完全相等,但也非常接近,因为软件只是根据设置条件进行估算,基本上很难得到完全相等的结果。如果要得到非常接近目标条件的数据组, 可能需要经过多次生成数据找到最接近组。接着看让人头痛的单边公差问题,把原先的规格要求改成单边有上限的规格。这里看到,当规格下线被改成五之后,标准差变得很小。那是因为目前计算标准差的公式 是从计算双边公拆 cbk 推导过来,在规格上限与样本均值差及规格下限与样本均值差这两者之间取交小值。把规格下限改成 乘五之后,就会让原本的计算 cbu 变成 cbl, 但有上限的单边公差只能计算 cbu, 所以可以把规格下线的值改成与规格上线相同,等于让公式只能计算 cbu, 但这样计算的结果会出现复数, 所以需要在计算标准差的单元格中,在原本的函数前面再加上 abs 函数,就是让单元格显示计算结果的绝对值。但这样的结果跟前面双边公差是一样的。 因为尽管可以推导出标准差,但无法限制随机生成的样本分布范围,所以生成的数据中会有一些超规格线的值。 因此想要在 c、 b、 k 或标准差不变的条件下生成在规格线内的随机正态数据,只能想办法把整个样本分布往融差中心移动, 这样只能不得已采取折中的方式,就是在相同的规格容差条件下,把单边公差改成双边公差。这里就是把规格要求改成六,正负一点零,规格上限维持原来的七, 规格下线变成五,然后把样本平均值尽量往新的规格中心靠近,或直接等于规格中心。也可以一样用计算的结果到 mini tab 生成一组随机正态数据, 再用这组数据进行过程能力分析,可以看到平均值标准差 cbk 也非常接近设定的目标值。然后样本分布并没有超过六正负一的范围,也勉强等于是原先单边公差的范围。 因此遇到要生成单边公叉的随机正态数据,就只能选择这种折中方式处理。如果各位 有更好的方法,欢迎在评论区留言建议。以上分享的是有钱的做法,但万一遇到老板打算换车买房子,不愿意花钱买这些专业软件,那就只能选择没钱的做法,便宜的笑或 wps 同样也可以做到这些功能。 先在 excel 工作表中先把设定条件改回原来的双边规格。先介绍第一个函数, r a and d red 函数可以在单元格中随机生成一个介于零到一之间的数值。 如果把这个函数稍加变化,在 run 函数后面乘以某个数值,就会变成在单元格中随机生成一个零到这个数值之间的数值。例如,在 run 函数后面乘以 七,那就会在单元格内随机生成一个零到七之间的数值。如果再进一步做些变化,让 ren 函数加上某个特定数值,例如三加上 ren 函数乘以四,这样就等于三加一个零到四之间的随机数。 结果就是会产生一个介于三到七之间的数值。但 ran 函数生成的是平均分布的随机数,如果生成的数据量够多,就可以容易的看出来数据是呈现均匀分布形态。 如果要生成的是随机且呈现正态分布的数据,就需要使用 normal 函数。使用 normal 函数需要提供三个参数,第一个参数是正态分布的概率,第二个参数是平均数,第三个参数是标准差。平均数是决定 生成的正态分布数据的样本分布中心。标准差是决定生成的正态分布数据的区间宽度,概率则是决定生成的数值在正态分布区间的位置。例如,概率越靠近零或越靠近一生成的数值越接近正态分布两端的位置, 概率零点五就会生成落在正态分布中间的数值,基本上就等于设定的样本均值。 样本均值与标准差在工作表中已经有,可以直接填选代率,这里先填入零点一。按前面的说法,代率越接近零或一生成的数值越靠近分布的两端零点,一是往零的方向靠近, 所以会往分布的下线靠近,以这里的案例,应该是会往三的方向靠近。由于刚刚输入的概率是一个固定值,所以复制工是到其他单元格 格产生的数值也是固定的。如果要生成很多数据,这样做就的逐个单元格更改概率值实在是太麻烦了。回到 normal 函数的对话窗口,可以看到下方的说明,概率参数是介于零到一之间的数值。 前面介绍的 ryan 函数刚好可以随机生成零到一之间数值,那就把 ryan 函数填入概率这里, 这样就可以利用复制粘贴的方式,快速的生成很多随机正态的数据。 因为概率是由 rain 函数决定,所以生成的数据位置也是随机产生,并不会依序排列。如果想要直接生成依序排列的随机正态数据,就必须对函数 的内容进一步修改。首先设置一个需要的样本数量,再回到 normal 函数的对话窗口中。这次利用 row 函数来设置概率, row 可以返回单元格的所在行数,随着单元格越往下, row 函数返回的数越大,因此概率也会越大, 这样 normal 函数就会随着单元格往下生成生序排列的随机正态数据。复制之后似乎有点问题, 确认一下函数的内容,原来是样本数量的单元格。第五没有写成绝对引用,这样复制公式时,其他单元格里面的公式就不会是引用第五。要改成绝对引用,只要在公式内的第五前面加上前符号, 或者在公式中鼠标点到第五的文字,再按下键盘上的 f 四,就会自动加上前符号。接着再从新复 布置公式到其他单元格,这次就没问题了。可以看到生成的随机数据是由小到大依序排列,且呈现左右几乎完全对称的正态分布。 最后是单边公差的随机正态分布。跟前面谈到使用 mini tab 生成随机正态数据的处理方式相同,直接改成双边公差的规格,然后把样本平均值尽量往新的规格中心值靠近。 以上就是使用笑生成随机正态分布数据的方法,学会了这个没钱的做法,就可以帮公司省下一笔买专业软件的费用,也可以帮老板更快的把五菱宏光换成大奔。 最后要声明的是,请正确且正当的使用这些数据。
345Aron 04:51查看AI文稿AI文稿
04:51查看AI文稿AI文稿欢迎观看 jump 三分钟玩转数据分析系列。本期我们的主题是基于 jump 的剧烈分析。在无监督学期中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质和规律,为进一步的数据分析提供基础。 其中研究最多、应用最广的就是剧类分析。剧类分析试图将数据集中的样本划分为若干不相交的子集,每个子集称为一个醋。 通过划分,每个错误可能对应于一些潜在的概念或类别,如左图归列下的有翅膀、多足、无足昆虫等。 需要强调的是,这些概念对于剧烈而言,事先未知。剧烈过程仅能自动形成促结构,而促所对应的概念是意,需要由分析者来把握和赋予。 剧类即可作为一个单独的分析过程,用于寻找数据的内在结构,也可作为分类等其他分析的前驱过程。在 jum 中提供了层次剧类,可以郡植剧类、正态混合剧类等常用剧烈方法。 接下来,我们将使用艾瑞斯经典数据集来演示层次剧类的典型应用场景和软件实现。认为花是对异族草本开花植物的统称,其下还有很多细分物种,而不同物种的花瓣则各具特色。 在艾瑞斯数据集中,包含了三种原尾花的恶片长度、恶片宽度、花瓣长度和花瓣宽度的观测值。我们将依据这些观测值对这些原尾花样本进行归类。这里的每一行都是一朵原尾花的实际观测结果,而这 这里的最后一列表示是这朵约尾花所属的实际物种。但是在稍后的剧烈过程之中,这列信息并不会纳入分析,我仅将其用于呈现实际分类情况和剧烈结果之间的比对。 用正软件进行层次聚类十分简单。点击分析聚类层次聚类,我们将四个维度的约尾花特征纳入歪裂,在左侧可以选择不同的统计意义上的距离的度量。在这里我们保持默认。点击确定。 系统数图展示了层次距离的过程。 起初,每一朵渊尾花的样本都是一个子错,根据统计意义上距离的定, 将距离最相近的两朵原尾花进行合并归类为一处,其后将距离次相近的两处合并为一处,直至所有的原尾花的样本都归为一处。 我们可以借助陡坡图、剧烈准则和星座图等手段辅助界定适宜的剧烈数目。我们仅以较为直观可视的星座图为例进行简单说明。 在清座图中,每一个点表示一个样本观测横纵坐标没有实际的物理意义,但图中点和点之间的距离表示的是样本观测之间相似或相异的程度。因此,从当前情况来看,我们将 所有样本归为三大子素可能较为适宜。因此,我们将剧烈数设置为三, 然后通过剧烈汇总来进一步洞察数据结构特征。我们可以看到,在当前剧烈结果下,剧烈二和剧烈三在四个特征尺寸维度的变化趋势上十分相似, 都是恶片长度、花瓣长度,花瓣宽度较大,而恶片宽度较小。此外,剧烈三的整体尺寸要比剧烈二更大一些, 而剧烈一在四个维度的变化趋势上则截然相反,可以把当前剧烈结果和实际结果进行比对, 可以看到其中一个物种被进行了很好的区分,而另外两个物种则存在着一定的焦点和些许的不规类, 我们还可以与其他可视化手段相互印证, 总体而言说明当前剧烈结果较好。以上就是本期所要介绍的内容,需要使用账或需要了解更多,欢迎联系我们,谢谢!
48JMP数据分析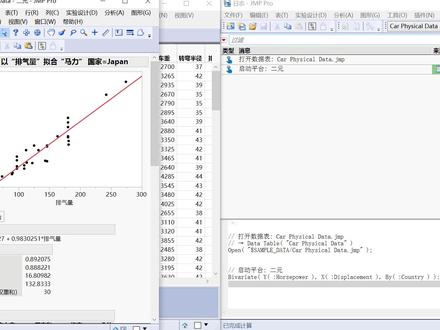 02:58查看AI文稿AI文稿
02:58查看AI文稿AI文稿欢迎观看战三分钟,玩转数据分析系列。本期我们的主题是操作录制和增强的日志模式。 操作录制和增强的日志模式是账目十六中内置的最新特性,依赖于他账目软件可以实时捕捉交互绘画过程中执行的活动,并自动记录事件相应的 gsl 代码。因此,我们 我们可以将自动生成的 jaco 脚本进一步集成为可重复的工作流程,以提高我们的数据处理与数据分析的效率。 我们双击打开章十六,依次点击文件,首选向日志,在模式的下拉框中选中增强,点击确定即可成功开启增强的日志模式。 如果您想具体对该模式的细节进行进一步的定制,可以在此界面上的表过滤器裂按窗口着色四个面板中做进一步的设置。 我们同时打开样例数据及贝克拉斯 fmax 与日制视图,接着把数据集中性别为飞秒的记录挑选出来,并依据年龄做一个身高体重的分布分析。 通过日制窗口,我们可以看到我们打开数据表匹配单元、格取子级、使用分布平台等操作都被记录了下来。我们也可以 可以单击相应的消息条目,或按住键盘 ctrl 加鼠标左键,在日志窗口的下方查看与操作记录对应的 jsl 代码。在日志窗口界面的过滤器中,帐篷允许我们输入关键词来过滤与其相匹配的 jsl 脚本,或使用关键字来过滤出相应的操作记录。 另外,我们还可以点击最右端的黑色三角形,允许过滤器接收正则表达式。我们打开另一个数据集卡尔 faccodet, 然后使用排气量你和马力依据国家分组。 再点击红色下三角,为国家等于这片的三点图添加礼盒线,再点击关闭礼盒。结果可以看到,我们打开数据到礼盒的所有操作都被记录了下来。此时我们又见 选中报表快照,点击运行脚本,之前的你和结果会重现出来。进一步的,我们还可选中所有的操作记录,并将其背后的 jsl 代码保存为一份完整的脚本文件。 将来只需要打开该脚本文件,点击运行脚本即可复盘。之前的操作需要了解更多请联系我们,谢谢!
39JMP数据分析 03:07查看AI文稿AI文稿
03:07查看AI文稿AI文稿各位朋友大家好,欢迎观看将三分钟玩转数据分析系列。本期我们的主题是定制设计。不得不提我们将 doe 的灵魂人物 doctor branley jeans, 两次布鲁保夫奖的得主,这是美国质量协会颁发给个人的最高奖项, 它是 gm 定制设计和确定性筛选设计的发明者。正因为有这样杰出的人物和团队, gm do 一不 仅包括传统的,而且包括更 modern 的。可以说我们 jump due 是世界一流的定制设计,可以输入各种不同类型的因子 构造包括特殊设计类型在内的众多设计,可谓一个定制设计在手,别无所求。今天我们来看一下来 来自四个不同产地的两种葡萄,经过怎样的处理才能获得最高的评级。将实验设计瞩目录下第一个就是定制设计。第一步,输入响应,本地只有一个响应就是评级。 接下来添加因子,可以添加的因子类型是多种多样,本地产地是四水平的分类因子产地,其他八个是凉水平的分类因子, 可以依次逐个添加品种,或者从定制设计旁边的红色下拉小按钮里面加载预保存的因子列表,加载因子因子就被加载进来。评机源是分区组因子,每个 有八次实验评级。原定制设计的另外一个很特殊的地方是可以让我们自定义因子的约束,可以添加或者修改各种其他类型的效应,像可以选择 必须或者弱可能。本例一共是四十次的实验制作设计,这就是根据我们的要求制作的一个四十个 run 的定制设计。 实验数据录入完成,将的实验设计会自动保存我们的礼盒模型,只需要点击模型左边的绿色小按钮进行即可。效应汇总统零 产地和温度的 p 值大于零点零五,就说明他们对响应影响并不是非常的显著。可以依次删除。利用预测刻画器来优化过程 因子的设置。利用意愿函数最大化意愿。记住这个设置 d 最优,同样记住波娜品种的最优设置。两个葡萄品种的的评级有所不同,这就决定了我们将来的 business 可能更多的选择这种品种。今天所讲的例子可以在张 帮助手册下面实验设计指南第四张定制设计找到。如果您需要试用 jum 或者想要了解更多,请联系我们,谢谢!
108JMP数据分析 05:56查看AI文稿AI文稿
05:56查看AI文稿AI文稿欢迎回到 drum 教学指南,我们会透过简易好懂的教学,带您快速了解一个使用 drum 的技巧。 今天我们要分享的主题是如何利用 drum 的 disco 功能,帮助使用者建购报告仪表板,快速观察资料在各分析报告间的资讯及相关性,并储存成 drum 的报告格式或是交互性 htm 格式报告,分享给工作伙伴。 作为一款统计分析软体, drum 的连接式资料分析功能往往能帮助使用者更快速地了解资料之间的关系性。 运用 job 独有的 dashbow 功能,可以在一个画面试窗上观察分析各个 job 报告带来的重要资讯,整合各报告间的讯息。 相较于其他统计软体,报告跟报告之间往往缺少关联性的整合。壮普可以提供更全面、更整体性的分析, 配合 drum 的交互性 htm 格式报告输出功能, drum 的报告可以分享给其他不是 drum 的使用者,使 drum 的报告更方便、更广泛的分享给工作伙伴。顺畅团队的沟通及发展。 让我利用 jump 的 big class 资料说明,您可以在 help 下载 simple data, 下载 open the popular big class, 点 jump simple data table 中打开 big class 资料, 执行左上角脚本区的 distribution 脚本。我们可以发现 dream 的资料表和所有报告的图表都是联动的。也就是说,当您在 在资料表上选取某些资料,报告上的图表也会随之选取,反之易然。利用这个方式,我们可以很快的了解资料彼此间的相关性。 接着执行脚本区的百 vere red 弯位及 grabute light chart 脚本。当完成想要呈现在报告仪表板的报告后,可以由两种方式产生 dashboard。 第一种方式,您可以打开 fire 下的 new 下的 dashbow, 选择适当的模板或是选择空白模板,依序将报告根据需求放入试窗。 也可以用拖拉的方式改变报告格式及位置,或是根据需求放入 data filter 等功能。按下 run script 完成 dashboard 制作, 并根据需求调整仪表板的板面设定。 你也可以按下 dashboard 左上方红色三角形内的 self script to data table, 储存缴本制资料表。 第二种方式,你可以按下任何想要合并到仪表板的报告下方的黑色三角形,按下 combine window, 勾选你想要合并的报告,按下 ok 产生报告。接着可以根据需求调整版面,但此种方式储存的结果无法储存 存版面更改后的设定,所以如果要储存为脚本作为后续使用,请用第一种方式储存。 我们可以观察产生的 dashbow。 在仪表板中可以发现 edge 和 weight 有正相关, weight 和 high 也有正相关。 此外,我们也可以观察在弯位的报告中男女身高,虽然体检定结果是有差距 p v 六等于零点零二三,但差异不大。 观察百 h 的亥图表, h 等于十二,汉是三十,男女身高差异不大,甚至在 h 等于十二十。女生身高大于男生身高可以说明女生发育早,而男生在十四岁后开始发育身高,开始抽高, 渐渐拉开与女生的身高差距。利用 graph builder 选取 edge 等于十二。按下滑鼠右键,选择 rose 下的 rohi and is crew, 隐藏 edge 等于十二资料并重新 redo analysis, 可以发现弯位的报告中 pv 六等于零点零零四五,男女身高差距更显著。 接下来我们试着储存生成的 dashboard, 在 dashboard 报告上按下 fire 下的 safs, 选择档案类型为复档名点 jrp 即可储存 drom repo 格式,可以将此档案分享给 drom 的使用者, 若分享的对象没有撞,可以 储存互动性 h t m 格式作为分享 drop 资源部分的互动性报告,可以转为互动性 h t m 格式一样,在 dashbow 报告上按下 fire 下的 service, 选择 interactive h t m l with data 格式储存,即可分享给非 drop 用户。 让我们的 dashboard 适用于各产业各单位帮助。希望借由整合各统计报告,针对资料整体性的分析,挖掘更全面的资讯通盘的分析,作出更准确的判断及剖析的人员,使用 搭配互动性的 htm 格式或是 drop report 格式分享分析报告,可以快速让工作伙伴了解分析成果,加快分析讨论的步骤。 想了解更多转步数据分析技巧吗?欢迎在底下留言或一秒给我们,我们下次影片见!
192JMP数据分析 10:57查看AI文稿AI文稿
10:57查看AI文稿AI文稿欢迎回到 jump 的教学指南,我们会通过简易好懂的教学带您快速了解一个使用 jump 的技巧。 今天我们要分享的主题是如何利用 jump process screening 及 process capability 快速得到制成统计量及判别制成的偏移程度,并了解多道制成改善方针。针对有问题的制成开展西部制成分析。 john the process screening 及 process capability 平台提供使用者快速制作制成能力分析报告初始报告提供整体的制成能力汇总,帮助使用者快速了解各制成的表现状况及制成能力。 根据使用者的需求可以调整调用 goal plus, performance plus, individual detail plus, ctrl chart 配合 dream 强大的关联性及互动性报表,帮助使用者由整体窒息部一层一层抽丝剥剪。讨论制成能力及获得相应的改善方向。 让我利用 jump semiconductor capability 资料说明您可以在 help 下的 simple data library 下打开 semiconductor capability 资料,此资料包含一百二十八道制成结果,每个辣包含二十四个 waver, 每个 waver 取五个 set 资料作为讨论。 首先,我们必须先设定参数的规格。您可以选择 analyze 下的 criteria 的 process 下的 manager spec limits。 打开 manager spec limits 平台,选择想要设立规格的参数,按下 process variables 并按下 ok, 依序填上适当的规格, 上下线及目标。如果您要显示规格线在您的报告或是图片上,请勾选 show limits 或按下红色三角形下的 show limits o, 接着按下 save to column properties 储存至参数属性内。 我们利用 process screening 快速获得制成能力指标。由 analyze 下的 screening 下的 process screening。 打开 process screening 平台 jump 七后,已经将平台移至 quality and process 列表下, 依序放入关心的变数至 process variable。 如果有分子群变数,可以放置 salt group 区块去做指群分类,并选择 ctrl type 为 x, y, n, r。 如果您用的是十六点一之后的版本,请勾选 sort by sag group。 你也可以利用左方的 ctrl chart 设定区设定指群数量或是其他管制图参数。设定完成相关参数后,按下 ok 产生报告。 初始报告产生 c p k p p k stability index 及 all of speccom 跟 red 等参数。如果想要调出其他制成统计量,可以按下 plus screening 躺的红色三角形下的 shock abability, 选择需要显示的统计量。 也可以根据需求按下表格表头排序,选择想要讨论的制成或变数。点选 process screening 旁的红色三角形下的 quick graph for select item, 出现选择参数的管制略图,可以 快速了解制成的表现。当想要细步观察参数的管制图及相关的分配状况及制成表现,可以选择想要讨论的制成或变数。点选 plus screening 旁的红色三角形下的 ctrl travel select item, 则会出现选择参数的管制图及相关统计量及测试结果。 接着我们利用 process capability 快速获得自成能力整体表现的报告。由 analyze 下的 quality in the process 下的 process capability。 打开 process capability 平台, 依序选择关心的变数,并按下 y process。 如果有分子群变数,可以在左侧选择用来作为分群的变数,右侧选 选择需要区分纸群的变数,并打开 process 小 grouping, 选择 sargroup id color, 并按下 next sargroup id color, 或是根据需求调整建构纸群的条件。 制定完相关参数后,按下 ok 产生报告。首先映入眼帘的是勾 plus, 此图反映了标准化标准差跟标准化距离规格中心。 按下 gopro 旁的红色三角形下的 shell levels, 可以根据你的 ppk 设定三个颜色区块, 粉红色区块是小于一倍的 p p k, 黄色区块是 p p k, 介于一到两倍的 p p k, 绿色区块则是大于两倍 p p k。 根据变数的位置可以判断变数的 p p k 及相对于其他的变数的标准差及距离规格中心的大小。若是偏离规格中心较远,需要将资料往规格中心调整。若是相对标准差较大,则需要改变变数的变异。 对于有兴趣的参数或变数,将邮标停留在点上,会带出管制图略图。双击滑鼠左键,可以进入西部管制图观察资料表现及探索,制成相关统计量及管制图相关分析, 下方的 capability bus plus 展示变数标准化后的分配情形,可以快速比较各参数分配对应规格的比例关系及各参数相对的分配概况。 capability index plus 展示 个变数的 ppk 大小,方便使用者快速的比较个变数的 ppk 大小。对于有兴趣的参数或变数, 将游标停留在点上,会带出管制图略图。双击滑出左键,可以进入西部管制图观察资料表现及探索,制成相关统计量及管制图相关分析。 点击 process capability 旁的红色三角形下的 individual detail report 可以带出每个参数的制成能力,分析细部结果, 包含直方图及规格线、主内及主间变异、 c p k、 c p l、 c p u、 p p k、 p p l、 p p u 及超过 a 百分比等统计量值。点击 process capability 旁的红色三角形下的 process performance plus, 产生 p p k 及 stability index, 所建构的 process performance plus x 轴为 stability index, 即为 p p k。 除以 d p k 同等于长期变异及短期变异的比值。 当 stability index 距离一很远,代表有非随机影响因子导致长期变异,需要找到长期变异的影响跟音。当 p p k 太小,则回查 gopro 寻找问题来源来自过大的变异,或是距离规格中心过远。 右边的 p p k 跟 stability index 乘以感,可以让使用者根据需求调整或是输入特定的 p p k 跟 stability index 值,并借此将全部变数分成四个不同的变数类比。 绿色代表制成能力不错,黄色代表 p p k 不错,不过相较于 c p k 还是有非随机影响因子导致长期变异,需要改善导致长期变异的问题。 橘色代表 ppk 不加,不过 cpk 跟 ppk 差异不大,问题来源可能是整体制成的通病,不会随着时间拉长增加变异。 粉红色则代表问题包含 ppk 过小及 ppk 和 cpk 差异较大,问题最大也是最需尽快处理的变数。 process capability 也提供使用者另外一个对变数寻找适当统计分配模型的选择。若您想要对变数寻找适当的统计模型,您可以打开 process capability 平台,再填入想要寻 寻找模型的变数后,选择右方想要做适配的变数。打开右侧下方的 distribution options, 选择想要做适配检验的统计模型,或是选择 best feed 对所有的模型适配, 并按下 set process distribution, 按下 ok, 将报告拉至 capability index ply。 若有其他统计分配模型较常态分配更适配变速,则模型会放入后方的挂号内, 若没有显示,则代表变数最适配统计分配为常态分配。点击 process capability 旁的红色三角形下的 individual detail reports, 可以发现 job 针对所选定的变数适配所提供的统计模型,并计算合则 为最实配的统计模型。 process capability 和 process screening 有许多报告同时存在两平台间,例如,除了在 process capability 上可以产生 go plot process performance plot, 你也可以在 process screening 上调用产生 go plot process performance plot。 您可以在 process capability 报上的红色三角形下选择 summary report, 打开 process screening 的至诚统计汇总报表, 也可以在 process screening 上的红色三角形下选择 process capability for selected item, 打开选择变数的 process capability 报告。 process capability her process screening 对于产线、产品及屏保等制成相关的单位人员提供非常实用的制成能力观测平台。其所包含的 summary reports 可以快速了解整体参数的制成能力,迅速找到偏移的制成或是有潜在偏移风险的变数。 go plus process performance plus 等 jump 独有的视觉化分析图可以帮助使用者快速了解个变数相对于整体的制成能力表现,并了解制成能力不佳的来源。 接着我们可以再利用 individual detail reports 或是利用 drum 的连接式报告功能,点击有问题的变数, 进入细部分析报告,去做进一步的问题分析,观察资料点是否有明显的偏移或变动,造成支撑能力不良。想了解更多 drop 数据分析技巧吗?欢迎在底下留言或一秒给我们,我们下次影片见。
143JMP数据分析 12:47
12:47 03:54查看AI文稿AI文稿
03:54查看AI文稿AI文稿欢迎观看这三分钟玩转数据分析系列。本期我们的主题是蒙娜卡拉,模拟二十世纪四十年代,在二战中美国研制原子弹的曼哈顿计划成员乌拉姆 和防动于慢敏锐的意识到,在计算机的帮助下,可以通过重复数百次模拟过程的方式对概率变量进行统计估计。首先提出了蒙特卡罗方法,并将其用于模拟计算合力变过程的中子随机扩散现象。 由于乌拉姆经常提及他的叔叔用在毛大哥的著名赌城蒙的卡洛书前,因此他的同事戏称该法为蒙的卡洛。 因为赌博和概率密切关联,所以这个命名风趣而贴切并附带神秘色彩,很快就被流传开来。接下来,我们将记忆症来演示这种统计模拟方法的典型应用场景 和软件实现。为了演示摩登卡拉模拟,我们使用这样自带的 teacher 亮本数据集。该亮本数据源自研究归时归玩硫磺三个因子对四个轮胎胎面性能测度的影响实验, 其中每个响应都设置了与之相对应的规格线列属性。通过回归分析,很容易构建三个因子对四个响应的回归模型,并以刻画期的形式动态交互的呈现。 末,点击红三角优化和意愿最大化意愿,我们可以获得一组平衡自由解。由于当前三个因子的设置为场数,因此四个响应军制的估计 也未常说。而通过点击红三角模拟器,我们将因子的设置由固定改为随机。 当前设置的含义是以龟石为例,表明龟石因子的设置源自以一点二为中心,零点二为标准差的正态分布下的一个随机抽样龟纹与硫磺同里, 我们保持默认的实验次数一万次点击模拟。当前模拟结果表明,在这一万次随机抽样因子设置的组合下,四个响应均值估计结果的分布情况,以及在各自规格线的定义下 及不合规的比例。我们可以根据实际业务场景和分析需要变更分布的类型、分布的形态, 添加随机造成因子 来继续模拟响应单直的分布情况,并根据对切线力的接受程度探寻与之适配的公益窗口。 我们还可以 将这一万次的模拟结果输出来,支持更细节的探寻,如基于模拟数据的过程能力分析 和动态交互的可视化分析和关联分析等等。 需要试用账或需要了解更多,欢迎联系我们,谢谢!
153JMP数据分析 07:41查看AI文稿AI文稿
07:41查看AI文稿AI文稿欢迎回到 jump 的教学指南,我们会透过简易好懂的教学,带您快速了解一个使用 jump 的技巧。今天我们要分享的主题是如何利用 jump 的 feetwife x 平台快速寻找两餐数间的相关性。 执行体检电影级很多法分析判断两群资料平均是否存在差异,以及确认多群间的平均值差异比较。 在 jump 的 fitwide bikes 平台上,提供了许多适配两参数间的模型选择,并提供许多两群体间的简定工具,如 tea test a nova test on equal barriceton, 并可一键将相关性由大到小排序 内,由互动性探索资料及图形化呈现分析结果。您可以更快速的了解资料分析结果 及挖掘潜在的讯息。打开 jump fit wipe x 平台,可以连续放入您想寻找相关性的 x 字变数及 y 响应变数 和 jump 会根据您百度的变速资料形态自动产生对应的分析。例如,当您百度的 xy 接尾连续变速会自动产生 byrina fee, 而当您摆入 x 为类别变速, y 为连续变速,则会自动产生出弯位 alexis 对应的分析模式可以参考 fifty 摆 x。 其实平台的左下方对应表 对于 x y 接尾连续变速的状况寻找相关性,并找到适当的模型去描述两变数的关系,是蛮常见的统计分析手法。我们利用 dram 的 shanpodai 塔及 featwide x 平台做说 名。在 football 点状的资料表上打开 featwide x 平台,将 head 放置歪参数 wet 放置 x 变数,按下 ok, 产生 by very feet 报告 按下百 very feet of high by weight 旁的红色三角形,开启 some resistance, 可以快速得到相关系数及供变数,相关系数及供变数越大,相关性越大。 接着反复按下 by very feet of hide by weight 旁的红色三角形,依据开启 fit me fit nine feet 的朋友 normal 下的二 grajatic, 分别得出三种模型。可以发现 poling normal fifty 归等于二下,因为考虑二次四具有较佳的 ask, 也代表有比较好的模型准确度。 但当我们细看普林 no more feet 低贵等于二的 pyramid estimate 中, weight 二次式的效应像影响不大,所以模型可以拿掉 wet 二次式效应像,也就是说以 fit line 生成的模型会更有效益 一样。讨论 football 点 jump 的资料表,这次在 fitwide by x 的起始平台上,一样将 high 放至 y 变速,在 x 变速区则摆入 wet fat speed neck bench squat leg price。 按下 ok, 产生多个对 hit 的 by variant feet 报告。 在键盘上按住 ctrl 并按下摆位置。 fit of high 摆位旁的红色三角形选择 fifth line, 可以对多个相同格式报告,一次性处理相同的动作,完成所有的摆位置 fit the fitline 报告。接着按下 fit group 旁的红色三角形,选择 odalify goodness of feet。 将所有的 byvertefit 根据模型的 ask 贵作排序,因为 fit line 模型的 ask 贵为两参数口味类选的品方,因此我们也得到两音之间的口味类选的排序。 我们也可以利用 fit wipe x 讨论不同分群变数下平均值是否有差异。先讨论用 x 变数分为两群的状况处理双样本减定,打开 big class 点状。在其次,平台上将 head 放至 y 变数,并将 sex 放至 x 变数区, 按下 ok, 产生弯位 analysis 报告。首先,先需确认两群间的变异数是否相等。打开弯位 analysis of hi by six 旁的红色三角形,按下, 按 equality 得到变异数相等的分析报告。壮谱针对不同的资料类型提供许多统计分析减定的结果。以此例,不论是哪一种分析都符合 pv 六大于零点零五,也就是接受两群变异数相等的假设。 洛宁分析出的结果为两群间变异数不相等,可以直接利用下方的 well 去 test 去确认两群间的平均值是否有差异。 卧室,打开弯位 alexes of high by six 旁的红色三角形,按下 t test, 得到 tetest 假设简定报告,您可以视您所需的情形分析假设。简定结果。 以此例,洛宁的虚无假设为男女两群的平均相等,您可以参考 polobe 的体大于绝对值 t 的数值。当小于零点零五时,拒绝 学术假设,即认为男女两群的平均值不相等。接着,在确立两群变异数相等的前提下,打开弯弯 analysis of hi by sex 旁的红色三角形,按下 meanova pro t 做平均值的假设。简地, 您可以视您所需的情形分析假设,检定结果。以此例落您的虚无假设为男女两群的平均相等,您可以参考跑跑避乐。体大于绝对值梯的数值,当小于零点零五时,拒绝虚无假设,即认为男女两群的平均值不相等。 我们也可以利用 fit y 摆 x 讨论不同分群变速下是否有差异一样,以 football 点 drop 为例,打开 fit y 摆 x, 在其实平台上将害放至 y 变速,并将 post entrop 放置 x 变速区,按下 ok, 产生弯位 analysis 报告。接着打开弯位 analysis of hive by position two 旁的红色三角形,按下 mengenova, 可以执行 nova test。 在这些群体间的 variants 为相等的前提下,由 nova 的分析结果发现, popparty 大于 f 为小于零点零零零一,代表群体间至少有一群的平均值与其他群不同。 接着我们要找出哪些群体间有明显的平均值差异。我们可以选择弯位 analysis of hi 摆 pose, 一群 two 旁的红色三角形下的 compare means。 点选 opius took hsd 比较美。裙间的差异在上方的图形中出现许多圆圈,秀出哪些裙之间的差异不大。以 k i 为圆心的圆 为例, dbowrj 对 k i 差异不大。下方的 connecting later report 将相似的群分为多个分类,如 l 和 t e 分为同一类, a 类, lb 和 wr 分为同一类, c 类。 old difference report 提供比较两两群体之间平均值差异。从这边知道,差异较大的群包含了 l 和 kil 和 o 等群。 对于所有工作上会需要对数据做分析的使用者, jumpfie 的 vipex 平台帮助您找到两餐数间适当的相关模型, 快速判断参数间的相关性,并判断不同群体间的差异程度。您可以利用此平台快速的找寻关键影响参数以及判别失误率较 大的群体。想了解更多 drop 的数据分析技巧吗?欢迎在底下留言或一秒给我们,我们下次影片见!
213JMP数据分析 02:28查看AI文稿AI文稿
02:28查看AI文稿AI文稿大家好,我是电工小张,今天我们讲一下我们 plc 中的跳转指令 gmp 与标签 lbl。 我们看网络一,网络一,我们用了个 m 零点零来触发我们的跳转指令。网络二,是我们之间的跳转指令之间的程序。网络三,是我们的标签指令 lbl, 我们的标签是一,我们跳转也是一, 如果 m 零点零由零变为一时,他就直接跳过二,直行三,然后就跳转到我们的网络二,我们来说明一下, g m p 为跳转指令, l b l 为标签指令,两个指令必须同时出现,配套使用 指令执行的过程。我们来讲一下,当跳转成立以后,也就是 m 零点零由零变为一后, plc 会跳 我们的跳转指令于标号之间的程序扫描,也就是不再进行程序扫描。网络二, 下面我们讲一下跳转指令的注意事项。我们的跳转指令和我们的标号指令必须配套配套使用,且必须在同一程序段中使用,也就是说我们的跳转指令在主程序使用。那么呢,标签指令也必须在主程序使用,不能说跳转指令在主程序, 标签只应在指程序或中段程序,这样是不可以的。第二,在执行跳转以后,被跳过的程序段应不再扫描对应一些原件的这些状态,会保持在跳转前的状态, 这点我们秒必须要注意,对于计数器来讲,计数器会停止工作,当前指不会丢失,会保持在跳转前的状态。 第四,第四点,对于我们的定时器来讲,因为我们的刷新的方式不一样,也就是一毫秒、十毫秒和一百毫秒刷新的方式不一样,那么在跳转期间,对应分辨率一百毫秒的定时器,他跟计入器一样的,他会停止计时, 但对于一毫秒跟十毫秒的定时器来说,他还会继续定时的,直到其设定之后,其状态也会发生改变, 也就是他的长开会变成长臂,跳转的长开点和长臂点都会有发生变化,而且他的当前指会到三二七六七才会停止,因为他最大指就是三二七六七。 这就是我们跳转指令的注意事项,也是我们比较简单的一个指令,喜欢的点关注,谢谢大家的观看。
59沧海星辰 03:35查看AI文稿AI文稿
03:35查看AI文稿AI文稿欢迎观看将三分钟网站数据分析系列。本期我们的主题是将与而拍摄的结合。 在日常业务数据分析的过程中,工程师可能会同时使用多种分析工具,因为这些工具本身各有优势,比如阿语言在统计领域的专业性,开送强大的机器学习模块以及酵母的交互式图表功能。 但这些工具的混用也造成了分细流,变得分繁复杂。一个可能的解决方案是将降谱软件与拍送而等编程语言进行连接, 通过将可视化游挨界面吊用相应外部脚本,从而在将不上一站式完成所有分析工作,简化业务数据分析流程。本视频以拍送为例,介绍如何在将不中调用其他编程语言。首先 需要完成拍送环境的搭建,您可以至拍送官网下载与降土软件匹配的拍送版本。以降十六为例,匹配的拍送版本为三点六到三点九点一。对于其他版本的降,您可以从帮助降温档库中获得相应信息。 你也可以使用安利扣打环境,但相应的环境设置会更复杂,具体设置方法同样可以参考帮助文档。 为了确保拍送与将部间数据的无缝交换,您需要在拍送中安装这些开源库。 最后,您需要到 windows 的系统属性界面中添加一个新的环境变量,变量名为将来拍送 pass, 变量值为拍送跟目录下的 dll 文件,文件名中的数字可能会因为拍送版本不同而不同。 做完所有上述操作,我们现在来看一个实力。你可以通过点击工具栏上的心电脚本按钮生成一个新的这样编程脚本。 在这个案例中,我们首先使用欧本函数来打开这样自带的数据表。 b class, big class 中包含了姓名,年龄,性别,身高,体重等信息,这些信息会不会储存在敌梯这个变量之中? 然后我们使用拍送眼睛,手打开拍送,使用拍送散的来将鼻涕中的信息传到拍送之中,使用拍送神面粉来运行拍送脚本。 在这个拍送小本中,我们具体做的事情是将鼻涕表的表头进行输出,然后在鼻涕中增加一个新的列,因为身高体重比的这样一列。这一列的数据是由满分为了这个函数来定义的。满分为了本质 是将身高处于体重,从而获得一个比值。更新后的数据表,我们可以通过宽松 get 函数传回到酵母之中,然后通过牛 ifu 函数将数据表在酵母中进行展示。 做完所有这些操作之后,我们通过拍松侧面的来关闭拍松。好,现在我们点击上方的绿色按钮来看一下具体输出的结果。 大家可以看到新生成的这张表中多了新的一列名为身高体重比的列,这一列的数据是由拍送计算得到的。 对于业务数据,您可以把案例中的拍送代码替换成任意的其他拍送代码,比如说探搜 flow 啊或者是 cometat vision 的代码来完成您的数据分析操作。对于啊,语言编程方式大同小异, 您只需要将其中的拍送替换成 r 即可,那相应的也需要把 r smith 中的代码替换成 r 的代码需要使用,这样或者想要了解更多,欢迎联系我们。
42JMP数据分析



猜你喜欢
- 2240程序员鱼皮