java native方法实现原理
在云云深时代,扎瓦的日子并不好过,最主要是因为扎瓦有三个很大的短板,分别是启动时间慢,到达分值性能的时间较长,内存占用大。这三个短板在云云深时代尤为突出, 使得嘉瓦基本上告别了 seventys 领域。在微服务上虽然问题不是很大,但是仍然面临来自 go ras 的和 no js 的竞争。 grow em 的出现为扎瓦在芸芸生领域找到了一条新的出路。新兴的扎瓦微服开花框架,如 clocks, micronaut 和 harryton 都提供了对 grow v m 的支持。 作为扎瓦开发框架中的老大哥, spring 在这一方面也不甘落后,只不过由于 spring 框架比较复杂, 历史包袱比较重,实现的速度并不是很快。之前推出了试验性的 speaking later 项目,后来被整合到了 speaking potent 三中。 speaking 六和 speaking potent 三会在十一月发布,目前可以使用 spine poot 三点零点零杠 m 版本进行测试。 speaking 对 granam 的支持分成几个部分,第一个部分是通过 springaot 来生成一些元代码,就是因为 granamvan 不支持动态内加载。 speaking 框架的一些初始化工作会在构建时完成。具体的做法是在构建时生成原代码,随着应用自身的代码一同编译,这样就不需要在启动时扫描 class pass 来获取这些信息。在每晚项目中,他给 the spinaot 目录下 是生成的原代码,如下图所示。第二个部分是生成实际的原声可置性文件,这一步是通过 gravm 提供的构建插件来完成的,支持美本和 gradal, 该插件负责调用 gravm, the atv mage 来完成构建,还支持对构建过程进行配置。 speaking 不集成的该插件原本项目中通过名为 latifu 的 profile 来启用。最后一个部分是应用层次对 guawaym 的支持。 由于 growth vim 的限制,嘉瓦的很多机器在 gratvm 上都需要进行修改,比如动态内加载,反射的使用,资源的加载,动态代理机制等。 gromvm 提供了不同的机制来允许扎瓦用绕开这些限制。对于通用的加瓦,第三方 酷可以使用共享的原数据。对于具体的应用来说,如果需要支持 grow ven, 可以使用 spring 提供的 hint 的支持声明。额外的 grow v m 配置,比如下面代码中的 rantime hints, 声明了与 proscrats 相关的反射调用。 最后看一下 springbook native 的实际使用,一共有三个实力,第一个是简单的 gipc 服务,第二个是 springgpa 和 webmvc, 第三个是反应是 gdbc 和 web flux。 每个视力都给出了 jvi 模式和原声模式的对比,从数据中可以看出,原声模式在启动时间和内存占用上都有很大的提升。完整的视力代码建 github, espnjpa 和 ybamvc 的视力来说, 在他给的目录下可以看到生成的可知性文件 jpa 呃,跟 ybamvc 点 xe 双击就可以直接运行,这降低了家网应用的分发和部署的难度。关于 spinboomballet 我的介绍就到这里,感谢观看。

粉丝401获赞3236
相关视频
 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿每天一个技术点,当我们查看加瓦库的圆码时,会将方法一层一层的往下点,但有时候会发现有的方法点不动了。这类方法没有方法体,也没有什么纸类重写,但偏偏还能钓鱼,还能正常执行功能。这种方法就是 native 方法,或者叫本地方法, 他们用内体无关键字来标识。简单来说,本地方法就是加瓦,调用非加瓦代码的接口,他由非加瓦语言来实现,比如 c 语言,当碰到一些用加瓦不太方便实现的功能时,就可以用到本地方法。你会发现加瓦库中绝大部分本地方法都适合底层 操作系统,把交到的功能,他们就调用了 c 或者 c 加加,甚至是汇编。其实大部分 jvm 主要也是用 c 或者 c 加加来实现的,果真 c 生万物是有道理的。出来 加瓦库以外,我们也可以用 at 五关键字来定义自己的本地方法,然后通过 jn i 技术调用其他语言的实现。当然像这种调用其他语言的特性并非加瓦特,有很多编程语言都有这一机制。跟着螃蟹哥技术不翻车。
34RudeCrab 18:13
18:13 03:28查看AI文稿AI文稿
03:28查看AI文稿AI文稿深入理解原码,分析 java cas 自选锁的底层实现原理 cas 自选锁有哪些问题?如何解决?哈喽,大家好,我是架构师奶爸。 cas compare and swap。 自选锁的底层实现原理依赖于硬件的原子性操作。在 java 中, cas 操作主要基于 unsafe 类实现。首先,我们来看一下 cas 操作的三个操作数内存地址或变量值预期原值核心值。在多线城环境下, 当多个县城同时尝试更新同一个共享变量时, c a s 操作可以通过比较内存地址中的值来判断当前值是否与预期原值相同,如果相同,则将新值写入内存地址。 c a s 操作的特点是它不保证阻塞,即当一个县城 在执行 cas 操作时,如果预期原值与当前内存地址中的值不匹配,他不会阻塞,而是会重新尝试。这种尝试的过程通常是通过自选等待实现的极限程会循环执行 cas 操作,直到成功为止。在底层实现中, c a s 操作主要基于硬件的原子性操作。例如,在 x 八六架构中, c a s 操作可以使用 lock c、 m p、 x、 c h、 g 八 b 指令,用于比较并交换八个字节的值实现。这个指令会将预期原值和内存地址中的值进行比较, 如果相同,则将心值写入内存地址,如果不同,则返回失败标志。需要注意的是,由于 c a s 操作是基于硬件实现的,因此它对于不同的 平台和架构可能会有所差异。此外,在 java 中, c a s 操作还可以通过 janey java native interface 调用底层的本地方法来实现。例如,在 j、 d、 k 中, cas 操作通常会使用 unsafe 类的 compare and swap in 和 compare and swap long 等方法来实现。我们在业务中使用 cas 自选锁策略时,也会带来一些问题。一、 aba 问题。在比较并交换的过程中,如果多个县城同时对数据进行修改, 可能导致判断数据没有变化,但实际上数据已经被修改。为了解决这个问题,可以引入版本号 version。 每次比较的时候,除了比较值,还要比较版本号。如果版本号不一致,说明数据可能被修改,需要重新读取最新数 举进行比较。二、自选等待问题。长时间自选等待会占用 cpu 资源,导致其他县城无法获取 cpu 资源。解决方法使用超时机制。如果自选等待时间超过某个预值,就放弃自选等待。使用自适应自选 adaptive spin 等待算法, 根据所的竞争情况动态调整自选时间和次数。需要注意的是,虽然 cas 自选锁是一种高效的同步机制,但是它并不适用于所有场景。例如,当线程数较少或者数据访问冲突较为频繁时, 使用 c、 a、 s 自选锁可能会导致性能下降。在这种情况下,使用传统的锁或者读写锁可能更加合适。 因此,在选择同步机制时,需要根据实际情况进行评估和选择。想学习更多 java 编程知识,请关注我架构师奶爸,共同筑基 java 架构师。
13架构师奶爸 03:39查看AI文稿AI文稿
03:39查看AI文稿AI文稿每天一个技术点,上期视频讲解了 ecose 方法,这期视频就讲讲 ecose 方法常搭配使用的哈西扣的方法。它和 ecose 方法一样,都是定义在 object 的点 成复类中,此类可以进行重写。哈西扣的方法是 native 方法,如果没有重写,那他通常会将内存地址转换为 int 数值进行返回。我们用哈西扣的方法获取到的这个 int 数值就是哈西马,也叫闪列马,它的作用就是确定对象在哈西表中的所引位置。 只要搞懂了哈西表的机制,也就能搞懂哈西扣的方法了。为了照顾还没有学过集合的小伙伴,这里就当做没有集合这些东西,我们从头来简单推导一下哈西表的基本原理。假设现在有这么一个需求,我想让一批对象能够存 存储起来,不允许存储重复的对象,并且能够随时获取对象。一说起存储,那自然就想到了数组。我们可以将对象挨个放在数组中,当判断对象是否重复存储时, 或者获取指定对象时,我们每次都得从头开始便利数组。挨个和数组中的对象进行 ecose 比较, ecose 结果为真,就代表找到了指定对象,这样确实满足了需求。但有一个问题就 是效率太低了,每次都得便利整个数组。假设数组中有一万个对象,那每次操作我都得比较一万次 时,时间复杂度为 on, 有没有办法可以提高效率呢?这时候通过哈西扣的获取到的哈西马就派上用场了。我们在存放对象时,可以通过哈西马来和数组长途取鱼,这样就能 得到数组要存放的位置,比如数组长度为十,对象的哈西马为十七,那十七除以十归于七,我们就可以将这个对象存放到下标七的位置上。这样无论是存储元素还是获取元素,通过数组下标就只用操作一次,时间复杂度为 oe。 现在大家应该能体会到哈西马的作用了,确定所引位置就能大幅提高效率。不过现在还有一个很大的问题,那就是哈西马是可能会重复的,毕竟哈西马 是通过一定的逻辑计算出来的 inter 数值,那两个不同的对象完全有可能哈西马会相同,这就是我们常说的哈西冲突。当要存储的对象和已经存储的对象发生哈西冲突时,我们首先要做的就是判断这两个对象是否相等,如果相等那就好办, 因为这算作重复元素吗?我就不用存储了。如果不相等,那我再将新对象想别的办法存起来。那两个哈西冲突的对象该怎么判断相等呢?当然是用 ecose 方法了,这里也就能明 为什么建议哈西扣的方法和 e cos 方法要同时重写。因为哈西扣的方法用来定力,所以位置以提高效率的同时可能会发生哈西冲突。当哈西冲突时, 我们就得通过 ecose 方法来判断冲突的对象是否相等。如果只重写了哈西扣的方法,那哈西冲突发生时, 即使两个对象相等,也不会判定为重复,进而导致数组里会存储一大堆重复对象。如果只重写了一 cos 方法,那两个相等的对象内存地址可不会相等,这样还是会造成重复元素的问题,所以两个方法最好 一起重写。最后总结一下,哈西扣的方法用来在最快时间内判断两个对象是否相等,并定位锁引位置,不过可能会出现误差。 ecose 方法用来判断两个对象是否绝对相等。哈西 coe 的方法用来保证性能, ecose 方法用来保证可靠。跟着螃蟹哥技术不翻车。
122RudeCrab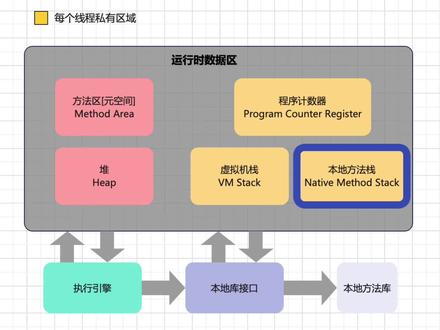 00:20查看AI文稿AI文稿
00:20查看AI文稿AI文稿本地方法债与抓把虚拟基站所发挥的作用是非常相似的,其区别不过是虚拟基站为虚拟机执行抓把方法服务, 而本地方法占则是为虚拟机使用到的 native 方法服务。本地方法占区域也会抛出 stick over forever 和 autaf memory ever 异常。点击关注,每天进步一点点。
35788 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿面试进行中。你好,我是来面试需要把开发工程师的。嗯,小伙子,我看你简历上面写熟悉。这样吧。那你说说抽象的 xx 方法是否可以同时是静态的?词语 是否可以同时是本地方法? aging 是否可以同时被 synchronize 都不能。抽象方法需要此类重写,而静态的方法是无法被重写的, 因此二者是矛盾的。本地方法是由本地代码实现的方法,而抽象方法是没有实现的,也是矛盾的。 scenarios 和方法的实现细节有关,抽象方法不涉及实现细节, 因此也是相互矛盾的。回答完毕。
 05:16查看AI文稿AI文稿
05:16查看AI文稿AI文稿大家好,今天给大家演示是用加瓦语言便携 tot 为服务。 toss 为我们提供了多元的开发框架。其中 tot 加瓦这个项目就是加瓦的开发框架。 塔子家务的服务端开发有四种方式,第一种是塔子原声方式,我们只需要集成 toss 的官方依赖即可。第二种是死不运的方式,第三种是集成死不运 boss 的方式,最后一种是集成死不运坑奥的方式。后面这三种方式可以帮助我们将已有的项目快速迁移到 toss 框架中来。 我们今天只讲第一种 touch 原声方式。先说一下思路,第一步要先安装 touch 加瓦框架的意外包。第二步按照官方手册的指引步骤来编写代码,最后被已打包通过 top 外部控制台上传发布即可。 先看第一步安装框架第一步比较简单,直接到 gtop 上拉取代码到本地,然后执行,没问题,可以指并已安装, 装一下就可以了。但是这里需要注意两点第一,拉取框架代码时,一定要拿取打好泰格的版本,而不是从官方地址 jcom 过来的代码,因为这个代码不全,程序无法运行。 第二,在执行维稳 install 安装框架时,会默认编译测试位,这时会与其他中心自动建立连接,比如他的 state, 连接失败的话不会进行后续的编辑安装。所以在执行没问意思,到时要加入 taste dare skip 等于处这个参数,以取消自动测试。 做完上述两点之后,就可以放心的在 touch 框架下进行加瓦开发了。 touch 原声的开发方式参考的是官方的 toss 加瓦 quick start 这个文档 首先是意外环境,要求 gdk 一点八或以上,每晚二点二点一或以上。这里已经准备好了。然后创建一个每晚外部工程。官方文档中是在 eclips 下进行的,我在 max 上用 westcold 直接面对行创建执行屏幕上这条职位。其中 artifact id 这个参数中填写好目标报名。这个参数指定了最后生成外观的名称,在上传发布包时会进行较页。接下来是在 pom 文件中添加相关依赖,包括两部分内容, 一个是框架依赖 thatsuver, 用于生成微服务。另一个是插件 topstv von plusv in, 用于生成 rpc 文件。对于每一个标签的作用,大家可以看官方的注视。添加完音海像之后就可以定义结合文件。在 srcmevcrcsm 楼下创建汉口。点 tops, 然后复制一下内容。 在这里我们添加一个新方法 hango 加入文贵,由参数 rotkey 输入参数 sreq 和输出参数 s response。 编辑好之后执行命令。 meivon toss toss 图加网这是插件里支持的命令,用来生成 rpc 文件的。执行之后生成了 hungoosevent。 点加网 这个是框架文件。接下来需要我们自己编写一个 hundle seventhimpr 文件,继承刚刚生成的 hundle seventy, 然后在这个文件里实现点 tops 文件中定义的方法。在项目开发过程中,就需要在这些自定义的结构中编写业务逻辑。 我们这里简单写一下。韩国计划的实现,在于这里打印出输入信息,然后给选用参数复制 ncis 加我 response 编写好代码之后进行最后一步配置。将服务报告给框架。在 resizes 蒙古下创建一个名为 certaintytmel 的配置文件。然后可以将官方文档中的内容复制过来。 这个文件也是 touch 框架自己去解析的。看标签名称也比较好理解。在 siri 的这位先声明对象名称 hello oppo b j, 然后指定客户端在断用这个对象时对应的处理位和我们 api 和和我们 clus。 上面所有的步骤完成之后就可以执行。没文牌可以指生成 无法不包。正常情况下,借口函数名尽量不要一样。我们改一下,改成 doohungo, 参数不变,然后没文。 toustostop 加瓦重新生成 hello siri 的调加网看一下内容读函头函数名称更新了。这时候不要忘了把实现文件中的函数名手动修改一下,因为这个是我们自己编写的不实声称的。 改好之后重新没文牌 aa 制。我们看一下在右边生成的发布包。 toss 加了 test 点腕。 下面来到控制台,新部署一个服务,跟之前的 c 家家服务均分开卖,起名叫做 test 加瓦。 app 服务名还是 hello serve。 服务类型一定要选 touss 加瓦模板一定要选 touss, 点 toss 加瓦点 default, 这两个一定不要选错了。其他步骤跟 c 家家服务一样,如果你每一个步骤都严格按照官方文档来做了的话,到这里服务会正常进行的。但实际情况中 由于种种原因会出现各种各样的问题,这里给大家分享一下。首先是上传发布包时,页面会报错,发布包与服务名称不匹配。这个问题是因为部署应用的 sever 名称与上传的发布包名称前缀不匹配导致的。比如你在控制台的部署的 sever 名称为 test 加瓦 app 点 hello sever 点星, 那么编译商城的点万的名称必须是 hello sever 点洼才能上传成功。第二个比较恶心的错误是服务启动后日之礼报错找不到或无法加载。准备 com 点 qq, 点 toss, 点 server, 点 style 点 me。 这是因为我们使用了错误的 toss, 加了版本。我编译的框架代码是直接 jacquelong 过来的, 编译好后到编译出来的家里确实找不到这个文件。解决办法就是视频开头提到的要下载打个太子的版本,然后编辑安装,比如一点七点二版本。最后一个需要注意的是, 在控制台上测试时,上传的点踏子文件一定不要跟之前的点踏子文件重名,否则上传不了也不会报错,没办法测试。这种情况下,我们把点踏子文件重命名即可。以上就是今天分享的主要内容,欢迎大家点赞收藏。
 04:23查看AI文稿AI文稿
04:23查看AI文稿AI文稿哈喽,大家好,我是麦克,一个工作了十四年的家务程序员和创业者,今天分享的这张面试呢,非常有意思啊,去大厂面试的时候,百分之九十的可能性都会被问到,但是真正能够去完整回答出来同学呢,非常少。最近一个工作的十一年的粉丝去面试就被问到这样一个问题, 他的问题是 my c 口的事物的底层实现原理。另外啊,我花了一个多星期的时间,把之前的所有高手的回答整理成了五万字的文档,想获取的小伙伴可以在我的主页去加微领取啊。下面我们来看看普通人和高手对这样一个问题的回答。普通人的回答,呃, my c 口的事物的实现原理啊, 他里面就因为事物他有一个很关键的特性啊,我是这么理解的,就是他会有一个就是原则性嘛,就是他要保证我事物同时成功同时失败,所以他为了保证 这个在一个回滚的一个机制上,所以他用到了一个呃,昂 dologo 的这个表,就是说他在更显更改这个事物的之前,他会把这个数据的快的保存到 ondologo 一点,嗯,然后对,嗯 高手的回答,好的,面试官, micro 里面的事物啊,满足 acid 的特性,所以在我看来呢, mac 口的事物的原理啊,就是英诺 db 是如何去保证 acid 这样一个特性的。 首先呢, a 呀,表示奥特曼的原则性,也是说需要保证多个 dm 操作的原则性,要么都成功,要么都失败, 那么失败就意味着对原本执行成功的数据要进行回滚。所以印度 db 里面呢,设计一个 angelog 表,在事物执行的过程中啊,把修改自己的数据快照保存到 angelog 里面,一旦出现错误,就直接从 angela 里面去读取数据,进行反向操作就行了。 其实啊,就是 c, c 表示一致性,也就是说数据的完整性约束没有被破坏。那么这个呢,更多的是依然业务层面的一些保障。数据股本身呢,也提供了一些比如说像组建的唯一约束,质量,长度和类型的一些保障等等。 接下来呢, i 呢,表示事物的隔离性,也是说多个并行事物对同一个数据进行操作的时候,如何去避免多个事物的干扰,导致数据混乱的一个问题。 而印度 db 里面呢,实现了 cq 九二的一个标准,提供了四种隔离级别的一个实践,分别是 ru, 也就是说未提交读, rc 表示乙笛加读, r 表示可重复读,以及 c 是来自否表示创新化 英德 db 默认采用的格力级别。是啊啊,也就是说可重复读,然后使用了 mvcc 机制啊,却解决了章读和不可重复读的一个问题,然后使用了行锁或者表锁的方式来解决了换读的问题。最后一个是 d 表示持久性,也是说只要事物提交 成功,那么对于这个数据的结果的影响一定是永久的,不能因为数据库当机或者其他原因导致数据变更的一个失效。理论上来说啊,事务提交之后,直接把数据直接发到磁盘里面就 ok 了。但是呢,因为随机磁盘 io 的效率啊,确实很低, 所以印度 db 里面设计了八个破的缓冲区来进行优化,也是说数据发生变更的时候,先更新内存缓冲区,然后在合适的时间在持久化的磁盘里面。那么在这个机制里面呢,有可能出现在持久化的这个过程中,如果数据故荡机,就会导致数据丢失,也是说无法去满足持久化。 所以在 enodb 里面引入了 redo log 这样一个文件,那么这个文件存储了数据库变更之后的一个值。当我们通过事物进行数据更改的时候,除了修改内存缓冲区里面的数据以外呢,还会把本质修改的一个值啊,追加到 redo log 里面。当事务提 教的实话,直接把 redologo 里面的日字刷新到词盘里面进行持久化,一旦数据库出现当机呢,在 mac 又重启的话,可以直接用 redoloc 里面保存的重写日字读取出来以后再去执行一遍,从而去保证数据的一个持久性。 因此啊,在我看来,事物的持久性原理核心本质就是如何去保证事物的 acid 特性。而在 onto log 里面呢,用到了 mvcc 行所表锁, onto log 以及 redo log 等等这样一些机制去保证这样一个特性。以上就是我对这个问题的理解, 英诺 db 里面的事物实现原理呢,有很多可以去值得借鉴的设计思想,比如说像乐观所啊,利用内存的缓冲区的方式来以空间换时间的思想去优化磁盘 io 的一个性能等等,这些思想我认为还挺重要的,比如说在分布式事物框架 c 塔的 at 模式的数据回滚,就借鉴了英诺 db 里面的 ongo logo 的一个 设计思想。好的,本期的普通人 vs 高手的面试系列的视频啊,就到这结束了,喜欢我作品的小伙伴记得点赞收藏加关注啊,我是麦克,我们下一期再见。
 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿一个工作三年的粉丝呢,最近去面试的时候遇到一个集合方面的问题,这个问题其实非常简单啊,可能大家没有去关注集合方面的底层实现原理,导致在面试的时候呢容易栽跟头。哈喽,大家好,我是麦克,一个工作了十四年的家务程序员和创业者。今天啊,分享的这道面试题呢,是 arist, 他的自动扩容机制的实现原理。另外我花了一个多星期的时间呢,把以往的高手回答整理成了十万字的一个文档,如果你想获取的话,可以在我的主页去加微领取啊。下面我们来看看普通人和高手对于这样一个问题的回答。普通人的回答,嗯, 呃, iris 的自动扩容,我记得应该是,就是他会去创建一个新的数组,然后把那个就是老的那个数组去直接 科比,就是数据的元素,直接科比到新数组里面,嗯,也是说,当也就是我的那个数组的这个长度啊,就是不够的时候,他就会去做这个动作。嗯, 高手的回答,好的面试官,艾瑞瑞斯呢,是一个数组结构的存储容器,默认情况下呢,数组的长度是十个,当然我们也可以在构建艾瑞瑞斯对称的时候指定初始长度,那么随着在程序里面不断的往艾瑞瑞斯里面添加数据,当添加的数据达到十个的时候, iris 里面就没有足够的容量去存储后续的数据。那么这个时候呢, iris 呢,会触发自动扩容,扩容的流程呢?其实也很简单,首先创建一个新的速度,那么这个速度的长度是原来速度长度的一点五倍,然后使用 iras 点 copial 这样一个方法去把老数组里面的数据 call 比到新数据里面。 扩容完成以后呢,再把当前需要添加的元素加入到新的数字里面,从而去完成动态扩容这样一个过程。以上就是我对这个问题的理解, 作为一个业务程序员呢,虽然工作的性质是让大家去写 ciud, 不需要过多的去关注技术的底层原理,但是在未来的职业竞争过程中呢,技术的理解程度就显得非常重要了,因为未来的岗位所需要的能力和当前的能力是完全不一样的。 好的,本期的普通人 vs 高手的灭速系列视频呢,就要到结束了,大家记得点赞收藏加关注,我是 mike, 我们下一期再见!
 00:30查看AI文稿AI文稿
00:30查看AI文稿AI文稿java released 和 linked list 的区别及实现原理?
 01:49查看AI文稿AI文稿
01:49查看AI文稿AI文稿华为一面真实面试题 we enter and read the right lock 实现原理如果有一个业务是读多写少,同时呢,还需要保证咱们的县城是安全的。那么如果使用伦春 log, 其实会导致效率是比较低的。 所以说,咱们出现了伦春的瑞的 red 读写所。读写所内部呢,给咱们提供了两种所机制,一种是写所,一种是读所。写所呢,其实依然还是一个互斥所。但是呢,在读所操作时,他是一个共享所,不会出现互斥的情况,就可以提高咱们的效率了。 而底层的实现原理,其实也是特别简单的,依然基于 aqs 实现。不过呢,使用 stay 的层面就不一样了,他会将高十六位作为读所,而低十六位作为写所。而且呢,读写所依然是支持 可重入操作的斜锁。因为是互斥锁,所以它的实现方式呢,跟润唇 local 是一样的,还是直接对自己的加一,就可以不断的实现这种重入的一个操作,只不过限制比原来增大了。 而独锁呢,是共享锁,它的宠物方式就是在独锁县城内部来一个死瑞的 local 来记录我所充的次数。那么虽然说由死瑞的 local 来记录啊,但是依然要修改 stat 的高十六倍的值。不然的话呢,释放独索资源时会出现一定的问题。 而读所,因为是共享所操作,他会一般直接修改 stat 的高穴位就可以了。但是呢,咱们要避免写所饥饿。所以说,在读所竞争所资源时,要先查看 aqs 中排在 head next 是否是写所。 如果是鞋锁的话呢,那毒锁就无法直接对 style 进行加的操作了,而是乖乖排在我鞋锁的后面。哈哈哈哈,哎呀,腰疼。
499Java老郑 02:51查看AI文稿AI文稿
02:51查看AI文稿AI文稿哈喽,大家好,我是专注加法干货分享的灰灰 mvcc 的实现原理啊,是一道非常高频的面试题。最近啊,也有很多粉丝跑来问我这道题到底应该怎么回答,那么今天我给大家细致的梳理一下。 到现在很多小伙伴在准备面试,所以我整理了一份三十五万字的程序员求职面试宝典,有需要的小伙伴可以在评论区口求分享,免费领取。 mvccl 是英乐 db 里面一种非锁定的方式去解决事物的并发问题,也就是多版本并发控制。 它在 rc 的隔离疾病下面能解决事物的并发产生的脏毒问题,同时在啊啊的隔离疾病下面能解决患毒以及不可重复的问题。 首先到底怎么解决脏读问题呢?脏读是指如果操作这个数据的事务没有提交,但是其他事务可能能读到你这一个事务操作的数据。要解决,无非就是在读取数据的时候, 判断一下我操作这个数据的事务有没有提交。因为我们的数据操作都是基于事务去做的,那么每一个操作都会有一个事务 id, 那么这个事务 id 会保存在我们行的隐藏字段里面,代表操作这个数据的最后的事务 id。 我们去查询的时候,就只要去判断一下这个数据的事务 id 有没有提交就行了。 那么怎么去判断呢?在查询的时候,我们会去生成一个 plus 数据结构,叫做 redbu, 里面有几个主要的信息,这些信息都是一些事物信息。第一个我们会去保存下一个即将分配的是 yd, 因为事物如果是一个非指读的,都会有一个递增的事务 id。 第二个,我们会去保存当前没有提交的事务 id 里面最小的。第三个,我们会去保存当前没有提交的事务 id 的集合,然后会根据 redbu 的事务信息,我们就能知道这个数据有没有提交了。比如数据 数据的事务 id 比我 read to me 里面下一个即将分配的事务 id 还要大或者相等,说明我在查询的时候,这个修改数据的事务 id 根本就还没有开启,那么这一次修改肯定不可见。第二,如果数据的事务 id 比我最小的没有提交的事务 id 还要小, 那么肯定在查询的时候,这个数据修改的事务 id 已经提交了,肯定能够读到。第三,如果数据的事务 id 比我最小的要大,但是呢,又比我下一个即将分布的事务 id 要小,那么在查询之前肯定已经开启了事务, 但是不确定他有没有提交,只要去判断这个事务 id 是否在我们没有提交的事务 id 的集合里面就可以了。这样呢,我能够去保证解决了脏读问题。当然啊的情况下面,他解决了不可重复读以及换读问题。那是因为啊啊他的每一次查询用的都是第一次 查询的 red 六,那么前面第一次查询的时候,如果查不到最新的数据,后面也查不到最新的数据。而 r c 呢,它是每次查询都会有一个新的 red 六,所以它没有解决不可重复读跟换读问题。那么这个呢,在官网也有明确的说明。 今天的内容就分享到这里,如果对你有帮助的话,请记得帮我一届三联。我是灰灰,我们下期再见。
136Java面试突击-灰灰 03:21查看AI文稿AI文稿
03:21查看AI文稿AI文稿之前分享过一期哈西 map 的面试题,然后有个小伙伴私信我说他遇到了一个 concurrent 哈西 map 的面试题,不知道该怎么回答,于是呢,就有了这一期的内容。哈喽,大家好,我是鼓跑科技的联合创始人麦克。 今天我给大家分享一下这个面试题的回答思路。如果你想要文字版本的回答,可以在我的评论区的置顶中去免费领取三十万字的面试文档。这个文档包括了各个一线大厂的面试真题,而且每道题目都有详细的解答,能够帮助你们对面试题的更深度的理解,从而去更好的应对面试的一个场景。 这个问题我需要从三个方面来回答。这个呢是康康的哈西 map 在 g t k 一点八中的存储结构,它是由数组、单项列表和红黑素组成。当我们初始化一个 concarra 哈西 map 实力的时候,默认会初始化一个长度为十六的数。 由于康康的哈西卖部他依然是一个哈西表,所以他必然会存在哈西冲突的问题。康康的哈西卖部采用了链式巡止法来解决哈西冲突。当哈西冲突比较多的时候,就会造成链表过长。这种情况就会使得康 caren 的哈西卖部中数据元素的查询复杂度变成了 o n。 因此在 gdk 一点八中引入了红黑素的机制。当速度长度大于六十四,并且链表长度大于等于八的时候,单向链表就会转化为红黑素。另外,随着慷慨的哈西卖部的动态扩容,一旦链表长度小于六,红黑素就会退化成单向链表。 concurrent 哈西 map 本质上是一个哈西 map, 因此功能和哈西 map 是一样的。但是 concurrent 哈西 map 在哈西 map 的基础上提供了并发安全的实现。并发安全主要实现是通过对指定的 note 节点枷锁来保证数据更 新的安全性。如何在并发性能和数据安全性之间做好平衡,在很多地方都有类似的设计,比如说 cpu 的三级缓存, my circle 的八八 pro single nine 的所升级等等。 康凯尔哈西卖部也做了类似的优化,主要体现在以下几个方面第一,在 g、 d k 一点八中,康 carry 的哈西卖部的锁的力度是数组的某一个节点。而在 g d k 一点七中呢,锁定的是一个 settlement, 锁的范围更大,因此呢,性能上会更低。第二,引入了红黑素,降低了数据查询的时间复杂度。红黑素的时间复杂度是 or logan。 第三,当数组长度不够的时候, con carry 哈新卖部需要对数组进行扩容。在扩容的实现上, con carry 哈新卖部引入了多线层并发扩容的机制。简单来说就是多个线层对原始数据进行分片以后,每个线层负责 一个分配的数据迁移,从而提升了扩容过程中的数据迁移的效率。慷慨的哈士卖部中呢,也有一个赛事方法来获取总的元素个数。在多线的并发产业中,在保证原子线的前提下来实现元素个数的累加,性能是非常低的。 concaller 的哈士 map 在这个方面的优化主要体现在两个点上。第一,当县城竞争不激烈的时候,直接采用 case 的机制来实现元素个数的原子递增。第二,如果县城竞争激烈的情况下,使用一个数组来维护元素个数, 如果要增加总元素个数,则直接从数组中随机选择一个,再通过 kiss 来实现原子递增。它的核心思想是引入了一个数组来实现对并发更新的负载均衡, 降低了锁的竞争。以上就是我对这个问题的理解,我是麦克,感谢大家关注和点赞,我们下期再见。
 07:11查看AI文稿AI文稿
07:11查看AI文稿AI文稿今天咱们说一个极简的扎瓦开发学习路径,思路跟以前一样啊,还是咱们先把项目做出来,有了项目之后呢,咱们是想横向扩展呢,还是纵向扩展呢?都无所谓啊,那今天的路径呢,目的就是把这个项目做出来,那做这个项目需要哪些必备的知识呢?我整理了一个思维导图,大家可以看一下, 我是把能砍的东西都砍掉了,尽量就是让大家学最少的东西来实现一个项目。好,那咱先说这个思维导图,第一步呢就是安装开发环境, 那首先呢,安装 jdk, 安装 idad, 现在公司主流的开发工具就是用 idad 啊,所以说大家就不要用一克利波斯啊,麦克利波斯了,这些学校可能会用啊,咱们真正学习的时候就不要用了。 那第二步呢,就是学习扎蛙的语言基础,那变量数据类型,运算符,配答式,控制流程语句啊,然后方法的使用啊,比如说如何传 餐呐,如何写返回值啊这些东西,然后数组,什么是数组?应该了解,这是扎哇的语言基础,差不多这些就够用了啊。然后是面相对象,面相对象像什么类呀,对象啊,继承啊,多态啊,访问权限啊,接口啊这些,大家知道基本语法就行了, 因为大家学面相对象的时候可能会听一些设计模式啊,还有一些可扩展性啊,高内聚,低友和呀,这些东西大家如果没有项目经验的话,学了也学不太会, 所以说面向对象这块,先了解他的基本语法就够了,不要想太多东西,想的太多了,迷糊了,影响后期学习。 然后学完面相对象之后看这个常用类,常用类的话像 string, every, mass, random 等等一些东西啊,这些常用类需要用什么的时候啊?直接看看文档,看看 api 就可以了,所以这个东西了解一下怎么用就行。那接下来呢,是集合,集合这块儿,知道范形, 然后学两个,一个是 every list, 一个是 has map 就可以了。向大家学集合的时候,有时候会看到很多的接口啊,很多累啊,谁实现了谁呀,谁继承了谁呀,这些东西大家不用特别的去记,因为新手刚开始学的时候也没有什么项目经验,记也记不住, 搞得自己痛不欲生,然后练习的时候还用不上,结果的话回头都忘了,等面试的时候还得回头背。所以说前期的话咱们先不用看啊,就艾瑞丽斯特和哈斯迈克就 够用了,一个是纯储列表,一个是纯储建支队的。好,那学完集合之后,咱们进入到扎外吧阶段,扎外外吧会涉及到一些前端的知识,比如说 at 毛 c s c s, 大家会做一些简单的页面效果就行,都不用做的特别漂亮。 这些东西是前端做的啊,后台扎哇的程序员的话不用特别的熟悉,能看懂代码就行。那接下来呢是 http 协议, azx 和 jc 数据 格式, htb 协议,这个是做外边开发,肯定是要用得到的。那 azx 和 jc 数据格式呢?主要是为了实现一个前后端数据的传输。 那接下来呢是买色扣和色扣语言,这就是数据库了,大家只要知道买色扣数据库如何实现征山改查就可以了啊,最多也就再了解一下这个表关系,比如说这个啊,一对多的关系啊,多对多的关系啊,就够用了,不用学的太多东西。 然后呢,就是这个叉 m l, 那了解一下叉 m l 的基本格式就可以。因为像以前的项目,比如说用 s s m 的项目的话,很多配置它是运用叉 m l 来实现的,但是现在用 spring 布特的话,基本上配置都不用叉 m l 了。那学叉 m l 主要就是 呃迈文配置的时候可能会用到它,其他的情况用的也不是特别多,大家了解一下格式就可以了。那在外部这块,最后还应该了解一下什么是情 端分离,什么是服务器端渲染的一个基本概念。那如果大家做一个前后端分离的项目的话,可能还需要学 vivo 或 react, 但是我建议大家第一个项目练手嘛,就直接做一个模板渲染的就可以了,不用学前后端分离的项目。 但是这个基本概念啊,一定要知道,因为有可能你要和同学一起做这个项目,比如说你有一个同学在学前端,你做后台,那么你如何在后台给前端提供数据接口的话,这个就应该对前后端分离有一个初步的了解。 好那招外部学完之后,咱们说这个项目开发的一些东西了,那这里呢,第一个就是 spring boots, springboot 相当于就是一个脚手架啊,用它就可以直接啪的一下搭建出一个项目来了。 有这个项目股价之后呢,咱们就可以在这个股价的基础上去不断添加一些功能,所以有了 sprrendboot 之后呢,咱们做项目就会非常的方便了啊,那接下来呢学迈文,迈文主要用来 管理依赖,比如说咱们做一个项目需要依赖很多的第三方工具,第三方框架,那这样用迈文可以做一个统一的管理,那他主要就是用一些 xm l 的格式来实现一些配置就可以了。那下面呢学习这个 timelife 的模板。那 刚才也说了,大家如果说做一个项目的话,如果没有前端的小伙伴,前端的同学和你一起配合的话,那大家就没有必要做成一个前端分离的项目了。 页面这块呢就可以用汤姆利夫来实现了,在汤姆利夫里面呢写一些 h m l c s s 的代码,然后呢可以绑定一些数据,这样就可以把服务器端的数据显示在页面上给用户看了。然后呢就是学买白提斯,买白提斯是一个 o r m 框架,大家知道就是用它来实现操作,买蛇扣数据库就可以了, 那这个是项目开发必备的东西。咱们也学完了之后,那最后一步呢,就是学这个项目制作的流程,项目制作流程我建议大家先做 一个这个突突历史,就是一个带座视仪列表啊,就比如说页面上有一个输入框,那这个输入框你添加一些内容的话,就可以把这个内容加到一个列表当中,那这个数据的话,就是从前端的页面一直加到服务器端,服务器端插到数据库里, 然后数据户在从后端一直显示到前端的页面,实现一个基本的数据的展示和数据的征山改查,这样大家对一个数据的整体流向就能有一个完整的了解了,然后大家可以看我之前发的视频说的这个,呃,一个小周 cms 的一个项目,就是一个内容管理系统, 那这个小周 cms 的内容管理系统呢?包括了一些前端页面的展示啊,后台数据的终身改查的一些功能啊啊,同时我还配了一些简洁的需求文档啊,数据模型还有设计稿。如果大家想做这个项目的话,可以在马云里面搜小周报告全拼,就能找到这个项目了啊,当然 我像这个思维导图也好啊,还有其他的一些资料啊,我全都会放在小周报告全拼的这个项目里面,方便大家获取资料。 最后再说一下,就是我砍掉了很多东西,对吧?大家会发现 io 啊,多线程啊,反射呀这些知识点的话,咱都砍掉了,因为做第一个项目的话,基本上这些原理可能用的不是特别多,那咱们就先不着急学,用的时候再学就可以了。 还有就是像 sirilita, gdbc 啊,这些其实被封装的也是比较好的,所以出去做项目咱们也不用学,做完项目之后有兴趣咱们可以再扩展扩展。 那像这 sp 呢,这个东西肯定是过时了,所以这 sp 的话以后都不用学了。还有就是有一些教程会讲这个汤姆凯特,但是咱们现在有 sprend 布特的话,汤姆 cat 其实是也用不上了,直接用 sprend 布特就可以运行项目打包项目了。这个整体呢,就是一个极简的扎挖开发学习路径,我感觉有了这个路径的话,大家应该能更方便更简洁, 觉得把第一个项目做出来,当然这个项目做出来之后,大家也仅仅只是入门了而已啊,因为还有好多好多的知识点没有学呢,而且看这个思维导图大家也能看到啊,如果说找这个其他的一些学习路径的思维导图,大家看到密密麻麻的像蜘蛛网一样啊,但是我这个呢,就很简洁了,只写了八部,还有一个说明,基本上就把 做项目必要的东西都给大家介绍出来了,所以大家如果感觉有用的话,长按点赞支持一下吧!好,那今天内容就是这些,我是陪你一起学习的小周,咱们下期再见。
2846晓舟 01:25查看AI文稿AI文稿
01:25查看AI文稿AI文稿在这个肯出了里边,这三个方法是模拟了三个查询,他们分别会耗时几百毫秒,那问题是什么呢?现在是这三个查询其实没有任何依赖关系,也就是说你想先查谁就先查谁,最后 只要把他们三个都查出来就行了。但现在这样写的话呢,他们就是串型的,也就说我查完一,再查二再查三,总耗时就是他们三个加一起。后来呢,我就想到了能不能模仿这个 gs 里的 pro miss 封装这么一个方法, 我给他加了一个 obate, 这样的话呢,这三个字任务就会并行的去执行,等最慢的那个执行完之后呢,这个方法就走完了。不过我发现 原来啊,一 gdk 一点八里边他有默认的支持了这种类似的方法就是这个 complitatboot future office, 然后里边还是用这个点 rans 创建子任务。但是呢,这里边最好我们自己准备一个现成池,你不准备这个现成池也可以,他用的就是一个公用的现成池,那个现成池就不太适合带 io 的这种操作,他就比较适合计算密集型的任务。 所以呢,我准备了一些成吃这样来执行。我们来看一下这三个的效果哈,我们先来第一个,大家看比较慢是吧?我们再看第二个,明显就会快了,我们再看第三个,一样的。
5049程序员小山与Bug 01:42查看AI文稿AI文稿
01:42查看AI文稿AI文稿你们知道佳话训练话为什么要实现三代的拨接口,并且指定一个固定的 uid 值吗?下面来通过一个简单的案例来演示下, 这里有一个测试方法,先用一个娱乐对象输出一下,再训练化一下这个对象,然后再反训练化这个对象,并且输出。这里先简单看一下这两个方法。第一个训练化将加号对象转换成字节,保存到词盘文件中, 再看一下反讯电话,这将保存在持盘文件中的加瓦字节,再恢复成加瓦对象。先回到这个遇到的将实现生态的宝接口去掉,并注视域外地址,然后回到这个测试内中运行一下这个方法 可以看到他报错说这个预热没有训练话,然后回到预热内中实现训练话接口,再运行一下这个方法,可以看到现在没有报错了,然后回到测试内容,将这个训练话方法给注释掉, 再到预热内中加一个子弹,比如说 a 加,这里的意思是在预热内中先增一个子弹,然后将我们之前训练化过的一个预热对象再直接反训的话测试一下看看。这里可以看到报错了, 他的一个错误信息是说训练化和反训练化时的与 id 不同,然后回到遇到内中证明一个固定的与 id 值,然后再回到设置方法中,将这个训练化给放开这里再重新运行下, 看到这里没有报错,然后再将这个训练话给注释掉,再在这里再加一个新的值, a 级三。然后我们再运行一下, 可以看到在反训电话之前加了一个新的 a 级三,自断后再进行反训电话时转换正常。通过这个简单的小案例,我们便能知道佳话训电话为什么要实现圣诞热播接口,并指定一个固定的 uid 词了。最后你们有没有什么看法呢?可以评论分享一下,谢谢!
1786程序员郑清 04:31查看AI文稿AI文稿
04:31查看AI文稿AI文稿责任内模式的应用场景非常多,比如说拦截器、过滤器等等,但是呢,要彻底理解责任内模式的实现原理还是有一定难度的,因此呢,责任内模式的实现原理也成为了一道互联网大场的高频面试题。那么今天呢,我就给小伙伴来详细的掰一掰,保证让大家搞明白。 关于责任链模式的定义,官方原文是这样描述的,他翻译过来就是将链中的每一个节点看作是一个对象, 每个节点呢,处理的请求均不相同,而且呢,内部要自动维护下一个节点对象,当一个请求从劣势的手段发出的时候, 会沿着责任链预售的路径依次传递给下一个节点,直到被链中的某个节点对象处理完为止。这个官方的解释呢,有点绕, 简单一句话总结就是将处理不同逻辑的对象啊,连接成一个列表结构,每个对象呢都要保存他下一个节点的引用,这就是责任链。举个例子啊, 我们在平时处理工作的时候呢,往往需要各部门的一个协调合作才能完成某一个任务,因为每个部门呢都有各自的职责,所以呢,很多时候做事情完成一半,就需要去转交给下一个部门,甚至还要盖章, 直到所有的部门都审批通过之后,这件事情才算完成,这就相当于是将皮球层层往上去踢。还有一个就是记得咱们小时候呢,看过一个电视剧, 八零后应该都看过有位太极高手,然后闯七层宝塔,每一层呢都住了一位武林高手,层层往上过五关斩六将,打赢了才能往上一层,打输了呢,就得踢回去,到 最后登顶,当时啊,看到我们是热血沸腾。其实这也是责任内模式的一个实现场景,不过我已经忘记电视剧叫什么名字了,小伙伴呢,可以在评论区告诉我一下。所以呢,责任内模式啊,又被称为踢皮球模式,那责任内模式的实现原理又是怎样的呢? 责任链模式又分为单向责任链和双线责任链,单线责任链比较简单,也容易理解,双线责任链呢,相当于是一个执行闭环,比较复杂。我们先来分析单线责任链,它的结构呢,是这样设计的, 首先呢,设计一个单向列表的上下文 contax, 然后去保存列表的头和尾。 contox 的通用代码结构呢,是这样写的。然后呢,在上下文去加入汉德,也就是说去处理业务逻辑的节点内,那每一个汉德呢,都保存了下 一个执行结点,引用,形成一个完整的执行链路。汉德兰通用代码结构是这样的,我们在接着一的标准中,比如说 filter 过滤器以及 supreme 的 intercept 拦截器,都是采用的这种单向折链表的设计。 那双线责任链又是如何设计的呢?它和单线责任链啊,它的结构基本一致,我们来看,它只是在 honda 上增加了一个对上一个节点的引用, 这样的话呢,折链它就形成了一个直线臂环,就好比是环线地铁来看,它的通用代码结构是这样的,那么在内体中呢,这个拍不烂管道,它就采用这么一个双向折链的设计。 责任链模式呢,一般还会去结合建造者模式来使用来实现链式编程。那责任链这样设计又有什么优点和缺点呢? 我先给大家总结一下他的优点。第一个呢,责任链实现了将请求和处理完美的结偶。第二个呢,请求处理者只需要关心自己的职责范围内的请求进行处理就可以了,那对于不是自己职责范围内的请求呢?可以直接转发到下一个解决对象。 第三个呢,他具备劣势传递处理请求的功能,请求方式者不需要知道链路结构,只需要去等待请求结果就可以了。第四个,链路结构比较灵活,他可以通过改变链路结构去动态的新增或者删除责任。 那这样设计的话会有哪些缺点呢?我也给大家总结一下。第一个,如果责任链路太长,或者是处理请求时间过长的话,他会影响程序的整个的执行性能。第二个,如果节点对象存在循环引用,有可能会造成使用 环,从而导致程序崩溃。都已经看到这里了,小伙伴们,你们还觉得责任内模式的原理难吗? 我是被编程耽误的文艺汤,如果大家还有其他不懂的面试题,或者需要视频配套的文字资料,可以关注我的主页加微,如果我的面试解析对你有帮助,请你动动手指,一键三连分享给更多的人,关注我,面试不再难!



猜你喜欢
最新视频
- 6.4万彭善假