pro painter整合包怎么用

粉丝2180获赞1.3万
相关视频
 07:21查看AI文稿AI文稿
07:21查看AI文稿AI文稿今天为大家介绍一下整合包的使用方法。我们下载下来的一点三版本的整合包是一个一键整合包,无需修改,双击大键。我们先解压出来, 解压好了,先来带大家看一看整合包的内容。大家打开整合包不要着急,先来看一下我们准备的 com view 整合包使用说明书文档。 注意整合包中的内容除了环境 python 三一零外,不要随意改动。文档最开始就提到了整合包使用的推荐设备, 这里需要大家自查自己电脑的驱动是否为最新。注意一点三版本整合包目前仅适用于 win 系统加三十系及以上的 n 卡,里面有我们在最初制作后的一些测试使用设备, 最终选择了 python 三百一十加 patrick 加 veran 二点幺幺点零加 ceo 一 百二十八使用到的模型也已经给大家放进网盘中了,我们对照着文件夹中的内容来看, 下载下来之后,直接把 models 文件夹拖进 com view 文件夹中,覆盖原有的 models。 我 们的 models 文件夹放在模型文件夹中,还没下载完,所以不能现在拖进来,等下下载完,直接拖进 com view 文件夹中,覆盖原有内容。 首次运行之前需要保证自己的电脑驱动为最新, 否则无法支持 peter q 二八会在后面启动时报错版本不匹配。我们可以按住 win 加 r, 输入 cmd, 打开运行对话框,输入 evadesme 回车, 这里可以看到 qd 为十二点九,大于等于我们的十二点八。固定版本无需更新驱动, 同样如果驱动已经是最新的了,接下来双击 com view 一 键启动,耐心等待,等到安装完所有环境后,会自动启动 com view。 我 们只需要在浏览器中打开对应网址 安装 peterk, 这里使用的是百度源安装其他一来固定使用清华源。如果 peterk 下载缓慢,可以在 pipos 中自行修改镜像源,只需要复制其他的镜像源,全选覆盖这个 txt 文档,然后保存下来。 整合包中已经内置了两个生图和视频的工作流。在 comefu 中的 user 下的 default 下的 workflow。 存件夹中可以找到 整合包的目录,结构及相关说明也已经在文档中写了出来。 comefu 是 我们整合包的核心主体 portable git, 大家可以不用管这个,这是一个便携版 git pisongs 三幺零是一个我们双击 com vivo 一 键启动后才会出现的一个独立环境文件夹。刚下载好的整合包中是没有的 twoslow 配置文件中放着配套 twoslow 专用配置文件,打开可以看到我们提前准备好的配置文件,按照之前的教程导入 twoslow 中即可。 这个压缩包是一个 python 三点一零嵌入版原始安装包,不用手动解压。 这里准备了一些备用镜像源,可以做替换用。整合包的内容差不多讲完了,下面的是我们 toonfall 官网网址和教程链接。 等到所有模型从网盘中下载好之后,我们打开模型文件夹,可以打开 models 文件夹,里面是很多存放不同模型的文件夹, 方便展示。这里打开两个文件管理器, 直接把模型文件夹中的 models 拖动到 comfy 中, 勾选替换目标中的文件。 现在打开 com view, 打开 models, 打开 chess blocks 文件夹,下面可以看到有下载的模型, 现在可以双击 com view 一 键启动了。这里可以看到在解压过程中创建了一个 python 三幺零的文件夹和一个该 pip 派的文件, 接下来耐心等待它的安装。 注意租用云电脑的用户,在安装过程中,如果启动窗口较长时间没有反应,可以手动敲击回车, 等到看到输出提示环境安装成功,说明已经搭建好环境了,目前正在启动 comfy, 出现 http 冒号斜杠斜杠一二七点零点零点一,冒号八一八八网址后,说明启动成功。我们直接复制下来,到浏览器中打开, 直接粘贴进去访问,稍等一会, 加载完可以看到我们的 com view 已经启动成功。左侧栏中有资产和工作流, 我们打开工作流,可以看到提前准备好的工作流可以单机打开, 有时候会加载不出来,但不影响使用。介意的话可以打开之前文档中提到的路径,到存放工作流的文件夹中,把工作流拖动进来。 已经启动了 comfy 后,我们打开 toon flow 来测试一下任务是否可以跑进 comfy 中。 这里是刚刚直击跑的视频工作流,但是由于生成时长较长,这里拿生图做演示, 生成成功记得评论区领取链接。
47Toonflow 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿避免问题不得不啰嗦第十三期更适合新手使用的 coffee ui 秋叶整合包全版本一、整合包版本我不生产水,我只是大自然搬运工。整合包有 v 一 点六、 v 一 点七、 v 二和 v 三版本,真正解压即用。注意, 一、文件解压前先测试一下文件完整性,避免文件包损坏导致启动不了。二、整合包路径不要出现空格,中文和特殊字体 comui 对 中文兼容性较差,路径尽量简单,避免启动报错。二、版本选择不同的整合包版本,内置的 python 版本不同, 有三点一一、三点一二和三点一三,根据自己需要安装对应版本即可。注意, python 高版本不兼容老旧节点,会导致报错,所以不要安装太高的版本。推荐使用 v 二版本,可以避免很多节点兼容性问题。 如果你工作流中包含老旧节点,使用低版本的就可以。或者使用多个版本整合包,它们环境都是独立的,互不影响。三、内核版本以上整合包版本都可以把内核升级到和官方同步的最新版, 只需要在启动器左侧版本管理下的内核板块找到需要的版本,点击右边切换即可。注意,升级内核后大概率要报错, 需要把扩展下面的节点也同步更新。另外还可能要升级显卡驱动版本和重新安装 py torch 加酷狗等,所以升级前需要做好重新折腾的准备。有其他问题参考往期视频,关注我,教你解决更多 comfy y 问题加教程模型工作流分享!
99AI云端货架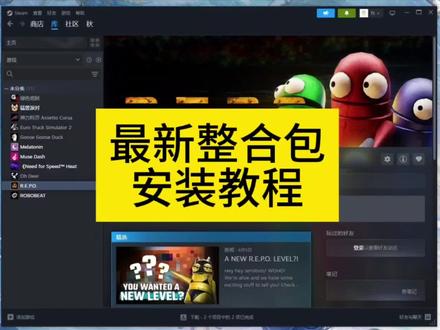 01:17查看AI文稿AI文稿
01:17查看AI文稿AI文稿先打开我们的 i u p o, 选择右键管理,浏览本地文件,全选删除, 再打开我们的 i u p o, 右键选择属性已安装文件,验证游戏文件的完整性,等它更新。 ok, 更新完之后打开我们的雷神,选择一键暗化, 到这一步之后打开我们的整合包,这个整合包的话,我们单机右键选择解压,解压到当前的位置, 这里出现的整合包的文件夹,我们双击点进去,我们全选上给它复制,再拿到我们的 i v p 哦。呃,选择浏览本地文件,再打开我们的第一个文件夹,然后最后一个文件夹给它粘贴到这里, 这里直接选择替换整合包就安装完毕了。整合包的话是需要你们的组队成员一起安装的,不然的话你们组队成员会卡在游戏关卡进不去的。
11🌈贤者 13:323百声AI
13:323百声AI 14:16查看AI文稿AI文稿
14:16查看AI文稿AI文稿是一个不限次数生成图片和视频的 ai 工具,它就是地表最强开源 ai 生产力工具 comfui v 八破线版,或许你早就听说过它,但这个大版本的更新完美解决了 comfui 安装困难和工作流报错问题,这种电影级的 ai 视频完全不在话下。和那些花钱还要排队的网站不同, 纯中文界面,完全不用懂英文,不用联网,更不用魔法上网,所有运行都在本地或限制无审查,最低支持一千零六十显卡。更惊喜的是,这次整合包直接内置了三百三十七个顶级工作流,全是大佬们认可的实用功能,使用也是超级简单的,三步就能搞定, 一,拿到整合包,二,解压缩,三,双击打开,还没有试试的老规矩,验个牌。接下来开始教 哈喽 b 站的小伙伴们大家好,我是你们的大宇老师,那么本堂课呢,大宇老师就来教一下大家怎么样做这种带货的跳舞视频呢?我相信很多小伙伴最近在抖音上也看过不少,甚至啊,有小伙伴确实来私信大宇老师,问大宇老师怎么做,那么 这节课呢,大宇老师就出一期这种工作流的教程。那么这一个工作流呢,我们主要用到的是万向二点二艾米的啊一个工作流,但是大宇老师这个工作流呢,是基于 kj 的 模型进行搭建的, 因为啊, k j 的 模型确实好用,并且 f p 八的是能达到普通的那种纳米的 b f 幺六的一个效果,我感觉啊,当然这一个感觉的话大家就自己去试,那么这个效果呢,大家也看到了,在前面大家也是已经放给大家看了,那么我们先看一下这个模型的一个加载,以及我们工作流的一个搭建, 那么本堂课会用到的这一套工作流呢以及模型我也是放在了这个评论区了,有需要的小伙伴们呢就直接去领取好吧,但是不要忘记大老师在评论区扣六六六,增加一下人气。 好,那么我们来看一下我们的工作流,那么工作流呢,大老师也主要分成了两大部分啊,旁边这一个呢是 red image turbo 的 工作流, 那么这里呢就是我们视频生成的一个工作流,那么 red image turbo 工作流呢,主要就是拿来出我们的啊一个人像的,因为 red image turbo 工作流呢,它对于人像的一个制作还是非常非常厉害的,那么我们可以看一下, 那么这张图片呢,就是由我们 red image turbo 做的一个人像了,那么这样子看起来好像还是存在一定的 ai 感的,对吧?但是我们后期需要加一点点那种柔光特效,它就会好很多了。 那么我们先看一下,对于这种啊画面的构图,我们要先怎么样去生成呢?第一步就是我们在进行视频的寻找的时候,就是说你去抖音上找到一段跳舞视频,那么我们生成这个人像的时候呢, 最好就跟这一段跳舞视频的构图基本上要保持一致,就是说人物的一个构图,可以看到我们视频里面的这个啊,画面刚刚好截到这个小腿的部分,对吧?那么我在 red 一 米七特保持生成图像的时候呢,我就让它截到小腿的这一个部分,因为我们这个万向二点二纳米的这个模型呢, 去生成视频的时候,它其实是一个骨骼墙绑定的一个过程,那么因为骨骼墙绑定呢,所以我们最好就制作这个人物,在构图上不要有太大的一个偏差,不要说你这里上传一个全身图,然后你这个 one n 米的啊,去参考的这个视频呢,又是这种半身图,那么他就很可能会崩掉, 所以这个大家是需要注意的。那么对于这种图像的一个构图,我们该怎么样去弄呢?其实非常的简单呢,我们可以直接来到豆包,比如说这里,我去直接截取了啊我们视频的 一帧啊,然后对这一帧呢,我让我让他参考这个画面构图,然后描述一段这个新的女孩子的人物提示词,然后他就会对我这个提示词进行描述,然后我们可以看到他描述的时候呢,他会分成啊这个准确的提示词以及中景构图的提示词,我们可以去节选一下,然后我们删除一下里面不需要的一些内容即可, 然后再把它给到我们在的 image gt turbo 的 啊这个模型以及他的工作流,然后把图片生成出来,我们可以看一下在的 image gt turbo 生成的原图是怎么样, 那么这里呢,大家都可以看到根据刚刚反推出来的提示词啊,这个 red image turbo 生成的这个图像其实还是非常非常真实的,对吧?不仅是人物的质感上,还有整个画面的这种真实感都是拉满的,但是由于是参考嘛,所以啊这个服装上可能跟原视频呢就有点相似,但是无所谓,反正后面我们要进行这种换装, 肯定要需要用到 banana 那 些模型了,那么这样子呢,得到我们的这个人物之后,我们第二步就是呃,去寻找我们想要的一个衣服的一个图片, 那么这个衣服的图片呢,如果你自己有的话那最好,如果没有的话,你只想尝试呢,那么你就上小母猪上去找一些,然后把它放上去。那么换装的提示词呢,也很简单,就是让图一的人物,然后参考图二的这个服装,然后穿到图一的人物身上,其他的场景保持不变,构图保持不变就可以了。 那么这里我就不给大家演示了啊,因为你用吉梦也可以没有任何的一个问题,只不过吉梦的质感可能会差一点。我建议大家是去找一些 nana 古娜娜使用的方式啊,那么这里大家老师就不去细讲。那我们在经过换装之后呢啊,他就会得到这种几套穿在身上的服装,但动作不变啊,动作无所谓啊,大家动作这样子就行, 然后我们就正式的可以用这个工作流对它进行舞蹈的一个迁移了。那么这个工作流我们先讲一下,首先是模型加载阶段,我这里用到的是万象二点二纳米十四 b f p 八的 k j 的 一个模型,然后呢前面我是加上了一个 come by 的 节点, 那么这个节点呢,主要是拿来加速我们的视频的,因为确实万象二点二纳米这个模型有点大,你要去直接拿来,现在视频的话速度会有点慢, 所以我就用了这一个去加速了一下我们的一个视频,然后呢另外要讲到的是外向二点二纳米的这个模型呢,它对于显存的要求蛮高的,所以大家尽量去用云服务器。 然后第二个我们的罗拉模型,这里面呢我是加载了几个啊?第一个是对于光线的一个控制,第二个呢就是我们的一个万向二点一 t 二 v 的 x 二 v 的 一个模型,那么这个模型呢,可以让我们在后面生成视频的时候,只需要啊用到四步就可以生成, 然后我也加入一个光圈 x 的 模型,那么这个模型呢,可以增加我们视频的一个动感。然后最后这一个呢,就是我们 放 i m p 的, 也就是我们的一个镜头控制镜头模仿的一个 logo 啊,这个可有可无吧,你也可以把它去掉,无所谓。然后其他的我觉得这些 logo 你 不加也可以,它最重要的就是这一个 p l v 的 like 叉二 v 的 这个模型呢,其他的我也觉得可以省略掉,你们就省略掉也行。然后这里面呢我们要注意,大卫老师加了一个 bros work, 我这里的 proswok 是 开到了最满是四十的一个 proswok, 所以 我生成视频的时候会非常非常的慢,因为这个四十的 proswok 就是 说它会有一大部分的啊,这一个数据的一个处理,或者说一个渲染的一个过程,它会交给 cpu 去进行处理。 但是啊,戴老师这个只是为了尝试一下,如果全部加到四十部所用到的时间会有多少,那么戴老师深刻体验了,确实是慢的 有点离谱。那么如果说你是一个显卡比较好的,比如说我这里用到云服务器五零九零也可以显卡,那么即使我这里把它调成零,或者说稍微提高一点,提到十也是可以的,那么这样子它的生成视频的速度就会快上很多很多,所以这里我们是需要注意的啊,那么 pro 最大的参数呢?好像是四十五吧,我们看一下,我看一下啊, 最大是多少啊?最大是四十八啊,那么刚刚是设置到了四十,那么其实大小设置到十也是可以的,没有任何的一个问题。那么如果说你是五零九零的显卡,你设置到十的话,是完全不会爆显存了,大家是需要自己知道的,所以说你把它设置到零可能也不会爆显存。然后我们看一下图像的处理部分,那么图像的处理部分呢,是比较重要的一点, 我们将视频先上传过来的时候呢,我们也要将这个呃视频进行一定的处理哦,这个视频处理的时候,是在我们加载视频的这里,先把它限制到了七二零乘以幺二八零的一个尺寸,那么这里我们需要注意,由于需要进行服装的一个展示,所以尽量把这个分辨率提高到七二零以上啊,这个是比较好的, 千万不要用四八零乘以啊,八三二就四八零 p 了,那么它的清晰度肯定是不够的啊,这一定要注意。然后这里呢我们看一下图像,图像呢,我们也是要给它限制在七二零乘以幺二八零啊,要跟我们的视频保持一致。那么这里呢可以看到大爷老师在这里准备了一个已知 z, 因为仅 b 二的节点呢,主要是拿来限制住我们图像的一个宽高, 然后这里呢,它的图像去进行处理的时候,我们需要用到一个 one video collaboration 的 一个节点去对我们这张参考图像进行处理,因为我们的 one enemy 是 用这张图像作为一个参考图进行跳舞的嘛,对吧?所以我们需要对图像进行编码,这个是可以理解的。 然后在我们的这个呃图像把它这缩放完之后呢,它应该是传到了下面的这一个核心节里面 one video enemy 的 这个节点啊,但是我们可以看到这里它会有一个预处理的一个节点,这个预处理呢,其实主要是对视频以及脸部的一个预处理哦, 那么这里呢,我们呃可以看一下对于脸部的易处理,其实这个跟我们后面会用到的 one enemy video 那 个节点里面的一个点有点关系,然后另外呢就是对我们姿态图的一个处理,那么这里呢,需要用到了 dw post 的 呃,这一个节点, 那么 dw 我 们都知道它的参考是基于脸部、手部以及身体的三重参考,那么这里我们可以去啊,就是设置一下我们这个 dw 的 节点,这里可以看到吧,有参考手部,参考身体,参考脸部,那么脸部呢,我这里是打开了,当然你也可以把它关闭掉啊,如果你不用的话,那么大宇老师在这工作里面呢,是 主要把他的脸部给他截出来,但是用不用呢?就是看我自己的啊,一个心情。然后这里呢,我们可以看到他的一个姿态参考,其实也是蛮准确的啊,这个 d w 了,然后我们得到了这一个姿态的视频之后呢,我们可以看到是从这连下来的, 然后他会直接把这条线给到我们 one v 九 enemy 的 这一个节点,那么这个节点可以看一下,他第一个要上传参考图片,也就是我们的一个 pose 图片,也就是我们的姿态视频, 那么这里是有是以图片的形式去进行读取的,但是啊,我们要注意它这里出来的其实也是图片,我们合并为视频,其实只是将我们的图片去合并为我们整一段视频嘛,对吧?然后直接就把这个线拉下来就可以了,然后点到它这里的 pos 的 image 的 这一个点, 这里有个 face image, face image 呢,其实就是在这个点可以拉出来一条线,也就是我们这里有一个预览的这个点,如果你想让它最后生成的跳舞视频呢?这个脸部的表情跟我们这个原声视频的啊里面这里比较相似的话,我们就就把这个 face image 的 这个参考给它。 这里我们需要知道,如果你给到 face image 了,那么人物的脸部会发生较大的一个改变,但是这里其实我们可以注意到一点是我们图像的这一个人物脸部跟我们最后生成出来的这一个人物脸部其实是有点差异的啊,即使没有这个 pose image, 它也会被影响到, 但是如果说你连的这一个 pos 一 米九的话,它的影响会更加大一点,所以这个就取决于自己啊。然后最后呢就是我们 k 长器,然后 k 长器呢,这里最需要注意的就是这里的步数了,如果你用的 like 叉二 b 的 那个模型的话,步数你可以设置为四步,也可以设置为六步。 那么这里呢?大叶老师是给到了六部的一个参数啊,因为六部的话生成的质量会稍微来说比较高一点点。然后这里有一个啊 clear 的 文本编码器,这个 clear 的 文本编码器呢,输入的题词很简单了,你只需要输入一个女孩正在跳舞即可,那么其他的呢?就没什么了。最后就是 v a e 解码,然后输出我们这一个视频, 然后视频输出的时候,我们需要注意,我们不要将一整段视频给到他进行姿态的一个参考,因为他实在太大了。可以看一下戴老师是通过跳过前面帧的方式去把他一段一段视频进行生成出来, 比如说,哎,我不跳过的时候,我就设置为零,我们可以看一下他的总帧数有四百一十九帧,那么四百一十九帧呢,其实是非常非常大的一个参数了,你直接让 one enemy 的 这个工作流程,那么你很可能就会爆显存。那么我们怎么办呢? 我们去限制一下,比如说我第一个图片,就比如说我第一个是穿的这样子衣服的图片,我就把它限制在一百一十针, 然后在这一百一十针这里,他跳完舞之后,我就跳过前面的一百一十针,然后他就会往第一百一十针往后面继续延续,也就是说这里的一百一十针呢,其实他是从一百一十一针开始,那么这样子呢,他就会去一直接住这一个不同的衣服进行跳舞, 在这里为了让他有更好的一个衔接呢,我们可以把这里跳过,这里帧数,这里我们设置为九十帧,那么也就是说原先我生成了一百一十帧的一个视频,但是这里我只让你跳过九十帧,对吧?那么他就会有二十帧的一个重复部分,那么我们只需要把二十帧的一个重复部分进行一定的裁切,那么我们就可以让他很顺畅的 我们把这个视频给他接上,那么以此类推,那么下一个呢,就是跳过一百一加九十,那么也就是我们的二百针,但是这里为了让他有衔接部分,就跳过一百八十针,那么以此类推,那么他跳过多少针的时候呢?我们就相对应的换上这另外的一个服装即可了, 那么这个就是我们整套工作流的一个拆解,其实非常的简单,但是我们需要注意,我们生产出来的视频其实蛮牛的,可以看到吧,对吧?那么如何达到大爱老师前面在 放置那一个视频的自然感呢?戴老师教大家去调试一下。那么比如说这里呢,我们可以看到其实他的 ai 感重的原因主要有两个,第一个是锐化非常的高,对吧?第二个是过分的一个清晰,那么在我们短视频的一个时代,不需要那么清晰的一个画质, 所以我们只需要解决这两个问题,第一个降低视频画质,第二个就是啊让他的锐化不要这么高,所以我们直接点击特效,那么点击特效之后,我们去搜索柔光啊, 然后柔光呢?其实我们要知道柔光它就是一种降低画质的一个手段,我们直接选择最普通的那一个柔光给他,可以看到吧?画面马上就不一样了,但这种柔光效果它太强了,我们需要剪一下,比如说把它剪到三十五左右,我们就可以看到,哎, 这整个画面就显得啊非常非常的好了,对吧?然后又不会太过于锐化那种效果,然后为了让它更加的真实呢,我们再对这个画面进行一下单独的一个调整,那么我们点击一下, 然后调整这里呢?像刚刚一样,我们主要的原因还是因为锐化高,对吧?那第二个是对比度比较高,然后我们把对比度降低一点, 降到七左右啊,这个是我试过一个参数,但是我们可以看到柔光的效果还是太强了,那么因为柔光效果太强了,所以我们压一下高光哎就可以了,然后就得到了我们的一个比较好看的一个视频,我们看一下这一个脸部啊,对吧? 现在这个脸部就不会有那种很强的 ai 的 油感了,并且头发也柔顺了不少,所以这个就是我们最终的一个调整的一个方式。 那么大家可以把生成的这几段视频呢全部导进来,然后你再把原视频的音乐也导进来,然后进行那一个动作的对照及卡点,就把整段视频给做出来了。那么本堂课内容呢?有那么多,如果你觉得大家讲的不错的话,不要忘记。接下来喽,我们下期再见,拜拜。
103comfyui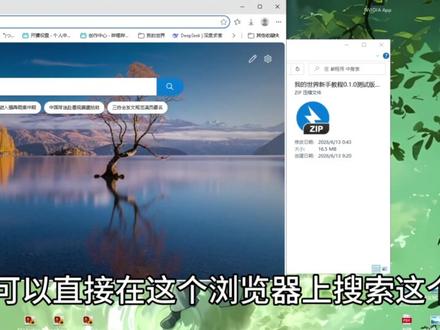 02:19查看AI文稿AI文稿
02:19查看AI文稿AI文稿大家好,如你所见,这是一个整合包发布视频,呃,我使用了一天时间把这个整合包给制作出来了,然后这个整合包呢是一个 呃算是我的世界的新手教程吧,然后它是完全基于原版,然后无模板无添加, 我也不知道这算不算算得上整合包啊,但是有用,然后我也就把它给做出来了。然后接下来教大家怎么下载和安装使用。首先呢是下载,大家呢可以直接在这个浏览器上搜索这个蓝奏云, 然后搜索完奏匀之后呢,我们找到它的官网点进去,然后我们在它的这个网址后面加一个斜杠,然后输入这个 mc x s j c 这就是呃, mc 新手教程啊,进去这里有一个密码,这个密码呢是我的世界啊,就 w d s j 进去就可以直接下载了。 那这边我们下载完成之后呢,教大家怎么使用,我们把它呢放到一个我们平时放游戏的盘,然后在这里面新建一个文件夹,然后呢我们就把它给智能解压一下, 解压之后我们可以看到两边里面有两个文件,一个呢是这个 pcl 启动器,把这个 pcl 启动器打开,然后把我们的新手教程这个包给拖进去,然后它就开始自动下载了, 然后这边下载完成后就可以启动游玩了, 然后现在是测试版,大家有问题可以在评论区指出,然后有,然后因为我现在制作的这个东西,呃它没有什么技术含量,然后大家如果有想 呃加入,比如说修改一些文本,或者添加一些文本也是可以的,可以私信我来加入我的这个制作。好的,谢谢大家。
7冰澜瀚海 03:19查看AI文稿AI文稿
03:19查看AI文稿AI文稿明明是在 comfy 官网下载的官方整合包,打开之后一用,为什么还是有各种报错呢?不是节点缺失,就是模型找不到,难道官方的也不靠谱吗?我相信这应该是你们开始学习 comfy 遇到的第一个困惑吧。 今天关于 comfy 的 本地安装部署一次性给大家说清楚,记得先点好关注收藏,需要解压即用满血版整合包的我已经给大家准备好了,先给大家解决视频开头的疑问, 为什么官方的整合包你用上了还是会有报错呢?首先是节点缺失,官方整合包中只有一些空 p y 官方自己构建的基础节点,除了这些节点以外,还有很多常用的第三方开发者构建的扩展节点,这些节点官方整合包中都是不会给你提前安装的, 所以当你加载进框架的工作流中,包含整合包里还没有安装的第三方节点时,就会出现节点缺失爆红的问题。 其次就是模型缺失, comfai 中的工作流运行时,一般都需要调用本地特定文件夹中的相关模型才能正常发挥作用,而官方整合包中也不会提前给你下载这些模型,所以当你没有下载模型直接运行工作流就会出现模型缺失的问题。 所以并不是官方整合包有问题,是你没有把零件给它安装好。但对于刚开始使用 comfai 的 新手来说,想要自己顺畅的安装节点和下载模型是有一定难度的, 因为你不仅需要提前安装一些环境文件,保证 ctrl 键正常打开运行,还需要配置好魔法网络用于下载模型和节点, 最后还要知道下载好的模型该放进哪个正确的根目录文件夹。但这些其实都很好解决,那就是直接使用节点和模型都已经提前安装好的满血版整合包, 这个是我一直都有在给大家分享的,而且还是长期持续更新的,这样你就可以省下大力气快速上手体验 kufi 的 使用了。除了以上所说的这些,还有一个问题是你无法回避的,那就是电脑配置问题。 想要在本地电脑流畅使用 kufi, 必须满足一定的电脑配置需求。首先就是显卡的显存一定要足够大,才能支持模型正常运行, 一般深图模型需要至少十二 g 显存,视频模型一般至少需要十六 g 显存。这里比较推荐新手入门的高性价比显卡,就是五零六零太十六 g 这张显卡了,什么牌子的一般都影响不大,主要是显存大,而且相对便宜。 除了显存以外,还有内存,做图建议至少需要三十二 g 内存,做视频建议至少六十四 g 内存。最后就是此款空间,本地模型一般体量都比较大,建议至少留有五百 g 的 此款空间用于存放模型。 以上所有这些配置都是上不封顶的,配置越高,使用体验越好,我相信大多数人的电脑配置可能都达不到这个要求, 如果你的电脑性能也不太够,那我真的非常不建议你在使用 ctrl 的 初期就花大价钱去购置高性能的电脑。上面所说的这些硬件配置,因为 ai 的 爆火,价格都一度水涨船高,但我们其实还有更加经济实惠的解决方式,那就是云端部署使用 ctrl y, 简单来说就是租用一台高性能的云电脑来部署使用软件,这个就比自己去买电脑要便宜多的多了。云端部署的方式我们会在下一期给大家讲。好了,这就是我们今天分享的所有内容了,记得点赞、关注、收藏,我们下期再见!
719南天AIGC 07:49查看AI文稿AI文稿
07:49查看AI文稿AI文稿ai 创作圈的性价比天花板,康菲 u i 九点五新版本重磅上线,这次更新聚焦高清创作需求,将视频与图像生成质量推向新高度, 更坚持永久免费开源的核心优势,让普通创作者无需花费一分钱就能轻松产出媲美专业团队的高清作品,彻底打破优质创作必付费的固有认知。生成的图像细节丰富立体色彩还原精准, 动态视频流畅丝滑,无锯齿模糊。无论是商业级海报设计、短视频创作,还是创意特效制作,都能呈现出影院级的高清质感,完全不输付费工具的输出效果。那么该如何使用呢?首先将我们的 v 九点五整合包下载到电脑上, 下载好之后,用鼠标右键点击这个压缩包,在弹出的菜单里选择解压软件进行解压。这里有一个非常重要的点,请一定要将文件解压到一个没有中文的目录下,也就是你的硬盘路径里不能出现中文字母,以免后续运行出现报错, 静静等待解压完成就好。解压完成后,咱们就可以准备打开了,在解压出的主目录里找到并双击那个粉色头像的会式启动器图标, 双击打开后,电脑会首先为你弹出一个图形化的秋叶启动器控制台。在这个界面里,我强烈建议大家先点开左侧的高级设置看一眼,确保系统已经准确识别,并且选中英伟达独立显卡。 确认无误后,点击右下角的一键启动按钮,点击之后,后台会弹出一个黑色的代码窗口,开始狂飙数据。 这期间,系统正在为你自动唤醒底层环境,并加载内置的五十多个精选插件。大家只需要耐心等待几秒到几十秒,他就会自动唤醒你的电脑默认浏览器,直接把你带入康复 ui 节点操作区。 当浏览器成功弹出带有网格和各种连线的深色界面时,恭喜大家,你已经正式推开了 ai 创作的大门。咱们这个 v 九点五整合包最大的魅力就在于把复杂留给底层,把简单教给你, 你完全不需要从零开始去学习怎么连线,直接在界面里点击加载预设好的最基础纹身图。工作流,咱们来简单跑个测试看看效果。 你只需要找到一个在上方的文本框,输入你想描绘的画面,比如简单敲上一句一个女孩毛衣白色背景,然后在下方文本框里填上如模糊、低质量、畸形之类的排雷词汇。 接着点击界面上的运行按钮,这时候你会看到屏幕上的节点开始依次亮起绿色的光效。得益于咱们非九点五底层强大的环境优化,仅仅几秒钟的功夫,一张光影细腻、质感拉满的美女照片就会在最终的图像节点里生成出来, 整个过程丝滑流畅,完全不需要你懂任何深奥的代码原理。当然,这种基础的纹身图仅仅是个热身, 咱们这个 v 九点五整合包真正的核心资产是里面为大家精心预制的两百多个大师级精品工作流。这 些工作流的特点可以用四个字来概括,那就是开箱即用。以前大家在网上找工作流,最怕的就是导入进去后满屏飘红,告诉你缺这个节点,少那个插件,折腾半天都跑不通。而在咱们的整合包里,几十个核心插件早就为你配置的明明白白。 不管你是想做高清的图声图,局部重绘,还是想玩点高级的 ai 换脸,数字人对口型,甚至是去挑战目前最前沿的视频生成模型,这里面都有现成的模板供你直接调用,那么你赶紧去自己动手试试吧。 欢迎来到我们的 comfy 视频生成系列课程。哈喽,大家好,那么这一节课呢,我们来学习我们六种视频生成方式之中的第四种,也就是动作迁移工作流。那么我们只需要上传一张图片, 然后再上传一个视频就可以了。那么首先我们来看一下我们刚才导入, ok, 然后再来看一下我们生成的结果, 整体的一个动作,包括人物的一致性都保持的还是很不错的, 同时呢,他会将我们原来的视频当中的音频自动与我们的视频进行一个结合,然后直接一键生成。那么像这一种我们图片可以模仿视频当中的人物动作,然后进行一个视频输出的工作流,是如何实现的呢? 我们来看一下怎么使用。那么首先呢,我们依旧要明白,第一步就是确认我们的模型使用, 这对于我们生成任何视频或者图片都直观的重要。像这里面我们依旧选择 g g u f 的 模型, 以及添加一个对应的加速 laura。 由于这里面我们使用的是一个动作迁移,所以我们还需要加一个 animate 的 加速流来进一步对这个工作流进行一个加速,我们加载好我们的这些模型之后呢 就可以直接输入到我们的彩样器当中,这个时候就要注意到我们彩样器还依旧缺少了正负相条件,那么正负相条件其实指的就是我们视频当中的人物运动部分, 这个时候我们需要加载我们的一个视频进来,那么这个视频呢会拆分成很多张的图像, 然后传入到我们的姿态与处理器这里面,然后通过这个处理器呢分别对我们的一个姿势以及面部来进行一个识别,最后将生成的这些图像呢输入到我们的动画短视频当中, 我们需要提供面部视频和姿态视频,那么这些都是通过我们的育处理器来得到的结果,同时这里面我们还需要输入我们的一个参考图像,也就是最后我们视频生成中的主体人物图像, 通过我们的视觉编码器呢进行一个编码,然后一同输入到我们的一个转视频节点当中, 然后这样子就提供了他的一个副像条件。同时由于我们的参考图像可能尺寸比较大, 所以这里面呢我们直接对整体的一个图像呢设置一下深层的视频宽高,那么像这里面这张图像呢是一个竖向的比例,所以我们最后设成一个宽四八零,然后长度为八三二的一个图像尺寸, 然后在这个地方我们进行一个设置,最后呢我们的彩样器上面的条件我们就都连接好, 然后再直接输入到我们的解码器当中,进行一个生成即可,最后呢就能得到这样的结果,这里面我们想要这个视频呢,更流畅一点,也可以添加一个补帧节点,又或者想让视频变得更清楚一点,可以添加一个高清放大节点。 那么这两个节点呢,在我上一节课讲设为真生成的时候都已经提过了,那么整体的工作流所使用到的文件我都已经为大家准备好, 比如说我们的插件,包括我们的 g g f, 我 们的视频转模型,包括我们的视频 c t r l, 再比如说我们的所需要的模型以及工作流。那么大家在拿到这样的文件链接之后呢, 就放到对应的文件夹目录即可,那么这个视频就到这里了,感谢大家的观看,如果对你有帮助的话,不妨点赞加关注,支持一下,我们下个视频再见。
1029AI教程-Comfyui 01:52查看AI文稿AI文稿
01:52查看AI文稿AI文稿这是一个不限次数生成图片和视频的 ai 工具,这就是地表最强 ai 生产力工具 comviv 九点五破线版,这个大版本的更新完美攻克软件安装难,工作流报错痛点, 全程开源,纯免费,无积分,无任何隐形消费,全系原声中文界面,内置海量工作流和主流模型整合包,解压即用无脑安装,最低支持一零六零显卡一键搞定电影级 ai 视频 高清声图,三维建模, ai 音乐制作,想试试的七七七。接下来我们正式开始教学,首先呢需要解压我给大家提供的空辅 u 安装包, 现在这个文件夹呢就已经解好了,为了以防报错,注意这个文件夹不要有任何的中文路径,再点击进来,接着我们再点击进来选择 print 的 文件夹, 在这里呢,我给大家提供了一个模型,把这个模型呢粘贴进去,我在这里放大模型的目的呢就是为了验证这个软件是否能够正常运行, 模型安装好之后呢,我们再退出来。接着我们再来到倒数第二个文件,这里要注意的是官方给我们提供的安装包,他跟我们传统所使用的秋叶启动器,他的界面呢是不太一样, 缺启动器呢,他是有一个启动界面,而官方提供的安装包,他的启动程序呢就是倒数第二个文件,我们选择第二个文件进行双击, 此时呢他就弹出了一个界面出来,启动时长呢大概是在两分钟的样子,我们需要耐心等待。好了,现在空辅 u i 本地部署呢就已经安装好了,接着我们来测试一下这工作流是否能够运行,选择我们刚刚安装好的大模型,我们先来测试一下他的纹身图功能, 点击运行来看一下效果。好了,现在这样图像呢就已经生成了,它能够正常使用,到了这一步代表软件安装成功。
 27:03查看AI文稿AI文稿
27:03查看AI文稿AI文稿生成图片免费,生成视频同样免费,这就是二零二六最强的 ai 生产力工具 comui 九点五中文破线版,和那些烧积分要排队买会员的网站不同,这个九点五版本不用联网, 不用魔法上网,所有运行均在本地支持,破限制,无审查,想生成什么就生成什么,而且原生中文自带三百八十八款顶级工作流, 你只需要拿到软件包,双击打开,输入提示词,点击运行就可以生成这样的 ai 视频。还没试试的直接抄作业。欢迎来到我的咖啡 u i 零基础从入门到精通系列的第二课,纹身图工作流的搭建。 呃,这节课呢,我们打算围绕 z image turbo 这个模型啊,来进行一个纹身图工作流的搭建啊。好了,现在我们来到工作流里面去看一下啊,我自己也是有实际去跑了一些图片的啊,大家可以在这里参考一下啊, 无论是人体的结构啊,还有这些发丝啊,都是非常细腻的啊,它的手指啊也是正确的,人体结构也是没有错误的。把这四个文件夹啊复制 ctrl c 复制一下,或者说直接剪切也可以。 我们剪辑到什么位置呢?我们打开会事启动器这里,点击这个根目录啊,这样它会弹出来我们客户 u i 本地部署的根目录位置。我们在根目录底下找到 models 文件夹, 把我们刚刚啊下载的这几个文件夹啊剪切,或者或者直接移动到这个文件夹下面就可以了啊。我们,呃,因为我已经安装好了,所以它会显示我有九个同名文件夹啊,那我就不替换了, 那么这个模型也是安装完成了啊。呃,模型完,安装完成之后呢,我们记得把 ctrl u i 重启一下啊,就可以正常地去使用了,那么这就是模型的安装环节啊。 ok, 那 我们来到工作流这里, 一个彩样区,提示词区和模型加载区啊,那我们现在来讲一下这个工作流它的搭建流程是什么样的?我们先新建一个工作流出来。好,我们先双击空白区域。 我们先放哪个节点呢?啊?我们先放 k 采暖器节点啊,因为,呃, k 采暖器它就是一个核心的胜图节点嘛,图片从零到有,它都都在 k 采暖器去实现的。那我们驱动 k 采暖器,不让它的脑袋空白,让它有东西可以画,让它可以画出来。那我们需要一个模型, 那我们按住模型这个点给它拉出来。我们这里选择一个 un 加载器 啊,然后在 unit 加载器上面选择我们要用的模型啊,我们这里选择 g m t double。 好, 我们拉到这里来,然后我们还需要正负面条件啊,去告诉 k 渲染器,我们需要什么,我们不需要什么。好,我们再给它拉出来。好,我们这里选择 clip 文本编码,然后封面条件也是一样的,我们也需要一个 clip 文本编码, 然后 k 裁剪器,它是一个绘画的工具,它是不是需要一个绘画的画布来供它去绘画?那我们拉出来 选择一个,选择一个空 later, 我 们这里选择 s d 上的空 later。 ok, 那 我们有了文本编码之后,我们还需要一个呃,将提示词翻译成机器的,能看懂语言的一个呃,模型,我们从这里拉一条线出来, 我们要需要加载一个啊,可以供我们的编码器使用的一个 clip 模型。好吧,那我们需要一个加载 clip 的 节点,我们给他也连上,选择 z match turbo 可以 适配的这个千问的 千问的这个 clip 模型啊,这个 clip 下划线三下划线四 b 的 这个 clip 模型。然后就是啊, 还有一个就是 ve 模型啊,我们先看一下它画完图之后,它在这个 comelon 上面画完图之后,啊,是从这个 laten 里面去啊,输出出来的,我们要将它进行一个 ve 解码, 通过这个节点将 k 传感器生成的图片解码成人类可以看懂的图像,我们拉出来预览图像啊, 那么这个 ve 解码它需要一个 ve 模型去进行驱动,我们拉一条线出来加载 ve 啊, ok, 我 们放到这里 ve 的 话就选择 对应的模型啊,我们选择这个 ve 的 这个模型啊,就可以了, 那么这个基础的纹身图工作流就搭出来了。那其实呢,这里这之间呢,还差一个啊,就是这个彩样算法, 我们选择这个 ur 的 flow 的 这个彩样算法, 我们能给它数字填成三。这个彩样算法的作用是什么呢?你可以理解成,呃,这个彩样算法,它是可以一定程度上的去影响 k 彩样系它的绘画方式啊,呃,加上这个节点的话,会让它出图的这个结果会更加好看一点。 ok, 我 们给它,呃,稍微整理一下,好吧,我们摁住 ctrl, 再摁住鼠标左键拖动方选这几个节点,然后我们 ctrl 加 g 给它打一个组,这个组我们就给它叫做模型加载区,然后同样的 cleveland 文本编码框,我们给它归类为这个提示词输入区。 其他的像这个 colon 啊, v a e 编码啊,我就给它分分类成这个呃参照区, 然后这里是预览图像,我还可以再出来一张图,叫做保存图像, 那保存图像的话,它就是会直接将生成出来的图片保存在本地,那么这 k 传感器还需要一些呃,对它的参数进行调整啊,我们把自己的步数啊改成八八或者九就可以了。 cf 句子改成一, ok, 那 么这个工作流啊,就相当于基本上就是搭建完成了啊,我们再给这个画布啊,给他大画布调整一个大小,我想生成一个数图,那就七六八幺二八零, 这是一个十六比九的一个画布大小。那么我们现在就呃试一下它能不能跑起来吧。好,我们现在就呃试一下它能不能跑起来吧。好,我们现在就呃找一个提示值给它输入进去。 那么底下的负面提示词的话,其实可填可不填?我这里可以啊,随便填一下,填一个比较通用的提示词。然后我们点击右上角的运行啊,我们也可以把这个运行摁住前面这个六个小点,给它拖下来, 然后我们点击一下运行,看看可不可以跑。哎,可以看到 k 传感器已经开始工作了。好,可以看到图片已经跑出来了,非常快啊, 我们可以看一下它总共花了多少时间,花了二十一秒啊,那么它因为它是呃在工作流里面首次加载这个模型啊,它花了一些时间, 如果你是第二次第三次去抷图的话啊,那么它的时间就会更快啊,差不多就十五秒上下,可以看到我之前跑出来的图片都是十五秒左右就可以跑出来了啊, 那个图画的质量啊,可以看到是非常不错的啊,我们可以看一下提示词写了什么,发丝凌乱蓬松,还遮面,尽显凌乱美。我们看一下它有没有啊, 有没有遵循我们的提示词指示啊?发丝凌乱蓬松,好吧, 看他是有这个遵循我们的提示词来进行深图的啊,我们现在对这个基础的节点啊做一个认识。首先呢,我把这工作流啊大致分成了一个三个区域,我们先看看场景区域,这里面 最重要的就是这个 k 传感器啊, k 传感器它可以说是,呃,这工作流里面啊最核心的一个生图节点,你可以把它理解成是一个绘画的机器啊,图片从零到有,它都是在这个节点里面完成的。 然后我们再看看提示磁区,这里有两个啊, clip 文本编码器, 这两个文本编码器的作用就是我们可以看到 k 采集器,它有正正面条件和负面条件,那么这个 clip 文本编码器的作用就是分别去对 k 采集器输入 啊,正面条件和负面条件,你想要生成的图片就往正面提示词这里输入你想要的,你不想要的内容呢,比如说啊,丑的坏的,质量低的,你就可以输输入。在这个负面条件这里可以看到 gmail, 它对于中文的语言的理解是比较到位的好吧, 甚至知道赛亚人物空是什么啊,说明这个模型里面它是有训练对应的这种,呃,赛亚人啊,孙悟空的这种合集的, ok, 那 这就是提示词区啊,提示词区就比较简单,这有两个克里普的编码器,然后我们再来看看这个模型加载区啊, 首先我们看看它加载模型一共有三个节点,一个是 unet, 那 么这个 unet 加载器呢,加载的就是我们的生图大模型。 那么这个声这个 ulike 的 加载器呢,它加载这个模型啊,就相当于是工作流的大脑没有 ulike 的 加载器啊,那么这个 k 传感器啊,它作为一个绘画的机机器,它相当于就是脑子空空的,它什么东西都画不出来, 也就是说 ulike 的 加载器的它加载的这个大模型啊,它可以一定程度上的去决定 k 传感器它能画什么东西,画出来的质量怎么样啊? 所以说我们在挑选大模型的时候,尽量去挑选那种质量好的那种大模型。然后就是 clip 加载器啊,可以看到这 clip 加载器这两根线,它是连到 文本编码器上面的,它的作用就是将我们输入的提示词啊,翻译成机器可以读的懂的语言。那么 clip 要加载的模型呢,就是语言翻译的模型。然后还有一个就是 ve 的 加载器,作用是什么呢?我们可以看到它这根线啊,是一直连到 ve 解码这里的, 我们刚刚说了啊,颗粒补本编码器,它是要将我们输入的这个提示词翻译成机器要读懂的语言,那么图片也是一样的,机器需要将它生成出来的图片解密啊,解码成人类能看得懂的图片, 那么这就是 v a e 解码的作用啊,那么 v a e 解码的话,它一样是需要有一个呃相对的模型来驱动的。那么还有一个节点就是这个空内存 啊,这两个节点是同一个节点啊,它只是尺寸不一样,那空阶的作用是什么呢?其实它就相当于啊,比如说 k 传感器,它是个绘画机器,那么它需要有一个画布, 提供一个地方去让它去绘画,那么空阶就相当于是一个画布,这个画布的大小就是它的宽高,这里的宽高也决定了它生成出来的这个图像它有多大。 比如我这里输入的是七六八,宽是七六八,高是一二八零,那么它伸出来的图片尺寸就是七六八和一二八零。 ok, 那 么这就是这几个这个工作流里面基础的这几个节点的认知啊。好的,那么这节课我们就是围绕这 image tabo 去搭建的一个纹身图的工作流。那么下节课呢,我们将会围绕啊,一个新模型 千问编辑啊,去搭建一个图生图的工作流啊。本节课呢,我们将围绕千问 edit 啊,就是千问编辑模型来展开一个图生图的工作流搭建啊。那么这节课的工作流它有什么作用呢?首先它可以呃建立角色资产库, 进行双图或者三图的编辑,风格转会,动作姿态的编辑,还有服装的更换。呃,特别是这个角色资产库的建立啊, 生成这个角色三四图是一种极具实战意义的使用方式啊,三四图可以用于 ai 视频生成时保持角色的一致性。 ok, 那 么来到工作流的这个搭建页面,我们可以大致的看一下它的呃结构。 我这里呢主要就分成了三个区,模型,加载区,提示词输入区,批量区,还有图片输入区,然后这边是这个跑出来图片的展示啊,好,那我们现在就开始演示怎么去搭建这个工作流,那我们先新建一个空白工作流, ok, 好, 双击。我们一样是先从 k 采暖器开始搭建啊,我们先需要有一个呃核心的升图工具,那就是这个 k 采暖器 跟昨天的搭建思路是一样的。呃, k 采暖器有了之后,我们需要有一个支持它升图的模型,我们给它拉出来。但是跟上期不一样的是,我们这期不选择 unit 加载器了,我们选择 我选择 diffusion model loader 的 这个这个加载器。这个加载器呢?它跟 这个加载器,它跟昨天用到的 unit 加载器其实它的作用是一样的,只不过 diffusion model loader 的 这个加载器,它的架构更新啊,要适配我们这节课要用到的这个新模型。接着往往下看啊, k 传感器下面是正负面条件, 我们需要拉出来给他一个文本编码器。啊,那我们这次用到的是千问编辑的这个模型啊,我们的文本编码也要用这个千问千问编辑的专用这个文本编码框啊, 我们正负面条件都需要一个文本编码框拉出来, 我们看文本编码框上面需要连接 clip 和 v a e 啊,那我们一样拉出来我们加载 clip。 同样的页面条件的文本编码框也需要连接加载 clip。 还有 ve 啊, ve 也要连接出来,我们加载 ve, 我 们这个工作流本质它是图声图嘛,那既然是图声图的话啊,图声图的工作流本质上就是你提供一张图片给机器,然后机器它会参考你的这张图片去进行一个图片的重绘, 那么我们这里就要引入一个新的节点,那就是啊,加载图像,我们需要把图片上传到这个节点,然后通过这个节点将图像输入到文本编码框中, 那我们可以看到这个文本编码框这里,它是可以支持输入三张图像的啊,我们给,所以说我们可以给加载图像复制多两张出来。 ok, 我 们将三个加载图像的节点都给它们连接上。 呃,正负面的这个两个文本编码器啊,都需要连啊。 好,然后这这里的 v e 也要连上,我们还需要在这个模型加载器和 k 采集器之间啊,再加上一个节点啊,我们也是一个新的节点啊,我们叫 laura, laura 加载器啊,仅模型我们只需要加载模型就行了,我们给它连上 啊,这个 ruler 的 作用是什么呢?我们一会再讲好吧。啊,还有就是还要再加上一个裁样算法。 呃,这个裁样算法的话,我们上节课也是有说过的啊,裁样算法的作用就相当于是一定程度上左右这个 k 裁样器的绘画方式啊,然后再加上一个 c f g 归一化。 那么 c f g 归一化的作用是什么呢?就是,呃,当你的 c f g 值调得很高的时候啊,它会让你伸出来的图片出现色彩溢出的情况, 或者对比度非常高,会炸图啊,那我们 c f g 归一化加上这个节点的话,会有效的防止这个情况的发生。 ok, 那 我们这边的这个像模型区域啊,模型区块还有彩样区块啊, 就搭建好了,我们给它分类一下,我们 ctrl g 这里的话就是模型加载区,这里就是提示值 输入区,然后这里是彩样区,彩样区这边还没有完全搭建好啊,我们就先不框,我们说了这个 k 彩样器,它是一个相当于是绘画的机器吧,它需要一个画布,我们给它拉出来啊, 我们还是选择这个控雷腾图像,还是第三去设置它的画布大小,然后出图码,我们需要用 ve 编码啊, ve 解码,好吧, ve 连接过来,然后图像预览, 然后还可以保存一下,可以保存到本地啊。好,我们再把这个加载图像给它分好类,要做图像输入,那么裁样区的话也搭完了,我也给它分好类。 好,那我们还差就是,呃,选择正确的模型啊,我们这里的话大模型选择千问编辑的啊,是千问 image edit 二五幺幺的这个模型 ok 啊,然后还有 laura laura, 我 们这里选择千万编辑 lightning 四部的这个 four steps 这个啊 laura 模型,然后 clip 的 话,我们这里选择千万二点五的啊,千万三的,这个是用不了的,我们要选择千万二点五的。好吧, 然后还有 veve 的 话,我们一样是选择千万 image 的 ve。 我先展示一下,那我们现在来讲一下这个 laura 的 作用是什么啊?这个 laura 作用其实是提速的作用,那它为什么能实现提速的作用呢?其实,呃,比如说 这个大模型啊,他假说他有,假如他有二十亿的参数量,那如果不放 lora 的 话,那这二十亿的参数他会在运行的时候全部流入这个 k 传感器里面啊,无论是用的上还是用不上的参数,他都会流进 k 传感器里面, 这样的话他跑图的话会花费很长的时间,因为他参数量太大了,那么这个 laura 加载器的作用就相当于啊,给他设置了一个过滤条件,组合条件呢,他就可以经过这个 laura 加载器, 可以输入到 k 传感器,不符合条件的它就会被保留下来,那么就相当于流入 k 传感器的它参数量就没有那么大,从而达到一个提速的效果啊。然后这里的话,我们可以看这个 啊,这个 log 加载器上面的这个千万的模型名称啊,这里有一个四步啊, four steps 就是 四步的意思啊,那我们这里的 k 传感器也要调整对应的步数,调成四, 那么刚刚说过 c f g 值如果调太高的话,会出现那种啊,对比度非常高啊,或者说色彩溢出的那种炸图现象,所以说我们要给它调低点,调成 c f g 为一就可以了。 然后,哎,然后我还有还有点差点忘记调了啊,我们再加载 clip, 这里啊,这里的类型我们得给它调成千万 image。 好,那我们这个工作流搭建呢,也是完成了啊,我们来看一下这个工作流它可以怎么使用,比如说我现在想让图片中的这个女生啊,改变一下她的这个动作姿势,我只需要用到一张图,那么我就选中这两张图片啊,按住 ctrl 可以 多选, 我们使用 ctrl 加 b 的 快捷键将它们先关闭掉啊,我们只需要用这一张图片,那我们就来到啊正向提示词这里输入,将图像一中的占着镜头 微笑就可以了啊,就这样就可以了,那负面提示词的话可填可不填啊,因为千万编辑的它这个模型训练质量本身就挺高的,就算你不填负面提示词,它跑出来的质量也不会很差,除非你有明确的 啊,不想让图片中出现的内容的话,就可以往这上面填东西啊,那我们现在我没什么特别的要求,我就不填了,那我们现在来运行一下看看效果。我现在看到这个 k 传感器这里啊好像有些异常啊,然后我检查了一下,发现 这里的彩样算法我们放错节点了啊,我们修正一下啊,我这里的彩样算法呢,应该是放这个 aura flow 的, 这个我们放成 s d 三的彩样算法了啊,是这就会出现异常,那我们重新修改一下啊, 我们再把这个移位调成三, 我们再去运行一下。好,这次采暖器它是正常工作了啊。好的,那运行结果也是出来了,我们把原图拉过来看一下 好了,可以看到啊,比心了,眼睛也是看着镜头了,然后也对着微也对着镜头微笑了啊, 这边是完完全全的按照我们的提示词进行了一个图像编辑,但是呢,我们可以看到我们上传的图片比例啊,它是一个竖图,但是生成出来的图像它是一比一的这个宽高啊,原因是这里的空位腾,我们没有调整它的宽高,那么它默认就是一比一的, 那我们这里的话就可以引入一个新的节点,我们给他这个图像拉过来,先 我们引入一个图像缩放,按我看一下 按边, ok, 我 们可以用这个节点啊,这个节点的作用是什么呢?比方说我想让它缩放到一二八零, 当图像经过这个节点之后,它的高就会被缩放成一二八零,因为这个尺寸是按照它的最长边来算的,这里的最长边显然是它的高嘛, 这图片的高是二幺三三,那么经过这个节点之后,它的高就变成一二八零,但是它的宽度也会按照比例进行啊缩短。好吧,最终它的这个进行缩放之后的图片宽高比也是一样不变的。然后我们再来一个节点 获取图像尺寸,就这个这个节点的作用是什么呢? 顾名思义嘛,就是获取这个图像的经过这个节点处理之后的这个图像尺寸,我们将宽度和高度同步到这个 comlayton 这里。好吧,那我们之后就不需要手动的去调整这个 comlayton 的 大小了, 跑出来的图片就跟我们的啊输入的图片它的宽高比例是一样的,我们运行一下看看效果,好的这个图片结果也是跑出来了啊,我们再把图片原图拉过来看一下, 这个宽高笔也是十分相近的了哈。啊,那像是其他的玩法呢,我们来看一下这里已经跑出来的这个效果了,如果你想让它生成角色三式图的话,那你也是只需要啊开启一个节点, 你可以跟题中女生的角色三式图分别为正视图、 测试图和背式图就可以了,但是你要注意你要将他的这个图像尺寸啊调成啊,横图啊,十六比九的这种比例会比较好一点,不然的话他会, 不然图片是会崩的,他因为因为竖图的话他是很难塞的,下三式图的比例就会变得非常奇怪, 那如果你想实现图片转绘的话,那也是一样的,在文本编码器这里直接输入你想转绘的风格就可以了啊,只要这个千万编辑它有训练到的那种,呃,绘画风格的话应该是都可以转绘的, 然后的话就是像是啊换衣服啊,或者说两个女生拥抱在一起啊,也是一样的,你只需要把图片上传到这个家的图像,需要几张就上传几张图片,最多三张图片,然后把你的提示词要求说清楚就可以运行了。 好吧,那么这就是这节课的千万编辑的一个图深图工作流搭建 啊,我们这节课的话,这个工作流就到此为止。下节课的话我们会讲一下这个基于 joycaption 的 一个啊提示词反推的工作流进行喜图操作啊,这个喜图有什么用呢?我们下一期会做讲解啊。
1907SD教程









