大模型 代码流程图
让我介绍一下关于 ai gc 方面如何产生这个代码的这样的一些模型啊,那么今天的话呢,他他想讲一下那个 starco 的这样的一个模型啊,这个模型的话呢,也是哈根飞是开源的啊, big code 里面的一个模型之一啊,这个模型跟大家来一起来介绍一下啊,我们可以一起来看一下,到底目前 在 aigc 产生这个原代码里面到底是哪些模型会更好一些,他们到底是怎么评测的啊? 我们先来看一下这个 star 扣的这样的一个项目啊,这个项目他其实是非常大的啊,他这个是一个大模型啊,他是要跑在那个八块的那个 类似于 a 一百的这种 g p u 上面的啊,它至少要四十 g 的这样的一个呃, g p u 的这个内存,它才能跑这样一个模型的啊,那么这个模型它这个里面讲了它一共有呃八十种开发的语言,它是都是能 够支持的啊,就我们市面上看得到的各种各样的开发的语言,他目前都是支持的,而且他这个是呃训练的是比较大,将近有六 t 的这样的一个原代码的这个数据啊,包含了将将近三百五十八种的这个开发语言啊,他做了这样的一个项目啊,那么这个语言里面他是啊精选了一些 语言,它是有八十种,像那种 javascript 啊, go 语言啊, python 加啊、 c 口啊,各种各样的这这些语言它是都是能够支持的, c 加加 c 啊,对吧? c 下爬它这种语言都是能够支持的啊,它主要是这样的它这个项目啊,目前这个 big start coder 这样的一个模型的话呢,且它的支持的 context window 的话,就是那个上下纹的这个环境变量的话呢,它是支持到八 k, 就是八千一百九十二个那个 token 十啊,它是这样,然后它还用了一种就是 编写原代码里面比较经常用的是呃, few middle 对这个 object 这样的一种方式,他这个主要是因为原原代码的话一一般都会,他不会是往下写,他主要是前面和后面都有了,让你中间来填空啊,他通过这种方式来来训练的, 所以他这个跟一般的这个大语言的这个模型还有些不太一样啊,他是他的训练方式啊,那目前他支持八十种的这个开发的语言,他用的话呢,也是比较简简单的啊,他也是基于这个 transformer 的这样的一个开源的类啊,也是可以运行的。 目前这个项目的话,像我们之前讲过的这个 t g i 啊,包括那个 faster chat 啊,它这种啊,它是都是能够进行加速的,而且,呃,它是目前是这样,这个项目的话,目前它在商业上面应用是有一些 license 的限制啊,它是有些 license 的限制啊,当然你就作为一些研究的话,你还是可以用的啊, 他也基于拍 touch 的这样的一个这样的一个底层的那个人工智能的那个模型啊,他是这样的啊,那么这个模型, star coder 这个 产生代码的这个模型是不是目前目前在开源界是最优的呢?啊?应该不是啊,他不是最优的,我给大家介绍一个最优的一个模式,那么他们一般的话呢,这个种啊,就是产生代码的这种大模型,他们也有一种叫评测的,对不对? apple 的这样的一个评测,那这个评测的话呢,它主要是自动的,可以做各种各样的这个告诉你一些原代码,写一些那个算法什么的,然后他进行评测的,他就是 pass 一一次性通过的这个准确率和十次通过的准确率,他有这样的一个评测,一般的话主要看这个 pass x e 的这样的一个评测指标啊,目前最高的话呢,是这个模型是最高的,而且他也比较小啊,他只有三 b 啊,三十 的这样一个,他在哈根 face 上也是有开源的这种内裤的啊,这个模型大概是在啊十个 gb 左右啊,他目前是目前是业界测下来他的性能是最好的啊,排名第二的话呢,是这个模型的话呢,也是一百五十亿参数的啊, 相对来讲性能也是不错的。这个 stock 的这个模型的话呢,也是一百五十亿的参数,排名是在第三的啊。其他模型的话呢,也有,如果大家有兴趣的话呢,也可以拿出来看一看,拿出来看一下, 像 l l a m a 杠七 b 的这种模型的话,它的啊,它是一个全能的通用模型啊,它也是能产生代码,但它的那个能力会差一点,你可以看到它这个能力相差还是比较大的, 一个是十二点一对吧,一个要六十三点五啊,相差将近要五倍到六倍的这样的一个性能,这个相差还是比较大的好的。在 big coder 里面呢,它其实还有一个模型啊,这 这个模型叫嗯, santaco 的啊,这个模型的话错的。嗯,这个模型也是相对来讲也是不错的,这个模型啊,他要比 starco 的要稍微小一些,然后更专注一点,他主要是专注于那个 python 加码和假巴 script 三种语言的这样的一个模型啊,这个模型差不多是一点一 十一个亿的这样的一个参数啊,所以这个模型的话虽然小,而他更加专注。如果你的产生代码主要是集中在在这三个语语言的话,用这个模型也是不错的。好啊,今天就简单的跟大家来交流一下,就是说我们在选择这个代码, a, i, g, c 产生代码的这些模型上面应该怎么选择?有哪些模型可以使用啊?哪些模型会更强一点?一般呢?他们用一些什么东西去评估啊?回头的话我可以把这个网址可以发给大家啊,这个网址的话叫 cold ever。 二,他这样的一个项目啊,这个项目的话也是不错的啊,他可以自动化的去评估你各种各样的这个大模型,产生这个代码,产生这个代码能够通过这个测试率的这个能力。好吧,好,今天我们就跟。

粉丝4.6万获赞33.8万
相关视频
 10:02查看AI文稿AI文稿
10:02查看AI文稿AI文稿今天跟大家介绍一下的是,呃,如何用这个大模型结合本地知识库呃,做这样的一个应用啊?在这个项目里面,如果拿到代码之后的话,你可以看到我这个里面有两个文件夹在 context 下面,一个呢是中文的,还有一个呢是英文的,英文的啊, 我我先,呃,因为用的比较多的还是中文,所以我给大家介绍一下中文怎么用啊?核心的话呢,它其实是三个,这个三个文件一个是 man 点 ph, 还有一个是呃, in guest 点 ph 啊,我们先来讲还有一个是 carry 杠 data ph, 这个三个 点 py 的这样的一个拍摄的这样的一个文件啊,这个三个文件呢,分别的作用,这个的话呢,主要是把现在的这些文件把它切片放到啊下降数据库放在这儿的,它,是啊,这是这个文件的作用,是做这件事情面呢,它是一个主函数, 它主要是提供了两个接口,一个接口它会返回一个 index 的这样的一个 h t m l 的一个页面,那么这个页面的话可以操作这个页面对这个机器人进行问答。第二个呢,它提供了一个接口,就是一个 web socket 的恰特的一个接口,那么这个接口的话呢,它的主要的功能就是把你的问题 扔到那个质量数据库里面来,然后再通过大模型,然后进行问答,他把一些内容返回出来啊,这个地方就是 result, 就是他返回的东西啊,这个就是他的问题啊,他把这个返回的问题可以放在这个 history 里面啊,他主要是做这样的一个事情啊。好,我们给大家一起来, 先给大家一起来演示一下啊,这个 carry, 我 carry data。 回头我再来重点来讲一讲啊,我们先给大家来演示一下,先给大家演示的是怎么查询打这个命令,当然前提是你要安装一些东西,安装这个东西的话,在 这个是内裤,你要打这个命令啊,你要打快门回撤,这个因为我已经装过了,那他就很快就已经过了,这个是安装完环境,安装完,安装完之后就可以了,打这个命令回撤, 这个时候呢,他你可以看到他已经在起这个 server 了,他起了一个九零零零的端口,那么九零零零的端口在哪里呢?他其实也是可以改的,他在这 port 九零零零。那么一般的话呢,我们 web 的呢?端口的话呢?是八零端口啊,那么当然你这个地方可以改,这个是你的 host 的 ip 地址,你也可以改,我用的是本机, 我们可以看一下 local host。 九零啊,他已经出来了,对吧?那么出来了一个界面,我们可以让他问他一下。 sorry, 翻车了啊,对不起,这个是个 bug, 回头我再来讲一讲,这个是个 bug, 这个是他的框架的一个 bug, 我们发现了,好,好了,他在 计算了,你看啊,他已经告诉你了,哒哒哒。根据什么什么什么条款执纳金的问题应该是怎么样子的?这个问题的话呢,他就是结合了这个里面的一些问题他去解答的,比如说我们再来看一个这个, 再问一个,那他又在算,算完之后他就讲了,好,我们再看一个啊,看第三个,我不知道他答的对不对,感觉还是对,好,我们先就这样。好吧,我们先演示这个,我们来看看他是怎么来实现的,我们跟大家一起来讲一下。好,这个我们就演示到这,先把它关掉, ctrl c 把它断开, 断开之后我们可以看到我们先看这个文件,这个文件是比较重,我先把这个文件先删除掉它,它的这个这个文件的作用是什么呢?它主要的作用就是把我前面讲的这些项链,就是这些文件,它会转成那个使量数据库啊,在这上面 他要转成使量数据库呢,我们就要用到那个就是 oppo ai 类似的这种大模型啊,这个是大模型的那个环境变量啊,他的地址啊,这个地方要有一个杠。 b 一是比较重要的啊,因为我们是引用的是本地部署的这个大模型, a p i k 的话你可以随便设,我这边设了一个 empty 是空的。好,我们看这些文档第一的话呢,它就是从这个目录下面, 这个目录下面,当前目录下 context 下面的这个目录新建一个 loud 的对象,这个 loud 对象他就可以把这些裸的这个文件把它读出来,读出来之后他再经过这个文件的这个拆分,这个拆分他是每一千个字符拆分一次,他等于是这样,你可以看到这个地方他是他这个已经七百 六十,所以他这个会拆成一个。我这个里面你看的话,我大家要注意的,我这边有两个换行,他这个会拆一个,这个会拆 一个,他是这样的啊,如果核心你可以看一下他的这个 a p i, 他这个 a p i 里面会去定义的。在这你看到他有一个叫分割符,他有两个空格啊,两个回车或者一个回车的时候呢,或者有空格的时候呢,他就会自动帮他拆分了,所以这个是最优先的。 如果他达到一千个字符,他会去看是不是有这个两个东西,有,那就开始拆,如果有这个他也拆,如果有空格也拆,当然你这个地方是可以自己定义的, 这个可以自己定义的,当然你可以在中文里面,你可以把那个句号或者逗号也定义进去,也是可以的啊,这个地方 好,我们看看啊,这个是比较重要,那么这个参数是指什么呢?你指了前面,如果我有一千个,如果你这个快,如果你是,我们看一下这个啊,如果你有一千个,快一千个字符啊,比如说这个假设他超过了一千个字符,那你怎么办呢?他会猜成 两部分,所以他要拆成两部分的时候,他有一个参数,这个参数就是是不是把前面那个块的一部分的内容,把它引用到后面块里面去。比如说如果你这边是一百的话,就把前面那一块 最后的一百个字符跟后面的一千个字符混合在一起,他等于是这样,一般的情况的话呢,就不要做重叠啊。 我一我一般是这样设的好,设完之后呢,我们就把裸的这个 document 放在这个 tax sprite 这个里面,把这个 document 给拆分出来,这个时候呢他会按一千个把它给拆出来,拆的他会更多。 开出来之后呢,我这边通过了一个 inbeding 的这样一个操作,我这个操作呢是用个本地的一个 m 三一杠贝斯的一个模型,当然你也可以用我上面的这个就是 lm 的一个大模型,这个的话呢比较适合于中文,比较适合于中文,这个模型中英文其实它是可以的。呃,如果是全英文的话呢,就不要用这个, 要用我上面这个注视掉的。好。然后进去了之后呢,我就用到了一个 vs 的数据史料数据库啊,这个地方,把这个 in bedding 和这个 document 的拆分之后,存放在这个 victor store 里面,这个就是矢量数据库,然后把它保存下来,然后 close 掉,所有的代码就很少,只有这么一点,我们看一下啊,跑了,你在运行查询之前,你必须要先跑这个东西回车,它自动会帮你把这个文件读起来。好了,你看到这个地方产生了这个 victor store, 点 p k l 的这个文件的时候,说明它已经 完成了这部分。好,我们这个代码就讲完了,我们再来讲这个主函数里面,我前面已经讲过了,它的核心就是这个 carry chain, carry chain 呢,它是放在这个 carry data 这个文件里面呢,就是这个主函数啊,我们来看看这个主函数主要是做些什么事。它的核心的话呢,它是主要是做了两件事情啊。第, 第一个他创建了一个 l l m 的大模型啊,他创建了两个大模型,一个呢是 question 的大模型,一个他主要是这个做回答的这个大模型。这个模型呢? question 的这个大模型呢,他主要是做 inbiting 的这个操作,他把这个 question 作为了一次 inbiting 的操作。第二次呢, in bed 完了之后呢?他把这个 in bed 的这些结果放在这个 context 的这个环境里面,我们看看啊,他是放在哪里?他在这你可以看到 context, 他这个里面有一个 template, 有一个提示模板,提示模板里面他会把这个 context 就是我们前面矢量数据库里面查出来的文档,他会放在这个变量找, 然后他把这个快速群会放在这个上面。哦,他会告诉你你回答他的这个答案是什么,他是通过这个来做的啊,他把这个 context 和快速群把它内读变量放到这个模板里面来就可以了,这个就叫提示工程啊。 好,那么我们这个 tnt type 的类型叫 staff, staff 的之前我也是介绍过的,有四四种类型,目前郎欠他虽然说支持四种类型,但只有这一种类型目前是可以正常工作的,另外三种类型是不能正常工作的,我们可以看一下 另外还有哪三种,一个叫 map reduce, 一个叫 refine, 还有一个叫 map 叫 re rank 的四种方式。这种方式是最简单的,就把查出来的所有的文档全一股脑塞在 context, 就是前面的那个环境变量里面。 map reduce 的话呢,它就是先要做先把所有的文档放在一起,再进行一个 压缩的操作啊,压缩的操作的话就是深层摘药啊,他主要是做这样一个事情,那就怕这个文档太大,呃, define, 他把一个一个文档都让他去迭代的去回答这个问题,嗯,这个是比较有价值的,这个他会把所有的文档一个一个的加 到 contex 里面,不去回答问题,我找一个他认为回答最准的一个问题啊,这个价值其实是比较大的,但他目前是报错的,是不支持的啊。好,我们就不要动弹,就用这一个。我这个地方的这个参数要跟大家讲一下,这个它是用于了一个 conversation 的,一个 一个,呃,基于这个文档获获取的这样的一个对话的一个欠啊。参数啊, k 等于三, k 等于三是指什么呢?就从这个时量数据库去拿取文档,拿回来三个 啊,这个因为要根据你的这个文档的这个数量要去看的,如果你是非常多的话,当然你拿回来要多一点。我之前介绍过一个 论文的,这个论文里面讲五到十个是最合适的,因为我这里面的话只有六个文档,所以的话拿三个的话已经拿了百分之五十了,已经非常多了,按照道理的话他应该更少一点,因为他有可能。呃,如果你拿过来的这个文档相关性不是太大的, 可能会影响到他的啊,好啊,这个就是这个文档最核心的代码,最核心代码还有一个代码,在这要跟大家讲一下这 temperature, temperature 你是否要用到这个大模型的这样的一个创新,如果你不要用到他创新的话,你可以用零, 也是可以的。用力,我们来看一看啊,如果是这样的情况,我们再来启动一下,给大家演示一下。好,又启动起来了,根据什么四十三号晚应该对的,我好像看到过。对的,好, 这个再来解答一下。对的,他这个打的都是比较准确的,所以这个两个参数是比较重要的,这两个参数是比较重要,如果你调一调的话,他的性能会好很多 啊,所以这个调餐是比较重要啊,这个 k 和这个 temperature 好,呃,今天的话呢,这个原代码的关于 l l m 的大模型,对吧?结合这个本地的这个知识库啊,就跟大家。呃,讲到这,好,谢谢各位。
523小工蚁 00:54查看AI文稿AI文稿
00:54查看AI文稿AI文稿第一步,输入化流程图的 prompt 指令。东爷尝试了很多版本的指令,目前这个是多次实验效果最好的,有需要可以在留言区扣一,我看到会单发,然后下期 pt 就会根据我们输入的指令自动生成 remix 代码格式的流程图,可以开出节点清晰,流程顺畅, 他还非常贴心的这个流程图进行解释。 第二步,一键复制代码到绘图网站启动,开始创建绘图文件,点击加号,先后选择高级 mermaid 格式,把刚刚复制的代码粘贴进去,即可自动生成流程图, 哇哦!第三步,点击文件,选择你需要的格式。这里东野选择的是 png 格式的图片,导出图片就大功告成了,让我们看一下图片效果,哇哦,觉得有用记得关注再走哦!
880东爷聊AI 00:37查看AI文稿AI文稿
00:37查看AI文稿AI文稿下面以吃肉串为例,我来教你如何画流程图。开始先看一下还有串吗?如果有就吃,是肥的吗?是就吐了,继续回去看还有串吗?如果不是就嚼一嚼,吃了,然后再回去看还有没有串,如果没有串了,那么就擦擦嘴,肉串吃完了。新手一定要多锻炼,画流程图, 锻炼自己的思维能力。介绍几个最基本的图例,椭圆表示开始与结束,矩形表示流程的步骤和操作。菱形用来做判断箭头流程的方向。在不会写代码之前,可以多使用流程图来设计日常生活的小事,锻炼成学思维逻辑。
1751李白不会编程 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿现在十行代码几十条数据,不能完成一次 gpt 大模型的微调。前几天 oppo ai 开发的大会更新了全线产品 sdk, 让我们仅用这十行代码就完成了微调。 一分钟快速讲解一下过程。首先拉取一下代码仓库并安装 sdk, 然后在环境变量中配置好开发者密要,接着准备好数据。这里我们以哈根 face 上的信息标注数据及为例,将几十条问答案 message 数组的形式拼装成阶层支付串数据,我们过一遍,非常的简单直观。然后把这些数据通过脚本传给 ai, 获得文件 id 待用。然后关键的部分就来了,可以看到这里总共十行代码,已经不需要再通过 api 传递参数了,直接使用 sdk。 这个简单程度怎么说呢,不能说没有门槛吧,只能说门都给他拆掉了,只要是个程序员就能完成微调。好了,我们运行一下拍摄 脚本。好家伙,这就成功了。看看开发者邮箱,收到了模型 id 的邮件,打开 playground 测试一下, nice 啊,定制的模型就到手了。 当大家都在感叹 gps 的时候,开发者们已经可以轻松的进行微调了,你觉得为啥他要叫做 oppoai 开发者大会呢?我是于博士,跟我学 ai, 我们下期再见,拜拜!
382地质大学博士说AI 19:08查看AI文稿AI文稿
19:08查看AI文稿AI文稿好,今天我们呃来聊一聊这个我们所使用到的这个基础模型,基座模型的一个代码结构啊,我们要在这个模型上什么样的模型上去微调它啊,那么我们一定要 大致了解一下它的一个结构啊,那么这个结构呢?呃,我们先 拿一这个图来给大家示例一下。那么这个图呢,就是调小一点 啊,这个图呢,就是我们的一个 nama 的一个用到的 nama 的一个整体的结构,它从 input 进来了之后呢,啊,我们做了一个 ims normal, ims normal 呢,基本上就是一 一个啊,规划啊,做做规划的一个东西,然后堆叠了很多的个 transformer 啊,我们可以看到 q k, v, 那么每一个 q 和 k 和 v 呢, q 和 k 呢,其实它都有对应对应位置的一个注入啊,对应位置的一个注入。 那么最终啊,我们再把 q k v 这个自注意力机制啊,最终啊形成一个 output, 然后我们再到下面一个呃 blog 块,这个 blog 块呢,啊,我们同样是 有一个啊,规划现在有一个规划纯规划的东西,然后我们会去做一个呃 啊,这个优优化函数啊,优化函数啊,是不是通过这个,还是通过这进进去啊,这两者都经过 get, 是啊是是有些要通过,有些不通过。然后最终啊,我们去形成了一个 啊输出的一个东西啊,输出的一个值。那么这里面比较特点呢,就是第一个是前置的 im snowmer, 第二个是在 q 和 k 上面使用了一个 呃旋转式的位置编码。呃,那么 同样呢,我们也使用了这个 mask, 只能让模型看到前部分,不会像 birth 那样啊,他会看到呃,只会看到这个这个数数据的前部分,输入的前部分,不会看到后面的部分啊,或者会看到后面的部分,或者是会把中间给 mask 掉,这个只会 啊,把后面的一个 mask 掉,只会让模型看到前面啊。那么 lama 可以将 k 和 v 拼接到当前的 k, v 的前面啊,可以用 q 去查询更早的信息啊, 这个并没有在图中表达出来。那么 l 这 m l p 也是最最后的一个 m l p 的一个表达。 m l p 的一个表达呢,主要是荡和这个这个 这个优化函数之间啊。呃,那么 down up gate 其实都是这个线性层,最终会输出到这个的一个结果。那么 那么它主要的一个结构的一个分析和区域的这个大小啊,我们看一下。就主要是 呃,比如说 nama 啊,我们 nama 是呃这里面分的一个参数,他比如说啊,六十七亿的一个呃,六六六十七亿的一个参数,呃,七六十七亿的参数量。 那么他所用到的这个呃 demonation 这个最大的这这里面的 intern 呃呃就是中间 间的这个呃,向量的这个数量是四零九六啊,我们说的四零九六。呃,那他用到的这个 head 头是三十二乘数呢,也是三十二啊,也是三十二。 我们可以看到这种层数的增加呢,也是跟模型的大小的能力有增加啊,有增加。同时呢,他这个 demolation 其实增加的并不多啊,到这边就增加了一倍啊。他的害的头也是顺序的跟着这个在网上 啊,往上再走。呃,那么同样的它的这个呃,这个这个 learning rate 啊, learning rate 啊,越大的模型呢,它 learning rate 就再往下降啊,这个是他在 a 一百上训练的需要的一个训练的时间啊。这两个好像一样啊,不对啊。 那么 i was normal 呢?其实这就是在之前贝尔特啊, g p t 啊,广泛使用的这个 nina normal。 那么 i was normal 做了什么呢?就是 呃, lena normal 呢,中心偏移没有什么用,就是减去均值。这种操作呢,就是减去均值,就相当于我嗯, 不放在中间了啊,就是我我,我把这个整个数数数列的一个均值给剪掉。那么他肯 定会呃,放大它本身的一个数据的误差,或者放大本身的方差。那么将其去掉之后呢,我发现它效果不变,而且这个提升了百分之四十啊。这个所以 i'm as normal 的其实就是 ninlomer 啊,其实 nlinomer 的一种变形啊。 呃,这种使用了之后呢,会使输出更稳定啊。我们要知道这个东西是干什么用的啊。 那么 nama 呢?它也没有使用 r e l u 这个常见的这个优化函数。我们使用的这个 switch g l u 啊,那么也叫 s i l u 啊。这个 sigmod 类似于平滑版的 r e l u。 注意啊, i l u 差不多也是这样的。好的,我在网上找到了这个语。 那么后面一个呢? r o p e r o p e 什么呢? nama 呢?使用呢,它使用了这个。呃,这个这个这个,这个叫什么旋旋转的啊,旋转的一个。呃,位置嵌入。 那么对于 q 的 d m 个位置的项链,项链 q, 通过以下方式,它去注入相应的位置编码啊,就是 以前的这种位置编码呢啊,就是就是,可能并不是他也是固定的。但是使用这种方式之后呢,我们可以去推理出 啊,无论这个多长啊,他的这个位置我们都能找到。比如说不管他是二零四八,四零九六,还是八一八幺九二啊,我们都能在相应的 位置给他注入一个相应的位置编码啊。他就表示他知道呃,这个 酱料,这个 inviting 它是在哪一个,或者这个 q 啊,它是在哪个位置的啊?我们这这这这就能那计算的公式就是这么一坨啊,这个也不是很复杂。呃。那么 再往下 lpe 可以去做一个相呃相对的位置编码 啊。上面的公式呢,我们可以看到 l p 是一个绝对的位置编码,它是根据一套公式算出来啊,它是有一个绝对的位置编码。那绝对位置编码的优点呢?是计算速度快,缺点呢是拓展长度比较麻烦。 呃那对这个呃这个在呃而且相对位置编码呢,去学习两个 token 之间的关系呢,也很有意义啊。呃这个所以呃, 我们我们只关注就是如比如说不管我们输入的这个 content, 这个 input 是多长,我们只需要关注最长距离之类的输入就行了。相对于位置编码的缺点是没有绝对位置编码计算的速度快啊。 当我们计算这个 attention 时候,这个 l p e 可以变为相对的位置编码啊。这就是 那么 q 和 k 的 attention 依赖相对距离 m 减 n, 所以 l p e 为 q k 处注入的绝对位置编码计算而得到 attention 啊,就变成了相对的位置变码啊,这个这一点在 lpe 里面的实现是非常巧妙的啊。呃,简化了非常多的东西,那么 大致的是这样的。我们啊,我们直接来看一下这个模型啊, 这是我在呃,这是这是直接在那个 transformer 里面, transform 里面啊,我们找的一个我们直接拉出来的一个啊。啊, nama 的 model 啊,这是它的 transform 里面的一个结构的定义啊,我们大致来浏览一下啊,一些细节可能也讲不到那么细。 呃,那么开始的时候就是 nama 的整体的这个呃, elite 我们 elite 的时候我们要输入这些东西,包括这个 pending, 包括这个词表的这个大小 啊,包括这个 inbeding 的这个 talking 啊,包括有多少层啊,定义这些啊,包括嗯用到的这个 normal 啊,就是这个 normal 就定义成啊啊,用用用的是 ims normal 啊,这个是 那么里面那么里面独独独独有的啊,目前来讲是独有的。那么 graded check point 这个是为了去做基础检查点,是为了我们 为了为了为了把一个大的模型啊,那个放放入到一个小的显显存里面去计算啊。啊去去需要这个东西啊,这个这个这个知识点,那个后面这个后面看 我们再讲到吧。这个这个这个也是一个节省现存的一个方式啊。呃,这这也没有什么。呃,这个是去它内置的一个呃, function, 这个 function 呢,主要 而是去写了一个这个 attention 的 mask 啊, attention mask 我们主要来看这个它的 forward 的计算主要是什么? forward 的计算呢啊,包括这个 input, 这 ideas, attention mask, position ideas 这些不必再说了吧。 啊,这这些东西就不必再说了吧,是 transformer, 包括 birth 呀,这些东西都有啊。呃,自己去看吧。啊没没有,没有什么可以说说的东西。 那么这里面的引扑的城呢?如果我们发现这个不为空呢,我们就把这个引扑的城呢,我们去做了一个 talking 化啊,那么如果有 talking 呢,我们直接用这个 talking。 那么 attention mask 呢?我们去去当然啊,这个相应的 一个初始化啊,都初始化为一。那么 addition 的这个最终的这个 attach mask 呢?我们在这一层,就是刚才看到这一层,就是之前定义的这一层里面我们去做 mask。 那么后面呢,就是最最呃,最 最主要的部分啊,就是 decode learn lingler, lingling linglers。 那么这个我们还记得刚才我们做初始化的时候啊,这个 model 做初始化的时候,我们要定义它的乘是多少啊,这个参数就用在这了啊,就是我们要多少个 clear, 拎点这个乘, 然后我们去呃去去呃,这个循环了多少遍,然后去呃 把这个 decoder 连着这个程序弄出来啊,看出来啊,这个先不用管它啊,先不用管它是这个播音的,我们先不用管它啊,我们先先先管这个东西啊,它就是去定义了 啊,循环了这么多次啊。那比如说我们我们需要这个三十二层啊,那我们就啊这个就循环三十二次啊,就是三十二个,大概 transform 的这个结构啊,那么每一个 transform 的结构 都是相同的啊,而且都是一致的,而且都是基本上一样啊,没有什么太大的区别。这个啊,再往下看这个 use cash 啊,这个 output attention 去,如果是 output attention 的话,我们就加入去把它进行相加啊,去做这个 output attention。 然后这个影层呢,我们去对影层去做了这个 normal。 我们记得这个之前这个 normal 呢,是 ims normal 啊,就是 inner 这个 normal 的一种方式去做这种规划方式。呃,然后再做这种。呃, 啊,是不是隐藏的状态啊?是是隐藏状态。如果我们要拿过来的话,把这个隐藏状态拿过来的话,我们同样把它加在一起啊, 后面也没有什么太多的东西了啊,基本上就是这些。 呃,看一下这个的 forward, 那么 for course i am 的 forward number of course l m 的 forward。 呃,同样啊,这些 model 定义呃, level 标签,然后输出最后这个 level。 如果是不为空的话啊,我们怎么去计算它的一个交叉商的值啊,它的 loss 是用交叉商去计算的。 呃,要做一个 shift shift 呢,就是说啊,我要用前面的计算后面一个 why 啊, why 是它的这个 label 标签。这也没有什么。然后计算出来这个 lost 输出。 其他还好,没有什么太多的东西啊。 呃,它这里面为什么没有 r o p e 的东西。呃,我来找一下啊, 哎,还真没有 lpe 的东西 哦,这儿有,我们看看。这就是实现这个 r o p e 的。呃,就是旋转的位置编码啊。这层啊,它的输入是 q k cosine sign cosine position ideas。 那么 呃,计算输出一个 q 和 k 的这个啊, inventing 在这里面呢,我们把这个相应的位置编码输入进去,也是他相对应的东西。那这一层他在哪表示的呢?哦,对,是在这表示的啊。 啊,我们在这个 llama 的 addition 里面,它去实现了这个东西啊,实现了这个 q 和 query 和 key key 的这个 status 啊,在这个 nation 里面去实现了 o okay, 那我们今天 我们今天整体的东西我们要明确一下啊。呃,整体的结构在这,那这里面的一些参数,我们要需要去定 参数,比如说我们一个七 b 的模型,那么他啊我们我们比如说我们要训练一个几种模型,我们得知道他的这个 demonation 是多多大,然后他的头是多少,然后他的乘数就是我们刚才说的这个有多少层,循环多少次啊,是多少, 然后我们初始的这个学习率是多少啊,大概是这样的啊。那么他还有一个 had 的一个 demo 啊,那么叫 had demo。 呃,这也是数。还有 demo 好像它是维持都是二百五十六吧。 啊,看看是不是二百五十六,二五六乘以二二九八。嗯, 这个应该是一百二十八乘以三十二。呃,就是说这个 head 的 game, 呃,是乘以这个 head 啊,应该跟这个 demonation 是啊,有一个相对应的关系的啊, 这个大家了解一下就行了啊。这个是呃可能这个可能这个这个这个这个可能也不是妈妈里面的巧合,这个这个也不是一个巧合。这个包括在 pam 里面,就是 后面我我用到的这个 pam 和这个 pam 二里面啊,那么它都是这种方式。
11象土课堂 02:40查看AI文稿AI文稿
02:40查看AI文稿AI文稿大名鼎鼎的编程大模型 codex, 那么 open ai 的这个编程大模型 codex 呢,它呢?啊是用 get up 上啊数十亿的代码训练而成的数十亿行代码啊,训练而成, 能够啊读懂代码,并且呢能够根据用户自然语的这个描述呢,来创建一些代码啊。那么同时呢,我们说 codex 呢,会非常擅长 python 啊,同时它也精于啊,像 javascript 啊,还有 go 还有 php 啊这样一系列的,目前非常通用的啊,这样的一些编程语言 来说啊,是一个功能非常强大的这个编程大模型。那目前来说啊,这个 codex 编程大模型呢,是集成到这 visual studio code 还有 github 上 copilot 这样的一系列工具当中,那么之前啊,我们应该有讨论过,对吧?啊, github 上的 copilot x 啊,这些使用方法,那么它的这些插件 背后的这个编程大模型,实际上都是啊 codex 这样的一个模型,那么这个模型也是目前啊,全球范围内非常领先的编程类的这样的一个大模型啊啊,但是现在啊,如果你去 openai 的官网上去看这个模型的话,那么它会显示啊,目前这个编程大模型呢,是处于一个 弃用的状态啊。所谓弃用呢,指的是未来呢,可能就不会维护啊这样的个编程大模型了。那这里啊,到底是呃什么样的情况呢?他明明功能会非常强大,但为什么现在呢是处于一个弃用这样的个状态呢?啊,实际上是因为 在 ola 未来的规划当中,编程类的这个大模型啊,是会和语言类大模型来合并的,也就是说未来的 cojects 相关的一些功能将会合并到 gpt 类的大模型当中去,比如说我们现在看到的 gpt 三点五杠 turbo 那个模型,其 其实他就已经具备了 cojects 当中的非常非常多的一些编程的功能了啊,所以未来呢,可能不会有单独的啊这个编程类的大模型啊,但是呢啊,他会有啊,他的这个语言类大模型当中会集成编程的一些功能。 当然这里我们需要强调一点啊,就是关于这个啊,大语言模型是如何具备编程能力的啊?实际上对大某语言模型来说,同样他也会把一些编程的一些代码啊,看成是一些语言的表达,然后呢,采用类似的学习的方法来进行学习, 再加上啊,这个啊,微软在几年前就已经收购了 github, 对吧?啊,所以对于 oi 来说,它的大语言模型基本上是学习了 gitab 上的全部的代码啊,来进行一个这个训练和升级。所以啊,你会发现在这么大庞大的雨料库的支撑的情况下,它当然啊,是能够训练出目前 全球范围内最强的啊这样的一个编程大模型啦。 ok, 那这个呢,是 codex 啊相关的一些解释。
18九天Hector 11:41查看AI文稿AI文稿
11:41查看AI文稿AI文稿怎么微调一个这样的个这样的一个模型啊?那么什么叫大型的语言模型呢?就是说你这个数啊,超只说一百啊,不过两百亿,那么这样的一个语言的这样的一个预处理模型,就算是大于非常大的这个预处理的这种模型。今天我主要跟大家聊这个东西, 他的基本原理是这样的,当我们这个模型非常大的时候,如果你去微调他其实是非常困难的,因为他这个参数非常多,所以你要为他非常多的语料,那你才能去做这样做这些模型的微调,他得是这样 啊,但是这个一般是当中的话呢,你很多的语料去做微调,这种可能性不是太大的,这个可能性不是太大,那么怎么办呢啊?这个 pg 他们提供的这样的一个微调的方法,叫 r l h f 的这样一个方法,这个方法的话呢,就是人类强化,就是人类这个反馈的这样一个强化学习的这样一个算法,它作为 一个大型的语言模型的一个微调的这样一个算法,他等于是这样。那么哈根 face 之前呢,他就也推了这样的一个开源的这样一个框架,这个叫 c r l 的这样的一个 transformer 的强化学习的这样的一个 开源的框架。那么你可以通过这个框架就可以实现这个对大型语言 transformer 的这些模型的这样的一个微调,他不是为这种语料库来进行微调的,他还是通过这个强化学习来进行微调的。那我我们来看看啊,到底是怎么来微调的?今天我就给大家讲个例子,这个例子是也是在这个项目里面, 他有一个 example 的这样死的这样的一个例子,他这个例子主要是他叫这个叫情感分析的这样的一个一个例子,他这个例子呢主要是讲就如何使用 g p t two 的这样的一个模型,能够产生一些比较积极的一些就是影评,他的意思就就电影的一些评论, 你怎么通过的这种方式,然后通过 t q 的这样的一个模型,自动的能够产生一些比较积极的一个些电影的评论,积极的评论主要是主要是那个一些比较好的,不是一些贬义的,因为我们清楚就是 g p t two 的话,如果你不经过微调的话,它产生的这种评论也有积极的,也有负面的,也有中性的,他可能有三种, 我们怎么通过这种强化学习的这种微调能够让他产生一些比较积极的,或者是中性偏多的这样的一些 影评,他等于这样,好吧,那么我们就来看一看。那么呃,如你要跑这样的一个类,跑这样的一个 zample, 你主要还是要安装 transformer 的这样的一个内裤, 同时你也要安装这 t r l 的这个 transform 的强化学习的这样的一个内裤,它的也是这样,当然这个是 n d b, 这个是一个可选的,它的安装是可选这个主要是监控它的这个训练的这样的一个指标啊, 他可是跟那个呃,他是 board 这样的一个工具有点类似,那么在的话他们会用这个会比较多,那就是这样,好吧,我们就赶紧来看看原代码,原代码的我带大家读的主要是在这,在 notebooks 里面他有一个够情感分析情感的这样的一个强化学习的这样的一个东西。啊,你刻一张图,你可以看到他是怎么来做的啊? 部分的话呢?它其实它不,它的微调的话,还是通过强化学习,就是做 g p d two, 对吧?啊?然后能够产生一些 response, 然后呢?它呢是通过一个 i m d b 的这样的一个语料库啊?然后它有些问问题,通过 g p d two 自动的能产生一些影评的评论, 然后通过这个影片的评论产生的这些内容,他通过查询和产生的这个内容,他会训练一个他们原来有一个 art 的这样一个模型,这个模型会自动地产生你到底是积极的评论还是是负负面的评论?他自动通过 叫情感分析的这样的一个人工智能的一个模型,它自动的能够产生这样的一个 reward, 你到这个称之奖励。强化学习里面一个非常重要的这个叫奖励。呃,如果他的这个回答是比较积极的,那么他的 reward 会高一些,如果他的回答是比较负面的,那么他的 re reward 会变成他的奖励,会变成一个复数。通过这样的一个强化学习的这样的一个过程,他会让他 g p t two, 他的这个经过他的这个强化学习的这个微调之后,他能产生的这些评论基本上都是一些积极的或者是一些中性的这样的一些词 啊,那我们来看看他是怎么来做的?这边会比较简单,这个是他要安装的这样的三个,呃,这个 library transformers, trl, 然后 w, a, m, d, b 装完之后的话要 input 这样的这些内裤啊,这个,呃它也是上面的啊,那就, 呃强化学习法里面的一些参数啊,这个是目的原始的一个 name, 这个是一个,就是绿之绿,他这个 log 的是用这样的一个内裤去做一个学习率和 los 的这样的一个跟踪,他是通过这个来做的。好啊,这个也是一些参数,是 bench size, 他用了十六,他等于是这样好, 那么这一片分担吧,这一部分,但主要是把 i n, d b 的这个 data scent, 就是影屏的一些数据能够把它给装载进来啊,这个,这个是比较简单的啊, 呃 b, 呃 g, 呃 g p t true 的一个大型的这样的一个模型,把它可以装载进来。呃,它这个 微调的这个模型啊,然后呢,它是经过 training 的这样一个这个强化学习的一个算法进行微调的,所以这个是这个就是它的模型,这个是它 refer 的这样的一个模型啊,是它真正后面要用 用的这个模型,这个 refer 模型就是它,这个就是 g p g two 的预处理的原始的模型就是数据,你要调,你要你要微调的这个数据, 它在这个里面它还是要去装载一个 but 分类的这样一个算法。这个算法呢,它主要是做情感分析的,前面我们去讲了,因为它一句句子来,它要去自动去判断它到底是积极的还是负面的,它是通过这个 过程的这个模型去判断的,而不是手势是人为去判断的。当然你也可以去人为的去打分,人为去打分,你的这个工作量会比较大,所以他是通过一个人工智能的一个模型,积极的去判断 gpd 就产生的这样的一些影评,他到底是积极的还是中性的还是负面的?他是通过这个模型 模型来进行这个预测,他的这个 reward 就是他的奖励,他的意思。讲到他这儿就举了一个例子,如果是 bad, 那么他这个负面,他的分就很高,正 面得分就很低,如果他是非常好的 very good, 对吧?那么他的负面得分就很低,正面得分就很高,他等于是这样,他就给你看一下他这个模型,还是说他这个,嗯,这个奖励的这个数值的好,看看这边的差呢?他主要是有 g p g 啊,主要是产生的这样的一些 他产生的内容,他要设置一些参数,什么 top key, 对吧? top p compos, 一些内容啊,也参数啊,那么这个 output 的最差,大的长度,最最小的长度,对,最最大的长度,他这个都在这边定义,定义完了之后呢,他就用这个 g p t two 的这个模型,要产生,要产生这种内容,对, 就产生这样的一些内容,产生这样的一些内容。产生内容完了之后的话呢,他要到要去预测,用前面的这个模型去预测这个 reward, 就是奖励,他要去判断你产生的这些内容,你是积极 还是负面的,如果积极的话呢,你就会比较高,如果是负负面的话呢,他这个 reward 也比较低,他等于是这样啊,就把呃查询和 response 和这个 re reward 放在这个 p p o 的这个 training 的这个里面去训练,他等于是这样,哎,但是其实还是蛮简单,然后就不断的去训练,只他这样的,这样的一个结果,你可以看到是这样的, 然后变的话,这个 reward 的真菌值啊,他的奖励就很会很高,他这个模型就会马上就会能够去往这个奖励高的地方去产生内容,他等于是这样,那么他产生的内容相对来讲都是积极的,他是这么来做大型的类似于 chat g p g 的这种模型的微调,他是通过这种方式来做 好,他现在就去把这个模型训练完了之后,他去检查一下,他要把这个两个模型要把它给产生一些内容,这个就是原始的 referred model, 它产生的内容,这个 model 是他训练之后微调之后的产生的这个内容,那他就自动的产生,他就把它加在反 呃这个这个 response 的这个里面,这个叫之前产生的叫 before, 之后产生的叫 after, 它等于是这样,这个也是一样的,它这个 reward 它也会把它给拉出来,拉出来之后的话呢,它就会变成这样,这个就是查询,查询就是是指他们提供了一些影评, 他又给了一些猝死的值,不让他能够产生反馈,如果没有微调过的,那么他的反馈是这样的,如果微调过之后的他的反馈是这样, 结论肯定是他最后都产生的比较积极或者偏中性的为主了,他这个事情好的,这还是比较简单的,这个就是他他在训练之前他的平均值,对吧?只有零点幺五,训练过之后啊,就上升到这个 一点六八了,就说明经过训练之后的这个 g b t two 的这样的一个模型,产生的这种产生的这种,那个产生的这些内容,它相对来讲会比较积极。那么这样的话呢, 就是通过这种方式来微调 gpd two 的这个模型,然后产生一些积极的评论,他是通过这种方式来做,好吧?好,这段代码就给大家读到这,那么这个代码他主要做什么呢?因为他的微调有两种方式,一种这种方式呢,他比较简单,还有一种方式呢,他可以做一些指令,指令的微调, 指令的微调差异在哪里?就是他的唯一的差异,给大家看一下,前面都是一样的,他的差异在这,他有一些叫 ctrl 的一些指令,有一些叫产生负面的,有一个产生中性的,有一个产生积极的,他是在这些 task 任务之前,他会把这个东西给放进来,他等于是这样, 这个就是一个任务,他是一个负面的一个任务,中性的任务和一个一个一个积极的任务,他会在这个指令里面进行预售,他等于是这样把这个指令也放在这个查询的这个里里面,一起扔到这个 gpt 里面进行微调。他是通过这种方式去做这种方式,他的 好处是在于他的指令可以来定义啊,我要产生一个积极的评论,那么我就打积极的这样的一个任务,如果我要产生负面的,那我只要用这样的一个关键词,我就产生的这个内容就偏负面,他等于是这样,哎,你可以定义啊,那么这样让 gpd 恰恰就会比较聪明,你想产生负面的也行,你想产生积极的也可以,他等于是这样, 那么他就是放在这里面去训练前面的训练过程一样的,他默认都会产生一些比较奖励比较高的,一些比较中性和一些比较积极的内容,他都是这样的,负面的内容他就会产生会比较少,默认情况下这个是他,最后 如果他是比较负面的,那么你的指定是负面的,那么他的这个奖励的得分就会比较低的一些内容会产生。如果是比较积极的,那么他的这个内容相对来讲就是比较正面,如果是中性的,那么他的内容就比较中性,那么他这个模型的话呢,也可以保留下来之后,你这个模型 经过微调过之后,那你就可以再用这个模型能产生你需要的这样的一些影评的一些内容。他这个例子是写的不错的哈,所以给大家一起带大家简单啊,这个的话呢,他用的型叫 t 五模型,其实都是一样的啊, t 五型只是不是 g p t two 的一个模型,是一个 t 五模型的强化学习,那它是一样模型的话呢,它用了一个它的方法,这上次我们也是讲过的 packed 方法的话呢,就是,呃, cpu, 你的 gpu 内存消耗的比较少,你的计算资源比较少的时候,你可以用这 packed 这个方法,那这个里面也简单的会顶你一下, packed 消耗的这个资源会比较少,如果大家有兴趣的话也可以看一下,这个我就不带家看了。那么这个模型的话呢,它是用的 g p g 杠 n e o x 杠两二零 b 的这个模型来进行训练,这个模型之前我们也是介绍过,他们是去去去去 可能去山寨 g p t, 掐着 g p t 背后的那个模型叫 g p t 三的这样的一个模型,在开源里面就是叫 g p t 杠 n e o x 杠二零 b 的这样一个模型,那么他们也可以用一个多个 c p u, 就是多个 g p u 进行同时训练,派的就是主要是做这件事情,如果大家有兴趣也可以看一下,所以这个项目还是很有价值的,很有价值 这个是主要我跟大家介绍的这样的一个例子,因为也有朋友在给我留言说怎么样去微调这个大型的语言的模型,那么大型语言模型一般是用叫指令学习,或者叫强化学习,人类反馈强化学习来进行微调的。今天我给大家介绍的这部分原代码主要是做这部分 啊,跑这个东西他至少是要四十 gb 的 gpu 的内存,他要四十 gb 安快 cpu 至少要四十个 gb 的内存,他才能跑这样一个东西啊,那我今天就跟大家就介绍到这。
215小工蚁 05:01查看AI文稿AI文稿
05:01查看AI文稿AI文稿如何绘制 am 图?一、什么是 am? am 是一种统一建模语言,是用来对软件密集系统进行可视化建模的一种语言。 arm 图有很多种,主要包含用力图、类图、对象图、序列图、协作图、状态图、活动图、构建图、部署图。其中最常用的就是类图、用力图、序列图。 二、类图的表示方法。二点一,类的 am 类图表示。 am 类图中用矩形框表示一个具体类,矩形框分为三层,第一层类名,第二层成员变量。第三层,成员方法。 举个例子,上面的代码对应的 arm 类图成员变量以及成员方法明前的访 问修饰符,用对应符号来表示成员变量以及成员方法名号请跟着冒号,后面再跟着成员变量的类型或者方法的返回类型。二点二,抽象类的 am 类图表示。 这是一个抽象类的定义,其对应的 am 类图。抽象类在 am 类图中同样用矩形框表示,不同的是,抽象类的类名以及抽象方法的名字都用斜体字表示,其他和具体类没有任何差别。二点三,接口的 am 类图表示 接口在类图中也是用矩形框表示,但是与类的表示法不同的是,接口在类图中的第一层顶端会用 interface 标注,这是一个接口,下面是接口的名字,第二层是方法。另外需要注意, 这是接口的方法,前面没有访问修饰符,默认就是 public 访问权限。二点四,包的 arm 类图表示类和接口一般都出现在包中。 am 类图中包的表示形势如图 三,类图表示类之间的关系。三点一,继承关系继承关系也称为泛化关系,是指对象与对象之间的继承关系。如在 am 类图中,继承关系是用空心三角和实线组成的箭头表示, 从此类指向副类。上面的例子中,散类继承了 parent 类。三点二,实现关系实现关系是指接口及其实现类之间的关系。在 up 类图中,实现关系用空心三角和虚线组成的箭头来表示, 是从实线类指向接口三点三,聚合关系聚合关系是一种特殊的关联关系,表示的是整体和部分的关系,整体与部分具有各自的生命周期, 即使整体没有了部分还能存在。典型的例子就是公司部门与员工的关系,一个部门撤销了,员工还能存在。在阿木图中,聚合关系用空心菱形加实线箭头表示,空心菱形在整体一方,从实线类指向接口 三点四,组合关系和聚合关系类似,组合关系表示的也是整体与部分的关系。但不同于聚合关系的是,组合关系中整体与部分不可以分开,一旦整体对象不存在,部分 对象也将不存在,部分对象与整体对象之间具有同生共死的关系。组合关系和聚合关系不关,概念很像,他们的 am 类图表示也很像。在 am 图中,组合关系用实心菱形加实线箭头表示,实心菱形在整体一方, 箭头指向部分一方。在 java 代码形式上,聚合和组合关系中的部分对象是整体对象的一个成员变量, 仅从类代码本身是区分不了聚合和组合的。如果一定要区分,那么需要结合业务角度上来看,如果作为整体的对象,必须要部分对象的参与 才能完成自己的职责,那么二者之间就是组合关系,否则就是聚合关系。三点五,依赖关系 依赖 dependency 关系是一种弱关联关系,否则就是聚合关系。但是和 b 的关系不是太明显的时候,就可以把这种关系看作是依赖关系。如工人 worker 要去拧螺丝,要依赖螺丝刀 screwdriver 来帮助你完成拧螺丝的工作。 依赖关系在 joy 中的具体代码表现形式为, b 为 a 的构造器或方法中的局部变量方法或构造器的参数方法的返回值,或者 a 调用 b 的静态方法,否则就是聚合关系。依赖关系用一个带虚线的箭头表示 有使用方,指向被使用方,可以看上面的例子案例分享,想要获得上面的流程图,记得点赞评论哦!以上就是本期内容,我们下期再见!
833乐述云享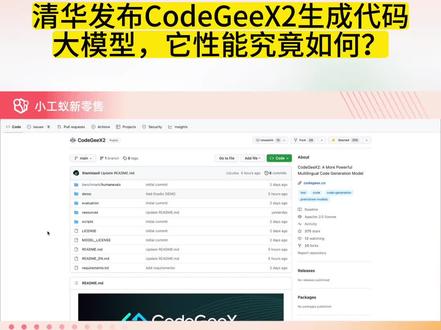 04:49查看AI文稿AI文稿
04:49查看AI文稿AI文稿跟大家直播介绍一下的是一个新的一个开源的一个项目啊, ec 的话呢,它主要是产生代码的啊,这个项目的名称叫 code g x 二代,这个的话也是清华清华智普他们研发的这样的一个模型啊,这个模型的话呢,它本质上呢主要是产生各种各样的代码啊, 这个是他们的二二代的模型,因为我们之前了解的是 chat g l m 二代,目前已经发布了,而且性能比一代的还是取得了蛮大的一些进步的,所以 g code g x 啊,他们也很快的在 chat g l m 二代的这个架构上啊,然后进行发布啊,发布之后的话,他发现就是 扣的 gx 二代的话呢,它的性能上面还是得到了比较大的提升啊,他比一代的话要提升了百分之一百零七啊,当然因为一代他可能太差了啊,所以的话呢,他他提升还是非常大的,我们可以一起来看一下,因为我之前也是介绍 过 ai 机器产生代码的话,它是有个排行榜的啊,他目前大概目前所处的这个位置在哪里?我们一起来看一下哈。他目前公布的这个数据,我看了一下, code g x 的话呢,他把权重公布出来了,但是呢,他如何训练的话呢?他还是这个代码还是没有公布出来, 如何啊?因为我们有些企业还是有私有的代码啊,需要在这个 code g x 二的这个基础上进行在微调啊,他这个代码没有公布出来,但是他把评估的代码公布出来了,他目前评估他主要用那个,我看了一下,主要是 叫 human ever 啊, pass 一和 pass 十啊,他把这个代码公布出来了,他目前能力来讲的话呢,他达到了大概是三十五点九啊,他跟他比那个哈根 face 的 cold 十五 b 的这个模型要强一点,他等于是这样。呃,之前我因为给大家 是公布一个一个榜单的,这个榜单的话呢,主要是呃评估这个代码的这个产生代码的这个准确率,它有一个评估指标叫 pass at 一。呃,最高的能力的话呢,就是 排名第二的话呢,就是百分之五十七,排名第三。前面给大家看的就是 stock coder 这样的一个,那么目前的话呢,清华公布的这个 code g x 二代超过了这个 stock coder 十五 b 的这样一个模型 啊,不错啊,成绩还算是不不错,但是还是没有到那个优秀的这个程度啊,只能算是中规中矩吧。他是目前我给他的评价是这样啊,这个模型他相对来讲他的啊,他是六十亿的这个参数,所以他是个六 b 的模型啊, 他六 b 的模型他也要超过了。原来这个十三幺零三 b 的就是一百三十亿参数的这个模型的啊。目前的话呢,他这个项目的话呢,他的原代码是居阿帕奇的 这个协议可以开源的啊,他这个权重协议他在学术研究上是完全开放的,如果申请商业,你要去登记,他的意思讲,但是他没有讲是否要收费啊,我看了一下,他没有讲是否要收费,估计他六 b 这个模型是不会收费的啊,也是可以免费的啊, 但是他这个模型跟原来一代的这个模型是一样,他是不能微调的啊,他这个模型怎么微调?目前这个代码是没有公布出来的,他在这个项目当中他也公布了一下他到底怎么来用啊?这个用法跟原来的那个 chat glm 二代的那个杠六 b 的那模型差不多啊,只是一个是产生文字,一个是产生代码啊,唯一的差异在这。 然后呢,他的生态的话呢,目前我也看了一下,他支持的还是不错的啊,像 v s 扣的啊,包括一些一些开发的框架啊,主流的一些开发的一些工具,他都能够支持啊。目前我看了一下,他能够支持的语言大概是也蛮多的,大概几十 这种语言都是能够支持的。支持的啊,这个项目上为什么就是我对 ai gc 产生代码这一部分还是很重点关注的,因为之前我介绍过那个麦肯锡那个一个 ai gc 的一个报告啊,这个报告里面也是讲到, 呃,对一些 ai 机器,他对四个行业可能冲击是最大的啊。排名第三的话呢,就是对工程师啊,通过 ai 能够自动产生代码这一部分,那么将来的话呢,他这个代码他不需要这个非常专业的工程师去写啊,高级代码你还是要工,要一些工程师去写的,但是初级代码的话,他是不需要工程师去写的, 他主要用一些自然语言去描述,他自动的就能产生一些代码,我觉得这个是这个方面的那个进展,目前来看也是非常快的,也是非常快的啊,下次有机会呢,我可以介绍一下目前排名第一的这这家公司也是很有故事很有背景的一家公司 叫 replete cold 啊,这家公司的话,原来他 google 愿意花十亿美金去收购他啊,但是这家公司就咬住不放啊,他就他,他就没有答应 google 这这这种大公司的收购。目前他们开源的这个 模型可以对标目前那个 oban ai, 他们背后的叫那个 co pilot 的这样的一个代码的,这样的一个生成的一个模型的, 所以也是非常强的,你可以看到他的那个帕斯一的这个指标的话,达到百分之六十三点五啊,跟目前清华推出来的只有百分之三十五,其实还要差了百分之二十几个百分点,所以差异还是比较大的,性能上面的差异还是比较大,好吧,好,今天的话这个话题就跟大家就聊到这。
245小工蚁 02:01查看AI文稿AI文稿
02:01查看AI文稿AI文稿公司要求降本增效,我们团队的技术被裁了一大半,项目还得继续进行。 原来五个人的工作,现在全落在我一个人的头上,压力太大,导致我的头发都快掉光了。天天写代码,写的代码全是 bug, 作为一个程序员,我该做些什么了?干活这个事情能少则少, 打开 chat gpt, 看看他能不能帮我干点活。先让他帮我写一个基于家外语言 spring boot 框架实现 mqtt 互联网通讯协议远程控制的功能吧。 再让它连接远程 m k t t 并且初始化, 再用 vivo 来实现调用后端订阅控制接口。 代码确实写的比我好,他不仅理解了我要干什么,而且给出清晰详细的注视,让我这个十五年的老程序员自惭形秽,随便修改一下就可以用了。 借助大模型,这代码效率提升了一半,原本要干三天的活,现在一天搞定,这就是 ai 的魅力。如果你对 ai 感兴趣,想要探索大模型的更多可能性, 比如如何做一个智能客服,那就来开启程序员 ai 大模型进阶之旅吧!点击 链接就可以轻松学习知乎学堂的 agi 课程,课程涵盖了大模型的专业知识训练方法,教你如何借助大模型提升代码能力,定制自己的专属模型, 还可以借助大模型来提升自己的收入,快来和我一起进步吧!
1989程序猿白瑞 00:23查看AI文稿AI文稿
00:23查看AI文稿AI文稿大模型相关论文在鼎会层出不穷,如何将大模型应用到自己的文章中呢?尤其是算力有限的情况下。今天给大家分享七种大模型的应用方法。 此外,为大家能够对应用方法有更深入的理解,还给大家准备了五篇相关的经典论文,原文和代码都有,一起来看看吧。
 01:21
01:21 00:38查看AI文稿AI文稿
00:38查看AI文稿AI文稿chat gpt 又上了一道颠覆认知的硬菜。最近很多人已经收到 code interpreter 的测试资格,这个模型有多恐怖?它支持数据可视化,会基本的视频编辑,能转换文件格式,可以从图像中提取颜色,做成调色盘。哦对了,在内存不足时还会自动压缩。有人上传了一份 csv 数据,问 chat gpt 可以进行哪些操作, 然后一键执行 chat p, 将大部分建议全部可视化,甚至包括哪些数据可视化之后会活,以及在哪里寻找这些数据。这些前置操作都是直接咨询 gpt 得到的,主打就是一个全自动化,现在还在测试阶段。申请地址在这里,运气好的话三个模型都能申请到。我在想,如果把彩票数据提供给他。
1574GPTalks 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿这是第一本大模型的入门指南,汇聚了 ai 大佬吴文达与 openai 合作打造的大语言模型系列经典课程,从模型原理到应用落地,全方位介绍大模型的开发技能,即便你没有丰富编程经验,也可以顺利入门, 开发出有实用价值的 ai 产品。具体看,书中首先介绍 prompt engineering 的方法,通过案例,你可以学习文本总结、推力转换等 prompt 设计技巧。然后,本书会指导你基于叉 gpt 提供的 api 开发一个完整的、全面的智能问答系统。 此外,在 long time 部分,你将会学习如何结合框架 long chain, 使用 chat g, p, t, a p i 来搭建基于 l l m 的应用程序。最后,本书重点探讨了如何使用 long chain 来整合自己的私有数据。
306誉浔信息 00:26查看AI文稿AI文稿
00:26查看AI文稿AI文稿我们是一家来自深圳的这种呃 ai 和三 d 技术服务公司。我们研发的这款六百五十亿参数的这个大模型产品呢,目前是 国内最大并且是最早进行开源和免费商用的这种大模型产品。我是一个专门做这种教育类产品的人,那我现在就想告诉大家如何去学习编程,所以我让他来生成一个 a p p 的这个思考的方式吧。
182第一现场 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿本文提出了一种基于大型视觉语言模型的工业异常检测方法 animalapt, 这也是第一个基于大语言模型的工业异常检测方法。该方法通过模拟异常图像并生成相应的文本描述来生成训练数据,并使用图像解码器提供细力度语意。 annamaliped 消除了手动预制调整的需要,直接评估异常的存在和位置。此外, annamaliped 支持多轮对话,并展现了令人印象深刻的少样本上下文学习能力。在 anne veticat 数据集上, mallet 实现了百分之八十六点一的准确率、百分之九十四点一的图像级 a、 u、 c 和百分之九十五点三的像素级 a、 u、 c 的最新性能。
258人工智能论文搬砖学姐 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿用大语言模型做应用才是正确的方向。今天给你们分享一个可以像搭积木一样构建 ai 应用的工具。 promot fro 是微软最新开源的一套开发工具,它大大简化了基于大语言模型端倒端开发 ai 应用程序的周期, 实现了从构思、圆形设计、测试评估到生产部署和监控一条龙服务。具体来说,你可以用 promote pro 把不同的工具和代码组合在一起,形成一个可以运行的工作流。接着利用 vsq 的将工作流可视化,方便你进行调试和修复问题。 特别是与大语言模型的交互部分,如果你对 python 比较熟悉,可以按照这个入门教程实践一下。另外,官方还提供了实用的案例,教你从零到一搭建和 pdf 聊天的 ai 应用。整体体验下来啊,我认为这个工具比我之前给你们分享的 province 好用不少, 我们最近也开始利用此类工具基于大于模型来开发 aibox。 如果刚好你也对 promtang new 感兴趣,欢迎一起学习交流。
1077艾克ai分享 00:46查看AI文稿AI文稿
00:46查看AI文稿AI文稿如何让 gpt 教你学习最新的开源项目?今天我们让大模型来教我们使用最新的开源项目游路 v 八。我们知道长安 gpt 最新的知识,直到二零一年九月,并且最多也只能输入一万个单词,根本无法处理这么长的文档。 所以今天我们要用的是 cloud 一百 k 能支持七万多个单词,可以直接把优乐微八的原文档一股脑的丢进去。我们先让大模型来做个总结,这里我们就知道优乐微八可以做目标检测、实力分割、关键点检测等任务。以目标检测为例,我们可以让他根据文档生成代码, 训练目标检测模型设计到的配置文件,同样也可以让他根据文档给出格式和参考视力,按照要求配置好后,就可以直接运行代码训练模型了。训练完成后可以再让大模型给出推力代码,这样我们就轻松学会了 ulov 八。
518渡码 01:19查看AI文稿AI文稿
01:19查看AI文稿AI文稿随手用下面这张草图纸画给 chagbt, 十分钟后就在他的帮助下做成了上面的这个网站。整个过程不用写任何代码,想知道我怎么做到的吗?第一步,先画出网站的草图。 第二步,把图纸上传到叉 gpt, 并给出以下指令,用草稿的样子帮我生成一个网页, stml 代码 复制粘贴到 vs code 的新建文件中,并且保存到桌面上。 第三步,用 majority 图声图功能生成一张可达诗歌的肖像图。第四步,将肖像图的文件地址和另一个网页的网址嵌入到叉 g p t。 贴心的给我们交代清楚的空缺位置,检查一下现在的网页。嗯,怎么觉得还差点意思啊?哦,原来那行飞行的文 文字他没给我做出来,那就再发送以下指令吧。请将 flowing tech 变成从左飞到右的效果。第五步,将新生成的代码结合几个网址链接填写到空缺位置,熄火。你看,点击 contact 还能跳出我的微信二维码,点击没有还能给我发邮件, 哎,这几个按钮也都顺滑流畅,一共不到十分钟。不会写代码的你学会了吗?
136可达师哥
