dalle使用教程
你想把这只狗换成这只猫,只要这么做是不是很简单呀?或文字描述,电脑就能够输出三维渲染图,而且精度更加高了。你想要把当中的内容换掉,马上呈现,神奇吗? 这就是现代人工智能 a i 打理 to 的创造能力。看一下 a i 制作名画,这是名画原图, 智能 ai 达丽 q 可以模拟所有的笔画笔促,它不但是模仿笔促,而且你看它的构图以及所有的风格都是非常类似的,但是里边的人物造型等等都是有了变化的, 等于是人工智能通过学习是现在可以自己创造内容了。而且如果作为一个艺术生学习这一幅画的话,嗯,是 需要花一定的时间。而作为人工智能,现在的速度就是几秒钟出化。关注涛涛,设计人生,开启新的生活方式!

粉丝181获赞2345
相关视频
 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿给各位同学看一下现在拆 g b t 的 daily three 可以申请使用了,然后给大家看一下我刚才生成的一些效果图啊。呃,首先呢,我先让他生成了一批的这个秋天的北京的样式, 然后还有按照马里奥风格和任天堂风格生成了呃,一系列的这个中国地图, 我还让他按照一个女性的角色样式不改变的情况之下,然后生成不同年龄段长什么样子,对吧?然后相相同的衣服姿势,头发,然后只是年龄不同有一个年龄的递进,对吧?然后我这里边还让他生成了一只狗的形象,这只狗呢,然后可以出现在火星上, 然后还可以让他比如说出现在海洋里潜水,我还希望让他和这个钢铁侠拯救世界,对吧?呃,虽然他现在测试下来看啊,应该是生成呃,三批到四批 之后啊,他生成的这个结果呢,有一点变化,但是没关系啊,我可以通过语言的一些啊描述呢,然后让他第一张里面的这只小狗,然后和第二张里面这个钢铁侠呢,可以出现在呃一张图片里面,是吧?然后来给大家看一下 现在用拆 g p t 生成的这个结果啊,都是可以通过一些自然语言就是正常的呃沟通,然后它就可以帮助我们生成一个更加准确的一个效果, 不再像是米之尼啊, s d 啊,之前生成那些效果需要有一个固定的关键词结构,现在不需要了,直接通过拆 g b t 的这个大语言模型和 daily 的弧向生成的模型进行了一个组合,然后就可以用最简单的语言生成想要的效果了, 然后现在呢?想要试用这个呃,拆 gbt 的代理思瑞还是相对来说有一些麻烦啊。现在还是需要有一步的这个申请,如果各位同学不知道去哪里申请的话,可以私信我或者来我的粉丝群也是可以的。
341胡泊Hubo 01:05查看AI文稿AI文稿
01:05查看AI文稿AI文稿mate 三零这一次真的是要慌了,新版的 del 一三已经融合到 gpd 里了,我原本以为呢,对 mate 三零的影响并不大, 但实际使用下来之后啊,发现他何止要慌啊,现在呢,你再也不需要输入复杂的提示词啊,想画什么?简单的输入你的要求, dle 就能帮你画出高质量的图片来。看看这个,我就输入了一个太空电梯,然后呢,他通过自己的联想设计了四组不同的提示词,然后给出了结果,你们看一下效果怎么样啊? 最后呢,还给我画了一个工程图,这难道是想让我施工吗?无论是让 doe 画儿童绘本,或者是设计 logo, 又或者是画表情包,他表现的都非常的出色。再看看这个表情包啊, 哭笑,尴尬,无奈,每一个表情都非常非常到位啊,你们觉得怎么样呢?而且他对文字的知识也真的是太好了,你不仅可以让他在图片上加上文字不满意的点 地方,你还可以通过继续对话让他随时调整。最重要的是,对于大部分普通用户来说,你不需要再花费每个月八到九十六美元的高额费用了。而且呢,目前似乎 doe 还没有限制生成的数量,完全可以满足大部分人的需求啊。
3317浩哥聊AI 01:22查看AI文稿AI文稿
01:22查看AI文稿AI文稿道理二,有一个扩图功能,比 ps 聪明多了。今天来尝试一下。点一下你的头像,跳出下拉有一个 all painting, 点右下角有小加号的标志,就可以选择你想加工的图片了。我们选择一张图片,把它缩小一些, 点这个勾勾放在这个框内,他就可以帮你把框内其他空白的部分填满。这里输入文字,我希望扩充的背景里面有树叶点生成,开始填充了, 怎么有字母出现了?点一下,这里有四个选项可以换。哎,这个不错。嗯,还是这个好,我接受点击下载即可, 这样就方便我统一排版啦。如果我不扩充背景的话,就只能这样子,而且它比 ps 做的效果好非常多,它非常的智能,很聪明。 ps 做出来的结果是这样子的,这里的 bug 非常明显,完全不能用,如果你认为手动去修的话,需要花大量的时间。 okay, 完美。
151一只设计戴 01:37查看AI文稿AI文稿
01:37查看AI文稿AI文稿oppy 在前段时间官宣了 dowe 三,没想到微软首先将其集成到了病中,接下来和我一起看看 dowe 三效果如何。首先我们进入病的官网,点击聊天,然后在聊天界面中选择 crea 更有创造力。模式打开之后,我们只需要在输入框输入创建一张什么样的图像, 例如我们生成一个牛顿被苹果砸中脑袋的图像,最后发送给并等待生成即可显示,这样就是正在生成相应的图像, 这就是图像生成后的效果。一般都是生成四幅图片,这里不知道为什么只给了我们三张高一三,生成速度还是很快的,而且效果也很不错。接下来我们尝试和病进行对话,让病给我们符合场景的图片。 在兵的回答中我们可以了解到并首先是使用上网功能查询牛顿的相关信息,然后总结成一段话,紧接着 他根据该总结内容调用刀位三来生成图像。生成图像的提示词是他自己总结了,这里不知道怎么回事,他一次性给了我们三组。三组图片的提示词都是一样的,唯一区别就是表现上的不同。 兵的图像实际上是通过病图像创建器来生成的,在图像创建器中,我们就可以直接在最上方的提示框中输入提示生成图像,他这里也告诉我们他的服务方式 dowa 三。 我们创建的图片就会存放在创作栏目中,在这里我们可以找到聊天过程中迭代生成的图片。在探索创意栏目中则是一些优秀图像和提示词展示,趁着现在还在免费白嫖阶段,推荐大家可以去尝尝鲜,这必定会是聊天和图像生成结合的关键一步。
91AI新视角 01:42查看AI文稿AI文稿
01:42查看AI文稿AI文稿本期给大家介绍使用 open ai 发布的高一二绘图服务。首先需要下载一个用于发送 http 请求的工具 postman, 当然还有别的工具可以替代,此处就不一一赘述。接下来第一步,打开 open ai 官网,找到绘图服务的接口说明, 这时我们能看到接口的调用样例。第二步,打开软件 postman, 新增一个 http 请求的窗口,然后将参数复制进去。 这里有个小插曲, 我们能看到有个参数 adversation, 这个参数的值需要如何获取呢?首先需要创建 open ai 账号并登录, 然后在 p i kiss 界面创建 secret key, 并将其复制到 postman。 第二步,调整参数内容参数 prompt 用于描述图片, 参数 n 表示要生成多少张图片,参数 size 表示生成图片的分辨率。调整好参数后,点击 sat 按钮, ok, 我们看到下面的窗口中返回了两个 url 地址,接下来我们将其复制到浏览器中, 见证奇迹的时刻到了。
11华庶说AI 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿只需要一句话,这个 ai 就能在两分钟内生成三滴模型。有人用他做一棵圣诞树,有人用他揭膜自己的绘画,还有人向他发起挑战。同一个模型,结果 ai 两分钟就搞定人类两享受工作。 这是 oppo a i 最近推出了三 d 剑魔神器 ponytai, 生成模型时只要一张显卡,速度是现有剑魔 a i 的六百倍。他之所以能更快的生成三 d 模型,关键在于他不是直接升上三 d 网格,而是选择更容易合成的点云。 整个生成过程分为三步,先根据文字描述生成一张预览图,接着通过扩散模型把图像变为粗略三 d 点匀,最后再进行细化,得到更精细的三 d 点匀模型。 但这样输出的图像看上去有些抽象。为了解决这个问题,研究团队还另外训练一个模型,可以把点云转化为网格。虽然效果不算完美,但解决以往算法建模时间长、成本高的通病,帮助 ai 建模更好的落地应用。如果你感兴趣的话,可以试试他们的 demo, 就冲这生成速度,建模圈也要卷起来了。
674量子位 00:37查看AI文稿AI文稿
00:37查看AI文稿AI文稿注意看,这张图片除了红框以内,都是由 i 智能拓展生成的,这就是刀 a two。 如果你有四月六日之前注册的阿 playi 账号,就可以来这里抢先体验,因为刀 a 的使用是积分制, 每次使用都要消耗积分。至于六日之前注册的账号,是可以每个月获得十五点积分的。这边再点击编辑图片,就可以进行图片的拓展生成了。选择拓展选项会有一个方格公标,选择画面生成的位置,然后在聊天框输入生成提示, 点击生成就会得到四张由 ai 生成的图片供我们选择。选择满意的图片之后,再依次生成剩下的部分,最后在页面的右上角点击保存,就可以得到我们生成的作品。
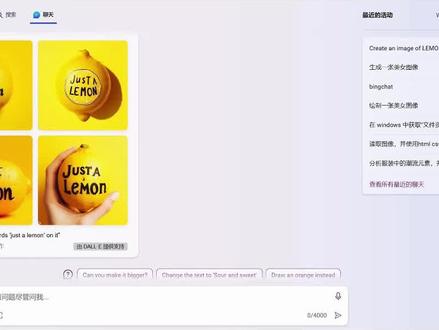 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿到一三的 ai 画图可以在微软上体验了。在浏览器搜索 image creator, 进入微软图像创建器,每天都有免费的画图额度。我们来试试他对中文的理解能力,让他画一张超级马里奥愁眉苦脸的坐在旧沙发上的图片, 旁边还放着公主的照片,打上一个红色的叉。从效果图来看, doe 三对中文的理解能力已经很好。发愁的马里奥坐在旧沙发上,公主的照片打上红色叉, 满地酒瓶都准确地表现了出来。我们再用同一段提示词,分别用倒意三、 mine、 journey、 stable, diffusion 等四个工具画出来,你更喜欢哪一张呢? 不仅如此, bowe 三还能给图片准确生成英文文字,只要在提示词上用双引号把要显示的文字内容括起来,准确度比一点管还要高。关注我,带你用 ai 提高效率!
64AI时速 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿大家好,本期视频带大家介绍一下如何免费使用 openai 发布的到三生成图片。首先第一步,前置条件,截至发稿时间,大家仅需解决自己的网络问题即可,然后打开定制的网站, 然后我们在这边点击登录注册我们自己的账号。那我们画一张图用来设置公众号的封面给大家看一下效果, 这个就是 dialog 三生成的图片,结果质量还是非常高的。 再画一个很火的对任意动漫形象的一些拆解图,还有这个书籍封面的制作 产品封面图的制作,制作贴纸,所有的提示词都在文章里去体验一下吧。好,本期视频就介绍这么多。
24竹竹AI 04:37查看AI文稿AI文稿
04:37查看AI文稿AI文稿嗨,大家好,欢迎来到我的频道。本周是 ai 大爆发的一周,其中之一是 open ai 发布了 deal e 三。 deo e 三是 open i 发布的最新版本,它使用自然语言可以生成令人惊叹的图像。 deal e 三支持多语言,你可以使用中文。作为提示上 deal e 三生成优质图像。 deal e 三的创新之处不仅在于它生成现实中存在的时候,还可以根据文字描述生成令人难以置信的创意图片。 另外一点就是它对文字处理有更好的处处理。从实际上看, deal e 三对自然语意的理解和对复杂提示词的理解是非常突出的,这是源于它源自 chat gtp 构建的一个模型。 目前上市面主流的生图工具 stable diffusion 的灵活度是最高的, major 的艺术创造型是最为突出的。而对于自然语言的理解能力, l e 三无疑是最强的。 所以我认为 dev 三目前是出图效率最高的工具,可以用自然语言快速生成有创业的图片。 deo e 三将于十月初向叉 s g d p plus 用户开放使用,目前可以通过 being imagine creator 连续使用 de o e 三 只需要注册一个微软账户即可使用。每个微软账户每天有一百点的使用额度,可以出一百次图,使用完一百点以后仍然可以 使用,只是出图速度会慢一些。使用 being imagine creator 出图时,只能使用纹身图的方式进行一次出四张图,图是正方形的,且不能精修和局部重毁。而官方演示的 open i 上的 del 一三具有图片编辑能力, 可以通过提示词来修改生成的图片,作为 del e 三正式发布前的免费而不限制数量的平台, being imagine creator 可以说是非常良心了,让我们开箱体验 bring imagine creator 平台的 del e 三。 首先我们亲测,我们测试一下 doe 三用中文提示生成创意图片的能力。我这准备了一些提示词,我们输入一个拿着火线的大蘑菇在太空中 冒冒险,然后粘贴,然后我们可以设置一些风格,比如说,嗯,奇幻,然后点击这,然后点击这里的创建, 在创建的过程中,这这儿会有不断的有呃提示的一些案例和使用方法, 很快生成了这种非常有创意的图片,我们可以看一下, 都是比较不错的,就是这个案例。然后我们接下来测试一下啊 l e 三对于画面文字处的处理能力。这儿准备了一个漫画,猪八 对孙悟空说,气泡里说话,然后对话,气泡里写着,猴哥,我是八戒。我们创建一下, 我们可以看到,呃,文字是没有我们讲,呃,没有出现我们的中文啊,我们再测试一下英文, 同样的内容,只是同样的内容,只是更换为英文了。 可以看到这里边的一些图,比如这个, 他的文字就可以控制的很好啊,大师兄,我是八戒对吧?总的来说, deu 一三是一个非常值得期待的产品,我们可以用 deu 一三快速声称创意稿。感谢大家今天的观看,欢迎大家点赞分享订阅我的频道,下次见。
 02:01查看AI文稿AI文稿
02:01查看AI文稿AI文稿ai 工具那么多,到底哪些才是真正门槛低、效果好、能用在工作中的呢?关注我,带你探索设计师必备的新鲜 ai 工具。第四, daily two 在 daily two 的官网可以看到它核心功能的介绍,主要是四个部分,图像生成、图像拓展、图像修改、 图像风格化。注册账号之后,点击首页的 triad led, 可以开始使用 led, 界面非常简洁,上方是输入指令框和上传图片进行编辑的入口,向下滑动则是部分官网视力的作品和关键词。比如我们输入一边骑摩托车一边吃苹果的猫, 就会生成四张效果图。如果你对风格不满意,还可以继续添加关键词或重新生成一遍。如果在效果图里有喜欢的,可以点开大图进行进一步编辑、变体或是下载等操作。而图像拓展、图像修改、 图像风格化处理,都需要上传一张原始图片。因为生成框的尺寸是幺零二四像素的宽高矩形,所以如果你图片较大,而且想要修改几乎整个画面,那么可以使用网站自带的工具进行裁剪。 接下来就是输入指定与生成,这里的指令是描述输入框中的内容与风格,因此当我们想要去掉画面中另一个人的时候,可以先用橡皮擦擦掉不要的人,然后输入指令,比如一个在户外的男人, 这样就可以得到一张单人照片了。同样啊,如果你只想要修改局部,也可以跳过裁剪移动生成框, 用橡皮擦擦出想要修改的部分或拓展的部分,再输入指令来达到局部调整或拓展画面的效果。但大家可以看出,如果你的画面比较大,这个生成框相对较小时,生成的效率也会降低。 there are two 的 画面生成需要消耗积分,新用户第一个月可以有五十积分,之后每个月获得十五积分,当月赠送积分,仅当月有效。 每次生成动作会消耗一个积分,如果不够用的话,只能额外进行付费购买,购买的积分有效期为十二个月。我是和你一起探索新鲜设计的美牙姐,让我们下期再见吧,拜拜!
21你丫才美工 01:55查看AI文稿AI文稿
01:55查看AI文稿AI文稿小伙伴们, chat gpd 公司推出的全新 ai 绘画大模型 deal e three 现在已经可以在并上完全免费使用了,而且它可以直接输入我们的中文,就像对话一样,直接输入你的要求就可以了,不需要什么英文关键词, 看他做这种多格连贯漫画效果会更好,而且他可以非常好的理解你的意思,现在使用不需要充值,也不需要会员,每天有积分可以使用。下面给大家演示一下如何使用。首先我们来到并应官网,然后点击这里图片, 来到这个界面,再点击这里 click, 就跳到了我们的 ai 作图界面。看这里的大模型使用的就是 chat jpt 推出的全新大模型 we three, 在这个框框里直接输入你的中文要求就可以了,比如我要一个漫画图,一个金色头发,口袋,红色蝴蝶结,身穿背带牛仔裤的小女孩跟一个穿黄色连衣裙的老师打招呼,然后我们点击这里生成即可,等待一下图片 立刻给到我们。我们可以看一下他生成的图片,他可以非常好的理解我中文的所有的要求,并且不会像 m g 那样会漏掉我的一些要求。比如这个图片中我要求金色的头发,红色的蝴蝶结,以及背带牛仔裤,还有老师的黄色连衣裙, 全都符合。那他的理解能力这么强,看,我让他帮我出了连贯的四格漫画,四格漫画要求讲述一个小女孩堆雪人的故事,这是他帮我们生成的。看四格漫画里面的人物都是统一的,而且是具有连贯性的。那我们再用 mejony 来做个对比,把这个要求用翻译软件翻译成英文之后,把它放入我们的 mejony, 同样的关键词生成出来的是这种效果, major need 就没有办法非常好地理解我的要求,但是个人更喜欢 major need 的画风,所以两款 ai 绘图软件各有千秋。再看一组对比,用 deale three 大模型出的龟兔赛跑 四格漫画。再看一下这个是用 majoring 输入同样要求的四格漫画也是没有办法非常好理解我的要求。怎么样?两款对比一下,大家更喜欢哪一个呢?快点去试一下吧,看我哦,每天分享 ai 前沿小技巧!
154AI画画的牛掰掰 03:20查看AI文稿AI文稿
03:20查看AI文稿AI文稿open ai 在一夜之间突然发布 dirty three, 毫不谦虚的说,它可以在你提供的任何创意想法下帮你生成文字提示,然后以独特的方式负责创作图像,最关键的是可以白嫖。我会在视频最后展示如何免费使用, 看这个通过德林 three 生成的小猫,只需要输入了一只现实画风的猫,就能呈现出高质量的图片,简直就跟拍出来的一样。而同样的提示词,德林兔生成的猫进行对比,两者质量高下力判, 可见德瑞瑞这次的提升很大。接下来让我们一起来看看官方的展示。这个故事是一个家长将他家五岁小朋友的脑海幻想变成了童话故事的一个例子。最初这位家长向 gbt 提出个问题,我家五岁的孩子在脑海中想象了一只超级向日葵刺猬,他应该是什么样子的呢? gbt 立刻生成了四段不同风格的提示词,并提供了相应的图像,选择了其中偏向童话插画风格的一张图后, 给他取名叫做 larry, 并给 gbt 添加了更多的细节,例如为 larry 画一个房子。在这里我们可以注意到 derry three 能够继续创作出与之前一致的形象,甚至正确的书写了 larry 的名字, 解决了之前版本无法书写的问题。接下来家长还借助了 g p t 来完善故事情节,然后提出了一些建议, dirty three 能够根据新编好的情节生成相关的插图,甚至还可以设 设计相应的贴纸。当然, three 也可以继续保持角色的形象,绘制出不同的贴纸风格。注意了,最厉害的地方来了,最后直接要求 gpt 总结前面的对话内容,编写成了一个完整的故事。 我们完全可以通过 gpt 故事生成能力和 dirty three 的绘画能力编写出一本属于我们自己的童话故事书。 dirty three 的官网拥有许多的案例, 每一张点开还可以看到相应的提示词,并且所有的描述都采用了通俗易懂的人类语言,并没有添加复杂的咒语。 例如这张图是通过组合复杂场景来呈现不存在的概念,效果其实非常惊艳的。讲到这里呢,相信许多小伙伴都已经想迫不及待的来尝试一下了,但是, 但是以 three 作为 gpt 的插件是需要 plus 会员才可以使用的。但是呢,小雨呢,作为资深的白嫖怪,怎么能被这小小的困难难住呢? 其实在妞病中已经集成了得瑞 three 的绘画功能,通过进入妞病的对话界面,让他随便画一张图,然后点击这里就可以看到微软的图像创建器, 服务提供方就是等人 three, 这里都是可以免费使用的。值得注意的是啊,右上角有一个积分,每周有一百积分的额度,如果使用完了也只会降低你出图的速。 在 ai 工具层出不穷的今天,只有找到了合适的自己的工具并熟练使用,提升效率,才不会在 ai 的浪潮中被淘汰。关注小雨,带你在 ai 的浪潮中探索前行的方向!
54爱科技的小羽 01:47查看AI文稿AI文稿
01:47查看AI文稿AI文稿假如甲方爸爸让你画一条狗,这只狗会骑单车,戴着墨镜和沙滩帽,还要出现在纽约时代广场。在你一筹莫展的时候,有个 ai 帮你解决了这个问题。 来自谷歌的强大 a 绘画设计师叫做一妹子,面对甲方大把各种奇怪的要求,他都能满足。比如参加奥林匹克四百米自由泳的运动狗,用巧克力、奶油芒果制作甜品猫头鹰,还有在多伦多夜空中燃放谷歌 logo 的烟花。 这些图片只需要甲方爸爸一句话,不需要提供任何图片的素材,也不要什么 ps 技术。那么这个 a i 是怎么画出神做的呢?它是一种根据文字进行绘画创作的扩散模型。 所谓扩散模型,你可以把它理解成一个画家,这个画家会先勾勒出草图轮廓,再慢慢补充图像细节。同理,音乐阵首先会生成一个六十四乘六十四像素的草图,通过补充细节,最终达到一零二四乘一零二四的分辨率。这种技术叫做超分辨率。和一般 ai 相比,音乐整的超分相当智能。举个例子,比如让他画一只狗,他会先升上一张小图。在图中,狗眼镜只有三个像素宽度,他在根据自己掌握的知识重绘狗的眼睛,将它放大到四十八个像素,使图片显得更清晰逼真。 哥还做了个盲册实验,让人们评价不同 ai 生成的图片。大部分人都认为音乐整的效果比其他 a i 更加逼真。那音美整是怎么知道狗眼睛长啥样呢?这是因为谷歌深圳一个超大语言模型,而类似的从文字到图像的技术并不是第一次出现,前不久欧本 a 开发了达利兔,也具备同样的能力。但 谷歌表示,我们的伊美枕比打粒兔更强。如果分别让两个 a 画一张制作拿铁拉花的熊猫图片,那么打粒兔会化成制作熊猫形状的拿铁拉花,而伊美枕则准确识别了这句话的意思,画出一只在做拉花的熊猫。 当然,如果甲方爸爸提说要求过于刁钻,医美诊也是无法完成的。比如让他画马骑着宇航员,他只会给出宇航员骑马的结果。不过可惜的是,由于一些社会伦理问题,谷歌暂时并不打算开源,也没有公开 demo, 所以我们暂时用不了这个 a。
1.2万量子位 01:31查看AI文稿AI文稿
01:31查看AI文稿AI文稿v x t 能用倒立三了?已经有人把倒立三接入 v x 了,不信你看。哇,一只热腾腾的包子 走啦!再试一试, 画一只可爱的猫咪! 哇,快看, 是一个!再试一下,比较复杂的 画一张桂林山水甲天下的水墨画。 哇,快看, 太牛了,太牛了!这不光是牛的问题,还非常的方便,已经集成在了微信上,相当于把 china gpt 放进了裤兜里,大家赶紧去试一试,记得关注再走哦。
140拉哆哆 00:32查看AI文稿AI文稿
00:32查看AI文稿AI文稿上传一张图像,自动生成相同风格的一张图像。再上传一张,又生成新的一张图像。 再上传一张,快速生成新的一张图像,让 gpp 写出这张图像的提示语,根据提示语再生成一张同样风格的图像。
17穿行者 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿整理了一份超全且实用的 ai 绘图软件,还没玩过的宝子看过来哟! ai 绘图的强大之处在于可根据图片或者关键词条生成各种不同的绘画,在灵感匮乏的时候,还可以从中找寻灵感,激发设计师的无限想象。 缺点就是 ai 对人或动物的位置有缺陷。最后记得收藏起来,你一定用的上!
395哆啦A梦的哆 02:39查看AI文稿AI文稿
02:39查看AI文稿AI文稿朋友们, gpd 四 v 和道义三强强联手, aip 图现在流嘴就行了,为此我们还专门采访了 gpd 四,本次下面请看现场的详细报道。你觉得我可以让 gpd 四 v 描述一张图片的风格,并让道义 free 重新生成,无需任何提示语吗? 啊,当然可以,你可以给我一个具体的图片描述,然后我会为你用 g p t 四 v 来描述这张图片的风格。之后我会使用 del e 三来重新生成这张图片。请提供你希望描述的图片内容。既然如此,我们现在现场实操一下,用 g p t 四 v 和道义三生成一个适合漫画来看看。 在移动端打开一个新对话,给 gpd 四 v 上传一张自己想要绘制风格的图片,然后就可以开始提问了。首先我们让 gpd 四 v 简单解释一下这张图片,请解释一下这张图像。 检查输出内容后,我们发现 gps v 的描述与图片高度匹配非常可靠。接着我们就可以让 gps v 根据图片内容输出到一三的提示语了。根据该图像提取从图像到文本的英文语句。提取结果将用于图像生成人工智能的输入数据或提示以生成类似的图像。 这里的输入我觉得还是不够简洁,幸好 gpd 最大的优点就是可以不断交互优化,所以这里我们可以给 gpd 四 v 输入常见 ai 声图的特点,它就能将这四句话合成一句。 图像生成 ai 提示的一般规则,用单词格式列出他们,而不是句子格式。使用逗号和空格连接单词和短语,写下高度重要相关的单词,包括角色的外貌、构图、拍摄角度、表情等文字,现在把这些关键词串联连接成一个 ai 图像生成的提示语吧。 新建对话,我们把上一步输出完整输入到道义三,一字不改。可以看到道义三准确画出了对应的画风,根据上面图像的风格生成一个讲述 kfc 疯狂信息式的四宫格漫画。学会了对应画风,道义三可以轻松生成具有文字内容的漫画。 更厉害的是,你只要输入你不满意的地方,套一删,还能够持续修改图片的内容,保持画风一致。我需要更连贯的情节,最好有文本内容。通常是前三幅画是比较平淡的故事情节,第四幅画出现搞笑和突然的转折。 现在大家都知道道义山的优势在于能够持续追问修改图片,并且前后风格能够保持一致,只要上 gp 四 v 就能做到复刻自己想要的画风。而且道义山成长飞速,已经能够驾驭各种各样的画风了。最后让我们一起来欣赏一下 我是卡的 ai 沃兹,关注我,带你用 ai 解锁百倍生产力!
89卡尔的AI沃茨


猜你喜欢
- 9583陈汉煜