comflyui 插件安装
大家好,今天为大家分享一个 chrome 插件,叫做 mobile simulator, 这个插件可以做一些网易的模拟浏览网页截屏、 g i f 录屏、带边框截屏等操作。 安装好之后,会在页面右上角出现一个图标,访问网页的时候,点击这个图标,切换当前页面的显示模式,我们点击一下图标完成效果切换, 点击之后,访问的页面样式将会发生变化,可以选不同的设备进行一些模拟操作,包括常见的安卓机型、 ios 机型等, 甚至还可以模拟 macbook 的电脑端的浏览器。 在选择设备之后呢, 可以去做一些截屏操作,测试一些截取当前页面的截屏效果, 可以看到已经按照预期结果输出,再换一个手机测试一下, 可以看到这个截屏效果,时代设备边框等截屏结果也是比较漂亮。 另外再测试一个不带边框的截屏效果,选择第二个结果,输出了不包含设备边框的截屏。 除了截屏功能之外,还可以做 g i f 录屏,我们测试一下点击开始,这时候可以对手机做一些简单的 操作,包括点击滑动等操作, 点击停止,我们刚刚模拟操作了大概七八秒,这个插件会将我们操作的过程完整地使用 g i f 截屏记录下来。 这个功能特别适合做一些网站的动态演示功能,非常不错, 今天就分享到这里,大家有空可以去 chrome 应用市场测试体验一下。更多创新创意敬请关注貌似到。

粉丝245获赞857
相关视频
 01:32查看AI文稿AI文稿
01:32查看AI文稿AI文稿你的 coffee u i 插件是不是安装不上?大家好,我是木心,今天给大家做一个关于 coffee u i 插件安装环境的教程,今天的教程涉及电脑的环境变量,建议大家把视频保留下来, 因为网络上找不到针对性这么强的教程。话不多说,我们直接开始。可能有很多人都了解过康菲幼儿的 manager 管理器啥价, 这是 coffeey 其他插件的合集,从辣椒酱或者我这里获取 coffeey 整个包的朋友安装后就已经自带这个插件了,没有 manager 插件的直接来私信我获取插件,然后把 manager 放到 coffeeyy 的这个文件夹下就可以了。 这里我们不做过多讲解,直接进入今天的主题环境变亮。当你想给你的康复用安装插件的时候,需要进入界面,然后点击这里的管理器,点击安装节点,找到我们想要安装的插件,点击安装,我们就能看到这里的红字提示我们 差价已安装,需要重启康复 ui, 此时重启后,大家发现差价依然没有安装上,就是环境变量出了问题,这个时候退出康复 ui, 找到我的电脑右键,点击属性,点击这里的高级系统设置,点击高级,点击环境变量, 找到这里的 pass, 看看自己是不是缺少这两个路径,缺少的话就要找到这两个文件夹,复制他们的路径,放到这里,点击确定,然后重新打开铁锅炖,启动康复 ui, 再次点击康复 ui 界面中的管理器,找到自己想要下载的插件,点击安装,看到绿色的文字提示就是完成安装了。这个问题很隐秘,同时很棘手,可以说不解决这个问题就不能正常的使用康复 ui。 今天的视频到这就结束了,我是木心,我们下期视频见。
592牧新学长 03:06查看AI文稿AI文稿
03:06查看AI文稿AI文稿伙伴们,如果我告诉你这个是我们的 stable 的标选新版界面,它可以随着我们的工作流一键直接生成四 k 高清大图,那么我再告诉你这个界面也是我们的 stable 的标选,它可以直接一键生成我们的动图,还自带一点五倍高清放大, 那么你一定会很好奇,随着今天的视频,我来告诉大家手把手如何安装咱们 stable 标选的新 ui 界面。康复 ui 康复 ui 的安装包我也已经打包好了,在视频的后半部分我会告诉大家到哪里进行获取。接下来我来教小伙伴们如何手把手安装我们的康复 ui 界面。 大家打开我们给大家准备好了康复 ui 安装包之后,会发现里面有我们的康复 ui 插件管理器加汉化插件,还有我们的康复 ui 工作流以及我们的康复 ui windows 的官方安装包,大家右键直接解压,解压完成之后可以看到 我们这边官方安装包点进去会有我们的 run cpu 跟 run mv 点 gpu, 如果说你是 amd 的显卡,或者说你没有一个独立显卡,你直接点击 run cpu 启动。如果说小伙伴跟我一样,我们有一个一张英伟达的显卡,你就直接双击 run mv 点 gpu 启动。 启动后小伙伴你们会来到这样的一个界面,你会发现它全部都是英文,并且我们如何去安装插件,那个管理器里面也没有,对不对?回到我们给大家提供的安装包界面,这里我们给大家去准备好了两款插件, 关于插件安装的方法,我也准备了一个 txd 文档给大家,大家可以跟着我们里面给大家提供的安装方法,安装到指定的文件夹路径就可以,就是把我们这两个文件夹给它复制。点击我们的 comfu 安装包,找到我们 comfui 我们的 custom 的 notes, 把我们的两个插件扔进来,放进来了之后直接重启我们的 coverui, 你就会发现界面已经变成中文的汉化界面了,右边也已经显示了提示词对列,下面有我们的插件管理器,如果说小伙伴你们导入了进来的工作流,有某些插件缺失,你可以在这里进行安装。 还有一些小伙伴非常关心我们之前外围 vi 所有安装的大模型以及 roi 模型能不能再放在里面一起使用是可以的。我来教大家如何把我们外围 vi 中的大模型和 roi 模型全部调用到我们的康复 vi 里面来。 大家回到我们的外部 ui 界面,记得复制文件的根目录地址。回到我们的 comfire 安装包界面,打开我们的 comfii, 找到我们 extra model pass, yml example 文件夹,重命名,把后缀点 example 删掉,直接右键 以记事本格式打开,打开之后发现这里有一个文件夹 pass to stable 的标选 y b u i, 记得把这里的文件地址改成我们刚刚复制的 stable 的标选根部路地址, 然后直接保存,最后再重启我们的康复 ui 界面,然后你就会发现我们所有大模型都从外部 ui 的根部路路径直接调用过来了,这样会节省我们很大的一个空间。以上就是我们康复 ui 的一个完整安装流程, 关于我们康复幼儿的安装包已经放在我们抖群群公告的 stable 标选知识库里面了,小伙伴可以进群自取哦!关注 ai 风险标,学会 ai 快人一步!
6851Ai风向标 08:00查看AI文稿AI文稿
08:00查看AI文稿AI文稿大家好,大家现在是不是在网上经常会看到一些这种或者这种都是由 ai 生成的丝滑的视频,那么呢它是由我们的 stable defusion 的 animate def 这个插件去进行生成的,那么在 web ui 上面呢,它会有一定的这个局限性,所以我们就会去使用 configui 生成 confiui, 它是基于 sable defusion 的一个工作流工具, 它会更节省我们的这个显存的占用速度也会有各种提升,也会让我们有生成更大尺寸图片的这个可能性,画面会更好种,视频呢也会更流畅。那我今天就带 带大家,我们从头安装一遍我们的 confus。 那首先呢,我们可以看到在官方的这个网站,他已经准备了安装包可以进行下载, 那么同时你也必须去下载的这个 git, 因为在 confiui 当中,它所有的插件节点的下载 都是通过我们的 get 命令,如果没有下载这个东西的话,你会下载失败啊,在后期你的使用当中会造成很多的麻烦。那么这些内容我也为大家在我的百度网盘当中进行了放置, 大家可以到时候去下载。关于 git 到了到了到了也带大家安装一下,大家可以看一下,下载完东西之后呢,我们全部的都是按照默认 即可进行安装, 如果安装完成了,我们可以在我们的命令提示服当中试一下 get 命令,如果弹出各种的 get 的后缀,那么就说明我们 get 是已经安装完成了。 首先我们在下载之后呢,我们会把它解压出来,大家注意解压出来之后,一定要解压到这个英文的安装目录下, 不然的话会有可能会产生报错,那么当我们在这边启动之后呢,我们可以看到这就是他的 文件内容,那我们首先要做安装他的这个插件管理器,他的这个汉化补丁,我们需要把我们这两个进行解压安装, 我们需要把这两个插件复制到我们的 come for ui, come for u i 的这个目录下的 cuts notes, 就这边是专门放我们插件的位置,大家需要把我们的这个插件管理器以及我们的汉化补音以及未来的插件都是放在这个目录当中,那么这是第一步,第二步呢是我们可能要去下载各种的 model, 就是我们大模型也需要放在我们的这个 comfy ui 的妈豆子里面。这边呢如果说大家之前用过我们的 webui, 那么这个时候它是可以通过直接读取我们 web u i 的大模型来减少你的这个硬盘空间的,那么在这边呢会看到这么一个文件,修改它的文件名, 我们以记事本的方式把它打开,然后呢把这边改成我们 web u i 的根目录就可以了。 接下来大家注意在这边呢我们需要去启动我们的 comfy ui, 如果是按卡显卡的话,大家使用这个启动就可以了,如果是 r 卡或者是没有显卡的,请使用上面这个启动,那我们这边去点击启动, 第一次启动的会比较慢,因为他可能会需要去下载一些东西,下载一些内容。 这边呢就进入了我们 confiui 的这个工作的页面,那这个时候呢,这里可能也不是中文,不要担心,我们在小齿轮当中,因为我们安装了汉化包,在这边选择中文就可以了。 然后呢我们因为前面也装了插件的管理器,如果都成功了,这边就会有一个管理器,会有我们 comfie ui 的一个管理器,那在我们前面呢是有把大模型映射过来,那我们在这个位置呢,就可以去选择我们 webui 里面的所有的大模型。 comfiui 页面简单介绍一下,这就是一个简单的工作流,在这边我们可以选择大模型,和我们的 webui 是一样的, 在这边呢是显示我们的正向提示词,这边呢是填写我们的反向提示词,下面的就是我们的宽,你教我们生成批次的一个设置, 那这边呢就是我们的种子以及我们随种子,还有我们的步数以及我们的 cfg, 然后还有我们的采样器设置,那这边呢就是我们图片的一个出具的地方,我们可以看一下,然后点击提示词对列,它就会开始进行我们的这个图片的生成, 可以看到它工作流执行到哪部节点的外边,它就会有绿色的框,那这是一个简单的 configui 的一个纹身图的一个 生成方式。那最后呢,我再给大家说一个比较重要的点,就是我们的 confus ui, 它是可以终止我们的这个任务的,如果出现这种卡顿,或者说是显卡吃力想停止的时候,我们是可以通过 ctrl 加 c 去停止我们的这个批量操作的, 那这个时候呢,我们只要关了网页就可以了。关于 comfy ui, 因为我们是属于一键安装版本的,那么我们就会涉及到升级的一个功能,大家这边呢会看到在 comfy ui 的 update 铜键家里我们会有这两个升级, 那大家注意这个升级是一定要升级到最新的,在大家第一次使用的时候,我建议就升级到最新啊,按顺序去直 之行。 大家注意在升级的时候呢,一定要挂我们的加速器啊, 挂魔法,那么这个时候呢,如果他超时了,说明我们的这个升级失败,你就可以换节点,或者说是一直的去执行,直到执行他跳出来, 我们这个升级完成就是我们的 down, 记得这边一定要出现 down, 就是他的这个升级完成了,不管是多少遍了,这两度一定要荡完成,因为如果你没有升级成功的话,在未来你使用这个我们的 confusion 的时候,当你载入比如说视频插件各种插件的时候, 你可能会爆出这种错误,那这种错误呢?可以看到就是当你插件安装上去之后呢,他会报错,或者说 说你的插件加载失败,这个时候就算你插件安装成功了,他也会无限的去提示你,你没有安装这个插件节点,你会无法使用,所以大家注意一定要把它升到最新,一定要升到这两个都是康非 ui 的安装,我们就到这里,那下一次我会带大家去用我们的这个视频生成, 以及我们的怎么去加入我们的 ipad app 去进行我们的视频控制,给大家出一期视频,谢谢大家。
 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿confu i 教程合集来了,那么接下来主要讲一下 confu i 的插件管理器和汉化的安装。 confu i manager 可以理解为在 confu i 上管理插件和模型的一个集合工具,你可以很方便的在上面下载你需要的插件和模型,或者使用大佬的工作流的时候发现自己缺失某个插件,可以在这里一键安装你缺失的插件,简直非常方便。 推荐每个使用 cover ui 的同学都需要下载汉化插件,安装之后可以轻松在设置中切换中文和英文,因为很多 cover ui 教程都是使用的英文版作为教学,所以在学习的时候建议同学先使用中英文来回切换对照,在熟练之后根据自己的喜好选择使用中文还是英文。 confu i manager 和汉化插件的安装包我已经打包放在了我的粉丝群众了,现在我们来讲一下如何安装。首先下载并解压这两个安装包,将这两个文件放到 confu ig 目录 confu x time 下划线 notes 文件夹中,再重启 confu i 即可。 打开之后可以在右侧看到 manager, 点开就可以进行插件的管理,并且在右上角这里能看到一个小齿轮, 打开之后在这里可以切换成中文界面,包括模块和节点都被很好的翻译了,这就是完成了 confu i 的准备工作了。下一期我们将用一个小案例讲解文声图的基础流程,并且如何在流程中加入 lower in beding control 节点。 最后,如果这个视频对你有帮助,请不要忘记点赞收藏,你的支持对我制作下一期教程非常重要。如果你有任何想学的内容,请随时在评论中告诉我们。感谢你的观看。我是设计师,学 ai 教你实操胜于虚言,我们下期再见。
333设计师学Ai 04:16查看AI文稿AI文稿
04:16查看AI文稿AI文稿country ui 它是一个基于节点的 slippertitution 的 ui 界面,在这里它可以把各个功能转化为一个个的节点,通过节点的连接来进行图片的输出和控制。 它的好处是比我们平常用到的 stabody shows 外部 ui 更加的容易操控,甚至可以自定义一些没有的功能,比如说在图上图里面它是没有生成图片后 就直接放大的,那么通过 confu i 我们可以自定义一个放大的功能,你可以直接安装 confu i, 但是安装的话会比较麻烦,而且如果你之前就使用过别的版本的启动器的话,比如说秋叶版本的会试,那么你的电脑上就会会存在两 个环境,会占用更多的体积,而且你启动器里面的模型还要再导到 confi 里面,这样子就会非常麻烦,所以我们可以在扩展里面找到这样一个插件,就是这个 comfi ui type, 我这里已经安装好了,它可以将 它可以将 ctrl ui 和你本身安装好的 cbt fusion 的环境或者是模型做一个共享,这样就可以节约很大的空间。安装好后重启一下外部 ui, 然后来到顶部的导航栏就可以看到 comfitui, 点击进来的话,它会提示你安装一个 ctrl ui, 我们可以在安装路径里面写上 ctrl ui 安装的位置,当然也可以留空,留空的话它会自动的安装在 ctrl ui 的插件里面,选择好路径之后就可以点击安装 ctrlfui。 安装好后再重启一下外部 ui, 之后 我们再次点击 comfi ui, 就可以看到 confiui 的页面,在里面是它预设好的一些节点,我觉 他这个的设计真的是非常非常的有意思,因为你看着他的话,就能够很直观的看到提示词在潜在空间里面匹配特征,然后通过解码最后输出成图片的过程。我们大致先来看一下他的流程, 最左边是加载模型,点击他的话可以加载我们安装好的模型,然后他这边是有三个点,一个是 model, 一个是 clever, 一个是 va e, model 的话就是模型,大家很好理解,然后 model 下面是 cleve, cleve 就是让 ai 来理解你的提示词的地方嘛。 所以说 click 连接的就是两个文本输入框,这时候我们要注意文本输入框他是不分正向提示词和负向提示词的,而是说他在右面来到这个采阳器的节点里面, 他上面会有正向提示词和负提示词,那么这个文本框他是连接到正向提示词里面,那他就是正向提示词的文本框, 他是连接到负向提示词里面呢,他就是负向提示词的文本框。比如说我们把这个节点给他拽开,这两个都拽开,然后把上面的这个拽到下面,那么这一个文本框他就是负面提示词的文本框,把他拽到上面呢, 那么他就是成了正面的文本框。接下来往下面看,下面是一个空白潜在图片 的节点,他这里可以决定你输出的图片的尺寸,然后一次生成了几张图片,这些都是可以调,然后这个节点他是会连接到彩阳器节点的潜在图像这个位置,在这里可以调节种子,也可以调节 采样、叠带步数,还有提示词间观性,也就是 c f g, 还有一些采样器或者是降噪的强度,然后再往右侧,他会来到 v a e 的解码器,然后再往右边,他就是生成图片的节点, 我们点击右侧的这个地方就可以开始生成图片,可以看到他这边会运行的一个运行流程, 运行完成之后,在这里就能够看到生成的图片,那么他生成图片存储的位置并不是在你原先装好的 c botifusion the output 文件夹里,而是说你刚才, 而是说你刚才安装的 confi ui 里面有一个 altprod, 在这个文件夹里面像 confi ui 的话,它真的有很多可以玩的地方,但是它我目前接触的还不多,如果大家感兴趣的话可以在评论区留言,我以后会多做一些关于 confi ui 的教程。
626松柏君 07:38查看AI文稿AI文稿
07:38查看AI文稿AI文稿大家好,还记得上期我们介绍了怎么安装 comfi ui, 那么这期我们就来教大家怎么用 comfiui 来生成这种丝滑的视频短片。首先在在我们生成视频之前, 我们首先需要安装一个插件,这个在未来你用 web u i 也好还是用 comfy u i 也好,在使用当中呢,未来我们只要生成各类的视频图片都会用到的一个插件, 那这个插件我们需要去他的官网进行下载,下载这个七十九兆的这个下载完成,我们把它解压出来之后, 找到他的这个病的文件,然后把他的这个文件的目录地址复制一下,在我们那 编辑环境变量当中,在这边环境变量点击之后在系统变量当中找到我们的 path, 然后点击 新建,把我们刚刚的这个地址复制进去,点击确定,点击确认好了,这种就配置完成了。接下来呢我们需要启动我们的 comfiui, 这个时候呢我们需要去配置节点,不用担心,节点我已经帮大家准备好了, 直接去百度网盘当中为大家准备好他的一些工作流,以及我们之后会用到的这个模型 也放进去了,这边找到我的这个工作流,然后把它拖入到我们的 confusion 当中,可以看到这边提示说我们缺失某些节点, 点击关闭,然后我们之前有安装过管理器,在这边有一个安装缺失节点,这个弹窗不用管,可以看到我们缺失了这三个插件,我们可以手动去进行这个安装,在这边安装的时候呢,他这边就会看到用 get 指令 再进行下载安装,把三个都安装完成之后就 ok 了, 大家在安装的时候呢一定要记得打开你的魔法, 那这样就是已经安装成功了,我们把其他几个都安装完成,大家在安装过程中可能会每次做完之后呢会失败,他这就换个节点继续点,一直到这边的缺失插件都已经变成这种状态之后,我们关闭这个管理器, 然后我们这个时候需要去重启 confi u i, 在重启 confi u i 之前,我们先要进到 confi u i 的目录当中下载等会要用的一个模型, 在这边可以看到这个文件夹当中我们刚刚已经下载好的插件就会在这边,在这边我们找到 models 的文件夹,去到这个网站去下载我们的 vr 的最新模型, 我也放在网盘当中为大家放好了,我们把 vr 模型放到这个文件夹当中,如果之前你有在 webui 当中使用该插件的话,也可以把它的模型直接复制过来。 这个时候我们再去重启我们的 comfy ui, 每次我们装完插件重启 confi u i 的时候,它都会在这边去重新下载一些配合的组件,所以启动会相对比较慢一点, 这个时候我们再去重新安装完所有的插件之后呢,我们再进来这边就可以看到,就不会再去报错了。我给大家介绍 一下它核心的一些节点。第一个是我们的大模型和我们的 laura, 这边是可以去进行选择的,然后呢 laura 模型的这边是它的权重,然后下面的是 v 的选择以及生成图片的种子的选择, 这边如果是固定的话,可以填写固定种子,然后下面选择固定,如果是随机的话,下面我们可以选择随机。接下来这边是我们视频的 animal deep 的节点, 首先这边呢是默认值,这边可以不用动,然后在这边第一个是模型选择,我们前面的 vr 模型, 我们去调整它下面的这个图片的大小, 我们根据宽度高度可以进行调整,那大家呢, 那可以根据自己显卡适当的去调整。然后批次大小相当于就是我们要生成多少张图片,也相当于我们要做多少张图, 这个配合和我们后面有个每秒有多少针,每秒放多少张图去进行组合的。比如说我这边是四十八,每秒钟我们要放映八张图片, 就相当于四十八除以八是一个六秒的视频,建议大家可以如果让它更丝滑的话可以设成,但尽量不要去高于十二进行设置, 相对来说八的话会比较合适,十也可以。然后下面是提示词的写法,下面 面的红色是负面提示词,这边是我们的正面提示词,可以看到我按照总共 四十八针,我按照零和二十一四十二针,我们去进行不同的描述,让他的地灵针二十一和四十二作为关键针可以去进行变化,这就是纹身图的一种方式。然后接下来呢是我们的步数, 二十至二十五会比较合适,这是我们 c i g 还有采样器,最后我们会设置输出参数 gif 的内容,这边呢就是我们刚刚介绍过的我们一共要每秒钟走多少张图片跟批次大小组合之后呢就是我们生成一个几秒的视频,这边呢是我们去命名生成的 gif 或者 m p 四的一个命名。然后这边呢是我们生成的是 shift 还是 mp 四格式设定,最终在这边呢我们会去输出它的一个预览, shift 预览好的,我们这边的去对它进行一个简单的生成, 他这边就会开始去调用,开始去进行生成,那根据不同的显卡,我们这边的速度会有不同。 在最后我们会去生成我们的视频动画,可以看到我们这边生成的是一个六秒的视频, 那最终它会放在我们的 comfi ui 的 output 里面生成对应的文件。那大家快去生成自己喜欢的视频吧,谢谢大家。
23滚筒洗衣机皮卡丘 04:58查看AI文稿AI文稿
04:58查看AI文稿AI文稿这期视频将详细讲解如何在康复 ui 中进行面部修复,并且将我搭建好的面部修复工作流分享给大家。先展示一下通过这个工作流修复的效果。 这个工作流一共分为两个部分,第一个是面部修复的流程,第二个是清晰度提升的流程。整个流程需要安装一个节点插件,这个插件是 comfy um pack pack, 你可以在我的视频简介或者粉丝群中获取这个插件安装包,当然你也可以在 comfy um manager 中直接下载。那我们调出一个纹身图的基础流程, 鼠标右键新建节点,可以看到 impact 节点。 packpack 是一个庞大的模块节点库,里面包含检测器、细节修复、高清修复等等非常实用的模块,具体的使用后续遇到会再继续讲解,大家也可以自己探索使用一下。 我们调出面部细化模块,可以看到这个模块可以调节的数值很多,并且上面需要连接的节点和采样器很类似,将采样器这些模块就可以删掉了。 那么连接一下,在图像节点上连接你需要进行面部修复的图像,这里我夹在一张我之前生成的图,最后这里选择图像预览。 现在看起来我们已经搭建好了,点击生成,尝试一下,出现了报错,翻译一下提示缺少输入。 b box detector 模块,也就是这个节点需要连接添加检测加载器模块,搜索 detector provider 就可以找到这个模块 需要下载的模型。我放到了视频简介或者粉丝群中,使用方式我也在其中写好了,这里可以切换识别的内容, face 是识别脸部, hand 是识别手部。将 bbox 检测连接到面部细化模块,填写好提示词,再选择好模型, 再次点击生成, 可以看到脸部已经能够被修复了。 b box 是识别了面部的矩形框,将整个脸部区域都进行了充会,那么如果想要识别脸部区域更加细致,就需要用到 sam 检测节点了。我们搜索 sam moder, 可以找到 sam 加载器, 将其也连接到面部细化模块上。再次点击生成, 可以看到遮罩的区域更加细致了,并且仅将面部进行了遮罩重绘。接下来我想要将这张图片变清晰,并且增加一些细节。这里我用到的是采样像素缩放器这个模块, 这个模块一般是和 latent 迭代缩放模块结合进行使用,连接也非常简单。 v、 a、 e 模型、政府提示词都正常连接,放大模 模型需要添加一个放大模型加载器模块,我们将其连接上,这样就连接好了采样像素缩放器。再将从面部细化导出的图片使用 vie 编码器连接到 latin 的迭代缩放模块上,连接好 vie 即可。 在这里需要注意一点,这里的降造值可以理解为重会幅度,降造值越小和原图效果越接近,越大越偏离原图,一般调整到零点二到零点五之间,经过测试最好不要超过零点五,否则会偏离原图过多。大家也可以根据自己对画面的要求进行调整。 这里为了方便对比,可以使用图片发送和图片接收模块,这两个模块也是 impact pack 插件附带的,可以在 impact 节点中的实用工具里找到 图片发送模块,直接连接到输出图片的位置,图片接收的位置可以随意放,但是要注意的一点就是需要将这两个模块的连接 id、 节点编号一一对应,这样就可以接收到正确的图片了。 再次点击生成,如果放大后脸部有不清晰或者眼神失色的情况,就可以再接一个脸部修复的模块,对图片再次进行脸部修复。我这里没有出现,但是我大概演示一下模块应该如何连接,不过在这里就可以选择脸部修复节点数,这个模块调出的位置和脸部修复一样, 使用细化节点数,可以直接将参数连接过来,真的非常方便了。如果你只是希望脸部微调,可以调低其中的降噪节点,这里的降噪和采样器中的降噪节点含义是一样的,你也可以多尝试一下不同降噪值带来的效果。再次点击生成, 可以看到生成的图片有一些色差,这个可能是有些同学不能接受的,所以我在分享一种图像放大高清的方法。这个方法需要下载另一个插件, 就是 automate sd up scale, 当然也可以在 manager 中直接下载。安装好之后可以在新建节点图像放大中找到 automate sd up scale, 节点调出之后连接上对应的节点即可, 记得降低一些降噪值呦。连接好之后生成一下,可以看到放大的图片不仅更加清晰,而且并没有产生颜色偏差,大家根据自己的需求选择图像放大方式即可。 这就是这期视频的全部内容,制作视频不易,如果这个视频对你有帮助,请不要忘记点赞收藏,你的支持对我制作下一期教程非常重要, 感谢你的观看。我是设计师,学 ai 教你实操,证于虚言。我们下期再见。
404设计师学Ai 14:12查看AI文稿AI文稿
14:12查看AI文稿AI文稿in just two steps anyone can draw an owl step one draw some circles here we got a circle and another circle step two draw the rest of the funny owl yes, you two can create masterpieces in almost real time thanks to the power of creator and comfy ui but look ma this absolutely no spaghetti this uses lcm so if you've already got comfy ui then you will be halfway there if on the other hand you don't even know what comfy ui is and don't worry as this will just install everything for you you get all the benefits of an app like creator such as all these different brushes and tools and everything you normally get with a painting package and almost anyone can scribble even a rodent moving and posing skeletons in real time is also another thing you can do and adds quite a new dimension to your image generations it does so much more too but for this video i'm simply going to focus on what you need to get this up and running in order to generate images in real time but before we get to carried away with all the fun stuff you can do with it it is worth making sure you've got a computer which can run stable diffusion thankfully the requirements are a pretty meager, 6 g4v ram and with regards to os like the linux or microsoft windows is a good choice with experimental support for mac oss also being available need creater installed for this which you can do via a single click in the free software store on linux or you could do it via the creater website as well links are down in the video description five point, two point one is the current release which is also the version they recommend i'll give you a second to do that now if you need one all done excellent with creator installed and running you'll need to check one bit of information before you add in this new extension, so head on over to settings and then the first option there configure creater over on this right hand side you've got the resources tab and that resources folder the whole path there is the thing that you need because that is where you're going to unzip the plug in the plug in you can download from the github paste there it is download the plug in like it says unpack into your pie creator directory which is this one we just saw here the resources folder once you've done that it should look something like this so there is my resources folder and it's got the ai image diffusion file that's the configuration file and also that directory there ai on discord diffusion with the files in the next step is to enable the plugin and this involves a few restarts of creator so go ahead and restart again now that you have unzipped that archive and then head back into settings again and configure creator but this time you're a score right down to the bottom where it says python plug in manager now yours will be unticked so there ai image diffusion so what you want to do is tick that and then click ok and restart creater once again start with a new image at 512 by 640 as that is a reasonable size for both stable diffusion 1.5 and for image generation speed okay now you're going to need to have this show up first of all and that's going over to settings make sure you got show docker's ticks and then this docker's menu ai image generation the one at the top there if you tick that then your docker will appear now as you can see there at same connection attempt failed click below to configure and reconnect which is exactly what you need to do whether you've got stable diffusion installed already or not here under connections it'll be on local server managed by the creator plugin by default and these are the two options you can either have it manage it or you can manage your own local server going to go with the local server managed by the plugin this is the easiest option and the best one if you don't already have comfy ui installed because this will download everything for you it's about 10 gig in total as you can see you got lots of options you can tick stable of vision 1.5 xl lots of models which overall is about 10 gig all you have to do then is click install wait for it to install and you're done you can move on to the next video chapter which deals with plug in options if you're already very comfy like me i am a very comfy nerd and that means you'll already have a bunch of models and stuff and you don't want that option so choose this other option connect to external server local or remote now you can see we've got a problem there error connection refused that's because i haven't got comfy ui set up yet back over on their github page under the optional custom compui server you'll see this link here please check the list of required extensions and models this version which is one point seven point one at the moment that are four custom nodes you will need there listed under the required custom nodes section you'll need some control nets pre processors, ip adapter, ultima, sd upscale and external tooling nodes as well, if you've used any of my free comfort ui workflows from the a very comfy nerd website, then you'll likely have three of these installed already anyway, whatever, the case the easiest way is to install these using companyui manager it's got a search facility so there searching for the external tooling obviously i've already got it installed but that way you can install all of the extra nodes along with those custom nodes you'll also need the models they list as required i already had everything apart from the specific upscaler they use and likely you will too as it's all pretty standard stuff now one thing to note here here is how it handles model names and directories because some things are fixed such as these lcm lauras, while others use a substring search to match part of the default file name this means it should find all of your dot bin or dot safe tensors files as long as the file names don't differ too much if you are having issues with it not finding any models then the trouble shooting section at the bottom there is available for help like it says open up the client log file to get more information about what is happening because the log file is in a directory, which starts with a dot going to make sure you have show hidden files enabled otherwise it will look like it isn't there so there it is dot logs and you got the client dot log and server dot log in there here is my client dot log file and as you can see it's nicely listed all the files it found for the control nets ip adapter and lcm if you have any errors in here, those should indicate what you need to fix okay with all the nodes installed and their models in their rightful places in sure comfort ui is up and running then when you pop back into here, back into your server configuration and click connect this time it should go green and say connected leaving just a few other bits to explore other than your connection options there are a few other things available in the style menu this is where you can do things like change the model lauras prompts and v ae or very standard stuff if you're used to stable diffusion click these tiny little arrows down here and you'll see even more settings personally i'm absolutely fine with the default but if you like to tinker that is where you can diffusion interface and performance i've also left on the defaults with diffusion having some selection options interface has some prompt settings and performance has some options for history and also for different devices as mentioned i basically just leave those all in the default automatic is absolutely fine with the plugin installed comfy ui, running and all of your options set it's time to get drawing for live mode you can click the tiny little box up there and you'll see the option for live you've also got a strength bar the denoising strength there by default at 30 and a seed which you can randomize by rolling the dice the cursor is blinking there ready for me to enter a prompt so let's enter one which is awesome now prompts in place we can just click the play button and we're ready to rock and roll marvel at my art skills as i definitely wield my digital brushes in order to create a masterpiece okay, so are you ready first of all let's make this brush a little bit smaller let's go down to six and yeah let's see if we draw or something like this and then if i give him a little hat there we go now as we know rodents have nearly perfectly triangular faces there we go now this isn't looking very much like a rodent gentleman yet is it well this is where the strength bar comes in now if we go all the way up to one obviously it's gonna change the image completely so i like it a little bit lower typically you know somewhere around fifty sixty seventy percent is pretty nice around there it's sort of got a bit of a sort of cartoony sketchy feel to it and the higher rapid goes more photographic and realistic so that's pretty cool put the little legs on having waving his arms about there we go all far too much fun maybe if i color the hat in it's going gonna give him that hat oh yeah that's more like it that is more like it see how smart that hat is now and if you think that's cool then it gets even cooler because if you remember you can use all of those control nets in real time as well just as an example if you add a new vector layer there's a tiny arrow there and vector layer then will add a new control layer as well select pose from that that'll give us a little button over here add character pose to selected layer there we go and then we'll get the character over there so we can select all the bits and pieces he's over there at the moment but now he's over there cause we've just moved him and then we can move him again or we could make it a little bit bigger let's have that character bigger or we could duplicate it as well let's copy and paste and then we've got we've got two people in the picture or maybe ones a little bit smaller or at an angle or who knows uh you can even click on the little joints there, as well as you see uh remove that dot up there and then move the little elbow the zoom in will move that one up there too and you know any little part of the skeleton you just move those legs out and have all sorts of funny things going on we can even scale it strangely too okay let's clean all this up and start over again with a little bit of scribbling we'll get rid of that that's all nice and clean because another fun thing that you can do is just do sort of free form scribbling without any prompts now i understand that most of you won't quite be up to my skill level here so if you're trying to emulate this at home you may have some difficulty but don't worry just try your best and the program will try its best too as you can see it's sort of interpreting it over there and you know it's it's not done a bad job that we let's give in some fate i have some little pause up there and there you go we've got like a kitten and it hasn't even got a prompt so you can just let it interpret your drawing and well see how good you are and see how good it is if you're happy with your generation you can click the copy the current result button and that will send your image over allowing you to carry on changing stuff such as i don't know coloring the eyes maybe you want red eyes or something let's make that big and oh not not quite that big there we go let's have some red in the eyes there we want it a bit more bit more evil now it hasn't changed very much, but don't worry if you change the prompt strength, it will eventually pick it up there you go so now i can copy that over it's got red eyes and i can draw within the lines now excellent brilliant got some slightly rosy cheeks there too as you can probably tell this is absolute bucket loads of fun and there's loads of other stuff you can do with it as well this real time drawing just being one very small part example it could be that you've already got an image maybe a face or a character or something and you'd like to somehow integrate that into your stable diffusion art in that case this next video will show you a really quick and easy way to do that。
10喜好儿网 02:48查看AI文稿AI文稿
02:48查看AI文稿AI文稿confu i 教程合集来了,我将从零基础开始讲解如何使用 confu i 这套教程我将结合几个案例来讲解文生图图生图中节点的基础知识,并且讲解如何安装选择自己需要的插件并建立起工作流。在之后也会分享一些大佬的 confu i 工作流,让观众老爷根据自己的工作需要学会搭建自己的工作流。 康菲 u i 的安装在上期视频中讲过了,这里我就不再赘述了。如果不知道怎么安装康菲 u i, 可以去看我的上期视频。 这期视频我将从个人的使用体验讲一下我为什么使用 come ui, 推荐哪些同学学习使用,再分享一下推荐使用 come ui 的电脑配。 首先讲一下我为什么开始学习并使用 confusion。 一、他更接近 stable diffusion 的底层逻辑,根据官方的 stable diffusion 论文可以看出 sd 的工作原理,而 confused 更像把其中的每个步骤单独变成一个模块,让你能够对模块进行自由的组合。二、他能很容易地参 参考学习其他大佬的生成图片工作流,并且搞明白是如何搭建这样的工作流的。会有一些大佬在 youtube cbdi 上分享自己的工作流。这里告诉你一个小技巧,你可以在 cbdi 里会有大佬分享的图片。点开在这里可以看到有一个 workfow, 只需要点击复制,再到你的 comfyui 界面,点击 ctrl 加微,你就可以服用大佬的工作流。到你的 compyui 之后我也会结合案例从零基础讲解常用模块的使用方式,在熟悉每个节点的作用之后,再结合参考大佬的节点使用方法,你可以搭建出属于你自己的工作流程。 三叉系统占用更小,生成图片的速度更快。其实在 s d x l 模型出来之前,大家的电脑都能基本上可以在 y b u r 运行使用,但是新发布的 s d x l 对性能的要求高出不少, 在 y b u i 上最低要求八 g 显存加三十二 g 内存,经常还会面临爆显存的问题。总结一下,如果你有以下的目标,我建议尝试学习 comfy u i, 一是想要了解 stable defusion 详细公 做原理。二是想要提升生成图片效率并且想要搭建自己的工作流程的同学。三是不希望功能限制自己操作思路的同学。 接下来简单讲一下 windows 电脑配置要求。使用 stable diffusion, 影响最大的因素就是显卡使用 comfy ui, 最低使用可用显存四 g 的显卡,建议使用六 g 及以上显存的英伟达显卡。第二影响因素是运行内存,内存建议十六 g 及以上。 第三是硬盘会影响加载模型速度,建议安装在固态硬盘中,加载模型的速度会更快。总结一下,如果你的电脑能流畅运行三类游戏,或者能流畅使用 ybui, 那使用 combeyui 是妥妥没问题的。如果有性价比比较高的配置单,希望有小伙伴可以分享到评论区中,给其他想要配电脑的同学一个配置参考。 如果是电脑没有达到以上要求,并且最近还不打算有过多的硬件投入,可以首选云端部署。我和一家高性能电脑桌面服务商进行了合作,后面 会专门出一期视频讲解,敬请期待哦!最后,如果这个视频对你有帮助,请不要忘记点赞收藏,你的支持对我制作下一期教程非常重要。如果你有任何想学的内容,请随时在评论中告诉我们,感谢你的观看。我是设计师,学 ai 教你实操胜于虚言,我们下期再见!
1428设计师学Ai 03:13查看AI文稿AI文稿
03:13查看AI文稿AI文稿最近大火的 animate def 插件,可以生成无闪烁并且比较丝滑的动画。不光模型进行了优化,而且这次官方还提供了八个运镜 laura 模型,可以控制视频镜头的运动。这个插件支持 y b u i 和 confu y, 如果你没有安装使用过 com v y 的话,可以在 s d y b y 上使用,而且还可以和 y b y 的其他插件结合使用,比如脸部修复 control net 换脸插件等。 animative 对显存的要求比较高,显存最少需要八至显存以上。 首先安装插件,在扩展可用里,我们搜索 animative, 选择这个,点击安装。安装后重启一下 y b y 就好了。 animate d i f f 插件还需要一个模型来使用。打开这个网址,下载最新的 vr 模型。如果下载不下来,模型和插件我上传到我的网盘了,包括八的运镜 laura 模型。 下载好模型后,在 sdwive ui 根部录下,找到插件文件夹 extensions, 打开刚才安装好的插件 enemy dive, 然后把模型下载到猫的文件夹里,运进 lora 模型,放到 lora 模型文件夹就好,和我们平时使用 lora 是一样的。 打开你的 y b y, 可以看到这个 animative 插件。 魔神 model 是动画模型,选最 最新的 vr 版本就可以了,这里可以选择输出动画的格式,勾选启用插件。前面是动画总帧数, 后面的是帧率,就是每秒多少帧。如果总帧数设置为十六,帧率设置为八,则单个动画的播放时长为两秒。这里可以调整视频循环次数,零代表一直循环,其他默认就行。 然后演示一个基础的动画,写上骑手关键词,比如 a running dog, 一直奔跑的狗, 尺寸就默认五百一十二乘以五百一十二。你也可以把高清修复打开,这里我就先不打开了,总帧数先设置十六,帧率设置为八,那么视频就是两秒钟 点击生成, 可以看到一个基础的视频就已经生成了。然后你可以再添加运镜 laura 控制视频的镜头, 比如 tired 这个 lara, 可以让镜头向右 点击生成,看下效果。 总共有八个 laura, 大家可以都尝试下。
703AI绘画小站 03:35查看AI文稿AI文稿
03:35查看AI文稿AI文稿你最近是否也刷到过这样的 ai 动图?这种背景不闪烁的动图是由 comfort ui 制作的,但是 comfort ui 上手难度较高,让很多想学的同学无从入手。拿了别的播主的工作流节点, 不是报错就是一片红,缺差件等等问题,今天这期视频呢,就直接教大家怎么制作出这种动图。 comecui 的安装包以及工作流我会放到粉丝群,点赞加关注即可领取。直接拖入工作流节点,输入关键词,调整好参数即可,一键生成, 无需再安装任何插件。当然缺少的大模型也可以到粉丝群领取。好了,话不多说,直接看实操。拿到 comfort ui 安装包后解压,然后再跟目录下这个 running vda gpu 是启动器,不过在启动 comfort ui 之前,我们要先配 设置一下大模型,这里推荐套用 stable diffusion 的你的大模型。在 comfi ui 跟目录里有个名为 comfi ui 的文件夹,打开这个文件夹,里面会有个这个文件,把这个文件后面的 example 从命名删掉,之后用记事本打开 记事本,打开该文件后,看到 basebass 就喊后把 stable diffusion 的根目录复制到这个命令的后面,然后保存,接着关闭记事本。 启动 comfigui。 第一次启动可能需要花点时间,等载入好了之后就能自动跳转到 comfigui 的界面了。来到 comfigui 的界面,可能默认是这样的, 这个默认的工作流节点不能做动图,所以我在这里准备了两个工作流节点,直接丢进去即可使用。这两个工作流都带了测试用的关键词,加载节点后可以跑一遍测试 看看效果。接下来说一下这两个节点的功能跟区别。节点一跟节点二的区别不大,功能也差不多。节点一是能在关键词输入那里控制某个帧数到下一个定义帧数之间的画面,但是不能直接都一组关键词进去生成,否则会报错。 不过可以在附加文本里添加一组关键词作为提高质量或者主体参数的关键词。节点二是可以在关键词框里直接输入一组关键词即可生成动图, 除了这两个区别就没其他的了。这两个工作流增加了双落热的支持,一个可以控制人物画风,另一个可以控制背景等,如果不想启用落热,只需要把模型强度改为零即可。 同时这两个工作流理论上支持无限增速的生成,前提是你的电脑显卡显存要够大,显卡要够先进。刚开始 可以生成六秒的动图或视频,看看效果,再慢慢调高生成帧数,这里给个公式来算秒数。如果图像输出设置那里的福瑞末锐的参数是八,且真设置那里的批次大小是四十八,那么就是四十八除以八等于六秒,默认的分辨率是五百一十二乘五百一十二, 如果想改分辨率,也是在真设置那里改。如果前期套用了 stable diffusion 的模型,那么可以在模型加在那里切换模型 v a 一加在一起的模型可以根据模型的类型来切换, 通常默认即可,其他的参数可以不变。好了,说了那么多,我们直接来生成一张动图看看吧。首先是工作流节点异的图出了,我们看看效果吧, 怎么样?效果还行吧,接下来 来我们看看几点二的图,粗了放大看看 效果怎么样,你有没有学会呢?关注我,每天带你了解一点 di 的知识。
38美夜赤月 01:29查看AI文稿AI文稿
01:29查看AI文稿AI文稿呃,最近 l c m 的这个模型呢,大家用的都非常的多,大家会用它的 lora 去快速的在几秒内生成一个图片,那么 comfort ur 呢?它是有自带的 l c m 的这个 采样器的,那么怎么样 web ui 也有这个 lcm 的采样器呢?我们今天就来告诉大家。首先呢 lcm 的这个采样器呢? web ui 它本身是没有的,呃,也有通过各种代码移植的方式让它实现,但是其实我们有更简单的方式,那就是安装我们的 现在目前最常见的 l medf 的这个视频插件,只要安装上它,它就会自带我们的这个 lcm 的这个采用器。那么怎么安装它呢?首先呢就是在我们的 扩展当中啊网从网址安装,把这段地址代码复制进去,安装完成就可以了。安装完成之后呢,有可能不是最新的啊,需要大家去我们的 扩展里面去把它升级到最新啊,升级到最新它就会自带有了,那么这个呢是我们通过 web ur 也可以去使用我们 lcm 采用器,配合我们的这个呃, cfg 的 一点五以及我们的极少的步数去实现我们声图的一个教程啊,谢谢大家。
 01:30查看AI文稿AI文稿
01:30查看AI文稿AI文稿如果插件的运行环境有问题,这个东西怎么办?我的解决方案是把这个运行环境给他补上,或者是找到他的具体原因,然后做调整。你们去看他就是复制粘贴后台里边的内容,就因为我后面还想让大家去把这个学会,不是说嗯,了解就行,还是会一些操作,就是复制粘贴这里边的,哪有问题就复制哪,然后放到百度翻译里边去翻译,翻译出来之后大概的问题都是环境缺失或者是缺失了某一个模块,这个时候就是把我的环境给到他,让他去下载,就是还是会出问题,这个是什么问题?就是 因为插件有自己的环境,康复医院也有自己的环境,如果说这两个环境他匹配不上,相当于就是这个杯子扣不上这个盖,他就用不了,他还是会产生红色,这也是运行环境问题,怎么办?去铁锅炖启动器里,在更新这个位置打开咨询节点,每一次打开这个咨询节点都会转很久,这个东西跟网络也没有太大关系。我们先来转悠, 在这边是调整这个插件的版本,在这边调整的版本,每一个插件不要轻易的去做更新,你看我现在很多都没有更新,不要轻易去做,去做更新,因为做了更新之后,我没有办法确认这个插件今天的环境明就是更新的环境,还能不能跟康复原本体结合上,因为他们每一个插件都是独立被独立开发的,他独立开发出来的插件他是不用去管这个运行环境的,他们自己开发者能运行了 可以,但是不一定和我们现在用的刚 b y 版本能够结合的起来,所以说一般情况下不要更新,然后更新之后如果出现了问题,就是点这个插件,然后往回调版本。你像这个 m、 n、 d 和右之前我也出现这个问题,就是更新到了最新版本就是用不了,他就是在某一个模块里缺了一个 model, 但我们不可能去, 我们作为一个非开发者,不是一个插件的开发者,我们去这个插件的代码要去找到这个板块,再把它补上,不现实,根本不现实,我们就等这个康复原的更新,然后再去把环境做整合。因为我们如果说现在自己整合了,环境康复原又更新了, 那我们就还要继续新的咖啡 ui 的喷剂,再去整个环境新的环境,这个是比较麻烦的,一般情况下插件的更新都很多都是例行更新,就是无所谓,除非说他有重大更新的时候,他会在里边有标注,就是在该踏位里边都会有标注,然后我们再去根据这个重点更新,去做自己的环境配置,这样的话我们能够用到的东西也是最好。这个就是运行环境的一个解决方案,这个东西一定要去尝试,可以一会你就可以去我分享这个资源里边下一个铁锅炖,然后把这个咖啡 y 部署上。
51牧新学长 08:21查看AI文稿AI文稿
08:21查看AI文稿AI文稿大家好,今天给大家分享一个新的换脸插件,那么就是这一款换脸插件叫 reaction, 这个插件它在 github 上面有 sd 版本,也就是 stable defusion 的版本,那么它还有 kangfi ui 的版本,等于说我们想在 sable defusion 和康飞 ui 都可以装这个插件, 用来进行换脸的操作。今天呢我们主要是来演示一下在 stable diffusion 里面的版本,他是怎么来使用的,讲完之后呢, 大家都知道它的操作原理,那么就可以在看 v u i 呢使用同样的操作。之后呢,你用这个插件可以生成图片,可以生成视频。 我在之前的视频给大家分享过关于 rope 这个换脸插件的使用,这个插件也是用来换脸的,我之前是讲过 stable defusion 如何来使用这个 rope 来对我们的图片进行换脸。除了这 这个视频呢,我还分享了一个单独的用来 rap 换脸生成视频的一个工具,就是这款工具,它是一个单独的工具,可以直接让我们上传一张图片呢,将视频中的人物的人脸进行换掉。如果大家需要直接视频换脸的话,可以使用这个工具来玩一下。 我在之前的视频当中呢,也给大家分享过这个视频,大家可以去搜我之前的视频,那么他在 github 上面呢,这个这个说明里面呢多了这个工具呢,不再继续更新了,并说明了他为什么不再更新,但是呢他仍然可以使用,这些网址呢,我都会放在视频下方,或者是我的微里面,大家复制粘贴就可以了。 今天我们主要说这个 reactor 呢,也是可以用于图片,也是可以用于视频,但是呢今天我主要是讲一下它用于图片上面的使用,如果大家要使用这个 reactor 这个 插件的话,我们要把我们 stable diffusion 里面那个肉谱的插件,我们来到这个扩展里面啊,我这里面显示错误了,所以说显示不出来这个插件,你可以来到你的扩展里面呢,将肉谱那个插件给它关掉,因为呢我们这个 reactor 和肉谱这个两个插件呢,它是有冲突的, 你只能使用其中一个,这两个不能同时使用。那我们先来说明如何安装,现在是来到这个 第一步 diffusion 的这个版本里面,我们来安装,我们来到右上角复制它的扣的这里面的连接,或者你来到下方说明安装步骤里面呢,也有就是复制这个连接,复制好这个连接地址呢 到 sleep defusion 里面的扩展,我们从网址安装粘贴到这里面,我们点击安装红起我们 sleep defusion, 那么呢他会在终端呢去直接报错,他基本上会 会报什么错误呢?报这种错误就是我们缺少这个换脸模型,叫 inswipe 这个换脸模型,这个时候呢可以手动来解决这个问题,就是你来到我们 stable 地球室里面,根目录里面的 models 这个文件夹里面去,自己去创建一个 inside face 这个文件夹,然后呢将这个 inswiper 这个换脸模型放进来。这个换脸模型呢,我是之前使用过 rope 那个换脸插件那个时候下载的,不过这个呢我会发在我的微里面啊,把它发在网盘里面, 大家也可以去从网盘去下载这个模型,我把这个链接呢提供给大家。那么再往上面这个 models 这里面的这些模型文件呢,这些你可以自己去下载,或者呢我把这些都打包, 你复制我的链接呢,直接把这个 inside face 这个文件夹里面所有的模型呢,都可以给你打包,你一并下载下来也可以。然后呢你去重启我们的 step defusion 终端,应该就不会有这方面的错误了。 那么另外说一个要注意的问题,你的电脑上呢,一定要装这个 visual studio 二零二二这个版本,不要忘记将 c 加加这个构建工具呢,也跟 visual studio 二零零二二里面一起给它安装上去。现在来到 cividos 里面,我们呢拆个 pose 模型呢, 你可以随便选择这些题日词,还有这些参数,你都自己自定义,上面的这些设置呢,不会影响这个插件的运行啊。那么现在吧,我们勾选启用这个插件,下面第二个这个勾选项它是什么呢?它是会保留我们的原图,就是说 他会把我们不启用这个插件的这个情况,按照上面的这个提示词呢,给我们生成一遍,图片会保存下来,然后呢再用换过脸的人物的图像呢,再给你生成一遍,总共生成两套图,就是这个样子,上面一排四张图是原图, 而下面四张图呢是换过人脸的图。好,那我们接着往下看第三个选项,这个选项是什么意思呢?他会锁引我们上传的人物头像图片,锁引为零的时候是我们这个第一张人物图片,那么锁引为一的时候呢, 是我们他后面检测到的第二个人物头像,所以说比如说我们来到图生图里面,现在呢上传了一张包含两张人脸的素材图片,那么用下面这两张头像进行更换,这里的我使用 参数就是我使用我们上传的头像的第一个,所以第一个也就是第二个人物脸,然后后面逗号 锁引第零个点,也就是第一个点,然后呢去替换结果图生成的这个图,结果图呢将使用锁引为零的就是第一个人脸的图,换成我们上面锁引,唯一的引收就是第二个人物脸的图,就是这两个位置进行替换,那第二个锁引呢,就是我们这两个位置 进行了人脸替换,那么后面呢可以指定性别,我这里呢没有指定性别,他会根据,所以直接换图, 如果你指定性别的话,那么你的缩影呢可能会出错,如果你指定性别不对的话,你的缩影可能会出错,他检测不到这个性别,也会给你提示的,所以说你指定性别的话,你在这里面可以 可以指定,如果你不指定的话,这里面就选择否,那么下面呢这个所以呢他也带了,他也指定了这个性别,那么我们来看这里边这里面呢默认的话, 我们是使用第二个来为我们生成人脸,如果你生成的人脸呢模糊不清,那么你可以使用面部修复,那么后面这两项是什么呢? 后面这两项我们一般你可以调下面这个权重,当权重为一的时候,我们生成的结果图的人脸就和我们上传的人脸相似度会达到百分之百,如果你设置为零点五的话,他的相似度呢会达到百分之五十,如果设置为零的话,那他将不会进行人脸交换, 就会按照原图来给你生成。那么最下面这两个选项呢?你不用动,那他的意思呢?就是交换 人脸在原图上,还是你交换人脸在生成的图像上?那我们当然是默认勾选是让交换人人脸呢在生成的图像上,我们再往后看第二个,他还有个图像放大的功能, 我们可以选择你 stable dq 神里面自带的,或者是你自己下载好的这些放大缩放彩像器,选择一个你常用的彩像器, 那么给他按比例缩放,缩放两倍,可以让我们的人脸更清晰。那么后面这个设置呢,你可以设置是 cpu 来渲染还是酷打来渲染,这里边呢,你使用的模型一般这里面的参数呢,我们都保持默认好了, 那么这个人物图片换脸,那么他这个功能呢,主要就是这些。那么我之前呢有一个视频给大 分享了,咖啡 ui 里面分享过两个工作流,就是用来生成视频转视频的人物动画,主要是提取人物骨骼的动作来生成动画,那么它可以配上这个插件的咖啡 ui 版本,它有这个节点,我们将这个节点呢安装到咖啡 ui 里面,然后配合上我们上次 给大家分享的工作流,在人物生成动画的这个过程当中呢,我们可以把他的人脸用这个插件给他换掉,那么这样的话,我们视频转动画的 这个人物的脸,我们就可以自己去选择更换了,那么这个方法的具体操作步骤呢?啊,以后再给大家讲,那么今天的视频呢,就分享到这里,如果这期视频呢,你觉得对你有所帮助,那么请为我点击关注加三连,我们下期再见。
1091BAD CAT VFX 05:19查看AI文稿AI文稿
05:19查看AI文稿AI文稿今天来给大家介绍一款 stable diffusion 换脸插件 reactor, 支持多脸部和性别检测,可以高清放大,兼容性强,支持 s d y b u i confuse 以及 mat 系统, 并且 nsfw 无过滤。安装方式和 rope 类似,打开它的插件网址,这里会有它的安装方式。首先安装 visual studio 二零二二,如果你安装过 rope 插件,那么这一步就跳过,没有安装过的话,这里有下载链接, 进去后选择第一个免费下载, 下载好后双击安装, 安装好后是这样一个界面,找到 visual studio community 二零二二,点击修改, 进来后需要勾选拍放开发, 还有下面这个使用 c 加加的桌面开发,然后点击下面这个修改,安装完成。 第二步就是安装插件,先复制这个插件地址链接, 在 y b y 中转到扩展插件选项卡,然后从网址安装,粘贴刚才复制的链接, 点击安装,安装成功后重启 y b y 因为 reactor 基于 rope, 如果安装过 rope 插件,在扩展里把 rope 停止使用。重新启动后,可以看到下面有一个 reactor 插件,它可以在文声图和图声图使用。第一次使用后台会下载模型, 这里是容易中断失败的,我把我的模型放到网盘了,有需要的可以把它下载下来,放到 s d one u i models 文件里的 inside face 文件, 重启下 y b y 这里我先生成一张单人的图片, 然后把你想要替换的脸上传到 reactor 点, 点击启用插件, 还要把种子锁定一下,最后点击生成, 可以看到后台会有一些的脸部的分析数据, 可以看到脸部就替换完成了。头发这里有一点小瑕疵,可以多尝试几次,总体效果还是很不错的。当然它还支持多人换脸。我先生成一张三个人的图片,我们来全部替换掉这张图像上的人物脸部。 首先在 reactor 里上传一张图片,可以看到我上传的图片里有许多面部。 reactor 按照从左到右,从上到下的顺序检测图像中的人脸,从零开始给脸排序,可以给这张图排一个序号,零幺二三四,总共五个人。 比如我选择中间这个男的和两边的女的来一一对应,替换原图的面部,那么就在下面 source, image 这里输入二零四,注意分格的逗号,用英文输入法状态下的逗号。 它右边的是性别检测,可以单独只检测男性或女性,如果图中有男有女,选择否就可以。下面 target image 是圆的,图中要被替换的脸, 上面这三张脸我都要替换掉,这里按顺序就要写零一二,换脸的数量要和上面这个对应上。最后点击生成, 这样原图的三张脸就被替换掉了。 下面这里可以调整权重,零是最大, 这一栏是放大算法,可以选择不同的算法,设置里就是一个脸部替换模型。接下是图声图的使用了,和文声图差不多, 就是先上传一张图像,比如我上传这张生成好的图片, 记得把从会幅度调整到零。然后把要替换的图上传到 react 插件里, 点击启用。使用方法和前面一模一样, 点击生成。
913AI绘画小站 02:58查看AI文稿AI文稿
02:58查看AI文稿AI文稿stability ai 发布新的模型 sdxl, 今天来说一下如何在线体验以及安装本地 sdxl 零点九。 sdxl 具备一个三十五亿参数的基础模型和一个六十六亿参数的附加模型。 s d x l 的工作原理就是使用基础模型创建粗略的细节,再使用附加模型精细化生成图片。 s d x l 也是开源模型。据悉, s d x l 将会在七月十八日开放下载。这次的模型对显存的要求非常高,八 g 显存起步。虽然 s d x l 有不输于 me journey 的能力, 但有个不好的消息就是过去训练的 lord 模型是无法运用到 s d x l 模型上的,因为 s d x l 的架构不一样。当然 stable diffusion 神级差 插件 control net 的模型也是需要作者从新训练。大家可以去这个网站在线体验一下,这里写上生成画面的关键词,还可以选择风格,然后生成一下,在线的可能会慢一些。 接下来说一下本地安装 s d x l 零点九的方法,可以直接在 s d y u r 上安装,但只支持 n 卡。首先先安装插件,在这里复制安装地址,我这里是一个官方最新版的 stable diffusion, 找到插件,通过 u r l 安装, 安装成功,下面会有一串这样的英文,然后重启 y b y, 然后可以看到上面有一个 s d x l demo 的窗口,这里写了必须要 g p u 运行,并且有步骤安装。首先是要注册一个哈丁飞 账号,可以点击 here, 这里会跳转到这个页面,在这里最下面有找到 logan, 登录下,没有的话就注册一个账号,登录好后可以看到这个界面, 随便填一下, 到了这个界面就不用管了。回到 stable diffusion web ui 第三步,要创建一个 token, 还是点 here 这里来到这个页面,如果 new token 不能点击的话,去你的邮箱验证一下, 验证完后回到刚才的页面,点击 new token 这里随便输入一个名称,下面的默认生成, 然后复制 token, 回到 stable diffusion, 点击 settings 左边找到 sdxl demo, 把 token 粘贴到这里,然后保存,关闭 stable diffusion, 重新启动,会自动下载 s d x l 零点九,大约十九 g, 这里就看你的网络了,我这里下载太慢了,成功安装后还是在 s d x l demo 这个窗口使用。
114AI绘画小站 01:11查看AI文稿AI文稿
01:11查看AI文稿AI文稿一个插件抓包抓天下,接着上一个视频介绍一个插件,这个时候你需要一个可以安装插件的浏览器, 目前有很多浏览器都支持了插件,我这里用到的是 cream 浏览器,这个插件呢叫猫抓,如果你可以的话,可以直接在 com 商店里搜索猫抓, 或者也可以在百度或者其他的地方找一下,把它下载下来安装,安装之后呢,像我的就直接在这里显示了,然后我们继续上一个视频的步骤,随便找一个网易云音乐吧,啊,看一下,随便找一个音乐播放, 在这里就直接会给你音频的链接,接着咱们可以看一下小的视频网站,嗯,再随便找一个吧, 然后我们随便点一个视频啊,在这里我们就能看到这个视频的链接了,就是 np 四,然后点击这里就可以下载了。 那类似爱奇艺、优酷这种大网站能不能下载呢?下个视频告诉你,我是童林泽,关注我以后你的数码问题交给我。
678Snake Sir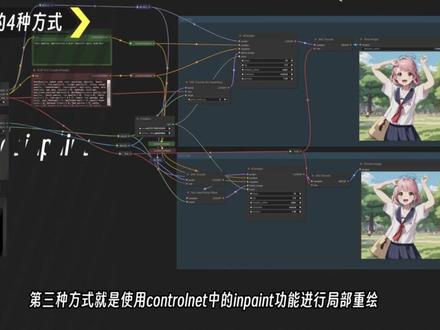 07:51查看AI文稿AI文稿
07:51查看AI文稿AI文稿这期视频我会展开讲一下怎么在康复 ui 中使用图升图,并且深入讲解在康复 ui 上四种不同的局部重绘方式。这条视频干货超多,相信看完这条视频你就弄明白了图升图局部重绘的正确使用方法。四种不同的局部重绘工作流也会在视频的最后分享给大家,进入正式讲解之前,记得一键三连哟! 我们先打开一个基础的文生图工作流,图生图的工作流在此基础上微调即可。首先我们调出捞 dimage 模块,这张图片就是用来进行图生图的图片。在之前的这节课中有讲到 stable diffusion, 在输入前空间的时候,需要添加一个空的噪点图,也就是 mt latintimage 模块,然后在空的噪点图片上进行降噪。 那么我们现在有一张图片之后,就不再需要这张空的造点图了,也就是将 low b max 的这张图输入到前空间再进行重新降噪即可。但是这张图是像素图片,不能直接输入到前空间,所以这里需要一个 va e 编码器对加载的图片进行编码, 变成前空间能够识别的内容,这样加载进来的图片就成功的输入到前空间了。这里 vie 编码器和最后输出图片时的微解码器是相反的功能,现在这个 m t latin dh 模块没有连接任何模块,所以可以直接删掉。这样我们就搭建好了一个图生图的基础流程。我们先来尝试生成一下, 可以看到生成的图片和我们的图片几乎一点不一样,这里就有一个新的知识点,就是 k 三 pro 采样器上的降噪功能,降噪可以简单地理解为融汇幅度,数值可以在零到一之间调整,降噪值越大和原图偏离越多,如果想要与原图更加类似,调低降噪值即可,这里我调整到零点六再来尝试一下。 生成的图片整体和原图还有些相似,但是细节已经完全不一样了。具体降造值和生成图片的效果大概是这样的,你在使用的时候可以根据自己的需求调整使用图声图,你可以对找到的参考 导图进行更换画风、添加细节等等,还可以进行面部修复、高清修复、图像扩展等更多的功能后面会讲到。 接下来如果我想要修改图片中的人物头发颜色,就需要用到局部重绘飞,这个功能我将展开讲解。四种在康复 ui 中使用局部重绘飞的方式, 你可以根据你自己的喜好选择最适合你的局部融汇方式。我可以说第四种方式是不仅方便使用,而且效果优秀,一定要看到最后。首先是在 confu i 最常用的方式使用 viencod for in painting 模块,这个模块和 vie 编码器一样,都是将图片直接变成前空间能够识别的内容。 不过这个模块上面多了一个输入遮罩的节点,那么可以看到图像上面也有一个遮罩节点,将他们之间可以连接起来。但是现在图片上还没有遮罩,我们可以在楼底美式模块上面使用。鼠标右键选择 open in maskdatter, 如果你是第一次打开,可能会需要下载一些东西,稍等一下即可,打开后就可以 直接在画面上进行涂抹,将需要局部重绘的内容使用画笔蒙住,在左下角可以调整画笔的大小。 绘制好蒙版,点击右下角的 sift note, 回到工作流,可以看到图片中画布涂抹的位置以及变成灰色,这样蒙版就建立好了。也可以从蒙版处调出蒙版到图像模块。预览一下你绘制的蒙版,然后我填写一下提示词,希望重绘出女孩的头发是粉色的。生成一下 翻车了是因为在输入到前空间的时候已经被蒙版去除了原图片的这部分信息,所以在生成的时候很很容易出现重绘的部分和原图片对不上的情况。我在经过多次尝试生成了一版能够看得过去的图。 接下来是第二种方式, set latin noise mask 模块,翻译过来是设置 latin 的噪波车照,它的原理是先把图片使用 vae 编码器变成前空间能够识别的内容,再到前空间中 将遮罩部分变成噪波内容重新生成一次,这样相比上一种方式能够更好地理解你要重新生成的内容,生成错误图片的概率也会更低一些。这种方式的连接就是遵循它的原理。先将图片使用 vae 编码器模块进行编码,将输出的内容连接到 satellite noise mask 模块,最后再输入到 k sample 采样器中, 我再重新复制一个采样器的模块进行同时生成。调出 v 解码器的模块,然后连接好其他的节点, 并且右键将这两个 k 三 pro 采样器上的 c 的值转为节点,固定这两个采样器的 c 的统一,这样能够很好地对比生成图片的质量。 生成一下可以看到使用设置 laten 的造波遮罩模块一次性就成功了。将种子只取消固定,两个都重新生成一次,可以对比一下这两种不同的方式生成的效果。我整理一下这两个 工作流,分别用不同的组来区分不同的局部重绘方式。然后使用转接点整理线条,争取让线条看看起来没那么杂乱,并且给提示词这些容易混淆的节点添加上颜色。红色是负向提示词,绿色是正向提示词。 第三种方式就是使用 control net 中的 inpent 功能进行局部重会连接方式和在 comfort ur 中使用 control net 是一样的,还是使用相同的条件输入搭建一个新的采样器,将 control net 应用模块连接到正向提示词和 k sample 采样器中串联, 然后添加 control mat in paint 模型和 in paint 与处理器 预处理器连接,加载进来的图像和对应的蒙版即可。可以看到图片不是直接输入前空间的,而是通过 conditioning 提示词输入, 而现在就没有输入 k sample 模块 latentmage 节点的内容了。我尝试了在这里使用 mt latentmage 和图片使用 vie 编码再输入都可以实现重绘的效果。我这里还是使用 vie 编码器输入到采样器中 生成一下。这里发现出现一个问题,输出的整个画面会偏离原图的颜色,我猜测偏离的颜色和使用的大模型与 vie 有关系,所以这个效果肯定是不能接受的。最后,经过我的尝试, 将 v a e 内部编码模块或者设置 latin 的噪波遮照模块,输出的 latin 节点连接到 k 三 pro 采样器上的 latin 节点,颜色就会恢复正常。这里我使用设置 latin 的噪波遮照模块生成一下,可以看到颜色恢复正常了, 不过局部重绘出来的部分和其他两种也是不一样的。排除这个问题之后,我发现使用 control night in paint 输出的图像是比较稳定的,而且融绘的内容 也比较精致。以上这三种局部重恢复的方式,小伙伴可以根据你自己的喜好去使用。不过我最推荐的是第二和第三种方式,因为输出的内容出错的概率小,重恢复的内容也比较精致。 以上的方案都依靠我们手动绘制的蒙版,那么有没有一种不依靠手动绘制蒙版,可以自动绘制蒙版的方式呢?这就是第四种方式,使用 crepe set 节点对画面内容进行识别,然后自动划分出蒙版区域,再进行局部重绘。 使用方式也相当简单,搜索调出 crepe set 模块之后,将图片连接到 creep set 模块上,然后在 tax 栏中填写你想要识别出的内容。这里我想要重绘头发,就填写 here, 可以看到头发被自动识别,并且绘制出了蒙版区域。 hit my mask 和 b w mask 可以分别预览划分出来的内容,然后这三个值可以分别调整遮罩的模糊程度、识别内容的精细度和识别出来的区域扩散程度。你可以根据你画面的需求去调整这三个数值,以 调整蒙版的精细程度。了解了这些,我们来搭建一下工作流,再调出一个采样器的模块,然后将设置 latin 的噪波遮罩模块复制过来, 然后将 mask 连接到设置 latent 造波遮罩模块。 click set 模块相当于替代了之前手动绘制的蒙版, 将节点连接好之后点击生成,重绘的效果还不错。需要注意的是, clip seg 模块需要到 comfi ui mini 这中进行下载,下载方式就是打开 mini 之后选择第一个安装节点,搜索 copsic 安装,然后重启 comfi ui 即可。 以上就是四种使用局部重绘复的方式了,其中有三个都使用到了设置 latin 的造波遮罩模块,所以看完之后记得一定要自己尝试使用一下,加深记忆哦。最后还记得最开始讲的降噪值吗?在局部重绘的时候也可以调整降噪值以达到混合的 效果。这部分我就不再展开讲了,感兴趣的小伙伴可以自己尝试一下,或许可以达到一些意想不到的效果。这就是本期视频的全部内容,下节课将讲一下怎么使用 confus 达到和 ps 贝塔类似的图像扩展功能。 大家的三连支持是我更新最大的动力。以上就是本期视频的全部内容了,我是设计师,学艾教你识操圣于虚言,我们下期再见!
388设计师学Ai


猜你喜欢
最新视频
- 1.9万次寻白