comfyui怎么使用多个lora

粉丝1.3万获赞33.3万
相关视频
 07:21查看AI文稿AI文稿
07:21查看AI文稿AI文稿今天为大家介绍一下整合包的使用方法。我们下载下来的一点三版本的整合包是一个一键整合包,无需修改,双击大键。我们先解压出来, 解压好了,先来带大家看一看整合包的内容。大家打开整合包不要着急,先来看一下我们准备的 com view 整合包使用说明书文档。 注意整合包中的内容除了环境 python 三一零外,不要随意改动。文档最开始就提到了整合包使用的推荐设备, 这里需要大家自查自己电脑的驱动是否为最新。注意一点三版本整合包目前仅适用于 win 系统加三十系及以上的 n 卡,里面有我们在最初制作后的一些测试使用设备, 最终选择了 python 三百一十加 patrick 加 veran 二点幺幺点零加 ceo 一 百二十八使用到的模型也已经给大家放进网盘中了,我们对照着文件夹中的内容来看, 下载下来之后,直接把 models 文件夹拖进 com view 文件夹中,覆盖原有的 models。 我 们的 models 文件夹放在模型文件夹中,还没下载完,所以不能现在拖进来,等下下载完,直接拖进 com view 文件夹中,覆盖原有内容。 首次运行之前需要保证自己的电脑驱动为最新, 否则无法支持 peter q 二八会在后面启动时报错版本不匹配。我们可以按住 win 加 r, 输入 cmd, 打开运行对话框,输入 evadesme 回车, 这里可以看到 qd 为十二点九,大于等于我们的十二点八。固定版本无需更新驱动, 同样如果驱动已经是最新的了,接下来双击 com view 一 键启动,耐心等待,等到安装完所有环境后,会自动启动 com view。 我 们只需要在浏览器中打开对应网址 安装 peterk, 这里使用的是百度源安装其他一来固定使用清华源。如果 peterk 下载缓慢,可以在 pipos 中自行修改镜像源,只需要复制其他的镜像源,全选覆盖这个 txt 文档,然后保存下来。 整合包中已经内置了两个生图和视频的工作流。在 comefu 中的 user 下的 default 下的 workflow。 存件夹中可以找到 整合包的目录,结构及相关说明也已经在文档中写了出来。 comefu 是 我们整合包的核心主体 portable git, 大家可以不用管这个,这是一个便携版 git pisongs 三幺零是一个我们双击 com vivo 一 键启动后才会出现的一个独立环境文件夹。刚下载好的整合包中是没有的 twoslow 配置文件中放着配套 twoslow 专用配置文件,打开可以看到我们提前准备好的配置文件,按照之前的教程导入 twoslow 中即可。 这个压缩包是一个 python 三点一零嵌入版原始安装包,不用手动解压。 这里准备了一些备用镜像源,可以做替换用。整合包的内容差不多讲完了,下面的是我们 toonfall 官网网址和教程链接。 等到所有模型从网盘中下载好之后,我们打开模型文件夹,可以打开 models 文件夹,里面是很多存放不同模型的文件夹, 方便展示。这里打开两个文件管理器, 直接把模型文件夹中的 models 拖动到 comfy 中, 勾选替换目标中的文件。 现在打开 com view, 打开 models, 打开 chess blocks 文件夹,下面可以看到有下载的模型, 现在可以双击 com view 一 键启动了。这里可以看到在解压过程中创建了一个 python 三幺零的文件夹和一个该 pip 派的文件, 接下来耐心等待它的安装。 注意租用云电脑的用户,在安装过程中,如果启动窗口较长时间没有反应,可以手动敲击回车, 等到看到输出提示环境安装成功,说明已经搭建好环境了,目前正在启动 comfy, 出现 http 冒号斜杠斜杠一二七点零点零点一,冒号八一八八网址后,说明启动成功。我们直接复制下来,到浏览器中打开, 直接粘贴进去访问,稍等一会, 加载完可以看到我们的 com view 已经启动成功。左侧栏中有资产和工作流, 我们打开工作流,可以看到提前准备好的工作流可以单机打开, 有时候会加载不出来,但不影响使用。介意的话可以打开之前文档中提到的路径,到存放工作流的文件夹中,把工作流拖动进来。 已经启动了 comfy 后,我们打开 toon flow 来测试一下任务是否可以跑进 comfy 中。 这里是刚刚直击跑的视频工作流,但是由于生成时长较长,这里拿生图做演示, 生成成功记得评论区领取链接。
47Toonflow 07:50查看AI文稿AI文稿
07:50查看AI文稿AI文稿帮我找到老墨,告诉他我想吃肯德基。强哥,今天不是星期四,不划算了,要不下次再吃啊?然后 接下来讲一个目前我用下来呃,最方便最省心的一个配音生成的一个模型, vox c p m two。 那 这个模型的话用下来第一呢,它就是非常非常的快啊,首先就是很快,第二个它功能比较强大。 呃,第三个呢,他能够实现的东西很多,比如说我们可以设计他的这个声音,而且可以设计声音当下的那个语气, 他可以把他这个方言也给他克隆出来。我觉得最强大的一点呢,他就是可以支持这个多人配音啊,一次性可以生成啊,至少最多的话可以生成十个人都设计好,那完全可以生成十个完全不同的声音,在那里说故事,对吧? 那这样一个简单的模型就可以就可以完全自己一个人生成一个广播剧啊,可以用 ai 来讲一个故事了。好,那我们直接开始演示哈。首先这个节点的话就超级简单啊,其实一共主要就是这个节点啊,然后他这边的话一共有四个功能啊, 第一个就是声音设计,你想要什么样的声音,比如说你要开心的女生声音,对吧?然后温柔甜美,然后写一个语速比较慢, ok, 这就可以了。然后你让他说什么的话就直接打 好,就是这么一句话,我们直接点运行, ok 啊,那就很快啊。好,我们现在直接来听一下你。好呀,你终于来了,我等你好久了。 好的,他这个生成的还是很符合我们的要求的。好,然后我们来看一下第二个啊,极致克隆,极致克隆的话呢,就是你上传一个声音,对吧?然后他可以完全把你这个声音克隆出来啊,比如说我们先听一下原版的, 哈哈,当然知道啊,因为我又不用上班。好,然后这个声音大家记住啊,我们继续让他说刚刚的那个,刚刚那句话啊,好,就这样一句话, ok, 已经生成出来了,听一下。 你好呀,你终于来了,等你好久了,好,那这个声音是完全一样的,甚至这个语音语调都非常的像,对吧?所以这就是我们的极致克隆。 好,然后我们来看一下可控克隆啊,可控克隆的话就是可以控制他的语速,还有他的这个当下的一个情绪啊,比方说我们可以写什么呢?吃惊,非常的吃惊感, 女生声音语速很快,好,还是刚刚那句话,等你好久了, ok, 就 这样一句话,我们来深沉一下试试。 你,好呀,你终于来了,等你好久了,好,他这个语速确实是很快啊,痴心感好像没有怎么体现出来啊,啊,就感觉很开心的样子,再来听一次。你好呀,你终于来了,等你好久了啊,还是有一点点惊喜的感觉在里面的。好,那这个就是可控克隆, 这个多人配音就比较重要啊,他这边角色角色的话最多可以有十个人,然后我们这边就拿五个来做个实验好了,那么他这个角色呢?他有一点点的这个,他有一点点的这个规则啊,我们把这个规则给大家看一下 啊,那么这就是多人配音的规则啊,就大家看一下啊,其实我们正是在写的时候啊,只要把这个规则啊全部复制啊复制粘贴然后给豆包啊或者给任何的 ai 模型,你直接跟他说啊根据这个规则帮我写一下这个提示词就可以了, 下面的话呢他还可以加入这个情绪在里面啊这个是情绪助词。好,然后我这边的话就给大家做一个示范啊。好,我们先来看一下啊这个提示词那么这个呢就是语气助词对吧?然后我们这边是五个人啊 speak 一 二三四五五个人然后五个人的这个 呃形象是不一样的对吧?啊?青年女性啊青年男生中年男性对吧?中年女性啊。这几个声音他还有少女五个声音好然后五个不一样的年龄段五个不一样的声音然后五个不一样的语气。 我们来看一下啊来深沉一下。那当中我们这边再做一件有趣的事情啊我们这个音频呃这是一个北京口音对吧?北京话我们先来听一下天一亮进了胡同口我端着小碗去吆喝 豆汁天下第一美味,您不信来一口尝尝。好,然后我们把这个音频直接接到这个角色音频三啊其实你每一个音频都可以选择一个自己特定的声音都是可以直接连上去的。阳光青年男生对吧?三号发言人有这个北京口音啊,我们来试一下啊能不能实现 好。这边就深圳好了啊,一共用了四十五秒就深圳好了,我们来听一下这个效果哈。哇哎,公司居然提前放假了 这下总算能好好休息不用天天加班了哈哈,太棒了正好可以出门短途旅行一趟。嗯忙活大半年也该回家陪陪家人了。嗯,真好呀,大家都能早点清闲下来了。 好,他这个功能啊,仔细听的话会发现他所有的要求都完美实现了,那这个模型就是这样,对吧?很方便很实用啊,而且特别特别的快。那这边的话我们多讲一句啊,多讲一个什么呢?多讲个 laura 训练啊,这个,其实,呃,我也把他这个训练的工作就做好了啊,其实也很简单不难的。 呃,这边看一下啊,如果你训练好了自己的 laura 以后呢,你这个地方就会出现一个 laura, 你 点一下就可以了。好好,然后我现在跟大家说一下这个 laura 怎么训练啊?我们先把这个工作流关掉。 那其实这工作流很简单啊,直接这边有快捷按钮的。那首先他就是第一步,第二步我们把第一步打开,第一步的话,这一边啊不太不是很方便,长音频的话你稍微长点都没关系的啊, 二十分钟、三十分钟都是可以的。那么第一部分的话呢?呃,这些都已经调好了啊,不需要改啊,除非你这边要改成英文, 对吧?啊?一般性我们都是选中文啊,他语言是可以控制的。点了,运行以后呢,这边就是我们训练级他输出的目录啊,我们 ctrl c 啊,复制一下这个目录这边,然后把第一部分给它关掉啊,第二部分打开, 然后这边有一个训练清单,这就是我们需要填录的这个训练级的地址啊,我们只要把刚刚那个地址复制过去啊,就可以了。好,复制过去了以后,然后我们直接再点运行 好最后这个 laura 啊,他这个输出的地址啊,就是在这里,我们只要去这个路径里面去找啊,这个 safe, 那 这就是我们两步啊,两步就可以训练好了, 整个工作流还是很简单的,那么我等一下就把这两个工作流,一个是全能工作流,还有一个是 lara 训练的工作流啊, 我把这两个工作流放在视频下面,有需求的小伙伴们可以自取,对大家有帮助的话呢啊,请给个一键三连。好,谢谢大家,别忘了把赞给我点了啊,什么档次?看完视频不点赞?
 01:20查看AI文稿AI文稿
01:20查看AI文稿AI文稿今天给大家分享一个常用的迁移工作流,进入康飞 ui 后导入羽翼遮罩,这个工作流可以稍微改一下模型,我习惯用 flux, 下面 ve 同样改为匹配的 flux 一 e clip 我 用的是千问的。 这边落染我们可以根据自己的风格去添加。右边上传我们的人物图像,左边上传我们的物品图像,我这里稍微替换一下物品图片, 我们运行一下看看效果。这里发现遮罩把整个人物全选中了,是因为我们遮罩的提示词没写对,我们把衣服改为旗袍,然后转成英文, 这边同样转为英文评论七七七,尝尝咸淡,这是我们没改提示词前生成的效果, 我们修改完提示词后再运行一下,能够发现遮罩已经改变了,这就是替换。好的,感谢您的观看。
 11:35查看AI文稿AI文稿
11:35查看AI文稿AI文稿今天分享的是一个呃精准的一个呃视角图像,视角转换的一个工作流。首先先简单的介绍一下 这个工作流是先要通过这个图像转高斯喷溅的 p、 l y 文件,这样子就可以轻松的转换到自己 合适的角度,然后把它截图下来,再通过底部这个呃高斯破件的一个 logo 上传原来的图片就是原图,再通过这个高斯碰见的一个截图就可以生成出这个高斯碰见的一个角度的完美的一个图像,而且产品基本都保持一致不变, 其他呃空白区域他会自自动填补,这样子就达到了一个精准的一个角度控制,相比之前那个转换角度内源这个节点的拖拉这个精准度最高,而且他优点就是可以 通过这个嗯去控制他的呃深度透视。 等一下我会详细介绍他的使用方法。首先介绍一下,我这边使用的是 端老云的在线镜像,大家不想本地步数,想即开即用就点开我的这个镜像,更新到最新版本就是我用现在用的这个镜像,这个工作没有,我放在这里边,嗯, 最外边这个工作没有二五幺幺这一枚机编辑二五幺幺,在这点开之后,我放在这里边有很多全套的都有,放在这最下面的右边, 这里边分两个,大概我这里边这个镜像里边包含的非常多,外边这些都是最新常用的一些工作,没有比如呃 高清图像放大,或者视频的一个高清放大,或者视频内容移除的,或者语音克隆,或者语音设计。千万三 tts, 大 概这个最前的目前是用美团这个语音克隆最强,还有中英文字体修改以及呃 封奥克斯二克莱因的全套里边有十几二十个工作没有 好,然后 t 叉二点三纹身图或者图身视频也是全套都在这里边,外边这些是最新采用的, 里边是分视频类,图片类,语音类,视频类就以往的一些视频生成工作类,图片类就很多啊,三百个工作类都是以往的一些视频啊。图片编辑工作类需要旧版的话也都在, 语音类也是旧版的也都在,不过目前的话用外边最新的就行。在线镜像的好处就是你看到我现在能用你们也就能用,而且我有的你们也就都有,就等于一键拥有我整个镜像跟我这一模一样。 这个就是在线镜像的好处啊,想要本地部署的人可以点开我的笔记,点开导航上 comui 教程,他会跳转到工作内的位置。 跟工作栏里边一样,分三类,视频,图片,语音。这个工作栏我放在图像类里边的第三个。呃千文编辑二五幺幺的点开下载设置,里边有安装教程, 这里边有所有模型的下载链接,还有下载的一个截图,这样子知道需要下载哪个模型,然后放置位置都很惊喜的, 然后这次用到的模型就在这,也有下载位置,下载链接,反制位置,还有这个高斯破解的一个 logo 反制位置,还有用到的这个节点 安装模型以及下载安装位置都有。还有一个呃在线编辑的一个高斯破解的上帝 告示破解文件,在线编辑的一个网址都在在下面,就是呃这个公众号的截图,看看这里边包含所有公众号的截图,而且所有的截图都可以看清上面的参数, 然后最底下是每个工作人的一个视频教程,最后是工作人的一个下载,这个笔记就适合本地部署的人去使用,我觉得使用我的在线进行,这样子就更方便,就不用考虑部署。 然后第一步先说这个教程,刚开始第一步是我们需要上传一张原图,这个就是原图, 下一步的时候也会用到这个原图,就是放在第一张这个位置上传这个原图。一般情况我们是有一张原图,然后需要通过这个工作呢就跑一下,跑的时候就不用,底下工作呢就不用跑,右键把这个 进院就可以了。在这个群主的蓝色框上面右键进院,先要解开了先进院,然后跑一下 就会出现一个这个呃图像转三 d 的 一个高斯破件的一个文件,然后这边有呃他的下载地址放在这,不懂的话看这里边,如果用的是端老银在线镜像的话,记得呃 在这边我的应用,然后文件夹管理打开就可以打开这个呃 control ui 的 安装目录, 在这里边找到这个呃输出文件,就是这个 out 什么什么,然后点开这个文件就是了, 然后直接点这个文件,把它下载下来就可以了,这样子你就得到了这个这个三 d 扩建的一个文件,最后再通过这个在线编辑 高斯破解文件的一个平台,免费的从这边点导入你刚才下载的这个文件,因为我放在桌面把它加载进来, 按住 ctrl 键缩放就可以缩放了, 然后就得到了这个一个图线转三 d 的 一个效果,这个三 d 的 一个模拟效果图, 最后通过这个在线编辑把它旋转到你想要的一个位置,比如说我想要这个位置,把它旋转一下, 好,确定好你想要的位置,到时候截图就可以了。然后点开这个设置,把网格都都去掉,因为那些是我们不需要, 看起来是很粗糙,但是可以可以用就是了,不用管它。 比如说调整好一个角度,我需要的是这个角度,这个用这个在线编辑有个优点,就是这个三 d 的 透视效果,也可以直接在这边编辑,我可以让他透视变得很夸张的透视, 就众生透视很强。然后用截图工具把他截图下来, 比如你要这个视角的一个,确定好这个视角,把它下载下来,保存到桌面,这个在线编辑就是这个作用。 截图完就可以把上面这个公众号禁用了,把底下的公众号解锁,鼠标要在这个群主上面 点这个解锁,然后把你刚才截图的上传在这个位置,点这个按钮上传上来,呃,这个乱七八糟的,不用管他,只要一个大概的角度就可以了。 然后这边是上传原图,原图没旋转的一个角度的图就做这两步就可以了,然后就直接运行,至于上面这个提示词默认就可以了,不用去改, 最后就可以把角度完全切换过来。而且产品,呃,原本的产品啊,什么基本保持不变,而且其他空白处他也会自动修补出来, 非常完美,这这个就达到了非常精准的一个角度控制,基本上跟这个角度是一样的,就是要这个角度 他就非常完美的生成出来,然后看一下这边对比图,原图是这是剪了一个 视角的图,非常乱七八糟,但是没关系,他理解就行了,他只要理解这个角度就可以了,然后生产出来就非常完美了,而且他会根据你前面的那个原图的参考,自动保持这些产品。啊,什么特征不变, 内容特征不变,这就是上传原图参考跟上传这个高斯破件的角度图参考的作用, 当然这边最重要是需要加载这个高斯破解的一个 logo, 至于这个模型,呃,千万二五幺幺的编辑模型都行, 其他就没有了,这样子就非常精准的一个视角转换就搞定了,而且可以改变这个透视,他最大的优点就是有了这个三 d 高斯破件的文件,可以轻松的控制这个透视的。呃,众生感, 就是这个众生感透视可以变得非常强, 这里边主要是调整角度,然后最终只要只需要截图就可以了,截图然后保存下来放在这边的第二张不懂的话可以点这个注字都有,然后这边是尺寸控制,最常见, 一般默认就可以了。好了,这期就到这,大家自己去玩吧。
11吴杨峰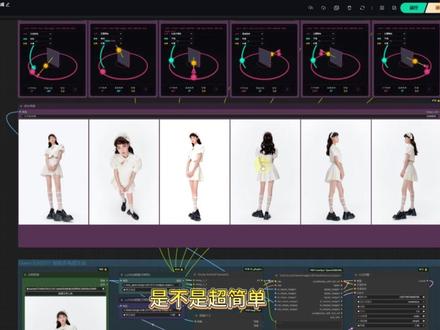 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿你可能不会相信, ai 终究是向三维进化了。一张图片上下左右无死角的控制镜头,不管是测试、俯视或者是任意视角, 只需要调整 x y z 轴都能得到。终于能说换个角度看问题,让我们一起来看看它是如何让视觉去式变得前所未有的简单。同一时间,社区里的开元大佬 terry dear 也马上制作了适配拷屏而已的节点,他可以很方便的控制相机角度,配合今天这个多角度罗尔,我们就可以实现非常便捷的生成多角度一致性照片的功能。一起 来看一下工作流哈。他会将我们的图像进行的摄像机角度设置转换成一组提示词输出,我们可以看到这里的提示词 在配合我们的多角度 noir 之后,就可以产生高一致性的多角度照片了。我换一张图片演示一下给大家看一下啊。接着我们点击运行,稍等一会,多角度一致性的照片就生成好了,是不是超简单?工作流和模型我已经调配好了,小伙伴快抄抄作业吧,同时也很期待大家的成片。
117秋葉aaakl 30:20查看AI文稿AI文稿
30:20查看AI文稿AI文稿逼自己一周练完,其实你很会 ai, 存下吧,全一百七十八集很难找,全的警告,本系列视频耗时两个半月,制作共计一百二十分钟,让你从康复 ui 小 白到 ai 大 神,这应该是目前抖音仅有的从入门到进阶的全套系统康复 ui 教程。 ai 界最全能的软件来了, 一款软件就承包了所有的 ai 需求,关键是官方正版完全免费,它就是康复 ui 工作,留意打包,还没试过的直接抄作业。 哈喽,朋友们大家好啊,欢迎来到 comui 全系列课程的第二节课,那么在这一节课呢,我将带领大家一起去深入了解 comui 纹身图以及背后的深图逻辑。 好,那么我们现在就开始我们第二节的一个课程了啊,首先大家看到我们的一个啊,工作流老师打开的这一个界面啊, 那么这个工作流的话呢,是我们用上了一个 laura 啊的一个组合生出来出来的一个效果,大家觉得还不错,对不对?好,那么我们先不管这一个界面啊,我们先加载一个新的界面啊,然后加载一个默认的工作流出来啊,加载一个默认的工作流 啊,这个默认的工作流呢,其实就是我们要讲的这一个,嗯,最基础的这个纹身图的啊,工作流了。好,那我们先来去理解一下每个节点的一个含义吧啊,每个节点的一个含义?首先呢,我们左边的这一个节点啊,左边这个节点呢,它就是 checkpoint 加尔器, 那么这个加尔器呢,它其实就相当于我们选择大模型的一个节点啊,那么在 函数 ui 中呢,我们基本上每一个参数啊,比如说大模型的选择, laura 的 选择, bay 的 一个选择,都是通过一个节点来去选择的啊,等下我们可以去了解到,那么在这里的话呢,大家就可以选择我们需要用到的一个模型,比如说我们用一个白菱 啊,白人的这一个模型,叉 l 的 一个模型,对不对?好,那么这个的话呢,就相当于是大模型的选择,对不对?那么除了大模型的选择,我们还需要什么呢?还需要提示词的一个出现,对不对啊?那么这两个节点啊,那么我们都叫它节点啊,那这两个节点呢,它分别是我们的 正向提示词的一个输入,以及负面提示词的一个输入,那么在上面的这一个输入呢,就是正面提示词, 那么怎么样分辨他们两个哪个是正面呢?其实就取决于他们后面的这一个线条啊,不说叫这个参数的这个条啊,他是连到哪一个的啊?连到这个 k 传感器,他是连到正面条件,他这个宽里面的就是正面条件, 如果我们把它给反过来,那么这个宽的话呢,他就会变成负面条件,明白吧?不管你这里面填的是什么啊,不管你里面填的是什么, 然后这个就会变成正面啊,他就这样反过来,所以说大家一定要在前期的时候呢,注意好我们的这一个参数信息的这个连接啊,正面条件记得连哪里啊?负面条件是连哪里,不要连错了。好, 那么我们这两个是文本的输入框,对不对啊?它叫 clip 文本编辑器啊,等一下我就会给大家去解释为什么它叫 clip 文本编辑器。好,那么这个 collate 这个节点呢,就相当于是我们图片的尺寸调节,以及我们 p 四大小 啊, p 大 小的意思呢,其实就是我们生成图片的张数,你想生成一张,那就是选一,那么如果你想生成两张呢,选二啊,这样的话呢,我们就可以生成两张图的意思啊。好,那么这个 k 采集器呢,其实就相当于把我们前面所有的一些信息 集合出,集合到他的这个节点里面,然后在这里呢进行我们的一个图片生成啊,然后里面有一些参数,我们等下会讲解, 那么这个 ve 解码呢啊,等一下我们会专门去讲一下这个 ve 解码它的一个作用,然后最后的话呢,我们就保存一下图片,那么我们这几个节点其实都已经出来了啊,他们每个节点的一个用法啊,然后的话呢我要去讲解一下,就是我们的这个线条的一个连接 啊,大家可以看到我们大模型这里有个模型对不对?那模型它代表的一个啊,参数的颜色就是紫色的对不对?所以说它一定要连到 跟紫色有关的一个节点上啊,大家看到没有,你这一个模型啊,如果你不连这个模型,你连正面条件是连不上的啊,同学们一定要注意啊,连不上的,所以说我们一定要注意这个, 嗯,对应参数的一个连接,就说信息不能错啊,黄色的就一定是啊,跟提示词有关的啊,你看这个红色的就是 v e 啊,你红色的是连不到黄色的上面的啊,就是这个意思,好,那么 我们了解了这一个每个节点他大概是什么样的一个作用之后呢?我们就来拆解一下他的一个真图原理啊,那么在这里的话呢,我们先升一张图啊,比如说一个弯钩儿啊,我们先升成一张图,对不对?我们其实选好大模型之后,我们只需要来一个提示词啊,点击一下生成, 他就给我们去升一张图啊,然后这里我们尺寸的话呢,应该是调错了啊,我们这里填一,然后一零二四乘以一零二四 啊,我们在这里去点一下生图,对不对?他这样的话呢,就会给我们生成一张啊,女生的一个图片,对吧?啊,很好看的一个女生图片,那么他是怎么样做到这一步的呢?那我们就来到了怎么样去 拆解这一个纹身图,他的一个厚涂的原理了啊,好,那我们就来到我们的这个 ppt, 我 们首先的话呢,呃,我们刚刚的那个步骤,其实就是这一个 ppt 的 一个作用啊,就是我们输入一个 w 就 能得到一个女孩,对吧?啊?那么他的一个后台到底是怎么样运行的呢?首先我们要讲一下大模型, 就说大模型它里面是什么东西啊?它里面有什么?它能这样子生成图片,对不对?大模型它其实就是把我们在训练的过程中啊,把我们很多真实的图片,就比如说它训练了很多女生,他把很多女生的一个图片,以及 女生图片对应的一些提示词,比如说这个女生可能是个黑色头发啊,然后呢棕色的眼睛,对不对?白白的皮肤,他把这些提示词呢,变成每一个图片都有的一个标识啊,那大家看到没有这张图 你就能看到啊,在这一个空间里面,这一个我们每一张女生的图,他都会变成这样的招生图啊,就像这种马赛克的啊,像那个电视没有信号的那种图片,对不对?那么在底下呢,有一些小字啊,但其实这些小字呢,其实就是 就是图片所对应的那些词转化成的一些参数啊,大家可以这么理解,然后呢,每一张图都有他对应的一些啊提示词的参数,所以说他这样子啊,素材多了,然后在这个浅空间里面,他就能当做是一个大模型 啊,大模型里面就是有这么多参数啊,有很多张图片,以及有每一张图片对应的一些参数的一个提示词。好, 那么这个就是大模型的作用啊,它储存了很多参数对不对?好,那么 clip 是 什么意思呢啊?大家可以看到,在我们大模型里面啊,大模型的一个输出里面,除了有模型对不对?那么这个紫色的模型其实大家就能理解了,这里面就是纯属了一些图片的数据。 好,那么这个 clip 呢?是什么意思呢? clip 呢?其实就相当于把我们输入出,输入进去的英文翻译成 ai, 它能听得懂的 talk 啊,那么大概可以理解成向量啊,那么 因为 ai 它是听不懂,比如说我们一个弯钩啊,或者说一个蓝色头发啊,棕色眼睛这样的一个提示词的,对不对? ai 它是听不懂的,它只能听得懂它属于它的语言啊,所以说 clip 这个东西就是帮助我们去翻译给 ai 听的啊,让 ai 能知道我们真正想要去出什么图啊,然后呢去大模型里面找对应的一些造声图啊, 明白吧?这个 clepe 就是 这样的一个作用。好,那么 ve 是 什么用呃的一个用法呢? ve 它的一个用法就相当于把我们的图片可以变成造声图, 因为我们的 ai 或者说这个 stable definition 在 浅空间里面只能理解这个造声图这种形式,所以说我们的 ve 它的一个作用就是把我们的图片变成 这个造声图,或者说把它生成出来的造声图解码成我们的一个正式图片啊,那么 ve 它的一个作用就相当于图片的一个翻译官 啊, clip 就 相当于我们文本的一个翻译官,那么它翻译进去的都是属于在浅空间里面进行计算。好,那么这个 k, 那么这个浅空间里面到底是在干什么呢?其实我们的深度流程就是通过我们的一个浅空间在浅空间里面进行计算的。好,那么它具体的一个步骤是什么呢?就是 我们输入一个提示词啊, one two, 那 么这个提示词啊, clip 就 会把它翻译成 一个项链啊,那么一下他能听得懂,那么他能听得懂之后呢,就会在我们的大模型里面找到对应的啊,跟弯戈尔对应的那一个造成图里面的照点 啊,然后这个时候呢,空 late 就 会确定一个招生图的尺寸啊,因为我们是随机生成一张招生图吗?那么那个招生图里面呢,就会带有这个弯个的一个属性啊,那么好了,那么得到了这个招生图之后呢,我们就会这个招生图就会经过我们这一个 k 产气 啊,来到这个 k 传感器里面,那么 k 传感器呢,就会把那个噪声图不断的把那个噪点给去除,那么具体去除多少步啊,以及去除的效果怎么样?那就是取决于我们里面的参数了 啊,我们里面的一个参数的话呢,就是通过调节我们的一个步数,或者说 c f g 值啊,以及我们的采暖器和调度器,那么采暖器和调度器呢,它其实就相当于我们怎么样把那个噪点去除啊?它的一个方法是什么样啊?那么其实 去除的差不多了,那个照点去除的差不多了,那么我们图片就会变成这样子,对吧?啊?但是呢还不能够达到我们这种画面的效果,对不对?这种画面就像真实的图片一样,那么我们就要通过 v e 烂吧烂它这一个 接近我们真实真实的图片的一个带照点的一个图转成,或者说解码成我们这个图片,那么其实我们的这个工作流程大家就能明白了啊,对不对啊?那么我再给大家去讲一遍, 大模型提供所有图片啊,造成图的一个数据集 click 文本,帮助我们去翻译我们的提示词啊, ai 他 就能知读的懂,我们想要什么画面,他就可以在大模型里面去找 啊,好,那么这个空内存呢,就负责是我们那张图片的一个大小和尺寸啊,以及我们的一下生成几张,那么所有的参数收集完成之后呢,就会在空内存 啊,就会在 k 产生器里面呢进行把我们那个噪声图呢啊,对应那张图像去降噪啊,最后的话呢,通过 ve 的 一个解码就能把我们这张图片给它真正的生成出来了。 那么这个图片的这一个流程的话呢,就是属于我们真正的一个生图的流程了啊,这样大家应该都能明白了。所以说大模型他的一个非常关键的啊,如果没有他的这些数据啊,你是不可能能生成出一个 很好看的一个效果的啊。然后再举个例子呢,就是如果我们的大模型他只训练了动漫的一个画面,对不对?他这里面所有的一个参数啊,都是属于动漫的, 那么你想让他去生成真实的一个图片就是不可能的,对不对?因为他根本就没有这个对应的数据级啊,那么你再给他写详细的提示词,他都不能够给你去生成很好的画面。好,那么我们讲完这个生图原理之后呢,大家就能明白了,我们这个 嗯背后的原理到底是什么样的啊?那么我们再来去讲一下这个纹身图怎么样去加 lara 啊,我给大家进阶一下,那么纹身图想要添加 lara, 那 么我们首先要理解 lara 它到底是个什么东西? lara 其实就相当于大模型的微调模型,因为有些大模型啊,他不能够,虽然说他训练了很多图片对不对?但是呢他不能针对某一种风格或者说某一种角色去深沉 比较精准的啊,不知道大家能不能明白,就比如说我要生成一个路飞的形象,虽然说这个大模型可能训练了一张或者说两张路飞,但是呢不够多啊,所以说他可能去生成路飞,他就不够像啊,那么这个时候呢,我们就要需要去专门用一个 啊,很精准的一个路飞的 lara, 因为路飞的 lara 它就相当于你可能有二十三五十三专门训练路飞的一个图片啊,那么训练出来的这个小模型就叫 lara 模型啊,那么我们就可以很精准的生成路飞了,那么 在这个这里的话呢,我们去讲解一下这个怎么样去添加我们的 lara, 那 么 lara 大家都知道喽,刚跟大家说了,我们这 lara 相当于一个小的模型,那么模型是在 所有的一个参数的一个输出啊,它是作为所有参数的一个输出的,所以说它一定是要连到前面的,不然的话呢,你前面你后面的这些节点,它都是接收不到数据,它就没有办法进行一个生成了。好,我们这个时候呢, 找一下啊,双击这个空白的区域,我们找出 lua 加载器这一个名称啊, 啊,找出这个节点,然后呢怎么连接呢?大家看到没有有一个很好的连接方式,就是说看它的左右的一个输入和输出的信息。 好,我们在这里看到呢,它左边的一个输入啊,那么必须是有一个模型和 clip, 对 不对?那么大家看一下哪一个节点呢?是可以直接给到它 这两个参数的呢?只有这一个节点对不对?那么我们就进行一个连接好,那么连接好之后呢,怎么样再连出去呢?其实大家就能一看就能明白了,那肯定是经过这个节点之后呢,再连给我们后面的一些节点的,对不对?那么 klipp 也是进行一个连接,其实这个东西就像一个串联一样, 对不对啊?就像一个串联一样,好,那么在这里的话呢,我们选用一个其他的一个 lala 啊,那么在这里的话呢,我们用一个魔法阵的一个 lala 啊,魔法阵的一个 lala 啊,我们去申图。好,那么在这里的话呢,老师给到大家推荐的一个提示词啊,那么包括我们推荐的一个啊,大模型啊, lala 啊,我们都是给了参数的啊,所以说大家可以去参考一下我们的这一个,嗯, 提示词啊,提示好,我们这个时候呢,点击一下生成,大家就可以看到我们生成的一个效果喽, 对不对?有了 loa 之后呢,我需要得到的一些画面效果,它就可以很精准的给我表现出来啊,如果我们没有用这个 loa, 那 么它的一个魔法阵的效果肯定就是 不太好的啊,效果不太强烈的。我们这一个大模型,包括我们的一个 lua, 以及我们这节课会用到的工作流呢,都会放在我们的一个评论区。好,那么我们这一个工作流就是搭完了,然后我们再来讲一下啊,这里面有没有什么需要注意的地方啊?其实就是这个 k 传感器喽 啊,黑铲器,这里呢有啊,步数的意思就相当于是他降噪了多少步啊,我们这里默认填二十到三十步就可以,三步距值呢,就相当于我们的提示词的听话程度,如果你想让他听话一点,那你就调高,如果想让他没那么听话 啊,你就调低一点,但是呢太高的话呢,会导致我们的一个棒面的一个质量降低啊,这个大家一定要注意,然后呢踩样器和调度器我们就选默认就好了, 降噪值在纹身图的一个过程中一定是要填一的。好,那么我们今天的一个纹身图的啊讲解,包括我们那个纹身图加拉拉啊,以及我们深图原理的一个课程的话呢,我们就讲到这里了啊,视频用到的工作流插件模型 啊,也可以在评论区留言啊,老师都会一一分享给同学们的啊,好了,大家一定要关注我啊,老师下一期会带大家继续的去深入了解靠谱 ui 图深图的各种参数节点的含义,以及背后的一个原理啊,还有使用方法。 哈喽,各位同学们大家好呀,欢迎来到本期靠谱 ui 全系列教学视频的课程, 那么这节课的话呢,我会带领大家去学习一下我们图深图的深图原理以及工作的搭建。好,那么我们就正片开始啊,好,首先的话呢,我们要去来了解一下这一个纹身图 和图深图他的一个深图原理的一个差别啊,其实他们是很接近的啊,大家可以看一下右下角的老师给出来的这一幅图啊,如果我们不看 这块区域啊,那我们打开一个形状啊,我们假如用这个形状把这个给遮挡啊,假如给把这个给遮挡好,那么把这个遮挡之后呢,其实 我们不看这块区域啊,那么这个流程就是我们看不出来纹身视频的一个流程了啊,纹身图的一个流程,那么大家可以看一下啊,纹身图的流程是什么?我们输入一个 text 提示词啊,就是文本的提示词,然后经过 clip 文本编码器,对不对?那么 ai 它才能理解到我们的提示词对不对? 提示转化为 talk 之后呢,再通过我们的这一个,呃,在潜空间里面,对于我们这个大模型,对不对啊?生成成一个随机的图,那么这个图的话呢,不断的进行叠代之后呢,就会生成我们的一个接近于真实画面的一个 带有照点的一个图片啊,然后通过我们的一个 ve 的 一个解码,对不对?然后呢,就能生成我们的一个真实的一个图片啊,然后如果我们图生图是怎么样? 图生图我们是不是想法是什么?有一张参考的图片,你要根据我这一张参考的图啊,或者说输入给 ai 的 一个图啊, 来让 ai 知道啊,我是要基于这张图去生成的,对不对?那么这个时候呢,图片怎么输入给 ai? 其实就是图生图工作流里面最大的一个 问题了,对不对啊?怎么样输入给 ai 呢?那么我们可以先知道啊,怎么样从噪声图转化成我们的图, 对不对啊?就是通过这个 v e 啊,它解码对不对?那么 v e 它能不能帮助我们把我们的原来的图片啊,就是一张真实的一个图片,然后能转成招生图呢?因为 static 选的模型在浅空间里面只能识别招生图, 所以说我们需要把我们的图片啊,就真实的图片,不管你是什么图啊,只要你你能看得懂的图 啊,通过 ve 的 一个编码器啊,跟这个解码器不一样啊,编码器,然后呢把我们的图转成造声图, 对不对?然后这一张造声图就会替代我们纹身图之前学习到的那张随机的图啊,那么对于这一张图呢,进行不断的降噪啊,不断去叠代降噪,这样我们就完成了我们图生图的一个生图流程了啊,其实很简单, 就是纹身图,他是生成一张随机的造型图,然后去叠带,对不对?那么图腾图的话呢,就是不是随机的,是我们给他一张图,然后呢他转成造型图,然后对于那张 我们转成的造成图再进行一个降噪叠带,所以说就能够去形成我们的图生图的一个效果了啊,那么这个东西的话呢,其实就是我们刚刚说的图生图的一个生图原理啊,好,那么具体的一个降噪啊啊,或者说去噪的一个过程中是什么样的呢?其实大家可以看一下我们左边这样图, 那么首先我们图片输入进去肯定是从右边开始的啊,从右边开始的啊,就是说我们的图如果是一张照相图的话啊,我们纹身图 一张照相图对不对?那就是最右边那么不断的去叠带成清晰的图片,就是从右到左啊,那么这个照点越来越少,越来越少啊,慢慢的去消失啊,就会成为我们这样的狗狗。那么如果我们是图生图呢, 真图的话呢,就是先输入一张狗狗,对不对?那么输入这张狗狗之后呢,他就会在我们从左到右,先把它变成一个造型图,再从右到左变回来 啊,这个东西的话呢,从左到右,再从右到左,其实就是我们的一个图生图的一个流程啊,这个大家能看的明白,好,我们就进入下一个啊,那么我们的图生图的工作流怎么样去搭建呢 啊?其实很简单,我们先去来啊,导出导入一个纹身图的工作流程吧,大家看到没有,这个就是最基础的纹身图的流程,对不对啊?我们输入一个 one boy, 他 就给我们出来一个男孩,那么我们如果想要去把它变成图身图怎么办? 其实就是从我们的空垒腾这里入手嘛,因为在浅空间里面,这个空垒腾会帮助我们创建一个随机的马赛克,对不对 啊?这个时候呢,我们把它给删掉,或者说断开这个 laten 的 连线啊,不要让这个空 laten 是 连到我们的潜空间里面,对不对?不然的话它又生一个随机的好,这个时候我们点击一下拉出来,这里有一个 ve 的 一个编码器 啊,那么 ve 的 一个编码器的话呢,它其实就相当于可以让我们上传一个图片啊,加了一张图,对不对? 那么加载完这一张图之后呢,我们需要注意了哦,这一个 v e 的 一个连接啊,一定要连上去,不然的话呢,他 v e 进行编码的时候呢,是没有模型的 啊,没有模型的,所以说一定要有模型,不然的话他会报错。好,这个时候的话呢,我们再输入一个对应啊,比如说一个弯歌,因为我们的图是弯歌吗?啊?点击一下生成, 这个时候大家有没有发现,我们这个女生跟这个这个女生完全不一样啊,对不对啊?效果完全不一样啊,为什么呢? 其实这个就跟我们的降噪有关了啊,就是这一个值,那么我们现在降噪填的是一对不对啊?那么在图升图的一个过程中呢,降噪就是我们 k 产生器里面最重要的一个值 啊,他相当于 web ui 里面的重绘幅度,其实大家就可以理解成重绘幅度啊,他写的这一个降噪是属于我们深度原理的一个,嗯,概念啊,那么 这个如果是重绘幅度那么一的话呢,是不是最大的,那就相当于你是百分之百对我们这张画面进行重绘了,那么他肯定跟左边的这个图是不一样的,他是会去参考,或者说他只会根据你的大模型以及你出的提示词 啊,什么意思呢?就是你输一点零,他其实就相当于纹身图啊,因为你完完全就跟你这个没有任何关系了,所以说如果我们想让这个画面生成出来,这个画面比较接近于我们的原图的话呢,你一定是要降低我们的降噪值的 啊,比如说零点五,对不对啊?我们降到一半这个时候呢,你就会发现这个图啊,他是会比较接近于左边这张图的,对不对啊?零点五就比较接近了,那么如果我们再调低呢啊,想让他无限的接近,我只想让他去刷一遍图,那么零点一其实都 ok, 对不对啊?零点一都是可以的啊,零点一之后呢,你就会发现这张画面基本上是没有什么太大的一个变化啊,除了这个人物细微的表情会有点变化,是不是啊?这个的话呢,就是我们图声图它的一个作用了,那么图声图它主要是用来干嘛的呢?其实我们用到最多的是什么? 就是我们的图片的转会啊,转风格嘛,啊,我真实的一个女生啊,转成一个动漫的女生啊,对不对? 动漫的一个男生,转成真实的一个男生啊,就是转会啊,我们就叫他转会不同的风格的进行的一个转换好,那么转会的话呢,怎么样去操作呢?其实很简单啊,老是拿一个,比如说我们拿这个女生,对不对啊?一个真人的一个小姐姐啊,那么我如果想把它转成一个 动漫的一个效果怎么办呢?首先其实最重要的就是把我们的一个大模型,你就换什么风格吗? 对不对啊?或者说你自己去添加一个 loa 加气啊?上一节课的话呢,我们已经讲过了,对不对?如果大家有兴趣听我们上一节课纹身图的一个原理的话呢,记得一定要关注我们的一个账号啊,然后呢,这样的话呢,大家就可以学习到整一套的康复 u i 课程了啊,然后 如果大家已经填好这一个啊,我们的大模型之后的话呢,就是我们的提示词了啊,那么提示词的话呢,你首先有两个方法啊,两个方法,一个是反推 啊,反推,怎么反推呢?其实很简单啊,我们双击空白区域啊,鼠标左键双击啊, w d 啊,一四反推标烟器,如果用过外部 y 反推的同学应该是知道这一个节点的啊,然后我们拉一个展示文本出来啊,也可以把这个展示文本直接连到我们的这个 文本编码器的这里啊,你这样的话呢,他输入出来的这个文本他就会直接变成我们的一个正面提示了啊,大家能明白这个意思吧?好,那么我们这个时候的话呢,最好就是不要接啊,不要接啊,我们把它转换为主键, 我们先把它的这个提示词给它进行一个反推出来,出来之后呢我们再去添加我们自己需要的,比如说加一些动漫的一个提示词,对不对啊?我们点击一下生成啊,先让它反推 好,返回出来之后呢,它是不是已经在跑我们的一个流程了啊?我们先不管它对不对啊?我们先不管它,我们先把这个提示词给它去复制啊,然后呢就粘贴一下啊,到我们的翻译的一个场景啊,我们转成中文对不对?它这里的提示词你就会发现它这里有什么现实主义啊 啊,或者说其他一些提示词,你你不需要,对不对?我们是要动漫的一个风格,所以说我们这个时候呢一定要改一下我们的提示词,比如说动漫风格对不对?二次 二次元效果是吧?然后呢再加一些高质量画面啊,或者说再加一个四 k 啊这种我们补充一下提示词,让提示词写的更好,是不是啊?这样的话呢,我们画面也会更好, 那么这个时候呢,我们把我们的题词给它去复制上去,然后我们就不需要这个反推了,不需要的话呢,我们可以把它删掉啊,你去按住 ctrl 键,然后选择这两个节点之后呢按 delete 啊,或者说呢啊宽选它之后呢按住 ctrl 加 b 啊,那么就可以把它给隐藏了啊,隐藏不是删除的意思啊,那么这个时候呢,我们提字词也写好了,对不对?我们点击一下生成, 我们会发现这一个画面啊,好像没有什么太大的变化啊,他没有太动漫化对不对啊?只是感觉脸型有点变化,也就是因为我们的降噪不够嘛,啊?重绘的一个值不够,那我们就调高一点零点五啊,点击一下生成 这个时候你就会发现零点五的一个效果,他就已经我觉得还是不错的,对不对啊?你看这个女生,他已经转成动画化了,但是呢他整一个画面也没有太大的一个变化,是不是啊?这样的话呢效果就是比较好了。好,那么如果我们想让他再动画化一点的,那就可以继续调高,比如说零点六 对不对?一点六啊,零点六的一个效果的话呢,我觉得也还是不错的,只不过他可能重回幅度大了之后啊,他就会更加的 啊,在画面里面添加一些我们原本没有的一个内容,比如说右上角他出现了一个窗帘,对不对啊?现在的话没有啊,那么如果我们再继续调高呢 啊?零点八呢,我们可以看一下他的效果啊,零点八的话呢,大家可以从预览图啊现在生成出来的一个图片可以看到啊,基本上他就跟左边这个图啊,差距有点大了啊,但是呢他会跟我们的一个提示词越来越接近 啊,提示词越来越接近,你调到一的话呢,就基本上是个纹身图了,明白吗?啊?为什么他还是坐在船上?因为我们提示词肯定是写了什么坐在船上,因为我们是通过这个反推出来的,对不对?所以说 具体你要达到什么样的一个效果啊?你想让他像一点原图,那么你就调低啊,那么就调低,比如说零点五,对不对?如果你想让他去,呃,没有那么像,只是参考一点点,那么就调高,是不是啊?但是你的题字词一定要写精准 啊,那么就这个意思好,那么我们这个工作流就已经给大家去讲完了啊,那么回到 ppt 给大家去再说一下啊,就是说 我们的一个降噪值 k 传感器里面的这个降噪值越高啊,画面是不越不接近原图的啊,然后呢,我们的降噪值越低,是越接近原图的提示词的影响,它就会越来越小 啊,因为你重会幅度就根本就没那么大吧,画面你都跟改变不了多少,你怎么去?呃,影响就提示词的影响呢,对不对啊?那么你只有在降噪值高的时候,也就是重会幅度高的时候呢,你这个画面改变的幅度才大 啊,你这个幅度改变大,你的这个画面才能去接近提示词啊,你提示词才能生效啊,那么这个的话呢,就是我们图升图的一个 啊,需要注意的一个点啊,其实最重要的就是这个降噪好吗?啊,然后今天这节课的话呢,我们就讲到这里,视频中使用到的这一个工作流啊,包括我们的一个模型插件啊,都 可以在评论区留言啊,我会一一分享给大家。好了,关注我下一期带同学们继续从零到一,搭建我们的高清放大和细节修复的工作流啦!
107AIComfyui 09:23查看AI文稿AI文稿
09:23查看AI文稿AI文稿等你们熟练的掌握了纹身图的这些基础工作流,那么接下来我就会开始讲如何使用 md 显卡进行一个 lora 的 炼制,也就是我们常说的炼丹。 今天给大家带来的是千万二五幺二纹身图的一个基础工作流,还有一个 四模态的切换工作流,总共是四个工作流,两个 f p 八的,两个 g g u f 的, 其实这个二五幺二的意思就是二五年十二月份发布的意思,然后他跟二五幺幺最大的不同就是二五幺幺是一个编辑模型,二五幺二是一个图片生成模型。 首先我们来看一下,第一个是一个主模型的加载,然后是一个加速 lara 的 加载,像现在的这个基础的两步工作流的话,是加载了一个两步的 lara。 接下来是小白工具箱的一个模型方块, 二五幺二的话它是有六十个层,至于分多少个层,大家根据自己的显存大小去决定。然后是一个 c j 层次的加速,这个加速节点的话,如果是 n 卡用的话,你把这个删掉,替换成 k g 的 那个节点就可以了。接下来是可立普的加载和 ve 的 加载, 那么除了这个以外的话,就是一个普通的纹身图了,输入提示词,选择自己的分辨率进行一个生成。那么为什么这么简单的纹身图我要拍一些视频呢? 主要是因为第一很多新手很迷茫,这么多的纹身图的模型,到底我应该选择哪一个?第二个的话,这个二五幺二的话,我做了一个四模态的切换版本,所以说要专门来讲一下。首先我们来看一下两步生成的一个效果, 这是一个提示词,因为千万的话,他是对中文支持的特别好,所以说我们直接使用中文提示词就可以了,分辨率的话使用一个七二零乘以一二八零。 这里有一点非常重要的,大家要注意的就是千万这个模型它有个特点是非常吃内存,现在大家可以看到下面的内存的话,我现在总共是一百三十五 g, 他 直接跑到了一百一十四 g 去,那么这个占用是非常恐怖的,所以说如果你的电脑内存不够的话,虚拟内存一定要开的很高。 然后这个就是一个两步生成的一个效果,大家可以看到其实还是细节是比较少的,毕竟是一个两步加速的一个效果。 那么同样我们来看一下 g g u f 的 模型, g g u f 的 模型的话,其实跟前面那个是一模一样的,只是模型加载我们使用了一个 g g u f 的 加载器,包括可立普的加载器的话,我们也使用了一个 g g u f 的 加载器。 之前有很多小伙伴他下载了 g g u f 的 模型,然后他放到了模型文件夹,发现加载不了,就是因为这个加载器一定要使用 g g u f 的 版本,如果普通的加载器他是搜索不到 g g u f 的 模型的,那么我们继续来看一下两部的 g g u f 模型生成的效果, 这个是两步 g g u f 生成的一个效果,接下来着重讲一下四模态切换的工作流,这个工作流的话在这里是加载了三个 loa, 这三个 loa 的 话,第一个是一个两步的 loa, 第二个是一个四步加速的 loa, 第三个的话是一个八步加速的 loa。 为什么要加载三个呢?因为我这个工作流现在是可以有四个模特可以给你切换的,第一个模特就是原版的五十步生成,第二个的话就是两步急速生成,第三个的话就是一个四步加速生成,和第四个一个八步加速生成, 那么不同加速生成的话耗时是不一样的,出来的效果的话也是不一样的。原版五十步肯定是效果最好的,但是它的耗时非常久,两步、四步、八步的话,大家可以根据自己的使用场景进行一个切换。 那我们现在来看一下这四种模式的区别。我们使用同样的提示词,然后首先使用两步加速生成一下,分辨率依旧是一个七二零乘以一二八零, 这个就是一个两步生成的效果。大家可以看到这上面的字的话比较模糊,有些地方的话都不太对,那我们来切换到四步再来运行一下, 现在就是一个四部生成的效果,明显是比两部好了很多。再来切换到八部, 这个就是一个八部生成的效果,而且现在分辨率是七二零乘以一二八零。像后面的这些字,包括这侧面的这个黄字,以及后面的这个全息投影,都是经过提示词单独来进行加载的, 它里面一共出现了三个角色和大量的这个文字。二五幺二最强的地方就是在于它对文字的识别特别好,无论是英文数字还是中文,它的识别都非常好, 对比之前的 flex 纹身图,或者说对比之前的 zm 纹身图的话,它在文字和图层的掌控上面要比他们两个都强。同样的它运行的话,再给大家来看一下五十步的一个效果, 那么其实七二零乘一二八零是发挥不出五十步的这个效果的,正常来说的话,要到一零八零才能达到那个效果。先来运行一下 现在这个就是一个五十步生成的效果,五十步生成的话,大家可以看到细节更多,包括之前讲的地面的反射, 以及侧面这些人物,以及后面字的这些东西。但是因为这个分辨率限制了模型的发挥,所以说看起来好像跟八步的区别不大,那是因为我们的分辨率太小了。 为了对比出二五幺二跟其他模型的区别呢?我们把同样的提示词复制到一个 z 位置的纹身图测试一下,运行一下, 同样是七二零乘以一二八零,他就愧了很多,但是他生出来的这个效果更多的像是对于这个人物的一个展示,不太像是像我们之前提示词里面想要的那个场景。 z 妹子最强的还是人像,所以说无论你是怎么样描述,他总是要展示的,主要是这个人物更像是把一个模特放在这展示,对比二五幺二对于场景的这种展现的话,还是差了很多。 我们再来看一下福克斯二的一个纹身图工作流的对比,因为福克斯二对中文的支持不是特别好,所以说我在这里使用了英文,这里使用的是一个 bios 模型,然后使用的是一个二十步的生成,没有使用四步的生成, 这个的话就是福克斯二 bios 模型生成的一个效果。上面的英文还好,中文的话呢就简直就是不忍直视, 包括各种其他地方的话,乍一看还行,但是细节上的话还是差了很多,分辨率的话依旧使用的是一个七二零乘以一二八零, 那么相对比下来的话,人像上来说的话,那位置是不错的,整体综合上来讲的话,二五幺二的实力还是更强一点,但是二五幺二对于显存和内存的消耗是特别大的,这一点需要注意。两步生成的一个 g g u f 模型给大家看一下数据, 现在进入到了模型加载的阶段,显存开始上升,显存的话来到了一个十四多 g, 内存最高的话来到了一个六十多 g 的 样子, 所以说像千万二五幺二的这个模型的话,一般的低配电脑是跑不了的,这个也是没有办法的事情。接下来还会有一个二五幺幺的编辑模型, 等你们熟练的掌握了纹身图的这些基础工作流,那么接下来我就会开始讲如何使用 amd 显卡进行一个 lowra 的 炼制,也就是我们常说的炼丹。在最新的六点零八版本,我已经加入了炼丹炉的功能,可以让 amd 显卡在本地进行一个 lowra 的 炼制。 既然大家都看到了这里,那我花点小时间给大家验证一下二五幺二为什么说他是第一梯队的王者,我来生成一张人像, 这个就是使用两步生成的一个效果,光影、头饰、背景、衣服都体现的比较完美,再来一个四步, 现在我再把分辨率来提高一点,提成一零八零, 大家可以看到眼睛,头发包括后面的服饰都完全不同了,再来试一下八步, 这还是在没有使用 nora 的 一个基础工作流就能达到这么好的效果,如果你们使用了 nora 的 话,那个效果就会更好。 现在的话我们可以看到人物的皮肤是更加自然了,包括衣服和这个貂毛上面的这些细节也更加多了,头发丝的话比刚才更细腻一点。 在目前所有开元的纹身图模型里面,千问二五幺二绝对是第一梯队的王者存在, zm 值和 flax 只能放到第二梯队。那么今天这期视频就拍到这里,感谢大家的观看。
113机智罗_LX 04:31查看AI文稿AI文稿
04:31查看AI文稿AI文稿那么今天推荐 anima 模型的批量训练, comfyy 加上 sd scripts, 直接把 anima lore 训练呢做成一座可以持续运转的 批量面单工厂,一键完成达标训练以及批量操作,只需要将图片文件夹丢进去,就可以直接启动任务。 comfyy 是 开圆的, sd crepes 也是开圆的,那么作为这两者的桥梁,我的这个插件呢,也是开圆的,并且我已经将它部署到了优云计算平台当中, 找到对应的镜像,点击部署指令,那么这是一个自启动的镜像,我们选择可以去租用的 gpu 及立即部署。 等待一下,我们点击 comui 来进入到 comui, 点击左侧的选择我们要去使用的工作流,那么第一个工作流是进行批量训练的,第二个工作流是训练完成之后来进行测试的,我们先选择第一个 快速启动来说,我们只需要完成两个步骤,点击文件管理,进入到对应的文件夹,在这里 如果我们想训练一个 low 二模型,我们就新建一个文件夹,设置一下名称,点击创建,上传一下我们的训练机, 以此类推。可以新增多个人,他们队列进行训练。个人建议是不要超过二十个,对于训练局的数量,那么二十张是一个非常不错的起步值。我们回到 copy y 就 可以点击运行开始训练了, 这里默认每个 lora 模型。我会训练三千个步,我们点击运行,这是一个自动打标自动训练的过程,除了步数设置之外,上方有设置。一共训了十轮,这里可以对二镜像调节以及设置每多少轮来保存一个 lora 模型, 训练的模型呢,会保存到 copy y 文件夹下的模型文件夹下面的 enigma lora 文件夹当中。 这个一分钟之前的 lucy 就是 我们刚刚训练的罗尔模型。到了这个地方,我们就在正常的进行 训练了。一般来说,在默认设置下三千步的话,要训三十分钟,两千步就是二十分钟。这里我做了一个进度条,可以查看我们训练的步数,相信到现在为止,快速启动就非常明确了。训练完成之后,我们要进第二个工作流,那么这是一个纹身图的基础流程。 点击编辑刷新节点,自定义把我们训练完成的模型呢刷出来,然后应用它设置以下提示,点击运行任务就可以进行测试。可以看到这个角色与我输入的训练级的相似度是非常的高的。那么这个批量训练的节点呢,是我与 codex 一 起去编的, 它主要的亮点有这些,我们的触发词以我们文件夹的名称来命名。使用了 jimmy 三的无限制模型来进行打标。那么为什么不用 jimmy 四?一开始我是准备使用 jimmy 四的,但是 jimmy 四过于的缓慢, jimmy 三只需要简单的调校一下, 它既是无限制的,而且打标的速度也非常的快。如果我们的训练文件夹下面包含子目录当中有非常多的图片 超过了两千零四十八张,我们可能需要调高该值。主要运行使用的是一个 number, c c p 的 v l m 节点,这个节点我已经预制了一些规则过了,它出来的结果呢,就是完全的符合我们艾利马模型训练要求的。我们来看一个 rebecca 把标的提示词,首先呢,触发词 rebecca 前置这个地方我是疏漏了,应当用 rebecca, 歌尔会更好一些。然后描述一下图像当中的内容,并且我有做约束, 因为 anim 模型它本身是支持标签和自然语言同时进行推理的训练的分辨率的话是一零二四乘一零二四,保持默认就可以。 那么 batch size 的 话,我用的是一个人认为对于人物类的需要捕捉细节的。罗尔的训练,开一足够了,如是画风可能需要开到五到十,最大训练人数呢是十轮。我这里的 repeat 次数呢,是自动去算的, 只需要去做我们最大的训练步数的调节,如两千步到三千步之间。学习率的话我用的是二一负五,更加温和,默认的值的话是一一负四, 二一附五的话,学习率的话要更低。这只是我自己个人的经验了,保留在我的工作流当中,其他均可以保持不变了。那么来看一些我复现的结果嘛,这两个角色都来自于边缘行者那样一个动漫中的角色,可以看到复现度是非常的好的。安尼玛模型绝对是最为强劲的动漫 插画像的模型,这是毋庸置疑的,觉得差异不大,较为落后的,有这种评价的人,我只能说他甚至对于 pony 模型,对于 illustration 模型根本一无所知,与 animal 模型的用户而言根本就不是一个圈子的。
30AI-KSK 02:10查看AI文稿AI文稿
02:10查看AI文稿AI文稿搓出了自己的第一个工作流,看看效果,简单输入个提示词。第一步,按提示词出图,接着出人物特写,即三式图。最后图片尺寸进行高清放大, 清晰度还是不错的,可以在极梦灵感中找一些不错的全身照像。这个机甲挺酷,试试行不行?把他的提示词直接复制过来即可。 好的粘贴进去运行,等待一下。 two thousand years later 千万出来的,和极梦不太一样,但是也挺不错。 下一步,等三式图效果,效果还是可以的, 四张图会在这里汇聚拼接成一张,最后高清放大,最终出图, 一致性控制的挺好的。再是个古风美女无脑复制粘贴 等待运行。古风这种特定风格的,加个 l o r a 会效果更好,我这里没加。 模型库里可选的乐尔还是非常丰富的,看效果美甲烙热也还是不错的, 高清修复后, 下次搓视频工作溜,哈哈。
18大卫骑不帅 04:21查看AI文稿AI文稿
04:21查看AI文稿AI文稿人物视角图,双击空白选择。 net 加载器添加 lora 加载器,即模型 添加采样算法 or flow 添加 c f 即归一化。 双击空白再添加加载 clip, 选择千万的文本编码器, 复制一个下来。 添加 k 彩样器 添加,加在 v 里, 把 k 彩样器里的步数改为四, c f g 改为一, 加入加载图像节点, 找到缩放图像像素这个节点, 像素数量改为二。 添加 ve 编码, 把它们链接起来, 再加入一个 ve 解码, 拖出一个预览图像, 我们开始选择模型 unit 二五零九 f p 八 mix c sensors laura 加载器选择 quick image lightning 四, steps d 二点零 safe sensors 未移,我们改为三, 再把模型链接起来。 clip 模型,我们选择 clip 二点五 v l 七 b f p 八 skills c sensors v a 选择千万的 va claim by safe for v e 链接 v e 上传我们需要的图像。 图像链接千万文本编码器 正面提示词输入,将相机移至后面位置,使角色的全身包括脚可见。角色站立时, 双臂略微向下伸展,靠近大腿,保持身体两侧平衡均匀。评论一二三,尝尝咸淡。感谢您的观看,喜欢的话点个关注吧,下次更新不迷路。
59AIGC-阿涛 03:36查看AI文稿AI文稿
03:36查看AI文稿AI文稿这个 k 彩样器中所有的数值呢,他都会对图片造成一个什么样的影响?我们先把这个种子固定,这样方便我们对比吗? 然后呢我们去调整一下将刀的步数,刚才我们已经说了,二十到三十之间呢,是我们一个常用的数值啊,除非有一些模型他会有特殊要求,我们现在可以尝试下,我们如果调到十呢, 大家可以看到生成速度比刚才快了,然后呢图片的质量呢,也有一些没刚才清晰,变得模糊了一点,但是对比不大,我们可以再降级一点,然后接降到,比方说降到五,我们看图片已经完全糊了,那如果我们把它调的更大呢?比方说我调到 大胆一点建调到六十,我们可以看到图片有些变得特别锐利,就不自然,所以说呢,我们还是调回来这个数值呢,大家可以自行测试一下,可以多试试下面的,这就是 c f g, 它呢就是对我们提示词听话的程度,那么我们换一个提示词,比方说呢,我们想生成一 座山,然后呢我们再对比一下,我们把它调到一, 那这是什么哦?生成一怪兽是吧?所以说这个听话程度呢,我们一般的情况下把它设置在到八之间,这是一个合适的范围。然后呢我们来讲一下提示词,提示词作用呢?正向呢,我们已经试验过了,那么负面提示词呢? 这时候我们生成一座山,我们发现呢山上有雪,对吧?我们如果不想要这个雪呢,我们可以试着在负面提示词中输入雪行, 这个图片呢就变成了一个绿绿意盎然的山。好了,那这就是一个最基本的纹身图的流程,那么刚才课前呢,我们提到了小模型,我们可以尝试一下小模型的作用,我们还是生成一个女孩吧。 然后呢我们在 cheap coin 的 加载器中拖拽出一个加载 lora, 然后呢我们可以选择一个模型,比方说我们选择一个小人输入模型, 哎,我们可以看到图片呢变了一种风格,这就是我们挠挠总,但是我们看完全跟刚才的图片不一样呢,对吧?这个时候我们也可以看修改扩散模型的强度,我们把它降低, 现在呢又完全没有了想认输的那种风格,我们可以适当的给它提高一下,比方说我们调了零点八,看现在的风格,我们可以对比一下,这是最开始的我们的图片, 然后 lores 呢是可以多个连接的,比方说我们再增加一个 lores, 然后我们就选一个 lores 模型,我们选国风插画,别忘了连接这个端口 啊。然后我们是运行一下,大家可以看这就是我们的 lores 对 于我们的画风的一个调节。 然后呢我们发现我们的图片会不会是比较暗呢?这个时候我们另一个小微型的洞出就出现了,我们可以添加一个 ve 模型,那么 ve 模型的作用呢?刚才我们也讲了,它的作用是给画面提亮,然后去灰,还有 当图片更清晰一些,我们可以加载下来,把 ve 连接到 ve 解码上,咱们运行那大家发现颜色就变得明亮了一些。
 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿你可能不会相信, ai 终究是向三维进化了。一张图片上下左右无死角的控制镜头,不管是侧视、俯视或者是任意视角,只需要调整 x y c 轴都能得到。 终于能说换个角度看问题,让我们一起来看看他是如何让视觉系试变得前所未有的简单。同一时间,社区里的开元大佬田瑞继宇也马上制作了适配康菲尔的节点,他可以很方便的控制相机角度,配合今天这个多角度 laura, 我 们就可以实现非常便捷的 生成多角度一致性照片的功能。我们一起来看一下工作流哈。他会将我们的图像进行的摄像机角度设置转换成一组提示词输出,我们可以看到这里的提示词 在配合我们的多角度 no 二之后,就可以产生高一致性的多角度照片了。我换一张图片演示一下给大家看一下哈。接着我们点击运行,稍等一会,多角度一致性的照片就生成好了,是不是超简单?工作流和模型我已经调配好了,小伙伴快抄抄作业吧,同时也很期待大家的成片。
32秋叶aaaki- 09:37查看AI文稿AI文稿
09:37查看AI文稿AI文稿今天这期视频我们来讲一下英菲尼特尔克数字人对口型的基础工作流,同样是一个 f p 八的工作流,再加上一个 g g u f 的 工作流, 这个数字人对口型的工作流的话有几个重点。先来讲一下,首先在模型加载的区域里面,它除了像我们之前常规的加载一个主模型,加载一个 lora, 加载一个可立普,加载一个 ve 以外,它还需要加载一个视频的模型补丁以及加载一个音频的编码器在上面。这两个绿色的呢,就是我们小白工具箱里的一个方块节点和一个 c j t 的 加速节点, 那么模型方块的话,通过这种颜色的方法区分的话,大家应该很容易就能知道怎么样去选择需要加载的东西。 同样过来在提示词这一块的话,在数字上对口型的工作流里面,正向提示词和副向提示词同样是不太重要的,你可以描述一下图片里的人对着镜头讲话,或者什么样子的没有也是完全可以的。 在工作流的中间部分,最核心的两个点,一个就是语音转视频的一个节点,还有一个就是音频的切片节点,那这两个节点我们放到最后来讲,先来讲一下基础的一些东西, 一张图片,也就是说你数字人的图片,你要提供一个最好是脸部能够露出来的这种图片,远景的话也行,但是远景的话效果没有这种近景的好。 然后的话就是一个参数的设置,参数设置的话你能设置比例分辨率,在这个单人对口型里面锁定的帧率就是二十五帧,锁定的帧数就是八十一帧,你可以上下浮动一点点,但是帧数浮动的大的话,效果会变差, 也就是说模型加载的帧数过长的话,他就会出现这种失帧的情况,在这种情况下,如果说你需要一个六秒或者九秒的视频的话,那么我们就需要三段这样的节点, 那么在今天的基础工作流里面,我就只讲这个三秒是怎么做的,等你把这个基础的工作流吃透了以后,后续我的进阶工作流就是无限时长的工作流,你就能够明白是怎么工作的了。 再来看一下后面的彩铅漆部分,彩铅漆部分的话,如果你要解包的话,点击上面的这个箭头,这就是里面的五个组件,因为五个组件的话放在工作流里太占地方了,把它打包成一个,将设置的参数放到这里,你可以设置就可以了。 最后的话是一个唯一的解码方块,同样这个方块的参数根据你的显卡去设置, 最后的话保存就不用多讲了。现在来讲前面的两个核心节点,先讲语音转换视频的一个方块,在这个里面他这里有个模式,这个模式的话有单人和双人,正常来说的话你来勾选单人就可以了。需要配套的就是说前面的模型, 前面的模型补丁他也是分为单人和双人的,如果说你下载了全套的这个模型补丁的话,你会看到这里面有一个双人和一个单人,正常的话我们选单人就可以了, 下面照样有这个 ve 的 分块,编码大小现在设置至三百二,如果你在编码阶段你的显存爆掉了, 或者说是速度特别慢的话,你可以尝试调节这个风快的大小就可以了,其他的地方就不用动了。现在我们来重点讲一下这个小白工具箱的一个全新节点,也就是说音频切片的一个节点。这个节点总共有三个, 一个是基础款,一个是单人版,还有一个是双人版,双人版的话支持两轨音频输出,还有一个合并的种音频输出,像基础版和单人版的话,只有音频的输出和一个时长的输出。 我们今天重点来讲一下这个音频切片的单人版,它和基础版的理论是一样的,双人版下次再讲。 在这个音频切片的这个节点里面,我们选择上传音频的话,既可以选择普通的像这种 wav 的 音频,也可以选择 mp 三的音频,同样我们也可以选择视频来加载音频, 像我现在就选择了一个 mp 四的视频,同样给你钱也没有用啊,也买不回你失去的东西, 同样也可以将视频里的音频提取出来,十分的方便。这个节点还支持你选你整条音频里的某一段节点, 不用你去用第三方软件去裁剪这个音频。比如说你要从第十秒到第十五秒这个阶段的话,你在提示时间输入 十,那就是第十秒结束时间输入十五,那么输出的时长就是十五减十等于五秒,也就是说我们输出的总时长等于结束的时间减去开始的时间。同样下面有播放按钮可以预览。 除了可以通过上面的输入数值来调节时间,我们也可以通过鼠标滑动来决定你的时间, 也支持下面通过鼠标来滑动这个分割线来分割时间,分割线的话前后都支持拖动,同样你也可以把你选定的区域在前后移动。 下面的这个屏处显示是只是为了好看,这个屏处显示只是为了让你看的更直观一点,它并不是一个真实的屏处显示啊。这一点需要特意说明一下,因为 comui 的 节点很难实现,真的根据你音量的大小来实现屏处, 这个后期如果能升级到的话,我在后面把这个节点升级一下。等你确定好了你上传的这段音频里的音频,你要把哪一段拿过去做?数字人生成的时候,你把参数设置好了以后,那么我们回到工作流, 确定好了以后,你确定好时长了以后,直接就可以点上面的运行工作流就可以了。像我的话,现在上传了一段音频,希望你以后能够做的比我还好哟。啊,同样的,这个节点还有一个调节音量的功能, 那么我们就用这一段话来生成一段视频,生成的效果大概是这个样子的,希望你以后能够做的比我还好呦。那么我们来跑一下,运行一下, 给大家看一下,一个工作流一定是要在本地能够运行的才是好的工作流。呃,我发现现在有好多人的工作流都是在云平台上面跑下来的,所以说他那些参数都奇奇怪怪的,你可能从他那里下载过来了以后,在本机跑的时候,各种各样规模各样的问题,有的时候解决都解决不掉, 那么这个视频现在就跑成功了,我们来看一下,希望你以后能够做的比我还好呦!口型的话几乎来说的话还是比较完美的,而且这人物也有一点眼神的动作以及眼睛的动作都是有的, 所以说的话这个模型整体来说还是可以的。我们来看一下总耗时,那么总共第一次能启动的话,花了一百五十秒的时间,如果热启动的话,大概在一百二三十秒的一个段落, 那么 g g u f 的 模型也是一样,而且我经过测试的话, g g u f q 四模型的话,生出来的效果也不是说很差, 跟 f p 八的话基本上来说的话看不出太大的区别。比我还好呦,希望你以后能够做的比我还好呦!数字人对口型的基础工作流就分享到这里, 着重的重点就是大家要学会怎么样使用这个小白工具箱的音频切片节点,把自己上传的音频进行一个裁切。 那么来总结一下这个基础工作流的几个重点,第一,模型千万不要选错,这些模型的名称都很接近,千万不要选错。第二, 这些参数里哪些该调哪些不该调,前面都已经讲过了,大家一定要注意,大家先把这个数字人对口型的三秒基础工作流吃透,吃透了的话后期的这个 时长比较长的工作流的话,大家就能够比较灵活的使用了。这个工作流正在搭建之中,等搭建好了以后,我会再拍一期进阶的工作流给大家看。最后这里讲一下模型和工作流的一个放置, 我的每条视频简介里都会放网盘的下载链接,你把模型目录和工作流全部下载下来了以后,放置到一个地方, 工作流的话,全选工作流,不管他是几个复制或者剪切都可以。然后点开机智启动器,选择左侧的工作流管理,在右上角选择本地 comui 工作流, 点开了以后,你选择一个你需要放置工作流的地方粘贴进去就可以了。工作流必须要放到工作流的目录里才能识别,放到别的地方是识别不了的。 模型的放置的话,点开这个 model 文件夹,一定要点到里面进去,不管这里面有多少个文件,多少个文件夹。 ctrl 加 a, 全选复制或者剪切,然后回到 comui, 然后在左下角选择模型目录,点击进去了以后,选择空白的地方,右击选择粘贴。 如果这时候提醒你替换目标中的文件,大家直接选择替换目标文件就可以了,因为有的时候他有同名的文件,但是他可能里面的东西不一样的,这种情况偶尔也会发生, 大家选择替换文件保存即可,保存完了回到 comfyui 的 页面, f 五刷新。大家一定不要偷懒说这,我电脑里有几个其他的版本的,我能不能试一下,版本有的时候一字之差,可能出来的效果就完全不一样了, 所以说模型或者可 live 这些东西混用的话,会导致你的工作流无法运行。那么今天的视频就到这里。
81机智罗_LX 11:45查看AI文稿AI文稿
11:45查看AI文稿AI文稿在昨天,秋叶大佬甩出王炸,新版康菲又爱懒人包终于来了,这次更新打破了一半的技术壁垒,以前老是安装报错工作流爆红,现在终于能迎刃而解了,真真正正开丧即用,全程中文操作,不懂英语也能拿捏,康菲又爱 市面上爆火的工作流都塞里面了。另外还会持续更新,你只需要把图片拉进来,点击生成,一键搞定,尝尝整盒包什么味道呢?七八九,尝尝咸淡,后面跟着教程学习吧。 口红都要送这么多吗?老板,再送就要破产了,今天就算破产我也要送。 哈喽,第一站的小朋友们大家好,我是你们的大鱼老师,那么在前面的展示视频呢,我们可以看到这节课会介绍的是一个 多功能的工作流啊,那么说到这个多功能的工作流呢,其实它是基于我们一个罗拉模型进行功能的复现的,那 那么这一个 logo 模型呢,我们把它叫做 i c a d 的 模型,那么它是属于我们 l t x 二点三的一个 logo 模型了。那么我们在学习这个工作流之前呢,我们先来看一下我们的作者对于 i c a d 的 啊这一个 logo 模型的一个介绍。那么首先呢,这一个 logo 模型呢,它就分成了四个种类, 第一个是视频的修复,也就是说可以将这种模糊的视频给它转换成这种稍微来说比较高清的视频。那么第二个呢,是将高清的视频变成 超轻的话,但是啊,这一个高清变超轻的一个视频功能呢,我是觉得它没有 flash v s r 或者说 c 的 vr two 啊,那一个插件比较好, 所以这一个的话,模型我们可以不去进行使用,但是下面这两个呢,应该说是比较重磅的两款模型了,第一个是去水印的,第二个则是去字幕的,但是去水印的这个呢,我给大家简单的试了一下,它的效果,可能只对国内的,比如说抖音平台啊, 哔哩哔哩啊,又比如说我们的快手啊,这种耳熟能详的啊,这种平台的水印去的比较好,那么其他的一些国外的一些啊,视频平台的水印呢,去的效果就没有那么好, 那么可能也是因为我们这个作者他是中国人,然后他训练的一些视频的一些参数呢,都是关于我们国内的这几个平台的比较多,所以这个大家是需要知道的。但是他这一个去字幕的啊,他这一个罗马的效果却非常非常的好,只要你画面中有的文字,他会给你全部去掉,不管这个文字出现在哪里。 那么这里呢,有小伙伴就应该可以讲到了,我们这两个罗拉模型其实可以叠用,就是我们可以把去水印跟去字幕的两个罗拉模型给他串联起来使用,那么这样子呢, 他就会将我们画面里面有的文字全部给他去干净,只剩下这种非常非常干净,没有任何字幕的一个视频。那么这样子呢,就加强了我们去水印的这一个罗拉模型的作用。然后这下面呢,我们也可以看到,他给出了我们这个罗拉模型 可以使用到的啊,一些触发提示词。那么对于视频修复、视频高清,去水印以及去字幕的这些触发提示词呢,他都已经给到了我们了,那么大约老师也是很贴心的给大家把它放在了工作流的啊这个版面里面, 那么对于这个工作流的版面的这四个的啊这一个提示词呢,我们直接进行连接即可,我们可以将这一个提示词文本的啊这一个点连出来一条线,直接给到我们的可莉的文本密码器的这一个板块 下面的这一个文本点,它就可以起到一个作用,然后配合上我们去加载的这个 lola 就 可以。那么这一个 lola 的 名称呢,我也一一给大家对应出来了。 那么这一个哎模糊变高清,也就是我们视频修复的这一个 lola 模型呢,叫做这个什么 restore 的 啊,这一个模型我们加载一下,然后下面这一个提高分辨率呢,就是 upscale 啊这一个模型,然后下面这个去水印呢,就是 workmark 云幕的啊这一个模型,那么下面这一个去字幕的呢,就直接是一个云幕的这一个模型,大家不要搞混了,当然你可以进行串用,但是串用的时候我们要注意,一般来说去水印搭配去字幕是可以的啊,然后 模糊变高清,再搭配这个提高分辨率的啊,这两个 lala 组合也是可以的。那么其他的组合呢?大家暂时来说没有试过,因为我怕它会有一些什么冲突啊,不利于我的视频的一个加载,所以这里大家可以自己去设置, 比如说我们可以用一个去字幕加上啊这一个提高分辨率的这种组合,去将我们的视频去生成出来,然后既让我们的视频变得干净,也让我们的视频的一个质量有所提升,那么这样子也效果也是很不错的啊。 到这里呢,我们可以看到这里有个演示,就是我前面上传了一个非常非常模糊的视频,可以看到吧,对吧?基本上人脸都糊成一团了。然后我们用到了那一个视频修复的那一个 logo, 可以 看到 效果非常非常的好啊,当然了这个第一针的时候,他依然是属于模糊的啊,因为这个是他这一个罗拉的一个缺点,那么这个大家后期可以进行一下裁剪,或者说你可以延长一下这个视频, 然后进行一个视频修复也是可以的。那么这里呢,我们来讲一下他的工作流搭建的逻辑啊,那么整一个工作流搭建的逻辑呢,其实也是非常非常简单的,大卫老师给大家拆成了几个板块, 第一个是模型加载板块,那么在模型加载板块里面呢,代表是加载的是 l t x 二点三二十二 b 的 官方模型的 f p 八的量化模型,那么你可以用到它的 b f 幺六模型,那么它所带来的效果呢,肯定会更好,但是对你电脑的显存呢要求会更高,当然如果你是用云服务器的话,这里就直接用它的原声模型就会更好了。 那么第二个呢,它的罗拉的加载呢?这里我们一定要注意啊,这一个 l t x 二点三二十二 b 的 真牛模型的罗拉,我们要给他加载进来 玩的话,你就需要用到它的原声步数去跑这个视频,大概是二十步到三十步的一个原声步数,那么对你的电脑显存的压力将会是一个巨大巨大的一个考验。那么这里呢,如果你用到了啊这一个真流的罗拉模型呢,我们就可以把它的整一个视频的 深层步数给他压到八步,那么这样子呢,就可以降低你电脑的显存的一个使用,然后剩下的这两个 lala 加载呢,就是我们的 i c a d 的 这两个 lala 加载了,在这里我们需要注意,它必须用到啊,它的指定的一个 i c lala load model 啊这个节点,那 我是不能用到原生的 lala 加载的。虽然说我们这一个 i c eddie 的 这一个 lala 模型呢,是放在我们后面的 model 文件夹下面的 lala 文件夹里面,但是它在进行加载这一个 lala 模型的时候,我们必须要用到这一个 i c lala 的 特定的节点啊,这里一定不要搞混。然后呢,这里我会加载一个 patch, 一个 attention 呢啊这么一个节点去对我们的视频生成进行一个加速,当然了你也可以不进行使用,那么如果你用了这一个节点的话,那么对你的视频质量肯定会有一点点的影响,但是这里如果你不用的话,那么视频生成的速度可能稍微来说会慢一点,所以说这个有舍有得就看大家 自己的啊,一个加载了,那么这里的呃 audio 的 模型呢,跟我们的音频的模型呢,用的是同一个,我们这里就是不再进行讲解,如果你去学过官方工作的话,那么我们接下来看一下下面这一个 clip 的 文本编码器呢?我们这里输入的 clip 的 这一个文本条件,我们就要注意,如果你用到的是单个模型的话,那么我们只需要用到单个模型对应的触发提示词即可。如果说你用到的是两个模型的话,比如说你把去水印跟去字幕的模型进行并用,那么我们就需要同时把 这两段提示词给它进行合并,输入到我们的 delete 的 文本编码器的正面条件,它才可以起作用,不然的话它有一个 rol 模型,它是起不了作用的。然后这里这整一个工作流呢,其实属于我们的作者给到的官方工作流, 这一个官方工作流呢,你可以不进行修改,你也可以直接拿到大鱼老师的这一个官方工作流就直接进行使用,因为对于啊原声的官方工作流呢,我有一定的调整,我把它的布局进行一下调整了,那么你用大鱼老师的这个也可以,你去到我们的啊这一个 hiphop 的 主页去下载它的这一个 wall flow 也是可以的,我们直接在这里找到 wall flow, 点开, 然后就可以看到两个工作流了,你可以直接下载下来,那么如果你需要在评论区扣六六六,然后就可以领取一份包括模型在内的所有资源, 然后我们继续讲解。我们这里需要注意的是,我们的视频加载进来之后,我们这整一个工作流,它是视频生成视频的工作流,所以我们要注意哦,我们要对视频的分辨率进行一定的处理, 就是说我们在这一整个的 l t x 二点三的模型加载以及工作加载的这一个流程中呢,我们需要注意到的一点是 l t x 二点三的模型,它对于你的图片或者说视频的分辨率的提取的话,你必须要满足于三十二的一个倍数, 所以我们这里可以直接设置一下。比如说啊,我这里在进节按宽高比缩放的时候,将这整一个视频,然后我会这里调整一个缩放到边的这一个参数,我选到了最后一个, 那么最后一个呢,是按照像素来进行缩放的意思,那么这里的九二零呢,也就是官方作者给到一个参数,大概这个参数是意思是说我们把整一个分辨率给他压缩到九十二万的一个像素点的这么一个宽高比, 那么当然如果你是一个横屏的话,他就是幺二八零的宽,对上七二零的一个高,如果是竖屏的话就反过来,这个大家必须了解一下。 然后呢这里有一个获取图像范围的一个节点,那么这个节点的作用是什么呢?它是获取我们整一个视频的第一帧,那么获取到我们整一个视频的第一帧,它的作用是什么呢?我们这里必须要明确的一点,是啊,由于他整一个视频生成视频的工作流,他是将我们整一个视频进行 重绘的一个方式,所以我们必须要获取到原先视频的第一帧作为参考,不然他进行重绘的时候,他很可能会跑偏,所以我们这一个获取图像范围的这个节点,就是拿来固定住我们整个视频的 移,真的为了让我们整个视频不进行跑偏的一个作用,然后这里我们可以看一下它的后半段呢,它是获取的一个纯色图像,那么这个纯色图像呢,它是给到了六个 f 的 一个参数,那么这六个 f 的 一个参数呢,就是我们要获取一个白色图像,那么这个白色图像呢,会被他用图像到遮罩了这一个节点, 将它变为我们完全的一个遮罩,然后这个遮罩呢会覆盖到我们的一个整个视频的上面,然后这一整个视频呢,由于被白色的一个遮罩覆盖,那么它就是整一个区域都要进行局部重绘,也就我刚刚说的这一个视频生成视频的工作流要将这一个 logo 起到作用呢,我们是 将整一个视频进行局部重绘的一个方式,当然因为是对整个视频进行重绘,所以这个就不叫局部重绘了啊,然后这里我们会发现 它会将整一个视频局部重绘的这个 linq 参数呢,给到我们这个 l t x e m g two video 的 这一个节点,那么这个节点我们就要发现了啊,这一个图像的这一个点,它就是我们单张图像的这一个点传出进来, 那么通过这一个点呢,它就会固定住我们原生的图像应该是怎么样子的,然后现在呢?哎,我们需要对这个图像进行重绘,我们将它重绘成什么样子,那么就取决于我们后面 lala 去发生的一个效果, 所以我们会发现在最后生成出来的啊,这整一个视频里面啊,你会发现他第一针是模糊的,对吧?然后后面他就把你高清化了,那么是因为这个节点在这里面起到一个作用,那这个节点我们又不能把它去掉,那么原因呢?就是我前面解释到的, 然后其他的呢,就跟我们官方的啊一个工作有没什么区别了?这下面有一个 l t x lantern audio 这么一个节点去生成我们的音频,然后这里呢有一个 l t x 二的这一个新品的一个节点,那么这个节点呢,主要是在后面生成这一个视频的时候,它可以有一个预览的一个效果,那么这个节点呢可有可无,大家可以把它删掉,然后这一个 就是我们的核心节点叫做 add video i c l a guide 这么一个节点,那么这一个节点呢,就是啊将我们的文本条件, 我们的视频条件呢进行一个组合,然后通过我们的文本引导去对我们整一个模糊的视频进行一个处理, 然后接下来再传到我们的 k 长器这里面,然后在 k 长器里面呢,我们的罗拉就会发生我们的一个作用,然后去将我们整一个啊文本条件跟罗拉里面的模型的条件,再将我们整一个视频的信息进行一个组合,然后 把我们的视频去影像到,我们的整一个条件需要去影像到的一个内容里面去,然后最后就生成出来了,我们整一个视频了,然后这个就是我们整一个工作流的啊一个过程, 然后这一个工作流呢,它是已经可以把四个罗马全部包含在里面了啊,你只需要去更改里面的罗马模型即可,然后更改一下里面的文本即可。那么本堂课内容呢?有那么多,如果觉得大家讲的不错的话,不要忘记接上喽,我们下期再见,拜拜。
74comfyui 17:32查看AI文稿AI文稿
17:32查看AI文稿AI文稿彻底免费,一分钱都不用花!快停下你给那些套路软件疯狂充值的手,别再去交每个月大几十块的智商税了!今天,我要把全网真正意义上的 ai 生产力天花板创优 id 九点五中文整合包毫无保留的直接送给你! 这一次的更新绝对是零基础小白的救急福利,原作者简直是丧心病狂,直接在这个免费包里给你硬塞了整整三百三 七个开箱即用的神级模板!这是什么概念?不管是全网爆火的无限延伸短视频,还是震撼眼球的电影级 cg 大 片,甚至连极具质感的电商三 d 换装,市面上最赚钱的核心玩法,他全都给你包圆了! 以前咱们学 ai 最怕的就是去连那几十上百个像蜘蛛网一样密密麻麻的复杂节点,参数,稍微填错一点,立马满屏飘红爆错,心态直接崩溃。但现在,这些让你头疼的底层逻辑, 已经全部被圈内大佬完美封装到了巅峰状态,彻底变成了傻瓜式操作。你的步骤被极度惊险到了,只有三步,找个纯英文的文件夹下载,一键解压,双击启动器点运行 进去之后,挑一个你最看顺眼的模板,随便敲上几句提示词,你甚至连脑子都不用动,只需要当一个无情的抽卡机器,喝口水的功夫,几秒钟就能跑出吊打收费平台的顶级大作! 首先将我们的 b 九点五整合包下载到电脑上,下载好之后,用鼠标右键点击这个压缩包,在弹出的菜单里选择减压软件进行减压。 这里有一个非常重要的点,请一定要将文件解压到一个没有中文的目录下,也就是你的硬盘路径里不能出现中文字体,以免后续运行出现报错。静静等待解压完成就好。 解压完成后,咱们就可以准备打开了,在解压出的主目录里找到并双击那个粉色头像的会式启动器图标。 双击打开后锁,电脑会首先为你弹出一个图形化的秋叶启动器控制台。在这个界面里,我强烈建议大家先点开左侧的高级设置看一眼,确保系统已经准确识别,并且选中英伟达独立显卡。 确认无误后,点击右下角的一键启动按钮。点击之后,后台会弹出一个黑色的代码窗口,开始狂飙数据。 这期间,系统正在为你自动唤醒底层环境,并加载内置的五十多个精选插件。大家只需要耐心等待几秒到几十秒,他就会自动唤醒你的电脑默认浏览器,直接把你带入康复 ui 节点操作区。 当浏览器成功弹出带有网格和各种连线的深色界面时,恭喜大家,你已经正式推开了 ai 创作的大门。咱们这个 v 九点五整合包最大的魅力就在于把复杂留给底层,把简单教给你,你完全不需要从零开始去学习怎么连线, 直接在界面里点击加载预设好的最基础纹身图工作流,咱们来简单跑个测试看看效果。 你只需要找到一个在上方的文本框,输入你想描绘的画面,比如简单敲上一句一个女孩毛衣白色背景,然后在下方文本框里填上如模糊、低质量机型之类的排雷词汇。接着点击界面上的运行按钮, 这时候你会看到屏幕上的节点开始依次亮起绿色的光效。得益于咱们非九点五底层强大的环境优化,仅仅几秒钟的功夫,一张光影细腻、质感拉满的美女照片就会在最终的图像节点里生成出来,整个过程丝滑流畅,完全不需要你懂任何深奥的代码原理。 当然,这种基础的纹身图仅仅是个热身。咱们这个 v 九点五整合包真正的核心资产是里面为大家精心预制的两百多个大师级精品工作流。这些工作流的特点可以用四个字来概括,那就是开箱即用。 以前大家在网上找工作流,最怕的就是导入进去后满屏飘红,告诉你缺这个节点,少那个插件,折腾半天都跑不通。而在咱们的整合包里,几十个核心插件早就为你配置的明明白白。 不管你是想做高清的图生图局部重绘,还是想玩点高级的 ai 换脸、数字人、对口型,甚至是去挑战目前最前沿的视频生成模型,这里面都有现成的模板供你直接调用。 需要完整整合包的朋友可以在评论区进行评论获取,我会依次发给你们。哈喽, b 站的小伙伴们大家好,我是你们的大鱼老师,那么欢迎大家来到我的二零二六最新的康复 u i 基础入门系列课,那么本堂课呢?将是我们整个系列课的先导片。 那么在仙岛篇呢,我们会讲到 comfort ui 是 什么,以及我们为什么要去学习我们的 comfort ui, 以及网上比较多争议的 comfort ui 还需不需要学习?做一个简单的解答,然后再简单的看一下其他模型的一个情况。 好,那么我们先基本介绍到这里,我们来看一下我们这个仙岛课的一个主题,那么我仙岛课的主题呢?叫做 comfort ui, 为什么是你 ai 创作了一个终极武器,下面也给到了一个回答,其实就是能让你告别抽卡以及做一个真正的 ai 掌控着。那么这里呢,借用一段其他博主的一个金句,如果你想从玩 ai 变成用 ai, 那 么 comfort ui 肯定是你绕不开的一座大山,也是风景最为美丽的一座。 好,我们先接着往下看。那么什么是我们的 comforion 呢?那么这里我们就用基本的概念以及定义来说一下。先说一下定义啊,它是我们目前最强大的基于节点的一个 用户图形生成的一个界面。好,我们要先搞清楚,这仅仅是一个界面,所以我们要知道的是, comforion 它不是一个 ai, 它是一个巨大的 ai 集成器。 那么从对比上来看呢,我们以 web ui 为例, web ui 它更像是一个美图秀秀以及傻瓜相机一样的功能固定的一个软件,那么 comforui 呢,它更像是一个乐高积木 以及模块化的一个工厂,然后每一个模块节点呢,都可以自由的去组合,所以你从市面上可以看到千变万化的工作流,对吧?并且工作流呢 也可以去进行售卖。那么这里我用 web ui 只是作为一个简单的代表,那么这一个代表呢,我们也可以往下延伸,比如说我们的吉梦可林,对吧? nano banana 或者吉 它的一些简单的傻瓜式操作的界面的这种 ai 软件都可以以 web ui 为代表,那我们这里说到 comui 属于一个节点式工作流形式的 ai 集成板块,那么什么是工作流呢?其实工作流用简单的话来讲,它更像是我们市面上的智能 体,我们同学应该都去看过一些扣子工作流的搭建,对吧?那么扣子工作流的底层逻辑很简单,只需要在首位 用一个 l m 大 模型,也就是我们的语言大模型去进行驱动,然后后面加入不同的一些功能,让这个大模型可以使用这些功能,然后达到我们要的一些效果,比如说 一键出剪映视频,比如说帮我们去搜索网页,又比如说帮我们去怎么样去规划我们的旅行路线,对吧?这个都是属于工作流智能体的一部分。那么其实在 comforu i 来看呢? comforu i 也相当于一个智能体, 只不过他的大模型更偏向于绘图大模型,也就是我们的扩散模型,那么我们把扩散模型先放到前面,然后用不同的节点去进行搭建一整套的工作流,让他去掉取不同的功能, 然后出图,对吧?那么这一系列的工作流下来呢?你发现不需要我们反复的去操作,而只需要点击生成,就可以得到我们想要的图片或者视频。当然前面搭建工作流肯定是需要时间的,毕竟就算是扣子你也需要去搭建工作流嘛, 对吧?那么简单的来概括呢,就是先通过加载模型,然后导入彩样器,然后输入提示词,变为条件设置参数,然后最后 v a 一 解码就可以生成图像,那么这个就是最基本的 一个工作的一个思路。除此之外呢,在 cover ui 里面,我们每个节点都是可调用的,并且可以自由的组合,那么这个就体现了它的一个模块化,当然了, 同时体现了他一个可塑化,他的流程呢,可以一目了然。当然有了解过康复 u i 的 同学肯定觉得里面连接的线密密麻麻的像什么?像电路板对吧?那么我没有学过电路板怎么办呢?其实他的底层逻辑非常的简单,只需要你跟着大鱼老师在后面一步一步的去操作,那么你肯定就能把他的电路板给他看明白, 另外呢,它还是可负用性的。那么什么是可负用性呢?你发现你在其他网站得到别人的工作流之后,你可以直接拖入你的 comforion 进行去使用,当然了,这里还有一些配合到节点的下载以及模型的下载,这个我们后面会说到,你也可以把你垃圾的工作流给它分享给 其他人,那么这里就体现了他的可付用性。那么我们接着往下看,这里就是我通常会在小某书或者呃抖音上看到的一些人在评论区去问的,对吧?那么 comforu i 还有没有必要去学? 那么我的答案是,不仅有必要,而且是现在最有必要学的时刻。那么我们需要注意的是,大宇老师这里说到的是时刻,而不是美刻,这个怎么去理解呢?那么这个理解就要说到我们上面,对吧。什么是 comforion 时候的介绍了,我都说到 comforion, 它是一个巨大的 ai 集成器,对吧?它并不是一个 ai 们所有最先用到的开源模型以及闭源模型,它都会先付现在 comforion 里面,那么我的 comforion 可以 通过付费的模式去掉取闭源模型的 api, 那 么也可以通过不付费的模式直接下载模型来进行 工作流的搭建,那么这个就体现了一个问题了,我们可以在 comforion 里面随时知道最新的 ai 绘画技术,或者说 l m 的 一个技术, 又或者说视频的技术,对吧?那么另外呢,在现有阶段,由于各大 ai 公司都去出了一些比较简单的操作,就比如说 nintendo 或者说吉梦,对吧?所以你发现在 ai 的 入门门槛是 比较低的,但是 comforu i 的 节点式呢,它有一定的门槛,那么就建立起了一定的门槛的集户的一个护城河,对吧? 那么稍微比较高的一个学习曲线呢,就更代表了一个更强的一个不可替代性,对吧?这也是为什么各大企业所对它所需要的啊,第一可能就是因为它门槛高,第二它所带来的工作流以及它的 功能的副线是为最前沿的,最为方便的,对吧?那么除此之外呢,我们可以接着往下看,那么学习 comfui 的 几大理由呢?我这里也给出了,第一个是它的一个全能性, 它属于一个超级的集成器,我前面也说过了,对吧?它是一个 ai 的 操作系统,那么它可以说由左右手,它的左手可以接住开源的模型,比如说 sd 一 点五 sd 叉 l plus, 千万 z 的 image turbo, 又或者说万向二点二,对吧?它的右手呢,又可以接住 api, 也就是 b 源的模型,然后让它们两个并用在一个界面里面,所以这个是非常方便的。当然了, 它还有其他的一些简单的一些用法,比如说它属于一个开源嘛,对吧?就算你有开源模型,你也可以做很多事情,所以它是一个全免费的一个软件。那么另外呢,它也有属于它自己一个拓展性,它属于一个多模态的霸主。 什么意思呢?就像我刚刚讲到的,它不仅仅是应用于绘画方面,它还可以应用于视频生成,比如说我们在 comforion 里面工作流,我们可以调取 sora 的 一个视频模型,对吧? 那么多少二的视频模型呢?你在抖音里面经常会看到,哎,我一分钟可以出多少百个视频,或者说我可以不断的批量性的出视频。其实它就是在 comui 里面去使用的,或者在扣子工作流这里面去使用的, 去完成它的一个流程化。那么这样子呢,它就可以一系列的处理完视频的水印,加长视频的时长,又或者说怎么样去 增加我们视频的一个高清度,那么这些都是 comui 里面可以做到的。那么另外呢,就是它的一个实用性,这里我用到了一个成语,叫做前人栽树,后人乘凉。那为什么这么说呢?我们都知道 comui 里面有许许多多的节点,对吧?那么单在现在可计算范围内的,我觉得就已经不 下十万个节点呢,但是这些节点呢,我们都可以直接通过 github 网页,或者说它里面的一些呃 manager 的 管理器的直接去把它下一下来,那么下一下来之后呢,我们其实可以直接去使用了,那么直接去使用呢,你就可以避免在 ps 里面的反复操作,或者说其他的一些呃工作的反复搭建,对吗?这个是比 要方便的。那么除此之外呢,我们的工作流还可以运用在应用化里面。那么什么是应用化呢?就是我们的工作流可以把它封装起来,封装起来之后,你发现你把工作流分享给别人的时候,它是属于什么格式?它属于这一层格式,对吧?它其实是一整串的一个代码, 也就是说这串代码其实都可以把它封装为一个简单的应用或者说小程序。那么这个呢,也是大约老师在接触完 comui 这么多年之后去得到的一个哎, 另外的一个赚钱思路就是有一些人会需要你去帮他把工作流封装在某个应用里面,那么这个也是可以赚钱的。那么这个呃赚米的途径在哪呢?建议去小红书上看一看啊,有非常多非常多人在找这一类。然后另外呢,是他的一个社区生态非常的完善,我们会发现 我们的 comforion 里面的闭源模型,虽然说可能不如开源模型强大,但是由于社区的完善,我们社区里面的人员会不断的对他进行 再开发,再开发。即使现在比较厉害的什么 study, dance 啊,或者说其他的 s, d, a, i, l 的 一个动作复刻的一个工作流,对吧?都是由万象二点一的模型进行开发的,那么万象二点一都没有开发完的一个情况下呢?我们万象二点二又出来了,那么还有其他的一些优化,万象二点二的 一些模型都会在后续的被开发出来,所以说基于社区的一个强大,急着说开源模型赶不上闭源模型,但是呢,你发现还是有很多人在用,为什么?就是因为开源社区非常的活跃,非常的发达,我们能得到很多不错 过的效果的工作流,可以对它进行一个再开发,然后再开发,对吧?这也是公司为什么还需要去要 cover ui 使用的一个人才,以及会呃接地开发的一个人才也是一样的。那么我们呃基于这个生态,我们就要讲到它的一个缺点呢?对它的门槛性, 对吧?那么许多小伙伴在了解完之后,为什么会被 comforo 刚入门就被劝退?第一个理由就是你刚进去看到那个节点非常的头疼。第二个就是拖用别人工作,有的时候一堆的报错,你觉得整整不了搞不定,对吧?然后学习周期又长,就觉得,哎,不学了,反正现在有其他的一些什么东西可以去用,对吧?但是用你发现你需要反复的几 个几个软件去跳,你就会发现它可能来说比较麻烦,并且你去找工作的时候可能又会要求你要 comforion, 那 么我们又回到 comforion, 然后又被这个反复的劝退,并且其他的一些社交平台上也会告诉你,哎, comforion 不 需要再去学了,对吧?那么 ai 是 趋于越来越简单的, 当然 ai 当然是趋于越来越简单了,只不过在此时此刻, comfui 还是有必要去学的,因为它这一个 ai 集成器的一个功能,并且优先接待其他 ai 的 一个功能,使它成为了呃行业必不可少的前沿的一个软件吧,只能这么说对吧? 那么我们需要呃理解的一个常见的误区是它密密麻麻连接的节点呢啊,当然它是麻烦的对吧?但是它的底层逻辑却很简单, 其实我们只需要把它拆开来看,它一共只包含了三部分而已,第一个就是加载模型,第二个输入提示词,第三采样生成,只要采样生成之外呢, 去加入一些功能节点,再把这工作流程完善就可以了,其实这个他的底层逻辑非常的简单的。那么我这里呢说到的基础课啊,当然是基础课了,所以有一定的承诺就是我的这道课程呢,会带着你从第一根线开始,然后慢慢编织你的一个神经网络,然后这一个神经网络呢, 我会把底层逻辑交过去。那么在以后你去学习一些新的节点之后,你根据这个底层逻辑,其实你马上的就可以复现别的工作流,或者把别的工作流拆解出来, 那么这样子呢,你就可以很快的学习到工作流的一个搭建方法。那么说了这么多之后,我们也要先为呃开篇第一节课来说一下我们现在的在 complain 里面比较常用的一些模型,比如说 s d, 一 点五, s, e, 叉 l, 其实这个都是比较老的模型了,我们现在一般不去进行学习,只要 flos 模型呢,对比起纤维一米九来说,它的模型还是适用于一定范围之内,但是由于它的 raw 模型比较多呢,所以,呃许多人还会用它,但是这里是不建议大家再去使用了。 flos 模型当然你也可以去用,如果想要得到一些某些风格化的一些效果, 我们也可以用 flash, 我 们现在一般用的是千万 image 以及 red image turbo, 或者说我们的会员模型,万象二点二模型以及一些编辑模型,像 flash compress 的 千万 image edit 模型呢,我们都会在 comforion 里面去使用。但是 这里我们需要知道的是,由于我们是二零二六年最新的一套课程,所以我会直接以 red image turbo 为起步去进行,教大家一些工作流的基础搭建, 以及后面会讲到一些万象二点二的基础工作流的搭建,都是为了让大家打开对于 comfort ui 的 这一个门口,让大家先踏进去, 然后其他后面的一些学习呢,就看大家的呃自己的一些本事了。好,那么其实本堂课内容呢,也就那么多,主要是带大家先了解一下 comfort ui 是 什么,以及回答那几个问题,有没有必要去学习 comfort ui 性阶段,我那个 答案就是有必要啊,完全是有必要的,以及带大家认识一下现在的模型的一个学习。那么 sd 一 点五 s 叉 l 确实不需要再学了, 因为它太老了啊,那么我们直接从这的 emoji turbo 来开始吧,就可以更好的让大家去对接一些比较前沿的模型。好那么表扬。看内容也这么多,如果小伙伴们觉得大一老师讲的不错的话,不要忘记一箭三雕,我们下期再见,拜拜!
58AI菩萨君-大鱼



