rvc模型推理批量转换怎么设置
哈喽,大家好,我是宗米,冷的瑟瑟发抖的宗米,大家不要只关注不点赞,也不要只点赞不关注啊, 现在呢,我们还是在推定其模型转换和优化的这个内容,因为在转换模块确实之前的内容呢有点多,所以最终呢还是分成三节内容。 今天主要去给大家汇报一下的就是模型转换的整体的流程,我们看一下之前讲到的一些内容。先来简单的回顾一下,之前呢我们去看了一下最基础的挑战和架构,然后看了一下网络模型怎么去返序列化和序列化 呢,进入了一个自定义的计算图,自定完计算图之后呢,现在来看看整体的转换模块的流程,还有相关的一些技术的细节。 下面我们来到转换模块的最后一个内容啊,就是模型转换的流程和技术细节。那说实话,这里面的更多的技术细节我们在分享,在每一节了,我们来看一看转换模块主要有两个思路啊,第一个呢就是直接转换, 那第二个呢,就是规范式的一种转换。直接转换呢,我们看刚才我们的一个转换的结构图可以看到,例如我们现在以 maxbone 为例呢,我们把 maxbone 通过一个 converter 转成推力引擎的,哎呀, 这种方式呢,就是直接把 a 框架的格式呢转换成为推进引擎的格式。第二种规范性的转换,主要是指使用开放镜的文件格式,然后呢让更多的主流的 a 框架都对应到这个格式范围,那说白了就是像我们的这个图,我们的架构图又出现了, 例如拍 touch, 他不是直接转拍 touch, 而是把拍 touch 转成 onlinx, 或者我们可以把 maxboard 转成 onlinx, 然后呢通过 online's converter 这个模块呢,转成推理引擎的,哎呀,那这种呢,就是第二种规范性的转换, 其实在我们现在啊,至少在中米了解过的很多的 ai 框架,基本上两种的转换的方式和转换的技术呢,都是同时支持的, 像直接转换的他整个算法呢还是比较清晰的,我们看一下就是第一个呢,就是内容的读取,把从不同的框架生成的一个网络模型呢, 通过识别几个内容非常重要,网络模型的张亮的数据的类型和格式,还有算子的类型和参数,另外还有计算图的结构和命名规范,还有他们之间的相关的信息进行读取。那这几个呢也是对应于我们制定 易计算图里面的张亮算子,还有图三个内容进行一个识别。接着呢第二步就是格式的转换,那格式的转换呢,就是把我们刚才识别到的一些内容了,其实在识别完之后呢,就变成了 内存的一个对象或者代码具体指向的一个地址呢,这个时候呢,我们就可以真正的做一些格式的转换,通过 commert 来进行转换。 转换之后呢就是对模型进行保存的保存呢,可能还会用回那个 p b 啊或者 f b 的这种文件的格式,然后用于我们下一次推进引擎真正 one time 的时候去调用的。 像第二种呢,规范式的转化呢,就是 onlinx 的 cheers, onlinx 是一个非常典型的代表,现在呢我们看一下 onlines 官网的一个 ir 的定义, 下面这个就是 onlinx 的 ir 的定义,确实大家也可以去看一看, onlinx 的 ir 跟普通 buffer 或者我们刚才定义的有什么不一样,对于他的网络模型呢,他的定义有什么不同?对于模型的一些可选的参数,还有 o p, o p set, 那还有当然还有很多那个风险的功能,还有 breath 的功能,确实它的定义呢比我们刚才讲的要多很多,那这里面呢,我就不跟大家一一去介绍了。 回到我们模型转换的一个通用的流程,那下面这个图呢,就是整个模型转换的通用流程,不管是直接转换还是像 only 的这种规范化的一个格式转换呢,其实流程还是这一套流程, 首先呢我们有 ai 框架,就 ai 训练好的框架生成一个计算图,那这个生成计算图的功能呢,主要是 ai 框架去实 线的,我们在推进引擎,实际上呢是不感知或者没怎么去接触的。接着呢,真正的在推进引擎里面的 comfort 呢,主要是三个模块,第一个是做一个算子的对接,我们需要把计算图里面的哎呀的算子,或者计算图里面的一些 premittive 的算子对接到我们刚才自定义的一些算子。 接着呢会进行一个具体的格式的转换,就真正的一些工程化的转换,把不同的计算图的 ir 转成自己的一个 ir。 最后呢就是模型的保存与导出,主要是这三步,而这里面的代码量确实基本上都是一一对应,你要做很多大量的工程,这里面呢就是大家各位兄弟们夜以继日 去开发的一些工作了,好了,今天的内容呢就到这里为止,我们简单的回顾一下,今天呢主要是给大家汇报了一下 整个转换模块最核心的计算图的一个概念,那计算图更重要的主要有三个模块,计算图的两个基本组成,张亮和算子。另外呢还有图相关的信息,就完成了我们整个计算图的定义, 我们中间还传承了 ai 框架的计算图跟推力引擎的计算图的区别。接着呢,我们去看了一下转换模块的一个整体的流程,还有他的技术的细节和算法的流程。那讲完这个之后呢,整个转换模块基本上就结束了, 我们将会在下一个内容里面呢,去给大家汇报一下图优化的相关的功能,这些功能呢也是在我们 abc 里面比较像的,所以后面呢应该会过得稍微快一点点,谢谢各位,拜了个拜, 卷的不行了,卷的不行了,记得一键三连加关注哦,所有的内容都会开源,在下面这条链接里面拜了个拜。

粉丝8414获赞2.7万
相关视频
 07:35查看AI文稿AI文稿
07:35查看AI文稿AI文稿同学们大家好,这段时间由于嗓子不舒服,也没有及时的来录这个视频啊,今天来说一下这个就是 r v c 的模型推理的问题,然后我们先打开 r v c 的这个根目录, 该目录呢?我们现在 r v c 已经升级到七幺七的这个版本了,还是没有中文的目录啊?没有中文的目录就是把它减压到我这是地盘的该目录, 然后双击这个 rvc 的七幺七的这个版本这个文件夹进来,文件夹进来之后呢,我们往下找,找到 g 开头的第三个啊,找到第三个,然后双击打开,双击打开了之后,他会出现一个命令提示符, mini 提示服,再等一会呢,他会出现一个这个,这个,这个,嗯,浏览器的这个窗口哈。 首先我们先介绍一下这个浏览器,这个窗口蹦出来之后,有模型推理,有伴奏分离人声这个,还有训练这个模型,还有模型的融合,也就是 这个。这个 cckp 啥玩意?这个处理啊?咱们只用到前面这四个就行了,其实中间这个第二项也不用也行,伴奏处理人声这个提取人声,这个我们用 uvr 也是一样的。 uvr, 咱们之前讲过这个处理人生这个,然后底下我们先说这个,今天先说这个模型推理,也就模型推 是啥意思呢?是比如说找一首歌的这个原唱的干声,然后替换成我的干声。 首先你要把这个什么,你要把你自己的模型练出来,比如说我这个练的是星星一 x x x e p t h。 这个 p t h。 这个文件呢?就和咱们实时这个推理是一样的,实时推理是一样的,那么 p t h 我们放哪呢? p t h, 我们放到看啊, p t h, 我们要放到这个根部录像,有一个叫 w e i g 呃, g h t s, 再放到这个文件夹里边,你看这里有个心心,一放到这个文件夹里边啊,放到这个文件夹的科目录啊, 直接得放到这,放到这以后你才能刷新到这个,刚才我说的这个,如果你是先打开的,刚才那个命令提示服,这个里边是没有的,那你把你的练好的这个 pth 这个文件,然后放进去以后,点击这个后边的这个刷新啊, 点击后边这个刷新音色,什么这个啊,直接点击这个,然后再来点击前面这个框里边,他就有了, 有了以后呢,最简单的,最简单的推理方法啊,然后别的都不用管,你先看这的地址,这有个地址, 这个地址呢,我们怎么弄呢?我们你看我这个地址是在地盘的干升这个文件夹里边,那你找到地盘,找到我们的地盘 地盘以后,然后找到干声这个文件夹,也就是说你你你拿出的歌曲的干声在哪?那么我们到干音这个文件夹, 然后找到,比如说我这个是兄弟抱一下,然后右键鼠标的右键有复制文件地址,然后咔嚓复制一下子,然后到这个地方把它粘贴进来啊, 把它全删了,然后粘贴进来就行了。或者是直接直接这么拿鼠标左键框住,把它框成蓝色的啊,然后直接 ctrl 加微粘贴一下子就行了。然后再说一下底下这个 当选择音高提取算法与什么这个这个算法你要用什么样的算法?低的就用 p m, 稍微中等的就用这个 h a, r, v, s, t, v e, s t, 就用这个就行了。我们只选择这个,或者是选择最后一个,最后一个是 r m, v, p e, 这个也行,我觉得这两个都可以啊。 h 开头的和这个都可以,然后这个选一下,选一下之后他推理的就是这个 pm 呢,他能推理的更快,但是他推理的这个出来的效果不是特别的好。 然后这个就开始那个什么选这个啊?选我们就选择第二个,选择完第二个之后别的啥都不用动了,然后直接点后边这个转换,直接点完转换之后他底下就会 有数字出来啊,底下就会有多少秒,那我这个已经点了三百多秒了,点完了之后,他待会等到他提取完成了之后呢,这个你的干声呢,就会在这个地方有个播放条, 等一下你来看啊,他等到等他到头了,这就会有个播放条。那么后边这些参数都是干什么的呢? 后边的这个第一个我们就不用管了,什么什么后后处理采样制,什么采样,这个为零了,这个就不用管了。然后这个是输入的因缘包落, 也就说你比较适合你自己的这个声音还是比较像那个原唱,如果像原唱的话,你就把这个推子,把这个输出这个包落 更接近一的这个这个这个推子呢,把它往左边推,他就像原唱把它往右边推,就比较像你这个模型的声音,就是这个意思,就他弄完了之后就是这个意思,然后底下这个呢?底下这个就是保护什么? 呃,保护清这个普音呼吸声和这个,呃,防止什么什么爆音呢?这个东西呢,你往左边拉,他就呼吸声更多一些,往右边拉他就更接近模型里边的这个呼吸声, 就是往左边拉会好一些。好,那这样的话他推理完成了。推理完成了之后,你可以点击这个播放按钮,然后来听一下 是什么样。你也可以直接点击右边这三个点,就是在他播放这个地方有三个点,然后直接来点击下载,他就像咱们网页上面下载东西一样,直接一下子就下载回来了。下载回来之后他就是一个单声道的 mp 三, 呃,单声道的 wav 或者单声道的 mp 三,他下回来了是个英文的,那么这个时候你就找兄弟抱一下的这个伴奏,然后把这个 mp 三把它对进去,把这个,把这个你下载回来,这个音频把它对进去,然后再加一些简单的混响或者是什么就完成了。 这就是我们推理自己的这个,也就是把原唱推理成自己的这个声音的方法,你学会了吗?如果我的视频对你有帮助,请点赞收藏,感谢,感谢,拜拜。
228鑫鑫鑫. 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿我就是那个把 ivc 骑士变身带火的男人,最近有没有遇到这种情况?小哥哥,可以把中单让给我吗? 哟,人家也是女孩子!为了避免这种尴尬的情况发生,我将把 ivc 的终极奥秘炼丹术分享给集美们。工具,在老地方双击勾 vap, 打开炼丹炉。看到页面不要慌,实际操作很简单,进入训练页面。模型名称,用英文训练素材,最好用干净的声音,注意路径一定要用英文。 保存频率拉满训练轮数,两百到五百都可以拉曲赛斯,根据你的显存来设定最后点,一键训练开练等模型出炉你就可以使用了。不会使用的看往期教程。友情提示,声音也是有版权的,别滥用哦!剧透一下,一键去除声音、背景杂音以及云端,一键炼丹教程正在路上!
1.5万AICK-KC 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿我们现在看一看这个 y v u i 的 stu, 这个块就有放我们的模型文件,这个呢就是我们需要 tv 里的音乐文件,这两个选好之后我们就可以开始点击转换, 反话完成之后下面会出现我们的音乐文件,这里我就不再敢撕。退一步, 接下来无法推理好的几个文件放在剪映里边给大家看一看。我用了五个模型推理出来的,这一步 这原先的伴奏文件,这是推理出来的音乐,你们可以播放一下。
 07:20查看AI文稿AI文稿
07:20查看AI文稿AI文稿哈喽,大家好,现在这一段声音是大家平时听到我原本的声音,这一段声音呢,是我用朋友的声音炼制的声音模型,接下来这一段呢,是我家楼下大爷的音色,接下来这一段呢,是我用自己的声音推理出来的歌曲。 没错,今天我们来分享一个关于训练声音模型的技术。其实训练声音的模型很早就已经接触了,但是一直没有准备做教程来分享,因为呃声音的训练和推理就像是这个二维码一样,都是比较敏感,容易在很多诈骗的场景被使用我所以我基本一直是自己来自娱 自乐一下。但是呢,前几天做了一件事,让我感觉这项技术其实可以拿来做很多非常有意义的事,比如说把家里人的声音训练成声音模型,或者是把照片训练成 sd 的模型。在一些非常遗憾,人力不可抗拒的情况下,这样的赛博飞升其实真的是非常有意义的。所以今天准备跟大家分享这个呃 有趣的技术吧。我们接下来进入正题,开始训练之前呢,首先要跟大家讲一下,这个软件其实还是利用 gpu 来训练的,所以对显卡有一定的要求,经过我的测试,应该是二零系的显卡基本都没问题了。 当然我们的显存尽量要大一点,最低最低最低应该是要六 g 甚至六 g, 我估计可能是训练不了模型,但是你可以用已有的模型来推理,保险一点的配置应该是八 g 的显存。首先呢,我们需要下载这个软件,软件的名字叫做 rvc, 这也是一个大佬基于这个技术原理来集成的一个这种 ui 界面,类似于 s d 的 y, 大家如果想去了解更多的这个使用知识,可以去 b 站去关注一下这位大佬,这个软件呢我也放在了链接当中,大家可以自行去下载, 下载完之后呢,我们把它解压出来,解压了之后我们打开下面这个 r v c, 在里面呢,我们找到有一个勾 v 点 b a t, 我们双击打开这个,这样的话我们就到了 ui 界面,这个 ui 界面里面呢,我们其实只要用 其中的两个功能。首先第一部分先教大家如何来训练我们的声音模型。首先需要准备素材,这个素材集呢,根据我的经验,我们需要准备至少 十到十五分钟的纯人生的素材,这个声音的质量是越高越好,而且不要有杂音,不要有混响。如果你没有专业的录制设备,其实我们现在的手机录音在一个安静的环境下就可以做得到。然后素材量呢,理论上是越多越好,但是一定是要在保证质量的前提下,呃,然后素材要注意的第二个点就是,如果我们训练出来的模型是想让他更多的用语说 话,那这个时候我们尽量就录制正常来说话沟通的这个声音。如果我们是想用来推理歌曲,想用来唱歌,那我们尽量素材就是我自己清唱的声音,不用担心唱的不好或者跑调,因为他最终训练的是我们的音色,但是尽量的要覆盖到高中低音,如果你的唱歌的声音里面全部都是低音, 或者你用纯说话的声音推理歌曲,他就会产生一些这种电子音或者是一些哑音的情况。当我们准备好了这个素材之后,接下来我们进入到这个 web ui 的训练界面里面。首先第一个部分,我们要给这个训练的模型起一个名字,然后呢这里的目标采样率我建议大家就保持默认,然后呢模型是否带有高音指导, 我们也是让他默认保持打开的状态。然后接下来版本,这里啊建议大家都是选择 v 一,因为 v 二目前不是特别稳定。然后最后这里呢就是除了在使用 gpu 处理的情况下, cpu 也可以辅助我们完成这个数据的处理,这个地方我们尽量给他拉满了,相对处理的会更快一些。第二步 这里我们要选择训练的文件夹路径,也就是说我们要把准备训练的声音素材,这个素材可以是一整段的,也可以是多段的,我们把它放到一个文件夹,然后呢复制这个文件夹的路径,然后粘贴到这里。然后第二步的其他所有的部分全部都是保持默认。接下来呢直接进入到第三个步骤,来填写一下他的训练设置。 首先我们先看一下总轮数吧,根据我的测试状态,如果你是有十五到三十分钟的素材,那么我建议这里的训练轮数是二百轮或者到三百轮,总轮数是二百轮。如果我们是五轮保存一次的话,那最后就会得到四十个模型, 其实没有必要的,所以这里建议我们改成每二十轮保存一次,这样最终我们就会得到十个模型来从中挑选。然后呢这里相当于一个并行处理的数量,这个越高的话处理的就会越快,但是越迟,我们的显存这里的话,它会自动根据我们的显卡来确定,我们保持默认就好。然后这里呢是说我们是否保存最新的一节是一般空间,也就说无论你这里填了多少, 如果你把这个勾选的话,他最后只给你保存最新的这个模型,我们当然是要选择否了,这个部分我们也可以给他选择否,然后最后这里是否在每次保存的时间点将最终小模型保存至这个文件夹。我们这里要选择是因为最终训练完的模型,我们要在这里找到他,接下来其他地方全部保持默认,然后我们点击 一键训练,这个时候我们就看到后台这里已经在处理,包括前台他正在处理数据,这里我们需要耐心做一个等待,做演示,我这里就不训练完了。训练结束之后,我们会看到一个英文单词 successful 的字样,就代表成功了,然后最后在结尾的时候,他会有一个二三三三三三这样结尾。当他整体训练完了之后,我们进入到这个 rvc 的这个根目录下面,然后我们在这个为此这个文件夹当中就可以找到我们训练完的,比如说这个是之前我训练过的,他就会显示,呃每一轮保留的一个模型,这些就都是我们训练好的模型。训练完之后,再当我们打开模型推理的时候,我们在下拉菜单 中就可以找到刚才训练的模型,到这一步我们的训练就结束了,那如果我们正常自己使用,其实在下拉菜单中找到进行下一步的推理就可以了。那如果我们想把训练好的音色分享给别人来使用,在 哪里找的?首先第一个我们需要把这个位词当中这个模型给他复制出来。然后第二个我们还要在这个 logs 里面找到我们刚才训练的这个音色,在这里面呢我们会看到非常多的文件,我们要找到其中的两个,一个是以 n p y 结尾的这个文件,另外一个就是上方的这个音 desk 结尾的这个文件,这三个文件组成了我们完整的模型文件。那第二步我们如何来进行声音的推理呢?首先我们需要把模型放到我们文件夹当中的位置里面, 然后在推理音色这里我们就可以找到刚才放进去的模型。我给大家展示一下,如果我们用这一首歌来做推理的话,首先第一个我们一般下载的歌曲都是带伴奏的,这个时候呢我们就要把伴奏跟人声 进行一个分离,这里呢推荐一个简单的工具,这个软件呢我也会把它放到链接中,他的使用其实非常简单,打开之后呢,我们直接选择他的输出路径,确认输出路径之后呢,我们就把这个想要分离的这个音乐给他 进来,处理完之后,在这个输出目录他就会生成一个文件夹,这个文件夹当中呢 ocas 就是我们的人声,然后上面一长串就是分离出来的伴奏,我们所需要用到的是这个人声,然后这个变调这个部分, 如果我们是男生转男声,或者女生转女生,音调是差不多高的,我们就默认保持为零。那如果原音是男生转为女生模型的音色,相当于他做了一个声调,那这里呢,我们就要填写十二。然后呢,如果是原音是女生,我们要转成男生的音色,那又给他填写负十二。我们这里呢,因为这个原音 是一个男生,我的这个声音也是男生,所以就不用给他做变调。然后这个地方的路径呢,就是我们之前保存那个 indesk, 如果这个模型是别人复制给你的,那我们 就是要把它放到 logs 里面,我们给它新建一个文件夹,然后把这个 indesk 给它放进来。如果是我们自己练的就不需要了,它自动已经就在这里了。然后其他的地方我们都不用去管它,直接点击转换, ok, 这样的话最终在剪辑软件里面把伴奏跟人声合在一起就完成了,学会的话就赶紧去尝试一下吧。
1.5万大桶子AI 02:05查看AI文稿AI文稿
02:05查看AI文稿AI文稿这里的都可以用吗?你看不可以,不可以,是中文的,你要用中文这些你要把它改字啊?我们用这个。 嗯,现在用这个,用这个吧,第一个选 p t h 文件,然后第二个还是选中刚才的文件夹啊, 刚才选的是这个,玩玩,我们就要选玩玩。哦,好像又中文了。卧槽,这不可以,要把它改掉才行。 我们先不选中文的吧,先选 c c 吧。 第二个文件也是选这个啊,它里面 有两个文件,然后开始。那你现在说话,现在听到我说话吗?现在有改变了吧?这个还是有点区别。对,这个现在有点区别, 像这些。嗯,像这些你要用的话,你要把它改掉啊,要把它改成别的名字或者数字,或者或者拼音。 但是你要用中文就不行啊,这个这对这个软件用不了中文, 这样子就可以了。比如说我现在改好了,改好了我就可以去切换了。还是同样的步骤啊?点这个, 然后我现在想换一个七的,点一下,点第二个,然后再找到刚才的,还是七啊?点一下,然后开始 来。你现在说话,现在我说话听得到吗?现在又变了一个,对不对啊?对,现在还是有区别。
 22:43查看AI文稿AI文稿
22:43查看AI文稿AI文稿大家好,我是七月,最近 ai 变声非常流行,我也跟着学习了一段时间这个视频呢,想跟大家做一个分享。目前大众方面流行的 ai 变声效果比较好的就是 rvc 变声器,是有 b 加 up 主患爱不哭大脑开发并开源的, 开源的意思是说大家都能免费享受到 ar 技术带来的福利。安装包链接我也放在了视频简介,大家可以直接下载,包括需要的蓄力声卡都在安装包里,希望大家都能点赞关注支持下。 up ic 变声依靠电脑来运行,并且需要一定的配置,最低的配置和推荐配置分别是这样,大家可以截图保存。软件是一键安装的,尽量放在固态硬盘,且路径越简单越好。路径名称可以有拼音,不可以有中文解压就是安装。安装完成后,我们 看一下软件文件夹,整个文件夹需要用的东西只有四个, nars、 wax, 还有两个 g o 开头的运营文件。 nars 就是日志的意思,装了语音模型的缩影文件, with 就是权重的意思,装的云模型,当然这些模型都是我辛苦收集整理的,大家可能没有这么多,初十好像有三个模型,其他的大家往往上慢慢找就好了。 然后往下看 go 开头的两个文件,第一个是实时变声需要用的客户端,第二个是推理和训练需要用的客户端。这个文件夹只要记住这四个就可以了,其他的都不用管。 接下来就讲怎么使用 r v c 变声器, r v c 变声器分为三个功能,第一个推理,第二个实时变声,第三个训练模型。 首先我们来看推理,双击 go web 点 bet, 然后会出现一个黑框,我们可以按下空格键,按下回车键, 催一催他,他不要按太猛,然后他会出现你的显卡信息,待会会跳出来一个网页, 本地网页,然后我们把这个黑框不要把它擦掉,把它缩小到菜单栏,我们我是菜单栏是在最最右面,大家可能是看不到的,然后我们看到这个界面,把其他的往后面 放一下,说一下,然后留我自己,我自己打开了我一个录音文件的一个位置,我们就可以对应的看一下,放下面一点线,那么我们先看整个界面,整个界面需要调的东西不多,第一个退了音 色是需要选我们需要的云模型的,我们这里选一下,选因为圆绳嘛,圆绳我都是标好的 ys, 圆绳,胡桃,因为我这个比较多啊,有一百多个模型,所以找的话相对来说需要一点时间, 找到模型之后选择相对应的缩影文件,然后这里呢我们需要一下变调,如果你的声音没有我音调这么高,就是普通的比较低沉的男性声音的话,是需要十二的,正常是需要十二, 那么因为我的音调比较高的,我一般八到十或者六都可能是这样,那么我们现在是调了三个东西,第一个推理音色,第二个自动检测缩影路线,第二个就是缩影,第三个变调, 第四个需要调的东西是这里,这是需要处理的音频,音频文件我刚刚已经打开了,我们需要把它录进输入进去,这个词电脑是不用管的,然后我们复制这个, 然后把它复制过来,这时候我们还没选到文件,因为这里有很多,对吧?我们首先打开录音我们听一下,我们欢迎来到提瓦特大陆, 欢迎来到提瓦特大陆,这是我原来的声音,我们需要把它一撇,六六六,六 点 m 四,哎,他有启动格式都是可以的,这个是因为是用电脑的录音记录的,就是 m c 格式,大家千万记得我有时候会用属性啊,然后选这个复制,这是不可以的,这是会出错啊,我也不知道为什么,反正就是不可以,所以大家最好就文件夹,然后文件夹路径复制完之后,然后手 动一撇,然后把这个录音的名字输入进去,这是我们整个页面需要调的第四个地方,第五个地方就是选成这个 rmvpe, 这个不用管,就算法是这个最好了,直接选这个 rmvpe 效果最好。然后接下来我们就可以直接点转换 他首次转换,一打开这个页面之后,首次转换是需要一些时间的,然后我们就可以听一下声音,欢迎来到 twat 大陆, 欢迎来到 t 瓦特大陆,这时候如果你觉得音调不好的话,你可以变高一点 w 十, 欢迎来到 twat 大陆,然后这样就可能有十二的话就特别假。 欢迎来到 t 瓦特大陆,然后我们可以选一下六给大家听一下, 欢迎来到提瓦特大陆,然后这个音调就根据你自己说话的,你自己这个录音的刚刚这个录音文件的音调来进行调整,慢慢调就调到你合适的那个位置就可以了。所以这个页面看的这么多东西,其实很多都是不需要你管的,那么我们再复习一下,需要的就是模型、 锁影、音调,还有需要处理的这个音频文件,然后还有这个 i m v p e 就 ok 了。然后最后完成之后,大家说保存,保存着就点这个下载,那么他就会直接下载到我们这个下载到 我们电脑的这个 c 盘的这个下载,下载文件夹里,它就会出现在这里,就会出现在这里,然后我们换成大图标看一下, 打开听一下,欢迎来到提瓦特大陆,这就是六的一个,当然了大家如果想音色比较越靠近胡桃越好的话,那么就尽量模仿一下胡桃说话的,就是你录音的时候,你在这里录音的时候,你尽量模仿一下胡桃说话,这种方式会更好一点,而且这个 这个 就是你模仿的越像胡桃,然后你最后得出来的效果越好。 然后其他的也可以根据包括这几个这三个数字,包括这几个数字这个这个是不需要管的,这三个数字可以根据自己的 一个情况来进行调整,那么大家推理的时候完全可以用音箱啊,用麦克风都没有关系。接下来我们来看实时变声,实时变声需要打开这个 go real time g o i 点 bet, 同样的他会小黑框出来, 然后我们继续把小灰缸给缩小,把其他不需要的先缩小。 实时变声相对来说复杂一点,对电脑配置要求也比较高。除了 rvc 软件之外,我们还需要虚拟声卡和调整声音设置,虚拟声卡已经在下载链接里提供了,就是这个东西大家可以安装好后就可以搜索虚拟声卡,可能是桌面没有标 的,可以搜索这个 vs meter, 但是我这是经常搜他就会出现了,然后我们打他有三个选项都可以,但是我觉得 blana 最好用嘛,我们打开这个文件,他会出现在右下角,然后我们把它点开, 打开这个文件之后,我们把它先摆好了,然后我们还需要打开声音的一个右键,右下角的一个小喇叭选择声音, 会出现一个这个声音的设置框,我们需要在播放和录制两个里面进行调整。然后我们来看这三个东西。首先的话就是我们来设置训练声卡,然后这里是麦选麦克风, m m e 麦克风就行了,你 你用的麦克风前面带 m m e 的就 ok, 这是麦克风,然后这里选 a e, 选 m m e 的扬声器,这个我正常就放声音的一个东西, 但是虚拟你做实时变声的时候最好是戴耳机的,我现在看着音箱待会可能有一些回音也是正常的。那么左下角的设置,第一个选 b 二就行了,其他都不用动。然后这里可以稍微调一下音量的争议,可以调大小,你可以小一点,也可以大一点都可以, 就是说如果你声音比较小的话,你这里可以调调高一点,给他有一些争议。然后第二第三栏是不用管的,然后这一栏,这一栏是 左边这个竖排啊,他是系统声音,你可以把它全关掉,或者你可以 a b e 都点开都可以,这是系统的一个声音,就是系统本身发出的声音,和游戏打 标游戏本身发出的声音都是有的,如果你把它全关掉,你就听不到了, 那么右边呢,就是我们这个 r v c 变声的一个声音,通过这两个通道来进行,一是可以关 a, 你可以关掉,这就是反听,反听的声音,如果你不想要反听的话,变声后的反听的话就可以把它关掉,但是一般我是会留。 接下来我们看声音选项的设置,那么这里呢?我是目前的没有调整的默认设备是麦克风,但是我们现在已经用了蓄力声卡了,就不需要使用来麦克风,我们需要使用的是设置这个为默认设备, 就 worth meter output 默认设备,然后播放的话我们调到放到最底下,我们选择 in input 做声音设备就可以点确定。然后我们再来看 g o i 的部分, g o i 的部分我们这里选择模型,我们继续找胡桃, 这里选缩影,这个是跟刚推理是这里这两个选项是跟 com 刚刚推理部分是一样的,把模型和缩影文件放进去, 然后这里输入输出设备的话,大家一定要看好,这里都是带 ax output 和 ax input, 跟刚刚那个声音设置不一样的,都是带 ax, 只要记得这个就行了, 大家要记得这两个带 ax 就 ok 了。然后剩下的一些设置,这个最后我们直接选最后设置就行了,就是我之前都已经设置好,打开就 就这样了。然后其他的几个音调设置,包括六和八是跟刚刚一样的,这个音调跟刚刚推理是一样的,因为我音调比较高,所以我一般六和八就差不多了,音调的原则就是越高越假, 越高就会有更假更更嗲的声音,然后越低呢,就越像御姐。如果是你是女生的话,变男生的话就得往下走了,打比方你女生原来是零,然后你就得负十二,这样子, 男男女之间正常是十二的一个,在软件里,软件的设置里是十二音标的一个差差异, 然后这个应所引的速率呢?我直接选了一个一,然后这个右边的材样其实可以根据你自己情况调整,然后这个净成数 harvest 呢?是 不需要,因为我们选了第四个选项,跟他就没有关系啊。偶尔推理时长呢,开的越高越好,但是相对来说你的你的这个推理时间就会变长,所以基本上在一左右吧。这两个降噪不建议开,不建议开,然后我们开始音频的转换, 他需要一点时间。喂喂 喂喂喂喂喂喂喂, 那么调整完之后,我们就调整完之后,我们就可以开始这个实时变箱,这个实时变箱啊,实时变箱,当然因为我是用的音箱, 是没有用耳机,是没有用耳机,所以这个回声比较重,所以这个回声比较重, 那么我们不想看到回声就直接把 a 给点掉,就是不想听到回声,直接把 a 点掉就行了。但是如果小伙伴有的时候会,但如果小伙伴有的时候会卡路的话,就可以在麦克风这个地方切换一下别的,然后再切换一下别的,然后再换换呢,他就会 可以正常的喂,可以正常的一个使用。我先把这个回声给反听给关一下。勇士是变声来直播,我测试了避战直播机和微信直播,直播机是不怎么需要调的,微信可以这样调, 那么这个就是实时变声的一个部分,那么我先把它关掉, 接下来是训练的部分,我们打开刚刚这个推理的客户端,我们黑框会出现,然后他需要运行,等页面打开之后,我们把黑框给缩小,不要把它擦掉,把它缩小就行了。 训练的部分就看上面的菜单,在第三个训练的部分,那么训练的话,这部分内容比较难,也需要前期语音处理等大量的工作,不建议新手玩家去尝试,我也不是很熟练啊,就是跟大家共同学习。 训练开始前你需要准备优良的语音包,那么我们刚刚这个语音文件啊,我这几个文件我就当他是语音包了,我就 假装他是语音包,就是几个语音嘛,尽量使干净的声音,然后语音包的质量与最终的模型质量是成正比的。那么我们来看训练页面,训练页面首先是输入十 签名,这个可以用个拼音啊,或者什么都可以,然后采用率的话,正常选个四十 k 就行了。如果你的录音文件是语音文件是呃, 会显示有比特率,四十八 k 的话,你就选择四十八 k 就好了。这个是否带晕膏?我觉得是要带一下吧, 然后版本选择 vivi 会更好一点。然后这里是输入训练文件夹的目录,还是这个一样,这里不需,这里不需要每个文件的名字,你只要把这个文件夹我们复制进去,把它原来的替代掉就 ok 了,这样就 ok。 这个就相当于训练我自己的模型了,我自己录音的几个文件,这个 id 是不用管的,然后处理数据特征提取这个我这个是用用来 做锁引的,因为我们要使用一键训练就可以不管它。然后我们看一下啊,这个 g p u 它是自动选好的,瑞 r m v p e, 这是离卡多的情况下,选零零和卡一卡二,但是我就一张卡就就完全不用管,就是这个地方选一下,就第二个大长方方的地方,就是选 r m v p e 就行了, 这是我们上半部分。然后这里比较重要的就是这一盘保存频率的话,他是默认是五,就说你每五轮保存一次,但我不建议每五轮啊,其实十轮打比方,你训练一百轮的话,你可以每十轮保存一次,保存一次 对吧?如果你三百轮的话,你三十轮保存一次就很好,这是怕你突然断电啊,或者什么,然后总总的训练,能 成数的来讲的话,一百以上基本上就可以用,但是就不够好,一千是最好,越高越好了,但是越高需要的时间就特别特别的长,那么我们正常就是一百以上, 然后如果你效果还不错的话,就三百或者五百都可以,五百的话你正常大概十几个小时,每张显卡的这个这个可以开大一点,你开个六啊或者八啊都可以, 但也不要开太高,怕你的显卡啊吃不住,对吧?是否仅保证最新的 c k p t 文件,这个就是模型的原生文件,这个选辅啊,一定要选辅,如果你要,呃,如果你空间特别小的话,硬盘特别少的话,你就选,是因为他中间会保存大概几十个 g 的文件在里面,几十甚至上百 g, 就说 你的这个盘的,我们打开你这个盘的盘的一个空余的空间最起码要剩一百到两百 g, 这样比较好一点, 就是你硬盘的剩余空间要大一点。是否返程所有训练极致险程直接选否就可以了,因为要不然就会 有可能你声卡不太行的话,就会炸线中。是否在美食保持终点时将小模型保存的位置文件其实可以选试啊,可以选试,那么如果你这里选试的话,你后面就减少一个这个 ckpt 处理的一个在这里处理的一个过程,就是如果你这里直接选是的话,他就自动就处理掉了,然后然后再看最下面这个是不用管的,这是我们花不哭大佬 做的底膜,然后直接点一键训练就 ok, 我们把这个黑框打开, 就这就正常了,他已经开始处理数据了,我们看黑框他跑了很多,但是因为我的数据很少很少很少, 对吧?这已经开始正常处理了,我们中途不要关了,当然我待会会会关掉,因为我这个就是演示给大家看嘛。我不是真的要去训练,他现在训练就是正常训练的一个过程了,完成之后他会在这个我们回到,嗯,我们回到这个, 我们回到这个文件文件夹里来,呃,它这里 max 里面会出现一个七月,对吧?我刚刚起名叫七月,我们上面这个 实验名称叫七月,这就会出现一个文件夹,嗯,他就是会把练好的东西放在这里面,所有训练的东西放在这里面,然后因为我们刚点了一个在外外科斯 就说如果最终训练好之后,他会把这种小模型直接放到这个模型文件夹里,位次里面,直接放到这里面来, 就是会出现一个叫七月的一个模型,等训练完成之后就会出现现在就是训练成功的状态,已经在正常的进行训练了,然后完五百轮完成之后,他就会生成文件, 然后你也可以单独的去处理数据特征题句,然后出。所以啊什么我觉得就是新手我们就不需要直接把选项选好之后,直接一键训练就 ok 了, 把它关掉吧,我们把黑框直接关掉去中断他,但是你们训练的时候不要去中断他,你们训练的时候不要去中断他,中断他就是整个训练过程就前面就白费了,但是我是因为演示吗?我们就把他中断掉。 模型训练好之后呢,大家就可以把模型复制到这两个文件里,一个缩影文件是 index index 结尾的缩影的,一个结尾的放到这里面来,然后把这个模型文件它会自动生成放到这里面来,模型文件就不管了, 因为我们选了,我们刚刚选了这个选项嘛,就模型文件就不用管了,它就自动这个 c k p t 的处理了,那么这就是所有训练的一个流, 影响你模型最终训练效果的就两个东西,第一个你是语音的,一个你原始语音的一个质量是否够清晰,数量是否够多。第二个就是你的训练轮数是否足够多, 对吧?然后最终你是有没有成功,如果你成功好了,你就可以放到推理里面进来使用了,这就是 rvc 变声器的三大功能了。接下来是总结部分, rvc 变声器目前来说是最适合大众的变声方式,相比较于同流派的 相近流派的 vits 来说,效果更逼真。相比于 tts 的文字转语音来说,音调及语音节奏掌握更好,因为你可以说话,你录音的时候可以说话很慢很慢出现这样的效果变音声,但是文字转语音是做不到的。很多 声卡也有男变女,女变男的功能,但远没有 rvc 变声器的潜力大。你只要有语音包,你就可以训练如任何你想要的人物的语音模型,然后开始使用,当然了,不要用来违法犯罪。 关于 rvc 变声器的效果,效果首先取决于模型包的质量,其次就是你自己录音的质量。录音的时候尽量字正腔圆,尽量去模仿语音模型的说话方式及情绪, 比较特别的比如胡桃说话比较开朗,你录音的时候也尽量保持开朗的语气,如果像拉西达这样比较闷声闷气的,你说话也录音的时候也尽量温柔一点。从应用上来讲,推理功能可以用来给 电影、电视、动画视频去配音,也可以用 qq 语音来戏耍小伙伴等等。实时变声功能呢,可以用 用来游戏语音直播及游戏陪玩等。从难度上来讲,除了训练之外啊,除了训练这一块可能稍微比较难一点,对电脑也要求比较高一点,那么沉下心来,大家多摸索摸索,把视频多回看一下还是不难的,大概一天就能熟练的去掌握他了。 那么不是太理解的小伙伴可以多在评论区提问,我会力所能及的回答大家。提问多了,我也会出视频解答相关的问题,大家也可以搜索其他大佬的视频进行学习, rvc 这一块相对来说已经是比较成熟的一个氛围了。然后模型来讲,网上的免费模型有很多,大家可以搜索 rvc 模型来查找下载。 最后,如果想体验 ar 变声又不想自己麻烦的小伙伴,可以加群了解远程安装服务及模型包,还有人工转换等服务, 群号在置顶的评论区。当然了,希望大家都能自己搞定,畅享 ar 技术给生活带来的便利。我是七月,点赞关注我们很快再见!
332七月AI实验室 07:59查看AI文稿AI文稿
07:59查看AI文稿AI文稿哈喽,同学们好,今天呢给同学们演示的视频是 lvc 的模型练字,很多同学们至今用的还是别人那里得到的公众模型,导致现在呢模型声音泛滥哈,很容易被认出来, 与其如此,那你们不如自己制作,今天呢,我就用简单的方法教同学们快速的啊制作一个自己的声音模型。 首先你要准备一段干声的素材,这个素材呢时长最好是在三十分钟左右,最好是没有任何噪声, 没有任何效果,完完全全的一段钢身。那么这里呢,我已经准备好了哈,同,到时候给同学们就直接演示了, 在任何盘单独创建一个文件夹,里面呢只存留你的杆身的啊素材。 然后呢,同学们打开你们下载的 r v c 变声器模型跟目录哈。呃,找到咱们的 r v c 跟目录, 然后呢找到勾开头的两个程序, 上面这一个长一点呢,属于咱们变声器的开始的地址哈,下面这一个呢就是咱们模型练字的一个地址,双击点开,双击点开之后哈会弹出一个黑色的框,这个框呢就是咱们推理的过程展示, 我们不要管他,把它衰减下去之后哈,等一会就会弹出一个网页,这个网页呢就是咱们训练模型的地址。好了,到了这里呢,同学们可以看到有很多五花八门的选项,咱们模型推理做伴奏,人声分离什么的哈, 到这里呢,同学们就会头皮发麻,看着简直是啊,就是眼眼睛都花了好,就不知道该选择什么。其实不是,我们要用的东西真的不多,我们接下来几个步骤就会很快的搞定这个模型推演。那么首先我们点击这个训练, 点击这个训练模块之后哈,咱们在第一行输入咱们要念字模型的名字,比如说刚才我是一段女生,那么这里我就打一个名字,叫什么呢?女生模型, 好在输入完成名字之后,咱们第一行再也不做任何选择,那这里呢?咱们选择什么呢?输入咱们的训练模型的地址,比如说刚才我教大家存放的模型的地址 在这里呢,咱们把这个文件夹进行复制一下,在这里呢进行粘贴。 然后之后我们再也不做任何选择,看最后一栏, 这最后一排呢,咱们首先哈第一个,这个是保存频率,这个就相当于咱们的游戏存档五十论以下哈,随便的选,你想多久保存一次都可以,呃,如果你想什么 麻烦啊,跟我一样五十轮存一次就可以了,那如果你电脑随时会出问题,你觉得随时会崩溃啊,非常的烂,那么你可以选择哈咱们频繁一点,比如说五轮,咱们就保存一次,那这里呢?因为我对我电脑非常自信,我选择五十 训练的总轮数,这个呢就相当于训练的时长,我一般是选择二百至五百之间, 呃,根据你模型的好坏,呃,其实如果你模型声音的话比较好,出自于什么录音谱啊,或者是他家庭环境录音优秀,那么我们可以选个两百轮就可以了, 做出来的声音其实就非常的优秀了,如果你的声音模型非常的糟糕,有杂音哈,还有混响什么的,那我建议你 你就填个五百轮啊这里,嗯,然后这里呢还有一个就每张显卡的,那么这里呢,我统一的我理解存哈咱们这个显存 呃,你需要用到多少的显存去训练这个模型?那么我这里哈,我把它填写的是十,因为我是十二 g 的显存,那么我选择用十 g 去进行运算。 接下来这两个选项呢,直接跳过咱们看最后一个啊,呃, 选择四啊,选择四这个是什么呢?这个意思就是说咱们要保存到哪里?咱们要保存到咱们的变声器的根末路,选择四之后哈,他就会保存到咱们变声器的根末路里面, 等会咱们就很容易找到以上选择。东通完成之后,咱们就点击一键训练就可以了哈,非常的简单对不对?其实这么多啊,其实都很多都没有用,咱们直接点击一键训练, 然后呢你就需要耐心的等待了,在这个过程中呢,咱们可以打开黑色的框啊,进行选择观察,同学们看到输出信息,这里就会有提示啊,咱们选择的训练素材在哪里?选择的大概参数是多少? 好,同学们看到哈现在这个模型就开始演示了哈,这里就开始跑人数了。首先你们可以看到这里显示 数字一代表着什么?代表着咱们这个开始第一轮的一个念字,这里显示呢是咱们的时间,接下来呢他会不停的就跑轮数这里呢一轮,然后开始两轮,开始三轮,直到咱们的五百轮或者是两百轮结束为止。 这里呢我就不给大家做演示了哈,我就直接结束了,假设咱们就已经训练完成了哈,咱们现在就回到咱们的根部路,回到咱们 lvc 的一个根部路, 找到这个 w 开头的一个文件哈,然后把后面后缀为 p t h 的文件直接拖到桌面上,或者是单独在 桌面上创建一个文件夹,存放这个文件,然后再返回咱们的个陌路,选择 logo 开头的文件夹,然后将里面的文件哈,就是咱们这个后追尾的文件 通通的啊,转移到咱们桌面上的文件夹里面去。那这里呢,其实是非常多的文件了,因为我为了让同学们更清楚的看到咱们的文件哈是哪两个,我就把这两个文件单独的哈给选择出来了,其他的文件我都给删掉了。 呃,这样的话,咱们桌面上就会形成哈,一个完整的哈,一个模型啊,三个文件一个模型嘛,咱们就会形成一个完整的人生模型,就可以直接用 r v c 哈,直接就跑了哈,就没 有任何问题了。那么今天的展示视频呢,就到这里啊,就结束了,平常呢也分享一些个人训练的模型,都放在群里面,我们的群呢,在我的个人的简介里面,有需要的同学可以进群免费的领取啊,没有任何套路,无偿的分享, 感谢大家的一个观看哈,后续的话,我们也会推出其他 r v c 唱歌教程的演示呃,有需要的同学们呢宝宝们呢,请点点关注啊,后续呢,关注不迷路!
 15:07查看AI文稿AI文稿
15:07查看AI文稿AI文稿hello, 大家好,我是宗米。那这里面呢,宗米两个英文单词呢都是大写, 因为他是我中文名字的一个缩写。今天我要给大家汇报的还是模型转换和优化这个内容里面。 在模型转换技术这个内容里面呢,后面的更新频率应该会越来越慢,因为很多知识啊,其实在网上很难搜得到,更多的是工程化的一些经验的总结。 这里面呢,应该会分开两个视频给大家介绍的。那我们可以看一下主要呢有很多内容。首先在第一个视频呢,我们更多的是聚焦于一些工程理念和知识概念,例如模型转换的挑战,还有整体的架构应该长什么样子。接着呢,我们去 看一看模型的序列化和反序列化的这个操作。序列化的工作就是把其他 ai 框架的网络模型呢,转换成为我们推进琴的模型。 反序列化呢,就是把已经保存下来的网络模型加载到我们的内存当中,给推进引擎去执行的。接着我们会去介绍序列化和反序列化当中用的很多的两种格式,一种呢是 photo buffer, 一种是 flat buffer。 讲完这两个内容之后呢,我们将会在下个内容里面来到一些比较核心的技术或者核心的内容,就是自定义计算图的 ir, 针对推理引擎的计算图的 ir 应该怎么定义。 然后呢,第二个内容也是很重要的一块转换的流程和技术的细节。那流程和细节这个呢,就是指导我们怎么去 开发,怎么去写代码的。下面呢,我们来到第一个正式的内容转换模块的挑战和架构。那其实挑战和架构我们在上一节里面已经详细的去给大家去汇报过。今天呢我们简单的去罗列一下。 科目特这个模块呢,其实有非常多的挑战。第一个呢就是 ai 框架或者 ai 本身呢,有非常多的模型,而且有非常多的框架,不同的框架有不同的知识格式,而且我们需要支持非常多主流的网络模型。 ai 发展的越来越多,很多模型都是千奇百怪。 最后就是需要支持很多 ai 特有的一些特性。为了应对上面的这些挑战呢,所以我们设计了一个转换模块的整体的架构,主要是由 graph converter 还有 graph automizer 两个模块来去组成。那 今天我们主要是围绕的 graph 就是我们的图转换的这个模块。下面我们可以看一下,主要就是聚焦于上面的这坨内容。每一个 ai 框架都会有自己的一个 commerter, 最终呢都会汇聚成我们自己推的引擎的。哎呀, 既然 ir 很重要,我们看一下整个转换模块的工作流程,当中可以看到左边的很多的不同的框架,最后都会汇聚成自己的一个独立的 ir。 转换模块的阶段呢,我们统一了整个计算图的 i r, 于是呢在优化模块的时候,我们就可以通过统一的资金一的 i r 完成很多不同的计算图的优化的模式,或者优化图的 pass。 这个就是为什么我们需要自定义的哎呀,为什么需要深入的去给大家讲解转换模块的这个作用。 下面我们来看一下。第二个比较重要的内容就是模型的序列化和反序列化。首先我们来了解一下模型的序列化的工作。其实序列化呢,很简单哦,就是我们把模型呢在部署的时候,怎么去把已经训练好的模型, ai 框架训练出来的模型,把它存储起来,给后续我们需要 fight, tuning 或者推理的时候使用的。而反训练坏了,就是把我们刚才保存下来的网络模型的结构,还有权重呢, 反序列到内存当中,那内存呢,就变成一个具体的对象。我们看一下下面的这个图。 在 ai 框架执行阶段呢,我们写的很多网络模型的代码,还有一些权重参数啊,其实都变成我们内存的一个对象,我们需要保存下来,把我们的权重,把我们的代码固化下来,变成 我们硬盘的一些具体的地址,最后要加载的时候呢,就变成我们需要反序列化回去我们的内存对象。那这个呢,就是一般 ai 框架里面所使用的一个流程。 而在推理引擎呢,也是相同的。左边呢,就是 ai 框架训练的一个网络模型,我们把它序列化,需要用推理引擎的序列化的 api 把它固化下来,成为我们硬盘的数据。在真正推理引擎执行的时候呢,我们需要把一些数据反序列化,成为内存的对象,最后再去执行,这个就是整体的流程。 下面我们来看一下序列化的分类。实际上序列化的格式有很多种,有 x、 m、 l 呢, j、 c 呢,还有 protobuffer 和 fat buffer。 而在 ai 框架或者 ai 的这个领域里面呢, poto buffer 是用 的最为广泛的,我们可以看到下面这个图。谷歌呢,是普陀 buffer 的一个发起者。最后我们现在经常用的 only, 是 facebook 和微软呢,组成一个联盟,一起去支持这种开放性的格式。 而另外方面呢,我们平时用的苹果很多 ai 功能,包括 siri 呢,用的就是 q m l 的格式。而 q m l 呢,也是继承于 portal buffer 进行自己一个魔改或者自己的一个修改定义的。 下面呢,我们以一个简单的例子去看一下拍 touch 的系列化的方式。拍 touch 的内部格式呢,只是存储已经讯号的网络模型的状态。 那所谓的这些状态呢,主要是包括指我们的权重了,偏移了优化器的更新的参数呢,更多的是对网络模型的权重参数信息进行加载和保存的。那其他参数呢,其实也有非常的多,我们只是不一 列举了。另外的话,像拍到取的内部格式呢,非常类似于拍成里面的序列化的方式,直接用 p 口来去做的。这个就是拍到原声的方式。那在代码里面呢,就直接 touch 点 c, 然后把我们的网络模型告诉 api, 我们要存在哪个地址就可以了。 下次加载的时候呢,直接 model 点 loads day distance, 然后就可以进行一个推理。所以用起来呢,是比较简单的。 但是呢,这种方式呢,实在是太难以服了。就是非常的原始,他只是保存了网络模型的对应的参数,网络模型的结构,网络模型的信息计算图。这些信息他都没有保存,而是通过代码来去承载。 下面我们来看一下另外一个方面,就是拍 touch 另外一个系列化的方式 on list o n n x。 大家都知道 pytosh 要导到一些推进引擎去计算的时候呢,一般呢,我们都会把它转成一个 only 的格式。那 pytosh on cut 拍套群内部呢,其实是支持 onlinx 的 export, 包括我们现在在升腾去对接到拍套职业框架,也是通过 onlinx 的一个接口去实现的。 下面呢,确实看到代码很简单,我们前面的都是一些加载网络模型,最重要的就是这条 torch unix is poor 这条语句呢,就告诉我们 需要把拍 touch 的一个网络模型呢,保存为 alex net 点 on next。 这里面的保存的信息呢,就会比拍 touch 原声要多很多。除了网络模型的权重偏移,还有油画器的参数,他还会保存网络模型的结构,每一层所使用的算子, tension 的 ship, 还有很多很多的额外的信息。 那这些呢,就是拍套序列化的一个过程。 在最后一个内容里面,也是比较长的一个内容。我们来看一下目标文件的格式。这里面用的更多的在 ai 领域啊,更多的是 portal perfect 和 fat perfect。 那现在呢,我们来看一下 proto buffer。 其实 proto buffer 它 aka 叫 proto buffer 嘛,实际上呢,它叫做 protoco buffer。 看一下它的 logo, 五颜六色的就知道,大部分都是像谷歌的风格, 也是谷歌发起的一个开源性的项目。因为它确实有很多特殊的优点,比 s m o 还有精神要好。所以现在很多 ai 框架, tenso、 four minus book、 pythote 都是使用 photo buffer 作为它一个主要的导出的格式。现在我们看一下 photo buffer 的一 个文件的语法,那基本的语法的规则呢?下面就是一段 message, 然后呢就告诉我这段 message 属于哪个域,然后在这个域里面呢加了个花括号。那中间的这两行呢,就是具体的字段的规则或者内容。 具体的中间两行呢,就是具体的内容了。我们看一下每一行代表什么意思啊。首先呢,我们有一个字段的规则,告告诉他这个字段呢是属于哪个范围,然后有个数据类型,有个名称等于,然后就有一个预值了,等于什么?那这个呢就是 photobook 的一个文件的最主要的语法规则。 下面呢就是 cafe 这个 ai 框架用 photo buffer 去表示的。那这里面呢有一个 data layer 去声明 data layer 是怎么组成的。那这种呢也是 photo buffer 的写的格式。那右边呢就是卷基层, 通过这种方式呢去表示我们的卷基层。下面我们看一下两个 a 框胶有什么区别啊。 像颗肺这种早期的 ai 框架呢,是使用 photo buffer 的格式呢,去写我们的网络模型的定义的。而后来呢, ten sofa 确实觉得大家去写这种网络模型的定义啊,去写底层的这些 photo buffer 很容易出错,那还不如 通过 python 去封装好,然后给到 tf tenso four 去封装好的 a p i 给用户去调。然后呢,通过简单的去调一些 a p i, 就可以把这个 photo 包粉给调起来,去写我们的网络模型。所以说当时后 ten sof 出来呢,确实大家觉得哇,原来 ai 框架 开发 ai 程序还能这么玩?在一七一八年的时候呢,确实它已经是一个很大的一个创新,不过后来拥有了派套,这也是另外一个故事,不在我们 今天的主线。现在呢,我们稍微深入的去看一下 photo buff 的一个编码的模式,简单的去理解一下哦。 我们的计算机啊,一般来说他是通过二进制进行编码的吗?就是零一零一零一这种方式, 它的基数是二,规则就是缝二进一。像 inter 这种类型呢,是由三十 o h 组成,每位的数值呢,就是二的 n 次方, n 的就是 零到三十一这个范围。大家可以去翻一翻计算机原理去了解一下。那这里面呢,就不详细的展开。而 poto buffer 这种呢,采用的是 t r v 的编码模式。那 t r v 说白了你可能听不懂,我一开始也听不懂。但是呢,我们把它的详写打印出来,它其实就是 tag length, 还有 value 的模式进行编码。 sound tech 跟 value 呢,它其实是一对的,对应起来的一个呢,类似于我们经常字典里面的一个 key, 一个呢,类似于 value。 而 lamp 呢,就代表我们整个 value 的长度。我们写 value 的时候呢,有一个长度告诉我们的计算机,我要保存多长,方便我们的地址。所以嘛,那这个时候呢,我们整个 protobover 的对外的对象呢,就用一个 message 来去描述这整一个数据结构,或者我们整个的对象结构。 通过这种方式呢,就比较好的进行一个编码。我们看一下它。 photo buff 的编码模式,我们字里面呢,就不详细的去给大家介绍了,因为它会有一个编码的过程,也会有一个解码的过程。 通过 t、 l、 b 的编码方式呢,就把我们内存的对象和内存的数据结构变成我们硬盘的数据啦。那第二个我们看一下 flat buffer。 可能很多人听过 proto buffer, 但是呃,至少呢,在中米开发推力引擎的时候呢,我是真没接触过。 fret buffer, 确实用的也比较小,像 proto buffer 用的会更多。让我们看一下 fret buffer 呢,他对比 proto buffer 有一些的主要的优点。所以我们会在推 引擎里面呢,大量的去用到 first buffer。 我们后面会去讲讲有哪些用到像 fret buffer 呢,他有自己主要的特点哦。一个就是数据的访问不需要解析。那这一点很重要,不需要解析,那我们证明呢,内存肯定会更高效,速度会更快,生成的代码量也会相对来说比较少,所以说这是他的一个很重要的优点。 那很多人就会问,那既然 fret buffer 那么好,为什么你不直接用 fret buffer 去代替掉 portal buffer 了?那 这个就是他们之间的一个对比,我就在这里面呢,不详细地展开。其实 protobover 知识的格式和类型呢,会更加多,而且它的接口呢,也会更加多,非常方便我们做一些常用的一些工作。 除了在 ai 框架里面用 photo buff 去表示神经网络模型的 meta 数据,还有它的全中数据。它其实还有很多作用,特别是在一些游戏的协议的传输啊,还有网络自断的传输里面, photo buff 还是做的非常好的。而且它经过编辑码,有利于数据的加减密。 那下面呢,我们看一下 fred buffer。 我们刚才说到 fred buffer, 其实也是谷歌去发起的,后来呢,很多 ai 推理的框架呢,确实把 fred buffer 用起来。那最主要的两个呢,有 m m m m n 呢,就是阿里推出的一个推力印 情。这个推理引擎呢,在 it 非常多的 a p p 里面已经用到了,官网宣传有十八个 a p p 已经用了,包括我们经常刷的淘宝里面的很多 ai 功能,就是用了 m m m 做一个推理的。那像华为的 master light 里面的 scree 码,或者里面的 i r 呢,也是用 fat buffer 去定义的。 好了,今天的内容就到这里为止,我们简单的总结一下。因为转换模块会遇到很多的挑战,于是呢,我们设计了一个转换模块的架构,去承载这些挑战,或者去应对这些挑战的。 在推力引擎里面的转换模块很重要的一个工作呢,就是把不同 ai 框架训练出来的网络模型呢,序列化成推力引擎,能够识别的网络模型。那在推力引擎真正去执行的时候呢,就会把这个网络模型反 反序列化为我们的内存的对象,然后给温太去执行。这个就是模型序列化和反序列化最重要的工作。那序列化和反序列化里面用到什么数据的格式或者文件的格式或者标准呢? 于是我们最后呢就介绍了 portal buffer 和 fret buffer 两种文件格式的内容。而在推理引擎里面呢,用的更多的是 fret buffer, 因为他在反序列化的过程当中,不需要解析反序列化,序列化的过程呢,会更加的快。 我们在推进引擎里面呢,更多的会用到 fret buffer, 而不是 porto buffer。 我们将会在下节内容里面呢,去跟大家看看如何自定义图答案啊,还有转换的流程和具体的技术细节。后面的这节课更吸引哦。谢谢各位,拜了个拜! 卷的不行了,卷的不行了!记得一键三连加关注哦!所有的内容都会开源,在下面这条链接里面拜了个拜!
 06:55查看AI文稿AI文稿
06:55查看AI文稿AI文稿哈喽,我又更新教程啦,这是一期 ai 实时语音转换的一个教程啊,简单来说就是变声器吧。 嗯,这变声器只能说等于秒杀目前市面上大多数的这种变声器了,因为它属于是那种 ai 模型训练的一个变声器,所以这个效果肯定是比就是普通调整的那种要好一些。好的, 嗯,然后是啊,我需要用到的工具啊,就是需要用到的一些工具,我放在视频的这个 简介里面了。好,那我们直接开始操作吧,我不知道现在这个声音怎么样,我听一下。嗯,其实这个模型训练的不是很好。然后,嗯,但是没关系吧,你们 懂我意思就可以,你们可以自己去训练的啊,我到时候后面也会教怎么训练模型。好了,那我就用原声吧。还是。然后,呃,我网盘里面分享的就是我简介下面分享的是这四个。四个东西啊,然后我放在这边了,然后我们把这个下好以后先把这两个下了。 呃,这个是 nv 的那个降噪软件。呃,可以给你们看一下,就是这么一个软件啊,这么一个软件,然后应该有很多打游喜欢打游戏的朋友用过吧, 然后这个的话就是虚拟声卡的一个。呃,软件包了,然后这边是变声器的一个软件包。好的,嗯,然后我们先把这个下,这两个下了,应该会让你重启电脑的。呃,然后如果没有让你重启的话,你也最好重启一下,因为有些东西呃,是需要 要重启才会响应的。好的,然后我想一下啊,应该从哪一步开始讲?嗯,首先我们打开就安装好以后应该是优先是这个啊,我先把这个打开来,就是这个 v 的这个东西打开来。嗯,这里麦克风就是扬声器这边,你可以给它关掉,就是不要。然后主要是麦克风这边,麦克风这边就用你的这个输入麦,然后如果你不知道哪个是呃音源的输入麦的话,就是你可以看 就是点开这个右键,然后声音。然后我是 win 十的系统啊, win 十一系统也是一样的。呃,然后你可以看到,呃,是这个在亮的,这个的话只是因为这个驱动他了,我不能改啊,因为我现在在使用中,所以我不能改。嗯,反正如果你不使用的话,其实这个是可以改掉的,这样的话 这个就不会亮了。好的,然后这边可以看到啊,就只有这一个是亮的,这是我的麦克风,然后,呃,我应该会放一段实拍的素材给你们看一下吧,就是我现在就在录。然后这是我的麦克风, ok, 上面有点灰尘,已经有点战损的感觉了,好的,问题不大。嗯,然后他默认是开了一个降噪的,然后 可以调整,就是给他关掉,关掉的话就杂音很多了。然后如果你要用变声器的话,最好还是把这个噪声消除开启,因为 nv 嘛,毕竟是大厂,这个降噪做的非常牛逼。呃,不管是键盘声啊什么的都处理的很好。 ok, 然后我们打开这个实时变身的一个软件,然后我们给大家解压一下吧。现在的话推荐就是这两个,这两个就是四幺六和五幺四的版, 这两个用起来,呃是比较好的,就是没有什么太多的 bug 什么的。嗯,不过最好还是老版本吧,四幺六的这个版本,嗯会比较好一点,就,呃更加不容易爆错什么的,好吧。呃。然后我这边,呃,我是就这些吧, 然后我这边已经解压好了,所以我就用解压好的这一边。我这边是五幺四的啊,反正里面都是一样的逻辑问题不大。然后我们打开了以后,其实就是这样子, 就这样子,就这样子的一个软件,然后,呃里面就是这样子的一个啊,这些东西啊, 里面就是这样子的,然后我们点开这个,这个,呃,你可以调一个大大的这个,这个可能会清楚一些吧。呃,我点开这个,好的,我给他打开了以后,他就这么一个界面啊,现在就默认 状态。然后这个模型,呃,我就是这个,然后我这边已经整理好了,然后这个模型的话一般就是在你解压的这个软件包这个底层。呃在这边这个,然后你给他添加一下,然后你这个路径啊不要有中文, 然后这边这是模型,然后还是同样的道理,你不要给他建立中文,你不要给他建立中文,要全英文。呃。我这边选择这这个,然后这个是索引的一个文件,嗯,搁在 然后我这边其实用了一个混合的一个方法啊,所以,嗯是可能会有一些问题啊,当然还是自己训练的比较好,自己训练的比较好,就是有点麻烦了。这个输入设备就选 的这个,就这个吗?这个东西,嗯,就是你安装好以后他会自动帮你。呃。在这边建立一些麦克风什么的输入输出的一些东西,然后我这边是把这些禁用了,就是多余的这个虚拟声卡的一个跳线 通道给他禁用掉了啊,你们也可以像我这样操作,不操作也可以,就是看着有点乱吧,就这样的话其实就是这样子一个状态输出设备,我们给他改成 这找一下,就现在就很乱,就改成这个,然后就是打开这个软件,打开这个软件你可以把麦克风设置为这个 nv 的这个,然后。嗯 嗯,你也可以像我这么操作啊。其实我这个操作的话啊,我这个操作还没有女生,我是等一下啊。嗯,要转的话就是。喂喂喂,不好意思忘记了一个事情忘记 开了。呃,我记一下参数吧,刚刚那个参数是多少呢?调其实也不用跟我调的一模一样啊。就是,哎,其实我刚刚调多少我也不知道了。忘记了,反正我刚刚是调好了,然后给他关了很难受, 就大概这样子调吧,然后具体这些东西到底是干什么的,我会到时候放一个图文的一个专栏的。好的,然后我们点击驱动啊,然后这边可以看到推理时间啊,推理时间的话其实就是你实时的一个延时, 然后这样的话就把声音输出出去,然后你想听耳返的话你可以开这个 a 一轨道,这样的话就没有问题了。然后我这个模型其实练的不是很好,所以有一些噪音灯下一些语音软件的话其实是没有问题的,你看这个麦荒其实是没有问题的,像 qq 这种的话其实是 有点优化,比较垃圾吧。喂喂,可以听到吗?哦,这样的话就没有问题啊,就反正是可以说话的,然后你比如说你打开游戏软件,哎,算了,我不演示了吧,反正就这个原理,你们懂就行。
1.4万Mu. 04:28查看AI文稿AI文稿
04:28查看AI文稿AI文稿大家好,今天给大家分享一下深度学习脏话模型的部署流程。当我们训练得到了深度学习脏话模型的时候,我们要把这个脏话模型去部署到机器上, 用它来做推理,把这个方案模型给他用起来。然后当我们工程部署的话,一般都是用 c 加加去接待吗?然后模型部署,这里分为服务器部署和前二十中单版的部署两部分给介绍。 首先是嵌入式重单板的部署,这个的话又可以分为两个部分,第一部分呢是针对一些智能芯片,也就是这个芯片内部它是有 tpunpu 这种智能推理单元的。我们嵌入式板子有很多厂家,比如说瑞鑫 威的,比特大陆的,还有一句华为英伟达这些。然后当我们去做啊模型部署的时候,首先我们要利用每个厂家提供的一些相应的转换工具和脚本,把我们训练得到的拍踏式,比如说用拍踏式训练得到的 pt 模型转换成不同厂家格式的模型, 然后转换完之后,一般每个芯片厂家他都会提供一些推理的 demo, c 间加 demo, 然后我们是基于这个厂家提供的推理 demo, 在他的基础上去做一些修改,然后完成我们自己的三网模型的一些 c 间加推理。 这里以瑞新 v 为例的话,当我们训练得到了三好模型之后,我们要先在电脑上安装瑞新 v 的转换工具 torque 的,然后我们利用拍 线脚板把我们的大模型转换成 r k n 格式的后缀,然后我们再利用瑞星微提供的西加加 demo 去完成我们的算法推理, 其他的一些一些芯片厂家,他们的原理或者过程都是一样的,也都会提供模型的转换工具和脚本,也都会提供吸烟加的推理代码,这话就是 tpu 和 npu 的推理,然后的话另一个是 cpu 推理, 我们的用我我们的芯片,它没有这种 tpu、 npu 这些推理的单元,也就是说它不是一个针对深度学习的智能芯片,就是一个普通的 cpu 芯片的话,那我们也可以去用这个芯片做一些深度学习算法模型的推理, 它也就是用 cpu 进行去进行推理,只不过它这样的话会比较慢。 cpu 推理的话,我们就因为我们它不是针对一些特定的智能芯片厂家,这个时候的话, 我们 cpu 就通用的像 onx、 mnncn 这些框,这些通用的框架,把我们训练得的三项模型转成 onx、 mnnncn 模型, 然后再用相应的库进行推理。假如说我们转成了 onx 模型的话,那我们可以用 onx 的软碳膜这一个库去做推理,而我们用了,比如说转换成 ncn 模型,那我们可以用 ncn 库去做推理, 这个 ncn 的话,一般在我们安卓手机上可以用这个 ncn 框架啊,这个的话 是枪,是中单板子的部署,这样是服务器的部署,服务器的部署话也是分为智能推理跟 cpu 推理,智能推理其实跟上面说的是类似,只不过我们上面 安板子的时候,我们是芯片内部他有这种智能推理单元,而服务器推理,智能推理的话,他是我们服务器上都会 安装一个相当于是显卡,比如说我们英伟达的话,我们就安装了英伟达的显卡,然后这个时候我们也是会用英伟达 提供的一些工具去把它把我的模型转换成英伟达的一些模型,然后也是去利用他的推理 demo 去完成我们萨瓦推理。其实跟上面的这个是类似的,然后服务器的 cpu 推理话跟上面也是一样的,我们也是可以把它比如转成文案 怎么行?然后利用 o s 库进行推理,可以可以看一下这个 这块就是我们转换完模型之后,我们可以利用这个 o s 软 time 库,然后去做推理。
33cumtchw 02:59查看AI文稿AI文稿
02:59查看AI文稿AI文稿哈喽,晚上好,这里是 kiki 今天做一期视频,讲一下 r v c 的基本参数设置。 其实 rvc 发展了大半年了,我以为这么基础的东西大家应该都懂了,但是其实从我接触的小伙伴来看,还是很多人对面板参数理解不够。 kk 经常要同样的问题回答好几遍,那今天我索性就来讲一下。话不多说,我们直接开始 首先响应预知,五脑负六十就可以了,他相当于一个门线,如果你往右边拉了,那么低于这个音量的数值,他声音就进不来。为了我们声音的完整,我们要把这个门完整的打开。 音调设置从左到右,声音越来越细,男变女加十二左右调整,女变男减十二左右调整, 男变男和女变女零附近左右调整即可。 index rate, 它的作用在于拉了它,你出来,声音会去模仿训练级的说话语气,也就是原素材,但是对于大多数人来说,没有听过原素材是否接近根本感觉不出来。 另一方面,拉了 index, 哪怕就一点点,资源占用都会提升非常多,所以一般我们使用保持零即可。 响度因子零,这边就是你说话的音量一,就是模型的音量。一零零六版本加入的这个新功能其实非常牛, et 的建议是选择零点八五到零点九,这样可以让你的声音增加一点起伏的同时能够过滤掉某些模型自带的底噪, 大家可以试一下。采用长度,我们可以理解成每次变身的时间单元,时间越久效果越好,但延迟越高 也越是资源,我们需要在颜值和效果之间找一个平衡点。 kk, 现在三零六零的显卡常用零点三,如果你显卡更好或者采用双卡方案,可以拿到更低试试。这里补充一下,就是算法延迟加推理时间,那加起来就等于你的实际颜值。 哈维斯的进程数现在几乎没有意义,因为我们现在都在用 r m v p e 算法,不需要哈维斯来提取,音高一般拉一就可以了。 弹幕弹出相当于一个说话的残影,长度短,声音清脆但不连贯,拉长说话更丝滑,但太长会口胡。如果你觉得人家用某个模型已经很好了,但是你自己口胡了, 请检查一下弹幕弹出这里是不是拉满了。一般零点零四到零点零八之间,自己找找感觉吧。额外 推理时长,它本身不增加延迟,但是也不能太短。按照之前跟方群说法,采样长度加额外推理要大于二,但是我们实测大于三的时候,第一个字会口呼,所以建议二到三之间。 至于树木和树树降噪,只能说条件允许,尽量不用吧,除非你不介意它吞字。好了, r v c 基本参数就介绍到这里,如果有帮助到你的话,记得给 kiki 一个三连哦。
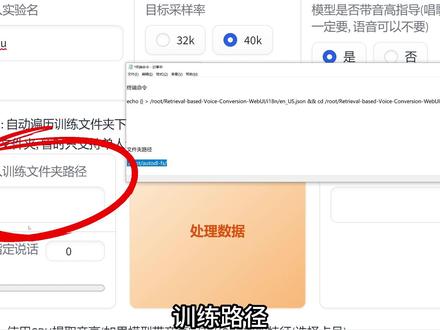 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿ivc 银根训练教程来了哦!首先创建一台四零九零的机子,进向社区输入 ivc, 选择第一个,开机后点击 japt lap, 进入左侧第一个文件夹,上传准备好的训练素材,没有素材的呢,可以去看片尾彩蛋哟。然后在终端里输入这个命令,按回车,再返回到快捷工具中,点击自定义服务, 你就能看到和相机教程相同的 weby 界面。操作上只有两点不同训练路径,必须使用这个固定的路径下方的 batch size 数字拉满。最后一键开练,让别人家的四零九零进行燃烧吧。完成后可以在 loves 和位置文件夹里找到 added 开头的 index 文件和对应的 pth 文件保存,添加到 ivc 中就可以使用了。 你是爱我的。训练素材来源可以是我在调试配音,知道成名的或是中文音声。宝贝你睡着了吗?老公我回来了!切记有版权的别滥用!
1809AICK-KC

