fit拟合函数使用技巧
大家好,欢迎来到日月光华的 pirtal, 是深度学习入门实战课程,上节课呢,我们为大家演示了多层感知器的整个的代码,包括我们啊如何去创建这个输入的 ttelode 以及如何创建模型,那么然后呢就是这种训练循环, 那在训练循环当中啊,我们为大家编写了这个训练函数春函数,编写了这个测试函数,胎死函数,最后呢是一个训练循环,那么我们知道 pitod 他是一个非常优秀的这种 框架,那实际上他对这种训练的输入部分,模型的创建部分以及训练部分,他是种低偶和的,也就是说我对于我们的这种啊收入,我们可以完全的封完全全部将它封装成这种 tello 的形式,然后模型呢,我们都使用 这种皮鞋套尺来创建模型,那对于训练部分这部分代码,我们完全可以服用一个写好的这种训练循环函数,真的话在这个函数里面,我们只需要去调用这个函数,他就会帮助我们去训练啊将这个模型和 teto 在这个 teto 上进行训练。 这段话以后我们再讲解课程还是编辑代码过程中,只要我们只关注创建输入 teto 的以及创建模型 model, 然后呢就将我们的 deetload 和 model 交给这个训练函数,那这个函数呢,它就会根据我们嗯输入的 deetload 还有 输入的模型进行训练。那这一点呢,我们就可以将这个训练循环这一部分给他编写成一个非特函数,编写成一个非特函数,那在这个非特函数里面呢,他就 会根据我们的书交给他的这种对他 low 的和模型进行训练循环,这样的话,对于训练循环的函数,我们就不用每一次讲解一部分,讲解一个实力,都为大家演示这个训练循环的这一部分代码了,我们直接丢用这个费的函数就完成训练了。 实际上大家如果说对于 curse, 对他的 flow 有时候有个意思了解的话,大家会知道 curse 呢为我们内置了这种 fit 这个方法,他实际上就是将这种输入和模型将输入在模型进行训练,那你告诉你只要告诉他需要训练多少个 epok 就就搞定了。好的,那么在这里我们如何去创建这么一个通用的费的函数呢?实际上非常非常简单,我们是在我们上级课代码的基础上,我们只需要将训练 循环的这一部分代码给他封装到一个函数里面就可以,封装一个函数里面就可以。好的,那我们把它编起封装一个函数里面叫做 fit 函数,我们把它抵翻 fit, 比如说我们将它底翻成一个废的函数,那么这个废的函数他首先 要告诉他我们需要训练多少个 epox 呢?这里所以以 pox 就作为一个参数传进去。这样的话,如果说你这个你这个例子需要训练一百个 epox, 你只要传入一百就可以了,所以这里不需要自定义了,这里不需要再专门定义了, 是作为一个韩放参数穿进去,那这里呢?其他的不用动,其他做缩进就可以了啊,这些都是做缩进。然后这里我们需要输入的是什么?除了 epox, 那么它还需要输入纯 date load 啊,就是纯数据的这这两个数据,这两个 dat load 以及模型 lost function 优化器啊,这些呢都需要传进来,就是我们需要传进 dat loader, 毛毛豆 lost 方式。哦,这个优化器以及我们还要用到的那个 test dit loader, text day loader, 我们把它写在这里吧。好的,这样的话这就是菲特函数他所接受的数据,那我们来看一下他接受这几个数据, epox data loader, test data loader, model lost function 以及 operator 以及我们的呃, optimize 啊,那这样的话,这里面的它,这里面这些 循环当中所需要的参数都在这个传奇的参数里面了。然后呢,我们就是这里做缩进就可以了,这里也是缩进四个, 其他的其实没有任何变化,没有任何变化,那这样的话,我们为什么创建成一个函数呢?就可以方便我们在之后的这种,嗯,课程还是我们的实际的编码过程中呢?去附用这些代码,这样的话我们就直接调用这个费的函数就可以了。 但是呢,我们还需要最后呢,我们还会将这个,嗯,将他给我们记录下来的这个 春老师,然后是春 accuracy, train accuracy, test loss 和 test accuracy 全部给返回回来, 全部给返回来,我们把它全部返回来。好的,这样的话就编写好了这个废的函数。好,那么我们边写这么一个废的函数,大家想一想 他是不是对于我们的训练就变得非常非常的方便了,非常方方便了。那假如说我们前面代码都已经运行完毕,我,我运行一下,在这里我没有运行 好的,我重新运行一遍。这里呢?前面这一部分代码主要做了什么事情?主要就是定义我们的,呃,定义我们的这种 输入啊,纯 date load, testdate load, 然后定义我们的模型,然后定义我们的损失函数,定义我们的优化器。那只要我们将这一部分全 全部定义好了之后,这时候怎么办?只需要调用这个 fit 函数就可以了,就是这么简单,所谓的训练过程,你就只需要去调用这个 fit, 比如说到这里,我们去调用这个 fit, 我现在需要训练 一百个 epok, 那么我就调用这个费的函数,这里写一百啊,以 poke 等一百,然后春 dyload, testiload, model, 还有劳斯方式, out, optimize。 前面这些代码当中啊,我们都已经定义好了, 这的话,他会返回什么?他会返回这四部分的值,就是这一百个 epok, 他所使用到的这个。嗯,所产生的这个春老师 纯 rc 太死老死,太死老死都会记录的以四个列表的形式返回,所以我们对他这里呢做一个接受。为让大家看清楚,这, 这里我做一个,我这样写一下,比较清楚。这样的话,所谓的训练过程,我们只需要去调用 fit 就可以了,那我们比如说我们调用 fit, 他就开始训练了, 就是这么简单。好的,那么我们现在编写好了这个费的函数之后,大家想想是不是以后在你以后的编写代码过程中啊,你只需要去关注什么?我只需要去考虑编写好,输入纯 de load, 还有台词 de load, 编写好了之后,然后我再关注编写模型, 然后再定义劳斯方审,然后定义优化器,然后训练部分你就不用操心了,直接调用 fit 函数就可以了。所以大家我们在这里呢为大家专门的去用一节课去讲一下我们将这一部分训练过程啊封装到这个 fit 函数里面。 当然这个非的函数他需要依赖于这两个函数,啊春函数和啊太子函数这样的话,比如说这三个,三个,嗯,这三个这种 单元格中的这些代码呢,你只全部拷贝到你的新代码当中去调用这个费他就可以了,直接去调用他就可以了,你不用关心训练的整个过程,我们只需要调用费的函数就可以完成训练。那我我们之后呢就只关注 输入部分以及我们的啊模型创,模型构建以及这些劳斯方式,还有 optimize。 嗯,好的,那么在之后的我们的课程当中啊,我也会去很多地方也会直接去调用这个费特函数,那么他也要理解的地方就是说费特函数他实际上就是把这个训练循环 做了一个封装啊,做了一个封装。那在这节课的最后呢,我想提醒大家一句话,就是说我们到目前为止是基础部分啊,在后面课程中我们会遇到一些层,比如说招帕特,比如说白痴,那么来贼深,那么这些层呢,他在训练过程中和在测试过程中他的表现 是不同的,那这个时候就需要对模型去设置一种啊,是训练状态还是测试状态。 那为了让大家这个我们的这个费的函数更通用,这个时候呢,其实可以可以加上,比如说叫做我们可以设置模型的这种 串模式还是训练模式,当然这部分代码这部分的解释呢,在我们后面课程当中会有介绍,比如说我们在训练函数当中啊,我们将模型设置为训练模式, 猫都得吹,那么在测试函当中呢,我们就可以将模型设置为测试模式,猫都在一碗啊,猫都在一碗,这样的话我们这这个肺的函数会更加的通用,比如说你调用这个肺的函数以后,你就只关注 创建输入,还有创建模型,训练部分就使用我本届为大家介绍的这个,呃,这个 fat 函数就可以了。好了,呃,关于这部分呢,我也是应学校应同学们的要求啊,专门做一个解释,就是说对于训练部分,我们只需要使用 fat 方法将这个训练循环做一个封装, 以后的训练就可以直接掉用 fit 这个方法了。好的,我们这节课时呢,就讲到这里,嗯,谢谢大家,再见。

粉丝7853获赞1.3万
相关视频
 03:28查看AI文稿AI文稿
03:28查看AI文稿AI文稿大家好,欢迎来到奥菲斯课堂,今天我们来给大家讲一下在 excel 表格里如何做数据礼盒。比如说我这里有年龄和身高这两类数据,年龄和身高明显看出他是有关系的 啊,在年龄比较小的一个范围内,是年龄越大身高也是越大,当然年龄到了一定范围他也是不着的了,像后面他一一米八,一直是一米八, 嗯,那么我们想知道说这两列数据具体的一个函数关系是什么?如果我们知道这个关系的话,像这里有七到十七到十三岁之间没有给出,那我想知道八九十到底是年龄是八九十岁的时候到底是多少身高。 如果有这样的函数关系,我就可以直接带进去计算了。如何得到这样的一个关系呢?我们首先把这两类设置, 呃,给选中,选中以后点击插入,插入图表,这里图表这里有个小箭头,点击小箭头,嗯, 就选择第一个趋势线这个长度啊,画一个三点图啊,这是他的整体的一个关系的一个图像,这个图像已经做出来了,那么我们如何得出这个图像对应的一个函数关系呢?这右上角有个加号,我们点击一下,然后有趋势线, 其实是这里有个小箭头,我们点一下,因为他有好多种啊,有更多选项,这就出来了, 这里全世界他的指数啊,谢谢。对手,这个意思就是说我们根据现有的数据观察他,嗯,可能是个什么样的分布啊?比如说我如果认为是谢谢,现在选中, 呃,他这个就是给一个谢谢的故事,我可以这里有显示故事,我点一下,你看他这个谢谢故事,就是一个系数是零点零五六三的一个谢谢故事, 这样的话我就可以根据这个股市计算出年龄等于八九十岁的时候他的身高。但实际上我们看出谢谢你和只能你和一个大概的趋势,他并不一样,因为 十十九岁,二十岁到二十多岁的时候,他年龄年龄变化身高是几乎不变的,说谢谢你们肯定是有问题的。呃,整体来看他反而 更像对手礼盒,试一下对手礼盒,他后边不怎么长了,但前期的幅度还是不一致,我们选个多项式礼盒,多项式礼盒的话就是这个像素可以调,如果 相声越高,他可以理合的曲线越复杂啊。二下的话你说还不是很好,我们可以调节他的下手,结束也就是来个五次的吧。嗯, 点击空白处确定一下。哎,五次的几乎就你合上了,发现他后面也没有怎么变化啊,我们把这个颜色给调一下啊,点击这里,把颜色给他调成红色的,往边看一点。哎,我们看从这个五次,你和他这个呃, 几乎是吻合的,然后他这个股市的话也显示到了这里,这个股市是最高次次五次,然后四次,三次,二次、一次和长寿项是这么一个股市, 这样的话我们就成完成了一个礼盒,我可以根据这个关系计算任意年龄段的身高。谢谢大家,如果喜欢的话可以点赞、关注、收藏。
786又一村博士 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿首先打开图形计算器,录入数据, 然后点击 可以得到它的模拟函数,在这里我们采用二次函数进行模拟,可以得到它 相应的二次函数的结果,我们点击绘制 就可以得到它对应的函数图像。
31sunrise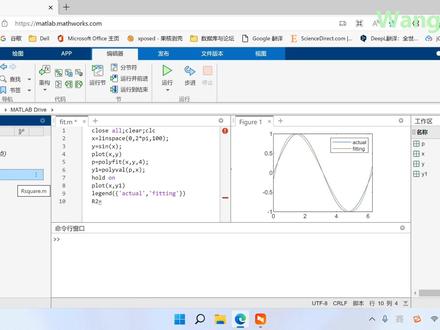 06:04查看AI文稿AI文稿
06:04查看AI文稿AI文稿分享一个用 matalev 你和你想要的曲线的一个方法。嗯,这里用的就是网页版的麦特莱,就是这个网址,然后打开之后建立一个新的脚本,新建脚本 这里重名为 face, 然后把它打开,打开,我们第一行还是进行一个初始框, 然后建立一个 x 数据和一个 y 的数据, x 轴和 y 轴, x 轴呢?就举个例子吧,就是生成一个零到二排之间的一个项链,用 nice space 零到二肽之间, 然后一百个数据外呢是三 x 函数, 那么就就是这两组项链,我们可以先给他输成一下看一下, 然后运行一下,也就是我们这样的一个正前曲线。对这样的曲线我们应该怎样去拧拧合呢?这运用的一个命令就是 polar eggs, 你把 xy 填上,这 对我们不知道他是几次你和,所以我们先去试一试,比如说一次,一次当然是个直线,我们已经知道直线,但是我们这里呢去来试一下,演示一下, 对你你和后的这个 p 呢?他是一个,嗯,权重系数,你这个权重系数怎么去给带入到原来的 x 当中去逆和出新的外置呢?新的外置是为外衣, 那么新的值的计算就是 polar value 这个值批举证,然后还是原来的 x, 然后是新的万一 对新的外衣我们进行一个绘制后档, 万一我们在运行,所以看到红色线是礼盒的,然后这个蓝色的是原来的原来的数据,可以看到这个偏差是非常大的,所以我们改动这个,呃,这个几次项,把这个一次改成二次看一看, 现在还是没有效果,那我们继续改比说改成四次,这个次数相越高呢,他跟原来的数据吻合程度越大,但是过高呢,他会反而会过,你和就是 离原来的数据比较偏远了,所以当四次的时候,我们看你和效果还是比较好的。那我们继续,比如说,比如说到五,我们再运行一下, 这个是完全拟合的,那为了看出这个效果呢,我们这里实际演示的时候改成四吧。 ok, 那么这个我们为了区别你这里加一个 legend, 加一个加一个标题吧,第一个是实际的,然后第二个是你喝的, ok, 这里个标题就出来了,那我们为了评价我们礼盒出来的这个纸跟原来是一的纸,他的偏差常常用到两个指标,一个是阿尔方, 这个阿芳指标呢,通常是衡量预测值和真实值,它接近成 度的一个指标,这个阿方越接近一说明这个预测值是更加完美的,贴近于真实值的,越小说明是越偏离的。我们这个二二方的函数呢,我们这里给出来了,这就提前写好了, 等于一减去残差平方和,比上一个总力差平方和。然后是这样的一个公式,我们直接 用阿斯乖尔这个函数,然后第一个第一项是,嗯,真实纸,第二项是,呃,预测纸,那我们带入这个函数就 ok 了。 us there, 真实纸是外,然后预测只是外衣,那另外呢,我们还用 mse 这个函数,也就是平方差,平方差函数衡量, 这是纸和预测之间的偏差大小,第一个是外,第二个是外衣。 来运行一下,可以看到二方是零点九九零四,那么这个值越接近一说明他的预测效果是越好的, 那么这个 mse 就是军方误差,他这个值越小,说明离合效果是越好的。因此我们当前得到的这两个指标 他都比较完美,所以说明我们四次相的时候你和效果是比较完美的,那么当然这个具体问题还要具体去分析是多少次。
7061Endless科研分享 10:11查看AI文稿AI文稿
10:11查看AI文稿AI文稿大家好,欢迎观看奥瑞枕视频教程。我是白东生, 这一节我们来一起学习自定义函数的你和方法。二位枕除了内置函数以外,还支持自定义的你和函数,这大大拓宽了可以进行你和的函数范围。 事实上,利用自定义函数功能,几乎任何函数的数据信息都可以拿来礼盒。奥瑞枕的所有函数全部 集中在函数管理器中。点击托斯菜单,打开你和函数管理器,或者使用快捷键 f 九,就可以弹出一个函数管理器窗口。 窗口左侧是已经存在的函数列表,这里既包含内置函数,又包含已经建立的自定义函数。选择一个函数中间部分就会列出这个函数所有的属性。 下边的三个页面还会显示函数的方程、视力曲线和相关提示信息。自定义一个函数就是要给出一个函数表达式,并告诉软件和函数有关的所有属性。我们来建立一个自定义函数。 首先在左侧定位到合适的函数类,你可以根据实际情况选择一个合适的类,或者使用最后一个自定义类 或者新建一个函数类。新建函数类的方法非常简单,只需点击右侧第二个按钮并输入一个名称即可。 左侧定位到新建的函数类,然后点击第三个按钮 new function, 就可以添加一个新函数了。下面我们需要做的就是输入或修改这些属性值。 在操作之前,建议大家把下面的显示窗口选到 hints 提示信息页面,这样每当你修改一个属性时,这里都会给出一些文字说 明。 第一项是方式内幕函数名,你可以输入一个名称。第二项是函数文件的保存路径,这一项是不可编辑的,默认会保存在 orange 文件家中。 第三项 breath description 可以让你对函数做一个简要描述, 这些描述信息将来会显示在你和对话框的函数选择页面里。方深 type 是函数型,包括自定义和外部 dll 两种函数型。 自定义型是通过调用奥瑞枕 c 语言或 leptalk 脚本语言实现韩束女孩的一种类型。外部 d l l 型是通过外部兵役器创建 dll 动态链接库文件,实现韩束礼盒的一种类型。如果选择了这种类型,还需要在下面 dll 一栏输入一个动态链接库文件名。 对于一般的你和操作而言,建议大家选择自定义型就可以了。接下来的是自变量,音变量和参数名称,你应该根据实际情况进行填写,多个变量之间用逗号隔开。 下边是函数结构,这里有四种结构供你选择。 wisecraft 使用的是 level talk 脚本语言,这种结构的运算速度较慢,但可以向下兼容较低 的版本。后面三种结构使用的都是 origin c 语言。 expression 是表达式结构,这时的函数表达是只能有一个音变量。 equations 是方程式结构,函数表达是可以有一个或多个音变量。 最后的奥瑞枕 c 是最常用也最为普遍的一种结构,建议大家选择这种结构。 以上这些都设置好以后,你就可以在方审这一项里添加自定义函数了。 注意,要按照 c 语言的格式书写 函数定义好之后,点击右侧的边翼按钮 进行编译,这时奥瑞枕会弹出一个编议对话框,并自动生成了 c 语言代码。我们点击 compile, 当奥瑞枕正确编译完成之后,会在下边的 outpaw 的窗口最终显示弹字样, 我们点击这个按钮,返回函数管理器窗口。 parameter settings 是参数设置项,可以为参数复出值确定,上下线等等。你可以直接书写代码,也可以点击右侧的编意按钮,在这里填写 接下来的复选框是是否自动初始化 参数以及初始化代码。 写好初始代码之后,同样要编议一次,好让奥瑞枕能够正确识别。 第二个复选框是是否添加约束以及约束条件。 最后一项是导出参数,在这里你可以由你和参数定义一些其他的参数,不过这些参数是不会 被你和的,他只在你和结束之后根据你和参数的值计算得到。比如在当前这个你和方程中,各多项事项和正选项的系数比是我关注的重点内容,那么我就可以定义一些导出参数。 这样软件在你和完成之后,除了输出各个你和参数的值以外,还会计算这些导出参数的值,这样就减少了我自己进行后期计算的工作量。 好,参数设置好以后,我们点击 save 进行保存。右侧第四个按钮是复制,这可以 把一个选中的函数复制出一个副本,你可以在这个副本上修改,而不会影响到原来的函数文件。 第五个按钮是添加,可以从外部导入一个函数文件,这非常方便于你和其他朋友之间互相共享自己的自定义函数文件。 第六个按钮是移除,可以删除一个不需要的函数。 倒数第二个按钮是 simulates 模拟按钮,点击这个按钮会打开 simulates club 功能,你可以调整不同的参数进行预览。这个功能我们在上一节给大家介绍过,这里不再坠数。 最后点击 ok, 关闭这个函数管理器窗口,一个新建的自定义函数就被保存到奥运镇当中了。 这时进行你和 就可以调用刚刚我们自定义的那个函数了。 在这个飞线性你和对话框中,你也可以点击中部第一个按钮,打开函数管理器,随时对函数进行修改, 点击 ok 完成你和。这时在你和报表中不仅可以看到你和参数的值三个导出参数 p 零, p 一, p 二也一并计算出来了。 好,今天就讲到这里,希望大家能够理解和掌握自定义函数的操作方法,尽量多的去做练习, 因为在你的科研工作中总会遇到各种各样的你和数据,在奥瑞镇的内置函数中找不到合适的模型是常有的事情,这时自定义函数功能就派上用场了, 用好自定义函数功能,一定会给你的数据处理工作锦上添花。我是白东生,感谢你的观看。
68aa 08:31查看AI文稿AI文稿
08:31查看AI文稿AI文稿神经网络可以你和万物吗?在这个视频中,我会带领大家深入探索神经网络如何在复杂的空间中学习各种形状。首先,简单来说,函数就是一个输入输出的机制,他们将一组输入数字转化为相应的输出数字,而函数则定义了这些数字之间的联系。 神经网络所要处理的核心问题是,当我们不确切知道所试图近似的函数时该如何操作,而我们所持有的只是该函数的部分数据点、样本及其输入和输出,这就构成了我们的数据集。 我们的目标是找到一个能够近似你和这些数据点的函数,并且能准确预测那些不在我们数据集中的输入与输出。这个过程叫做曲线。你和这个名称很形象,你看到的并不是某种预设的动画,而是一个真实 的神经网络在尝试对数据进行曲线拟合,以某种方法来调整他的曲线。这一过程的特点是,他可以拟合任何数据集,从而构造出任何函数,这让他成为一个非常通用的函数近似器。这个网络本质上也是一个函数,目标是近似某个未知的目标函数。 本视频中涉及的特定神经结构被称为全连接乾坤网络,通常他的输入和输出被称为特征和预测,都是以项量或数字数组的形式存在。 这个大函数是由许多简单函数构成,这些简单函数称为神经元。每个神经元接收多个输入,但仅产生一个输出,每个输入都与一个特定的权重相乘,再加上一个被称为偏差的额外权重。这个计算过程可以通过先性代数来表示。我们可以把输入组 合成一个项量,被偏差添加一个额外的一值,然后将权重组合成另一个项量,之后计算所谓的点击。我们可以用一些视力值来演示这一过程。在计算点击时,我们乘以每个输入与其相应的权重,然后将他们相加。 最后,这个点击被传输到一个简单的激活函数,这里我们使用的是 realu, 其返回值为零。 当然,我们可以选择使用不同的激活函数。激活函数决定了神经元的数学形态,而权重则可以移动、缩放或拉伸这个形态。 我们将原始输入传递给一层神经元,其中每个神经元都有自己学习到的权重,并产生自己的输出。这些输出被组合成一个项量,然后这个输出项量被作为下一层的输入,以此类推,直到我们得到网络的最终输出。每个神经元 都专注于学习函数的特定部分或特征。通过组合多个神经元,我们可以构造越来越复杂的函数。理论上,有足够多的神经元时,我们可以构造出任何函数。 权重或参数的值是通过训练过程得到的。我们给网络提供数据集中的输入,让他尝试预测正确的输出。反复进行,目标是最小化。网络预测输出与真实输出之间的误差或损失。随着时间的推移,随着误差减少,网络的表现会逐渐提升。 这个算法名为反向传播。我在本视频中不准备深入介绍。他真的是一个魔法般的算法,但这里只是个开始。那对于那些不仅有一个输入或输出的函数如何呢?也就是更高维度的情况。项量的维度由其中的数字数量决定。 针对一个高维度的问题,我们试图学习一幅图像输入像量代表像素的行列坐标,而输出像量代表像素的值。用数学数与描述,这个函数是从二二映射到二一的。 我们的数据集包括图像中的所有像素。以这张看起来不太开心的男子为例,像素直领表示黑色,亦表示白色。不过我选择了一个不同的颜色模式,因为他更加吸引人。 在训练过程中,我们逐步捕获到函数学习的变化。需要明确的是,这幅图像不是网络的唯一输出。事实上,每个独立的像素都是单独的输出。 我们同时查看整个函数,因为其维度相对较低。你也可能已经注意到学习的速度似乎有所放缓。他不再像刚开始时那样迅速的变化, 这是因为我们逐步减少了学习率。他决定了我们的训练算法如何调整当前函数的参数。这样做是为了更细致的调整。虽然我们的神经网络理论上应能学习任意函数,但在实际应用中,我们仍可以采取措施来提升近似度和优化学习过程。 例如,我在此实践中对行列输入进行了标准化,这意味着我将直从零杠一千四百的区间调整到了一至一之间。我采用了一个简单的线性变换来进行值得移动和缩放。负一到一的范围对于网络来说,处理起来更为简便,因为它是以零为中心的。 另外,我并没有采用 real u 作为激活函数,而是选择了 v t real u。 v t real u 可以输出复数,但同时还保持飞线性。它已被证明能够通常提升性能。所以我在所有层中都是 使用了 leaky real you。 除了最后一层之外,由于最终的输出是一个像素值,他应该位于零和一之间。为了达到这个效果,我们在最后一层使用了 sigma 激活函数,将其输入压缩到零至一的范围内。 不过还有另一个压缩函数 g ten, 他将输入压缩到一至一的范围内。之后,我将这些输出标准化到零至一的区间。为何这么做呢? 事实上, ten 与 sigma 相比效果更佳。简单的说,这是因为 ten 以零为中心更适合与反向传播协同工作,但具体原因不如结果来的重要。 这里的两个网络在理论上都是万能的,函数进四起,但在实践中,其中一个的表现更出色。我们可以通过计算并比较这两个网络的误差率来实证性 评估他们。我认为这就是数学之美。我们需要测试我们的假设,并根据实证结果来验证他们,而不仅仅是提供形式化的证明。接下来我们增加难度。这里我们有一个函数,他接受两个输入 u 和 v, 并输出三个值, x, y 和 z。 这是一个参数化的表面函数,我们将采用球面的方程来描述。我们可以像之前一样去学习它从球面上随机取样,并让网络近似这些样点。 这显然是一个制作球形的非常间接的方法,但网络正在努力的调整表面已匹配数据点。我希望这也能让你对参数化表面有一个更为直观的理解。 他接收一个平面的二 d 片段,并根据某个函数在三 d 空间中进行扭曲。尽管这种方法在某种程度上很有效,但他在两级部分 可能不会完美闭合。对于更大的挑战,我们来研究这个精美的螺旋壳面。我从一个提供各种壳面演示的精巧网站中获得了这个公式。这里可以说展示了函数是如何描述这个世界的。首先,我们在螺旋壳面上随机选取几个点,然后开始学习。 确实,他正在尝试学习,但显然我们在这里碰到了一些难题。我采用了一个规模较大的神经网络,但面对如此复杂的形状,他显得稍显困惑。我们也可以通过加大函数的复杂性,而非紧增加维度来增加挑战难度。 尝试一下 mendobro 级,这是一个无尽的复杂分型。我们可以为 mendobro 函数定义一个简单的形式,它接受两个实数输入,然后输出一个值,这与我们之前研究的图像维度类 四。我为我的 mandobro 函数设置了输出值在零和一之间,其中一表示处于 mandobolo 其中,而第一的值则不在。实际上,他在复数上执行了迭代操作。我加入了一些元素,使其在零和一之间有平滑的输出。但我不会深入解释, 毕竟神经网络本身并不知晓这个函数的定义,这不应成为问题。他应当可以得到相似的近似这里的数据及从特定范围内均匀随机抽取。 我希望你能感受到其独特之处。尽管维度如此之低, mendobro 函数却展现了无尽的复杂性。他真正的利用了复数构件,并且近似他特别具有挑战性。 你可以不停的尝试去逼近这个函数,但总还是有一些误差。当然,你可以选择任何分型来尝试。这里我选择了著名的 mendal blow 级。经过一段时间的训练, mendal blow 级得到一定程度的拟合,不过可以尝试更加复杂的神经网络,那会拟合的更好,大家可以自行尝试。
3881Eve的科学频道 02:07查看AI文稿AI文稿
02:07查看AI文稿AI文稿一个例子说明神经网络如何拟合非线性函数, 设置一个简单的飞线性函数 y 等于 x 的绝对值。我们的目标是找到一个合适的神经网络,使其输出尽可能接近该函数。 具体来说,设置一个输入层和输出层有一个神经元,隐藏层有两个神经元的网络。另外,在隐藏层中使用 reno 激活函数, 第一个神经元的权重设为一,第二个神经元的权重设为负一,他们的偏置都设为零。 因此,第一个神经元的输出为 real x 乘一加零等于 max 零 x。 第二个神经元的输出为 real, x 乘负一加零等于 max 零负 x。 神经网络的输出 y 等于两个神经元的输出相加。当输入 x 大于等于零时, max 零 x 等于 x, max 零负 x 等于零,因此输出 y 等于 x。 当输入 x 小于零时, max 零 x 等于零, max 零负 x 等于负 x, 输出 y 等于负 x。 这样,神经网络就模拟出了 y 等于 x 的绝对值这个简单的非线性函数了。 那么到这里,神经网络你和非线性函数的案例就讲完了,感谢大家的观看,我们下节课再会。
61小黑黑讲AI 00:30查看AI文稿AI文稿
00:30查看AI文稿AI文稿前端开发小技巧,使用 object fit contain 使图片能够完整地显示在 div 中。 如果要在一个固定宽高的 div 中显示一张任意宽高比的图片,要使图片能够完整地显示在 div 中,又能最大化地展示图片并保持其宽高比。 比如这两种不同比例的图片,可以在 i m g 标签上使用 object fit contain 这个属性,浏览器会自动计算出图片应该展示的尺寸。
896学数学的程序猿 01:18查看AI文稿AI文稿
01:18查看AI文稿AI文稿深入了解浪漫算法成为曲线礼盒高手 origin 的秘密武器,揭晓非线性礼盒变得轻松有趣。在 origin 软件中, lama livingburg marquard 算法通常用于非线性曲线礼盒。您可以按照以下步骤在 origin 中找到浪漫。 打开 origin 软件,并加载您的数据文件。在 origin 工作区中选择您想要进行曲线礼盒的数据图。在菜单栏中找到,并点击分析 analysis 选项。 在下拉菜单中选择非线性礼盒 non linear curfet。 在弹出的对话框中选择您想要礼盒的曲线类型,并确保选择了 livingburg mark world 作为礼盒算法。通常,您可以在算法选项中找到浪漫配置其他礼盒参数, 例如初始参数值等。然后点击确定,开始拟合。这样您就可以使用 liver margard 算法进行非线性曲线拟合。请注意,具体的步骤可能会有些变化,具体取决于 origin 软件的版本。 如果您使用的是较新的版本,建议查阅软件的帮助文档或在线手册,以确保获取最准确的信息。数据科学曲线礼盒。
19科兴测试 02:48查看AI文稿AI文稿
02:48查看AI文稿AI文稿今天一个小技巧哈喽,大家好,我是 pink 老师。今天啊,给小伙伴分享的是四 s 的一个属性,叫做 apecat fit。 哎,这个属性啊,它主要使用场景是可以使我们的图片或者是我们的视频呀,它的内容来适用我们的宽度和高度。它的使用方法呢,跟我们的白光的 size 非常类似, 但是要区别开来,跟上塞子,它只能针对于背景图片啊,做一个呃拉伸呢,或者是来一个缩放。而我们这个 oppojitofit 呀,可以直接对图片,对插入图片做一个操作。它里面的属性呢,也是有像卡通呢卡哇这一些 来,我给小伙伴们举直接演示一下这个属性到底有多好用。那比如说哎,同学们看一下。这那这呢?有一个 pink 老师的头像还是非常帅气的。那我想呢,哎,因为我们的头像上传的时候是因为用了插入图片,他用的不是背景图片。这一点小伙伴们,我们想打成共识,那我可以把这个 m 图片呢,叉斗英文当中。现在呢,我想做成是不是一个圆角的一个效果呀,现在我们可以这么去做啊啊,我可以把我这图片最个修饰啊,比如说写上 img, 然后写上一个宽度,改成个三百四十 p x ok, 高度呢,也改个三百四啊,因为我要做圆角吗?宽高是一样高的,然后再加一个包格, 然后呢? apx sorry 的。然后我改成一个呃,粉色吧, pink 色。然后呢,我再加一个包单干 reduce 百分之五十好。小伙伴们注意仔细看,因为这个图片本身是宽度啊,和高度有点不太一样,高度啊,稍微高了那么一丢丢。 那现在呢?我让他宽高一样的,然后改了个圆角,我考上驾驶,保存一下。走着。那我们会发现他把图片呢来了一个拉伸,因为他的宽度稍微小了一点嘛,所以把图片拉的有点扁了。那这样的话是不是就不太好看了呀。那这个时候呢,我们为了保证这个比例啊, 宽度和高度的一个比例。那怎么做呢?哎,记住这样不能用白沟上撒一子,因为白沟上撒一的只能是针对于背景图片来做修饰的。而我这呢,是 xr 图片,难道没有办法解决了吗?哎,答案就是可以有的,就是用到我们 objectophyd 这个方法来做。里面呢有一个 像啃吞呀, cover 呀。啊,这个。这前面两个小伙伴应该是很熟了,只要你会掰更塞,就知道他是什么意思。好,我选择你们的 cover 啊。好,那我在这里面给小伙伴做对比一下。这是我们原来没有加这个属性的哎,我这个图片是压扁的,而我现在加的这个属性可加自保存。走着。哎,小伙伴们能对比出来吗?哪个你会更喜欢? 哎,当然了,这两个呃,骗老师头像都帅,都喜欢。但在用户的角度来说,是不是我们加完了这个属性,是不是展示的效果会更好看一些?所以说,如果以后再遇到啊,比如说上山图像,针对于我们图片的一个操作。 那个这个时候呢,我们可以通过奥布扎克的 fit 这个属性来做一个处理。他呢,可以使我们的内容呢,根据宽度和高度来做一个拉伸,或者一个变化。怎么样?这个小技巧还是比较有价值的吧。那了解更多小伙伴们可以去 mdn 呢,来查一查它里面每一个选项什么意思,小伙伴们来填一下吧。
1585黑马pink 03:46查看AI文稿AI文稿
03:46查看AI文稿AI文稿哈喽,大家好,我是叶博士,这一讲教大家如何进行直线礼盒。在科研与生产当中呢,我们常常需要进行数据处理,一个常见的数据处理呢,就是把数据点拟合成直线,比如说这个案例,我们要把 x 和 y 这两个数列拟合成直线, 直线礼盒呢,在 excel 当中有两种做法,分别是画图法和公式法。首先我们来讲一讲画图法,画图法呢就是利用这两列数据来作图, 在完成图形之后呢,我们点击右键选择添加趋势线,然后我们选择趋势线类型为线性,然后我们显示 四显示翻叉,那么这样一来呢,我们就得到了这个礼盒的结果。这里呢,我们还建议将系数设定为科学技术法,因为当 x 与外相差几个数量级的时候, 可能导致这些参数的值非常小,如果这个时候你用小数来显示的话,他位数可能不够,就会引起出错。因此呢,我们在这里设定数字类型为科学技术,然后根据我们的需要设定保留的小数位数啊,这样就行了。 画图法比较常见,但有一个不方便的地方,就是如果我们的后续计算要利用到这些参数的时候呢,我们需要把这些参数抄下来,然后再进行计算。比如说我们后续要计算 a 加 b, 我们就需要把这个参数给抄下来, 然后我们再进行计算。 这样计算完了之后呢,我们发现,如果我们改了原始数据,虽然这个图里面的数他会变化, 但是这两个数呢,是我们从图里抄写下来的,他不会自动的发生变化,这就非常的不方便,只要我们改了原始数据,我们就要把这图里面的数再给他抄一遍,而且有的时候我们会忘记把它抄下来,那么后续计算就会发生错误, 那么在这里呢,我们就来介绍第二种方法,就是通过公式直接计算协律和拮据。在这里呢就要用到两个函数,第一个是十六盘函数, 十六排函数呢可以用来计算这个依次函数的斜率,我们来使用一下,我们输入十六, 我们发现他这里有两个参数,第一个参数呢是外值的集合,也就是这一列。第二个参数呢是 x 值的集合,也就是这一列, 那么我们输入以后,我们发现他的计算结果就自动显示出来了,如果我们要计算结局的话呢,我们就需要使用 intercept 函数,使用方法呢和 slope 函数是一样的, 这样我们就把它的结局也计算出来了,经过这样的计算以后呢,我们随意的改动我们的初始值,那么它这里的斜率和结局呢,就会自动的进行变化,我们如果引用了这些变化的斜率和结局,就可以直接进行下一步的计算。 这一讲就到这里,我是叶博士,一个搞一点科普的化学工程师,欢迎大家点赞支持,添加关注。
470法式滚筒YEboss 00:59查看AI文稿AI文稿
00:59查看AI文稿AI文稿各位朋友大家好,我们今天来讲数据礼盒,数据礼盒的第一讲,首先什么是数据礼盒?在生产和生活当中,我们往往要面对很多的数据,比方说 dxi 年的人口十五 y i 就是这样一个有序时数,对,我们可以把它看作 d i 格数据点 pi, 有了数据点之后,我们就可以把他们描绘在平面直角坐标器当中。那什么是数据礼盒呢?就是去寻找函数 y 等于 fx, 使得这个函数的函数图像能够尽可能的反映数据的趋势。 那数据礼盒有什么用呢?最起码可以来做差值和预测。那什么是做差值呢?比方说中间有一个年份 x 零,我们去估计这一年的人口数歪零,这个操作就是在做差值。那预测就更好理解了,就是去估计未来的数据走势啊,当然估计过去的数据走势也是预测, 那数据你和有什么方法呢?高中阶段我们能够使用的有三个方法,拉个朗日多样式、三阶样条和最小二乘法。其中拉格朗日多样式和三阶样条更多的是面向差值最小二。
177遇见数学





