tbtools使用方法
凌波微视组学小视频生命大视野 t b toos fast 序列处理小工具之 t b toos 提取目标序列片段当我们进行基因组学研究时,有时需要从生物的基因组中获取某些特定的基因序列或者是部分序列片段,那么这就是对基因序列进行部分提取。 t b toos 是一种简单易操作,适合大众化的基因序列提取的小工具。下面我们就如何使用 t b toos 众 fast 完成对基因或蛋白质序列的部分提取,和大家做一个简单的展示。 本期视频演示的是 faster abstract recommend that 功能。首先进入 t b tools 程序,从左上角 sequence tokid 中的 faster tools 里打开 faster abstract recommend that 界面,界面如图所示。第一步,再 set up input faster file 栏,导入 faster 格式的文件 和点击右侧链接按钮,关联文件、 dna 或蛋白质序列均可。第二步,点击右侧的 initialize 完成初始化,随即会在 相应的路径中生成该序列的 fa 和 fai 格式的两个文件。第三步,在 set and output fast file 指定输出路径和结果文件名用于输出结果。第四步,在 set input id 类似的栏中输入序列 id 起始位点、中指位点使用 type 键进行分隔。 第五步,在 other options 重选中 use tapped as column separator。 第六步,点击 start 后即可生成如下结果, 这次的分享就到这里,后续会继续推出 t b tooth 系列其他课程。 t b tooth 是研究基因序列的实用工具,而 关于基因组学技术,灵恩商务整合多种优势技术及信息分析平台,提供高难度基因组解决方案,多种技术组合实现完整基因组组装,为复杂研究提供基础框架。实力雄厚,经验丰富,为广大科研工作者提供国际领先的动植物基因组 dnobo 测序方案,测序找灵恩组学科研好伙伴。

粉丝308获赞3788
相关视频
 04:29查看AI文稿AI文稿
04:29查看AI文稿AI文稿朋友们大家好,我们今天一起来学习 t b tools 这个软件平台。首先第一节课呢,我们讲讲如何一步构建 imos。 所谓的一步构建就是说跳过序列的比对,修剪模型筛选,选择合适的系统发育软件, 那么输入序列,输出 m l 数。好,咱们直接开始。打开软件后,在 others phylogenities 中选择一步构建 m l 数。在跳出的 对话框中有上下两个框,上面是输入,下面是输出,那么在上面的对话框右边点击按钮,之后跳出对话框,选择你要输入的序列文件,打开 在 start 旁边这个对话框,检查一下各种参数的设置,那么只需要改动竖行这地方一比例,这样我们可以看到字长。 然后在下面这个输出区域的对话框中,同样的点击右边这个按钮,设置你的输出文件放在哪个文件夹,设置好之后点打开,然后点击 start, 就可以开始构建系统发育数了,然后到你指定的文件当中生成了一系列的文件文件,根据他们的时间可以看到进度。 当系统发音处建建好之后,他会跳出一个对话框,点击确定,跳出一个竖文件,可以保存成图片。 同时呢,在他的生成的文件中有一个重要的日字文件,我们选择用记事本打开 查看相关的重要信息,比如开始的时候,他对序列进行一个分析,其实有些序列是一样的,然后进行比对 和模型筛选,他用的是 model fonder 进行模型筛选,给出了模型的清单,也给出了在 aic 和 bic 标准下最优的模型, 那么在这个模型下进行,使用 iq tree 这个插件构建系统发育数, 首先是抽样五百棵树,然后进行一次数的统计, 最后一字数放在 ctrl 这个文件中,而抽样的数放在 u u f boot 啊 这个文件中。好, ctrl 这个文件我们可以重命名, 为了备份,我们可以以副本重新命名为 m l, 后缀名以 n w k 格式, 这样的话方便我们使用 mega 等软件打开查看, 这样就出来了一个带支持率的系统发育术。 好,这就是我们今天一起学习的内容。如何使用 t p two 是一个软件非常简单的,非常便捷的构建系统发育数。 那么这个文件不需要比对,也不需要我们自己进行模型的筛选,只要输入这个文件,最终输出我们所需要的最大自然数,也就是这个 ml 数这个文件。好,今天的学习就到这里了,朋友们再见。
64爵士熊 18:16查看AI文稿AI文稿
18:16查看AI文稿AI文稿我们在准备好这些这些前期的文件之后呢,我们就要进行新家族的筛选与鉴定 啊。一般的来说的话,呃,现在用最用的,用的最多的文件,也就是用的最多的方式,也就是 blas 的 blas 的比对,这种方式去筛选一部分啊, 然后然后我,我呢我呢是用,呃用 blast 和 p f p 结合,然后再结合表面进行筛选,所以我们今天来就是做一下,对, 然后也是我们是之前是下载好 tpq 之之后啊,然后我们就打开 tpqs, 然后在 sequence check it 里面去找它的 c f f sequence distractor, 然后把它的芒果杨的 g f 文件点放进去,放置进去,然后初始化, 说实话,好,他说实话已经完成,提示你 擦掉,然后我们在这里选择选择 cds, 在这选择 parent, 然后把它的全金组文件放进来,然后设置一个输出路径,命名为 p t r 点 c d s, 然后点击 start 啊,可以看到他这他这个地方还是还是还是灰的,说明他还是没好,还在进行中当中的,等他完全弹出来之后就说明已经好了,他是有个弹窗的, 感觉这个左边已经出 cds 了,但是他还是没有显示好的,说明还是在进行的。看他说 attraction finish 的,就说明 t 区已经结束了, 然后我们需要把 c d s 变为蛋白质文件,就是对,你看可以看到 o f prediction 里面有个 c d s to 变成蛋白质,然后我们把这个 p t r c d s 放到这儿,然后设置一个输出路径,设置一个输出文件,把它命名为 pad, 对, 可以看到它的转化已经结束了,然后然后我们就要进行进行 blast 比对去筛选出啊,毛果洋蛋白质中就是 跟,呃,就是它的 j 二零 o x 五的基因家族,然后我们选择 two sequence fires, 然后把它的 把这个放到这,你看一下,把这个放到这啊,然后把芒果羊的蛋白 设置设置,然后我们也是输出,呃,设置一个输出文件啊,设置为 p t r, 点 one friend, 点 g a, 二零 o x 五,点 table, 点叉 s, 然后把这个输出输出格式设置为 table, 然后 start, 就等一下, 这个就是 blast 比对出来的结果,对,他说已经结束了,然后我们要打开这个文件夹,然后 我就,我们其实我们文件夹就在这这边啊,我们可以可以看一下,对,这就是我们得到的结果。嗯,对,我们点击它,把它打开,因为它是已经是插,就是已经是 excel 的那种格式了,对 啊,这个是我昨天昨天做的,他这个不知道为什么没有,没有没有没有,没有那什么掉, 然后可以看到这么多,他这应该是有对两百多条,两百多条都是我们比对出来的,我们要看的是第二列啊,第二列,然后我们 把它稍微排个序吧,降序,然后对它进行一个重复像的筛选 啊,去除重复项,因为它有些 id 是相同的,选择 b 列,那删除五个重复项,留,保留一百九十九个为一值,但是一百九十九个为一值也是非常多的,对吧? 删掉,但他这个太多了也是不行的。对,然后我们把我们修改好的保存一下 啊,接下来就是我们需要,需要做,需要做 perfame 的筛选,那我们看一下我的是不是 benja smart fame, 那就是 h m n h m n setter, 搜索 simple h m n search, 然后你看到他需要我们提交什么文件呢?他们 需要提交一个蛋白质的文件,蛋白质 fasta 格式的文件,然后一个 perfam h h 们文件,然后还有一个 perfam 的 id 号,然后 output insert table。 对,所以我们去也是打开 a 九浏览器去下载它的 h h m h m m 文件,然后我们在这儿搜索 the fame phone 数据库,点击 可以看到他这个网速是很慢的啊,这网速太慢了。 嗯,看这个就好了。这个呢?这个就好了。对,我们在这儿看到 keyword search, 然后在这里面输入 它的 g a 二零,然后 o x 五,看能不能直接搜到它的 g 二零 x 五,它是没有这个的,那我们就 chao 求其次,因为 因为我昨天是就是为了教学而做过的,做过,我发现他的 ga 二零 ox。 哦, ga 二零家族他是有五个吗?但是五个一起做的话太多了,我的电脑 性能不太好,是带不动的,所以我就叉二求其次,就做了他其中的一个成员的家族的一个成员的一个分析,然后我们在这搜索 g 二零吧,我把原理告诉你们,其实你们也后来也可以自己做的,那我们就是选择第一个吧, 其实这两个都可以的,就是我是选择第一个吧,选择第一个进行教学,然后点击这里,然后去下载他的 点击。对,点击,点击这里啊,回退了,在这下载 就是它的 h h m 文件,然后我们也是下载,然后进家做分析,然后把这个文件拖进来就下载。好的 啊,是这个,是这个,我们就拖进来吧,拖进来,然后我们还是需要, 因为你可以看到他这,他这有个需要他的 id list fill 的,我们是还是需要把他的那个这个 film 号给下载下来的, 直接复制,然后在文件夹里面新建一下新建文文档,然后在这里输入 p p p t r, 点 p t r 不用崩, p t r 就是 g a 二零 o s, 点 perfam, 点 id 哦,粘贴就可以了,然后保存,然后我们也是打开我们的 tv tools, 把我们的 type 文件提交上去, type 文件, 对,提交上去,然后 perfam 就是 h m m 文件也是提交上去的这个地方,然后也是把我们的刚才刚才命名的 id 放置上去,然后这个地方就需要我们 设置一个输出文件啊,我把它命名为 p t r, 点 one and 点 j 二零 o x 五点 profan, 点 table, 点叉 s, 还是点击输出,你看到很快就结束了, 去找一下他的,对,在这 也是也是同理啊,对他进行一个排序哦,你看他这个,你点击一下,看他这个,全部都是在一个一个表格里面的内容,所以我们要对他进行分裂啊,不然 待会排序,然后序数重复项都是不太不太不太好进行的,我们要把它对它进行分裂,对固定宽度下一步,下一步完成,然后你可以看到它就已经分裂了,然后对它进行排序 还是 然后也是去除重复项啊? 发现二百四十,保留二百六十四个,确定,然后把拉到下面去看看, 那边是一百九十几个,这边是二百四十几个, 然后把这个也是复制,然后我们在这里面去取它的交集啊,去,因为是筛选,所以去取它的交集,在这有个 wen 图, wen 图在这对 wen 图 十年,我把这个改成 fm, 然后刚才这个是 blast 比对出来的结果,我们也是把这个第二列的 id 复制过来, 在这粘贴,把这个改成 blast blast 去其他交警,你可以看到, 对,你看就是说明筛选出来一百九十八条,就是他 需要的一百九十八条,然后我们去怎么就是把它的这个一百九十八条 id 给取出来呢?这儿有个 save id list to fails。 然后我们也是 找到添加组分析,我们把这个秘密为 p t r 点 one round then choose text 叉 s 更好点叉 s 保存保存一下, 看到没有?出来, 点击,点击看一下啊,你可以看到我们虽然说是叉 s 文件,但是它保存的还是。呃,保存的还是这种 text 文件,我们把这个这个 text 文件用 excel 打开,这个是,这个是它独特的,就是呃 blast, 这个是 perfame, 可以看到这个是我,我给你们讲解一下吧。这个是 perfam 和 blas 的交集,这个是 blas 独有的,这个是 perfam 独有的。嗯, perfam 独有四九四十九个,他是 perfam 独有的,就零个,这是 perfam 独有的,是一百九十八条,可以去看一下 看下。对,他用 excel 打开,这这些都是他的 id, 一百九十八条,然后我们把这个 id 给复制,然后我们去从从 从 tpq 上,然后利用他的 type 文件把它的只有一百九十八条序列给吸取出来,然后也是打开 sequence pasta attractor, 对,然后找我的文件夹, 把 type 文件提交进去。 type 文件啊, type 文件, 这边输入 id, 刚才我们复制过的 id, 就一百九八条的那个 id, 然后这边设置输出文件, 那我们也是 p t r 点 y round 点 g a g a 二零 o x 五点 fast f a t s t f a s t a 发特,然后这儿有个初始化,要点击初始化一下 触发完成,然后我们点击 start 就可以提取了,你看它非常快啊,一下就好了,所以我们这边就得到它的, 当它的呃,一百九十八条接二零 o x 五的,这个 就是基因文件,对,然后还有个筛选的,还还,我们还要进行一次筛选啊,就是我这有个 table table or so faster, faster, 那个 faster, to table convert, 然后就是把这个 这个 faster 文件转变为 table 文件的。哦,点击这个,然后设置一个输出文件啊,这个粘贴过来,选择位,卧槽, 按下 a, 删除,按下 c, 按下 v, 要把这个变成 to run, 把这个画面后缀改成 table, 点叉 s 空位儿体,然后一下就好了, 看到它是在它在这的打,打开它,然后你可以看到这个正符号,其实说说明它是正脸还是负脸,我们其实可以把它删除掉的 啊,这是他序列,我们看一下有没有序列相似。就是啊,有没有序列的相似性啊,因为他有些是可能存在序列相似性的。我们点击设置重复项, 你看到删除一十三个重复像,然后保留了一百一百八十五个,以为一只对,然后我们保存就行了, ctrl s, 对, 但是这个是我们没法进行后续分析的,所以我们还要需要把它变回 fast 格式,在这里面把这个也是提交上去,对,然后把这个变成 of asta first time, 然后点击这个, 好,他就变了,就这样啊,那我们这一轮的金家族的 筛选就到这里,我们今下集要讲的是它的短面分析、 motif 分析等保守结构域分析吧。
231红提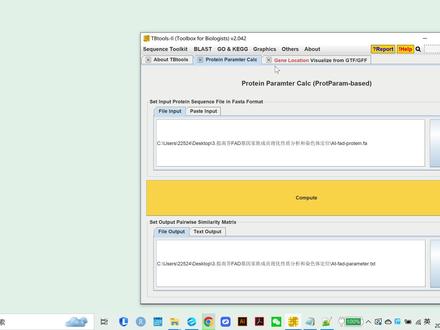 11:00查看AI文稿AI文稿
11:00查看AI文稿AI文稿上次视频呢,我们讲了如何用呃,就是说对这个 f a d 的金家族成员的一个呃隐化性质和染色体定位的这个分析。那第四部分呢,我们就想要去做它的一个结构方面的分析,所以我们也是在这新建一个文件, 叫李兰介 fad 新家族 家族成员的一个结构分析。结构分析, 这个结构分析呢?嗯,在这个地方我打算以三个方面来讲。三个方面来讲, 首先呢是这个叫 if, 叫 c, 呃 c d d 的就是 c d search, 通过它的一个呃 n c b a 的保守结构域的一个教训去做这种,嗯,结构域的分析。第二个方面呢是呃 m m e 的一个保守积蓄分析。第三方面呢是基于这个叫 我想要 c d 十二级的 me 的还有一个金结构的基金 structure 的,它是基于 注射文件来的。我们首先先讲这个,这个地方呢会产出三张图片。好,我们第一个想,嗯,先讲这 这个金 structure, 这个金 structure 呢,它是基于这个金结构的,我们会发现我们还是点开 t p toos 啊,我们用这个 graphics 点这个,嗯, l sequence structure, 比如 street 就是这个序列的一个结构的可视化。这个地方呢去选这个 j f f 三文件这样一种方式,我们先把这个 j f f 三金组里面的话,找到这个 j f f 三的这个文件,我们改放进去, j f f 三的放进去,然后呢它会让你放这个 id, 放这个 id id, 等我们刚刚在做这个 ct 定位的时候呢,我们已经做了有这个 id 了,我们就把它放进去。然后呢在这个地方其他都不用,就基本上不用改了, 打开之后呢,人发现第一个图片已经出来了,包括它的一个 utr, 它的 cds 的 写结果就是这样出来了,出来之后呢,我们就可以把这个图片整体的去做一个表保存,就是保存成 pdf 啊,方便我们后续在 ai 里面,或者是啊其他的一些。呃,编辑软件呢,我们可以后续的去进行排版啊,进行点这个 save, 保存到这个桌面,保存到桌面,我们用这个是第四部分,那这个这个在这个叫 instructor 这里呢,我们就 instructure 这样一个文件,是我们可以看到他的这个应该是在 这个文件夹里面已经刷了,在这已经有这么一个图片了,这样子的,它的 utr 和 cts 区域,这是第一部分,那第二部分呢?呃, cd search 和这个 mme 呢?它都是需要基于这个网页来的,所以我们这个地方呢,我们就需要去打开,哎, cd search cbi 的还有一个是 m m e 的, m m e 的话它是,嗯, 找到他这个数据库的这个网站,我们可以去看一下别人的一个相册,他就已经有一个 me 的一个网站,我们随便可以去找一下。 我们先把这个 n, c, b, a 打开,我们找到这个 domas and structures, 去点这个,看到这个地方有 cons serve 的独门 database, 就是这个防水结构域的数据库啊,点这个 batch 啊,就批量的 cd search, 这样呢,可以方便我们去把这个文件导进来选择的。我们就是啊,一开始我们的这个成员鉴定啊,已经鉴定好的这个 a t 的这个 fad 的这个 protein a c 进去之后呢,其实参数不用修改参数直接 submate, 它就会自动的去进入到这个搜寻,有一定的时间,那我们就可以在同时呢去做这个 m m e 的这个结构域的一个找寻。 m m e 的结构找寻呢,在这个是我们要 在这边找到 motive discovery 保守积蓄,保守积蓄的这个 discovery 选这个 m m e, 那选这个 m m e 之后呢,它也是需要让你去做一个,嗯,上传一个 prime 原始序列的上传,我们选择这个文件是我们一开始 f a d 鉴定出来的 f a d protein, 看啊,这个时候呢,它如果你这个呃 文件上传之后啊,他会系自自动识别一下你这是 protect, 然后呢,这地方可以去选,你要发现多少个 motive 啊?这种叫应该被发现,这个数字是你自己选的 啊,别说一个呃,没有没有固定的标准,一般像十二是这种应该都是可以的,像我这地方我就设成一个十嘛。然后呢,那我就开始 start search, 这边它也是会去进入一个自动的,这两个呢就需要一定的时间,等它做完了之后呢,就会出来一个结果。当我们的这个 cd search 完了之后呢,我们就会发现,呃,这个结果出来了,我们就可以点这个 download, 点这个 download 之后呢,它就会自动的开始下载,下下载,呃,这个 m m e 的结果也出来了,我们就可以在里面去选择这个呃, mast 叉 x m l 的这个 output 的这种形式去给他,嗯, 相当于是把这个链接呢给他下载下来, 那这个是已经下载了这个 hit data 的是这个,然后我们也是给他呃,切一下,这这一步呢,这时候我们就可以分别对这两个进行可说话了。首先呢一个是 cd search, c search 是这个啊,它会需要你把这个 cdd 的这个数据库的这个,呃, table 呢, table five 就放进来,我们就把这个放进来,然后呢它会需要你去放这个 fast input, 这个 fast, 这个就是我们刚刚其实在第二步呢,我们呃 第一步就做了的它的一个尖家族的一个 proton 的文件,然后呢就 我们就会发现结果已经出来了,结果出来了就会发现,哎,这好多的这种颜色基本上都是一致的嘛,主要是会有一些,呃,这种一致的啊,这种结构玉,就说他是些保守的结构玉嘛,那我们再回过头看的话就会发现,呃,在这个 city search 的结构里面啊,我们发现他有一些 super family 呢,他是啊一致的,比如说像这个零零六幺五呢,在这个结构域呢,虽然叫 p l n 零二四九八零二五零五,他好像 其实都是这种从一个 super family 的。这个呢,其实你是可以把他们像这这种是可以把他们调整成为一致的啊,是可以自己手动去修改这个黑色 data 去,在黑色 data 的这个原始文件里面,这里面呢你是可以去做修改的, 做修改让他们呢就是说,呃,看起来就更保守一点,就把他更保守的,这个结果呢转换一下, 这地方我可以保证成这个 pdf 也是。嗯,在这个四部分 cd search 里面,我们可以看一下 search 的 这一个结果, x t 就可以, pdf 就可以。这时候他这边已经出来了嘛, 现在这个结果已经。然后呢是像刚刚的那个 motif 的一个 motif 的话,我们就是也是用 graphics, 然后呢选这个 basic 什么追法?再就是选这个 m m e 的这个 m m e 的这个结果,嗯,把这个我们刚刚下载的 m m e 这个叫 m a s t 点儿 x m l 的这个结果呢放进来,放进来,然后呢给他一个,哎 input id, id 呢?这个 id 就是我们开始鉴定到的那个 id 权限鉴定的时候呢,我们不是有 id 吗?我们可以把这个放进去,放进去, 然后呢点 start, 这个 motif 的结果也出来了,嗯,这 motif 的结结果出来之后呢, 也是可以去去结果保证。 这时候呢我们再回过头去看,在几个月的这个文件夹下面呢,我们就 research 的一个结果, 然后呢 instruction 的一个结果,现在是 m m e 一个结果, 这三个呢都清晰的就啊如果说你想让他们后面对应的话,或者是那个你,你可以在绘制的时候呢,给他们一个一致的这个 id, 就让他们的这个顺序排到一块,就是一样的顺序去排。 这个部分呢就是它的一个结构的一个分析,包括它的金结构和这个蛋白的这个保守结构域的。
98Senn生物学长 17:55查看AI文稿AI文稿
17:55查看AI文稿AI文稿大家好,欢迎收看由私房居室给大家带来的视频教程, 今天给大家介绍一下用 tiptoes 来绘制卡通热图,也就是 fancy hate map 的绘制教程。在正式教程开始之前,先给大家介绍一下为什么要做这些视频啊? 前两天在咱们讨论群里,有一位同学发了这么一张图片啊, 他问一下这个图片是用什么软件做的,当时他只发了这么一张图片,没有任何其他关于这个图片出诉或者这篇论文啊,以及 其他任何相关的信息。当时我看到这个图片的时候,一眼就发现他确实真的很漂亮,是吧,所以我也很想知道他是用什么软件做的,然后就去找了一下, 因为关于这个图片的任何信息都没有吗?就用这个图片上的显示的一些文字啊,以及这个植物问了下的同学,他说这是甜瓜,这是仅有的一点信息,去各大引擎去搜索,以图搜图,去找文献,找图 那天晚上咱们还开了直播是吧,找了好久都没找到,然后最后突然间想到,要不用微信去搜一搜吧,现在微信好多这公众号不都是会发这个最近发表的这些文章的介绍啊什么之类的吗?然后我就 用微信搜了一下,哎,结果就用甜瓜和表达量这两个词啊,一下就搜到了,因为大家可以从这个图片明显看出来,这是一个不同组织某个基因的表达量差异图吗?所以说找到这篇文献呢, 然后就去他这个文献的原始链接啊,把这个 pdf 下载下来的 那文献的名字叫甜瓜 s d m 基因家族鉴定及特性分析,这是一个比较典型的 对经家族经济生物学分析,而且发的比较好的文章,如果大家有做这种类似工作的,可以来看看这篇文章,我觉得还是很不错的,这发表在国内的中文旗杆遗传上的水平还是可以的。我一开始以为 他这个图应该是出自一篇英文文献的,所以一开始搜的时候也是在搜各种各样的英文文献,去找啊,所以找了好久没找到,结果最终发现,呃,是发在中文的旗杆上的 图吧。填关 s t m 基因在不同组织的表达分析,他这个图版面很大呃,群里同学发的这个呢,只是上面的几个截图,他下面还有一个普通的表达量热图, 所以整体看起来,我们先不管他说了什么,但是从这个整体绘图的情况来看,这个图的质量可以说是非常非常高的。所以说也就借着一个机会,想给大家介绍一下这个图到底 怎么做出来的。当你以各种各样的形式去搜这种图怎么去做的时候,网上会有一些教程出来啊。 当然这个文章中本身也提到了它这个图就是用 tiptoes 来绘制的,那么在 tiptoes 里面呢,这个功能就叫 fancy hit map 啊,翻译过来可以叫它卡通热图。 网上关于卡通掉头的绘制呢,有一些教程,但是都是纯文字的, 我为例,我因为之前完全没有接触到这个图的绘制,所以说我看了好多教程,反正也能看懂,但是比较费时间,所以说为了方便大家呢,我就把我整个的这个流程给大家演示一下啊,同时也是自己在学习的一个过程, 希望大家能看我这个视频之后,就能自己绘制出这种图片来。好了,别的 咱们就不多说了,来看一下绘制这个图所需要的软件有哪些。首先 t p toss 肯定是需要的,另外需要 ppt 或者是 ai, 这个是可选的,就是 adobe illustrator 或者是其他的可以绘制矢量图形的这种软件都可以啊,但是最简单的我觉得还是用 ppt 比较容易上手。 全部流程大概分为四个主要的步骤吧,第一就是模板图片的准备,第二是颜色编码文件的准备,第三是表达量矩阵的准备。第四图形输出与最终的一个优化。 那么因为这个整体介绍下来,这个流程可能时间比较长,所以这是视频录制呢,我应该会一次性录完,但是为了让大家看的时候更轻量化 大一点,我会把这个视频分段或分级啊上传到平台上去。那么针对这四个步骤呢,我们先看一下他需要哪些文件啊, 这是我之前来绘制的时候啊,做的一个文件夹。 第一个模板图片呢,就是我们这个 s v g 或 t g a 格式的模板图片,这个指的就是 最终效果里面的左上角,这个就是你将来用于显示不能组织表达量里面的要填色的这个图啊,就是一个模板,那不同基因的显示呢?那只是在 tiptos 里来设置不同的表达量就行了, 我们只需要一个模板图就可以了。所以说这个图片我们需要准备一下, 早期的 tv tools 里,它只支持 t g a 格式的,那么现在更新之后呢?呃,也支持这个 s v g 时长格式了,所以说这两种图片格式都可以的。第二个就是编码文件,就是这个 colorcore 的, 可以是 t s t 或者是 excel 的 x l s 格式,包括第三个的表达量矩阵,就是基因的表达量数据文件,也可以是 t s t 或者是。呃, excel 文件 最后的图形输出,我这里使用的都是 s v d, 因为方便后期的编辑嘛,都是用的适量输出啊,就我们演示的时候可以看到。好的,那么下面就按着这 步走来,一个一个的走下去。首先是模板图片的准备, 我这个 ppt 里有之前绘制的这些图啊,呃,因为这个图呢,你要是完全自己手绘的话,这个时间还是需要一些时间的,所以说我在这里呃就提前绘制好了,就不一点点的绘制了。那么现在就给大家说一下,你在 ppt 如果绘图的话,怎么去画? 这个是我们需要参考的这个图片,因为我这个教程是给大家演示吗?如果你想做你自己的项目的话,那肯定有你自己的职务,你自己的这个不同的组织,是吧,你要根据你的 这个物种去画你自己的土,那么我们这里演示呢,就尽量和他这个文章里的显示图 图效果达到一致的效果啊,这样的话大家看起来可能会比较容易一点。我们把那个文章里的图啊抠了一部分,这个截下来放在这里作为参考。 然后这个绘制呢,这里有一个草图,它只用到了 ppt 了两个,主要是两个吧,就是这个任意多边形和曲线 啊,可能卖家呢,这个直线和文母框吗?就是这些字简单演示一下怎么画吧,我就不详细的去画了,比如说我们画这个叶子啊,就是这个 这里我是组合起来,大家可以把它取消组合看一下啊,它是里面每一条线都是单独绘制起来的,那怎么画呢?我们选一条 任意多变形这个形状,把它改个颜色啊,改红色吧, 实现 你选择任意多变性之后,可以把这个图片放大一点,为了看的仔细一点, 我们画这个叶子,比如说沿着这个轮廓 直接去点击这个线就可以了。 我这里画的比较粗糙了,就给大家演示一下过程,大家画的时候可以稍微仔细 几点,然后最后封口,这样的话这个叶片轮廓就画好了,那里面的这些叶脉呢?你也可以同样的啊,用这个任意多边形形状来画就行了。 那么有时候可能有的同学就会说了,我这个植物很复杂,我这样一点点画起来也要花好多时间,怎么办呢?呃,给大家来拆解一下。我之前在做 ppt 教程的时候也给大家说过,在 ppt 里用基本行为来绘图的时候呢,你一定要学会分析你最终所展示的 这个图片里面的组件结构,是吧?那如果我们把这个甜瓜的这个整个植株啊,每个部分打散分类看一下,左边这个是他的藤蔓,也就是主径嘛,啊,这个肯定需要自己去一点点去绘制的,那么中间呢,这三个叶子啊,你仔细看会 发现他其实是一样的,是吧?就是换了一下方向,然后缩放了一下大小,包括这两片三角形的叶子也是一样的水平翻转了一下,然后大小调了一下。 这里面有好几个部分啊,他其实都是通过复制平移、翻转大小缩放来达到的,所以说我们只需要画这里面黑色线条的这个组件就行了,这红色的我们都可以通过简单的操作来得到,这样的话对你绘制的工作量就 讲解能减少三分之一左右啊,如果你的图没有这么复杂,是那种简单的卡通图的话,那可能会更简单一点啊。 啊对,这里还要说一点, 在 ppt 里 绘制的,你看这里有一条这个藤蔓,他是重叠起来的是吧?如果你直接用任意多边形来绘制这个重叠形状是可以绘制的,但是将来填充的时候,他重叠的这部分啊,就不会被填充上颜色。这个时候你要么做一个组合处理, 保证你在填充的时候不要给他留空白啊,这样会影响最后的效果。那我在这里为了避免他有空白的话,做了一个处理啊,就是没让他重叠下去, 包括这里这一条小的藤板也没有做重叠啊,这个因为影响也不大,就是为了这种美观一点吧。也跟大家说一下, 然后绘制图,不管你是用 ppt 还是用其他软件绘制这个图,想让他有最终能在 tptopos 里实现这种按表 大量来填充颜色的效果呢?最最最最关键的也是你必须要记住的就是什么这个图形一定是封闭的,看到没有?比如说我这个叶片,他外围这个轮廓一定是封闭的,这样的话他填充颜色的时候才会完整的进行填充 啊。如果我们其实在用多变性绘制的时候,你也可以绘制这种不封闭的图形,你在 ppt 填充的时候,它也是 呃可以填充起来的,但是如果你把它做成图片去放在其他软件里填充的时候,他这个不封闭的地方,这个颜色就可能会漏到背景上,把背景也填充成这个颜色,所以有可能会出问题。 所以说大家在绘制的时候就保证你每一个部分是封闭的就行。当然那些你不需要填充颜色的,比如说这个 文章里这个他只有标着这个文字的这几个部分啊,需要填充颜色, 所以大家一定要记着绘制的时候一定要保证他是封闭的里面的这个叶脉啊,这些不影响啊,只要保证他填充的是一个完整的一个轮廓图形就行。 然后你这个叶脉以及需要在填充颜色上层显示的,你在绘制的时候就把它置于顶层,是吧?大家知道如果你这个线条在这个叶片的下层的话,你填充之后就把那个叶脉挡住了吗?就不好看了是吧?图层的顺序要注意一下。 好的,假如说我们最终把这个图各个部分都绘制起来了,然后按照这个目标效果图已经把位置摆放整齐了啊,就得到这个效果了。左边是我们这个等比例的模板, 右边是咱们手工绘制出来的这个图,同时呢,在他文章中左上角也放了这个原始的 图片,就是这个本身颜色的图片,所以说我们这里也按照他这个模板,先把我们这个图片给他填充一个粉底的颜色啊,咱们这里就直接使用形状填充里面的取色器啊,直接吸他这个颜色就行了。 填充完之后,我们看这个效果和我们这个目标图片基本上还是大差不差的。然后这些文字啊,你按照目标的这个文字给它输进去就行了。 那这个时候我们的主图就准备好了,接着下一步就要来准备我们 要填充颜色的这些组织部位的 r g b 值。 因为咱们如果是在 ppt 绘图的话啊,我建议大家就直接用 ppt 里的这个填充颜色,这个其他填充颜色 在自定义这里啊,可以直接看到 r g b 值,就是这个值啊,三个数值,你把它单独记录下来,比如说我这个八十三、一百五、四十八,是是哪一个呀? 那我们重新给大家演示一下,比如说我要看这个甜瓜这个黄色啊,这种土黄色是到底数值是多少呢?我可以放一个任意的图形进来,然后选择去 取色器,然后取这个颜色,这个时候我们这个色块里不就有了这个颜色了吗?然后点击 tr 前面颜色啊,就可以看到这是二二七幺八零五十二二二七幺八零五十二啊,把它记录下来,你每一个组织部位的这个值,一定要先记录下来。 好,这个是我们的图片准备,就基本上达到最终的这个目的了,但是呢,我这里为了最终他显示效果比较好看啊,我一开始绘制的时候,这个不同部位这个轮廓的颜色啊,我用的是不同的颜色,比如说这个叶片啊,这个轮廓我用的是这个深绿色,然后 这个甜瓜呢,轮廓用的是深褐色啊,这个轮廓颜色不一样,但是我发现这个不一样的话,可能最终处理起来比较也是比较 二,就是显示效果不好,所以说最终我把这个整体轮廓啊加粗了点,然后同时换成了一个颜色,这样的话这种效果会好一点。 这个时候我们就准备把这个图输出了,输出的时候呢,这个颜色的 rgb 值就不要放在这里嘛,因为我们最终的显示的效果里,他不需要那个,我们可以用一个啊,我们最终需要的这个组织部位和文字的这个图来做输出。 输入前最后一步需要检查一下你这个图片所有的这些原件,就是你画的这些形状,他有没有组合在一起,如果有组合在一起的啊,全选右键 组合,取消组合,直到他最终所有的都没有组合在一起的就行了。一定要是让他散开的, 展开的情况下,全部选中右键,另存为图片,我们存到我们这个文件夹里吧。 啊,之前有一个,我们再新建一个原来二啊 格式,选择可缩放的向量图形 s v g 命名成买了二。 好,这个时候我们可以去文件间看一下啊,这个 s v g 的图片就准备好了,双击它默认是用浏览器打开的,可以看一下。呃,是不是你想要的效果 svg 图片呢?它是使量的,使量的意思就是什么?你怎么放大啊?它这个边界都是很清晰的, 都是很清晰的,不是其他那种图片。 gpg 什么格式的,你一放大之后它这个边界就会显得模糊啊?还有有那个渐变的变化,那样的话,呃,是不适合 tptox 来做填充处理的,所以说你看看效果是不是这样的。
 14:03查看AI文稿AI文稿
14:03查看AI文稿AI文稿好,这个时候我们就准备好所需要的食量模板图片了,接下来第二步就要准备 这个图片所对应的颜色编码文件, 也就是这个 colorcore 的文件。这个文件呢,有两种方式可以把它做出来,第一种就是利用 tiptores 里面自有的一个工具来生成这个文件。 另外一种方式就是我们一会可以给大家看到的啊,你可以按照这个文件的格式来自己手动编辑这个文件。 现在呢,因为我们第一次给大家演示,好多人可能之前没有操作过,我们还是以软件里面的这个功能来给大家演示一下怎么来生成这个颜色编码文件。 打开 tv toos 之后,在图形化热图里面的最后一个 super heat map 里第一个 prepare tga information 这个功能。 当你打开之后,你会发现这里需要的是一个 t g a 图片格式,所以我们还是需要准备一个 t g a 的适量图片。但是在 ppt 里呢, 这个输出图片的时候,他没有 t g a 的这个格式,所以这个时候我们还是要借助一下 ai 这个软件。当然我说了,呃,因为我们演示完这个流程之后,你看到那个 color code 文件的格式,就可以自己手动去编辑那个文件,这个时候不需要 ar 也是可以的,而且那样可能会更省时间一点。 我们现在打开 ai, 把我们刚才这个 svg 图片直接拖进来, 他这里会有个提示啊,这个提示应该是,呃,我们这个文字他这个字体好像没有,这个不用管,直接点确定就行。 好,这个时候 a r 就把这个 s v g 图片导入进来了,呃,因为我们刚才说过了嘛, p v t 它不能直接把这个图片舒适成 t g a 格式的。如果你之前比如说自己会 绘图的时候,更习惯使用 a r 这个软件啊,那你可以直接在这里绘制完之后来按照接下来的流程把它导出成 t g a 格式就行了。在 a r 里把这个图片输出成 t g a 文件之前呢,和 ppt 有一个类似的操作啊,就是 把这个图片的全部选中,然后在对象里取消编组,把所有的编组都取消到没有编组,也就说所有的原件都处于一个分散的状态,然后再选中他对象。这里进行一个山格化 颜色模型,就是默认的 r g b, 不要改分辨率可以根据你的需要,一般呢就是三百 p p r 背景白色默认就行。特别 需要注意的这一点就是消除锯齿这一项啊,要把它改成无,一定要改成无,然后其他的保持默认,点击确定就行。 好,这个时候我们在 a r 里处理 s v g 图片的所有操作就完成了。点击文件里的导出,导出为选择下面的 t g a 格式,点击导出, 这个时候他会再次跳出一个山格化选项,其实和我们刚才那个是呃一样的参数还是颜色? rgb 分辨率,我们调到三百 销售锯齿和刚才是一样的,也点击选无,然后点击确定, 接着他有一个分辨率的选项,选择二十四位,每 像素好像要二十四位或二十四位以下,二十四或十六三十二,我倒是没试过。呃,有些人说可能分辨率太高了之后他在 tptos 会报错,大家可以去,有时间的话可以试一下,按我这选择二十四位肯定是没问题的。然后点击确定 好,这个时候我们模板文件所需要的 t g 格式文件就做出来了,但是这个文件呢,用常规的图片查看器是不能打开的,你如果要查看这个文件的话,还是需要 ar 才能把它打开。 这个时候我们回到 tiptoes 里,直接把这个 t g a 文件拖入到第一个框中,下面两个指定一下路径,我们用同一个路径, 然后第一个 output 文件就是我们的颜色编码文件,这个我们把它改成 tst 格式, 叫 many 二 color code, 同时它会输出一个 p n g 的色标文件,我们应该指点名字, 点击开始。这软件处理需要一定的时间,点完之后大家要等一下。 好,现在提示提取颜色编码信息,完成点击确定。这个时候我们发现在目标文件夹里就生成了 两个新的文件,一个是 png, 还有一个就是 color code 这个 tst 编码文件。好,我们看一下这个 png 啊,这个文件就是我们刚才做的这个 模板图片里所用到的颜色的一个颜色标签卡,同时它旁边备注了每一个颜色所对应的 r g b 值。 那么这个颜色编码文件呢?里面的信息其实很简单,有两列,一列是样品的名字, 然后第二点是所对应颜色的颜色 rgb 值。所以说如果你现在看到这个 colorcore 的文件的文件格式了,你可以完全手动去编辑这个文件啊,没必要导出成 t g a 图片,然后再重新生成这个信息啊,直接用手动输入也是可以的。 这里我们再说一下,为什么刚才在 ar 软件处理的时候,一定要把那个销售句词选择成无,就是没有销售句词那个去掉, 目的就是让我们所有的颜色啊,他仍然是单色的状态,就是他是什么颜色就是什么颜色,比如说我们这个叶片的绿色,那你标注过来他一定就是还是他这个绿色。 因为如果你选择了那个销售锯齿之后, ar 软件会对这个图片里面的这些转折的地方,比较有棱有角的地方,他会做一个过渡处理,这样的话就会生成好多这种过渡的颜色,或者叫渐变色吧,将来你生成的这个 png 文件里啊, 就会有好多个颜色。我们这个图片本身就有点复杂了,现在可能都有十几个颜色了,如果你加上那个小苏巨石之后呢,他可能会有几十种颜色出来,那个时候我们处理起来就比较费劲了,而且对 tp tos 来说了,他处理起来可能也会更复杂。 而且我们在做图的时候啊,尽量把这个颜色或这个图形的复杂度降到最低吧,保证美观的同时,让他这个颜色的种类尽量少一些,这样的话就比较好操作好。然后我们就需要 对这个编码文件进行一个手动的修改,我们前面不是把每一种颜色的每一个组织的他所对应的颜色的阿基比值已经提取出来了吗?这个时候你就可以直接对应我们提取出来的这个数值来进行 给这个样品命名了。或者如果你之前没有把这个颜色值提取出来的话,这个时候就可以对应着 软件给出的平机的这个标签来一一对应这个颜色来给他命名。就比如说啊,我这个甜瓜 啊,果实是这个深黄色,应该是就是二二七这个吧?对,二二七这个,假如我们之前没有提取这个颜色来的话,你就要从这个标签里找到这个颜色,哎,和这个甜瓜是对应的,那你就知道这个二二七幺八零五十二 啊,这个颜色就是我们对应的 fruit 这个组织部位了,你把它标在这里,好吧,因为现在我们之前已经把这个各个颜色给提取出来了,这样的话我们就不用对和那个 色卡标签一个去找了,我们直接找 r g b 值数值对应就行了。比如说叶子的是幺七九二幺零,就这个改成叶子 此花呢是二五五二幺七, 脂肪幺八零二二二 跟幺八四幺六九, 过时就是二十七了。 寻花二二四二零九, 进六零幺幺九。 好,我们把各个组织部位的名字修改好之后,点击保存就行。 当然了,我们看这个标签卡的时候啊,你自己如果想手动去写这个文件,大家可以 试一下,看看这个颜色排列顺序有没有关系。我觉得应该是没关系,但是我没有去试他这个色卡深层的时候,默认好像都是白色和黑色在最上面,然后下面这个有没有规律啊?可能是有一定规律的,但是我觉得可能不影响那个软件的识别啊。大家如果手动去编辑的时候可以试一下 啊,如果它出了问题,那你还是按照 t p tos 来深层的这个文件顺序来修改就行了。 另外一个需要注意的,如果你是用 t s t 这个格式的啊,每一个列之间的这个间隔是用 tab 字表符隔开的啊,不是空格,这个要注意一下, 包括下面每一列的这个单元格之间吧,如果你是 excel 表格的,那就他默认就是一列了。 另外,因为咱们这个图片里的颜色相对来说比较多嘛,同时有一些部位啊,在我们最终那个表达量里,它是没有需要体现的,也就是说它的颜色是不变的,这个地方呢,就空着这里就行了。 大家其实在做自己的图片的时候,尽量让你想要展示的不同组织的表达量的那个组织部位都有颜色的填充,这样的话,他最终所形成的这个图片呢,美观度会高一点。我们看这个文章里啊, 他虽然标注了循花和雌花,但是从这个图片来看,他循花和雌花之间,我不知道是表达量十分接近呢,还是可能就没有做区别处理。因为所有的这二十个 音里面,雌花和雄花的表达量,呃,就是这个图片里啊,看起来都是一致的。尤其我们看右下角这个传统热图里 gmg 十一这个基因啊,它的雌花蓝色的嘛,表达量应该是比较低的,然后雄花是红色的,应该是高的。 当我们看十一的这个单独的这个图形显示的时候,会发现他的雄花和雌花都是红色的。我觉得作者可能在处理的时候,这可能出了一点问题, 所以说大家如果自己在处理自己的图片的时候,一定要每个组织部位,一是尽量给他都分配上颜色。第二呢尽量是简单一点,就是比如说我有些组织部位不想让他显示的,那么你就这个图里可以不要这样的话,就是让你显示的每一个部分他 将来都会有颜色填充,那样是比较好的。 好,这个时候我们所需要的模板图片的颜色编码文件也准备好了, 我们把这个文件也按流程顺序给它标名字啊,这是我们以后要用的。 一 svg, 二 color code。
 03:31查看AI文稿AI文稿
03:31查看AI文稿AI文稿下面看一下常用工具里面的包木工具,我们先打开一个装配体, 在做这个装配之前呢,这些零部件的属性的我们都是添加好的,然后我们打开这个爆米工具,然后显示出来了。好,大家看一下这里面的一些内容, 我们通过设置呢,可以让他读取这个显示的令 啊,进行这里的勾选啊,如果我们不想让他显示呢,我们可以让他删除, 然后确定我们刷新一下, 因为内容比较多呢,所以他刷新的可能就稍微有一点慢,大家要耐心的等待一下刷新出来了,我们要与刚才刷新之前的那个内容比较一下, 我们可以通过这个添加修改属性,然后可以把这个向关键中进行一下更改,我们现在更改一下这个材料 覆盖已有的这个属性值,开始写入, 然后改一下 这个材质的好,开始写入, 其实已经完成,我们再刷新一下,然后检查一下是不是已经更改过来了, 我们可以添加刚才显示的这个列的选项啊,我们可以通过这里进行手动的更改, 看一下是不是我们想要的内容 啊,也可以通过设置这里让他显示啊,我们有 显示是我们想要的内容,然后再进行一下刷新, 那这个表格呢,我们已经把它给透出来了,透出来之后呢,我们要进行导入到 excel 当中,最终生成在这个 excel 爆目表,这是我们想要的, 所以呢我们检查一下,没有问题的话,我们直接保存另存为。嗯,那我们把它保存在桌面保姆表 保存一下。这个报名工具呢,已经简单讲解 完了。好,谢谢大家。
51机械设计资源分享 08:28查看AI文稿AI文稿
08:28查看AI文稿AI文稿大家好,欢迎来到我的频道,今天我们来给大家分享一款非常好用的虚拟机,这款虚拟机最近已经升级到了最新版时期,今天我们就来介绍这款虚拟机最新版的使用方法。我们首先来下载这款虚拟机, 这个就是虚拟,记得官方网站,这个网站的网址我会放到视频下方的说明栏,打开之后我们往下,这个是最新版的时期,这个版本已经可以更好的支持 windows 十一系统, 然后找到这里,这个是 windows 版本,这个是 nanax 版本,我们需要下载 windows 版本,点击直接下载,正在下载。这个速度取决于你的网络速度, 如果下载速度很慢,可以将这个地址复制到训练里面下载, 我已经提前下载好了, 下载好了之后我们来安装, 如果我们在安装的时候提示电脑需要重启,我们可以重启电脑再安装,这里点击下一步, 勾选,我接受下一步。然后是选择安装位置,我这里安装到 c 盘,如果你需要更改到其他盘,可以在这里进行更改,这个选项可以去掉 下一步,这两个选项可以去掉, 当然勾选也没有关系,下一步,下一步安装,然后点击完成, 已经安装成功,这个就是 vmv 虚拟机,我们点击打开, 如果你有许可证,可以在这里输入,如果没有的话可以点击我试用,点击继续 完成。然后我们来创建一个新的虚拟机, 这里选择典型下一步。然后我们这里选择一个 so 文件, 我这里选择 windows 十一的 so 文件,如果大家需要 windows 十一的 so 文件,可以去微软的官方下载,选中它,打开下一步, 可以给虚拟机取一个名称,然后是保存的位置,也就是说将这个虚拟机保存到哪里,我这里选择默认下一步,这里需要设置一个密码,这个密码需要大于八位数, 然后点击下一步,这个是设置词盘大小,默认是六十四,大家可以根据自己的硬盘空间来设置,如果你的硬盘空间很大,可以加 将这个容量设置大一点。这里是将虚拟机磁盘存储为单个文件还是多个文件?多个文件的好处是可以更轻松的在计算机之间移动虚拟机,但可能会降低大容量磁盘的性能。我这里选择存储为单个文件, 然后点击下一步,这里有一个创建号,开启此虚拟机。我们将这个勾先去掉,点击完成 正在创建词盘,稍微等一下,出现这个界面,就表示虚拟机已经创建完成,如果需要编辑的话,可以点击编辑虚拟机。 第一个是内存大小,默认是四 gb, 大家可以根据自己电脑的内存 来设置合适的大小,如果你的电脑是十六 gb 内存,可以设置八 gb。 然后是处理器,一般的电脑只有一个处理器,我这里选择一个,然后设置几个核心,如果你电脑的 cpu 核心特别多,可以设置多一点,我这里设置四个, 这个是硬盘大小,这个是网络连接方式,默认是 nat, 这个模式也可以,如果你需要改成调节模式,也可以选择这一项, 其他不需要设置。点击确定, 然后我们来启动这个虚拟机,点击开启, 然后我们点击一下这个屏幕,然后点击回车,正在启动 windows 十一安装程序,出现这个界面就表示已经可以安装 windows 十一了,我们点击下页,现在安装 这个可以关掉,这里有个小技巧给大家说一下,我们的鼠标现在可以在这个虚拟机里面移动, 如果我们想要将鼠标移出来,现在是可以移出来的,如果不能移出来,只能在这个虚拟机里面移动,我们可以按住键盘上的 ctrl 键加奥特键,这样就可以移出来。 这里我们选择我没有产品蜜药, 然后选择版本,我这里选择专业版下页, 下页选择自定义安装,选择这个硬盘,下页 正在安装,接下来我就快进了,这个安装非常简单,我之前也有介绍过如何安装 windows 系统,如果大家不知道怎么安装 windows 十一系统,可以去看一下我之前的视频。 windows 十一系统已经安装完成,然后我们需要安装一个工具,点击安装,或者是 点击虚拟机点击安装,这两个地方安装都可以, 稍微等一下,然后会弹出来这个窗口,我们点击,然后点击运行 安装这个工具,可以更好的操作这个 windows 十一系统。比如说我们可以将文件复制到这个里面,或者是将里面的文件复制出来, 已经安装完成,然后重启一下 windows 十一系统, 重启完了之后,我们就可以更好的操作这个 windows 十一系统了,我们来设置一下, 可以更改这个分辨率, 也可以全屏显示,点击这个按钮可以全屏显示 windows 十一系统,如果需要关机的话,可以点击这里, 这样可以正常关闭这个 windows 系统,也可以将这个虚拟机系统也关闭了。 我们还可以创建虚拟机,我们刚刚创建了一个 windows 十一,还可以再创建其他的虚拟机,可以同时开启。 以上就是 vmyl 虚拟机最新版的上手体验,大家可以去试一下,这款虚拟机还是非常好用的。 如果大家还有其他的问题,也可以在视频的下方留言交流,我们下一期视频再见!拜拜!
1080科技发现 05:04查看AI文稿AI文稿
05:04查看AI文稿AI文稿大家好啊,我是一果,大家期待已久的修改器教程来了,用到的就是这几款修改器。教程开始, 首先我们打开植物大战僵尸, 随便打开一个砸罐子,首先也是放置罐子,用终极修改器, 先调整这个坐标,然后点击生成,修改一下内容, 现在就生成了罐子,如果你生成错了罐子不用删除,可以用这个 点击这里的罐子, 选中你想修改的罐子, 点击卡槽,选择此卡无限制。接着是键盘移动植物,拿出终极修改器, 选择插件列表,点击键盘控制植物, 通过选择植物序号来选择要控制的植物。 接下来是随机, 用这个咸鱼修改器, 选择常规修改输入频率,点击打上对勾, 这就是随机植物, 别问我 wifi 怎么变了,问就是神的力量。接下来是掉卡片,怎么打不开, 关掉了。 好的,教程开始, 点击高级一 别出了, 刚才让你出来你不出来,现在全出来了,看我的步骤,先这样,再那样 你特么没完了是吧? 嗯。
356异果






