现在我们来看 b 加数, b 加数是 b 数的变种,直接来看图,你会发现在 b 加数里面只有椰子节点挂的有数据,其他节点都没有挂数据,而且所有的节点都会出现在椰子节点, 比如这个十八叶子结点有,四十五叶子结点有,六十九叶子结点也有。对于毕加速来说,上面的这些非叶子结点,他们的作用仅仅是缩影叶子结点采用的存放数据。其次是每一个叶子结点都会有一个指针 指向下一个叶子节点,从而形成了一个单项链表,这样我们就可以通过当前叶子节点指针直接访问下一个叶子节点范围,查询的时候会更加方便。 ok, 然后我们来模拟一下毕加速电话过程,还是这个网站 选择毕加数还是选择五级表示。非椰子界点有五个指针,四个 k, 我们就按照之前这个数据来插入三十四十五、五十二、 四十八,然后当我们插入十六的时候,超过四个 k, 中间远数四十五就会向上分离,我们把动画调慢一点,插入十六, 四十五向上分离,他向上分离的同时,叶子节点也是存在,四十五的同时叶子节点形成了一个单项链表,接着我们再插入一个六十九,现在这个节点又有四个 k 了, 我们再插入八十的话,中间元素五十二又会向上分离,来试试看。八十技能五十二向上分离,同时也会出现在叶子节点,并形成单向列表。 ok, 我就不往下演示了,你可以自己打开这个网站试一下。然后我们在这里记录一下毕加索的特点, 所有数据都会出现在叶子节点,叶子节点会形成一个单向列表。

粉丝5.4万获赞37.7万
相关视频
 03:57查看AI文稿AI文稿
03:57查看AI文稿AI文稿今天的问题是呢,一棵毕加数可以存放多少条数据呢?那要回答这个问题,我们首先要两点要知道,第一个就是数据在存储期中的存储组织结构是怎么样的, 第二个就是我们常用的 innodb, 所以数据结构是怎么样的?首先数据在存储期中存储呢,这边会涉及到三个概念,一个就是磁盘的散区,一个就是文件系统快,一个就是 innodb 的存储引擎。那我们字体向上看,首先呢数据最终都会存储在磁盘里, 磁盘的最小单元呢是单区,一个单区的大小是五百一十二个字节,一个字节呢是八个比特。那再往上一层呢,就到了我们的文件系统,文件系统的最小单元呢是快一个快,大小呢是四 kb, 也就是四乘以一零二四个字节。 在网上的话,就到了我们存储引擎音的一层。 innodb 的最小存储单元呢是页,一个页的大小呢是十六 k b, 也就是十六乘以一零二四个字节。那这边简单理一下,就是 撕盘五百一十二字结的善区,到文件系统四 kb 的快,再到 innodb 十六 kb 的页。那知道了这些以后呢,我们可以来算一下,一页可以存储多少条数据,假设我们一行的数据大小是一 kb, 就是一零二四个字节,那么按照一页是十六 kb 来计算的话,十六除以一就是十六条, 也就是说我一页大概能存放十六条数据。我们再来看一下 innodb 的所有数据结构,在上一期视频中呢,我们已经讲了必加数的结构, 麦斯和默认的存储引擎呢, innodb 使用的是毕加数的数据结构,才是存储数据的,那 innodb 呢,也使用毕加数来管理表的锁引和数据,那其中叶子结点存放的是数据,非叶子结点呢,存放是见值和指向数据的指针, 就这些飞页结点有指针和箭指,那表都是根据主件顺序来组织存放的,那我们称这种就是锁引组织表,每个表呢都有一个主锁引,称之为 聚集,所以那用于存储表的数据并根据主见呢进行排序。如果这个表中没有显示定义主见呢?印度 dp 呢,会根据一些规则选择一个唯一的,所以作为一个句句,所以, ok, 有了上面两个知识铺垫呢,我们再来算一下,一棵毕加数可以存放多少条数据呢?假设我们现在有一颗三层的毕加数, 那存储总记录条数呢,就等于是最终得到的指向根节点的这个指针数,就这是一个指针嘛?指针数 乘以单个叶子节点的记录条数,就这个叶叶叶子节点记录条数。那假设我们主振 id 是 big inter 类型的,也就是八个字节,而指针大小呢,就指针它本身的大小呢, 在印度 db 原码中呢,是六个字节,那也就是说我飞页的节点,它的键值加上一个指针,这么一个组合,就需要十四个字节。然后再回忆一下,我们前面讲的一页的大小呢,是十六 kb, 它可以存放一 kb 左右大小,这个记录呢,有十六条。 ok, 那我们是否可以计算出来,我们飞页的节点这么一页能存放多少条指针呢?就我们飞页节点,那我们一页就是一六三八四字节嘛,就十六 kb, 除以我们前面这么一个键和缩音的组合,就十四个字节, 那就说相当于有一七零个这样的指针,就这样的指针会有一七零个,那我最终都是一个指针指向一个跟节点,也就是一页,那一页可以存十六条数据,相当于说我一个指针就能指向十六条数据嘛,那这样就可以得到一颗高度为三的毕加数, 能存放,大概是第一层,就我们这边第一层一一七零个指针,那第二层的每一个也还是一一七零个指针,那就是一一七零乘以一一七零,最终都要这么多的一个指针,然后乘以我们每个根节点的记录条数就十六条,那差不多就是 两千一百九十万零,两千四百条,那注意啊,我们前面说这个一一四零乘一一七零,就是前两层的这个非业界点指针数的江城就得到最后指向根据点,这个指针数总数多少,那这说明什么呢?就是说明 我千万值的数据啊,大概只需要高度为三的这么一个必加数,那同时呢,我查询数据的时候,每加载一页就是一次 d b i o 码,如果说我是根据主见 id 所以来查询的,那我千万值的数据里面找一条数据,大概只需要三次 i o 就可以找到目标结果了, 那这也体现了我毕加数在大数据这样情况下插走的一个高效。好的,本期的视频呢就到这里,欢迎大家点赞、关注、收藏、留言,后续不迷路,让我们一起进步!
407程序员一棵树 03:14查看AI文稿AI文稿
03:14查看AI文稿AI文稿一位六年级的小伙伴去字节面试的时候,被问到这样一个问题,为什么 mcco 所引结构要采用 b 加数?这位小伙伴从来没有思考过这个问题,只因为现在都这么卷,后面呢,就特意查了很多资料,他也希望听听我的见解。 另外呢,我花了一个多星期整理了一份十多万字的面试题解析文档,想获取的小伙伴可以在我的主页简介中找到。 一般来说呢,数据库的存储引擎都是采用 b 数或者是 b 加数来实现所有的存储。首先来看 b 数,如图所示, b 数呢,是一种多弱平衡数,用这种程序结构呢,可以来存储大量的数据,它的整个高度呢,会相比凹槽数来说会矮很多。而对于数据库而言呢,所有的数据都会保存到磁盘上,而磁盘 io 的效率呢,又比较低,特别是在随机磁盘的 i 情况下,效率就更低了。所以呢,书的高度就决定了磁盘 io 的次数,那么磁盘 io 次数越少,对于性能的提升呢,也就越大。这也是为什么要采用 b 数作为所引存储的结构的原因。 而 mac 口的 interdb 存储眼镜呢,它采用了一种增强的 b 数结构,也就是用 b 加速来作为所有的数据存储的结构。相比 b 数的结构来说, b 加数做了两个方面的优化,如图所示。 第一个, b 加速的所有的数据存储啊,都在叶子接点,非叶子接点呢,只存储所有数据。第二个呢,叶子接点中的数据呢,使用的是双向列表的方式进行关联。 我认为 myself 的所有结构采用 b 加速有以下四个原因,第一个原因呢,就是从十八 i o 效率方面来说, b 加速的这个飞页直接点不存 数据,所以呢,数的每一层就能够去存储更多的所有数据,也就是说, b 加数在层高相等的情况下,比 b 数的存储数量要更多,从而能够去间接减少磁盘 io 的次数。 第二个呢,是从范围查询的效率方面来看,在 mac 口中,范围查询呢,是一个比较常用的操作,而 b 加速的所有存储在叶子结底的数据使用了双向列表的关联, 所以呢, b 加速在查询的时候呢,只要查询两个节点进行便利就行,而 b 数呢,就需要查询所有的节点,因此 b 加速在范围查询上效率会更高一些。 第三个呢,是从全表扫描方面来看,因为 b 加速的叶子节点存储了所有的数据,所以呢, b 加速的全局扫描能力要更强一些,因为他只需要去扫描叶子节点,而 b 数呢,需要便利整 整个数。第四个,从字针 id 方面来看,我们如果采用字针的整形数据作为组建的话,基于 b 加数的这种数据结构呢,可以更好地去避免增加数据带来的叶子结节分裂,从而导致大量运算的问题。 总体来说,我认为技术方的选型更多的是要根据具体业务场景来决定, b 加数呢,并不一定是最好的选择,就像蒙古 db 里面,它采用的就是 b 数,本质上来说呢,其实是关系型数据库和非关系型数据库的一个差异。 以上呢,就是我对为什么 mcgo 俗影结构要采用 b 加数的一个理解,我是被变成耽误的文艺汤。如果我的分享对你有帮助,请你动动手指,一键三连分享给更多的人,关注我,面试不再难。
 04:33查看AI文稿AI文稿
04:33查看AI文稿AI文稿my circle 为什么采用 b 加数来进行存储?好存储,我们首先需要知道的是一些背景知识,这个背景知识呢就是我们的关系形数据库 my circle, 它的数据呢是存储在磁盘当中的,先来了解一下背景 好,这个背景的主要目的呢是来帮助我们来理解为什么要采用 b 加数。好,首先呢我们的数据存储呢? 好,是在磁盘当中的,我们的所有的数据。好,那大家都知道我们操作系统, 我们去操作磁盘的时候,磁啊,磁盘呢是一个,我们如果要去操作磁盘,是要通过系统调用的,对不对?我们是在用户层,我们的 mysql 呢,是用户层,他要去操作磁盘数据 的话,是要通过系统调用的,对不对?从用户太切到内核太的好,那么我们切切换到内核太,系统调用的这个流程,这个速度呢,它是比较慢的啊,因为我们的 cpu 呢,它的运行速度跟我们的磁盘读取的这个运行速度呢啊,磁盘的这个读取的速度呢,它是 远小于我们的这个 cpu 的一个指令运转的速度,对不对?好,所以呢这里速度呢会比较慢,这个比较慢呢,所以我们的操作系统他不会,就是比如说我们读一个啊十啊十个字结,他不会返回,直接返回十个字结, 我们去读磁盘数据呢,它会是以磁盘的这个单位,以业为单位呢进行读取的。好,这个能理解的朋友帮 mark 老师阿姨好,因为呢根据我们操作系统当中的啊, 我们在这里先写一下。好,我们操作系统呢,它的最小读取就是读写的单位为页,通常呢就是四 k 好,有的是八 k 对不对?好,最小读写单位 四 k b 啊,也就是四 k 字节对不对?好,那么我们了解了这个之后呢,我们如果要采用一个具体的结构来存,来组织这个磁盘数据的话,那么我们的就需要 尽量避免去读取磁盘,对不对?要较少的磁盘 i o, 好,这个呢是我们等一会选择数据结构的时候有一个重要的凭证,这个凭证呢就是我们需要有较少的磁盘 i o 啊,也就是从磁盘里面读数 去读到我们的用不太的这个流程呢,我们希望这种次数呢少一些。好,那么还有一个作为 myself, 我们在使用的过程当中,大家应该都知道,我们呢可能会 select, 像我们前面的 select 语句,可能是单点查询,也就是查询某一行数据好,也有可能呢是范围查询好,就是 well, 条件语句当中,比如说 age 啊,某一个人的年龄大于三十岁的诱惑, 好,那么这里呢就是属于范围查询对不对?好,那么我们需要考虑这一个单点查询和范围查询,也就是说呢,我们这个数据结构应该要具备一个高效的单点查询和一个高效的范围查询 好,那么大家可能会有疑问了,我们为什么不在这个地方 写一个需要提供一个高效的插入和更新呢?好,为什么不是一个插高效的插入和更新,好,那么大家需要注意,因为在 mysocal 当中,我们进行插入或者是更新某一行数据的时候, 他也是,他是属于就地更新,就地更新就是我先要去看这一个行在哪里,或者呢我代插入的行在哪个地方,我们要找到那一个具体的位置,然后呢进行插入, 所以呢我们进行征商改查,他都是需要先查询,所以呢我们只需要有一个高效的单点查询,只要去符合这样的一个条件就行了。好,因为我们的 mexico 啊,因为我们的 mystrical 呢值啊,它是属于一种就地更新啊,就地更新呢,就是要找到 相应的位置我们才去更新他,那么也就是说更新、删除,修更新,删除增加,他都是需要先找到这个具体的位置,先要进行查询,然后呢再去操作, 所以呢我们都是需要查询的。好,这个呢是我们去考虑这个问题的时候所需要知道的一个背景,知道这。
 00:25查看AI文稿AI文稿
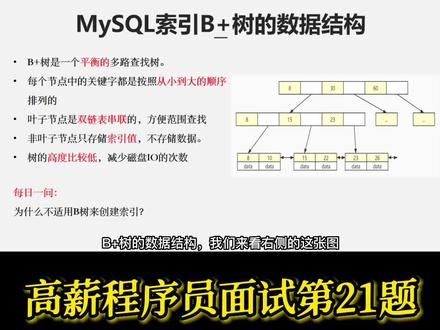
00:25查看AI文稿AI文稿毕加数的数据结构,我们来看右侧的这张图,毕加数是一颗平衡的多路查找数,每一个层级的节点按照从小到大的顺序排列,非叶子结点不存储数据,只存储所以值数据都存储在叶子结点上,叶子结点通过双向列表连接,方便范围查询。毕加数的数高很低, 一般在三到四层,能够减少次判 i o 的次数,提高查询的效率。那么这里问题来了,为什么不使用避数来创建,所以呢?
434程序员面试宝典 04:34查看AI文稿AI文稿
04:34查看AI文稿AI文稿my circle 连环问带你吊打面试官!问题一,什么是 b 加数?为什么 b 加数是 my circle 主要的的缩影,实现 b 加 tree 是基于 bt 瑞和叶子节点顺序访问指针进行实现,它具有 b tree 的平衡性, 并且通过顺序访问指针来提高区间查询的性能。在毕加吹中,一个节点中的 t 从左到右非递减排列, 如果某个指针的左右相邻 t 分别是 k 和 k i 加一且不为 now, 则该指针指向节点的所有 k 大于等于 k i 且小于等于 k i 加一。如图中的数字从左到右非递减,那为什么是 b 加 tree 呢? 首先我们弄明白为什么不是红黑树或者其他的二叉数,因为二叉数中节点的度不大于二。这种结构就决 定了随着数据量的增多,数的深度会越来越深。对于外存数据来说,就意味着增加了 io 次数,因此为了减少磁盘读取次数,数的高度就不能高,所以必须先是 btree, 而红黑数则多用于内存排序, 而对于 btree 只支持随机访问,也就不适用于数据库锁引了。 b 加数是对 b 数的改进,内节点不保存数据地址指针,这样就可以保存更多关键字。内节点可看作为页节点的锁引, 所有数据地址存储在页结点,数据搜索效率一致。同时,因为内结点不保存数值指针,内结点占用空间较小,竖的度更大,深度更低,读取所引文件 进行的 io 次数也更小。页结点一关键字组成顺序列表,支持区间搜索,且空间局部性好,缓存命中率也更高。以上就是 myserk 采用 b 加速锁引的原因?问题二,除了 b 加速, myserk 还有哪些锁引? 锁引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的锁引类型和实现。 miceq 中除了毕加数,还有以下锁引类型, 一,哈吸锁引哈吸锁引能以 oe 时间进行查找,但是失去了有序性应用 db 存储引擎有一个特殊的功能叫自适应哈吸锁引,当某个锁引值被使用的非常频繁时,会在 b 加出于锁引之上 再创建一个哈西索引,这样就让 b 加 tree 索引具有哈西索引的一些优点,比如快速的哈西查找。二,全文索引 masum 存储引擎支持全文索引用于查找文本中的关键词, 而不是直接比较是否相等查找条件使用 match against, 而不是普通的 where。 全文锁引一般使用倒牌锁引实现, ese 是如此,它记录着关键词到期所在文档的映射。三,空间数据锁引 missing 存储引擎支持空间数据锁引, 可以用于地理数据存储。空间数据所引会从所有维度来所引数据可以有效地使用任意维度来进行组合查询。问题三,什么是句促所引和非句促所引?句促所引 一般指的是主键锁引,也被称之为聚集锁引。在聚塑锁引的叶子节点直接存储数据的内存地址,使用内存地址可以直接找到相应的行数据。如图中 id 为九和五十五的两条数据, 在非聚促所引的叶子节点上存储的并不是真正的行数据,而是主见 id。 当我们使用非聚促所引进行查询时,首先会得到一个主见 id, 然后在使用主见 id 去聚促所引上找到真正的行数据,这个过程称之为回表查询。 问题四,什么是覆盖所引和回表覆盖所引指的是在一次查询中,如果一个所引包含或者说覆盖所有需要查询的字段的值,我们就称之为覆盖所引,而不 在需要回表查询。如图中代码,假设我们在 h 字段创建了锁引,而 name 字段未创建锁引,那么查询 id 和 h 信息时就可以直接从锁引中获取,而获取 name 信息 则要通过前面提到的句促所引来回表查询。以上就是麦瑟 q 连环问上篇的内容,欢迎留言讨论。
16云端行笔 03:54查看AI文稿AI文稿
03:54查看AI文稿AI文稿买蛇口水库英德 db 存储引擎必加速。所以排序查询是如何执行的?好,那我们看一下。那首先看一下我们的表呢,我们有一张表 啊,他有这么几个字段,一个就是 a、 d, k, c 和 pad 三个四个字段,然后他的所以结构看一下, id 是左键啊,他是左键,他是左键,所以。那么 k 和 c 呢?也算四个,所以这个派的不是,所以 k 和 c 是,所以我们可以看一下 k 和 c 啊, k 和 c 两个字段是,所以,但是最后这个字段派的不是,所以好,结构是这样的。那现在我们要做这个查询啊,排序查询 排序查询,那我们现在这个做一个,哎,又一个这个,这一计划来去看一下这个排序查询,我们现在是以这个 k 做排序查询。好,那么这个是走一下, 走一下,我们发现他是个哦,对吧,他说哦,然后他里面用的是你看叫文件排序,因为我们这里面有总共这里面是五百万数据啊,数量比较大,总共是五百万这个表五百万数据。那我们这个没有做限制的话呢,他是他是需要借助文件的去进行排序的,因为他内存 这个数据调太大,那么他需要借助文件提排序。好,那如果我们限制一下,比如说我们限制个啊,一千条对吧,好,一千条,那我们这个排序一下, 那这个时候我们发现呢,他用了所以的对吧,又做了,所以这奥德拜是用了所以的。好,那我们这个 k, 然后还有一个 c, 我们将后面加上 c 啊,以先以 k 排序,然后以 c 来排序。好, 这个时候我们走一下就没用的,所以那么这个时候也是用的所以的,对吧?还有所以的好,那如果我们在后面再加一个,比如说加个派, 然后再再加一个派的啊,再加一个派的是排排序好,派的好,那么派的他不是一个,所以啊,不是。所以。那么这个时候我们排序一下好,走一下好,那么这个时候你看他是是哦,类型是哦,然后他是是用了右转的文件排序这里吧, 对吧?哎,用,用到了这个文件排序,我把它折一下啊,对不对?这就是用到了文件排序好,所以呢,我们这个啊,在排序里面呢,他是这样的,我们分析一下。好,那我们这个开合 c 是这个所以那 他有个最左原则啊,所以你以 k 或者 c 都可以啊,这个排序都可以,那么加上派的就不行了,但是如果你以 c 的话行不行呢?那么以 c 的话就不符合最左原则, 那么这个时候他排序的话就有问题了,他就不是那个就是就需要用借助文件去排序的哎,而且这个类型是哦,对吧,没没有用的。所以。 好。那么这是我们的一个现象,这个现象我们就看完了。好,那么我们接下来就要分析一下这个排序,那么他实际上也是一个哎,必加速对吧?好。我们刚才是把 k 和 c 加了,有个所以 k 和 c 加,所以他的数据存页的节点好,那么这个是相当于这一个 k, 再存一个 k, 有个 c 的值,然后下面是左键 id 对不对?哎,这边也是一样啊,先存一个 k 的纸,然后存一个 c 的纸,然后下边呢存一个左键 id, 就是这种方式去存储的对不对? 好,那么而且我们在叶子结节里面,他除了数据,他是有顺序的,他已经是排好序的。好,所以如果我们用到了这个所以。 哎,我们排序的字段刚好是所以的话,那么他就可以用的。这个所就是可以用的所以的。因为在这个叶子节点的数据,他已经是排好序的,我们就可以利用这个所以的这个有顺序这个结构,然后就可以排序。 就不需要我们再去把数据读进来,在内存中或者在磁盘上通过文件的方式再去排序了。好,这就是我们啊这个排序的阶段。如果是所以的话,那么就可以用到。所以如果你不是所以的话,那你可能需要把数据读了,类似于中或者在磁盘上进行这个文件的排序。
148动力节点IT教育 04:32查看AI文稿AI文稿
04:32查看AI文稿AI文稿一面他说 b 加 b 数和 b 加数的区别,为什么卖收口使用 b 加数,所以他还是数啊?好,我们来看, 首先逼数的一个特点就是节点是排序了,就是数数里面的节点,包括一个节点里面他可以存多个元素,那这多个元素也是排序的,就是有小到大的一个顺序啊,所以这是逼数的一个特点。那逼加速实实际上是逼数的一个升级吧?就是 呃,拥有逼数的所有的特点,但是呢,额外啊,他的叶子节点之间是有指针的,这是必交数,那么并且 叶子节点上面的元素在叶子节点上面都融于了一份,也就是说叶子节点上面是存储了我们所有的元素的,并且是排好序的,所以这是必加速的特点。那麦收口为什么使用的是必加速呢?因为我们通常讲麦收口,所以 他其实就就是用来查询,加快查询的,对吧?而必加速通过对数据进行排序,所以是可以提高查询速度的。大家知道如果说我们一个数数字吗?比如说一、三、 二、呃,五、四,也对于这是没有排序的,没有排序的这么一串数列,我们要去查找某一个的话,其实比如说我们要去查找二, 我们要找一三二,要找到这样子才能够找到二,对吧?或者我们要找四,嗯,一三、二、五四,我们这几个元素都要背定完,我们才能够找到四。那么假设我一个现在是一个跑去的一二三四 五,要,比如说我现在要找二,我,我肯定直接找到这个就可以了,比如说我现在要找四,要,或者说我,我现在呃要,或者说我举一个特殊类的例子,比如说我现在排好序了,比如说一三啊,然后五,然后六,然后七,对吧?别说我现在要去找 四,那我要找四的话,我是不是找到一三找,找到这个五就够了?因为我找到五发现五大于四,那我就不用再往后面去找了,我就直接,我就直接可以确定这个四他是不存在的。对,那如果说我们没有排好序,比如说我们这个数列他是无序的,那么你就不能确定这个四到底存不存在,对吧?你,你这样子跑,你 是不是要把所有的这个数字都便利完,你才能够确定?哎,这个是他不存在,所以说是对于我们通常加快数据查询,其实就是我们常说利用数据结构可以加快数据 加快查找的速度,其实就是利用那种排序的特定不特点啊,不管是我们上面的那种呃暗查搜索数啊,还是什么红黑数啊,还是我们的 b 加数啊, b 数啊等等,其实都是对数据去进行的排序,所以这种数据结构他才有起到作用,那么我们的 b 加速他除不开啊。首先一,第一点肯定是对数据进行的排序, 所以可以提高查询速度,而且通过一个节点可以存储德国元素,一个节点可以存储德国元素,这也是 b 数以及 b 加数的特点,那么从而可以使得 b 丽江树的高度不会太高,因为像我们一个麦收回一个表里面,我们可能会有存储很多很多很多条记录,那么我说如果说我们一棵树里面的一个节点我们只存储一条记录的话,那 就是我们说产生这个数可能会很高很高,那么我们利用逼数的这个特点,一个节点里面你可以存多个元素,那么这样子就可以,呃,让我们一个表所对应的那个数,他就会稍微的就没那么高啊,因为你数越高的话,那么你查找的这个时间复杂度, 那么也就相应的增加,那样,所以说,呃,在 macebook 的一个英的英的 db 其实就是一个比加速的节点,一个英的 db 或者就是十六 kb, 那所以一般情况下面一颗两 两层的必加速可以存储两千万行左右的一个数据,但这是基于一些估算子啊,比如说基于你的,呃,那个组建 是 b 个印头,然后基于你的一行记录是 ekb, 那么我们大概就可以算出来一颗两层的必交数,我们是可以存储两千多万行数据的,然后我们再去利用必交数叶子结点存储了,这比较出来的特点就是他的叶子结点是存储了所有的元素,对吧? 那么就相当于我一个表现在我我我一个比较数对应一一个麦硕果。所以的话,那么也就是说 我利用 b 加数的叶子节点,我存储了所有数据并进行的排序,并且叶子节点之前是有指认的,就可以很好的支持全苗撒苗、范围查找等售后语句。当然这位老师我之前讲过一个卖售后所有的课程啊,那么课程里面也讲了两个小时,所以说大家也可以去找一下啊辅助 啊去呃联系一下阿博主,然后,哎,好好的去看一下这位老师我讲的那个麦收口所有的课啊,那么这个在那个课里面我就详细的给 给大家去分析了, b 数和 b 加速已经卖收口,那到底是如何去使用 b 加速的啊?比这个要讲的清晰很多啊,所以大家可以去联系一下二五组啊,去看一下那个课,好吧?
66Java进阶之路 03:08查看AI文稿AI文稿
03:08查看AI文稿AI文稿不管是二叉数还是红黑数,本次都是二叉数,他们仍然存在一个问题,上节课的数据才是一条,红黑数的高度就已经到了五层,我们要查找五次才可以定位到他。当数据量特别大的时候,成绩肯定是非常深的,查找速度同样会很慢。 要解决大数据量下成绩较深的问题,我们应该怎么做呢?其实成绩过深的原因就是每个节点的直接点太少了,而查数每个节点的直接点只有两个,如果我们把每个节点的直接点数量增加,增加到二十个,二百个,是不是就可以解决这个问题呢?肯定是可以的,接下来我们就来介绍避数,避数又成为多路平衡踏草树, 这个多路指的就是一个节点,下面可以包含多个指节点。直接来看图,这是一颗五节的避数,也就是最大多数为五,这也就意味着他每个节点可以有四个 k, 五个指针,每个指针分别指向一个指节点。指针你现在就理解为地址就行,内存里面的指针就是内存地址, 我们这个缩影是存在磁盘的,那就是磁盘上的一块地址。我们先来看根节点,根节点里面有四个 k, 五个指针,小于十八就走第一个指针,大于十八小于四十五就走第二个指针,以此类推,每一个节点都是个规律,然后每一个节点的 k 下面我都画了一个蓝色的块。右边这里我也给了图例,他指的是具体的一行行数据。 ok, 这个懂了之后,我们就来模拟一下必输的构建过程。数据我这里也准备好了,还是打开这个网站, 选择这里的 b、 c、 s, 然后把最大度数改成五,表示这是五阶的 b 数,每个节点最多可以五个指针,四个 k, 现在我们按照这个数据来插入,先插入三十, 然后四十五、五十二、四十八,现在这个节点已经存了四个 k, 对吧?如果再插入一个 k, 他将会有五个 k, 六个指针超过五节了,那就会进行裂变, 中间元素向上分离。现在我插入一个十六的话,四十五就会变成中间元素。我们把动画调慢一点,然后插入一个十六十六,进去四十五变中间元素,然后向上分离。由于根结点有一个 t, 那指针就是两个,所以就会分裂成两个指节点。我们把动画调快一点,再来插入一个六十九、八十, 现在这个节点又是个 k 了,当我再插入一个七十一之后,七十一比六十九,大比八十小,六十九就会变成中间元素,然后向上分离。我们把动画调慢一点,插入七十一,七十一比四十五,大走右边,然后插入六十九,向上分离。此时根节点有两个指针,下面就分离成了三个指节点。 ok。 把动画调快一点, 我们继续插入十二十八,然后我们再插入二十五,十八,就会变成中间元素,然后向上分离。这个规律你应该很清楚了,插入二十五没问题吧?我们继续插入 九十四、九十六,然后九十一向上分裂,这时候根节点已经有四个 k 了,当我们再向上分裂一组的时候,根节点也会变成五个 k, 他也要进行分裂了。我们继续插入一百一十五、九十九,然后还有最后一个,我们把动画调慢一点,插入一百一, 比九十一大肘,最右边指针到这里来,然后九十九变,中间元素向上分离,跟节点五个 k 不满足无结, 所以中间元数六十九继续向上分裂,现在这个数的成绩就变成三层了,这就是 b 数的演变过程,他背后的算法我们现在不需要掌握,知道他的演变方式就行。需要注意的是,对于 b 数来说,他的数据是挂在 k 下面的,也就是我们一开始看的这个图,这个蓝色的块就是数据。
453小飞有点东西 02:28查看AI文稿AI文稿
02:28查看AI文稿AI文稿为什么 mc 口的锁引要用 b 加速来实现而不是 b 数呢?首先,常规的数据库存储引擎一般都是采用 b 数或者 b 加数来实现,因为 b 数是一种多路平衡数,用重存储结构来存储大量数据的时候,它的整个数的高度相比奥加数来说会矮很多。 而对于数据库来说,所有的数据必然都是存在磁盘上,而磁盘 io 的效率实际上是比较低的,特别是在随机磁盘 io 的情况下,效率更低。所以数的高度能够决定磁盘 io 的次数, 直板 l 次数越小,那么对于性能的提升就越大,这也是为什么采用 b 数作为锁引存储结构的原因。但是在 mysaco 的英诺 db 存储引擎里面呢,它用到了一种增强的 b 数结构,也就是 b 加速来作为锁引和数据的存储结构。相比于 b 数结构来说, b 加速做了几个方面的优化。第一个, b 加速 所有数据都存储在叶子节点,非叶子节点只存储,所以第二个叶子节点的数据使用双向列表的方式进行关联。关于 micago 相关的面试啊,我给大家准备了一千道带有标准答案的面试题,只有十份,大家可以在评论区的咨询中去领取。 使用 b 加速来实现锁引的原因呢?我认为有几个方面。第一个, b 加速的非叶子节点不存储数据,所以每一层能够存储的锁引数量会增加,意味着 b 加速在层高相同的情况下,存储的数据量要比 b 数更多,使得磁盘的 io 次数更少。 第二个,在 masco 里面,范围查询是一个比较常用的操作,而 b 加数的所有存储在叶子节点,数据使用了双向列表的方式来关联,所以在查询的时候只需要查询两个节点进行便利就行。而 b 数呢,需要获取所有节点,所以 b b 加速在范围查询上的效率更高。第三个,在数据的解锁方面,由于所有的数据啊都存储在叶子节点,所以 b 加速的 io 次数会更加稳定。第四个,因为叶子节点啊存储了所有数据,所以 b 加速的全局扫描能力 要更强,因为他只需要扫描叶子结点,但是逼数呢,需要便利整棵树。另外,基于 b 加数这样一个结构,如果采用自增的整形数据作为组件,还能更好的避免数据增加的时候带来的叶子结点分裂导致大量运算的问题。 总的来说啊,我认为技术方案的选型更多的是去解决当前场景下的特定问题,并不一定是说 b 加数就是最好的选择。就像芒果 db 里面采用 b 数的结构本上来说,其实是关系型数据库和非关系数据库的差异。好了,今天的分享就到这里结束。
 02:32查看AI文稿AI文稿
02:32查看AI文稿AI文稿专为经典面试题,买色口种 b 加数索引和哈士索引的区别这是一道非常经典的面试题,面试官之所以问这个问题,主要出于两个目的, 目的一,考察你对买 circle 所以概念掌握的情况。目的二,考察你对数据结构掌握的情况。对于第一个考察的目的,你可以把毕加数所以和哈西所以的应用场景展开来说,比如毕加数所以的查询效率是比较稳定的,而哈西所以的查询效率是没有那么稳定的。 而且哈西所引只能在 memory 存储引擎下才可以使用,而且呢, memory 存储隐形,他不支持事务,而且也不支持行,所所以说并不适合这种写多读少的业务场景。 但是哈西所引的查询时间乏度是欧一,在没有大量哈西冲突的情况下,他的查询效率是远高于必加数的。所以 说在一些数据量没有那么的大,并且携少读多的场景下,咱们是更适合用哈西所引的。 但是啊,哈吸缩引还有一些限制,因为哈吸缩引的值与原值是完全不一样的,所以说在一些排序或是范围查找,或是模糊查询的这种条件下,他是不支持的。对于第二个考察点,咱们可以通过数据结构的方向来产出这个问题。 首先针对咱们的必加数,所以那咱们要阐述为什么不用二差数,不用平衡二差数,不用逼数而反而用必加数呢?那么首先二差数他没有办法保证自平衡,所以说在极端情况下,他的查询时间法度是 on, 那么平衡二叉数虽然说保证了平衡,但是它毕竟还是二叉数,每一个节点下只会有两个子节点,所以说在数据量特别庞大的时候呢,它的数高是非常 高的。那么其次逼数,他的每一个节点都会存储数据,但是呢,每一个磁盘块的大小是固定的,所以说他严重影响了我买 celco 存储数据的性能。 显然毕加数是更适合做的,因为毕加数只有叶子节点在存储数据,他的非叶子节点只会存储这个数据的 t, 并且呢,毕加数的叶子节点有一个指针指向旁边的叶子节点,这更适合咱们做范围查询,而且呢,毕加数只需要三到四层的树高就可以制成千万级别的数据。 而关于哈西结构呢,他就没有太多可以阐述的了,他直接根据你的哈西值去定位到你的内存位置,所以说他的查询是 f, 发度是 oe, 所以咱们可以选择自己掌握的更好的方向去阐述这样的问题,哈哈哈哈哈,哎呀,腰疼。
646Java老郑



